| Issue |
A&A
Volume 619, November 2018
|
|
|---|---|---|
| Article Number | A119 | |
| Number of page(s) | 16 | |
| Section | Astronomical instrumentation | |
| DOI | https://doi.org/10.1051/0004-6361/201832781 | |
| Published online | 15 November 2018 | |
Denoising, deconvolving, and decomposing multi-domain photon observations
The D4PO algorithm
Max Planck Institute for Astrophysics, Karl-Schwarzschild-Str. 1, 85741
Garching, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
6
February
2018
Accepted:
23
August
2018
Abstract
Astronomical imaging based on photon count data is a non-trivial task. In this context we show how to denoise, deconvolve, and decompose multi-domain photon observations. The primary objective is to incorporate accurate and well motivated likelihood and prior models in order to give reliable estimates about morphologically different but superimposed photon flux components present in the data set. Thereby we denoise and deconvolve photon counts, while simultaneously decomposing them into diffuse, point-like and uninteresting background radiation fluxes. The decomposition is based on a probabilistic hierarchical Bayesian parameter model within the framework of information field theory (IFT). In contrast to its predecessor D3PO, D4PO reconstructs multi-domain components. Thereby each component is defined over its own direct product of multiple independent domains, for example location and energy. D4PO has the capability to reconstruct correlation structures over each of the sub-domains of a component separately. Thereby the inferred correlations implicitly define the morphologically different source components, except for the spatial correlations of the point-like flux. Point-like source fluxes are spatially uncorrelated by definition. The capabilities of the algorithm are demonstrated by means of a synthetic, but realistic, mock data set, providing spectral and spatial information about each detected photon. D4PO successfully denoised, deconvolved, and decomposed a photon count image into diffuse, point-like and background flux, each being functions of location as well as energy. Moreover, uncertainty estimates of the reconstructed fields as well as of their correlation structure are provided employing their posterior density function and accounting for the manifolds the domains reside on.
Key words: methods: data analysis / methods: numerical / methods: statistical / techniques: image processing / gamma rays: general / X-rays: general
© ESO 2018
1. Introduction
In most astrophysical data sets arising from photon counting observations, different physical fluxes superimpose each other. Point-like sources, compact objects, diffuse emission, background radiation, and other sky structures imprint on the data. Furthermore multiple instrumental distortions such as an imperfect instrument response and noise complicate the data interpretation. In particular the data of high energy photon and particle telescopes are subject to Poissonian shot noise which turns any smooth emission region into a granular image in the detector plane. In this paper, a novel technique is developed with the ultimate goal to provide reliable estimates of the actual sky photon flux components, diffuse and point-like, which both vary as a function of location and photon energy. This is achieved by a rigorous mathematical and statistical treatment.
Individual photon counts are subject to Poissonian shot noise, whose amplitude depends on the count rate itself. The signal-to-noise ratio (S/N) drops for low count rates, limiting the detection and discrimination of faint sources. The ill-posed inverse problem is complicated also by the fact that telescopes are inexact in the sense that the exposure is inhomogeneous across their field of view. In addition, the instrument response function may be non-linear and only known up to a certain accuracy. Especially point sources are smeared out in the data plane by the instrument’s point spread function (PSF), which might let the point sources appear as extended objects in the data plane.
The observed photon flux is a superposition of multiple morphologically different emission structures that are best decomposed into their original components to better understand their causes. Typical morphologically different emitters in astrophysics can be characterised as diffuse, compact, and point-like sources. On the one hand, diffuse objects illuminate the sky over extended areas and show distinct spatial and spectrally extended structures, for example galaxy clusters. On the other hand, point sources, as main sequence stars, are local features that do not show any spatial structure by definition. They typically have well structured broad-band energy spectra. Compact objects, for example cool core clusters in between the extremes of point-like sources and diffuse emission regions, will not be considered here as a separate morphological class. They should either be regarded as part of the diffuse or the point-like flux. In addition to the detected cosmic sources, the recorded counts might contain events due to background radiation (such as instrumental background, charged particle induced background, scattered solar radiation, cosmic rays and other unwanted signals). If its morphological structure is significantly different from that caused by diffuse and/or point-like sources, one may be able to distinguish it from sky emission. Overall, this leads to the obvious question how to denoise, deconvolve, and decompose the observed data set into its original emission components. The ill-posed inverse problem arises because no unique solution exists to split the observed counts into the three accounted components, i.e. diffuse, point-like source and background radiation fluxes. To tackle this generic inference problem in astrophysics, we introduce D4PO for denoise, deconcolve, and decompose multi-domain photon observations. In this context we aim to reconstruct the outlined flux components not only in the spatial domain, but also simultaneously with respect to other domains like energy or time. This requires that spatial and spectral or temporal information is available for each detected photon or at least most of them. We show how to infer multiple morphologically different photon flux components while each component can depend on multiple domains, such as energy, time and location. As the decomposition of superimposed signals is degenerate, a detector event can in principle be assigned to any of the considered components. Therefore additional information has to be folded into the inference. For this, D4PO relies on a Bayesian approach which allows in a natural way to incorporate a valid data model and a priori knowledge about the source structures to break the degeneracy between the different flux contributions.
First attempts in this direction have been pursued by a maximum likelihood analysis (Valdes 1982), followed by maximum entropy analysis (Cornwell & Evans 1985; Strong 2003) and leastsquare techniques for sparse systems (Bouchet et al. 2013) which were applied to various astrophysical photon count data sets, such as INTEGRAL/SPI (Vedrenne et al. 2003), COMPTEL (Schoenfelder et al. 1993) etc. A popular tool to separate point-like sources from diffuse emission regions is SExtractor (Bertin & Arnouts 1996), which provides a catalogue of point-like sources. However SExtractor is not highly sensitive in the detection of faint and extended sources (Knollmüller et al. 2018), but it was successfully applied in the X-ray regime on filtered images (Valtchanov et al. 2001). To identify point-like sources in ROSAT X-ray photon observations (Voges et al. 1999), which includes background radiation, Boese & Doebereiner (2001) developed an inference technique based on a maximum likelihood estimator for each detected photon, taking into account energy and position. Thereby they assume a parametric Poisson model for the likelihood and can therefore denoise and identify point-like sources in the data set. Within the field of sparse regularisation multiple techniques exploiting an assumed signal sparsity with respect to various functional basis systems or waveforms have been proven to successfully denoise and deconvolve different types of data (González-Nuevo et al. 2006; Willett et al. 2007; Dupe et al. 2009; Bioucas-Dias & Figueiredo 2010; Willett & Nowak 2007; Lahmiri 2017; Osoba & Kosko 2016; Venkatesh Gubbi & Sekhar Seelamantula 2014; Dolui et al. 2014; Figueiredo & Bioucas-Dias 2010).
Disregarding the Poissonian statistics of photon counts, a generic method to denoise, deconvolve and decompose simulated radio data assuming Gaussian noise statistics has been developed (Bobin et al. 2008; Chapman et al. 2013). Further in the regime of Gaussian noise statistics, Giovannelli & Coulais (2005) developed an algorithm to decompose point and extended sources based on the minimisation of least squares residuals. The CLEAN algorithm (Högbom 1974), widely used in radio interferometery, assumes that the whole sky emission is composed of point-like sources, which leads to inferior reconstructions of the diffuse and background emission (Sault & Oosterloo 2007). Extensions of CLEAN to model the sky with Gaussian blobs to account for diffuse emission structures have improved on this (Abrantes et al. 2009; Rau & Cornwell 2011), however it is still unclear how to optimally set the width of these Gaussians. The algorithm PowellSnakes I/II (Carvalho et al. 2009, 2012) was successfully applied on the Planck sky data (Planck Collaboration VII 2011). It is capable of analysing multi-frequency data and to detect point-like sources within diffuse emission regions.
A Bayesian approach close to ours has been developed to separate the background signal from the sky sources in the X-ray part of the electromagnetic spectrum (Guglielmetti et al. 2009; Guglielmetti et al. 2004). This method is based on a two-component mixture model which jointly infers point-like sources and diffuse emissions including their uncertainties.
This work builds on the D3PO algorithm (Selig & Enßlin 2015), which was successfully applied to the Fermi LAT data (Selig et al. 2015). D3PO denoises, deconvolves and decomposes photon counts into two signals, a point-like and a diffuse one, while it simultaneously reconstructs the spatial power spectrum of the latter. This is done through a hierarchical parameter model incorporating prior knowledge.
D4PO advances upon D3PO in several ways. First, the number of components to be inferred is extended to be more than two. Second, the components can live over different domains: a brightness distribution on the sky can be inferred jointly with a background level living only in a temporal domain. Third, and most importantly, the manifolds, i.e. where the different components live on, can be product manifolds from different domains, as a flux can be a function of location, time, and energy.
Following the work of Selig & Enßlin (2015), we derive the algorithm within the framework of information field theory (IFT, Enßlin et al. 2009), which allows in a natural way the incorporation of priors. This prior knowledge is crucial as it is used to discriminate between the morphologically different sources via their individual statistical properties. While D3PO could reconstruct the diffuse component depending purely on its location, we show how to incorporate further information present in the data to get reconstructions that do not only depend on the location of the reconstruction but also on its energy and/or time.
All fluxes, be they diffuse, point-like or background, are modelled individually as signal fields. A field is a continuous quantity defined over a continuous space. A space here is the domain of one or several manifolds or sub-domains. For example the sky emissivity is regarded to be a field living over the product of the two dimensional angular manifold of the celestial sphere times a one-dimensional spectral energy manifold. Diffuse continuum emission is a smooth function of both sky position and photon energy. Within each sub-manifold of a field space we assume statistical homogeneity and isotropy separately for the field. This joint field correlation over the composed space is assumed to be a direct product of the sub-domain correlations. This provides the novel possibility to reconstruct fields which do not only depend on one parameter (in this case, location), but on multiple parameters, such as location and energy.
