| Issue |
A&A
Volume 642, October 2020
|
|
|---|---|---|
| Article Number | A148 | |
| Number of page(s) | 19 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202038067 | |
| Published online | 13 October 2020 | |
Survey of Gravitationally-lensed Objects in HSC Imaging (SuGOHI)
VI. Crowdsourced lens finding with Space Warps⋆
1
Leiden Observatory, Leiden University, Niels Bohrweg 2, 2333 CA Leiden, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Kavli IPMU (WPI), UTIAS, The University of Tokyo, Kashiwa, Chiba 277-8583, Japan
3
Sub-department of Astrophysics, University of Oxford, Denys Wilkinson Building, Keble Road, Oxford OX1 3RH, UK
4
The Inter-University Center for Astronomy and Astrophysics, Post bag 4, Ganeshkhind, Pune 411007, India
5
Zooniverse, c/o Astrophysics Department, University of Oxford, Oxford, UK
6
Institute of Physics, Laboratory of Astrophysics, École Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, 1290 Versoix, Switzerland
7
Department of Physics, Kindai University, 3-4-1 Kowakae, Higashi-Osaka, Osaka 577-8502, Japan
8
Astronomy Study Program and Bosscha Observatory, FMIPA, Institut Teknologi Bandung, Jl. Ganesha 10, Bandung 40132, Indonesia
9
National Optical Astronomy Observatory, 950 N Cherry Avenue, Tucson, AZ 85719, USA
10
Kavli Institute for Particle Astrophysics and Cosmology, Stanford University, 452 Lomita Mall, Stanford, CA 94035, USA
11
Department of Physics, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo 113-0033, Japan
12
Research Center for the Early Universe, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo 113-0033, Japan
13
Subaru Telescope, National Astronomical Observatory of Japan, 2-21-1 Osawa, Mitaka, Tokyo 181-0015, Japan
14
National Astronomical Observatory of Japan, 2-21-1 Osawa, Mitaka, Tokyo 181-8588, Japan
15
Adler Planetarium, Chicago, IL 60605, USA
Received:
1
April
2020
Accepted:
17
July
2020
Abstract
Context. Strong lenses are extremely useful probes of the distribution of matter on galaxy and cluster scales at cosmological distances, however, they are rare and difficult to find. The number of currently known lenses is on the order of 1000.
Aims. The aim of this study is to use crowdsourcing to carry out a lens search targeting massive galaxies selected from over 442 square degrees of photometric data from the Hyper Suprime-Cam (HSC) survey.
Methods. Based on the S16A internal data release of the HSC survey, we chose a sample of ∼300 000 galaxies with photometric redshifts in the range of 0.2 < zphot < 1.2 and photometrically inferred stellar masses of log M* > 11.2. We crowdsourced lens finding on this sample of galaxies on the Zooniverse platform as part of the Space Warps project. The sample was complemented by a large set of simulated lenses and visually selected non-lenses for training purposes. Nearly 6000 citizen volunteers participated in the experiment. In parallel, we used YATTALENS, an automated lens-finding algorithm, to look for lenses in the same sample of galaxies.
Results. Based on a statistical analysis of classification data from the volunteers, we selected a sample of the most promising ∼1500 candidates, which we then visually inspected: half of them turned out to be possible (grade C) lenses or better. By including lenses found by YATTALENS or serendipitously noticed in the discussion section of the Space Warps website, we were able to find 14 definite lenses (grade A), 129 probable lenses (grade B), and 581 possible lenses. YATTALENS found half the number of lenses that were discovered via crowdsourcing.
Conclusions. Crowdsourcing is able to produce samples of lens candidates with high completeness, when multiple images are clearly detected, and with higher purity compared to the currently available automated algorithms. A hybrid approach, in which the visual inspection of samples of lens candidates pre-selected by discovery algorithms or coupled to machine learning is crowdsourced, will be a viable option for lens finding in the 2020s, with forthcoming wide-area surveys such as LSST, Euclid, and WFIRST.
Key words: gravitational lensing: strong / galaxies: elliptical and lenticular, cD
Full list of lens candidates with grade C and better are only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/642/A148
Marie Skłodowska-Curie Fellow.
© ESO 2020
1. Introduction
Strong gravitational lensing is a very powerful tool for studying galaxy evolution and cosmology. For example, strong lenses have been used to explore the inner structure of galaxies and their evolution (e.g. Treu & Koopmans 2002; Koopmans & Treu 2003; Auger et al. 2010; Ruff et al. 2011; Bolton et al. 2012; Sonnenfeld et al. 2013a), as well as to put constraints on the stellar initial mass function (IMF) of massive galaxies (e.g. Treu et al. 2010; Spiniello et al. 2012; Barnabè et al. 2013; Smith et al. 2015; Sonnenfeld et al. 2019) and on their dark matter content (e.g. Sonnenfeld et al. 2012; Newman et al. 2015; Oldham & Auger 2018). Strong lensing is a unique tool for detecting the presence of substructures inside or along the line of sight of massive galaxies (e.g. Mao & Schneider 1998; More et al. 2009; Vegetti et al. 2010; Hsueh et al. 2020). Strongly lensed compact sources, such as quasars or supernovae, have been used to measure the surface mass density in stellar objects via the microlensing effect (e.g. Mediavilla et al. 2009; Schechter et al. 2014; Oguri et al. 2014) and to measure cosmological parameters from time delay observations (e.g. Suyu et al. 2017; Grillo et al. 2018; Wong et al. 2019; Millon et al. 2020). While they are very useful, strong lenses are rare, as they require the chance alignment of a light source with a foreground object with a sufficiently large surface mass density. The number of currently known strong lenses is on the order of 1000, with the exact number depending on the purity of the sample1. Despite this seemingly high number, the effective sample size is, in practice, much smaller for many strong lensing applications once the selection criteria for obtaining suitable objects for a given study are applied. For example, most known lens galaxies have redshifts of z < 0.5, limiting the time range that can be explored in evolution studies. For this reason, many strong lensing-based inferences are still dominated by statistical uncertainties due to small sample sizes. Expanding the sample of known lenses would, therefore, broaden the range of investigations that can be carried out, providing statistical power that is presently lacking.
Current wide-field photometric surveys, such as the Hyper Suprime-Cam Subaru Strategic Program (HSC SSP, Aihara et al. 2018a; Miyazaki et al. 2018), the Kilo Degree Survey (KiDS, de Jong et al. 2015), and the Dark Energy Survey (DES, Dark Energy Survey Collaboration 2016) are allowing the discovery of hundreds of new promising strong lens candidates (e.g. Sonnenfeld et al. 2018; Petrillo et al. 2019; Jacobs et al. 2019). Although the details vary between surveys, the general strategy for finding new lenses consists of scanning images of galaxies that exhibit the potential of serving as lenses, given their mass and redshift, and looking for the presence of strongly lensed features around them. Due to the large areas covered by the aforementioned surveys (the HSC SSP is planned to acquire data over 1400 square degrees of sky), the number of galaxies that are to be analysed in order to obtain a lens sample as complete as possible can easily reach into the hundreds of thousands. In order to deal with such a large scale, the lens finding task is usually automated, either by making use of a lens finding algorithm or artificial neural networks trained on simulated data (see Metcalf et al. 2019, for an overview of some of the latest methods employed for lens finding in purely photometric data). We point out how the current implementations of automatic lens finding algorithms, including those based on artificial neural networks, require some degree of visual inspection: typically these methods are applied in such a way as to prioritise completeness, resulting in a relatively low purity. For example, out of 1480 lens candidates found by the algorithm YATTALENS in the HSC data, only 46 were labelled as highly probable lens candidates (Sonnenfeld et al. 2018). Similarly, the convolutional neural networks developed by Petrillo et al. (2019) for a lens search in KiDS data produced a list of 3500 candidates, of which only 89 were recognised to be strong lenses with high confidence after visual inspection. Nevertheless, Petrillo et al. (2019) showed how high purity can still be achieved without human intervention, albeit with a great loss in completeness.
While it is both desirable and plausible that future improvements in the development of lens finding algorithms will lead to higher purity and completeness in lens searches, a currently viable and very powerful approach to lens finding is crowdsourcing, which harnesses the skill and adaptability of human pattern recognition. With crowdsourcing, lens candidates are distributed among a large number of trained volunteers for visual inspection. The Space Warps collaboration has been pioneering this method and has applied it successfully to data from the Canada-France-Hawaii Telescope Legacy Survey (CFHT-LS, Marshall et al. 2016; More et al. 2016). In this work, we use crowdsourcing and the tools developed by the Space Warps team to look for strong lenses in 442 square degrees of imaging data collected from the HSC survey.
We obtained cutouts around ∼300 000 massive galaxies selected with the criteria listed above and submitted them for inspection to a team of citizen scientist volunteers, together with training images consisting of known lenses, simulated lenses, and non-lens galaxies, via the Space Warps platform. The volunteers were asked to simply label each image as either a lens or a non-lens. After collecting multiple classifications for each galaxy in the sample, we combined them in a Bayesian framework to obtain a probability for an object to be a strong lens. The science team then visually inspected the most likely lens candidates and classified them with more stringent criteria. In parallel to crowdsourcing, we searched for strong lenses in the same sample of massive galaxies by using the YATTALENS software, which has been used for past lens searches in HSC data (Sonnenfeld et al. 2018; Wong et al. 2018). By merging the crowdsourced lens candidates with those obtained by YATTALENS, we were able to discover a sample of 143 high-probability lens candidates. Most of these very promising candidates were successfully identified as such by citizen participants.
