| Issue |
A&A
Volume 677, September 2023
|
|
|---|---|---|
| Article Number | A16 | |
| Number of page(s) | 19 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202245189 | |
| Published online | 28 August 2023 | |
Understanding of the properties of neural network approaches for transient light curve approximations★
1
Max-Planck-Institut für Astronomie,
Königstuhl 17,
69117
Heidelberg,
Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Department of Astronomy, University of Illinois at Urbana-Champaign,
1002 West Green Street,
Urbana,
IL 61801,
USA
3
Lomonosov Moscow State University, Sternberg Astronomical Institute,
Universitetsky pr. 13,
Moscow
119234,
Russia
4
Lomonosov Moscow State University, Department of Mechanics and Mathematics,
Leninskie gory 1,
Moscow
119234,
Russia
5
Moscow Institute of Physics and Technology,
Institutskii Pereulok 9,
Dolgoprudny, Moscow Region
141700,
Russia
6
Moscow Polytechnic University,
Tverskaya street, 11,
Moscow
125993,
Russia
7
HSE University,
11 Pokrovsky Bulvar,
Moscow
101000,
Russia
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
12
October
2022
Accepted:
8
June
2023
Abstract
Context. Modern-day time-domain photometric surveys collect a lot of observations of various astronomical objects and the coming era of large-scale surveys will provide even more information on their properties. Spectroscopic follow-ups are especially crucial for transients such as supernovae and most of these objects have not been subject to such studies.
Aims. Flux time series are actively used as an affordable alternative for photometric classification and characterization, for instance, peak identifications and luminosity decline estimations. However, the collected time series are multidimensional and irregularly sampled, while also containing outliers and without any well-defined systematic uncertainties. This paper presents a search for the best-performing methods to approximate the observed light curves over time and wavelength for the purpose of generating time series with regular time steps in each passband.
Methods. We examined several light curve approximation methods based on neural networks such as multilayer perceptrons, Bayesian neural networks, and normalizing flows to approximate observations of a single light curve. Test datasets include simulated PLAsTiCC and real Zwicky Transient Facility Bright Transient Survey light curves of transients.
Results. The tests demonstrate that even just a few observations are enough to fit the networks and improve the quality of approximation, compared to state-of-the-art models. The methods described in this work have a low computational complexity and are significantly faster than Gaussian processes. Additionally, we analyzed the performance of the approximation techniques from the perspective of further peak identification and transients classification. The study results have been released in an open and user-friendly Fulu Python library available on GitHub for the scientific community.
Key words: methods: data analysis / supernovae: general / methods: statistical
Full Table 9 is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/677/A16
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
Time-domain photometric surveys such as the All-Sky Automated Survey (ASAS; Pojmanski 1997), MASTER Robotic Network (Lipunov et al. 2010), the Zwicky Transient Facility (ZTF; Bellm et al. 2019), Young Supernova Experiment (YSE; Jones et al. 2021), and others (Drake et al. 2009; Tonry et al. 2018) collect numerous observations of various astronomical objects. These photometric data are analyzed both in near-realtime and in archives by survey teams, alert brokers, such as ANTARES (Matheson et al. 2021), Alerce (Förster et al. 2021), Fink (Möller et al. 2021), and others, and the scientific community in order to detect, classify, and characterize variable astronomical sources. Most of the objects have never received spec-troscopic, multiwavelength, or any other follow-up observations, which are especially crucial for transients such as supernovae, making the photometric classification and characterization methods significant. Besides that, the upcoming Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST; Ivezić et al. 2019) will have a transient detection rate that is 10-100 times higher than all existing surveys combined, which makes this issue even more acute.
Photometric time series collected by ground-based optical surveys usually have the following properties: 1) irregular sampling due to seasonal factors, weather conditions, and survey strategies; 2) multidimensionality if the objects are observed in multiple passbands; 3) numerous outliers caused by overlapping sources and photometric pipeline artifacts; and 4) poorly defined systematic uncertainties and/or underestimated stochastic uncertainties. The main challenge revealed in the era of big data research is how to extract useful information most efficiently from imperfect available data. In this respect, the application of machine learning and artificial intelligence methods is a promising solution.
Supernovae Type Ia (SNe Ia) light curves are commonly used to train machine learning models applied to SNe classification and characterization problems. SNe Ia were found to be standard candles via the relation between their peak luminosity and the luminosity decline rate (Rust 1974; Pskovskii 1977; Phillips 1993; Riess et al. 1996). This property of SNe Ia is widely used for luminosity distance measurements and consequent cosmo-logical analysis (Riess et al. 1998; Perlmutter et al. 1999; Jones et al. 2019). In the upcoming era of large photometric surveys, it becomes crucial to have a robust pipeline which finds SNe Ia among other transient and variable sources, and extracts its peak flux, decline rate, and color.
Recently, a variety of machine learning approaches for transients and variable stars classification have been presented. Participants of the Supernova Photometric Classification Challenge (Kessler et al. 2010) used many different machine-learning and classification approaches including random forests (RF) and neural networks. Richards et al. (2011) applied the RF algorithm for a variable star classification, where the light curves were represented by a set of periodic and non-periodic features. A list of different statistical parameters such as the mean, skew-ness, standard deviation, and kurtosis are presented in Ferreira Lopes & Cross (2017) and Dubath et al. (2011) for the classification with RF. Pashchenko et al. (2017) solved the problem using support vector machines (SVM), neural networks and RF classifiers with 18 input features. This paper describes the scatter and correlation between observations of light curves. Other similar approaches are presented in Ball & Brunner (2010) and Baron (2019).
The further evolution of this approach is closely related to the development of neural network models. The method proposed in Mahabal et al. (2017) includes a transformation of the light curves into 2D histograms, where each dimension corresponds to a difference between magnitudes and timestamps for each pair of observations in the light curve. The histograms are treated as images and used as inputs of a convolutional neural network (CNN) for the model training. Similar differences are used in Bassi et al. (2021) as inputs for a 1D CNN and long short-term memory (LSTM) model for the variable stars classification. Aguirre et al. (2018) take the difference between consecutive time and magnitude values in a light curve. These vectors of differences form a 1D image with two channels, which is passed to a 1D CNN model for solving the classification problem. A similar approach is described in Becker et al. (2020) and Möller & de Boissière (2020), where the matrix of the differences in time and magnitude are considered as sequences and used as inputs for a recurrent neural network (RNN) classifier. In Dobryakov et al. (2021) a linear interpolation of light curve values is used as well as the differences in magnitude for each consecutive pair of data points as inputs for various classification algorithms. An RNN autoencoder in Naul et al. (2017) learns a latent representation of the light curves. It then processes the curve observations as a sequence. The obtained representation is used as an input of a RF algorithm for object classification.
One more method is based on different approximation approaches of the light curves and uses the best-fit parameters of phenomenological functions as features for classification models. In Bazin et al. (2009), Villar et al. (2019), and Sánchez-Sáez et al. (2021) light curves are approximated using specific parameterized models. The fitted parameters of these models as well as their uncertainties are used as inputs for different classification algorithms. One of the first applications of neural networks for supernovae classification based on this approach is described in Karpenka et al. (2012). A similar model is used in Newling et al. (2011) for the classification of simulated Dark Energy Survey (DES) light curves using boosting decision trees (BDTs) and kernel density estimation (KDE) methods. Other functions for light curve approximations are demonstrated in Guy et al. (2007), Newling et al. (2011), and Taddia et al. (2015). Different parameterization methods and wavelet decomposition approaches for input feature generation are presented in Lochner et al. (2016) and tested in photometric supernova classification using a list of machine learning algorithms.
