| Issue |
A&A
Volume 603, July 2017
|
|
|---|---|---|
| Article Number | A118 | |
| Number of page(s) | 30 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201730698 | |
| Published online | 18 July 2017 | |
Systematic survey of the effects of wind mass loss algorithms on the evolution of single massive stars⋆
1 Astronomical Institute Anton Pannekoek, University of Amsterdam, 1098 XH Amsterdam, The Netherlands
e-mail: mailto:This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Dipartimento di Fisica “Enrico Fermi”, University of Pisa, 56127 Pisa, Italy
3 TAPIR, Walter Burke Institute for Theoretical Physics, MC 350-17, California Institute of Technology, Pasadena, CA 91125, USA
4 Kavli Institute for Theoretical Physics, University of California, Santa Barbara, CA 93106, USA
Received: 24 February 2017
Accepted: 28 March 2017
Abstract
Mass loss processes are a key uncertainty in the evolution of massive stars. They determine the amount of mass and angular momentum retained by the star, thus influencing its evolution and presupernova structure. Because of the high complexity of the physical processes driving mass loss, stellar evolution calculations must employ parametric algorithms, and usually only include wind mass loss. We carried out an extensive parameter study of wind mass loss and its effects on massive star evolution using the open-source stellar evolution code MESA. We provide a systematic comparison of wind mass loss algorithms for solar-metallicity, nonrotating, single stars in the initial mass range of 15 M⊙ to 35 M⊙. We consider combinations drawn from two hot phase (i.e., roughly the main sequence) algorithms, three cool phase (i.e., post-main-sequence) algorithms, and two Wolf-Rayet mass loss algorithms. We discuss separately the effects of mass loss in each of these phases. In addition, we consider linear wind efficiency scale factors of 1, 0.33, and 0.1 to account for suggested reductions in mass loss rates due to wind inhomogeneities. We find that the initial to final mass mapping for each zero-age main-sequence (ZAMS) mass has a ~ 50% uncertainty if all algorithm combinations and wind efficiencies are considered. The ad-hoc efficiency scale factor dominates this uncertainty. While the final total mass and internal structure of our models vary tremendously with mass loss treatment, final luminosity and effective temperature are much less sensitive for stars with ZAMS mass ≲ 30 M⊙. This indicates that uncertainty in wind mass loss does not negatively affect estimates of the ZAMS mass of most single-star supernova progenitors from pre-explosion observations. Our results furthermore show that the internal structure of presupernova stars is sensitive to variations in both main sequence and post main-sequence mass loss. The compactness parameter ξ ∝ ℳ /R(ℳ) has been identified as a proxy for the “explodability” of a given presupernova model. We find that ξ varies by as much as 30% for models of the same ZAMS mass evolved with different wind efficiencies and mass loss algorithm combinations. This suggests that the details of the mass loss treatment might bias the outcome of detailed core-collapse supernova calculations and the predictions for neutron star and black hole formation.
Key words: stars: evolution / stars: massive / stars: mass-loss / stars: winds, outflows / supernovae: general
Data output is available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/603/A118
© ESO, 2017
1. Introduction
Mass loss is a key phenomenon for the co-evolution of massive stars (M ≳ 8 M⊙) and their environment, yet it is poorly understood. It plays an important role throughout the stellar evolution and it may have a deciding influence on the outcome of core collapse. Mass loss is responsible for a large part of the chemical enrichment of the interstellar medium, and its momentum input can trigger star formation, but it can also sweep away gas from stellar clusters, preventing further star formation.
In the standard picture of single massive star evolution, mass loss influences the duration of different evolutionary phases (e.g., Meynet et al. 2015), especially the amount of time spent on the red supergiant (RSG) branch. It has been suggested to be important for the solution of the so-called red supergiant problem (Smartt et al. 2009; Smith et al. 2011), that is the discrepancy between the observed maximum mass for type IIP supernovae (SNe) and the theoretical predictions for the core collapse of RSG stars. This discrepancy indicates an incomplete theoretical understanding of the evolution and explosion of massive stars, especially in the mass range ~16–30 M⊙.
Mass loss also plays an essential role in the formation of Wolf-Rayet (WR) stars. Two competing scenarios exist for the removal of (most of) the hydrogen-rich envelope of stars: the single star picture (so-called Conti scenario, Conti 1975; Maeder & Conti 1994; Lamers 2013) and the binary formation channel (e.g., Woosley et al. 1995; Wellstein & Langer 1999; Smith & Tombleson 2015; Shara et al. 2017). Understanding mass loss phenomena is necessary to discriminate between these two scenarios. Mass loss is invoked to explain the variety of core-collapse SNe (e.g., Eldridge & Tout 2004; Smith et al. 2011; Georgy 2012; Groh et al. 2013; Smith 2014), because it can modify the surface composition of the pre-SN star, possibly removing the hydrogen-rich envelope (and perhaps some of the helium-rich shell) and leading to type Ib/c SNe. Observations of SNe IIn and superluminous SNe may perhaps be explained by the strong interaction between the SN shock and shells of material ejected from the star in late stages of its evolution, (e.g., Smith et al. 2011; Smith 2014; Shiode & Quataert 2014). It has also been proposed that the coupling of mass loss and rotation might prevent pair instability SNe for very massive, low metallicity stars (Ekström et al. 2008; Woosley 2017).
Finally, mass loss plays a key role in shaping the (hydrostatic) internal structure of massive stars at the pre-SN stage, which can influence the expected SN outcome (see, e.g., Belczynski et al. 2010; O’Connor & Ott 2011, 2013; Ugliano et al. 2012; Sukhbold et al. 2016): will the star successfully explode and leave a neutron star (NS) remnant? Will the explosion be highly asymmetric or weak, leading to fallback accretion and black hole (BH) formation? Or will the explosion fail completely, leaving a BH with little (Lovegrove & Woosley 2013) or no electromagnetic counterpart?
Depending on the amount and geometry of the ejecta, which are governed by the mass loss during the stellar lifetime and the SN energetics, also the SN kick can vary (Zwicky 1957; Blaauw 1961; Boersma 1961; Janka 2013, 2017). The kick can change the post-explosion orbital parameters if the star is in a binary system and, therefore, our incomplete understanding of massive star mass loss affects the predicted populations of sources for gravitational wave astronomy (Abbott et al. 2016).
There exist three main channels of mass loss in the evolution of massive stars:
-
1.
Steady-state winds. These are radiatively driven in hot stars(i.e., on the main sequence; see Pulset al. 2008, for a review). In thesupergiant phase, the driving mechanism is uncertain. Windscould be radiatively driven via lines or dust, or by othermechanisms, e.g., wave energy deposition (see, e.g.,Bennett 2010, for a brief review).
-
2.
Impulsive, pulsational and/or eruptive mass loss, for example disk shedding at criticial rotation or giant eruptions such as those of luminous blue variables (LBVs, e.g., Puls et al. 2008, 2015; Smith 2014);
-
3.
Roche lobe overflow (RLOF) and possibly common envelope ejection in binary systems, which can result in mass loss from the donor star and also mass loss from the system as a whole in non-conservative cases.
Which of these processes dominates in terms of the total mass shed has been a matter of debate in the literature (see Smith 2014, and references therein).
Mass loss is an intrinsically dynamical phenomenon which involves bulk acceleration of matter for escaping the star. Because of the dynamical nature of mass loss, it is difficult to include in stellar evolution codes: most simulations focus on single stars, and are carried out with hydrostatic codes which cannot account for dynamical or impulsive events in a physical way. Even hydrodynamical codes do not permit a self-consistent development of impulsive events, since the physical processes triggering them are currently poorly understood or even unknown. Impulsive outbursts of mass loss can, however, be included using physically plausible prescriptions (e.g., Morozova et al. 2015).
Most massive stars are found in binary systems (e.g., Mason et al. 2009; Sana & Evans 2011; Sana et al. 2012; Kiminki & Kobulnicky 2012; Chini et al. 2012; Kobulnicky et al. 2014; Almeida et al. 2017), where mass loss also determines the angular momentum losses, thus the orbital evolution, and ultimately the binary evolution path and its end point (merger, disruption of the binary system, double compact object binary, etc.).
In this paper, our focus is on steady, radiatively-driven wind mass loss (Lucy & Solomon 1970) and our goal is to understand how different treatments of this process affect massive star evolution and pre-SN structure. We consider single massive stars and do not address the problem of mass loss in binaries directly.
Most evolutionary calculations of massive stars only include wind mass loss, which can be treated in the steady state approximation, although, strictly speaking, a wind is dynamical as well.
The wind is in fact driven by a radiative acceleration which formally enters into the momentum equation for the stellar plasma (Castor et al. 1975), the stellar structure responds secularly, since wind mass loss rates are low and change only slowly compared to impulsive mass loss events. At solar metallicity, the wind mass loss rate is 10-10M⊙ yr-1 ≲ Ṁwind ≲ 10-5M⊙ yr-1, while RLOF and LBV eruptions yield 10-6M⊙ yr-1 ≲ ṀRLOF ≲ ṀLBV ≲ 10-2M⊙ yr-1, (e.g., de Jager et al. 1988; Vink et al. 2001; van Loon et al. 2005; Smith & Owocki 2006; Crowther 2007; Puls et al. 2008; Langer 2012; Smith 2014). These mass loss rates correspond to timescales τwind = M/Ṁwind ≫ τRLOF,τLBV. Therefore, wind mass loss can be included in stellar evolution calculations using parametric algorithms1.
Stellar winds are radiatively driven by the interaction of photons with metallic ions (line-driven mass loss) or dust grains (dust-driven mass loss). Therefore, they depend on the opacity and thus chemical composition, ionization state, and density stratification, so indirectly also on the equation of state of the outermost stellar layers. Metals effectively provide all the opacity in stellar atmospheres because of their large number of lines. Photons come out of the photosphere with well defined direction, interact with metallic atoms/ions via bound-bound processes (absorption and line scattering) and cede their momentum to the atoms/ions. When these de-excite, they emit photons isotropically. The momentum of de-excitation photons averages out, and the result is a net gain of momentum in the direction of the initial photon (see, e.g., Puls et al. 2008).
We note that the radiation field in the stellar atmosphere, that is above the photosphere, is not isotropic. If there were not a net radial flux of photons, also the momentum of the incoming photons would average out. In a nutshell, the incident photons push metals outward, and metals drag hydrogen and helium through collisional Coulomb coupling (see Puls et al. 2008; Vink 2015, and references therein).
This simple theoretical picture of line-driven stellar winds is complicated by two phenomena: the high nonlinearity of the driving mechanism, and the possible presence of inhomogeneities (so called “clumpiness”) in the stellar atmosphere. The high nonlinearity arises because the outflow of mass is driven by the rate of interaction of photons with metals, but this in turn depends on the local opacity, and therefore on the outflow properties, such as density, and velocity (which can Doppler shift the lines), see Lamers & Cassinelli (1999), Puls et al. (2008) and references therein. The presence of inhomogeneities in the stellar atmosphere is both theoretically expected (see, e.g., Owocki & Rybicki 1984; Owocki et al. 1988; Feldmeier 1995; Owocki & Puls 1999; Dessart & Owocki 2005; Puls et al. 2008; Smith 2014) and observed comparing diagnostic spectral lines sensitive to the density ρ (e.g., lines with P Cygni profiles) and ρ2 (e.g., recombination lines, such as Hα) in the same stellar wind (see, e.g., Fullerton et al. 2006; Bouret et al. 2005; Evans et al. 2004). This comparison shows that the averaged ⟨ ρ2 ⟩ > ⟨ ρ ⟩ 2 (for reviews see Puls et al. 2008; and Smith 2014). Therefore, the presence of over-dense clumps in the wind causes an overestimation of the density inferred from observed spectral features sensitive to ρ2. This is not taken into account in most wind mass loss algorithms in the literature. The overestimation of the density directly results in an overestimated mass loss rate. Work by Crowther et al. (2002), Hillier et al. (2003), Bouret et al. (2005), Fullerton et al. (2006), Puls et al. (2008), Smith (2014), Abbott et al. (2016), suggests that the algorithms used in stellar evolution calculations may yield mass loss rates that are a factor of 2 to 10 too high. Puls et al. (2008) and Smith (2014) suggest a factor of 3 as the most realistic overestimate. We refer the interested reader to Puls et al. (2008), Smith (2014), and Renzo (2015) for more details.
To date, there has been no systematic comparison of the various wind mass loss algorithms, with varying corrections for clumpiness, and their combinations and effects throughout the evolution and on the final structure of massive stars. However, Eldridge & Tout (2004) compared different combinations of semi-empirical mass loss rates to find the threshold in mass between type Ibc and type II SNe. Yoon et al. (2010) discussed consequences of the revision of mass loss rates because of the clumpiness during the WR phase.
In this study, we employ the open-source stellar evolution code MESA (Paxton et al. 2011, 2013, 2015) to compare various combinations of mass loss algorithms, using different efficiency factors to account for the inhomogeneities in the wind (albeit in an ad hoc fashion). Our aim is to understand the systematics of massive star evolution and pre-SN structure caused by variations in the treatment of wind mass loss, focusing on the differences in the evolution and pre-SN structure (effective temperature, total mass, core masses, and interior structure).
The remainder of this paper is structured as follows. In Sect. 2, we discuss some general aspects of the implementation of wind mass loss in stellar evolution codes and give a very brief overview of the physical bases of the wind mass loss algorithms we compare. A longer review of these, including the limitations and the formulae implemented in MESA, can be found in Appendix A. The more technical points not relevant to the physics of stellar winds are discussed in Appendix B, with the explicit aim of making our result reproducible. We compare our models when their final pre-SN mass is determined in Sect. 3.1. We discuss the impact of winds during the hot, cool, and WR phases (if reached) separately in Sects. 3.2–3.4, respectively. We compare a subset of our models at oxygen depletion in Sect. 3.5. The evolution and pre-SN structure of the core is also sensitive to the mass loss history of the stellar model, including the early mass loss during the main sequence, as we show in Sect. 3.6. In Sect. 3.7, we discuss the evolution of a subset of our models from oxygen depletion to the onset of core collapse. We discuss the implications of uncertainties in wind mass loss and potential observational constraints in Sect. 4, before concluding in Sect. 5.
2. Methods
2.1. Overview of the mass loss algorithms
Stellar evolution codes do not explicitly compute the acceleration of the gas unbound in mass loss processes. The usual approach for including wind mass loss is to use parametric algorithms prescribing a mass loss rate averaged over each timestep. The time averaging is needed to compute each timestep with a constant mass loss rate. Homogeneity of the wind is implicit in the standard formalism, which is known to be a poor approximation and could cause a significant overestimate of the mass loss rate. Stellar wind algorithms are either parametric fits to observed mass loss rates, or theoretically derived models with free parameters chosen empirically or heuristically. Each algorithm gives a formula for the mass loss rate as a function of some quantities characterizing the star Ṁ ≡ Ṁ(L,Teff,Z,... ). The precise set of variables assumed to be independent varies between the algorithms. Most algorithms do not include an explicit metallicity dependence, because they either assume a specific chemical composition of the stellar atmosphere or are based on observed samples with a specific metallicity Z. It is common practice to impose a smooth scaling with Z such as 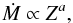 (1)with a ≃ 0.5 (e.g., Vink et al. 2000; Woosley et al. 2002). Equation (1) is in reasonable agreement with more sophisticated mass loss rate determinations (see, e.g., Vink et al. 2001), but deviations should be expected both at very low Z (because of the lack of metal lines to drive the wind) and very high Z (because of line saturation preventing further driving of the wind). In this study, we only consider solar metallicity. We note also that stellar evolution codes usually neglect the errors on the coefficients of the algorithms obtained as fits to observations.
(1)with a ≃ 0.5 (e.g., Vink et al. 2000; Woosley et al. 2002). Equation (1) is in reasonable agreement with more sophisticated mass loss rate determinations (see, e.g., Vink et al. 2001), but deviations should be expected both at very low Z (because of the lack of metal lines to drive the wind) and very high Z (because of line saturation preventing further driving of the wind). In this study, we only consider solar metallicity. We note also that stellar evolution codes usually neglect the errors on the coefficients of the algorithms obtained as fits to observations.
Since mass loss rates have large uncertainties, it is common practice to employ a linear efficiency factor η to rescale rates to account for various physical uncertainties. For example, η ≲ 1 can be used to account for wind clumpiness (e.g., Hamann & Koesterke 1998; Woosley et al. 2002; Woosley & Heger 2007). Mass loss channels other than winds exist (e.g., LBV eruptions, binary interactions, etc.) and some authors (e.g., Dessart et al. 2013; Meynet et al. 2015) use η> 1 to explore the effects of increased total mass loss. However, an averaged steady wind approximation might not properly capture the readjustment of the stellar structure to non-wind mass loss events, which may be sensitive to mass loss timing, and/or the physical process triggering them, and may not be radiatively driven.
Most wind mass loss algorithms are tailored to a specific evolutionary stage. To carry out a simulation of the entire evolution of the star, several mass loss algorithms are commonly combined using computational definitions of the evolutionary phases. This may introduce somewhat arbitrary switching points in the evolution. Below, we list the physical basis and the abbreviations for the two hot phase, three cool phase, and two WR phase wind mass loss algorithms that we combine and compare here. We define each phase of the evolution in Sect. 2.2.
-
Vink et al. (2000; 2001; V): this windscheme is a theoretical algorithm obtained with numericalsimulation of the line-driven process. It explicitly includes themetallicity dependence and applies to OB stars during their hotevolutionary phase. It also includes a detailed treatment of theso-called “bistability jump”. This corresponds to anon-monotonic behavior of the mass loss rate Ṁ as a function of effective temperature Teff in certain temperature ranges (e.g.,
 ) because of the recombination of certain ions, which provides more lines in the spectral domain relevant to drive the wind, cf. Appendix A.1.
) because of the recombination of certain ions, which provides more lines in the spectral domain relevant to drive the wind, cf. Appendix A.1. -
Kudritzki et al. (1989; K): this analytical mass loss rate is obtained using the Castor et al. (1975) model for line-driven acceleration. It assumes that the wind is stationary, isothermal, spherically symmetric, and without viscosity and heat conduction. The analytical solution is obtained assuming a velocity structure v ≡ v(r) as a function of the radius of the wind, and solving self-consistently for density and radiative acceleration, cf. Appendix A.2.
-
de Jager et al. (1988; dJ): this empirical mass loss rate describes the “averaged statistical behavior” of stars (excluding WR and Be stars) in the HR diagram. It is commonly used for the cool (giant) phase of the evolution of massive stars, cf. also Appendix A.3.
Table 1Approximate scaling of the mass loss rate with luminosity and effective temperature, log 10(Ṁ) ∝ αlog 10(L) + βlog 10(Teff), predicted by the considered mass loss algorithms.
-
Nieuwenhuijzen & de Jager (1990; NJ): this algorithm is also an empirical mass loss rate drawn from the same sample of stars used by de Jager et al. (1988). The two algorithms differ in the physical quantities the mass loss rate is assumed to depend on: NJ used pre-computed stellar models to add a dependence on the total mass (Ṁ ≡ Ṁ(M)), which is not a directly observable quantity for single stars. It is also usually adopted for the cool phase of stellar evolution. See Appendix A.4 for more details.
-
van Loon et al. (2005; vL): this empirical mass loss rate is derived from a sample of oxygen rich asymptotic giant branch (AGB) and red supergiants (RSG) stars in the Large Magellanic Cloud. It assumes a dust-driven wind, that is mass loss is driven by photons impinging on dust grains instead of metallic ions. We note, however, that the presence of dust and its role as a wind driving agent in supergiant stars is still debated in the literature (van Loon et al. 2005; Ferrarotti & Gail 2006), cf. Appendix A.5.
-
Nugis & Lamers (2000; NL): this empirical mass loss rate is for WR stars. Fitting the data for two populations of WR stars (one of known distance and one for which they carry out a distance determination), they provide an algorithm, which depends strongly on the surface chemical composition of the star, cf. Appendix A.6.
-
Hamann et al. (1982; 1995; H): this is a theoretical mass loss rate for WR stars. It is derived assuming a spherically symmetric, homogeneous, and stationary wind. They avoid solving for the dynamics with a complicated radiative acceleration term by imposing a velocity structure v ≡ v(r). In this way, they are able to produce synthetic spectra, which they then fit to observed WR stars to infer Ṁ. Hamann & Koesterke (1998) suggest to reduce the mass loss rate by a factor between 2 and 3 to account for wind clumpiness, cf. Appendix A.7.