Figure 1 illustrates such a reconstruction scenario, the denoising, deconvolving, and decomposition of an exemplary data set generated by an emission that consists of diffuse and point-like fluxes, each living over two different sub-domains. Thereby the data set contains information about photon observations including their location and energy. The first sub-domain of both photon flux components is a one-dimensional continuous space representing the spatial domain, while the second sub-domain represents the spectral information of the photons. The exact statistical properties of both components will be discussed in detail in Sect. 2.3, but from Fig. 1 our implicit understanding of diffuse and point-like fluxes, which depend on energy and location, becomes apparent. Here the spatial correlation length of the diffuse flux in the spatial sub-domain is significantly longer compared to that of the point-like sources, which only illuminate the sky at distinct locations. In contrast to this are the correlations in the energy sub domain, where the point-like sources shine over a broader energy range compared to the diffuse emission.
 |
Fig. 1. Showcase for the D4PO algorithm to denoise, deconvolve, and decompose multi-domain photon observations. This is a simplified test scenario, which disregards a potential background flux and has only a unit response function (a perfect PSF). Top panels: (from left to right) data, providing spatial versus spectral information about each detected photon, original multi-domain point-like flux, as well as the multi-domain diffuse fields. Bottom panels: reconstruction of both fields. All fields are living over a regular grid with 350 × 350 pixels. |
The numerical implementation of the algorithm is done in NIFTY3 (Steininger et al. 2017; Selig et al. 2013). This allows us to set up the algorithm in a rather abstract way by being independent of a concrete data set, domain discretisation and number of fields. Thanks to the abstractness and the flexibility of NIFTY3, reconstructions such as those shown in Fig. 1 can easily be extended to different domains (i.e. the sphere) and to more source components, i.e. additional backgrounds.
The structure of this work is as follows: in Sect. 2 we give a detailed derivation of the outlined algorithm, with an in-depth discussion of the incorporated models and priors. Section 3 describes different approaches to calculate the derived posterior probability density function (PDF). In Sect. 4 we discuss numerically efficient implementations of the algorithm. Its performance is demonstrated in Sect. 5 by its application to a simulated astrophysical data set, whose results are compared to a Maximum Likelihood approach. Finally we conclude in Sect. 6.
2. Inference from photon observation
2.1. Signal inference
Our goal is to image the high energy sky based on photon count data as it is provided by the astroparticle physics instruments like Fermi (Atwood et al. 2009), Integral (Vedrenne et al. 2003), Comptel (Schoenfelder et al. 1993), CTA (Acharya et al. 2013). The sky emissivity is a function of the sky position and photon energy, that is generated by a number of spectral and morphologically different sources.
Due to experimental constraints and practical limitations (such as limited observation time, energy range, and spatial and spectral resolution), the obtained data set of any photon count experiment cannot capture all degrees of freedom of the underlying photon flux. As a physical photon flux is a continuous scalar field that can vary with respect to various parameters, such as time, location and energy, we let all signals of interest live in a continuous space over some domain Ω. Hence we are facing an underdetermined inference problem as there are infinitely many signal field configurations leading to the same finite data set. Consequently we need to use probabilistic data analysis methods, which do not necessarily provide the physically correct underlying signal field configuration but provide expectations and remaining uncertainties of the signal field.
In this context we are investigating the a posteriori probability distribution P(φ|d), which states how likely a potential signal φ is given the data set d. This is provided by Bayes’ theorem
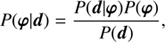 (1)
(1)
which is the quotient of the product of the likelihood PDF P(d|φ) and the signal prior PDF P(φ) divided by the evidence PDF P(d). The likelihood describes how likely it was to observe the measured data set d given a signal field φ. It covers all processes that are relevant for the measurement. The prior describes all a priori knowledge on φ and must therefore not depend on d itself. We estimate the posteriori mean m of the signal field given the data and its uncertainty covariance D, which are defined as
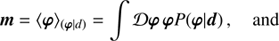 (2)
(2)
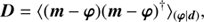 (3)
(3)
where † denotes adjunction and ⟨ ⋅ ⟩(φ|d) the expectation value with respect to the posterior probability distribution P(φ|d).
In the following sections we will gradually derive the posterior PDF of the physical flux distribution of multiple superimposed photon fluxes given in a data set. This will partly follow and build on the existing D3PO algorithm by Selig & Enßlin (2015).
2.2. Poissonian likelihood
A typical photon count instrument provides us with a data vector d consisting of integer photon counts that are spatially binned into NPIX pixels. The sky emissivity ρ = ρ(x, E), which caused the photon counts, is defined for each continuous sky position x and energy E. Since high energy astrophysical spectra cover orders of magnitude in energy, it is convenient to introduce the logarithmic energy coordinate y = log(E/E0) with some reference energy E0. The flux is a function of the combined coordinates z = (x, y), such that ρ(z)=ρ(x, y) and lives over the associated domain Ω = 𝕊 ⊗ 𝕂, i.e. the product of spatial and spectral domains. 𝕊 = 𝒮2 if the full sky is treated, 𝕊 = ℝ2 if a patch of the sky is described as in the flat sky approximation, or 𝕊 = ℝ as in the mock examples in this paper, and finally 𝕂 = ℝ as logarithmic energies can be positive and negative. The flux ρ is a superposition of two morphologically different signal fields, such as a diffuse and point-like flux. Hence
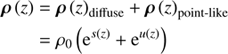 (4)
(4)
where we introduce the dimensionless fields s(z)= : s and u(z)= : u, to represent the logarithmic diffuse and point-like source fluxes over the signal domain Ω. Further we introduce the convention that a scalar function is applied to a field value by values on its natural domain, (f(s))(z) = f(s(z)) if z ∈ Ω. The constant ρ0 is absorbing the physical dimensions of the photon flux.
The imaging device observing the celestial photon flux ρ is expected to measure a number of events λ, informing us about s and u, as well as other event sources like cosmic ray hits or radioactivity, which we will refer to as background. This dependence of λ on the sky emissivity ρ can be modelled via a linear instrument response operator R0 acting on ρ: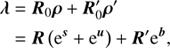 (5)
(5)
with R = R0ρ0 and R′=R′0ρ′0. The response operator R0 describes all aspects of the measurement processes which relate the sky brightness to the average photon count. To describe the background counts we further introduce the background event emissivity ρ′=ρ′0eb, the background event instrument response R′0, as well as the abbreviation R′=R′0ρ′0. The background field is a function of the two coordinates exposure time t and the log-energy y, such that z′=(t, y) and its domain Ω′=𝕋 ⊗ 𝕂 with 𝕋 ∈ ℝ. In our applications, we assume that the observing time interval and the sky are identified with each other. In real observations, the sky is often scanned multiple times, providing redundancies in the data, which facilitates the separation of sky and background. The background response R′ describes the instruments sensitivity to background processes, such as cosmic ray events which produce uninteresting counts and need to be filtered out. For each pixel in the detector we get
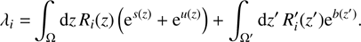 (6)
(6)
The individual events are assumed to follow a Poisson distribution 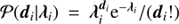 in each data bin. Hence the likelihood of the data vector d = (d1, …, dNPIX) given an expected number of photons λ is a product of statistically independent Poisson processes,
in each data bin. Hence the likelihood of the data vector d = (d1, …, dNPIX) given an expected number of photons λ is a product of statistically independent Poisson processes,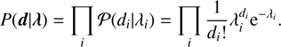 (7)
(7)
In total, the likelihood of photon count data given two superimposed morphologically different photon fluxes and some background fluxes is consequently described by Eqs. (6) and (7). To simplify and clarify the notations in the following, we introduce the three component vector φ = (s†, u†, b†)† consisting of the diffuse, point-like and the background flux. Further we introduce the combined response [BOLD]ℛ = (R, R, R′). This allows us to state the information Hamiltonian, defined as the negative logarithm of P(d|φ), compactly as
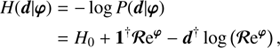 (8)
(8)
where we absorbed all terms that are constant in φ into H0 and introduced the scalar product of concatenated vectors
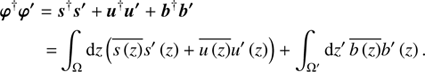 (9)
(9)
1† is a constant data vector being one everywhere on the data space.
We note that the likelihood, Eq. (7), can be accountable for n signals in data space, with
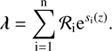 (10)
(10)
This would only extend φ and [BOLD]ℛ while Eq. (8) stays untouched. For this reason, D4PO can reconstruct n such fields, each living over its own space, and all contributing to the expected counts through an individual response function.
2.3. Prior assumptions
As we are seeking to decompose the photon counts into background flux and two sky flux components, prior PDFs are taken into consideration. Prior knowledge is important to incorporate in the modelling process in order to constrain the degeneracy of the inverse problem, since without prior knowledge one can explain the full data set by the diffuse and the point-like signal alone or even purely by a background or any combination thereof. We introduce priors on the fields s, u, and b. Priors are employed to describe and implicitly define the typical expected morphology of the three different components: diffuse, point-like and background fluxes.
2.3.1. The diffuse component
The diffuse photon flux ρ(s) = ρ0es is a strictly positive quantity which might vary over several orders of magnitude. Its morphology may be described by cloud-like and smoothly varying patches on the sky. Hence the diffuse flux shows spatial correlations. Furthermore, we concentrate here on radiation processes due to cosmic ray interactions in the interstellar medium like the inverse Compton scattering and π0 production and decay. These processes show smooth, often power-law like spectra, with considerable correlation in the log-energy dimension. According to the principle of maximum entropy the log-normal model can be regarded as a minimalistic description of our a priori knowledge on ρ(s) (Oppermann et al. 2013; Kinney 2014). The log-normal model has shown to be suitable within various observational (Kitaura et al. 2009; Selig et al. 2015; Pumpe et al. 2018) and theoretical (Coles & Jones 1991; Sheth 1995; Kayo et al. 2001; Vio et al. 2001; Neyrinck et al. 2009; Selig & Enßlin 2015; Pumpe et al. 2016; Junklewitz et al. 2016; Greiner et al. 2016; Knollmüller et al. 2017; Böhm et al. 2017) considerations. Hence, we adopt a multivariate Gaussian distribution as a prior for the logarithmic s: (11)
(11)
with a covariance 𝒮 = ⟨ss†⟩(s|𝒮). The covariance 𝒮 describes the strength of spatial correlation in the log-energy y = logE/E0 and space domain x of s. As these two correlations need to be modelled individually, we chose the following ansatz
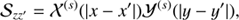 (12)
(12)
being a direct product of the two correlation functions, 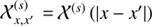 and
and 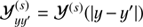 , which only depend on the relative differences in position x and log-energy y. This is equivalent to the assumption that s is statistically homogeneous and isotropic on the celestial sphere and statistically homogeneous in the log-energy space. Statistical homogeneity in log-energy models the fact that typical high energy astrophysics spectra exhibit similar features on a log-log perspective. Thanks to the assumed statistical homogeneity we can find a diagonal representation of 𝒳 and 𝒴 in their harmonic bases, such that
, which only depend on the relative differences in position x and log-energy y. This is equivalent to the assumption that s is statistically homogeneous and isotropic on the celestial sphere and statistically homogeneous in the log-energy space. Statistical homogeneity in log-energy models the fact that typical high energy astrophysics spectra exhibit similar features on a log-log perspective. Thanks to the assumed statistical homogeneity we can find a diagonal representation of 𝒳 and 𝒴 in their harmonic bases, such that
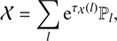 (13)
(13)
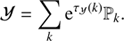 (14)
(14)
Here τ𝒳(l) and τ𝒴(k) are spectral parameters determining the logarithmic power spectra in the spatial and spectral domain, respectively, according to the chosen harmonic basis (l, k) for each corresponding harmonic space. ℙ is a projection operator onto spectral bands. We assume a similar level of variance for the fields within each of these bands separately. The projection operator is given by: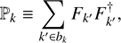 (15)
(15)
where Fk′y = eik′y is the Fourier basis (or spherical harmonic basis if the subdomain is 𝒮2) and bk denotes the set of Fourier modes belonging to the corresponding Fourier band k. The inverses of the two covariances are
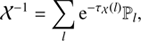 (16)
(16)
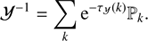 (17)
(17)
The spectral parameters τ𝒳 and τ𝒴 are in general unknown a priori. These spectral parameters are reconstructed from the same data as the signal, introducing another prior for their covariances.
