| Issue |
A&A
Volume 635, March 2020
|
|
|---|---|---|
| Article Number | A101 | |
| Number of page(s) | 18 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201937228 | |
| Published online | 16 March 2020 | |
Probabilistic fibre-to-target assignment algorithm for multi-object spectroscopic surveys
1
Tartu Observatory, University of Tartu, Observatooriumi 1, 61602 Tõravere, Estonia
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Institute for Computational Cosmology and Centre for Extragalactic Astronomy, Department of Physics, Durham University, South Road, Durham DH1 3LE, UK
3
Lund Observatory, Department of Astronomy and Theoretical Physics, Box 43, 221 00 Lund, Sweden
4
Leibniz-Institut für Astrophysik Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
5
Zentrum für Astronomie der Universität Heidelberg, Landessternwarte, Königstuhl 12, 69117 Heidelberg, Germany
6
Max-Planck-Institut für Extraterrestrische Physik (MPE), Giessenbachstraße, 85748 Garching, Germany
7
ICRAR, The University of Western Australia, 35 Stirling Highway, Crawley, WA 6009, Australia
8
Zentrum für Astronomie der Universität Heidelberg, Astronomisches Rechen-Institut, Mönchhofstr. 12, 69120 Heidelberg, Germany
9
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange, France
10
Astronomy Centre, University of Sussex, Falmer, Brighton BN1 9QH, UK
11
Institute of Astronomy, Faculty of Physics, Astronomy and Informatics, Nicolaus Copernicus University, Grudziadzka 5, 87-100 Toruń, Poland
12
Université Lyon 1, Ens de Lyon, CNRS, Centre de Recherche Astrophysique de Lyon UMR5574, 69230 Saint-Genis-Laval, France
13
Institute of Cosmology and Gravitation, University of Portsmouth, Burnaby Road, Portsmouth PO1 3FX, UK
Received:
2
December
2019
Accepted:
28
January
2020
Abstract
Context. Several new multi-object spectrographs are currently planned or under construction that are capable of observing thousands of Galactic and extragalactic objects simultaneously.
Aims. In this paper we present a probabilistic fibre-to-target assignment algorithm that takes spectrograph targeting constraints into account and is capable of dealing with multiple concurrent surveys. We present this algorithm using the 4-m Multi-Object Spectroscopic Telescope (4MOST) as an example.
Methods. The key idea of the proposed algorithm is to assign probabilities to fibre-target pairs. The assignment of probabilities takes the fibre positioner’s capabilities and constraints into account. Additionally, these probabilities include requirements from surveys and take the required exposure time, number density variation, and angular clustering of targets across each survey into account. The main advantage of a probabilistic approach is that it allows for accurate and easy computation of the target selection function for the different surveys, which involves determining the probability of observing a target, given an input catalogue.
Results. The probabilistic fibre-to-target assignment allows us to achieve maximally uniform completeness within a single field of view. The proposed algorithm maximises the fraction of successfully observed targets whilst minimising the selection bias as a function of exposure time. In the case of several concurrent surveys, the algorithm maximally satisfies the scientific requirements of each survey and no specific survey is penalised or prioritised.
Conclusions. The algorithm presented is a proposed solution for the 4MOST project that allows for an unbiased targeting of many simultaneous surveys. With some modifications, the algorithm may also be applied to other multi-object spectroscopic surveys.
Key words: methods: statistical / techniques: miscellaneous / instrumentation: spectrographs / surveys
© ESO 2020
1. Introduction
Currently, there are many new multi-object spectroscopic facilities planned or undergoing construction. These include the forthcoming wide-field multi-object spectrographs for the William Herschel Telescope (WEAVE, Dalton et al. 2012), the Dark Energy Spectroscopic Instrument (DESI, DESI Collaboration 2016), the Subaru Prime Focus Spectrograph (PFS, Tamura et al. 2016), the Maunakea Spectroscopic Explorer (MSE, The MSE Science Team 2019), the Multi-Object Optical and Near-infrared Spectrograph (MOONS, Cirasuolo & MOONS Consortium 2016), and the VISTA 4-m Multi-Object Spectroscopic Telescope (4MOST, de Jong et al. 2019). All of these instruments are capable of observing thousands of objects simultaneously, allowing the community to carry out several surveys at the same time. To maximise instrument efficiency, several Galactic and extragalactic science cases are addressed in tandem; during a single science exposure, targets from several different surveys are observed simultaneously. This parallel mode of operations poses new challenges, such as how to prioritise different surveys, which were not encountered by previously undertaken surveys that usually only had one main science goal.
In this paper we address this challenge and propose a probabilistic fibre-to-target assignment algorithm for multi-object spectroscopic surveys. A related challenge is the generation of an optimal tiling pattern that will be treated in a separate work (Tempel et al., in prep.). The proposed targeting algorithm is currently being developed for the 4MOST survey, but it can be generalised to all multi-object spectroscopic surveys. The algorithm is one potential approach for 4MOST, and its development is an important step forward in defining the best strategy for 4MOST observations. However, at this stage the algorithm is a proposed one and ultimately the implemented algorithm for 4MOST may slightly differ from the one described in this paper.
The 4MOST is a new high-multiplex, wide-field spectroscopic survey facility under development for the four-metre-class Visible and Infrared Survey Telescope for Astronomy (VISTA) at Paranal. 4MOST has a large field of view of 4.3 square degrees and a high multiplex capability, with 1624 fibres feeding two low-resolution spectrographs and 812 fibres transferring light to the high-resolution spectrograph. Spectrograph specifications are described in Hansen et al. (2015). An overview of the 4MOST project is given by de Jong et al. (2019), scientific operations are described in Walcher et al. (2019), and the current survey strategy is described in Guiglion et al. (2019). The 4MOST consortium survey includes the following ten surveys; the Milky Way Halo Low-Resolution Survey (Helmi et al. 2019), the Milky Way Halo High-Resolution Survey (Christlieb et al. 2019), the Milky Way Disc and Bulge Low-Resolution Survey (4MIDABLE-LR, Chiappini et al. 2019), the Milky Way Disc and Bulge High-Resolution Survey (4MIDABLE-HR, Bensby et al. 2019), the eROSITA Galaxy Cluster Redshift Survey (Finoguenov et al. 2019), the Active Galactic Nuclei Survey (Merloni et al. 2019), the Wide-Area VISTA Extragalactic Survey (WAVES, Driver et al. 2019), the Cosmology Redshift Survey (CRS, Richard et al. 2019), the One Thousand and One Magellanic Fields Survey (1001MC, Cioni et al. 2019), and the Time-Domain Extragalactic Survey (TiDES, Swann et al. 2019). In addition to these 4MOST consortium surveys, additional public surveys will have to be included into the whole 4MOST project planning. The first five-year survey will start at the end of 2022.
One of the challenges for multi-object spectroscopic instruments to conduct several surveys in parallel is the computation of target selection functions. In 4MOST, each fibre’s home (resting) position in the focal plane is fixed where each fibre has a limited patrol area in which it can move1. At any position in the sky, there can be a large choice of targets that can be observed by a specific fibre. The actual strategy to choose the targets has to fulfil certain requirements. Thus, the selection function at small angular scales is sophisticated and this significantly complicates any statistical analysis of observed data. For example, in order to recover the two-point correlation function, assuming that one already knows the sky-plane and line-of-sight selection functions of the target catalogue, requires a detailed knowledge and understanding of the targeting probability for all individual targets and target pairs. Bianchi & Percival (2017) developed an advanced algorithm to exactly recover the two-point correlation function and they applied it to the DESI dark time surveys (Bianchi et al. 2018), in particular, with Smith et al. (2019) considering its use within the DESI Bright Galaxy Survey. The probabilistic fibre-to-target assignment algorithm proposed in this paper allows us to use a similar approach in a straightforward manner.
The algorithm proposed in the current paper was specifically developed to meet the following conditions. First, the proposed algorithm should be able to recover the targeting selection function. Second, the selection of targets from the input catalogues should be random and the algorithm should achieve a nearly uniform completeness as a function of the required exposure time of targets. Third, the algorithm should balance the surveys observed in parallel while taking the completeness goals of each individual survey into account. The algorithm we propose in this current paper covers all three of these aspects.
The structure of the paper is as follows. In Sect. 2 we describe the probabilistic fibre-to-target assignment algorithm in detail. We test the algorithm by using Poisson distributed targets in Sect. 3 and then by using mock survey catalogue targets in Sect. 4. We conclude the paper and discuss further improvements in Sect. 5.
2. Probabilistic targeting algorithm
In this section we present the probabilistic fibre-to-target assignment algorithm, using the 4MOST project with its numerous surveys as an example. The presentation of the algorithm is organised as follows. In Sect. 2.1 we describe the requirements and assumptions of the algorithm and define the problem. Section 2.2 defines how we assign an initial probability for each target-fibre pair and in Sect. 2.3 we describe how the previously assigned probabilities are altered to balance the number densities of targets and how to take survey completeness goals into account. At this point, we have assigned a probability for each fibre-target pair that is used to assign targets for each fibre. Finally, Sect. 2.4 gives an overview about the target allocation scheme used by the algorithm described in the current paper.
2.1. Set-up of the problem
The 4MOST instrument is a multi-fibre spectrograph with the following constraints. Firstly, the field of view is a hexagon covering 4.3 square degrees of the sky in a single pointing. Secondly, fibre positions across the field of view are fixed in a regular pattern. Each fibre can move only within a small patrol area of radius r ∼ 3.2 arcmin (see Fig. 1). Thirdly, one third of the fibres are feeding a high-resolution spectrograph (HRS), whilst two-thirds are feeding a low-resolution spectrograph (LRS). During each exposure, high- and low-resolution spectrographs fibres are used simultaneously.
 |
Fig. 1. Left panel: 4MOST field of view with 1624 low-resolution (blue) and 812 high-resolution spectrograph fibres (red) at their home positions. One field of view covers 4.3 square degrees in the sky (see also Fig. 7). Black rectangle depicts the area shown in the middle and right panels. Middle and right panels: patrol area (3.2 arcmin from the fibre home position) of each low- and high-resolution spectrograph fibre, respectively. Fibre home positions are marked as points for a given resolution or as small crosses for fibres with alternative resolution. Any location in a field of view can be reached by two to six low-resolution spectrograph fibres and by one to three high-resolution spectrograph fibres. Table 1 gives the fraction of area that is covered by a given number of fibres. |
Fraction of area in the 4MOST field of view that can be reached only by Nfib fibres (left side of the table) or at least with Nfib fibres (right side of the table).
