Fig. 2
Download original image
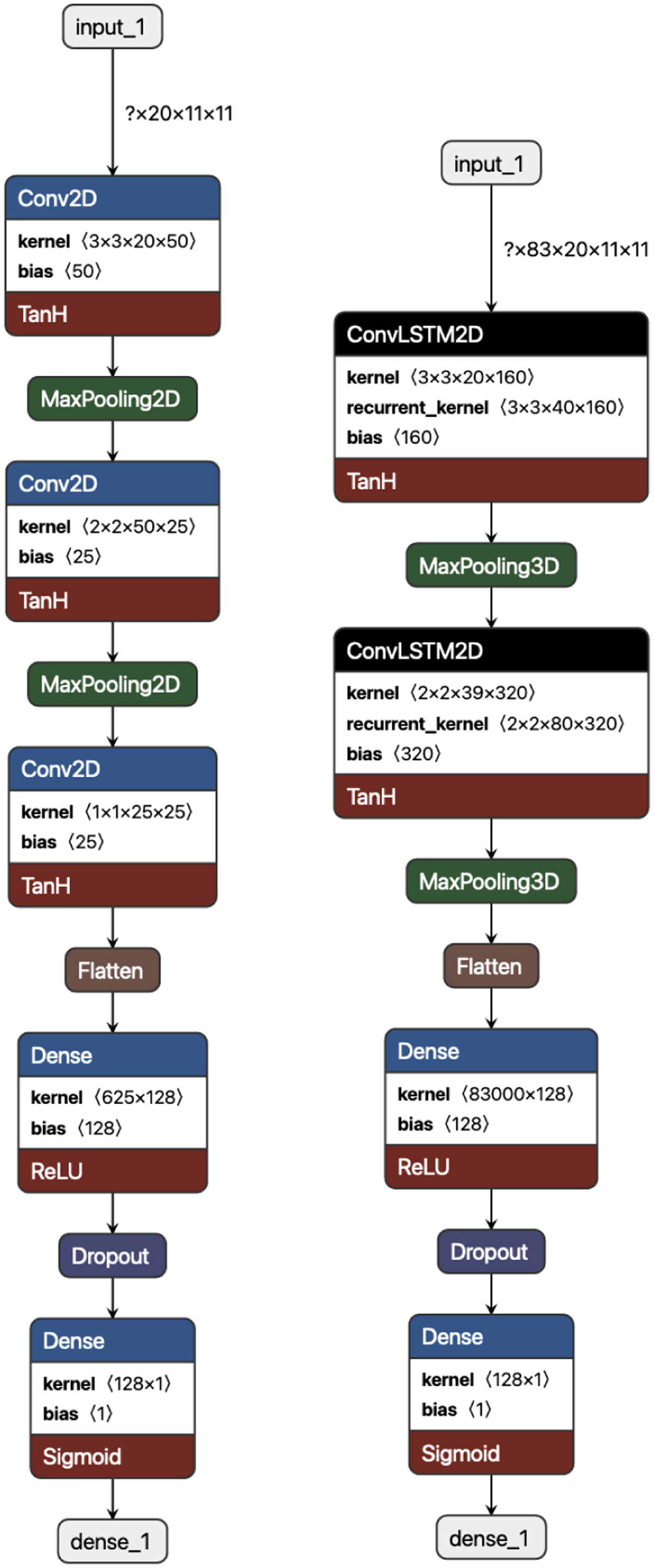
Schematic of the C3PO (left) and C-LANDO (right) architectures, showing the different layers and sizes of the input, the dilation of this input at different layers, and finally the output format. The top grey block represents the input, with dimensions printed next to the arrow (e.g., for C3PO: 20 velocity bins, 11 × 11 pixel image size as explained in Sec. 4, and batch size given as input labelled with a question mark). Each block represents a layer and has three parts: the blue or black part represents the type of neuron, the white part is the number of neurons represented by a convolutional kernel size and number of bias units, and the red part represents the non-linearity (hyperbolic tangent). The kernel has four dimensions: the first three represent the input shape and the last represents the depth of the kernel. The kernel shape also represents the output dimensions of a layer and the input to its following layer. Between each layer we have pooling layers marked in green, a flatten layer in brown, and a dropout layer in the end. The output is just a single neuron with a sigmoid activation (dense_1).
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.