| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A34 | |
| Number of page(s) | 17 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202451608 | |
| Published online | 31 January 2025 | |
Best of both worlds: Fusing hyperspectral data from two generations of spectro-imagers for X-ray astrophysics
1
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, AIM,
91191
Gif-sur-Yvette,
France
2
FSLAC IRL 2009, CNRS/IAC,
La Laguna,
Tenerife,
Spain
★ Corresponding author; julia.lascar@cea.fr
Received:
22
July
2024
Accepted:
25
November
2024
Context. With the recent launch of the X-Ray Imaging and Spectroscopy Mission (XRISM) and the advent of microcalorimeter detectors, X-ray astrophysics is entering in a new era of spatially resolved high-resolution spectroscopy. But while this new generation of X-ray telescopes offers much finer spectral resolution than the previous one (e.g. XMM-Newton, Chandra), these instruments also have coarser spatial resolutions, leading to problematic cross-pixel contamination. This issue is currently a critical limitation for the study of extended sources, such as galaxy clusters or supernova remnants (SNRs).
Aims. To increase the scientific output of XRISM’s hyperspectral data, we propose that it be fused with XMM-Newton data, and seek to obtain a cube with the best spatial and spectral resolution of both generations. This is the aim of hyperspectral fusion. In this article, we explore the potential and limitations of hyperspectral fusion for X-ray astrophysics.
Methods. We implemented an algorithm that jointly deconvolves the spatial response of XRISM and the spectral response of XMM- Newton. To do so, we construct a forward model adapted for instrumental systematic degradations and Poisson noise, and then tackle hyperspectral fusion as a regularized inverse problem. We test three methods of regularization: spectral low-rank approximation with a spatial Sobolev regularization; spectral low-rank approximation with a 2D wavelet sparsity constraint; and a 2D–1D wavelet sparsity constraint.
Results. We test our method on toy models constructed from hydrodynamic simulations of SNRs. We find that our method reconstructs the ground truth well even when the toy model is complex. For the regularization term, we find that while the low-rank approximation works well as a spectral denoiser in models with less spectral variability, it introduces a bias in models with more spectral variability, in which case the 2D-1D wavelet sparsity regularization works best. Following the present proof of concept, we aim to apply this method to real X-ray astrophysical data in the near future.
Key words: methods: data analysis / methods: statistical / ISM: supernova remnants / X-rays: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
With the advent of microcalorimeter detectors, X-ray astrophysics has entered a new era of spatially resolved high-resolution spectroscopy. Indeed, the recent launch of the X-Ray Imaging and Spectroscopy Mission (XRISM) and its microcalorimeter array “Resolve”1, and the future Athena telescope and its X-ray Integral Field Unit (X-IFU)2 camera, has granted access to spatially resolved spectroscopy at spectral resolutions improved by an order of magnitude. This is set to allow astrophysicists to investigate previously indistinguishable spectral features, such as the emission lines of rare elements, line broadening, or velocity measurements. These characteristics are essential in the study of extended sources such as supernova remnants (SNRs), galaxy clusters, and many of the other exotic sources of the X-ray Universe.
However, while the XRISM/Resolve instrument has a much finer spectral resolution than the Chandra X-ray Observatory’s Advanced CCD Imaging Spectrometer (Chandra/ACIS)3 or the X-ray Multi-Mirror-Newton’s European Photon Imaging Camera (XMM-Newton/EPIC)4 cameras, its spatial resolution is much lower than that of its predecessors. As we demonstrate here, this spatial blur is an important obstacle when analyzing XRISM/Resolve data. Given this trade-off, we set out to establish whether or not it is possible to combine the data from these two generations of X-ray observatories and obtain a result with the best spectral and spatial resolution of each instrument. This is the idea at the heart of hyperspectral fusion.
In this paper, we explore the potential and limitations of hyperspectral fusion for X-ray data taken by pairs of telescopes such as XMM-Newton/EPIC with XRISM/Resolve, or Chandra with Athena-X-IFU.
We implemented a modular optimization algorithm that can use one of three potential regularizations: first, inspired by Guilloteau et al. (2020), and given the widespread usage of low-rank approximations in the literature, we implement a low- rank approximation with Sobolev spatial regularization. Since Sobolev regularization does not take into account multi-scale features, we then considered a low-rank approximation with a 2D wavelet sparsity regularization. Finally, to investigate whether low-rankedness is indeed appropriate, we implemented a heuristic approach using a 2D–1D Wavelet sparsity regularization. This hyperspectral fusion code is openly available on Github5.
In Section 2, we present the astrophysical and methodological context behind our work. In Section 3, we present our methodology, and describe the forward model we have developed for X-ray astrophysics, and the proposed regularization schemes. In Section 4, we test our method on toy models of varying complexity using synthetic X-ray data cubes constructed from hydrodynamic simulation of SNRs. We discuss the achievements, limitations, and perspective for future work in Section 5.
2 Context
2.1 Astrophysical context: X-ray spectro-imaging and microcalorimeters
X-ray spectro-imagers can collect hyperspectral images. These are 3D data arrays: they have two spatial dimensions, like a classical image, and a third spectral dimension (energy or wavelength). In other words, an energy spectrum is associated to each spatial pixel.
In recent decades, charge-coupled device (CCD) cameras have been the main spectro-imaging instruments on board X-ray telescopes such as XMM-Newton, Chandra, Swift, Suzaku, and eROSITA. When the X-ray photon interacts with the semiconductor material, an electric charge is generated proportional to the energy of the incident photon. The charge is then transferred row by row to a readout register. For example, the XMM-Newton MOS camera can accommodate a large number (600×600) of small pixels (40 µm, Turner et al. 2001). The energy resolution is of the order 150 eV6 at 6 keV (E/ΔE ~ 40), which is close to the Fano limit, the physical lower bound of energy resolution due to the statistical fluctuations in the number of electron-hole pairs produced in the photon-material interaction.
To overcome this limit, a change of technology is required. Microcalorimeter devices are providing this revolutionary leap forward for X-ray spectro-imaging instruments. The fundamental principle of microcalorimeters is to measure the photon energy via the small increase in temperature caused by the conversion of this energy into heat in the sensor. To be sensitive to small heat increments and reach a spectral resolution on the order of a few electron volts, the device has to be cooled down to 50 mK and remain at very stable temperature. It is important to note that, unlike gratings on board XMM-Newton or Chandra, microcalorimeters are non-dispersive spectrometers and can be used to study diffuse structure.
However, with the current available technology, only a limited number of pixels can be accommodated on the focal plane. The XRISM/Resolve instrument is a microcalorimeter array of 6 × 6 sensors (pixel size of 800 μm, Takahashi et al. 2014) with a constant spectral resolution over the entire bandpass of 5 eV FWHM (XRISM Science Team 2020). While future X-ray telescopes combining microcalorimeter and high spatial resolution are planned (Athena/XIFU, see Barret et al. 2018, for more details), they are expected to launch in the late 2030s, and will still not reach the spatial resolution of the X-ray telescope Chandra.
In the meantime, mitigation plans to overcome this spatial-resolution limitation should be investigated to try to partially recover some of the spatial information. To that end, we explore in this study the performance of hyperspectral fusion to combine data sets with high spectral resolution and high spatial resolution using the example of fusion between XMM-Newton and XRISM/Resolve data. The final goal of this reconstruction is to enhance the scientific return of XRISM/Resolve by retrieving maps of physical parameters (plasma temperature, velocity, abundances, etc.) at higher resolution with reduced crosscontamination between pixels (spectrospatial mixing).