The 4MOST project consists of several consortium surveys and their own sub-surveys of which each is characterised by a specific target selection. The sub-surveys share the focal plane and are observed in parallel as if they are one survey. The challenges the targeting algorithm has to address are the following:
– As the focal plane is shared by several sub-surveys, objects from multiple sub-surveys are targeted during the same exposure. This is necessary as the target density in the majority of sub-surveys is not high enough to efficiently fill up all fibres in one pointing. In some fields, several sub-surveys require less than a few percent of fibres per pointing, whilst other sub-surveys can fill up all the fibres.
– Exposure time requests for different targets vary significantly across each sub-survey. However, due to the above mentioned point, targets with differing exposure time requests must be observed simultaneously. Hence, for a large fraction of targets, repeated observations are necessary to reach the requested total exposure times. Depending on their properties, different targets can be observed more or less efficiently in bright, grey and dark sky conditions; for example, some targets can be easily observed during bright time, whilst in the same field other targets require a long exposure during dark time.
– For some sub-surveys, a pre-defined fraction of targets is sufficient to fulfil the sub-survey’s science goals. Hence, not all targets in the input catalogue need to be observed. This poses a challenge as to how targets can be selected in a way that all sub-surveys are successfully completed and the required fraction of targets observed.
It is clear that the target allocation problem in 4MOST is much more complicated than in surveys with only one target class (or single survey). In such surveys, the main problem that occurs is how to most effectively observe the given list of targets. In 4MOST, the problem is how to observe the right set of targets so that the science output of each sub-survey is maximised. Since the mix of sub-surveys and the total target density changes across the sky, there is need for a flexible solution. The solution proposed for the 4MOST survey is a probabilistic fibre-to-target assignment scheme. The key idea is that for each target, the probability that the target is selected for observation by a given fibre is assigned. A detailed description of the probability assignment is presented below.
2.2. Assigning probabilities for fibre-target pairs
In this section we describe how we assign a probability for a given fibre-target pair. Also, we explain how these probabilities are used and how a target is selected for each fibre are described in Sects. 2.3 and 2.4.
The probabilistic fibre-to-target assignment assumes that for each fibre-target pair, we can assign a probability that a given target should be observed with a given fibre. In order to be able to assign probabilities for each fibre-target pair, the following assumptions have to be met:
– The field pattern (pointing or tile centres as well as orientations) is fixed2. Before observations begin, we know the centre and orientation of all fields that are to be observed. This is required, as it is necessary to know how many fibres for each target, across all fields that cover the target, could potentially reach this target as well as the total exposure time available for the target.
– We know the exposure time and sky condition3 for each field (for a single science exposure). These are used to compute probabilities for each fibre-target pair. However, during actual observations, the exposure time of a field for a given set of targets can be adjusted with respect to the real observing conditions, such as sky brightness, seeing, and airmass, in order to increase survey efficiency.
– For each target we know the required exposure time as a function of the sky condition.
– We assume that all fields (generated tiles) in a given sky area are completed by the end of the survey. Since probabilities for fibre-target pairs are assigned using all fields over a given area, the assumption is that all fields are completed. As a result, the proposed algorithm strongly prefers the completion of individual sky areas versus half-completing the entire sky. However, the algorithm does not require that generated fields should allow us to observe all required targets in the input catalogue. In general, the algorithm assumes that the generated field pattern is optimised based on the input target catalogue.
The probabilistic targeting algorithm starts by performing a probability assignment for each fibre-target pair. For each target t and fibre k in a field i, we assign a probability as follows (see Fig. 2 for illustration):
 |
Fig. 2. Left panel: two partially overlapping 4MOST fields with low-resolution (blue) and high-resolution (red) spectrograph fibres at their home positions. Right panel: patrol areas of high-resolution spectrograph fibres and four targets in a zoom in region highlighted in left-hand panel. Fibre home positions are marked as points and labelled with fibre numbers. Possible fibre-target pairs are illustrated with lines. Targets T2 and T3 can be reached by fibres from two fields; target T3 can be reached by three fibres from Field 1 and two fibres from Field 2; fibre 2313 can reach two targets (T2 and T3). Section 2.2 and Eq. (1) define the probability ptar, field, fib for each fibre-target pair. |
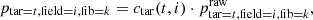 (1)
(1)
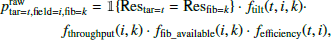 (2)
(2)
where ctar(t, i) is a normalising constant that depends on the target t and field i (see Eq. (4)). We note that 𝟙 {Restar=t = Resfib=k} equals one if the resolution (HR or LR) of the fibre and target is the same, and it is zero otherwise. The factors f…(⋅) in Eq. (2) are defined as follows.
The fibre tilt angle αtilt(tar, field, fib) between a target and a fibre for a given field are taken into account by ftilt(tar, field, fib), which is non-zero for fibres that can reach the given target. In the current paper, we use the following simple definition:
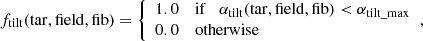 (3)
(3)
where αtilt_max is the maximum tilt angle of a fibre. This guarantees that fibres which cannot reach a given target are not considered. In principle, any function depending on αtilt(tar, field, fib), in which αtilt(tar, field, fib) < αtilt_max, can be used instead of a constant value of 1.0.
It is important to note that fthroughput(field, fib) allows us to take the fibre throughput into account. If a target can be accessed by many fibres, a higher probability is assigned to high-throughput fibres. In cases where the throughput of each fibre is not known, this term can be ignored and fthroughput(field, fib) = 1.0. The distribution of fibre throughputs used in the current paper are shown in Fig. 3.
 |
Fig. 3. Distribution of fibres throughputs used in the current paper. Each fibre has a fixed throughput value during our test simulations. |
We note that ffib_available(i, k) defines a probability that a fibre k in a field i is available for new or repeated (see Sect. 2.4) science targets. Some of the fibres are used for standard stars and therefore are not available to be assigned to science targets. As a first approximation, ffib_available(i, k) = 1.0. For more accurate treatment, ffib_available(i, k) can be estimated by repeating the targeting algorithm hundreds or thousands of times.
The efficiency coefficient that a given target should be observed within field i is described by fefficiency(t, i). This is only relevant if exposure times or sky conditions are not the same for all fields that cover a given target. For example, if a target requires a short exposure time and could be observed using short or long exposures, we can assign a very low probability to the target for fields with long exposures. Furthermore, if a target requires a long exposure during dark time and if some possible fields that include this target are observed during bright time with short exposures, then we can assign zero probability to the target in fields that are observed during bright time.
Finally, the normalising constant ctar(t, i) for a target t in field i is determined by meeting the following condition:
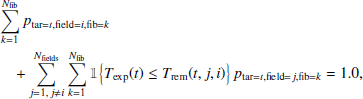 (4)
(4)
where Nfib is the number of fibres in one field and Nfields is the total number of fields that should be observed during the entire survey. The condition Texp(t) ≤ Trem(t, j, i) in Eq. (4) should be interpreted as a condition that the remaining exposure time is sufficient to successfully observe the target t. The calculation of the remaining exposure time depends on the used field order if fields have different exposure times. In Eq. (4), Texp(t) is the required exposure time of a target t and Trem(t, j, i) is the remaining exposure time that can be used for this target, which is summed over fields that cover the target t. Additionally, Trem(t, j, i) is defined as
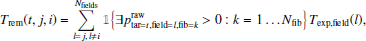 (5)
(5)
where Texp, field is the exposure time for a given field. The calculation of Trem assumes that the required exposure time of a target is fixed.
The probability p defines the probability that an unobserved target is observed with a given fibre. Additionally, it is assumed that we start observing a target if there is sufficient time left in order to successfully complete the target. If there is not enough time left to successfully observe the target, it is removed from the target list before the probabilistic target selection (see Sect. 2.4).
Regarding the normalisation constant ctar(t, i) in Eq. (4) (see also Eq. (1)), the calculation of remaining time in Eq. (5) assumes that we know in which order the fields are observed. The normalisation constant ctar(t, i) is calculated beforehand and does not depend on the field assignment during real observations. If the field order is not known and exposure times differ in different fields, then the normalisation depends on the assumed field order. In this case, we can use a random field order to calculate the normalisation or we can perform several calculations of normalisation over many different field orders and use the mean normalising constant.
In Eq. (4) the sum is performed over all fields and all fibres. The sum is undoubtedly over all fibres that could be used to start observing a given target. The defined probability only applies to new targets that have not been observed previously. Targets that require repeated observations are targeted with the highest priority. Additionally, if an observation of a target cannot be successfully completed, as the remaining exposure time is not sufficient, then the object is only targeted if no other targets are available (see Sect. 2.4).
The most important aspect of the normalisation given with Eq. (4) is that it gives a higher probability for targets that require long exposures. In general, the normalisation counts the number of fields where a target can be observed for the first time. One aim of this normalisation is to have nearly uniform completeness that does not depend on exposure time or magnitude. This aspect is later analysed in Sect. 4.3 and Fig. 15.