In the following paragraphs we will introduce two constraints on the spectral parameters τ. These hyperpriors on the prior itself lead to a hierarchical parameter model. To shorten and clarify notations we will only discuss τ𝒳(l) in full detail; the expressions for τ𝒴(k) are analogous.
Moreover, s may not only depend on location and energy but also on further parameters such as time etc. In this case the covariance 𝒮 extends as follows: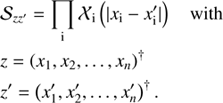 (18)
(18)
Equation (18) leads to multiple spectral parameters that need to be inferred from the data if not known a priori. D4PO is also prepared to handle such cases.
2.3.2. Unknown magnitude of the power spectrum
As the spectral parameters τ𝒳(l) might vary over several orders of magnitude, this demands for a logarithmically uniform prior for each element of the power spectrum and in consequence for a uniform prior Pun for each spectral parameter τ𝒳(l). Following the work of Enßlin & Frommert (2011); Enßlin & Weig (2010) and Selig & Enßlin (2015) we initially assume inverse-Gamma distributions for each individual element,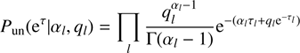 (19)
(19)
and hence,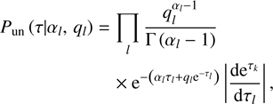 (20)
(20)
where αl and ql denote shape and scale parameters for the spectral hyperpriors, and Γ the Gamma function. The form of Eq. (20) shows that for αl → 1 and ql → 0, ∀l > 0, the inverse gamma distribution becomes asymptotically flat on a logarithmic scale and therefore for these parameter values do not provide any constraints on the magnitudes of τ.
2.3.3. Smoothness of power spectrum
Up to now we have only treated each element of the power spectrum separately, permitting the power to change strongly as a function of scale l (and k). However, similar spatial (or energetic) scales should exhibit similar amounts of variance for most astrophysical emission processes in the interstellar medium. Thus we assume that the power spectrum is smooth on a logarithmic scale of l and k, respectively. In accordance with Enßlin & Frommert (2011) and Oppermann et al. (2013) this can be enforced by introducing a smoothness enforcing prior Psm
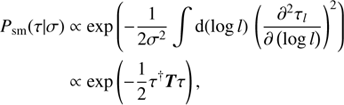 (21)
(21)
which is based on the second logarithmic derivative of the spectral parameters τ. The parameter σ specifies the expected roughness of the spectrum. In the limit σ → ∞ spectral roughness is not suppressed in contrast to σ → 0 which enforces a smooth power-law power spectrum. For a more detailed explanation and demonstration of the influence of σ on the reconstruction of τ we refer to Pumpe et al. (2018).
In total the resulting priors for the diffuse flux field are determined by the spectral parameters 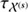 for spatial correlation and
for spatial correlation and 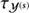 for correlations in the log-energy domain. These spectral parameters are constrained by the product of the priors discussed above
for correlations in the log-energy domain. These spectral parameters are constrained by the product of the priors discussed above
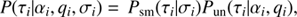 (22)
(22)
with i ∈ {𝒳(s), 𝒴(s)}
2.3.4. The point-like component
The photon flux contributions of neighbouring point-like sources in the image space can be assumed to be statistically independent of each other if we ignore knowledge on source clustering. Consequently, statistically independent priors for the photon flux contribution of each point-like source are introduced in the following.
As the point-like flux ρ(u) = ρ0eu is also a strictly positive quantity, we mainly follow the same arguments as for the diffuse flux to derive its prior for correlations within in the log energy domain (Sect. 2.3.1). We adopt for the spectral correlation in the energy domain y of u a multivariate Gaussian distribution 𝒢(u, 𝒴(u)), with 𝒴(u) = ⟨uu†⟩(u|d). As we may again assume statistical homogeneity, we can find a diagonal representation of the yet unknown 𝒴(u), such that
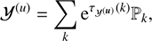 (23)
(23)
with ℙ being the projection operator according to Eq. (15), τ𝒴(u)(k) being the spectral parameter determining the logarithmic power spectrum of 𝒴(u). Since τ𝒴(u)(k) is usually unknown we introduce again a hierarchical parameter model as in Sects. 2.3.2 and 2.3.3. This gives us
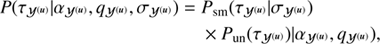 (24)
(24)
with 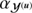 and
and 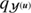 being the scale and shape parameters of the inverse gamma distribution and
being the scale and shape parameters of the inverse gamma distribution and 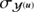 the parameter to specify the expected roughness of the spectrum.
the parameter to specify the expected roughness of the spectrum.
To derive a suitable prior for the spatial dimension of u, one may look at the following basic considerations. Let us assume that the universe hosts a homogenous distribution of point sources. Therefore the number of point sources would scale with the observable volume, i.e. with distance cubed. But the apparent brightness of a source is reduced by the spreading of the light rays, i.e. decreases with distances squared. Hence one may expect a power law behaviour between the number of point-like sources and their brightness with a slope of β = 3/2. As such a power-law is not necessarily normalisable, since it diverges at zero we further impose an exponential cut-off slightly above 0. This yields an inverse Gamma distribution, which has been shown to be a suitable prior for point-like photon fluxes (Guglielmetti et al. 2009; Carvalho et al. 2009, 2012; Selig & Enßlin 2015; Selig et al. 2015). The spatial prior for u is therefore given by a product of independent inverse-Gamma distributions
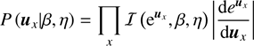 (25)
(25)
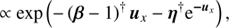 (26)
(26)
where β = β, ∀x and η = η, ∀x are the shape and scale parameters of the inverse gamma distribution ℐ.
In total the prior for the point-like flux becomes
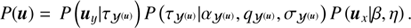 (27)
(27)
2.3.5. Modelling the background
Since the background b is also a strictly positive but unknown field, we assume the prior P(b) to have the same structure as the one for s, except for the fact that it might be defined over different spaces. Hence we may again follow Sect. 2.3.1 to build a hierarchical prior model for P(b).
2.3.6. Parameter model
Figure 2 shows the complete hierarchical Bayesian network introduced in Sect. 2. The goal is to model the data d by our quantities s and u and the background described by b. The three logarithmic power spectra 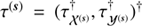 ,
, 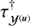 , and
, and 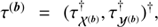 can be reconstructed from the data. In case additional information sources are available to further constraint these parameters one may certainly use those and adjust the known logarithmic power spectra accordingly. However, in total the suggested algorithm is steered by the parameters α, q, and σ, for which we can partly provide canonical values: αk, i = σk, i = 1 ∀ k = 0, β = 3/2, as well as η, qi ≳ 0 for i ∈ {𝒳(s), 𝒴(s), 𝒴(u), 𝒳(b), 𝒴(b)}.
can be reconstructed from the data. In case additional information sources are available to further constraint these parameters one may certainly use those and adjust the known logarithmic power spectra accordingly. However, in total the suggested algorithm is steered by the parameters α, q, and σ, for which we can partly provide canonical values: αk, i = σk, i = 1 ∀ k = 0, β = 3/2, as well as η, qi ≳ 0 for i ∈ {𝒳(s), 𝒴(s), 𝒴(u), 𝒳(b), 𝒴(b)}.
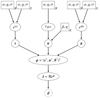 |
Fig. 2. Graphical model of the hierarchical Bayesian network introduced in Sect. 2. Shown are the model parameters α, q, σ, η and β, in rectangular boxes, as they have to be specified by the user. The logarithmic spectral parameters |
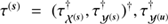
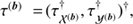
3. The inference
The likelihood constructed in Sect. 2 and the prior assumptions for the diffuse, point-like, and background signal field contain together all information available to tackle this inference problem. The resulting posterior PDF is given by
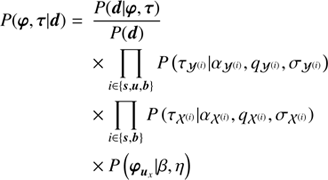 (28)
(28)
where we have introduced 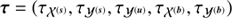 .
.
In an ideal case with unlimited computational power, we would now calculate the mean and its variances according to Eqs. (2) and (3) for φ, by integrating over all possible combinations of φ and τ. This would also provide us with all spectral parameters τ. But due to the complexity of the posterior probability distribution this is not worth pursuing.
We are relying on numerical approaches. Phase space sampling techniques like Markov chain Monte Carlo methods (Metropolis & Ullam 1949; Wandelt 2004; Jasche & Kitaura 2010; Jasche et al. 2010; Jasche & Wandelt 2013) are hardly applicable to our inference problem due to the extremely large phase space to be sampled over. Consequently we have to find suitable approximations to tackle the problem.
In Sect. 3.1 we introduce a Maximum a posteriori approach to solve the inference problem and in Sect. 3.2 we show how to obtain physical solutions from this approximation.