A poor approximator choice can negatively affect the classification quality and the results of the analysis. Parametric functions usually are not connected with physical processes in transients, and also have limited generalizability. Therefore, it is inefficient to use this approach for datasets of different object types since each class requires its own custom parametric function fit. However, a Gaussian process (GP) model is used in Angus et al. (2017) as an alternative for the light curve approximation in each passband. A range of parameterizations and classification approaches are considered in the Photometric LSST Astronomical Time-series Classification Challenge (PLAsTiCC; Hložek et al. 2020). The winner of the challenge demonstrates that approximation of the light curves using GP may lead to better results than other methods (Boone 2019). Currently, this approach is the state-of-the-art method for the SN light-curve pre-processing (see, e.g., Qu et al. 2021; Alves et al. 2022; Burhanudin & Maund 2022 for classification and Pruzhinskaya et al. 2019; Villar et al. 2021; Ishida et al. 2021; Muthukrishna et al. 2022 for anomaly detection) and we use it as a baseline result.
GP has also become a popular method of SN light curve characterization since it was first used for standardization of the peak SN Ia absolute magnitude (Kim et al. 2013). Müller-Bravo et al. (2022) proposed a GP instead of commonly used light-curve templates for the data-driven SN Ia fitting. Stevance & Lee (2022) use a GP-approximated light curve to get the rising time and the decline rate of SN Type II and IIb and study their morphology and genealogy. Sravan et al. (2022) proposed using 2D GP for light-curve forecasting to optimize the follow-up strategy.
In this work, we consider different neural network models such as multilayer perceptron (MLP), Bayesian neural networks (BNN), and normalizing flows (NF) as alternatives to the light curve approximation. We demonstrate that these models trained on observations of a single light curve provide a high-quality approximation. To prove it, we compare the approximation metrics of the neural network methods with the GP. In addition, we explore how the models influence the metrics of indirect physical-motivated tasks such as binary classification for various transients including SNe Ia as well as the identification of the light-curve peak. As Dobryakov et al. (2021) showed a deterioration in quality metrics when applying machine learning models to real data compared to simulated data, we test our models on both the simulated PLAsTiCC and real ZTF Bright Transient Survey (BTS) datasets.
While neural network methods could be adopted for catalog-level studies aggregating the data from different objects into a single model, we focus our research on methods for the multipassband light curve approximation of individual objects. Aggregation models potentially could improve the average quality of catalog-level light curve approximation, but they also introduce a bias for every single object. This bias may affect consequent studies, such as classification, because the behavior of the light curves of the type dominating the data could be transferred to the objects of other types. The single-object approach makes our algorithms work out-of-the-box for different domains and object classes with predictable performance. We present open-source Python 3 package Fulu1, implementing the Neural Network light-curve approximation models described in this paper.
 |
Fig. 1 Light curve of SN Ibc (ID 34299) from the PLAsTiCC dataset (a) before approximation. The points represent measurements in the corresponding passbands. (b) The light curve after approximation using the GP method. The solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band for the light curve approximation. |
2 Problem statement
We investigate the problem of approximation of irregular time series consisting of non-simultaneous observations in different photometric passbands. The main requirement for all models is considered to be the ability to find correlations among the observations both over time and across different passbands, as well as to calculate an approximation of the light curve within the time and wavelength ranges of the input data. Within this approach, a single training dataset consists of the light curve of a single object only. Thus, we prepared an independent approximation model for each object, ignoring any other objects.
We describe each point of a light curve by an observed flux value, yi, its error, ɛi, a timestamp, ti, and a photometric pass-band characterized by an effective wavelength, λi. For simplicity, we defined an input feature vector, xi = (ti, λi)T. Then, the light curve is represented by a conditional probability density distribution, p(y\x). Here, we assume that the flux y is a random variable and its values, yi, are sampled from the distribution below:
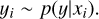 (1)
(1)
Generally, it is hard to find the distribution for a given sample, which, however, is not necessary for many practical cases. In this respect, the goal of our work is to estimate the mean flux µ(x) and the standard deviation σ(x) for the given features x of the light curve. At the next stage, we use these calculated functions for the light curve interpolation. Figure 1 shows an example of a light curve for a SN Ibc from the PLAsTiCC dataset, measured in the {u, g, r, i, z, y} passbands, before and after the approximation. The light curve approximation problem can be solved using several machine learning algorithms. We describe a set of such models in the following section.
The radiation flux in mJy units for the ZTF BTS catalog observations can be calculated from the {ɡ, r} magnitudes as follows:
![Mathematical equation: $ {\rm{Flux}}\left[ {{\rm{mJy}}} \right] = {10^{ - 0.4\left( {m - 16.4} \right)}}, $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq2.png) (2)
(2)
where m is ZTF BTS magnitude. The PLAsTiCC uses calibrated flux in units of FLUXCAL of SNANA (Kessler et al. 2009) having 27.5 AB-magnitude as zero point. Therefore, we adapted it to have flux values in the same mJy units as we used for the ZTF BTS catalog:
![Mathematical equation: $ {\rm{Flux}}\left[ {{\rm{mJy}}} \right] = {\rm{FLUXCAL}} \times {10^{ - 4.44}}. $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq3.png) (3)
(3)
The timestamps in the light curve observations are measured in Modified Julian Date (MJD) units.
3 Approximation methods
In our study, we tested various neural networks based on different ideas for the light curve approximation. The most obvious solution is to take regression models based on MLP. They learn to predict the mean flux value for the given timestamp and passband. To be precise, we use two different implementations: PyTorch (Paszke et al. 2019) and scikit-learn (Pedregosa et al. 2011). The PyTorch library uses computation graphs with an automatic differentiation which significantly simplifies building models and architectures. Scikit-learn is based on NumPy arrays with manual definitions of all derivatives. It makes this library less flexible, but faster than PyTorch, which is also demonstrated in this work.
We also explored BNN, which learn the optimal distributions of each weight of the model. Injecting weight uncertainty helps to estimate the variation in the flux predictions. In theory, BNNs are powerful predictors with peculiar properties, however, in practice it is too complicated to fit them properly. In addition, we tested normalizing flow (NF) as a representative of generative models. The NF estimates a distribution of the light curve observations. The knowledge of this distribution allows us to calculate the mean and variance of the flux. The following subsections describe the details of all models used in this work.
