| Issue |
A&A
Volume 642, October 2020
|
|
|---|---|---|
| Article Number | A58 | |
| Number of page(s) | 38 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202038314 | |
| Published online | 07 October 2020 | |
Automatic catalog of RR Lyrae from ∼14 million VVV light curves: How far can we go with traditional machine-learning?
1
Centro Internacional Franco Argentino de Ciencias de la Información y de Sistemas (CIFASIS, CONICET–UNR), Rosario, Santa Fé, Argentina
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Instituto De Astronomía Teórica y Experimental – Observatorio Astronómico Córdoba (IATE–OAC–UNC–CONICET), Córdoba, Córdoba, Argentina
3
Western Sydney University (WSU), Locked Bag 1797, Penrith South DC, NSW 2751, Australia
Received:
1
May
2020
Accepted:
27
July
2020
Abstract
Context. The creation of a 3D map of the bulge using RR Lyrae (RRL) is one of the main goals of the VISTA Variables in the Via Lactea Survey (VVV) and VVV(X) surveys. The overwhelming number of sources undergoing analysis undoubtedly requires the use of automatic procedures. In this context, previous studies have introduced the use of machine learning (ML) methods for the task of variable star classification.
Aims. Our goal is to develop and test an entirely automatic ML-based procedure for the identification of RRLs in the VVV Survey. This automatic procedure is meant to be used to generate reliable catalogs integrated over several tiles in the survey.
Methods. Following the reconstruction of light curves, we extracted a set of period- and intensity-based features, which were already defined in previous works. Also, for the first time, we put a new subset of useful color features to use. We discuss in considerable detail all the appropriate steps needed to define our fully automatic pipeline, namely: the selection of quality measurements; sampling procedures; classifier setup, and model selection.
Results. As a result, we were able to construct an ensemble classifier with an average recall of 0.48 and average precision of 0.86 over 15 tiles. We also made all our processed datasets available and we published a catalog of candidate RRLs.
Conclusions. Perhaps most interestingly, from a classification perspective based on photometric broad-band data, our results indicate that color is an informative feature type of the RRL objective class that should always be considered in automatic classification methods via ML. We also argue that recall and precision in both tables and curves are high-quality metrics with regard to this highly imbalanced problem. Furthermore, we show for our VVV data-set that to have good estimates, it is important to use the original distribution more abundantly than reduced samples with an artificial balance. Finally, we show that the use of ensemble classifiers helps resolve the crucial model selection step and that most errors in the identification of RRLs are related to low-quality observations of some sources or to the increased difficulty in resolving the RRL-C type given the data.
Key words: methods: data analysis / methods: statistical / surveys / catalogs / stars: variables: RR Lyrae / Galaxy: bulge
Honorary Visiting Fellow.
© ESO 2020
1. Introduction
The stars of RR Lyrae (RRL) were first imaged in the last decade of the 19th century. Although it is uncertain as to who made the first observations, some authors report that it was Williamina Fleming. Fleming led Pickering’s Harvard Computer group in early studies of variable stars towards globular clusters (Burnham 1978; Silbermann & Smith 1995). Towards the end of the 19th century, J. C. Kapteyn and D. E. Packer independently published results of variable stars which were also likely to be RRL stars (Smith 2004). In the decade following Fleming’s initial work, Bailey (1902) classified RRL into three subtypes. Bailey also proposed that RRL be used as “standard candles” to measure distances to clusters. Later works by Seares & Shapley (1914) found that variability in RRL, or so-called “cluster variables,” was probably caused by the radial pulsation of RRL stellar atmospheres. Several years later Shapley (1918), used RRL to estimate the distance to globular clusters in the Galaxy. Later, Baade (1946) used them to measure the distance to the galactic center.
Now, over a century after Fleming’s initial discovery and after a plethora of systematic studies, RRL have come to be known as a class of multi-mode pulsating population II stars with spectral (color) type A or F that reside in the so-called “horizontal branch” of the C-M diagram. They are also considered excellent standard candles with periodic light curves (LC) and characteristic features that are sensitive to the chemical abundance of the primordial fossil gas from which they formed Smith (2004). These short-period variables have periods typically ranging between 0.2 and 1.2 days (Smith 2004) and they are old (aged ∼14 Gyr), with progenitor masses typically about 0.8 Solar M⊙ and absolute magnitudes consistent with core helium burning stars. When it comes to how many RRL there are in the Galaxy, Smith (2004), estimated some 85 000. We now know, thanks to a recent work by OGLE (Soszyński et al. 2019) and Gaia (Gaia Collaboration 2018) data releases, that there are over 140 000 RRL in The Galaxy. Interestingly from a galaxy formation and evolution perspective, RRL chemical abundances could be used as evidence to piece together the structural formation and evolution of the bulge, disk, and halo components of the Galaxy, as well as in near-by ones. Lee (1992) presented evidence that bulge RRL stars may even be older than the Galaxy Halo stars, implying that galaxies may have formed inside-out. So RRL are also important for testing the physics of pulsating stars and the stellar evolution of low mas stars. RRLs have also been used extensively for studies of globular clusters and nearby galaxies. They have been used successfully and systematically as a rung in the extra-galactic distance ladder (de Grijs et al. 2017) which, along with other methods, Cepheid distances, tip of the red giant branch methods, etc. (Sakai & Madore 2001), have provided primary distance estimates to boot-strap distance measurements to external galaxies (Clementini et al. 2001) and reddening determinations within our own.
The list of objectives of the VISTA Variables in the Via Lactea Survey (VVV, Minniti et al. 2010), as designed, includes a 3(+1) dimensional mapping of the bulge using RRLs. As shown by Dwek et al. (1995), most of the bulge light is contained within ten degrees of the bulge center, so most of the mass, assuming a constant mass-to-light ratio, should also be contained within this radius.
Our study (and sample) was made after the OGLE-IV release but it precedes the OGLE catalog presented in Soszyński et al. (2019) and Gaia Data release. We use the VISTA data to extract characteristic RRL features based on NIR VVV photometry. A star-by-star approach to the reduction and process analysis of light curves (LC) is too costly, prone to external biases, and largely inefficient due to the overwhelmingly high number of light curves collected by modern surveys like VVV. The automatic methods developed for this study statistically handle subtleties involved in normalizing the observational parameter space to obtain a machine-eye view at the physical parameter space. Our study, we hope, will serve to refine previous attempts at the use of machine learning (ML) and data mining techniques to detect and tag RRL candidates for studies of bulge dynamics of the Galaxy. We also attempt to take into account the inhomogeneity of Galactic extinction and reddening, as well as varying stellar density at different lines-of-sight, considering these in a computationally statistical manner during the feature extraction and classification steps.
While panchromatic studies from the UV through the near-IR (NIR) and beyond, including spectroscopic studies, will undoubtedly better constrain the observed and physical RRL parameter space, this is not yet possible, so for this study we draw mostly on learning from visual data taken from the literature and from NIR VVV photometry. Our objective class is the set of known RRL stars from the literature. These stars are tagged based on OGLE-III/OGLE-IV and other catalogs accessed through VizieR. They are listed in Appendix A.
We wish to note that stellar population synthesis studies based on broadband colors, for example: Bell & de Jong (2001) and Gurovich et al. (2010) appear to suggest that the evolution of stellar mass in massive disk galaxies is better constrained by NIR photometry than by broadband photometry at shorter effective wavelengths. Although predicted effective temperatures for RRL with given spectral types are more closely matched to bluer filters, we made a compromise and chose to draw our characteristic feature set preferentially on NIR light. Moreover, at NIR wavelengths, Galactic extinction effects (and errors) due to differential reddening are also significantly reduced, so any method of feature engineering for RRL classification using NIR data should also prove to be insightful.
Previous works have attempted to develop ML methods for the identification of variable stars on massive datasets. For example, Richards et al. (2011, 2012) introduced a series of more than 60 features measured over folded light curves and used a dataset with 28 classes of variable stars. Armstrong et al. (2015) discussed the use of an unsupervised method before a classifier for K2 targets. Mackenzie et al. (2016) introduced the use of an automatic method to extract features from a LC based on clustering of patterns detected in the LC. Shin et al. (2009, 2012) introduced the use of an outlier detection technique for the identification of variable stars and Moretti et al. (2018) used another unsupervised technique, PCA, for the same task. Pashchenko et al. (2018) considered the task of detecting variable stars over a set of ∼30 000 OGLE-II sources with 18 features and several ML methods. In the most relevant antecedent to our work, Elorrieta et al. (2016) described the use of ML methods in the search of RRLs in the VVV. They consider the complete development of the classifier, starting from the collected data (2265 RRLs and 15 436 other variables), the extraction of 32 features and the evaluation of several classifiers. As most previous works, they found that methods based on ensembles of trees are the best performers for this task. In this particular case they show an small edge in favor of boosting versions over more traditional random forest (RF; Breiman 2001).
As always in this line of research, there are several ways in which we can improve upon earlier results, particularly for the findings of Elorrieta et al. (2016). First, they chose not to use color so as to avoid extinction related difficulties and they do not use reddening-free indices. Second, as in most previous works, they use a data sample that is clearly skewed in favor of variable stars. This over-representation of RRLs produces, in general, over-optimistic results, as we show later in this work. Lastly, they used performance measures (ROC-AUC and F1 at a fixed threshold, see Sect. 3) that are not appropriate for highly imbalanced problems and low performance.
Furthermore, modern surveys request for fully automatic methods, starting from the extraction of a subset of stable features through the training and setup of efficient classifiers up to the identification of candidate RRLs. In this work, we attempt to develop a completely automatic method to detect RRLs in the VVV survey. We show the effectiveness of our subset of features (including color features), along with ways to automatically select the complete setup of the classifier and to produce unbiased and useful estimates of its performance.