3.1. Maximum a posteriori
In case the posterior distribution is single peaked and symmetric, its maximum and mean coincide. At least in first order approximation this holds for Eq. (28), which allows us to use the so called maximum a posteriori (MAP) approach. This method can be enforced by introducing either a δ−function at the posterior’s mode,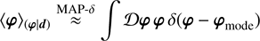 (29)
(29)
or by using a Laplace approximation, with its uncertainty covariance D, estimated from the curvature around the maximum. A field expectation value is given by
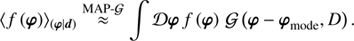 (30)
(30)
In either case we are required to find the mode which is the maximum of the posterior distribution (28). Rather than maximizing the full posterior, it is convenient to minimize the information Hamiltonian, defined by its negative logarithm
![Mathematical equation: $$ \begin{aligned} H(\boldsymbol{\varphi }, \boldsymbol{\tau } \vert \boldsymbol{d}) =&- \log P(\boldsymbol{\varphi }, \boldsymbol{\tau } \vert \boldsymbol{d}) \nonumber \\ =&\, H_0 + \boldsymbol{1}^{\dagger } \boldsymbol{\mathcal{R} }\mathrm{e}^{\boldsymbol{\varphi }} - \boldsymbol{d}^{\dagger } \log \left[\boldsymbol{\mathcal{R} }\mathrm{e}^{\boldsymbol{\varphi }} \right] \nonumber \\&+ \frac{1}{2} \left[ \log (\det \Phi ) + \boldsymbol{\varphi }^{\dagger } \Phi ^{-1} \boldsymbol{\varphi } \right] \nonumber \\&+ \sum _{i \in \mathcal{I} } (\boldsymbol{\alpha }_i -1)^{\dagger } \tau _i + \boldsymbol{q}_i^{\dagger } \mathrm{e}^{-\tau _i} + \frac{1}{2} \tau _i^{\dagger } \boldsymbol{T}_{i} \tau _i \nonumber \\&+ \left(\boldsymbol{\beta } - 1\right)^{\dagger }\boldsymbol{\varphi }_{\boldsymbol{u}_x} + \boldsymbol{\eta }^{\dagger } \mathrm{e}^{-\boldsymbol{\varphi }_{\boldsymbol{u}_x}} \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq45.gif) (31)
(31)
with Φ = diag(𝒮, 𝒰, ℬ)T and ℐ ∈ {𝒳(s), 𝒴(s), 𝒴(u), 𝒳(b), 𝒴(b)}. We have absorbed all terms that are constant in φ and τ into H0. The MAP-ansatz seeks for the minimum of Eq. (31), which is equivalent to maximizing the posterior Eq. (28). This minimum can be found by taking the first partial derivatives of Eq. (31) with respect to all components of φ and τ, respectively and equalling them to zero. The resulting filtering formulas for the diffuse and point-like flux read as
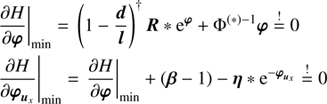 (32)
(32)
with
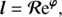 (33)
(33)
 (34)
(34)
 (35)
(35)
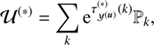 (36)
(36)
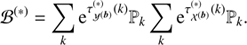 (37)
(37)
By and  we refer to component wise multiplication and division, respectively. The filtering formulas for the power spectra, which are also derived by taking the first partial derivatives with respect to the components of τ read as
we refer to component wise multiplication and division, respectively. The filtering formulas for the power spectra, which are also derived by taking the first partial derivatives with respect to the components of τ read as
![Mathematical equation: $$ \begin{aligned} \mathrm{e}^{\tau _{{\mathcal{Y} }^{(\boldsymbol{i})}}}&= \frac{q_{{\mathcal{Y} }^{(\boldsymbol{i})}} + \frac{1}{2} \left( \text{ Tr}\left[\boldsymbol{i}\boldsymbol{i}^{\dagger } \mathbb{P} ^{\dagger }{\mathcal{X} }^{-1}\right]\right)}{\alpha _{{\mathcal{Y} }^{(\boldsymbol{i})}} -1 + \frac{1}{2} \left( \text{ Tr} \left[ \mathbb{P} \mathbb{P} ^{\dagger } {\mathcal{X} }\right]\right)_k + \boldsymbol{T}_{{\mathcal{Y} }^{(i)}}\tau _{{\mathcal{Y} }^{(\boldsymbol{i})}}}, \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq53.gif) (38)
(38)
and
![Mathematical equation: $$ \begin{aligned} \mathrm{e}^{\tau _{{\mathcal{X} }^{(\boldsymbol{j})}}}&= \frac{q_{{\mathcal{X} }^{(\boldsymbol{j})}} + \frac{1}{2} \left( \text{ Tr}\left[\boldsymbol{j}\boldsymbol{j}^{\dagger } \mathbb{P} ^{\dagger }{\mathcal{Y} }^{-1}\right]\right)}{\alpha _{{\mathcal{X} }^{(\boldsymbol{j})}} -1 + \frac{1}{2} \left( \text{ Tr} \left[ \mathbb{P} \mathbb{P} ^{\dagger } {\mathcal{Y} }\right]\right)_l + \boldsymbol{T}_{{\mathcal{X} }^{(j)}}\tau _{{\mathcal{X} }^{(\boldsymbol{j})}}}, \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq54.gif) (39)
(39)
with i ∈ {s, u, b} and j ∈ {s, b}. These filtering formulas for the spectral parameters τ are in accordance with Enßlin & Frommert (2011) and Oppermann et al. (2013). Unfortunately the Eqs. (32)–(39) lead to eight implicit equations rather than one explicit. Hence these equations need to be solved by an iterative minimization of Eq. (31) using a minimisation algorithm such as steepest descent. The second derivative of the Hamiltonian, i.e. the Hessian around the minimum, may serve as a first order approximation of the uncertainty covariance,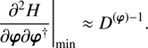 (40)
(40)
A detailed derivation and closed form of D(φ) − 1 can be found in Appendix A.
It has been shown (Enßlin & Frommert 2011) that MAP-estimating of a field and its power spectrum simultaneously is suboptimal. The reason is that the joined posterior is far from being symmetric and exhibits long tails in directions correlated in the field and in its spectrum. The resulting scheme can strongly underestimate the field variance in low S/N situations. To overcome this difficulty, a number of approaches have been pursued like renormalization techniques. They lead to improved schemes which are closely related to each other. The most transparent of these approaches is the mean field approximation that involves the construction and minimization of an action, the Gibbs free energy (Enßlin & Weig 2010). A detailed derivation of this approach can be found in Appendix B.
The filtering formulas in a Gibbs free energy approach for φ only change within the exponent, while the one for τ yields
![Mathematical equation: $$ \begin{aligned} \mathrm{e}^{\tau _{{{\mathcal{Y} }}^{(\boldsymbol{i})}}}&= \frac{q_{{\mathcal{Y} }^{(\boldsymbol{i})}} + \frac{1}{2} \left( \text{ Tr}\left[\left(\boldsymbol{i}\boldsymbol{i}^{\dagger } + D^{\left(j\right)}\right) \mathbb{P} ^{\dagger }{\mathcal{X} }^{-1}\right]\right)}{\alpha _{{\mathcal{Y} }^{(\boldsymbol{i})}} -1 + \frac{1}{2} \left( \text{ Tr} \left[ \mathbb{P} \mathbb{P} ^{\dagger } {\mathcal{X} }\right]\right)_k + \boldsymbol{T}_{{\mathcal{Y} }^{(i)}}\boldsymbol{t}_{{\mathcal{Y} }^{(\boldsymbol{i})}}}, \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq56.gif) (41)
(41)
and
![Mathematical equation: $$ \begin{aligned} \mathrm{e}^{\tau _{{\mathcal{X} }^{(\boldsymbol{j})}}}&= \frac{q_{{\mathcal{X} }^{(\boldsymbol{j})}} + \frac{1}{2} \left( \text{ Tr}\left[\left(\boldsymbol{j}\boldsymbol{j}^{\dagger } + D^{\left(j\right)}\right) \mathbb{P} ^{\dagger }{\mathcal{Y} }^{-1}\right]\right)}{\alpha _{{\mathcal{X} }^{(\boldsymbol{j})}} -1 + \frac{1}{2} \left( \text{ Tr} \left[ \mathbb{P} \mathbb{P} ^{\dagger } {\mathcal{Y} }\right]\right)_l + \boldsymbol{T}_{{\mathcal{X} }^{(j)}}\boldsymbol{t}_{{\mathcal{X} }^{(\boldsymbol{j})}}}, \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq57.gif) (42)
(42)
with i ∈ {s, u, b} and j ∈ {s, b}. These formulas are in close accordance with the critical filtering technique (Oppermann et al. 2013). Equations (41) and (42) give a reconstruction of the spectral parameters of a field which does not necessarily need to be statistically isotropic and homogeneous over its combined domains. The appearing correction term D in the trace term of the numerator of Eqs. (42) and (41) compared to the MAP-solutions Eqs. (38) and (39) is positive definite. Hence it introduces a positive contribution to the logarithmic power spectrum and therefore lowers a potential perception threshold (Enßlin & Frommert 2011).
3.2. The physical solution
All previously described methods only recover logarithmic fluxes, but the actual quantities of interest are the physical fluxes ρ. These physical fluxes can be calculated employing the following approximation: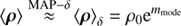 (43)
(43)
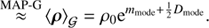 (44)
(44)
The uncertainty of the reconstructed fields may be approximated by
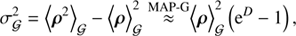 (45)
(45)
with its square root being the relative uncertainty.
The full Gibbs approach described in Sect. B.1 would require to know D(φ) at all times during the minimisation of Eq. (B.9), and is numerically not feasible. We only consider the MAP-𝒢 approach here to infer the signal fields. D3PO has shown that such an approach does produce accurate signal field reconstructions. For the reconstruction of the spectral parameters τ, we use the full Gibbs approach as given by Eqs. (41) and (42), as these take higher order correction terms into account.
It must be noted that the mode approximation only holds for strictly convex problems and can perform poorly if this property does not hold. The precise form of the posterior is neither analytically nor numerically fully accessible due to the potentially extremely large phase space of the degrees of freedom. However in first order approximation, the posterior Hamiltonian may be assumed to be convex close to its minimum.
4. The inference algorithm
To denoise, deconvolve, and decompose photon observations, while simultaneously learning the statistical properties of the fields, i.e. their power spectra, is a highly relevant but non-trivial task.
The derived information Hamiltonian Eq. (31) and Gibbs free energy Eq. (B.9) are scalar quantities defined over a potentially huge phase space of φ and τ. Even within an ideal measurement scenario the inference has to estimate three numbers plus the spectral parameters for each location and energy of the field from just one data value. Hence the inference can become highly degenerate if the data or priors do not sufficiently constrain the reconstruction. Such a scenario would likely lead to multiple local minima in a non-convex manifold of the landscape of the information Hamiltonian and Gibbs free energy, respectively. In total the complexity of the inference has its main roots at the non-linear coupling between the individual fields and spectral parameters to be inferred.
After numerous numerical tests we can propose an iterative optimisation scheme, which divides the global minimisation into multiple, more easily solvable subsets. By now, the following guide has given the best results:
-
Initialise the algorithm with naive starting values, i.e. φ = 0 and
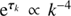 . If more profound knowledge is at hand you may certainly use this to construct a suitable initial field prior in order to speed up the inference and to overcome the outlined issues about the non-convexity of the minimisation.
