| Issue |
A&A
Volume 651, July 2021
|
|
|---|---|---|
| Article Number | A18 | |
| Number of page(s) | 17 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202140549 | |
| Published online | 02 July 2021 | |
Statistical strong lensing
I. Constraints on the inner structure of galaxies from samples of a thousand lenses
Leiden Observatory, Leiden University, Niels Bohrweg 2, 2333 CA Leiden, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
12
February
2021
Accepted:
29
April
2021
Abstract
Context. The number of known strong gravitational lenses is expected to grow substantially in the next few years. The combination of large samples of lenses has the potential to provide strong constraints on the inner structure of galaxies.
Aims. We investigate the extent to which we can calibrate stellar mass measurements and constrain the average dark matter density profile of galaxies by combining strong lensing data from thousands of lenses.
Methods. We generated mock samples of axisymmetric lenses. We assume that, for each lens, we have measurements of two image positions of a strongly lensed background source, as well as magnification information from full surface brightness modelling, and a stellar-population-synthesis-based estimate of the lens stellar mass. We then fitted models describing the distribution of the stellar population synthesis mismatch parameter αsps (the ratio between the true stellar mass and the stellar-population-synthesis-based estimate) and the dark matter density profile of the population of lenses to an ensemble of 1000 mock lenses.
Results. We obtain the average αsps, projected dark matter mass, and dark matter density slope with greater precision and accuracy compared with current constraints. A flexible model and knowledge of the lens detection efficiency as a function of image configuration are required in order to avoid a biased inference.
Conclusions. Statistical strong lensing inferences from upcoming surveys provide a way to calibrate stellar mass measurements and to constrain the inner dark matter density profile of massive galaxies.
Key words: gravitational lensing: strong / galaxies: fundamental parameters
Marie Skłodowska-Curie Fellow.
© ESO 2021
1. Introduction
Strong gravitational lensing is one of the few available methods for measuring the masses of galaxies at cosmological distances. Strong lensing has been used to determine the average density profile of massive galaxies (Koopmans et al. 2006; Auger et al. 2010a; Sonnenfeld et al. 2013a) and to put constraints on the stellar (Treu et al. 2010; Auger et al. 2010b; Barnabè et al. 2013; Spiniello et al. 2015; Sonnenfeld et al. 2015; Smith et al. 2015) and dark matter content of these objects (Sonnenfeld et al. 2012; Oldham & Auger 2018; Schuldt et al. 2019).
There are two possible approaches to inferring the properties of the mass distribution of galaxies from strong gravitational lensing data. The first consists of focusing on a selected sample of objects with high-quality data and obtaining as much information as possible from each individual lens. This is the approach adopted, for example, with time-delay lenses for the measurement of cosmological parameters (Suyu et al. 2017; Millon et al. 2020), and typically involves modelling deep high-resolution images of a lens and combining lensing data with complementary information such as stellar kinematics (Shajib et al. 2018; Yıldırım et al. 2020).
The second approach consists in combining measurements from a large sample of lenses and inferring the properties of the lens population statistically. This requires assumptions to be made about the functional form of the distribution of the parameters describing each lens. In the simplest case, lenses can be assumed to be homologous systems that are scaled-up versions of each other. Under that assumption, the problem reduces to the determination of a handful of parameters describing the average of the distribution and possible scaling relations between the mass parameters of each lens and some galaxy properties (see, e.g. Rusin & Kochanek 2005; Grillo 2012; Oguri et al. 2014; Schechter et al. 2014). A more general method for inferring the statistical properties of an ensemble of lenses is hierarchical modelling, in which lenses are still assumed to be drawn from a common distribution to be inferred from the data, but where the parameters describing individual objects are allowed to vary independently of each other (see Sonnenfeld et al. 2015, 2019a; Birrer et al. 2020; Shajib et al. 2021). The advantage of a statistical approach to strong lensing inference is that it allows the user to constrain, at a population level, parameters that would otherwise be under-constrained on an individual lens basis. While large statistics usually implies high precision, not all statistical measurements lead to an accurate result. Any element of complexity in the true distribution of lens properties that is not captured by the model can potentially lead to bias. The main challenge for a successful statistical strong-lensing measurement is therefore in building a model that is sufficiently flexible to guarantee an accurate answer, yet not too flexible such that it cannot be constrained with strong lensing data alone. This is the problem addressed by this work.
The constraining power of a statistical sample of strong lenses increases with the number of objects. So far, statistical strong-lensing analyses have been carried out on samples of tens of lenses at most, the limiting factor being the availability of spectroscopic data: the redshift of both the lens and the source galaxy is needed to convert angular measurements obtained from the analysis of strongly lensed images into physical measurements of the lens mass. In the next few years, however, both the number of known lenses and the number of lenses with available spectroscopic observations is expected to grow substantially. On the one hand, current imaging surveys such as the Hyper Suprime-Cam survey (Aihara et al. 2018), the Dark Energy Survey (Dark Energy Survey Collaboration 2016), and the Kilo Degree Survey (de Jong et al. 2015; Kuijken et al. 2015) are leading to the discovery of hundreds of new lenses (Sonnenfeld et al. 2018a, 2020; Wong et al. 2018; Petrillo et al. 2019; Jacobs et al. 2019; Chan et al. 2020; Li et al. 2020) and the total number of known lenses is expected to reach approximately 105 with Euclid1 and the Vera Rubin Observatory2 (Collett 2015). On the other hand, new spectroscopic facilities such as the Prime Focus Spectrograph3, the Dark Energy Spectroscopic Instrument4, the 4-metre Multi-Object Spectroscopic Telescope5, and the Near Infrared Spectrometer and Photometer on board Euclid will offer the opportunity to obtain spectroscopic data for samples of lenses of unprecedented size.
In this study, we investigate the aspects of the mass distribution of galaxies that can be best determined with the statistical combination of strong lensing measurements on a large sample of lenses. We focus on two properties: the mass-to-light ratio of the stellar component and the inner density profile of the dark matter halo. Being able to accurately determine the former is crucial for calibrating galaxy stellar mass measurements and therefore obtaining an unbiased account of the baryon cycle in the Universe. The latter is currently very poorly known and could hold important clues as to the relative importance of baryonic physics processes in galaxy formation and evolution (see Schaller et al. 2015) or even the nature of dark matter itself.
Statistical strong lensing studies are usually carried out in two steps: at first, each lens is modelled in isolation and its information content is compressed into a handful of parameters summarising the mass distribution of the lens. These inferences on the individual lens parameters are then combined to constrain a model for the lens population. Here we focus mostly on the second step.
