| Issue |
A&A
Volume 588, April 2016
|
|
|---|---|---|
| Article Number | A31 | |
| Number of page(s) | 7 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/201527899 | |
| Published online | 14 March 2016 | |
Uncovering the planets and stellar activity of CoRoT-7 using only radial velocities ⋆
1
Instituto de Astrofísica e Ciências do Espaço, Universidade do
Porto,
CAUP, Rua das Estrelas,
4150-762
Porto,
Portugal
e-mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Física e Astronomia, Faculdade de Ciências,
Universidade do Porto, Rua Campo
Alegre, 4169-007
Porto,
Portugal
3
Harvard-Smithsonian Center for Astrophysics, 60 Garden
Street, Cambridge,
MA
02138,
USA
4
Department of Statistics, The University of
Auckland, Private Bag
92019, 1142
Auckland, New
Zealand
5
Institut für Astrophysik, Georg-August-Universität,
Friedrich-Hund-Platz 1,
37077
Göttingen,
Germany
Received: 4 December 2015
Accepted: 27 January 2016
Abstract
Stellar activity can induce signals in the radial velocities of stars, complicating the detection of orbiting low-mass planets. We present a method to determine the number of planetary signals present in radial-velocity datasets of active stars, using only radial-velocity observations. Instead of considering separate fits with different number of planets, we use a birth-death Markov chain Monte Carlo algorithm to infer the posterior distribution for the number of planets in a single run. In a natural way, the marginal distributions for the orbital parameters of all planets are also inferred. This method is applied to HARPS data of CoRoT-7. We confidently recover the orbits of both CoRoT-7b and CoRoT-7c although the data show evidence for the presence of additional signals.
Key words: methods: data analysis / planetary systems / stars: individual: CoRoT-7 / techniques: radial velocities
All data and software presented in this article are available online at https://github.com/j-faria/exoBD-CoRoT7
© ESO, 2016
1. Introduction
Imagine we have at our disposal a set of spectroscopic observations of an unknown star, and we can obtain precise radial-velocity (RV) measurements, using the cross-correlation function (CCF) technique (Baranne et al. 1996; Pepe et al. 2002). The so-called line profile indicators (such as the full width at half maximum of the CCF, its bisector span, and associated quantities, e.g. Figueira et al. 2013) and activity indicators, like the 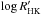 (Noyes et al. 1984), are also usually available but are not necessary for our analysis. And without other instruments at hand, we cannot measure the star’s photometric variations, as is the case for most targets in RV surveys.
(Noyes et al. 1984), are also usually available but are not necessary for our analysis. And without other instruments at hand, we cannot measure the star’s photometric variations, as is the case for most targets in RV surveys.
Armed with some statistical artillery, we aim to answer the following question: how many orbiting planets can be confidently detected in these data, and what are their orbital parameters and minimum masses?
Besides planets, other physical processes can induce variations in the radial velocities of a star. These include stellar oscillations, granulation, spots and faculae/plages, and long-term magnetic activity cycles (see, e.g. Saar & Donahue 1997; Santos et al. 2010; Boisse et al. 2011; Dumusque et al. 2011a). Some of these activity-induced signals can be mitigated or averaged out by adapting the observational strategy (Dumusque et al. 2011b). But signals caused by the presence of active regions on the stellar surface can show periodicities and amplitudes similar to the ones induced by real planetary signals, and may be harder to disentangle. Indeed, these signals can even mimic planetary signals (e.g. Figueira et al. 2010; Santos et al. 2014; Robertson et al. 2015).
Simultaneous photometric and RV observations have been successfully used to constrain activity-induced RV signals. However, this approach requires either a joint model for photometric and RV variations, which can be statistical (e.g. Rajpaul et al. 2015) or based on a description of the stellar features inducing the signal (e.g. Lanza et al. 2010), or a conversion from photometric variations to RV variations (e.g. Haywood et al. 2014, hereafter H14).
