| Issue |
A&A
Volume 554, June 2013
|
|
|---|---|---|
| Article Number | A131 | |
| Number of page(s) | 12 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201220790 | |
| Published online | 17 June 2013 | |
An optimized correlation function estimator for galaxy surveys
1
APC, Astroparticule et Cosmologie, Université Paris Diderot, CNRS/IN2P3,
CEA/Irfu, Observatoire de Paris,
Sorbonne Paris Cité, 10 rue Alice Domon et Lonie
Duquet,
75205
Paris Cedex 13,
France
e-mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Laboratoire AIM, CEA/DSM-CNRS-Université Paris Diderot,
IRFU, SEDI-SAP, Service
d’Astrophysique, Centre de Saclay, 91191
Gif-Sur-Yvette Cedex,
France
3
CEA centre de Saclay, irfu/SPP, 91191
Gif-sur-Yvette,
France
4
CPPM, Aix-Marseille Université, CNRS/IN2P3,
13288
Marseille, Cedex 9,
France
5
Institute of Cosmology and Gravitation, Portsmouth University,
Dennis Sciama Building, PO1
3 FX Portsmouth,
UK
6
Harvard-Smithsonian Center for Astrophysics, 60 Garden St.,
Cambridge,
MA
02138,
USA
7
Department of Astronomy and Astrophysics, The Pennsylvania State
University, University
Park, PA
16802,
USA
8
Institute for Gravitation and the Cosmos, The Pennsylvania State
University, University
Park, PA
16802,
USA
9
Steward Observatory, University of Arizona 933,
N. Cherry Avenue,
Tucson, AZ, 85721, USA
Received:
26
November
2012
Accepted:
28
March
2013
Abstract
Measuring the two-point correlation function of the galaxies in the Universe gives access to the underlying dark matter distribution, which is related to cosmological parameters and to the physics of the primordial Universe. The estimation of the correlation function for current galaxy surveys makes use of the Landy-Szalay estimator, which is supposed to reach minimal variance. This is only true, however, for a vanishing correlation function. We study the Landy-Szalay estimator when these conditions are not fulfilled and propose a new estimator that provides the smallest variance for a given survey geometry. Our estimator is a linear combination of ratios between pair counts of data and/or random catalogues (DD, RR, and DR). The optimal combination for a given geometry is determined by using lognormal mock catalogues. The resulting estimator is biased in a model-dependent way, but we propose a simple iterative procedure for obtaining an unbiased model-independent estimator. Our method can be easily applied to any dataset and requires few extra mock catalogues compared to the standard Landy-Szalay analysis. Using various sets of simulated data (lognormal, second-order LPT, and N-body), we obtain a 20–25% gain on the error bars on the two-point correlation function for the SDSS geometry and ΛCDM correlation function. When applied to SDSS data (DR7 and DR9), we achieve a similar gain on the correlation functions, which translates into a 10–15% improvement over the estimation of the densities of matter Ωm and dark energy ΩΛ in an open ΛCDM model. The constraints derived from DR7 data with our estimator are similar to those obtained with the DR9 data and the Landy-Szalay estimator, which covers a volume twice as large and has a density that is three times higher.
Key words: surveys / large-scale structure of Universe / galaxies: statistics / distance scale / cosmology: observations / methods: data analysis
© ESO, 2013
1. Introduction
The distribution of galaxies in the Universe is an extremely rich source of information for cosmology. Indeed, galaxies trace the underlying dark matter distribution in a way that is typically described with a multiplicative factor known as the bias. To a good approximation, this bias can be considered independent of scale. On larger scales where fluctuations are still small, one can apply linear theory and have a direct access to cosmological parameters. On smaller scales, gravity acts in a non-linear manner and the galaxy clustering allows one to investigate the structuration of dark matter into haloes. Observing the large-scale structure of the Universe is a promising approach for improving our understanding of its accelerated expansion observed by various cosmological probes in the past decade. The cosmic acceleration was initially proposed as a way to reconcile the apparent low matter content of the Universe with a flat geometry in a standard cold dark matter scenario (Efstathiou et al. 1990). The first convincing measurement of cosmic acceleration came from observations that type Ia supernovae appeared less luminous than expected in a decelerating Universe (Riess et al. 1998; Perlmutter et al. 1999). These observations can be accommodated by modifying general relativity on cosmological scales or, within a Friedmann-Lemaître-Robertson-Walker (FLRW) cosmology, by adding a dark energy component with a density ΩX ~ 0.7, a negative pressure, and a possibly evolving equation of state. Since then, the cosmic acceleration has been confirmed by other probes, including the cosmic microwave background (CMB) fluctuations (Komatsu et al. 2011; Sherwin et al. 2011), integrated Sachs-Wolfe (ISW) effect (Granett et al. 2009) and baryonic acoustic oscillations (BAO, Weinberg et al. 2012, for a general review and Anderson et al. 2012 for the latest measurement). These data point towards a dark energy with a constant equation-of-state parameter, w = −1, or equivalently a pure cosmological constant. BAO measurements are based on the observation of an acoustic peak in the correlation function of the matter density fluctuations, corresponding to the acoustic horizon at the epoch of matter-radiation decoupling (Eisenstein & Hu 1998). The acoustic scale is used as a standard ruler at various redshifts, allowing for the measurement of the angular distance in the transverse directions and the expansion rate in the radial direction (Reid et al. 2012).
When investigating the large-scale structure of the Universe using galaxies, one needs large field-of-view deep galaxy surveys such as the Sloan Digital Sky Survey (SDSS-III) Baryon Oscillation Spectroscopic Survey (BOSS, Eisenstein et al. 2011), i.e. high density galaxy catalogues, where the radial positions of galaxies are measured by their redshifts. The two-point correlation function is commonly used for characterizing the large-scale structure within such galaxy surveys. One does not directly measure the density within the survey volume, but samples this density through galaxy locations, makes the estimation of the two-point correlation function more complex. The observed quantity is the average number of neighbours at a given distance in the survey volume and is biased by the fact that galaxies near the edges of the catalogue volume have less neighbours than they should have, which needs to be corrected for in an optimal way. This issue does not occur, for example when directly measuring a function of the matter density through the Lyman-α forest of distant quasars (Slosar et al. 2011).
 |
Fig. 1 Input (dotted line) and reconstructed (various colours and linestyles, see legend) two-point correlation function obtained using the various estimators available in the literature for a cubic geometry (left) or a realistic (BOSS DR9) survey volume (right). The bottom panels show the root mean square of each estimator with corresponding colour and linestyle. In each case, the Hamilton and Landy-Szalay lines are exactly superposed as well as the Davis-Peebles and Hewett lines. (Coloured version of the figure available online). |
In this article, we introduce a novel estimator for the two-point correlation function of galaxies. Its performance can be optimized for a given galaxy survey geometry. In Sect. 2 we justify this effort, showing that various well-known estimators for the two-point correlation function have a residual bias and a variance that strongly depend on the survey geometry. The commonly used Landy-Szalay estimator (Landy & Szalay 1993) has been shown to have no bias or have minimal variance in the limit of a vanishing correlation function. We show that in realistic cases, where the correlation function is not zero, the Landy-Szalay estimator does not reach the Poisson noise limit. For pedagogical reasons, we start in Sect. 3 with a simpler but biased version of our optimal estimator, and in Sect. 4 we develop a simple iterative procedure that allows the final estimator to be model-independent, with an improvement in the accuracy around 20–25% with respect to the Landy-Szalay estimator. In Sect. 5 we apply our final estimator to data from the SDSS-II Seventh Data Release (DR7) Luminous Red Galaxy sample and on the SDSS-III/BOSS DR9 “CMASS” sample and show the improvement in the two-point correlation function measurement and cosmological parameters over previous analyses.