We simulate samples of 1000 lenses and then try to recover the properties of their population distribution with a Bayesian hierarchical inference method. We then emulate the lens modelling step: each lens is assumed to be spherical and the observational constraints are compressed into the positions of the two brightest images of a strongly lensed source and the ratio of the radial magnification at these two locations. This choice allows us to greatly simplify the computational burden of our experiment with respect to a real-world case, while still enabling us to explore the sensitivity of the inference method to a variety of possible systematic effects. These include non-trivial variations in the functional form of the distribution of individual lens parameters, departures of the true dark matter density profile from the family of parameterised models assumed in the fit, and uncertainties in the lens selection function. We base our simulations both on existing constraints on the structure of strong lenses and on predictions from hydrodynamical simulations.
While it is common to add stellar kinematics constraints to strong lensing data, we do not explore such a possibility here. This is because in order to model stellar kinematics measurements it is necessary to make a series of additional assumptions, for instance on the geometry of the lens and the distribution of the stellar orbits, each of which could introduce a systematic bias that is difficult to quantify. Instead, we are interested in finding the precision and accuracy with which strong lensing, with the addition of spectroscopic measurements of the lens and source redshift, can constrain the stellar and dark matter distribution of a large sample of galaxies.
The structure of this paper is as follows. In Sect. 2 we introduce the basic concept of strong lensing, including a section describing the aspects of individual lenses that photometric observations can typically constrain. In Sect. 3 we describe the simulation of the lens population on which our experiments are based. In Sect. 4 we describe the inference method used to analyse the lens sample. In Sect. 5 we show the results of our inference, along with several tests used to quantify the importance of various possible systematic effects. In Sect. 6 we discuss our results and in Sect. 7 provide our conclusions. The Python code used for the simulation and analysis of our lens sample can be found in a dedicated section of a GitHub repository6.
2. Strong lensing theory
2.1. Basics
Throughout this work we assume that lenses are (i) isolated, that is they consist of only one galaxy and its dark matter halo, and (ii) circularly symmetric. Under these assumptions and in the thin lens approximation, which is always valid in the galaxy-scale regime (Schneider et al. 1992), the lensing properties of a galaxy depend exclusively on its surface mass density projected along the line-of sight, Σ(θ), where θ is the angular coordinate along an arbitrary axis in the lens plane, also referred to as the image plane, with origin at the lens centre. A background source at angular position β will form images at positions θ in the lens plane that are solutions of the lens equation:
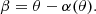 (1)
(1)
The variable α(θ) is the deflection angle and can be calculated from the mass distribution of the lens:
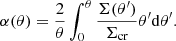 (2)
(2)
The integral in the above equation is proportional to the projected mass enclosed within θ, divided by the critical surface mass density Σcr. This is defined as
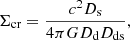 (3)
(3)
where c is the speed of light and Dd, Ds, and Dds are the angular diameter distances between the observer and the lens, the observer and the source, and the lens and the source, respectively. The ratio between the surface mass density of the lens and the critical surface mass density of the lens–source system is defined as the dimensionless surface mass density:
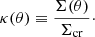 (4)
(4)
An axisymmetric lens with surface mass density that declines monotonically with distance from the centre can produce either one, two, or three multiple images of the same background source, depending on the source position and on the dimensionless surface mass density profile κ(θ). Assuming that β > 0, one image is always produced at θ1 > θEin, where θEin is the radius of the tangential critical curve or Einstein radius, defined as the solution of the lens equation for β = 0:
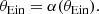 (5)
(5)
Depending on the source position, a second image may appear at position θ2, with −θEin < θ2 < 0, in which case the source is strongly lensed. A third fainter image may be present at position θ3 with θ2 < θ3 < 0.
As an illustrative example we consider the case of a power-law lens, with deflection angle given by
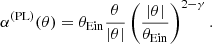 (6)
(6)
This corresponds to the deflection induced by a spherically symmetric mass distribution with 3D density profile ρ(r) ∝ r−γ.
In Fig. 1 we plot the quantity θ − α(θ) for two different values of the power-law index γ and fixed Einstein radius. For each lens, images of a background source at position β form at values of θ where the horizontal dashed line intersects the curve, as these points are the solutions to the lens equation. If γ < 2, corresponding to a shallower-than-isothermal density profile, the curve θ − α(θ) has two stationary points at non-zero values of θ and, as a result, three images form, provided that β is sufficiently small. These stationary points correspond to the radial critical curve, that is the curve in the image plane where the magnification in the radial direction of an image is infinite.
 |
Fig. 1. Solutions of the lens equation for axisymmetric power-law lens models. The coloured solid curves show θ − α(θ) as a function of θ for two lenses with the same Einstein radius and different values of the density slope parameter γ. The horizontal dashed line marks the position β of a background source. Its images form at solutions of the lens equation, β = θ − α(θ), indicated by the vertical dotted lines with the colour of the corresponding lens model. For the lens with density profile shallower than isothermal, γ < 2, three images form, while the γ > 2 lens produces only two images. The slope of the θ − α(θ) curve is the inverse of the radial magnification. Stationary points, only visible in the γ < 2 case, correspond to the radial critical curve. |
The radial magnification is given by
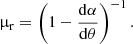 (7)
(7)
This is the inverse of the derivative of the function θ − α(θ), and is therefore infinite at the stationary points of the function plotted in Fig. 1. The total magnification of an image is given by the product between the radial magnification and the magnification in the tangential direction, which is given by
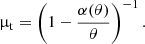 (8)
(8)
As θ approaches the centre of the lens, the ratio α/θ becomes very large, and μt tends to zero: for this reason, images close to the centre are typically very faint.
By mapping the radial critical curve to the source plane through the lens equation, we find the position βr of the radial caustic, which delimits the region in the source plane where sources can be strongly lensed: sources with β > βr are not strongly lensed into multiple images. However, not all lenses have a radial critical curve, as can be seen in Fig. 1 in the γ > 2 case. Lenses of this kind always produce two images. Nevertheless, as the source position moves farther away from the lens, the position θ2 of the second image gets progressively closer to the centre; both its tangential and radial magnification approach zero, making it invisible. Regardless of the number of multiple images, in our analysis we only consider the two brighter ones, θ1 and θ2, as central images are hardly ever observed in galaxy-scale lenses (see Schuldt et al. 2019, for a notable exception).