3.1 Regression model
A simple model that can be used for light curve approximation is a MLP for a regression task. It assumes that the flux y is normally distributed with mean µ(x\w) and constant standard deviation, σ(x) = σ , values:
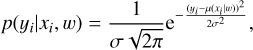 (4)
(4)
where µ(xi\w) is estimated by the neural network with weights w. The model takes {xi} as inputs and learns its weights by optimizing the log-likelihood function:
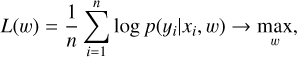 (5)
(5)
where n is the number of observations in the light curve. Let us denote the optimal weights wML = arg max L(w). According to Sect. 3.1.1 in Bishop (2006), this optimization problem is equivalent to the MSE loss minimization:
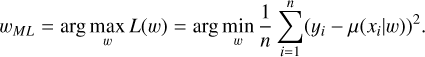 (6)
(6)
The optimal solution provides the following functions for the light curve approximation:
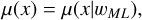 (7)
(7)
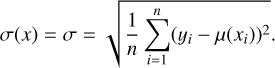 (8)
(8)
In this work, we use two MLP models implemented in two frameworks: PyTorch and scikit-learn. The PyTorch model is a one-layer neural network with 20 neurons, having tanh as the activation function, and is trained with an Adam optimizer. The scikit-learn model has two layers with 20 and ten neurons, the activation function tanh, which is trained with the optimizer LBFGS. LBFGS is a second-order optimizer, which converges to the optimum faster than first-order algorithms such as Adam. Furthermore, in the text and tables, these two models are designated based on the framework on which they are implemented: MLP (sklearn) and MLP (pytorch). The results provided in the following sections show that the scikit-learn implementation is dramatically faster than other considered approximation algorithms. An example of an SN II light curve approximation using MLP (sklearn) and MLP (pytorch) is shown in Figs. 2c,d.
3.2 Bayesian neural network
The BNN uses the same observation model described in Eq. (4) as the MLP models. In addition, in the BNN model, it is assumed that its weights w is a random variable with a distribution defined by the light curve observations, D = {x1, x2,…,xi,…, xn}. Let us define a prior distribution p(w) of the weights:
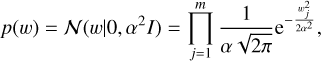 (9)
(9)
where m is the number of weights of the network and α is an adjustable parameter. Applying Bayes’ rule to Eqs. (4) and (9), we derive the posterior probability density distribution p(w\D) of the BNN model’s weights given the light curve observations:
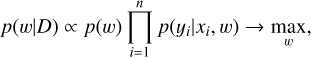 (10)
(10)
where the objective of the model is to maximize this distribution with respect to the weights. However, it is difficult to estimate the exact expression of the prior distribution. Blundell et al. (2015) suggest approximating it with a normal distribution q(w), which has a diagonal covariance matrix Σ:
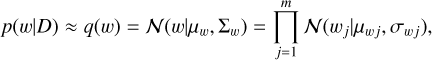 (11)
(11)
where µwj and σwj are the mean and the standard deviation for the weight wj of the BNN model. Following Blundell et al. (2015), the optimization problem in Eq. (10) is approximated by maximizing the lower variational bound:
![Mathematical equation: $ L\left( {{\mu _{wj}},{\sigma _{wj}}} \right) = \mathop {\rm{E}}\limits_{q\left( w \right)} \left[ {\sum\limits_{i = 1}^n {\log \,p\left( {{y_i}\left| {{x_i},w} \right.} \right)} } \right] - KL\left( {q\left( w \right)\left\| {p\left( w \right)} \right.} \right) \to \mathop {\max }\limits_{{\mu _{wj}},{\sigma _{wj}}} , $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq12.png) (12)
(12)
where KL(q(w)||p(w)) is the Kullback–Leibler divergence between the distributions q(w) and p(w). The mean µ(x) and the standard deviation o(x) for the light curve approximation are defined as
![Mathematical equation: $ \mu \left( x \right) = \mathop {\rm{E}}\limits_{w\~q\left( w \right)} \left[ {\mu \left( {x\left| w \right.} \right)} \right], $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq13.png) (13)
(13)
![Mathematical equation: $ \sigma \left( x \right) = \sqrt {\mathop {\rm{V}}\limits_{w\~q\left( w \right)} \left[ {\mu \left( {x\left| w \right.} \right)} \right]} . $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq14.png) (14)
(14)
As shown in Sect. 5.7.1 of Bishop (2006), the variance of the approximation can be represented as the sum of two terms:
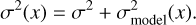 (15)
(15)
where σ2 is the variance that arises from the intrinsic noise in the flux y as shown in Eq. (4). The second term stands for the uncertainty in the BNN model due to the uncertainty of the weights.
In this work, we use the BNN model with one linear layer of 20 neurons, and weight priors in the form of standard normal distributions 𝒩 (0, 0.1). In such a model, the optimizer Adam and the activation function tanh are used. The example of a SN II light curve approximation with the use of BNN is shown in Fig. 2e.
3.3 Normalizing flows
We start by defining a latent random variable, z, with the standard normal distribution, q(z) = 𝒩(z|0,I). The goal of a normalizing flow (NF) model (Tabak & Turner 2013; Rezende & Mohamed 2015) is to find an invertible function which transforms the flux yi into the latent variable zi with the given xi:
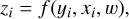 (16)
(16)
where w is the vector of learnable parameters of the function. Then, the change of variables theorem defines the following relation between the flux p(yi|xi, w) and the latent variable q(z) distributions:
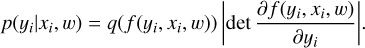 (17)
(17)
In this work, we use real-valued non-volume preserving (real NVP) NF model (Dinh et al. 2017), where the function f(yi, xi, w) is designed using neural networks with weights, w. The optimal weights, wML, are estimated by maximizing the log-likelihood function:
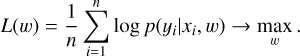 (18)
(18)
The main advantage of this model is that it can estimate any probability density function of the flux p(yi|xi, w). Then, the mean µ(x) and the standard deviation σ(x) for the light curve approximation are defined as:
![Mathematical equation: $ \mu \left( x \right) = \mathop {\rm{E}}\limits_{z\~q\left( z \right)} \left[ {{f^{ - 1}}\left( {z,x,{w_{ML}}} \right)} \right], $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq19.png) (19)
(19)
![Mathematical equation: $ \sigma \left( x \right) = \sqrt {\mathop V\limits_{Z\~q\left( z \right)} \left[ {{f^{ - 1}}\left( {z,x,{w_{ML}}} \right)} \right]} . $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq20.png) (20)
(20)
We used eight real NVP transformations, where two simple fully connected neural networks are exploited in each transformation. The model uses the Adam optimizer and the tanh activa-tion function. The example of a SN II light curve approximation using NF is shown in Fig. 2f.
 |
Fig. 2 Examples of SN II ZTF20aahbamv light curve approximations using different methods: (a) the light curve before approximation, (b) GP, (c) MLP (sklearn), (d) MLP (pytorch), (e) BNN, and (f) NF. The points represent measurements in the corresponding passbands. The solid lines are the estimated mean µ(x) values. The shaded areas represent the ±1σ(x) uncertainty band. |
3.4 Gaussian processes
Let us consider a light curve with observations {(x1,y1), (x2,y2),(xn,yn)}. The GP (Williams & Rasmussen 1995) model assumes that the joint probability density function of the observations is multivariate normal with a zero mean and the covariance matrix, K:
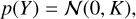 (21)
(21)
with
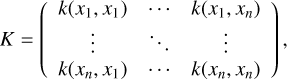 (22)
(22)
where Y = [y1, y2,…, yn]T and k(xi, xj) is a covariance function and is considered as the model hyperparameter. In this work, we use combinations of RBF, Matern, and White kernels as the covariance function. The best combination of these kernels for each dataset is estimated by the optimization procedure. In its turn, parameters of the kernels are estimated by maximizing the log-likelihood function:
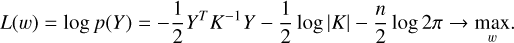 (23)
(23)
With Eq. (21), we can find the joint distribution with a new pair (x, y) as the following form:
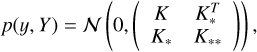 (24)
(24)
where K* = [k(x,x1),… ,k(x,xn)], and K** = k(x,x). Following Williams & Rasmussen (1995), the posterior probability density function for the prediction of y is also assumed normal:
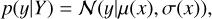 (25)
(25)
where the mean µ(x) and the standard deviation σ(x) functions are used for the light curve approximation and are defined as follows:
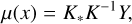 (26)
(26)
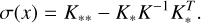 (27)
(27)
Boone (2019) demonstrates that the approximation of light curves using GP provides better results than other methods. Currently, this approach is the state-of-the-art method and we consider it to be as a baseline in this work. The example of a SN II light curve approximation using GP is shown in Fig. 2b.