The aim of this paper is to describe the details of our lens finding effort, present the sample of newly discovered lens candidates, discuss the relative performance of crowdsourcing and of the YATTALENS software, and to suggest strategies for future searches. The structure of this work is as follows. In Sect. 2, we describe the data used for the lens search, including the training set for crowdsourcing. In Sect. 3, we describe the setup of the crowdsourcing experiment and the algorithm used for the analysis of the classifications from the citizen scientist volunteers. In Sect. 4, we show our results, including the sample of candidates found with YATTALENS and highlighting interesting lens candidates of different types. In Sect. 5, we discuss the merits and limitations of the two lens finding strategies. We conclude in Sect. 6. All magnitudes are in AB units and all images are oriented with north up and east to the left.
2. The data
2.1. The parent sample
Our lens-finding effort was based on a targeted search, as opposed to a blind one: we looked for lensed features among a set of galaxies based on the properties that make them potential lenses. Specifically, we targeted galaxies in the redshift range of 0.2 < z < 1.2 and with stellar mass M* larger than 1011.2 M⊙, with photometric data from the HSC survey. The upper redshift and lower stellar mass bounds are a compromise between the goal of obtaining a sample of lenses as complete as possible and the need to keep the number of galaxies to be inspected by the volunteers within a reasonable value, while the lower redshift cut was introduced to avoid dealing with galaxies too bright for the detection of lensed features, which are typically faint. In order to select such a sample, we relied on the photometric redshift catalogue from the S16A internal data release of the HSC survey (Tanaka et al. 2018). In particular, we used data products obtained with the template fitting-based photometric redshift software MIZUKI (Tanaka 2015), which fits, explicitly and self-consistently, the star-formation history of a galaxy and its redshift, using the five bands of HSC (g, r, i, z, y). We applied the redshift and stellar mass cuts listed above to the median value of the photometric redshift and the stellar mass provided by MIZUKI, for each galaxy with photometric data in all five HSC bands and detections in at least three bands, regardless of depth. We removed galaxies with saturated pixels, as well as probable stars, by setting i_extendedness_value > 0 and by removing objects brighter than 21 mag in the i-band and a moments-derived size smaller than 0.4″. Typical statistical uncertainties are 0.02 on the photo-z and 0.05 on log M*.
The steps described above led us to a sample of ∼300 000 galaxies. From these, we removed 70 known lenses from the literature, mostly from our previous searches (Sonnenfeld et al. 2018; Wong et al. 2018; Chan et al. 2020), as well as a few hundred galaxies that have already been inspected and identified as possible lenses (grade C candidates in our notation) in the aforementioned studies. Many of the known lenses were used for training purposes, which is further explained in Sect. 3.1. The Sonnenfeld et al. (2018) search covered the same area as the present study, but targeted exclusively ∼43 000 luminous red galaxies with spectra from the Baryonic Oscillation Spectroscopic Survey. Only about half of those galaxies belong to the sample used for our study, while the remaining half was excluded because of our stellar mass limit. Finally, we removed from the sample ∼4000 galaxies used as negative (i.e. non-lens) training subjects2. The selection of these objects is described in Sect. 3.1. The final sample size consisted of 288, 109 subjects.
Although our goal is to maximise completeness, some lenses were inevitably missed in this initial step. These are lenses for which the deflector is outside the redshift range considered or below the stellar mass cut. Additionally, blending between lens and source light can be responsible for inaccuracies and, in the worst cases, catastrophic failures in the determination of the lens photometric redshift or stellar mass, which compromises completeness. Lenses with a relatively bright source and small image separation are particularly affected by this and, thus, likely to be missing from our sample.
2.2. HSC imaging
We used g, r, i-band data from HSC S17A3 for our experiment. The target depth of the Wide layer of the HSC SSP, where our targets are located, is 26.2, 26.4 and 26.8 in i-, r- and g-band respectively (5σ detection for a point source, Aihara et al. 2018b). Roughly 70% of our objects lie in parts of the survey for which the target depth has been reached in S17A. The median seeing in the i-, r- and g-band is 0.57″, 0.67″ and 0.72″, respectively (Aihara et al. 2018b). Image quality and depth are critical for the purpose of finding lenses. Compared to KiDS and DES, HSC data is both sharper and deeper and should therefore allow the discovery of lenses that are fainter or have smaller image separation, with respect to the typical lenses found in these other surveys (for more, see our discussion in Sect. 5.3).
For each subject, we obtained 101 × 101 pixel (i.e. 17.0 × 17.0″) cutouts from co-added and sky-subtracted data in each band, which we used both for our crowdsourced search and for the search with YATTALENS. These data, among with corresponding variance maps and models of the point spread function (PSF), were produced by the HSC data reduction pipeline HSCPIPE version 5.4 (Bosch et al. 2018), a version of the Large Synoptic Survey Telescope stack (Ivezić et al. 2019; Axelrod et al. 2010; Jurić et al. 2017).
2.3. RGB image preparation
In order to facilitate the visual detection of faint lensed features that would normally be blended with the lens light, we produced versions of the images of the subjects with the light from the main (foreground, putative lens) galaxy subtracted off. Foreground light subtraction was carried out by fitting a Sérsic surface brightness profile to the data, using YATTALENS. The structural parameters of the Sérsic model (e.g. the half-light radius, position angle, etc.) were first optimised on the i-band data (the band with the best image quality), then a scaled-up version of the model, convolved with the model PSF, was subtracted from the data in each band. The presence of lens light-subtracted images was one of the main elements of novelty in our experiment, compared to past searches with Space Warps, which, in fact, recommended the adoption of such a procedure to improve the detection of lenses.
The original and foreground-subtracted data were used to make two sets of RGB images, with different colour schemes. All colour schemes were based on a linear mapping between the flux in each pixel and the intensity in the 8-bit RGB channel of the corresponding band:
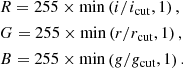 (1)
(1)
In the above equations, i, r, g indicate the flux in each band, while icut, rcut and gcut are threshold values: pixels with higher flux than these thresholds are assigned the maximum allowed intensity, 255. In a similar vein, pixels with negative flux are given 0 intensity. In the first colour scheme, dubbed “standard”, we fixed icut, rcut and gcut for all images, set to sufficiently low values so as to make it possible to detect objects with surface brightness close to the background noise level. This choice resulted in images with consistent colours for different targets, though often with saturated centres, especially for the brightest galaxies. We also adopted a second colour scheme, named “optimal”, where we used a dynamical definition of the threshold flux for each subject: in the original image (i.e. without foreground subtraction), this was set to the 99%-ile of the pixel values in each band, so that the main galaxy, typically the brightest object in the cutout, was not saturated, except for the very central pixels. The “optimal” threshold flux of the foreground-subtracted images was instead set to the minimum between the 90%-ile of the residual image and the flux corresponding to ten times the sky background fluctuation. We made this choice to highlight features close to the background noise level. As an example, we show the aforementioned four versions of the RGB images of a known lens, SL2SJ021411−040502, in Fig. 1.
 |
Fig. 1. Colour-composite HSC images of lens SL2SJ021411−040502. Images with the light from the foreground galaxy subtracted are shown on the right, while original images are on the left. The images at the top and bottom row were created with the “standard” and “optimal” colour schemes, respectively. |
3. Crowdsourcing experiment setup
Our crowdsourcing project, named Space Warps – HSC, is hosted on the Zooniverse4 platform. The setup of the experiment followed largely that of previous Space Warps efforts, with minor modifications. We summarise it here and refer to Marshall et al. (2016) for further details.
Upon landing on the Space Warps website5, volunteers were presented with two main options: reading a brief documentation on the basic concepts of gravitational lensing or moving directly to the image classification phase. The documentation includes various examples of typical strong lens configurations, as well as false positives: non-lens galaxies with lens-like features such as spiral arms or star-forming rings and typical image artefacts. During the image classification phase, volunteers were shown sets of four images of individual subjects, of the kind shown in Fig. 1, and asked to decide whether the subject showed any signs of gravitational lensing, in which case they were asked to click on the image, or to proceed to the next subject. On the side of the classification interface, a “Field Guide” with a summary of various lens types and common impostors was always available for volunteers to consult. Users accessing the image classification interface for the first time were guided through a brief tutorial, which summarised the goals of the crowdsourcing experiment, the basics of gravitational lensing, and the classification submission procedure.
In addition to the documentation, the “Field Guide” and the tutorial, we relied on training images to help volunteers sharpen their classification skills. Participants were shown subjects, to be graded, interleaved with training images of lenses (known or simulated), known as “sims” for simplicity, or of non-lens galaxies, referred to as “duds”. They were not told whether a subject was a training one until after they submitted their classification, when a positive or negative feedback message was displayed, depending on whether they guessed the correct nature of the subject (lens or non-lens) or not (with some exceptions, described later). Training images were interleaved in the classification stream with a frequency of one in three for the first 15 subjects shown, reducing to one in five for the next 25 subjects and then settling to a rate of one in ten as volunteers became more experienced. The sims and duds were randomly served throughout the experiment to each registered volunteer. As the number of sims was 50% higher than the duds in the training subject pool, the sims were shown with correspondingly higher frequency than the duds. We describe in detail the properties of the training images in Sect. 3.1.