2.2. Constraints on lens models
The standard approach to obtaining information on the mass distribution of a lens galaxy involves fitting a lens model to strong lensing data. The data consist usually of an image of the lens and the strongly lensed background source, typically made of a large number of pixels. Modelling a lens requires reproduction of the full surface brightness distribution of the lens and the source. This is a mature technique (see e.g. Warren & Dye 2003; Suyu et al. 2006; Vegetti & Koopmans 2009; Birrer & Amara 2018), but a time-consuming one, both in terms of human and computational effort. In order to carry out our experiment within a reasonable time-frame, we emulate the lens modelling process. Instead of simulating realistic images of lenses and modelling them, we compress the information content of a lens into a handful of summary observables: the positions and sizes of the two images. These quantities can be measured robustly with currently available lens modelling tools. In this section we discuss the properties of a lens that can be recovered with these summary observables.
Two image positions can be used to constrain two degrees of freedom in a lens model. One of these degrees of freedom must be the position β of the source, while the other one can be a quantity related to the mass distribution of the lens, for instance the Einstein radius, which can be determined very robustly (i.e. in a model-independent way) when the image configuration is close to symmetric.
When the background source is extended, the two main images have arc-like shapes. If they are well resolved, it is possible to obtain additional constraints on the density profile of the lens by modelling their full surface brightness distribution. In particular, the width of each arc is proportional to the radial magnification of the lens at its position. While the radial magnification of a single arc is degenerate with the size of the source, which is unknown unless it is a standard ruler, the ratio between the two arc widths is independent of source size and can be used to constrain an additional degree of freedom in the density profile of a lens. More precisely, the radial magnification ratio is closely related to the third derivative of the lens potential around θEin (see e.g. Sonnenfeld 2018).
When lens models with a power-law radial dependence of the deflection angle –described by Eq. (6)– are used to fit high-resolution images of strongly lensed extended sources, the slope γ of the density profile can be determined from the radial magnification ratio information. However, the inferred value of γ can be more or less sensitive to the radial magnification ratio, depending on the image configuration. We illustrate this concept in Fig. 2, where we plot the radial magnification ratio between image 1 and 2,
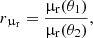 (9)
(9)
 |
Fig. 2. Radial magnification ratio between image 1 and 2 for a lens with a power-law density profile, as a function of the power-law index γ. Curves obtained for image configurations with different values of the asymmetry parameter ξasymm defined in Eq. (10) are shown. The vertical shaded region indicates the typical uncertainty on the power-law slope, Δγ = 0.05, obtained by modelling high-resolution images of strongly lensed extended sources (Shajib et al. 2021). The horizontal shaded region is the uncertainty on rμr corresponding to an error on the power-law slope of Δγ = 0.05 in the case of an image asymmetry ξasymm = 0.4. |
as a function of the slope γ, for a few values of the asymmetry parameter ξasymm, defined as
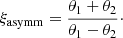 (10)
(10)
For more asymmetric image configurations (larger values of ξasymm), the curve rμr(γ) is steeper, meaning that a small change in the density slope of the lens model results in a relatively large change in the predicted radial magnification ratio compared to a case in which the image configuration is close to symmetric. If rμr is determined with a given uncertainty Δrμr, the propagated uncertainty on γ becomes greater as the value of ξasymm decreases. In the limiting case in which the image consists of a perfect Einstein ring, when the source is at β = 0, the radial magnification ratio between the images is one, independently of the mass model, and therefore it does not have any constraining power.
Based on the above argument, and owing to the popularity of power-law lens models, it is sometimes said that by modelling the full surface brightness distribution of a strongly lensed source it is possible to measure the local slope of the projected density profile at the location of the Einstein radius. While this statement is true under the assumption that the true density profile of a lens is strictly a power law, it does not hold in general: given a power-law lens model that reproduces the observed image positions and radial magnification ratio, it is always possible to find alternative solutions that fit the data equally well and have different values of the local density slope, because of the mass–sheet degeneracy (Falco et al. 1985). For example, Birrer et al. (2020) found that the strong lensing data from the TDCOSMO sample (Millon et al. 2020) can be fitted equally well with a pure power-law model or the sum of a scaled-up version of it and a constant mass sheet accounting for up to 10% of the mass within the Einstein radius.
2.3. The non-axisymmetric case
Almost all strong lenses exhibit some departure from axial symmetry. The biggest qualitative difference with respect to the axisymmetric case is that, in the general case, more images of the background source can be formed. Nevertheless, when the source is extended, the image configuration still usually consists of a main arc and a counter-image. We can then still summarise the information content of the images of a strongly lensed source with two positions and a radial magnification ratio obtained by comparing the relative widths of the arcs. As in the axisymmetric case, for a lens with elliptical symmetry, the value of rμr depends primarily on the third radial derivative of the lens potential at the Einstein radius (compare Eqs. (16) and (36) of Sonnenfeld 2018). Therefore, the constraining power on the radial mass distribution of such a lens is similar to the axisymmetric case considered in the previous section. This justifies our choice to treat the lenses as axisymmetric in our experiment.
3. Simulations
In this section we describe the procedure that we used to simulate a sample of strong lenses. We generated strong lenses directly, as opposed to first simulating a population of galaxies and then applying a strong lensing selection. However, as we explain in Sect. 3.4, we still take into consideration the fact that some strong lenses are more easily detectable than others when assigning a source to each lens.
Each lens in our sample consists of the sum of a stellar component and a dark matter halo, both concentric and with axial symmetry. For the sake of saving computational time, all lenses were taken to be at the same redshift, zd = 0.4, and all sources were placed at redshift zs = 1.5. These values are close to the average of the expected distribution in lens and source redshift from a survey like Euclid (Collett 2015). However, our experiment can be generalised to the more realistic case of lenses and sources being distributed in redshift space. In the following sections we describe the properties of each element of the lenses and their population distribution in detail.
3.1. Stellar component
We describe the stellar mass distribution within each galaxy as a de Vaucouleurs profile:
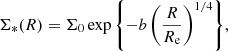 (11)
(11)
where
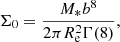 (12)
(12)
M* is the total stellar mass, b ≃ = 7.669 is a numerical constant that ensures that the mass enclosed within a radius equal to R = Re is M*/2 (Ciotti & Bertin 1999), and Γ is the complete gamma function.
