| Issue |
A&A
Volume 688, August 2024
|
|
|---|---|---|
| Article Number | A69 | |
| Number of page(s) | 13 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202449224 | |
| Published online | 06 August 2024 | |
LIME: A LIne MEasuring library for large and complex spectroscopic data sets
I. Implementation of a virtual observatory for JWST spectra
1
Departamento de Astronomía, Universidad de La Serena,
Av. Juan Cisternas 1200 Norte,
La Serena,
Chile
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Michigan Institute for Data Science, University of Michigan,
500 Church Street,
Ann Arbor,
MI
48109,
USA
3
ARAID Foundation, Centro de Estudios de Física del Cosmos de Aragón (CEFCA), Unidad Asociada al CSIC,
Plaza San Juan 1E,
44001
Teruel,
Spain
4
Gemini Observatory/NSF’s NOIRLab,
Casilla 603,
La Serena,
Chile
5
Universidad Nacional Autonoma de México, Instituto de Astronomía (IA),
Apdo. postal 106, C.P. 22800 Ensenada,
Baja California,
Mexico
6
Instituto de Ciencias Físicas, Universidad Nacional Autonoma de México,
Av. Universidad s/n,
62210
Cuernavaca,
Mor.,
Mexico
Received:
12
January
2024
Accepted:
8
May
2024
Abstract
Context. The upcoming generation of telescopes, instruments, and surveys is poised to usher in an unprecedented “Big Data” era in the field of astronomy. Within this context, even seemingly modest tasks such as spectral line analyses could become increasingly challenging for astronomers.
Aims. In this paper, we announce the release of LIME. This package is tailored for multidisciplinary observations with long-slit and integral field spectroscopy (IFS) support. LIME functions encompass the reading of observational files, detecting lines, conditioned line fitting, and the plotting and storage of results. Most importantly, these measurements are structured to support the subsequent chemical and kinematic analyses.
Methods. To reduce the coding effort required from users, we introduced a notation system for atomic transitions that is accessible to humans and machine-readable. Along with this system, we present an extensive database of line bands, spanning from the ultraviolet to the infrared wavelength range. Additionally, we propose a model designed to train machine learning algorithms in line detection. LIME features a comprehensive online documentation, which details the command attributes and includes several tutorials. These tutorials range from measuring a single line to analyzing an entire IFS data cube.
Results. This library functions and measurements are showcased in an online virtual observatory. The data in this interactive website come from the JWST NIRSpec observations of the CEERs survey. In this regard, LIME offers improvements related to the dissemination and accessibility of astronomical spectra.
Key words: methods: data analysis / techniques: spectroscopic / galaxies: abundances / galaxies: kinematics and dynamics
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The term “spectrum” originates from the Latin verb “specere,” meaning “to look.” Over time, this meaning evolved to refer to a sudden image or apparition. Newton et al. (1704) coined this term to describe the colorful dispersion of light, when he demonstrated that it was not an intrinsic property of the prism but a manifestation of light itself. This image, however, was not as continuous as it seemed. During the measurement of the refractive power of various substances, via the implementation of the “camera lucida”, Wollaston (1802) encountered a “well defined line, free from colour.” The author argued that these were boundaries in the spectrum colours. However, a decade later, Fraunhofer’s development of the modern spectroscope has enabled observations of almost 600 lines. In another remarkable contribution, Fraunhofer (1815) compared the solar spectrum against the one from Sirius. The author noted that “these stars, in regard to the stripes, seem to differ among themselves.” The implementation of spectroscopes and spectrographs in telescopes had critical repercussions in the astronomical field and beyond. In this regard, we refer to the research of William and Margaret Huggins. Huggins & Miller (1864) were the first to use a “spectrum apparatus” to observe several nebulae. The authors described how at first they thought there was a “derangement of the instrument” since “no spectrum was seen but only a short line of light perpendicular to the dispersion direction". The authors correctly linked the nebula’s “faintest” line to the hydrogen dark Fraunhofer F line (Hβ). The astronomers argued that these objects were not “aggregations of suns” but “enormous masses of luminous gas” since the emission line spectrum is characteristic of this medium. In “The Origin of the Nebu-lium Spectrum", Bowen (1927) linked these unknown lines to “familiar atoms” under “unfamiliar conditions”. This condition is the extreme low density, which makes possible the natural de-excitation of collisionally excited electrons. Particle physics also explains the observed profiles of these lines with the arrival of high resolution spectrographs. Natural and pressure broadening are responsible for Lorentzian and Cauchy profiles, while thermal or Doppler broadening is responsible for Gaussian profiles. In particle transitions, where both mechanisms have similar weights, we observe the convolution of both profiles: a Voigt line (see Armstrong 1967). Since the intensity and shape of these features depend on the gas chemistry and kinematics respectively, much of what humanity will ever know about the composition and motion of the Universe starts with the analysis of these lines.
In the past two centuries, scientific developments in optical, electrical, and computational disciplines have translated into remarkable achievements in spectrograph design. In observational astrophysics, integral field spectroscopy (IFS) and massively-multiplexed spectroscopy, arguably provide the most valuable datasets: a uniform spectra sample covering a large field. Moreover, novel spectrograph designs can support both a large wavelength range and high resolution. Upcoming spec-troscopic surveys are expected to produce more data per day than the complete historical release in past surveys (see Zhang & Zhao 2015), opening up a new era in our understanding of astronomical phenomena. On the negative side, this will involve the measurement of many lines. Additionally, a single Gaussian fitting (see Mezger & Hoglund 1967; Smith & Weedman 1970; Hippelein 1986; Chu & Kennicutt 1994) is no longer sufficient as the new instruments reveal more kinematic components (see Hagele et al. 2012; Bosch et al. 2019; Hogarth et al. 2020). This means that not only do we have more spectra to analyze, but their analyses must be tailored to a range of transitions.
To support the community, the authors have developed the Line Measuring package: LIME. This library design is aimed at facilitating multi-disciplinary research, with support for long-slit and echelle spectra and IFS data cubes, line detection, emission and/or absorption profiles, integrated and profile fluxes, multi-component and multi-boundary fittings, pixel flux-uncertainty, and pixel masks. The package includes several tools to plot and interact with the input spectra and the output measurements. Furthermore, it features a simple installation procedure, comprehensive documentation, and a modern testing framework.
Measurements made using LIME have been utilized in the chemical and kinematic analysis of the extreme emission line galaxy CGCG007-025 by Fernández et al. (2022), del Valle Espinosa et al. (2023), and Amorín et al. (2024) as well as in observations from the James Webb Space Telescope (JWST) by the Cosmic Evolution Early Release Science survey (CEERS) (see Finkelstein et al. 2022). These initial applications have had a significant impact on the development of the LIME methodology. We seize this opportunity to introduce the line naming which effectively describes transition properties and a line bands database, which covers from the ultraviolet to the infrared. Lastly, we present a theoretical model designed to train machine learning algorithms for the automatic identification of lines. All these features are illustrated with an interactive website to visualize the spectra from the CEERs field with over 600 galaxies in the 0.29 ≤ z ≤ 9.62 redshift range.