Volunteers also had the opportunity to discuss the nature of individual subjects on the “Talk” (i.e. forum) section of the Space Warps website: after deciding the class of a subject, clicking on the “Done & Talk” button would submit the classification and prompt the volunteer to a dedicated forum page, where they could leave comments, ask questions, and view any previous related discussion. Volunteers did not have the possibility of changing their classification once it was submitted, so the main purposes of this forum tool was to give them a chance to bring the attention on specific subjects and ask for opinions from other volunteers or experts. This helped the volunteers in building a better understanding of gravitational lensing, as well as creating a sense of community. We regularly browsed “Talk” to answer questions and to look for outstanding subjects highlighted by volunteers.
Volunteer classifications were compiled and analysed using the Space Warps Analysis Pipeline (SWAP, Marshall et al. 2016) to obtain probabilities of each subject being a lens. We describe SWAP in Sect. 3.2, and in practice use a modified version of the implementation of SWAP written for the Zooniverse platform by Michael Laraia et al.6.
3.1. The training sample
Training subjects served three different purposes. The first was helping volunteers to learn how to distinguish lenses from non-lenses, as discussed above. The second purpose was to keep volunteers alert through pop-up boxes that give real-time feedback on their classifications of the training images: given that the fraction of galaxies that are strong lenses in real data is very low, showing long uninterrupted sequences of subjects could have led volunteers to adopt a default non-lens classification, which could have resulted in the mis-classification of the rare, but extremely valuable, real lenses. The third purpose was allowing us to evaluate the accuracy of the classifications by volunteers, so as to adjust the weight of their scores in the calculation of the lens probabilities of subjects (more details to follow in Sect. 3.2). In order to serve these functions properly, it was crucial for training subjects to be as similar as possible to real ones. This required having a large number of them, so that volunteers could always be shown training images that had never been seen previously7. We prepared images of thousands of training subjects across two classes: lenses and non-lens impostors.
3.1.1. The lens sample
Lens-training subjects were, for the most part, simulated ones, generated by adding images of strongly lensed galaxies on top of HSC images of galaxies from the Baryon Acoustic Oscillations Survey (BOSS, Dawson et al. 2013) luminous red galaxy samples. Our priority was to generate simulations covering as large a volume of parameter space as possible, within the realm of galaxy-scale lenses, so as not to create a bias against rare lens configurations. For this reason, rather than assuming a physical model, we imposed very loose conditions on the mapping between the observed properties of the galaxies selected to act as lenses and their mass distribution. Given a BOSS galaxy, we first assigned a lens mass profile to it in the form of a singular isothermal ellipsoid (SIE, Kormann et al. 1994). We drew the value of the Einstein radius θEin from a Gaussian distribution centred on θEin = 1.5″, with a dispersion of 0.5″, and truncated below 0.5″ and above 3.0″. The lower limit was set to roughly match the resolution limit of HSC data (the typical i-band seeing is 0.6″), while the upper limit was imposed to restrict the simulations to galaxy-scale lenses (as opposed to group- or cluster-scale lenses, which have typical Einstein radii of several arcseconds). We drew the lens mass centroid from a uniform distribution within a circle of one pixel radius, centred on the central pixel of the cutout (which typically coincides with the galaxy light centroid). We drew the axis ratio of the SIE from a uniform distribution between 0.4 and 1.0, while the orientation of the major axis was drawn from a Normal distribution centred on the lens galaxy light major axis and with a 10 degree dispersion.
The background source was modelled with an elliptical Sérsic light distribution. Its half-light radius, Sérsic index and axis ratio were drawn from uniform distributions in the ranges 0.2″ − 3.0″, 0.5 − 2.0 and 0.4 − 1.0, respectively, and its position angle was randomly oriented. We assigned intrinsic (i.e. unlensed) source magnitudes in g, r, i bands to those of objects randomly drawn from the CFHTLenS photometric catalogue (Hildebrandt et al. 2012; Erben et al. 2013). Although the CFHTLenS survey has comparable depth to HSC, magnification by lensing makes it possible to detect sources that are fainter than the nominal survey limits, but these faint sources are missing from our training sample. Nevertheless, for extended sources such as strongly lensed images, surface brightness is more important than magnitude in determining detectability. Since we assigned source half-light radii independently of magnitudes, our source sample spanned a broad range in surface brightness, including sources that are below the sky background fluctuation level.
The source position distribution was drawn from the following axi-symmetric distribution:
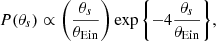 (2)
(2)
where θs is the radial distance between the source centroid and the centre of the image. The above distribution is approximately linear in θs at small radii, as one would expect for sources uniformly distributed in the plane of the sky, but then peaks at θEin/4 and turns off exponentially at large radii. The rationale for this choice was to down-weight the number of lenses with a very asymmetric image configuration, which correspond to values of θs that are close to the radial caustic of the SIE lens (i.e. the largest allowed value of θs for a source to be strongly lensed), at an angular scale ≈θEin. Sources close to the radial caustic are lensed into a main image, subject to minimal lensing distortion, and a very faint (usually practically invisible) counter-image close to the centre. These systems are strong lenses from a formal point of view, but in practice, they are hard to identify as such. They would dominate the simulated lens population if we assumed a strictly uniform spatial distribution of sources, hence the alternative distribution of Eq. (2).
Not all lens-source pairs generated this way were strong lenses: in ∼13% of cases the source fell outside the radial caustic. Such systems were simply removed from the sample. Among the remaining simulations, most showed clear signatures of strong lensing (e.g. multiple images or arcs). For some, however, it was difficult to identify them as lenses from visual inspection alone. We decided to include in the training sample all strong lenses, regardless of how obvious their lens nature was, so that volunteers would have the opportunity to learn how to identify lenses in the broadest possible range of configurations. This choice could also allow us to carry out a quantitative analysis of the completeness of crowdsourced lens finding as a function of a variety of lens parameters, although that is beyond the scope of this work.
We split the lens training sample in two categories: an “easy” subsample, consisting of objects showing fairly obvious strong lens features, and a “hard” subsample, consisting of less trivial lenses to identify visually. After classifying an easy lens, volunteers received a positive feedback message (“Congratulations! You spotted a simulated lens”) or a negative one (“Oops, you missed a simulated lens. Better luck next time!”), depending on whether they correctly identified it as a lens or not. For hard lenses, we used a different feedback rule: a correct identification still triggered a positive feedback message (“Congratulations! You’ve found a simulated lens. This was a tough one to spot, well done for finding it.”), but no feedback message was provided in case of misidentification, in order not to discourage volunteers with unrealistic expectations (often the lensed images in these hard sims were impossible to see at all). The implementation of two levels of feedback is a novelty of this study, compared to previous Space Warps experiments.
The separation of the lens training sample in easy and hard categories was based on the following algorithm, developed in a few iterations involving the visual inspection of a small sample of simulated lenses. For each lens, we first defined the lensed source footprint as the ensemble of cutout pixels in which the source g-band flux exceeded the sky background noise by more than 3σ. We then counted the number of connected regions in pixel space, using the function LABEL from the MEASURE module of the Python SCIKIT-IMAGE package, and used it as a proxy for the number of images Nimg. We also counted the number nvisible of “visible” source pixels (not necessarily connected) where the source surface brightness exceeded that of the lens galaxy in the g-band. The latter was estimated from the best-fit Sérsic model of the lens light. Any subject with nvisible < 40 pixels or Nimg = 0 was labelled as a hard one. Hard lenses were also systems with Nimg = 1 but with a source footprint smaller than 100 pixels. Among lenses with Nimg > 1, those with the footprints of the brightest and second brightest images smaller than 100 and 20 pixels respectively were also given a hard lens label. All other lenses were classified as easy. We converged to these values after inspecting a sample of simulated lenses, by making sure that the classification obtained with this algorithm matched our judgement of what constitutes an easy and a hard lens. We show examples of lenses from the two categories in Fig. 2. We generated a total of ∼12 000 simulated lenses, to which we added 52 known lenses from the literature. About 60% of them were easy lenses.
 |
Fig. 2. Set of four simulated lenses, rendered using the “optimised” colour scheme, with and without foreground subtraction. The first two lenses from the top are labelled as easy, while the bottom two are examples of hard lenses. |
Although the BOSS galaxies used as lenses are labelled as red, a substantial fraction of them are late-type galaxies, meaning that they exhibit spiral arms, disks, or rings. Simulations with a late-type galaxy as a lens are more difficult to recognise because the colours of the lensed images are often similar to those of star-forming regions in the lens galaxy. Nevertheless, we allowed late-type galaxies as lenses in the training sample as we did not want to bias the volunteers against this class of objects. Similarly, we did not apply any cut aimed at eliminating simulated lenses with an unusually large Einstein radius for their stellar mass. While unlikely, the existence of lenses with a large mass-to-light ratio cannot be excluded a priori due to the presence of dark matter and we wished the volunteers to be able to recognise them if they happened to be present in the data. In general, it is not crucial for the lens sample to closely follow the distribution of real lenses; in terms of lens or source properties: in order to meet our training goals, the most important requirement is to span the largest volume in parameter space.
