Fig. 3
Download original image
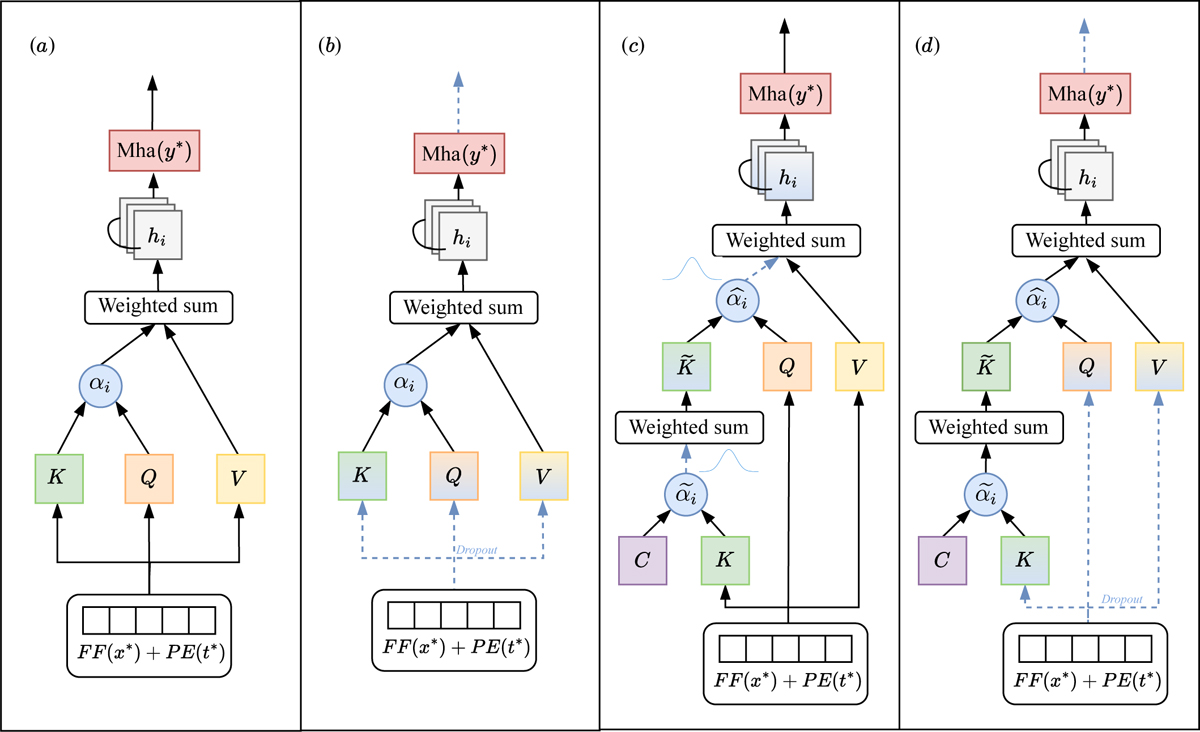
Graphical representation of each method. For simplicity, each panel shows the first self-attention block, from the input representation (F F(x*) + P E(x*)) to the output of multi-head attention. Panel a shows the DEs approach, which relies on standard multi-head attention; attention scores αi are derived from the key (K) and query (Q) matrices (Eq. (2)), which are used to calculate the output hi (Eq. (4)). Panel b shows MC Dropout, which activates dropout both after the input and within the attention blocks (dashed blue lines). As a result, the query (Q), key (K) and value (V) matrices change with each forward pass. Panel c corresponds to the HSA approach, which introduces a hierarchical component, specifically, the key representation is redefined using a set of centroids (C) to produce a new key matrix (![]() ); attention weights (
); attention weights (![]() ) are sampled from a Gumbel-softmax distribution, introducing stochasticity into the attention computation. Panel d corresponds to the HA-MC Dropout approach, which combines dropout (as in b) and the hierarchical component (as in c with no sampling from a Gumbel-softmax distribution); this configuration retains the hierarchical component and applies dropout within the attention block, resulting in varying attention weights across forward passes.
) are sampled from a Gumbel-softmax distribution, introducing stochasticity into the attention computation. Panel d corresponds to the HA-MC Dropout approach, which combines dropout (as in b) and the hierarchical component (as in c with no sampling from a Gumbel-softmax distribution); this configuration retains the hierarchical component and applies dropout within the attention block, resulting in varying attention weights across forward passes.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.