Here we present a framework that models activity-induced signals as correlated noise in the RV observations and does not require simultaneous photometric observations. The method is based on the fact that, for data of sufficient quality, it is possible to distinguish if an oscillating signal has the Keplerian shape that is expected from a planet, or some other approximately-periodic shape as expected from stellar activity. Below we describe our model and apply it to High Accuracy Radial Velocity Planet Searcher (HARPS; Mayor et al. 2003) observations of CoRoT-7.
2. A Bayesian model for RV data
In this section we present in detail our model for RV data and describe the two types of signals we consider: planetary signals and activity-induced noise.
2.1. RV planetary signals
The dynamical evolution of a planetary system is governed by the gravitational interactions of its constituent bodies. For most systems with multiple planets one can assume, to a good approximation, that the mutual planetary perturbations are negligible on timescales that are comparable to the duration of observations. The stellar RV perturbations that are due to a multiple-planet system can then be modelled as a linear superposition of Keplerian orbits.
Each Keplerian can be described with five RV observables: the semi-amplitude K, the orbital period P, the eccentricity e, an orbital phase φ, and the longitude of the line-of-sight, ω. We also consider a systemic velocity, vsys, of the centre of mass of the system, which corresponds to an RV zero-point measured by HARPS.
2.2. Gaussian processes to model stellar activity
Even if activity signals cannot be easily described analytically (a complete description would require knowledge of the active region distribution and evolution, temperature contrast and stellar parameters, such as inclination and limb darkening), we can make some assumptions about their form. Besides assuming the signals will be continuous and smooth, stellar rotation induces a periodicity or quasi-periodicity, as active regions evolve and cycle in and out of view on the stellar surface.
For the purposes of detecting planets using RV measurements, the signals caused by stellar activity can then be seen as correlated quasi-periodic noise. Gaussian processes (GP) are an increasingly common tool to deal with correlated noise (e.g. Roberts et al. 2012). In their application to regression problems, GPs can be seen as prior distributions over functions, which will be constrained by the data (e.g. Rasmussen & Williams 2006). For our purposes, we use the GP to model the stochastic component of our signal – that is, the stellar noise.
A GP is defined by its mean function, the deterministic component of the signal, and its covariance function, which defines the overall behaviour of the functions under the GP distribution. When the covariance function is evaluated at the observed times, the covariance matrix is obtained. From the many possible choices for a covariance function, the quasi-periodic kernel is the most widely used in the exoplanet literature (e.g. H14; Grunblatt et al. 2015; Rajpaul et al. 2015), which results in a covariance matrix of the form ![Mathematical equation: \begin{equation} \label{eq:covariance_matrix} \Sigma_{ij} = \eta_1^2 \exp\left[ - \frac{(t_i - t_j)^2}{2\eta_2^2} - \frac{2\sin^2\left(\frac{\pi (t_i-t_j)}{\eta_3}\right)}{\eta_4^2} \right] + \left( \sigma_i^2 + s^2 \right) \delta_{ij} \text{.} \end{equation}](/articles/aa/full_html/2016/04/aa27899-15/aa27899-15-eq8.png) (1)This represents some of our expectations for the activity-induced RV signals: the correlations decay on a timescale of η2 days and have a periodic component with period η3 days. The parameter η4 controls the relative importance of the periodic and decaying components. The parameter η1 represents the amplitude of the correlations. This covariance matrix also takes additional uncorrelated noise into account, added quadratically to the diagonal, where σi are the reported RV uncertainties and s is a free parameter.
(1)This represents some of our expectations for the activity-induced RV signals: the correlations decay on a timescale of η2 days and have a periodic component with period η3 days. The parameter η4 controls the relative importance of the periodic and decaying components. The parameter η1 represents the amplitude of the correlations. This covariance matrix also takes additional uncorrelated noise into account, added quadratically to the diagonal, where σi are the reported RV uncertainties and s is a free parameter.