3.5 Other models
In addition to the models described above, we also analyzed other regression models in machine learning such as decision trees, random forest, gradient boosting decision trees, support vector machines, and linear regression. However, the tests show poor approximation quality for all of these models. Therefore, in this paper, we do not consider them further. Moreover, we tested other generative models such as Variation Autoencoders (VAE) and Generative Adversarial Networks (GAN). However, they also show unsatisfactory approximation metrics and we do not consider them further.
4 Quality metrics
4.1 Approximation quality
We measured the quality of the proposed approximation methods using direct and indirect approaches. In the direct approach, we measured the difference between the models’ predictions and observations of the light curves. In order to achieve this, the observations were divided into train and test samples using a time-binned split. Consider a light curve as an object with n points {(x1, y1), (x2, y2),…, (xn, yn)} at timestamps of {t1, t2,…, tn}, where t1 ≤ t2 ≤ … ≤ tn. We then define the width, Δt, of a time bin and split the observations into k bins,
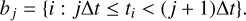 (28)
(28)
We randomly selected two nonempty bins btest, with the exclusion of the first b1 and the last bk, to be the test set and to measure the approximation quality. All observations in the other bins were used for training. We note that we did not limit the bins selection by passbands, so the test split could contain observations in a passband that was not present in the training set. To estimate the quality, we calculated the following metrics: root mean squared error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), relative squared error (RSE), and relative absolute error (RAE), defined as follows:
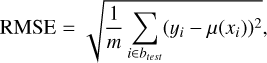 (29)
(29)
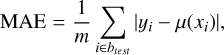 (30)
(30)
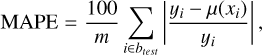 (31)
(31)
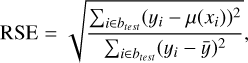 (32)
(32)
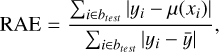 (33)
(33)
where µ(xi) is a prediction of an approximation model, m is the number of observations inside the test bins, btest, and ӯ is the average of flux measurements yi· inside the bins.
The deviation of the true curve from the predicted one can be important in the case of particular physically motivated measurements. In order to characterize the set of estimated deviations we used the following metrics to measure the quality of the flux standard deviation o(x) estimated by the models. These metrics are negative log predictive density (NLPD), normalized root mean squared error based on observed error (nRMSEo), normalized root mean squared error based on predicted error (nRMSEp; Quiñonero-Candela et al. 2006), and prediction interval coverage probability (PICP; Shrestha & Solomatine 2006), which are defined as follows:
![Mathematical equation: $ {\rm{NLPD}} = {1 \over 2}\log \left( {2\pi } \right) + {1 \over m}\sum\limits_{i \in {b_{best}}} {\left[ {\log \left( {\sigma \left( {{x_i}} \right)} \right) + {{{{\left( {{y_i} - \mu \left( {{x_i}} \right)} \right)}^2}} \over {2\sigma {{\left( {{x_i}} \right)}^2}}}} \right]} , $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq34.png) (34)
(34)
![Mathematical equation: $ {\rm{nRMSEo}} = {1 \over m}\sum\limits_{i \in {b_{best}}} {\left[ {{{{{\left( {{y_i} - \mu \left( {{x_i}} \right)} \right)}^2}} \over {2\varepsilon _i^2}}} \right]} , $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq35.png) (35)
(35)
![Mathematical equation: $ {\rm{nRMSEp}} = {1 \over m}\sum\limits_{i \in {b_{best}}} {\left[ {{{{{\left( {{y_i} - \mu \left( {{x_i}} \right)} \right)}^2}} \over {2\sigma {{\left( {{x_i}} \right)}^2}}}} \right]} , $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq36.png) (36)
(36)
![Mathematical equation: $ {\rm{PIC}}{{\rm{P}}_\alpha } = {1 \over m}\sum\limits_{i \in {b_{best}}} {I\left[ {PL_i^L \le {y_i} \le PL_i^U} \right] \times 100\% ,} $](/articles/aa/full_html/2023/09/aa45189-22/aa45189-22-eq37.png) (37)
(37)
where ɛi· is the observed flux error, 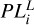 and
and 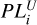 are the lower and upper prediction limits for the i-th observation, respectively. The limits are symmetric and estimated based on the normal distribution, 𝒩(µ(xi·), σ(xi·)), for a given coverage probability, α. We calculated these metrics for each light curve and then averaged them over all curves in the dataset. The values obtained are used as the final quality metrics of the approximation.
are the lower and upper prediction limits for the i-th observation, respectively. The limits are symmetric and estimated based on the normal distribution, 𝒩(µ(xi·), σ(xi·)), for a given coverage probability, α. We calculated these metrics for each light curve and then averaged them over all curves in the dataset. The values obtained are used as the final quality metrics of the approximation.
While the metrics mentioned above give us an accurate estimation of the quality of the obtained approximation, this cannot be used as an ultimate check. In order to check that these approximations do not change the physical features of the light curve, we solve two practical astrophysical problems: supernova classification and peak identification.
 |
Fig. 3 Example of 1D image I with 128 × 1 pixels and 6 channels, and corresponding light curve: (a) Light curve after approximation. The solid lines are the estimated mean µ(x) values; (b) Example of the light curve transformation into a 1D image with 128 pixels and 6 channels, which is used as input of the CNN. |
 |
Fig. 4 Architecture of the CNN model for supernovae type classification and peak identification. |
4.2 Supernova classification
In this work, we evaluated metrics of a supernova classification task to measure the light curve approximation quality indirectly. Similarly to the direct approach, we consider a light curve as an object with n points at timestamps {t1,t2, …, tn}, where t1 ≤ t2 ≤ … ≤ tn, and with c passbands {λ1,λ2, …,λc}. All these observations were used to fit an approximation model to estimate the µ(x) and σ(x) functions. Then, we generated k = 128 new regular timestamps {τ1,τ2, …,τk} between t1 and t2 with the step Δτ = (tn – t1)/k. Using the approximation function µ(x), we created the following matrix of size (128, c):
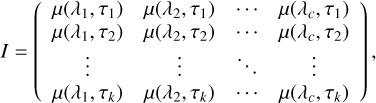 (38)
(38)
where the notation x = (λ, t) is used. We consider this matrix I as a one-dimensional image with k × 1 pixels and c channels. An example of such an image is demonstrated in Fig. 3.