Although we limit ourselves to classifying RRLs based on VVV aperture magnitudes in this work, we note our method could be adapted for VVV point spread function (PSF) magnitudes or used to classify other Variables such as Cepheids, Transients, or even employed on other surveys such as the Vera Rubin Observatory’s Legacy Survey of Space and Time (LSST) or Gaia (Brough et al. 2020; Ivezić et al. 2019).
This paper is organized as follows. In Sect. 2, we outline the input data based on the VVV survey: type, size, structure, and how we clean it. Section 3 describes the computational environment and method used in this work. Section 4 summarizes the steps taken to build and extract the features from the LC, along with details on how we incorporate our positive class (variable stars) into our dataset, and, finally, we present an evaluation of diverse feature subsets. In Sect. 5, we describe the selection of an appropriate ML method and in Sect. 6, we discuss the best way to sample the data in order to obtain good performance and error estimations. Then we select the final classifier (Sect. 7), analyze how some errors are produced (Sect. 8), and discuss the data release (Sect. 9). We summarize our work in Sect. 10.
2. The VVV survey and data reduction
The VVV completed observations in 2015 after about 2000 hours of observations, for which the Milky Way bulge and an adjacent section of the mid-plane (with high star formation rates) were systematically scanned. Its scientific goals were related to the structure, formation, and evolution of the Galaxy and galaxies in general. The data for both VVV and VVV(X) is obtained by VIRCAM, the VISTA infrared camera mounted on ESO’s VISTA survey telescope (Sutherland et al 2015). At the time of its commissioning, VIRCAM was the largest NIR camera with 16 non-contiguous 2k × 2k detectors. All 16 detectors are exposed simultaneously capturing a standard “pawprint” of a patch of sky. To fill the spaces between the 16 detectors and for more uniform sampling, 6 pawprints are observed consecutively at suitable chosen offsets of a large fraction of a detector. When combined into a “tile,” these six pawprints sample a rectangular field of roughly 1.5 × 1.0 degrees, so that each pixel of sky is observed in at least 2 pawprints. There are also two small strips in which there is only one observation. These strips overlap another such strip on the adjacent tile. Over the course of the survey, the same tile is re-observed for variability studies. In the first year of VVV survey observations more stricter conditions were required and for most tiles five astronomical pass-bands where observed that included in increasing wavelength Z, Y, J, H, and Ks, separated only by a couple hours. However, for a small number of tiles, when the required survey conditions were not met (e.g., seeing), simultaneous multi-band observations for that tile were made later, some, even, in subsequent years. We would like to note that we use the Cambridge Astronomical Survey Unit (CASU) search service to group the multi-epoch data for the construction of our band-merge catalog for CASU version 1.3 release. Finally, during the multi-epoch campaign mostly Ks observations were made, which we use for our variability study for the same release. Typically, for each tile, around 80 observation were recorded for the Ks band and only one, the first tile epoch, for the other four bands. We also note that the input data preprocessed by the CASU VISTA Data Flow System pipeline (Emerson et al. 2004), include photometric and astrometric corrections, made for each pawprint and tile (González-Fernández et al. 2018) image and catalog pre-processed data produced by CASU as standard FITS files (Hanisch et al. 2001).
The work in this study is based mainly on the 3rd aperture photometry data (as suggested by CASU for stellar photometry in less crowded fields) from the single pawprint CASU FITS catalogs. The magnitudes are extrapolated or total magnitudes. The FITS catalogs were converted to ascii catalogs using an adapted CASU cat_fit_list.f program. Over the course of the survey, given the high data rates (∼200 MB/pawprint), several hundred terabytes of astronomical data were produced. Systematic methods are required to extract, in a homogeneous way, astrophysical information across ∼1000 tiles for a wide range of scientific goals. The “first” phase of the pre-reduction process is done by CASU’s VISTA Data Flow System (VDFS), which produces, among other results, the pawprint, and tile catalogs that we use as our inputs.
2.1. Data for this work
Based on the VDFS results, we create two kind of post-processed data sources:
Tile catalogs. The J, H, and Ks consolidated master source list were defined from the first epoch of observations. These data were selected because source color information is available and also because the “first” epoch data have constraints that include more stringent observational and prepossessing data requirements (seeing, photometric conditional limits, etc.) than for any other epoch of observation. The cross-matching proximity algorithm employed was modified for multiple bands. It is based on a KD-tree implementation from the SciPy Python library. It reduces the matching complexity of traditional algorithms from O(N2) to O(LogN)1, with a threshold of 1/3′′ used to define which sources are the same across different bands. The KD-tree implementation was developed in collaboration with Erik Tollerud for the Astropysics library (the precursor of Astropy). Its implementation is also based on the Scipy package (Tollerud 2012; Astropy Collaboration 2013; Oliphant 2007).
Pawprint Stacks. Each pawprint stack is associated to a Tile Catalog and includes the six pawprint observation of the detectors for a single Ks-band epoch.
3. Environment: software, hardware, methods
We took VDFS data catalogs of CASUVER 1.3 to begin our processing. The processing phase was made within a custom multiprocess environment pipeline called Carpyncho (Cabral et al. 2016), developed on top of the Corral Framework (Cabral et al. 2017), the Python2 Scientific Stack Numpy (Van Der Walt et al. 2011), Scipy (Oliphant 2007), and Matplotlib (Hunter 2007). Additional astronomy routines employed were provided by the Astropy (Astropy Collaboration 2013) and PyAstronomy (Czesla et al. 2019) libraries. The feature extraction from the light-curve data was handled using feets (Cabral et al. 2018) packages, which, in turn, had been previously reingineered from an existing package called FATS (Nun et al. 2015) and later incorporated as an affiliated package to astropy. The feature extraction was executed in a 50 cores CPU computer provided by the IATE3. The Jupyter Notebooks (Ragan-Kelley et al. 2014; for interactive analysis), Scikit-Learn (Pedregosa et al. 2011; for ML), and Matplotlib (for the plotting routine) are our tools of choice in the exploratory phase with the aim of selecting the most useful model and creating the catalog.
We considered the use of four diverse classical ML methods as classifiers in this work. We first selected the support vector machine (SVM; Vapnik 2013), a method that finds a maximum-margin solution in the original feature space (using the so-called linear kernel) or in a transformed feature space for non-linear solutions; we selected the radial-base-function, or RBF kernels, as a second classifier in this case. Third we selected the K-nearest neighbors (KNN) method (Mitchell 1997), a simple but efficient local solution. Last, we selected RF, an ensemble-based method, which requires almost no tuning and provides competitive performance in most datasets.
In order to estimate performance measures, we used two different strategies. In some cases, we relied on an internal cross-validation procedure, usually known as K-fold CV. In this case, the available data is divided in K separate folds of approximately equal length and we repeat K times the procedure of fitting our methods on (K − 1) folds, using the last one as a test set. Finally, the K measurements are averaged. In other cases, we use complete tiles to fit the classifiers and other complete tiles as test sets.
We selected three performance measures that are appropriate for highly imbalanced binary classification problems. The RRLs are considered the positive class and all other sources as the negative class (Sect. 4.4). RRLs correctly identified by a classifier are called true positives (TP) and those not detected are called false negatives (FN). Other sources wrongly classified as RRLs are called false positives (FP), and those correctly identified are called true negatives (TN). Using the proportion of these four outcomes on a given dataset, we can define two complementary measures. Precision is defined as TP/(TP + FP). It measures the fraction of real RRLs detected over all those retrieved by the classifier. Recall is defined as TP/(TP + FN). It measures the proportion of the total of RRLs that are detected by the classifier. Classifiers that output probabilities can change their decisions simply by changing the threshold at which a case is considered as positive. Using a very low threshold leads to high Recall and low Precision, as more sources are classified as positive. High thresholds, on the other hand, lead to the opposite result, high Precision and low Recall. Precision and Recall should be always evaluated at the same time. One of the best ways to evaluate a classifier in our context (highly imbalanced binary problem) is to consider Precision-Recall curves, in which we plot a set of pairs of values corresponding to different thresholds. In general, curves that approach the top-right corner are considered as better classifiers.
A more traditional measure of performance for binary problems is the accuracy, defined as (TP + TN)/(TP + FP + TN + FN). In relation to accuracy, it is also customary to create ROC-curves and to measure the area under the curve (ROC-AUC) as a global performance measure. We show in Sect. 5 that these two measures do not provide any information in our case.
4. Feature extraction: from light-curves to features
To identify and typify a variable-periodic star of any type, it is necessary to precisely measure its magnitude variation in a characteristic time period. To this end, we need to match each source present in a Tile Catalog with all the existing observations of the same source in all available Pawprint-Stacks and then to reconstruct its corresponding time series.
All the features that we extracted for this work correspond to sources that share two characteristics:
– An average magnitude between 12 and 16.5, where the VVV photometry is highly reliable (Gran et al. 2015).
– At least 30 epochs in its light curve to make the features more reliable, each source needs to have
4.1. Proximity cross-matching
We take measurements of positions and magnitudes for every source in each Pawprint Stack catalog with known tile identification number, as well as the mid-time of the observation. Since the input source catalogs do not have star identification numbers, we use cross-matching to determine the correspondence between observed sources in the Tile Catalog and the Pawprint Stack using our matching algorithm.
4.2. Date–time correction
The dates in the Pawprint Stack are recorded as the average date across all the “pawprints” involved in the “stack” in Modified Julian Days (MJD) in UTC. The recorded MJDs are subject to the light travel time delays caused by the Earth’s orbital motion around the Sun. These delays are relevant for short-period variable stars. In consequence, we transform our dates to Heliocentric Julian Days (HJD), which modifies the MJD using differences in the position of the Earth with respect to the Sun and the source (Eastman et al. 2010).