2.3. The complete model
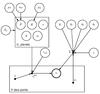 |
Fig. 1 Representation of the relations between parameters and observations in our RV model, as a probabilistic graphical model. An arrow between two nodes indicates the direction of conditional dependence. The circled nodes are the parameters of the model, whose joint distribution is sampled by the Markov chain Monte Carlo (MCMC) algorithm. The double circled node vi represents the observed RVs. The filled nodes represent deterministic variables: if these variables have parent nodes ( |
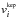
Our complete model for the RV observations is shown in Fig. 1, in the form of a probabilistic graphical model. The diagram relates all the parameters (see Table 1 for their description) and observables in the model, stating their inter-dependencies. From this graphical representation we can build an expression for the joint probability of the parameters of interest and the data.
Let Θ be the vector of all the parameters in the model: ![Mathematical equation: \hbox{$ \Theta = \left[ N_{\rm p}, \mu_P, w_P, \mu_K, \{P, K, e, \phi, \omega\}, v_{\rm sys}, \eta_1, \eta_2, \eta_3, \eta_4, s \right] $}](/articles/aa/full_html/2016/04/aa27899-15/aa27899-15-eq20.png) . The notation means that the subset { P,K,e,φ,ω } will be repeated Np times (for each of the Np planets). An observed dataset is composed of N radial-velocity observations vi, at times ti and with associated uncertainty estimates σi. The diagram in Fig. 1 is a representation of the joint probability density function (PDF) for all the variables:
. The notation means that the subset { P,K,e,φ,ω } will be repeated Np times (for each of the Np planets). An observed dataset is composed of N radial-velocity observations vi, at times ti and with associated uncertainty estimates σi. The diagram in Fig. 1 is a representation of the joint probability density function (PDF) for all the variables: 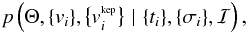 where we condition on the information ℐ1. In the remainder of the paper we will include { ti } and { σi } in ℐ, because they are assumed to be fixed. To ease the notation, we also group the RV values in a proposition D = { vi }. The
where we condition on the information ℐ1. In the remainder of the paper we will include { ti } and { σi } in ℐ, because they are assumed to be fixed. To ease the notation, we also group the RV values in a proposition D = { vi }. The 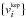 are obtained from evaluating the sum of Keplerian signals at the observed times.
are obtained from evaluating the sum of Keplerian signals at the observed times.
The joint PDF can be factored and rearranged to give Bayes’s theorem, 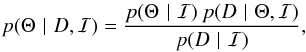 (2)providing an expression for the posterior distribution for all the parameters, conditioned on the observed data. The posterior distribution contains all the information about the parameters that is available to us. With this distribution to hand, we can then infer how many planets are supported by the data and their orbital parameters and masses.
(2)providing an expression for the posterior distribution for all the parameters, conditioned on the observed data. The posterior distribution contains all the information about the parameters that is available to us. With this distribution to hand, we can then infer how many planets are supported by the data and their orbital parameters and masses.
2.4. Determining the number of planets
To calculate the joint posterior distribution, following Eq. (2), we need the three terms on the right-hand side: the prior p(Θ | ℐ), likelihood p(D | Θ,ℐ), and evidence p(D | ℐ).
For the likelihood, the choice that reflects most genuinely our state of knowledge is a multivariate Gaussian distribution2, with mean and covariance matrix Σ. The complete covariance matrix can be obtained, deterministically, from the values of η1,η2,η3,η4,σi, and s, according to Eq. (1). The log-likelihood is then given by: 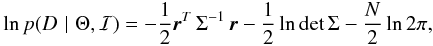 (3)where r is the vector given by
(3)where r is the vector given by 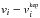 for all data points.
for all data points.