2.3. Probabilistic targeting algorithm
A target is assigned to each fibre in the targeting algorithm. For a given fibre k in a field i, we assigned a probability to each target that can be targeted. This only applies for targets that are not yet observed. Targets that need repeated observations are allocated prior to this (see Sect. 2.4). The probability that a target t should be assigned to a fibre k in a field i is defined as
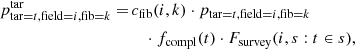 (6)
(6)
where fcompl is a small-scale-merit function that defines the fraction of targets averaged over a small sky area that should be observed for a successful survey4. If a survey is expected to observe a constant fraction of targets independent of target parameters and coordinates, then fcompl(t ∈ s) = const ≤ 1.0 for a survey s.
The factor Fsurvey(i, s) takes into account that the number density of targets varies between surveys, that targets are clustered, and that there is a fixed fibre pattern in the 4MOST instrument (see Fig. 1). The factor Fsurvey(i, s) is defined as
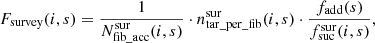 (7)
(7)
where each component is described below. We note that Fsurvey(i, s) is calculated per field, based on targets that are accessible by fibres in field i.
The probabilities ptar = t, field = i, fib = k do not take the fixed fibre pattern of the 4MOST instrument into account. Additionally, the probabilities ptar = t, field = i, fib = k assume that all fibres in a field can be used for all targets in a single survey. These assumptions are not valid in reality and are taken into account by Fsurvey(i, s). The parameter 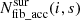 takes into account that not all fibres are accessible by all surveys by counting the number of fibres in a field i that are accessible by a survey s:
takes into account that not all fibres are accessible by all surveys by counting the number of fibres in a field i that are accessible by a survey s:
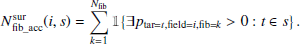 (8)
(8)
The parameter 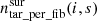 determines the mean number of targets (from all surveys) per fibre for the fibres that are accessible by survey s. It is defined as
determines the mean number of targets (from all surveys) per fibre for the fibres that are accessible by survey s. It is defined as
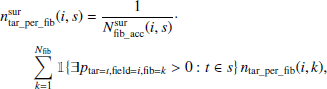 (9)
(9)
where ntar_per_fib(i, k) is the number of potential targets per fibre
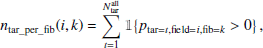 (10)
(10)
where 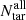 represents the number of all targets over all surveys.
represents the number of all targets over all surveys.
The factor 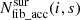 takes into account that not all fibres are accessible by all surveys. Also, for surveys with sparse sampling of targets, which have a lower
takes into account that not all fibres are accessible by all surveys. Also, for surveys with sparse sampling of targets, which have a lower 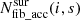 value, the targeting probability is increased. Additionally, we have to take into account that target density varies within a field of view, hence some fibres can reach more targets than other fibres. This is described by
value, the targeting probability is increased. Additionally, we have to take into account that target density varies within a field of view, hence some fibres can reach more targets than other fibres. This is described by 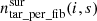 . If a survey can only use fibres that can reach more targets than average, then the targeting probability for this survey’s targets is increased.
. If a survey can only use fibres that can reach more targets than average, then the targeting probability for this survey’s targets is increased.
An additional factor 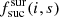 is added to the parameter Fsurvey(i, s) to better balance the fibre usage between surveys. This factor is estimated based upon targeting simulations. Based on these simulations, for each target t we can estimate the probability
is added to the parameter Fsurvey(i, s) to better balance the fibre usage between surveys. This factor is estimated based upon targeting simulations. Based on these simulations, for each target t we can estimate the probability 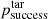 that it was successfully observed with sufficient exposure time. The factor
that it was successfully observed with sufficient exposure time. The factor 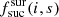 is defined as
is defined as
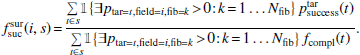 (11)
(11)
This factor is calculated per field and it boosts surveys that do not observe enough targets compared to their expected number of targets (fcompl). Initially we can assume 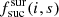 = 1.0.
= 1.0.
Furthermore, we can manually add another factor fadd(s) if none of the previous adjustments present satisfactory results. For the majority of surveys, this factor should be fadd(s) = 1.0.
The probabilities 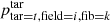 without a normalising constant cfib(i, k) are calculated beforehand for all fibre-target pairs. The normalising constant in Eq. (6) normalises the targeting probabilities for each fibre, and it is calculated during fibre to target assignment as explained in Sect. 2.4. The normalisation cannot be calculated beforehand as it depends on the set of targets that are available, including fibre collisions, for a given fibre.
without a normalising constant cfib(i, k) are calculated beforehand for all fibre-target pairs. The normalising constant in Eq. (6) normalises the targeting probabilities for each fibre, and it is calculated during fibre to target assignment as explained in Sect. 2.4. The normalisation cannot be calculated beforehand as it depends on the set of targets that are available, including fibre collisions, for a given fibre.
2.4. Fibre to target assignment
During fibre to target assignment, the aim is to find a target for each fibre, to reserve some fibres for standard stars, and to allocate sky fibres. In the current paper, we use a simple and straightforward algorithm for this. It requires additional analysis to find the most optimal algorithm. In our test simulations, we used the following algorithm for targeting:
– Fibres are allocated to standard stars. If the number of good standard stars in a field of view is large enough, then it is preferential to use fibres that cannot be allocated to science targets.
– Fibres are allocated to targets that require repeated observations. The highest priority is to allocate fibres to targets that have been previously observed but need more exposure time to be completed. This guarantees that most of the observed targets are successfully completed. Wherever possible, fibres should be used that cannot be allocated to new science targets, increasing the efficiency of fibre to target allocation. Additionally, fibres that are closer to the target and/or fibres with fewer potential new targets are preferred.
– Targets that cannot be observed due to fibre collisions are removed. All targets that are closer than the fibre collision radius for previously allocated fibres need to be removed.
– Targets that require more time than is remaining are removed. These targets are put on hold and are then observed if some fibres are left empty.
– New science targets are allocated to each fibre as follows:
-
(a)
An empty fibre, which is not yet allocated, needs to be found and can then be used for a new science target. This can be performed randomly or by ranking the fibres by the number of remaining targets per fibre and selecting the one with the lowest number of targets per fibre. The latter is more efficient because it first uses fibres with only one or a few targets.
-
(b)
A target for a fibre using probabilities
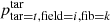 , as described below, must be found.
, as described below, must be found. -
(c)
Targets around a recently allocated target, which cannot be observed due to fibre collisions, need to be removed.
-
(d)
The step from point (a) needs to be repeated and a new empty fibre must be found. However, if there are no empty fibres left or if the science target list is empty, the search for empty fibres should stop.
– Sky fibres need to be allocated. First, fibres that are not yet allocated should be used. If the number density of empty fibres is not high enough, some science fibres should be reallocated as sky fibres. Then fibres that have been allocated to new science targets should be preferentially selected.
– The remaining empty fibres to science targets that were put on hold, as they require more time than is remaining, need to be allocated. Our assumption is that even partially observed targets are scientifically useful. If this is not the case for some targets, then these targets should be removed completely from the potential target list. Additionally, targets that can reach higher completion are preferred if there is more than one target available per fibre.
– The remaining fibres are allocated to auxiliary science targets, that is, targets that are not part of survey’s input catalogues but might be scientifically interesting per se.
To find a new science target t for an empty fibre k in a field i, we can use the probabilities 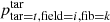 . At this point only targets that are as follows should be considered:
. At this point only targets that are as follows should be considered:
– have not been previously observed;
– require less exposure time than remains for this target (i.e. the sum of exposure times of all remaining fields in a target’s location);
– can be reached by a fibre k, that is, a target is within a patrol radius of a fibre and targets in fibre collision regions are not considered.
The set of these targets is designated as taccessible(i, k) and the probabilities 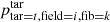 are normalised so as to satisfy
are normalised so as to satisfy
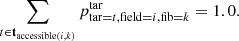 (12)
(12)
Once we have the normalised probabilities 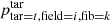 for all targets accessible by a given fibre, we can select one of them at random according to the probabilities assigned.
for all targets accessible by a given fibre, we can select one of them at random according to the probabilities assigned.
3. Target allocation for Poisson distributed targets
In this section we run some basic tests using Poisson distributed targets. Random targets in the sky are the simplest case and this analysis gives a rough estimate of what we should expect from the targeting algorithm with a given number density of targets. A more realistic distribution of targets, such as clustered targets, are analysed in Sect. 4.
As a starting point, we must analyse the 4MOST field of view. Figure 1 shows the fibre pattern layout over a field of view for low- and high-resolution spectrograph fibres. The fibre density in the 4MOST field of view is not uniform across small scales. Table 1 gives the fraction of area that is covered by one to six fibres for low- and high-resolution spectrograph fibres. In the low-resolution regime, most of the field of view can be reached by three or four fibres. In the high-resolution regime most of the field can only be reached by one or two fibres. Hence, in high-resolution, targeting is less efficient than for low-resolution targets.
Figure 4 shows the fibre density across the 4MOST field of view. On average there are 391 low- and 196 high-resolution spectrograph fibres per square degree. However, due to the geometry of the fibre patrol areas, the number density can vary significantly, particularly over smaller areas. Figure 4 also shows the maximum and minimum fibre density, whilst taking into account the fibre patrol area. For example, in a circle with radius 0.2°, the number density of fibres can be up to twice as high or low as the mean fibre density; in a circle with a radius of 0.6°, the number density can be up to 20% higher or lower than the mean fibre density.
Physically, we cannot place two fibres closer than 17 arcsec, which limits the maximum fibre density over a small area. The fibre collision line is shown on the left-hand panels in Fig. 4. The fibre collision is only a dominant problem in an area with a radius less than 0.5 arcmin.
For simple test simulations, we generated Poisson distributed targets across the sky with different number densities. We generated different targets with differing number densities for low- and high-resolution. For the test simulation, we only used one 4MOST field with either one, two, or three tiles (pointings) stacked on top of each other. In the case of two or three tiles, we slightly shifted the field centres in order to mitigate the fixed fibre pattern. The targeting algorithm was run as described in Sect. 2.4. Each target was observed only once (no repeat observations) and all fibres were used for science targets (zero fibres were allocated to standard stars and sky).