We used these images as inputs to a CNN classifier, which is trained to separate Type Ia SNe from all other types of objects. The network contains three ID convolutional layers with a ReLU activation function, a max pooling layer, and a dropout layer followed by a fully connected layer, as shown in Fig. 4. The classifier returns the probability that the input image corresponds to a Type Ia SN. This model is fitted using a binary cross-entropy loss function.
Light curves in the dataset were divided into train and test samples. The first one was used to train the CNN model, while the second one was used to calculate the following classification quality metrics: area under the ROC curve (ROC AUC), area under the precision-recall curve (PR AUC), Accuracy, Recall, and Precision (James et al. 2013). We used these metrics of physically motivated classification problem as an indirect approach for estimation of the light curve approximation quality.
4.3 Peak identification
Peak identification is an additional indirect approach to the approximation quality of measurements. We used two methods to estimate the peak time stamp. In the first method, we took the light curve image defined in Eq. (38), Fig. 3 and calculated the sum of fluxes for all passbands. Then, the peak position, τpeak, was estimated as the timestamp with maximum total flux value with equation:
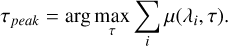 (39)
(39)
In the second method, we used a CNN regression model. It takes the light curve matrices, I, as inputs and predicts the peak position. Following the terminology used for convolution neural networks, these matrices are considered as ID images with k × 1 pixels, representing flux for each time stamp and c channels, representing passbands. The network has the same architecture as for the classification. The model is fitted using the MSE loss function.
The light curves in a dataset were divided into train and test samples. The first one is used to train the CNN model, while the second one was used to calculate the regression quality metrics such as RMSE, MAE, RSE, RAE, and MAPE for both of the estimation methods. We use them for indirect measurements of the light curve approximation quality.
Regression quality metrics for approximation models applied to the PLAsTiCC.
Regression quality metrics for approximation models applied to the PLAsTiCC.
5 PLAsTiCC dataset
5.1 Approximation quality
First, we applied the approximation methods to the PLAsTiCC dataset (The PLAsTiCC Team 2018). This dataset is produced as a simulation of the upcoming observations from the Vera C. Rubin Observatory. It contains 199434 simulated light curves of transient astronomical events of different classes. The light curves represent measurements of an object’s flux in six different passbands {u, ɡ, r, i, z, y}, covering ultra-violet, optical, and infrared wavelength ranges.
For our tests, we selected 10764 light curves based on the following criteria. Firstly, we kept only objects with positive fluxes. Also, we checked the number of observations in each filter and kept only the light curves having at least seven observations per passband in at least three different passbands. Finally, we took into consideration points from all passbands and selected only the light curves with time gaps between neighboring observations in any filter smaller than 50 days. Examples of light curves, which are the closest to the limit of our selection criteria, before and after approximation are shown in Figs. A.1–A.3. After that, points of each selected light curve were split into train and test sets to fit analyzed models and measure the quality of all the approximation methods, as described in Sect. 4.1. The optimal hyperparameter values of the methods were estimated using a grid search with the MAPE objective function. The obtained quality metrics values are presented in Table 1 for approximated fluxes and Table 2 for predicted errors for the fluxes.
The results in Table 1 demonstrate that MLP (sklearn) model outperforms GP by MAE and MAPE metrics and has the same quality evaluated by RMSE. Overall, NF is better by RSE and RAE metrics. This fact proves that neural networks are effective even if trained on a small dataset from one light curve and can be used for single light curve approximation in astronomy. In particular, neural network approximation models are helpful when a researcher does not have prior information or a full physical model of a studied object. Neural networks have a stronger generalizing ability compared to GP, wherein we would need to choose a covariance matrix manually.
The results presented in Table 2 illustrate the ability of the methods to estimate the uncertainty of the flux measurements. GP shows better quality metrics than other methods for all metrics except nRMSEo. Neural networks tend to underestimate uncertainties. NF demonstrates the best results in uncertainty estimation among neural network models.
The PLAsTiCC dataset includes light curves with no observations in one or several passbands. All approximation methods we use in this study are able to predict the flux in these missing filters. The models learn the flux dependency on both time and passband central wavelength. Similarly to approximation over time, the models interpolate and extrapolate the learned dependencies for missing passbands. To demonstrate this, we took a PLAsTiCC SN Ibc (ID 34299) light curve and removed all observations in the r and y passbands. Examples of light curve approximations using different methods are shown in Fig. A.4. All presented methods interpolate the flux values for {r} and extrapolate them for the {y} band. The quality depends on the number of observations in each filter. A minimal theoretical requirement for the interpolation and extrapolation through passbands is the presence of observations in at least two passbands.
5.2 Supernova classification
We also tested the approximation methods in application to the supernova classification problem. To accomplish that, we took the same light curves as described in the previous section and divided them in two classes. To be more precise, objects with {90, 67, 52} class labels in the PLAsTiCC which are SN Ia, SN Ia-91 bg, and SN Iax supernova types respectively, were considered as the positive class. All other objects were labeled as a negative class.
As a next step, we used the approximation methods for light curve augmentation and transformed the light curves into 1D images with 6 channels as it is described in Sect. 4.2. Here we used the same optimal hyperparameter values estimated in the previous section. The images were used as an input for the CNN classifier model. About 60% of the light curves were used to train the CNN and the other 40% were used to estimate the classification quality. The metric values are demonstrated in Table 3.
The results show that GP model is the best approximation method if we compare all the quality metrics. However, the NF model can be ranked second with differences from the GP model within the margin of the error. In general, all methods demonstrate similar results. In conclusion, it should be stated that the choice of the approximation method does not have a significant impact on the supernova classification results.
Supernova classification quality metrics for approximation models applied to the PLAsTiCC.
Peak identification quality metrics for approximation models applied to the PLAsTiCC.
Peak identification quality metrics for approximation models applied to the PLAsTiCC.
5.3 Peak identification
For the peak identification test, we considered only Type Ia SNe. Similar to the classification task, we used approximation methods to convert light curves into 1D images. After that, we use them to estimate the time of peak applying two approaches described in Sect. 4.3: direct and CNN-based. About 60% of the light curves were used to train the CNN, while the other 40% are used to estimate the peak identification quality. The quality metric values are demonstrated in Table 4 for direct method and Table 5 for CNN-based method.
Table 4 shows that the direct approach to the peak identification demonstrates better results when it is applied to the light curves approximated with GP model, compared to the neural network-based methods. Table 5 illustrates that CNN helps reduce the error of the peak prediction by more than half, depending on the approximation methods. In this case, the best results were achieved with the MLP method (sklearn) and the GP model ranked second.
6 ZTF BTS observations
6.1 Approximation quality
The ZTF scans the entire visible northern sky with a cadence of three days. The ZTF Bright Transient Survey (BTS; Fremling et al. 2020) is a major spectroscopic project that complements the ZTF photometric survey. The objective of the BTS is to spec-troscopically classify extra-galactic transients with a mpeak ≤ 18.5 mag in ZTF {ɡ, r, i} passbands, and to publicly announce these classifications. Transients discovered by the BTS are predominantly supernovae. It is the largest flux-limited SN survey to date.