Indeed, this mixing is an important problem when analyzing hyperspectral data. If an instrument’s spatial resolution is larger than the coherence scale of a physical parameter, the reconstructed information will be an average of the small-scale features. To take the example of a velocity map from the ejecta of a SNR, the small-scale redshifted and blueshifted ejecta features can mistakenly be measured at small or close-to-zero redshift values, as was demonstrated by the detailed analysis of Tycho’s SNR in Godinaud et al. (2023). By jointly deconvolving the data sets from two X-ray instruments, hyperspectral data fusion could solve this problem and recover higher-fidelity scientific information at small scale.
2.2 Hyperspectral fusion
Given two hyperspectral (HS) images, the general task of hyperspectral fusion consists in obtaining a cube with the best spatial and spectral resolution of each data set. For instance, Fig. 1 shows HS images of the Perseus galaxy cluster taken by the X-ray telescopes XMM-Newton and Hitomi/SXS7. XMM-Newton has better spatial resolution, and Hitomi has better spectral resolution. The goal of fusing the two datasets would be to obtain a HS image with XMM-Newton’s spatial resolution and Hitomi’s spectral resolution.
This problem has been explored in the literature for applications to satellite pictures of the earth, and has recently received some attention in astrophysics with the launch of the James Webb Space Telescope (JWST). However, X-ray astrophysics has its own specific challenges. X-ray data are dominated by Poisson noise, and both instruments produce HS images with many spectral channels, as opposed to one of the data sets being a multi-spectral image with a small number of spectral bands typically obtained with different filters. To use hyperspectral fusion for X-ray astrophysics, it is thus important to find the fusion method most appropriate for this case study.
In this section, we provide an overview of the various aspects to take into account when approaching a problem of hyperspectral fusion in order to find the best way to solve the problem. For a detailed review of the literature, we refer the interested reader to Yokoya et al. (2017).
The first aspect to consider is the forward model of the two instruments. This defines how a source image will be degraded in the process of image formation and recording, which depends on the systematic characteristics of the instrument, and the noise we expect to measure.
When considering systematic instrumental degradation, two dimensions may be taken into account: the spatial degradation, and the spectral degradation. Spatially, the degradation will be due to optical diffraction or other systematic blurs, and this information is encapsulated in the point spread function (PSF). Given a point source, the PSF returns its radiance distribution on the recorded image. Similarly, if a source emits a Dirac spectrum, the measured spectrum will be the instrument’s spectral response function, and this will be affected by, for instance, the chemical and physical properties of the spectro-imager. Depending on the instrument, the PSF and spectral response may depend on the energy, on the spatial location of the pixel on the camera, or both.
Then, for the stochastic noise, while most of the literature on fusion assumes additive Gaussian noise, it is important to realize this is not always appropriate. In X-ray astrophysics, photons have a low flux and are measured individually, and thus follow a Poisson distribution.
Once the instrumental systematic degradation and the stochastic noise have been taken into account, if we take two HS images X and Y of sizes (M × N × l) and (m × n × L), the general problem of fusing two HS images can be written as:
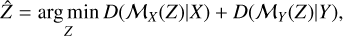 (1)
(1)
where Z is the fusion result, ℳX and ℳY are the model operators that take into account the systematic instrumental degradation (PSF, spectral response, etc.) and the rebinning needed to take account different voxel sizes, and D is a well-chosen function that evaluates the difference between the model ℳX (Z) and data X, and between model ℳY(Z) and data Y, given the expected noise distribution. Thus, this problem ensures that Z is a plausible source from which the first instrument can measure X and the second can measure Y. In the case of X-ray astrophysics, the forward model is the one described in Section 3.1 and Fig. 2.
However, this problem is often ill-posed (in the sense of Hadamard 1923) and ill-conditioned, meaning that while there might be a unique solution, the noise will be amplified when inverting the model, corrupting the solution, and slight changes in the data would lead to drastic changes in the solution (Bertero et al. 2022). One well-studied approach to solving ill-posed inverse problems is to regularize the problem, which restricts the space of acceptable solutions. This can be approached by considering the spatial features of Z, its spectral features, or both. To regularize in the spectral dimension, one classic method is to project the spectra of Z onto a lowerdimensional subspace, as is done with source separation (e.g., Yokoya et al. 2012; Prévost et al. 2022; Pineau et al. 2023) or low-rank approximation (e.g., Simões et al. 2015; Xu et al. 2022; Guilloteau et al. 2020). We can also add a regularization term φ(Z) to the function we seek to minimize, which leads us to:
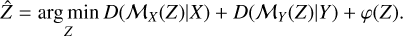 (2)
(2)
This φ(Z) will promote certain spatial or spectral structures in the solution. Its choice must thus be appropriate for our data. For instance, in remote sensing (i.e., the study of satellite pictures of the earth), it may be useful to promote spatial piece-wise smoothness using a total variation term, as done by Simões et al. (2015), but this would be ill-advised for astrophysical data, where such features are rarely observed. For our case of X-ray astrophysics, we consider three potential regularization approaches, which are described in Section 3.3.
Finally, to solve the problem in Equation (2), we need to choose an appropriate optimization scheme. In some cases, there might be an analytical solution (as in the work of Pineau et al. 2023 for JWST, when the spectral content is assumed to be a linear combination of known spectra), but most often an iterative algorithm must be constructed. The choice of optimizer will depend on the data size, the specific challenges presented by the forward model, and the chosen regularization terms. It may also be the case that constraints placed on the optimizer (such as insisting that the algorithm reaches convergence as quickly as possible) will lead to constraints on the choice of regularization and cost function.
In astrophysics, work has been done to tackle multi-spectral/HS fusion for the JWST (see Guilloteau et al. 2022; Pineau et al. 2023) in order to fuse images taken by two of its instruments (NIRCam and NIRSpec), but to our knowledge, no algorithm has been implemented for HS/HS fusion with Poisson statistics, considering two instruments with their PSF and spectral responses, as is needed in X-ray astrophysics.
 |
Fig. 1 Comparison of hyperspectral data of the Perseus galaxy cluster as observed by two generations of X-ray spectro-imagers. The XMM- Newton/MOS (top) and Hitomi/SXS (bottom) data have pixels of 8″730″ and spectral channels of 15/1 eV respectively. The left panels show the counts maps summed over all spectral channels and the right panels the spectra summed over all pixels. |
 |
Fig. 2 Simplified diagram of the forward model of two X-ray telescopes (here, XMM-Newton/EPIC and XRISM/Resolve). The problem of fusion consists in inverting this model and using the observed data X and Y to retrieve the deconvoluted cube Z. The mathematical details behind the operators and kernels are detailed in Section 3. Not shown is the exposure time of each data set. |
3 Methodology
In this section, we present the methodology of our fusion algorithm for X-ray astrophysics. We present the general problem to be solved in Section 3.1. Section 3.2 presents the rebinning operator needed when the data sets have different voxel sizes. Section 3.3 describes our choices of potential regularization terms. Section 3.4 presents our algorithmic strategy to solve the inverse problem.
3.1 Forward model
Let X be the hyperspectral data from the instrument with higher spatial resolution but lower spectral resolution (e.g., XMM-Newton/EPIC). Let Y be the data from the other instrument, with lower spatial resolution and higher spectral resolution (e.g., XRISM/Resolve). When available, 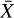 and
and 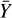 are the ground truths at the resolutions of the respective instruments.
are the ground truths at the resolutions of the respective instruments.