The priors used for all the parameters are listed in Table 1. Most of them are the same as those used by Brewer & Donovan (2015) and were chosen to represent uninformative or vague prior knowledge. For the orbital periods and semi-amplitudes we assign hierarchical priors that are conditional on the hyperparameters, μP, wP, and μK, respectively (see Table 1). This reflects our belief that knowing the parameters of one planet provides a small amount of information about the parameters of another planet.
Meaning and prior distribution for the parameters in the model. In some cases we sample on the logarithm of the parameter.
For most of the parameters of the GP covariance kernel, we assigned log-uniform priors in sensible ranges. For η3, the parameter that can be interpreted as the stellar rotation period, we assumed a uniform prior between 10 and 40 days.
To sample the joint posterior distribution, we used the algorithm proposed by Brewer (2014). The particular difficulty here – since Np is not known – is that the sampling algorithm needs to jump between candidate solutions with different numbers of planets. Brewer (2014) proposed a method that uses birth-death Markov chain Monte Carlo (MCMC) moves to infer Np, within the diffusive nested sampling framework (Brewer et al. 2011). This way, one can estimate the value of the evidence while improving the mixing in complex posteriors (affected by multimodality and phase transitions). Brewer & Donovan (2015) applied this method to RV data of ν Oph and Gliese 581, although these authors did not incorporate GPs in their analysis.
3. Application to HARPS data
We apply the method described in the previous section to HARPS observations of CoRoT-7. The planet CoRoT-7b was first announced by Léger et al. (2009) and was the first super-Earth with a measured radius. Its orbital period is estimated from the transits in the CoRoT light curve as being Pb = 0.854 days (Léger et al. 2009). A second non-transiting planet, with Pc = 3.69 days, was detected in a follow-up RV campaign (Queloz et al. 2009) and a more disputed detection of a third planetary signal was reported by Hatzes et al. (2010).
Owing to the high activity levels of the host star, this system has since generated a wealth of discussion, resulting in different estimates for the masses of the planets (Lanza et al. 2010; Boisse et al. 2011; Ferraz-Mello et al. 2011; Pont et al. 2011; Hatzes et al. 2011). Simultaneous observations from CoRoT and HARPS were obtained in 2012 to help settle these issues (Barros et al. 2014; H14). These observations were analysed by H14 with an RV model that is similar to ours but considering information from the simultaneous photometric observations.
We emphasise that, in the following, we analyse the full set of RV observations. In summary, the star was observed with HARPS in 2009 and 2012, with a total of 177 public RV measurements. The average error bar on these measurements is 2 m s-1 (which includes photon and instrumental noise) and the RV dispersion is 10 m s-1, over the complete 3-yr timespan.
A common procedure in (current) RV studies is to fix the number of planets and sample the posterior for the remaining parameters (and possibly calculate the evidence) in a step-by-step approach. If we fix Np = 2, we recover the orbital parameters of the two known planets, CoRoT-7b and CoRoT-7c, within the errors reported in H14 and Barros et al. (2014). The method we present in this paper is, however, much more general and allows for the full posterior for Np to be obtained from one run. We now proceed with this general method.
We ran our algorithm on the full set of RVs, using the priors in Table 1, and obtained 16 248 effective samples from the joint posterior distribution3. The evidence for our model is log (p(D | ℐ)) = −530.9. The resulting marginal posterior distribution for Np is shown in Fig. 2.
 |
Fig. 2 Posterior distribution for the number of planets Np. The counts are number of posterior samples in models with a given number of planets. The two ratios of probabilities between models with 1, 2, and 3 planets are highlighted; note that p(0) = p(1) = 0. |
 |
Fig. 3 Joint posterior distribution for the semi-amplitudes (top panel) and the eccentricities (bottom panel) together with the orbital periods of the Keplerian signals. |
The posterior distribution for Np is one of the main outputs of our method. But to actually decide on what is the number of planets orbiting CoRoT-7, and answer our initial question, we need to clarify what we mean by “confidently detected”. Based on a scale suggested by Jeffreys (1998; see also Kass & Raftery 1995), some authors (e.g. Tuomi 2011; Feroz et al. 2011) have proposed that, to claim a detection of Np planets, the probability of Np should be 150 times greater than the probability of Np − 1. This criterion requires “strong” (Jeffreys 1998) evidence for detecting a planet, thus considering false positives to be much worse than false negatives. By applying this rule to our results, we choose Np = 2 as the number of planets confidently detected in our dataset.