With 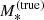 we indicate the true stellar mass of a galaxy. In addition, we introduce a ‘stellar population synthesis stellar mass’,
we indicate the true stellar mass of a galaxy. In addition, we introduce a ‘stellar population synthesis stellar mass’, 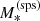 , defined as the stellar mass an observer would measure by fitting a stellar population synthesis model to multi-band photometric data with no errors. The quantity
, defined as the stellar mass an observer would measure by fitting a stellar population synthesis model to multi-band photometric data with no errors. The quantity 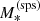 is directly accessible from observations, while
is directly accessible from observations, while 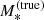 is not. The former is needed to simulate stellar mass measurements on the lens sample. The relation between
is not. The former is needed to simulate stellar mass measurements on the lens sample. The relation between 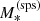 and
and 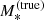 is described by a parameter αsps, which is defined as
is described by a parameter αsps, which is defined as
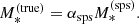 (13)
(13)
We refer to αsps as the stellar population synthesis mismatch parameter.
In past studies, the ratio between the true stellar mass and 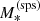 is usually called the initial mass function (IMF) mismatch parameter, based on the fact that the dominant source of systematic uncertainty when measuring stellar masses photometrically is the choice of the IMF. However, other choices made during the stellar population synthesis phase, such as priors on the metallicity or the details of the treatment of various evolutionary phases of a stellar population, can also introduce systematic biases in the observed stellar masses. At the precision level that can be reached with large samples of lenses, such systematic errors can be important. We therefore use a more general definition for αsps.
is usually called the initial mass function (IMF) mismatch parameter, based on the fact that the dominant source of systematic uncertainty when measuring stellar masses photometrically is the choice of the IMF. However, other choices made during the stellar population synthesis phase, such as priors on the metallicity or the details of the treatment of various evolutionary phases of a stellar population, can also introduce systematic biases in the observed stellar masses. At the precision level that can be reached with large samples of lenses, such systematic errors can be important. We therefore use a more general definition for αsps.
We drew values of 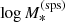 from a Gaussian distribution with mean 11.4 and dispersion 0.3:
from a Gaussian distribution with mean 11.4 and dispersion 0.3:
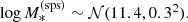 (14)
(14)
This roughly matches the stellar mass distribution of known samples of strong lenses when measured under the assumption of a Chabrier IMF (Auger et al. 2010a; Sonnenfeld et al. 2013b, 2019a). We then assigned a half-mass radius to each lens, drawn from the following log-Gaussian distribution with a mean that scales linearly with 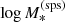 :
:
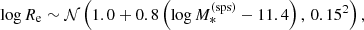 (15)
(15)
where the values of the coefficients were chosen to approximately reproduce the observed stellar mass–size relation of strong lenses from the Sloan Lens ACS Survey (SLACS, Auger et al. 2010a). Finally, we set log αsps = 0.1 for all lenses in the sample. This is in the middle of the range of values of the IMF mismatch parameter of strong lenses found in the literature (Smith et al. 2015; Posacki et al. 2015; Sonnenfeld et al. 2019a).
3.2. Dark matter halo
We drew dark matter halo masses from a log-Gaussian distribution with mean that scales with the stellar mass of a galaxy:
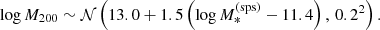 (16)
(16)
The halo mass M200 is defined as the mass enclosed within a spherical shell with mean density equal to 200 times the critical density of the Universe.
We used results obtained from hydrodynamical simulations to define the density profile of each dark matter halo. These consists of modifications to the halo profile found in dark-matter-only simulations, where halos follow a universal profile that is well described by the Navarro, Frenk & White functional form (NFW; Navarro et al. 1997):
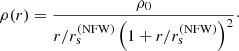 (17)
(17)
For simplicity, in our mocks we imposed a fixed relation between 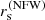 and M200. In particular, we set
and M200. In particular, we set
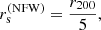 (18)
(18)
where r200 is the virial radius, that is the radius of the spherical shell enclosing a mass equal to M200. This corresponds to all halos having the same concentration, 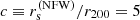 .
.
The condensation of cold gas at the centre of their halos and the growth of the stellar component leads to deviations (e.g. Blumenthal et al. 1986; Gnedin et al. 2004) from the NFW profile that are largest in the inner regions of halos, which is the very regime probed by strong lensing. We calculated the changes in the dark matter distribution using the Cautun et al. (2020) relation which has been empirically derived from the EAGLE and Illustris simulations (Vogelsberger et al. 2014; Schaye et al. 2015). The enclosed 3D dark matter mass, MDM(< r), as a function of distance from the halo centre is taken as
![Mathematical equation: $$ \begin{aligned} M_{\rm DM}({<}r) = (1-f_{\rm bar})M^\mathrm{(NFW)}({ < }r) \left[0.45 + 0.38 \left( \eta _{\rm bar} + 1.16 \right)^{0.53}\right] , \end{aligned} $$](/articles/aa/full_html/2021/07/aa40549-21/aa40549-21-eq30.gif) (19)
(19)
where fbar is the cosmic baryon fraction and M(NFW)(< r) is the enclosed mass of the NFW profile that describe the halo in a dark-matter-only simulation. The ηbar(< r) parameter describes the level of radial concentration of the baryons with respect to dark matter, and is given by the ratio between the actual enclosed baryonic mass and the expected mass distribution, fbarM(NFW)(< r), assuming baryons follow the same radial profile as the dark matter.
In Fig. 3 we show as an example the projected dark matter density profile obtained with the above procedure for a galaxy with stellar mass log M* = 11.5, half-light radius Re = 7 kpc, and halo mass log M200 = 13. In the same plot, we show the original NFW density profile of an uncontracted dark matter halo with the same mass (cyan line).
 |
Fig. 3. Projected surface mass density of a dark matter halo with mass log M200 = 13, contracted following the procedure described in Sect. 3.2 (magenta line). Cyan line: original, pre-contraction dark matter halo described by an NFW profile. Blue dotted line: gNFW profile fitted to the contracted dark matter halo. Black line: stellar component of the lens, consisting of a de Vaucouleurs profile with total mass log M* = 11.5 and half-light radius Re = 7 kpc. The values of the halo mass, stellar mass, and half-light radius are close to the median of the distribution of the simulated lens sample. |
By applying the prescriptions described so far, we generated a sample of 1000 lenses. In Fig. 4 we show the distribution in Einstein radius of the sample. The bulk of the sample has an Einstein radius in the range 0.5″ < θEin < 2.0″. This is similar to existing samples of lenses such as the SLACS and the Strong Lensing Legacy Survey (SL2S, Sonnenfeld et al. 2013b).
 |
Fig. 4. Distribution of the Einstein radii of a sample of 1000 lenses, simulated following the procedure described in Sect. 3. |
3.3. Generalised NFW approximation
The dark matter density profile introduced above is not described by an analytic expression. However, when fitting lensing observations it is convenient to work with analytical models. A relatively popular choice for the parameterisation of the dark matter density profile of strong lenses is the generalised Navarro Frenk & White (gNFW) profile:
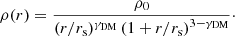 (20)
(20)
A gNFW profile has one additional degree of freedom compared to the standard NFW model: the inner density slope γDM. As we explain in Sect. 4, this is the dark matter density profile that we adopt in the model that we use to fit the simulated data.
