| Issue |
A&A
Volume 576, April 2015
|
|
|---|---|---|
| Article Number | A25 | |
| Number of page(s) | 15 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201425382 | |
| Published online | 17 March 2015 | |
High redshift galaxies in the ALHAMBRA survey
I. Selection method and number counts based on redshift PDFs⋆
1
Centro de Estudios de Física del Cosmos de Aragón, Plaza San Juan 1, planta
2,
44001
Teruel,
Spain
e-mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Instituto de Astronomia, Geofísica e Ciências Atmosféricas,
Universidade de São Paulo, 05508-090
São Paulo,
Brazil
3
Instituto de Astrofísica de Andalucía (IAA-CSIC),
Glorieta de la astronomía s/n,
18008
Granada,
Spain
4
Instituto de Física de Cantabria, Avenida de los Castros s/n, 39005
Santander,
Spain
5
Unidad Asociada Observatori Astronomic (IFCA-UV),
C/ Catedrático José Beltrán 2,
46980
Paterna,
Spain
6
GEPI, Paris Observatory, 77 av. Denfert Rochereau, 75014
Paris,
France
7
Instituto de Astrofísica de Canarias, Vía Láctea s/n, La Laguna, 38200
Tenerife,
Spain
8
Departamento de Astrofísica, Facultad de Física, Universidad de la
Laguna, 38200
La Laguna,
Spain
9
Institute for Astronomy, University of Edinburgh, Royal
Observatory, Blackford
Hill, Edinburgh
EH9 3HJ,
UK
10
European Southern Observatory, Karl-Schwarzschild-Str. 2, 85748
Garching,
Germany
11
Observatório Nacional, COAA, Rua General José Cristino 77,
20921-400
Rio de Janeiro,
Brazil
12
Department of Theoretical Physics, University of the Basque
Country UPV/EHU, Bilbao, Spain
13
Departamento de Física Atómica, Molecular y Nuclear, Facultad de
Física, Universidad de Sevilla, 41012
Sevilla,
Spain
14
Institut de Ciències de l’Espai (ICE-CSIC), Facultat de
Ciències, Campus
UAB, 08193
Bellaterra,
Spain
15
Departamento de Astronomía, Ponticia Universidad
Católica, Santiago,
Chile
16
Departament d’Astronomia i Astrofísica, Universitat de
València, 46100
Burjassot,
Spain
Received: 20 November 2014
Accepted: 20 January 2015
Abstract
Context. Most observational results on the high redshift restframe UV-bright galaxies are based on samples pinpointed using the so-called dropout technique or Ly-α selection. However, the availability of multifilter data now allows the dropout selections to be replaced by direct methods based on photometric redshifts. In this paper we present the methodology to select and study the population of high redshift galaxies in the ALHAMBRA survey data.
Aims. Our aim is to develop a less biased methodology than the traditional dropout technique to study the high redshift galaxies in ALHAMBRA and other multifilter data. Thanks to the wide area ALHAMBRA covers, we especially aim at contributing to the study of the brightest, least frequent, high redshift galaxies.
Methods. The methodology is based on redshift probability distribution functions (zPDFs). It is shown how a clean galaxy sample can be obtained by selecting the galaxies with high integrated probability of being within a given redshift interval. However, reaching both a complete and clean sample with this method is challenging. Hence, a method to derive statistical properties by summing the zPDFs of all the galaxies in the redshift bin of interest is introduced.
Results. Using this methodology we derive the galaxy rest frame UV number counts in five redshift bins centred at z = 2.5,3.0,3.5,4.0, and 4.5, being complete up to the limiting magnitude at mUV(AB) = 24, where mUV refers to the first ALHAMBRA filter redwards of the Ly-α line. With the wide field ALHAMBRA data we especially contribute to the study of the brightest ends of these counts, accurately sampling the surface densities down to mUV(AB) = 21–22.
Conclusions. We show that using the zPDFs it is easy to select a very clean sample of high redshift galaxies. We also show that it is better to do statistical analysis of the properties of galaxies using a probabilistic approach, which takes into account both the incompleteness and contamination issues in a natural way.
Key words: galaxies: evolution / galaxies: distances and redshifts / galaxies: high-redshift / galaxies: statistics
Based on observations collected at the German-Spanish Astronomical Center, Calar Alto, jointly operated by the Max-Planck-Institut für Astronomie (MPIA) at Heidelberg and the Instituto de Astrofísica de Andalucía (CSIC).
© ESO, 2015
1. Introduction
Identifying and studying high redshift galaxies is crucial for our understanding of the early epochs of galaxy evolution. At the beginning of the nineties, the implementation of the so-called dropout technique opened the era for detections of copious numbers of these early galaxies (e.g. Guhathakurta et al. 1990; Steidel & Hamilton 1992, 1993; Steidel et al. 1996a,b). These galaxies are discovered based on their broadband colours, i.e. by measuring the drop in brightness due to the Lyman break at rest frame 912 Å and/or the Lyman forest between 912 Å and 1216 Å. For high redshift galaxies (z ≥ 2) these features are detected at optical or infrared wavelengths and permit the detection of these so-called Lyman-break galaxies (LBGs) from the ground. The dropout technique is sensitive to galaxies that are young enough to produce copious amounts of ultraviolet light, and are sufficiently dust free for a fair amount of this light to escape the galaxy.
Detections of high redshift galaxies opened the possibility for observational studies of some fundamental questions of galaxy evolution and cosmology at early epochs. One of the most widely studied properties are the LBG rest frame ultraviolet (UV) luminosity functions. The UV luminosities of the galaxies (once corrected for dust extinction) are directly proportional to their star formation rates. Hence, the study of the UV luminosity density, derived by integrating the luminosity function at different redshifts, gives information about the star formation history in the Universe.
Lyman-break galaxies can also act as tracers of dark matter at high redshift through the study of their clustering properties. The formation history of galaxies is basically understood through two fundamental evolutionary processes, i.e. the production of stars and the accumulation of dark matter. While the baryonic matter, i.e. stars, gas, and dust, can be studied through the light they emit, the dark matter cannot be directly detected using electromagnetic waves. However, the clustering properties of galaxies are closely related to the distribution and amount of the underlying dark matter (see Ouchi et al. 2004b, and references therein).
Most of these studies, up to the very recent ones, have applied the dropout technique for candidate selection (e.g. Ouchi et al. 2004b,a; Shim et al. 2007; Reddy et al. 2008; Ly et al. 2011; Bouwens et al. 2014, and many more). While this technique is efficient at selecting high redshift galaxies, it is also affected by significant incompleteness and contamination, losing some fraction of the population at the selected redshift, or allowing galaxies at other redshifts to enter the sample. While the latter can be dealt with by obtaining spectroscopic redshifts (see e.g. Steidel et al. 1996a,b; Reddy et al. 2006), the former remains a serious difficulty. We are not yet at the point of spectroscopic blind surveys, hence, a step forward towards less biased candidate selection is offered by multifilter surveys. They combine the efficiency and unbiased nature of photometric surveys with very low resolution spectral information, permitting us to derive more information on the surveyed objects such as their accurate photometric redshifts.
Many authors (e.g. Shim et al. 2007; Ly et al. 2011) have combined the data of their colour selected LBG samples with information at other passbands in order to carry out spectral energy distribution (SED) fitting and to derive more information on the objects in question, like their photometric redshifts. However, basing the actual candidate selection on photometric redshifts as, for example, McLure et al. (2006) have done, has only recently started to become a common practice. As discussed by McLure et al. (2011), when multifilter data are available this approach has several advantages over the traditional colour selection. It makes the best use of the available information in multiple filters, it should be less biased as any colour preselection is not required, and it directly offers the photometric redshifts for the galaxies of interest and allows the competing photometric redshift solutions at low redshift to be investigated. Recently, Le Fevre et al. (2015) have used photometric redshifts to select an unbiased target sample of high redshift galaxies for the VUDS survey. Photometric redshift selection is also used in the framework of the CLASH survey (e.g. Bradley et al. 2014) and in the recent works of Finkelstein et al. (2014) and Bowler et al. (2014).
In this paper we introduce a method for studying high redshift (z ~ 2−5) galaxies based on their photometric redshifts. Our study makes use of the complete redshift probability distribution functions (zPDFs), rather than the best redshift (i.e. the median derived from the zPDF or the highest peak of the zPDF). We show how a very clean candidate selection can be made based on the zPDFs and discuss how this technique also suffers from contamination issues if completeness is tried to be reached. Finally, we discuss why for many statistical purposes candidate selection is not needed. Instead, these studies can be based directly on the redshift (and the corresponding luminosity, mass, star formation rate, etc.) probability distributions. As an example we present probabilistic number counts for several high redshift bins. These counts should be free from contamination and incompleteness issues, if the used zPDFs correctly reflect the uncertainties in the redshift estimations.
The method is developed and tested with the data from the Advanced Large, Homogeneous Area Medium Band Redshift Astronomical (ALHAMBRA, Moles et al. 2008) Survey. The total area used for our study is 2.38 deg2, covered with 20 medium band optical filters, plus J,H, and Ks in the near infrared (NIR). In addition to the novel methodology, an advantage of our ALHAMBRA high redshift galaxy study as compared to the previous LBG studies is the large area the survey covers, split into eight independent fields, reducing biases due to the cosmic variance and allowing the study of the rarest, brightest, high redshift galaxies. Galaxies at z ~ 1 in ALHAMBRA (plus GALEX, IRAC, MIPS, and PACS) were studied in Oteo et al. (2013a,b). In this first paper about ALHAMBRA z> 2 galaxies, we concentrate on the methodology of studying the galaxy properties using the whole information in their zPDFs. In the subsequent papers, this methodology will be applied to studying the properties of these galaxies.