We emphasise that having confidently detected two planets is a different matter from knowing that the number of planets is actually two. According to the posterior distribution, it is more likely that there are four planets. But our detection criterion depends on the ratio of probabilities for consecutive values of Np (see Fig. 2), not on the probability values themselves. Of course, the posterior distribution is sensitive to the prior distributions, in particular as to how small we believe K might be.
The joint posterior distributions for the orbital periods, semi-amplitudes, and eccentricities of the signals are shown in Fig. 3, where the samples for all Keplerians were combined. The figure shows a 2-dimensional histogram of the posterior samples, where the colourmap represents bin counts and is set in a logarithmic scale.
The two detected planets are seen as overdensity regions at Pb = 0.85 days and Pc = 3.69 days. Their amplitudes and eccentricities are well constrained. There is a clear posterior peak around two days with amplitude and eccentricity mostly unconstrained. The posterior also shows a smaller peak at 9 days, the period reported by Hatzes et al. (2010) as a possible third planet (see also Tuomi et al. 2014).
Marginal posterior distributions for the parameters of the GP and the extra white noise parameter s are shown in Fig. 4. The posterior for η3 is particularly interesting as it provides a constraint to CoRoT-7’s rotation period, obtained exclusively from the RVs. Our inferred value for the stellar rotation period of 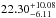 days is obtained solely from the RV time-series and is in agreement (see Table 2) with earlier estimates which used the CoRoT light curve (Léger et al. 2009; Lanza et al. 2010; H14).
days is obtained solely from the RV time-series and is in agreement (see Table 2) with earlier estimates which used the CoRoT light curve (Léger et al. 2009; Lanza et al. 2010; H14).
Also interesting is the joint behaviour of η2, η3, and η4. For higher values of η4, the periodic component of the covariance function loses importance relative to the decaying component, η2 gets smaller and η3 becomes unconstrained. In this case, the GP smooths the RVs on a timescale of η2 ≈ 3 days. But when η4 is of order unity (meaning the periodic component is present), the decaying timescale is higher and η3 is constrained around 22 days. The values of η2 in this situation (20−30 days) are closer to the stellar rotation period and are also consistent with the average lifetime of active regions measured in the CoRoT 2012 photometry (20.6 ± 2.5 days, H14). Our results therefore validate the approach taken by, e.g. H14 and Grunblatt et al. (2015), of modelling the activity-induced RV variations with a GP that has the covariance properties of the light curve.
 |
Fig. 4 Marginalised 1D and 2D posterior distributions for the parameters of the GP and the extra white noise. The samples for all values of Np were combined. The titles above each column show the median of the posterior and the uncertainties calculated from the 16% and 84% quantiles. The solid lines are kernel density estimations of the marginal distributions. |
Considering only the posterior samples with Np = 2, Table 2 lists the median values of some orbital parameters for the two planets, and the maximum likelihood RV curves are shown in Fig. 5. Our estimates for the orbital parameters are in agreement, within the uncertainties, with the ones obtained by H14.
 |
Fig. 5 Panel a): RV measurements of CoRoT-7 from 2009 and 2012 and the two-planet best-fit model (black curve). Note the different scales in the abscissae on the left and right parts of the plot. Panels b) and c) show the phased RV curves after subtracting each planet signal and the GP. |
4. Discussion and conclusions
Building on the work of Brewer & Donovan (2015), we have developed a simple method to estimate the number of orbiting planets around active stars, using only RV measurements. We applied this method to HARPS observations of CoRoT-7 and confidently detect CoRoT-7b and CoRoT-7c, while finding weaker evidence for two additional signals. In this framework, there is no need to use photometric observations, information from transit detections, or auxiliary activity indicators.