4.3. Period
Once the observation instances for each source have been identified and the HJD calculated, the next step consists of calculating periods for our sources. The VVV is an irregular time-sampled survey, so for sampling consistency across the survey, we make the assumption that the frequency of observational data is random. Figure 1 shows the observed magnitude of an RRL as a function of HDJ time of measurement. No periodic signal is evident since the cadence sampling is on the order of tens of days, which far exceeds the expected period of RRL stars. We know RRL in the NIR have approximately sinusoidal light curves with variations between ∼0.1 and ∼0.5 mags as opposed to ∼0.2 and ∼2.0 mags in bluer broad-band filters, and if we assume that therein may lie hidden useful features, to increase sensitivity in the feature analysis that follows, we automatically analyse the Periodogram, extract a period, and proceed by folding the RRL time series by this period. We extract what we expect may be many useful features from the folded LC in the following section.
 |
Fig. 1. Light curve of an RRL AB variable star from Gran et al. (2015) identified with the ID VVV J2703536.01-412829.4. The horizontal axis is the measurement date in heliocentric-corrected days (HJD) and the vertical one is the source magnitude. |
We note that to recover the period of the RRL source, we use the family of Fast Lomb-Scargle methods (Lomb 1976; Scargle 1982; VanderPlas 2018). This method finds the least squares error fit of a sinusoid to the sampled data. Folding the LC by this period puts the LC in-phase, as shown in Fig. 2, allowing for the extraction of interesting features, for example the first Fourier Components that have been found in other work to be sensitive to [Fe/H] (e.g., Kovács & Walker 2001).
 |
Fig. 2. Folded light curve for the same star as Fig. 1, using a period of ∼0.757 days. The horizontal axis is the phase, and the vertical shows the source magnitude. For visual ease, two periods are shown. |
4.4. Tagging: positive and negative samples
We selected our positive samples using the following procedure. First, we identified all the variable stars in our Tile Catalogs (Sect. 2.1) by proximity cross-matching (using a threshold of 1/3 arc sec) mainly from the variable-star catalogs of OGLE-III (Udalski 2003; Soszyński et al. 2011), OGLE-IV (Udalski et al. 2015; Soszyński et al. 2014) and from other catalogs accessed through VizieR (Ochsenbein et al. 2000), listed in Appendix A we give all literature RRL with common spatial fields to the VVV. From those variable sources, we selected only the RRLs as our positive class and discarded the rest. Then, any other source present in our Tile Catalogs were considered as members of the negative class.
It is worth mentioning that our positive and negative classes cannot be considered as completely accurate as they were not validated with a manual (visual or spectroscopic) inspection of each source. In this context, it is possible that a reduced number of already known RRLs were missed in our cross-matching process and were, as a consequence, incorrectly labeled as negative. These missed RRLs will most probably appear as FP to our classifiers, increasing the estimated error levels of our methods slightly over the levels that would be estimated with a verified dataset.
The selected sample of RRLs, Unknown (negative class), and VVV tile-ids are shown in Table 1 and Fig. 3.
Number of epochs in Ks band, RRL, and other stars by tile.
 |
Fig. 3. Map of the bulge tiles of the VVV survey. In blue, we mark the tiles used for this paper. |
4.5. Features extraction
The feature extraction process (including the period as previously described) was carried out mostly using feets (Cabral et al. 2018). We obtained a set of sixty-two features, which are summarized in Table 2. A brief description of these features (accompanied by references) can be found in Appendix B. Also, in the following paragraph, we include a more detailed explanation of a particular new set of features considered in this work.
Features selected for the creation of catalogs of RRL stars on tiles of VVV.
Aside from the period, magnitude variation, and LC morphology, variable stars may also be characterized by their temperatures or intrinsic color(s) as a function of time. A color may be calculated as the difference of two standard broad-band magnitudes with one important caveat: colors are sensitive to LOS or external foreground reddening. In fact, its effect increases towards the mid-plane of the Galaxy. At visual wavelengths that are within our range of tiles, this is a serious problem because an absorption of several magnitudes in the V-band is observed near the galactic mid-plane towards the bulge of the Galaxy. Extinction depends on dust grain type, size, spacing, and density, but generally affects shorter wavelengths preferentially, hence causing reddening. We correct the VVV data using different extinction laws and maps obtained from the literature. We also include reddening-free indices that are photometric indices chosen to be relatively insensitive to the effect of extinction. For further information, see Catelan et al. (2011).
This work was planned and partly executed prior to the Schultheis et al. (2014) 3D maps and the incorporation into the updated version of the BEAM-II calculator that provides 3D distances. Thus, to maintain a homogeneous analysis across all fields, we chose to correct for reddening by using the 2D dust-maps from BEAM-I and dust laws employing the work of Gonzalez et al. (2011, 2012) for which we estimate the absorption coefficients of our sources with the BEAM-I - A VVV and 2MASS Bulge Extinction And Metallicity Calculator4. Unfortunately the extinction maps of the VVV(X) zones were not available when we developed this work, so in this paper, we limit ourselves to the VVV tiles.
The BEAM mappings have pixel resolutions of 2 arcmin × 2 arcmin or 6 arcmin × 6 arcmin, depending on the density of the red-clump bulge stars in the field. In some cases, BEAM fails to calculate the extinction to a source. In those situations, we replace it with the average of the extinction of the hundred nearest neighbors, weighed by angular proximity.
Thus, for each source we obtain the Av absorption magnitude and use it to calculate the reddening and convert it from the photometry of the 2MASS survey (Skrutskie et al. 2006) to the photometry of VVV (González-Fernández et al. 2018), given the two laws of extinction, Cardelli et al. (1989) and Nishiyama et al. (2009). These laws describe the amount of extinction as a function of wavelength.
Finally, the last stumbling block in calculating color is that, unfortunately, the VVV multi-band observations were only made in the first epoch systematically across all fields. Obtaining a good color-index is not possible because, first, the classic calculation of color index (implemented in feets) cannot be used, since it requires several observations in both bands to subtract; and second, because the first epoch of two light curves may have been observed in different phases, and the relations between the subtraction of two points of different phases in two bands, even for the same star, is not constant.
Under these conditions, the following strategy was chosen: The colors were calculated using only the first observation epoch and both extinction laws; in addition, a pseudo phase multi band was calculated, which is related to where in the phase is the first epoch of the source, also including the number of epochs; finally, the pseudo-magnitudes and pseudo-colors (with both extinction laws) proposed in the work of Catelan et al. (2011) were calculated. These values are reddening free indices.
The following color features were obtained. The reddening free indices are shown with subscript “m2”, “m4”, and “c3”:
c89_c3 − C3 Pseudo-color using the Cardelli et al. (1989) extinction law (Catelan et al. 2011).
c89_ab_color − Extinction-corrected color from the first epoch data between the band a and the band b using the Cardelli et al. (1989) extinction law, where a and b can be the bands H, J, and Ks.
c89_m2, c89_m4 − m2 (defined as H − 1.13(J − Ks)) and m4 (defined as Ks − 1.22(J − H)) pseudo-magnitudes using the Cardelli et al. (1989) extinction law (Catelan et al. 2011).
n09_c3 − C3 Pseudo-color using the Nishiyama et al. (2009) extinction law o (Catelan et al. 2011).
n09_ab_color − Extinction corrected color from the first epoch data between the band a and the band b using the Nishiyama et al. (2009) extinction law, where a and b can be the bands H, J and Ks.
n09_m2, n09_m4 m2 and m4 pseudo-magnitudes using the Nishiyama et al. (2009) extinction law (Catelan et al. 2011).
ppmb − “Pseudo-Phase Multi-Band”. This index sets the first time in phase with respect to the average time in all bands, using the period calculated by feets.

where HJDH, HJDJ and HJDKs are the time of observations in the band H, J and Ks; T0 is the time of observation of maximum magnitude in the Ks band; mean calculates the mean of the three times, frac returns only the decimal part of the number, and P is the extracted period.
4.6. Evaluation of feature subsets
We consider three subsets of features based on the root of feature type. We bundle all color-derived features into the “color feature” sub-type. Features that are related to the extracted period are placed into the “period based” sub-type, including, for example, PeriodLS, Period_fit, Psi_eta, Psi_CS, ppmb and all the Fourier components (see Appendix B). This subset depends on the correct determination of the period as a first step, which makes them less reliable than features that are measured directly from the observations. Then, in the third and final subset, we include all classical features with this last property that we call “magnitude-based” features.
We designed a first experiment and established a handle on the predictive power of our selected feature sets and restricted subsets. We selected four tiles in the VVV Bulge footprint; b234, b261, b278, and b360, as a compromise between RRL number density and coverage. For each tile, we created a reduced dataset with all the RRL stars and 5000 unknown sources. We use RF as classifier, with the setup explained in the next section (we will also support this decision in that section). For every tile, we train four classifiers: one with the full set of features, another with only the period + magnitude subsets, a third with the color + magnitude subsets and a fourth with the period + color feature subsets. Every classifier was then tested using all other tiles as test sets (obviously using the same feature subsets).