2 Technical description
LIME is developed in PYTHON and is compatible with its latest version (v3.11). The numerical arrays are managed using NUMPY (Harris et al. 2020), while minimization operations employ LMFIT syntax (Newville et al. 2014). The plots use MATPLOTLIB (Hunter 2007), and measurements are stored as PANDAS DataFrames (Pandas Development Team 2023). This library also facilitates saving the measurements in .txt and .csv file formats. The ASTROPY package (Astropy Collaboration 2022) is employed for handling .fits files, as well as for managing the World Coordinate System (WCS) in IFS observation coordinates. Lastly, for PYTHON versions below 3.11, users are required to install the TOMLI package1 to read TOML configuration files2.
In addition to these core dependencies, LIME supports .pdf, .xlsx, and .asdf output files via the PYLATEX, OPENPYXL, and ASDF pacakges respectively. Additionally, when MPLCURSORS is installed, clicking on Gaussian profile figure displays a popup with data regarding the line measurements. LIME can be installed from its P
pip install lime-stable.
The LIME version is included in all the output measurement files, regardless of their type. Users can install a specific version or upgrade to the latest version using these commands:
pip install lime-stable==1.0.0 pip install lime-stable --upgrade.
LIME documentation is compiled at each update online3. The documentation’s tutorial section ranges from fitting a single line to analyzing an IFS cube from the MANGA survey (see Blanton et al. 2017). These tutorials, created from a series of notebooks, are available for download (along with the equivalent python scripts and scientific data) from the main author’s GITHUB page4.
In order to guarantee consistency on the measurements, as new features are added, LIME includes a testing framework, which compiles automatically online5. Prospective users are encouraged to submit any comments, requests, or bug reports6.
2.1 Library structure
LIME features a composite software design, utilizing instances of other classes to implement the target functionality. This approach is akin to that of IRAF (see Tody 1986): functions are organized into multi-level packages, which users access to perform the corresponding task. The diagram in Fig. 1 outlines this workflow.
At the highest level, LIME provides of observational classes: spectrum, cube, and sample. The first two are essentially 2D and 3D data containers, respectively. The third class functions as a dictionary-like container for multiple spectrum or cube objects. Moreover, as illustrated in Fig. 1, various tools can be invoked via the LIME import for tasks, such as loading and saving data. Many of these functions are also within the observations.
At an intermediate level, each observational class includes the .fit, .plot, and .check objects. The first provides functions to launch the measurements from the observation data. The second organizes functions to plot the observations and/or measurements, while the .check object facilitates interactive plots, allowing users to select or adjust data through mouse clicks or widgets. In these functions, users must specify an output file to store these user inputs.
Finally, at the lowest level, we find the functions that execute the measurements or plots. Beyond the aforementioned functionality, the main distinction between these commands lies in the extent of the data they handle. For instance, the
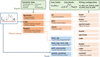 |
Fig. 1 LIME structure with some of the available functions. In the color version of the figure, the green background represents the library inputs, the orange cells cover the observations workflow, and the blue cell includes auxiliary functions. |
2.2 Declaration of observations
At present, LIME can generate observation objects described above directly from ISIS, OSIRIS, MEGARA, SDSS, MANGA, MUSE, AND NIRSPEC .fits files. For other instruments users are required to use PYTHON to load the observation data. The documentation provides
Wavelength, flux, and flux uncertainty arrays: these numerical arrays contain the spectrum’s dispersion axis, the energy density axis, and the energy density standard deviation. The latter uncertainty array must match the units of the input flux, but it is optional. LIME assumes that the spectroscopic data is in the observed frame. At the creation of the observation variable, users can specify the minimum and maximum dispersion axis values to crop the spectra arrays.
Redshift: much of LIME’s automation require the object’s cosmological redshift. This includes the line detection functions and the bands calculation. However, the measurements are still performed in the observed frame.
-
Units: by default, LIME assumes unit_wave = “Angstrom” (Å) and unit_flux = “FLAM” (
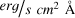 ) for the dispersion and flux energy density units, respectively.
) for the dispersion and flux energy density units, respectively.However, users can specify the observation units using the online notation
A . Additionally, users can convert the spectra units and normalization by calling theSTRO PY notation.unit_conversion function. Finally, the units can include a scale factor. The output files with the measurements will include the input spectrum units. Normalization: spectra using the centimetre-gram-second system (cgs) may display a flux density several orders of magnitude below unity. Most minimizing algorithms struggle to fit a theoretical profile at such a scale. LIME computes a normalization for the observation, if none is provided. Similarly, users should be mindful of the spectral dispersion axis units (such as µm), where the wavelength resolution may be several orders of magnitude below unity. This normalization is removed from the output measurements.
Pixel mask: when declaring the observation, users can specify a boolean array for pixels to be excluded from the analysis. This can be used to tag bad pixels (for example, non-numerical values) or non-physical entries (such as 0 or negative values). LIME ignores these pixels during measurements but displays them in plots as red crosses. It must be noted that LIME uses
N , in which masked entries have a True boolean value.UM PY masked arrays
In addition to the core attributes mentioned above, the observation classes have optional inputs that may contribute to the measurements workflow:
At the
At the
At the
 |
Fig. 2 LIME fitting of the Hα and [NII]6548, 6583 Å transitions in the MUSE observation of NGC1386 black hole region. In this fitting, we are exporting the kinematics of [OIII]5007 Å components to the corresponding three transitions to facilitate the fitting. |
3 Fitting inputs
As displayed in the top right corner of Fig. 1, each line measurement in LIME requires three inputs: the line label, line bands, and fitting configuration. Unlike other packages, LIME has a strict definition for these inputs. In the recommended workflow, these inputs should be stored in external files: the line labels and bands in a tabulated file, and the fitting configuration in a
This complexity is even higher in IFS observations, where ionization and kinematic conditions vary from spaxel to spaxel. Explicit boundary conditions are therefore essential to ensure the minimizer assigns a consistent label to each profile parameter prior to the fitting. As a result, the transition notation must be highly informative to keep boundary conditions and output measurements organized. The subsequent sections describe how LIME addresses these challenges, while reducing the coding requirements for the user.
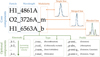 |
Fig. 3 Line notation used in LIME. In the color version, the core components are displayed in blue, while the optional components are in green. The modularity suffix establishes the type of line components: Single for just one transition in the profile. Multi-component transitions are labeled as Merged if the components cannot be isolated, and blended when isolation is possible. |
3.1 Line labels
Although the notation for atomic transitions is well established (see Osterbrock 1974, and references therein), it poses challenges for computational readability and processing. For starters, parsing roman numerals alongside alphabetic characters. Additionally, programming languages have limited alphanumeric characters7. This leaves many unit characters and mathematical operators without a symbolic representation. Finally, some characters like dots (.), commas (,), and square brackets ([]) have strict definitions in programming scripts and configuration files. These limitations are well-known to researchers in software development. In private communications, the author engaged with developers of CLOUDY (see Chatzikos et al. 2023), HII-to-CHEMISTRY (see Pérez-Montero 2014), and FIASCO to discuss the line label formatting in their databases. The ultimate aim is to ensure that LlME’s notation is easily recognized by chemical and kinematic packages using its fluxes.
Figure 3 summarizes our transition notations. This is an expansion of the labeling used in PYNEB by Luridiana et al. (2015). For example, the Balmer and Paschen alpha transitions are typified as Hl_6563A and Hl_l8750A respectively. A line label is divided into components using underscores (_), while each component may be further split into items via dashes (−). In LIME, there are three core components, which are compulsory and their order is fixed:
The first core component represents the particle responsible for the transition. By default LIME expects the particle chemical symbol followed by the ionization state in arabic numerals. This particle mass will be used to compute the thermal dispersion velocity in the output measurements. The user can add additional details to the transition by via dashses. For example: H1_18750A, H1-PashchenAlpha_1875nm, or H1-4-3_1875.0nm are all processed similarly.