Figures 5 and 6 show the results of the test simulations using Poisson distributed targets. Figure 5 shows the fraction of used fibres as a function of target density. If the target density is low, then nearly all targets are observed and the fraction of used fibres increases linearly. If the number density of targets is significantly higher than the fibre density, all fibres are successfully used for science targets. Vertical lines in Fig. 5 show the fibre density multiplied by one, two, or three. If the target density is equal to the fibre density, then we can use ∼90% of low-resolution and ∼75% of high-resolution spectrograph fibres when using only one pointing. If we observe the same region more than once, then the fraction of used fibres increases due to increased flexibility of target allocation. During real observations, the fibres that cannot be used for science targets are then used as sky fibres.
 |
Fig. 4. Fibre density for low-resolution (upper panel) and high-resolution (lower panel) spectrograph fibres. Right-hand panels: fibre density up to one degree, left-hand panels: fibre density at small angular scales. Fibre density is defined inside a circle (circumscribed the field of view) as a function of radius (grey points). Fibre density depends on circle location due to the fixed fibre pattern (see Fig. 1) and the scatter is higher when the radius is smaller. Red and blue points show the maximum and minimum fibre number density inside a circle, taking the fibre patrol radius into account. The solid black line shows the mean fibre density in the 4MOST field of view, which is 391.4 and 195.9 fibres per square degree for low- and high-resolution spectrograph fibres, respectively. The black dashed line shows 1.2 times higher or lower density, and the black dotted line shows two times higher or lower density compared with fibre mean density. In a circle with a radius of 0.2°, the fibre density can be twice as high or low as the mean value. In the left-hand panels, the black solid line shows fibre collision regions, where everything above the line is forbidden due to fibre collisions. |
 |
Fig. 5. Fraction of used fibres as a function of target density, assuming a Poisson distribution of targets in the sky. Upper and lower panels: fibre usage efficiency for low- and high-resolution spectrograph fibres, respectively. Colours indicate target density for high- (upper panel) and low-resolution (lower panel) targets. The targeting simulation has been run using one, two, or three tiles (pointings) that are overlaid with small random shifts, which are indicated by three different groups of points on both panels. Each target was observed only once and all fibres were used for science targets. Solid green lines show theoretical expectations for perfect targeting. Vertical dashed lines indicate the fibre densities on the sky using one, two, or three overlapping tiles. |
 |
Fig. 6. Fraction of observed targets as a function of target density for low- (upper panel) and high-resolution (lower panel) targets. The targeting simulation has been run using one, two, or three tiles overlaid (with small random shifts). Each target was observed only once and all fibres were used for science targets. Green solid lines show theoretical expectations for perfect fibre to target allocation. Vertical dashed lines show fibre density on the sky for low- (upper panel) and high-resolution (lower panel) spectrograph fibres. |
Figure 6 shows the fraction of observed targets as a function of target density. If the number density of targets is low, then most of the targets are observed. If the target density is significantly higher than the fibre density, then the fraction of observed targets follows the theoretical expectation, which is that fibre density is divided by target density.
Since we observed both low- and high-resolution targets simultaneously, the obvious question to explore is how the fraction of used fibres or fraction of observed targets depends on the target density of alternative resolution. In Figs. 5 and 6 the colour of the points show the target density of alternative resolution. These figures show that there is no clear dependence on the target density of alternative resolution, that is, the fraction of observed low-resolution targets does not depend on the target density of high-resolution spectrograph fibres, and vice versa. The scatter seen in Figs. 5 and 6 is caused by the Poisson distributed nature of the generated targets.
Another question we consider is the targeting completeness across the field of view and how it is affected by the fixed fibre pattern. To test this, we ran a test simulation with 1.5 times higher number density of targets than fibre density. We ran the targeting simulation thousands of times to accumulate sufficient statistics. The results are shown in Fig. 7. The edges of the field in low- and high-resolution are different due to a differing fibre pattern across low- and high-resolution. Hence, the accessible field of view for low-resolution targets is 4.37 deg2, and for high-resolution targets it is 4.27 deg2. In both cases, the targeting completeness drops at the edges of the field. With regards to the fibre pattern, in low-resolution the pattern is only weakly noticeable as probabilistic fibre to target assignment has erased most of the fibre pattern. In high-resolution the fibre pattern is clearly visible as a large fraction of the field of view can only be reached by one fibre (see Table 1).
Considering the selection function, one advantage of the proposed probabilistic fibre to target assignment algorithm is that the fixed fibre pattern is significantly mitigated. To demonstrate this, we ran the targeting algorithm by selecting a random target for each fibre. The results are shown on the right-hand panels of Fig. 7. We can clearly see that in low- and high-resolution, the fixed fibre pattern is strongly visible on the sky. Total completeness over one field is the same for both random and probabilistic targeting. The advantage of probabilistic targeting is that the fibre pattern is significantly mitigated for high-resolution or almost erased for low-resolution on the sky. Figure 7 shows the results for a single pointing. If the same region is observed more than once, the fixed fibre pattern is almost erased, even for high-resolution targets. This is shown in Fig. 8.
 |
Fig. 7. Targeting completeness in a single field of view. Top row: completeness map for low-resolution targets; bottom row: for high-resolution targets. In the targeting simulation, we used Poisson distributed targets across the sky with 1.5 times higher number density than the number density of fibres. Targeting was performed using the probabilistic fibre-to-target assignment as described in Sect. 2. Left panels: full field of view for a single field. The completeness decreases towards the edge of the field. Middle panels: zoom-in region of the left panel. For comparison, in the right panels we show a completeness map for random targeting in which each fibre-target pair has the same probability. In the right panel, we can clearly see the patrol regions of fibres (see also Fig. 1), which are significantly reduced when using probabilistic fibre-to-target assignment. |
 |
Fig. 8. Targeting completeness for Poisson distributed targets using one, two, or three visits. The number density of targets was set to 1.5 times higher than the total number density of fibres. For low-resolution spectrograph fibres, the patrol area of some fibres is visible and they have slightly higher completeness. This reflects the varying throughput of fibres. Probabilistic targeting slightly prefers fibres with a higher throughput. However, this effect is only visible if the field is observed more than once. For a single visit, a fixed fibre pattern determines the completeness on small angular scales. |
4. An example test case with mock surveys
4.1. Setup of the test simulations
In this section we run a test, where we use three high-resolution surveys and six low-resolution surveys, which are observed simultaneously. These surveys were selected to somewhat maximise the difference between them, that is, the number density, clustering, and targets exposure times distribution. The surveys were selected from 4MOST mock target catalogues. The high-resolution surveys and LR 1 are Milky Way stellar surveys constructed using the Galaxia model (Sharma et al. 2011). LR 2 and LR 3 are galaxy cluster surveys, where LR 2 represents cluster main galaxies and LR 3 illustrates cluster member galaxies. The mock catalogue of the clusters is based on the MultiDark dark matter only N-body simulations (Klypin et al. 2016). The construction of the mock is described in Comparat et al. (2019). LR 4 represents the eRosita AGN mock catalogue and LR 5 is the mock catalogue of TiDES host galaxies. The distribution of targets in LR 4 and LR 5 is uniform in the current mock catalogues. The last survey, LR 6, is a galaxy redshift survey constructed based on the SDSS data5. The selection of these surveys is arbitrary and in the current paper they are used to analyse the main aspects of the target allocation problem. The presented conclusions do not depend on the choice of the selected mock surveys.
We selected targets over a fixed sky area and used a fixed tiling pattern as shown in Fig. 9. The tiling pattern was constructed manually to cover the entire test region with minimal overlap between fields. The tiling pattern in this test is not optimised based on the targets in the test region. Table 2 shows the number density and exposure times of each survey. Figure 15 also shows how the exposure time of targets vary within a survey. The number density and exposure times vary significantly between surveys, which allowed us to test several aspects of the proposed targeting algorithm. Table 3 shows the mean targeting parameters for each survey. The definition of these parameters is given in Sect. 2.4.
 |
Fig. 9. Tiling pattern across the sky area used during our tests. The underlying heat map shows the number density of targets on the sky. Darker areas show higher number density of targets. The light gradient from left to right is because of the Milky Way stellar surveys; there are more stars close to the Milky Way disc, which is located on the left side of the selected survey area. The red box highlights the smaller area that we use as a zoom region on Figs. 10, 16, and 17. |
Target densities and exposure times of six low-resolution and three high-resolution surveys used in this example.
Surveys in our example.
Figure 10 shows the distribution of targets on the sky for the nine surveys used in our test. The target density varies across surveys, but in general it is homogeneous across the chosen area. One exception is LR 3, where targets are highly clustered. The dense blob (a stellar cluster) that is visible in LR 1 and the slightly higher density region in the middle of HR 1 and HR 2 are features in the Galaxia mock catalogue. We selected these survey regions on purpose to show that surveys affect each other. Figure 11 shows the target density as a function of smoothing radius. For some surveys, the targets are highly clustered at small scales (< 0.1°), despite the target density being roughly homogeneous across the entire field of view. The clustering at small scales is a challenge for the targeting algorithm since, at small scales, the target density exceeds the fibre density on the sky. This is clearly visible when comparing Fig. 11 with Fig. 4.
 |
Fig. 10. Sky coordinates of targets in six low-resolution and three high-resolution surveys used during our test. A telescope field of view is superimposed. |
 |
Fig. 11. Target density on the sky for low- (upper panel) and high-resolution (lower panel) test surveys. Target density was calculated within a circle (with random location within a fixed sky area) of radius r as indicated in abscissa. Black lines show the total target density for a given resolution, coloured lines show target density for individual surveys. Solid lines show median target density on the sky, while dashed lines indicate the 90% quantiles. Due to the clustering of targets, the target density (90% quantile) increases towards small sky areas. |
For test simulations, we used the fixed tiling pattern as shown in Fig. 9. For the base simulation, we used 15 min exposures six times. Targeting parameters for the base simulation are given in Table 3. In order to test different aspects of the algorithm we slightly modified the targeting parameters of the base simulation. The description and the deviation from the base simulation is as follows:
– Base, the simulation with parameters as described above. Additionally, for each survey fadd = 1 and ftilt = 1.