First, we evaluate the results using precision–recall curves. While all the validation curves can be found in Appendix C, we present the curves trained only with the tile b278 in Fig. 4. We selected b278 not only because it is the one with the most RRL, but also for historical reasons; Baade’s window is centred therein. It can be seen in Fig. 4 that the Period subset of features contains most of the information since its removal causes the greatest loss in performance for all test cases (the green curve corresponding to magnitude + color is always the lowest and furthest from the 1-1 upper-right corner point). However the Color subset of features is also significantly relevant since its removal produces considerable loss to performance (but to a smaller degree than does the removal of the Period subset). Finally, the Magnitude subset is the least informative of all subsets. Its removal produces marginal performance loss, which is somewhat expected if we consider RRL as standard candles that are isotropically distributed about the bulge, the typical RRL’s apparent magnitude should be weakly correlated to their class type. The full set of curves shows the same behaviour (see Appendix C).
 |
Fig. 4. Recall vs. precision curves of trained RF classifiers for different feature subsets. On the left, center, and right panels, the test tiles are b234, b261, and b360, respectively. All models were trained on tile b278. |
In order to make a quantitative comparison, we selected a fixed value of Recall (∼0.9) and produced tables with the corresponding precision values for a RF classifier trained with each subset of features. Figure 5 shows that in all cases, the results are consistent with the previous qualitative analysis as far as the relative importance of our RRL feature subtype.
 |
Fig. 5. Precision for different subsets of features for the tiles b234, b261, b278, and b360 for a fixed recall (∼0.9). From left to right: the first panel includes the total set of features; in the second, only the magnitude- and period-based features is used; in the third, the magnitude- and extinction-based ones; and, finally, the extinction- and period-based features are used. In all cases, the rows indicate which tile was used for train the RF classifier and the columns indicate the one used for the test. |
5. Model selection
In a second experiment, we compared the performance of the four classifiers considered in this work: SVM with linear kernel, SVM with RBF kernel, KNN and RF.
Most of the classifiers have hyperparameters that need to be set to optimal values. We carried out a grid search considering all possible combinations of values for each hyperparameter over a fixed list. We used a 10 k-folds setup on tile b278, considering the precision for a fixed recall of ∼0.9 as the performance measure.
With this setup, we selected the following hyperparameters values:
SVM-Linear: C = 50.
SVM-RBF: C = 10 and γ = 0.003.
KNN: K = 5 with a manhattan metric; also, the importance of the neighbor class wasn’t weighted by distance.
RF: We created 500 decision trees with Information-Gain as metric, the maximum number of random selected features for each tree is the log2 of the total number of features, and the minimum number of observations in each leaf is 2.
We trained the four classifiers using the same datasets and general setup as in the previous experiments. Again, we selected a threshold for each classifier that results in a fixed Recall of ∼0.9. Figure 6 presents the results of the experiment. In this case, we show (in addition to the Precision), the ROC-AUC and the accuracy (for the same threshold as precision).
 |
Fig. 6. Accuracy, ROC-AUC, and precision for different classifiers. All details are the same as in Fig. 5. |
In the first place, all classifiers have a similar (and quite high) accuracy and ROC-AUC for all test and train cases. Both measurements give the same weight to positive and negative classes and, as a consequence, both are dominated by the overwhelming majority of negative class. The comparison with Precision values (with very different values for different cases) shows why both measurements are not informative in the context of this work. When analysing, then, only the precision results, the best method is clearly RF, followed by KNN, SVM-RBF, and, finally, SVM-Linear.
In Fig. 7, we show the complete precision vs. recall curves for tile b278 (the complete set of curves for all tiles can be found in the Appendix D). All figures show that in any situation RF is the best method (or comparable to the best with few exceptions). Given these results, we proceed to selecting RF as the choice classifier for the remainder of this work.
 |
Fig. 7. Recall vs. recision curves for different classification methods. In the left, center, and right panel, the test tiles are b234, b261, and b360, respectively. All models were trained on tile b278. |
6. Sampling size and class imbalance
The treatment of highly imbalanced datasets posses several problems to learning, as is discussed, for example, in a recent work by Hosenie et al. (2020). In particular, there is a problem that is usually not considered by practitioners which considers whether learning be improved by changing the balance between classes. Or whether, by changing the imbalance, we can validate a real performance boost.
Among the various strategies in the literature, Japkowicz & Stephen (2002) provides a scheme that is appropriate to our problem, achieved by subsampling on the negative class, as we already implemented in the first two experiments. Aside from a windfall in gained sensitivity towards the objective class, reducing the sample size is desirable as it always leads to a considerable decrease in the computational burden for any ML solution. This scheme is implicitly used in most previous works; only a small sample of the negative class is considered (Pashchenko et al. 2018; Mackenzie et al. 2016).
In our third experiment, we evaluate the relationship between the size of the negative class and the performance of the classifiers. We use RF as classifier, with the same setup as the previous section. We also use the same four tiles and evaluation method (we train RF on one tile and test it on the other three, using precision–recall curves).
We considered five different sizes for the negative class. First, we used all sources available (“full sample”). Then we considered three fixed size samples: 20 000 sources (“large sample”), 5000 sources (“mid sample”), and 2500 sources (“small sample”). Finally, we considered a completely balanced sample, equal to the number of RRLs in the tile (“one–to–one sample”). Each sample was taken from the precedent one so for example, the small sample for tile b278 was taken from the mid sample of the same tile. In all cases, we used all the RRLs in the corresponding tile.
Figure 8 shows the results of the experiment for tile b278 (results for all datasets in all the experiments in this section can be found in Appendix E). The figure shows that the one-to-one sample is clearly superior in performance than are the imbalanced samples: there is a clear advantage in using balanced datasets over highly imbalanced ones and not only in performance, but also in running time.
 |
Fig. 8. Recall vs. precision curves for different imbalance levels. All models were trained on tile b278. The left, center, and right panels are for the test tiles: b234, b261, and b360, respectively. Test and corresponding training sets have the same imbalance level. |
There is a hidden flaw in our last results. We compared curves taken from datasets with different imbalances. If we apply a one–to–one model to predict a new tile, it will have to classify all the unknown sources, and not only a sample taken from them. In that situation, the number of FP will certainly increase from what the model estimated using a reduced sample. A fairer comparison involves the use of a complete tile to estimate our performance metrics, or at least the use of a corrected estimate of the performance that takes into account the proportions in the evaluated sample and on the full sample.
If we assume that the training sample is a fair sample (even though the RRL number densities may vary from tile to tile) within a specific tile, say b278, we could argue that local densities will be conserved and, as a consequence, for each FP in the sample, there should be a higher number of incorrect sources in the full dataset, with a proportion inverse to the sampling proportion. This reasoning leads to the equation:
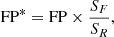
where FP* is the estimate of the real number of FP, FP is the number measured on the reduced sample, SF is the size of the Full sample, and SR is the size of the reduced sample. Using this value, we can produce a corrected estimate of the Precision on the sample:
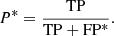 (1)
(1)
where P* is the estimation of the corrected precision and TP is the value estimated in the reduced sample. On the other side, recall values only use the positive class for its estimation and do not need a sample size correction.
In Fig. 9, we show “corrected precision” recall curves, using Eq. (1), for the same classifiers as in the previous figure. The correction seems to be a good approximation only in the low Recall regions, where the number of FP and TP is always bigger. For higher thresholds, when TP and FP become smaller, there is a clear “discrete” effect in the correction and it becomes useless.
 |
Fig. 9. Recall vs. corrected precision (P*) curves for different imbalance levels. In the left, center, and right panels, the test tiles are b234, b261, and b360, respectively. All models were trained on tile b278. Test sets have the same imbalance level than the corresponding training set. |
Therefore, the only valid method to compare the different samplings is to estimate performances using the complete tiles, with the associated computational burden. Figure 10 shows the corresponding results. The performances of the diverse sampling strategies are mostly similar, as the only full sample results that are consistently better than the rest. Our results show that when there are enough computational resources, the best modeling strategy is to use all data available.
 |
Fig. 10. Recall vs. Precision curves for different imbalance levels, using always test sets of full size. In the left, center and right panel the test tiles are b234, b261 and b360. All models were trained on tile b278. |
7. Setting the final classifier
Throughout the previous sections, we show that the best modeling strategy is to use a RF classifier with all the features available and training and testing on complete tiles. We applied this recipe to all the 16 tiles included in our study. Fig. 11 shows the corresponding results. There are very diverse behaviours, depending on the training and test tiles. Overall, it seems that we can select a recall value of 0.5 and find precision values over 0.5 in almost all cases. It means that we can expect, in a completely automatic way, to recover at least half of the RRLs in a tile paying the price of manually checking a maximum of a false alarm for each correct new finding.
 |
Fig. 11. Tables of precision and recall, training and testing with complete data of the 16 tiles. The last (separated) row shows the estimated precision (left) achieved by selecting a threshold value that sets the recall to ∼0.5 (right), training and testing on each tile with a 10 K-Folds procedure. The upper rows shows the recall and precision values observed on the test set (columns) when training on diverse tiles (rows), using the thresholds selected by 10 K-Folds (used on the last row). |
There is a last problem to be solved. In a real situation, we do not have the correct labels and we cannot fix the threshold directly to secure the desired recall level. We need to set the expected recall value using the training data, and assume it will be similar to the recall that is actually observed in the test data. We used a 10-fold CV procedure to estimate the performance of our classifiers on training data only and selected the corresponding thresholds that leads to a recall of ∼0.5. In Fig. 12, we show the full results of our final individual classifiers. Each panel shows the prediction of a different tile using all the classifiers trained on the other tiles. We added a red point to each curve showing the observed recall value on each test set for the thresholds set by 10 folds CV. We find that in most situations, our procedure leads to real recall values in the 0.3–0.7 zone.
 |
Fig. 12. Precision vs. recall curves for the final classifiers on each test tile. In each panel, the colored curves represent a classifier trained with a tile, while the black curve is the ensemble classifier. Red dots correspond to a precision and recall fixed at a threshold equivalent to the recall ∼0.5 when training and testing on the same tile with 10 k-folds. The blue stars represent the working point selected by averaging the thresholds corresponding to the red points. |
On the other hand, another clear result from Figs. 11 and 12 is that classifiers trained over different tiles produce very diverse results on a given tile and, of course, we cannot know in advance which classifier will work better for each tile. A practical solution to this problem is the use of ensemble classifiers (Rokach 2010; Granitto et al. 2005). An ensemble classifier is a new type of classifier formed by the composition of a set of (already trained) individual classifiers. In order to predict the class of a new source, the ensemble combines the prediction of all the individual classifiers that form it. The ensemble is in fact using information from all tiles at the same time with no additional computational cost. This additional information can produce improved performances in some cases and, more importantly, it usually produces more uniform results over diverse situations (diverse tiles). In our case, we combined all classifiers trained on the diverse tiles in order to make predictions of a new tile. In this evaluation phase, we exclude the classifier trained on the tile that is being tested. Our combination method is to average over all classifiers (with equal weight) the estimated probabilities of being an RRL. The threshold for this ensemble classifiers is taken as the average of individual thresholds.