3.1.2. The non-lens sample
The most difficult aspect of lens finding through visual inspection is distinguishing true lenses, which are intrinsically rare, from non-lens galaxies with lens-like features such as spiral arms or, more generally, tangentially elongated components with different colours than those of the main galaxy body. The latter are much more common than the former, so any inaccuracy in the classification has typically a large impact on the purity of a sample of lens candidates. In order to maximise opportunities for volunteers to learn how to differentiate between the two categories, we designed our duds training set by including exclusively non-lens objects bearing some degree of resemblance to strong lenses.
We searched for suitable galaxies among a sample of ∼6600 lens candidates identified by YATTALENS, which we ran over the whole sample of subjects before starting the crowdsourcing experiment. Details on the lens search with the YATTALENS algorithm are given in Sect. 4.2. Upon visual inspection, a subset of ∼3800 galaxies were identified as unambiguous non-lenses and deemed suitable for training purposes. These were used as our sample of duds. We show examples of duds in Fig. 3. In order to double the number of available duds, we also included in the training set versions of the original duds rotated by 180 degrees.
 |
Fig. 3. Set of four non-lens duds from the training set, rendered using the “optimised” colour scheme. |
3.2. The classification analysis algorithm
The SWAP algorithm was introduced and discussed extensively by Marshall et al. (2016). Here, we summarise its main assumptions. The goal of the crowdsourcing experiment is to quantify for each subject the posterior probability of it being a lens based on the data, P(LENS|d). The data used for the analysis consists of the ensemble of classifications from all users who have seen the subject. This includes, for the k-th user, the classification on the subject itself, Ck, as well as past classifications on training subjects 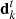 :
:
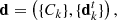 (3)
(3)
where curly brackets denote ensembles over all volunteers who have classified the subject and the classification Ck can take the values “LENS” or “NOT”.
Using Bayes’ theorem, the posterior probability of a subject being a lens given the data is
 (4)
(4)
where P(LENS) is the prior probability of a subject being a lens,  is the likelihood of obtaining the ensemble of classifications given that the subject is a lens and given the past classifications of volunteers on training subjects, while
is the likelihood of obtaining the ensemble of classifications given that the subject is a lens and given the past classifications of volunteers on training subjects, while 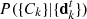 is the probability of obtaining the classifications, marginalised over all possible subject classes:
is the probability of obtaining the classifications, marginalised over all possible subject classes:
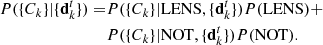 (5)
(5)
Before any classification takes place, the posterior probability of a subject being a lens is equal to its prior, which we assume to be
 (6)
(6)
loosely based on estimates from past lens searches in CFHT-LS data. Although our HSC data is slightly better than CFHT-LS both in terms of image quality and depth, which should correspond in principle to a higher fraction of lenses, we do not expect that to make a significant difference. This is because, as we clarify later in this paper, we designed our experiment so that the final posterior probability of a subject is always dominated by the likelihood and not by the prior.
After the first classification is made, C1, we update the posterior probability, which becomes
 (7)
(7)
We evaluate the likelihood based on past performance of the volunteer on training subjects. We approximate the probability of the volunteer correctly classifying a lens subject with the rate at which they did so on training subjects:
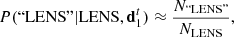 (8)
(8)
where NLENS is the number of sims the volunteer classified and N“LENS” the number of times they classified these sims as lenses. Given that “LENS” and “NOT” are the only two possible choices, the probability of the same volunteer wrongly classifying a lens as a non-lens is
 (9)
(9)
Similarly, we approximate the probability of a volunteer correctly classifying a dud as
 (10)
(10)
Let us now consider a subject for which k classifications from an equal number of volunteers have been gathered. If a k + 1-th classification is collected, we can use the posterior probability of the subject being a lens after the first k classifications, 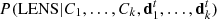 , as a prior for the probability of the subject being a lens before the new classification is read. The posterior probability of the subject being a lens after the k + 1th classification then becomes:
, as a prior for the probability of the subject being a lens before the new classification is read. The posterior probability of the subject being a lens after the k + 1th classification then becomes:
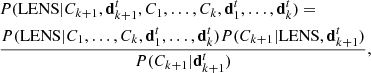 (11)
(11)
where the probability of observing a classification Ck + 1, the denominator of the above equation, is
 (12)
(12)
Equation (11) allows us to update the probability of a subject being a lens every time a new classification is submitted.
As shown in past Space Warps experiments, after a small number of classifications is collected (typically 11 for a lens and 4 for a non-lens), P(LENS|d) almost always converges to either very low values, indicating that the subject is most likely not a lens, or to values very close to unity, suggesting that the subject is a lens (see e.g. Fig. 5 of Marshall et al. 2016). The posterior probability is in either case very different from the prior, indicating that the likelihood terms are driving the inference. In order to make the experiment more efficient, we retired subjects (i.e. we stopped showing them to the volunteers) when they reached a lens probability smaller than 10−5 after at least four classifications: gathering additional classifications would not have changed the probability of those subjects significantly, and removing them from the sample allowed us to prioritise subjects with fewer classifications. Regardless of P(LENS|d), we retired subjects after 30 classifications were collected. In practice, SWAP was not run continuously, but only every 24 hours. This caused minor inconsistencies between the retirement rules described above and the subjects being shown to the volunteers. These inconsistencies, along with other unreported issues, such as the retirement server being offline and a delayed release of subjects, did slightly reduce the overall efficiency of the experiment, but these did not affect the probability analysis.
4. Results
4.1. Search with Space Warps
The Space Warps – HSC crowdsourcing experiment was launched on April 27, 2018. It saw the participation of ∼6000 volunteers, who carried out 2.5 million classifications over a period of two months. With the goal of assessing the degree of involvement of the volunteers, we show in Fig. 4 the distribution in the number of classified subjects per user, Nseen. This is a declining function of Nseen, typical of crowdsourcing experiments: while most volunteers classified less than twenty subjects, nearly 20% of them contributed each with at least a hundred classifications. It is thanks to these highly committed volunteers that the vast majority of the classifications needed for our analysis was gathered.
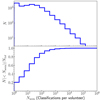 |
Fig. 4. Top: distribution in the number of classified subjects per volunteer. Bottom: cumulative distribution. |
In Fig. 5, we show the distribution of lens probabilities of the full sample of subjects (thick blue histograms), as quantified with the SWAP software. This is a highly bimodal distribution: most of the subjects have very low lens probabilities, as expected, given the rare occurrence of the strong lensing phenomenon, but there is a high probability peak, corresponding to the objects identified as lenses by the volunteers. We then made an arbitrary cut at P(LENS) = 0.5: 1577 subjects with a lens probability that was larger than this value were declared “promising candidates” and promoted to the next step in our analysis, which consisted of visual inspection by the experts in strong lensing. This further refinement of the lens candidate sample is described in detail in Sect. 4.3.
 |
Fig. 5. Top: distribution in the posterior probability of subjects, duds, and sims being lenses given the classification data from the volunteers. Bottom: cumulative distribution. The vertical dotted line marks the limit above which subjects are declared promising candidates and promoted to the expert visual inspection step. |
In Fig. 5, we also plot the distributions in lens probability of the three sets of training subjects: duds, easy sims, and hard sims. These roughly follow our expectations: most of the duds are correctly identified as such, with 90% of the easy lenses having P(LENS) > 0.5, while only a third of the hard lenses make it into our promising candidate cut. This validates our set of choices and criteria that went into compiling the easy and hard sims. Of the 52 known lenses used for training, 49 were successfully classified as lenses (not shown in Fig. 5). The three missed ones were all hard lenses.
With the goal of better quantifying the ability of the volunteers at finding lenses, we analysed the true positive rate (i.e. the fraction of lenses correctly classified as such over the total number of lenses inspected) on the simulated lenses as a function of lens properties. In order for a human to recognise a gravitational lens, it is necessary for the lensed image to be detected with a sufficiently high signal-to-noise ratio (S/N) and for it to be spatially resolved, so that the image configuration typical of a strong lens can be observed. For this reason, we focused on two parameters: the S/N of the lensed images, summed within the footprint of the lensed source, and the angular size of the Einstein radius. We defined the lensed source footprint as the ensemble of pixels where the surface brightness of the lensed source is 3σ above the sky background fluctuation level in the g-band.
In Fig. 6, we show the true positive rate on the simulated lenses, separated into easy and hard ones, as a function of lensed images S/N and θEin. The volunteers were able to identify most of the easy lenses, largely regardless of θEin and S/N. On the contrary, most of the hard lenses were missed, with the exception of systems with S/N > 100. The marked difference between the true positive rate on the easy and hard lenses of similar θEin and S/N indicates once again that our criteria for the definition of the two categories are appropriate. As described in Sect. 3.1.1, in order for a lens to be considered easy, the lensed image must have a high contrast with respect to the lens light and must consist of either two or more clearly visible images or one fairly extended arc. It is reassuring that the volunteers achieved a high true positive rate on these systems, even for lenses with Einstein radius close to the resolution limit of 0.7″.
 |
Fig. 6. True positive rate (i.e. fraction of lenses correctly classified as such) on the classification of simulated lenses as a function of lensed image S/N and lens Einstein radius for easy and hard lenses separately. Parts of the parameter space occupied by only ten or fewer lenses are left white. |
At the same time, the extent of the low efficiency area among the hard lenses seen in Fig. 6 shows how the true positive rate depends nontrivially on a series of lens properties other than lensed image S/N and size of the Einstein radius, including the contrast between lens and source light and image configuration. This is true for volunteers and lensing experts alike, as we remark in Sect. 4.4, and in the absence of a simulation that realistically reproduces the true distribution of strong lenses in all its detail makes it difficult to obtain an estimate of the completeness achieved by our crowdsourced search in HSC data.
4.2. Search with YATTALENS
YATTALENS is a lens finding algorithm developed by Sonnenfeld et al. (2018) consisting of two main steps. In the first step, it runs SEXTRACTOR (Bertin & Arnouts 1996) on foreground light-subtracted g-band images to look for tangentially elongated images (i.e. arcs) and possible counter-images with similar colours. In the second step, it fits a lens model to the data and compares the goodness-of-fit with that obtained from two alternative non-lens models. In the cases when the lens model fits best, it keeps the system as a candidate strong lens.
We ran YATTALENS on the sample of ∼300 000 galaxies obtained by applying the stellar mass and photometric redshift cuts described in Sect. 2.1 to the S16A internal data release catalogue of HSC. More than 90% of the subjects were discarded at the arc detection step. Of the remaining ∼22 000, 6779 were flagged as possible lens candidates by YATTALENS and the rest was discarded on the basis of the lens model not providing a good fit. We then visually inspected the sample of lens candidates with the purpose of identifying non-lenses erroneously classified by YATTALENS that could be used for training purposes. The ∼3800 galaxies that made up the duds were drawn entirely from this sample.
4.3. Lens candidate grading
We merged the sample of lens candidates identified by the volunteers, 1577 subjects with P(LENS|d) > 0.5, with the YATTALENS sample, from which we removed the ∼3800 subjects used as duds.
We also added to the sample 264 outstanding candidates flagged by volunteers on the “Talk” section of the Space Warps website, which we browsed on a roughly daily basis, quickly inspecting subjects that had recently been commented on (typically on the order of a few tens each day). This last subsample is by no means complete (we did not systematically inspect all subjects flagged by the volunteers) and it has a large overlap with the set of probable lenses produced by the classification algorithm. Nevertheless, we included it in order to make sure that potentially interesting candidates would not get lost. Although most of the candidates inspected in this way turned out not to be lenses, this step still proved to be useful because it enabled the discovery of a few lenses that would have otherwise been missed (as we show later in this paper).
We then visually inspected the resulting sample with the purpose of refining the candidate classification. Nine co-authors of this paper assigned to each candidate an integer score from 0 to 3 to indicate the likelihood of the subject being a strong lens. We used the following scoring convention:
– Score = 3: almost certainly a lens. A textbook example for which all characteristics of lensed images are verified: image configuration, consistency of colour and, in case of extended sources, surface brightness among all images. Additionally, the possibility of lensed features being the result of contamination can be ruled out with high confidence.
– Score = 2: probably a lens. All of the features match those expected for a strong lens, but the possibility that some of the features are due to contaminants cannot be ruled out.
– Score = 1: possibly a lens. Most of the features are consistent with those expected for a strong lens, but they may as well be explained by contaminants.
– Score = 0: almost certainly not a lens. Features are inconsistent with those expected for a strong lens.
Additionally, in order to ensure consistency in grading criteria across the whole sample and among different graders, we proposed the following algorithm for assigning scores.
1. Identify the images that could be lensed counterparts of each other
2. Depending on the image multiplicity and configuration, assign an initial score as follows:
-
Einstein rings, sets of four or more images, sets consisting of at least one arc and a counter-image: 3 points.
-
Sets of three or two images, single arcs: 2 points.
3. If the lens is a clear group or cluster, add an extra point up to a maximum provisional score of 3.
4. Remove points based on how likely it is that the observed features are the result of contamination or image artefacts: if artefacts are present, then multiple images may not preserve surface brightness, may show mismatch of colours, or may have the wrong orientation or curvature around the lens galaxy.
5. Make sure that the final score is reasonable given the definitions outlined above.
The rationale for the third point is to take into account the fact that (a) groups and clusters are more likely to be lenses, due to their high mass concentration and (b) often produce non-trivial image configurations which might be penalised during the fourth step. Finally, we averaged the scores of all nine graders, and assigned a final grade as follows:
-
Grade A: 〈Score〉 > 2.5.
-
Grade B: 1.5 < 〈Score〉 < = 2.5.
-
Grade C: 0.5 < 〈Score〉 < = 1.5.
-
Grade 0: 〈Score〉 < = 0.5.
We found 14 grade A lenses, 129 grade B, and 581 C lens candidates. In Table we provide a summary of the number of lens candidates of each grade found separately by Space Warps, both from the selection based on classification data and from the “Talk” section, and with YATTALENS.
The first thing we can see from Table is that, among the 724 lens candidates with grade C and above (sum of the first three columns in the bottom row), 597 of them (82%) are in the sample of subjects with P(LENS|d) > 0.5. Only 11 of the 129 grade B candidates and none of the grade A ones were missed by the analysis of volunteer classification data (i.e. have P(LENS|d) < = 0.5). In contrast, only about half of the grade A, B and C candidates were flagged as possible lenses by YATTALENS. This clearly indicates that crowdsourcing returned a relatively more complete sample of candidates compared to YATTALENS. We discuss this and other differences in performance between the two methods in Sect. 5.1.
In Table A.1, we list all the grade A and B candidates discovered. The full list of lens candidates with grade C and better is provided online, in our database containing all lens candidates found or analysed by SuGOHI8, and as an ASCII table at the CDS. This database was created by merging samples of lenses from our previous studies. Lens candidates that have been independently discovered as part of different lens searches can have different grades because of differences in the photometric data used for grading, including the size and colour scheme of the image cutouts or in the composition of the team who performed the visual inspection. In such cases, the higher grade was taken under the assumption that it was driven by a higher quality in the image cutout used for the inspection (in terms of the lensed features being more clearly visible). As a result, the number of grade A and B lens candidates from this study present in the SuGOHI database is slightly larger than the 143 candidates listed in Table A.1. This is due to an overlap between the lens candidates found in this work and those from our visual inspection of galaxy clusters by Jaelani et al. (2020a, Paper V), carried out in parallel.
One of the main goals of this experiment was to extend the sample of known lenses to higher lens redshifts. In Fig. 7, we plot a histogram with the distribution in photo-z of our grade A and B lens candidates, together with candidates from our previous searches and compared to the lens redshift distribution from other surveys. The SuGOHI sample consists now of 324 highly probable (grade A or B) lens candidates. This is comparable to strong lens samples found in the Dark Energy Survey (DES, where Jacobs et al. 2019, discovered 438 previously unknown lens candidates, one of which is also in our sample) and in the Kilo-Degree Survey (KiDS: Petrillo et al. 2019, presented ∼300 new candidates, not shown in Fig. 7 due to a lack of published redshifts, 15 of which are also in our sample). Most notably, 41 of our lenses have photo-zs larger than 0.8, which is more than any other survey.
 |
Fig. 7. Shaded region: distribution in lens photometric redshift of all grade A and B SuGOHI lenses. The blue portion of the histogram corresponds to lenses discovered in this study. The green part indicates BOSS galaxy lenses discovered with YATTALENS, presented in Paper I, II, and IV (Sonnenfeld et al. 2018; Wong et al. 2019; Chan et al. 2020). The cyan part shows lenses discovered by means of visual inspection of galaxy clusters, as presented in Paper V. The striped regions indicate lenses discovered independently in this study and in the study of Paper V. Grey solid lines: distribution in lens spectroscopic redshift of lenses from the Sloan ACS Lens Survey (SLACS, Auger et al. 2010). Red solid lines: distribution in lens spectroscopic redshift of lenses from the SL2S Survey (Sonnenfeld et al. 2013b,a, 2015). Orange solid lines: distribution in lens photometric redshift of likely lenses discovered in DES by Jacobs et al. (2019). Dashed lines: distribution in photometric redshift of all subjects examined in this study, rescaled downwards by a factor of 1000. |
Some caution is required when using photometric redshifts, however: the distribution in photo-z of all our subjects (shown as a dashed histogram in Fig. 7) shows unusual peaks around a few values, which appear to be reflected in the photo-z distribution of the lenses (dotted line). Given the large sky area covered by our sample, we would have expected a much smoother photo-z distribution. Therefore, we believe these peaks to be the result of systematic errors in the photo-z. In order to obtain an estimate for the magnitude of such errors, we considered the subset of galaxies from our sample with spectroscopic redshift measurements from the literature (see Tanaka et al. 2018, for details on the spectroscopic surveys overlapping with HSC). The distribution in spectroscopic redshift of galaxies with photo-z larger than 1.0 has a median value of 1.05 and a tail that extends towards low redshifts. The tenth percentile of this distribution is at a spectroscopic redshift of 0.65. Assuming that the distribution in spectroscopic redshift of the lens sample follows a similar distribution, we can use this as a lower limit to the true redshift of our zphot > 1.0 candidates. Since we are not using photo-z information to perform any physical measurement, we defer any further investigation of photo-z systematics to future studies.
4.4. A diverse population of lenses
In the rest of this section, we highlight a selected sample of lens candidates that we find interesting, grouped by type. We begin by showing in Fig. 8 a set of eight lenses with a compact background source, that is, lenses with images that are visually indistinguishable from a point source. Compact strongly lensed sources are interesting because they could be associated with active galactic nuclei or, alternatively, they could be used to measure the sizes of galaxies that would be difficult to resolve otherwise (see e.g. More et al. 2017; Jaelani et al. 2020b). The two lenses in the top row of Fig. 8 were also featured in the fourth paper of our series, dedicated to a search for strongly lensed quasars (Chan et al. 2020). All lenses shown in Fig. 8 were classified as such by the volunteers (the value of P(LENS|d) is shown in the top left corner of each image), with the exception of HSCJ091843.38−022007.3. We were able to include it in our sample thanks to a single volunteer who flagged it in the “Talk” section.
 |
Fig. 8. Set of eight lenses associated with a compact lensed source. In each panel, we show the probability of the subject of being a lens, according to the volunteer classification data (top left), the lens galaxy photo-z (top right), the final grade after our inspection (left). The circled “Y” and “T” on the right, if present, indicate that the candidate was discovered by YATTALENS and noted by us in the “Talk” section of the Space Warps website, respectively. |
Eight of the grade B candidates, shown in Fig. 9, and more among the grade C ones, have a disk galaxy as lens. Disk galaxies represent a minority among all lenses and most of the previously studied ones are at a lower redshift compared to the average of our sample (but see Suyu et al. 2012, for an exception). The largest sample of disk lenses studied so far is the Sloan WFC Edge-on Late-type Lens Survey (SWELLS, Treu et al. 2011), which consists of 19 lenses at z < 0.3. Our newly discovered disk lenses extend this family of objects to higher redshift, and, with appropriate follow-up observations, could be used to study the evolution in the mass structure of disks9.
 |
Fig. 9. Set of eight disk galaxy lens candidates discovered in our sample. |
Most of the lensed sources in our sample have blue colours. This is related to the fact that the typical source redshift is in the range 1 < z < 3 (see e.g. Sonnenfeld et al. 2019), close to the peak of cosmic star formation activity. Nevertheless, we were able to discover a limited number of lenses with a red background source. Two of them were classified as grade B candidates and are shown in Fig. 10. The object on the left has a standard fold configuration and was conservatively given a grade B only because one of the images is barely detected in the data. However, it was not classified as lens by the volunteers (although the final value of P(LENS|d) is higher than the prior probability). Our training sample consisted almost exclusively of blue sources: it is then possible that the volunteers were not ready to recognise such an unusual lens (although past crowdsourcing experiments proved otherwise, Geach et al. 2015). We included it in the sample after it was flagged by one volunteer in the “Talk” section. Both lenses in Fig. 10 were missed by YATTALENS, as it was set up to discard red arcs in order to eliminate contaminants in the form of neighbouring tangentially aligned galaxies.
 |
Fig. 10. Two lens candidates with strongly lensed red sources. |
Finally, we point out how roughly half of our grade C lens candidates consist of systems with either a single visible arc, the counter-image of which, if present, is very close to the centre and not detected, or a double in a highly asymmetric configuration. It is very difficult to determine whether such candidates are lenses or not using photometric data alone but given their abundance (a few hundred in the whole sample), they constitute a very interesting category of lenses: even if only a fraction of them turned out to be real lenses, they would end up dominating the lens population. This is not surprising but, rather, it is to be expected from the simple geometrical arguments that we made when describing our procedure for simulating lenses, in Sect. 3.1.1: the area in the source plane that gets mapped into highly asymmetric image configurations is larger than the area corresponding to configurations that are close to symmetric10.
In Fig. 11, we show a collection of some of the best examples of highly asymmetric doubles that we were able to discover. The figure highlights the importance of the foreground light subtraction step which, although far from perfect (large negative residuals are typically left in the centre of the image), helps greatly in the detection of faint counter-images close to the centre. Such asymmetric systems are interesting because they allow constraints to be put on the mass in the very inner regions of a lens, which is dominated by the stars and with a possible contribution from the central supermassive black hole, even in cases when a counter-image is not detected (Smith et al. 2018, 2020). Incidentally, Fig. 11 also illustrates the difficulty in assigning consistent grades to large samples of lens candidates: the object in the top left was given a grade B, in accordance to the criteria discussed in Sect. 4.3, while all the other ones were assigned a grade C despite having a very similar image configuration. In our past searches, we used to collectively re-discuss lens candidate grades on a one-by-one basis after a first round of inspection. This, however, was not feasible in the present study due to the large data volume.
 |
Fig. 11. Selected sample of ten lens candidates with a highly asymmetric image configuration. In each row, the left panel shows the original image, while the right one shows the foreground-subtracted one. |
5. Discussion
5.1. Performance of different lens finding methods
The two most important quantities that define the performance of a lens-finding method are completeness and purity. The former is the fraction of strong lenses among the ones present in the surveyed sample that are recovered by the method, while the latter is the fraction of objects among the ones labelled as strong lenses that are indeed lenses. Unfortunately, it is very difficult to determine either of them in an absolute sense: it would require us to apply our lens-finding methods to a large complete sample of real lenses and to a large sample of galaxies representative of our survey the nature of which is known exactly. We can, however, evaluate the relative performance between our two methods, namely, crowdsourcing and YATTALENS. The data reported in Table shows clearly how the former outperformed the latter both in terms of completeness, with roughly twice the number of lens candidates with grade C or higher, and purity, with 40% of the inspected candidates having grade C or higher, against only 5% for YATTALENS. The comparison is not entirely fair: first of all, YATTALENS correctly identified most of the 52 known lenses used in the training sample, which have been excluded from the summary of Table and would have otherwise increased the completeness of YATTALENS (many of these lenses belong to the sample of lenses discovered with YATTALENS by Sonnenfeld et al. 2018). Secondly, 3800 duds initially found by YATTALENS were removed from the subject sample and only shown to the volunteers as training images, making their classification job slightly easier. However, given the relatively good performance of the volunteers on the training subjects, with only ∼10% of the duds being classified as lenses (see Fig. 5), the purity of the sample produced by the volunteers would only have changed by a small margin by including the duds.
Most of the lens candidates missed by YATTALENS were discarded at the arc detection step for various reasons: either their lensed images are point-like (as two of the candidates shown in Fig. 8) or too red (as in the two cases shown in Fig. 10), or consist of arcs that are considered too faint or too far from the lens galaxy by YATTALENS. In principle, we could adjust the settings of YATTALENS to be able to detect such lenses in future searches, although most likely entailing a penalty in terms of purity.
In the previous section, we also reported the discovery of a number of highly probable lenses that were flagged by volunteers in the “Talk” section of Space Warps, including some that were missed by both the volunteer classification data and YATTALENS. Based on the numbers reported in Table 1, with as many as 11 grade A and 86 grade B lens candidates found among 264 inspected candidates, we could be inclined to conclude that the “Talk” section provides much purer samples compared to the analysis of classification data. However, those numbers are misleading: 264 were the candidates that were deemed sufficiently interesting to be included in the final grading step, and were selected after sorting through thousands of subjects flagged by volunteers. The effective purity of this lens search method is therefore much lower than suggested by Table 1.
Number of lens candidates of grades of each grade found among subjects selected by the cut P(LENS|d) > 0.5, from the “Talk” section of Space Warps, by YATTALENS and in the merged sample.
5.2. Comparison with the Metcalf et al. (2019) lens-finding challenge
Metcalf et al. (2019) carried out a lens finding challenge, in which 100 000 simulated images of lenses and non-lenses were classified with a variety of lens finding methods over the course of 48 h. Among the lens finders that took part in the challenge, there were several machine learning-based methods, a visual inspection effort led by strong lensing experts, and a simplified version of YATTALENS, dubbed YATTALENS LITE, limited to the arc-finding step and stripped of the modelling part to meet the time constraints of the challenge. The methods characterised by the best performance were based on machine learning, some of which achieved better results than visual inspection. YATTALENS LITE achieved a false positive rate of ∼10% and a true positive rate of 75%, while the performance of visual inspection was marginally better.
The performance of YATTALENS on the real data used in this work is different from that of YATTALENS LITE on the lens finding challenge. We achieved a false positive rate of ≈2% (given by the number of grade 0 candidates classified as lenses by YATTALENS, 6470, among the 300 000 scanned subjects). This lower value can be explained partly by the presence of the modelling step, which was skipped in the lens-finding challenge and which typically brings an improvement in purity of a factor of three, and partly by the different composition of the non-lens sample of the challenge as compared to the sample of real galaxies. The true positive rate is also lower in this experiment: although we do not know the total number of lenses present among all scanned subjects, we can obtain an upper limit on the true positive rate by dividing the number of grade A and B candidates recovered by YATTALENS (6 + 68 = 74) by the total number of grade A and B candidates found (14 + 130 = 144), roughly 50% this fraction increases if we also consider the 52 real lenses used as training subjects, but it is still below the 75% true positive rate scored in the lens finding challenge. As for the false positive rate, the true positive rate is also sensitive to the details of the distribution of lens properties in the sample: for example, we suspect that the lens finding challenge had a higher fraction of lenses that would be classified as “easy” according to our definition, boosting the true positive rate. Indeed, the lens sample of Metcalf et al. (2019) is known for having an unusually large number of lenses with a large Einstein radius (4″ or more), as also noted by Davies et al. (2019).
The main lesson from this comparison is that while lens-finding challenges carried out on simulated data can be very useful tests of lens finding methods, results can vary a lot depending on the details of the test samples used. Therefore, tests on real data are essential to accurately assess the performance of a given lens finding method. These are not a viable option at the moment due to the relatively low number of known lenses but it might become feasible in the future.