The methodology presented here is generic and can be applied to any multifilter data set with accurate zPDFs, such as the data from the Survey for High-z Absorption Red and Dead Sources (SHARDS, Pérez-González et al. 2013), and the future Javalambre Photometric Local Universe Survey (J-PLUS, Cenarro et al., in prep.) and Javalambre-PAU Astrophysical Survey (J-PAS Benitez et al. 2014).
The outline of this paper is as follows. Section 2 describes the ALHAMBRA data used for this study. Section 3 gives an introduction to the ALHAMBRA photo-z derivation and its validity for high redshift galaxies. In Sect. 4 the sample selection is described, the contamination and completeness of the sample are discussed, and our sample selection is compared with the traditional dropout selections. In Sect. 5 the probabilistic approach is introduced and the rest frame UV number counts are derived. A summary is given in Sect. 6. Where necessary, we assume Ωm = 0.3, ΩΛ = 0.7, and H0 = 70 km s-1 Mpc-1. Magnitudes are given in the AB system (Oke & Gunn 1983).
 |
Fig. 1 The z ~ 3 composite LBG spectrum of Shapley et al. (2003) moved to redshifts z = 2.2,3.0,4.0, and 5.0 considering the variation of the intergalactic opacity with redshift (blue lines). For clarity, the spectra are shifted vertically and plotted only up to 1460 Å (restframe). The ALHAMBRA optical filter transmission curves are overplotted as shaded grey areas, and the dashed red line corresponds to the synthetic F814W filter. The first filter redwards of the Ly-α line in each redshift is marked in darker grey. (A colour version of this figure is available in the online edition.) |
2. Data
ALHAMBRA (Moles et al. 2008) has mapped a total of 4 deg2 of the northern sky in eight separate fields during a seven year period (2005–2012). Of the total surveyed area, 2.8 deg2 have been completed with all the filters (2.38 deg2 after masking, as will be detailed in Sect. 4). ALHAMBRA uses a specially designed filter system (Aparicio Villegas et al. 2010) that covers the optical range from 3500 Å to 9700 Å with 20 contiguous, equal width (~300 Å FWHM), medium band filters, plus the three standard broadbands, J, H, and Ks, in the NIR. The photometric system has been specifically designed to optimise photometric redshift depth and accuracy (Benítez et al. 2009). The observations were carried out with the Calar Alto 3.5 m telescope using two wide field cameras: LAICA in the optical, and OMEGA-2000 in the NIR. The 5σ limiting magnitude reaches ≳24 for all filters below 8000 Å and decreases steeply towards redder medium-band filters, down to m(AB) ~ 21.5 for the reddest optical filter at 9700 Å (see Fig. 37 of Molino et al. 2014). In the NIR the limiting magnitude is ~23 for J, ~22.5 for H, and ~22 for Ks. For details about the NIR data reduction see Cristóbal-Hornillos et al. (2009), while the optical reduction is described in Cristóbal-Hornillos et al. (in prep.). The ALHAMBRA object catalogues and the associated Bayesian photometric redshifts (BPZs) are described in Molino et al. (2014) and are available through the ALHAMBRA web page1. At the moment only the best BPZs are public; the full zPDFs will be published in the future. In Fig. 1 we show the transmission curves of the optical ALHAMBRA filters together with the z ~ 3 composite spectrum of 811 LBGs of Shapley et al. (2003) moved to different redshifts.
 |
Fig. 2 Maximum likelihood (solid blue line) and Bayesian (dashed green line) zPDFs for eight galaxies with spectroscopic redshifts. The spectroscopic redshifts (zs) are given in each panel and are also marked as dashed black vertical lines. See the text for more details. (A colour version of this figure is available in the online edition.) |
3. Photometric redshifts
The work in this paper relies on the photometric redshifts provided for all the objects in the ALHAMBRA catalogue as detailed by Molino et al. (2014). These photometric redshifts were estimated using BPZ2.0 (Benítez et al., in prep.), an updated version of the Bayesian Photometric Redshift (BPZ) code (Benítez 2000). This code uses Bayesian inference where a maximum likelihood, resulting from a χ2 minimisation between the observed and predicted colours for a galaxy among a range of redshifts and templates, is weighted by a prior probability. The maximum likelihood (ML) method may suffer from colour–redshift degeneracies (like 4000 Å break vs. Lyman break) and the inclusion of a suitable prior information can help to break these degeneracies. However, both maximum likelihood and Bayesian redshift probability distributions are available for all the ALHAMBRA sources.
The BPZ2.0 SED library (see Molino et al. 2014) consists of 11 SEDs: five templates for elliptical galaxies, two for spiral galaxies, and four for starburst galaxies along with emission lines and dust extinction. The opacity of the intergalactic medium has been applied as described in Madau (1995). The prior used gives the probability of a galaxy with apparent magnitude m0 having a certain redshift z and spectral type T. The prior has been empirically derived for each spectral type and magnitude by fitting luminosity functions provided by GOODS-MUSIC (Santini et al. 2009), COSMOS (Scoville et al. 2007), and UDF (Coe et al. 2006).
For each catalogued ALHAMBRA object both the maximum likelihood and Bayesian redshift probability distribution functions (zPDFs) are given separately for each template used in the χ2-fitting. We are not interested in limiting ourselves to any galaxy type, hence, we use the redshift PDFs integrated over all templates, and normalised to one: 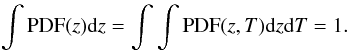 (1)These zPDFs give the probability along the redshift axis of a galaxy in question to be at that redshift. Hence, the probability, p, that a galaxy is within the redshift bin z1<z<z2 is
(1)These zPDFs give the probability along the redshift axis of a galaxy in question to be at that redshift. Hence, the probability, p, that a galaxy is within the redshift bin z1<z<z2 is 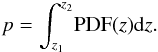 (2)
(2)
3.1. ALHAMBRA redshifts for high-z galaxies
The first questions to solve before blindly using the photometric redshift information for analysing high redshift galaxies are: can we really trust these redshifts for high-z galaxies? Is it more reliable to use the maximum likelihood (ML) or the Bayesian, full probability (FP), redshift probability distributions?
The idea of the prior information is to reduce the redshift estimation uncertainties. However, the prior information should be used only if it really can be trusted. The complete census of high redshift galaxies is still poorly known and the known census is most probably biased (see e.g. Le Fevre et al. 2015). Hence, using any prior information based on such a census could introduce undesired biases or uncertainties. For this reason, our answer to the second question above would a priori be to base our study on the ML redshift information. This will be further studied in the following.
While the accuracy of the ALHAMBRA BPZs is well tested and demonstrated (Molino et al. 2014) for galaxies up to z ~ 1.5 (being ~1%), this is not the case for the galaxies that we are interested in because of the small number of spectroscopic redshifts for high redshift galaxies in ALHAMBRA area. In the sample of ~7200 galaxies with spectroscopic redshifts used to verify the ALHAMBRA photo-z accuracy (Molino et al. 2014), there are only 57 with redshifts above z = 2.2 (the lowest redshift at which the Lyman forest would be sampled by at least one ALHAMBRA filter). Of these only 12 are brighter than m = 24 in the first filter redwards of the Ly-α line. A literature search reveales that five of these are classified as quasars, and as the BPZ template library does not include quasar spectra, we do not expect to be able to accurately recover their redshifts. Hence, we are left with seven spectroscopically confirmed bright normal high redshift galaxies. In Fig. 2 we show the ALHAMBRA ML and FP zPDFs for these seven galaxies together with their ALHAMBRA coordinates and spectroscopic redshift (from Barger et al. 2008). We see that for five of them (Nos. 1, 3, 4, 6, 7), the redshift is reasonably well recovered, Δz ≲ 0.3, where Δz is the difference between the first peak of the zPDF and the spectroscopic redshift. For galaxy 4, whose shift between the spectroscopic and photomnetric redshift is the largest of the five, the shift corresponds almost exactly to a width of one filter, i.e. it seems BPZ has mistaken the location of the Ly-α break by one filter. Of the remaining two, for galaxy 2, the first peaks of both ML and FP zPDFs are located at low redshift, but the peaks at high redshift enclose most of the probability. Galaxy 5 shows a secondary peak at high redshift (higher than the spectroscopic redshift), but most of the probability resides at low redshift. The spectra of these objects are not public making it hard to further study the reason for these discrepancies between the spectroscopic and photometric redshifts. However from the ALHAMBRA SEDs we infer that, most probably, these discrepancies derive from the common confusion between the 4000 Å break and Lyman break.
To have a better control on the expected redshifts, and a wider range of magnitudes to be tested, we carried out a simulation. For this purpose we used the z = 3 composite LBG spectrum of Shapley et al. (2003). We moved this spectrum to different redshifts: z = 2.2,3.0,4.0,5.0. The lowest redshift was selected such that the Lyman forest would be sampled at least by one ALHAMBRA filter, while considering the previous work on LBG number counts (e.g. Yoshida et al. 2006), we do not expect to discover many galaxies above z = 5 owing to the magnitude limits of ALHAMBRA.
To simulate the different redshifts, the original spectrum was first moved to redshift z = 0 removing the effect of cosmic opacity using the equations of Madau (1995), then the same equations were used to simulate the spectra at different redshifts. The original spectrum cover the wavelength range from 920 Å to 2000 Å. To cover the whole ALHAMBRA optical wavelength range in the simulated redshifts, we artificially extended it assuming a flat behaviour of the UV continuum (Fν = const., i.e. Fλ ∝ λ-2) from 2000 Å redwards up to the Balmer break at 4000 Å, and from 920 Å bluewards, down to 912 Å where the flux is assumed to drop abruptly adopting a cosmic opacity τeff = 10 for λ< 912 Å.