Figure 12 also shows the results of the ensemble for all tiles in the paper as a bold black line. It is clear from the figure that the ensemble is equal or better, on average, than any of the individual classifiers. In Fig. 13, we show the specific recall and accuracy values for each tile using the ensemble classifier with the previous setup. We also include the average of each column of Fig. 11 as a comparison (the average of all classifiers). It is clear from the figure that our automatic procedure produce a classifier that works well in all tiles and produce the expected result of recall and precision (all but one recall values are bigger than 0.3 and all but one precision values are bigger than 0.5).
 |
Fig. 13. Precision (left) and recall (right) values of the ensemble classifier (see text). For comparison, we include in the first row the average of the values or each individual classifier in the ensemble, as shown in Fig. 11. |
8. Analysis of misidentifications
There are two classes of possible errors (misidentifications) for our ensemble classifier. First, there are FPs. These are sources that are identified as RRLs by our method but are not registered as so in the catalogs (variable stars discarded in another survey or present in new catalogs that were not taken into account in our work). In Fig. 14, we show the light curves corresponding to the five FPs identified with the highest probabilities. It is clear that all five are potential RRLs, with clear periodicity. Most FPs are similar to these and based on this evidence, we consider them as RRL candidates more than errors.
 |
Fig. 14. Light curves in time (blue on the left) and in two phases (red on the right) for the five FPs with the highest probability of being an RRL. The titles of each left panel shows probabilities, tile, and identifier of the source. The titles on the right panel shows the estimated period, right ascension (RAKs), and declination (DecKs). |
Second, there are FNs. These are already known RRLs that our pipeline assigned to the unknown-star class. In Fig. 15 we show the light curves corresponding to the five FNs identified with the lowest probabilities. These low-probability FNs are stars for which available observations on VVV were not adequate as to find the periodicity in the light curves for a correct features extraction. Typically, these errors are more related to the limitations on the feature extraction process than to limitations of the classifier itself.
We also found another distinct group of FNs with the help of an innovative use of ML methods. We devised a new experiment looking for explanations about why some RRLs are misidentified. Our hypothesis is that if there are some patterns that clearly distinguishes FNs and TPs (RRLs that are correctly and incorrectly identified), a good classifier will be able to learn the patterns.
We started by creating a dataset to learn. To achieve this we trained a RF with the complete data of all available tiles. RF has a simple and unbiased way to estimate the classification probabilities of training samples that is equivalent to a K-fold procedure, called Out-of-Bag (OOB) estimation (Breiman 2001). We set the threshold of our RF to obtain an OOB Recall ∼0.9. Next, we used this RF to OOB-classify all RRLs in our dataset and split them in two classes: TPs or FNs. At this point, we create a reduced dataset of only RRLs, with a new positive class of those correctly identified in the last step, and a new negative class with the rest of the RRLs. Finally, we train a new RF on this reduced dataset, trying to differentiate between these two kind of RRLs. We find that this RF has an OOB error level well below random guessing, showing that there are patterns that discriminate these two classes.
The RF method is also capable of estimating the relative importance of each feature in the dataset for the classification task (again, see Breiman 2001 for a detailed explanation of the procedure). Figure 16 presents in a boxplot the relative importance of all our features for the problem of splitting between the FN and TP RRLs. We can see that there are six features that are outliers from the entire set, which means that these six features are highly related to the learned patterns. The six features are freq1_harmonic_amplitude_0 (the first amplitude of the Fourier component), Psi_CS (folded range cumulative sum), ppmb (pseudo-Phase Multi-Band), PeriodLS (the period extracted with the Lomb-Scargle method), Psi_eta (phase folded dependency of the observations respect or the previous one), and Period_fit (the period false alarm probability). It is interesting to note that all are period-based.
 |
Fig. 16. Distribution of the relative feature importance of a RF classifier trained with all the RRLs and the objective class of TP and FN; see text for more. |
For a more detailed analysis, we compared how the FN and TP classes are distributed in our sample of RRLs according to these six features. The complete results can be found in Appendix F, but we show in Fig. 17 the results for the three more relevant features. In the figure, we also divided the sample into RRLs-AB and RRLs-C types because we found with these plots that the shoulders in the distribution are related to RRL subtypes. In the lower panel of the figure, there is an evident relationship between subtypes and FNs. In fact, we find that from the 155 FN in our dataset, 98 are RRL-C. The complete analysis shows that we have two main sources of FN; first some sources are poorly observed in VVV, leading to poor estimates of periods and all derived features; second, RRL-C stars are much more difficult to identify than AB type RRL.
 |
Fig. 17. Distributions of the TP and FN classes for the RRL stars in all tiles according to the three most important features to differentiate them. In the top row all the stars are compared, in the mid row only the RRL-AB type, and in the low row the RRL-C type. Left column corresponds to period_fit, mid column to Psi_eta and right column to PeriodLS. All features were converted to z-scores and are dimensionless. |
9. Data release
All the data produced in this work, light curves, features for each source and our catalog of RRL candidates are available to the community via the Carpyncho tool-set facility5 (Cabral et al. 2020). At this time, we share ∼14.3 million Ks band light curves and ∼11.2 million features, all for curves that have at least 30 epochs.
We also publish a list of 242 RRL candidates distributed in 11 tiles as shown in Table 3 (The full list of candidates can be found in Appendix F). We find using our final classifier a large sample of 117 candidate RRL in tile b396 and it is our estimate that more than half of these candidates are bona fide RRL stars. This number is between one and two orders of magnitude higher than the RRL that were previously known, in part because this region lies mostly outside of the OGLE-IV sensitivity footprint for RRL and our study was concluded prior to the Gaia data Release 2 and RRL catalogs of Clementini et al. (2019). Nevertheless a comparison of our RRL candidates and those of Clementini et al. (2019) can be used to refine our method (as we hope to do after more data is released onto the Carpyncho facility). Given the importance of RRL as dynamical test particles for the formation and evolution modeling of the bulge in the Galaxy, we promptly present our first data release of RRL, as described above, to the community.
Number of RRL candidates per tile.
10. Summary, conclusions, and future work
In this work, we derive a method for the automatic classification of RRL stars. We begin by discussing the context of RRL as keystones for stellar evolution and pulsation astrophysics and their importance as rungs on the intra- and extragalactic distance scale ladder, as well as for galaxy formation models. We base our models on RRL that have previously been classified in the literature prior to Gaia DR2. We match VVV data to those stars, and extract features using the feets package affiliated to astropy, presented in Cabral et al. (2018). We explore the difficulty inherent in existing semi-automatic methods as found in the literature and set out to test some of these pitfalls to learn from them to build a more robust classifier of RRL for the VVV survey based on a newly crafted ML tool.
We start by considering a set of traditional period- and intensity-based features, plus a subset of new pseudo-color and pseudo-magnitudes-based features. We show that period-based features are the most relevant for RRLs identification and that the incorporation of color features also add information that improves performance. We next discuss the choice of classifier and find that as in previous studies, classifiers based on multiple classification trees are the best for this particular task. We used RF in this work because of its reliability and internal OOB estimations, but boosting is a valid option, as shown by Elorrieta et al. (2016).
We discuss extensively the need for appropriate quality metrics for these highly imbalanced problems and the issues related to the use of reduced samples. We show that precision-recall tables and curves are well suited to these problems and that the best strategy for obtaining good estimations of performance is to work on the complete, highly imbalanced dataset.
The last step of the pipeline is the model selection process. We show that the threshold of our classifiers can be correctly selected using the internal K-fold method and that the use of an ensemble classifier can overcome the problem of selecting of the appropriate tile for modeling.
In the last sections of this work, we discuss how this analysis led us to a reliable and completely automatic selection of RRL candidates, with a precision ≥0.6 and a recall ≥0.3 in almost all tiles. Averaging over all tiles except b396 we have a recall of 0.48 and a precision of 0.86, or what is the same, we expect to recover the 48% of RRLs candidate stars in any new tile, and more than 8 out of 10 of them will be confirmed as RRLs. We left tile b396 aside because there were previously no classified RRL in this region.
We also discuss the most common errors of the automatic procedure, related to the low quality of some observations and the more difficult identification of the RRL-C type. All data produced in this work, including light curves, features, and the catalog of candidates has been released and made public trough the Carpyncho tool.