The second item is the transition wavelength. This positive real number must be followed by the transition’s wavelength or frequency units. These units must follow the ASTROPY notation8. The only exception is the “Angstrom” which in
A convention must be defined as “AA” or “Angstrom” but in this notation we can use “A”. Importantly, this wavelength must be in the rest frame.STRO PY The third core item is the line’s modularity. This component, which must be last, even if there are optional components, indicates whether the label designates more than one particle transition. The component informs LIME on the profile fitting type. Figure 3 illustrates three possible scenarios: a “single line” is the default, where only one transition contributes to the line, and hence there isn’t a modularity component; a “blended line” consists of two or more transitions, designated by the “_b” suffix, where LIME fits one Gaussian profile per component in the fitting configuration; a “merged line,” also consisting of two or more transitions and designated by the “_m” suffix. In this case LIME fits a single Gaussian but the output measurements keep track of the components. This notation is useful in observations, where spectral resolution is insufficient to resolve individual components but posterior work, such as the fitting of photo-ionization models (see Pérez-Montero 2014), need this information.
In contrast, the optional components in this notation have limited values. For example, the first item is a single string character that acts as a key for the component type. The order of these components can be arbitrary. Moreover, LIME will assign default values if they are not included in the transition. This design allows for future expansions, however, at present, the optional components are as follows:
The kinematic component: this first item is the letter “k”, while the second one is the component cardinal number. In single and merged lines, LIME assumes the unique component is “0”. Therefore, in blended lines, the user should name the second component k-1, the third as k-2, and so on. It’s recommended to define these components from lower to higher dispersion velocity. However, users need to specify the boundary conditions in the fitting configuration to ensure this pattern.
The type component: the first item is the “t” followed by a string specifying the particle transition type. Currently, LIME recognizes “t-rec” for recombination, “t-col” for col-lisionally excited, and “t-sem” for semi-forbidden lines. If this component is not provided, LIME will check the particle component and try to assign a recombination or collision-ally excited tag automatically. This component is used to reconstruct the standard transition notation in LATEX.
The profile component: the first item is the letter “p” followed by strings to declare the profile type. At present, LIME only fits Gaussian (g), Lorentz (l), pseudo-Voigt (pv) and exponential (e) in emission (emis) or absorption (abs). The default profile is a Gaussian curve in emission (_p-g-emi). The default profile can be changed with the arguments in the .fit. commands.
Further details and examples of this notation can be found in the LIME documentation9.
3.2 Line bands
As shown in Fig. 1 top right corner, the line bands constitute the second input in a line fitting. These is a 6-value array specifying the line spectral location and two bands of adjacent continua. It is essential that these array values are in the same units as the spectroscopic observation. Furthermore, it is recommended that the array is sorted. This design is based on the Lick system introduced by Burstein et al. (1984) and Faber et al. (1985), used in the chemical analysis of absorption features in stellar spectra. These band-passes are limited to the 4000 Å ≲ λ ≲ 6500 Å wavelength range. Based on the authors’ past observations, including JWST data described in Sect. 5.1, we propose a set of bands covering lines from the ultraviolet to the infrared. The online supplementary material of this manuscript includes a text file with these bands. Additionally, users can call the
3.3 Spatial masking
In the case of IFS observations, the user is encouraged to use spatial masks. These are matrices, where the True entries correspond to spaxels where line measurements are to be performed. This design ensures that the analysis is limited to regions with scientific data. Additionally, masks can be used to adjust the fitting configuration for different objects or physical conditions within an IFS cube. LIME includes the
Band flux (flux): this option sums up the input band flux across the spatial coordinates. The flux does not remove the continuum level in the case of an absorption or emission line. Users can specify flux percentiles to establish the number and extent of multiple masks.
-
Continuum signal-to-noise (SN_cont): this option uses the input band to calculate the continuum S/N using the root mean square (RMS):
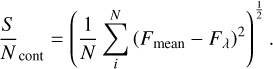 (1)
(1)Here, Fλ is the flux from each pixel in the band, Fmean is the mean flux value from all the pixels, and N is the number of pixels. Users can specify S/N percentiles to adjust the number and extent of the masks.
-
Line signal-to-noise (SN_line): this option uses the line and adjacent continua bands to calculate the S/N of the input line using the definition by Rola & Pelat (1994):
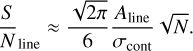 (2)
(2)Here, ALINE is the amplitude of the line peak, and σcont is the sigma flux from the adjacent continua bands. For mask computation, the first term is calculated as the maximum pixel flux in the line band minus the mean continua flux. The second term is derived from the adjacent continua flux standard deviation. Users can specify S/N percentiles to adjust the number and extent of the masks.
More details regarding the masking generation process can be found in the 4th
3.4 Fit configuration
Given the previous inputs, LIME has sufficient information to start measuring lines. In this scenario, however, all lines will be fitted with a single Gaussian. Indeed, even if the lines are correctly labeled with the merged (“_m”) and blended (“_b”) suffixes, they will still be treated as single transitions unless the components are explicitly specified. This is done via the fitting configuration files.
Figure 4 illustrates an example of a fitting configuration file for analyzing an IFS observation. The configuration file follows a
Default configuration: these settings are applied to all the spaxels. As shown in Fig. 4, the “defαult_line_fitting” section includes the components for the merged and blended lines. The individual components must follow the notation described in Sect. 3.1, joined by (+) symbols.
Mask configuration: in Fig. 4, there are three additional sections, one for each mask. In a star-forming galaxy, such as SHOC579 (see Pérez-Montero et al. 2013), the localized radiation at the central stellar produces a rich emission spectra at the core. This emission gradually decreases towards the outskirts of the galaxy. Consequently, it is recommended to leverage LIME’s spatial treatment to adjust the analysis: moving from more lines with more complex profiles towards regions with only single and merged lines as the S/N decreases. For spaxels within each mask, this information updates the fitting configuration from the default line fitting, inclusively. For example, for spaxels in the Mαsk_2, whose section [MASK_2_line_fitting] does not contain additional information, the [default_line_fitting] would be used. In contrast, for Mask_0 spaxels, the data in [MASK_0_line_fitting] would overwrite existing entries in the default configuration, while appending the new ones.
-
configuration: in cases where certain spaxels need their own fitting configuration, the user can add a section titled with the spaxel array coordinates (Y–X, in NUMPY array index).
In Fig. 4, the 38–35 spaxel inherits the default, Mask_0, and 38–35 line fitting configuration. Here, higher levels overwrite values from the lower levels. In this case, the O3_5007A_b deblending at this spaxel will include the He1_5016A line as the spaxel blended components are updated from the Mask_0 configuration.