In this section, we consider the problem where both HS images are of the same size, that is, X and 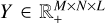 , and therefore so does Z (see Section 3.2 for the case where X and Y have different sizes). Our forward model (seen in Fig. 2) must include the spatial degradation of each instrument, which is modeled by their PSFs, as well as the spectral degradation, which is modeled by their spectral responses. We must also account for the effective area of the instrument, and the exposure time. For the former, we assume an effective area with no vignetting; that is, the effective area does not vary spatially8. We use AX and AY to denote the effective area cubes, which have the same shape as X and Y. tX and tY are scalars, the exposure times of each data set. The spectral responses of the instruments are sX and sY, and their PSFs are BX and BY.
, and therefore so does Z (see Section 3.2 for the case where X and Y have different sizes). Our forward model (seen in Fig. 2) must include the spatial degradation of each instrument, which is modeled by their PSFs, as well as the spectral degradation, which is modeled by their spectral responses. We must also account for the effective area of the instrument, and the exposure time. For the former, we assume an effective area with no vignetting; that is, the effective area does not vary spatially8. We use AX and AY to denote the effective area cubes, which have the same shape as X and Y. tX and tY are scalars, the exposure times of each data set. The spectral responses of the instruments are sX and sY, and their PSFs are BX and BY.
We define ℬX and ℬY as the operators which, given a cube Z, apply a 2D convolution on its spatial slices with the PSF BX or BY . Similarly, we use 𝒮X and 𝒮Y to denote the operators that convolve each spectra of Z with sX or sY, respectively. Formally, if Zk is the 2D slice of Z at the kth spectral channel, and Zij is the spectra of Z at pixel (i, j):
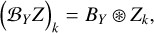 (3)
(3)
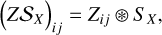 (4)
(4)
where ⊛ represents the convolution operator (for simplicity of notation, this is written in the same way for 2D and 1D convolution).
The aim is to reach, as closely as possible given the noisy data, a fused cube Z that has the spatial resolution of X and the spectral resolution of Y. The general problem is
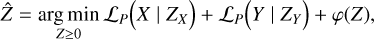 (5)
(5)
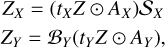
where ⊙ is the term-by-term product, the data-fidelity metric ℒP is the negative Poisson log-likelihood, and φ(Z) is the regularization term. We impose Z ≥ 0, as there is no physical interpretation for a negative spectra. The likelihood terms promote faithfulness between our model and the data at comparable resolutions.
It is worth noting that in order to fully invert the forward model, we would need to compare X with ℬX (tXZ ⊙ AX)𝒮X, and likewise for Y. However, our aim is not to retrieve a cube Z with infinite resolution, but rather our intention is for Z to have the spatial resolution of X, and the spectral resolution Y. The problem expressed in Equations (5) and (6) will promote such a solution, since no spatial degradation is applied to go from Z to ZX, and likewise spectrally for ZY with Y.
More explicitly, we obtain
![$\eqalign{ & \hat Z = \mathop {\arg \min }\limits_{Z \ge 0} \sum\limits_{i = 1}^M {\sum\limits_{j = 1}^N {\sum\limits_{k = 1}^L {\left[ {{{\left( {\left( {{t_X}Z \odot {A_X}} \right){{\cal S}_X}} \right)}_{i\,jk}}} \right.} } } \cr & \,\,\,\,\,\,\,\,\,\, - {X_{i\,jk}}ln{\left( {\left( {{t_X}Z \odot {A_X}} \right){{\cal S}_X}} \right)_{i\,jk}} \cr & \left. {\,\,\,\,\,\,\,\,\,\, + {{\left( {{{\cal B}_Y}\left( {{t_Y}Z \odot {A_Y}} \right)} \right)}_{i\,jk}} - {Y_{i\,jk}}\ln {{\left( {{{\cal B}_Y}\left( {{t_Y}Z \odot {A_Y}} \right)} \right)}_{i\,jk}}} \right] + \varphi (Z), \cr} $](/articles/aa/full_html/2025/02/aa51608-24/aa51608-24-eq10.png) (7)
(7)
where the shape of Z, X, Y, are all (M, N, L).
3.2 Rebinning operator
In most cases, two different hyperspectral instruments will not produce data of the same voxel size. Rather, we will have 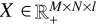 and
and 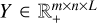 , where L > l, M > m, and N > n. In other words, X has more pixels than Y, and Y has more spectral channels than X. Our result Z should be of size (M × N × L). In order to compare Z to the data X and Y in the data fidelity terms of Equation (5), we thus need to change the size of Z to that of X and Y, respectively. This is done by applying a rebinning operator.
, where L > l, M > m, and N > n. In other words, X has more pixels than Y, and Y has more spectral channels than X. Our result Z should be of size (M × N × L). In order to compare Z to the data X and Y in the data fidelity terms of Equation (5), we thus need to change the size of Z to that of X and Y, respectively. This is done by applying a rebinning operator.
For the sake of simplicity, and to keep this operator differentiable, we assume that M is a multiple of m, N is a multiple of n, and L is a multiple of l. Let us denote the multiplying factors (vM, vN, vL), such that M = vMm, and likewise for the other dimensions. We need three rebinning operators: ℛM, ℛN, and ℛL.
In this case, the rebinning operator is that which sums together pixels in nearby groups of ν.
For instance, for ℛM, a single voxel (s, j, k) of the rebinned tensor is
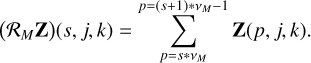 (8)
(8)
Such an operator can be neatly written as a matrix product between each slice of the tensor Z and a block diagonal matrix filled only with zeroes and ones. For simplicity, we use ℛMN to denote the spatial rebinning operator (which applies ℛM on the lines, and ℛN on the columns).
Now, to include rebinning in our optimization problem posed in Equation (5), ZX and ZY become
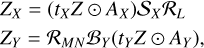 (9)
(9)
and plugging this into the Poisson likelihood, we obtain
![$\eqalign{ & \hat Z = \mathop {\arg \min }\limits_{Z \ge 0} \sum\limits_{i = 1}^M {\sum\limits_{j = 1}^N {\sum\limits_{k = 1}^L {\left[ {{{\left( {\left( {{t_X}Z \odot {A_X}} \right){{\cal S}_X}{{\cal R}_L}} \right)}_{i\,jk}}} \right.} } } \cr & \;\,\,\,\,\,\,\,\, - {X_{ijk}}ln{\left( {\left( {{t_X}Z \odot {A_X}} \right){{\cal S}_X}{{\cal R}_L}} \right)_{i\,jk}} + {\left( {{{\cal R}_{MN}}{{\cal B}_Y}\left( {{t_Y}Z \odot {A_Y}} \right)} \right)_{i\,jk}} \cr & \,\,\,\,\,\,\,\,\,\left. { - {Y_{i\,jk}}ln{{\left( {{{\cal R}_{MN}}{{\cal B}_Y}\left( {{t_Y}Z \odot {A_Y}} \right)} \right)}_{i\,jk}}} \right] + \varphi (Z). \cr} $](/articles/aa/full_html/2025/02/aa51608-24/aa51608-24-eq15.png) (10)
(10)
3.3 Regularization
In X-ray astrophysics, low signal-to-noise ratio presents a major problem, as HS images are dominated by Poisson noise. Thus, we are looking for regularization terms that will be efficient denoisers for Poisson statistics, and that will be appropriate for astrophysical images (often displaying diffuse and/or isotropic features) and X-ray spectra (which can present strong spectral variability).
Our first consideration was sparsity under a 2D–1D starlet transform. Then, inspired by the work of Guilloteau et al. (2022) regarding JWST, we implemented a low-rank approximation with Sobolev spatial regularization. Finally, we wished to test a compromise between the two, with a low-rank approximation and a 2D spatial wavelet sparsity regularization. The following sections describe these three options.
3.3.1 2D-1D wavelet sparsity
A classic regularization method is to choose a term that promotes the sparsity of Z under a well-chosen orthogonal transform – that is to say, that in some domain, Z can be represented by only a small number of non-zero coefficients. Wavelets are useful for capturing multi-scale features. In particular, the isotropic undecimated wavelet transform, dubbed the starlet transform, is appropriate for astrophysical data due to its isotropic structure (Starck & Murtagh 1994). The data are convolved by B3-spline filters, which produce a set of increasingly coarse resolution versions of the data, and the S wavelet scales are defined as the difference between two subsequent resolutions. The coarsest resolution is dubbed the coarse scale, and no assumption of sparsity is placed upon it. This allows the regularization to represent data with a smooth continuum (the coarse scale) and sharp features (the non-zero elements of the fine scales).
More specifically, we chose the 2D-1D starlet transform, which we define as applying the 2D starlet transform channelwise, then the 1D starlet transform pixel-wise. Thus, in this case, φ(Z) is the l1 norm (the minimization of which promotes sparsity; see Bach et al. 2011) of the 2D-1D starlet transform coefficients of Z. For S wavelet scales, we define the 2D-1D starlet transform as 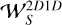 , and the l1 norm regularization term is
, and the l1 norm regularization term is
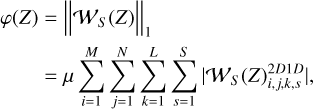 (11)
(11)
where μ is a hyperparameter to control the intensity of regularization.
3.3.2 Low rank and Sobolev
This regularization option was inspired by work regarding JWST carried out by Guilloteau et al. (2020), though we designed an implementation adapted for HS-HS fusion and the specifics of X-ray astronomy. The spectral regularization is a low-rank approximation, which corresponds to decomposing Z = WV, where V ∊ ℝL×r spans the subspace of rank r onto which Z is projected, and W ∊ Rr×M×N is the tensor of representation coefficients in that subspace. V is found by performing principal component analysis on Y (the hyperspectral image with the most spectral information) and keeping only the highest singular values. Therefore, now ZX and ZY from Equation (9) become variables of W, where
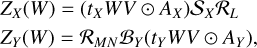 (12)
(12)
and these can be plugged into Equation (10), now seeking to minimize W. For spatial regularization, the Sobolev regularization (Karl 2005) implies adding the following term to the cost function:
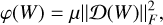 (13)
(13)
where Ɗ is a first-order 2D finite difference operator. This term will act to minimize the differences between neighboring pixels on the representation coefficients of the subspace spanned by V.
Both the Sobolev regularization and the low-rankedness will result in a faster algorithm, due to the dimension reduction and simple expression of the Ɗ operator. However, Sobolev does not capture multi-scale spatial features. Further, as V is extracted from Y, it may reproduce features found in Y too strongly. This is acceptable (and even desirable) in MS /HS fusion, where the MS image does not bring a significant amount of spectral information, but in HS /HS fusion, X contains spectral information, in particular because it displays much less spatial mixing than Y . The assumption that all spectra in Z can be decomposed as linear combinations of Y is not necessarily true, and forcing a low-rank approximation in this case will bring on spectral distortions. However, if this assumption is valid, low-rankedness will be an undeniable asset.
3.3.3 Low rank and 2D wavelet sparsity
As Sobolev regularization does not capture multi-scale information in the same way wavelets do, we considered the option to keep a low-rank approximation as described in the previous section, and then to use a starlet sparsity term for the spatial regularization:
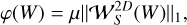 (14)
(14)
where the operator 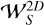 applies the 2D starlet transform to every slice of W.
applies the 2D starlet transform to every slice of W.
3.4 Algorithm description
3.4.1 Proximal gradient descent
If we consider the problem posed in Equations (7) or (10), and replace the regularization term by one of the three options we consider above, we note that the cost function is convex, and can be separated into two parts, one differentiable and one non-differentiable. In such cases, proximal gradient methods have been shown to be very effective (Parikh & Boyd 2014).
The proximal gradient descent is an iterative method where, for each iteration, we first undergo a gradient descent step on the differentiable part of the cost function before applying a proximal operator (prox), the purpose of which is to find a solution close to the result obtained by gradient descent while minimizing the function’s non-differentiable part. Formally, if the result obtained by the gradient descent step is x, and the non-differentiable part of the function is φ, the operator is:
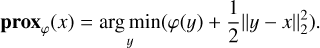 (15)
(15)
For the l1 norm, the proximal operator is a soft thresholding function:
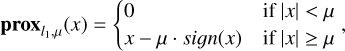 (16)
(16)
where µ is the parameter that controls the strength of regularization. For the non-negativity constraint, the prox is simply the operator that forces all negative values to 0.
The gradient of the differentiable part in Equation (5) is
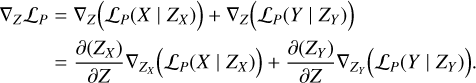 (17)
(17)
In the case with rebinning, we have
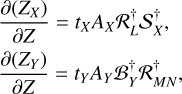 (18)
(18)
where † denotes the conjugate transpose of the operators, in the sense that, if we were to vectorize the spatial dimensions of our data and write the operator 𝒮 as a product with the 2D matrice S , 𝒮† would apply the product with matrix S† . In the case with a low-rank approximation, where the gradient descent is done on W = ZVT:
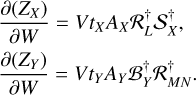 (19)
(19)
In the case of Sobolev regularization, 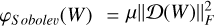 is differentiable, and so a term is added to the gradient:
is differentiable, and so a term is added to the gradient:
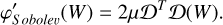 (20)
(20)
As is the case for the other operators, Ɗ can be interpreted as a product with the 2D matrix D, since the operator Ɗ is a convolution with a kernel of [1, −1] on the lines followed by a convolution with a kernel of [1, −1]T on the columns. ƊT applies the product with DT.
In the code, the operators ℛ and Ɗ are written as matrix products. The operators ℬY and 𝒮X , however, can be dealt with more efficiently by taking advantage of the diagonalization of the convolution operation in the Fourier domain. To do so, we pad the kernels and Z with zeros so that they are the same size (dimension of Z + dimension of the kernel in question). We then take their Fourier transform, and convolution becomes a Hadamar product in the Fourier space. The Fourier transform of Z will need to be calculated at each iteration, but the transform of the kernels need only be calculated once.
Putting all this together, we obtain Algorithm 22, which we have dubbed HIFReD: Hyperspectral Image Fusion with Regularized Deconvolution. For simplicity, rebinning is not explicit in the pseudo-code.
1 Input: data (X, Y), instrument response kernels (SX, BY), regularization function (φ), Low Rank (True/False), rank r, regularization parameter µ, number of wavelet scales S 2D, S1D, maximum number of iterations tmax.
