Fig. 4
Download original image
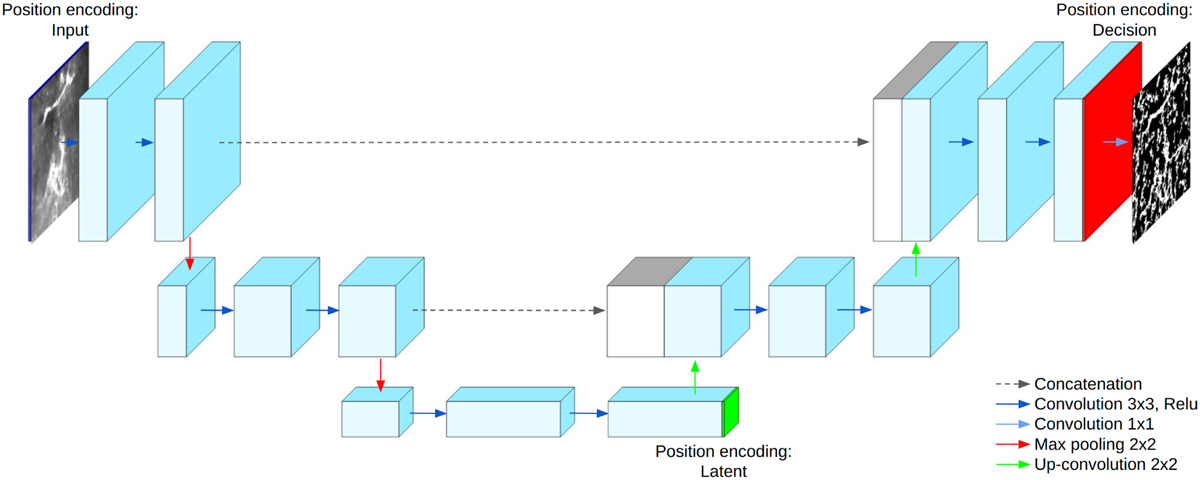
Position Encoding UNet architecture. The model consists of a UNet architecture with the patch position as an additional input. Three alternatives of PE-UNet have been explored, Input (in orange), where we input the position as two additional channels before the first layer; Latent (in green), where we input the position as two additional features after the bottleneck; Decision (in red), where we input the position as two additional features before the last convolution. In our experiment, the PE-UNets are composed of five UNet blocks reducing the dimension to 2 × 2 × 1024 at the bottleneck level given a patch of size 32 × 32 × 1.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.