With the goal of understanding how well a gNFW profile can approximate our simulated dark matter halos, we fitted the projected dark matter density of each lens with a gNFW profile. The fit was done by finding the values of γDM and rs that minimise the difference in projected density on a grid of points logarithmically spaced between 1 and 30 kpc, while keeping the value of the halo mass fixed. The best-fit gNFW model corresponding to the contracted dark matter halo of Fig. 3 is shown as a red-dotted line in the same plot. The best-fit values of the inner slope and scale radius are γDM = 1.57 and rs = 180 kpc (approximately a factor of 2.3 larger than the scale radius of the original NFW halo).
As the amount of halo contraction depends on the ratio between baryonic and dark matter mass and on the final distribution of the baryons, we expect the inner dark matter slope to be steeper in galaxies with a larger ratio between stellar and halo mass and with a smaller size for a given stellar mass. Such correlations are indeed observed in our simulated sample, as shown in the left and middle panels of Fig. 5.
 |
Fig. 5. Left panel: inner density slope of the dark matter halo of the simulated lenses, γDM, obtained by fitting a gNFW density profile to the projected surface mass density of a lens, as a function of the logarithm of the ratio between the stellar and dark matter halo mass. Middle panel: γDM as a function of the logarithm of the ratio between the stellar half-mass radius and the average half-mass radius of galaxies with the same stellar mass. The latter is given by Eq. (15). Right panel: γDM as a function of the gNFW concentration parameter, defined as the ratio between the virial radius and the scale radius obtained from the gNFW profile fit. The vertical dashed line marks the value of c200 adopted for the NFW profile describing the initial (pre-contraction) density profile of the dark matter halo. |
In the right panel of Fig. 5, we plot γDM as a function of the concentration parameter 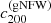 , defined as the ratio between the virial radius and the scale radius of the best-fit gNFW profile,
, defined as the ratio between the virial radius and the scale radius of the best-fit gNFW profile, 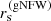 . We see that γDM is negatively correlated with
. We see that γDM is negatively correlated with 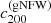 and that the value of the latter is almost always smaller than 5, which is the value of the concentration adopted for the initial (pre-contraction) NFW dark matter density profile.
and that the value of the latter is almost always smaller than 5, which is the value of the concentration adopted for the initial (pre-contraction) NFW dark matter density profile.
3.4. Background source position
In a complete sample of strong lenses, the position of the source and that of the lens are not causally related. Therefore, drawing source positions from a uniform distribution in space appears to be an appropriate choice in such a case. However, the farther away the source is from the optical axis, the more asymmetric the image configuration is. Strong lenses with a highly asymmetric image configuration are very difficult to find and model, because the second image tends to be highly de-magnified.
We want to exclusively simulate lenses that can realistically be part of a strong lens sample; therefore, we set a limit to how far from the optical axis a source can be for a given lens, based on the corresponding magnification of the second image. In particular, we found the smallest value of β for which the magnification of the second image reaches a minimum allowed value of μmin = 1. We refer to this value as βmax. We then drew a value of β from a uniform distribution within a circle of radius βmax:
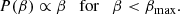 (21)
(21)
This is a simplification of what we expect the source position distribution to be in real samples of lenses. The detection efficiency of a lens survey depends not only on the magnification of the second image, but also on the source surface brightness and possibly on the contrast with the lens light. However, for the purpose of our experiment, the most important feature is the fact that the source position distribution is modified in a non-trivial way from a uniform distribution within the region that is mapped into multiple images. The resulting distribution in ξasymm is shown in Fig. 6.
 |
Fig. 6. Distribution in the image configuration asymmetry parameter ξasymm, defined in Eq. (10), of 1000 lenses simulated following the procedure described in Sect. 3. |
3.5. Observational data
For each lens, we assume that the positions of the two brightest images, θ1 and θ2, are measured exactly. This is a good approximation, because the observational errors on image positions are typically very small (much less than a pixel). We then assume that the radial magnification ratio between the two images can be measured with a Gaussian error of Δrμr = 0.05. We model this by adding a Gaussian random error with a mean of zero and a dispersion of 0.05. We indicate the observed radial magnification ratio as 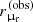 to distinguish it from the true value. As Fig. 2 shows, for an image configuration asymmetry of ξasymm = 0.4 (a standard value of this quantity), this translates into an error of 0.05 on the slope of the density profile of a power-law model, which is the typical uncertainty achieved in lens modelling with current high-resolution data (Shajib et al. 2021). Finally, we added a log-Gaussian noise of 0.15 dex to the stellar population synthesis-based stellar masses and indicate the resulting values as
to distinguish it from the true value. As Fig. 2 shows, for an image configuration asymmetry of ξasymm = 0.4 (a standard value of this quantity), this translates into an error of 0.05 on the slope of the density profile of a power-law model, which is the typical uncertainty achieved in lens modelling with current high-resolution data (Shajib et al. 2021). Finally, we added a log-Gaussian noise of 0.15 dex to the stellar population synthesis-based stellar masses and indicate the resulting values as 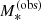 . Lens and source redshifts and lens half-light radii are assumed to be known exactly. These can typically be determined with very high precision when spectroscopic measurements are available (see e.g. Sonnenfeld et al. 2019a).
. Lens and source redshifts and lens half-light radii are assumed to be known exactly. These can typically be determined with very high precision when spectroscopic measurements are available (see e.g. Sonnenfeld et al. 2019a).
4. Inference method
We have a mock sample of 1000 strong lenses, each with measurements of two image positions, radial magnification ratios, and stellar-population-synthesis-based stellar masses generated as described in Sect. 3. We want to use these data to characterise the distribution of the parameters describing the inner structure of strong lenses. We adopt a Bayesian hierarchical approach for this purpose.
We assume that the density profile of each lens can be described with a handful of parameters. We then assume that these parameters are all drawn from a common probability distribution describing the population of lenses. This population distribution is in turn summarised by a small number of high-level parameters, which we refer to as hyper-parameters. Our goal is to constrain the hyper-parameters describing the population. In the following sections, we describe the different elements of this technique in detail. For past examples of applications of the hierarchical inference formalism to samples of strong lenses, we refer to Sonnenfeld et al. (2015, 2019a).