The ANTARES data broker (Matheson et al. 2021) was used to download the light curves of the ZTF Bright Transient Survey catalog. With the help of this broker, light curves were downloaded from the ZTF release date by the names of the objects from the Bright Transient Survey. To test the models, all 3374 light curves of the objects presented in the ZTF BTS at the time of 23:29 09/22/2021 were downloaded.
For the approximation method tests, we kept only objects with at least ten observations per each {ɡ} and {r} passbands. We did not consider measurements in the {i} passband, because it contains very few observations and not for all objects. An example of the light curve, which is the closest to our limitation (ten observations in each passband), is demonstrated in Fig. A.5. The total number of selected light curves is 1870. Then, points of each light curve were split into training and testing datasets to fit and measure the quality of all approximation methods, as described in Sect. 4.1. The optimal hyperparameters of the methods were estimated using a grid search with the MAPE as the objective function. The gained quality metric values are demonstrated in Table 6 for approximated fluxes and Table 7 for predicted errors of fluxes.
The results in Table 6 show that the MLP (sklearn) model outperforms the GP model by the RAE and MAPE metrics, and has the same values for the RMSE, MAE, and RSE. It demonstrates that neural networks demonstrate excellent performance on real time series and definitely can be used for approximation of the light curves from the ZTF BTS. The reasons for a higher performance of neural network models on real data in comparison with the PLAsTiCC can be the following: (i) the ZTF BTS light curves have a smaller mean cadence. This circumstance is visualized on the cadence histogram Fig. 5c; (ii) the ZTF BTS sample includes only bright object light curves with a more prominent amplitude of possible features; (iii) the ZTF BTS light curves have a larger number of observations compared to the PLAsTiCC sample in keeping with Fig. 5a illustrating probability density distributions; (iv) We did not take poor ZTF_i passband into account. The PLAsTiCC has six passbands, including passbands with a small number of observations, in contrast to using two passbands (ZTF_r, ZTF_g) out of three released in the ZTF BTS sample.
As in the case of the simulations, we quantified the ability of the methods to estimate the uncertainties of the flux measurements as presented in Table 7. It shows that NF model shows better quality metrics than other methods for all metrics except for nRMSEo and PICP68. The GP demonstrates similar results. In general, neural networks tend to underestimate the uncertainties on the ZTF BTS as well as on the PLAsTiCC.
We conducted an additional experiment to measure the dependency of the approximation quality on the number of observations in a light curve. We split each individual light curve in our PLAsTiCC and ZTF BTS datasets into training and testing samples. The testing sample contains points from two time bins with a width of five days. We used them to calculate the MAPE metric values. From the training sample, we randomly selected N observations from each light curve for the approximation fitting. If there were fewer than N points in the curve, it was discarded. We estimated the MAPE mean value and its uncertainty using the bootstrap technique over the selected light curves. This procedure was repeated for N ranging from six to 60 observations for the PLAsTiCC and from six to 100 observations for the ZTF BTS with a step of two. The results are demonstrated in Fig. 6. As expected, the plots show that the approximation error significantly drops with the increase in the number of observations. The metric values flatten after the number of observations in the training sample reaches the point of 50. MLP method shows a better approximation quality than GP in all ranges of N. We conclude that neural networks reach appropriate results – even when they are trained on a light curve with a very small number of observations.
Regression quality metrics for approximation models applied to the ZTF BTS.
Regression quality metrics for approximation models applied to the ZTF BTS.
 |
Fig. 5 Probability densities of (a) observations number (b) difference between maximum and minimum time points (c) cadence of the light curves. Selected subsamples of the PLAsTiCC and the ZTF BTS used for our experiments correspond to the blue and orange colors. |
 |
Fig. 6 Dependence of MAPE approximation quality metric on the number of observations in (a) PLAsTiCC and (b) ZTF BTS light curves for GP and MLP (sklearn) methods. The horizontal axis shows how many observations were used to fit each method. The number of light curves in our samples drops with increasing the number of observations. Error bars show the uncertainty of MAPE measurements. |
 |
Fig. 7 Examples of peak direct estimation using MLP (sklearn) approximations for a range of the ZTF BTS objects: (a) ZTF18aatgdph; (b) ZTF18aaykjei; (c) ZTF18abcfdzu; (d) ZTF18acbwaxk; (e) ZTF18acnnevs; (f) ZTF18aawgrxz. The points represent measurements in the corresponding passbands. The solid lines are the estimated mean µ(x) values. The shaded areas represent ±1σ(x) uncertainty band. |
Supernovae classification quality metrics for approximated ZTF BTS light curves.
Estimated peaks for the ZTF BTS objects.
6.2 Supernova classification
We additionally performed a test of the various approximation methods on the supernova classification problem. For that, we took the same light curves described in the previous section and divided them into two classes. Objects of SN Ia, SN Ia-91T, SN Ia-pec, SN Ia-91bg, SN Iax, and SN Ia-CSM supernova types were labeled as the positive class. All other types: SN II, SN IIn, SN Ic, SN Ib, SN IIb, SN Ib-pec, SN Ic-BL, TDE, SN Ib/c, SLSN-I, SN IIP, LBV, SN II-pec, SLSN-II, nova, SN Ibn, ILRT, and others (unclassified in the ZTF BTS), were considered as a negative class.
We used the approximation methods for the light curve augmentation and transformed them into 1D images with 2 channels as it is described in Sect. 4.2. Here we used the same optimal hyperparameters as estimated in the previous section. The images were used as input for the CNN classifier model training. About 60% of the light curves were used to train the CNN, while the other 40% were used to estimate the classification quality. The metric values are demonstrated in Table 8. The results show that all methods produce similar results. We conclude that choosing a specific approximation method does not have a significant impact on supernova classification results.
6.3 Peak identification
Similarly to the classification task, we approximated light curves into a regular high-cadence time grid. Then, we used them to estimate the time of peaks using the direct approach described in Sect. 4.3. Examples of ZTF BTS light curves with estimated peaks are shown in Fig. 7. Table 9 shows the peak positions and magnitudes of the ZTF BTS objects.
7 Conclusions
This work shows the results of the light curve approximation over time and wavelength using neural networks on the PLAsTiCC and the ZTF BTS datasets. The outcomes have led us to draw the following conclusions:
Neural networks trained on a single multipassband light curve are a reasonable alternative to other approximation methods (including Gaussian processes). This approach is suitable for both single-object and catalog-level studies.
Neural networks require O(N) operations for the approximation fitting, compared to O(N3) for the GP method, where N is the number of observations in a light curve. The real computational time significantly depends on specific implementations of the methods. In this respect, we recommend using LBFGS optimizer for any approximation model.
Approximation models can be used to generate additional observations for the light curves. These synthetic observations help to estimate various physical properties of astronomical objects, such as the peak time and the supernova type.
The supernova type identification and peak identification using CNNs do not show any dependence on the approximation methods. Neural networks and GP demonstrate similar qualities.
Fulu Python library for the light-curve approximation which implements neural network methods for light curves having as small as ~10 observations. The quality of individual approximations can be judged using built-in metrics or further physics-based analysis.
The evolution of light-curve approximations has significantly progressed with advancements in mathematical and software tools: from manually drawing curves through data to interpolating with polynomials and splines, through approximating observations with uncertainties using smoothing splines, and up to fitting the data with Gaussian processes. This work presented a suite of innovative methods for light-curve approximation, utilizing the power of neural networks. These methods have been made into the publicly available Python package, Fulu, which provides a user-friendly interface for precise approximation. The methodologies described in this work could find applications in data reduction, machine learning, or detailed analysis of specific astronomical objects, particularly within the field of time-domain astronomy.
Acknowledgements
K.M.’s work on the data preparation is supported by the RFBR and CNRS according to the research project no. 21-52-15024. D.D., M.H., and M.D. are supported by the HSE Basic Research Fund in the design, construction, and testing of the data augmentation techniques. We express our appreciation to Matvey Volkov, who developed a website for visualizing the results of this paper. We appreciate Dr. Jacob Isbell and Dr. Anton Afanasyev for their contribution to the discussion and editing of the paper and an anonymous referee for valuable comments and suggestions. Facilities: This research was supported in part through computational resources of HPC facilities at HSE University (Kostenetskiy et al. 2021). Data availability: Python library is available in the GitHub repository Fulu (https://github.com/HSE-LAMBDA/fulu). Scripts of all our experiments in this work are provided in the GitHub repository (https://github.com/HSE-LAMBDA/light_curve_approx) as well. It also contains five CSV tables with the results of peak identification experiments for the ZTF BTS for different approximation models. The website with interactive plots for approximation experiments on the ZTF BTS (http://lc-dev.voxastro.org/) can help to understand which model is more useful for each object in this catalog.
Appendix A Light curve examples
 |
Fig. A.1 Examples of PLAsTiCC light curve (ID 4551) approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
 |
Fig. A.2 Examples of PLAsTiCC light curve (ID 31087708) approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
 |
Fig. A.3 Examples of PLAsTiCC light curve (ID 68731) approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
 |
Fig. A.4 Examples of PLAsTiCC SN Ibc (ID 34299) light curve approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. Measurements in the r and y passbands are removed. The methods interpolate and extrapolate the predictions in these passbands, respectively. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
 |
Fig. A.5 Examples of SN Ia ZTF21abvrfsr light curve approximations using different methods: (a) light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. The solid lines are the estimated mean µ(x) values. The shaded areas represent the ±1σ(x) uncertainty band. |
References
- Aguirre, C., Pichara, K., & Becker, I. 2018, MNRAS, 482, 5078 [Google Scholar]
- Alves, C. S., Peiris, H. V., Lochner, M., et al. 2022, ApJS, 258, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Angus, R., Morton, T., Aigrain, S., Foreman-Mackey, D., & Rajpaul, V. 2017, MNRAS, 474, 2094 [Google Scholar]
- Ball, N. M., & Brunner, R. J. 2010, Int. J. Mod. Phys. D, 19, 1049 [Google Scholar]
- Baron, D. 2019, ArXiv e-prints [arXiv:1904.07248] [Google Scholar]
- Bassi, S., Sharma, K., & Gomekar, A. 2021, Front. Astron. Space Sci., 8, 168 [NASA ADS] [CrossRef] [Google Scholar]
- Bazin, G., Palanque-Delabrouille, N., Rich, J., et al. 2009, A&A, 499, 653 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Becker, I., Pichara, K., Catelan, M., et al. 2020, MNRAS, 493, 2981 [NASA ADS] [CrossRef] [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Barlow, T., et al. 2019, PASP, 131, 068003 [Google Scholar]
- Bishop, C. M. 2006, Pattern Recognition and Machine Learning (Information Science and Statistics) (Berlin, Heidelberg: Springer-Verlag) [Google Scholar]
- Blundell, C., Cornebise, J., Kavukcuoglu, K., & Wierstra, D. 2015, in Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), 37 [Google Scholar]
- Boone, K. 2019, AJ, 158, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Burhanudin, U. F., & Maund, J. R. 2022, MNRAS, 521, 1601 [Google Scholar]
- Dinh, L., Sohl-Dickstein, J., & Bengio, S. 2017, in International Conference on Learning Representations [Google Scholar]
- Dobryakov, S., Malanchev, K., Derkach, D., & Hushchyn, M. 2021, Astron. Comput., 35, 100451 [NASA ADS] [CrossRef] [Google Scholar]
- Drake, A. J., Djorgovski, S. G., Mahabal, A., et al. 2009, ApJ, 696, 870 [Google Scholar]
- Dubath, P., Rimoldini, L., Süveges, M., et al. 2011, MNRAS, 414, 2602 [Google Scholar]
- Ferreira Lopes, C. E., & Cross, N. J. G. 2017, A&A, 604, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Förster, F., Cabrera-Vives, G., Castillo-Navarrete, E., et al. 2021, AJ, 161, 242 [CrossRef] [Google Scholar]
- Fremling, U. C., Miller, A. A., Sharma, Y., et al. 2020, ApJ, 895, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Guy, J., Astier, P., Baumont, S., et al. 2007, A&A, 466, 11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hložek, R., Ponder, K. A., Malz, A. I., et al. 2020, ArXiv e-prints [arXiv:2012.12392] [Google Scholar]
- Ishida, E. E. O., Kornilov, M. V., Malanchev, K. L., et al. 2021, A&A, 650, A195 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- James, G., Witten, D., Hastie, T., & Tibshirani, R. 2013, An Introduction to Statistical Learning: with Applications in R (Springer) [Google Scholar]
- Jones, D. O., Scolnic, D. M., Foley, R. J., et al. 2019, ApJ, 881, 19 [Google Scholar]
- Jones, D. O., Foley, R. J., Narayan, G., et al. 2021, ApJ, 908, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Karpenka, N. V., Feroz, F., & Hobson, M. P. 2012, MNRAS, 429, 1278 [Google Scholar]
- Kessler, R., Bernstein, J. P., Cinabro, D., et al. 2009, PASP, 121, 1028 [Google Scholar]
- Kessler, R., Bassett, B., Belov, P., et al. 2010, PASP, 122, 1415 [CrossRef] [Google Scholar]
- Kim, A. G., Thomas, R. C., Aldering, G., et al. 2013, ApJ, 766, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Kostenetskiy, P. S., Chulkevich, R. A., & Kozyrev, V. I. 2021, J. Phys. Conf. Ser., 1740, 012050 [NASA ADS] [CrossRef] [Google Scholar]
- Lipunov, V., Kornilov, V., Gorbovskoy, E., et al. 2010, Adv. Astron., 2010, 349171 [Google Scholar]
- Lochner, M., McEwen, J. D., Peiris, H. V., Lahav, O., & Winter, M. K. 2016, Astrophys. J. Suppl. Ser., 225, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Mahabal, A., Sheth, K., Gieseke, F., et al. 2017, in 2017 IEEE Symp. Ser. Comput. Intell. (SSCI), 1-8 [Google Scholar]
- Matheson, T., Stubens, C., Wolf, N., et al. 2021, AJ, 161, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Möller, A., & de Boissière, T. 2020, MNRAS, 491, 4277 [CrossRef] [Google Scholar]
- Möller, A., Peloton, J., Ishida, E. E. O., et al. 2021, MNRAS, 501, 3272 [CrossRef] [Google Scholar]