We report in Table 1 an approximate scaling of the mass loss rate with the luminosity (L), which quantifies the amount of photons available to drive the wind (neglecting the frequency dependence of the line transitions), and the effective temperature (Teff), which can be considered as a rough parametrization of the ionization state at the base of the wind and therefore the opacity. We strongly recommend to consult Table A.1 for the scaling of Ṁ with physical stellar quantities for each of these algorithms for anything beyond simple order of magnitude estimates.
Combinations of wind mass loss algorithms employed in this study.
2.2. Combination of mass loss algorithms
The wind mass loss of massive stars is usually divided into three separate phases, whose definition is somewhat arbitrary. When using the algorithm K for the hot phase, we adopt the following thresholds based on the effective temperature Teff and surface (i.e., outermost computational cell) hydrogen mass fraction Xs:
-
Hot phase: Teff ≥ 15 000 K;
-
Cool phase: Teff< 15 000 K;
-
WR phase: Xs< 0.4 regardless of Teff.
To follow the suggestions of Glebbeek et al. (2009), and to have a smoother transition between the hot and cool phase wind algorithm, we use a slightly different definition of the cool and hot evolutionary stages when using the V mass loss algorithm for the hot phase:
-
Hot phase: Teff ≥ 11 000 K;
-
Cool phase: Teff ≤ 10 000 K;
and we use a linear interpolation between the hot phase wind and cool phase wind in between. We choose this different threshold when using V to match how the cool and hot phases are defined for the “Dutch” wind scheme in the MESA code. We note that the interval from Teff ≃ 10 kK to ~ 15 kK is covered during a fraction of the Hertzsprung gap, in a very short time.
The threshold dividing the cool and hot phases is qualitatively justified as follows: the radiation pressure is determined by the product of opacity and flux, which peaks between 10 000–15 000 K because of iron recombination. Therefore, an effective temperature (i.e., in other words, a radius, for each given luminosity) in this range is a physically meaningful threshold to switch between wind mass loss algorithms.
The third phase is the WR phase and our criterion Xs< 0.4 just requires a hydrogen-poor stellar surface. This has very little in common with the observational definition of what a WR star is, which is based on spectral features that are not tracked by stellar evolution codes. Specifically, WR stars are identified by their surface hydrogen depletion (Schmutz & Drissen 1999) and the presence of broad emission lines (van der Hucht 2001; Marchenko et al. 2010), indicating the presence of a wind with a steep density and velocity gradient. Moreover, typical WR stars have high Teff, and our definition might, in principle, produce unrealistically cold (and red) WR stars. However, in absence of strong mixing processes (e.g., due to rotation), the required surface hydrogen depletion can only be reached by removing mass from the surface and revealing deep and hot stellar layers. We do not find in our calculations cool but hydrogen depleted models. WR stars are further subdivided into classes (WNH, WN, WC, WO, etc.) based on the relative flux of specific lines. Here, we do not attempt to distinguish between different WR sub-classes, because our simulations do not produce the stellar spectra that would be necessary to distinguish these sub-classes (see however Meynet & Maeder 2003; Groh et al. 2014, and references therein).
Our definitions of the evolutionary phases are commonly used in the literature (see, e.g., Limongi & Chieffi 2006; Eggenberger et al. 2007; Woosley & Heger 2007). We list in Table 2 the algorithm combinations explored here: each combination is labeled by combining the abbreviations for each wind algorithm introduced above.
 |
Fig. 1 Uncertainty in the mapping between MZAMS and the relative final mass M/MZAMS due to wind mass loss. Each colored bar corresponds to a specific wind algorithm combination defined in Table 2. The pluses, crosses, and circles correspond to η = 1.0, 0.33, 0.1, respectively. We employ the vertical bars to emphasize the spread. The uncertainty in wind mass loss limits the predictive power of stellar evolution studies for the final mass of stars of given initial mass. Only models with MZAMS = 35 M⊙ and wind efficiency η = 1 reach the WR stage (cf. Table 4 and Sect. 3.4). They are shown in the rightmost panel and we list the WR mass loss algorithm only for them. The maximum relative mass for the four algorithm combinations using the H WR mass loss algorithm in the rightmost panel are the results obtained using the corresponding hot and cool mass loss combination with η = 0.1 (not reaching the WR phase). |
To study the effects of the possible overestimate of the mass loss rate caused, for example, by wind inhomogeneities (i.e., “clumpiness”), we use three different values of the wind efficiency η = 1.0, 0.33, 0.1. These values span the range of observational estimates of the volume filling factor of clumps (see Smith 2014 for a review). For simplicity, we use the same η during the entire evolution of a given model.
2.3. The grid of stellar models
We employ release version 7624 of the open-source stellar evolution code MESA (Paxton et al. 2011, 2013, 2015) and compute a grid of nonrotating solar metallicity models. We choose Z⊙ = 0.019 to match precisely the value adopted in Vink et al. (2001). We consider initial masses of 15, 20, 25, 30, and 35 M⊙. Higher initial mass models are more strongly affected by numerical (and possibly physical) instabilities (see Appendix B and references therein), which makes them less reliable for our purpose. Appendix B describes the details of our MESA simulations that are not directly related to mass loss. Here, we only mention that we use a 45-isotope nuclear reaction network (mesa_45.net) until oxygen depletion, and a mixing length parameter αmlt = 2.0 with exponential overshooting.
We run our grid of models in three steps and at each checkpoint we make a selection of models to run to the next step2. This selection is necessary to reduce the total computational cost of our grid of models. In the first step, we evolve our models from the zero age main sequence (ZAMS) to when the temperature in the central computational cell rises above Tc ≥ 109 K (“end of the mass loss phase”). At this point, the star has only a few years to live and lose mass through winds (for a typical mass loss rate the star loses less than 10-4M⊙). Also, when Tc ≥ 109 K is reached, MESA starts to artificially damp the mass loss rate for stability reasons. Mass loss is completely shut off when Tc ≥ 2 × 109 K.
We note, however, that the observation of SN impostors, type IIn SNe, and intra-night flash spectroscopy of normal type II SNe suggests that non-wind mass loss phenomena (neglected here) may occur in the very late phase of the stellar life (see, e.g., Quataert & Shiode 2012; Smith & Arnett 2014; Quataert et al. 2016; Khazov et al. 2016).
In the second step, we restart a subset of MESA models and run to oxygen depletion (see Sect. 3.5). This is defined as the first time when the mass fraction of 16O in the central cell drops below 0.04 and the mass fraction of 28Si is higher than 0.01 (indicating that some oxygen burning has already occurred, following Sukhbold & Woosley 2014). We note that these thresholds are an artificial choice, since the evolution of the star is continuous throughout its lifetime.
Finally, we restart a select subset of stars at oxygen depletion and run to the onset of core collapse, defined by  (2)where v is the radial infall velocity (see, e.g., Heger et al. 2005; Sukhbold & Woosley 2014). For this last phase of the evolution, we switch from the 45-isotopes nuclear reaction network to a customized 203-isotopes nuclear reaction network (see also Appendix B), to capture the details of the weak interaction physics (electron captures and β-decays) occurring during silicon burning and before collapse. This physics determines the final number of electrons per nucleon Ye, thus the effective Chandrasekhar mass of the stellar core, and ultimately the core structure at the onset of core collapse. Experiments with a single-zone model for silicon burning show that at least ~ 200 isotopes are required to obtain a converged final value of Ye in the core (i.e., one that is independent of the size of the nuclear reaction network; see also Farmer et al. 2016). Since MESA solves the fully coupled set of equations for the chemical composition and structure of the star, the increase in the number of isotopes forces us to reduce the number of spatial mesh points in each model because of memory limitations (see Appendix B.1.3).
(2)where v is the radial infall velocity (see, e.g., Heger et al. 2005; Sukhbold & Woosley 2014). For this last phase of the evolution, we switch from the 45-isotopes nuclear reaction network to a customized 203-isotopes nuclear reaction network (see also Appendix B), to capture the details of the weak interaction physics (electron captures and β-decays) occurring during silicon burning and before collapse. This physics determines the final number of electrons per nucleon Ye, thus the effective Chandrasekhar mass of the stellar core, and ultimately the core structure at the onset of core collapse. Experiments with a single-zone model for silicon burning show that at least ~ 200 isotopes are required to obtain a converged final value of Ye in the core (i.e., one that is independent of the size of the nuclear reaction network; see also Farmer et al. 2016). Since MESA solves the fully coupled set of equations for the chemical composition and structure of the star, the increase in the number of isotopes forces us to reduce the number of spatial mesh points in each model because of memory limitations (see Appendix B.1.3).
3. Results
3.1. Overview at the end of the mass loss phase, Tc ≥ 109 K
The lifetime remaining for the star after Tc ≥ 109 K is short (~ 15 yr for 15 M⊙, ~ 4 yr for 30 M⊙), and the photosphere of the star remains frozen at the same effective temperature Teff and luminosity L as long as no impulsive mass loss events or other instabilities take place. The subsequent evolution will lead to changes of the internal structure only. Therefore, we discuss the final mass and pre-SN appearance of our models already at this stage.
Figure 1 shows the overall impact of the uncertainty in stellar wind mass loss rates on the final mass. We plot the final mass relative to the initial mass for each considered MZAMS and the large vertical spread illustrates the uncertainty. As an example, we can consider a star of MZAMS = 20 M⊙. It can, in principle, reach the onset of collapse with M = 19.38 M⊙ if evolved with the V-NJ mass loss combination with reduced efficiency η = 0.1. But it might also evolve to M = 8.81 M⊙ with the K-vL combination and efficiency η = 1.0. If these are truly limiting cases and anything in between is unconstrained, then the uncertainty in the final mass is greater than 50%. For more quantitative results, see Table 5 where we report the maximum spreads of the ZAMS to pre-SN mass mapping for our entire grid of models. Tables 3 and 4 list the main physical quantities for all the stars in our grid at the end of the mass loss phase.
Model summary at the end of the mass loss phase (when Tc ≥ 109 K, roughly corresponding to neon core ignition).
Final color and surface properties of the computed models.
Maximum spread in total mass, core masses, and radius at the end of the mass loss phase, for models differing in mass loss algorithm combination and efficiency η.
It is important to note that the vertical spread in the ZAMS to pre-SN mass mapping shown in Fig. 1 is dominated by the highly uncertain wind efficiency η. At fixed η, variations due to different wind algorithm combinations are minor. This makes η the most important free parameter for wind mass loss in stellar evolution calculations.
In Fig. 1, the spread in MZAMS to pre-SN mass decreases for higher MZAMS. This is, however, only because we show the relative final mass, that is at higher MZAMS we divide the final mass by a larger number. In absolute numbers, the uncertainty in the final to initial mass relation increases for more massive stars. We summarize this in Table 3. As an example, the maximum spread between the final masses of 35 M⊙ models is maxΔM ≡ 33.99 M⊙ − 19.48 M⊙ = 14.51 M⊙. In the 15 M⊙ case, it is maxΔM ≡ 14.66 M⊙ − 5.25 M⊙ = 9.42 M⊙. As expected, all wind mass loss algorithm combinations yield a higher mass loss rate for more massive (and thus more luminous) stars. For stars with MZAMS ≲ 20 M⊙, the models using the vL algorithm (dust driven mass loss in the cool evolutionary phase) produce much higher mass loss than all other algorithms (see also Sect. 3.3): for example, the 15 M⊙ model using the V-vL combination with full efficiency η = 1.0 results in a pre-SN mass of only 5.25 M⊙, while using the combination V-dJ or V-NJ, we obtain a final mass of ~ 12.7 M⊙. We discuss this effect in more detail in Sect. 3.3.
From Fig. 1, we also note that for MZAMS ≳ 20 M⊙ we obtain a range 1.0 ≲ M/MZAMS ≲ 0.5. For any given η, the range is smaller. In any case, the size of this interval does not decrease going to higher masses, indicating that the different mass loss prescriptions and efficiencies do not appear to be converging with MZAMS in the mass range we consider here.
 |
Fig. 2 Total stellar mass as a function of time for the 15 M⊙ models. Each color corresponds to a given combination of wind algorithms (see Table 2). None of these 15 M⊙ models reach the WR phase. The solid, dashed, and dot-dashed curves correspond to efficiency η = 0.1, 0.33, 1.0, respectively, regardless of color. The red vertical line indicates roughly the terminal age main sequence (TAMS, i.e., Xc< 0.01). The enhanced mass loss of models using the Vink et al. (2000; 2001; V) algorithm close to TAMS in the left panel is due to the bistability jump, see Sect. 3.2. The left panel has a different vertical scale to magnify the differences in the tracks during the main sequence evolution. |
In Fig. 2, we show, as a representative example, the time evolution of the total mass for our 15 M⊙ models. The overall qualitative behavior is the same for all the other considered MZAMS. Figure 2 shows that the amount of mass lost during the main sequence (i.e., prior to the vertical dot-dashed line) is relatively small, only a few percent of the total mass for MZAMS = 15 M⊙, even when using η = 1.0. Most of the mass is lost after hydrogen core burning. Both the mass loss rate and the spread between the predictions of different algorithms increases dramatically after the end of the main sequence. Hence, uncertainties in the post-main-sequence cool phase mass loss rates have by far the greatest effect on the final mass of the star.
Using our nonrotating single-star models at the end of the mass loss phase and ignoring any potential subsequent non-wind mass loss events, we can attempt to classify their pre-SN color. We follow Georgy (2012) by assuming log 10(Teff/ [ K ] ) ≲ 3.6 for RSG, 3.6 ≲ log 10(Teff/ [ K ] ) ≲ 3.8 for YSG, log 10(Teff/ [ K ] ) ≳ 3.8 for BSG, and we only require the surface abundance of hydrogen to be Xs< 0.4 without temperature thresholds for WR stars. We list the outcome of this classification in Table 4. Almost all of our 15 M⊙ and 20 M⊙ models end their evolution as RSGs. The exceptions are those using the vL cool mass loss algorithm and η = 1.0, which end their lives as YSGs. All of our 25 M⊙ and 30 M⊙ models end as YSGs. The 35 M⊙ models computed with η = 0.1 also end as YSGs. With η = 0.33 they instead become BSGs, because of the higher mass loss rate, except when using the vL cool mass loss rate (cf. Sect. 3.3), which produces YSGs. With η = 1.0 we find WR pre-SN models, unless vL is used during the cool phase, in which case our 35 M⊙ models would explode as BSGs. However, these results are highly dependent on the somewhat arbitrary temperature thresholds assumed to divide the categories. For example, assuming log 10(Teff/ [ K ] ) ≤ 3.68 as the threshold dividing RSG and YSG, all models with MZAMS ≤ 25 M⊙ would be RSGs.
 |
Fig. 3 Mass loss rate during the hot evolutionary phase (including the main sequence, see Sect. 2.2) as a function of time for all computed MZAMS and wind efficiency η = 1. The solid and dashed curves are computed using the V (Vink et al. 2000, 2001) and K (Kudritzki et al. 1989) mass loss algorithm, respectively. The rapid rise of the solid curves is due to the inclusion of the bistability jump (see Sect. 3.2). The qualitative behavior of the curves shown does not change substantially when varying η. The curves end when Teff = 15 000 K. |
3.2. The “hot phase” mass loss
“Hot phase” evolution, i.e., Teff ≳ 15 000 K if using the Kudritzki et al. (1989; K) mass loss algorithm, or Teff ≳ 11 000 K if using Vink et al. (2000; 2001; V), roughly covers the main sequence evolution, the subsequent overall contraction caused by hydrogen depletion (known as the main sequence “hook”), and the initial part of the Hertzsprung gap.
Stellar properties at the end of hot phase, when Teff decreases below 15 000 K for the first time.
In Table 6, we summarize key quantitative results for our models at the end of the hot phase. While this is the longest phase of the evolution, covering ≳90% of the stellar lifetime, the amount of mass lost during this phase is relatively small regardless of the algorithm used. For example, initially 35 M⊙ stars computed with η = 1.0 lose ~ 15% of their mass, while initially 15 M⊙ stars only lose a few percent
We can also infer from Table 6 that the amount of mass lost during the hot phase is always higher with V than with K, and the difference increases with increasing η and MZAMS: it is only ~ 0.02 M⊙ for η = 0.1 and MZAMS = 15 M⊙, and grows to ~ 0.2 M⊙ for η = 1.0 and the same initial mass. For the 35 M⊙ models and η = 1.0, the difference between the total mass shed using V or K reaches ~ 0.5 M⊙ with η = 1.0.
In Fig. 3, we plot the mass loss rates Ṁ given by V and K as a function of time in the hot phase for models with η = 1. The reason for the higher total mass lost with V is that this algorithm includes a detailed treatment of the bistability jump, which is an increase in the cross section for photon interactions caused by the recombination of ions driving the mass loss. This enhancement of the cross section happens when the effective temperature drops below , Vink et al. (2000). This is what causes the sudden tremendous increase in the mass loss rate in V models seen in Fig. 3. The subsequent drop in models with masses higher than 20 M⊙ happens because these cross the bistability jump region twice during the contraction following core hydrogen depletion. Overall, the average mass loss rate ⟨ | Ṁhot | ⟩ of V models is driven up and surpasses that of K models on the main sequence, resulting in higher mass loss in V models. We note that the use of two different thresholds to separate the hot and cool phase of evolution for V and K does not significantly influence the duration of the hot phase: the gap between the two thresholds is covered in a fraction of the Herzsprung gap duration.
Different values of η produce small (≲ 2%) age differences: models remaining more massive (i.e., computed with lower η) evolve slightly faster. However, these differences are too small to potentially be used as observational tests for the wind efficiency.
Figure 3 also shows that at any point in time, the mass loss rate of more massive stars is higher, because they produce a higher photon flux to drive the wind. A factor of ~ 2.3( ≃ 35 / 15) in initial mass translates to a difference of almost two orders of magnitude in the mass loss rate. The difference between the V and K rates is a non-monotonic function of the mass, because of the different functional dependencies of the two algorithms: for 20 M⊙ models they are roughly equal before the surface cools enough for the bistability jump to occur; for 15 M⊙ models, the K algorithm gives an initially higher mass loss rate, and, for 30 M⊙ models, K mass loss is instead lower.
Although only a small amount of mass is lost, the hot phase mass loss can significantly influence the core evolution. This is because no shell sources decouple the surface from the convective core during most of this phase. The use of different algorithms during the hot phase can thus create small (seed) differences in the core structure, which may then be amplified by the subsequent evolution of the star and contraction of the core. These differences are small at the end of the hot phase, and we will discuss them at later stages in the evolution in Sect. 3.6 and 3.7.
In Table 6, we also list the helium core masses MHe of our models at the end of the hot phase. The effects of hot phase wind mass loss on MHe are less straightforward to interpret than its influence on the total mass. First, the value of MHe depends on the definition of the helium core. We define the outer edge of the helium core as the first location going inward where X(1H) < 0.01. Second, where this interface is at the end of the hot phase is very sensitive to mixing: depending on the mass and metallicity of the star (and the convective stability criterion adopted), deep convective shells can develop at the beginning of the Hertzsprung gap, and they shape the chemical composition profile and determine MHe. Table 6 shows that the maximum spread in MHe increases with MZAMS, starting from max(ΔMHe) ≃ 0.1 M⊙ for 15 M⊙ models, up to max(ΔMHe) ≃ 0.9 M⊙ for 35 M⊙ models. The spread in these values is almost entirely due to variations in η. The difference in MHe between models of same mass and η (thus differing only in the use of V or K) is also increasing with increasing MZAMS but remains below ~ 0.2 M⊙. This trend directly reflects the larger uncertainties in the modeling of winds from more massive stars.
3.3. The “cool phase” mass loss
Regardless of efficiency η and mass loss algorithm, most of the mass loss through stellar winds happens during the cool phase of the evolution. Figure 2 demonstrates this clearly for the 15 M⊙ models, which lose 2%–60% of their total initial mass during this phase, depending on the algorithm combination and wind efficiency. The increase in the mass loss rate from the hot phase can be understood in terms of the effective gravity of the star (although we stress that the algorithms compared here do not depend explicitly on it): for any given luminosity of a massive star, if the stellar surface is cool, necessarily its radius must be large, and thus it will be easier for matter to leave the gravitational potential well of the star. Moreover, at lower temperature the opacity tends to be higher because of recombination of ions and possibly dust formation, thus enhancing the wind driving.
Table 3 summarizes key quantitative results of our models at the end of the mass loss phase, including the total mass and the core masses. One striking result is that the dust-driven van Loon et al. (2005; vL) mass loss algorithm results in significantly different total masses and core masses than the de Jager et al. (1988; dJ) and the Nieuwenhuijzen & de Jager (1990; NJ) algorithms. This can also be seen in Fig. 1, where wind combinations using vL for the cool phase produce different vertical spreads. These differences are strongest for η = 1.0. The most extreme example are 15 M⊙ models computed with η = 1.0: regardless of the hot phase mass loss algorithm, they end their evolution with masses of ~ 5 − 6 M⊙ with vL in the cool phase, while they remain as massive as ~ 11 − 12 M⊙ with dJ or NJ. We find the opposite trend at the upper end of our mass range: a 30 M⊙ star computed with η = 1.0 and V during the hot phase reaches the end of the mass loss phase with a total mass of ~ 15 M⊙ if using either dJ or NJ in the cool phase, while it ends its life with ~ 18 M⊙ with vL.
On the one hand, the similarities between the dJ and the NJ rates are expected (see also Mauron & Josselin 2011; Eldridge & Tout 2004): both are semi-empirical rates derived from the same sample of observed stars. They differ only in the choice of the stellar variables used to parametrize Ṁ. On the other hand, the vL algorithm is also semi-empirical, but based on the analysis of a different sample of stars assuming a dust-driven model of the wind, that is wind mass loss is not driven by photons impinging on metallic ions, but rather on dust particles. If a dust-driven (instead of line-driven) model of the wind is assumed, the resulting mass loss rate is generally higher, and much more Teff-dependent (see Tables 1 and A.1).
The very steep dependence of the vL rate on Teff causes the different evolution of models above and below ~ 25 M⊙. During the early stage of the cool phase, the vL rate is always much higher than the others, and the stellar wind described by this algorithm reveals the deeper and hotter layers of the star (see also Table 4). As Teff increases, the vL mass loss rate decreases rapidly (∝ T-6.3, see Tables 1 and A.1), which is attributed to the temperature sensitivity of the microscopic dust formation processes (Wachter et al. 2002) that we of course do not track explicitly in our calculations. Also, for any mass loss process at a given luminosity, higher Teff correspond to smaller radii, and thus higher effective gravity at the stellar surface. For MZAMS ≳ 25 M⊙, the steep Teff-dependence leads to a self regulation of the vL rate. For lower initial masses, the vL rate is also initially higher than the dJ or NJ rate, but not high enough to reach the self-regulating regime: the vL rate remains higher than the dJ and NJ rates for the whole evolution and produces pre-SN structures of a much lower final mass than when dJ or NJ are used. This is summarized in Table 3.
The comparison of MHe listed in Table 3 for models with the same η and hot phase mass loss (either V or K) reveals that the effect of the cool phase mass loss on the helium core mass is very small and almost negligible. We find the only appreciable differences when using η = 1.0 and the vL cool mass loss rate, and they are only of order ~ 0.01 M⊙.
3.4. Models reaching the WR stage
Out of the 94 models computed to Tc ≥ 109 K, only 8 reach the conditions to switch to the WR wind scheme. These are all 35 M⊙ models computed with η = 1.0, and none use the vL algorithm in the cool phase that precedes the WR phase (cf. Table 4). The lack of WR models using vL is explained by the self-damping of this mass loss scheme for more massive and thus more luminous stars (see Sect. 3.3).
The typical duration of the WR phase is ~ 0.02 − 0.05 Myr. The differences in duration of the WR phase with the Nugis & Lamers (2000; NL) and Hamann et al. (1982, 1995), Hamann & Koesterke (1998; H) algorithms are negligible. However, models computed with the dJ algorithm in the cool phase have WR phases that are systematically longer by a few ten thousand years than the corresponding models computed with the NJ algorithm. Moreover, the duration of the WR phase of models computed with the K algorithm in the hot phase is about a factor of ~ 2.3 longer than in models using the V algorithm. This is because MZAMS = 35 M⊙ models computed with η = 1.0 and the V algorithm reach the end of the hot phase with a helium core that is 0.22 M⊙ less massive than models computed with the K algorithm (cf. Table 6). Therefore, the subsequent evolution is slowed down, and the WR phase is reached slightly later.
The NL WR phase algorithm produces higher final masses than the H algorithm: the difference is ~ 0.3(~ 0.8) M⊙ for models using the V (K) hot phase algorithm and does not depend strongly on cool phase mass loss (cf. Table 3). These differences are very small fractions of the initial mass MZAMS = 35 M⊙ of these models (cf. Fig. 1).
The WR wind does not have a strong influence on MHe at the end of the mass loss phase. For stars with MZAMS ≲ 40 M⊙, the He core mass is determined well before the beginning of the WR phase, and the wind mass loss is not strong enough to dig into the He core directly. More massive stars with stronger winds, may become hydrogen depleted already during the core hydrogen burning phase. In that case, the WR mass loss rate might have an impact on MHe through the quasi-static response of the convective core to mass loss (Meynet et al. 1994; de Koter et al. 1997; Crowther et al. 2010; Bestenlehner et al. 2011). Also, in even more massive stars, the entire hydrogen-rich envelope can be lost to winds, making MHe the total mass of the star, and winds can then further reduce it (e.g., Woosley 2017).
While we find no systematic effect of WR mass loss on MHe, the situation is different for MCO (cf. Table 3). NL models yield MCO that are systematically lower by ~ 0.05 − 0.1 M⊙ than H models and the largest differences are between models that also use different hot phase mass loss algorithms. We find that models differing only in the WR algorithm have lower MCO for higher final masses. For example, the V-dJ-NL model has MCO = 9.81 M⊙ and final mass M = 20.03 M⊙. In contrast, the V-dJ-H model has a higher MCO = 9.93 M⊙, but a lower final mass of M = 19.73 M⊙. However, we note that the trend that lower final masses correspond to higher MCO holds for most of our 35 M⊙ models, independent of if they become WR stars or not.
The differences in both total mass and MCO found varying the WR mass loss algorithm are more sensitive to the previously employed hot phase mass loss algorithm than to the cool phase algorithm. Moreover, MHe is also almost insensitive to the cool phase (cf. Sect. 3.3) and WR phase mass loss. Therefore, the differences found here are most likely related to the differences in MHe at the end of the hot phase (and in the total mass for a given MHe), and consequently the position of the hydrogen burning shell, which indirectly influences the helium burning, the mixing processes shaping the composition profile, and ultimately the resulting MCO and the amount of mass lost during the WR phase.
3.5. Models at oxygen depletion
To reduce the computational cost of our model grid, we select a subset of 44 stars to continue until oxygen depletion, which we define as the time when Xc(16O) ≤ 0.04 and Xc(28Si) ≥ 0.01. These models span the range of properties found at the end of the mass loss phase, and are listed in Table 7 together with their properties at oxygen depletion. This selection allows us to avoid running multiple models that have very similar evolutionary paths from the end of the mass loss phase onward. The duration of the evolution between the end of the mass loss phase (Tc ≥ 109 K) and oxygen depletion is of order years to decades, depending on the total mass and core masses at the end of the mass loss phase.
Stellar properties at core oxygen depletion, i.e. Xc(16O) < 0.04 and Xc(28Si) > 0.01.
In the very short time to oxygen depletion, neither total mass nor helium core mass change appreciably. This can be inferred by comparing the entries of Tables 3 and 7, which also reveals that the stellar radii vary only within ± 3 R⊙ in most models.
The CO core masses at oxygen depletion summarized in Table 7 are systematically a few percent lower than those listed in Table 3 at the end of the mass loss phase. This seems counter-intuitive, since one would expect the CO core to grow in mass because of the ashes of helium shell burning. However, the boundary location for the CO core is determined by convective mixing within and above the He burning shell, which brings helium-rich material inward and moves the CO core boundary to a smaller mass coordinate. This implies that the core mass is very sensitive to the mixing parameters. The maximum spread in MCO obtained varying the wind algorithm is of order ~ 0.1 M⊙ and it increases with MZAMS up to about max(ΔMCO) ≃ 0.5 M⊙ for 30 M⊙ models (see also Table 5). We note that the 15 M⊙ models are outliers in that they show a larger spread of CO core masses of up to 0.28 M⊙ between models using the V and K hot mass loss algorithm. This is a consequence of a combination of (i) the V algorithm leading to a lower total mass and a lower He core mass at the end of the hot phase and (ii) the relatively low mass loss during the cool phase (compared to more massive stars), which results in deeper convective episodes. Together, these lead to small CO cores: the two 15 M⊙ models using the V algorithm with η = 1.0 have MCO ≃ 2.95 M⊙ at the end of the mass loss phase, which is about 0.2 M⊙ smaller than the average for 15 M⊙ models.
3.6. The compactness parameter ξℳ
Although the internal structure of our models is not yet final at oxygen depletion, some quantities (e.g., core masses) are already close to their final values, and it becomes possible to draw first connections between internal structure and the potential final outcome of core collapse (Sukhbold & Woosley 2014). For this, we include the compactness parameter  in Table 7. O’Connor & Ott (2011) define the compactness parameter as
in Table 7. O’Connor & Ott (2011) define the compactness parameter as  (3)This parameter provides a single measure for the complex inner core structure (mass coordinate smaller than ℳ) of a star, allowing for a simplified discussion of the differences in the internal structure produced by the various mass loss algorithms we compare.
(3)This parameter provides a single measure for the complex inner core structure (mass coordinate smaller than ℳ) of a star, allowing for a simplified discussion of the differences in the internal structure produced by the various mass loss algorithms we compare.
We set ℳ = 2.5 M⊙ because this is the typical mass above which the proto-NS that will form during core collapse will become a BH (O’Connor & Ott 2011). This mass cut remains well outside of the typical iron core mass and includes the layers of the star that the shock will encounter after core bounce. These layers determine the accretion ram pressure that the shock has to overcome for a successful explosion. The qualitative behavior of the supernova dynamics and outcome with ξℳ is known to be robust against different choices of ℳ (O’Connor & Ott 2011, 2013; Ugliano et al. 2012; Sukhbold & Woosley 2014).
One-dimensional parametric core-collapse SN explosion simulations (O’Connor & Ott 2011, 2013; Ugliano et al. 2012; Ertl et al. 2016; Sukhbold et al. 2016) show that the value of ξ2.5 at the onset of core collapse indicates the most probable remnant. High values of ξ2.5 indicate a more compact pre-SN structure that is harder to explode and that will more likely result in a BH remnant. Conversely, low values of ξ2.5 indicate a steeper density gradient and an easier to explode structure, suggesting that the remnant will more likely be a NS (O’Connor & Ott 2011; Ugliano et al. 2012; Clausen et al. 2015). Sukhbold & Woosley (2014) suggest that the value of the compactness parameter evaluated at oxygen depletion,  , can already be used to infer the most likely outcome of the core collapse event. The evolution from oxygen depletion to core collapse tends to increase the compactness and amplify the differences between different stellar models, but the key features that determine the interpretation of ξ2.5 appear to be set already at oxygen depletion. Other parameters to relate the pre-SN structure to the most-likely remnant can be defined in the context of neutrino-driven explosions (see Ertl et al. 2016), but they rely on physical quantities that are not at all set at earlier stages of the evolution (e.g., the entropy profile throughout the silicon layer and iron core), and therefore they are not useful diagnostics before the onset of core collapse.
, can already be used to infer the most likely outcome of the core collapse event. The evolution from oxygen depletion to core collapse tends to increase the compactness and amplify the differences between different stellar models, but the key features that determine the interpretation of ξ2.5 appear to be set already at oxygen depletion. Other parameters to relate the pre-SN structure to the most-likely remnant can be defined in the context of neutrino-driven explosions (see Ertl et al. 2016), but they rely on physical quantities that are not at all set at earlier stages of the evolution (e.g., the entropy profile throughout the silicon layer and iron core), and therefore they are not useful diagnostics before the onset of core collapse.
3.6.1. Evolution of ξ2.5 until oxygen depletion
 |
Fig. 4 Top panel: time evolution of the compactness parameter ξ2.5 for all MZAMS = 25 M⊙ models computed until oxygen depletion. Bottom panel: central temperature and density for the same models from when the central density increases above 106 g cm-3. All curves end at oxygen depletion (Xc(16O) ≤ 0.04 and Xc(28Si) ≥ 0.01). The color indicates the wind algorithm combination, labeled according to Table 2. Dot-dashed, dashed, and solid curves are calculated using η = 0.1, 0.33, 1.0, respectively. We only show models listed in Table 7. The vertical dot-dashed lines in the top panel approximately indicate core hydrogen exhaustion (TAMS), core helium exhaustion (Yc ≃ 0), and end of the mass loss phase (Tc ≥ 109 K). |
The compactness parameter is a function of time, ξℳ ≡ ξℳ(t), because of the changes in the radius of a given mass coordinate ℳ. These can be caused by contraction of the core, onset of partial electron degeneracy within the mass coordinate ℳ, and by episodes of convective mixing and shell burning (Sukhbold & Woosley 2014). The top panel of Fig. 4 shows examples of the evolution of ξ2.5 until oxygen depletion in our 25 M⊙ models. We use a reversed logarithmic scale on the x axis to emphasize the late evolutionary stages.
Figure 4 shows that the compactness parameter is constant during the main sequence evolution. During this phase, it is also almost independent of MZAMS and mass loss algorithm because all stars considered here have convective main-sequence cores that are always much larger than the mass coordinate at which we evaluate the compactness. After core hydrogen exhaustion, ξ2.5 increases because of the overall contraction, reaching ξ2.5 ≃ 0.02 in our 25 M⊙ models. Then it slowly continues to increase during the hydrogen-shell burning and helium core burning phases. The increase speeds up significantly during core carbon burning, reaching values of ξ2.5 ≃ 0.1 in our 25 M⊙ models. Neon core burning ignition and the onset of carbon shell burning mark a critical point in the evolution of ξ2.5 at which the various curves in Fig. 4 begin to diverge. Sukhbold & Woosley (2014) find the same and point out that the subsequent evolution of ξ2.5 is highly sensitive to the details of carbon shell burning (i.e., the number, locations, and durations of shell burning episodes). It is important to note from Fig. 4 that the effects of mass loss on core structure (represented by ξ2.5) are delayed: At the time mass loss ends in our models (at Tc> 109 K), differences in ξ2.5 are minute. These seed differences grow and become substantial only in the last decade before core collapse.
The bottom panel of Fig. 4 depicts central density–temperature tracks for our 25 M⊙ models that are evolved to oxygen depletion. The tracks start roughly at neon core ignition and show that the mass-loss history (i.e., the choice of wind mass loss algorithm combination) also influences the innermost core thermodynamics and structure. This is because the nuclear burning processes in the core are regulated by the amount of mass that needs to be sustained by the core itself, that is the mass below the innermost burning shell above the core. This in turn depends on the location and luminosity of the shell burning regions and therefore on the total mass of the star.
In Fig. 5, we show the values of for all models that we run to oxygen depletion. The spread in each panel is due to the different algorithmic treatments of wind mass loss: for example, 25 M⊙ models show values ranging between 0.210 and 0.157. Generally speaking, the spread in increases with increasing η and MZAMS, that is the stronger the stellar wind, the more it influences the core structure. We emphasize that a few percent variation of can result in important differences in the core structure at the onset of core collapse: the subsequent contraction of the core and the details of carbon, oxygen, and silicon shell burning, amplify the differences between models that are still relatively similar at oxygen depletion (see Sect. 3.7 and Sukhbold & Woosley 2014).
 |
Fig. 5 Compactness parameter at oxygen depletion Xc(16O) ≤ 0.04 and Xc(28Si) ≤ 0.01. Each color corresponds to a wind algorithm combination (top axis), and each panel shows a different initial mass, indicated on the bottom. Crosses, pluses, and circles correspond to η = 0.1, 0.33, 1.0, respectively. We show only the models listed in Table 7. The vertical spread indicates different core structures, which will evolve differently to the onset of core collapse, and possibly result in different SN outcomes. |
3.6.2. Effects of the wind efficiency on 
The effects of varying η on  can be inferred from the comparison of models in Table 7 of the same MZAMS using the same wind algorithm combinations but different efficiencies. The variations of with η are typically non-monotonic: for example, the 25 M⊙ model computed using the V-vL combination reaches oxygen depletion with
can be inferred from the comparison of models in Table 7 of the same MZAMS using the same wind algorithm combinations but different efficiencies. The variations of with η are typically non-monotonic: for example, the 25 M⊙ model computed using the V-vL combination reaches oxygen depletion with  , 0.164, and 0.211 for η = 0.1, 0.33, and 1.0, respectively. Within the framework of each wind algorithm, higher values of η correspond to higher mass loss rates and thus to a progressive shift of the evolution toward that of lower initial mass. However, the compactness parameter is known to be a highly non-monotonic function of MZAMS (Sukhbold & Woosley 2014). Therefore, a higher mass loss rate can sometimes result in a decrease, an increase, or even almost no variation of . For example, in 15 M⊙ models computed with V-vL, decreases when going from η = 0.1 to η = 1.0. In 25 M⊙ models computed with V-vL, we instead find that increases with the same change in η. And in the case of 20 M⊙ models computed with V-dJ, we find only tiny variations of when η is varied from 0.1 to 1.0. See Table 7 for more examples and details.
, 0.164, and 0.211 for η = 0.1, 0.33, and 1.0, respectively. Within the framework of each wind algorithm, higher values of η correspond to higher mass loss rates and thus to a progressive shift of the evolution toward that of lower initial mass. However, the compactness parameter is known to be a highly non-monotonic function of MZAMS (Sukhbold & Woosley 2014). Therefore, a higher mass loss rate can sometimes result in a decrease, an increase, or even almost no variation of . For example, in 15 M⊙ models computed with V-vL, decreases when going from η = 0.1 to η = 1.0. In 25 M⊙ models computed with V-vL, we instead find that increases with the same change in η. And in the case of 20 M⊙ models computed with V-dJ, we find only tiny variations of when η is varied from 0.1 to 1.0. See Table 7 for more examples and details.
3.6.3. Effects of varying the mass loss algorithm on
The last column of Table 7 shows that the effects of different wind mass loss algorithms on ξ2.5 are in most cases small until oxygen depletion for η = 0.1 and η = 0.33. For η = 0.1, the V algorithm generally results in higher values of than the K algorithm. This holds for all studied ZAMS masses with the exception of the 30 M⊙ models. These do not exhibit this trend because all their burning shells are outside the mass coordinate ℳ = 2.5 M⊙, as can be seen from the values of MCO listed in Table 7.
The spread in between different mass loss algorithms increases for models with η = 0.33. For example, Fig. 5 shows that the 25 M⊙ model with the K-dJ combination reaches  (similar to its 20 M⊙ counterpart, cf. Table 7), which is ~ 30% higher than with other algorithm combinations.
(similar to its 20 M⊙ counterpart, cf. Table 7), which is ~ 30% higher than with other algorithm combinations.
Models computed with η = 1.0 are most suitable to discuss the effect of different wind mass loss algorithm combinations. Both the hot phase and the cool phase mass loss algorithms influence , but their detailed effect varies with MZAMS and is strongest in the 25 M⊙ and 30 M⊙ models. For example, from Table 7, we find 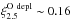 , for the η = 1.0, 25 M⊙ models with the V-NJ and K-dJ combinations, while models with V-vL and K-vL result in
, for the η = 1.0, 25 M⊙ models with the V-NJ and K-dJ combinations, while models with V-vL and K-vL result in  . At lower MZAMS, even for η = 1.0, differences in due to the choice of mass loss algorithm combination are overall (with few exceptions) rather small and typically at the few percent level. While these differences will be amplified by the subsequent evolution toward core collapse, they are small compared to the tremendous differences in total mass resulting from the different algorithm combinations (cf. Table 7).