4.1. Individual lens parameters
We describe each lens as the sum of a stellar component and a dark matter halo. We model the stellar component with a de Vaucouleurs profile, which we parameterise by means of the true stellar mass 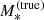 and the half-light radius Re. However, in order to compare our model to the observed stellar mass measurements, it is also necessary to provide the value of the stellar population synthesis stellar mass,
and the half-light radius Re. However, in order to compare our model to the observed stellar mass measurements, it is also necessary to provide the value of the stellar population synthesis stellar mass, 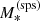 . Three parameters then describe the stellar component.
. Three parameters then describe the stellar component.
We model the dark matter component with a gNFW profile. As explained in Sect. 3.3, a gNFW profile has three degrees of freedom. However, we are only interested in constraining the average dark matter mass and density slope on the scales probed by strong lensing observations. We believe that a model with two degrees of freedom in the dark matter density profile is sufficient for that purpose; therefore, we fixed the scale radius to a value of rs = 100 kpc for the sake of reducing the dimensionality of the problem7. With the goal of working with quantities that are well constrained by our data, we parameterised the dark matter distribution with the projected mass enclosed within 5 kpc, MDM, 5, and the inner slope γDM.
Each lens system is then described by a set of six parameters: the true stellar mass, the stellar population synthesis stellar mass, the half-light radius, the projected dark matter mass within 5 kpc, the inner dark matter density slope, and the position of the source galaxy. We refer to these parameters collectively as
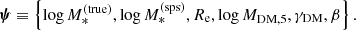 (22)
(22)
We point out that, on an individual lens basis, the model is under-constrained, as only five observables per lens are available: the two image positions, the radial magnification ratio, and the observed stellar mass and half-light radius. We rely on the large sample size and on our statistical model to gain precision on the properties of the lens sample as a whole.
4.2. Lens population distribution
The individual lens parameters defined in the previous section are drawn from a probability distribution P(ψ|η), where η are the hyper-parameters that describe the population of lenses, and that we want to infer. We have the freedom to assert a functional form for this distribution. Our model must have sufficient flexibility to capture the key features of the lens population that we want to measure. In our case, these features are the average dark matter mass, the average inner dark matter slope, the intrinsic scatter of the dark matter distribution, and the average stellar population synthesis mismatch parameter. One of the simplest models that can allow us to constrain these properties is the following:
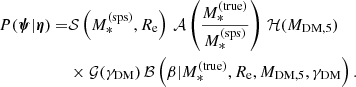 (23)
(23)
Each term in the above equation describes the distribution of a different property of the lens-source system. We now proceed to describe these terms and provide a motivation for each choice.
The term 𝒮 in the above equation represents the distribution in the stellar population synthesis stellar mass and half-light radius of the lenses. This term needs to be constrained with the measurements of 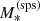 and Re of the lens sample. In order to simplify our calculations, we assume that it is known exactly, which means that we fix 𝒮 to the product of the two Gaussians of Eqs. (14) and (15). This is a reasonable assumption, as the distribution in stellar mass and half-light radius of a sample of thousands of galaxies can be determined with high precision (see e.g. Sonnenfeld et al. 2019b).
and Re of the lens sample. In order to simplify our calculations, we assume that it is known exactly, which means that we fix 𝒮 to the product of the two Gaussians of Eqs. (14) and (15). This is a reasonable assumption, as the distribution in stellar mass and half-light radius of a sample of thousands of galaxies can be determined with high precision (see e.g. Sonnenfeld et al. 2019b).
The next term in Eq. (23), labelled 𝒜, describes the distribution in the stellar population synthesis mismatch parameter αsps, defined in Eq. (13). In principle, this parameter can vary from lens to lens. For simplicity, we assume a single value in our model for the whole population of lenses. Therefore, we write 𝒜 as a Dirac delta function:
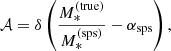 (24)
(24)
where αsps is a hyper-parameter of the model in the sense that it describes the distribution of the stellar population synthesis mismatch parameter of the whole population.
The term ℋ describes the distribution in dark matter mass of the lens sample. We assume that it has a log-Gaussian functional form,
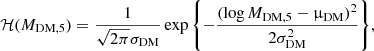 (25)
(25)
with mean μDM and intrinsic scatter σDM.
The term 𝒢 describes the distribution of the inner dark matter slope. We assume a Gaussian distribution for it, truncated for γDM < 0.8 and γDM > 1.8:
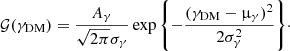 (26)
(26)
The coefficient Aγ is a normalisation constant that ensures that the integral over γDM of 𝒢 on its support, (0.8, 1.8), is one.
The motivation for the upper bound on γDM is that we assert that the density profile of the dark matter halo must be shallower than that of the total matter. As typical lenses have a total density profile close to isothermal, ρ(r) ∝ r−2 (Koopmans et al. 2006), this is achieved by truncating the distribution of the dark matter slope at γDM = 1.8. The lower bound at γDM = 0.8 is imposed purely to speed up computations by reducing the volume of the parameter space. We verified that the results do not change by modifying the value of the lower bound.
Finally, the term ℬ describes the distribution in the source position β. As explained in Sect. 3.4, this is directly related to the selection function of the strong lens sample: at fixed lens density profile, the position of the source determines the brightness of the multiple images and therefore their detectability. For simplicity, we assume that the source position distribution, and implicitly also the lens sample detection efficiency, are known exactly. We discuss the impact of this assumption in Sect. 6.1. Given the procedure that was used to assign source positions to the mock lenses, the term ℬ is therefore
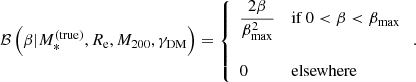 (27)
(27)
In other words, the source position distribution is uniform within a circle of radius βmax, where βmax is the smallest8 value of β for which the magnification of the second image is equal to μmin = 1. The value of βmax depends in turn on the lens structural parameters M*, Re, M200 and γDM.
We refer to the model described so far as the ‘base model’, to distinguish it from more complex models that we introduce in the following section. We stress that this model does not correspond to the true mass distribution of the simulated sample of lenses for any value of its hyper-parameters because of the differences in the description of the dark matter density profile (both on a single lens basis and in terms of the population distribution). This was a deliberate choice, the aim being to reproduce the conditions of an inference on real data, in which any model that is fitted is inevitably only an approximation of the truth.