The posterior distribution for Np shows evidence for the presence of extra signals, even if they do not meet our detection criteria. We note that the effects of considering a uniform prior for Np (thus giving considerable prior weight to large numbers of planets) and a hierarchical prior for the semi-amplitudes (which changes how the Occam’s razor penalty is taken into account) can be important and will be studied in the future.
Our choices for the likelihood, covariance function, and priors provide the model with a robustness against possible outliers which is similar to most analyses of RV data. If we had reason to suspect the presence of outliers, it would be straightforward to extend our model, e.g. by scaling each error bar with a common value or with individual values whose common prior is defined hierarchically.
Stepping back to appreciate our results, we find that there is a lot of information contained in the RVs, both about planetary and (arguably more importantly) activity signals, and that this information can be recovered. The GP provides a flexible and accommodating model for activity-induced signals, allowing us to infer the planetary masses and orbital parameters with more realistic uncertainties.
In the analysis of H14, the authors modelled the out-of-transit photometry using a GP (as an interpolator) and applied the FF’ method of Aigrain et al. (2012) to obtain the RV signal that is due to activity. By comparing the evidence of models containing this activity signal plus zero, one, two, or three planets, they asserted that the two-planet model was the most probable. To model all the quasi-periodic signals in the data, H14 included a GP (with the covariance properties of the CoRoT light curve) as part of the RV model. This was justified because “the FF’ method is likely to provide an incomplete representation of activity-induced RV variations” (H14). We also note that these authors use a very strong Gaussian prior for Pb (and the time of periastron), which was nevertheless completely justified by the transit observations.
Our analysis rests on much fewer assumptions – only the RV measurements were used, the rotation period of the star was allowed to vary, the prior for the orbital periods is much less stringent – but we are still able to recover the same number of confidently detected planets and reliable estimates of the orbital parameters and the stellar rotation period (see Table 2). This shows that all this information is contained in the RV measurements and can be recovered with the flexibility of the GP, if we better account for the uncertainty associated with it.
We should finally note two important properties of the CoRoT-7 system, which made it ideal for this analysis. First, the amplitudes of the planet signals are much higher than the mean error bar of the HARPS observations, regardless of the stellar activity contamination. Second, the time sampling of the observations is almost ideal for the detection of short-period planets, and is very difficult to obtain as part of a typical RV survey. We highlight here the importance of further tests, using other well-studied datasets of active host stars as well as simulated datasets, for assessing the limits of applicability of our method.
Nevertheless, the importance of this work is not on the specific application to CoRoT-7, but instead on providing a simple and fast method to infer the number of planetary signals in the presence of stellar activity. With small modifications, this method can be used to search for planets around stars with different activity levels.
Here, ℐ encodes the assumptions considered when setting up the problem, e.g. the form of the GP kernel or the fact that we ignore planet-planet interactions, etc.
Figure 1 shows that all we know about the distribution of the { vi } are its first and second moments. The multivariate Gaussian follows from the principle of maximum entropy when the distribution is constrained to having a specified covariance matrix (e.g. Cover & Thomas 2006).
The computer used to run the simulations was equipped with an Intel Core i5-4460 CPU running at 3.20 GHz and 4 GB of RAM. The running time to obtain 50 000 samples (from diffusive nested sampling’s target mixture distribution) was four days. Since the computational cost of the algorithm is dominated by the inversion of the covariance matrix, it is expected to scale roughly with N3.
Acknowledgments
The work presented here grew directly from a collaboration that started at the Astro Hack Week 2015. We thank Andrew Collier Cameron for insightful discussions. We acknowledge the excellent open-source Python packages made available to the community (in particular DAFT and George). This work was supported by Fundação para a Ciência e a Tecnologia (FCT) through the research grant UID/FIS/04434/2013 and the grant PTDC/FIS-AST/1526/2014. J.P.F. acknowledges support from FCT through the grant reference SFRH/BD/93848/2013. R.D.H. gratefully acknowledges a grant from the John Templeton Foundation. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the John Templeton Foundation. B.J.B. is supported by a Fast Start grant from the Royal Society of New Zealand. P.F. and N.C.S. acknowledge support by FCT through Investigador FCT contracts (IF/01037/2013 and IF/00169/2012, respectively), and POPH/FSE (EC) by FEDER funding through the program Programa Operacional de Factores de Competitividade – COMPETE. P.F. further acknowledges support from FCT in the form of an exploratory project of reference IF/01037/2013CP1191/CT0001. M.O. acknowledges research funding from the Deutsche Forschungsgemeinschft (DFG, German Research Foundation) – OS 508/1-1. A.S. is supported by the European Union under a Marie Curie Intra-European Fellowship for Career Development with reference FP7-PEOPLE-2013-IEF, No. 627202.
References
- Aigrain, S., Pont, F., & Zucker, S. 2012, MNRAS, 419, 3147 [NASA ADS] [CrossRef] [Google Scholar]
- Baranne, A., Queloz, D., Mayor, M., et al. 1996, A&AS, 119, 373 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barros, S. C. C., Almenara, J. M., Deleuil, M., et al. 2014, A&A, 569, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boisse, I., Bouchy, F., Hébrard, G., et al. 2011, A&A, 528, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brewer, B. J. 2014, ArXiv eprints [arXiv:1411.3921] [Google Scholar]
- Brewer, B. J., & Donovan, C. P. 2015, MNRAS, 448, 3206 [NASA ADS] [CrossRef] [Google Scholar]
- Brewer, B. J., Pártay, L. B., & Csányi, G. 2011, Stat. Comput., 21, 649 [Google Scholar]
- Cover, T. M., & Thomas, J. A. 2006, Elements of information theory, 2nd edn. (Hoboken, N.J.: Wiley-Interscience) [Google Scholar]
- Dumusque, X., Santos, N. C., Udry, S., Lovis, C., & Bonfils, X. 2011a, A&A, 527, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dumusque, X., Udry, S., Lovis, C., Santos, N. C., & Monteiro, M. J. P. F. G. 2011b, A&A, 525, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Feroz, F., Balan, S. T., & Hobson, M. P. 2011, MNRAS, 415, 3462 [NASA ADS] [CrossRef] [Google Scholar]
- Ferraz-Mello, S., Tadeu dos Santos, M., Beaugé, C., Michtchenko, T. A., & Rodríguez, A. 2011, A&A, 531, A161 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Figueira, P., Marmier, M., Bonfils, X., et al. 2010, A&A, 513, L8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Figueira, P., Santos, N. C., Pepe, F., Lovis, C., & Nardetto, N. 2013, A&A, 557, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Grunblatt, S. K., Howard, A. W., & Haywood, R. D. 2015, ApJ, 808, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Hatzes, A. P., Dvorak, R., Wuchterl, G., et al. 2010, A&A, 520, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hatzes, A. P., Fridlund, M., Nachmani, G., et al. 2011, ApJ, 743, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Haywood, R. D., Collier Cameron, A., Queloz, D., et al. 2014, MNRAS, 443, 2517 [NASA ADS] [CrossRef] [Google Scholar]
- Jeffreys, H. 1998, Theory of probability, 3rd edn. (Oxford University Press) [Google Scholar]
- Kass, R. E., & Raftery, A. E. 1995, J. Am. Stat. Assoc., 90, 773 [Google Scholar]