. At lower MZAMS, even for η = 1.0, differences in due to the choice of mass loss algorithm combination are overall (with few exceptions) rather small and typically at the few percent level. While these differences will be amplified by the subsequent evolution toward core collapse, they are small compared to the tremendous differences in total mass resulting from the different algorithm combinations (cf. Table 7).
An interesting question to address is the relative importance of hot phase (i.e., main sequence) and cool phase (i.e., post main sequence) mass loss for . Naively, one would think that by the time the core and envelope are essentially decoupled, loss of envelope mass should have limited impact on the subsequent evolution of the core. Our results suggest that this is not generally the case.
The limited set of models run to oxygen depletion and listed in Table 7 give a complex, but necessarily incomplete picture of the relative importance of each mass loss phase for the core structure. Which phase is most relevant depends on MZAMS and η. For brevity, we focus here on the η = 1 case and compare models evolved with the same hot phase mass loss algorithm (V or K) and different cool phase algorithms.
For 15 M⊙ models with η = 1, the tremendous mass loss with the vL algorithm in the cool phase has little effect on He and CO core masses and on . For example, the final masses of K-vL and K-NJ are 5.70 M⊙ and 11.87 M⊙, respectively. Yet their are very close to each other, 0.152 and 0.153, respectively. Qualitatively, the same is true for the V-NJ and V-vL combinations. On the other hand there is a larger spread between combinations using V and K, suggesting that the small differences seeded by hot phase mass loss dominate in the 15 M⊙η = 1 case. Similarly, we find for 30 M⊙ models with η = 1 that K-dJ and K-vL lead to final masses of 18.51 M⊙ and 22.53 M⊙, respectively, but their are 0.244 and 0.243. The situation is more complicated for 25 M⊙ and 20 M⊙ models that straddle the MZAMS range where ξ2.5 varies chaotically (Sukhbold & Woosley 2014). From Table 7 we see that for the 20 M⊙, η = 1 models all considered K- and V-combinations yield roughly the same . In 25 M⊙, η = 1 models, on the other hand, cool phase mass loss has the dominant impact on . For example, K-dJ and K-vL have compactness of 0.161 and 0.200, respectively, although their final masses differ by only ~ 1 M⊙ due to the self-regulation of the vL algorithm in this mass range.
3.6.4. Comparison with Sukhbold & Woosley (2014)
Sukhbold & Woosley (2014) employed the NJ mass loss algorithm without any efficiency scaling factor (i.e., at efficiency η = 1.0) throughout the entire evolution of their models. Comparing our Table 7 with their Fig. 23, we find that the compactness parameter values at oxygen depletion of our models lie in the same range as theirs, with a tendency toward slightly higher values.
Our 15 M⊙ models produce values of  , which is slightly higher than their value of ~ 0.11–0.13, especially for reduced wind mass loss rates (i.e., η< 1.0). For this initial mass, increasing η decreases the compactness of the core and reduces the difference between our models and those of Sukhbold & Woosley (2014).
, which is slightly higher than their value of ~ 0.11–0.13, especially for reduced wind mass loss rates (i.e., η< 1.0). For this initial mass, increasing η decreases the compactness of the core and reduces the difference between our models and those of Sukhbold & Woosley (2014).
Most of our 20 M⊙ models have  , close to the corresponding models of Sukhbold & Woosley (2014). For these models, the maximum difference varying the wind mass loss algorithm is
, close to the corresponding models of Sukhbold & Woosley (2014). For these models, the maximum difference varying the wind mass loss algorithm is  . This is not surprising, because large variations of ξ2.5 are expected because of the transition from convective to neutrino-cooled and radiative carbon shell burning, which happens around MZAMS ≃ 20 M⊙ (Sukhbold & Woosley 2014). Therefore, in this mass range, changing the wind mass loss algorithm can substantially change
. This is not surprising, because large variations of ξ2.5 are expected because of the transition from convective to neutrino-cooled and radiative carbon shell burning, which happens around MZAMS ≃ 20 M⊙ (Sukhbold & Woosley 2014). Therefore, in this mass range, changing the wind mass loss algorithm can substantially change  by shifting the evolutionary track of the star in the slightest way.
by shifting the evolutionary track of the star in the slightest way.
Our 25 M⊙ models have values of similar to those of the 20 M⊙ models, in agreement with Sukhbold & Woosley (2014). However, once again, we obtain a large variation of changing the treatment of mass loss ( ).
).
Most of our 30 M⊙ models have  , which is significantly larger than the corresponding value of ~ 0.16 found by Sukhbold & Woosley (2014). The variations of the compactness parameter with mass loss algorithm combination and efficiency are smaller for the 30 M⊙ models than for lower MZAMS, except for the model computed with η = 1.0 and the V-dJ algorithm. This model has , which is much closer to the values of Sukhbold & Woosley (2014). We expect that the similar V-NJ algorithm combination with η = 1.0 would produce a structure close to this model at oxygen depletion, based on the similarities between the models at the end of the mass loss phase. The relatively low compactness of this model is therefore likely a consequence of the V hot phase mass loss algorithm. For MZAMS ≳ 30 M⊙, V with η = 1.0 produces substantially more mass loss than K (cf. Table 6), and therefore, the subsequent evolution is closer to the path of less massive stars – which are also expected to reach oxygen depletion with a lower compactness.
, which is significantly larger than the corresponding value of ~ 0.16 found by Sukhbold & Woosley (2014). The variations of the compactness parameter with mass loss algorithm combination and efficiency are smaller for the 30 M⊙ models than for lower MZAMS, except for the model computed with η = 1.0 and the V-dJ algorithm. This model has , which is much closer to the values of Sukhbold & Woosley (2014). We expect that the similar V-NJ algorithm combination with η = 1.0 would produce a structure close to this model at oxygen depletion, based on the similarities between the models at the end of the mass loss phase. The relatively low compactness of this model is therefore likely a consequence of the V hot phase mass loss algorithm. For MZAMS ≳ 30 M⊙, V with η = 1.0 produces substantially more mass loss than K (cf. Table 6), and therefore, the subsequent evolution is closer to the path of less massive stars – which are also expected to reach oxygen depletion with a lower compactness.
We speculate that the quantitative differences between our findings for the compactness parameter at oxygen depletion and those of Sukhbold & Woosley (2014) are in fact due primarily to their choice of mass loss algorithm: they employ the NJ algorithm in both the hot and the cold phase, which results in overall greater early mass loss than the K algorithm (and the V algorithm until the bistability jump). This notion is corroborated by our finding that our 30 M⊙ model closest to theirs is the one that loses the most mass during the hot phase (using η = 1 and the V-dJ combination; cf. Table 6).
3.7. Models at the onset of core collapse
We select a subset of six of our models at oxygen depletion for continuation to the onset of core collapse. Reducing the model set is necessary to limit the computational cost of this study. We choose two 15 M⊙ models with efficiency η = 1.0 and mass loss algorithm combination V-NJ and K-VL, two 20 M⊙ models with η = 0.33 computed using the V-vL and the K-dJ combination, and two 30 M⊙ models with η = 0.33 and the V-dJ or the K-NJ combination. When restarting our models from oxygen depletion, we switch from the 45-isotopes nuclear reaction network used so far to a larger customized network with 203-isotopes (see Appendix B). This is necessary to capture core deleptonization due to electron capture during and after silicon burning. Continuing the evolution with a larger nuclear reaction network also requires reducing the number of computational mesh points (from ~ 104 to ~ 103) to run the simulations within the memory constraints of MESA (see Appendix B for details). By the time oxygen depletion is reached, the effect of wind mass loss on the core structure is already pronounced, and our reduced-resolution models still have spatial resolution that is comparable to that of published models (e.g., Woosley et al. 2002; Woosley & Heger 2007). Furthermore, resolution tests in Appendix B.1.3 give us confidence that the presently unavoidable reduction in resolution does not affect our overall results and conclusions.
 |
Fig. 6 Time evolution of the compactness parameter ξ2.5 (top panel) and evolution in ρc−Tc space (bottom panel) from oxygen depletion to the onset of core collapse. Solid curves correspond to 15 M⊙ models computed with η = 1.0, dashed and dot-dashed curves correspond to 25 M⊙ and 30 M⊙ models, respectively, computed with η = 0.33. The vertical dot-dashed line in the top panel indicates roughly the time of core silicon depletion (X(28Si) ≤ 0.01). |
Figure 6 shows the time evolution of ξ2.5 (top panel) and the central temperature–central density evolutionary tracks (bottom panel) from oxygen depletion to the onset of core collapse for our pre-SN model set. The top panel shows that ξ2.5 settles onto its final value before the criterion for the onset of core collapse is reached. The bottom panel clearly shows a hook at log 10(Tc/ [ K ] ) ≃ 9.55, where ρc decreases at roughly constant temperature, indicating the point of silicon core ignition. This is also the more “noisy” part of these tracks, indicating that this phase of nuclear burning with very high and nearly balancing reaction rates is the most challenging to simulate (Hix & Thielemann 1996; Hix et al. 2007).
 |
Fig. 7 Neutrino luminosity from oxygen depletion to core collapse for the 15 M⊙ model run with the V-NJ scheme and η = 1.0. This shows that variations in the nuclear burning rate cause the oscillations in ξ2.5. The red curve shows only neutrinos coming from nuclear reactions, the cyan curve shows thermal neutrinos, and the blue curve is the sum of the two. The dotted line shows the compactness parameter (right hand side vertical axis). The vertical dot-dashed line indicates the approximate time of core silicon depletion. The ξ2.5 oscillations are driven by variations in silicon and oxygen shell burning. |
The evolution of the compactness parameter shows maxima and minima, which are related to oxygen shell ignition, around log 10( { tpre − SN − t } / [ yr ] ) ≃ − 2, silicon core ignition around log 10( { tpre − SN − t } / [ yr ] ) ≃ − 3, and silicon shell ignition at about log 10( { tpre − SN − t } / [ yr ] ) ≃ − 4.5. However, note that the ignition times and the durations of these burning phases are mass-dependent. Figure 7 shows the corresponding increase in the neutrino emission from nuclear reactions for the 15 M⊙ model computed with the V-NJ combination and η = 1.0. Similar features are present in the Tc(ρc) evolutionary tracks. However, while the Tc(ρc) track only probes the innermost part of the stellar core, the ξ2.5 evolution is determined by the interplay between silicon, oxygen, and carbon burning shells, core contraction, and onset of electron degeneracy.
Interestingly, the final compactness of the 15 M⊙ models is lower at the onset of core collapse than at oxygen depletion: for example, the 15 M⊙ model computed with K-VL and η = 1.0 has 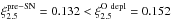 . This is because of the presence of nuclear burning shells within ℳ = 2.5 M⊙ whose energy generation tends to expand the material in the layers above them (the same process happens during the Hertzsprung gap for hydrogen-shell-burning stars). The location of the shells can be estimated using the core masses listed in Table 8 (and Table 7): the 15 M⊙ models have two shells of nuclear burning (Si and O, respectively) within the 2.5 M⊙ mass coordinate, while only one shell exists in this region at oxygen depletion. Models with MZAMS> 15 M⊙ settle on a pre-SN compactness that is higher than the corresponding , because only the silicon burning shell is within ℳ = 2.5 M⊙.
. This is because of the presence of nuclear burning shells within ℳ = 2.5 M⊙ whose energy generation tends to expand the material in the layers above them (the same process happens during the Hertzsprung gap for hydrogen-shell-burning stars). The location of the shells can be estimated using the core masses listed in Table 8 (and Table 7): the 15 M⊙ models have two shells of nuclear burning (Si and O, respectively) within the 2.5 M⊙ mass coordinate, while only one shell exists in this region at oxygen depletion. Models with MZAMS> 15 M⊙ settle on a pre-SN compactness that is higher than the corresponding , because only the silicon burning shell is within ℳ = 2.5 M⊙.
Properties of the subset of models run to the onset of core collapse, defined as the time when max { | v | } ≥ 103 km s-1.
Table 8 lists the properties of the six models that we run to the onset of core collapse.  , and (M4, μ4), where
, and (M4, μ4), where  is the mass location where the specific entropy is s = 4 kb baryon-1 and
is the mass location where the specific entropy is s = 4 kb baryon-1 and  is the mass gradient at that location, offer two different ways to estimate how hard it will be for the SN shock to unbind the stellar mantle and leave a NS remnant (see Ertl et al. 2016). The total mass at density higher than 106 g cm-3 (Mρ6), the carbon-oxygen core mass (MCO), and the iron core mass (MFe), defined as the location where X(28Si) < 0.01) can be used to estimate the nickel yields of the possible SN explosion and the remnant mass (Fryer et al. 2012; Sukhbold et al. 2016).
is the mass gradient at that location, offer two different ways to estimate how hard it will be for the SN shock to unbind the stellar mantle and leave a NS remnant (see Ertl et al. 2016). The total mass at density higher than 106 g cm-3 (Mρ6), the carbon-oxygen core mass (MCO), and the iron core mass (MFe), defined as the location where X(28Si) < 0.01) can be used to estimate the nickel yields of the possible SN explosion and the remnant mass (Fryer et al. 2012; Sukhbold et al. 2016).
The final MCO and MFe depend, although weakly, on the mass loss algorithm adopted during the hot evolutionary phase (V or K). The V algorithm yields slightly smaller cores (and total masses at the end of the hot phase, cf. Sect. 3.2). The 15 M⊙ models with η = 1.0 reach core collapse with MCO = 2.91 (3.07) M⊙, and MFe = 1.39 (1.50) M⊙ when using the combination V-NJ (K-vL). For 25 M⊙ models with η = 0.33, we find MCO = 6.38 (6.40) M⊙, and MFe = 1.51 (1.63) M⊙ for V-vL (K-dJ). Finally, the 30 M⊙ models with η = 0.33 yield MCO = 7.98 (7.90) M⊙, and MFe = 1.56 (1.58) M⊙ for the combination V-dJ (K-NJ). The differences in MCO (and to a lesser extent MFe) decrease with MZAMS. However, note that the decreasing difference is most likely caused by the lower wind efficiency η = 0.33 for the 25 M⊙ and 30 M⊙ models, while our 15 M⊙ models use full efficiency, i.e., η = 1.0.
 |
Fig. 8 Chemical composition profiles at the onset of core collapse. We show all models computed to this point and listed in Table 8. Blue, cyan, yellow, green, magenta, orange, and gray curves correspond to the mass fractions of 1H, 4He,12C, 16O, 20Ne, 28Si, and iron group elements (i.e., with atomic number 50 ≤ A ≤ 70), respectively. Note the different horizontal scale in each panel. |
As anticipated in Sect. 3.5, the spread in ξ2.5 increases between oxygen depletion and the onset of core collapse: the final variations are about ~ 30% for models with the same initial mass (cf. Table 8). The two 15 M⊙ models have  , and
, and  . For the 25 M⊙ models, the spread at oxygen depletion is
. For the 25 M⊙ models, the spread at oxygen depletion is  , while it is
, while it is  at the onset of core collapse. The two 30 M⊙ models go from
at the onset of core collapse. The two 30 M⊙ models go from  to
to 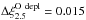 .
.
The pre-SN chemical abundances in the core are also affected by the choice of the mass loss algorithm combination. Figure 8 shows a comparison of the distribution of the dominant isotopes for our pre-SN models. The composition of the oxygen rich layer is sensitive to the early (hot phase) mass loss, with the V scheme producing a lower ratio of X(16O) /X(20Ne), owing to the higher early mass loss (cf. Sect. 3.2), and thus lower core temperature during the late phases (cf. bottom panel of Fig. 6). The distribution of the chemical elements in mass coordinate is also sensitive to the adopted mass loss algorithm combination. However, it is likely to depend more strongly on the treatment of mixing processes (which we do not vary here), mainly convection and overshooting, which are the only processes fast enough to have an effect inside the CO core of a star before the onset of collapse.
4. Discussion
4.1. Sensitivity of wind mass loss to evolving stellar properties and parameters
For a given MZAMS, the luminosity varies little between models that experience different mass loss rates and the effective temperature (and radius) varies much more. Once mass-loss induced differences in Teff appear, they feed back on mass loss to amplify these differences. Hence, the Teff evolution is most important for governing the mass loss of models of a given MZAMS. The dependence of Teff is particularly strong if the dust-driven vL algorithm is included.
The role of dust as a driver of RSG winds is a subject of debate (e.g., van Loon et al. 2005; Ferrarotti & Gail 2006; Bennett 2010). Dust-driven mass loss might occur in only a part of RSG evolution, and possibly even under only rather specific conditions. Even if dust exists in the envelopes of cool, evolved, massive stars, uncertainties in the grain properties result in highly uncertain mass loss rates (van Loon et al. 2005). The extreme dust-driven vL mass loss seen in our models is just one example (see Sect. 3.3). In this context, it is important to mention that our models switch to the vL algorithm already at Teff ≲ 15 000 K (≲11 000 K) when K (V) is used in the hot phase. These temperatures are clearly far too hot for dust to form. However, the strong temperature dependence (~ T-6.3) in combination with the extremely short time spent in the Hertzsprung gap prevent this from having a substantial consequence for the stellar mass. Hence, the extreme mass loss we find for MZAMS ≲ 20 M⊙ with vL and η = 1 is not an artifact of how we use the vL algorithm. Within its framework the predicted very low final masses for 15 M⊙ and 20 M⊙ stars, 5.25–5.70 M⊙ and 8.8 M⊙, respectively, are robust. It may thus be possible to rule out the extreme case of vL with η = 1 using pre-explosion imaging and SN ejecta mass estimates.
We also note that in stars with MZAMS ≳ 20 M⊙ the vL algorithm self-regulates since its extreme mass loss uncovers hotter layers of the stars. The steep temperature dependence of the vL algorithm then results in lower mass loss rates than dJ and NJ.
The wind efficiency η is the parameter that has the greatest impact on the evolution of initially identical models (cf. Fig. 1 and Table 3). However, it lacks an interpretation from first principles. Here, we investigate only values η ≤ 1, focusing on reduced wind mass loss motivated by possible inhomogeneities in the wind structure (also called “clumpiness”, Smith 2014; Puls et al. 2008, and references therein). However, starting from first principles, it cannot be excluded that clumps might actually enhance the mass loss rate (Lucy & White 1980). This might be the case if the overdense clumps are efficiently pushed outward by impinging photons.
Furthermore, we assume a constant efficiency factor throughout the evolution, but in principle the “clumpiness” of the wind might evolve (possibly even in a stochastic way) and may require different η in different evolutionary phases. The mass loss routines in MESA3 are already adapted for varying this parameter in different evolutionary phases. It is also possible that during each single evolutionary phase we define, the efficiency of mass loss may vary significantly, producing enhanced mass loss episodes separated by reduced mass loss phases.
Although changing η induces substantial changes in the mass loss rate and final mass, the appearance (i.e., luminosity, effective temperature) is less affected, making it difficult to use observed stellar populations to constrain η (Renzo 2015).
In this study, we have only varied the mass loss algorithms used throughout the evolution and their efficiency parameter η. However, other uncertainties (with possible degeneracies) are known, for example in the treatment of rotation, magnetic fields (e.g., Petit et al. 2017), convective mixing, and overshooting (e.g., Arnett et al. 2015; Arnett 2015; Arnett & Meakin 2016; Farmer et al. 2016). The coupling of these uncertainties with the wind mass loss may modify the outcomes of our numerical experiments.
4.2. Metallicity effects
We do not investigate the effects of decreasing the metallicity in this study. However, an approximate picture can be drawn by considering models with reduced efficiency η as proxy for low metallicity models. Most stellar evolution codes implement the metallicity dependence of the wind mass loss by just rescaling the mass loss rate at solar metallicity (cf. Eq. (1)), which is exactly the purpose of η. While the metallicity at the surface of the star can change throughout the evolution, the main element driving a wind is iron (Vink et al. 2001; Tramper et al. 2016), and its abundance is unlikely to change because of upward mixing from the stellar interior. Therefore, it is not unrealistic to consider a constant metallicity-related reduction factor for the entire evolution. Nevertheless, the approach of considering reduced η as a proxy for lower metallicity does not take into account metallicity effects on stellar radius and nuclear burning. These could indirectly affect wind mass loss.
4.3. WR stars
We emphasize in Sect. 2.2 the shortcomings of the computational definition of WR stars adopted in stellar evolution codes (Xs< 0.4). Although this definition is artificial, we stress that the mass loss algorithms used during this phase are derived from the observation of real WR stars. In the mass range considered here, few WR stars are expected, and indeed our results show that only MZAMS = 35 M⊙ stars with η = 1.0 can become sufficiently hydrogen-depleted at their surface to switch to a WR mass loss algorithm. We compare only two WR mass loss algorithms (NL and H), and neglect algorithms obtained by fitting either very luminous (i.e., more massive) or hydrogen-free WR stars (e.g., Gräfener & Hamann 2008; Tramper et al. 2016), since none of our WR models reach the corresponding regions of the parameter space. Therefore, in the framework of single nonrotating stars with wind efficiency η = 1.0, the minimum ZAMS mass to obtain a WR model is somewhere between 30 and 35M⊙. Although on the high end, this is in relatively good agreement with the results obtained with other stellar evolution codes (e.g., Woosley et al. 2002; Limongi & Chieffi 2006; Eldridge & Vink 2006; Georgy et al. 2015). Even with full efficiency of the wind before the WR phase, our models would likely underestimate the number of observable WR stars.
Lowering η has the obvious consequence of decreasing the mass loss rate, and thus increasing the minimum ZAMS mass for single nonrotating WR stars. However, the standard picture of a single nonrotating star misses pieces of physics of great importance for the formation of WR stars (see, e.g., Maeder 1996; Meynet & Maeder 2003; Eldridge & Vink 2006). These include, but are not necessarily limited to, rotationally-enhanced mass loss, rotational mixing processes (which can help depleting hydrogen from the surface, Meynet & Maeder 2003; Maeder 1996), and binary interactions. Binarity can lead to the formation of WR stars via envelope stripping in RLOF. Alternatively, accretion or merger with a companion could increase the mass (and luminosity) of the star sufficiently to enhance the wind mass loss and remove the hydrogen-rich envelope. Also note that the envelope hydrogen depletion needed to switch to a WR mass loss algorithm can be reached also because of upward mixing of thermonuclearly processed material, e.g., because of efficient rotational mixing, and not only because of mass loss. The choice for the algorithmic representation of mixing processes (see Appendix B) influences directly the surface mass fraction of hydrogen, but also the core mass, and consequently the luminosity. Indirectly, these effects can change the mass loss rate and consequently the fate of a model from/to WR.
4.4. Nucleosynthetic yields
The nucleosynthetic yields of massive stars are mass loss (and angular momentum loss) dependent (see, e.g., Maeder 1992; Frischknecht et al. 2016). Processes such as rotational mixing can bring thermonuclearly processed material upward that is then lost through winds. This is especially relevant for s-process elements which are synthesized during the hydrostatic lifetime of massive stars and the ratio of carbon to oxygen abundance in the stellar wind yields. On top of this, the success or failure of the SN explosion, and the details of the explosive nucleosynthesis, depend on the interior structure of the exploding star and thus on its mass loss history (e.g., Sukhbold et al. 2016).
4.5. Consequences for SN explosions and compact remnants
We find that mass loss affects the core structure and the burning shells surrounding the core. Mass loss during the hot phase of the evolution (i.e., the main sequence, roughly speaking) is important for the core structure, because the core itself re-adjusts quasi-statically to the wind from the stellar atmosphere. During this phase, different algorithms produce small variations in the core, which are then amplified by the subsequent evolution (cf. Sect. 3.2 and Fig. 4). The general trend is that a higher mass loss rate during the hot phase produces structures with lower core compactness (cf. Sect. 3.6). The cool phase mass loss also impacts the core compactness, but more indirectly, through its effect on the burning shells. Most of the mass is lost during the cool phase of the evolution (cf. Sect. 3.3), and the vigor, extent and type of mixing in the burning shells all depend on the amount and the timing of mass loss. Since our present understanding of core-collapse SN explosions strongly depends on the details of the input stellar models (e.g., Janka et al. 2012; Couch & Ott 2015; Chatzopoulos et al. 2016), overlooking the impact of wind mass loss on the core structure might bias detailed hydrodynamical simulations of stellar explosions. This, in turn, can have significant implications for the NS/BH ratio and mass distribution, and consequently also for the inferred gravitational wave sources. We provide4 stellar models at the end of the main sequence, at the end of the hot phase of the evolution, at the end of the mass loss phase (Tc ≥ 109 [ K ]), at oxygen depletion, and at the onset of core collapse. These models can be used as starting points for stellar experiments during late evolutionary phases (see e.g., Couch & Ott 2015; Chatzopoulos et al. 2016).
4.6. Observational consequences and potential constraints
The large vertical spread in final mass caused by differences in mass loss for a given MZAMS (Fig. 1) suggests at first sight that these large uncertainties may map to equally large uncertainties in MZAMS estimates from pre-explosion observations. However, the pre-SN mass is not a direct observable. Rather, MZAMS estimates typically rely on observational measurements of luminosity and effective temperature that are then compared with stellar models (e.g., Smartt 2009). In Fig. 9, we plot the final luminosity L and effective temperature Teff for our entire model set. Table 4 summarizes the numerical results. These results demonstrate that wind mass loss variations have very little effect on the final luminosity for stars with MZAMS ≲ 30 M⊙ and luminosity variations are smaller than typical observational uncertainties (see, e.g., Smartt 2009). The similarity in luminosity of models of a given MZAMS is a consequence of the rather small effect that mass loss has on the core mass (cf. Table 3). Interestingly, Teff variations are also small for MZAMS ≲ 30 M⊙. The maximum variation from the average Teff of a ZAMS mass is only 0.08 dex and comes from the η = 1 K-vL and V-vL 20 M⊙ models that are YSGs at the end of their lives. Wind mass-loss dependent variations in L and Teff are much larger for 35 M⊙ models, some of which die as BSGs and some as WR stars.
Given the above results, it appears that for massive stars with MZAMS ≲ 30 M⊙ wind mass loss uncertainties do not increase the overall level of uncertainty with which the SN progenitor MZAMS can be estimated from pre-explosion observations. However, our results do not say anything about the other possibly existing mass loss channels (e.g., binary interactions and/or impulsive phenomena, see, for example, Smith 2014; Smith & Arnett 2014; Morozova et al. 2015; Margutti et al. 2017) that are usually neglected in stellar evolution calculations, or included in an very simplified way using enhanced winds (see, e.g., Meynet et al. 2015).
 |
Fig. 9 Spread in pre-SN appearance due to the uncertainty in wind mass loss. Each color represents an initial mass MZAMS, each marker corresponds to a different efficiency factor η. The vertical dot-dashed lines indicate the BSG-YSG boundary, and YSG-RSG boundary according to Georgy et al. (2017). 35 M⊙ models exhibit a larger spread, because some models (indicated by a thick black edge on their markers) develop into WR stars. |
The observed lack of RSG SN progenitors with MZAMS ≳ 16 M⊙ (Smartt et al. 2009; Smartt 2009) might be explained with the effects of mass loss on the pre-SN stellar appearance (Georgy et al. 2017). Table 4 and Fig. 9 show that different wind algorithms can change the pre-explosion appearance of a massive star. However, this effect is relatively small in luminosity and Teff, and the relative number of YSG to RSG we find (cf. Sect. 3) largely depends on the adopted definition of YSG vs. RSG. Therefore, the systematic uncertainty in the treatment of wind mass loss for 16 ≲ MZAMS/M⊙ ≲ 30 does not seem sufficient to solve the RSG problem. It is likely that either (i) stars with initial mass in the range ~ 16 − 30 M⊙ do not produce a bright transient at their death; or (ii) mass loss phenomena other than winds, happening at late stages in the evolution, change the pre-SN appearance of the star. SN observations can constrain the total ejected mass and pre-explosion imaging might also provide constraints (although subject to large uncertainties) on the total mass lost and on the mass loss timing (if the surface chemical composition can be inferred, e.g., Smartt et al. 2009; Gordon et al. 2016).
A range of special systems, events, and phenomena offer alternative and complimentary ways to constrain mass loss to the more traditional spectral observations of massive stars. These special systems include bow shocks of runaway stars (e.g., Gull & Sofia 1979; Meyer et al. 2016), SN shocks running into the circumstellar material (e.g., Maeda et al. 2015; Chakraborti et al. 2016; Margutti et al. 2017), flash-spectroscopy of material ejected shortly before core collapse (e.g., Khazov et al. 2016), accretion in wind-fed high mass X-ray binaries, or binary wind collisions. Constraints from special systems can be combined with those arising from observed populations of stars and their compact remnants (including gravitational wave sources). The different mass loss algorithms that we compare here give a range of mass loss timing, which suggests that the chemical composition and dust properties of the circumstellar material may also contain hints regarding the mass loss of massive stars.
5. Conclusions
Massive star mass loss is a longstanding issue in stellar evolution. Despite decades of observational and theoretical work it remains incompletely understood. Mass loss influences the lifetime and appearance of massive stars, their internal structure at the onset of core collapse, and their total nucleosynthetic yields. Through its effect on the pre-supernova (pre-SN) structure, wind mass loss can impact the outcome of core collapse and the nature of the compact remant, with potential implications for gravitational wave astronomy.
We studied the impact of a broad range of wind mass loss algorithm combinations on the evolution and pre-collapse structure of nonrotating, single, solar-metallicity stars with initial masses of 15, 20, 25, 30, and 35 M⊙. We compared 12 different mass loss algorithm combinations, drawing from 2 algorithms for the hot phase of the evolution (corresponding roughly to the main sequence), 3 for the cool phase of evolution, and 2 for the Wolf-Rayet phase (if it is reached). We explored the effects of reducing the mass loss rate with an efficiency scaling factor η = 1.0, 0.33, or 0.1 to crudely account for reduced stellar mass loss that could be caused, for example, by inhomogeneities in the wind (e.g., clumpiness). The resulting differences in stellar structure and total mass at various stages of the evolution are caused by the different algorithmic representations of stellar winds.
The different mass loss efficiencies and algorithm combinations have profound effects on the evolution and the pre-SN masses of massive stars. On the one hand, this can be expected given the inherent differences of the various mass loss algorithms and the various assumptions that enter them. On the other hand, these algorithms all attempt to describe the same physical process – steady wind mass loss – and less sensitivity to the theoretical/empirical treatment of mass loss would in general be desirable.
We find that the choice of wind efficiency scaling factor η has the greatest impact on our stellar models. It affects their total mass loss, their evolutionary path, and their pre-SN structure. η is therefore the main uncertainty and limiting factor for our present understanding of wind mass loss and its effects. If the wind efficiency is low, the differences between various mass loss algorithms are less important.
Considering the full range of wind efficiencies 0.1 ≤ η ≤ 1.0, we find that there is a ~ 50% uncertainty in the pre-SN mass for a given MZAMS. For fixed efficiency η = 1.0, the uncertainty varies with initial mass and is ~ 15–30% in most cases. Impulsive mass loss events (eruptions, pulsational instabilities, etc., all neglected here) could only make the uncertainties in the initial to pre-SN mapping more severe.
Despite the large uncertainty in the pre-SN mass, we find that the key observables from pre-SN imaging, the luminosity and effective temperature before explosion, are only mildly affected by varying the mass loss algorithm combination and wind efficiency. The uncertainties in L and Teff from our models are within observational limits, suggesting that wind mass-loss uncertainties do not affect observational estimates of SN progenitor masses from pre-SN observations for most massive stars (assuming a single star evolution scenario). Nevertheless, the impact of stellar winds on the internal structure of the star can affect the mass and composition of the SN ejecta.
Independent of the employed algorithm during the hot phase, the amount of mass lost in this phase is only a small fraction (~few percent) of the total mass. However, since the core can respond directly to it, mass loss during the hot phase creates seed differences that grow during the subsequent evolution, leading to changes in the pre-SN structure and composition of the stellar core. Later, burning shells re-adjust to the mass loss instead of the core itself, and the effect of mass loss is more indirect.
Most of the mass is lost during the late and short cool phase of the evolution. Wind mass loss during this phase is more uncertain. On the cool side of the Hertzsprung-Russel diagram, two different wind driving mechanism might exist: line-driving or dust-driving. The latter, assumed by the van Loon et al. (2005) (vL) algorithm, has a much stronger temperature dependence and produces much higher mass loss rates than algorithms describing line-driven mass loss. vL mass loss can be so strong that it reveals the deep and hot layers of the star. This results in self-damping of the wind itself for higher mass progenitors and thus a higher value of the final mass. The vL algorithm produces very different evolutionary tracks from those obtained with algorithms assuming line driving, with the vL algorithm driving blueward displacements on the Hertzsprung-Russel diagram. The more indirect effect of late mass loss on the pre-SN core structure is difficult to pinpoint with our limited model grid.
In our model grid, only models with MZAMS ≥ 35 M⊙ and full wind efficiency (η = 1.0) develop into Wolf-Rayet stars. The absence of Wolf-Rayet models with reduced wind efficiency suggests that either (i) our initial mass range is too small to produce Wolf-Rayet stars from single, nonrotating stars; or (ii) other formation channels, such as binarity or impulsive mass loss events, might be dominant. The standard picture for the evolution of massive stars, the so-called “Conti scenario” (e.g., Maeder & Conti 1994; Lamers 2013; Smith & Tombleson 2015), predicts the formation of Wolf-Rayet stars with MZAMS ≲ 40 M⊙, therefore, if mass loss occurs in nature with reduced efficiency (η< 1), then our results with reduced wind efficiency disagree with this prediction.
From our limited sample of six models that we were able to evolve to the pre-SN stage, we find that changing the wind mass loss algorithm combination can lead to changes of the compactness parameter ξ2.5 of up to 30% for a given MZAMS. Moreover, the pre-SN models show a spread in terms of composition profiles, density profiles, and core masses. These uncertainties add to those arising from the incomplete understanding of mixing processes (mainly convection and overshooting). They complicate the study of the core-collapse SN explosion mechanism by adding uncertainty to the initial conditions from which core-collapse SN simulations start. This finding underlines that systematic uncertainty in massive star mass loss can have important implications for the relative number of BHs and NSs resulting from core collapse events, and consequently for gravitational wave sources, and for the nucleosynthetic yields from the explosions of massive stars.
Although the present study provides new insights into the effects of wind mass loss on the evolution and pre-SN structure and appearance of massive stars, it suffers from a number of important limitations that must be addressed by future work.
Our model grid coarsely samples a limited mass range, includes only nonrotating solar-metalicity models, and we could evolve only six models to the onset of core collapse. Extending this grid to finer mass sampling, higher masses, lower metallicity, and evolving all models to the pre-SN stage will be important future work needed to infer more robustly how wind mass loss affects pre-SN structure. Furthermore, we did not consider time-dependent wind efficiency, rotation and magnetic fields, and varitations in mixing processes, which all may have important implications for wind mass loss and its effects on evolution and pre-SN structure.
As in any computational astrophysics study, numerical resolution is a major concern in our work. Initially, the effect of mass loss on the core structure is small, and impossible to resolve with a coarse spatial mesh. We tested our numerical resolution (cf. Appendix B) and ran our calculations at unprecedented spatial resolution (between 20 000 and 100 000 mesh points) until oxygen depletion to capture the delayed effect of mass loss on the core structure. However, in order to follow the core deleptonization after oxygen depletion with a large nuclear reaction network, we were forced to reduce the spatial resolution. We find that by the end of core oxygen burning, the differences in core structure due to different mass loss algorithm combinations are already pronounced. The limited resolution study that we were able to perform suggests that resolution effects are smaller than the overall effects of mass loss and do not affect our conclusions. Future work is needed to more formally demonstrate robustness and numerical convergence of simulations of the late evolutionary stages.
These are often called “recipes” in jargon. However, we prefer the term “algorithm” (Fibonacci 1202) because it underlines that these are mathematical representations of physical phenomena relying on specific sets of assumptions.
The models saved at each checkpoint are available at https://zenodo.org/record/292924#.WK_eENWi60i. The input files and customized routines are available at https://stellarcollapse.org/renzo2017
These are available at https://stellarcollapse.org/renzo2017
Data are available at https://zenodo.org/record/292924#.WK_eENWi60i and input parameter files at https://stellarcollapse.org/renzo2017
Which excludes WR and Be stars.
The formula in the abstract of Nieuwenhuijzen & de Jager (1990) has a typo, see their Eq. (2).
The bolometric correction is the difference between the bolometric magnitude and the observed (visual) magnitude, influenced by the instrumental intrinsic band pass, BC M − Mobs.
M − Mobs.
These are binary files that allow one to restart a run and obtain bit-to-bit identical results (provided that the parameter set does not change). See also http://mesa.sourceforge.net/
Preliminary calculations with low resolution showed that in some rare cases, e.g., during the Herzsprung gap, MESA would try to overstep the Kelvin-Helmholtz timescale.
Acknowledgments
We wish to thank B. Paxton, F. Timmes, and R. Farmer for invaluable help with MESA. We acknowledge helpful exchanges with W. D. Arnett, M. Cantiello, D. Clausen, A. de Koter, L. Dessart, Y. Götberg, A. L. Piro, J. Fuller, N. Smith, and E. Zapartas. We are also grateful to the referee, G. Meynet, for the helpful comments and suggested improvements. M.R. thanks the University of Pisa, where this study was initiated as part of his Master Thesis in Physics, and acknowledges the precious support of the “Lorentz group”. This work is supported in part by NSF under grant numbers AST-1205732, AST-1212170, PHY-1151197, and PHY-1125915 and by the Sherman Fairchild Foundation. Some of the computations used resources of NSF’s XSEDE network under allocation TG-PHY100033. Most of the simulation were carried out using the Caltech compute cluster Zwicky funded through NSF grant no. PHY-0960291 and the Sherman Fairchild Foundation. The runs to the onset of core collapse were carried out on the Dutch national e-infrastructure (Cartesius, project number 15162) with the support of the SURF Cooperative.
References
- Abbott, D. C. 1982, ApJ, 259, 282 [NASA ADS] [CrossRef] [Google Scholar]
- Abbott, B. P., Abbott, R., Abbott, T. D., et al. 2016, ApJ, 818, L22 [Google Scholar]
- Almeida, L. A., Sana, H., Taylor, W., et al. 2017, A&A, 598, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arnett, W. D. 2015, in New Windows on Massive Stars, eds. G. Meynet, C. Georgy, J. Groh, & P. Stee, IAU Symp., 307, 459 [Google Scholar]
- Arnett, W. D., & Meakin, C. 2016, Rep. Prog. Phys., 79, 102901 [NASA ADS] [CrossRef] [Google Scholar]
- Arnett, W. D., Meakin, C., Viallet, M., et al. 2015, ApJ, 809, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Belczynski, K., Bulik, T., Fryer, C. L., et al. 2010, ApJ, 714, 1217 [NASA ADS] [CrossRef] [Google Scholar]
- Bennett, P. D. 2010, in Hot and Cool: Bridging Gaps in Massive Star Evolution, eds. C. Leitherer, P. D. Bennett, P. W. Morris, & J. T. Van Loon, ASP Conf. Ser., 425, 181 [Google Scholar]
- Bestenlehner, J. M., Vink, J. S., Gräfener, G., et al. 2011, A&A, 530, L14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blaauw, A. 1961, Bull. Astron. Inst. Netherlands, 15, 265 [NASA ADS] [Google Scholar]
- Boersma, J. 1961, Bull. Astron. Inst. Netherlands, 15, 291 [Google Scholar]
- Böhm-Vitense, E. 1958, Z. Astrophys., 46, 108 [Google Scholar]
- Bouret, J., Lanz, T., & Hillier, D. J. 2005, A&A, 438, 301 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castor, J. I., Abbott, D. C., & Klein, R. I. 1975, ApJ, 195, 157 [NASA ADS] [CrossRef] [Google Scholar]
- Chakraborti, S., Ray, A., Smith, R., et al. 2016, ApJ, 817, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Chatzopoulos, E., Couch, S. M., Arnett, W. D., & Timmes, F. X. 2016, ApJ, 822, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Chini, R., Hoffmeister, V. H., Nasseri, A., Stahl, O., & Zinnecker, H. 2012, MNRAS, 424, 1925 [NASA ADS] [CrossRef] [Google Scholar]
- Clausen, D., Piro, A. L., & Ott, C. D. 2015, ApJ, 799, 190 [NASA ADS] [CrossRef] [Google Scholar]
- Conti, P. S. 1975, Mem. Soc. Roy. Sci. Liège, 9, 193 [Google Scholar]
- Couch, S. M., & Ott, C. D. 2015, ApJ, 799, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Crowther, P. A. 2007, ARA&A, 45, 177 [NASA ADS] [CrossRef] [Google Scholar]
- Crowther, P. A., Hillier, D. J., Evans, C. J., et al. 2002, ApJ, 579, 774 [NASA ADS] [CrossRef] [Google Scholar]
- Crowther, P. A., Schnurr, O., Hirschi, R., et al. 2010, MNRAS, 408, 731 [NASA ADS] [CrossRef] [Google Scholar]
- de Jager, C., Nieuwenhuijzen, H., & van der Hucht, K. A. 1988, A&AS, 72, 259 [NASA ADS] [Google Scholar]
- de Koter, A., Heap, S. R., & Hubeny, I. 1997, ApJ, 477, 792 [Google Scholar]
- Dessart, L., & Owocki, S. P. 2005, A&A, 437, 657 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dessart, L., Hillier, D. J., Waldman, R., & Livne, E. 2013, MNRAS, 433, 1745 [NASA ADS] [CrossRef] [Google Scholar]
- Eggenberger, P., Meynet, G., Maeder, A., et al. 2007, Astrophys. Space Sci., 316, 43 [Google Scholar]
- Ekström, S., Meynet, G., & Maeder, A. 2008, in First Stars III, eds. B. W. O’Shea, & A. Heger, AIP Conf. Ser., 990, 220 [Google Scholar]
- Eldridge, J. J., & Tout, C. A. 2004, MNRAS, 353, 87 [NASA ADS] [CrossRef] [Google Scholar]
- Eldridge, J. J., & Vink, J. S. 2006, A&A, 452, 295 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ertl, T., Janka, H.-T., Woosley, S. E., Sukhbold, T., & Ugliano, M. 2016, ApJ, 818, 124 [NASA ADS] [CrossRef] [Google Scholar]
- Evans, C. J., Crowther, P. A., Fullerton, A. W., & Hillier, D. J. 2004, ApJ, 610, 1021 [NASA ADS] [CrossRef] [Google Scholar]
- Farmer, R., Fields, C. E., Petermann, I., et al. 2016, ApJS, 227, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Feldmeier, A. 1995, A&A, 299, 523 [NASA ADS] [Google Scholar]
- Ferrarotti, A. S., & Gail, H.-P. 2006, A&A, 447, 553 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fibonacci, L. 1202, Liber Abaci [Google Scholar]
- Frischknecht, U., Hirschi, R., Pignatari, M., et al. 2016, MNRAS, 456, 1803 [NASA ADS] [CrossRef] [Google Scholar]
- Fryer, C. L., Belczynski, K., Wiktorowicz, G., et al. 2012, ApJ, 749, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Fullerton, A. W., Massa, D. L., & Prinja, R. K. 2006, ApJ, 637, 1025 [NASA ADS] [CrossRef] [Google Scholar]
- Georgy, C. 2012, A&A, 538, L8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Georgy, C., Ekström, S., Hirschi, R., et al. 2015, in Wolf-Rayet Stars: Proceedings of an International Workshop held in Potsdam, Germany, 1–5 June 2015, Wolf-Rainer Hamann, Andreas Sander, Helge Todt, Universitätsverlag Potsdam, eds. W.-R. Hamann, A. Sander, & H. Todt, 229 [Google Scholar]
- Georgy, C., Saio, H., Ekström, S., & Meynet, G. 2017, Proc. Conf. The B[e] Phenomenom: Forty Years of Studies, 508, 99 [NASA ADS] [Google Scholar]
- Glebbeek, E., Gaburov, E., de Mink, S. E., Pols, O. R., & Portegies Zwart, S. F. 2009, A&A, 497, 255 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gordon, M. S., Humphreys, R. M., & Jones, T. J. 2016, ApJ, 825, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Gräfener, G., & Hamann, W.-R. 2008, A&A, 482, 945 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Groh, J. H., Meynet, G., & Ekström, S. 2013, A&A, 550, L7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Groh, J. H., Meynet, G., Ekström, S., & Georgy, C. 2014, A&A, 564, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gull, T. R., & Sofia, S. 1979, ApJ, 230, 782 [NASA ADS] [CrossRef] [Google Scholar]
- Hamann, W. R., & Koesterke, L. 1998, A&A, 335, 1003 [NASA ADS] [Google Scholar]
- Hamann, W.-R., Schoenberner, D., & Heber, U. 1982, A&A, 116, 273 [NASA ADS] [Google Scholar]
- Hamann, W.-R., Koesterke, L., & Wessolowski, U. 1995, A&A, 299, 151 [NASA ADS] [Google Scholar]
- Heger, A., Woosley, S. E., & Spruit, H. C. 2005, ApJ, 626, 350 [NASA ADS] [CrossRef] [Google Scholar]
- Hillier, D. J., Lanz, T., Heap, S. R., et al. 2003, ApJ, 588, 1039 [NASA ADS] [CrossRef] [Google Scholar]
- Hix, W. R., & Thielemann, F.-K. 1996, ApJ, 460, 869 [Google Scholar]
- Hix, W. R., Parete-Koon, S. T., Freiburghaus, C., & Thielemann, F.-K. 2007, ApJ, 667, 476 [NASA ADS] [CrossRef] [Google Scholar]
- Janka, H.-T. 2013, MNRAS, 434, 1355 [Google Scholar]
- Janka, H.-T. 2017, ApJ, 837, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Janka, H.-T., Hanke, F., Hüdepohl, L., et al. 2012, Prog. Theoretical and Experimental Physics, 01A309 [Google Scholar]
- Joss, P. C., Salpeter, E. E., & Ostriker, J. P. 1973, ApJ, 181, 429 [NASA ADS] [CrossRef] [Google Scholar]
- Khazov, D., Yaron, O., Gal-Yam, A., et al. 2016, ApJ, 818, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Kiminki, D. C., & Kobulnicky, H. A. 2012, ApJ, 751, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Kippenhahn, R., Ruschenplatt, G., & Thomas, H.-C. 1980, A&A, 91, 175 [NASA ADS] [Google Scholar]
- Kobulnicky, H. A., Kiminki, D. C., Lundquist, M. J., et al. 2014, ApJS, 213, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Kudritzki, R. P., Pauldrach, A., Puls, J., & Abbott, D. C. 1989, A&A, 219, 205 [NASA ADS] [Google Scholar]
- Lamers, H. J. G. L. M. 2013, in 370 Years of Astronomy in Utrecht, eds. G. Pugliese, A. de Koter, & M. Wijburg, ASP Conf. Ser., 470, 97 [Google Scholar]
- Lamers, H. J. G. L. M., & Cassinelli, J. P. 1999, Introduction to Stellar Winds (Cambridge, UK: Cambridge University Press) [Google Scholar]
- Langer, N. 1997, in Luminous Blue Variables: Massive Stars in Transition, eds. A. Nota, & H. Lamers, ASP Conf. Ser., 120, 83 [Google Scholar]
- Langer, N. 2012, ARA&A, 50, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Ledoux, P. 1947, ApJ, 105, 305 [NASA ADS] [CrossRef] [Google Scholar]
- Limongi, M., & Chieffi, A. 2006, ApJ, 647, 483 [NASA ADS] [CrossRef] [Google Scholar]
- Lovegrove, E., & Woosley, S. E. 2013, ApJ, 769, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Lucy, L. B., & Solomon, P. M. 1970, ApJ, 159, 879 [NASA ADS] [CrossRef] [Google Scholar]
- Lucy, L. B., & White, R. L. 1980, ApJ, 241, 300 [NASA ADS] [CrossRef] [Google Scholar]
- Maeda, K., Hattori, T., Milisavljevic, D., et al. 2015, ApJ, 807, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Maeder, A. 1992, A&A, 264, 105 [NASA ADS] [Google Scholar]
- Maeder, A. 1996, in Liège International Astrophysical Colloquia, eds. J. M. Vreux, A. Detal, D. Fraipont-Caro, E. Gosset, & G. Rauw, 33, 39 [Google Scholar]
- Maeder, A., & Conti, P. S. 1994, ARA&A, 32, 227 [NASA ADS] [CrossRef] [Google Scholar]
- Maeder, A., & Meynet, G. 1988, A&AS, 76, 411 [NASA ADS] [Google Scholar]
- Maeder, A., & Meynet, G. 1989, A&A, 210, 155 [Google Scholar]
- Marchenko, S. V., Moffat, A. F. J., & Crowther, P. A. 2010, ApJ, 724, L90 [NASA ADS] [CrossRef] [Google Scholar]
- Margutti, R., Kamble, A., Milisavljevic, D., et al. 2017, ApJ, 835, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Mason, B. D., Hartkopf, W. I., Gies, D. R., Henry, T. J., & Helsel, J. W. 2009, AJ, 137, 3358 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mauron, N., & Josselin, E. 2011, A&A, 526, A156 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meyer, D. M.-A., van Marle, A.-J., Kuiper, R., & Kley, W. 2016, MNRAS, 459, 1146 [NASA ADS] [CrossRef] [Google Scholar]
- Meynet, G., & Maeder, A. 2003, A&A, 404, 975 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meynet, G., Maeder, A., Schaller, G., Schaerer, D., & Charbonnel, C. 1994, A&AS, 103 [Google Scholar]
- Meynet, G., Chomienne, V., Ekström, S., et al. 2015, A&A, 575, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Moravveji, E., Townsend, R. H. D., Aerts, C., & Mathis, S. 2016, ApJ, 823, 130 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Morozova, V., Piro, A. L., Renzo, M., et al. 2015, ApJ, 814, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Nieuwenhuijzen, H., & de Jager, C. 1990, A&A, 231, 134 [NASA ADS] [Google Scholar]
- Nugis, T., & Lamers, H. J. G. L. M. 2000, A&A, 360, 227 [NASA ADS] [Google Scholar]
- O’Connor, E., & Ott, C. D. 2011, ApJ, 730, 70 [NASA ADS] [CrossRef] [Google Scholar]
- O’Connor, E., & Ott, C. D. 2013, ApJ, 762, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Owocki, S. P., & Puls, J. 1999, ApJ, 510, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Owocki, S. P., & Rybicki, G. B. 1984, ApJ, 284, 337 [NASA ADS] [CrossRef] [Google Scholar]
- Owocki, S. P., Castor, J. I., & Rybicki, G. B. 1988, ApJ, 335, 914 [NASA ADS] [CrossRef] [Google Scholar]
- Pauldrach, A., Puls, J., & Kudritzki, R. P. 1986, A&A, 164, 86 [NASA ADS] [Google Scholar]
- Pauldrach, A. W. A., Kudritzki, R. P., Puls, J., Butler, K., & Hunsinger, J. 1994, A&A, 283, 525 [Google Scholar]
- Paxton, B., Bildsten, L., Dotter, A., et al. 2011, ApJS, 192, 3 [Google Scholar]
- Paxton, B., Cantiello, M., Arras, P., et al. 2013, ApJS, 208, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Paxton, B., Marchant, P., Schwab, J., et al. 2015, ApJS, 220, 15 [Google Scholar]
- Petit, V., Keszthelyi, Z., MacInnis, R., et al. 2017, MNRAS, 466, 1052 [NASA ADS] [CrossRef] [Google Scholar]
- Puls, J., Vink, J. S., & Najarro, F. 2008, A&A, 16, 209 [Google Scholar]
- Puls, J., Sundqvist, J. O., & Markova, N. 2015, in New Windows on Massive Stars, eds. G. Meynet, C. Georgy, J. Groh, & P. Stee, IAU Symp., 307, 25 [Google Scholar]
- Quataert, E., Fernández, R., Kasen, D., Klion, H., & Paxton, B. 2016, MNRAS, 458, 1214 [NASA ADS] [CrossRef] [Google Scholar]
- Quataert, E., & Shiode, J. 2012, MNRAS, 423, L92 [NASA ADS] [CrossRef] [Google Scholar]
- Renzo, M. 2015, Master’s Thesis, Università di Pisa, Italy, https://etd.adm.unipi.it/t/etd-05062015-125630/ [Google Scholar]
- Sana, H., & Evans, C. J. 2011, in Active OB Stars: Structure, Evolution, Mass Loss, and Critical Limits, eds. C. Neiner, G. Wade, G. Meynet, & G. Peters, IAU Symp., 272, 474 [Google Scholar]
- Sana, H., de Mink, S. E., de Koter, A., et al. 2012, Science, 337, 444 [Google Scholar]
- Schmutz, W., & Drissen, L. 1999, eds. N. I. Morrell, V. S. Niemela, & R. H. Barbá, Rev. Mex. Astron. Astrofis., 8, 41 [Google Scholar]
- Shara, M. M., Crawford, S. M., Vanbeveren, D., et al. 2017, MNRAS, 464, 2066 [NASA ADS] [CrossRef] [Google Scholar]
- Shiode, J. H., & Quataert, E. 2014, ApJ, 780, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Smartt, S. J. 2009, ARA&A, 47, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Smartt, S. J., Eldridge, J. J., Crockett, R. M., & Maund, J. R. 2009, MNRAS, 395, 1409 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, N. 2014, ARA&A, 52, 487 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Smith, N., & Arnett, W. D. 2014, ApJ, 785, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, N., & Owocki, S. P. 2006, ApJ, 645, L45 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, N., & Tombleson, R. 2015, MNRAS, 447, 598 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, N., Li, W., Filippenko, A. V., & Chornock, R. 2011, MNRAS, 412, 1522 [NASA ADS] [CrossRef] [Google Scholar]
- Sukhbold, T., & Woosley, S. E. 2014, ApJ, 783, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Sukhbold, T., Ertl, T., Woosley, S. E., Brown, J. M., & Janka, H.-T. 2016, ApJ, 821, 38 [Google Scholar]
- Tramper, F., Sana, H., & de Koter, A. 2016, ApJ, 833, 133 [NASA ADS] [CrossRef] [Google Scholar]
- Ugliano, M., Janka, H.-T., Marek, A., & Arcones, A. 2012, ApJ, 757, 69 [NASA ADS] [CrossRef] [Google Scholar]
- van der Hucht, K. A. 2001, New Astron. Rev., 45, 135 [NASA ADS] [CrossRef] [Google Scholar]
- van Loon, J. T., Cioni, M.-R. L., Zijlstra, A. A., & Loup, C. 2005, A&A, 438, 273 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vink, J. S. 2015, in Very Massive Stars in the Local Universe (Springer Verlag, Heidelberg, Germany), 412, 77 [Google Scholar]
- Vink, J. S., de Koter, A., & Lamers, H. J. G. L. M. 2000, A&A, 362, 295 [NASA ADS] [Google Scholar]
- Vink, J. S., de Koter, A., & Lamers, H. J. G. L. M. 2001, A&A, 369, 574 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wachter, A., Schröder, K.-P., Winters, J. M., Arndt, T. U., & Sedlmayr, E. 2002, A&A, 384, 452 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wellstein, S., & Langer, N. 1999, A&A, 350, 148 [NASA ADS] [Google Scholar]
- Woosley, S. E. 2017, ApJ, 836, 244 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., & Heger, A. 2007, Phys. Rep., 442, 269 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., Langer, N., & Weaver, T. A. 1995, ApJ, 448, 315 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., Heger, A., & Weaver, T. A. 2002, Rev. Mod. Phys., 74, 1015 [NASA ADS] [CrossRef] [Google Scholar]
- Yoon, S.-C., Woosley, S. E., & Langer, N. 2010, ApJ, 725, 940 [NASA ADS] [CrossRef] [Google Scholar]
- Zwicky, F. 1957, Z. Astrophys., 44, 64 [NASA ADS] [Google Scholar]
Appendix A: Parametric wind algorithms
Here, we give a brief review of the physical assumptions entering in each mass loss algorithm and the corresponding prescribed rate. We summarize in Table A.1 the scaling of the mass loss rate with physical parameters of the stellar model for each mass loss algorithm considered in this study.
Functional dependence of the mass loss rate Ṁ on stellar and wind parameters for each algorithm combination and mass loss phase.
Appendix A.1: Vink et al. (V)
The wind mass loss algorithm proposed by Vink et al. (2000, 2001) is based on Monte Carlo simulations of the photon transport in the stellar atmosphere to evaluate the radiative acceleration. Their algorithm is explicitly metallicity dependent and is supposed to be applied only to single OB stars with metallicity 1 / 30 ≤ Z/Z⊙ ≤ 3 and effective temperature 12 500 K <Teff< 50 000 K, so during the hot, blue evolutionary phase. In this temperature range, a non-monotonic behavior of Ṁ as a function of Teff is expected (the so-called “bi-stability jumps”): normally the lower the temperature, the lower the mass loss rate (because the radiation pressure is proportional to T4). However, when the temperature drops below ~ 25 000 K, the recombination of Fe IV → Fe III provides a new ion with an increased number of lines to drive the wind, resulting in an increased mass loss rate at lower temperatures around Teff ~ 25 000 K. This happens with different iron ion recombinations also at Teff ~ 12 000 K.
Vink et al. (2000, 2001) provide two different formulae for above and below Teff ~ 25 000 K,  (A.1)for 27 500 K <Teff ≤ 50 000 K, and
(A.1)for 27 500 K <Teff ≤ 50 000 K, and  (A.2)for 12500 K <Teff ≤ 22500 K. In between these two temperature ranges, it is common practice to simply interpolate between the two formulae (cf. Appendix B). The numbers in parenthesis are the estimates of the error on the last digit reported, according to Vink et al. (2001). These error estimates are usually neglected in stellar evolutionary calculations.
(A.2)for 12500 K <Teff ≤ 22500 K. In between these two temperature ranges, it is common practice to simply interpolate between the two formulae (cf. Appendix B). The numbers in parenthesis are the estimates of the error on the last digit reported, according to Vink et al. (2001). These error estimates are usually neglected in stellar evolutionary calculations.
Appendix A.2: Kudritzki et al. (K)
The mass loss algorithm proposed by Kudritzki et al. (1989) is based on an analytic solution of the equations for a stationary, isothermal, spherically-symmetric, ideal (neither viscosity nor heat conduction) gas flow with no magnetic fields and no rotation. They include the radiative acceleration gph in the momentum equation using the standard parametrization of Castor et al. (1975; see also Eq. (16) in Pauldrach et al. 1986),  (A.3)where
(A.3)where  is the radiative acceleration due to Thomson scattering, and the second term in the brackets is the so-called “force multiplier”, that is the line acceleration in units of . It depends on the Thomson cross section σTh, the speed of sound cs, the electron number density ne, and three free parameters k, α, and δ. k can be interpreted roughly as the number of lines strong enough to have an effect, and α as the slope of the distribution of the number of lines as a function of their strength. The parameter δ and the correction factor CF, which is the ratio between the opacity as a function of the incoming angle and the opacity in the radial direction, are used to include the “finite cone-angle effect” to account for photons travelling in non-radial directions (e.g., Castor et al. 1975). If δ and CF were both equal to one, the parametrization would be valid only in the “radial streaming” limit (Abbott 1982; Pauldrach et al. 1986), that is considering only incoming photons from the radial direction. While this is a good approximation in the outer portion of the wind, where r ≫ R and R is the stellar radius, it is quite poor in the inner portion, where the mass loss rate is determined and photons traveling in non-radial directions can have a relevant effect. For completeness, we report the expression for the correction factor CF as a function of the dimensionless radial coordinate
is the radiative acceleration due to Thomson scattering, and the second term in the brackets is the so-called “force multiplier”, that is the line acceleration in units of . It depends on the Thomson cross section σTh, the speed of sound cs, the electron number density ne, and three free parameters k, α, and δ. k can be interpreted roughly as the number of lines strong enough to have an effect, and α as the slope of the distribution of the number of lines as a function of their strength. The parameter δ and the correction factor CF, which is the ratio between the opacity as a function of the incoming angle and the opacity in the radial direction, are used to include the “finite cone-angle effect” to account for photons travelling in non-radial directions (e.g., Castor et al. 1975). If δ and CF were both equal to one, the parametrization would be valid only in the “radial streaming” limit (Abbott 1982; Pauldrach et al. 1986), that is considering only incoming photons from the radial direction. While this is a good approximation in the outer portion of the wind, where r ≫ R and R is the stellar radius, it is quite poor in the inner portion, where the mass loss rate is determined and photons traveling in non-radial directions can have a relevant effect. For completeness, we report the expression for the correction factor CF as a function of the dimensionless radial coordinate  and
and  , cf. Eq. (4) in Kudritzki et al. (1989),
, cf. Eq. (4) in Kudritzki et al. (1989),  (A.4)We refer the reader to Castor et al. (1975), Pauldrach et al. (1986), Vink (2015) and references therein for more details on this parametrization.
(A.4)We refer the reader to Castor et al. (1975), Pauldrach et al. (1986), Vink (2015) and references therein for more details on this parametrization.
To find an analytic solution to their model, further assumptions are needed. Kudritzki et al. (1989) impose a “β-law” velocity field (a common assumption found to be close to numerical solutions, see Lamers 2013),  (A.5)where β is a free parameter assumed to be β = 1, v∞ is the asymptotic velocity of the wind and R is the stellar radius. This assumption means Kudritzki et al. (1989) do not solve for the dynamics of the system, but rather assume the velocity structure and solve self-consistently for the density and the acceleration. In the limit where v ≫ cs (reasonable in the outer portion of the wind), Kudritzki et al. (1989) find a solution of the form
(A.5)where β is a free parameter assumed to be β = 1, v∞ is the asymptotic velocity of the wind and R is the stellar radius. This assumption means Kudritzki et al. (1989) do not solve for the dynamics of the system, but rather assume the velocity structure and solve self-consistently for the density and the acceleration. In the limit where v ≫ cs (reasonable in the outer portion of the wind), Kudritzki et al. (1989) find a solution of the form  (A.6)where vth is the thermal velocity of protons, k, α, and δ are the free parameters, L is the luminosity, vth is the thermal velocity, Γ = L/LEdd is the Eddington ratio, and
(A.6)where vth is the thermal velocity of protons, k, α, and δ are the free parameters, L is the luminosity, vth is the thermal velocity, Γ = L/LEdd is the Eddington ratio, and 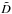 is a function of the free parameters and the velocity (cf. Eqs. (47), (62), (65) in Kudritzki et al. 1989).
is a function of the free parameters and the velocity (cf. Eqs. (47), (62), (65) in Kudritzki et al. 1989).
The main limitation of Eq. (A.6) is that the parameters k, α and δ are not constants, but rather depend on the optical depth. The numerical values commonly adopted are α = 0.657, β = 1, δ = 0.095, and k = 0.085 and they are calibrated on ζ Puppis by Pauldrach et al. (1994). These should be interpreted as values averaged over the optical depth.
Appendix A.3: de Jager et al. (dJ)
The wind algorithm proposed by de Jager et al. (1988) is an empirical relationship of the form Ṁ ≡ Ṁ(Teff,L). This choice of variables uses only observable quantities, making it easy to track the mass loss rate while the star moves on the HR diagram. This allows a better understanding of how mass loss changes during stellar evolution. The drawback is that no information about the physical mechanism driving the wind is considered.
To formulate a reliable mass loss algorithm, de Jager et al. (1988) collect from the literature mass loss rates observed with different techniques for a sample of galactic stars with spectral types from O to M. They determine the “average” measured mass loss rate for stars observed with multiple techniques and the deviation from this average for each available measurement and for each star. Then, they define the “average intrinsic error per determination” as the one-sigma value of the distribution of these deviations. They fit their entire data sample with a sum of Chebychev polynomials of the first kind Tn(x) = cos(n arccos(x)):  (A.7)What is commonly used in stellar evolution codes is the first-order approximation to Eq. (A.7),
(A.7)What is commonly used in stellar evolution codes is the first-order approximation to Eq. (A.7), ![Mathematical equation: \appendix \setcounter{section}{1} \begin{equation} \label{eq:dejager} \log_{10}(-\dot{M}) = 1.769\log_{10}(L/L_\odot)-1.676\log_{10}(T_\mathrm{eff}/[\mathrm{K}])-8.158 . \end{equation}](/articles/aa/full_html/2017/07/aa30698-17/aa30698-17-eq382.png) (A.8)To asses the quality of this fit, they derive the distribution of the differences between the observed values of log 10( − Ṁ) with the result of Eq. (A.8). The standard deviation of this distribution is ~ 0.45, slightly larger than the “averaged intrinsic error per determination” previously determined. This indicates that quantities other than Teff and L must physically enter in the determination of Ṁ, and the parametrization in Eq. (A.8) is incomplete. The main limitation of the dJ algorithm is that it is representative of the “averaged statistical behavior” of stellar winds in the entire HR diagram, which might average over different physical regimes. It is important to note that WR and Be stars are intentionally excluded from the data sample used to derive Eq. (A.8).
(A.8)To asses the quality of this fit, they derive the distribution of the differences between the observed values of log 10( − Ṁ) with the result of Eq. (A.8). The standard deviation of this distribution is ~ 0.45, slightly larger than the “averaged intrinsic error per determination” previously determined. This indicates that quantities other than Teff and L must physically enter in the determination of Ṁ, and the parametrization in Eq. (A.8) is incomplete. The main limitation of the dJ algorithm is that it is representative of the “averaged statistical behavior” of stellar winds in the entire HR diagram, which might average over different physical regimes. It is important to note that WR and Be stars are intentionally excluded from the data sample used to derive Eq. (A.8).
Appendix A.4: Nieuwenhuijzen & de Jager (NJ)
The algorithm of Nieuwenhuijzen & de Jager (1990) is intended as an improvement over the de Jager et al. (1988) algorithm of Eq. (A.8), since it is derived from the same data sample with a similar method but includes the dependence of mass loss on the total stellar mass. The goal of this is to capture one of the missing stellar parameters entering in the mass loss determination indicated by the large standard deviation of Eq. (A.8). The Nieuwenhuijzen & de Jager (1990) algorithm also translates the temperature dependence into a radius dependence.
Since the total mass is not a directly observable quantity for single stars, the authors’ mass determination is based on stellar model calculations. The theoretical models used are from Maeder & Meynet (1988, 1989). However, different stellar evolution codes consider a large variety of physical processes (e.g., for mixing, mass loss, etc.), or just use different implementations of them. Hence, there is spread in the stellar masses found at the same point of an evolutionary track. This implies that the Nieuwenhuijzen & de Jager (1990) mass loss algorithm depends on the set of stellar models used to derive it. This drawback applies to all mass loss algorithms involving a functional dependence of the form Ṁ ≡ Ṁ(M) derived from stellar evolution calculations. However, Mauron & Josselin (2011) suggests that the dependence on the total mass of the Nieuwenhuijzen & de Jager (1990) mass loss rate is so weak (see Eq. (A.11)) that it can be averaged (by substituting M, which changes during the evolution, with a constant value) without dramatic consequences on the evolved stellar model.
Stars with different masses pass through the same point on the HR diagram at different stages of their evolution. Therefore, in order to include the total mass as a variable for the mass loss rate, Nieuwenhuijzen & de Jager (1990) determine an “average expected mass”  of a star at a given (Teff,L) point. This value is derived as follows. The authors define a “dwell time” representing the time for a star to travel over a unit length track on the HR diagram,
of a star at a given (Teff,L) point. This value is derived as follows. The authors define a “dwell time” representing the time for a star to travel over a unit length track on the HR diagram, ![Mathematical equation: \appendix \setcounter{section}{1} \begin{equation} \label{eq:dwell_time} t^{(d)} \udef \frac{\delta t}{\sqrt{[\delta \log_{10}(T_\mathrm{eff}/ \mathrm{[K]})]^2+[\delta \log_{10}(L/L_\odot)]^2}} , \end{equation}](/articles/aa/full_html/2017/07/aa30698-17/aa30698-17-eq387.png) (A.9)where δt is the time spent to travel over the (δlog 10(Teff/ [ K ] ),δlog 10(L/L⊙)) distance.
(A.9)where δt is the time spent to travel over the (δlog 10(Teff/ [ K ] ),δlog 10(L/L⊙)) distance.
For every point on the HR diagram, there are N left-ward or right-ward subtracks of the stellar evolutionary tracks crossing it. Let  be the dwell time for the n-th subtrack. The average expected mass is obtained as:
be the dwell time for the n-th subtrack. The average expected mass is obtained as: 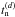 (A.10)where Ψ is the initial mass function for stars on the subtrack considered, and dMn/ dlog 10(L/L⊙) is the density of tracks over a unit log 10(L/L⊙) interval.
(A.10)where Ψ is the initial mass function for stars on the subtrack considered, and dMn/ dlog 10(L/L⊙) is the density of tracks over a unit log 10(L/L⊙) interval.
The authors perform a fit of the data set5 used in de Jager et al. (1988), adding the value of from Eq. (A.10) to the set, and they find the interpolation formula6 (where is substitued by the total mass M to use the formula in a stellar evolution simulation)  (A.11)With the inclusion of M among the parameters determining Ṁ, Nieuwenhuijzen & de Jager (1990) obtain a standard deviation of ~ 0.37 for the distribution of the differences between the prediction of Eq. (A.11) and the observed values, comparable to the standard deviation of the distribution of the differences between individual mass loss determination used as input data. The main limitations of this algorithm are its dependence on the input stellar models, and its statistical-average nature (in the same sense as de Jager et al. 1988).
(A.11)With the inclusion of M among the parameters determining Ṁ, Nieuwenhuijzen & de Jager (1990) obtain a standard deviation of ~ 0.37 for the distribution of the differences between the prediction of Eq. (A.11) and the observed values, comparable to the standard deviation of the distribution of the differences between individual mass loss determination used as input data. The main limitations of this algorithm are its dependence on the input stellar models, and its statistical-average nature (in the same sense as de Jager et al. 1988).
Appendix A.5: Van Loon et al. (vL)
The mass loss rate of van Loon et al. (2005) is empirically determined on the basis of observations of a sample of oxygen-rich AGB and RSG stars in the Large Magellanic Cloud (LMC). The van Loon et al. (2005) analysis is based on a dust-driven wind model: AGB and RSG stars have very extended and cool envelopes where dust grains might form through sublimation. The photons from the radiation field transfer momentum to these grains, pushing them away. The dust grains drag the gas with them through collisional coupling. To obtain their mass loss algorithm, van Loon et al. (2005) fit the observed IR spectra to synthetic spectra obtained with a simple model of the gas/dust mixture (identical grains and dust-to-gas ratio set to the value observed at Z⊙ rescaled to ZLMC), using Teff and L as variables. They obtain the relationship  (A.12)where the numbers in parentheses indicate the estimated errors on the last digits. These errors are typically neglected in stellar evolution codes. The main limitation of this algorithm is the high uncertainty of the dust grain properties (mass fraction, opacity, when they form, etc.). Since it gives such a high mass loss rate, the van Loon et al. (2005) algorithm is sometimes combined with a high efficiency factor to ad hoc mimic non-wind mass loss phenomena (e.g., Meynet et al. 2015).
(A.12)where the numbers in parentheses indicate the estimated errors on the last digits. These errors are typically neglected in stellar evolution codes. The main limitation of this algorithm is the high uncertainty of the dust grain properties (mass fraction, opacity, when they form, etc.). Since it gives such a high mass loss rate, the van Loon et al. (2005) algorithm is sometimes combined with a high efficiency factor to ad hoc mimic non-wind mass loss phenomena (e.g., Meynet et al. 2015).
Appendix A.6: Nugis & Lamers (NL)
The mass loss algorithm derived by Nugis & Lamers (2000) applies only to WR stars. The wind mass loss rate of these stars depends strongly on their chemical composition: not only the metallicity has an important role, but also the helium mass fraction Y. This is because the amount of helium in the stellar atmosphere influences its temperature and therefore the ionization fraction and the level populations of all other atoms and ions. Nugis & Lamers (2000) derive a mass loss rate algorithm as a function of the luminosity and the chemical composition starting from a relevant sample of observed galactic WR stars. Their sample is made of two subsets of stars: one in which both mass and distance (i.e., luminosity) are known, thanks to binarity and membership association in open clusters; and another subset for which the intrinsic luminosity is not known. They use stars from the first subset to derive an empirical bolometric correction7. They then use a theoretical mass-luminosity relation to infer the luminosity of stars in the second subset, and correct it with the previously derived bolometric correction. We note that the mass-luminosity relation is determined using as input the age of the star and its spectral type, not its luminosity, therefore this relation can be consistently used to estimate the luminosity of stars in the second subset (Nugis & Lamers 2000).
The mass loss rate observed for the stars in the sample are then fitted as follows. The authors make two independent fits for stars of different composition and then merge them together in a single formula, valid for all WR stars:  (A.13)where the numbers in parentheses are the estimates of the error on the last digits reported. According to Nugis & Lamers (2000), the mass loss algorithm for WR stars cannot be expressed as a function of Teff and/or the radius of the star R. This is because WR winds are so strong (i.e., dense) that they are optically thick, and thus the observed radius is a function of the wavelength: the black body relation
(A.13)where the numbers in parentheses are the estimates of the error on the last digits reported. According to Nugis & Lamers (2000), the mass loss algorithm for WR stars cannot be expressed as a function of Teff and/or the radius of the star R. This is because WR winds are so strong (i.e., dense) that they are optically thick, and thus the observed radius is a function of the wavelength: the black body relation  , where σ is the Stefan-Boltzmann constant, loses its meaning.
, where σ is the Stefan-Boltzmann constant, loses its meaning.
Appendix A.7: Hamann et al. (H)
This wind scheme, which applies only to WR stars, is a combination of the algorithms from Hamann et al. (1982), Hamann et al. (1995), and Hamann & Koesterke (1998). It is derived from a spherically-symmetric, homogeneous, and stationary (but not static, i.e., ∂t = 0 but v ≠ 0) expanding WR atmosphere model. The authors assume an ad-hoc velocity structure v ≡ v(r) as follows. For the supersonic part of the wind, they assume a β-law of the form of Eq. (A.5) with β = 1, while for the subsonic part, v(r) is chosen in such way that the density approaches the hydrostatic limit. These assumptions are in reasonable agreement with the numerical solutions. Since the velocity field is imposed, the acceleration is not computed. This allows the authors to adopt a very simple chemical composition, since they do not need to evaluate the line-driven acceleration and do not need to keep track of all atomic/ionic species and their level populations. The authors include only ions of H and He, and the radiation field is considered only to determine non-LTE populations of these species. The temperature stratification is derived with the assumption of a gray LTE model, assuming a value of Teff at the base of the atmosphere determined by the stellar luminosity L and the radius R via a black body relation  , in contrast to the suggestion of Nugis & Lamers (2000). A synthetic spectrum is derived from the simulations and a best fit to the observed line profiles for the ions of H and He is obtained via variation of the stellar parameters (i.e., the radius of the inner boundary of the atmosphere R and the luminosity L, the surface hydrogen mass fraction Xs and Ṁ, Hamann et al. 1995). Once the stellar parameters are known from this fit, a mass loss formula is derived for high luminosity WR stars, i.e., log 10(L/L⊙) > 4.5. The algorithm for the low luminosity WR stars, i.e., log 10(L/L⊙) < 4.5, is derived with a similar technique in Hamann et al. (1982), but the spectra fitted are from a small sample of Helium stars (i.e., stars undergoing He shell burning with most of the mass in a CO core, without H lines in their spectra). The resulting formula is
, in contrast to the suggestion of Nugis & Lamers (2000). A synthetic spectrum is derived from the simulations and a best fit to the observed line profiles for the ions of H and He is obtained via variation of the stellar parameters (i.e., the radius of the inner boundary of the atmosphere R and the luminosity L, the surface hydrogen mass fraction Xs and Ṁ, Hamann et al. 1995). Once the stellar parameters are known from this fit, a mass loss formula is derived for high luminosity WR stars, i.e., log 10(L/L⊙) > 4.5. The algorithm for the low luminosity WR stars, i.e., log 10(L/L⊙) < 4.5, is derived with a similar technique in Hamann et al. (1982), but the spectra fitted are from a small sample of Helium stars (i.e., stars undergoing He shell burning with most of the mass in a CO core, without H lines in their spectra). The resulting formula is  (A.14)Improvements that take into account inhomogeneities in the wind are suggested in Hamann & Koesterke (1998). Specifically, the authors suggest to reduce the wind efficiency by a factor between 2 and 3 to account for the wind clumpiness, which strongly affects the fitted spectral lines.
(A.14)Improvements that take into account inhomogeneities in the wind are suggested in Hamann & Koesterke (1998). Specifically, the authors suggest to reduce the wind efficiency by a factor between 2 and 3 to account for the wind clumpiness, which strongly affects the fitted spectral lines.
Appendix B: MESA input physics, customization, and resolution study
Here, we provide and discuss the MESA parameters not directly related to the physics of mass loss that we omit in Sect. 2 for brevity.
We employ the Ledoux criterion (Ledoux 1947) to determine convective stability. This means that we consider the effects of the temperature and chemical composition gradients on the stability of a region, and allow for semiconvective mixing driven by compositional gradients. We follow the suggestions of Sukhbold & Woosley (2014) for the treatment of convective mixing (relying on mixing length theory; Böhm-Vitense 1958) and overshooting, but we also include thermohaline mixing using the default MESA treatment of this process (Kippenhahn et al. 1980). Our specific MESA parameter choices are as follows: mixing length parameter αmlt = 2, exponential overshooting/undershooting parameters fov = 0.025 and f0 = 0.05 for all regions (see Moravveji et al. 2016; Paxton et al. 2011), semiconvection efficiency of 0.2, and thermohaline mixing with coefficient 2 according to Kippenhahn et al. (1980).
We employ the 45-isotope nuclear reaction network mesa_45.net (in $MESA_DIR/data/net_data/nets/) for all models until oxygen depletion. We switch to a customized 203-isotope network for models evolved further, and initialize to zero the abundances of all the new isotopes introduced (i.e., adjust_abundances_for_new_isos = .false.). We obtain the 203-isotope network by taking the union of the isotope sets of mesa_45.net and mesa_201.net. The list of isotopes included in the network is available at https://stellarcollapse.org/renzo2017.
Stars more massive than ~ 20 M⊙ can develop a radiation-dominated, near super-Eddington convective envelope (e.g., because of the iron opacity bump) in which the convective flux is not sufficient to transport energy outward. This can lead to numerical (and possibly physical, e.g., Langer 1997) density and pressure inversions and consequently dynamical instabilities (see, e.g., Joss et al. 1973; Paxton et al. 2013, and references therein). To handle these envelope issues, MESA introduces the so-called MLT++ scheme (see Paxton et al. 2013). MLT++ arbitrarily decreases the superadiabaticity in near-to-Eddington (L ≥ 0.5LEdd) radiation dominated (Pgas/Ptot ≤ 0.35) convective envelopes in order to prevent numerical issues. We note that MLT++ can modify the radius and luminosity of the star by artificially enhancing the energy flux carried by convection, and thus indirectly, it can also change the mass loss rate. Furthermore, we find that MLT++ combined with the simple_atmosphere option for the outer boundary condition causes an unphysical oscillation of the mass loss rate and surface characteristics (e.g., luminosity L, effective temperature Teff, and radius R; Renzo 2015). To avoid this issue, we employ the more realistic atmosphere boundary condition provided by the Eddington_grey option in all our models. This uses the Eddington gray T(τ) relation,  (B.1)to find the boundary pressure on the photosphere, instead of guessing the approximate photosphere location.
(B.1)to find the boundary pressure on the photosphere, instead of guessing the approximate photosphere location.
 |
Fig. B.1 Time evolution of the mass loss rate around the bistability jump of the Vink et al. (2000; 2001; V) mass loss rate (Appendix A.1) in a M = 15 M⊙, η = 1.0 model at Z = Z⊙. The black dashed line is the effective temperature Teff, reached near the terminal age main sequence (TAMS, Xc< 0.01) in these simulations. The blue curve corresponds to the mass loss rate from the default MESA routine, which uses a linear interpolation between Eqs. (A.1) and (A.2). The red curve is the mass loss rate from our customized routine, where we interpolate using a hyperbolic tangent. |
At the beginning of each evolutionary step, MESA evaluates the mass loss rate Ṁ according to the algorithm specified by the user, and then removes from the surface the amount of mass Ṁ × Δt, where Δt is the timestep. The mass loss algorithm to evaluate Ṁ can be chosen from the many built-in algorithms, or it can be implemented by the user using the run_star_extras.f hooks to override the default MESA routines8. We use the latter option to combine three different algorithms (one for the hot phase of the evolution, one for the cool phase, and one for the WR phase, see Sect. 2.2). When possible, we call the built-in MESA mass loss routines from our run_star_extras.f, except for the V algorithm. The default implementation of the V mass loss algorithm in MESA uses a linear interpolation between Eqs. (A.1) and (A.2). This results in a jump of Ṁ (as a function of time t) with discontinuous derivative (i.e., M(t) is not  ) as Teff drops below 25 000 K during the evolution. For a physically more realistic, smoother time dependence of Ṁ, we implement a hyperbolic tangent interpolation between the two formulae. This is depicted in Fig. B.1.
) as Teff drops below 25 000 K during the evolution. For a physically more realistic, smoother time dependence of Ṁ, we implement a hyperbolic tangent interpolation between the two formulae. This is depicted in Fig. B.1.
To save MESA “photos”9 and to call the built-in implementation of the K algorithm from run_star_extras.f, we copy the Fortran modules write_model.mod and kuma.mod from $MESA_DIR/star/make into $MESA_DIR/include in our standard MESA installation. This is necessary since these two modules do not have a “public” interface (Paxton et al. 2011) in MESA release version 7624.
We describe the settings for spatial and temporal resultion in the next Sect. B.1. We use the default MESA settings for massive stars (see $MESA_DIR/star/inlist_massive_defaults) for anything else not explicitly mentioned.
Appendix B.1: Resolution dependence
Any computational study in astrophysics must carefully assess the effects of numerical resolution (in both space and time) on its results. To study the sensitivity of our results to variations in temporal and spatial resolution, we carry out a resolution study using a 30M⊙ star since stars of this MZAMS appeared to be the most sensitive to the resolution in our preliminary calculations using the default MESA parameters. The post core carbon depletion evolutionary tracks produced by the default MESA parameters show large amplitude oscillations (e.g., in the central temperature–central density plane) when varying the spatial discretization. It is unlikely that nature would do this. Thus, such oscillations are most likely artificial, and they are generally worse at higher initial mass. The aim of this section is to find a set of parameters that reduces and possibly eliminates these oscillations.
For each set of resolution parameters, we run our test model to oxygen depletion with two different mesh refinement parameters (mesh_delta_coeff=1.0 and mesh_delta_coeff=0.5), and two different wind mass loss algorithm combinations (V-dJ and K-NJ; both with η = 1.0). The use of two different mass loss algorithm combinations allows us to check that our settings are not cherry-picked for a particular model in our grid. However, the results of our study indicate that the resolution dependence is insensitive to the mass loss algorithm combination.
To obtain numerically converged results, we use both the available MESA controls (specified in the inlists) and customized routines in run_star_extras.f. Both are available at https://stellarcollapse.org/renzo2017/.
 |
Fig. B.2 Mass fractions, temperature, and density profiles (top three panels) at oxygen depletion and central temperature – central density evolutionary track (bottom panel) from ZAMS to core oxygen depletion for the MZAMS = 30 M⊙ test case with the V-dJ algorithm and η = 1.0. We run the test case at the standard spatial resolution (Δ ≡mesh_delta_coeff=1.0, dashed lines) and twice that resolution (Δ ≡mesh_delta_coeff=0.5, solid lines). |
Appendix B.1.1: Timestep selection throughout the evolution
To avoid overstepping relevant physical processes10, we enforce a customized timestep control for the evolution of our models (see the routine extras_finish_step in our run_star_extras.f). In particular, we tighten the default MESA (release version 7624) timestep controls by manually enforcing  (B.2)where Δtn + 1 is the timestep proposed at the end of the n − th step for the next ((n + 1) − th) step, and all the timescales on the right hand side refer to the n − th step. On the right hand side of condition B.2,
(B.2)where Δtn + 1 is the timestep proposed at the end of the n − th step for the next ((n + 1) − th) step, and all the timescales on the right hand side refer to the n − th step. On the right hand side of condition B.2,  (B.3)are the Kelvin-Helmholtz timescale and the mass change timescale, respectively.
(B.3)are the Kelvin-Helmholtz timescale and the mass change timescale, respectively.
The right-hand side of condition B.2 is evaluated with the quantities of the n − th step, but it limits the (n + 1) − th step. Moreover, until oxygen depletion, we limit the timestep by setting varcontrol_target = 1.0d-4 as the maximum relative variation for quantities in each computational cell. We also limit the amount of matter nuclearly processed in one single timestep by setting the maximum variation of the mass fraction of each element due to nuclear buring in each time step to dX_nuc_drop_limit = 1.0d-4.
Appendix B.1.2: Spatial meshing until oxygen depletion
Until oxygen depletion, we impose a maximum value for the fraction of the total mass in each computational cell by setting max_dq = 0.5d-4 in the inlist. This means that each of our models has at least 1 / max˙dq = 2 × 104 computational cells. Moreover, we refine the mesh around some specific regions of the star to focus resolution there:
-
Regions with steep temperature gradients: to better resolvethe deep interior of the star, we limit the maximum variation ofdlog 10(T) / dm across adjacent cells, where T is the temperature and m is the mass coordinate. Specifically, we impose a maximum variation of mesh_delta_coeff/ 10 for log 10(dlog 10(T) / dm + 1). This is is achieved using the other_mesh_fcns_data routine in run_star_extras.f;
-
Stellar surface: to properly resolve the amount of mass lost at each timestep, we impose that the outermost 0.5 M⊙ of the star is sampled by at least 500 × (mesh˙delta˙coeff)-1 cells (see other_mesh_fcns_data routine in run_star_extras.f for the implementation). We note that for each timestep Δt, Ṁ × Δt ≪ 0.5 M⊙;
-
Edges of burning regions: to resolve the edges of burning regions, we constrain the spatial variation of dlog 10(εnuc) / dlog 10(P) by multiplying its maximum allowed variation (regulated by mesh_delta_coeff) by 0.015 (as in Dessart et al. 2013, priv. comm.). This is done separately for each nuclear burning process, see mesh_dlog_*_dlogP_extra in the inlists;
-
Edges of the cores of different composition: to resolve sharp variations in the chemical composition, we impose mesh_delta_coeff/ 20 as the maximum spatial variation allowed for the mass fractions of several isotopes (1H, 4He, 12C, 16O, 20Ne, 28Si,24Mg, 32S, 54Fe, 56Fe). These are specified via xa_function_* in the inlists.
Our models with these settings and mesh_delta_coeff = 1.0 have typically between ~ 50 000 and ~ 100 000 mesh points. Figure B.2 illustrates for the model using the V-dJ-NL mass loss algorithm combination and η = 1.0 that our setup does not produce any appreciable variations when changing mesh_delta_coeff by a factor of 2 (corresponding to an increase of the number of spatial mesh points from 54 814 to 77 400 at oxygen depletion). We note the linear scale for the central temperature – central density evolutionary tracks.
Appendix B.1.3: Re-meshing after oxygen depletion
After oxygen depletion, we switch from a 45-isotope to a 203-isotope nuclear reaction network (cf. Appendix B). This switch forces us to decrease the number of spatial mesh points for the following reason: MESA solves the fully coupled set of equations for stellar structure and evolution Paxton et al. (2011). This results in the use of a work array of length ℒ which scales as  (B.4)where Niso is number of isotopes in the nuclear reaction network and Nz is the number of mesh points (see the routine get_newton_work_sizes in $MESA_DIR/star/ private/star_newton.f90). ℒ is stored as a 4-byte integer in MESA, which sets the maximum adressable memory to ~ 17 GB (R. Farmer, priv. comm.). Therefore, for a nuclear reaction network including ~ 200 isotopes, the maximum number of mesh points cannot exceed ~ 17 000. Changing the relevant variables to an 8-byte integer data type would require substantial changes throughout MESA, which we have opted to defer to future work.
(B.4)where Niso is number of isotopes in the nuclear reaction network and Nz is the number of mesh points (see the routine get_newton_work_sizes in $MESA_DIR/star/ private/star_newton.f90). ℒ is stored as a 4-byte integer in MESA, which sets the maximum adressable memory to ~ 17 GB (R. Farmer, priv. comm.). Therefore, for a nuclear reaction network including ~ 200 isotopes, the maximum number of mesh points cannot exceed ~ 17 000. Changing the relevant variables to an 8-byte integer data type would require substantial changes throughout MESA, which we have opted to defer to future work.
Another significant limitation on the resolution that can be achieved in the very late evolutionary phases is the stability of stellar evolution codes: many highly uncertain and/or poorly understood physical phenomena take place in the cores of evolved massive stars, and the evolutionary timescale gets progressively closer to the (neutrino-)thermal timescale and, finally, the dynamical timescale.
Experiments with the highest achievable resolution resulted in frequent failures of the code to find solutions to the stellar structure equations. However, note that by the time core oxygen burning is complete, the variations in core structure caused by different mass loss algorithm combinations are already largely developed and will be amplified by the subsequent evolution.
 |
Fig. B.3 Variations in the late-time evolution of the compactness parameter with spatial resolution. The magnitude of these variations is smaller than the variations caused by uncertainties in the wind mass loss. The curves start at oxygen depletion (after the re-meshing described in Appendix B.1.3) and end at the onset of core collapse. They correspond to 25 M⊙ models computed with a 203-isotope nuclear reaction network, using the V-vL algorithm and η = 0.33 and varying Δ≡mesh˙delta˙coeff, and Δhigh T≡mesh˙delta˙coeff˙for˙highT (higher numbers correspond to lower resolution, see text). The highest resolution model (cyan curve) is the model described in Sect. 3.7. |
We reduce the number of mesh points in our models down to a few thousand (the precise value varies from model to model). We do this by restarting from oxygen depletion and running MESA’s re-meshingalgorithm for 100 timesteps of Δt< 10-9 s with nuclear burning and neutrino cooling turned off (see inlist_remesh). At the same time, we shut down thermohaline mixing, which is a secular process that does not have time to produce any physically relevant change in the star after core oxygen burning. We also drop the spatial mesh refinement criteria described above for the remaining evolution. After the 100 re-meshing timesteps during which the star is de facto frozen in its state, we resume the evolution by again turning on nuclear burning and neutrino cooling and not imposing a maximum timestep, but we do not re-enable thermohaline mixing. We compare pre-re-meshing and post-re-meshing core structure, thermodynamics, and compactness parameter and ensure that the post-re-meshing core is still very well resolved with the reduced resolution as we proceed in the evolution toward core collapse.
As the temperature in the core increases, the nuclear burning rate accelerates. When the central temperature rises above 3 × 109 K, we progressively relax the constraints on the timestep from nuclear burning. We do this by modifying, at the beginning of each timestep, the parameters loaded in our inlist using the routine extras_startup of our run_star_extras.f. Specifically, for 3.0 ≤ Tc/ [ 109 K ] ≤ 3.5 we impose dX_nuc_drop = 5d-3, and for even higher Tc we only require dX_nuc_drop = 5d-2 (cf. Sect. B.1.1). After silicon core depletion (Xc(28Si) ≤ 0.001), we also decrease the spatial resolution of the innermost infalling core by increasing mesh_delta_coeff_for_highT=3.0 (used where log 10(T/ [ K ] ) ≥ 9.3, the value used during the previous evolution is 1.0).
Finally, an important question to address is the sensitivity to numerical resolution of the subsequent evolution toward core collapse and of the final pre-collapse structure and compactness parameter. Due to the memory limitations and computational difficulties described in the above, we are unable to carry out a rigorous convergence test with MESA at this time. However, in order to gain some insight into the effects of resolution, we choose the 25 M⊙ V-vL η = 0.33 model and carry out two additional simulations at reduced resolution from oxygen depletion to the onset of core collapse using our 203-isotope nuclear reaction network. Specifically, we choose (mesh_delta_coeff, mesh_delta_coeff_for_highT) = (1.75, 2.75) and (2, 3), whereas the standard setting for our models discussed in Sect. 3.7 is (1, 1). Figure B.3 shows the evolution of the compactness parameter from oxygen depletion (after re-meshing) to the onset of core collapse for these models. We find that these lower-resolution models evolve qualitatively very similar to our standard model, but produce variations in the pre-SN compactness parameter of about ~9%, which is smaller than the variations of ~ 30% caused by different wind mass loss algorithm combinations.
All Tables
Approximate scaling of the mass loss rate with luminosity and effective temperature, log 10(Ṁ) ∝ αlog 10(L) + βlog 10(Teff), predicted by the considered mass loss algorithms.
Model summary at the end of the mass loss phase (when Tc ≥ 109 K, roughly corresponding to neon core ignition).
Maximum spread in total mass, core masses, and radius at the end of the mass loss phase, for models differing in mass loss algorithm combination and efficiency η.
Stellar properties at the end of hot phase, when Teff decreases below 15 000 K for the first time.
Stellar properties at core oxygen depletion, i.e. Xc(16O) < 0.04 and Xc(28Si) > 0.01.
Properties of the subset of models run to the onset of core collapse, defined as the time when max { | v | } ≥ 103 km s-1.
Functional dependence of the mass loss rate Ṁ on stellar and wind parameters for each algorithm combination and mass loss phase.
All Figures
|
Fig. 1 Uncertainty in the mapping between MZAMS and the relative final mass M/MZAMS due to wind mass loss. Each colored bar corresponds to a specific wind algorithm combination defined in Table 2. The pluses, crosses, and circles correspond to η = 1.0, 0.33, 0.1, respectively. We employ the vertical bars to emphasize the spread. The uncertainty in wind mass loss limits the predictive power of stellar evolution studies for the final mass of stars of given initial mass. Only models with MZAMS = 35 M⊙ and wind efficiency η = 1 reach the WR stage (cf. Table 4 and Sect. 3.4). They are shown in the rightmost panel and we list the WR mass loss algorithm only for them. The maximum relative mass for the four algorithm combinations using the H WR mass loss algorithm in the rightmost panel are the results obtained using the corresponding hot and cool mass loss combination with η = 0.1 (not reaching the WR phase). |
| In the text | |
|
Fig. 2 Total stellar mass as a function of time for the 15 M⊙ models. Each color corresponds to a given combination of wind algorithms (see Table 2). None of these 15 M⊙ models reach the WR phase. The solid, dashed, and dot-dashed curves correspond to efficiency η = 0.1, 0.33, 1.0, respectively, regardless of color. The red vertical line indicates roughly the terminal age main sequence (TAMS, i.e., Xc< 0.01). The enhanced mass loss of models using the Vink et al. (2000; 2001; V) algorithm close to TAMS in the left panel is due to the bistability jump, see Sect. 3.2. The left panel has a different vertical scale to magnify the differences in the tracks during the main sequence evolution. |
| In the text | |
|
Fig. 3 Mass loss rate during the hot evolutionary phase (including the main sequence, see Sect. 2.2) as a function of time for all computed MZAMS and wind efficiency η = 1. The solid and dashed curves are computed using the V (Vink et al. 2000, 2001) and K (Kudritzki et al. 1989) mass loss algorithm, respectively. The rapid rise of the solid curves is due to the inclusion of the bistability jump (see Sect. 3.2). The qualitative behavior of the curves shown does not change substantially when varying η. The curves end when Teff = 15 000 K. |
| In the text | |
|
Fig. 4 Top panel: time evolution of the compactness parameter ξ2.5 for all MZAMS = 25 M⊙ models computed until oxygen depletion. Bottom panel: central temperature and density for the same models from when the central density increases above 106 g cm-3. All curves end at oxygen depletion (Xc(16O) ≤ 0.04 and Xc(28Si) ≥ 0.01). The color indicates the wind algorithm combination, labeled according to Table 2. Dot-dashed, dashed, and solid curves are calculated using η = 0.1, 0.33, 1.0, respectively. We only show models listed in Table 7. The vertical dot-dashed lines in the top panel approximately indicate core hydrogen exhaustion (TAMS), core helium exhaustion (Yc ≃ 0), and end of the mass loss phase (Tc ≥ 109 K). |
| In the text | |
|
Fig. 5 Compactness parameter at oxygen depletion Xc(16O) ≤ 0.04 and Xc(28Si) ≤ 0.01. Each color corresponds to a wind algorithm combination (top axis), and each panel shows a different initial mass, indicated on the bottom. Crosses, pluses, and circles correspond to η = 0.1, 0.33, 1.0, respectively. We show only the models listed in Table 7. The vertical spread indicates different core structures, which will evolve differently to the onset of core collapse, and possibly result in different SN outcomes. |
| In the text | |
|
Fig. 6 Time evolution of the compactness parameter ξ2.5 (top panel) and evolution in ρc−Tc space (bottom panel) from oxygen depletion to the onset of core collapse. Solid curves correspond to 15 M⊙ models computed with η = 1.0, dashed and dot-dashed curves correspond to 25 M⊙ and 30 M⊙ models, respectively, computed with η = 0.33. The vertical dot-dashed line in the top panel indicates roughly the time of core silicon depletion (X(28Si) ≤ 0.01). |
| In the text | |
|
Fig. 7 Neutrino luminosity from oxygen depletion to core collapse for the 15 M⊙ model run with the V-NJ scheme and η = 1.0. This shows that variations in the nuclear burning rate cause the oscillations in ξ2.5. The red curve shows only neutrinos coming from nuclear reactions, the cyan curve shows thermal neutrinos, and the blue curve is the sum of the two. The dotted line shows the compactness parameter (right hand side vertical axis). The vertical dot-dashed line indicates the approximate time of core silicon depletion. The ξ2.5 oscillations are driven by variations in silicon and oxygen shell burning. |
| In the text | |
|
Fig. 8 Chemical composition profiles at the onset of core collapse. We show all models computed to this point and listed in Table 8. Blue, cyan, yellow, green, magenta, orange, and gray curves correspond to the mass fractions of 1H, 4He,12C, 16O, 20Ne, 28Si, and iron group elements (i.e., with atomic number 50 ≤ A ≤ 70), respectively. Note the different horizontal scale in each panel. |
| In the text | |
|
Fig. 9 Spread in pre-SN appearance due to the uncertainty in wind mass loss. Each color represents an initial mass MZAMS, each marker corresponds to a different efficiency factor η. The vertical dot-dashed lines indicate the BSG-YSG boundary, and YSG-RSG boundary according to Georgy et al. (2017). 35 M⊙ models exhibit a larger spread, because some models (indicated by a thick black edge on their markers) develop into WR stars. |
| In the text | |
|
Fig. B.1 Time evolution of the mass loss rate around the bistability jump of the Vink et al. (2000; 2001; V) mass loss rate (Appendix A.1) in a M = 15 M⊙, η = 1.0 model at Z = Z⊙. The black dashed line is the effective temperature Teff, reached near the terminal age main sequence (TAMS, Xc< 0.01) in these simulations. The blue curve corresponds to the mass loss rate from the default MESA routine, which uses a linear interpolation between Eqs. (A.1) and (A.2). The red curve is the mass loss rate from our customized routine, where we interpolate using a hyperbolic tangent. |
| In the text | |
|
Fig. B.2 Mass fractions, temperature, and density profiles (top three panels) at oxygen depletion and central temperature – central density evolutionary track (bottom panel) from ZAMS to core oxygen depletion for the MZAMS = 30 M⊙ test case with the V-dJ algorithm and η = 1.0. We run the test case at the standard spatial resolution (Δ ≡mesh_delta_coeff=1.0, dashed lines) and twice that resolution (Δ ≡mesh_delta_coeff=0.5, solid lines). |
| In the text | |
|
Fig. B.3 Variations in the late-time evolution of the compactness parameter with spatial resolution. The magnitude of these variations is smaller than the variations caused by uncertainties in the wind mass loss. The curves start at oxygen depletion (after the re-meshing described in Appendix B.1.3) and end at the onset of core collapse. They correspond to 25 M⊙ models computed with a 203-isotope nuclear reaction network, using the V-vL algorithm and η = 0.33 and varying Δ≡mesh˙delta˙coeff, and Δhigh T≡mesh˙delta˙coeff˙for˙highT (higher numbers correspond to lower resolution, see text). The highest resolution model (cyan curve) is the model described in Sect. 3.7. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.