4.3. Inference technique
We need to estimate the posterior probability distribution function of the model hyper-parameters given the data, P(η|d). From Bayes theorem, this is proportional to the product of the prior probability of the hyper-parameters, P(η), multiplied by the likelihood of observing the data given the hyper-parameters, P(d|η):
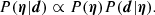 (28)
(28)
As measurements performed on the different lenses are independent of each other, the likelihood can be written as the following product over the lenses:
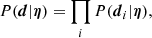 (29)
(29)
where di indicates the observational data of the ith lens. These consist of the two image positions  , the radial magnification ratio
, the radial magnification ratio 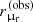 , the observed (stellar population model-dependent) stellar mass
, the observed (stellar population model-dependent) stellar mass 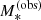 , and related uncertainties.
, and related uncertainties.
In addition to the hyper-parameters, these data depend on the parameters describing each lens, ψi. In order to evaluate P(di|η), it is therefore necessary to consider all possible values taken by the individual lens parameters ψi, that is to marginalise over them:
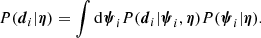 (30)
(30)
Formally, ψi is a six-dimensional variable. Of the integrals over these dimensions, the one over Re is a trivial one, as we assume that the half-light radius is measured exactly (the likelihood in the half-light radius is a Dirac delta function centred on the true value). Consequently, at fixed true stellar mass 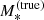 , the integral over
, the integral over 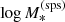 returns the value of the integrand evaluated at
returns the value of the integrand evaluated at 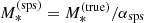 . In other words, the value of the hyper-parameter αsps and the value of
. In other words, the value of the hyper-parameter αsps and the value of 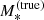 determine
determine 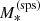 exactly. Equation (30) subsequently becomes the following four-dimensional integral:
exactly. Equation (30) subsequently becomes the following four-dimensional integral:
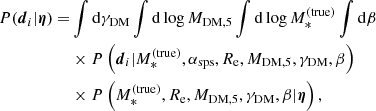 (31)
(31)
where we omit the subscript i on the lens parameter variables for the sake of keeping the notation compact. Because the two image positions are measured exactly, two of these integrals are integrals over Dirac delta functions, which can be computed analytically. As we show in Appendix A, integrating over β and 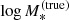 we obtain
we obtain
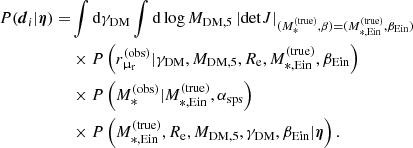 (32)
(32)
In the above equation, 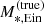 and βEin are the values of the stellar mass and source position that, for a given combination of the parameters (MDM, 5, γDM), are needed to reproduce the two image positions,
and βEin are the values of the stellar mass and source position that, for a given combination of the parameters (MDM, 5, γDM), are needed to reproduce the two image positions, 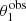 and
and 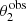 . The term detJ is the Jacobian determinant corresponding to the following variable change,
. The term detJ is the Jacobian determinant corresponding to the following variable change,
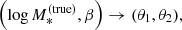 (33)
(33)
evaluated at 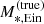 and βEin. The Jacobian determinant is also a function of MDM, 5 and γDM.
and βEin. The Jacobian determinant is also a function of MDM, 5 and γDM.
Equation (32) is a two-dimensional integral. While this is much more tractable than that of Eq. (31), it still needs to be evaluated numerically. The precision requirement on the calculation of these integrals is very high: as the likelihood of the hyper-parameters given the data, Eq. (29), is the product of a thousand such terms, a small systematic error in the calculation of Eq. (32) can introduce large biases in the posterior probability. For instance, a 0.1% error on each P(di|η) term translates into a factor 2.7 error on the product of 1000 such terms.
We calculated the integrals of Eq. (32) via spline integration. We first defined a two-dimensional grid in the (γDM, log MDM, 5) parameter space. We then evaluated the integrand function at each point on the grid. This required calculation of the values of 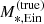 , βEin, and detJ for each value of (γDM, log MDM, 5), which was done only once per lens at the beginning of the analysis. Subsequently, for each value of γDM on the grid, we approximated the integrand function with a third-order polynomial spline in log MDM, 5 and used it to integrate over log MDM, 5. Finally, we repeated this procedure over the γDM variable.
, βEin, and detJ for each value of (γDM, log MDM, 5), which was done only once per lens at the beginning of the analysis. Subsequently, for each value of γDM on the grid, we approximated the integrand function with a third-order polynomial spline in log MDM, 5 and used it to integrate over log MDM, 5. Finally, we repeated this procedure over the γDM variable.
We sampled the posterior probability distribution of the hyper-parameters given the data using EMCEE (Foreman-Mackey et al. 2013), the Python implementation of the affine-invariant sampling method introduced by Goodman & Weare (2010). We assumed flat priors over finite intervals for all hyper-parameters, as described in the first column of Table 1. We verified that our inference method is accurate by applying it to a mock sample of lenses generated from the same model family assumed in this section. We also verified that the inference is converged with respect to the resolution of the (γDM, log MDM, 5) grid used for the computation of the integrals of Eq. (32).
Inference on the hyper-parameters of the base model given mock data from a sample of 1000 strong lenses.
5. Results
Figure 7 shows the posterior probability distribution of the hyper-parameters of the model described in Sect. 4 given the simulated data described in Sect. 3. The median and the 16th and 84th percentiles of the marginal posterior of each hyper-parameter are reported in the second column of Table 1.
 |
Fig. 7. Posterior probability distribution of the hyper-parameters of the model described in Sect. 4, dubbed the ‘base model’, given the mock data of a sample of 1000 lenses generated with the procedure described in Sect. 3. Red lines show the fit to the whole dataset (image positions and radial magnification ratios). Filled contours show the fit to image position only. Contour levels correspond to 68% and 95% enclosed probability regions. Dashed lines indicate the true values of the hyper-parameters, which are defined by fitting each model directly to the distribution of log M200, γDM, and log αsps of the mock sample. |
Both in Fig. 7 and in Table 1 we report the true values of the hyper-parameters. The true values of the hyper-parameters describing the distribution in the dark matter mass and slope were defined by fitting our base model directly to the individual values of MDM, 5 and γDM of the lenses. The inner slope γDM was defined by fitting a gNFW profile with rs = 100 kpc and the true value of MDM, 5 to the projected dark matter mass in the range 1−30 kpc. This procedure is different from the one adopted in Sect. 3.3; therefore, the resulting values of γDM are slightly different from those shown in Fig. 5. Visual inspection suggests that the distributions in MDM, 5 and γDM of the sample appear qualitatively close to Gaussian.