– Raw is the same as the base simulation, but 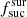 = 1 for each survey. This simulation was used in order to estimate
= 1 for each survey. This simulation was used in order to estimate 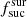 values for each survey.
values for each survey.
– Boost is the same as the base simulation, but fadd = 100 for LR 2 and LR 3 and fadd = 0.01 for LR 5 and LR 6. This simulation was run to test how the additional boost factor affects the completeness of surveys. The factor fadd was included for surveys that were significantly under- or over-observed in the base simulation.
– Tilt is the same as the base simulation, but ftilt(α) = 1 − α/αmax, where αmax is the maximum allowed tilt angle for fibres and α is the tilt angle for a given fibre-target pair.
– Four is the same as the base simulation, but it uses 30 min exposures two times plus 15 min exposures two times, instead of 15 min exposures six times.
In the next section, we analyse the test simulations and explore various aspects of the targeting algorithm by analysing the simulations that deviated from the base simulation.
4.2. Results of the test simulations
Each test simulation is characterised by the fraction of successfully completed targets for each survey. An additional useful parameter to explore is the fraction of successfully completed targets over all observed targets. Both of these values are shown in Table 4 for each test simulation and for each survey.
Results of the targeting algorithm for five different simulations with slightly altered targeting algorithm parameters.
Figure 12 shows the fibre usage efficiency in the base simulation. Since the number density of targets varies across the selected area (see Fig. 9), the fibre usage efficiency is not homogeneous. The efficiency is largely determined by the tiling pattern and can be improved if the tiling pattern is estimated using a given set of targets as a prior. In the current paper our aim is to test the fibre to target assignment algorithm for which a fixed tiling pattern is better suited.
 |
Fig. 12. Fibre usage efficiency for low- (upper panel) and high-resolution (lower panel) surveys. The visible gradient from left to right is due to the fixed tiling and varying number density of objects (see Fig. 9). |
4.2.1. Analysing the base simulation
We start our analysis with the base simulation. The fraction of successfully completed targets should be compared with the fcompl value of each survey. We can see that for surveys LR 2 and LR 3, the fraction of successfully completed targets is lower than the fcompl value. Both surveys include highly clustered targets as seen in Table 3. The mean number of targets per fibre for LR 2 and LR 3 is above 25, which is more than three times higher than other surveys. Hence the fraction of successfully completed targets for LR 2 and LR 3 is limited by the fixed number density of fibres in the sky.
For surveys LR 5 and LR 6, the situation is the opposite; the fraction of successfully completed targets for these surveys is significantly higher than the fcompl value. For these surveys, the number density of targets is larger than for other surveys, which means that a large fraction of fibres can only be used for targets in these surveys (see Table 3). Hence there are many fibres that can only be used for these two surveys. This explains why targets from surveys LR 5 and LR 6 are targeted more frequently than required as the targeting algorithm attempts to find a target for each fibre.
The target density is very similar across all high-resolution surveys. Nevertheless, the fraction of successfully completed targets is lower than expected for surveys HR 2 and HR 3. This can be explained by looking at the exposure times of the high-resolution surveys (see Table 2 and Fig. 15). For HR 1 the exposure times are significantly shorter than for HR 2 and HR 3, and targets from HR 1 are observed more frequently. Since targets from HR 3 require all six exposures (the target exposure time is close to 90 min), then this limits the number of fibres that can be potentially used for new science targets. Only targets observed during the first exposure can be successfully completed.
In general, the targeting algorithm observes the expected number of targets for each survey. The deviations from the expected number are logically explained and results can only be improved by updating the input catalogues or by improving the tiling pattern. A modification of the targeting algorithm does not significantly improve the results.
4.2.2. Influence of the factor 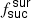
As described above, the factor 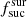 indicates the success of the targeting algorithm for each survey. If the
indicates the success of the targeting algorithm for each survey. If the 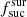 value is lower than 1.0, then the algorithm targets less objects than expected. However if the value is higher than 1.0, then the algorithm targets more objects than expected. In Table 3 we give the
value is lower than 1.0, then the algorithm targets less objects than expected. However if the value is higher than 1.0, then the algorithm targets more objects than expected. In Table 3 we give the 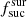 values estimated based on the raw simulation setting
values estimated based on the raw simulation setting 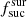 = 1.0 for each survey. For the majority of surveys, the value is around 1.0 as expected. The only exception is LR 5, where the value is significantly higher. This is because the fcompl value for LR 5 is only 0.1, and the number density in LR 5 is relatively high. Hence some of the fibres can only be used for LR 5 targets.
= 1.0 for each survey. For the majority of surveys, the value is around 1.0 as expected. The only exception is LR 5, where the value is significantly higher. This is because the fcompl value for LR 5 is only 0.1, and the number density in LR 5 is relatively high. Hence some of the fibres can only be used for LR 5 targets.
Comparing the Raw and Base simulations (see Table 4) shows that when including 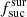 , the algorithm reduces the fraction of observed targets for LR 5. At the same time, the fraction of successfully completed targets is increased for LR 3 and LR 4. Hence, the factor
, the algorithm reduces the fraction of observed targets for LR 5. At the same time, the fraction of successfully completed targets is increased for LR 3 and LR 4. Hence, the factor 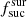 balances different surveys. The same effect is visible for high-resolution surveys where some fibres from HR 1 are moved to HR 3. In general the inclusion of the factor
balances different surveys. The same effect is visible for high-resolution surveys where some fibres from HR 1 are moved to HR 3. In general the inclusion of the factor 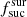 does what is expected.
does what is expected.
4.2.3. Influence of the factor fadd
By analysing the base simulation, we can see that for surveys LR 2 and LR 3 the completion fraction is lower than expected; while for surveys LR 5 and LR 6, it is significantly higher than requested by fcompl. To determine how the performance of these surveys can be improved, we used fadd = 100 for LR 2 and LR 3, and we set fadd = 0.01 for LR 5 and LR 6.
Table 4 shows that including the additional boost factor for surveys LR 2 and LR 3 does not increase the completeness of these surveys. This means that the completeness of these surveys is primarily limited by the fixed number density of fibres and the influence of other surveys is marginal. The completeness of LR 2 and LR 3 surveys can only be increased when increasing the number of exposures, which increases the total number of fibres per sky area.
By analysing surveys LR 5 and LR 6 where the boost factor was set to fadd = 0.01, we see that the completeness is only marginally affected (i.e. less than 1%). This can be explained by looking at Table 3. The number of accessible fibres for LR 6 is the highest, while for most of the other surveys it is significantly lower. This means that there are fibres that can only reach LR 6 targets and cannot be used for other surveys. Since fibre usage is maximised in the targeting algorithm, the targets from LR 6 are more often observed than requested. The situation is similar for LR5, but, additionally, the requested completion fraction for LR 5 is very low (0.1), which also plays a key role.
Adding a boost factor for some surveys has a side effect. Since some fibres are taken away from surveys LR 5 and LR 6, the completion fraction for other surveys (LR 1 and LR 4) is slightly increased. Whether this is a positive or negative effect depends on the viewpoint of the survey science case. In general, the fadd factor can be used to fine tune the balance between surveys if necessary.
4.2.4. Influence of the factor ftilt
Due to the fibre positioner design (Echidna fibre-positioning technology), fibre throughput is reduced if fibres are tilted from their home position. The instrument is most effective if targets are allocated close to the fibre home positions. In the proposed targeting algorithm, targets that are close to the fibre home position can be preferred by using a weight factor ftilt. The results where targets close to fibre home positions were preferentially selected are shown in Table 4, in the column Tilt. For survey completion, the effect of ftilt is less than 1% for all surveys.
Figure 13 shows the fibre tilt angle distribution for the base simulation and for a simulation that prefers targets close to the fibre home position. We can see that introducing a factor ftilt has a significant effect on low-resolution spectrograph fibres. The effect is much smaller for high-resolution spectrograph fibres because their flexibility is lower. For high-resolution spectrograph fibres roughly 40% of the field of view can only be reached by a single fibre (see Table 1).
 |
Fig. 13. Distribution of tilt angles for low- (upper panel) and high-resolution (lower panel) spectrograph fibres. Tilt angle was measured from the fibre home position. The red line shows the distribution for the base simulation whilst the blue line shows the tilt angle distribution after introducing the non-constant ftilt(α) function (see Sect. 4.2.4 for more details). The dashed line shows the uniform distribution of tilt angles. The local bump around 80 arcsec is due to the fixed fibre pattern (see Fig. 1). |
Although the introduction of ftilt prefers targets that are close to the fibre home positions, it should still be evaluated as to whether and how this affects survey scientific goals. Introducing the factor ftilt affects the selection function at small scales.
4.2.5. Influence of the number of visits
For an optimal tiling pattern, we should combine exposures with different lengths. It is clear that in some sky regions the required exposure time is determined by the objects with the longest exposures, whilst in other sky regions the required exposure time is determined by a high density of targets with low exposure times.