The line fitting using the
At the present time, LIME can fit Gaussian, Lorentz, pseudo-Voigt, and exponential profiles. Gaussian is the default profile, if none is specified via the label profile suffix (see Fig. 3). As commented before, we use the LMFIT by Newville et al. (2014) to perform the fittings. However, we do not use the default models but our own expressions, which include the theoretical area and the FWHM for these profiles. For example, the Gaussian one is defined as:
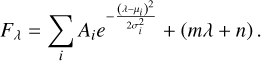 (3)
(3)
On the left-hand side, Fλ represents the line flux. On the right-hand side, there are two components: the Gaussian profile flux, where Ai is the height of the Gaussian profile above the continuum level, µi is the center of the Gaussian profile, and σi is the standard deviation of the profile. The subscript i denotes the transition. In the fitting configuration, these parameters are labeled with the name of the line, plus the suffixes _amp, _center, and _sigma respectively. The second component is the continuum, modeled as a linear profile, where m is the gradient and n the intercept. In the configuration logs, these parameters are named after the blended line with the _slope and _intercept suffixes, respectively. Regardless of the number of components, there is only one continuum level, with the continuum linear parameters fixed by default from values derived from the adjacent bands continuum analysis carried out before the profile fitting. The online documentation10 provides a comprehensive description of the options available to adjust the profile fitting. However, the following paragraphs summarize the key features:
Parameter boundaries: in Fig. 4, we see parameters constrained with min and max boundaries. This limits the parameter value range during the fitting. Additionally, the user can specify an initial value for the fitting. If the attribute vary=False the parameter’s initial value remains fixed during the profile fitting. These attributes correspond to
LmFIT parameters declaration. For the Gaussian line center, constraints should be introduced in the rest-frame, and LIME will transform them to the observed-frame.Intra-parameter boundaries: for blended lines, the user can include the expr attribute in parameter constraints. This attribute takes a mathematical string expression involving the parameter values. This relation will be enforced during the fitting. In Fig. 4, we have an example where we use an expression to keep the [OIII]4959, 5007Å amplitude fixed to their theoretical emissivity ratio. The expr attribute is limited to blended lines. This ensures that conflicts in samples, where the same line can be a found in blended group, can be avoided. This is a small trade-off for single lines since the expr attribute is unlikely to be necessary.
Inequality boundaries: the user can include inequality symbols in the expr value to define boundaries, as seen in Fig. 4 for 03_4959A_k-1_sigma. This inequality ensures that the kinematic component _k-1 maintains a larger magnitude than the narrower 03_4959A. This enhancement is built over the LMFIT syntax by LIME and currently only supports a multiplicative factor.
Pixel mask: in addition to global pixel masks (Sect. 2.2), users can specify a pixel mask for a specific fitting. These keys are specified with the line name plus _mask. The user can specify a single wavelength value or a two-limits interval with dash-separated floats, and combine multiple values or intervals with underscores.
-
Export line kinematics: including a line with the _kinem suffix allows the user to match the kinematics of another line. This transformation occurs in the velocity plane, considering the Doppler effect. The child line kinematics are defined as:
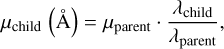 (4)
(4)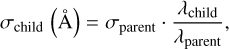 (5)
(5)The parent line can be from a previous measurement or in the current one. In the former case, the parent line must be measured in advance, and the Gaussian centroid and standard deviation remain fixed during fitting. In blended lines, parent and child line kinematics are tied during the fitting. This methodology was first introduced by Bosch et al. (2019).
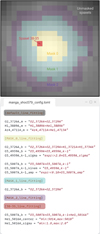 |
Fig. 4 Spatial mask SHOC579 Manga observation (top). Part of the LIME configuration file for the IFU fitting (bottom). |
4 Line detection, measurement, and outputs
In an ideal world, astronomers would have the time to individually check each spectrum before performing measurements. However, in the current age of Big Data, this is no longer feasible. As hinted in the previous section, one alternative is to group data into sub-samples of spectra or spatial regions sharing a common fitting configuration. Another critical aspect of automation is the detection of lines prior to their measurement. In this section, we present the peak or trough detection algorithm and line measurements.
4.1 Emission and absorption detection
As outlined in the review by Yang et al. (2009), the classical methodology to detect peaks on spectra involves three steps. The first is a smoothing operation, where the spectrum is convolved by a Gaussian filter to artificially remove noise from the continuum. The second step is normalization: the spectrum is divided by a polynomial fit of the continuum to produce a flattened continuum. Finally, the actual peak/trough detection involves passing the smoothed and normalized spectrum through a noise threshold. Flux points above/bellow these limits indicate an emission/absorption line. This is the very approach used by Astropy-Specutils Development Team (2019). In LIME this procedure is managed by the following tasks:
The users can specify the attributes for these tasks within the configuration file. As in the case of the line fitting configuration described in Sect. 3.4, these attributes can be assigned in a multi-level priority that LIME will automatically assign for the corresponding spectrum and/or spatial mask.
 |
Fig. 5 LIME measurements division into several categories. Direct measurements are calculated from the integration of the line bands. Profile-based measurements depend on the theoretical profile assumption. The identity entries include information regarding the particle transition. Finally, the diagnostic measurements provide information regarding the quality of the fittings. A more detailed information can be found online |
4.2 Output measurements
Figure 5 provides a summary of the line measurements produced by LIME after each fitting. Furthermore, the online documentation11 offers a detailed explanation of how these parameters are calculated. Therefore, this section will focus on the main characteristics of LIME measurements.
-
LIME yields two flux measurements for every line fitting. The first is an integration of the line bands pixels, via a bootstrap algorithm. in this process, every pixel receives a stochastic flux from a Gaussian distribution centered at zero, whose width comes from the pixel flux uncertainty. This is executed in a 1000-step loop. The output integrated flux and uncertainty are derived from the mean and standard deviation of these randoms arrays. In contrast, the profile flux is calculated from the theoretical relation. For a multi-Gaussian profile, we have, for example:
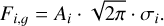 (6)
(6)The Gaussian flux uncertainty depends on the algorithm chosen for the minimization12. in most cases, this uncertainty is the standard error, indicating how much the parameter value must increase to raise the χ2 value by one unit. Both flux measurements are in the observed frame.
If the user provides the spectrum flux uncertainty as detailed in Sect. 2.2, LIME considers the individual pixel error in the flux calculations. If not, LIME calculates a uniform pixel flux uncertainty for each line, assuming a linear continuum from the adjacent bands’ continua.
Reference velocity: the radial velocity in the line of sight (υr) and velocity dispersion (σvel) calculation require a reference point. instead of using the line’s peak, we use the theoretical transition wavelength (for blended/merged lines, the wavelength of the line with the modularity suffix) in the observed frame (accounting for the observation redshift). This approach is advantageous, as exemplified in the complex line fitting shown in Fig. 2. In IFS observations with multiple lines, the component with the highest peak may vary significantly as well due to the ionization conditions, making the interpretation of kinematic maps very challenging. Nevertheless, the output logs include both the peak wavelength and the Gaussian centroids of the components. This makes it easy to calculate the radial velocity using other point of reference.