The inference is very precise: the uncertainties on the hyper-parameters are very small compared to current constraints on the dark matter density profile and stellar IMF of strong lenses. However, it is not accurate: the true values of all hyper-parameters lie outside of the 95% credible region of the posterior probability distribution.
5.1. Extending the model
When fitting the base model introduced in Sect. 4 to our mock sample of lenses, we obtain an inference with high precision but poor accuracy. In other words, we are in a systematic-errors-dominated regime. We can try to gain accuracy by adding flexibility to the model. The base model does not allow for correlations between the dark matter parameters and any other property of the lenses. Such correlations are present in the mock sample, as shown in Fig. 5, and more generally it is reasonable to believe that the distribution of stars in a galaxy is linked to the distribution of dark matter.
We then generalise the base model by modifying the mean parameter of the MDM, 5 and γDM distributions as follows:
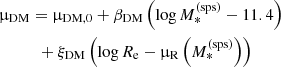 (34)
(34)
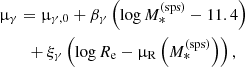 (35)
(35)
where 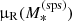 is the average value of log Re of lenses with stellar-population-synthesis-derived stellar mass
is the average value of log Re of lenses with stellar-population-synthesis-derived stellar mass 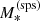 . We introduced four new parameters: βDM and βγ describe the correlation between MDM, 5 and γDM and the stellar mass, while ξDM and ξγ describe correlations between MDM, 5 and γDM and the ratio between the size of a galaxy and the average size of galaxies of the same stellar mass. In principle, we could also add an explicit correlation between MDM, 5 and γDM, but we chose not to for the sake of simplicity. All other aspects of the model are kept as in the base model. We refer to this as the extended model.
. We introduced four new parameters: βDM and βγ describe the correlation between MDM, 5 and γDM and the stellar mass, while ξDM and ξγ describe correlations between MDM, 5 and γDM and the ratio between the size of a galaxy and the average size of galaxies of the same stellar mass. In principle, we could also add an explicit correlation between MDM, 5 and γDM, but we chose not to for the sake of simplicity. All other aspects of the model are kept as in the base model. We refer to this as the extended model.
We first measured the true values of the new set of hyper-parameters related to the inner dark matter slope by fitting the extended model directly to the distribution of γDM. These are reported in Table 2 and shown in Fig. 7 as black dashed lines.
Inference on the hyper-parameters of the extended model given mock data from a sample of 1000 strong lenses.
As the stellar mass increases, the projected dark matter mass within 5 kpc also increases, albeit in a sublinear way: βDM = 0.60. Conversely, the inner dark matter slope decreases: βγ = −0.41. At fixed stellar mass, galaxies with a larger half-light radius have both a smaller dark matter mass and a shallower dark matter slope: ξDM = −0.21 and ξγ = −0.34. The values of μγ and σγ are also modified with respect to those obtained when fitting the base model. In particular, the intrinsic scatter is much smaller: this is because part of the scatter observed in the context of the base model can be accounted for by correlations with 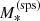 and Re.
and Re.
In Fig. 8 we show the posterior probability distribution of the hyper-parameters of the extended model given the mock data, in red contours. The inferred marginal posterior probability distribution of each parameter is summarised in Table 2. The extended model allows for a much more accurate inference of all hyper-parameters compared to the base model. All true values are recovered, with the exception of the parameter describing the stellar mass dependence of the dark matter slope, βγ.
 |
Fig. 8. Posterior probability distribution of the hyper-parameters of the extended model introduced in Sect. 5.1 given the mock data of a sample of 1000 lenses. Red lines show the fit to the whole dataset (image positions and radial magnification ratios). Filled contours show the fit to image position only. Contour levels correspond to 68% and 95% enclosed probability regions. Dashed lines indicate the true values of the hyper-parameters, which are defined by fitting the each model directly to the distribution of log M200, γDM, and log αsps of the mock sample. |
5.2. Dependence on the data used
The results presented so far are based on fits to image positions and radial magnification ratios of the lenses. The fitting procedure is meant to simulate a situation in which high-resolution imaging data is available for every lens, from which the radial magnification ratios can be obtained. However, when only ground-based imaging data are available, it is not possible to measure radial magnifications, because the strongly lensed arcs are typically not resolved. In this section we investigate how the constraining power of a sample of 1000 lenses changes in such a case.
We repeated the analysis without using any radial magnification information, that is removing the term relative to rμr from the likelihood in Eq. (32), both for the base and the extended models. The posterior probability distributions of the two inferences are shown as purple filled contours in Figs. 7 and 8 and summarised in Tables 1 and 2.
With the base model, a fit to image position information alone produces a highly biased result. Removing radial magnification information does not appear to produce a decrease in precision: the uncertainty on the hyper-parameters is comparable to that attained in the fit to the whole dataset. However, a closer look at the posterior probability distribution reveals that the inference on the average dark matter slope parameter, μγ, is driven by the prior: the values preferred by the data are very close to the lower bound. Presumably, a less restrictive prior on μγ would have resulted in a higher overall uncertainty, and possibly an even more biased inference.
By comparing the results of the fit of the base and extended models to the full dataset, we see that models that are not sufficiently flexible lead to biased inferences. This last test shows, additionally, that the amount of bias increases as the data become less constraining, at least when working with lens samples with similar properties to the mock that we generated.
Fitting the extended model to image positions only (purple contours in Fig. 8) appears to produce a more accurate answer compared to the base model case: for example, the inferred value of αsps is less than 3σ away from the truth. However, there is now a strong degeneracy between the three key parameters of the model: the average dark matter mass, the average dark matter slope, and the stellar-population-synthesis mismatch parameter. We therefore conclude that, in order to disentangle the stellar and dark matter contribution to the total mass of a sample of 1000 strong lenses using only strong lensing data, magnification information is necessary.
6. Discussion
With the experiments presented so far, we quantified the precision and accuracy that can be achieved on the measurement of the distribution of the dark matter density profile and of the stellar mass-to-light ratio of galaxies by statistically combining a sample of 1000 strong lenses. An important assumption on which our analysis is based is that the source position distribution, the term ℬ in Eq. (23), is known exactly when making the inference. We discuss the impact of this assumption in Sect. 6.1. Subsequently, in Sect. 6.2 we describe a general strategy with which to decide whether or not a model is sufficiently flexible to fit the data. In Sect. 6.3 we discuss possible systematic effects that were not explored by our experiment but that could potentially lead to biases in the inference. In Sect. 6.4 we discuss the limitations of our treatment of the lens modelling step. