Fig. 3.
Download original image
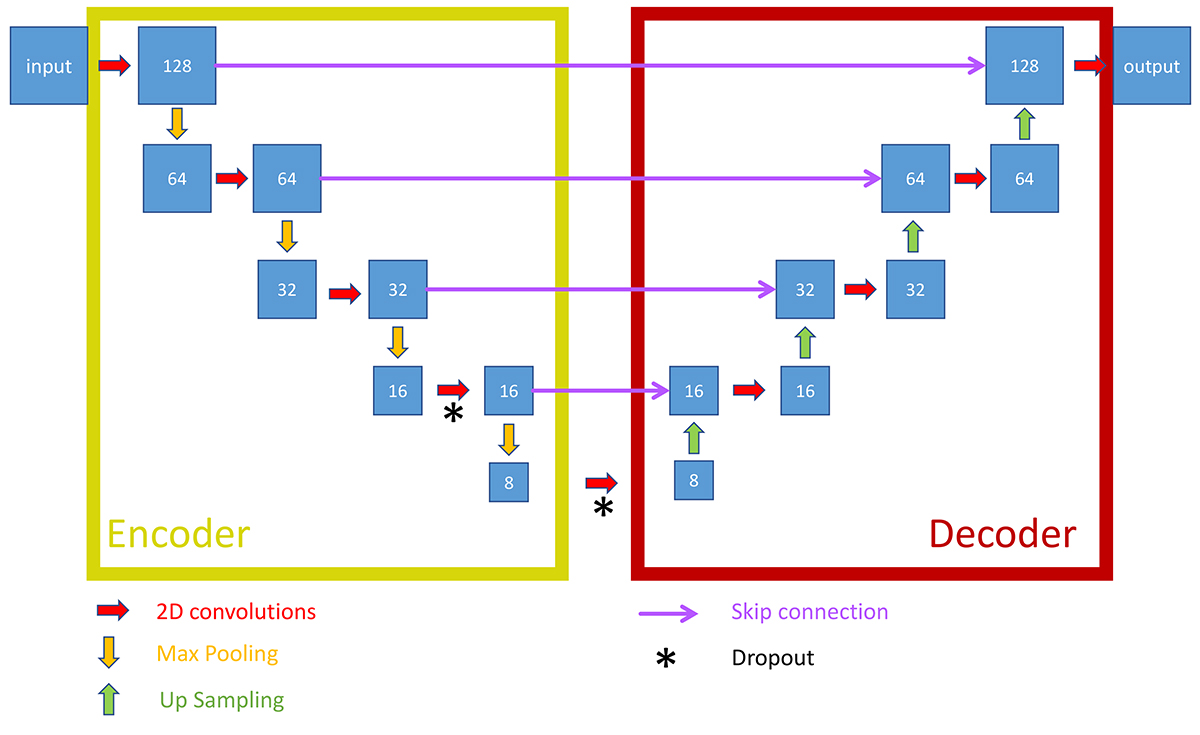
Convolutional neural network used in this work. The Encoder (left) refers to the first sequence of 2D convolutions and Max Pooling operations, while the Decoder (right) refers to the second sequence of 2D convolutions and upsampling operations. Each Max Pooling operation reduces the input map size by a factor of 2, keeping mainly large-scale information. The upsampling operator does the opposite, propagating the information at larger scales and increasing the input map size. Each convolution modifies the number of filters in such a way that we have the maximum number of filters at the deepest point of the network. Dropout and skip connection layers are depicted with black asterisks and purple arrows, respectively. Each square contains the size of the feature maps, which remain consistent along a given horizontal line (see Appendix A for additional details about the CNN model).
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.