- Kipping, D. M. 2013, MNRAS, 434, L51 [NASA ADS] [CrossRef] [Google Scholar]
- Lanza, A. F., Bonomo, A. S., Moutou, C., et al. 2010, A&A, 520, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Léger, A., Rouan, D., Schneider, J., et al. 2009, A&A, 506, 287 [NASA ADS] [CrossRef] [EDP Sciences] [MathSciNet] [Google Scholar]
- Mayor, M., Pepe, F., Queloz, D., et al. 2003, The Messenger, 114, 20 [NASA ADS] [Google Scholar]
- Noyes, R. W., Hartmann, L. W., Baliunas, S. L., Duncan, D. K., & Vaughan, A. H. 1984, ApJ, 279, 763 [NASA ADS] [CrossRef] [Google Scholar]
- Pepe, F., Mayor, M., Galland, F., et al. 2002, A&A, 388, 632 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pont, F., Aigrain, S., & Zucker, S. 2011, MNRAS, 411, 1953 [NASA ADS] [CrossRef] [Google Scholar]
- Queloz, D., Bouchy, F., Moutou, C., et al. 2009, A&A, 506, 303 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rajpaul, V., Aigrain, S., Osborne, M. A., Reece, S., & Roberts, S. 2015, MNRAS, 452, 2269 [NASA ADS] [CrossRef] [Google Scholar]
- Rasmussen, C. E., & Williams, C. K. I. 2006, Gaussian processes for machine learning (Cambridge: MIT Press) [Google Scholar]
- Roberts, S., Osborne, M., Ebden, M., et al. 2012, Philos. Trans. R. Soc. Lond. Math. Phys. Eng. Sci., 371 [Google Scholar]
- Robertson, P., Roy, A., & Mahadevan, S. 2015, ApJ, 805, L22 [NASA ADS] [CrossRef] [Google Scholar]
- Saar, S. H., & Donahue, R. A. 1997, ApJ, 485, 319 [NASA ADS] [CrossRef] [Google Scholar]
- Santos, N. C., Gomes da Silva, J., Lovis, C., & Melo, C. 2010, A&A, 511, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Santos, N. C., Mortier, A., Faria, J. P., et al. 2014, A&A, 566, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tuomi, M. 2011, A&A, 528, L5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tuomi, M., Anglada-Escude, G., Jenkins, J. S., & Jones, H. R. A. 2014, MNRAS, submitted [arXiv:1405.2016] [Google Scholar]
All Tables
Meaning and prior distribution for the parameters in the model. In some cases we sample on the logarithm of the parameter.
All Figures
|
Fig. 1 Representation of the relations between parameters and observations in our RV model, as a probabilistic graphical model. An arrow between two nodes indicates the direction of conditional dependence. The circled nodes are the parameters of the model, whose joint distribution is sampled by the Markov chain Monte Carlo (MCMC) algorithm. The double circled node vi represents the observed RVs. The filled nodes represent deterministic variables: if these variables have parent nodes ( |
| In the text | |
|
Fig. 2 Posterior distribution for the number of planets Np. The counts are number of posterior samples in models with a given number of planets. The two ratios of probabilities between models with 1, 2, and 3 planets are highlighted; note that p(0) = p(1) = 0. |
| In the text | |
|
Fig. 3 Joint posterior distribution for the semi-amplitudes (top panel) and the eccentricities (bottom panel) together with the orbital periods of the Keplerian signals. |
| In the text | |
|
Fig. 4 Marginalised 1D and 2D posterior distributions for the parameters of the GP and the extra white noise. The samples for all values of Np were combined. The titles above each column show the median of the posterior and the uncertainties calculated from the 16% and 84% quantiles. The solid lines are kernel density estimations of the marginal distributions. |
| In the text | |
|
Fig. 5 Panel a): RV measurements of CoRoT-7 from 2009 and 2012 and the two-planet best-fit model (black curve). Note the different scales in the abscissae on the left and right parts of the plot. Panels b) and c) show the phased RV curves after subtracting each planet signal and the GP. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.