| Issue |
A&A
Volume 656, December 2021
|
|
|---|---|---|
| Article Number | A153 | |
| Number of page(s) | 12 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202142062 | |
| Published online | 16 December 2021 | |
Statistical strong lensing
II. Cosmology and galaxy structure with time-delay lenses
Leiden Observatory, Leiden University, Niels Bohrweg 2, 2333 CA Leiden, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
22
August
2021
Accepted:
1
October
2021
Abstract
Context. Time-delay lensing is a powerful tool for measuring the Hubble constant H0. However, in order to obtain an accurate estimate of H0 from a sample of time-delay lenses, very good knowledge of the mass structure of the lens galaxies is needed. Strong lensing data on their own are not sufficient to break the degeneracy between H0 and the lens model parameters on a single object basis.
Aims. The goal of this study is to determine whether it is possible to break the H0-lens structure degeneracy with the statistical combination of a large sample of time-delay lenses, relying purely on strong lensing data with no stellar kinematics information.
Methods. I simulated a set of 100 lenses with doubly imaged quasars and related time-delay measurements. I fitted these data with a Bayesian hierarchical method and a flexible model for the lens population, emulating the lens modelling step.
Results. The sample of 100 lenses on its own provides a measurement of H0 with 3% precision, but with a −4% bias. However, the addition of prior information on the lens structural parameters from a large sample of lenses with no time delays, such as that considered in Paper I, allows for a 1% level inference. Moreover, the 100 lenses allow for a 0.03 dex calibration of galaxy stellar masses, regardless of the level of prior knowledge of the Hubble constant.
Conclusions. Breaking the H0-lens model degeneracy with lensing data alone is possible, but 1% measurements of H0 require either many more than 100 time-delay lenses or knowledge of the structural parameter distribution of the lens population from a separate sample of lenses.
Key words: cosmological parameters / gravitational lensing: strong / galaxies: fundamental parameters
© ESO 2021
1. Introduction
Gravitational lensing time delays, the difference in light travel time between two or more strongly lensed images of the same source, are powerful probes of cosmology (Treu & Marshall 2016). For a single strong gravitational lens, the time delay between the multiple images of the background source depends on the lens mass distribution and on the geometry of the lens–source system, which in turn depends on the structure and expansion history of the Universe. In particular, in a Universe described by a Friedman-Lemaître-Robertson-Walker metric, time delays scale with the inverse of the Hubble constant H0 (Refsdal 1964). The typical time delays of galaxy-scale strong lenses are on the order of weeks (see e.g., Millon et al. 2020), and can be measured if the flux from the background source varies in time. However, knowledge of the mass distribution of the lens is required in order to convert a time-delay measurement into an estimate on H0.
Some lens properties, such as the total projected mass enclosed within the multiple images, can be inferred very accurately by modelling the strongly lensed images. However, there is a fundamental limit to how much information can be extracted from strong lensing data alone, which is set by the mass-sheet degeneracy (Falco et al. 1985): given a model that reproduces the image positions and magnification ratios of a strongly lensed source, it is always possible to define a family of alternative models that leave those observables unchanged and predict different time delays.
There are a few ways to break the degeneracy between the lens mass profile and H0. One possibility is to assert a lens model that artificially breaks the mass-sheet degeneracy, such as, for example, a model with a density profile described by a single power law. The parameters of a power-law lens model can be unambiguously constrained with lensing data alone, provided that the images of the background source can be well resolved (see e.g., Suyu 2012). By modelling a time-delay lens with a power-law lens model, it is possible to estimate H0 directly given the observed time delays. However, if the true density profile of the lens is different from a power law, that estimate will be biased (see e.g., Schneider & Sluse 2013).
Another possibility is to use stellar kinematics data to further constrain the mass model of the lens. This is the approach used in the latest analysis of the TDCOSMO collaboration1 by Birrer et al. (2020). In their study of seven time-delay lenses, Birrer et al. (2020) combined lensing data with stellar kinematics observations consisting for the most part of measurements of the central velocity dispersion of the lens galaxy, and obtained a measurement of H0 with 8% precision. The addition of prior information from similar measurements on gravitational lenses with no time delays allowed these latter authors to reduce the uncertainty to 5%, and the precision can be further improved by replacing central velocity dispersion measurements with spatially resolved kinematics data (Yıldırım et al. 2020; Birrer & Treu 2021).
Nevertheless, in order to incorporate stellar kinematics constraints into a time-delay lensing study, it is necessary to model a variety of additional aspects of the lens system: most critically, the full 3D mass distribution of the lens galaxy and the phase-space distribution of the kinematical tracers (i.e., the stars that contribute to the observed spectrum). This can be very challenging, especially if percent precision on the measurement of H0 is required.
In this paper, I explore an alternative method for breaking the degeneracy between the lens mass profile and H0 based on the statistical combination of a large number of time-delay lenses. Building on the work of Sonnenfeld & Cautun (2021, hereafter Paper I), I use a Bayesian hierarchical inference approach to simultaneously fit strong lensing data from a large sample of lenses including time-delay observations. As in Paper I, the challenge is to find a model that is sufficiently flexible to allow for an accurate inference of the key parameters, most importantly H0, while not be so flexible that it can no longer be constrained without the need for stellar kinematics data.
While there are currently only a few lenses with the necessary data to carry out a time-delay analysis, the number of known strongly lensed quasars that could be followed-up and used for this purpose is already greater than 2002, and is expected to grow steadily thanks to new surveys like Euclid3 and the Large Synoptic Survey Telescope (LSST4). Most importantly, the LSST will enable the measurement of hundreds of time delays (Liao et al. 2015) in virtue of its observations over hundreds of epochs with a cadence of a few days. This paper lays out a strategy for the optimal use of these data.
Here I test this approach on simulated data for a set of 100 time-delay lenses. As in Paper I, I emulate the lens-modelling process: instead of simulating and modelling lens images in full detail – a lengthy process in terms of both human and computational time–, I compress the information that can be obtained via modelling with a handful of summary observables. With this choice it is possible to focus on the statistical aspect of the problem, leaving aside the technical challenges associated with lens modelling. The recent work of Park et al. (2021) on Bayesian neural networks offers a viable solution to such challenges.
Here, I address three questions: the extent to which we can constrain H0 with strong lensing information from a sample of 100 time-delay lenses on its own; how the inference improves with the addition of prior information from a larger set of strong lenses with no time-delay measurements, such as the sample considered in Paper I; and finally, what can be learned about the structure of massive galaxies by combining external information – the value of H0 known from a different experiment – with a sample of 100 time-delay lenses.
The structure of this paper is as follows. In Sect. 2 I explain the basics of lensing time delays. In Sect. 3 I present the simulations. In Sect. 4 I describe the model that I fit to the simulated data. In Sect. 5 I show the results of the experiment. I discuss the findings and draw conclusions in Sect. 6.
A flat Lambda cold dark matter cosmology with matter energy density ΩM = 0.3 and cosmological constant ΩΛ = 0.7 is assumed throughout the paper. With this choice, I reduce the degrees of freedom in the cosmological model to the value of the Hubble constant alone. For the creation of the simulated data, I assume H0 = 70 km s−1 Mpc−1. The Python code used for the simulation and analysis of the lens sample can be found in a dedicated section of a GitHub repository5.
2. Lensing time delays
2.1. Basic formalism
In this section, I present the theoretical foundation for the simulation and modelling of time-delay data. For an introduction to the strong lensing formalism, including an overview of the image configurations produced by axisymmetric lenses, I refer to Sect. 2 of Paper I.
Let us consider a point source at angular position β, gravitationally lensed by a single lens plane with lensing potential ψ(θ). If θ1 is the position of one of the images associated to the source, then the difference in the light travel time with respect to the case without lensing is
![Mathematical equation: $$ \begin{aligned} t(\boldsymbol{\theta }_1) = \frac{D_{\Delta t}}{c}\left[\frac{(\boldsymbol{\theta }_1 - \boldsymbol{\beta })^2}{2} - \psi (\boldsymbol{\theta }_1)\right]. \end{aligned} $$](/articles/aa/full_html/2021/12/aa42062-21/aa42062-21-eq1.gif) (1)
(1)
In the above equation, c is the speed of light and DΔt is the time-delay distance, defined as
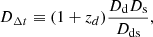 (2)
(2)
where zd is the lens redshift, and Dd, Ds, and Dds are the angular diameter distances between observer and lens, observer and source, and lens and source, respectively. In a Friedman-Lemaître-Robertson-Walker Universe, DΔt scales with the inverse of the Hubble constant H0.
The part in square brackets in Eq. (1) is the sum of two terms: the first is a geometrical term describing the increase in the light travel time due to the extra distance covered by a light ray compared to a straight line; the second term is a delay due to the lens potential. When no lensing is present, θ = β and both terms go to zero. From Eq. (1), it follows that if the source is strongly lensed into an additional image at angular position θ2, then the time delay Δt2, 1 between the two images is
![Mathematical equation: $$ \begin{aligned} \Delta t_{2,1} = \frac{D_{\Delta t}}{c}\left[\frac{(\boldsymbol{\theta }_2 - \boldsymbol{\beta })^2}{2} - \psi (\boldsymbol{\theta }_2) - \frac{(\boldsymbol{\theta }_1 - \boldsymbol{\beta })^2}{2} + \psi (\boldsymbol{\theta }_1)\right]. \end{aligned} $$](/articles/aa/full_html/2021/12/aa42062-21/aa42062-21-eq3.gif) (3)
(3)
In summary, the time delay between two images is the product of a term that depends on cosmology, DΔt/c, and a part that depends on the lens configuration and mass distribution, the term in square brackets. Of the quantities that enter the latter term, only the image positions (θ1, θ2) are directly observable: the lens potential ψ and the source position β must be inferred via lens modelling.
2.2. Mass-sheet transformations
Given a lens model – consisting of a lens potential ψ(θ) and a source position β – that reproduces all of the observed image positions and magnification ratios between images, the following class of transformations
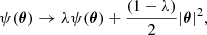 (4)
(4)
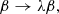 (5)
(5)
leaves those observables unchanged. Equation (4) is called a mass-sheet transformation. The fact that image positions and magnification ratios alone can only constrain a lens model up to a transformation of this kind is referred to as the mass-sheet degeneracy.
Time delays on the other hand are not invariant under a mass-sheet transformation. By applying the transformation of Eqs. (4)–(3), I find that the time delay between the two images transforms as
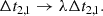 (6)
(6)
This means that, without any assumptions on the lens mass distribution, it is not possible to use image positions and magnification ratios to unambiguously predict the time delay between two images. The strategy that I propose to break the mass-sheet degeneracy consists in the adoption of physically motivated lens models and on the statistical combination of a large number of lenses.
3. Simulations
The experiment is carried out on a sample of 100 simulated lenses. I generated this sample using a very similar prescription to that of Paper I, then added time-delay measurements. In this section, I summarise the procedure used to create this simulation and show the time-delay distribution of the sample.
3.1. Properties of the lens systems
All of the lenses are assumed to be isolated and to have an axisymmetric mass distribution. Moreover, for the sake of reducing the computational burden of the analysis, all of the lenses are at the same redshift zd = 0.4 and all of the sources are at zs = 1.5. Each lens consists of the sum of a stellar component – described by a de Vaucouleurs profile – and a dark matter halo. The density profile of the dark matter halo is determined following the prescription of Cautun et al. (2020): starting from a Navarro, Frenk & White (NFW Navarro et al. 1997) halo, the mass distribution is modified to simulate the contraction of the dark-matter distribution in response to the infall of baryons. The resulting dark-matter profile can be well approximated by a generalised NFW (gNFW) model with an inner density slope steeper than that of an NFW profile (see Fig. 3 in Paper I).
The source is approximated as a point. This is intended to describe both a time-varying active galactic nucleus (AGN) component, used for the measurement of the time delay, and its host galaxy. The point source approximation for the host galaxy is done to reduce the amount of data that needs to be simulated and modelled. In real time-delay lens analyses, the full surface brightness distribution of the source is used to constrain important parameters of the lens model (see e.g., Suyu et al. 2013; Ding et al. 2021). While a point source does not allow for such a measurement, I still take into account the information provided by the source surface brightness distribution by emulating the lens modelling process. Section 3.3 explains how this is done.
The properties of each lens system are fully determined by the following set of parameters.
-
The total stellar mass of the galaxy,
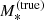 .
. -
The ‘stellar population synthesis-based stellar mass’,
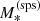 . This is the stellar mass corresponding to a stellar population synthesis model that reproduces the observed luminosity and colours of the galaxy in the absence of photometric errors. The relation between
. This is the stellar mass corresponding to a stellar population synthesis model that reproduces the observed luminosity and colours of the galaxy in the absence of photometric errors. The relation between 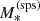 and
and 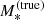 is described by the stellar population synthesis mismatch parameter,
is described by the stellar population synthesis mismatch parameter, 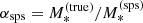 , which is in general different from unity because of unknown systematic uncertainties associated with the stellar population synthesis model.
, which is in general different from unity because of unknown systematic uncertainties associated with the stellar population synthesis model. -
The galaxy half-light radius, Re. I assume that the stellar mass surface mass density follows the surface brightness profile of the galaxy. Therefore, Re is also the half-mass radius of the stellar component.
-
The virial mass of the dark matter halo, M200.
-
The source position with respect to the lens centre, β.
As a consequence of the axisymmetric lens assumption, every lens produces either two or three images of the background source. Only the two brighter images are considered for the analysis, as the third image, if present, is usually highly de-magnified. Although five of the seven time-delay lenses studied in the latest analysis of the TDCOSMO collaboration are quadruple (quad) lenses (Birrer et al. 2020), which are qualitatively different from the doubly imaged systems of this simulation, doubles are expected to dominate over quads in a survey like the LSST by a factor of about six (Oguri & Marshall 2010). Therefore, a sample consisting entirely of doubles is a good first approximation of upcoming samples of time-delay lenses.
Let us consider a Cartesian coordinate frame centred on the lens, with the 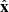 axis aligned with the source position so that
axis aligned with the source position so that 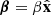 with β > 0. For a lens with Einstein radius θEin, the two images are located at
with β > 0. For a lens with Einstein radius θEin, the two images are located at 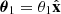 with θ1 > θEin, and
with θ1 > θEin, and 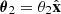 with −θEin < θ2 < 0. In other words, image 1, which is referred to here as the main image, is outside of the tangential critical curve, while image 2, the counter-image, is inside of the critical curve on the opposite side with respect to the lens centre.
with −θEin < θ2 < 0. In other words, image 1, which is referred to here as the main image, is outside of the tangential critical curve, while image 2, the counter-image, is inside of the critical curve on the opposite side with respect to the lens centre.
3.2. Sample creation algorithm
The sample was created as follows.
-
Values of log
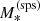 were drawn from a Gaussian distribution set to approximate the stellar mass distribution of known lens samples.
were drawn from a Gaussian distribution set to approximate the stellar mass distribution of known lens samples. -
The true stellar masses were obtained by setting the stellar population synthesis mismatch parameter to log αsps = 0.1 for all galaxies.
-
Half-light radii were assigned using a power-law mass-size relation with log-Gaussian scatter.
-
Values of the halo mass were drawn using a power-law scaling relation with
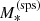 and log-Gaussian scatter.
and log-Gaussian scatter. -
The concentration parameter (the ratio between the virial radius and the scale radius) of the initial (pre-contraction) NFW profile of the dark matter halo was set to 5.
-
The Cautun et al. (2020) prescription was applied to obtain the contracted dark-matter density profile.
-
The position of the source β was drawn from a uniform distribution within a circle of radius βmax, where βmax was set in such a way as to avoid very asymmetric image configurations. In particular, the asymmetry parameter ξasymm was considered, which is defined as
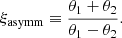 (7)
(7)This quantity is 0 for a lens with θ2 = −θ1, corresponding to the case in which the source is aligned with the optical axis (β = 0), and increases as the relative position of the two images with respect to the lens centre becomes more asymmetric. I set βmax to be the value of the source position corresponding to a maximum allowed asymmetry parameter ξasymm = 0.5. This criterion is meant to simu late an arbitrary selection effect associated with the detectability of lenses: in a real survey, strong lenses can only be identified as such if multiple images are detected. In a lens with a highly asymmetric configuration, the counter-image is close to the centre and has typically low magnification, and is therefore more difficult to detect. The choice of the ξasymm threshold is arbitrary, but does not affect the results. Paper I used a slightly different criterion to assign the source position based on the magnification of the inner image. I opted for a different criterion for this experiment, one that is not based on any magnification information, which is difficult to obtain in practice.
3.3. Observational data
I take the two image positions, (θ1, θ2), to be measured exactly. In addition, I simulate measurements of the radial magnification ratio between the two images, rμr. For a lensed extended source, such as the host galaxy of a strongly lensed AGN or supernova, it is possible to measure the radial magnification ratio between the main image and its counter-image by comparing the widths of the two arcs. This information is usually implicitly obtained by modelling the full surface brightness distribution of the source, and is a model-independent constraint on the radial profile of the lens mass distribution (Sonnenfeld 2018; Shajib et al. 2021). By directly providing an estimate of rμr, I am emulating the lens-modelling process.
I set the uncertainty on rμr to be 0.05 based on the constraining power of Hubble Space Telescope data on the density profile of typical lenses, as indicated by the work of Shajib et al. (2021). I am thus assuming a scenario in which imaging data with sufficient depth and resolution to detect and resolve the host galaxy are available for each lens.
I then calculated the time delays of the sample. The bottom-left panel of Fig. 1 shows the distribution of Δt2, 1 as a function of the Einstein radius. The two quantities are strongly correlated. This is expected given Eq. (3): the time delay scales as the square of the angular scale of a lens, which in turn is set by the Einstein radius. The time delays of the sample span the range between 2 and 469 days, with a median value of 55 days.
 |
Fig. 1. Distribution in the time delay between images 2 and 1, as well as the Einstein radius, and the image configuration asymmetry parameter ξasymm of the lens sample. |
Figure 1 also shows the distribution of the image configuration asymmetry parameter ξ. As the top-left panel of Fig. 1 shows, ξasymm does not correlate with the Einstein radius. However, the time delay correlates with ξasymm, as shown in the bottom-right panel of Fig. 1: lenses with a more asymmetric image configuration tend to have longer time delays. In the limiting case of a perfectly symmetric image configuration (θ2 = −θ1), the time delay is zero.
For some of these lenses, it might be difficult to obtain precise time-delay measurements, in practice: for example, microlensing introduces a systematic error on the order of a day (Tie & Kochanek 2018), which limits the usefulness of the lenses with the smallest time delays. For this reason, in a real time-delay lensing campaign one might wish to exclude lenses with a small Einstein radius and image configuration close to symmetric. I did not apply any such cut to the sample, for simplicity.
I added a Gaussian observational noise to the time-delay measurements with a dispersion equal to 10% of the true time delay. The uncertainty on a time delay of 50 days is therefore 5 days. This value is similar to the uncertainties observed in the Time Delay Challenge II (Liao et al. 2015), which was designed on the basis of expectations for the LSST. A constant relative error on the time delays is perhaps not very realistic, as it translates into an uncertainty of only a few hours for the lenses with the smallest values of Δt2, 1, which is difficult to achieve.
However, this choice makes interpretation of the results easier (particularly the discussion of Sect. 5), as it ensures that each lens has equal weight on the inference of H0. On the contrary, if I were to adopt a constant absolute uncertainty on Δt2, 1 in a sample such as this, which spans more than two orders of magnitude in the time delay, the lenses with the longest time delays would end up dominating the inference. Nevertheless, I repeated the analysis assuming a five-day constant error on Δt2, 1 instead, finding very similar results to the ones shown in this paper.
I also assume the lens and source redshifts to be known exactly. Finally, for each galaxy, I simulated a measurement of the stellar-population-synthesis-based stellar mass, 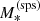 , with an uncertainty of 0.15 dex.
, with an uncertainty of 0.15 dex.
In summary, for each lens I have the following data.
-
The positions of the two brightest images of the source, (θ1, θ2), measured exactly.
-
The lens and source redshift, known exactly.
-
The observed ratio of the radial magnification between images 1 and 2,
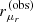 , measured with an uncertainty of 0.05.
, measured with an uncertainty of 0.05. -
The observed time delay between images 2 and 1,
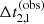 , measured with an uncertainty of 10%.
, measured with an uncertainty of 10%. -
The observed stellar mass,
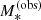 , obtained from stellar population synthesis fitting and under the assumption of a reference value of the Hubble constant, measured with an uncertainty of 0.15 dex.
, obtained from stellar population synthesis fitting and under the assumption of a reference value of the Hubble constant, measured with an uncertainty of 0.15 dex.
Among these measurements, only the last one depends on assumptions on cosmology. In order to make it independent of H0, I consider the following quantity instead:
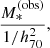 (8)
(8)
where 1/h70 is the ratio between the assumed value of H0 and the reference value of 70 km s−1 Mpc−1,
 (9)
(9)
The fact that the reference value of H0 is the same as the value used to generate the mock has no influence on the analysis.
4. The model
I want to fit a model to the mock data in order to simultaneously infer the distribution in the mass structure of the lenses and the value of H0. In Sonnenfeld (2018), I showed that, in order to predict the time delay of a strong lens with an accuracy of 1%, a lens model with at least three degrees of freedom in the radial direction is needed. Motivated by this result, I employ the same model used in Paper I, which satisfies this requirement, with slight modifications to allow for the additional freedom in the value of the Hubble constant. In this section, I describe the model, as well as the Bayesian hierarchical inference method that I use to fit it to the data.
4.1. Individual lens model
I describe each lens as the sum of a stellar component and a dark matter halo. I assume that the stellar profile of each lens can be measured exactly up to a constant scaling of the mass-to-light ratio. This is a reasonable assumption, as the light profile of a lens galaxy can be determined with high precision, at least in the region enclosed by the Einstein radius.
I describe the dark matter component with a gNFW profile, which is a model with q 3D density profile given by
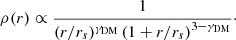 (10)
(10)
The parameter γDM is the inner density slope. If γDM = 1, the gNFW profile reduces to the NFW case.
A gNFW profile has three degrees of freedom: γDM, the scale radius rs, and an overall normalisation. As in Paper I, one degree of freedom is eliminated by fixing the value of the scale radius to
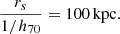 (11)
(11)
With this choice, the angular size of the scale radius is fixed and independent of the assumed value of H0. I parameterise the remaining two degrees of freedom of the dark matter component with the inner slope γDM and the projected mass enclosed within an aperture of 5 kpc 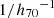 ,
, 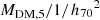 . Each lens system is then fully described by the following set of parameters:
. Each lens system is then fully described by the following set of parameters:
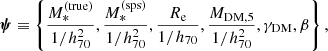 (12)
(12)
where β is the source position and Re is in physical units.
This model is underconstrained on an individual lens basis: the two image positions and the radial magnification ratio can only constrain three degrees of freedom, one of which must be the source position β. The time-delay measurement provides an additional constraint, but its interpretation depends on the value of H0, which I want to infer. As shown in Appendix A, the model does not break the mass-sheet degeneracy for physically allowed values of the mass-sheet transformation parameter λ. The strategy here consists in statistically constraining only the overall properties of the lens population, together with H0, rather than determining the exact structure of each lens.
4.2. Population distribution
I assume that the parameters of each lens, ψ, are drawn from a common probability distribution P(ψ|η) describing the population, which is in turn summarised by a set of parameters η. I choose the following functional form for the population distribution,
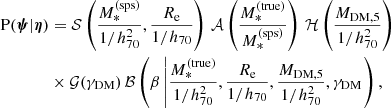 (13)
(13)
which is the same used in Paper I.
The first term, 𝒮, describes the distribution in stellar mass and half-light radius of the lens sample. For the sake of simplifying calculations, I assume that it is known exactly. Therefore, I set it equal to the distribution used to generate the sample, which is a bi-variate Gaussian in 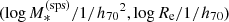 . This is a reasonable approximation, because this term can be constrained very well with a sample of 100 lenses (see e.g., Sonnenfeld et al. 2015).
. This is a reasonable approximation, because this term can be constrained very well with a sample of 100 lenses (see e.g., Sonnenfeld et al. 2015).
The term 𝒜 describes the distribution in the stellar-population-synthesis mismatch parameter introduced in Sect. 3.1, 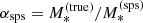 . I model this term as a Dirac delta function, that is, I assume a single value of αsps for the whole lens sample:
. I model this term as a Dirac delta function, that is, I assume a single value of αsps for the whole lens sample:
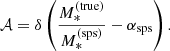 (14)
(14)
The terms ℋ and 𝒢 describe the distribution in the two parameters related to the dark matter distribution, MDM, 5 and γDM. I model the former as a Gaussian in log 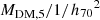 and the latter as a Gaussian in γDM:
and the latter as a Gaussian in γDM:
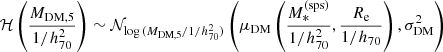 (15)
(15)
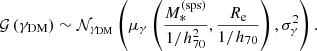 (16)
(16)
One of the main results of Paper I was the finding that, in order to obtain an accurate inference of the average properties of the dark matter distribution of a lens sample, it is necessary to allow for a dependence of the average dark matter mass and inner slope with all of the dynamically relevant properties of the lens galaxy: in this case, the stellar mass and half-light radius. For this reason, I allow for the means of the Gaussian distributions in the above equations to scale with 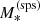 and Re as follows:
and Re as follows:
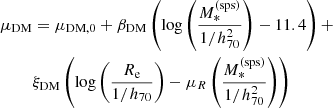 (17)
(17)
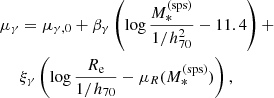 (18)
(18)
where μR is the average value of log(Re/1/h70) for a lens with stellar mass 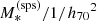 .
.
The last term in Eq. (13) is ℬ, which describes the distribution in the source position. At fixed lens properties, this term determines the distribution in the asymmetry of the image configuration. This aspect is directly related to the selection function of the sample: when building the mock data, I imposed a condition on the maximum value of ξasymm to simulate a selection that disfavours highly asymmetric configurations with a de-magnified counter-image. I assume an uninformative prior on the source position: given the lens mass model parameters, I assume that the source has equal prior probability of being anywhere within the source plane circle of radius βSL, which is strongly lensed into multiple images. If the lens has a radial caustic, then this sets the value of βSL. Otherwise, I set βSL to the value that produces a counter-image at a very small distance from the lens centre. With this definition, the source prior term reads
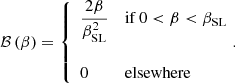 (19)
(19)
The functional form of Eq. (19) is the same as the probability distribution used to generate the sample, with one important difference: instead of truncating the distribution at the value βmax corresponding to ξasymm = 0.5, I use the more conservative value of βSL. This is a different choice compared to the analysis of Paper I, where it was assumed that the source position distribution, which is related to the selection function, was known exactly by the observer.
The population model is then described by the set of free parameters introduced in Eqs. (14), (15), (16), (17), and (18), plus the Hubble constant H0:
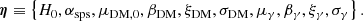 (20)
(20)
Table 1 provides a brief description of each parameter.
Inference on the model parameters.
I point out that this model differs from the one used to generate the mock, described in Sect. 3, in two key aspects: (1) the true dark matter density profile is not a gNFW model with fixed scale radius; and (2) the distributions in the projected dark matter mass within 5 kpc and inner dark matter slope do not strictly follow Eqs. (15) and (16). These differences make the experiment realistic: in a real-world application, it is unlikely that a simply parameterised model can reproduce the dark matter distribution of a sample of galaxies exactly.
4.3. Inference technique
I want to calculate the posterior probability distribution of the model parameters, η, given the data d. Using Bayes’ theorem, this is
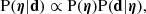 (21)
(21)
where P(η) is the prior probability of the parameters and P(d|η) the likelihood of observing the data given the model. As measurements carried out on different lenses are independent of each other, the latter is the following product:
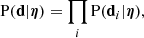 (22)
(22)
where di is the data relative to lens i.
The parameters η do not directly predict the data: those depend on the values of ψ taken by the individual lenses. In order to evaluate each product P(di|η), it is therefore necessary to marginalise over all possible values of ψ:
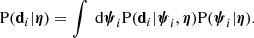 (23)
(23)
Formally, this is a six-dimensional integral. A similar calculation to that performed in Paper I allows one to reduce it to the following:
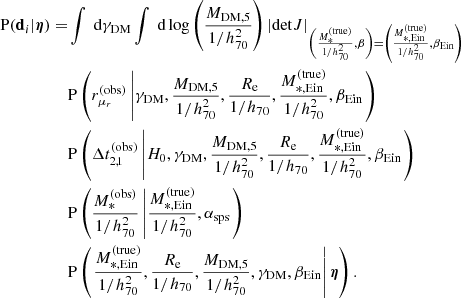 (24)
(24)
In the integrand function, 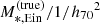 , and βEin are the values of the stellar mass and source position needed to reproduce the two image positions given the dark matter parameters MDM, 5 and γDM. The factor det J is the Jacobian determinant corresponding to the variable change from
, and βEin are the values of the stellar mass and source position needed to reproduce the two image positions given the dark matter parameters MDM, 5 and γDM. The factor det J is the Jacobian determinant corresponding to the variable change from 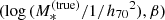 to the image positions (θ1, θ2), evaluated at
to the image positions (θ1, θ2), evaluated at 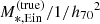 and βEin.
and βEin.
I assumed uniform priors on all of the population parameters in Eq. (20), with the exception of αsps, for which I assumed a uniform prior on its base-ten logarithm. The bounds on each parameter are listed in Table 1. I sampled the posterior probability distribution P(η|d) with EMCEE (Foreman-Mackey et al. 2013), a Python implementation of the Goodman & Weare (2010) affine-invariant sampling method. At each draw of the parameters η, I calculated the integrals of Eq. (24) numerically by computing the integrand function on a grid and doing a spline interpolation and integration over the two dimensions. I verified that the inference method is accurate within the uncertainties by applying it to mock lens populations generated with the same properties as the model fitted to them.
5. Results
Before showing the results of the inference, it is useful to make a few general considerations on the degree of precision that we can expect given the dataset. A single lens in the sample provides a time-delay measurement with 10% precision. This means that, if the lens model parameters were known exactly, this single measurement could be used to obtain an estimate of H0 with the same precision.
The statistical combination of 100 such lenses would reduce the uncertainty to 1%. This is the highest possible precision attainable in the ideal case with no uncertainties related to the lens model. However, in this experiment, not only does one need to determine the lens model parameters from noisy data, but also these parameters are underconstrained on an individual lens basis: by fitting the model of Sect. 4.1 to a single lens, one obtains a posterior probability that is dominated by the prior (Sect. 5.4 shows this more quantitatively). This means that a single-lens inference on H0 carries, in addition to the uncertainty on the time delay, an uncertainty related to the lens model parameters, which in turn depends on their prior probability distribution.
When combining the 100 lenses in the sample with a hierarchical inference formalism, the population distribution of Eq. (13) acts as a prior on the individual lens parameters ψ. This distribution is not fixed, but its parameters η are inferred from the data at the same time as H0. In summary, the final uncertainty on H0 will depend on (1) the uncertainties on the time-delay measurements, (2) the uncertainties associated with the lens models of the individual lenses, and (3) the uncertainties on the population distribution parameters η. Each one of these aspects can dominate over the others, depending on the sample size, data quality, and model complexity. As I show in this section, (3) is the dominant source of error on H0 in this experiment.
5.1. Inference from 100 time-delay lenses
Figure 2 shows the posterior probability distribution of the main parameters of the model: the Hubble constant, the stellar population synthesis mismatch parameter, the average dark matter mass within 5 kpc, and the average dark matter slope. The median and 68% credible bounds of the marginal posterior probability of each parameter are reported in Table 1. I defined the true values of the model parameters by fitting the model distribution of Sect. 4.2 directly to the values of MDM, 5 and γDM of the mock sample, which I obtained by fitting a gNFW profile to the projected surface mass density of each lens.
 |
Fig. 2. Posterior probability distribution of the four key parameters of the model: the Hubble constant, the stellar population synthesis mismatch parameter, the average log MDM, 5, and the average γDM. Purple filled contours correspond to the fit to the sample of 100 time-delay lenses, with no extra information. Red lines show the posterior probability obtained by using prior information on the model parameters from the sample of 1000 strong lenses simulated in Paper I. Contour levels correspond to 68% and 95% enclosed probability regions. Dashed lines indicate the true values of the parameters, which are defined by fitting the model directly to the distribution of log MDM, 5, γDM, and log αsps of the mock sample. |
Most of the lens structure parameters are recovered within 1σ. However, the true value of the Hubble constant is outside of the inferred 68% credible region: the measured value is 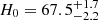 km s−1 Mpc−1. This corresponds to a statistical uncertainty of ∼3%, with a systematic bias of ∼ − 4%. I verified that the bias is significant by repeating the analysis on new samples of 100 lenses generated with the same procedure as outlined in Sect. 3 but with different noise realisations. The origin of this bias must be searched for in the differences between the truth and the model used to fit the sample: these differences are the dark matter density profile, the population distribution of the dark matter parameters, and the assumed source position distribution.
km s−1 Mpc−1. This corresponds to a statistical uncertainty of ∼3%, with a systematic bias of ∼ − 4%. I verified that the bias is significant by repeating the analysis on new samples of 100 lenses generated with the same procedure as outlined in Sect. 3 but with different noise realisations. The origin of this bias must be searched for in the differences between the truth and the model used to fit the sample: these differences are the dark matter density profile, the population distribution of the dark matter parameters, and the assumed source position distribution.
As we can see from Fig. 2, the uncertainty on H0 is due in large part to a strong degeneracy with the parameters αsps, μDM, 0, and μγ, 0. In the following section, I investigate whether the precision and the accuracy on H0 can be improved by making use of prior information from a separate lens sample.
5.2. Inference with a prior from a sample of 1000 strong lenses
Paper I simulated a statistical strong-lensing measurement on a sample of 1000 lenses. This showed how, with such a sample, it is possible to measure the average properties of the lens population with much higher precision than that obtained with the sample of 100 time-delay lenses considered in this work so far. For example, the average stellar population synthesis mismatch parameter αsps was recovered with a precision of ∼0.01 dex compared to the ∼0.03 dex precision obtained in Sect. 5.1. In this section, I investigate a scenario in which the information from a such a sample of 1000 lenses is used as a prior on the parameters describing the lens population in combination with the 100 time-delay lenses simulated in this work.
I proceeded as follow. I repeated the analysis of Sect. 5.1 using the posterior probability distribution from Paper I as a prior on the model parameters η (with the exception of H0, which is unconstrained by the analysis of Paper I). There is an important caveat with this approach: I implicitly assumed that the two lens samples are drawn from the same population of galaxies. To simplify the calculations, I approximated this prior probability distribution as a multivariate Gaussian, with mean and covariance matrix equal to those of the sample obtained from the Markov chain Monte Carlo of Paper I. The resulting posterior probability distribution in the key parameters is shown as solid red contours in Fig. 2, while the median and 68% credible region of the marginal posterior probability of all parameters is reported in Table 1.
Remarkably, H0 is now recovered with a precision slightly above 1%. As pointed out in Sect. 5, 1% is the maximum attainable precision on H0 in the case of perfect knowledge of the lens model parameters, as this is the amplitude of the uncertainty associated with the time-delay measurements alone. This result tells us that, once the parameters describing the lens population are known with sufficient precision, the main remaining source of uncertainty on H0 is that related to the measurements of Δt2, 1. This is a key advantage of using a Bayesian hierarchical approach, which is further illustrated in Sect. 5.4.
5.3. Inference with a narrow prior on H0
There are many different ways of measuring the Hubble constant. Therefore, there is the possibility that H0 will be determined with high precision with an experiment different from time-delay lensing. In that case, measurements of time delays could be used to constrain the properties of the lens population. I investigated this scenario by repeating the analysis of the 100 time-delay lenses of Sect. 5.1, with the addition of a prior on H0 with 1% precision. The resulting posterior probability distribution is shown in green in Fig. 2.
The main improvement brought by the prior knowledge of H0 is in the precision on the inferred average dark matter slope parameter, μγ, 0: its uncertainty becomes 0.06, which is much smaller than the value of 0.12 obtained in the fiducial analysis. The other parameters are relatively unchanged: the stellar population synthesis mismatch parameter αsps, for instance, is determined with a 0.02 − 0.03 dex precision, independently of whether or not an H0 prior is applied.
5.4. What Bayesian hierarchical inference does
Early statistical analyses of time-delay lenses (that is, prior to the Birrer et al. 2020, study) consisted in obtaining estimates of the time-delay distance DΔt separately for each lens system by marginalising each posterior probability distribution over the parameters describing the lens mass and then combining the resulting marginal posterior probabilities to infer H0 (see e.g., Bonvin et al. 2017). Here, I investigate how this approach compares to the Bayesian hierarchical inference method in terms of precision and accuracy.
Firstly, I calculated for each lens the marginal posterior probability distribution in H0 given the data, P(H0|di). Formally, this is given by
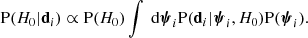 (25)
(25)
The term P(ψi) is the prior on the individual lens parameters. In a Bayesian hierarchical approach, this is a function of population-level parameters η, while in this context the prior is fixed. I assumed a flat prior on the following parameters:
 (26)
(26)
and the same prior as Eq. (19) on the source position β.
Figure 3 shows P(H0|di) for ten lenses of the sample (grey curves). The 1σ uncertainty on H0 is typically around 15%−20%. If I consider this to be the result of the quadrature sum between the error on the time delay, which is 10%, and that on the individual lens parameters, it follows that the latter is the dominant source of uncertainty. This is not surprising, because the lens model is under-constrained.
 |
Fig. 3. Marginal posterior probability on H0. Grey curves: Individual lens P(H0|di) obtained from Eq. (25) assuming flat priors on the lens model parameters, for ten time-delay lenses. Cyan curve: Statistical combination of the marginal posterior probabilities from the 100 time-delay lenses obtained following Eq. (26). Filled purple histogram: Hierarchical inference from Sect. 5.1 Red histogram: Hierarchical inference with a prior from Paper I, from Sect. 5.2. The vertical dashed line marks the true value of H0 used to simulate the data. |
I then considered the joint inference on H0, which was obtained by combining the marginal posterior probabilities of the 100 lenses of the sample. This is defined as
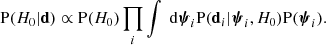 (27)
(27)
The resulting posterior probability distribution is shown as a cyan curve in Fig. 3. The value of the Hubble constant inferred in this way is H0 = 66.6 ± 1.2 km s−1 Mpc−1. The relative uncertainty on H0 is 1.7%, a factor 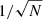 smaller than the individual lens measurements, which is the standard result when N independent measurements of a given quantity are combined. However, the inference is highly biased.
smaller than the individual lens measurements, which is the standard result when N independent measurements of a given quantity are combined. However, the inference is highly biased.
This is a good example of a result driven by the prior. The choice of prior on the dark matter slope made with Eq. (26) is particularly detrimental in this case: P(γDM) is centred at γDM = 1, corresponding to an NFW profile, and gives equal probability to values of γDM above or below it. While this appears to be a reasonable choice, the true dark matter slope of the lenses is on average much steeper than that of an NFW profile. As a result, the inferred value of H0 is biased low. I verified that, repeating this analysis with a higher lower bound on γDM, the inference on H0 gets closer to the truth.
With the Bayesian hierarchical approach, the inference on H0 is more uncertain, but also more accurate: the true value of H0 is recovered within 2σ. This is because the hierarchical model is designed in such a way that one can infer the probability distribution of the individual lens parameters, P(ψ|η), along with H0, instead of assuming a fixed prior on them. As a result, the uncertainty on quantities such as the average dark matter slope (parameter μγ, 0) propagates over the inference on H0 and ends up being the dominant source of error. The data from the 100 simulated lenses does not allow us to distinguish between a scenario in which (a) H0 is close to the true value and the average γDM is 1.5, and one where (b) H0 ≈ 65 km s−1 Mpc−1 and μγDM, 0 ≈ 1.2. This uncertainty is properly taken into account by the hierarchical model. In other terms, while the simple statistical combination of Eq. (27) treats each lens independently from the others, the hierarchical model takes into account correlated errors due to our ignorance of the average properties of galaxies.
Finally, the Bayesian hierarchical method can also provide higher precision than a traditional approach when prior information on the lens population parameters is available. This is illustrated by the example of Sect. 5.2, which makes use of the prior from the sample of Paper I. The resulting marginal posterior on H0, shown as a red curve in Fig. 3, has a 1σ uncertainty of 1.3%, which is significantly smaller than the 1.7% uncertainty obtained when assuming flat priors on the individual lens parameters. This is because, if the population-level parameters η are known with sufficient precision, lens models corresponding to the tails of the P(ψ|η) distribution are suppressed, resulting in a more precise measurement.
6. Discussion and summary
The experiments carried out in this work were realised under a series of simplifying assumptions. In order to apply the statistical inference method developed here to a real sample of lenses, there are several challenges to be overcome. Many of these challenges apply in the same way to the analysis of Paper I. These are: generalising the lens model to the non-axisymmetric case and modelling the full surface brightness distribution of the lensed source and computing the individual lens parameter marginalisation integrals of Eq. (23) in a computationally efficient yet accurate way. Dropping the axisymmetric lens assumption can be particularly challenging, as it requires increasing the dimensionality of the problem. I refer to Sect. 6.5 of Paper I for a thorough discussion of these points.
One important aspect in time-delay lensing studies that I have left out in this work is the line-of-sight structure. The effect of mass perturbers along the line of sight can usually be described with a constant sheet of mass. As such, the line-of-sight structure has the same impact on the time delay as the mass-sheet transformation described in 2.2: if not taken into account, it will bias the inference on H0. In state-of-the-art time-delay lensing studies, the effect of line-of-sight perturbers is modelled on the basis of measurements of the environment of each lens (see e.g., Rusu et al. 2017, for details). In principle, the modelling of the line of sight could be incorporated into the same hierarchical model describing the lens galaxy population, although that would complicate the analysis.
The first result of this study is the finding that, with a sample of 100 doubly lensed quasars, each with a 10% precision measurement of the time delay and with high-resolution imaging data, the Hubble constant can be measured with a precision of about 3%. The main source of uncertainty is the knowledge of the distribution of the lens structural parameters: the stellar mass-to-light ratio and the dark matter density profile. However, the experiment also showed that the inference can suffer a bias of comparable amplitude. The origin of this bias lies most likely in the fact that the model that I used for the inference, although relatively flexible, is not a perfect description of the reality assumed when creating the simulated sample of lenses. While I cannot exclude that a higher degree of accuracy could be reached with alternative models, it is clear that in order to obtain a 1% measurement of H0, additional information is needed, either from a much larger sample of time-delay lenses, from external datasets, or from predictions from hydrodynamical simulations (such as with the method proposed by Harvey 2020).
The LSST should be able to provide the data necessary to measure time delays for about 400 strongly lensed quasars (Liao et al. 2015), with the actual number depending on the observing strategy and the required precision on these measurements (see also Sect. 5.2 of Lochner et al. 2021). Such a sample would allow to achieve a substantially higher precision on the inferred lens population parameters, and consequently on the Hubble constant, compared to the 100-lens scenario examined here. However, a quantitative forecast of the constraining power of LSST time-delay lenses is beyond the goals of this work.
The second result is that, when prior information on the lens structure distribution from a large external lens sample is combined to a set of 100 time-delay lenses, it is possible to reach a precision and accuracy of about 1%. This result also showed that, when the lens population parameters are known very well, uncertainties associated with the modelling of individual lenses are greatly reduced in virtue of the knowledge of their probability distribution.
Combining time-delay lenses with larger samples of regular strong lenses (i.e., with no time delays) is the strategy currently pursued by the TDCOSMO collaboration (Birrer et al. 2020; Birrer & Treu 2021). Birrer & Treu (2021) forecast that a joint sample of 40 time-delay lenses and 200 regular lenses can lead to a 1.5% precision on H0. The main difference between their work and this one is that Birrer & Treu (2021) relied on stellar kinematics measurements to further constrain the lens model parameters. While a larger sample of lenses is needed to achieve the same precision with the approach of the present paper, the advantage of not relying on stellar kinematics is that the inference is immune to possible systematic effects associated with the stellar dynamical modelling step. In order to have a good handle on systematic errors, it is therefore worth pursuing both of these strategies.
An implicit assumption made in both this and the Birrer & Treu (2021) study is that the samples of time-delay and non-time-delay lenses are drawn from a population of galaxies with the same properties. However, differences in the selection criteria can mean that the two samples probe different subsets of the general galaxy population, with potentially different underlying distributions in the lens structural parameters. When applying this method in practice, it is therefore important to either make sure that these differences do not introduce significant biases, or to explicitly model the selection effects relative to both lens samples. Sonnenfeld (2021, Paper III) provides a framework for taking lens selection effects into account in a Bayesian hierarchical inference.
Finally, I show that if a 1% measurement of H0 is available from a separate experiment, then a sample of 100 time-delay lenses can be used to constrain the properties of the mass structure of the lens population. The main effect of the prior information on H0 is that of improving the determination of the average dark matter density slope. Stellar mass measurements can be calibrated with a 0.03 dex precision with such a sample, regardless of prior knowledge on H0.
The strong lensing data simulated in this study consisted of image positions, magnification ratios, and time delays. However, if the background source is a standardisable candle, such as a type Ia supernova, it is possible to obtain information on the absolute magnification, which can break the mass-sheet degeneracy. A scenario in which such magnification measurements are available was explored by Birrer et al. (2021) with promising results.
In summary, time-delay lenses are very powerful probes of both cosmology and galaxy structure. The LSST will provide data that will enable time-delay measurements for hundreds of lenses. This work presents a strategy to exploit these data with minimal use of external (non-lensing) information.
Acknowledgments
I thank Phil Marshall, Marius Cautun, Simon Birrer, Timo Anguita and Frederic Courbin for useful discussions and suggestions.
References
- Birrer, S., & Treu, T. 2021, A&A, 649, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Birrer, S., Dhawan, S., & Shajib, A. J. 2021, AAS J., submitted [arXiv:2107.12385] [Google Scholar]
- Bonvin, V., Courbin, F., Suyu, S. H., et al. 2017, MNRAS, 465, 4914 [NASA ADS] [CrossRef] [Google Scholar]
- Cautun, M., Benítez-Llambay, A., Deason, A. J., et al. 2020, MNRAS, 494, 4291 [Google Scholar]
- Ding, X., Treu, T., Birrer, S., et al. 2021, MNRAS, 503, 1096 [Google Scholar]
- Falco, E. E., Gorenstein, M. V., & Shapiro, I. I. 1985, ApJ, 289, L1 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Goodman, J., & Weare, J. 2010, Comm. App. Math. Comp. Sci., 5, 65 [Google Scholar]
- Harvey, D. 2020, MNRAS, 498, 2871 [NASA ADS] [CrossRef] [Google Scholar]
- Liao, K., Treu, T., Marshall, P., et al. 2015, ApJ, 800, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Lochner, M., Scolnic, D., Almoubayyed, H., et al. 2021, ArXiv e-prints [arXiv:2104.05676] [Google Scholar]
- Millon, M., Courbin, F., Bonvin, V., et al. 2020, A&A, 642, A193 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Oguri, M., & Marshall, P. J. 2010, MNRAS, 405, 2579 [NASA ADS] [Google Scholar]
- Park, J. W., Wagner-Carena, S., Birrer, S., et al. 2021, ApJ, 910, 39 [Google Scholar]
- Refsdal, S. 1964, MNRAS, 128, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Rusu, C. E., Fassnacht, C. D., Sluse, D., et al. 2017, MNRAS, 467, 4220 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., & Sluse, D. 2013, A&A, 559, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shajib, A. J., Treu, T., Birrer, S., & Sonnenfeld, A. 2021, MNRAS, 503, 2380 [Google Scholar]
- Sonnenfeld, A. 2018, MNRAS, 474, 4648 [Google Scholar]
- Sonnenfeld, A. 2021, A&A, submitted [arXiv:2109.13246] (Paper III) [Google Scholar]
- Sonnenfeld, A., & Cautun, M. 2021, A&A, 651, A18 (Paper I) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [Google Scholar]
- Suyu, S. H. 2012, MNRAS, 426, 868 [Google Scholar]
- Suyu, S. H., Auger, M. W., Hilbert, S., et al. 2013, ApJ, 766, 70 [Google Scholar]
- Tie, S. S., & Kochanek, C. S. 2018, MNRAS, 473, 80 [Google Scholar]
- Treu, T., & Marshall, P. J. 2016, A&ARv, 24, 11 [Google Scholar]
- Yıldırım, A., Suyu, S. H., & Halkola, A. 2020, MNRAS, 493, 4783 [Google Scholar]
Appendix A: Mass-sheet transformations of the lens model
When modelling a time-delay lens for the purpose of measuring H0, it is important to ensure that the assumed lens model family does not break the mass-sheet degeneracy. This means verifying that, when applying a mass-sheet transformation of the kind of Equation 4 to the lens model, the transformed model still belongs to the original model family. Strictly speaking, this is not the case for the model adopted in this paper (or any physically motivated model). For instance, the dimensionless surface mass density changes as follows under a mass-sheet transformation:
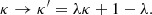 (A.1)
(A.1)
When λ > 1, κ′ becomes negative at large radii, where κ approaches zero. A negative surface mass density cannot be produced by the lens model of section 4.1, for any combination of parameters.
However, for the purpose of ensuring accuracy in the inference of H0, it is sufficient to show that the mass-sheet degeneracy is not broken over the region constrained by the lensing data. The relevant quantities are then the local derivatives of the lens potential at the Einstein radius. In Sonnenfeld (2018) I showed that, for small displacements around the Einstein radius, the time delay is proportional to the product of the first and second derivative of the potential, ψ′ψ″, where ψ′ is equal to the Einstein radius. The image positions and the radial magnification ratio, instead, only constrain the first derivative ψ′ and the following combination of derivatives:
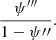 (A.2)
(A.2)
A mass-sheet transformation has the following effect on the first three derivatives of the potential:
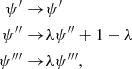 (A.3)
(A.3)
from which it follows that the quantity in Equation A.2 does not change under a mass-sheet transformation (both the numerator and the denominator scale with λ). If the lens model allows for variations in the potential derivatives of the kind of Equation A.3, then it does not break the mass-sheet degeneracy.
To check whether this condition is satisfied, I considered the following example. I generated a lens using the model of section 4.1, with a stellar mass of log M* = 11.5, a half-light radius Re = 7 kpc, a dark matter mass log MDM, 5 = 11.0, and dark matter slope γDM = 1.5. The Einstein radius of this lens (for the same lens and source redshift used in the main experiment) is ψ′ = 1.15″. I then varied the three lens model parameters while keeping the Einstein radius fixed, examined the corresponding variation in the lens potential derivatives, and compared this with that produced by a mass-sheet transformation.
Figure A.1 shows the distribution in the (dimensionless) product ψ′ψ″′ as a function of 1 − ψ″ covered by the lens model (pink region). The true values of these quantities (those corresponding to the lens generated initially) are marked by a star. A mass-sheet transformation changes both ψ′ψ″′ and 1 − ψ″ by a factor λ. The purple line shows such a transformation over the range λ ∈ [0.9, 1.1]. The transformed lens falls in the region covered by the lens model, with the exception of values of λ > 1.03. Large positive values of λ can anyway be excluded, because they correspond to unphysical models, with negative convergence at large radii. I therefore conclude that the lens model used in the analysis does not break the mass-sheet degeneracy for physically acceptable values of λ.
 |
Fig. A.1. Degrees of freedom of the model and the mass-sheet transformation. Values of the product between the third and first derivative of the lens potential, evaluated at the Einstein radius, ψ′ψ″′, as a function of 1 − ψ″, for various lenses with fixed Einstein radius. The star marks the values of a lens generated with the model of section 4.1, assuming log M* = 11.5, Re = 7 kpc, log MDM, 5 = 11.0, γDM = 1.5. The pink region covers the range of values spanned by the model, obtained by varying the three model parameters while keeping the Einstein radius fixed. The blue line indicates the range of values obtained by applying the mass-sheet transformation of Equation 4 to the original lens, with values λ ∈ [0.9, 1.1]. The green line corresponds to a power-law lens model. |
All Tables
All Figures
|
Fig. 1. Distribution in the time delay between images 2 and 1, as well as the Einstein radius, and the image configuration asymmetry parameter ξasymm of the lens sample. |
| In the text | |
|
Fig. 2. Posterior probability distribution of the four key parameters of the model: the Hubble constant, the stellar population synthesis mismatch parameter, the average log MDM, 5, and the average γDM. Purple filled contours correspond to the fit to the sample of 100 time-delay lenses, with no extra information. Red lines show the posterior probability obtained by using prior information on the model parameters from the sample of 1000 strong lenses simulated in Paper I. Contour levels correspond to 68% and 95% enclosed probability regions. Dashed lines indicate the true values of the parameters, which are defined by fitting the model directly to the distribution of log MDM, 5, γDM, and log αsps of the mock sample. |
| In the text | |
|
Fig. 3. Marginal posterior probability on H0. Grey curves: Individual lens P(H0|di) obtained from Eq. (25) assuming flat priors on the lens model parameters, for ten time-delay lenses. Cyan curve: Statistical combination of the marginal posterior probabilities from the 100 time-delay lenses obtained following Eq. (26). Filled purple histogram: Hierarchical inference from Sect. 5.1 Red histogram: Hierarchical inference with a prior from Paper I, from Sect. 5.2. The vertical dashed line marks the true value of H0 used to simulate the data. |
| In the text | |
|
Fig. A.1. Degrees of freedom of the model and the mass-sheet transformation. Values of the product between the third and first derivative of the lens potential, evaluated at the Einstein radius, ψ′ψ″′, as a function of 1 − ψ″, for various lenses with fixed Einstein radius. The star marks the values of a lens generated with the model of section 4.1, assuming log M* = 11.5, Re = 7 kpc, log MDM, 5 = 11.0, γDM = 1.5. The pink region covers the range of values spanned by the model, obtained by varying the three model parameters while keeping the Einstein radius fixed. The blue line indicates the range of values obtained by applying the mass-sheet transformation of Equation 4 to the original lens, with values λ ∈ [0.9, 1.1]. The green line corresponds to a power-law lens model. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.