2. Motivations for an optimized two-point correlation function estimator
2.1. Commonly used estimators
Estimators of the two-point correlation function ξ(s) (s being the comoving separation) have been studied by various authors (Peebles & Hauser 1974; Davis & Peebles 1983; Hewett 1982; Hamilton 1993; Landy & Szalay 1993). Generically, pair counts in data are compared to pair counts in random samples that follow the geometry of the survey. We assume a catalogue of nd objects in the data sample and nr in the random sample and then calculate three sets of numbers of pairs as a function of the binned comoving separation s1
-
within the data sample, dd(s) that can be normalized by the total numberof pairs as
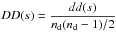 ;
;
-
within the random sample, leading to rr(s) normalized as
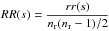 ;
;
-
among both samples (cross correlation) leading to dr(s) normalized as
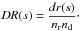
The most common estimators discussed in the literature are:
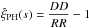
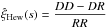
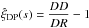
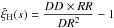

Some studies have compared the behaviour of the different two-point correlation function estimators, mainly in the small-scale regime and using smaller samples. In Pons-Bordería et al. (1999), six estimators were analyzed, including both the Hamilton and Landy-Szalay estimators, and the authors did not find any outstanding winner among those estimators. In Kerscher (1999) and Kerscher et al. (2000), nine estimators were considered, and the estimators presenting the best properties were the Landy-Szalay and Hamilton estimators.
2.2. Relative performances of the common estimators
To compare the performances of these estimators, we used two sets of 120 mock catalogues obtained from lognormal (Coles & Jones 1991) density field simulations containing about 271 000 galaxies in both a cube of 1 h-1 Gpc size and a far more complex geometry corresponding to the BOSS (DR9) survey (Anderson et al. 2012) which, roughly contains the same volume as the cube. In addition we used random catalogues with three time as many galaxies as the mock catalogues for both geometries. The cosmology used for the lognormal fields is taken from the Wilkinson Microwave Anisotropy Probe (WMAP) 7 years analysis (Komatsu et al. 2011).
Figure 1 shows the correlation function obtained with the different estimators for the cubic and DR9 geometries. We clearly see differences between the performances of the estimators in the cube and in the DR9, both in their mean result and in their root-mean-square errors (rms). In the case of the DR9 geometry, the mean results obtained with the Peebles-Hauser, Davis-Peebles and Hewett estimators are more biased than the theory on large scales. Landy-Szalay and Hamilton estimators are much less biased than the others in this more complex geometry. Examining the rms, all estimators have their accuracy degraded by the effects of geometry. Landy-Szalay and Hamilton again show best performances with the lowest variances in both geometries as expected.
 |
Fig. 2 rms of the Landy-Szalay estimator for lognormal simulations in a cubic geometry and for a zero two-point correlation function (left) and for a ΛCDM model (right). The upper, middle, and lower solid lines correspond to a random sample with 1, 3, and 30 times more galaxies, respectively than the data sample. Dotted lines show the Poisson noise associated with each number of randoms (in the same order as solid lines). The thick dashed line shows the limit corresponding to an infinite number of random galaxies. (Coloured version of the figure available online.) |
2.3. Optimality of Landy-Szalay estimator
In the limit of an infinitely large random catalogue, for which the volume is much larger than the observed scales, and of a vanishing two-point correlation function (uniform galaxy distribution), the Landy-Szalay estimator is known to have no bias or have minimal variance. It is therefore used most widely in modern galaxy surveys (e.g., Eisenstein et al. 2005; Percival et al. 2007; Kazin et al. 2010; Blake et al. 2011; Anderson et al. 2012; Sánchez et al. 2012). In practice the volume of modern surveys is sufficiently large, and one can also produce a large enough random catalogue, but the correlation function to be measured is non-zero, so it is crucial to check residual bias and variance of estimators in the case of realistic non-zero correlation functions.
Using additional lognormal simulations, we investigated the rms of the Landy-Szalay estimator as a function of the size of the random catalogue for both a zero correlation function and the one expected from the Lambda cold dark matter (ΛCDM) scenario. Fifty realizations were produced in both cases where a cubic geometry was used in order to be insensitive to the degradation due to the survey geometry. The resulting rms are shown in Fig. 2, along with the expectations for an optimal estimator (from Eq. (48) in Landy & Szalay 1993 ) accounting for the finite size of the random catalogue. It appears that, when the correlation function is not vanishing, the Landy-Szalay estimator does not reach the Poisson noise limit. This suggests that a better estimator can be found in the case of a non-vanishing correlation function and a more complicated survey geometry.
The nineteen ratios formed by using pair counts up to second order.
3. An optimized estimator
3.1. General form and optimization criterion
Our search for a better estimator started from the observation that the commonly used
estimators are linear combinations of ratios of pair counts, DD,
DR, and RR (hereafter the s dependence is
described by vectors), with the exception of the Hamilton estimator, that involves ratios
of second-order products of pair counts. We therefore investigate an estimator which would
be an optimal linear combination of all possible ratios
Ri up to the second order. Table 1 summarizes the six ratios at first order and the
twelve at second order. The generic optimal estimator can then be expressed as
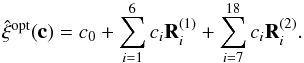 (1)The nineteen
ci coefficients are optimized lognormal to
minimize the variance of the estimator for a given geometry. This optimization is done
through a χ2 minimization using a large set of mock catalogues
generated using lognormal fields, for which DD, DR, and
RR are stored, so that all the
Ri terms can be calculated. The
χ2 is minimized with respect to the vector of parameters
c as
(1)The nineteen
ci coefficients are optimized lognormal to
minimize the variance of the estimator for a given geometry. This optimization is done
through a χ2 minimization using a large set of mock catalogues
generated using lognormal fields, for which DD, DR, and
RR are stored, so that all the
Ri terms can be calculated. The
χ2 is minimized with respect to the vector of parameters
c as ![Mathematical equation: \begin{equation} \chi^2 = \sum_j \left[ \hat{\vec{\xi}}^\mathrm{opt}_j(\vec{c}) -\vec{\xi}_\mathrm{th}\right]^T \cdot {\bf N}_\mathrm{LS}^{-1} \cdot \left[ \hat{\vec{\xi}}^\mathrm{opt}_j(\vec{c}) -\vec{\xi}_\mathrm{th}\right] , \label{eq:chi2} \end{equation}](/articles/aa/full_html/2013/06/aa20790-12/aa20790-12-eq57.png) (2)where the
j index stands for the j-th realization,
(2)where the
j index stands for the j-th realization,
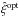 is the vector of the values of the estimator in the comoving distance s
bins, and ξth the vector for the theoretical input correlation
function. The quantity NLS is the covariance matrix of
fluctuations of
is the vector of the values of the estimator in the comoving distance s
bins, and ξth the vector for the theoretical input correlation
function. The quantity NLS is the covariance matrix of
fluctuations of 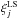 around the
mean Landy-Szalay correlation function ⟨ ξLS ⟩, the mean taken
over the mock realizations.
around the
mean Landy-Szalay correlation function ⟨ ξLS ⟩, the mean taken
over the mock realizations.
This approach will result in an estimator with a variance that is at most as large as that of the Landy-Szalay estimator, but which might have a significant bias. This bias with respect to the “true” correlation function will be referred to as residual bias in this article to distinguish it from the luminous matter bias with respect to dark matter. The residual bias can be calculated and corrected for to an arbitrary precision for a given input correlation function (therefore for a given cosmological model). However, this residual bias correction is model dependent and would only work perfectly when the input cosmology in the mock data matches the one to be measured in the real data. In Sect. 4 we propose a simple iterative method that allows efficient circumvention of this problem with modest extra CPU time.
3.2. Performances on simulations
Using lognormal simulations, we produced 120 realizations of galaxy catalogues with a
geometry similar to that of the SDSS-III/BOSS (DR9) survey (Eisenstein et al. 2011; Anderson et al.
2012). The fiducial cosmology was defined by h = 0.7,
Ωm = 0.27, ΩΛ = 0.73, Ωb = 0.045,
σ8 = 0.8, and ns = 1.0. For each
realization, we generated a random catalogue with the same geometry and calculated
DD, DR, and RR for comoving separations between 0
and 200 h-1 Mpc with bins of 4
h-1 Mpc. We then calculated the Landy-Szalay estimator for
each simulation , the
average estimator ⟨ ξLS ⟩, and its covariance matrix
NLS, empirically, i.e., from the dispersion of the individual
realizations.
We then had all the ingredients required to minimize the χ2 in Eq. (2) and obtain an optimal estimator, which was done by limiting the χ2 to the region [40, 200] h-1 Mpc. This range corresponds to the typical interval used in BAO analyses. However, this choice is not fundamental, so our method could be applied to any other range depending on the purpose of the analysis. The actual values of the coefficients ci are not particularly meaningful for two reasons: they depend on the geometry of the survey and are therefore not “general”; in addition, the parameters are degenerate because the nineteen Ri terms are not independent.
 |
Fig. 3 Residuals with respect to the input correlation function for the Landy-Szalay estimator (dashed-blue) and for the minimum variance estimator (solid-red). We also show the corresponding ± 1σ (rms from lognormal simulations) for Landy-Szalay (dotted-blue) and for the minimum variance estimator (dot-dashed-red). Residuals and rms are rescaled by s2. The optimal estimator has been obtained limiting the χ2 to the region [40, 200] h-1 Mpc. This range has been chosen accordingly to the typical range used in BAO analysis. (Coloured version of the figure available online.) |
Figure 3 compares our estimator to the Landy-Szalay
estimator. The residual bias with respect to the theoretical input correlation and the rms
are shown for both estimators. The residual bias is defined as
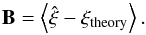 (3)These rms are
just the square roots of the diagonal elements of the estimator covariance matrix,
calculated empirically from the individual lognormal realizations. The covariance matrix
is defined as
(3)These rms are
just the square roots of the diagonal elements of the estimator covariance matrix,
calculated empirically from the individual lognormal realizations. The covariance matrix
is defined as ![Mathematical equation: \begin{equation} {\bf C} = \left\langle \left[ \vec{\xi} - \bar{\vec{\xi}} \right] \left[ \vec{\xi} - \bar{\vec{\xi}}\right]^T \right\rangle. \end{equation}](/articles/aa/full_html/2013/06/aa20790-12/aa20790-12-eq74.png) (4)The residual and the
rms are both rescaled by s2. The Landy-Szalay estimator
essentially has no residual bias, while a significant residual bias is observed for our
estimator, which, however, remains within the 1σ range. In contrast, our
optimized estimator appears to have smaller variances than the Landy-Szalay estimator in
the region [40, 200] h-1 Mpc , where the fit was performed.
Figure 4 shows the covariance and correlation
matrices for the Landy-Szalay and optimized estimators. The latter have a smaller
covariance matrix and no extra correlation between the bins. The correlation matrix is
defined as
(4)The residual and the
rms are both rescaled by s2. The Landy-Szalay estimator
essentially has no residual bias, while a significant residual bias is observed for our
estimator, which, however, remains within the 1σ range. In contrast, our
optimized estimator appears to have smaller variances than the Landy-Szalay estimator in
the region [40, 200] h-1 Mpc , where the fit was performed.
Figure 4 shows the covariance and correlation
matrices for the Landy-Szalay and optimized estimators. The latter have a smaller
covariance matrix and no extra correlation between the bins. The correlation matrix is
defined as 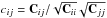 .
.
 |
Fig. 4 (Top panels) Covariance matrices multiplied by the square of the comoving distance. (Bottom panels) Correlation matrices for both the Landy-Szalay estimator (left panels) and the optimized estimator (right panels). (Coloured version of the figure available online.) |
3.3. Model dependance
Figures 3 and 4 show that by correcting the optimized estimator by its average residual bias, which can be known with excellent accuracy by having a large number of mock realizations, one can achieve better accuracy on the correlation function than the Landy-Szalay estimator. Unfortunately, the residual bias exhibits a peak at the location of the BAO scale and therefore will be different in another cosmology: it is strongly model dependent. If one uses an estimator that is optimized with a set of simulations that assumed a cosmology different from the actual one, the peak position in the residual bias will be different from the one in the data, resulting in a strong distortion of the peak shape after bias correction and in a shift in its location. This is illustrated in Fig. 5, and discussed further. Fortunately, one can eliminate the cosmology dependence of the fitting, as described in the next section.
4. Iterative optimized estimator
To transform the optimized estimator into a model-independent one, we investigated the possibility of iterating with an estimator that assumes the same cosmology as the one derived from the data. This procedure could be quite time consuming, because one needs a large number of mock realizations for a given cosmology to optimize the estimator for this cosmology. We have found a way to do this efficiently by limiting the number of simulations to a few times the initial one.
 |
Fig. 5 Bias on αMeasured as a function of αInput (from lognormal simulations) for Landy-Szalay (blue points), iterative optimal (red triangles) and two non-iterative minimum-variance estimators with α = 0.96 (orange crosses) and α = 1.04 (green squares). The error bars indicate the rms among the lognormal simulations. Simple linear functions were fitted to the points in each case with corresponding slopes shown in the legend. A strong bias can be seen for the non-iterative estimators while the iterative optimal and Landy-Szalay estimators are not biased. (Coloured version of the figure available online.) |
4.1. Description of the method
Our iterative procedure starts with a first calculation of the correlation function using
the Landy-Szalay estimator. We then fit the resulting correlation function with a model
that has considerable freedom on the general broadband shape, so that it is essentially
sensitive to the location of the acoustic peak, as used in the BOSS analysis (Anderson et al. 2012): 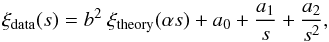 (5)where
ξtheory is the theoretical linear model from Eisenstein & Hu (1998), b the
constant galaxy dark-matter bias factor, and a0,
a1, and a2 are nuisance
parameters.
(5)where
ξtheory is the theoretical linear model from Eisenstein & Hu (1998), b the
constant galaxy dark-matter bias factor, and a0,
a1, and a2 are nuisance
parameters.
From this fit, we obtain the first iteration of the dilation scale parameter,
α, that characterizes the location of the peak: 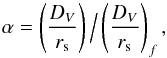 (6)where
rs is the comoving sound horizon at decoupling. The
subscript f means that the quantity is calculated using our fiducial
cosmology, for which rs = 157.42 Mpc;
DV(z) is the spherically
averaged distance to redshift z and is defined by (Mehta et al. 2012):
(6)where
rs is the comoving sound horizon at decoupling. The
subscript f means that the quantity is calculated using our fiducial
cosmology, for which rs = 157.42 Mpc;
DV(z) is the spherically
averaged distance to redshift z and is defined by (Mehta et al. 2012):
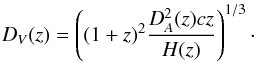 (7)The parameter
α is unity if the actual cosmology matches the fiducial one. The result
of this fit is a first estimate of the cosmological model suggested by the data, labelled
by α0. This is actually the result of the standard analysis
with the Landy-Szalay estimator.
(7)The parameter
α is unity if the actual cosmology matches the fiducial one. The result
of this fit is a first estimate of the cosmological model suggested by the data, labelled
by α0. This is actually the result of the standard analysis
with the Landy-Szalay estimator.
We then perform a large number of realizations of mock catalogues with the same geometry as the data, for various values of α around α0. For this work we use lognormal simulations that can be quickly generated.
For the set of simulations corresponding to a given input
αk, one can find the coefficients
ck by minimizing the
χ2 defined in Eq. (2). The resulting correlation function, 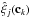 ,
for the realization j is given by Eq. (1). We compute the average residual bias
Bk of the correlation function with respect
to the theory
ξtheory(αk):
,
for the realization j is given by Eq. (1). We compute the average residual bias
Bk of the correlation function with respect
to the theory
ξtheory(αk):
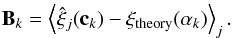 (8)The covariance matrix
Nopt(αk) is
obtained from the fluctuations of the same n realizations:
(8)The covariance matrix
Nopt(αk) is
obtained from the fluctuations of the same n realizations:
![Mathematical equation: \begin{equation} {\bf N}_\mathrm{opt}(\alpha_k) = \left\langle \left[\vec{\xi}_j(\vec{c}_k) - \bar{\vec{\xi}}(\vec{c}_k) \right] \left[\vec{\xi}_j(\vec{c}_k) - \bar{\vec{\xi}}(\vec{c}_k) \right]^T \right\rangle_j . \end{equation}](/articles/aa/full_html/2013/06/aa20790-12/aa20790-12-eq103.png) (9)Hereafter we
redefine the process of applying the estimator corresponding to
αk to a data sample in two steps:
(9)Hereafter we
redefine the process of applying the estimator corresponding to
αk to a data sample in two steps:
-
use Eq. ( 1 ) with coefficients c k to calculate
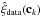
-
add the residual bias of the estimator, B k .
We can now proceed with the iterative procedure. Since the first iteration value,
α = α0, is not exactly one of the nine
available αk, we apply the estimator
corresponding to the closest two values of α0,
αlo, and αhi, to the data, and
we interpolate between the two resulting correlation functions: 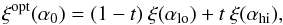 (10)where
t = (α0 − αlo)/(αhi − αlo).
Similarly, the covariance matrix can be written as a function of the two covariance
matrices Nopt(αlo) and
Nopt(αhi) as
(10)where
t = (α0 − αlo)/(αhi − αlo).
Similarly, the covariance matrix can be written as a function of the two covariance
matrices Nopt(αlo) and
Nopt(αhi) as 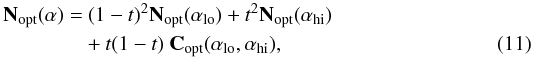 (11)where
Copt(αlo,αhi)
is the cross-covariance between
ξopt(αlo) and
ξopt(αhi) given by
(11)where
Copt(αlo,αhi)
is the cross-covariance between
ξopt(αlo) and
ξopt(αhi) given by
![Mathematical equation: \begin{eqnarray} {\bf C}_\mathrm{opt}(\alpha_\mathrm{lo},\alpha_\mathrm{hi}) &=& \nonumber\\ &&\Big\langle \left[ \vec{\xi}^\mathrm{opt}(\alpha_\mathrm{lo}) - \bar{\vec{\xi}}^\mathrm{opt}(\alpha_\mathrm{lo}) \right] \left[ \vec{\xi}^\mathrm{opt}(\alpha_\mathrm{hi}) - \bar{\vec{\xi}}^\mathrm{opt}(\alpha_\mathrm{hi}) \right]^T \nonumber \\ &&+ \left[ \vec{\xi}^\mathrm{opt}(\alpha_\mathrm{hi}) - \bar{\vec{\xi}}^\mathrm{opt}(\alpha_\mathrm{hi}) \right] \left[ \vec{\xi}^\mathrm{opt}(\alpha_\mathrm{lo}) - \bar{\vec{\xi}}^\mathrm{opt}(\alpha_\mathrm{lo}) \right]^T \Big\rangle_{\rm s}. \end{eqnarray}](/articles/aa/full_html/2013/06/aa20790-12/aa20790-12-eq117.png) (12)Finally,
we fit the correlation function (Eq. (10))
with the template (Eq. (5)) using the
covariance matrix (Eq. (11)), which yields
a new value α1 at the second iteration. We then iterate until
the estimated αi varies less than a given
quantity between two successive iterations. In practice, convergence is achieved after a
few iterations.
(12)Finally,
we fit the correlation function (Eq. (10))
with the template (Eq. (5)) using the
covariance matrix (Eq. (11)), which yields
a new value α1 at the second iteration. We then iterate until
the estimated αi varies less than a given
quantity between two successive iterations. In practice, convergence is achieved after a
few iterations.
4.2. Implementation of the method
We have used lognormal simulations to calculate the estimator for each cosmology (through different values of α). There are several reasons for this choice: the first one is that the theoretical input correlation function is known for such simulations, allowing Bk to be calculated in a straightforward manner. The second reason is that such mock catalogues are easy and fast to produce, allowing for a large number of realizations. The method could, however, be adapted to any other kind of simulations.
We perform a large number of realizations of mock catalogues with the same DR9 geometry as the data, for various values of α around α0. For this work we simulated 120 realizations of 9 different cosmologies such that the dilation parameter α covers the range [0.96,1.04] in steps of width 0.01. For each realization we used 271 000 galaxies and a random catalogue that is 15 times larger. We then applied the iterative optimal estimator described in the previous section until the estimated αi vary less than Δα = 0.0001 (achieved after just a few iterations).
The method proposed requires modest extra CPU time compared to the standard analysis. In general, the pair counting is one of the most time-consuming processes of any galaxy correlation analysis, and it needs to be done for any kind of estimator. The extra CPU time comes from pair counting of the mock catalogues with different cosmologies. The iterative procedure required to have an unbiased estimator needs at least two extra sets of mock catalogues with different BAO peak positions. In the case considered here (9 cosmologies) the production and pair counting of the lognormal mock catalogues required a few days on a single desktop machine. As shown in the following sections, the improvement in terms of error on α is around 20% showing that it is worth the effort.
4.3. Performance on simulations
In this section, we investigate the properties of the iterative optimal estimator on mock catalogues. We start with the lognormal simulations used to optimize the estimator and show that we derive an estimator that is indeed independent of the input cosmological model. We obtain a 20–25% increase in the accuracy of the α parameter with these simulations. We also test our estimator on simulations that are different from the lognormal ones used to optimize it. These are more realistic simulations than the lognomal simulations; they were produced in the framework of the SDSS-III/BOSS galaxy clustering working groups.
4.3.1. Lognormal mock data
As an illustration, we first considered what happens when we do not use the iterative procedure. The nine different sets of 120 lognormal simulations provide nine different optimal estimators, defined by ck and Bk. We choose two of them to apply to the nine sets of simulations without the iterative procedure. We fit the resulting correlation function with the template of Eq. (5) to obtain the scale parameter, αMeasured. In Fig. 5, αMeasured is averaged over the 120 simulations with the same given αInput, and its difference with αInput is plotted versus αInput. The non-iterative estimators do not recover αInput. This result occurs because the peak-shaped (Fig. 3) residual bias correction, Bk(α,r) slightly shifts the peak position of the data to the left (α = 0.96) or to the right (α = 1.04). As emphasized by the linear fits in the figure, the residual bias increases with the difference α − αInput.
Figure 5 also demonstrates what happens with the iterative optimal estimator. The iterative procedure indeed removes the residual bias, since the iterative optimal estimator appears to be unbiased. The error bars in the figure are rms of the values of αMeasured for the 120 different simulations. The optimal estimator gives smaller rms than the Landy-Szalay estimator. This result is confirmed in Fig. 6, which shows this rms as a function of αInput. The gain obtained with the optimal estimator is ≈22% relative to the Landy-Szalay estimator (this number is not a general one; the precise value depends on the geometry of the survey) leading to similar improvement on subsequent cosmological constraints.
 |
Fig. 6 Error on αMeasured for the iterative optimal (red triangles) and Landy-Szalay (blue points) estimators for the nine sets of realizations with different αInput. Error bars indicate the rms among the lognormal simulations. The gain using the iterative optimal estimator is obvious. (Coloured version of the figure available online.) |
4.3.2. PTHalos and LasDamas mock data
The studies in the previous section were performed by applying the iterative optimal estimator to the lognormal simulations that were used to optimize the estimator. We repeated the calculations using two other sets of mock catalogues that have very similar geometries, based on the BOSS DR9 footprint (Anderson et al. 2012).
The first set is based on the second-order Lagrangian perturbation theory matter field (Scoccimarro & Sheth 2002) and halo occupation function named PTHalos (Manera et al. 2013). A total of 610 realizations were produced with h = 0.7, Ωm = 0.274, ΩΛ = 0.726, Ωbh2 = 0.0224, σ8 = 0.8, and ns = 0.972. Since the fiducial cosmology used to compute the comoving distances of the galaxies is slightly different than the one used in mock catalogues, α (Eq. (6)) is not expected to be 1 but 1.002.
The second set is even more realistic; it uses N-body simulations, named large suite of dark matter simulations (LasDamas, McBride et al., in prep.); developed within the SDSS I-II galaxy clustering working group for the DR7 LRG analysis. A total of 153 realizations were produced assuming a flat ΛCDM cosmology with Ωb = 0.04, Ωm = 0.25, h = 0.7, ns = 1.0 and σ8 = 0.8, for which α is expected to be 0.988.
 |
Fig. 7 “Pull” distribution of correlation functions measured with PTHalos (top) and LasDamas (bottom) mocks in the range 40 < s < 200 h-1 Mpc with the Landy-Szalay (dashed-blue) and the iterative optimal estimator (solid red). The standard deviation of the Gaussian fit shows a smaller scatter for the latter estimator. (Coloured version of the figure available online.) |
Figure 7 shows the “pull” histogram of the correlation functions, i.e., the residuals of the correlation functions relative to the average Landy-Szalay correlation function, normalized to the empirical rms of the Landy-Szalay estimator, (ξ − ⟨ ξLS ⟩ )/σLS. By construction, the width of the pull distribution for the Landy-Szalay estimator is close to one for both sets of mock data, while it is 0.80 for the iterative optimal estimator (PTHalos) and 0.84 (LasDamas), which is similar to the 22% gain on the error bars obtained with the lognormal simulations.
This result is confirmed by Fig. 8, which shows the covariance and correlation matrices obtained with both estimators on the PTHalos mocks. The gain in the covariance matrix elements is obvious and not partially cancelled by an increase in the off-diagonal terms in the correlation matrix. Figure 9 shows the same information for the LasDamas simulations. The matrices are noisier since we have fewer realizations, but the improvement is visible, and again the correlation does not change. A small increase in the covariance matrix is present between 40 and 60 h-1 Mpc, which can also be seen in Fig. 3. However, these scales are much smaller than the scales of interest here (BAO peak) where we indeed see a clear reduction of the covariance.
 |
Fig. 8 Covariance matrices times the square of the comoving distance (top panels) and correlation matrices (bottom panels) of PTHalos mock catalogues using Landy-Szalay (left panels) and the iterative optimal estimator (right panels). (Coloured version of the figure available online). |
Finally, Fig. 10 displays the improvement on the estimation of α obtained using the iterative optimal estimator. The scatter of αMeasured with the optimal estimator is reduced relative to Landy-Szalay by 21% for PTHalos and 17% for LasDamas mocks. These gains are consistent with the observed “pull” distribution (Fig. 7) and confirm the gain observed with the lognormal simulations.
5. Application to real data
5.1. Data description
We apply our final estimator on two galaxy samples: the SDSS I-II DR7 luminous red galaxy sample (LRG, Eisenstein et al. 2001) and the SDSS-III/BOSS DR9 CMASS (Padmanabhan et al., in prep.).
Both surveys, SDSS-I-II and SDSS-III/BOSS use the same wide field and a dedicated telescope, the 2.5 m-aperture Sloan Foundation Telescope at Apache Point Observatory in New Mexico (Gunn et al. 2006). Those surveys imaged the sky at high latitude in the ugriz bands (Fukugita et al. 1996), using a mosaic CCD camera with a field of view spanning 2.5 deg (Gunn et al. 1998). The SDSS-I-II imaging survey is described in Abazajian et al. (2009). This galaxy catalogue had been built based on the prescription in Eisenstein et al. (2001), selecting the most luminous galaxies since they are more massive and then more biased with respect to the dark-matter density field. More details about the construction of the catalogue can be found in Kazin et al. (2010). The galaxies in the LRG sample have redshifts in the range 0.16 < z < 0.47 and a density of about 10-4 h3 Mpc-3.
The BOSS imaging survey data are described in Aihara et al. (2011), the spectrograph design and performance in Smee et al. (2012), and the spectral data reductions in Schlegel et al. (2012, in prep.) and Bolton et al. (2012). A summary of BOSS can be found in Dawson et al. (2013). The SDSS Data Release 9 (Ahn et al. 2012) CMASS sample of galaxies is constructed using an extension of the selection algorithm of DR7 LRG sample in order to detect fainter and bluer massive galaxies lying in the redshift range 0.43 < z < 0.7. The final density of this sample is 3 × 10-4 h3 Mpc-3. A more detailed explanation of the target selection is given in Padmanabhan et al. (in prep.).
5.2. DR7
We compared the iterative optimal estimator to the Landy-Szalay estimator for estimating the spherically averaged two-point correlation function of the SDSS DR7 (Abazajian et al. 2009) LRG sample (Fig. 11). To estimate the correlation function, we used a random catalogue that is 15 times larger than the data sample. The coefficients ck and residual biases Bk(r) for the iterative estimator were obtained using the nine sets of lognormal simulations as described in Sect. 4.1. The covariance matrix of the data correlation function for both estimators comes from the 153 realizations of the LasDamas mocks. Figure 11 show the resulting correlation function for both estimators. The error bars obtained for the iterative estimator are smaller than for the Landy-Szalay estimator, but both curves are consistent with each other. The error bars in the figure are the diagonal terms of the covariance matrix. These plots do not show the correlation between different separation bins (see Fig. 8). As a consequence, certain points show small offsets from the fit that are not significant when the full covariance matrix is considered. The χ2/d.o.f. = 28.4/35 and p = 0.78 for Landy-Szalay and χ2/d.o.f. = 29.9/35 and p = 0.71 for the optimal estimator, indicating a good fit in both cases.
 |
Fig. 9 Same as Fig. 8 for LasDamas mock catalogues. (Coloured version of the figure available online.) |
The correlation functions were fitted as for the mock catalogues, using the template defined by Eq. (5). The resulting values of αMeasured are compatible with unity, and the error for the optimal estimator is lower by 31%, as shown in Table 2. This improvement is larger than the 17% improvement on the mean error observed on mock data, but it is consistent with the scatter of the errors (Fig. 13).
In Fig. 12 we use both estimators to compare αMeasured for the DR7 LRG sample and LasDamas realizations. The DR7 measurement is well inside the LasDamas cloud, since very close to the mean.
Another way to improve the measurement accuracy of the BAO peak is through the reconstruction technique, where galaxies are slightly displaced so that the density field is as it should be without non-linear structure growth effects (Eisenstein et al. 2007). Xu et al. (2013) used the reconstruction technique on the DR7 LRG sample. Before reconstruction they obtained α = 1.015 ± 0.044, and after reconstruction α = 1.012 ± 0.024, an improvement of errors of 45%. Our estimator, with a 31% improvement, yields α = 1.008 ± 0.018, which is consistent with the reconstruction result. This comparison shows that it is possible to gain in accuracy in two independent ways, and the combination of both methods is expected to provide even better constraints on cosmological parameters.
 |
Fig. 10 Histogram of αMeasured for the PTHalos (left) and LasDamas (right) realizations using the Landy-Szalay (dashed blue) and the iterative optimal estimators (solid red). The average values over the realizations, shown in the legend, are represented as vertical lines with corresponding colours and linestyles, while the rms of the histograms are shown as horizontal thick lines (corresponding colours). The expected theoretical value is shown as a vertical black dotted line. (Coloured version of the figure available online.) |
 |
Fig. 11 Correlation functions obtained for DR7 LRG (top) and DR9 CMASS (bottom) data samples using the Landy-Szalay (left panels) and the iterative optimal estimator (right panels). The corresponding best fit is shown in solid red for Landy-Szalay and dashed blue for the iterative optimal estimator, and αMeasured is given in the legend, together with the χ2 /d.o.f. and its probability. The blue points are shifted by 1 Mpc/h to improve visibility. The covariance matrices used for these fits are based upon the LasDamas (DR7) or PTHalos (DR9) mock catalogues. (Coloured version of the figure available online.) |
 |
Fig. 12 Comparison of αMeasured using the Landy-Szalay and the iterative optimal estimators for the mocks (points) and the real data (crosses) for LasDamas and DR7 (left), and PTHalos and DR9 (right). The expected values of α are shown by dashed lines. (Coloured version of the figure available online.) |
 |
Fig. 13 Comparison of the error on αMeasured using Landy-Szalay and the iterative optimal estimators for the mocks (points) and the real data sample (crosses). As in Fig. 12, the left plot is for LasDamas and DR7 LRG data and the right one for PTHalos and DR9 data. The dotted line corresponds to the same error for the two estimators. (Coloured version of the figure available online.) |
5.3. DR9
Following the same procedure as for the DR7 LRG sample, we computed the spherically averaged two-point correlation function using the Landy-Szalay estimator and the iterative optimal estimator. The results as shown in Fig. 11, we insist again that the plots do not show the correlation between different separation bins. The corresponding values of α are given in Table 2. The χ2/d.o.f. and p-values are shown in the legend of the figure, where we get χ2/d.o.f. = 27.7/35 and p = 0.80 for Landy-Szalay and χ2/d.o.f. = 29.5/35 and p = 0.73 for the optimal estimator, indicating a good fit in both cases.
Values of α found with two different estimators of the correlation function for each sample.
We see clear improvement in the precision of the α measurement compared to the Landy-Szalay one. The values agree, but the iterative estimator gives us a 28% more accurate result.
As discussed for the DR7 data, αMeasured and its error for DR9 CMASS data are consistent with the measurements with PTHalos mocks, as can be seen in Figs. 12 (right) and 13 (right).
The BOSS DR9 CMASS result (Anderson et al. 2012), using the correlation function, only is α = 1.016 ± 0.017 before and α = 1.024 ± 0.016 after reconstruction; however in the case of DR9, the improvement of 6% due to reconstruction is much lower that expected with the new iterative estimator. Meanwhile, this result is consistent with our values with both estimators (Table 2) well within 1-σ.
6. Cosmological constraints
The improvement on cosmological parameter constraints using the iterative optimal estimator is illustrated in Fig. 14. These constraints are obtained using a Monte Carlo Markov chain within an open ΛCDM cosmology using CMB data alone. The chain3 was resampled with our BAO α constraints. The marginalized constraints on Ωm and ΩΛ are given in Table 3.
The overall gain on the cosmological parameters is between 13% and 22% (except for ΩΛ for DR9). With the iterative optimal estimator applied to DR7 data, the accuracy on Ωm and ΩΛ is comparable to what is measured with the Landy-Szalay estimator applied to the DR9 sample, even though the DR9 has a density that is three times higher and has twice the volume of DR7.
Improvement in cosmological parameters with the iterative optimal estimator.
7. Conclusions
We have designed a new two-point correlation function estimator, which is a linear combination of all possible ratios (up to the second order) of pair counts between data and random samples. The linear combination can be optimized to minimize the variance of the correlation function for a given geometry. We developed an iterative procedure to make this new estimator independent of the cosmology of the simulated data used in its optimization. We have shown on lognormal, second-order perturbation theory and N-body simulations that the decrease in size of the correlation function error bars is around 25%, relative to the well known Landy-Szalay estimator. The improvement is not mitigated by extra correlations in the covariance matrix of the two-point correlation function.
This result is not contradictory with the fact that the Landy-Szalay estimator was shown to be of minimal variance, since this is only true for a vanishing correlation function and simple geometry. Current galaxy surveys do measure a non-zero correlation function even on large scales, and they have quite complex geometry.
Our method can be easily applied to any dataset and requires few extra mock catalogues compared to the standard Landy-Szalay-based analysis. Extra mock catalogues with different cosmologies are required to evaluate the iterative optimal estimator that we have shown is unbiased. In our implementation we used lognormal simulations to produce these extra mock catalogues, since the production of lognormal mocks is straightforward and fast, but our method could be adapted to any kinds of simulations. The method requires modest extra CPU time (in our implementation, just a few days on a single desktop machine).
Finally, we have applied our method to SDSS DR7 and DR9 data, achieving an improvement of 10–15% on the value of the cosmological parameters Ωm and ΩΛ. We achieve a similar accuracy with our estimator on the DR7 sample as with the Landy-Szalay estimator on the DR9 sample.
For future developments, we would use principal component analysis to identify the combination of ratios that contributes most to minimize the correlation function variance. The optimization could then be limited to the most relevant combinations. This method can be easily extended to the study of the anisotropic correlation function. The coefficients would be optimized to simultaneously minimize the variance of the monopole and quadrupole. That approach would produce better constraints on redshift space distortions (Kaiser 1987) physical parameters and on the Alcock-Paczynski test (Alcock & Paczynski 1979).
The optimized iterative estimator could be easily applied to marked correlation functions as well (e.g., Skibba et al. 2006; Martínez et al. 2010).
 |
Fig. 14 The 68% joint constraints in the (Ωm,ΩΛ) plane for an open ΛCDM cosmology combining CMB (WMAP 7 years Komatsu et al. 2011) and either DR7 (dashed lines) or DR9 (solid lines) SDSS BAO data, with either the Landy-Szalay estimator (blue thin lines) or the iterative optimal estimator (red thick lines). (Coloured version of the figure available online.) |
The number of pairs can be spherically averaged in the simplest approach. Its dependence on the angle with respect to the line of sight can be considered in a more elaborated analysis, in order to account for the sensitivity to angular distance in the transverse direction and H(z) in the radial one (see Cabré & Gaztañaga 2009, for details).
For this work we used 598 of the 610 realizations available.
The MCMC from WMAP7 is available at http://lambda.gsfc.nasa.gov/
Acknowledgments
We would like to thank the SDSS-III collaboration for such wonderful data. We thank N. Padmanabhan, and J.K. Parejko for making their kd-tree code available. We used the “gamma” release LRG galaxy mock catalogues produced by the LasDamas projecta and we thank the LasDamas collaboration for providing us with this data. We would like to thank R. Skibba, Chia-Hsun Chuang, Lado Samushia, and Graziano Rossi for helpful suggestions and comments. This project was supported by the Agence Nationale de la Recherche under contract ANR-08-BLAN-0222. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, University of Cambridge, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
References
- Abazajian, K. N., Adelman-McCarthy, J. K., Agüeros, M. A., et al. 2009, ApJS, 182, 543 [NASA ADS] [CrossRef] [Google Scholar]
- Ahn, C. P., Alexandroff, R., Allen de Prieto, C., et al. 2012, ApJS, 203, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Aihara, H., Allen de Prieto, C., An, D., et al. 2011, ApJS, 193, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Alcock, C., & Paczynski, B. 1979, Nature, 281, 358 [NASA ADS] [CrossRef] [Google Scholar]
- Anderson, L., Aubourg, E., Bailey, S., et al. 2012, MNRAS, 427, 3435 [Google Scholar]
- Blake, C., Kazin, E. A., Beutler, F., et al. 2011, MNRAS, 418, 1707 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Bolton, A. S., Schlegel, D. J., Aubourg, É., et al. 2012, AJ, 144, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Cabré, A., & Gaztañaga, E. 2009, MNRAS, 393, 1183 [NASA ADS] [CrossRef] [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Davis, M., & Peebles, P. J. E. 1983, ApJ, 267, 465 [NASA ADS] [CrossRef] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Efstathiou, G., Sutherland, W. J., & Maddox, S. J. 1990, Nature, 348, 705 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., Annis, J., Gunn, J. E., et al. 2001, AJ, 122, 2267 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., Zehavi, I., Hogg, D. W., et al. 2005, ApJ, 633, 560 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., Seo, H.-J., Sirko, E., & Spergel, D. N. 2007, ApJ, 664, 675 [Google Scholar]
- Eisenstein, D. J., Weinberg, D. H., Agol, E., et al. 2011, AJ, 142, 72 [Google Scholar]
- Fukugita, M., Ichikawa, T., Gunn, J. E., et al. 1996, AJ, 111, 1748 [NASA ADS] [CrossRef] [Google Scholar]
- Granett, B. R., Neyrinck, M. C., & Szapudi, I. 2009, ApJ, 701, 414 [NASA ADS] [CrossRef] [Google Scholar]
- Gunn, J. E., Carr, M., Rockosi, C., et al. 1998, AJ, 116, 3040 [NASA ADS] [CrossRef] [Google Scholar]
- Gunn, J. E., Siegmund, W. A., Mannery, E. J., et al. 2006, AJ, 131, 2332 [NASA ADS] [CrossRef] [Google Scholar]
- Hamilton, A. J. S. 1993, ApJ, 417, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Hewett, P. C. 1982, MNRAS, 201, 867 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N. 1987, MNRAS, 227, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Kazin, E. A., Blanton, M. R., Scoccimarro, R., et al. 2010, ApJ, 710, 1444 [NASA ADS] [CrossRef] [Google Scholar]
- Kerscher, M. 1999, A&A, 343, 333 [NASA ADS] [Google Scholar]
- Kerscher, M., Szapudi, I., & Szalay, A. S. 2000, ApJ, 535, L13 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Komatsu, E., Smith, K. M., Dunkley, J., et al. 2011, ApJS, 192, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Landy, S. D., & Szalay, A. S. 1993, ApJ, 412, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Manera, M., Scoccimarro, R., Percival, W. J., et al. 2013, MNRAS, 428, 1036 [NASA ADS] [CrossRef] [Google Scholar]
- Martínez, V. J., Arnalte-Mur, P., & Stoyan, D. 2010, A&A, 513, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mehta, K. T., Cuesta, A. J., Xu, X., Eisenstein, D. J., & Padmanabhan, N. 2012, MNRAS, 427, 2168 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E., & Hauser, M. G. 1974, ApJS, 28, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Percival, W. J., Cole, S., Eisenstein, D. J., et al. 2007, MNRAS, 381, 1053 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Pons-Bordería, M.-J., Martínez, V. J., Stoyan, D., Stoyan, H., & Saar, E. 1999, ApJ, 523, 480 [NASA ADS] [CrossRef] [Google Scholar]
- Reid, B. A., Samushia, L., White, M., et al. 2012, MNRAS, 426, 2719 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez, A. G., Scóccola, C. G., Ross, A. J., et al. 2012, MNRAS, 425, 415 [NASA ADS] [CrossRef] [Google Scholar]
- Scoccimarro, R., & Sheth, R. K. 2002, MNRAS, 329, 629 [NASA ADS] [CrossRef] [Google Scholar]
- Sherwin, B. D., Dunkley, J., Das, S., et al. 2011, Phys. Rev. Lett., 107, 1302 [Google Scholar]
- Skibba, R., Sheth, R. K., Connolly, A. J., & Scranton, R. 2006, MNRAS, 369, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Slosar, A., Font-Ribera, A., Pieri, M. M., et al. 2011, J. Cosmology Astropart. Phys., 9, 1 [Google Scholar]
- Smee, S., Gunn, J. E., Uomoto, A., et al. 2012, AJ, accepted [arXiv:1208.2233] [Google Scholar]
- Weinberg, D. H., Mortonson, M. J., Eisenstein, D. J., et al. 2012, Phys. Rep., accepted [arXiv:1201.2434] [Google Scholar]
- Xu, X., Cuesta, A. J., Padmanabhan, N., Eisenstein, D. J., & McBride, C. K. 2013, MNRAS, 431, 2834 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Values of α found with two different estimators of the correlation function for each sample.
All Figures
|
Fig. 1 Input (dotted line) and reconstructed (various colours and linestyles, see legend) two-point correlation function obtained using the various estimators available in the literature for a cubic geometry (left) or a realistic (BOSS DR9) survey volume (right). The bottom panels show the root mean square of each estimator with corresponding colour and linestyle. In each case, the Hamilton and Landy-Szalay lines are exactly superposed as well as the Davis-Peebles and Hewett lines. (Coloured version of the figure available online). |
| In the text | |
|
Fig. 2 rms of the Landy-Szalay estimator for lognormal simulations in a cubic geometry and for a zero two-point correlation function (left) and for a ΛCDM model (right). The upper, middle, and lower solid lines correspond to a random sample with 1, 3, and 30 times more galaxies, respectively than the data sample. Dotted lines show the Poisson noise associated with each number of randoms (in the same order as solid lines). The thick dashed line shows the limit corresponding to an infinite number of random galaxies. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 3 Residuals with respect to the input correlation function for the Landy-Szalay estimator (dashed-blue) and for the minimum variance estimator (solid-red). We also show the corresponding ± 1σ (rms from lognormal simulations) for Landy-Szalay (dotted-blue) and for the minimum variance estimator (dot-dashed-red). Residuals and rms are rescaled by s2. The optimal estimator has been obtained limiting the χ2 to the region [40, 200] h-1 Mpc. This range has been chosen accordingly to the typical range used in BAO analysis. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 4 (Top panels) Covariance matrices multiplied by the square of the comoving distance. (Bottom panels) Correlation matrices for both the Landy-Szalay estimator (left panels) and the optimized estimator (right panels). (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 5 Bias on αMeasured as a function of αInput (from lognormal simulations) for Landy-Szalay (blue points), iterative optimal (red triangles) and two non-iterative minimum-variance estimators with α = 0.96 (orange crosses) and α = 1.04 (green squares). The error bars indicate the rms among the lognormal simulations. Simple linear functions were fitted to the points in each case with corresponding slopes shown in the legend. A strong bias can be seen for the non-iterative estimators while the iterative optimal and Landy-Szalay estimators are not biased. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 6 Error on αMeasured for the iterative optimal (red triangles) and Landy-Szalay (blue points) estimators for the nine sets of realizations with different αInput. Error bars indicate the rms among the lognormal simulations. The gain using the iterative optimal estimator is obvious. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 7 “Pull” distribution of correlation functions measured with PTHalos (top) and LasDamas (bottom) mocks in the range 40 < s < 200 h-1 Mpc with the Landy-Szalay (dashed-blue) and the iterative optimal estimator (solid red). The standard deviation of the Gaussian fit shows a smaller scatter for the latter estimator. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 8 Covariance matrices times the square of the comoving distance (top panels) and correlation matrices (bottom panels) of PTHalos mock catalogues using Landy-Szalay (left panels) and the iterative optimal estimator (right panels). (Coloured version of the figure available online). |
| In the text | |
|
Fig. 9 Same as Fig. 8 for LasDamas mock catalogues. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 10 Histogram of αMeasured for the PTHalos (left) and LasDamas (right) realizations using the Landy-Szalay (dashed blue) and the iterative optimal estimators (solid red). The average values over the realizations, shown in the legend, are represented as vertical lines with corresponding colours and linestyles, while the rms of the histograms are shown as horizontal thick lines (corresponding colours). The expected theoretical value is shown as a vertical black dotted line. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 11 Correlation functions obtained for DR7 LRG (top) and DR9 CMASS (bottom) data samples using the Landy-Szalay (left panels) and the iterative optimal estimator (right panels). The corresponding best fit is shown in solid red for Landy-Szalay and dashed blue for the iterative optimal estimator, and αMeasured is given in the legend, together with the χ2 /d.o.f. and its probability. The blue points are shifted by 1 Mpc/h to improve visibility. The covariance matrices used for these fits are based upon the LasDamas (DR7) or PTHalos (DR9) mock catalogues. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 12 Comparison of αMeasured using the Landy-Szalay and the iterative optimal estimators for the mocks (points) and the real data (crosses) for LasDamas and DR7 (left), and PTHalos and DR9 (right). The expected values of α are shown by dashed lines. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 13 Comparison of the error on αMeasured using Landy-Szalay and the iterative optimal estimators for the mocks (points) and the real data sample (crosses). As in Fig. 12, the left plot is for LasDamas and DR7 LRG data and the right one for PTHalos and DR9 data. The dotted line corresponds to the same error for the two estimators. (Coloured version of the figure available online.) |
| In the text | |
|
Fig. 14 The 68% joint constraints in the (Ωm,ΩΛ) plane for an open ΛCDM cosmology combining CMB (WMAP 7 years Komatsu et al. 2011) and either DR7 (dashed lines) or DR9 (solid lines) SDSS BAO data, with either the Landy-Szalay estimator (blue thin lines) or the iterative optimal estimator (red thick lines). (Coloured version of the figure available online.) |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.