. If more profound knowledge is at hand you may certainly use this to construct a suitable initial field prior in order to speed up the inference and to overcome the outlined issues about the non-convexity of the minimisation. -
Optimise the diffuse signal field, by minimising the information Hamiltonian Eq. (31) or the Gibbs free energy Eq. (B.9), respectively, by a method of your choice. As the gradients are always analytically accessible, we recommend using methods which make use of this, such as steepest descent.
-
Optimise the point-like and background signal field, accordingly to the diffuse signal field in the step before.
-
Update both spectral parameters of the diffuse flux field by again minimising Eqs. (31) and (B.9), respectively, with respect to
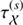 and
and 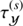 . This optimisation step may be executed via a quasi Newton method.
. This optimisation step may be executed via a quasi Newton method. -
Optimise the diffuse flux field, analogous to step two.
-
Optimise the spectral parameters and maps of the point-like and background signal field according to step four and five, analog to the diffuse signal field.
-
Iterate between the steps four to six, until you have reached a global optimum. This may take a couple cycles. In order to get rough estimates of the signal in early cycles it is not necessary to let each minimisation run until it has reached its global desired convergence criteria. These may be retightened gradually as one gets closer to the global minimum.
-
At the reached minimum, calculate D(φ) in order to obtain the physical fluxes Eq. (44).
It must be noted that the outlined iterative minimisation scheme has proven in multiple numerical tests to lead to the global minimum. However due to the extremely large phase space it is almost impossible to judge whether the algorithm has truly converged to the global optimum in case one works with real astrophysical data sets. Nevertheless this should not matter too much, in case the local minimum and the global optimum are close to each other and therefore do not differ substantially.
5. An inference example
5.1. Performance of D4
In order to demonstrate the performance of the inference algorithm we apply the D4P0 algorithm to a realistic but simulated astrophysical data set. In this mock example the algorithm is required to reconstruct the diffuse, the point-like, and the background fluxes. Additionally we request to infer all statistical properties of the diffuse flux, i.e. 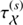 and
and 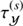 , and
, and 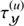 of the point flux. The statistical properties of the background radiation are assumed to be known, otherwise the inference problem would be completely degenerate as no prior information would separate the background from the diffuse flux. The mock data set originates from a hypothetical observation with a field of view of 350 × 350 pixels and a resolution of 0.005 × 0.01 [a.u.]. All signal fields were drawn from Gaussian random fields with different correlation structures. The functional form of all correlation structures is
of the point flux. The statistical properties of the background radiation are assumed to be known, otherwise the inference problem would be completely degenerate as no prior information would separate the background from the diffuse flux. The mock data set originates from a hypothetical observation with a field of view of 350 × 350 pixels and a resolution of 0.005 × 0.01 [a.u.]. All signal fields were drawn from Gaussian random fields with different correlation structures. The functional form of all correlation structures is
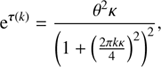 (46)
(46)
but the correlation length κ and the variance θ differ for each field and their sub-domains. The chosen parameters are given by Table 1.
Parameters to define correlation structure of s, u, and b.
The assumed instrument’s response incorporates a convolution with a Gaussian-like PSF with a FWHM of two times the pixelation size in each direction and an inhomogeneous exposure. The logarithmic exposure, the logarithmic PSF, the logarithmic photon counts, as well as the raw photon counts are shown in the top panel of Fig. 3. The obtained data set provides spatial and spectral information about each observed photon.
 |
Fig. 3. Demonstration of the capabilities of D4PO based on a simulated but realistic data set gathered from a potential astrophysical high energy telescope. The spatial dimension is orientated vertically and the spectral/energy dimension horizontally. Point-like sources appear therefore as the horizontal lines. All fields are living over a regular grid of 350 × 350 pixels. Top panel: the assumed instrument’s exposure map, its Gaussian convolution kernel and the obtained data set, once on logarithmic scale and once the raw photon counts. For each photon count we obtain spectral and spatial information. The panels below display the diffuse, point-like, and background flux. For all signal fields we show the ground truth on the left hand side ( |

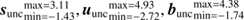
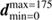
Further rows of Fig. 3 show all signal fields in terms of logarithmic fluxes, i.e. s, u, and b, all depending on location on the vertical axis and energy on the horizontal axis. For each field we show the ground truth, i.e. the drawn Gaussian random field, its reconstruction, the error (or residual) between reconstruction and truth flux, i.e. |ρrec−ρtruth|, as well as the uncertainty σ𝒢 of the reconstruction provided by D4PO, according to Eq. (45). For the reconstruction we used the following parameter setup, 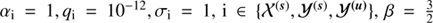 , and η = 10−4 in a MAP-𝒢 approach as this has proven to give the best results within a reasonable amount of computing time (Selig & Enßlin 2015).
, and η = 10−4 in a MAP-𝒢 approach as this has proven to give the best results within a reasonable amount of computing time (Selig & Enßlin 2015).
Looking more closely at the diffuse flux field, the original and its reconstruction are in good agreement. The strongest deviation may be found in regions with low amplitudes, which is not surprising as we are using an exponential ansatz to enforce positivity for all our fields. Hence small errors in s → (1±ϵ)s factorise in the physical photon flux field, ρ(s) → ese±ϵ, that scales exponentially with the amplitude of the diffuse flux field. Further, in almost all regions the absolute error shows that the reconstruction is in very good agreement with the original one. Only in areas with a relatively weak point flux and a rather strong diffuse flux the decomposition seems to run into a fundamental problem, as the priors and the likelihood can no longer break the degeneracies between the different sources.
From Fig. 4 it becomes apparent that the reconstructed power spectra of s track all large scale modes in good agreement up to ν ≲ 20. At higher harmonic modes the reconstructed power spectra start to deviate from the reference and fall more steeply. The drop off point at ν ≈ 20 roughly corresponds to the support of the PSF of the instrument’s response. As the power spectrum still shows a smooth shape at ν ≳ 20, the action of the smoothness enforcing prior starts to set in. Would σ be significantly smaller than the used one, the spectra would start to scatter wildly, which we do not expect in astrophysical spectra. Hence the smoothness enforcing prior allows some kind of superresolution up to a certain threshold.
 |
Fig. 4. Reconstructed power spectrum of s in its spatial (panel a) and spectral sub-domain (panel b) and u in its spectral domain (panel c). The dashed black line indicates the default spectrum from which the Gaussian random fields, shown in Fig. 3, were drawn, while the solid black lines show its reconstruction. In case of |
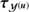
Having a closer look at the logarithmic point-like flux field (Fig. 3), we observe a similar situation as for diffuse flux field. This is supported by the reconstructed power spectrum, 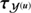 and its original one which match perfectly (Fig. 4c). Up to where the reconstruction is mainly driven by the data may not read of as the algorithm recovered all modes correctly. This is of course due to an appropriate setup of the smoothness enforcing prior.
and its original one which match perfectly (Fig. 4c). Up to where the reconstruction is mainly driven by the data may not read of as the algorithm recovered all modes correctly. This is of course due to an appropriate setup of the smoothness enforcing prior.
Nevertheless it must be noted that σ (see Sect. 2.3.3) has to be set accurately as it can have significant influence on the reconstructed power spectrum. For a detailed discussion about its influence we refer to Pumpe et al. (2018).
The results for the spatial reconstruction performance of the point-like sources are plotted in Fig. 5. For all energies we show individually the match between original and reconstructed flux at all locations. As a point-like source illuminates the sky over a broad range of energies at a fixed location these serpentine pattern appear in Fig. 5. In total the reconstructed point-like flux is in good agreement within the 2σ confidence interval. This confidence interval corresponds to a diffuse and background free data set, it only illustrates the expected photon shot noise of point sources. The higher flux point-like sources tend to be reconstructed more accurately as a better S/N allows a sharper decomposition of the different sources. In the same way, the accuracy of the reconstruction for sources with low count rates becomes worse as the S/N becomes severe. The calculated absolute error supports these findings.
 |
Fig. 5. Reconstructed versus original physical point-like flux in its spatial and spectral domain for all energies. The grey contour indicates the 2σ confidence interval of the Poissonian shot noise. |
Figure 6 illustrates the quality of the spatial and spectral reconstruction of the diffuse flux. For all energies and locations we compare the reconstructed flux with its original one. The confidence interval corresponds, similar as in Fig. 5, to a point-like and background free data set. Therefore it only shows the expected photon shot noise of diffuse flux and is consequently only a lower bound on the uncertainty. As already mentioned before, the reconstructed spectra (Fig. 4) of the diffuse flux in both dimensions are not falling as steeply as the original one and therefore the reconstructed diffuse flux picks up small scale features from the background flux. Consequently the reconstructed flux is overestimated at low flux levels. This behaviour can also be observed in Fig. 3 by looking at the error of the reconstructed diffuse flux, which tends to be larger in regions where the original diffuse flux was low. This indicates that small-scale features from the background radiation are misinterpreted as diffuse flux. This is an expected behaviour as the decomposition is primarily based on the correlation structure of each component. On the one hand, if these components show correlations on similar scale the decomposition becomes more and more degenerate. On the other hand, it becomes more a one-to-one correspondence if the scales of the correlations differ more significantly. It would be beneficial if they live over completely different domains as it actually is the case in many real world measurement situations. In total the results of the performed inference, demonstrated in Fig. 3 display exactly this behaviour. The decomposition performs well on scales where the correlations of the components are different to each other in contrast to those where they are more similar. As the correlation length of the background flux is similar to the support of the assumed PSF of the instrument’s response, not all of its small features could be reconstructed even though its statistical properties, i.e. the power spectrum, were provided and not inferred from the data. Hence the reconstruction is smeared out as one would expect. Therefore the calculated absolute error is more finely grained and its absolute magnitude is smaller compared to the reconstruction.
 |
Fig. 6. Reconstructed versus original physical diffuse flux in its spatial and spectral domain for all energies. The grey contour indicates the 2σ confidence interval of the Poissonian shot noise. |
In order to get a quantitative statement about the quality of the reconstructed fields we define a relative error ϵ for each component
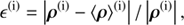 (47)
(47)
with i ∈ {s, u, b}. The errors are ϵ(s) ≈ 2.910%,ϵ(u) ≈ 9.470%, and ϵ(b) ≈ 8.542%. For a detailed discussion on how such measures can change the view on Bayesian inference algorithms we refer to Burger & Lucka (2014).