2 PWS: Proximal Wavelet Step, defined in Alg. 2.
3 Output: Z
4 Initialization
Calculate ℱ1D (SX), ℱ2D (ΒY).
Z ← X
if Low Rank then

22 return Zt
1 input cube Z, wavelet transform 𝒲, regularization parameter µ, number of wavelet scales S
{wc, w1,…, wS} ← 𝒲(Z)
ρ ← μ mad(w1,1) (median absolute deviation)
for i in {1,…, S} do
2 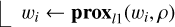 . (16)
. (16)
3 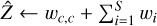
Return 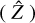
3.4.2 Hyperparameters
For the choice of hyperparameters (namely the regularizing factor µ, the gradient step α, and the rank r), we need to take a heuristic approach. Indeed, the Poisson likelihood is not globally Lipschitz-continuous, and so we cannot analytically calculate an optimal gradient step, and there is no a priori best choice for the regularization parameters either. Further, we find that one set of hyperparameters that works best for one toy model is not necessarily ideal for another model. The photon count, level of spectral variability, shape of the effective area, and more are all factors that will impact the choice of best parameters. It would be very costly to compute every single combination of hyperparameters to find the best suited for every single model, but below, we describe some guidelines to help pick suitable parameters, if not the exact optimal value.
The gradient step should be taken as high as possible for a faster rate of convergence, but if it is taken too high, the likelihood will diverge dramatically. This is easily diagnosed, and is seen as huge jumps in the cost function, when it should rather decrease monotonously. This usually happens in early iterations, and so we checked the value of the likelihood periodically at the start (first 1000 iterations, which takes less than an hour), and then stopped if it became pathological. If it this was the case, we then lowered the gradient step and tried again with that parameter. As the Poisson likelihood is convex, there is no risk of falling into a local minimum, provided this step is well-chosen as described.
For the µ parameter of the Sobolev regularization, for the Gaussian toy model, we tested values of between 0.01 and 0.1, and found the best value to be 0.03. This value turned out to be well suited for the other toy models as well. An overly high value of this parameter is detectable as an over-smoothing of spatial features, while an excessively low value will be recognized in the presence of visible noise on spatial slices.
For the rank r, we tested values of between 5 and 50, and selected 10. The rank has a similar impact to µ, but on the spectral features. A lower rank might over-smooth and lead to a biased result, while a higher rank might not be enough of a denoiser. On top of that, the rank will impact the algorithm’s computational complexity, with a lower rank implying fewer dimensions and thus a faster algorithm.
For the wavelet threshold parameter µ, this is usually taken to be between 0.5 and 3, which in the case of Gaussian noise is comparable to a 0.5 σ–3 σ interval. There is no such easy interpretation for Poisson noise, but even so, like with the Sobolev, lower µ will allow more variability and less bias, while higher µ will lead to more smoothing, and thus potentially more bias. In particular, we find that in dim voxels (close to zero, and dominated by noise), higher values of µ (close to 3) are effective in smoothing out noise, while in brighter voxels, those high µ will over-smooth spectral features. We find the opposite to be true with lower values of µ. As a compromise, and to account for the high variabilities of flux between voxels, it is advantageous to apply a varying μ, using a sigmoid function going from 0.5 to 3. Let the coarsest scale of Z in the wavelet domain be CZ . Further, let 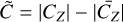 . In this case,
. In this case,
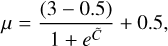 (21)
(21)
which will make μ(i, j, k) close to 1.25 when |CZ| is close to 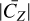 , and go towards 0.5 for small values of |CZ|, and towards 3 for high values of |CZ|. This simple scheme is however ineffective in cases where the toy model is not very sparse in the wavelet domain, as is the case for the realistic model. In this case, it is better to pick a low, constant value of µ, such as 0.5. Further, one needs to consider the number of wavelet scales defined in the starlet transform, be it the 2D or the 2D–1D transform. As the coarse scale is left untouched, the number of fine scales will determine the maximum size of the features that can be thresholded, as for each scale the size of the filter increases by a factor of 2 (Starck et al. 2010). The number of 2D wavelet scales was chosen to be 2 for all models, and the number of 1D scales was selected to be 3 for the Gaussian model, and 1 for the realistic model, for which the spectral details are much finer due to the finer spectral response.
, and go towards 0.5 for small values of |CZ|, and towards 3 for high values of |CZ|. This simple scheme is however ineffective in cases where the toy model is not very sparse in the wavelet domain, as is the case for the realistic model. In this case, it is better to pick a low, constant value of µ, such as 0.5. Further, one needs to consider the number of wavelet scales defined in the starlet transform, be it the 2D or the 2D–1D transform. As the coarse scale is left untouched, the number of fine scales will determine the maximum size of the features that can be thresholded, as for each scale the size of the filter increases by a factor of 2 (Starck et al. 2010). The number of 2D wavelet scales was chosen to be 2 for all models, and the number of 1D scales was selected to be 3 for the Gaussian model, and 1 for the realistic model, for which the spectral details are much finer due to the finer spectral response.
The last hyperparameter to consider is tmax, the maximum number of iterations. The user should check the cost function curve at the end to see whether optimization has converged. If not, they may begin another batch of iterations, using the last result as first guess. An automatic stopping criterion could easily be implemented, with iterations stopping at iteration t once 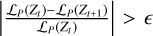 for a small є, but the results in this article were obtained with a manually set tmax.
for a small є, but the results in this article were obtained with a manually set tmax.
Characteristics of the simulated data sets.
4 Results on simulated data
In this section, we present the results of our method on toy models derived from hydrodynamics simulations of a SNR. Section 4.1 presents our three considered toy models: the Gaussian model, the Gaussian model with rebinning, and the realistic model with rebinning. Section 4.2 then presents our results for each using the three regularization schemes described in Section 3.3.
4.1 Toy models
The toy models we constructed are intended to resemble the case study of SNRs, such as Cassiopeia A. To this end, we used the 3D hydrodynamics simulations of Orlando et al. (2016). For each voxel of the 3D simulation, a synthetic X-ray spectrum was generated using the non-equilibrium ionization Xspec model NEI9. In the numerical simulation dataset, the temperature kT ranges from 0.2 keV to 3 keV, the ionization timescale log(τ) from 8 to 11.5 cm−3 s, and the velocity along the line of sight Vz from −7000 to 7000 km s−1. The absorption along the line of sight was fixed to nH = 0.5 × 1022 cm−2. Then the hypercube (X, Y, Z, E) is projected along the Z axis to emulate a synthetic X-ray observation of a SNR. Due to the projection effect, the spectrum for each pixel can be quite complex, and can contain, for example, double-peaked spectral features associated with the red- and blueshifted half spheres of the SNR or different temperatures and ionization timescales.
We then wished to consider different levels of complexity for our algorithm benchmarking. In particular, we considered three characteristics that can make the problem more complex: the intensity of spectral variability, the inclusion of a rebinning operator (X and Y have different voxel size), and the ratio between the spectral and spatial responses of the two data sets.