5 Discussion
In the literature, there are outstanding packages avaiilable for the measurement of lines. These include IRAF by Tody (1986), ALFA by Wesson (2016), LZIFU by Ho et al. (2016), LSD-CAT by Herenz & Wisotzki (2017), GAUSSPY by Riener et al. (2019), and GLEAM by Stroe & Savu (2021), among others. Some of these tools, such as PIPE3D by Sánchez et al. (2016) or PPXF by Cappellari (2017), provide a stellar population synthesis in addition to the line flux measurements. Furthermore, numerous astronomers rely on their custom scripts to quantify spectral features. At this juncture, one might ask how can LIME contribute. The authors believe that there are two key tests, which will determine the mid-term success of astronomical software:
Multi-disciplinary design: the first programming task for many early career astronomers involves accessing and opening digital telescope observations. Afterwards, many will proceed to measure the lines on the spectra. While this is a valuable learning exercise for new astronomers and programmers, this treatment complexity increases very fast, for example, to change the observation type, manage bad pixels or sharing scripts between colleagues. Moreover, this is redundant not only for newcomers but also for their mentors, who are responsible for reviewing the results quality. To avoid these challenges, LIME was designed to support both long-slit and IFS data sets, emission and absorption lines and different profile shapes. No matter whether the stellar or galactic study focuses on the chemical or kinematic (or both) analysis, our package can support the procedure.
Big data design: the workload expected from next-generation surveys cannot be managed with the standard algorithms used by the astronomical community. Some of these challenges include remotely processing large IFS data cubes (exceeding 10 GB) or fitting lines with a large number of Gaussian components (more than 15 dimensions). In such scenarios, the data treatment must be simplified to maintain the astronomer’s focus on the data interpretation. LIME addresses these challenges through standardization. Line labels and bands adhere to a strict format for unique indexing. Fitting properties are defined in external and readable configuration files. Additionally, the multi-level design allows users to set default line types and fittings, with the option to specify specific boundaries for certain objects or lines. This approach significantly reduces the astronomer’s coding requirements and facilitates future upgrades, such as implementing machine learning algorithms for line and profile detection. Trained models can confirm line presence and fitting configuration, while these inputs format and workflow remain constant.
Finally, LlME’s design offers novel options to the community to perform and distribute spectroscopic line measurements.
5.1 Self-hosted spectroscopic surveys
An observable trend in software development is the migration towards online platforms. This phenomenon, known as Eric Schmidt’s Law, is driven by increasing network speeds. In scientific programming applications, this approach offers two significant advantages for the user. First, there is no need to install specialized software, nor its dependencies. Second, complex operations, such as reading data from online platforms, can be centralized and managed by the developer.
The JDAVIZ package Developers et al. (2023), implemented within the Space Telescope Science Institute (STScI) data analysis tools ecosystem, exemplifies this principle. This is a line measuring package, based on Jupyter notebooks, which can be run as an offline application or embedded within a website. While LIME is compatible with Jupyter notebooks (indeed, the documentation tutorials13 are compiled from them), its design is geared towards lower-level functions, which are platform-agnostic. This facilitates the integration into other online platforms, both the current ones and those that may become popular in the future.
This design is also viable for online platforms, such as the spectroscopy virtual observatory hosted at
This virtual observatory is powered by the STREAMLIT platform14. Upon linking a STREAMLIT account with a GITHUB repository using this platform API, the website is automatically compiled. The complete code structure is available at the first author’s WEBSITE GITHUB15. In this setup, LIME is included as a dependency and the widget-based interface is used to pass user inputs to its functions. This enables the user to perform various tasks such as constraining sample selection, plotting spectra, computing redshifts, or inspecting line fittings. For this specific case, the spectra are hosted directly on GITHUB. The
These measurements have been used in the works by Arrabal Haro et al. (2023a,b), Seillé et al. (2023), Davis et al. (2023), a. At this time, NIRSpec instrument calibration from the Space Telescope Science Institute (STScI) continues to be updated, and the CEERS team is continuing to improve the fidelity of its data reduction. There are several known issues with flux calibration, path-loss correction, background subtraction for extended sources, and in some cases with wavelength calibration. Once the CEERS collaboration is more confident about these calibration issues, it will be possible to download the line measurements from the LiMe website. Redshift measurements and quality flags based on evaluation by multiple CEERS team members will be published in Arrabal Haro et al. (in prep.).
 |
Fig. 6 Histogram showing the number of galaxies in the CEERs virtual observatory with LIME flux measurements as a function of redshiſt. |
 |
Fig. 7 Accuracy and precision evaluation plots for parameters contributing to a line flux’s nominal and standard deviation values: line amplitude (Agas), standard deviation (σgas), line flux noise (σnoise), and spectrum resolution (∆λinst). The black solid line indicates the emission line detection boundary, and dashed lines represent the cosmic rays (or dead pixel) “lines” limit. Each circle represents the Gaussian fitting of a synthetic line. Left: points are color-coded by the absolute relative error between measured and true flux. Inset histogram shows relative error of integrated and Gaussian fluxes. Red crosses indicate points where LIME Gaussian fitting failed. Right: points color-coded by coefficient of variation for Gaussian uncertainty and nominal flux. Inset histogram shows difference between Gaussian and integrated fluxes against true coefficient of variation. |
5.2 Accuracy and precision
An absorption or emission line flux is determined by the number of missing or excess photons from a specific transition. This is quantified by the area covered by the line. As detailed in Sect. 4.2, there are two types of fluxes per line: one based on Monte Carlo integration and the second on the Gaussian area as given by 6. Assuming a single line with a Gaussian shape and a linear continuum, four parameters contribute to the line flux measurement and its accuracy: the line amplitude (Agas), the noise standard deviation (σnoise), the gas dispersion velocity (σgas), and the spectrum resolution (AÀ). These parameters can be effectively represented by the dimensionless ratios Agas/σnoise and σgas/Δλ. The first ratio traces the S/N of the line, while the second is a measured of the number of pixels covered by the line. Generating and measuring synthetic lines based on these ratios allows us to quantify LlME’s (or any algorithm’s) accuracy and precision across the entire parameter space. Here, the “true flux” is given by Eq. (6), while the “true error” can be calculated as:
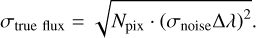 (7)
(7)
Where Npix is the number of pixels covered by the line. Assuming the Gaussian reaches 4 × σgas for a given spectrum resolution, the number of pixels is Npix = 2 • 4σgas/Δλ Rewriting the equation as:
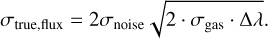 (8)
(8)
Figure 7 shows the relative error and coefficient of variation for emission line fitting tests. The black solid line marks the visual detection boundary, detailed in Sect. 5.3. Scatter points represent the parameter space coordinates for generated and measured emission lines, with color-coding indicating the magnitude of absolute relative error for measured Gaussian fluxes and the coefficient of variation for Gaussian uncertainty. Red crosses mark points where LIME Gaussian fitting failed, mostly below the “cosmic ray boundary” where lines occupy a single pixel. These failed measurements, where the minimizer does not converged, have the profile measurements (see Fig. 5) output as nan. By default LIME settings impose the spectrum pixel width as the lower limit for σgas, leading to automatic failure in these cases. However, in some instruments, lines might have this cosmic ray profile. Therefore, it may be necessary to ease this constraint. Additional failures are observed well below the line detection boundary, likely due to noisy spectra complicating Gaussian fitting.
