Fig. 4
Download original image
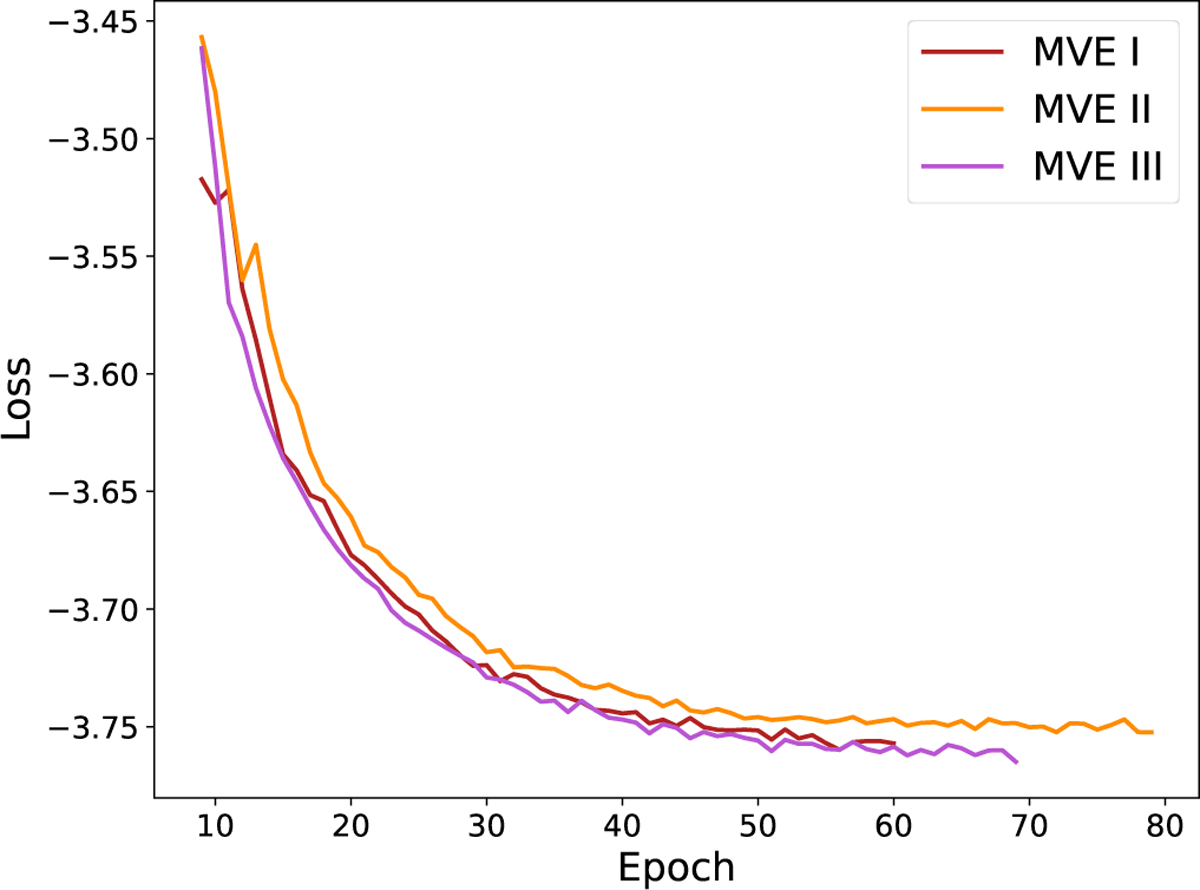
Training negative Gaussian loglikelihood loss for the three models with different initialisations: MVE I, MVE II, and MVE III. The plot shows the loss values computed over multiple training iterations on the dataset. Results suggest that MVE III outperforms the other models in minimising the loss function. However, all three models are used being an ensemble setting.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.