For the base simulation, we used 15 min exposures six times. To test the combination of different exposure times, we ran the algorithm using 30 min exposures two times and 15 min exposures two times. The total exposure time (90 min) for both cases is the same. The mean target density before each visit, which is normalised by the fibre density, is shown in Fig. 14. For high-resolution, the target density is always higher than fibre density; whilst for low-resolution, the target density for later visits is lower than the fibre density. This is due to most of the high-resolution targets requiring long exposures and the number density of remaining targets not dropping rapidly. In the low-resolution regime the majority of targets require short exposures; for low-resolution, the number density of remaining targets does drop rapidly.
 |
Fig. 14. Fibre usage efficiency (red circles) for low- (upper panel) and high-resolution (lower panel) surveys as a function of survey progress. For both resolutions, we used only 80% of fibres for science targets, where the rest of the fibres were reserved for standard stars and the sky background. Hence the maximum fibre efficiency is 0.8. Blue squares show the mean target density on the sky normalised by the number density of science fibres. At the beginning of the survey, the target density exceeds the fibre density by two times, but for the last exposures the target density in the low-resolution regime is lower (less than 1.0) than the fibre density. Hence, for the last exposures we do not have enough targets to fill all fibres. Filled points represent the base simulation (15 min exposure six times) and empty points indicate the simulation with four visits (30 min twice plus 15 min twice). |
Figure 14 shows that the fibre usage efficiency is almost independent of the number of visits, that is, six or four. Table 4 shows that the survey completion fraction only slightly depends on the number of visits. For some surveys the completion fraction is slightly better with four visits whilst for other surveys it is the opposite. In general there are no large differences between these two cases. From a practical standpoint, a smaller number of visits is preferred as there is an additional overhead associated with each exposure.
4.3. Analysing selection functions
The selection function defines the survey completeness as a function of some parameter, such as sky coordinates or magnitude. To understand the targeting algorithm, we analysed the selection function as a function of target exposure time and as a function of sky coordinates. In our test simulations, the expected completeness as a function of these parameters should be uniform.
Figure 15 shows the completeness of each survey as a function of target exposure time. The horizontal dashed line shows the expected completeness, and the solid red line shows the fraction of successfully completed targets. Ideally this should match the dashed horizontal line. The completeness for short exposure targets is higher than for long exposure targets. This is expected as during later visits, the empty fibres are used to observe short exposure targets. For long exposure targets, the completeness is roughly constant, as required, and the targeting algorithm tries to achieve uniform completeness regardless of the target exposure time, or magnitude. This cannot be achieved perfectly, mainly due to the fixed fibre density and clustering of targets; we note that for some fibres there are more targets than for other fibres. In general, the achieved uniformity with regards to exposure time is not perfect, but it is nearly independent of the exposure time distribution (grey shaded areas on Fig. 15). The remaining dependence on exposure time is mainly caused by the fixed fibre pattern of the 4MOST instrument, by the distribution of targets and their exposure times, and by the used tiling pattern. Full survey strategy optimisation is required to balance the survey input catalogues and to find the optimal tiling solution.
 |
Fig. 15. Survey completeness as a function of target exposure time. The grey area shows the distribution of exposure times for each survey. The dashed horizontal line shows the required completeness fraction (fcompl value) for each survey. The dotted red line shows the fraction of observed targets for each survey whilst the solid red line shows the fraction of successfully completed targets. The dashed blue line shows the fraction of successfully completed targets over all observed targets. |
By comparing the expected completeness (horizontal dashed line) with survey completeness (solid red line), we see that the survey completeness of LR 2 and LR 3 is lower than expected. Both surveys are galaxy cluster surveys and the number of successfully completed targets is limited by the number density of fibres. However, everything that is possible to observe with six visits is observed. For high resolution, the completeness is slightly lower than expected. This is because most of the high-resolution targets require long exposures and with one fibre you cannot observe two targets that require more than a 45 min exposure each. Taking that into account, the completion fraction for high-resolution targets is also limited by the fibre density. The targeting algorithm balances different surveys in a way that each survey is under-observed in a roughly equal manner. The targeting algorithm does not prefer one survey to another.
The question is inevitably posed as to how we can improve the completion of surveys. For surveys that require short exposures, we can increase the number of visits whilst reducing the exposure time per visit. Even if the total exposure time is the same, we achieve better completeness as there is more freedom to place fibres on targets. However, with short exposures we increase the noise due to the larger numbers of read-outs and we have to observe for longer periods of time to achieve the same signal-to-noise ratio. Hence, the optimal solution is not straightforward. For surveys that require long exposures, the only way to improve the completion is to increase the total exposure time. In the current setup, if most of the targets require more than 45 min exposures, then it does not matter whether they are observed six times for 15 min, three times for 30 min, or two times for 45 min; the completion is roughly the same in all three cases. Determining the optimal number of visits and exposure times is a complicated optimisation problem, which is not further discussed in this paper.
Figure 16 shows the fraction of successfully observed targets as a function of sky coordinates for each survey. At scales larger than the field of view, the completeness is homogeneous, which is as expected. For surveys where the completeness is less than 1.0, we can see a visible tiling pattern in the sky. In regions where tiles overlap, the completeness is significantly higher. Additionally we see that if there is a high density region in one survey, such that there is a dense blob of targets to the right of the field, for example, then the completeness is affected in all surveys. The targeting algorithm tries to observe all targets equally, and if tiling does not allow for this, then all surveys are penalised equally. This emphasises that for a homogeneous selection function, the tiling pattern should match the target density. In looking at the target distribution for high-resolution surveys (see Fig. 10), we can see that for HR 1 and HR 2 there is a clear pattern present in the middle of the field. Although this pattern is not present in HR 3, it is clearly visible in the completeness map (see Fig. 16). In principle, the footprint of all surveys and all inhomogeneities are visible in the final completeness map of all surveys. This is a side effect of all surveys sharing the focal plane and observing targets simultaneously. The increase in survey efficiency comes with the price that the selection function is more complicated.
Figure 17 shows the fraction of successfully observed targets over all observed targets. From this map, we see that most of the targets that are observed are successfully completed. This success rate is homogeneous and it barely depends on the target density. For example, the dense cloud of low-resolution targets does not affect the success rate. The tiling footprint is most strongly visible for HR 3 and LR 5. These are the surveys where most of the targets require long exposures. For all other surveys the success rate depends only very weakly on the tiling pattern. This is expected as the targeting algorithm tries to only observe targets that can be successfully completed. The targeting algorithm only observes targets that cannot be successfully completed if no other options are available.
 |
Fig. 16. Fraction of successfully completed targets out of all targets as a function of sky coordinates for each survey. The tiling pattern is clearly visible in the selection function. Additionally if there is a feature (a denser region) in one survey, it leaves a footprint in all other surveys. However, the feature visible in one survey mainly affects surveys with the same resolution. Hence, the cluster visible in LR surveys (lower right corner) does not affect the completeness for HR surveys. |
 |
Fig. 17. Fraction of successfully observed targets over all observed targets. Yellow points show successfully completed targets. The tiling pattern is clearly visible for surveys that contain a large number of targets with long requested exposure times (e.g. HR 3 in the bottom right panel). For surveys with targets requiring short exposures, the tiling pattern is not as pronounced. |
Figure 18 shows the targeting efficiency as a function of angular separation between targets. In an ideal case, the selection of targets should be independent of the angular separation of targets. Figure 18 shows that targeting efficiency decreases for targets where angular separation is less than ∼5 arcmin. This is the outcome of a fixed fibre pattern and a limited patrol area around each fibre. There is an additional decrease of efficiency at very small scales (17 arcsec), which is caused by the fibre collision issue; two fibres in a single field of view cannot be placed closer than 17 arcsec. Figure 18 clearly shows that the fixed fibre pattern has a more severe effect than the fibre collision issue. In a forthcoming paper, we will analyse how these effects affect the three-dimensional clustering measurements. We will use the methodology presented in Bianchi & Percival (2017) and analyse how well we can recover the galaxy two-point correlation function in a 4MOST cosmology redshift survey.
 |
Fig. 18. Selection of targets as a function of angular separation. The distribution of angular separation of observed targets was divided by the distribution of angular separation of all targets. The blue line shows low-resolution targets and the red line shows high-resolution targets. The vertical dashed line shows the fibre patrol radius (3.2 arcmin) and the vertical dotted line shows the fibre collision distance (17 arcsec). Due to the fixed fibre pattern, targets with smaller angular separation are less likely to be targeted. Targeting efficiency rapidly drops for targets closer than fibre collision distance. |
5. Conclusion and discussion
In this paper we propose a probabilistic fibre-to-target assignment algorithm that can deal with concurrent surveys that are observed simultaneously. The proposed algorithm takes the limitations of a fibre positioner system into account (Echidna in case of 4MOST), and it can deal with surveys with different targeting requirements and number densities. One aim of the proposed algorithm is to maximise the target completion, thus minimising the number of half-completed targets, while achieving survey completion that is independent of the target exposure time or magnitude. Due to the fixed fibre pattern of the 4MOST instrument, the targeting completeness at small scales is not random. In fact, the fixed fibre pattern of the 4MOST instrument has a much larger impact than the fibre collision issue, which only has an effect at very small scales. The probabilistic approach minimises a fixed fibre pattern effect and allows one to achieve nearly uniform targeting completeness even at small angular scales. An additional benefit of the proposed algorithm is that the targeting completeness with respect to the target exposure time is homogeneous, hence, the algorithm does not penalise long-exposure targets nor prefer short-exposure targets.
In general, the free parameters and functions, such as ftilt, that are introduced in the algorithm can be used to control certain aspects of the survey optimisation problem. The optimal choice of these parameters and functions should be determined during the survey preparation and optimisation. The need and value of these parameters depend on the instrument characteristics and input target catalogues.
Computationally, the proposed algorithm works reasonably fast. For example, when taking the full five-year 4MOST survey that contains about 40 million targets and 40 000 individual observations on a decent server with 18 cores and 256 GB of memory, it takes about 20 min to calculate the fibre-target pair probabilities. Then it takes less than 5 min to simulate the five-year survey observations. Hence, it is reasonable to use the computational cost during the real 4MOST observations.