Percentage fraction of simulated LBGs of different redshifts and magnitudes fulfilling our selection criterion.
The resulting spectra were convolved with the ALHAMBRA filters. The convolved spectra were scaled to the desired magnitudes (at the first filter redwards from the Ly-α) to sample the magnitude range m = 20.2−24.0. The lower magnitude was defined so that we really could expect to have galaxies of this magnitude at our lowest redshift bin (see Ly et al. 2011), while the upper limit was set to reach the ALHAMBRA sensitivity limit.
We also considered realistic errors for each magnitude at each filter. To obtain these, we selected one arbitrary ALHAMBRA field and studied how the magnitude error varied with magnitude for each filter. Using all the objects in the field, we created mag vs. mag_err curves for each filter and found the best fitting solutions of the form mag_err = a + b ∗ ec ∗ mag. The expected errors at each magnitude and filter were then obtained from these equations and assigned to the simulated LBG spectra.
Finally, a Monte Carlo simulation was carried out. Each LBG spectrum was perturbed inside its error bars 100 times. When the simulated magnitude was below the 1σ detection limit (adapted again from one arbitrary ALHAMBRA field), it was replaced by this 1σ limiting magnitude, as required by BPZ for non-detections. The BPZ code was run for each of the simulated spectra to obtain both their FP and ML redshift probability distributions. We studied the recovered distributions with two questions in mind: 1) How well can we recover LBGs as high redshift galaxies? For this, we used Eq. (2) and tested how often the galaxies would be recovered to have a probability p> 0.9 to be within a redshift bin 1.9 <z< 5.3. The redshift bin was selected to be wider than the range of the input redshifts so that small errors in redshift would not place the borderline objects outside the tested range; and 2) How accurately is the redshift of these simulated galaxies recovered?
The recovery rate of LBGs as high-redshift galaxies is summarised in Table 1, where the percentage of simulated LBGs having a probability greater than 90% to be within the desired redshift range for each input redshift and magnitude are listed for both the FP and ML redshift distributions. We see that, in general, the recovered fraction is worse for the z = 2.2 LBGs than for the higher redshift sources. We assume that the lower redshifts are recovered with less accuracy, because the lower the redshift, the less pronounced is the characteristic Ly-α break and it is seen with fewer filters. We also see that while the ML method recovers the high redshift nature of the simulated galaxies very well, the Bayesian approach gives worse results. It systematically fails for the brightest magnitudes, reducing the probability of the LBGs to be at high redshift below our 90% limit, and also starts failing for the fainter magnitudes earlier than the ML approach.
We note that according to earlier studies (see Yoshida et al. 2006) for galaxies at redshift z ≥ 4 we possibly could not expect to observe rest frame UV magnitudes brighter than 22. This would partially justify why the Bayesian approach fails to recover the redshifts of these galaxies. If in addition the brightest end of the Ly et al. (2011) surface density plots were dominated by interlopers, the redshift recovered by the Bayesian method could actually be reasonable. However, knowledge of the high redshift galaxy population is still very incomplete and most probably biased. Hence, basing any study on prior knowledge of such a population might be dangerous and could lead to further biases as our simulation also indicates. We do not want to take the risk of losing the especially interesting bright objects. For these reasons, we decided to base our study on the ML redshift probability distributions, i.e. to assume a flat prior.
 |
Fig. 3 Recovered summed redshift distributions, normalised to one at the integrated probability, for 100 simulated LBGs at z = 2.2 (blue lines), z = 3.0 (red lines), z = 4.0 (black lines), and z = 5.0 (green lines) for three different rest frame UV magnitudes. The solid lines correspond to the simulation with the original composite LBG spectrum, and the dashed and dotted lines to the simulations with the same spectrum, but the Ly-α line removed and doubled, respectively. (A colour version of this figure is available in the online edition.) |
To test the accuracy of the recovered redshifts, we summed the ML zPDFs of the simulated LBGs in order to see how well the input redshifts were recovered. In Fig. 3 we show these summed zPDFs at three different magnitudes. In Table 2 we list the input redshifts and the recovered average redshifts and their sigma, derived from Gaussian approximations of the summed zPDFs. The recovered redshifts generally show a bias towards smaller or higher z than the input redshift, the bias becoming smaller with increasing z. It is not surprising that the redshift is worse recovered at the lower simulated z, as at lower z the Lyman forest is sampled by fewer ALHAMBRA filters (see Fig. 1), and the Ly-α break is less pronounced at lower redshifts. However, it is intriguing to see that even though the recovered redshift becomes more and more peaked towards higher z, a systematic bias towards smaller redshift remains. Bayesian Photometric Redshift templates do not include the Ly-α emission line, while this line is present in the composite spectrum used for the simulations. The presence of the line could dilute the Ly-α break and cause the bias in the redshift estimation towards lower z. To test this hypothesis, we manually removed the Ly-α line from the composite spectrum, and repeated the simulation. We also repeated the simulation doubling the Ly-α line strength. We have plotted the resulting summed zPDFs in Fig. 3 together with the original results. In the two largest simulated redshifts the tendency of increasing Ly-α line strength to increasingly underestimate the redshift is obvious. At the two lower redshifts this is not enough to explain the involved uncertainties. However, in all the simulated redshifts the average sizes of the biases are Δz ≤ 0.3, and, since we work with rather rough redshift bins, we consider the obtained accuracy acceptable.
4. A sample selection approach
In this section we present one way of selecting a clean sample of high redshift galaxy candidates, using the zPDFs, and check it against traditional dropout selections. Our sample selection consists of two steps: cleaning the catalogue from non-desired detections, and applying a redshift selection. While the first step is always needed, we will discuss later that, while sometimes useful, for many purposes a redshift selection is actually not needed.
4.1. Catalogue selection
We start our candidate selection by cleaning the ALHAMBRA catalogues of any possible spurious or false detections, duplicated detections, and stars. For this purpose we used the masks defined in Arnalte-Mur et al. (2014) describing the sky area which has been reliably observed, and the stellar flag provided in the ALHAMBRA catalogues (see Molino et al. 2014), setting “Stellar_Flag” < 0.51 in order to remove stars. This should remove the stars up to m< 22.5 in the reference filter, F814W. Above this magnitude the stellar flag is not defined, and slight contamination by faint stars may remain. However, for fainter magnitudes, the fraction of stars compared to galaxies declines rapidly, with a contribution of ~10% for magnitudes m(F814W) = 22.5, declining to ~1% for magnitudes m(F814W) = 23.5 (Molino et al. 2014). After these steps, our data consist of a total of 362 788 galaxies in 2.38 deg2.
4.2. The redshift selection
There is no one single correct way of applying zPDFs for candidate selection. The best redshift (e.g. the first peak) can be derived from the zPDF and assigned to each galaxy (e.g. Le Fevre et al. 2015) or the zPDF can be integrated and used in one way or another to select a list of candidates (e.g. McLure et al. 2011; Duncan et al. 2014). Here we use the second approach in a very simplified way in order to select a clean sample of high redshift ALHAMBRA galaxies. With this approach one is not obliged to be limited to any specific redshift range. However, we limit our study to the redshift range 2.2 <z ≤ 5.0. The lower limit is set so that we sample the Lyman forest, i.e. the spectrum bluewards of the Lyα line, with at least one filter. Because of the depth of ALHAMBRA we do not expect to find many galaxies at the upper limit of z> 5.0. In addition, the ALHAMBRA sensitivity limit worsens rapidly for wavelengths above ~8000 Å, and with the upper redshift limit we make sure to measure the UV continuum redwards the Lyα break in at least two filters bluer than 8000 Å.
Recovered redshifts for 100 simulated LBGs at different magnitudes and redshifts.
When all of the information on the redshift probability distribution is used, one can select as candidates all the galaxies that have a probability greater than a given threshold of being at the desired redshift interval. This threshold can then be selected to obtain the desired balance between completeness and contamination. To introduce this technique, we decided to opt for a clean selection and select as candidates the objects fulfilling the criterion 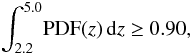 (3)i.e. all the galaxies with a probability of 90% or higher of being at the redshift range that we are interested in. This leads to a sample of a total of 9203 high redshift galaxies.
(3)i.e. all the galaxies with a probability of 90% or higher of being at the redshift range that we are interested in. This leads to a sample of a total of 9203 high redshift galaxies.
 |
Fig. 4 zPDFs for two galaxies with very different ML Odds (black lines). Top: ML Odds = 0.898, Bottom: ML Odds = 0.084. Overplotted are the corresponding Gaussian approximations of the distributions (dashed red lines). (A colour version of this figure is available in the online edition.) |
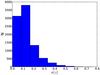 |
Fig. 5 Redshift error distribution for a Gaussian approximation for our sample of galaxies at high redshift. |
We note that methodologically this selection could easily be further refined, if needed. One way would be to study the concentration of the probability distribution around its peak value, e.g. by calculating the ML analogy for the Odds parameter offered by the BPZ (Benítez 2000). The Odds quality parameter is a proxy for the photometric redshift reliability of the sources. The Odds parameter is defined as the redshift probability enclosed on a ±K(1 + z) region around the main peak in the zPDF of the source, where the constant K is specific for each photometric survey. Molino et al. (2014) find that K = 0.0125 is the best value for ALHAMBRA since this is the expected averaged accuracy for most galaxies in the survey. Thus, Odds∈ [ 0,1 ] and it is related to the confidence of the photometric redshifts, making it possible to derive high quality samples with better accuracy and a lower rate of catastrophic outliers. As an example, in Fig. 4 we show two zPDFs satisfying criterion (3), but with very different ML Odds parameters. We also show the Gaussian approximations of the corresponding redshift distributions. While it is obvious that a selection in Odds can refine the redshift selection, we do not make any further selection of this kind. We do not need such a high precision in redshift in order to reject the objects like the one in the bottom panel of Fig. 4. Instead, for all of the galaxies that pass our selection criterion, we calculated the σ of their redshift distribution for the Gaussian approximation. The σ distribution for the sample galaxies is shown in Fig. 5. The average and median of this distribution are 0.13 and 0.11, respectively. We consider this precision to be high enough. Alternatively, in the probabilistic approach (Sect. 5), the whole redshift distribution is taken into account in a natural way; however, we will come back to the question of Odds in Sect. 5. We note that in addition to the random errors, we can expect to have systematic errors in the derived redshifts, as was discussed in Sect. 3.1 and shown in Fig. 3 and Table 2. However, considering the expected size of these biases, when working with coarse redshift bins, this should not be a problem.
4.3. Completeness and contamination
We estimate here the expected level of contamination and incompleteness of our sample within the limiting magnitude of ALHAMBRA and assuming that the zPDFs correctly reflect the uncertainties in the redshift estimations.
4.3.1. Contamination
Presuming the assumption of a flat prior is true, the upper limit for the contamination is directly set by our selection criterion: as we select the objects with a ≥90% probability of being at desired redshift, we automatically allow a contamination of ≤10% by galaxies at other redshifts. To get a more exact value of the expected contamination, we summed the probabilities of the objects selected by criterion (3) within the redshift interval 2.2 ≤ z ≤ 5.0. The resultant average probability is ~96.5%, meaning that we could expect a contamination by lower redshift galaxies of only 3.5%. We can expect a low level of contamination as our selection criterion (3) is rather strict; there may be galaxies with, e.g., a >50% probability of being within our redshift bin but which are not selected by our criterion. This naturally leads to a low level of completeness in our sample as will be discussed in the next section.
We expect that the most significant source of contamination of our high redshift galaxy sample are the faint red galaxies at low redshifts because of the confusion between the 4000 Å and Lyman breaks. In addition, some faint cold stars may be included, as the preselection against stars is statistical and not defined for magnitudes fainter than m ~ 22.5 (Molino et al. 2014), and the noisy spectra of cold stars could be confused with the LBG spectra.
4.3.2. Completeness
The completeness at a given redshift bin is defined as the ratio of galaxies at the corresponding redshift that are detected and that also pass the selection criteria to all the rest frame UV-bright galaxies at the given redshift bin actually present in the Universe. It has been shown in Molino et al. (2014) that the ALHAMBRA catalogues are ~100% complete up to m = 24 in the F814W detection filter. For the high redshift galaxies that we are interested in, this filter traces the UV continuum redwards of the Ly-α, the Ly-α break only slightly entering the F814W passband at z = 5 (see Fig. 1). Hence, considering the UV continuum of the LBGs are generally flat (Fν = const.), we can also expect a complete detection up to m = 24 in the first filter towards the Ly-α line for the galaxies that we are interested in.
If the flat prior assumption is correct, the expected completeness due to our candidate selection can be derived by summing the probability distributions within the redshift interval that we are interested in for all the objects in our cleaned catalogue which do not fulfil our selection criterion, i.e. 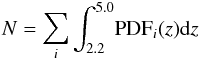 (4)for all the objects i fulfilling the criterion
(4)for all the objects i fulfilling the criterion 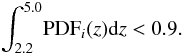 (5)This sum gives the expected total number of galaxies that are located in the redshift range that we are interested in, but not selected as such by our criterion. The total number is 40 166.8, i.e. ~4.4 times the objects in our sample. The completeness could be made higher by relaxing the criterion (3), at the cost of increasing the contamination. To carry out statistical studies on the high redshift galaxy population, we certainly should find a better compromise between the contamination and completeness. However, we will discuss later on how statistical studies can be carried out using the zPDFs directly without any previous candidate selection. Hence, we stick to this candidate selection, which we know to be clean but incomplete, and we name it the clean sample.
(5)This sum gives the expected total number of galaxies that are located in the redshift range that we are interested in, but not selected as such by our criterion. The total number is 40 166.8, i.e. ~4.4 times the objects in our sample. The completeness could be made higher by relaxing the criterion (3), at the cost of increasing the contamination. To carry out statistical studies on the high redshift galaxy population, we certainly should find a better compromise between the contamination and completeness. However, we will discuss later on how statistical studies can be carried out using the zPDFs directly without any previous candidate selection. Hence, we stick to this candidate selection, which we know to be clean but incomplete, and we name it the clean sample.
4.3.3. Quasars
Quasar spectra are not included in the BPZ spectral templates. Hence, our selection can contain quasars, but we do not expect a complete selection of quasars. We tested if the known quasars observed by ALHAMBRA would fulfil our redshift selection criterion (3). In total we found 205 ALHAMBRA objects that had counterparts identified as quasars with spectroscopic redshift in other surveys. They consist of 170 sources from Matute et al. (2012; see also references therein), one quasar at z = 5.41 from Matute et al. (2013), 15 sources from the SDSS quasar catalogue DR10 (Pâris et al. 2014), and 19 X-ray sources from CHANDRA that have an associated optical and infrared counterpart (Civano et al. 2012). For the CHANDRA sources we also demanded that they were classified as point sources and their variability parameter was greater than 0.25, in agreement with Salvato et al. (2009). Of these 205 quasars, 48 have a spectroscopic redshift in the range that we are interested in (2.2 ≤ z ≤ 5.0) and 2 are at higher redshifts (z = 5.07 and z = 5.41), while the rest are located at lower redshifts. Of the objects at the redshift interval that we are interested in, 19 (40%) fulfil our z-selection criteria. In addition, 11 out of the remaining 155 objects at lower-z (7%) enter our z-selection. The quasar at z = 5.07 is placed at z = 4.88 ± 0.03, i.e. also enters our redshift selection, and the quasar at z = 5.41 is placed at z = 5.30 ± 0.02, if Gaussian approximations are used (which in these cases is a good approximation as the redshift distributions show only one significant peak). However, the stellarity flag removes most of the quasars from our final sample so that in the end only five high redshift quasars (10%) and two (1.3%) lower redshift quasars enter our sample. We expect to have a better control of these objects once the ALHAMBRA quasar catalogue is available (Chaves-Montero et al., in prep.).
To get an estimation of the maximum expected contamination of quasars in our clean sample, we compared the i-band number counts of quasars at the redshift range z = 2.2−3.5 (Ross et al. 2013) to the total number of objects in our sample at the same redshift range. The redshift range z ≃ 2−3 is often known as the quasar epoch (Croom et al. 2009), as this is where the number density of bright quasars peaks. Hence, the comparison at this redshift range gives an upper limit of the expected total contamination by high redshift quasars in our sample of high redshift galaxies. From the double power-law fit to the cumulative i-band number counts of quasars at z = 2.2−3.5 (Ross et al. 2013), a total surface density of 263 deg-1 quasars with mi< = 24 is derived. Hence, in the ALHAMBRA area we would expect to have 2.38 deg × 263 deg-1 = 626 quasars brighter than mi = 24. The total number of galaxies brighter than m = 24 in our clean sample at the same redshift bin is 1707. We roughly compare these numbers without considering a k-correction between the i-band and our ALHAMBRA bands. If 10% of the quasars at the ALHAMBRA area enter our selection, as we infer from the spectroscopic sample, the total (maximum) rate of contamination of our clean sample by high-redshift quasars is 0.1 × 626 / 1707 = 0.037, i.e. <4%.
In addition, we showed above that 1.3% of quasars at z< 2.2 can be included in our sample. Ross et al. (2013) also give the prescription to calculate the quasar surface density at the redshift range 1.0 <z< 2.2, giving 99.6 deg-1 quasars with mi< = 24. Doubling this to account for (i.e. overestimate for the much smaller volume) the quasars at the redshift range 0.0 <z< 1.0, gives an additional maximum contamination of 2 × 99.6 deg-1 × 2.38 deg × 0.013 = 6 quasars brighter than mi = 24 at 0.0 <z< 2.2 in the ALHAMBRA area. If this is compared to the total amount of galaxies brighter than m = 24 in our clean sample (2296 galaxies), an additional maximum contamination rate of 0.3% is obtained.
4.4. Comparison with traditional colour selections
To see if the candidates in our clean sample would have been selected by traditional dropout methods, we tested how they would be located in some traditional colour–colour diagrams. In particular, we opted for testing the BX selection (⟨ z ⟩ = 2.20 ± 0.32) of Steidel et al. (2004); the LBG selection (⟨ z ⟩ = 2.96 ± 0.29) of Steidel et al. (2003); and the BRi′ (⟨ z ⟩ = 4.0 ± 0.3), Vi′z′ (⟨ z ⟩ = 4.7 ± 0.3), and Ri′z′ (⟨ z ⟩ = 4.9 ± 0.2) LBG selections of Yoshida et al. (2006).
First, we carried out SED fitting on our sample galaxies in order to find a spectrum which we could then convolve with the broadband filters used in the above dropout selections. To assure a good SED-fitting, we considered only the galaxies with good quality photometry in all of the filters by setting “irms_OPT_Flag” = 0 and “irms_NIR_Flag” = 0. This requirement reduced our sample to 8023 galaxies. For the SED fitting we used the single stellar population (SSP) models of Bruzual & Charlot (2003) of all the available metallicities (six metallicity values in the range Z = 0.001−0.05) and of 40 ages roughly logarithmically spaced from 10 Myr to the age of the Universe. We added the extinction law of Leitherer et al. (2002) at the wavelength range 970–1200 Å, and that of Calzetti et al. (2000) for longer wavelengths. At wavelengths below 970 Å, where neither of the two laws is defined, we adopted a constant extinction with a value equal to that at 970 Å. The colour excess, E(B − V), was varied in a range of realistic values: from 0.0 to 0.5 (Shapley et al. 2003) in steps of ΔE(B − V) = 0.025. The model spectra were moved in redshift in steps of Δz = 0.025 to sample the redshift range that we are interested in, so that at each redshift only the SSPs up to the age of the Universe at that time were considered. The Lyman forest was modelled following the prescriptions of Madau (1995), considering the Hα, Hβ, Hγ, and Hδ line blanketing. Below 912 Å the opacity was assumed to increase abruptly, leading to practically zero flux bluewards of the Lyman break.
These template spectra were convolved with the ALHAMBRA filter passbands. Each galaxy in our sample was fitted by this template library using the χ2-method so that only the templates with redshifts ztemplate = ⟨ z ⟩ ± σz were considered, i.e. those templates whose redshift is inside 1σ from the median redshift of the fitted galaxy as derived from its zPDF. The template spectrum whose fit produced the lowest value of χ2 was then assigned as the best fit template for each galaxy in our sample. Finally, only the galaxies brighter than m = 24 in the first filter redwards from the Ly-α line and with the reduced 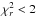 (
(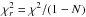 , where N is the number of filters used in the fit) were accepted for the analysis. These steps reduced our sample to 1844 and 1327 galaxies, respectively.
, where N is the number of filters used in the fit) were accepted for the analysis. These steps reduced our sample to 1844 and 1327 galaxies, respectively.
The original spectra of these best fit templates were then convolved with the filter passbands of the broadband filters of interest and the objects were placed in the colour–colour diagrams used in the dropout selections (Fig. 6). To simulate the G, R, and Un passband data used in the selections of Steidel et al. (2003) and Steidel et al. (2004), we downloaded the corresponding transmission curves from KPNO website2. To simulate the selection of Yoshida et al. (2006), the B,R,V,i′, and z′ transmission curves were downloaded from NAOJ website3.
In each diagram in Fig. 6 we plotted only those candidates of our sample whose (ALHAMBRA median) redshifts are within 1σ from the one targeted by the corresponding dropout selections. We see that basically all of our candidates would also be selected by these traditional colour–colour diagrams. The percentages of the candidates inside the selection boxes are 99%, 99%, 97%, and 94%, for the LBG, BRi′, Vi′z′, and Ri′z′ selections, respectively. The BX diagram shows the largest scatter outside the selection box, the fraction of candidates inside the box being 83%. The galaxy clearly outside the selection boxes in the bottom right corners of the Vi′z′ and Ri′z′ diagrams is the same one in both diagrams. It is a very faint object, and even though it is brighter than m = 24 in the first filter redwards of the Ly-α (the magnitude being m = 23.8), in all the other filters it is fainter than the 5σ limiting magnitude for the corresponding filter.
 |
Fig. 6 Locations of our clean sample candidates in four colour–colour diagrams used for traditional dropout selections. The selection boxes in each diagram are shown with dashed lines and the redshift ranges they target are indicated in each panel. We only plot the candidates in the redshift range within 1σ of the one targeted by these diagrams (blue crosses). In the top diagram the blue crosses refer to the BX selection while the magenta dots to the LBG selection. See the text for more details. (A colour version of this figure is available in the online edition.) |
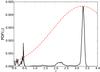 |
Fig. 7 Redshift probability distribution of a galaxy with a significant probability at both high and low redshift (black line). Overplotted is the corresponding Gaussian approximation of the distribution (dashed red line). (A colour version of this figure is available in the online edition.) |
5. Probabilistic approach
The selection of the clean sample above is an example of the use of zPDFs when one needs a candidate selection and wants to be certain that the selected galaxies really are at desired redshift. However, selecting both a clean and complete sample is challenging. If one would like to have a more complete sample, one could relax selection criterion (3). However, relaxing it, for example, to allow all the galaxies with a probability ≥50% to be at high redshift to enter the sample would automatically lead to a contamination rate of ≤50% (assuming the flat prior assumption is correct). Hence, for any statistical study one should carefully take care of the incompleteness and contamination corrections.
For many purposes the candidate selection is not needed, but the galaxies and their properties can instead be considered as continua described by their zPDFs. For each catalogued ALHAMBRA object, a zPDF is provided. For some galaxies, as for many objects in our clean sample, this distribution is narrow and could be approximated by a Gaussian distribution without losing much information. However, in other cases the distribution is much more spread out and/or is double peaked. This issue was recently discussed in detail by López-Sanjuan et al. (2015). In Fig. 7 we show an example of a two-peaked and a spread out distribution. Now, if we claimed the galaxy of Fig. 7 to be at any certain redshift bin z1 − z2 we would certainly fail (unless this bin were wide enough to cover the whole range where the PDF(z) > 0). However, for statistical purposes we can interpret the probabilities p of Eq. (2) as fractions. A similar approach was adopted by McLure et al. (2009) when deriving LBG luminosity functions.
 |
Fig. 8 Density of the ALHAMBRA high redshift galaxies in four colour–colour diagrams used for traditional dropout selections. The densities are derived using our probabilistic approach. The selection boxes in each diagram are shown with dashed lines, and the redshift ranges they target are indicated in each panel. The contours enclosing 20%, 40%, 60%, 80%, and 90% of the objects are marked as solid lines (dashed lines for the BX selection). See the text for more details. (A colour version of this figure is available in the online edition.) |
5.1. Colour–colour diagrams
In Fig. 8 we show the distribution of the whole set of ALHAMBRA galaxies as density contours in the same colour–colour diagrams as in Fig. 6. To obtain these contours, the catalogue was cleaned as explained in Sect. 4.1. In addition, good quality photometry was required in all the filters. All the objects were fitted by Bruzual & Charlot (2003) SSP models and convolved with the broadband filter passbands to find their broadband colours as in Sect. 4.4. Finally, only the galaxies brighter than mUV = 24 in the first filter redwards from the Ly-α, and of good quality SED-fitting (χr< 2), were used for the analysis (105 280 objects). The zPDF of each object was integrated within the redshift interval targeted by each colour–colour diagram (Eq. (2)). To create the density plot in Fig. 6, each object was weighted by this fraction. We see that while most of the density of the galaxies lie within the boundaries of the dropout selection boxes, there are also galaxies outside the boxes. The percentages of galaxies outside the boxes are for the BX, LBG, BRi′, Vi , and Ri selections, respectively, 35%, 39%, 46%, 37%, and 39%, i.e. more than one third of the restframe UV bright galaxies would be missed by these selections. The existence of galaxies outside the selection boxes supports the known fact that the dropout selections are not complete. A recent spectroscopic study of high redshift galaxies in VUDS survey (Le Fevre et al. 2015) also demonstrates the existence of high redshift galaxies outside the UGR-selection box, albeit finding a smaller percentage than we did (20%) of galaxies in the redshift range 2.5 <z< 3.5 outside the box. On the other hand a similar study in the VVDS survey (Le Fevre et al. 2013) reveals that 46% of the galaxies at the redshift range 2.7 ≤ z ≤ 3.4 and with a “reliable” spectral flag are outside the UGR-selection box, while 17% of those with a “very reliable” flag are located outside the box. Of these two surveys, our selection function resembles more that of the VVDS survey (pure magnitude selection) than that of the VUDS where a photometric redshift selection was also carried out.
, and Ri selections, respectively, 35%, 39%, 46%, 37%, and 39%, i.e. more than one third of the restframe UV bright galaxies would be missed by these selections. The existence of galaxies outside the selection boxes supports the known fact that the dropout selections are not complete. A recent spectroscopic study of high redshift galaxies in VUDS survey (Le Fevre et al. 2015) also demonstrates the existence of high redshift galaxies outside the UGR-selection box, albeit finding a smaller percentage than we did (20%) of galaxies in the redshift range 2.5 <z< 3.5 outside the box. On the other hand a similar study in the VVDS survey (Le Fevre et al. 2013) reveals that 46% of the galaxies at the redshift range 2.7 ≤ z ≤ 3.4 and with a “reliable” spectral flag are outside the UGR-selection box, while 17% of those with a “very reliable” flag are located outside the box. Of these two surveys, our selection function resembles more that of the VVDS survey (pure magnitude selection) than that of the VUDS where a photometric redshift selection was also carried out.
5.2. Number counts
 |
Fig. 9 Observed number counts for high redshift ALHAMBRA galaxies (crosses). The error bars reflect Poisson errors. For comparison, we show the BX (z ~ 2.20 ± 0.32, filled triangles) and LBG (z ~ 2.96 ± 0.29, filled squares) number counts of Reddy et al. (2008; R08), the BRi′ (z ~ 4.0 ± 0.3, open circles) and Vi′z′ (z ~ 4.7 ± 0.3, filled circles) LBG number counts of Yoshida et al. (2006; Y06), and the ~4 (open triangles) and ~5 (open inverted triangles) LBG number counts of Bouwens et al. (2014; B14). The ALHAMBRA limiting magnitude is marked at m = 24 with a blue dashed line. See the text for more details. (A colour version of this figure is available in the online edition.) |
 |
Fig. 10 Observed probabilistic number counts for high redshift ALHAMBRA galaxies. The ML counts are shown as crosses, the FP counts as open squares, and the counts derived from an “Odds” selected sample are shown as open circles. The error bars reflect Poisson errors. The ALHAMBRA limiting magnitude is marked at m = 24 with a blue dashed line. See the text for more details. (A colour version of this figure is available in the online edition.) |
In order to obtain the number N of objects in a redshift bin z1<z<z2 and magnitude bin m1<m<m2, we carried out a summation over all the objects i in the cleaned ALHAMBRA catalogue of the form 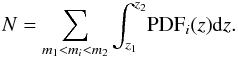 (6)For each redshift bin the apparent magnitude refers to the magnitude at the UV continuum as measured by the first filter redwards from the Ly-α (and not containing the possible Ly-α line) at the corresponding redshift. The summation was carried out in five redshift bins. The redshift bins were selected inside the redshift range we consider reliable in our ALHAMBRA data (see Sect. 3.1), i.e. 2.2 <z< 5.0, and we opted for a bin width of Δz = 0.6 to mimic the typical redshift ranges of dropout selected LBGs with which we compare our resulting number counts (see the references in the next paragraph). The resulting probabilistic number counts in bins of 0.5 mag and in redshift bins centred at z = 2.5,3.0,3.5,4.0, and 4.5 in a total area of 8572.5 arcmin2 are shown in Fig. 9. These counts are also listed in Table 3.
(6)For each redshift bin the apparent magnitude refers to the magnitude at the UV continuum as measured by the first filter redwards from the Ly-α (and not containing the possible Ly-α line) at the corresponding redshift. The summation was carried out in five redshift bins. The redshift bins were selected inside the redshift range we consider reliable in our ALHAMBRA data (see Sect. 3.1), i.e. 2.2 <z< 5.0, and we opted for a bin width of Δz = 0.6 to mimic the typical redshift ranges of dropout selected LBGs with which we compare our resulting number counts (see the references in the next paragraph). The resulting probabilistic number counts in bins of 0.5 mag and in redshift bins centred at z = 2.5,3.0,3.5,4.0, and 4.5 in a total area of 8572.5 arcmin2 are shown in Fig. 9. These counts are also listed in Table 3.
This method implicitly takes into account both the incompleteness and contamination issues. However, this method also suffers from quasar contamination as these objects are not considered by the BPZ. We estimated the maximum quasar contamination rate in the same way as in Sect. 4.3.3 above. We carried out the summation (6) over all the magnitudes and from z1 = 2.2 to z2 = 3.5 for all non-stellar ALHAMBRA quasars with spectroscopic redshift z> 2.2 (19 out of 50 quasars). This summation gives 8.27, i.e. 8.27 / 50 = 0.165 ≃ 17% of the high-redshift quasars contaminate our counts. A similar exercise for all non-stellar ALHAMBRA quasars with spectroscopic redshift z< 2.2 (64 out of 155 quasars) leads to 2.48, i.e. 1.6% of lower redshift quasars contaminating our counts. On the other hand, the total number of ALHAMBRA galaxies brighter than m = 24 in the redshift range 2.2 <z< 3.5 given by Eq. (6) is 5269.5. Following the prescription in Sect. 4.3.3, this leads to a maximum contamination by high-redshift quasars of 0.165 × 626 / 5269.5 = 0.019, i.e. <2%. The total number of ALHAMBRA galaxies brighter than m = 24 in the redshift range 2.2 <z< 5.0 given by Eq. (6) is 5680.9. Hence, the lower-redshift quasars add an additional maximum contamination rate of 2 × 99.6 deg-1 × 2.38 deg × 0.019 / 5680.9 = 0.0016 < 0.2%.
For comparison, in Fig. 9 we have also plotted the dropout selected BX and LBG candidates of Reddy et al. (2008, R08), and the BRi′ and Vi′z′ dropout selected LBG candidates of Yoshida et al. (2006, Y06). According to R08, their samples are centred at redshifts z ~ 2.20 ± 0.32 (BX) and z ~ 2.96 ± 0.29 (LBG). The LBG samples of Y06 are centred at z ~ 4.0 ± 0.3 (BRi′) and z ~ 4.7 ± 0.3 (Vi′z′). We have also overplotted in Fig. 9 the z ~ 4 and z ~ 5 dropout selected LBGs of Bouwens et al. (2014, B14). In our first redshift bin in Fig. 9 (z = 2.5 ± 0.3) we have plotted both the BX and LBG candidates of Reddy et al. (2008) as our redshift bin is actually in between the redshift ranges targeted by these two selections.
Bouwens et al. (2014) lists the surface densities and their errors in a table (Table 6 in B14) and we have plotted them in Fig. 9. The plotted errors for the Y06 and R08 samples reflect the Poisson errors, and we have corrected the Y06 and R08 counts for incompleteness and contamination according to the information given in the corresponding articles: Y06 have studied the completeness and contamination of their sample by simulations. They list the expected number of interlopers for each redshift selection and magnitude bin in tables while the completeness vs. redshift is given in graphic form for each magnitude bin. For each magnitude bin we opted to adopt the maximum completeness from the distribution for the corresponding magnitude bin. The spectroscopic sample of R08 gives the expected contamination rate for each magnitude and redshift bin, while R08 studied the completeness of their sample (limited to MAB (1700 Å) < −19.33) by simulations and found that ~58% of the restframe UV-bright galaxies in the redshift bin 1.9 ≤ z ≤ 2.7 fulfil the BX colour selection criteria while ~47% of the similar galaxies in the redshift bin 2.7 ≤ z ≤ 3.4 fulfil the LBG colour selection criteria. In other words, they would expect to find ~42% and ~53% of these galaxies outside the BX and LBG selection boxes, respectively, quite higher fractions than our estimate in Sect. 5.1 above.
Detailed comparison of our counts with the counts derived from dropout selections is not straightforward. The dropout selections target a certain redshift range, but a fraction of galaxies from a much wider range of redshift can enter the selections. For example, the BX selection of R08 targets the redshift range z ~ 2.20 ± 0.32, but the spectroscopic redshift distribution of the galaxies entering the sample, and not considered as contaminants, varies from z ~ 1.4 to z ~ 3.4. Our methodology simply targets the adopted redshift range. The dropout selections rely on contamination and incompleteness corrections, while our methodology takes these into account implicitly. Despite these differences, the general trends of our counts and the counts from literature coincide. However, in the two lowest redshift bins (centred at z = 2.5 and z = 3.0) there is a clear difference between the brightest end of our counts and the brightest bin of R08 counts. The last bin of R08 is wide (from m = 19 to m = 22) and we can expect that the counts inside the bin are dominated by the fainter objects. We have plotted their brightest point at the centre of this bin, which slightly exaggerates the difference between our counts and their counts. However, this is not enough to explain the difference. We do not know where this difference comes from, but we note that our sampling at the brightest end is clearly better which inclines us to consider our counts more reliable.
 |
Fig. 11 Fraction of galaxies with Odds> 0.3 as a function of F814W magnitude for different redshift bins: 0.4 <z< 1 (black line), z = 2.5 ± 0.3 (blue line), z = 3.0 ± 0.3 (green line), z = 3.5 ± 0.3 (magenta line), z = 4.0 ± 0.3 (red line), and z = 4.5 ± 0.3 (cyan line). (A colour version of this figure is available in the online edition.) |
Finally, we want to note that in all the redshift bins our counts offer a good sampling of the bright end of the surface densities, down to the magnitudes m = 21−22. It is also remarkable that according to our counts the total number of ALHAMBRA galaxies brighter than mUV = 24 and at redshifts as high as ~4.0 and ~4.5 is several hundreds, 406 and 348, respectively.
Probabilistic number counts per magnitude bin at each redshift bin.
5.3. The assumption of a flat prior
The use of flat (i.e. no prior at all) or very permissive priors in high redshift studies is a common practice (e.g. McLure et al. 2009; Bradley et al. 2014; Le Fevre et al. 2015; Duncan et al. 2014) due to the uncertainties of the prior at high redshift. This means that variation in the density of galaxies as a function of redshift was not considered when deriving the zPDFs. This, in turn, could lead to net contribution of objects from the denser redshift bins to the less dense ones caused by the galaxies with badly defined, flat zPDFs. To test the possible effect of this on our number counts, we carried out two tests.
First, we derived the counts using a slightly different approach. For each object in the cleaned ALHAMBRA catalogue we calculated its ML Odds (see Sect. 4) integrating the ML zPDF within the range zml ± 0.0125(1 + zml), where zml refers to the redshift of the highest peak of the distribution. Then we eliminated the galaxies with a low ML Odds value in order to discard the objects with flat zPDFs. To do this, we opted to set ML Odds > 0.3. For these galaxies, we derived their redshift distribution for each magnitude bin and each filter in Fig. 9 by summing their ML zPDFs. Next, we scaled these redshift distributions to the total number of ALHAMBRA objects in each magnitude bin. From these distributions, we derived the number counts for each redshift bin of interest.
Second, despite the possible problems the Bayesian prior could cause at the bright end, as was shown in Sect. 3.1, we tested how probabilistic number counts would turn out if the FP zPDFs were used. The Bayesian prior takes into account the expected number density variations with redshift and should thus take care of the possible net contributions caused by badly defined, flat zPDFs.
The resulting number counts from the two experiments described above are plotted in Fig. 10 together with the counts derived directly by integrating the ML zPDF of each object. Interestingly indeed, we see that the ML and FP counts roughly coincide. This means that the influence of the prior in the ALHAMBRA high redshift galaxy zPDFs is not significant; i.e. thanks to the ALHAMBRA multifilter system, the ML method alone is capable of recovering the galaxy redshifts. We do not have enough objects at the very brightest ends of the counts to study if the prior works well there. For this we need to wait for data from larger area surveys.
We see that at the brightest end the results of the Odds experiment coincide with the direct ML counts. At the fainter magnitudes, the Odds derived counts tend to be lower than the ML (and FP) counts for the two lowest redshift bins (centred at z = 2.5 and z = 3.0); in the two following bins (centred at z = 3.5 and z = 4.0) all counts coincide in all magnitudes (up to the limiting magnitude), and in the last bin (centred at z = 4.5) the Odds derived counts tend to be higher in the faintest magnitudes than the ML/FP counts. This could mean that at the lower redshift bins and fainter magnitudes a net contribution from low redshift galaxies with flat zPDFs affects our counts and tends to overestimate them, while at the brightest magnitude bins the effect is the opposite. However, considering that the ML and FP counts do agree in these magnitude bins, we do not believe this is the case. The same effect can be obtained if a smaller number of high redshift galaxies have good Odds values at the first redshift bins than the lower redshift galaxies, and the opposite would be true for the last redshift bin.
To study this in greater detail, we derived the Odds sampling rate (OSR) as introduced in López-Sanjuan et al. (2015). This gives the fraction of galaxies with good Odds values (in this case Odds> 0.3) to the total number of galaxies as a function of magnitude in the detection filter, F814W. In Fig. 11 we show the OSR vs. magnitude derived for 0.4 <z< 1 as a reference curve for lower redshift galaxies, and the corresponding curves for the redshift bins that we are interested in: z = 2.5 ± 0.3,3.0 ± 0.3,3.5 ± 0.3,4.0 ± 0.3, and 4.5 ± 0.3. We see that, at magnitudes fainter than ~20, the OSR indeed depends on redshift, being lowest for our lowest redshift bin and systematically increasing with redshift, the OSR of our highest redshift bin being higher than that of the reference curve. Actually, this behaviour is also visible in the recovered summed zPDFs of our simulated high redshift galaxies in Sect. 3.1. In Fig. 3 we see how the recovered summed zPDF becomes narrower with increasing redshift.
To summarise, deriving the galaxy redshift distribution from an Odds selected sample should be considered with caution as at high redshift OSR strongly depends on redshift. Luckily, we do not need to rely on such an approach as, despite our worries about the use of a prior in our high redshift study (Sect. 3.1), the prior does not seem to influence our counts significantly; both ML and FP zPDFs give similar results. As the prior takes into account the varying galaxy density with redshift, and the FP and ML counts coincide, there clearly is no significant net contribution of objects with spread out zPDFs from the denser redshift bins to the less dense ones. The study of the very brightest and noisy end of our counts (from m ~ 19 to m ~ 21−22) needs to wait for data from larger area surveys, like J-PLUS and J-PAS. From the number counts derived in this section, we estimate that these surveys will detect tens of thousands of high redshift galaxies brighter than m = 22.5.
6. Summary
So far, most of the studies of the high redshift UV bright galaxy population have been based on dropout selections. Spectroscopic follow-up of dropout selected samples (e.g. Reddy et al. 2008) have shown that the dropout selection suffers from severe contamination. Simulations (e.g. Yoshida et al. 2006; Reddy et al. 2008) and a spectroscopic study of high redshift galaxies selected from a purely flux-selected sample (Le Fèvre et al. 2005) have shown that the dropout selection is also highly incomplete. This is further supported by a wide spectroscopic sample by Le Fevre et al. (2015), where the candidates are selected using photometric redshifts. We expect an alternative probabilistic method, like the one presented here, would help to remove this kind of biases.
We have studied the high redshift UV bright galaxy population in ALHAMBRA data adopting a novel approach based on redshift probability distribution functions (zPDFs). We have shown how a clean sample of high redshift galaxies can be derived from the ALHAMBRA catalogue, integrating the zPDFs and selecting only those galaxies with very high probability to be at high redshift. We studied whether this clean sample would be selected by the traditional dropout techniques, and basically all of the galaxies in our sample actually would also be selected by these methods at 83–99% levels. However, the benefit of our selection compared to the traditional dropout selections is the expected very low percentage of interlopers.
We have also shown that our clean sample suffers from severe incompleteness and is not able to derive any reliable statistical properties about the high redshift galaxy population. We have introduced a probabilistic method which takes into account both incompleteness and contamination in a natural way. In this approach, the galaxies are not treated as unities but rather as fractions in each redshift, where the size of this fraction is derived by integrating the corresponding zPDF of each galaxy at the redshift range of interest. Using this approach, we have studied the distribution of the ALHAMBRA high redshift galaxies in the traditional colour–colour diagrams and discovered that a significant percentage of them (>30%) are located outside the traditional selection boxes. We have also derived the probabilistic number counts in five redshift bins from z = 2.5 to z = 4.5. The strength of our counts is the good sampling of the bright end, down to mUV(AB) = 21–22.
In our simulation we discovered that if the Bayesian prior was used, very bright high redshift galaxies would systematically not be selected to form part of our clean sample. For this reason, all the above studies are based on maximum likelihood (ML) zPDFs, i.e. throughout the paper we have assumed a flat prior. However, we tested how the probabilistic number counts would turn out if the full probability (FP) zPDFs were used. We found that the FP and ML counts closely match. This reinforces the reliability of these counts. To know if this holds at the very brightest magnitudes, where our data is dominated by noise, data from still larger area surveys is needed. We would like to be able to come back to this issue once the data from wide area (~8500 deg2) J-PLUS and J-PAS multifilter surveys are available. From the number counts derived in this work, we estimate that we could detect tens of thousands of high redshift galaxies brighter than mUV(AB) = 22.5 in these surveys.
We also repeated the probabilistic number counts calculation deriving the ML redshift distributions in each magnitude bin from a selection of galaxies with well-defined photometric redshifts (ML Odds > 0.3) and scaling these to the total number of objects in each magnitude bin. In the faintest magnitude bins we find differences between these and the direct ML counts. Considering that the FP and ML counts roughly coincide in all magnitude bins, we inferred that the differences seen with the counts derived from the Odds selected sample are due to variations in the fractional amount of galaxies with good Odds values with redshift. We studied the evolution of this fraction as a function of magnitude and redshift, and found out that at faint magnitudes this fraction indeed varies with redshift.
Even though we have discussed here only the application of the probabilistic method of deriving the galaxy number counts, a similar approach could be used to study any redshift dependent galaxy property. McLure et al. (2009) used a similar approach to derive LBG luminosity functions and, recently, López-Sanjuan et al. (2015) discussed a similar approach to study the galaxy merger fraction. We will further study the ALHAMBRA high redshift galaxies using this methodology in the forthcoming papers.
Theoretically, our probabilistic method is totally free of biases due to incompleteness and contamination. However, this is not totally true, as our photo-z estimations are limited to what is already known about the galaxy population because empirical templates are used. The way to improve this aspect of the method is to create unbiased lists of candidates, spectroscopically confirm them, and consequently refine the high redshift templates. For the unbiased candidate selection, zPDFs offer a unique opportunity. A wide spectroscopic campaign on candidates selected using zPDFs is already in progress (Le Fevre et al. 2015). Once the spectra of objects derived from unbiased samples are available, these can be used to improve the photo-z estimations at high redshift, and subsequently improve the accuracy of the statistical methods like the one presented here.
Acknowledgments
We acknowledge the anonymous referee for the useful comments. K. Viironen acknowledges the Juan de la Cierva fellowship of the Spanish government. We acknowledge funding from the FITE (Fondos de Inversiones de Teruel) and support from the Spanish Ministry for Economy and Competitiveness and FEDER funds through grants AYA2012-30789, AYA2006-14056, AYA 2003-00128, AYA 2006-01325, AYA 2007-62190, AYA2010-15169, AYA2010-22111-C03-02 and AYA2013-48623-C2-2. We also acknowledge Junta de Andalucía through the grant TIC 114 and Generalitat Valenciana projects Prometeo 2009/064 and PROMETEOII/2014/060, and the financial support from the Aragón Government through the Research Group E103. I. Oteo acknowledges support from the European Research Council (ERC) in the form of Advanced Grant, cosmicism. A. J. Cenarro acknowledges the Ramón y Cajal fellowship of the Spanish government. M. Pović acknowledges financial support from JAE-Doc program of the Spanish National Research Council (CSIC), co-funded by the European Social Fund. This research made use of Matplotlib, a 2D graphics package used for Python for publication-quality image generation across user interfaces and operating systems (Hunter 2007).
References
- Aparicio Villegas, T., Alfaro, E. J., Cabrera-Caño, J., et al. 2010, AJ, 139, 1242 [NASA ADS] [CrossRef] [Google Scholar]
- Arnalte-Mur, P., Martínez, V. J., Norberg, P., et al. 2014, MNRAS, 441, 1783 [NASA ADS] [CrossRef] [Google Scholar]
- Barger, A. J., Cowie, L. L., & Wang, W.-H. 2008, ApJ, 689, 687 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N., Moles, M., Aguerri, J. A. L., et al. 2009, ApJ, 692, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Benitez, N., Dupke, R., Moles, M., et al. 2014 [arXiv:1403.5237] [Google Scholar]
- Bouwens, R. J., Illingworth, G. D., Oesch, P. A., et al. 2014, ApJ, accepted [arXiv:1403.4295] [Google Scholar]
- Bowler, R. A. A., Dunlop, J. S., McLure, R. J., et al. 2014, MNRAS, submitted [arXiv:1411.2976] [Google Scholar]
- Bradley, L. D., Zitrin, A., Coe, D., et al. 2014, ApJ, 792, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Civano, F., Elvis, M., Brusa, M., et al. 2012, ApJS, 201, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Coe, D., Benítez, N., Sánchez, S. F., et al. 2006, AJ, 132, 926 [NASA ADS] [CrossRef] [Google Scholar]
- Cristóbal-Hornillos, D., Aguerri, J. A. L., Moles, M., et al. 2009, ApJ, 696, 1554 [NASA ADS] [CrossRef] [Google Scholar]
- Croom, S. M., Richards, G. T., Shanks, T., et al. 2009, MNRAS, 399, 1755 [NASA ADS] [CrossRef] [Google Scholar]
- Duncan, K., Conselice, C. J., Mortlock, A., et al. 2014, MNRAS, 444, 2960 [NASA ADS] [CrossRef] [Google Scholar]
- Finkelstein, S. L., Ryan, Jr., R. E., Papovich, C., et al. 2014, ApJ, submitted [arXiv:1410.5439] [Google Scholar]
- Guhathakurta, P., Tyson, J. A., & Majewski, S. R. 1990, ApJ, 357, L9 [NASA ADS] [CrossRef] [Google Scholar]
- LeFèvre, O., Paltani, S., Arnouts, S., et al. 2005, Nature, 437, 519 [NASA ADS] [CrossRef] [Google Scholar]
- Le Fevre, O., Cassata, P., Cucciati, O., et al. 2013, A&A, submitted [arXiv:1307.6518] [Google Scholar]
- Le Fevre, O., Tasca, L. A. M., Cassata, P., et al. 2015, in press, DOI: 10.1051/0004-6361/201423829 [Google Scholar]
- Leitherer, C., Li, I.-H., Calzetti, D., & Heckman, T. M. 2002, ApJS, 140, 303 [NASA ADS] [CrossRef] [Google Scholar]
- López-Sanjuan, C., Cenarro, A. J., Varela, J., et al. 2015, A&A, in press, DOI: 10.1051/0004-6361/201424913 [Google Scholar]
- Ly, C., Malkan, M. A., Hayashi, M., et al. 2011, ApJ, 735, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Madau, P. 1995, ApJ, 441, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Matute, I., Márquez, I., Masegosa, J., et al. 2012, A&A, 542, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matute, I., Masegosa, J., Márquez, I., et al. 2013, A&A, 557, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McLure, R. J., Cirasuolo, M., Dunlop, J. S., et al. 2006, MNRAS, 372, 357 [NASA ADS] [CrossRef] [Google Scholar]
- McLure, R. J., Cirasuolo, M., Dunlop, J. S., Foucaud, S., & Almaini, O. 2009, MNRAS, 395, 2196 [NASA ADS] [CrossRef] [Google Scholar]
- McLure, R. J., Dunlop, J. S., de Ravel, L., et al. 2011, MNRAS, 418, 2074 [NASA ADS] [CrossRef] [Google Scholar]
- Moles, M., Benítez, N., Aguerri, J. A. L., et al. 2008, AJ, 136, 1325 [Google Scholar]
- Molino, A., Benítez, N., Moles, M., et al. 2014, MNRAS, 441, 2891 [NASA ADS] [CrossRef] [Google Scholar]
- Oke, J. B., & Gunn, J. E. 1983, ApJ, 266, 713 [NASA ADS] [CrossRef] [Google Scholar]
- Oteo, I., Bongiovanni, Á., Cepa, J., et al. 2013a, MNRAS, 433, 2706 [NASA ADS] [CrossRef] [Google Scholar]
- Oteo, I., Magdis, G., Bongiovanni, Á., et al. 2013b, MNRAS, 435, 158 [NASA ADS] [CrossRef] [Google Scholar]
- Ouchi, M., Shimasaku, K., Okamura, S., et al. 2004a, ApJ, 611, 660 [NASA ADS] [CrossRef] [Google Scholar]
- Ouchi, M., Shimasaku, K., Okamura, S., et al. 2004b, ApJ, 611, 685 [NASA ADS] [CrossRef] [Google Scholar]
- Pâris, I., Petitjean, P., Aubourg, É., et al. 2014, A&A, 563, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pérez-González, P. G., Cava, A., Barro, G., et al. 2013, ApJ, 762, 46 [NASA ADS] [CrossRef] [Google Scholar]
- Reddy, N. A., Steidel, C. C., Erb, D. K., Shapley, A. E., & Pettini, M. 2006, ApJ, 653, 1004 [Google Scholar]
- Reddy, N. A., Steidel, C. C., Pettini, M., et al. 2008, ApJS, 175, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Ross, N. P., McGreer, I. D., White, M., et al. 2013, ApJ, 773, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Hasinger, G., Ilbert, O., et al. 2009, ApJ, 690, 1250 [CrossRef] [Google Scholar]
- Santini, P., Fontana, A., Grazian, A., et al. 2009, VizieR Online Data Catalog: J/A+A/504/751 [Google Scholar]
- Scoville, N., Abraham, R. G., Aussel, H., et al. 2007, ApJS, 172, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Shapley, A. E., Steidel, C. C., Pettini, M., & Adelberger, K. L. 2003, ApJ, 588, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Shim, H., Im, M., Choi, P., Yan, L., & Storrie-Lombardi, L. 2007, ApJ, 669, 749 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., & Hamilton, D. 1992, AJ, 104, 941 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., & Hamilton, D. 1993, AJ, 105, 2017 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Giavalisco, M., Dickinson, M., & Adelberger, K. L. 1996a, AJ, 112, 352 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Giavalisco, M., Pettini, M., Dickinson, M., & Adelberger, K. L. 1996b, ApJ, 462, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Adelberger, K. L., Shapley, A. E., et al. 2003, ApJ, 592, 728 [NASA ADS] [CrossRef] [Google Scholar]
- Steidel, C. C., Shapley, A. E., Pettini, M., et al. 2004, ApJ, 604, 534 [NASA ADS] [CrossRef] [Google Scholar]
- Yoshida, M., Shimasaku, K., Kashikawa, N., et al. 2006, ApJ, 653, 988 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Percentage fraction of simulated LBGs of different redshifts and magnitudes fulfilling our selection criterion.
Recovered redshifts for 100 simulated LBGs at different magnitudes and redshifts.
All Figures
|
Fig. 1 The z ~ 3 composite LBG spectrum of Shapley et al. (2003) moved to redshifts z = 2.2,3.0,4.0, and 5.0 considering the variation of the intergalactic opacity with redshift (blue lines). For clarity, the spectra are shifted vertically and plotted only up to 1460 Å (restframe). The ALHAMBRA optical filter transmission curves are overplotted as shaded grey areas, and the dashed red line corresponds to the synthetic F814W filter. The first filter redwards of the Ly-α line in each redshift is marked in darker grey. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 2 Maximum likelihood (solid blue line) and Bayesian (dashed green line) zPDFs for eight galaxies with spectroscopic redshifts. The spectroscopic redshifts (zs) are given in each panel and are also marked as dashed black vertical lines. See the text for more details. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 3 Recovered summed redshift distributions, normalised to one at the integrated probability, for 100 simulated LBGs at z = 2.2 (blue lines), z = 3.0 (red lines), z = 4.0 (black lines), and z = 5.0 (green lines) for three different rest frame UV magnitudes. The solid lines correspond to the simulation with the original composite LBG spectrum, and the dashed and dotted lines to the simulations with the same spectrum, but the Ly-α line removed and doubled, respectively. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 4 zPDFs for two galaxies with very different ML Odds (black lines). Top: ML Odds = 0.898, Bottom: ML Odds = 0.084. Overplotted are the corresponding Gaussian approximations of the distributions (dashed red lines). (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 5 Redshift error distribution for a Gaussian approximation for our sample of galaxies at high redshift. |
| In the text | |
|
Fig. 6 Locations of our clean sample candidates in four colour–colour diagrams used for traditional dropout selections. The selection boxes in each diagram are shown with dashed lines and the redshift ranges they target are indicated in each panel. We only plot the candidates in the redshift range within 1σ of the one targeted by these diagrams (blue crosses). In the top diagram the blue crosses refer to the BX selection while the magenta dots to the LBG selection. See the text for more details. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 7 Redshift probability distribution of a galaxy with a significant probability at both high and low redshift (black line). Overplotted is the corresponding Gaussian approximation of the distribution (dashed red line). (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 8 Density of the ALHAMBRA high redshift galaxies in four colour–colour diagrams used for traditional dropout selections. The densities are derived using our probabilistic approach. The selection boxes in each diagram are shown with dashed lines, and the redshift ranges they target are indicated in each panel. The contours enclosing 20%, 40%, 60%, 80%, and 90% of the objects are marked as solid lines (dashed lines for the BX selection). See the text for more details. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 9 Observed number counts for high redshift ALHAMBRA galaxies (crosses). The error bars reflect Poisson errors. For comparison, we show the BX (z ~ 2.20 ± 0.32, filled triangles) and LBG (z ~ 2.96 ± 0.29, filled squares) number counts of Reddy et al. (2008; R08), the BRi′ (z ~ 4.0 ± 0.3, open circles) and Vi′z′ (z ~ 4.7 ± 0.3, filled circles) LBG number counts of Yoshida et al. (2006; Y06), and the ~4 (open triangles) and ~5 (open inverted triangles) LBG number counts of Bouwens et al. (2014; B14). The ALHAMBRA limiting magnitude is marked at m = 24 with a blue dashed line. See the text for more details. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 10 Observed probabilistic number counts for high redshift ALHAMBRA galaxies. The ML counts are shown as crosses, the FP counts as open squares, and the counts derived from an “Odds” selected sample are shown as open circles. The error bars reflect Poisson errors. The ALHAMBRA limiting magnitude is marked at m = 24 with a blue dashed line. See the text for more details. (A colour version of this figure is available in the online edition.) |
| In the text | |
|
Fig. 11 Fraction of galaxies with Odds> 0.3 as a function of F814W magnitude for different redshift bins: 0.4 <z< 1 (black line), z = 2.5 ± 0.3 (blue line), z = 3.0 ± 0.3 (green line), z = 3.5 ± 0.3 (magenta line), z = 4.0 ± 0.3 (red line), and z = 4.5 ± 0.3 (cyan line). (A colour version of this figure is available in the online edition.) |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.