The plots show in general a very good accuracy and precision (less than 5%) above the line detection boundary. The most uncertain region is where Agas/σnoise < 10 and σggs/∆λ < 2, corresponding to lines close to noise level and narrower than 12 pixels. Here, measurement accuracy is dominated by random error, with relative uncertainty up to 30%. However, this is not unique to LIME measurements, as emission lines with S/N < 5 (see Eq. (2)) are subject to a strong positive bias (see Rola & Pelat 1994). This means that in most cases the line intensity measured is higher than the true one. Assuming Agas/σnoise ≈ S/N, if we take the points in Fig. 7 with Agas/σnoise < 5, but above the detection boundary (Eq. (9)) we observe a skewed distribution for the Gaussian fluxes peaking around 10% higher than the true values. In contrast, the integrated fluxes seem to be closer to the true values but this distribution also has large wings. In our tests, where an emission line always exists, the relative error stabilizes below 5% when Agas/σnoise ≳ 13. The same pattern is observed with Monte Carlo measurements, as shown in the left inset histogram, comparing density distributions for two flux measurements. While integrated fluxes might be slightly larger than Gaussian for some regions, this is influenced by line band selection. On the right diagram of Fig. 7, the plot structure is similar but color-coded by coefficient of variation. Here, Gaussian fittings tend to report slightly smaller uncertainties than expected, indicating more stable measurements for weaker lines but with a tendency to underestimate uncertainties.
5.3 Line detection and measurement issues
The first published work using LIME was the chemical analysis of the galaxy CGCG007-025 in Fernández et al. (2023). Since the beta release in that manuscript, feedback from collaborators has highlighted two key areas for LIME’s future development. The first issue concerns the fitting of blended lines with four or more transitions. For example, a multi-Gaussian profile fitting is a non-linear process, and as such, exploring the parameter space for an optimal solution becomes increasingly complex with higher dimensions. Fittings, such as those shown in Fig. 2, are very sensitive to initial conditions and may not converge at all. Packages such as PPXF or GANDALF linearize this model by simultaneously fitting several transitions with a unique radial velocity in the line of sight and dispersion velocity per kinematic component. Alternatively, LIME can export kinematics from one line to another to reduce the number of effective dimensions. However, as demonstrated in Amorín et al. (2012), high-resolution observations of strong emission lines like Hα can have many components, both narrow and broad. This makes the finding the solution very time-consuming. In Fernandez et al. (2019), we introduced a novel methodology using neural networks to fit the complete chemical space parameters under the direct method paradigm. This approach was expanded in Fernández et al. (2022, 2023) to fit photo-ionization models. Future work will explore the use of neural networks for fitting complex multi-Gaussian profiles.
Early feedback also identified LIME’s main user error source: attempting to measure a non-existent line or kinematic component. The line detection procedure outlined in Sect. 4.1 is effective as long as the user provides a good continuum parametrization and a reasonable list of expected lines. However, it cannot autonomously confirm the presence of lines. Ideally, three independent diagnostics should be compared to confirm a line’s presence. In Fig. 8, we revisit the parameter space from the previous sub-section. For the given parameter range, Gaussian curves are generated and tagged with positive (green), negative (red), or inconclusive (blue) based on the author’s visual criteria. This exercise highlights the region where line detection is expected. The boundary can be approximated by:
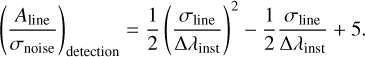 (9)
(9)
This empirical model can label synthetic data for training machine learning algorithms: users provide a range of parameters to generate lines (detailed as in Sect. 5.2), then use Eq. (9) to label data arrays with positive line detections. A supervised learning algorithm (see Baron 2019, and references therein) can then be used to create a model for line detection in spectral bands. Initial tests with binary classifiers have been successful in predicting lines. The main advantage from this approach is that it requires very little input from the user for an efficient line detection. However, unlike the traditional technique described in Sect. 5.3, trained-models can be very sensitive to the expected. For example, a model trained with Gaussian lines, will fail to detect blended lines even if their signal to noise is very high. Currently, the authors are exploring a chain of machine-learning models to reproduce the human vision pattern (seen in Fig. 8), while avoiding these pitfalls.
 |
Fig. 8 Parameter space for line measurement as described in the text, with scatter points color-coded according to a visual criterion for line detection. In the color version, these are green for positive detection, red for negative, and blue for inconclusive. The inset plots show examples of each case. The black solid line represents the empirical detection boundary. |
5.4 Benchmarks
To assess the performance of LIME, a script is provided on the library’s GITHUB16 for fitting the MUSE observation of the galaxy CGCG007-025. This is a low-mass blue compact dwarf (log(M*) = 8.17, see Gavilán et al. 2013), undergoing a galaxy-wide star-forming burst. In Fernández et al. (2023), we analyzed its chemical composition, focusing on 6 spatial regions encompassing 7774 spaxels. These regions display an ionization gradient, from the hard radiation at the central stellar cluster, to the low ionization regions in the galaxy outskirts, where only Hα, Hβ, and the [OIII]4959, 5007 å doublet are observed. Unlike the emission line quantity, the number of spaxels per mask increases, as we move to lower ionization regions. Detailed fitting properties are described in that manuscript, but the measurement performance is illustrated in Fig. 9. The left (blue) ordinate axis shows the cumulative number of lines, while the right (orange) one corresponds to the number of spaxel spectra. The complete cube analysis took 11.77 min for 46775 line measurements. Fig. 9 details the rate of lines and spaxels measured per second. These rates vary because the computational load is split between two tasks: line tasks (profile fitting and parameters calculation) and spaxel tasks (spectrum extraction, line detection, data formatting, and writing to memory). Fewer lines mean that spaxel tasks dominate the computational time. These tests were performed on a mid-to-high range desktop processor Intel Core i5-13600KF 3.5 GHz 14-Core.
To gauge LIME’s efficiency, we can compare it with a state-of-the-art library like ALFA by Wesson (2016). This FORTRAN based package was developed to analyze emission-rich, high-resolution spectra of planetary nebulae. The library’s paper includes benchmarks for a 5.1 Gb MUSE cube, where 41 022 spaxels were treated, resulting in over 2 million emission line measurements in 20 h. This translates to about 49 lines per spaxel, similar to our first mask in Fig. 9, suggesting LIME would take approximately 5.7 h for a comparable observation. While this is a simplistic comparison involving different observations, CPUs, line profile types, and likely, file-saving procedures, it’s reasonable to conclude that LIME is on par, performance-wise, with highly optimized packages.
Beyond quantitative benchmarks, a more realistic approach consists in setting efficiency targets. There are three scenarios, where astronomers have to deal with Big Data. The first one involves individual researchers. For a scientific manuscript discussing the results from tens of thousand of spectra (as in Fig. 9) a few hours for the line measurements are negligible. The second scenario involves the collaboration between several researchers across institutions. If we scale the previous data size by the number of researchers, even a few days of measurements are acceptable for the workflow. In this scenario, however, the main challenges involve distributing the data among the collaborators so it can be reviewed. As we show in Fig. 9 and describe in Sect. 5.1, the LIME design is particularly well positioned to address these two scenarios. The third case is the analysis of large surveys. At this point, the software needs to treat the data as fast as it is produced (observation + calibration). In this case, LIME will need to explore performance-enhancing techniques such as CPU/GPU parallelisation or machine learning based models. Before this is possible, however, it is necessary to enhance the data workflow to make sure it can handle very large data files. Currently, Pignata et al. (in prep.), are using LIME to measure very large MUSE data sets (> 40 GBs) within a CPU cluster. From this feedback, we will explore advanced techniques to handle the data reading, management and writing.