The proposed algorithm assumes that the tiling pattern is fixed and known beforehand. The generation of an optimal tiling pattern is a critical step and ultimately decides the summed exposure time and number of visits for a given sky region. Finding an optimal tiling pattern for a given set of targets is a complicated optimisation problem (see for example, Blanton et al. 2003). Robotham et al. (2010) developed the Greedy algorithm that works efficiently for spatially dense surveys. Due to the low number density of targets in some sky areas, the Greedy algorithm does not work everywhere in the 4MOST footprint. We will address the optimal tiling pattern question in a future paper, where we model the tiling pattern as a marked point process. In this framework, the tiling pattern is seen as a configuration of random interacting objects driven by the probability density of a marked point process. The solution of the optimal tiling problem is given by the construction and manipulation of such a probability density. Details of this algorithm are given in Tempel et al. (in prep.).
The current paper addresses the key aspects of the fibre-to-target assignment problem. However, there are several other aspects that should be considered during real observations. All of these are potentially useful improvements that would extend beyond the proposed algorithm. Below we mention and discuss some of these aspects.
Realistic target progress updates. In this paper target progress is estimated based upon the required and observed exposure times. In reality, targets are observed during several sky conditions, and the summed exposure time may not be sufficient to track target progress. In addition to monitoring the exposure time per target, 4MOST also monitors the signal-to-noise ratio of the observed spectrum or redshift success as a criterion of target progress. These aspects are important and should be included in the algorithm, depending on what is desired for quantifying success during the observations.
Duplicated targets. During real observations, one target can be present in many surveys. Depending on the survey’s scientific goals, exposure time requirements for the same target can be different for different surveys. A straightforward way to take this into account in the targeting algorithm is to include the target in all survey input catalogues. This allows us to calculate correct probabilities for fibre-target pairs. To avoid observing the same target multiple times, the target should be removed from all input catalogues once the target is successfully completed. The success of the target should be estimated based on the most demanding survey requirement.
Prioritising specific targets. In the proposed algorithm, targets are not specifically prioritised. However, there might be a scientifically justified need to prioritise certain targets in some surveys. One example is the clusters survey in which a cluster main galaxy is scientifically more important than the cluster member galaxies. Whether this can be automatically solved by the probabilistic targeting algorithm or whether it needs special tuning requires additional analysis. This also depends on the specific requirements of the survey.
Transients in the input catalogue. The calculation of fibre-target pair priorities assumes that the list of all targets is known and does not change during observations. However, this assumption is violated if we want to observe transients. The list of targets is not known beforehand and cannot be included in the probability calculations. We expect that if the fraction of transients is small, then this has a negligible effect on the main surveys. However, this should be tested using real mock catalogues.
Repeated observations of the same target. In the proposed algorithm, repeated observations of targets are prioritised to guarantee that they are successfully completed. Since exposure times and sky conditions of single observations are different, some observations are more efficient than others to successfully complete partially observed targets. To increase survey efficiency, this should be taken into account in the proposed algorithm.
Cross-talk. If faint and bright object are observed side-by-side (neighbouring traces on the CCD), then the light from the bright object affects the spectrum of the faint object. If cross-talk is a serious issue, then selecting bright and faint objects that are neighbours on the CCD should be avoided with the targeting algorithm.
Optimising fibre usage efficiency. In the current paper, the fibre allocation starts with fibres with the lowest number of potential targets. This is a very simple implementation and tends to maximise the fibre usage. However the fibre usage efficiency can be increased by using a Monte-Carlo method with simulated annealing during the fibre-to-target assignment. This increases the computational cost of the algorithm and requires further analysis to test whether increased computational cost provides a sufficient increase in efficiency to be justified.
Field order and cadence. Fibre-target pair probability calculation assumes that field order is known. In many cases this is not known beforehand and it is determined during real observations depending, for example, on the sky conditions. To overcome this problem, the targeting algorithm can use a random field order, or a best estimate. This has some effect on the survey efficiency. A cadence, which is the required minimum time difference between repeated observations or the requirement that a target should be completed during one night, is another factor that affects the field order. However, it does not have a direct impact on the fibre-to-target assignment algorithm.
To conclude, the algorithm presented in this paper is only a baseline and it does not yet address all aspects of real-life observations that should be considered. Most of these can be tested using more realistic target catalogues. In preparation for the 4MOST survey, we will test these effects and modify the targeting algorithm as needed. The current algorithm is a proposed solution for the 4MOST survey and based on tests presented in this paper, it provides a promising solution for multi-fibre spectroscopic surveys with several concurrent sub-surveys. With the appropriate modifications, the proposed approach can be applied to any other multi-object survey. The required modifications in a fibre-to-target probability assignment for other instruments and surveys depend on the instrument’s capabilities and survey science cases.
4MOST uses the Echidna fibre-positioning technology (Sheinis et al. 2014; Brzeski et al. 2018).
Finding an optimal tiling pattern is an independent algorithm that is described in a separate paper. The tiling algorithm is a critical part of the 4MOST survey optimisation. It essentially decides how many times a given sky region is observed and what is the summed exposure time in a given sky region.
Sky brightness condition is ignored in the current paper and we impose the same sky brightness everywhere, meaning that requested exposure time per target does not depend on the sky brightness.
The 4MOST survey consist of several sub-surveys. From here on, s represents a single sub-survey.
LR 6 is not part of the 4MOST mock catalogues. It is used in the current paper to represent a realistic galaxy redshift survey.
Acknowledgments
This work has made use of the development effort for 4MOST, an instrument under construction by the 4MOST Consortium (https://www.4most.eu/cms/consortium/) for the European Southern Observatory (ESO). Part of this work was supported by institutional research funding IUT26-2 and IUT40-2 of the Estonian Ministry of Education and Research. We acknowledge the support by the Centre of Excellence “Dark side of the Universe” (TK133) and by the grant MOBTP86 financed by the European Union through the European Regional Development Fund. P.N. acknowledges support from the STFC through ST/P000541/1 and the Royal Society through the award of a University Research Fellowship. M.-R.L.C. acknowledges funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement nr. 682115). A. K. acknowledges support from the Sonderforschungsbereich SFB 881 “The Milky Way System” (subprojects A03, A05, A08) of the DFG. M.K. acknowledges support from DLR grant 50OR1904. B. F. R acknowledges support by MNiSW grant DIR/WK/2018/12 and by grant 314 at the PSNC. G. T. was supported by the grant The New Milky Way from the Knut and Alice Wallenberg foundation, by the grant 2016-03412 from the Swedish Research Council, and by the Swedish strategic research programme eSSENCE.
References
- Bensby, T., Bergemann, M., Rybizki, J., et al. 2019, The Messenger, 175, 35 [NASA ADS] [Google Scholar]
- Bianchi, D., & Percival, W. J. 2017, MNRAS, 472, 1106 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, D., Burden, A., Percival, W. J., et al. 2018, MNRAS, 481, 2338 [NASA ADS] [CrossRef] [Google Scholar]
- Blanton, M. R., Lin, H., Lupton, R. H., et al. 2003, AJ, 125, 2276 [NASA ADS] [CrossRef] [Google Scholar]
- Brzeski, J., Baker, G., Baker, S., et al. 2018, Proc SPIE, 10702, 1070279 [Google Scholar]
- Chiappini, C., Minchev, I., Starkenburg, E., et al. 2019, The Messenger, 175, 30 [NASA ADS] [Google Scholar]
- Christlieb, N., Battistini, C., Bonifacio, P., et al. 2019, The Messenger, 175, 26 [NASA ADS] [Google Scholar]
- Cioni, M. R. L., Storm, J., Bell, C. P. M., et al. 2019, The Messenger, 175, 54 [NASA ADS] [Google Scholar]
- Cirasuolo, M. & MOONS Consortium 2016, in Multi-Object Spectroscopy in the Next Decade: Big Questions, Large Surveys, and Wide Fields, eds. I. Skillen, M. Balcells, & S. Trager, ASP Conf. Ser., 507, 109 [NASA ADS] [Google Scholar]
- Comparat, J., Merloni, A., Salvato, M., et al. 2019, MNRAS, 1335 [Google Scholar]
- Dalton, G., Trager, S. C., Abrams, D. C., et al. 2012, in Ground-based and Airborne Instrumentation for Astronomy IV, SPIE Conf. Ser., 8446, 84460P [CrossRef] [Google Scholar]
- de Jong, R. S., Agertz, O., Berbel, A. A., et al. 2019, The Messenger, 175, 3 [NASA ADS] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, ArXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Driver, S. P., Liske, J., Davies, L. J. M., et al. 2019, The Messenger, 175, 46 [NASA ADS] [Google Scholar]
- Finoguenov, A., Merloni, A., Comparat, J., et al. 2019, The Messenger, 175, 39 [NASA ADS] [Google Scholar]
- Guiglion, G., Battistini, C., Bell, C. P. M., et al. 2019, The Messenger, 175, 17 [NASA ADS] [Google Scholar]
- Hansen, C. J., Ludwig, H. G., Seifert, W., et al. 2015, Astron. Nachr., 336, 665 [Google Scholar]
- Helmi, A., Irwin, M., Deason, A., et al. 2019, The Messenger, 175, 23 [NASA ADS] [Google Scholar]
- Klypin, A., Yepes, G., Gottlöber, S., Prada, F., & Heß, S. 2016, MNRAS, 457, 4340 [NASA ADS] [CrossRef] [Google Scholar]
- Merloni, A., Alexander, D. A., Banerji, M., et al. 2019, The Messenger, 175, 42 [NASA ADS] [Google Scholar]
- Richard, J., Kneib, J.-P., Blake, C., et al. 2019, The Messenger, 175, 50 [NASA ADS] [Google Scholar]
- Robotham, A., Driver, S. P., Norberg, P., et al. 2010, PASA, 27, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Sharma, S., Bland-Hawthorn, J., Johnston, K. V., & Binney, J. 2011, ApJ, 730, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Sheinis, A., Saunders, W., Gillingham, P., et al. 2014, Proc SPIE, 9151, 91511X [CrossRef] [Google Scholar]
- Smith, A., He, J.-H., Cole, S., et al. 2019, MNRAS, 484, 1285 [NASA ADS] [CrossRef] [Google Scholar]
- Swann, E., Sullivan, M., Carrick, J., et al. 2019, The Messenger, 175, 58 [NASA ADS] [Google Scholar]
- Tamura, N., Takato, N., Shimono, A., et al. 2016, in Ground-based and Airborne Instrumentation for Astronomy VI, SPIE Conf. Ser., 99081M, 9908 [Google Scholar]
- The MSE Science Team (Babusiaux, C., et al.) 2019, ArXiv e-prints [arXiv:1904.04907] [Google Scholar]
- Walcher, C. J., Banerji, M., Battistini, C., et al. 2019, The Messenger, 175, 12 [NASA ADS] [Google Scholar]
All Tables
Fraction of area in the 4MOST field of view that can be reached only by Nfib fibres (left side of the table) or at least with Nfib fibres (right side of the table).