The calculated uncertainty estimates of the reconstructions, s, u, and b are as one would expect them to be, given the Poissonian shot noise and the Gaussian convolution of the response operator. The absolute magnitudes of the uncertainties are in all cases smaller than the amplitude of the reconstruction itself. Figure 7 shows that uncertainty estimates are useful, however one has to keep in mind that approximation to the non-Gaussian posterior were done. Consequently for heavy tails of the posterior PDF the approximated uncertainty do not account for.
 |
Fig. 7. Differences between |ρerror−ρuncertainty| on their native scale, by devision through the uncertainty estimates. The image-mean of the normalised errors is ≈0.6 for the diffuse flux, ≈0.85 for the point-like flux, and ≈1.5 for the background flux. Hence they show, that some uncertainties are overestimated and others underestimated, respectively. |
The inference algorithm is steered by the model parameters, shown in rectangular boxes in Fig. 2. In this mock data demonstration run we set them all to physically motivated values. Changing these, especially σ of the smoothness enforcing prior and β, the shape parameter of the spatial prior for the point-like flux can have a significant influence on the reconstruction. A detailed parameter study of α, q, β, and η can be found in Selig & Enßlin (2015).
It may be summarised that the advancements of D4PO to denoise, deconvolve, and decompose multidimensional photon observations into multiple morphologically different sources, such as diffuse, point-like and background sources, while simultaneously learning their statistical properties in each of the field domains independently, have shown to give reliable estimates about the physical fluxes for data of sufficient quality.
5.2. Comparison to maximum likelihood methods
The maximum likelihood (ML) method is a well known technique to reconstruct fluxes in astrophysics (Guillaume et al. 1998; Han & Carlin 2001; Boese & Doebereiner 2001; Willsky & Jones 1976). ML tries to purely maximise the likelihood (Sect. 2.2) and disregards any prior assumptions. Therefore minimising Eq. (8) is equal to maximising the likelihood and can only yield an estimate of the total photon flux of all components φ. In Fig. 8 exactly such a ML-reconstruction is shown and compared to a D4PO reconstruction. To examine the differences between the two methods, we show the total sum of all components
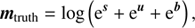 (48)
(48)
 |
Fig. 8. Differences between the introduced D4PO reconstruction technique and a regular ML reconstruction. Top left panel: sum of all ground truth components (diffuse, point-like, and background flux fields), mML from Fig. 3. Top middle panel: sum of the reconstructed flux components by D4PO, mΣD4PO (sum of reconstructions from Fig. 3), top right panel: regular maximum likelihood reconstruction: mML, using the same data set as in Fig. 3. Below are shown the absolute differences between the sum of all D4PO reconstructions and the ground truth, |mtruth − mΣ D4PO| shown. The same applies for the maximum likelihood reconstruction, |mtruth − mML| at the bottom right. |
all reconstructed fluxes by D4PO
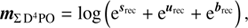 (49)
(49)
(compare Fig. 3) and the reconstructed total flux by ML
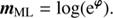 (50)
(50)
From this comparison it becomes apparent that prior assumptions about the different photon flux components are not only essential to decompose a data set into morphologically different sources, but also for the quality of the reconstruction of the total flux. These break the degeneracy between different photon source components, especially when reconstructing and estimating more than one component. Further, Fig. 8 shows that the reconstructed correlation structures of Fig. 4 help to recover more detailed features present in the original flux components (s, u, b), than not using this information in a ML approach. Applying the same quantitative measure as in Eq. (47), the relative error of mΣ D4PO compared to mtruth is ϵΣD4PO ≈ 13.72%, while the relative error of mML is ϵML ≈ 8896%.
6. Conclusion
We derived the D4PO algorithm, to denoise, deconvolve and decompose multi-domain photon observations, into multiple morphologically different components. In this context we focused on the decomposition of astrophysical high energy photon count data into three different types of sources, diffuse, point-like and background radiation. Each of these components lives over a continuous space over multiple domains, such as energy and location. In addition to the simultaneous reconstruction of all components the algorithm can infer the correlation structure of each field over each of its sub-domains. Thereby D4PO takes accurate care of the instruments response function and the induced photon shot noise. Finally the algorithm can provide a posteriori uncertainty estimates of the reconstructed fields.
The introduced algorithm is based on D3PO (Selig & Enßlin 2015), which was successfully applied to the Fermi LAT data (Selig et al. 2015) and giant magnetar flare observations (Pumpe et al. 2018). D4PO provides an advancement towards multidimensional fields analysis with multiple components. The D4PO algorithm is based on the derived hierarchical Bayesian parameter model within the framework of IFT (Enßlin et al. 2009). The model incorporates multiple a priori assumptions for the signal fields of interest. These assumptions account for the known statistical properties of the fields in order to decompose the data set into their different sources. As some of these statistical identities are often not known a priori, the algorithm can learn them from the data set itself. Thereby we assume that each field follows a log-normal distribution over each of its sub-domains, except for the spatial correlations of point-sources. The correlations over these sub-domains may then be encoded via a power spectrum, implicitly assuming statistical homogeneity and isotropy over each sub-domain. As the point-like flux is implicitly defined to be statistically independent in its spatial sub-domain, we motivated an independent Inverse-Gamma prior, which implies a power law behaviour of the amplitudes of the flux.
To denoise and deconvolve astrophysical counts we took detailed care of an adequate likelihood modelling. The derived likelihood is a Poisson distribution to denoise the photon shot noise and incorporates all instruments artefacts, which are imprinted in the data set.
In total the hierarchical Bayesian parameter model is steered by only five parameters, for which we can provide well motivated a priori values. None of these parameters drives the inference dominantly as they may all be set to values where they provide minimal additional information to the inference problem.
In a simulated high energy photon count data set we demonstrated the performance of D4PO. The algorithm successfully denoised, deconvolved, and decomposed the raw photon counts into diffuse, point-like and background radiation. Simultaneously it recovered the power spectrum of the diffuse flux in its spatial and spectral sub-domain. The correlation structure in the spectral sub-domain of the point-like flux was also inferred from the data. In total the analysis yielded detailed reconstructions and uncertainty estimates which are in good agreement with the simulated input.
The introduced algorithm is applicable to a wide range of inference problems. Its main advancement to reconstruct fields over multiple manifolds, each with different statistical identities, should find use in various data inference problems. Besides the most obvious applications in high energy astrophysics, such as Fermi, XMM-Newton, Chandra, Comptel, etc. to reconstruct the diffuse and point-like flux dependent on energy and location on the sphere, one may also infer energy dependent light curves of gamma ray bursts. Hence D4PO has a broad range of applications.
Acknowledgments
We would like to thank Jakob Knollmüller, Reimar Leike, Sebastian Hutschenreuter, Philipp Arras and an anonymous referee for their beneficial discussions during this project.
References
- Abrantes, F., Lopes, C., Rodrigues, T., et al. 2009, Geochem. Geophys. Geosyst., 10, Q09U07 [Google Scholar]
- Acharya, B. S., Actis, M., Aghajani, T., et al. 2013, Astropart. Phys., 43, 3 [Google Scholar]
- Atwood, W. B., Abdo, A. A., Ackermann, M., et al. 2009, ApJ, 697, 1071 [NASA ADS] [CrossRef] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bioucas-Dias, J. M., & Figueiredo, M. A. T. 2010, IEEE Trans. Image Process., 19, 1720 [NASA ADS] [CrossRef] [Google Scholar]
- Bobin, J., Moudden, Y., Starck, J.-L., Fadili, J., & Aghanim, N. 2008, Stat. Methodol., 5, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Boese, F. G., & Doebereiner, S. 2001, A&A, 370, 649 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Böhm, V., Hilbert, S., Greiner, M., & Enßlin, T. A. 2017, Phys. Rev. D, 96, 123510 [NASA ADS] [CrossRef] [Google Scholar]
- Bouchet, L., Amestoy, P., Buttari, A., Rouet, F.-H., & Chauvin, M. 2013, Astron. Comput., 1, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Burger, M., & Lucka, F. 2014, Inverse Prob., 30, 114004 [NASA ADS] [CrossRef] [Google Scholar]
- Carvalho, P., Rocha, G., & Hobson, M. P. 2009, MNRAS, 393, 681 [NASA ADS] [CrossRef] [Google Scholar]
- Carvalho, P., Rocha, G., Hobson, M. P., & Lasenby, A. 2012, MNRAS, 427, 1384 [NASA ADS] [CrossRef] [Google Scholar]
- Chapman, E., Abdalla, F. B., Bobin, J., et al. 2013, MNRAS, 429, 165 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Cornwell, T. J., & Evans, K. F. 1985, A&A, 143, 77 [NASA ADS] [Google Scholar]
- Dolui, S., Salgado Patarroyo, I. C., & Michailovich, O. V. 2014, Proc. SPIE, 9019, 90190B [Google Scholar]
- Dupe, F.-X., Fadili, J. M., & Starck, J.-L. 2009, IEEE Trans. Image Process., 18, 310 [NASA ADS] [CrossRef] [Google Scholar]
- Enßlin, T. A., & Frommert, M. 2011, Phys. Rev. D, 83, 105014 [NASA ADS] [CrossRef] [Google Scholar]