In terms of future work, we propose to extend the data collection contained in Carpyncho to more tiles in the VVV, along with the complete publication of the internal database (Tile-Catalogs and Pawprint-Stacks). We wish to cross-check our candidate RRL with those of Gaia-2 and determine metallicities for our RRL based on our derived light curves to make spatial metallicity maps for our RRL and independent dust extinction maps. We hope to tune our classifier for other variables. In particular, to delta-Scuti type variables that have historically been misclassified as RRL, and to determine confusion thresholds for our model RRL candidates. Although the color features used for this work are based on the first epoch VVV data we hope to be able to incorporate more color epochs from a subsample of tiles for which that information exists in later epochs. This will allow for the introduction of color features that are not fixed in time. We also wish to tune our classifier to other populations of RRL, for example, the disk population and the Sag dSph population of RRL that both fall within the foot-print of the VVV and VVV(X) data. We could hope to tune our classifier for halo RRL, given that some halo RRL are also within the VVV and VVV(X) data. We also hope to explore the change of the photometric base of our VVV RRL data, from one that is based on aperture magnitudes to one that is based on PSF magnitudes, as derived from the work of Alonso-García et al. (2018). This will permit a higher level of precision in feature observables for future studies of RRL.
The cross-matching assumes that objects A and B from two different catalogs are the same if object A is the closest to object B, and object B is the closest to object A.
Flux or luminosity is the amount of energy given by some star in one unit of time.
Acknowledgments
The authors would like to thank to their families and friends, and also IATE astronomers for useful comments and suggestions. This work was partially supported by the Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET, Argentina) and the Secretaría de Ciencia y Tecnología de la Universidad Nacional de Córdoba (SeCyT-UNC, Argentina). F.R. and J.B.C. are supported by fellowships from CONICET. P. M. G. acknowledge partial support from PIP0066-CONICET. Some processing was achieved with Argentine VO (NOVA) infrastructure, for which the authors express their gratitude. SG would like to thank Ken Freeman for infecting him with the RRL Bug and Marcio Catelan, Dante Minniti, Roberto Saito, Javier Alonso and other members of the VVV scientific team for their genuine intellectual generosity. We gratefully acknowledge data from the ESO Public Survey program ID 179.B-2002 taken with the VISTA telescope and products from the Cambridge Astronomical Survey Unit (CASU). J.B.C. thanks to Jim Emerson for extend explanations about the VISTA instruments, and finally Bruno Sínchez, Laura Baravalle and Martín Beroiz for the continuous support and friendship. This research has made use of the http://adsabs.harvard.edu/, Cornell University www.arxiv.org repository, adstex (https://github.com/yymao/adstex), astropy and the Python programming language.
References
- Alonso-García, J., Saito, R. K., Hempel, M., et al. 2018, A&A, 619, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Armstrong, D. J., Kirk, J., Lam, K. W. F., et al. 2015, A&A, 579, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baade, W. 1946, PASP, 58, 249 [NASA ADS] [CrossRef] [Google Scholar]
- Bailey, S. I. 1902, Ann. Harvard Coll. Observ., 38, 1 [NASA ADS] [Google Scholar]
- Bell, E. F., & de Jong, R. S. 2001, ApJ, 550, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Bowley, A. 1901, RR Lyrae Stars (London: PS King and Son) [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [CrossRef] [Google Scholar]
- Brough, S., Collins, C., Demarco, R., et al. 2020, ArXiv e-prints [arXiv:2001.11067] [Google Scholar]
- Burnham, R., Jr. 1978, Burnham’s Celestial Handbook: An Observer’s Guide to the Universe Beyond the Solar System, in three Volumes (New York: Dover Publ.) [Google Scholar]
- Cabral, J., Gurovich, S., Gran, F., & Minnitti, D. 2016, 7th VVV Science Workshop [Google Scholar]
- Cabral, J. B., Sánchez, B., Beroiz, M., et al. 2017, Astron. Comput., 20, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Cabral, J. B., Sánchez, B., Ramos, F., et al. 2018, Astron. Comput., 25, 213 [NASA ADS] [CrossRef] [Google Scholar]
- Cabral, J. B., Ramos, F., Gurovich, S., & Granitto, P. 2020, Carpyncho: VVV Catalog Browser Toolkit [Google Scholar]
- Cardelli, J. A., Clayton, G. C., & Mathis, J. S. 1989, ApJ, 345, 245 [NASA ADS] [CrossRef] [Google Scholar]
- Catelan, M., Minniti, D., Lucas, P. W., et al. 2011, in RR Lyrae Stars, Metal-Poor Stars, and the Galaxy, ed. A. McWilliam, et al., 5, 145 [NASA ADS] [Google Scholar]
- Clement, C. M. 2017, VizieR Online Data Catalog: V/150 [Google Scholar]
- Clementini, G., Federici, L., Corsi, C., et al. 2001, ApJ, 559, L109 [NASA ADS] [CrossRef] [Google Scholar]
- Clementini, G., Ripepi, V., Molinaro, R., et al. 2019, A&A, 622, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Collinge, M. J., Sumi, T., & Fabrycky, D. 2006, ApJ, 651, 197 [NASA ADS] [CrossRef] [Google Scholar]
- Czesla, S., Schröter, S., Schneider, C. P., et al. 2019, PyA: Python Astronomy-related Packages [Google Scholar]
- de Grijs, R., Courbin, F., Martínez-Vázquez, C. E., et al. 2017, Space Sci. Rev., 212, 1743 [NASA ADS] [CrossRef] [Google Scholar]
- Dwek, E., Arendt, R. G., Hauser, M. G., et al. 1995, ApJ, 445, 716 [CrossRef] [Google Scholar]
- Eastman, J., Siverd, R., & Gaudi, B. S. 2010, PASP, 122, 935 [NASA ADS] [CrossRef] [Google Scholar]
- Elorrieta, F., Eyheramendy, S., Jordán, A., et al. 2016, A&A, 595, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Emerson, J. P., Irwin, M. J., Lewis, J., et al. 2004, in Proc. SPIE, eds. P. J. Quinn, A. Bridger, et al., SPIE Conf. Ser., 5493, 401 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gavrilchenko, T., Klein, C. R., Bloom, J. S., & Richards, J. W. 2014, MNRAS, 441, 715 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gonzalez, O. A., Rejkuba, M., Zoccali, M., Valenti, E., & Minniti, D. 2011, A&A, 534, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gonzalez, O. A., Rejkuba, M., Zoccali, M., et al. 2012, A&A, 543, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- González-Fernández, C., Hodgkin, S. T., Irwin, M. J., et al. 2018, MNRAS, 474, 5459 [Google Scholar]
- Gran, F., Minniti, D., Saito, R. K., et al. 2015, A&A, 575, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gran, F., Minniti, D., Saito, R. K., et al. 2016, A&A, 591, A145 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Granitto, P. M., Verdes, P. F., & Ceccatto, H. A. 2005, Artif. Intell., 163, 139 [CrossRef] [Google Scholar]
- Gurovich, S., Freeman, K., Jerjen, H., Staveley-Smith, L., & Puerari, I. 2010, AJ, 140, 663 [NASA ADS] [CrossRef] [Google Scholar]
- Hanisch, R. J., Farris, A., Greisen, E. W., et al. 2001, A&A, 376, 359 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hosenie, Z., Lyon, R., Stappers, B., Mootoovaloo, A., & McBride, V. 2020, MNRAS, 493, 6050 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Japkowicz, N., & Stephen, S. 2002, Intell. Data Anal., 6, 429 [Google Scholar]
- Kim, D.-W., Protopapas, P., Byun, Y.-I., et al. 2011, ApJ, 735, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, D.-W., Protopapas, P., Bailer-Jones, C. A. L., et al. 2014, A&A, 566, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kovács, G., & Walker, A. R. 2001, A&A, 371, 579 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kunder, A., & Chaboyer, B. 2008, AJ, 136, 2441 [NASA ADS] [CrossRef] [Google Scholar]
- Kunder, A., Popowski, P., Cook, K. H., & Chaboyer, B. 2008, AJ, 135, 631 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, Y.-W. 1992, AJ, 104, 1780 [NASA ADS] [CrossRef] [Google Scholar]
- Liška, J., Skarka, M., Zejda, M., Mikulášek, Z., & de Villiers, S. N. 2016, MNRAS, 459, 4360 [NASA ADS] [CrossRef] [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [Google Scholar]
- Mackenzie, C., Pichara, K., & Protopapas, P. 2016, ApJ, 820, 138 [NASA ADS] [CrossRef] [Google Scholar]
- Majaess, D., Dékány, I., Hajdu, G., et al. 2018, Ap&SS, 363, 127 [Google Scholar]
- Minniti, D., Lucas, P. W., Emerson, J. P., et al. 2010, New Astron., 15, 433 [Google Scholar]
- Mitchell, T. M. 1997, Mach. Learn. (McGraw-hill New York) [Google Scholar]
- Moretti, M. I., Hatzidimitriou, D., Karampelas, A., et al. 2018, MNRAS, 477, 2664 [NASA ADS] [CrossRef] [Google Scholar]
- Nishiyama, S., Tamura, M., Hatano, H., et al. 2009, ApJ, 696, 1407 [NASA ADS] [CrossRef] [Google Scholar]
- Nun, I., Protopapas, P., Sim, B., et al. 2015, ArXiv e-prints [arXiv:1506.00010] [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oliphant, T. E. 2007, Comput. Sci. Eng., 9, 10 [CrossRef] [PubMed] [Google Scholar]