5.3. Lens-finding efficiency dependence on image depth
One of the most important aspects of photometric data for lens finding purposes is image depth: in principle, deeper data should allow the detection of fainter background sources, and therefore more lenses. The data used for our study, taken from the S17A internal data release of HSC, span a wide range in depth: the number of individual exposures that make up the coadded images used for our analysis goes from a minimum of one to the survey standard value of six in i-band, and even more in regions where multiple pointings overlap. We can then check whether the number density of lens candidates correlates with image depth. In Fig. 12 we plot the distribution in i- and g-band sky background fluctuation of all subjects, of grade A and B lens candidates combined, and of grade C ones. By looking at the i-band distribution (left panel), we can see how the distribution of grade A and B candidates is shifted towards lower levels of background noise compared to the distribution of all subjects. A Kolmogorov–Smirnov test reveals a p-value of 8.8 × 10−4, hence a low probability that the two samples (all subjects and grade A and B candidates) are drawn from the same distribution. While the i-band data confirms the idea that deeper data leads to a higher number of detected lenses, the g-band distribution appears to tell a different story: there is no obvious difference between the distribution in the background fluctuation of lens candidates and all subjects, with the Kolmogorov–Smirnov test giving a p-value of 0.16. Given that the g-band is, for the vast majority of our candidates, the one with the highest contrast between lens and source, we would have expected an even higher difference between the two distributions. This result instead suggests that g-band depth is probably not the limiting factor in our lens finding campaign, but i-band depth is more important. This could be related to the foreground light subtraction step, for which we rely on the i-band image to obtain a model for the surface brightness profile of the lens.
 |
Fig. 12. Distribution in sky background rms (in AB magnitudes per pixel) of all subjects, grade A and B candidates combined, and grade C candidates, in i- (left) and g-band (right). |
5.4. Comparison with past crowdsourcing experiments
This was the third crowd-sourced lens finding experiment carried out by Space Warps following the search based on CFHT-LS data (Marshall et al. 2016; More et al. 2016) and on the VISTA-CFHT Stripe 82 survey (Geach et al. 2015). More et al. (2016) were able to find 91 probable lenses, 29 of which were previously unknown, in 160 square degrees of data. The number density of grade A and B lenses found in the present search is similar, though it is hard to make a quantitative comparison, due to different definitions of what constitutes a probable lens candidate and to the fact that we excluded known lenses from our subject sample from the start. An essential difference between the present study and the CFHT-LS Space Warps campaign is that this was a targeted search: we looked for lenses only among a set of galaxies in a given redshift and stellar mass range. The search carried out by More et al. (2016) instead consisted of two stages: a blind search over tiles of the whole survey area, followed by a re-inspection of the most promising candidates. Compared to the More et al. (2016) study, we found a much larger fraction of “undecided” subjects, for which their probability of being a lens did not converge neither to a value close to unity nor to very low values, and they were retired from the sample only after reaching the maximum allowed number of classifications. We think this is a consequence of the fact that volunteers have been able to detect fainter lens-like features that are intrinsically more difficult to classify as compared to the CFHT-LS campaign. There are a few reasons for this. First of all, the chances of finding faint arcs are higher in a targeted search, when the attention is focused on a well-defined object, as opposed to a blind search. Secondly, HSC data is deeper than CFHT-LS, increasing the number density of fainter features in the vicinity of a foreground galaxy. Thirdly, the presence of foreground-subtracted images in our experiment allows the identification of lenses with a lower contrast between source and lens light. These factors lead to a higher fraction of ambiguous lens candidates in our sample.
6. Conclusions
We carried out a crowdsourced lens search based on over 442 square degrees of data from the HSC survey. The search was carried out on a sample of ∼300 000 galaxies with photometric redshift between 0.2 and 1.2 and a stellar mass larger than 1011.2 M⊙. Almost 6000 citizen volunteers participated in the crowdsourcing experiment, named Space Warps - HSC. We collected ∼2.5 million classifications, which we then analysed with an algorithm developed in past editions of Space Warps. In parallel, we searched for lenses in the same sample of galaxies using the automated lens finding method YATTALENS. From the two searches combined, we found 143 highly probable (grade A or B) new lens candidates, in an area that already included 70 known lenses. Compared to YATTALENS, crowdsourcing was by far the most successful lens finding method, both in terms of completeness and purity. We found lenses of a variety of kinds, including lenses with a compact source, with a red source, group-scale lenses, and lens candidates with highly asymmetric configurations. From an analysis of the performance of crowdsourcing on simulated lens images, we determined that volunteers are able to correctly classify most lenses, including those with Einstein radius comparable to the resolution limit, as long as multiple images are clearly detected.
In the coming years, the volume of data available for lens finding purposes will increase greatly, as the Euclid space telescope11 and the Large Synoptic Survey Telescope12 (LSST) are each planned to cover areas of the sky that are more than a factor of 30 larger than that scanned in our study. Scaling up Space Warps to such data volumes will be challenging: a much larger number of volunteers and a higher number of classification per volunteer will be needed. We can aim to improve the efficiency of our search by modifying the definition of the parent sample of subjects passed on to the volunteers. For instance, machine learning-based methods could potentially be used to pre-select large samples of possible lenses that are then refined in a visual inspection step via crowdsourcing. Nevertheless, our experiment shows how crowdsourcing is a very powerful tool for finding lenses and delivering samples of lens candidates with relatively high purity and completeness, and so, we expect it to play a major role in lens finding in the 2020s. YATTALENS can produce samples of roughly one grade-C lens candidate or better per square degree in HSC-like data and it is, therefore, confirmed to be a useful and efficient tool for finding galaxy-scale lenses in a semi-automated way provided that high completeness is not a critical requirement.
More than half of the systems considered for this estimate are candidates with high probability of being lenses, but no spectroscopic confirmation.
The term subject refers to cutouts centred on our target galaxies.
S17A is a more recent data release than S16A, on which the target selection was based. While reduced data from S17A were available at the start of our experiment, the photo-z catalogue was not, hence we used the S16A photo-z catalogue to define the sample of targets.
The modified SWAP-2 branch used here can be found at https://github.com/cpadavis/swap-2 which is based on https://github.com/miclaraia/swap-2
In practice, due to some platform/image server issues, some volunteers saw a small fraction of training subjects more than once. However, only the first classification made by a user of any given subject was used in SWAP.
http://www-utap.phys.s.u-tokyo.ac.jp/~oguri/sugohi/ Candidates from this study are identified by the value “SuGOHI6” in the “Reference” field.
Although the mass within the Einstein radius of these systems is likely dominated by the bulge.
The picture is complicated by magnification effects: more symmetric configurations correspond in general to a higher magnification, allowing to detect fainter sources in a flux-limited survey. The net effect depends on the slope of the source luminosity function.