- Enßlin, T. A., & Weig, C. 2010, Phys. Rev. E, 82, 051112 [NASA ADS] [CrossRef] [Google Scholar]
- Enßlin, T. A., Frommert, M., & Kitaura, F. S. 2009, Phys. Rev. D, 80, 105005 [NASA ADS] [CrossRef] [Google Scholar]
- Figueiredo, M. A. T., & Bioucas-Dias, J. M. 2010, IEEE Trans. Image Process., 19, 3133 [NASA ADS] [CrossRef] [Google Scholar]
- Giovannelli, J.-F., & Coulais, A. 2005, A&A, 439, 401 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- González-Nuevo, J., Argüeso, F., López-Caniego, M., et al. 2006, MNRAS, 369, 1603 [NASA ADS] [CrossRef] [Google Scholar]
- Greiner, M., Vacca, V., Junklewitz, H., & Enßlin, T. A. 2016, ArXiv e-prints [arXiv:1605.04317] [Google Scholar]
- Guglielmetti, F., Voges, W., Fischer, R., Boese, G., & Dose, V. 2004, in Astronomical Data Analysis Software and Systems (ADASS) XIII, eds. F. Ochsenbein, M. G. Allen, & D. Egret, ASP Conf. Ser., 314, 253 [NASA ADS] [Google Scholar]
- Guglielmetti, F., Fischer, R., & Dose, V. 2009, MNRAS, 396, 165 [NASA ADS] [CrossRef] [Google Scholar]
- Guillaume, M., Melon, P., Réfrégier, P., & Llebaria, A. 1998, J. Opt. Soc. Am. A, 15, 2841 [NASA ADS] [CrossRef] [Google Scholar]
- Han, C., & Carlin, B. P. 2001, J. Am. Stat. Assoc., 96, 1122 [CrossRef] [Google Scholar]
- Högbom, J. A. 1974, A&AS, 15, 417 [Google Scholar]
- Jasche, J., & Kitaura, F. S. 2010, MNRAS, 407, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Wandelt, B. D. 2013, ApJ, 779, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., Kitaura, F. S., Wandelt, B. D., & Enßlin, T. A. 2010, MNRAS, 406, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Junklewitz, H., Bell, M. R., Selig, M., & Enßlin, T. A. 2016, A&A, 586, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kayo, I., Taruya, A., & Suto, Y. 2001, ApJ, 561, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Kinney, J. B. 2014, Phys. Rev. E, 90, 011301 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F. S., Jasche, J., Li, C., et al. 2009, MNRAS, 400, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Knollmüller, J., Steininger, T., & Enßlin, T. A. 2017, ArXiv e-prints [arXiv:1711.02955] [Google Scholar]
- Knollmüller, J., Frank, P., & Enßlin, T. A. 2018, ArXiv e-prints [arXiv:1804.05591] [Google Scholar]
- Lahmiri, S. 2017, Opt. Laser Technol., 90, 128 [NASA ADS] [CrossRef] [Google Scholar]
- Metropolis, N., & Ullam, S. 1949, J. Am. Stat. Assoc., 44, 335 [Google Scholar]
- Neyrinck, M. C., Szapudi, I., & Szalay, A. S. 2009, ApJ, 698, L90 [NASA ADS] [CrossRef] [Google Scholar]
- Oppermann, N., Selig, M., Bell, M. R., & Enßlin, T. A. 2013, Phys. Rev. E, 87, 032136 [NASA ADS] [CrossRef] [Google Scholar]
- Osoba, O., & Kosko, B. 2016, Fluctuat. Noise Lett., 15, 1650007 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration VII 2011, A&A, 536, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pumpe, D., Greiner, M., Müller, E., & Enßlin, T. A. 2016, Phys. Rev. E, 94, 012132 [NASA ADS] [CrossRef] [Google Scholar]
- Pumpe, D., Gabler, M., Steininger, T., & Enßlin, T. A. 2018, A&A, 610, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rau, U., & Cornwell, T. J. 2011, A&A, 532, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sault, R. J., & Oosterloo, T. A. 2007, ArXiv e-prints [arXiv:astro-ph/0701171] [Google Scholar]
- Schoenfelder, V., Aarts, H., Bennett, K., et al. 1993, ApJS, 86, 657 [NASA ADS] [CrossRef] [Google Scholar]
- Selig, M., & Enßlin, T. 2015, A&A, 574, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Selig, M., Bell, M. R., Junklewitz, H., et al. 2013, A&A, 554, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Selig, M., Vacca, V., Oppermann, N., & Enßlin, T. A. 2015, A&A, 581, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sheth, R. K. 1995, MNRAS, 277, 933 [NASA ADS] [CrossRef] [Google Scholar]
- Steininger, T., Dixit, J., Frank, P., et al. 2017, ArXiv e-prints [arxiv:1708.01073] [Google Scholar]
- Strong, A. W. 2003, A&A, 411, L127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valdes, F. 1982, Instrum. Astron. IV, 331, 465 [NASA ADS] [CrossRef] [Google Scholar]
- Valtchanov, I., Pierre, M., & Gastaud, R. 2001, A&A, 370, 689 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vedrenne, G., Roques, J.-P., Schönfelder, V., et al. 2003, A&A, 411, L63 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Venkatesh Gubbi, S., & Sekhar Seelamantula, C. 2014, ArXiv e-prints [arXiv:1412.2210] [Google Scholar]
- Vio, R., Andreani, P., & Wamsteker, W. 2001, PASP, 113, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Voges, W., Aschenbach, B., Boller, T., et al. 1999, A&A, 349, 389 [NASA ADS] [Google Scholar]
- Wandelt, B. D. 2004, ArXiv e-prints [arXiv:astro-ph/0401623] [Google Scholar]
- Willett, R. 2007, in Statistical Challenges in Modern Astronomy IV, eds. G. J.Babu, & E. D. Feigelson, ASP Conf. Ser., 371, 247 [NASA ADS] [Google Scholar]
- Willett, R., & Nowak, R. D. 2007, IEEE Trans. Inf. Theory, 53, 3171 [CrossRef] [MathSciNet] [Google Scholar]
- Willsky, A., & Jones, H. 1976, IEEE Trans. Autom. Control, 21, 108 [CrossRef] [Google Scholar]
Appendix A: Covariances and curvatures
The covariance D of a Gaussian 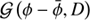 describes the uncertainty associated with the mean of the distribution. It may be computed via the inverse Hessian of the corresponding information Hamiltonian or Gibbs free energy respectively,
describes the uncertainty associated with the mean of the distribution. It may be computed via the inverse Hessian of the corresponding information Hamiltonian or Gibbs free energy respectively,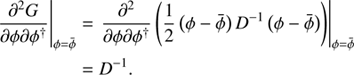 (A.1)
(A.1)
The uncertainty covariances of the derived information Hamiltonian Eq. (31) are,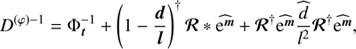 (A.2)
(A.2)
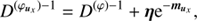 (A.3)
(A.3)
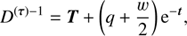 (A.4)
(A.4)
with
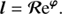 (A.5)
(A.5)
The corresponding covariances of the chosen Gibbs approach in Eq. (B.9) are,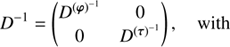 (A.6)
(A.6)
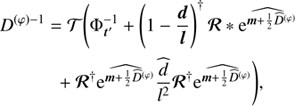 (A.7)
(A.7)
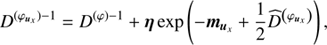 (A.8)
(A.8)
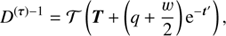 (A.9)
(A.9)
with
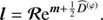 (A.10)
(A.10)
Up to the term 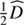 in the exponential functions, these covariances are identical to the ones derived via the maximum a posteriori ansatz Eq. (A.4). This shows that these higher order corrections terms change the uncertainty covariances, however their influence is hard to judge as they introduce terms that couple to all elements of D. It must be noted that the inverse Hessian only describes the curvature of the potential, hence it may only be regarded as the uncertainty of a reconstruction if the potential is quadratic. However, numerous numerical experiments showed that this assumption holds in most cases.
in the exponential functions, these covariances are identical to the ones derived via the maximum a posteriori ansatz Eq. (A.4). This shows that these higher order corrections terms change the uncertainty covariances, however their influence is hard to judge as they introduce terms that couple to all elements of D. It must be noted that the inverse Hessian only describes the curvature of the potential, hence it may only be regarded as the uncertainty of a reconstruction if the potential is quadratic. However, numerous numerical experiments showed that this assumption holds in most cases.
Appendix B: Deriving the Gibbs free energy
Due to the complex structure of the information Hamiltonian in Eq. (31), we are seeking for an approximation to the true posterior Eq. (28). To this end we adapt a Gaussian distribution for our posterior approximation and require it to be close in an information theoretical sense to the correct posterior. The correct information distance is the Kullback–Leibler divergence, which is equivalent, up to irrelevant constants, to the Gibbs free energy (Enßlin & Weig 2010). We directly adopt the final functional form of the posterior in the construction of the Gibbs free energy. Here we use an approximate Gaussian ansatz for the posterior Eq. (28) of our signal vector ϕ = (φ†,τ†)†: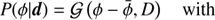 (B.1)
(B.1)
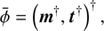 (B.2)
(B.2)
the posterior mean, and
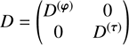 (B.3)
(B.3)
the posterior uncertainty covariance. The posterior mean 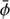 consists of the mean field m = ⟨φ⟩(ϕ|d), as well as the mean log power spectrum t = ⟨τ⟩(ϕ|d). The signal covariance
consists of the mean field m = ⟨φ⟩(ϕ|d), as well as the mean log power spectrum t = ⟨τ⟩(ϕ|d). The signal covariance 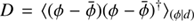 consists of 2 × 2 block matrices, where the off diagonal terms are set to zero to reduce the complexity of the resulting algorithm. The non zero blocks are the signal uncertainty
consists of 2 × 2 block matrices, where the off diagonal terms are set to zero to reduce the complexity of the resulting algorithm. The non zero blocks are the signal uncertainty
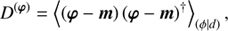 (B.4)
(B.4)
and the log-spectrum uncertainty
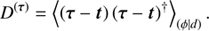 (B.5)
(B.5)
In terms of these parameters the Gibbs free energy is given by
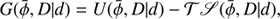 (B.6)
(B.6)
with
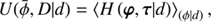 (B.7)
(B.7)
being the internal energy, describing the full non-Gaussian Hamiltonian Eq. (31), averaged by the approximated posterior Eq. (B.1). The entropy of the approximated Gaussian posterior is
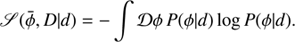 (B.8)
(B.8)
Up to an irrelevant sign and an additive constant the Gibbs free energy Eq. (B.6) is equal to the Kullback–Leibler distance of the posterior approximation if 𝒯 = 1. Unless stated differently, we therefore usually set 𝒯 = 1. If 𝒯 = 0, the approximate posterior given by Eq. (B.1) becomes a delta function at the maximum of the correct posterior, Eq. (28), which might perform poorly in case nuisance parameters, such as τ also need to be reconstructed.