- Pashchenko, I. N., Sokolovsky, K. V., & Gavras, P. 2018, MNRAS, 475, 2326 [NASA ADS] [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Prudil, Z., & Skarka, M. 2017, MNRAS, 466, 2602 [NASA ADS] [CrossRef] [Google Scholar]
- Ragan-Kelley, M., Perez, F., Granger, B., et al. 2014, AGU Fall Meeting Abstracts, 1, 07 [Google Scholar]
- Richards, J. W., Starr, D. L., Butler, N. R., et al. 2011, ApJ, 733, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Richards, J. W., Starr, D. L., Miller, A. A., et al. 2012, ApJS, 203, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Rokach, L. 2010, Artif. Intell. Rev., 33, 1 [CrossRef] [Google Scholar]
- Sakai, S., & Madore, B. F. 2001, ApJ, 555, 280 [NASA ADS] [CrossRef] [Google Scholar]
- Samus’, N. N., Kazarovets, E. V., Durlevich, O. V., Kireeva, N. N., & Pastukhova, E. N. 2017, Astron. Rep., 61, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [Google Scholar]
- Schultheis, M., Chen, B. Q., Jiang, B. W., et al. 2014, A&A, 566, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Seares, F. H., & Shapley, H. 1914, PASP, 26, 202 [NASA ADS] [CrossRef] [Google Scholar]
- Sesar, B., Hernitschek, N., Mitrović, S., et al. 2017, AJ, 153, 204 [Google Scholar]
- Shapley, H. 1918, ApJ, 48, 154 [NASA ADS] [CrossRef] [Google Scholar]
- Shin, M.-S., Sekora, M., & Byun, Y.-I. 2009, MNRAS, 400, 1897 [NASA ADS] [CrossRef] [Google Scholar]
- Shin, M.-S., Yi, H., Kim, D.-W., Chang, S.-W., & Byun, Y.-I. 2012, AJ, 143, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Silbermann, N. A., & Smith, H. A. 1995, AJ, 110, 704 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, H. A. 2004, RR Lyrae Stars (UK: Cambridge University Press) [Google Scholar]
- Soszyński, I., Dziembowski, W. A., Udalski, A., et al. 2011, Acta Astron., 61, 1 [NASA ADS] [Google Scholar]
- Soszyński, I., Udalski, A., Szymański, M. K., et al. 2014, Acta Astron., 64, 177 [NASA ADS] [Google Scholar]
- Soszyński, I., Udalski, A., Szymański, M. K., et al. 2017, Acta Astron., 67, 297 [NASA ADS] [Google Scholar]
- Soszyński, I., Udalski, A., Wrona, M., et al. 2019, Acta Astron., 69, 321 [Google Scholar]
- Tollerud, E. 2012, Astropysics: Astrophysics Utilities for Python (Astrophysics Source Code Library) [Google Scholar]
- Udalski, A. 2003, Acta Astron., 53, 291 [NASA ADS] [Google Scholar]
- Udalski, A., Kubiak, M., Szymanski, M., et al. 1994, Acta Astron., 44, 317 [NASA ADS] [Google Scholar]
- Udalski, A., Szymański, M. K., & Szymański, G. 2015, Acta Astron., 65, 1 [NASA ADS] [Google Scholar]
- Van Der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [CrossRef] [Google Scholar]
- VanderPlas, J. T. 2018, ApJS, 236, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Vapnik, V. 2013, The Nature of Statistical Learning Theory (Springer science& business media) [Google Scholar]
- Watson, C. L., Henden, A. A., & Price, A. 2006, Soc. Astron. Sci. Annu. Symp., 25, 47 [Google Scholar]
- Wozniak, P. R. 2000, Acta Astron., 50, 421 [NASA ADS] [Google Scholar]
- Zejda, M., Paunzen, E., Baumann, B., Mikulášek, Z., & Liška, J. 2012, A&A, 548, A97 [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: List of catalogs accessed in this work
-
The Optical Gravitational Lensing Experiment. The OGLE-III Catalog of Variable Stars. XI. RR Lyrae Stars in the Galactic Bulge (Soszyński et al. 2011).
-
Gaia Data Release 2. Summary of the contents and survey properties (Gaia Collaboration 2018).
-
Metallicity Analysis of MACHO Galactic Bulge RR0 Lyrae Stars from their Light Curves (Kunder & Chaboyer 2008).
-
VizieR Online Data Catalog: Updated catalog of variable stars in globular clusters (Clement+ 2017) (Clement 2017).
-
The International Variable Star Index (VSX) (Watson et al. 2006).
-
The Extinction Toward the Galactic Bulge from RR Lyrae Stars (Kunder et al. 2008).
-
A mid-infrared study of RR Lyrae stars with the Wide-field Infrared Survey Explorer all-sky data release (Gavrilchenko et al. 2014).
-
Blazhko effect in the Galactic bulge fundamental mode RR Lyrae stars - I. Incidence rate and differences between modulated and non-modulated stars (Prudil & Skarka 2017).
-
The Gaia mission (Gaia Collaboration 2016).
-
Mapping the outer bulge with RRab stars from the VVV Survey (Gran et al. 2016).
-
Establishing the Galactic Centre distance using VVV Bulge RR Lyrae variables (Majaess et al. 2018).
-
Over 38000 RR Lyrae Stars in the OGLE Galactic Bulge Fields (Soszyński et al. 2014).
-
General catalogue of variable stars: Version GCVS 5.1 (Samus’ et al. 2017).
-
Machine-learned Identification of RR Lyrae Stars from Sparse, Multi-band Data: The PS1 Sample (Sesar et al. 2017).
-
Catalogue of variable stars in open cluster fields (Zejda et al. 2012).
-
Cyclic variations in O-C diagrams of field RR Lyrae stars as a result of LiTE (Liška et al. 2016).
-
Catalog of Fundamental-Mode RR Lyrae Stars in the Galactic Bulge from the Optical Gravitational Lensing Experiment (Collinge et al. 2006).
-
The Optical Gravitational Lensing Experiment. The Catalog of Periodic Variable Stars in the Galactic Bulge. I. Periodic Variables in the Center of the Baade’s Window (Udalski et al. 1994).
-
The OGLE Collection of Variable Stars. Classical, Type II, and Anomalous Cepheids toward the Galactic Center (Soszyński et al. 2017).
Appendix B: Features related to feets
Most of these descriptions are adapted from the feets documentation6.
Amplitude (AKs) the half of difference between the median of the 5% upper values and the median of the 5% of the lower values of the Ks band (Richards et al. 2011).
Autocor_length Auto-Correlation Length is the cross correlation of the signal with itself. Is useful to find patterns like noise hidden periodic signal (Kim et al. 2011).
Beyond1Std Percentage of points beyond one standard deviation from the weighted mean. For a normal distribution, it should take a value close to 0.32 (Richards et al. 2011).
Con “Consecutive points”. number of three consecutive points greater or lesser than 2σ (normalized by N − 200). This index was created by the OGLE survey to find variable stars (Wozniak 2000; Kim et al. 2011).
Eta_e (ηe) Verify the dependency of the observations respect or the previous ones (Kim et al. 2014).
FluxPercentileRatioMid The “Middle flux percentiles Ratio” characterizes the distributions of sorted magnitudes based on their fluxes percentiles7. If Fi, j is the difference between the flux percentil j and the flux percentile i we can calculate:
-
FluxPercentileRatioMid20 = F40, 60/F5, 95
-
FluxPercentileRatioMid35 = F32.5, 67.5/F5, 95
-
FluxPercentileRatioMid50 = F25, 75/F5, 95
-
FluxPercentileRatioMid65 = F17.5, 82.5/F5, 95
-
FluxPercentileRatioMid80 = F10, 90/F5, 95
Fourier components The first three Fourier components for the first three period candidates. Freqk_harmonics_amplitude_i y Freqk_harmonics_rel_phase_j represents the i-nth amplitude ant the j-nth phase of the signal for the k-nth period. (Richards et al. 2011).
Gskew Median-of-magnitudes based measure of the skew
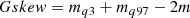
where: mq3 is the median of magnitudes lesser or equal than the quantile 3, mq97 is the median of magnitudes greater or equal than the quantile 97; and m is the median of magnitudes (Bowley 1901).
LinearTrend Linear tendency. the slope of the linear regression of the data (Richards et al. 2011).
MaxSlope Maximum absolute slope between two consecutive observations(Richards et al. 2011).
Mean Mean of magnitudes (Kim et al. 2014).
MedianAbsDev The Median of the absolute deviations, is defined as the median of the difference of every observed magnitude with the median of the entire time-serie. In simbols MedianAbsoluteDeviation = median(|mag − median(mag)|) (Richards et al. 2011).
MedianBRP – The “Median Buffer Range Percentage” can be interpreted as the percentage closest to the median. Proportion of the magnitudes between the 10th part of the total range around the median (Richards et al. 2011).
PairSlopeTrend Considering the last 30 (time-sorted) measurements of source magnitude, the fraction of increasing first differences minus the fraction of decreasing first differences (Richards et al. 2011).
PercentAmplitude Largest percentage difference between either the max or min magnitude and the median. (Richards et al. 2011).
PercentDifferenceFluxPercentile Ratio of F5, 95 (converted to magnitude) over the median magnitude (Richards et al. 2011).
PeriodLSLomb-Scargle Period. Is the first period extracted with the Lomb-Scargle method (Kim et al. 2011, 2014; VanderPlas 2018).
Period_fit “Period Fitness”. Measure of the reliability of the PeriodLS value. The reliability falls as it approaches the value of 1 (Kim et al. 2011, 2014; VanderPlas 2018).
Psi_CS (ΨCS)RCS applied to the phase-folded light curve (generated using the period as estimated from the Lomb-Scargle method) (Kim et al. 2011, 2014).
Psi_eta (Ψη)ηe index calculated from the folded light curve (generated using the period estimate from the Lomb-Scargle method) (Kim et al. 2011, 2014).
Q31 (Q3−1) Is the difference between the third quartile, Q3, and the first quartile, Q1 of magnitudes (Kim et al. 2014).