Target densities and exposure times of six low-resolution and three high-resolution surveys used in this example.
Results of the targeting algorithm for five different simulations with slightly altered targeting algorithm parameters.
All Figures
|
Fig. 1. Left panel: 4MOST field of view with 1624 low-resolution (blue) and 812 high-resolution spectrograph fibres (red) at their home positions. One field of view covers 4.3 square degrees in the sky (see also Fig. 7). Black rectangle depicts the area shown in the middle and right panels. Middle and right panels: patrol area (3.2 arcmin from the fibre home position) of each low- and high-resolution spectrograph fibre, respectively. Fibre home positions are marked as points for a given resolution or as small crosses for fibres with alternative resolution. Any location in a field of view can be reached by two to six low-resolution spectrograph fibres and by one to three high-resolution spectrograph fibres. Table 1 gives the fraction of area that is covered by a given number of fibres. |
| In the text | |
|
Fig. 2. Left panel: two partially overlapping 4MOST fields with low-resolution (blue) and high-resolution (red) spectrograph fibres at their home positions. Right panel: patrol areas of high-resolution spectrograph fibres and four targets in a zoom in region highlighted in left-hand panel. Fibre home positions are marked as points and labelled with fibre numbers. Possible fibre-target pairs are illustrated with lines. Targets T2 and T3 can be reached by fibres from two fields; target T3 can be reached by three fibres from Field 1 and two fibres from Field 2; fibre 2313 can reach two targets (T2 and T3). Section 2.2 and Eq. (1) define the probability ptar, field, fib for each fibre-target pair. |
| In the text | |
|
Fig. 3. Distribution of fibres throughputs used in the current paper. Each fibre has a fixed throughput value during our test simulations. |
| In the text | |
|
Fig. 4. Fibre density for low-resolution (upper panel) and high-resolution (lower panel) spectrograph fibres. Right-hand panels: fibre density up to one degree, left-hand panels: fibre density at small angular scales. Fibre density is defined inside a circle (circumscribed the field of view) as a function of radius (grey points). Fibre density depends on circle location due to the fixed fibre pattern (see Fig. 1) and the scatter is higher when the radius is smaller. Red and blue points show the maximum and minimum fibre number density inside a circle, taking the fibre patrol radius into account. The solid black line shows the mean fibre density in the 4MOST field of view, which is 391.4 and 195.9 fibres per square degree for low- and high-resolution spectrograph fibres, respectively. The black dashed line shows 1.2 times higher or lower density, and the black dotted line shows two times higher or lower density compared with fibre mean density. In a circle with a radius of 0.2°, the fibre density can be twice as high or low as the mean value. In the left-hand panels, the black solid line shows fibre collision regions, where everything above the line is forbidden due to fibre collisions. |
| In the text | |
|
Fig. 5. Fraction of used fibres as a function of target density, assuming a Poisson distribution of targets in the sky. Upper and lower panels: fibre usage efficiency for low- and high-resolution spectrograph fibres, respectively. Colours indicate target density for high- (upper panel) and low-resolution (lower panel) targets. The targeting simulation has been run using one, two, or three tiles (pointings) that are overlaid with small random shifts, which are indicated by three different groups of points on both panels. Each target was observed only once and all fibres were used for science targets. Solid green lines show theoretical expectations for perfect targeting. Vertical dashed lines indicate the fibre densities on the sky using one, two, or three overlapping tiles. |
| In the text | |
|
Fig. 6. Fraction of observed targets as a function of target density for low- (upper panel) and high-resolution (lower panel) targets. The targeting simulation has been run using one, two, or three tiles overlaid (with small random shifts). Each target was observed only once and all fibres were used for science targets. Green solid lines show theoretical expectations for perfect fibre to target allocation. Vertical dashed lines show fibre density on the sky for low- (upper panel) and high-resolution (lower panel) spectrograph fibres. |
| In the text | |
|
Fig. 7. Targeting completeness in a single field of view. Top row: completeness map for low-resolution targets; bottom row: for high-resolution targets. In the targeting simulation, we used Poisson distributed targets across the sky with 1.5 times higher number density than the number density of fibres. Targeting was performed using the probabilistic fibre-to-target assignment as described in Sect. 2. Left panels: full field of view for a single field. The completeness decreases towards the edge of the field. Middle panels: zoom-in region of the left panel. For comparison, in the right panels we show a completeness map for random targeting in which each fibre-target pair has the same probability. In the right panel, we can clearly see the patrol regions of fibres (see also Fig. 1), which are significantly reduced when using probabilistic fibre-to-target assignment. |
| In the text | |
|
Fig. 8. Targeting completeness for Poisson distributed targets using one, two, or three visits. The number density of targets was set to 1.5 times higher than the total number density of fibres. For low-resolution spectrograph fibres, the patrol area of some fibres is visible and they have slightly higher completeness. This reflects the varying throughput of fibres. Probabilistic targeting slightly prefers fibres with a higher throughput. However, this effect is only visible if the field is observed more than once. For a single visit, a fixed fibre pattern determines the completeness on small angular scales. |
| In the text | |
|
Fig. 9. Tiling pattern across the sky area used during our tests. The underlying heat map shows the number density of targets on the sky. Darker areas show higher number density of targets. The light gradient from left to right is because of the Milky Way stellar surveys; there are more stars close to the Milky Way disc, which is located on the left side of the selected survey area. The red box highlights the smaller area that we use as a zoom region on Figs. 10, 16, and 17. |
| In the text | |
|
Fig. 10. Sky coordinates of targets in six low-resolution and three high-resolution surveys used during our test. A telescope field of view is superimposed. |
| In the text | |
|
Fig. 11. Target density on the sky for low- (upper panel) and high-resolution (lower panel) test surveys. Target density was calculated within a circle (with random location within a fixed sky area) of radius r as indicated in abscissa. Black lines show the total target density for a given resolution, coloured lines show target density for individual surveys. Solid lines show median target density on the sky, while dashed lines indicate the 90% quantiles. Due to the clustering of targets, the target density (90% quantile) increases towards small sky areas. |
| In the text | |
|
Fig. 12. Fibre usage efficiency for low- (upper panel) and high-resolution (lower panel) surveys. The visible gradient from left to right is due to the fixed tiling and varying number density of objects (see Fig. 9). |
| In the text | |
|
Fig. 13. Distribution of tilt angles for low- (upper panel) and high-resolution (lower panel) spectrograph fibres. Tilt angle was measured from the fibre home position. The red line shows the distribution for the base simulation whilst the blue line shows the tilt angle distribution after introducing the non-constant ftilt(α) function (see Sect. 4.2.4 for more details). The dashed line shows the uniform distribution of tilt angles. The local bump around 80 arcsec is due to the fixed fibre pattern (see Fig. 1). |
| In the text | |
|
Fig. 14. Fibre usage efficiency (red circles) for low- (upper panel) and high-resolution (lower panel) surveys as a function of survey progress. For both resolutions, we used only 80% of fibres for science targets, where the rest of the fibres were reserved for standard stars and the sky background. Hence the maximum fibre efficiency is 0.8. Blue squares show the mean target density on the sky normalised by the number density of science fibres. At the beginning of the survey, the target density exceeds the fibre density by two times, but for the last exposures the target density in the low-resolution regime is lower (less than 1.0) than the fibre density. Hence, for the last exposures we do not have enough targets to fill all fibres. Filled points represent the base simulation (15 min exposure six times) and empty points indicate the simulation with four visits (30 min twice plus 15 min twice). |
| In the text | |
|
Fig. 15. Survey completeness as a function of target exposure time. The grey area shows the distribution of exposure times for each survey. The dashed horizontal line shows the required completeness fraction (fcompl value) for each survey. The dotted red line shows the fraction of observed targets for each survey whilst the solid red line shows the fraction of successfully completed targets. The dashed blue line shows the fraction of successfully completed targets over all observed targets. |
| In the text | |
|
Fig. 16. Fraction of successfully completed targets out of all targets as a function of sky coordinates for each survey. The tiling pattern is clearly visible in the selection function. Additionally if there is a feature (a denser region) in one survey, it leaves a footprint in all other surveys. However, the feature visible in one survey mainly affects surveys with the same resolution. Hence, the cluster visible in LR surveys (lower right corner) does not affect the completeness for HR surveys. |
| In the text | |
|
Fig. 17. Fraction of successfully observed targets over all observed targets. Yellow points show successfully completed targets. The tiling pattern is clearly visible for surveys that contain a large number of targets with long requested exposure times (e.g. HR 3 in the bottom right panel). For surveys with targets requiring short exposures, the tiling pattern is not as pronounced. |
| In the text | |
|
Fig. 18. Selection of targets as a function of angular separation. The distribution of angular separation of observed targets was divided by the distribution of angular separation of all targets. The blue line shows low-resolution targets and the red line shows high-resolution targets. The vertical dashed line shows the fibre patrol radius (3.2 arcmin) and the vertical dotted line shows the fibre collision distance (17 arcsec). Due to the fixed fibre pattern, targets with smaller angular separation are less likely to be targeted. Targeting efficiency rapidly drops for targets closer than fibre collision distance. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.