 |
Fig. 9 LIME benchmarks for the analysis of CGCG007-025 described in Fernández et al. (2023) with the cumulative sum of lines and spaxels. The 6 masks have [459, 3418, 3431, 17390, 9579, 12498] spaxels. At each mask, we measure [96, 91, 81, 77, 59, 54] lines per second for [2, 2, 9, 9, 13, 13] spaxels per second. |
6 Conclusions
In this manuscript, we introduce a new Line MEasuring package: LIME. This library boasts a simple yet flexible design, accommodating both long-slit and integral field spectroscopy (IFS) data. It is freely available, comprehensively documented with tutorials, measurements description, and an API detailing the commands and their inputs. Additionally, LIME features commands to plot and interact with the measurements. The library easy installation, modular design, and competitive performance further enhance its usability. We also discuss various topics to engage the community in addressing Big Data challenges in astronomy and to foster LIME future development:
LIME is designed to support both chemical and kinematic studies. We present a notation system for describing transitions, which is both human and machine readable and provides a flexible format for specifying transition particles, wavelengths, kinematic components, or profile types. For multiple species transitions or kinematic components, this notation distinguishes between lines that can be isolated mathematically (blended) and those that cannot (merged). LIME relies on a set of bands to locate lines and derive flux uncertainty. We include a line bands database, which the user can adjust to their observations
The profile fittings in LIME support a wide range of boundaries. Users can fix parameter values, establish limits, and define relationships between them, including inequality relations. The transition components and fitting boundaries can be specified in an external, human-readable file, eliminating coding requirements. For handling multiple spectra or IFS data cubes, a multi-level fitting configuration simplifies user input by establishing global and local fitting configurations.
LIME’s modern implementation makes it suitable for state-of-the-art interactive and programmatic platforms. As a practical example, we showcase a spectroscopic virtual observatory at
ceers-data.streamlit.app . This repository contains JWST NIRSpec observations from the CEERs survey for a total of 4408, ID and 2D sepctra. Using LIME, we have measured redshift in 647 unique objects within a range of 0.29 ≤ ɀ ≤ 9.62. While direct data download is not currently available, users can inspect individual fittings, illustrating how LIME can be used to facilitate the access to spectroscopic data.In our discussion of LIME’s accuracy and precision, we propose a parameter space normalization that highlights the specific S/N and instrument resolution regions where line measurements can be challenging. In regimes where Agas/σnoise ≲ 13 and lines consist of fewer than 12 pixels, users should be wary of random errors dominating the flux. At this region, Gaussian fluxes provide more accurate measurements, while integrated errors better approximate the intrinsic uncertainty.
Building on this normalization, we suggest an empirical relation to define the Agas/σnoise detection limit as a function of σgas/Δλinst. This relation can label synthetic lines in samples to train supervised machine learning models. We are currently exploring the best approach to integrate this methodology into LIME, with an aim to reduce the workload for astronomers.
Future LIME development will take into consideration the requests from the community to improve its workflow and add new features.
Acknowledgements
The authors want to thank the anonymous referee for his/her comments. V.F. acknowledges financial support provided by FONDECYT grant 3200473. V.F. also acknowledges the support by the Eric and Wendy Schmidt AI in Science Postdoctoral Fellowship, a Schmidt Futures program, at the Michigan Institute for Data Science, University of Michigan. R.A. acknowledges the support of ANID FONDECYT Regular Grant 1202007 and DIDULS/ULS PTE2053851. C.M. acknowledges the support of UNAM/DGAPA/PAPIIT grant IG101223. V.F. wants to thank all the early LIME users for their feedback. Finally, V.F. wants to thank Juan Luis Cano Rodriguez for his support and insight in LIME documentation.
References
- Amorín, R., Vílchez, J. M., Hägele, G. F., et al. 2012, ApJ, 754, L22 [CrossRef] [Google Scholar]
- Amorin, R. O., Rodríguez-Henríquez, M., Fernández, V., et al. 2024, A&A, 682, L25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Armstrong, B. H. 1967, JQSRT, 7, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Arrabal Haro, P., Dickinson, M., Finkelstein, S. L., et al. 2023a, ApJ, 951, L22 [NASA ADS] [CrossRef] [Google Scholar]
- Arrabal Haro, P., Dickinson, M., Finkelstein, S. L., et al. 2023b, Nature, 622, 707 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy-Specutils Development Team 2019, Astrophysics Source Code Library, [record ascl:1902.012] [Google Scholar]
- Bacon, R., Accardo, M., Adjali, L., et al. 2010, in Ground-based and Airborne Instrumentation for Astronomy III, 7735 (SPIE), 131 [Google Scholar]
- Baron, D. 2019, [arXiv: 1904.07248] [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bosch, G., Hägele, G. F., Amorín, R., et al. 2019, MNRAS, 489, 1787 [NASA ADS] [CrossRef] [Google Scholar]
- Bowen, I. S. 1927, Nature, 120, 473 [NASA ADS] [CrossRef] [Google Scholar]
- Burstein, D., Faber, S. M., Gaskell, C. M., & Krumm, N. 1984, ApJ, 287, 586 [Google Scholar]
- Cappellari, M. 2017, MNRAS, 466, 798 [Google Scholar]
- Chatzikos, M., Bianchi, S., Camilloni, F., et al. 2023, Rev. Mex. Astron. Astrofis., 59, 327 [Google Scholar]
- Chu, Y. H., & Kennicutt, R. C. 1994, Astrophys. Space Sci., 216, 253 [NASA ADS] [CrossRef] [Google Scholar]
- Davis, K., Trump, J. R., Simons, R. C., et al. 2023, ApJ, submitted [arXiv:2312.07799] [Google Scholar]
- del Valle Espinosa, M. G., Sánchez-Janssen, R., Amorín, R., et al. 2023, MNRAS, 522, 2089 [NASA ADS] [CrossRef] [Google Scholar]
- Developers, J., Averbukh, J., Bradley, L., et al. 2023, https://zenodo.org/records/7971665 [Google Scholar]
- Faber, S. M., Friel, E. D., Burstein, D., & Gaskell, C. M. 1985, ApJS, 57, 711 [NASA ADS] [CrossRef] [Google Scholar]
- Fernández, V., Terlevich, E., Díaz, A. I., & Terlevich, R. 2019, MNRAS, 487, 3221 [CrossRef] [Google Scholar]
- Fernández, V., Amorín, R., Pérez-Montero, E., et al. 2022, MNRAS, 511, 2515 [CrossRef] [Google Scholar]
- Fernández, V., Amorín, R., Sanchez-Janssen, R., del Valle-Espinosa, M. G., & Papaderos, P. 2023, MNRAS, 520, 3576 [CrossRef] [Google Scholar]
- Finkelstein, S. L., Bagley, M. B., Haro, P. A., et al. 2022, ApJ, 940, L55 [NASA ADS] [CrossRef] [Google Scholar]
- Finkelstein, S. L., Bagley, M. B., Ferguson, H. C., et al. 2023, ApJ, 946, L13 [NASA ADS] [CrossRef] [Google Scholar]
- Fraunhofer, J. 1815, Denksch. Königl. Akad. Wissensch. München, 5, 193 [Google Scholar]
- Gavilán, M., Ascasibar, Y., Mollá, M., & Ángeles I. Díaz. 2013, MNRAS, 434, 2491 [CrossRef] [Google Scholar]