Rcs (RCS) “Range Cumulative Sum” is literally the range of the cumulative sum of magnitudes normalized by 1/Nσ, where N is the number of observations and σ is the standard deviation of magnitudes (Kim et al. 2011).
Skew The skewness of magnitudes (Kim et al. 2011).
SmallKurtosis Small sample kurtosis of the magnitudes. For a normal distribution this values is ∼0 (Richards et al. 2011).
Std The standard deviation of magnitudes (Richards et al. 2011).
Appendix C: Feature analysis
 |
Fig. C.1. Precision vs. recall curves for different features sub-sets for different tile combinations in training and testing. Every plot is one combination of train and test and every curve is one feature subset. |
Appendix D: Model selection
 |
Fig. D.1. Precision vs. recall curves for different models for different tile combinations in training and testing. Every plot is one combination of training and testing and every curve is one model. |
Appendix E: Unbalance analysis
 |
Fig. E.1. Precision vs. recall curves training and testing on the same sample sizes (one-to-one, small, mid, large, and full) for different tile combinations in training and testing. Every plot is one combination of training and testing and every curve is one sample size. |
 |
Fig. E.2. Precision* vs. recall curves training on different sample sizes (one-to-one, small, mid, large, and full) and testing on the full sample for different tile combinations in training and testing. Every plot is one combination of train and test and every curve is one sample size. |
 |
Fig. E.3. Precision vs. recall curves training on different sample sizes (one-to-one, small, mid, large, and full) and testing on the full sample for different tile combinations in training and testing. Every plot is one combination of train and test and every curve is one sample size. |
Appendix F: Analysis of misidentifications
 |
Fig. F.1. Distributions of the TP and FN classes for the RRL stars in all tiles according to the six most important features to differentiate them. In the top row, all the stars are compared, in the mid row, only the RRL-AB type, and in the low row, the RRL-C type. From right to left, the columns corresponds to: period_fit, Psi_eta, PeriodLS, ppmb, Psi_CS, and Freq1_harmonics_amplitude_0. All features were converted to z-scores and are dimensionless. |
Appendix G: Catalog
Candidates 1–61 candidates to RRL sorted by probability of being an RRL.
Candidates 62–122 to RRL sorted by probability to be an RRL.
Candidates 123–182 to RRL sorted by probability to be an RRL.
Candidates 183–242 to RRL sorted by probability to be an RRL.
 |
Fig. G.1. Folded light curve for the candidates 1–27 to RRL sorted by probability to be an RRL. In the title of every plot are displayed number of the source, the VVV identification and the probability to be a RRL. The horizontal axis is the phase, and the vertical shows the source magnitude. For visual ease, two periods are shown. |
 |
Fig. G.2. Folded light curve for the candidates 28–54 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.3. Folded light curve for the candidates 55–81 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.4. Folded light curve for the candidates 82–108 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.5. Folded light curve for the candidates 109–135 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.6. Folded light curve for the candidates 136–162 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.7. Folded light curve for the candidates 163–189 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.8. Folded light curve for the candidates 190–216 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
 |
Fig. G.9. Folded light curve for the candidates 217–242 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
All Tables
All Figures
|
Fig. 1. Light curve of an RRL AB variable star from Gran et al. (2015) identified with the ID VVV J2703536.01-412829.4. The horizontal axis is the measurement date in heliocentric-corrected days (HJD) and the vertical one is the source magnitude. |
| In the text | |
|
Fig. 2. Folded light curve for the same star as Fig. 1, using a period of ∼0.757 days. The horizontal axis is the phase, and the vertical shows the source magnitude. For visual ease, two periods are shown. |
| In the text | |
|
Fig. 3. Map of the bulge tiles of the VVV survey. In blue, we mark the tiles used for this paper. |
| In the text | |
|
Fig. 4. Recall vs. precision curves of trained RF classifiers for different feature subsets. On the left, center, and right panels, the test tiles are b234, b261, and b360, respectively. All models were trained on tile b278. |
| In the text | |
|
Fig. 5. Precision for different subsets of features for the tiles b234, b261, b278, and b360 for a fixed recall (∼0.9). From left to right: the first panel includes the total set of features; in the second, only the magnitude- and period-based features is used; in the third, the magnitude- and extinction-based ones; and, finally, the extinction- and period-based features are used. In all cases, the rows indicate which tile was used for train the RF classifier and the columns indicate the one used for the test. |
| In the text | |
|
Fig. 6. Accuracy, ROC-AUC, and precision for different classifiers. All details are the same as in Fig. 5. |
| In the text | |
|
Fig. 7. Recall vs. recision curves for different classification methods. In the left, center, and right panel, the test tiles are b234, b261, and b360, respectively. All models were trained on tile b278. |
| In the text | |
|
Fig. 8. Recall vs. precision curves for different imbalance levels. All models were trained on tile b278. The left, center, and right panels are for the test tiles: b234, b261, and b360, respectively. Test and corresponding training sets have the same imbalance level. |
| In the text | |
|
Fig. 9. Recall vs. corrected precision (P*) curves for different imbalance levels. In the left, center, and right panels, the test tiles are b234, b261, and b360, respectively. All models were trained on tile b278. Test sets have the same imbalance level than the corresponding training set. |
| In the text | |
|
Fig. 10. Recall vs. Precision curves for different imbalance levels, using always test sets of full size. In the left, center and right panel the test tiles are b234, b261 and b360. All models were trained on tile b278. |
| In the text | |
|
Fig. 11. Tables of precision and recall, training and testing with complete data of the 16 tiles. The last (separated) row shows the estimated precision (left) achieved by selecting a threshold value that sets the recall to ∼0.5 (right), training and testing on each tile with a 10 K-Folds procedure. The upper rows shows the recall and precision values observed on the test set (columns) when training on diverse tiles (rows), using the thresholds selected by 10 K-Folds (used on the last row). |
| In the text | |
|
Fig. 12. Precision vs. recall curves for the final classifiers on each test tile. In each panel, the colored curves represent a classifier trained with a tile, while the black curve is the ensemble classifier. Red dots correspond to a precision and recall fixed at a threshold equivalent to the recall ∼0.5 when training and testing on the same tile with 10 k-folds. The blue stars represent the working point selected by averaging the thresholds corresponding to the red points. |
| In the text | |
|
Fig. 13. Precision (left) and recall (right) values of the ensemble classifier (see text). For comparison, we include in the first row the average of the values or each individual classifier in the ensemble, as shown in Fig. 11. |
| In the text | |
|
Fig. 14. Light curves in time (blue on the left) and in two phases (red on the right) for the five FPs with the highest probability of being an RRL. The titles of each left panel shows probabilities, tile, and identifier of the source. The titles on the right panel shows the estimated period, right ascension (RAKs), and declination (DecKs). |
| In the text | |
 |
Fig. 15. Same as Fig. 14 for the five FNs with the lowest probability of being an RRL. |
| In the text | |
|
Fig. 16. Distribution of the relative feature importance of a RF classifier trained with all the RRLs and the objective class of TP and FN; see text for more. |
| In the text | |
|
Fig. 17. Distributions of the TP and FN classes for the RRL stars in all tiles according to the three most important features to differentiate them. In the top row all the stars are compared, in the mid row only the RRL-AB type, and in the low row the RRL-C type. Left column corresponds to period_fit, mid column to Psi_eta and right column to PeriodLS. All features were converted to z-scores and are dimensionless. |
| In the text | |
|
Fig. C.1. Precision vs. recall curves for different features sub-sets for different tile combinations in training and testing. Every plot is one combination of train and test and every curve is one feature subset. |
| In the text | |
|
Fig. D.1. Precision vs. recall curves for different models for different tile combinations in training and testing. Every plot is one combination of training and testing and every curve is one model. |
| In the text | |
|
Fig. E.1. Precision vs. recall curves training and testing on the same sample sizes (one-to-one, small, mid, large, and full) for different tile combinations in training and testing. Every plot is one combination of training and testing and every curve is one sample size. |
| In the text | |
|
Fig. E.2. Precision* vs. recall curves training on different sample sizes (one-to-one, small, mid, large, and full) and testing on the full sample for different tile combinations in training and testing. Every plot is one combination of train and test and every curve is one sample size. |
| In the text | |
|
Fig. E.3. Precision vs. recall curves training on different sample sizes (one-to-one, small, mid, large, and full) and testing on the full sample for different tile combinations in training and testing. Every plot is one combination of train and test and every curve is one sample size. |
| In the text | |
|
Fig. F.1. Distributions of the TP and FN classes for the RRL stars in all tiles according to the six most important features to differentiate them. In the top row, all the stars are compared, in the mid row, only the RRL-AB type, and in the low row, the RRL-C type. From right to left, the columns corresponds to: period_fit, Psi_eta, PeriodLS, ppmb, Psi_CS, and Freq1_harmonics_amplitude_0. All features were converted to z-scores and are dimensionless. |
| In the text | |
|
Fig. G.1. Folded light curve for the candidates 1–27 to RRL sorted by probability to be an RRL. In the title of every plot are displayed number of the source, the VVV identification and the probability to be a RRL. The horizontal axis is the phase, and the vertical shows the source magnitude. For visual ease, two periods are shown. |
| In the text | |
|
Fig. G.2. Folded light curve for the candidates 28–54 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.3. Folded light curve for the candidates 55–81 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.4. Folded light curve for the candidates 82–108 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.5. Folded light curve for the candidates 109–135 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.6. Folded light curve for the candidates 136–162 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.7. Folded light curve for the candidates 163–189 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.8. Folded light curve for the candidates 190–216 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
|
Fig. G.9. Folded light curve for the candidates 217–242 to RRL sorted by probability of being an RRL. All details are the same as in Fig. G.1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.