The first toy model we considered is dubbed the Gaussian model. The PSFs and spectral responses of each instrument are assumed to be Gaussian, whose parameters are summarized in Table 1, and shown in Figs. 3 and 4. Further, we assumed a flat effective area, and that X has the same size as Y. With these parameters, we generated one set of X and Y between 0.5 and 1.4 keV, and one between 6.2 and 6.9 keV (around the iron emission lines). The dataset around the iron lines displays more spectral variability, as is demonstrated more formally in Fig. 5, which shows the average angular distance θ between neighboring pixels for each model. For a given pixel’s spectra Zk, it is calculated as
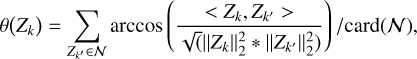 (22)
(22)
where N is the set of pixels neighboring Zk, that is, the eight closest pixels to Zk, and card(𝒩) is the number of elements in that set. This angular distance provides information about the spectral variations across the remnant. As we see, the Gaussian model around the iron line has the strongest variations.
Then, we considered the same Gaussian model (same PSF/spectral response, same flat effective area) between 0.5 and 1.4 keV, but this time with X and Y having different voxel sizes. X has the dimensions (45 × 45 × 60), with square pixels of 10″ in width and energy channels of 14 eV in width, and Y has the dimensions (15 × 15 × 2400), with square pixels of 30″ in width and energy channels of 0.36 eV in width. This allows us to see the impact of the rebinning operator on our algorithm.
Finally, we set out to obtain a more realistic model, which would mimic the case where we try to fuse data from XMM- Newton/EPIC and XRISM/Resolve. We chose PSFs and spectral responses meant to be as close as possible to those of the instruments in question (see Figs. 3 and 4), and likewise for the effective areas. The energy range was (0.5–1.4 keV), and we chose the same dimensions and voxel size as the Gaussian model with rebinning.
In all of these case studies, we generated toy models with a photon count of around 107 . We then applied Poisson noise. Some sample spectra and 2D slices are shown in Fig. 6.
 |
Fig. 3 Comparison of the four PSFs used to generate the toy models. On the left, the Gaussian approximation of a XRISM-like and XMM-Newton-like instrument. On the right, the actual PSFs of XRISM/Resolve and XMM-Newton/EPIC. All PSFs are shown on images of size 4′50″×4′50″. Colors are displayed in square-root scale. |
 |
Fig. 4 Comparison of the four spectral responses used to generate the toy models. The responses for the XMM-Newton-like instrument are shown on the right, while those for the XRISM-like are shown on the left. The full orange line is for the Gaussian approximations, and the dashed blue line is for the realistic instrument responses. |
4.2 Results
This section presents the results we obtained with the four toy models. We compare the wavelet 2D–1D regularization (W2D1D), the low-rank approximation with Sobolev regularization (LRS), and the low-rank approximation with wavelet 2D regularization (LRW2D). We present our results in the form of sample pixel fits, amplitude maps, error histograms, error maps, and scalar metrics.
First, the reconstructed spectra obtained on two sample pixels are shown in Figure 7. Once again, for visual clarity, we only show the W2D1D and LRS methods. These results allow us to draw several conclusions. First of all, the Gaussian model around the iron line (c, d) is difficult to reconstruct for both methods, but the LRS method appears more biased. Second, we see that the W2D1D method results in smoother spectra, but this can be accompanied by more bias, as seen in the Gaussian model with rebinning (e, f). This occurs when the underlying assumption of sparsity in the wavelet domain is not appropriate.
The amplitude maps are displayed in Fig. B.1. Overall, for all regularizations, we see that the method is able to reconstruct the general spatial features of the remnant. For the Gaussian model with rebinning, we do notice some amount of leakage on the edges of the remnant for all regularizations, particularly on the western side. For the Gaussian model around 6 keV (b), we also see that LRS has over-smoothed some of the features – this effect is visible in the other toy models but is more subtle. Finally, in models with rebinning (c, d), the LRW2D seems to smooth out finer features and give a biased result.
In Fig. B.2, we present the map of the spectral angle mapper (SAM), an error metric defined as (for a spectra Zi)
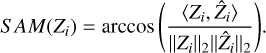 (23)
(23)
The SAM is best if low (close to zero), and is designed to capture spectral distortions. In Fig. B.2, we observe some leakage on the low-count pixels at the edges of the remnant, which is present for all methods, but more so for W2D1D. The results shown in panel a suggest that the wavelet regularization presents slightly more spatial distortion for the simplest model (Gaussian model with low spectral variability), while it appears more successful in panel b for the Gaussian model with high spectral variability. In panel b, the higher SAM pixels in LRS and LRW2D correspond to some local features, in areas of high spectral variability (see the middle of Fig. 5); we highlight, for instance, the cluster of bright spots above the center of the remnant. In panel c, the low rank with Sobolev appears to be doing better in the center. All models display a high error close to the bright spot south of the remnant. In panel d, for the realistic model, LRS obtains better result in the center of the remnant. While all three methods struggle to reach a result close to the ground truth in the bright area to the south of a remnant, LRW2D and W2D1D show the poorest performance, which could suggest that the Sobolev regularization is better at handling outliers. As this bright spot is also seen as a problem in the model shown in panel c, this area of high flux and high spatial variability seems especially difficult to reconstruct in models with rebinning.
In Fig. B.3, we display the relative error maps averaged per pixel. We draw similar conclusions about the Gaussian model without rebinning. The difficulty that low-rank methods have in reconstructing high spectral variabilities areas is once again seen in panel b. For panel c, we again notice the leakage on the edges, with the amplitude being judged too high in red areas, and too low in blue areas. There is a general bias on all models that seems to overestimate the northwest part of the remnant, while underestimating the southeast part. This is likely due to the rebinning, as it is also present in panel d. Further, in panel d, we note that W2D1D and LRW2D underestimated the amplitude of the bright spot in the south of the remnant, while LRS was not as biased. Overall, W2D1D displays more bias in the southern bright outlier than the other methods.
Finally, we measured scalar error metrics. All results can be found in Table 2. The best results are highlighted in bold. As Zhang (2008) showed for the case of fusion between panchromatic and MS images, scalar metrics do not necessarily agree when comparing the efficacy of fusion methods, and are not always easily interpretable. Thus, we present four metrics in order to provide a more complete comparison. The definitions of the metrics can be found in Appendix A. Namely, we calculate the normalised mean squared error (NMSE), the average spectral angle mapper (aSAM), average complementary structural similarity (acSSIM) index, and the relative dimensionless global error (ERGAS).
Looking at the obtained values in Table 2, we see that the four metrics rarely draw the same conclusion, except in the case of the Gaussian model around 6 keV, which is the model with the highest spectral variability between pixels. This allows us to draw a similar conclusion as for the error maps: the methods using a low-rank approximation have more trouble accounting for high spectral variability. This may be due to the fact that the low-rank approximation is learnt by performing PCA on Y, the data set that has the best spectral resolution, but its poor spatial resolution will smooth out spectral variability between pixels. If the low rank could be learnt on Z , this would not be a problem, but of course that is not possible.
The results on the Gaussian model around 1 keV show that all three methods are the best in at least one metric, and so it is hard to choose an outright leader. In this case, low rankedness does seem to lower spectral distortion (looking at the aSAM and the ERGAS). For the Gaussian model around 1 keV with rebinning, the low-rank methods are more successful, but the difference is small, and the bright southern spot we note on the maps likely plays a part in the W2D1D being a little less successful. We also observe this for the realistic model with rebinning. Overall, it appears that the low-rank methods are best at dealing with outliers, especially the low rank with Sobolev, but they are not as appropriate for models with high spectral variability.