- Hagele, G. F., Firpo, V., Bosch, G., Diaz, A. I., & Morrell, N. 2012, MNRAS, 422, 3475 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Herenz, E. C., & Wisotzki, L. 2017, A&A, 602, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hippelein, H. H. 1986, A&A, 160, 374 [NASA ADS] [Google Scholar]
- Ho, I.-T., Medling, A. M., Groves, B., et al. 2016, Astrophys. Space Sci., 361, 280 [NASA ADS] [CrossRef] [Google Scholar]
- Hogarth, L., Amorín, R., Vílchez, J. M., et al. 2020, MNRAS, 494, 3541 [NASA ADS] [CrossRef] [Google Scholar]
- Huggins, W., & Miller, W. A. 1864, Philos. Trans. Roy. Soc. Lond., 154, 437 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jakobsen, P., Ferruit, P., Oliveira, C. A. d., et al. 2022, A&A, 661, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luridiana, V., Morisset, C., & Shaw, R. A. 2015, A&A, 573, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mezger, P. G., & Hoglund, B. 1967, ApJ, 147, 490 [NASA ADS] [CrossRef] [Google Scholar]
- Newton, I., Hemming, G. W., & Burndy Library, d. D. 1704, Opticks: or, A Treatise of the Reflections, Refractions, Inflexions and Colours of Light: Also Two Treatises of the Species and Magnitude of Curvilinear Figures (London: Printed for Sam. Smith, and Benj. Walford) [Google Scholar]
- Newville, M., Stensitzki, T., Allen, D. B., & Ingargiola, A. 2014, https://zenodo.org/records/11813 [Google Scholar]
- Osterbrock, D. E. 1974, Astrophysics of Gaseous Nebulae (University Science Books) [Google Scholar]
- Pandas Development Team, T. 2023, https://zenodo.org/records/7794821 [Google Scholar]
- Pérez-Montero, E. 2014, MNRAS, 441, 2663 [CrossRef] [Google Scholar]
- Pérez-Montero, E., Kehrig, C., Brinchmann, J., et al. 2013, Adv. Astron., 2013, 837392 [Google Scholar]
- Riener, M., Kainulainen, J., Henshaw, J. D., et al. 2019, A&A, 628, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rola, C., & Pelat, D. 1994, A&A, 287, 676 [NASA ADS] [Google Scholar]
- Sánchez, S. F., Pérez, E., Sánchez-Blázquez, P., et al. 2016, Rev. Mex. Astron. Astrofis., 52, 21 [NASA ADS] [Google Scholar]
- Seillé, L. M., Buat, V., & Fernandez, V. 2023, Probing the attenuation curve of 1 < z < 3 galaxies with the JWST/CEERs in SF2A-2023: Proceedings of the Annual meeting of the French Society of Astronomy and Astrophysics, eds. M. N’Diaye, A. Siebert, N. Lagarde, O. Venot, K. Bailliée, M. Béthermin, E. Lagadec, J. Malzac, & J. Richard, 329 [Google Scholar]
- Smith, M. G., & Weedman, D. W. 1970, ApJ, 161, 33 [Google Scholar]
- Stroe, A., & Savu, V.-N. 2021, AJ, 161, 158 [NASA ADS] [CrossRef] [Google Scholar]
- STScI. 2022, Large-Volume Spectroscopic Analyses of AGN and Star Forming Galaxies in the Era of JWST [Google Scholar]
- Tody, D. 1986, in Instrumentation in Astronomy VI, 0627 (International Society for Optics and Photonics), 733 [NASA ADS] [CrossRef] [Google Scholar]
- Wesson, R. 2016, MNRAS, 456, 3774 [NASA ADS] [CrossRef] [Google Scholar]
- Wollaston, W. 1802, Philos. Trans. Roy. Soc. Lond., 92, 365 [CrossRef] [Google Scholar]
- Yang, C., He, Z., & Yu, W. 2009, BMC Bioinformatics, 10, 4 [CrossRef] [Google Scholar]
- Zhang, Y., & Zhao, Y. 2015, Data Sci. J., 14, 11 [NASA ADS] [CrossRef] [Google Scholar]
Available at https://pypi.org/project/tomli/
Documentation https://lime-stable.readthedocs.io/en/latest
Tests compilation app.codecov.io/gh/Vital-Fernandez/lime
Reporting issues
As indicated in the
See
Profile fitting
Online
The minimization algorithm is specified in the fitting functions via the min_method attribute, using
GITHUB tutorials folder
CEERs virtual observatory website https://ceers-data.streamlit.app/
CEERs virtual observatory GITHUB https://github.com/Vital-Fernandez/ceers-data
CGCG007-025 analysis
All Figures
|
Fig. 1 LIME structure with some of the available functions. In the color version of the figure, the green background represents the library inputs, the orange cells cover the observations workflow, and the blue cell includes auxiliary functions. |
| In the text | |
|
Fig. 2 LIME fitting of the Hα and [NII]6548, 6583 Å transitions in the MUSE observation of NGC1386 black hole region. In this fitting, we are exporting the kinematics of [OIII]5007 Å components to the corresponding three transitions to facilitate the fitting. |
| In the text | |
|
Fig. 3 Line notation used in LIME. In the color version, the core components are displayed in blue, while the optional components are in green. The modularity suffix establishes the type of line components: Single for just one transition in the profile. Multi-component transitions are labeled as Merged if the components cannot be isolated, and blended when isolation is possible. |
| In the text | |
|
Fig. 4 Spatial mask SHOC579 Manga observation (top). Part of the LIME configuration file for the IFU fitting (bottom). |
| In the text | |
|
Fig. 5 LIME measurements division into several categories. Direct measurements are calculated from the integration of the line bands. Profile-based measurements depend on the theoretical profile assumption. The identity entries include information regarding the particle transition. Finally, the diagnostic measurements provide information regarding the quality of the fittings. A more detailed information can be found online |
| In the text | |
|
Fig. 6 Histogram showing the number of galaxies in the CEERs virtual observatory with LIME flux measurements as a function of redshiſt. |
| In the text | |
|
Fig. 7 Accuracy and precision evaluation plots for parameters contributing to a line flux’s nominal and standard deviation values: line amplitude (Agas), standard deviation (σgas), line flux noise (σnoise), and spectrum resolution (∆λinst). The black solid line indicates the emission line detection boundary, and dashed lines represent the cosmic rays (or dead pixel) “lines” limit. Each circle represents the Gaussian fitting of a synthetic line. Left: points are color-coded by the absolute relative error between measured and true flux. Inset histogram shows relative error of integrated and Gaussian fluxes. Red crosses indicate points where LIME Gaussian fitting failed. Right: points color-coded by coefficient of variation for Gaussian uncertainty and nominal flux. Inset histogram shows difference between Gaussian and integrated fluxes against true coefficient of variation. |
| In the text | |
|
Fig. 8 Parameter space for line measurement as described in the text, with scatter points color-coded according to a visual criterion for line detection. In the color version, these are green for positive detection, red for negative, and blue for inconclusive. The inset plots show examples of each case. The black solid line represents the empirical detection boundary. |
| In the text | |
|
Fig. 9 LIME benchmarks for the analysis of CGCG007-025 described in Fernández et al. (2023) with the cumulative sum of lines and spaxels. The 6 masks have [459, 3418, 3431, 17390, 9579, 12498] spaxels. At each mask, we measure [96, 91, 81, 77, 59, 54] lines per second for [2, 2, 9, 9, 13, 13] spaxels per second. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.