Acknowledgments
We thank all of the volunteers who participated in Space Warps - HSC, whose Zooniverse usernames are listed at the end of https://www.zooniverse.org/projects/aprajita/space-warps-hsc/about/team, with particular thanks to Ivan A. Terentev for flagging the lens HSCJ021134.26−023752.4 and many other good candidates. We thank all of the Science Friday Team (in particular Ariel Zych, Christopher Intagliata, Brandon Echter and Ira Flatow) for featuring the SW-HSC project in two broadcasts, that greatly enhanced and promoted the project to a wider community. We also thank Michael Laraia, Hugh Dickinson and Lucy Fortson (University of Minnesota) for use of their implementation of the Space Warps Analysis Pipeline for the PANOPTES Zooniverse platform and integration with CAESAR functionality. AS acknowledges funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 792916, as well as a KAKENHI Grant from the Japan Society for the Promotion of Science (JSPS), MEXT, Number JP17K14250. ATJ is supported by JSPS KAKENHI Grant number JP17H02868. JHHC acknowledges support from the Swiss National Science Foundation (SNSF). This work was supported by World Premier International Research Center Initiative (WPI Initiative), MEXT, Japan. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan and Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST programme from Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science, and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
References
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018a, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Aihara, H., Armstrong, R., Bickerton, S., et al. 2018b, PASJ, 70, S8 [NASA ADS] [Google Scholar]
- Auger, M. W., Treu, T., Gavazzi, R., et al. 2010, ApJ, 721, L163 [NASA ADS] [CrossRef] [Google Scholar]
- Axelrod, T., Kantor, J., Lupton, R. H., & Pierfederici, F. 2010, in Software and Cyberinfrastructure for Astronomy, Proc. SPIE, 7740, 774015 [CrossRef] [Google Scholar]
- Barnabè, M., Spiniello, C., Koopmans, L. V. E., et al. 2013, MNRAS, 436, 253 [NASA ADS] [CrossRef] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&A, 117, 393 [Google Scholar]
- Bolton, A. S., Brownstein, J. R., Kochanek, C. S., et al. 2012, ApJ, 757, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Bosch, J., Armstrong, R., Bickerton, S., et al. 2018, PASJ, 70, S5 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Sonnenfeld, A., et al. 2020, A&A, 636, A87 [CrossRef] [EDP Sciences] [Google Scholar]
- Dark Energy Survey Collaboration (Abbott, T., et al.) 2016, MNRAS, 460, 1270 [NASA ADS] [CrossRef] [Google Scholar]
- Davies, A., Serjeant, S., & Bromley, J. M. 2019, MNRAS, 487, 5263 [CrossRef] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Boxhoorn, D. R., et al. 2015, A&A, 582, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Erben, T., Hildebrandt, H., Miller, L., et al. 2013, MNRAS, 433, 2545 [NASA ADS] [CrossRef] [Google Scholar]
- Geach, J. E., More, A., Verma, A., et al. 2015, MNRAS, 452, 502 [NASA ADS] [CrossRef] [Google Scholar]
- Grillo, C., Rosati, P., Suyu, S. H., et al. 2018, ApJ, 860, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Erben, T., Kuijken, K., et al. 2012, MNRAS, 421, 2355 [Google Scholar]
- Hsueh, J. W., Enzi, W., Vegetti, S., et al. 2020, MNRAS, 492, 3047 [CrossRef] [Google Scholar]
- Huang, X., Storfer, C., Ravi, V., et al. 2020, ApJ, 894, 78 [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jacobs, C., Collett, T., Glazebrook, K., et al. 2019, ApJS, 243, 17 [CrossRef] [Google Scholar]
- Jaelani, A. T., More, A., Oguri, M., et al. 2020a, MNRAS, 495, 1291 [CrossRef] [Google Scholar]
- Jaelani, A. T., More, A., Sonnenfeld, A., et al. 2020b, MNRAS, 494, 3156 [CrossRef] [Google Scholar]
- Jurić, M., Kantor, J., Lim, K., et al. 2017, Astronomical Data Analysis Software and Systems XXV, 512, 279 [Google Scholar]
- Koopmans, L. V. E., & Treu, T. 2003, ApJ, 583, 606 [NASA ADS] [CrossRef] [Google Scholar]
- Kormann, R., Schneider, P., & Bartelmann, M. 1994, A&A, 284, 285 [NASA ADS] [Google Scholar]
- Mao, S., & Schneider, P. 1998, MNRAS, 295, 587 [NASA ADS] [CrossRef] [Google Scholar]
- Marshall, P. J., Verma, A., More, A., et al. 2016, MNRAS, 455, 1171 [NASA ADS] [CrossRef] [Google Scholar]
- Mediavilla, E., Muñoz, J. A., Falco, E., et al. 2009, ApJ, 706, 1451 [NASA ADS] [CrossRef] [Google Scholar]
- Metcalf, R. B., Meneghetti, M., Avestruz, C., et al. 2019, A&A, 625, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Millon, M., Galan, A., Courbin, F., et al. 2020, A&A, 639, A101 [CrossRef] [EDP Sciences] [Google Scholar]
- Miyazaki, S., Komiyama, Y., Kawanomoto, S., et al. 2018, PASJ, 70, S1 [NASA ADS] [Google Scholar]
- More, A., McKean, J. P., More, S., et al. 2009, MNRAS, 394, 174 [NASA ADS] [CrossRef] [Google Scholar]
- More, A., Verma, A., Marshall, P. J., et al. 2016, MNRAS, 455, 1191 [NASA ADS] [CrossRef] [Google Scholar]
- More, A., Lee, C.-H., Oguri, M., et al. 2017, MNRAS, 465, 2411 [NASA ADS] [CrossRef] [Google Scholar]
- Newman, A. B., Ellis, R. S., & Treu, T. 2015, ApJ, 814, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., Rusu, C. E., & Falco, E. E. 2014, MNRAS, 439, 2494 [NASA ADS] [CrossRef] [Google Scholar]
- Oldham, L. J., & Auger, M. W. 2018, MNRAS, 476, 133 [NASA ADS] [CrossRef] [Google Scholar]
- Petrillo, C. E., Tortora, C., Vernardos, G., et al. 2019, MNRAS, 484, 3879 [NASA ADS] [CrossRef] [Google Scholar]
- Ruff, A. J., Gavazzi, R., Marshall, P. J., et al. 2011, ApJ, 727, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Schechter, P. L., Pooley, D., Blackburne, J. A., & Wambsganss, J. 2014, ApJ, 793, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. J., Lucey, J. R., & Conroy, C. 2015, MNRAS, 449, 3441 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. J., Lucey, J. R., & Collier, W. P. 2018, MNRAS, 481, 2115 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. J., Collier, W. P., Ozaki, S., & Lucey, J. R. 2020, MNRAS, 493, L33 [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2012, ApJ, 752, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2013a, ApJ, 777, 98 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Gavazzi, R., Suyu, S. H., Treu, T., & Marshall, P. J. 2013b, ApJ, 777, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018, PASJ, 70, S29 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Jaelani, A. T., Chan, J., et al. 2019, A&A, 630, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spiniello, C., Trager, S. C., Koopmans, L. V. E., & Chen, Y. P. 2012, ApJ, 753, L32 [NASA ADS] [CrossRef] [Google Scholar]
- Suyu, S. H., Hensel, S. W., McKean, J. P., et al. 2012, ApJ, 750, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Suyu, S. H., Bonvin, V., Courbin, F., et al. 2017, MNRAS, 468, 2590 [Google Scholar]
- Tanaka, M. 2015, ApJ, 801, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Tanaka, M., Coupon, J., Hsieh, B.-C., et al. 2018, PASJ, 70, S9 [Google Scholar]
- Treu, T., & Koopmans, L. V. E. 2002, ApJ, 575, 87 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Auger, M. W., Koopmans, L. V. E., et al. 2010, ApJ, 709, 1195 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Dutton, A. A., Auger, M. W., et al. 2011, MNRAS, 417, 1601 [NASA ADS] [CrossRef] [Google Scholar]
- Vegetti, S., Koopmans, L. V. E., Bolton, A., Treu, T., & Gavazzi, R. 2010, MNRAS, 408, 1969 [NASA ADS] [CrossRef] [Google Scholar]
- Wong, K. C., Sonnenfeld, A., Chan, J. H. H., et al. 2018, ApJ, 867, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Wong, K. C., Suyu, S. H., Chen, G. C. F., et al. 2019, MNRAS, 498, 1420 [CrossRef] [Google Scholar]
Appendix A: Additional table
Grade A and B lens candidates.
All Tables
Number of lens candidates of grades of each grade found among subjects selected by the cut P(LENS|d) > 0.5, from the “Talk” section of Space Warps, by YATTALENS and in the merged sample.
All Figures
|
Fig. 1. Colour-composite HSC images of lens SL2SJ021411−040502. Images with the light from the foreground galaxy subtracted are shown on the right, while original images are on the left. The images at the top and bottom row were created with the “standard” and “optimal” colour schemes, respectively. |
| In the text | |
|
Fig. 2. Set of four simulated lenses, rendered using the “optimised” colour scheme, with and without foreground subtraction. The first two lenses from the top are labelled as easy, while the bottom two are examples of hard lenses. |
| In the text | |
|
Fig. 3. Set of four non-lens duds from the training set, rendered using the “optimised” colour scheme. |
| In the text | |
|
Fig. 4. Top: distribution in the number of classified subjects per volunteer. Bottom: cumulative distribution. |
| In the text | |
|
Fig. 5. Top: distribution in the posterior probability of subjects, duds, and sims being lenses given the classification data from the volunteers. Bottom: cumulative distribution. The vertical dotted line marks the limit above which subjects are declared promising candidates and promoted to the expert visual inspection step. |
| In the text | |
|
Fig. 6. True positive rate (i.e. fraction of lenses correctly classified as such) on the classification of simulated lenses as a function of lensed image S/N and lens Einstein radius for easy and hard lenses separately. Parts of the parameter space occupied by only ten or fewer lenses are left white. |
| In the text | |
|
Fig. 7. Shaded region: distribution in lens photometric redshift of all grade A and B SuGOHI lenses. The blue portion of the histogram corresponds to lenses discovered in this study. The green part indicates BOSS galaxy lenses discovered with YATTALENS, presented in Paper I, II, and IV (Sonnenfeld et al. 2018; Wong et al. 2019; Chan et al. 2020). The cyan part shows lenses discovered by means of visual inspection of galaxy clusters, as presented in Paper V. The striped regions indicate lenses discovered independently in this study and in the study of Paper V. Grey solid lines: distribution in lens spectroscopic redshift of lenses from the Sloan ACS Lens Survey (SLACS, Auger et al. 2010). Red solid lines: distribution in lens spectroscopic redshift of lenses from the SL2S Survey (Sonnenfeld et al. 2013b,a, 2015). Orange solid lines: distribution in lens photometric redshift of likely lenses discovered in DES by Jacobs et al. (2019). Dashed lines: distribution in photometric redshift of all subjects examined in this study, rescaled downwards by a factor of 1000. |
| In the text | |
|
Fig. 8. Set of eight lenses associated with a compact lensed source. In each panel, we show the probability of the subject of being a lens, according to the volunteer classification data (top left), the lens galaxy photo-z (top right), the final grade after our inspection (left). The circled “Y” and “T” on the right, if present, indicate that the candidate was discovered by YATTALENS and noted by us in the “Talk” section of the Space Warps website, respectively. |
| In the text | |
|
Fig. 9. Set of eight disk galaxy lens candidates discovered in our sample. |
| In the text | |
|
Fig. 10. Two lens candidates with strongly lensed red sources. |
| In the text | |
|
Fig. 11. Selected sample of ten lens candidates with a highly asymmetric image configuration. In each row, the left panel shows the original image, while the right one shows the foreground-subtracted one. |
| In the text | |
|
Fig. 12. Distribution in sky background rms (in AB magnitudes per pixel) of all subjects, grade A and B candidates combined, and grade C candidates, in i- (left) and g-band (right). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.