Convergence took between 30k and 100k iterations, depending on the toy model. On average, one iteration of the algorithm took around 3 s with the method with 2D-1D wavelet regularization, resulting in a computation time of between 25 h and 83 h. With the low-rank approximation with Sobolev, each iteration took around 2 s, resulting in a computation time of between 15 h and 55 h; the low rank with wavelet 2D was around the same.
 |
Fig. 5 Average angular distance between neighboring pixels on a window of neighboring pixels, given by Equation (22). Higher values indicate a location of high spectral variability between pixels. |
Error metric results comparing regularizations for the four toy models.
5 Discussion
Overall, the wavelet 2D-1D regularization is more successful than the low-rank approximations at dealing with strong spectral variability across the image. However, the assumption of wavelet sparsity is not necessarily ideal to account for certain structures, such as in the presence of singular bright spots like the one in the southern part of the remnant, and this is especially difficult to treat with the inclusion of a rebinning operator. Nonetheless, we find that for all three regularization methods, the fusion results are satisfactory given the difficulty of the problem; however, they still contain some bias.
The low-rank approximation, while ill-suited for SNRs that display strong spectral variability due to the variations of their physical parameters, was found to accelerate the algorithm by half thanks to the dimension reduction. As the data sets are large and the algorithm takes a long time to converge, this is a useful attribute.
Thus, it would be ideal to find a spectral regularization less biased than the wavelet sparsity or the low-rank approximation, but that nonetheless includes a reduction in dimensions. This may be done by exploring a low-rank approximation more refined than one learnt using PCA on the high-spectral- resolution data set. We could also explore acceleration methods, such as algorithm unrolling, as in Fahes et al. (2022).
Alternatively, a promising avenue would be to include physical information. Indeed, while having a blind fusion result is useful (as it requires no assumptions on the model), in order to obtain physical parameter maps, a model will need to be fitted to the result. In the case of SNRs, more than one model would be needed, as the emission comes from a mixture composed of thermal radiation from the shocked interstellar media and synchrotron radiation due to particle acceleration.
An algorithm for source separation that includes spectral variations was developed by Lascar et al. (2024). Our future work will focus on combining this approach to HIFReD, we the aim being to develop a method capable of simultaneously fusing data sets from two generations of telescopes and perform unmixing with a physical spectral model.
On a final note, one limitation of the proposed method is that as it is implemented, it cannot account for spatially varying PSF, or a spectrally varying spectral response. In this case, the convolution is no longer a term-by-term product in Fourier. This is an issue with XMM/Resolve, where a constant spectral response over a wide energy range is not realistic. Therefore, we are currently working on developing a version of HIFReD than can handle varying convolution kernels, with promising results so far. The main obstacle is the computational complexity, which is greatly increased, but by working on an accelerated version of the code using the JAX10 Python package, we find that we should be able to achieve even faster performances than those described in this article, even when using a non-stationary convolution.
 |
Fig. 6 Example of spectra and 2D slices from the four toy-model data sets. The ground truth |
 |
Fig. 7 Example of how the fusion output compares to the ground truth for two pixels. From top to bottom, the models are: (a, b) Gaussian model between 0.5 and 1.4 keV, (c, d) Gaussian model between 6.2 and 6.9 keV, (e, f) Gaussian model with rebinning, and (g, h) the Realistic model. The left column shows results for pixel (22, 22), which is lower in brightness than pixel (11, 31) on the right. |
6 Conclusions
We have developed an algorithm for fusing hyperspectral images taken by two generations of X-ray telescopes with complementary spatial and spectral resolutions. Our method simultaneously deconvolves the instruments’ spatial and spectral responses in order to return to the best resolutions of the two telescopes.
We implemented three regularization schemes, the first being a term to promote sparsity under a 2D-1D wavelet transform, the second being a low-rank approximation with Sobolev regularization (inspired by Guilloteau et al. 2020), and the third being a low-rank approximation with a 2D wavelet sparsity term.
We tested our method on five toy models constructed from hydrodynamic simulations of SNRs by Orlando et al. (2016) and convolved with an increasing complexity of instrumental response. Spatial features are well reconstructed, apart from a slight leakage in the bright shell in the toy model with rebinning. The reconstruction of spectral features depends on the regularizations and model.
We find that while low-rank methods accelerated the algorithm by half, they struggled to account for the strong spectral variability present around the iron line. The 2D-1D wavelet method better accounts for this variability, but it is somewhat biased in reconstructing the realistic model.
In conclusion, we believe that hyperspectral fusion shows promise and would greatly benefit the analysis of XRISM/Resolve data; though it would be useful to explore other regularization terms more suited to the variabilities of the data. In particular, we intend to combine fusion with a spectral physical model and source-separation algorithm in future works. While the purpose of this article is to present a proof of concept, we are now actively working on applying this method to real data.
Acknowledgements
The research leading to these results has received funding from the European Union’s Horizon 2020 Programme under the AHEAD2020 project (grant agreement no. 871158). This work was supported by CNES, focused on methodology for X-ray analysis. This work was supported by the Action Thématique Hautes Energies of CNRS/INSU with INP and IN2P3, cofunded by CEA and CNES. We thank S. Orlando for kindly providing the simulation from Orlando et al. (2016) to generate our toy model.
Appendix A Metrics definition
In this section, we define the scalar metrics calculated in Table 2. First, the Normalised Mean Squared Error (NMSE) is defined as such (where Zi is the value of Z at the voxel i):
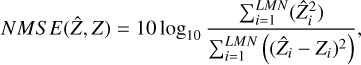 (A.1)
(A.1)
By this definition, a higher NMSE implies a result of better quality. Then, the average Spectral Angle Mapper (aSAM) is defined as:
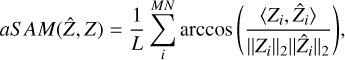 (A.2)
(A.2)
where Zi is the spectra for the pixel i. A lower aSAM implies a result of better quality, and an ideal value is 0.
The average complementary Structural Similarity (SSIM) index, is:
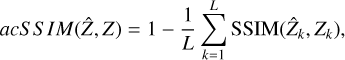 (A.3)
(A.3)
where SSIM is the Structural Similarity index, as defined by Wang et al. (2004). The aim of the acSSIM is to measure the capacity to reconstruct local image structure, luminance, and contrast. The lower the acSSIM, the better the result. An ideal value is 0.
Finally, the Relative Dimensionless Global Error (ERGAS), is defined as:
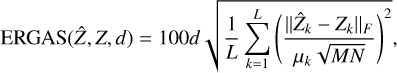 (A.4)
(A.4)
where d is the ratio between the spatial resolution of X and the spatial resolution of Y, and µk is the mean of 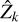 . The lower the ERGAS, the better, and an ideal value is 0.
. The lower the ERGAS, the better, and an ideal value is 0.
Appendix B Additional Figures
This section presents additional figures for the results of section 4. Fig. B.1 shows the obtained amplitude for for the three potential regularization, for each of the four toy models. For these same options, Fig. B.2 shows the spectral angle maps. Fig. B.3 displays the relative error maps averaged per pixel.