- Müller-Bravo, T. E., Sullivan, M., Smith, M., et al. 2022, MNRAS, 512, 3266 [CrossRef] [Google Scholar]
- Muthukrishna, D., Mandel, K. S., Lochner, M., Webb, S., & Narayan, G. 2022, MNRAS, 517, 393 [NASA ADS] [CrossRef] [Google Scholar]
- Naul, B., Bloom, J. S., Pérez, F., & van der Walt, S. 2017, Nat. Astron., 2, 151 [NASA ADS] [CrossRef] [Google Scholar]
- Newling, J., Varughese, M., Bassett, B., et al. 2011, MNRAS, 414, 1987 [NASA ADS] [CrossRef] [Google Scholar]
- Pashchenko, I. N., Sokolovsky, K. V., & Gavras, P. 2017, MNRAS, 475, 2326 [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Informa- tion Processing Systems 32, eds. H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, & R. Garnett (Curran Associates, Inc.), 8024 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565 [Google Scholar]
- Phillips, M. M. 1993, ApJ, 413, L105 [Google Scholar]
- Pojmanski, G. 1997, Acta Astron., 47, 467 [Google Scholar]
- Pruzhinskaya, M. V., Malanchev, K. L., Kornilov, M. V., et al. 2019, MNRAS, 489, 3591 [Google Scholar]
- Pskovskii, I. P. 1977, Soviet Ast., 21, 675 [Google Scholar]
- Qu, H., Sako, M., Möller, A., & Doux, C. 2021, AJ, 162, 67 [NASA ADS] [CrossRef] [Google Scholar]
- Quiñonero-Candela, J., Rasmussen, C., Sinz, F., Bousquet, O., & Schölkopf, B. 2006, in Machine Learning Challenges. Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Tectual Entailment (Springer), 3944, 1 [CrossRef] [Google Scholar]
- Rezende, D., & Mohamed, S. 2015, in Proceedings of the 32nd International Conference on Machine Learning, eds. F. Bach, & D. Blei (Lille, France: PMLR), 37, 1530 [Google Scholar]
- Richards, J. W., Starr, D. L., Butler, N. R., et al. 2011, ApJ, 733, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Press, W. H., & Kirshner, R. P. 1996, ApJ, 473, 88 [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [Google Scholar]
- Rust, B. W. 1974, Ph.D. Thesis, Oak Ridge National Laboratory, Tennessee, USA [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Shrestha, D. L., & Solomatine, D. P. 2006, Neural Networks, 19, 225 [CrossRef] [Google Scholar]
- Sravan, N., Graham, M. J., Fremling, C., & Coughlin, M. W. 2022, in Big-Data-Analytics in Astronomy, Science, and Engineering, eds. S. Sachdeva, Y. Watanobe, & S. Bhalla (Cham: Springer International Publishing), 59 [CrossRef] [Google Scholar]
- Stevance, H. F., & Lee, A. 2022, MNRAS, 518, 5741 [CrossRef] [Google Scholar]
- Tabak, E. G., & Turner, C. V. 2013, Commun. Pure Appl. Math., 66, 145 [CrossRef] [Google Scholar]
- Taddia, F., Sollerman, J., Leloudas, G., et al. 2015, A&A, 574, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- The PLAsTiCC Team (Allam, T., et al.) 2018, ArXiv e-prints [arXiv: 1810.00001] [Google Scholar]
- Tonry, J. L., Denneau, L., Heinze, A. N., et al. 2018, PASP, 130, 064505 [Google Scholar]
- Villar, V. A., Berger, E., Miller, G., et al. 2019, ApJ, 884, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Villar, V. A., Cranmer, M., Berger, E., et al. 2021, ApJS, 255, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Williams, C., & Rasmussen, C. 1995, in Advances in Neural Information Processing Systems 8 (NIPS 1995), eds. D. Touretzky, M.C. Mozer, & M. Hasselm (MIT Press) [Google Scholar]
All Tables
Supernova classification quality metrics for approximation models applied to the PLAsTiCC.
Peak identification quality metrics for approximation models applied to the PLAsTiCC.
Peak identification quality metrics for approximation models applied to the PLAsTiCC.
All Figures
|
Fig. 1 Light curve of SN Ibc (ID 34299) from the PLAsTiCC dataset (a) before approximation. The points represent measurements in the corresponding passbands. (b) The light curve after approximation using the GP method. The solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band for the light curve approximation. |
| In the text | |
|
Fig. 2 Examples of SN II ZTF20aahbamv light curve approximations using different methods: (a) the light curve before approximation, (b) GP, (c) MLP (sklearn), (d) MLP (pytorch), (e) BNN, and (f) NF. The points represent measurements in the corresponding passbands. The solid lines are the estimated mean µ(x) values. The shaded areas represent the ±1σ(x) uncertainty band. |
| In the text | |
|
Fig. 3 Example of 1D image I with 128 × 1 pixels and 6 channels, and corresponding light curve: (a) Light curve after approximation. The solid lines are the estimated mean µ(x) values; (b) Example of the light curve transformation into a 1D image with 128 pixels and 6 channels, which is used as input of the CNN. |
| In the text | |
|
Fig. 4 Architecture of the CNN model for supernovae type classification and peak identification. |
| In the text | |
|
Fig. 5 Probability densities of (a) observations number (b) difference between maximum and minimum time points (c) cadence of the light curves. Selected subsamples of the PLAsTiCC and the ZTF BTS used for our experiments correspond to the blue and orange colors. |
| In the text | |
|
Fig. 6 Dependence of MAPE approximation quality metric on the number of observations in (a) PLAsTiCC and (b) ZTF BTS light curves for GP and MLP (sklearn) methods. The horizontal axis shows how many observations were used to fit each method. The number of light curves in our samples drops with increasing the number of observations. Error bars show the uncertainty of MAPE measurements. |
| In the text | |
|
Fig. 7 Examples of peak direct estimation using MLP (sklearn) approximations for a range of the ZTF BTS objects: (a) ZTF18aatgdph; (b) ZTF18aaykjei; (c) ZTF18abcfdzu; (d) ZTF18acbwaxk; (e) ZTF18acnnevs; (f) ZTF18aawgrxz. The points represent measurements in the corresponding passbands. The solid lines are the estimated mean µ(x) values. The shaded areas represent ±1σ(x) uncertainty band. |
| In the text | |
|
Fig. A.1 Examples of PLAsTiCC light curve (ID 4551) approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
| In the text | |
|
Fig. A.2 Examples of PLAsTiCC light curve (ID 31087708) approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
| In the text | |
|
Fig. A.3 Examples of PLAsTiCC light curve (ID 68731) approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
| In the text | |
|
Fig. A.4 Examples of PLAsTiCC SN Ibc (ID 34299) light curve approximations using different methods: (a) the light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. Measurements in the r and y passbands are removed. The methods interpolate and extrapolate the predictions in these passbands, respectively. The points represent measurements in the corresponding passbands. Solid lines are the estimated mean µ(x) values. The shaded areas represent the ±3σ(x) uncertainty band. |
| In the text | |
|
Fig. A.5 Examples of SN Ia ZTF21abvrfsr light curve approximations using different methods: (a) light curve before approximation; (b) GP; (c) MLP (sklearn); (d) MLP (pytorch); (e) BNN; and (f) NF. The points represent measurements in the corresponding passbands. The solid lines are the estimated mean µ(x) values. The shaded areas represent the ±1σ(x) uncertainty band. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.