In total the Gibbs free energy becomes
![Mathematical equation: $$ \begin{aligned} G=&G \left( \bar{\phi }, D \vert \boldsymbol{d} \right) \nonumber \\ =&G_0 + \boldsymbol{1}^{\dagger } \boldsymbol{l} - \boldsymbol{d}^{\dagger } \log \boldsymbol{l} \nonumber \\&+ \frac{1}{2} \Big [\text{ Tr} \left[ \log \Phi \right] +\boldsymbol{m}^{\dagger }\Phi ^{-1} \boldsymbol{m} + \text{ Tr}\left(\Phi ^{-1} D^{(\boldsymbol{\varphi })}\right) \Big ]\nonumber \\&+ \left( \alpha -1 \right)^{\dagger } \boldsymbol{t} + q^{\dagger } \exp \left(-\boldsymbol{t}+ \frac{1}{2}\widehat{D}^{(\boldsymbol{\tau })}\right) \nonumber \\&+ \frac{1}{2} \boldsymbol{t}^{\dagger } \boldsymbol{T} \boldsymbol{t} + \frac{1}{2} \text{ Tr} \left[ \boldsymbol{T} D^{\left(\boldsymbol{\tau }\right)}\right] \nonumber \\&+ \left(\beta -1\right)^{\dagger } \boldsymbol{m}_{\boldsymbol{u}_x} + \boldsymbol{\eta }^{\dagger } \exp \left(-\boldsymbol{m}_{\boldsymbol{u}_x} + \frac{1}{2}\widehat{D}^{\left(\varphi _{\boldsymbol{u}_x}\right)}\right) \nonumber \\&- \frac{\mathcal{T} }{2} \text{ Tr} \left[\mathbb{1} + \ln \left( 2 \pi D\right) \right], \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq107.gif) (B.9)
(B.9)
with Φ = diag(𝒮,𝒰,ℬ), G0 is absorbing all constants, and
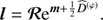 (B.10)
(B.10)
Comparing Eq. (B.9) with the information Hamiltonian Eq. (31), there are a number of correction terms appearing which properly account for the uncertainty of the inferred map m. In particular l differs, comparing Eqs. (33) with (B.10), which in the framework of Gibbs free energy describes the expectation value of λ over the approximate posterior Eq. (B.1). Minimizing the Gibbs free energy with respect to m, t and D would optimize the inference under the assumed Gaussian posterior.
In the following sections we will gradually derive the Gibbs free energy.
B.1. The Entropy
Due to the Gaussian ansatz Eq. (B.1) the entropy Eq. (B.8) is independent of  ,
,![Mathematical equation: $$ \begin{aligned} \fancyscript {S}(\bar{\phi }, D\vert d)= \frac{1}{2} \text{ Tr} \left[\mathbb{1} + \ln (2\pi D)\right] \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq110.gif) (B.11)
(B.11)
and therefore its gradients with respect to m and t vanish,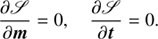 (B.12)
(B.12)
B.2. Internal energy of the hyperprior
The internal energy of the hierarchical Gaussian prior P(τ|σ, α, q) is
![Mathematical equation: $$ \begin{aligned} U^{\left(\boldsymbol{\tau }\right)}\left( \bar{\phi }, D \vert \boldsymbol{d}\right) =&\left\langle H(\boldsymbol{\tau })\right\rangle _{(\phi , D\vert \boldsymbol{d})}\nonumber \\ \simeq&\frac{1}{2} \boldsymbol{t}^{\dagger } \boldsymbol{T} \boldsymbol{t} + \frac{1}{2} \text{ Tr} \left[ \boldsymbol{T} D^{\left(\boldsymbol{\tau }\right)}\right] \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq112.gif) (B.13)
(B.13)
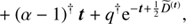 (B.14)
(B.14)
with 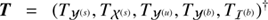 . A hat on a tensor denotes the diagonal vector in the position basis,
. A hat on a tensor denotes the diagonal vector in the position basis, 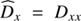 , while a hat on a vector refers to a tensor with the vector as its diagonal,
, while a hat on a vector refers to a tensor with the vector as its diagonal, 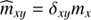 . Similarly we define a tilde on a tensor as the diagonal vector in the band harmonic basis,
. Similarly we define a tilde on a tensor as the diagonal vector in the band harmonic basis, 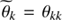 , and a tilde on a vector denotes a tensor with the vector on its diagonal in the band harmonic basis,
, and a tilde on a vector denotes a tensor with the vector on its diagonal in the band harmonic basis, 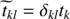 .
.
The corresponding non-vanishing gradients of the hyperprior’s internal energy Eq. (B.14) are
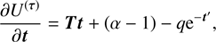 (B.15)
(B.15)
![Mathematical equation: $$ \begin{aligned} \frac{\partial U^{\left(\boldsymbol{\tau }\right)}}{\partial D^{\left(\boldsymbol{\tau }\right)}}=&\frac{1}{2} \left[ \boldsymbol{T} + \widetilde{q \mathrm{e}^ {-\boldsymbol{t}^{\prime }}}\right], \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq120.gif) (B.16)
(B.16)
with 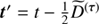 .
.
B.3. Internal energy of the prior for φ
The priors for φ provide the internal energy
![Mathematical equation: $$ \begin{aligned} U^{\left(\boldsymbol{\varphi }\right)}(\bar{\phi }, D\vert \boldsymbol{d}) =&\frac{1}{2}\text{ Tr} \left[ \log \Phi _{\boldsymbol{t}^{\prime }}\right] \nonumber \\&+ \frac{1}{2}\left[ \boldsymbol{m}^{\dagger }\Phi _{\boldsymbol{t}^{\prime }}^{-1} \boldsymbol{m} + \text{ Tr}\left[\Phi _{\boldsymbol{t}^{\prime }}^{-1} D^{(\boldsymbol{\varphi })}\right]\right]. \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq122.gif) (B.17)
(B.17)
The corresponding gradients are
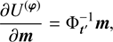 (B.18)
(B.18)
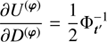 (B.19)
(B.19)
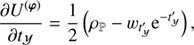 (B.20)
(B.20)
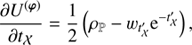 (B.21)
(B.21)
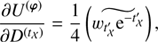 (B.22)
(B.22)
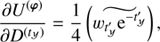 (B.23)
(B.23)
with
![Mathematical equation: $$ \begin{aligned} w_{t^{\prime }_{\mathcal{Y} }}&= \text{ Tr} \left[\mathcal{X} ^{(\boldsymbol{\varphi })^{-1}} \mathbb{P} \left(\boldsymbol{m}^{\dagger } \boldsymbol{m} + D^{(\boldsymbol{\varphi })}\right)\right],\end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq129.gif) (B.24)
(B.24)
![Mathematical equation: $$ \begin{aligned} w_{t^{\prime }_{\mathcal{X} }}&= \text{ Tr} \left[\mathcal{Y} ^{(\boldsymbol{\varphi })^{-1}} \mathbb{P} \left(\boldsymbol{m}^{\dagger } \boldsymbol{m} +D^{(\boldsymbol{\varphi })}\right)\right] \end{aligned} $$](/articles/aa/full_html/2018/11/aa32781-18/aa32781-18-eq130.gif) (B.25)
(B.25)
and with the multiplicities ρℙ = Trℙ of the spectral bands k and l, which are sharing the same harmonic eigenvalue.
B.4. Internal energy of the Inverse-Gamma prior
The internal energy of the inverse-gamma prior on φux is
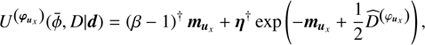 (B.26)
(B.26)
with its corresponding gradient
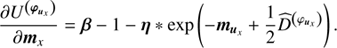 (B.27)
(B.27)
B.5. Internal energy of the likelihood
The internal energy of the likelihood Eq. (8) is
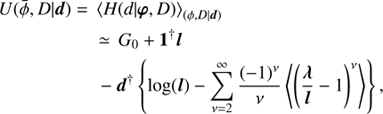 (B.28)
(B.28)
with
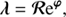 (B.29)
(B.29)
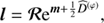 (B.30)
(B.30)
where we absorbed all terms that are constant in φ into G0. The evolution of the internal energy would require to know all entries of D(φ) explicitly. As this is computationally infeasible and the term 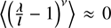 at the mode where λ ≈ l, this sum can be neglected. As a consequence all cross correlations, such as D(su) are implicitly set to zero.
at the mode where λ ≈ l, this sum can be neglected. As a consequence all cross correlations, such as D(su) are implicitly set to zero.
The gradient of Eq. (B.28) can be derived by taking the first derivative of 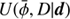 with respect to the approximate mean estimates,
with respect to the approximate mean estimates,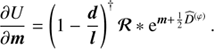 (B.31)
(B.31)
All Tables
All Figures
|
Fig. 1. Showcase for the D4PO algorithm to denoise, deconvolve, and decompose multi-domain photon observations. This is a simplified test scenario, which disregards a potential background flux and has only a unit response function (a perfect PSF). Top panels: (from left to right) data, providing spatial versus spectral information about each detected photon, original multi-domain point-like flux, as well as the multi-domain diffuse fields. Bottom panels: reconstruction of both fields. All fields are living over a regular grid with 350 × 350 pixels. |
| In the text | |
|
Fig. 2. Graphical model of the hierarchical Bayesian network introduced in Sect. 2. Shown are the model parameters α, q, σ, η and β, in rectangular boxes, as they have to be specified by the user. The logarithmic spectral parameters |
| In the text | |
|
Fig. 3. Demonstration of the capabilities of D4PO based on a simulated but realistic data set gathered from a potential astrophysical high energy telescope. The spatial dimension is orientated vertically and the spectral/energy dimension horizontally. Point-like sources appear therefore as the horizontal lines. All fields are living over a regular grid of 350 × 350 pixels. Top panel: the assumed instrument’s exposure map, its Gaussian convolution kernel and the obtained data set, once on logarithmic scale and once the raw photon counts. For each photon count we obtain spectral and spatial information. The panels below display the diffuse, point-like, and background flux. For all signal fields we show the ground truth on the left hand side ( |
| In the text | |
|
Fig. 4. Reconstructed power spectrum of s in its spatial (panel a) and spectral sub-domain (panel b) and u in its spectral domain (panel c). The dashed black line indicates the default spectrum from which the Gaussian random fields, shown in Fig. 3, were drawn, while the solid black lines show its reconstruction. In case of |
| In the text | |
|
Fig. 5. Reconstructed versus original physical point-like flux in its spatial and spectral domain for all energies. The grey contour indicates the 2σ confidence interval of the Poissonian shot noise. |
| In the text | |
|
Fig. 6. Reconstructed versus original physical diffuse flux in its spatial and spectral domain for all energies. The grey contour indicates the 2σ confidence interval of the Poissonian shot noise. |
| In the text | |
|
Fig. 7. Differences between |ρerror−ρuncertainty| on their native scale, by devision through the uncertainty estimates. The image-mean of the normalised errors is ≈0.6 for the diffuse flux, ≈0.85 for the point-like flux, and ≈1.5 for the background flux. Hence they show, that some uncertainties are overestimated and others underestimated, respectively. |
| In the text | |
|
Fig. 8. Differences between the introduced D4PO reconstruction technique and a regular ML reconstruction. Top left panel: sum of all ground truth components (diffuse, point-like, and background flux fields), mML from Fig. 3. Top middle panel: sum of the reconstructed flux components by D4PO, mΣD4PO (sum of reconstructions from Fig. 3), top right panel: regular maximum likelihood reconstruction: mML, using the same data set as in Fig. 3. Below are shown the absolute differences between the sum of all D4PO reconstructions and the ground truth, |mtruth − mΣ D4PO| shown. The same applies for the maximum likelihood reconstruction, |mtruth − mML| at the bottom right. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.