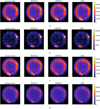 |
Fig. B.1 Amplitude maps (i.e. sum of counts per pixel over every spectral channel) obtained by the three regularizers and compared to the ground truth. (a) Gaussian model between 0.5-1.4 keV, (b) Gaussian model between 6.2-6.9 keV, (c) Gaussian model with rebinning between 0.5-1.4 keV, and (d), Realistic model between 0.5-1.4 keV. |
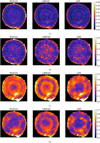 |
Fig. B.2 Maps of the SAM (Equation 23) for the four toy models, and the three regularizations. A higher SAM means a worse spectral reconstruction. (a) Gaussian model between 0.5-1.4 keV, (b) Gaussian model between 6.2-6.9 keV, (c) Gaussian model with rebinning between 0.5-1.4 keV, and (d), Realistic model between 0.5-1.4 keV. |
 |
Fig. B.3 Maps of the relative error: |
References
- Bach, F., Jenatton, R., Mairal, J., & Obozinski, G. 2011, Found. Trends Mach. Learn., 4, 1 [CrossRef] [Google Scholar]
- Barret, D., Lam Trong, T., den Herder, J.-W., et al. 2018, SPIE Conf. Ser., 10699, 106991G [Google Scholar]
- Bertero, M., Boccacci P., & De Mol, C. 2022, Introduction to Inverse Problems in Imaging (CRC Press) [Google Scholar]
- Fahes, M., Kervazo, C., Bobin, J., & Tupin, F. 2022, in International Conference on Learning Representations [Google Scholar]
- Godinaud, L., Acero, F., Decourchelle, A., & Ballet, J. 2023, A&A, 680, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guilloteau, C., Oberlin, T., Berné, O., Émilie Habart, & Dobigeon, N. 2020, AJ, 160, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Guilloteau, C., Oberlin, T., Berné, O., & Dobigeon, N. 2022, in IEEE International Conference on Image Processing (ICIP 2022), Bordeaux, France, 1 [Google Scholar]
- Hadamard, J. 1923, Lectures on the Cauchy Problem in Linear Partial Differential Equations (New Haven: Yale University Press) [Google Scholar]
- Karl, W. C. 2005, in LHandbook of Image and Video Processing (Elsevier) [Google Scholar]
- Lascar, J., Bobin, J., & Acero, F. 2024, A&A, 686, A259 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Orlando, S., Miceli, M., Pumo, M. L., & Bocchino, F. 2016, ApJ, 822, 22 [Google Scholar]
- Parikh, N., & Boyd, S. 2014, Found. Trends Optim., 1, 127 [Google Scholar]
- Pineau, D., Orieux, F., & Abergel, A. 2023, Fast Multispectral and Hyperspectral Image Fusion via Hessian Inversion. hal-04337970 [Google Scholar]
- Prévost, C., Borsoi, R. A., Usevich, K., et al. 2022, SIAM J. Imaging Sci., 15, 110 [CrossRef] [Google Scholar]
- Simões, M., Bioucas-Dias, J., Almeida, L. B., & Chanussot, J. 2015, IEEE Trans. Geosci. Rem. Sens., 53, 3373 [CrossRef] [Google Scholar]
- Starck, J.-L., & Murtagh, F. 1994, A&A, 342 [Google Scholar]
- Starck, J.-L., Murtagh, F., & Fadili, Jalal, M. 2010, Sparse Image and Signal Processing: Wavelets, Curvelets, Morphological Diversity (Cambridge University Press) [CrossRef] [Google Scholar]
- Takahashi, T., Mitsuda, K., Kelley, R., et al. 2014, SPIE Conf. Ser., 9144, 914425 [NASA ADS] [Google Scholar]
- Turner, M. J. L., Abbey, A., Arnaud, M., et al. 2001, A&A, 365, L27 [CrossRef] [EDP Sciences] [Google Scholar]
- Wang, Z., Bovik, A., Sheikh, H., & Simoncelli, E. 2004, IEEE Trans. Image Process., 13, 600 [CrossRef] [Google Scholar]
- XRISM Science Team 2020, arXiv e-prints [arXiv:2003.04962] [Google Scholar]
- Xu, T., Huang, T.-Z., Deng, L.-J., & Yokoya, N. 2022, IEEE Trans. Geosci. Remote Sens., 60, 1 [CrossRef] [Google Scholar]
- Yokoya, N., Yairi, T., & Iwasaki, A. 2012, IEEE Trans. Geosci. Rem. Sens., 50, 528 [NASA ADS] [CrossRef] [Google Scholar]
- Yokoya, N., Grohnfeldt, C., & Chanussot, J. 2017, IEEE Geosci. Rem. Sens. Mag., 5, 29 [CrossRef] [Google Scholar]
- Zhang, Y. 2008, The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 37 [Google Scholar]
All Tables
All Figures
|
Fig. 1 Comparison of hyperspectral data of the Perseus galaxy cluster as observed by two generations of X-ray spectro-imagers. The XMM- Newton/MOS (top) and Hitomi/SXS (bottom) data have pixels of 8″730″ and spectral channels of 15/1 eV respectively. The left panels show the counts maps summed over all spectral channels and the right panels the spectra summed over all pixels. |
| In the text | |
|
Fig. 2 Simplified diagram of the forward model of two X-ray telescopes (here, XMM-Newton/EPIC and XRISM/Resolve). The problem of fusion consists in inverting this model and using the observed data X and Y to retrieve the deconvoluted cube Z. The mathematical details behind the operators and kernels are detailed in Section 3. Not shown is the exposure time of each data set. |
| In the text | |
|
Fig. 3 Comparison of the four PSFs used to generate the toy models. On the left, the Gaussian approximation of a XRISM-like and XMM-Newton-like instrument. On the right, the actual PSFs of XRISM/Resolve and XMM-Newton/EPIC. All PSFs are shown on images of size 4′50″×4′50″. Colors are displayed in square-root scale. |
| In the text | |
|
Fig. 4 Comparison of the four spectral responses used to generate the toy models. The responses for the XMM-Newton-like instrument are shown on the right, while those for the XRISM-like are shown on the left. The full orange line is for the Gaussian approximations, and the dashed blue line is for the realistic instrument responses. |
| In the text | |
|
Fig. 5 Average angular distance between neighboring pixels on a window of neighboring pixels, given by Equation (22). Higher values indicate a location of high spectral variability between pixels. |
| In the text | |
|
Fig. 6 Example of spectra and 2D slices from the four toy-model data sets. The ground truth |
| In the text | |
|
Fig. 7 Example of how the fusion output compares to the ground truth for two pixels. From top to bottom, the models are: (a, b) Gaussian model between 0.5 and 1.4 keV, (c, d) Gaussian model between 6.2 and 6.9 keV, (e, f) Gaussian model with rebinning, and (g, h) the Realistic model. The left column shows results for pixel (22, 22), which is lower in brightness than pixel (11, 31) on the right. |
| In the text | |
|
Fig. B.1 Amplitude maps (i.e. sum of counts per pixel over every spectral channel) obtained by the three regularizers and compared to the ground truth. (a) Gaussian model between 0.5-1.4 keV, (b) Gaussian model between 6.2-6.9 keV, (c) Gaussian model with rebinning between 0.5-1.4 keV, and (d), Realistic model between 0.5-1.4 keV. |
| In the text | |
|
Fig. B.2 Maps of the SAM (Equation 23) for the four toy models, and the three regularizations. A higher SAM means a worse spectral reconstruction. (a) Gaussian model between 0.5-1.4 keV, (b) Gaussian model between 6.2-6.9 keV, (c) Gaussian model with rebinning between 0.5-1.4 keV, and (d), Realistic model between 0.5-1.4 keV. |
| In the text | |
|
Fig. B.3 Maps of the relative error: |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.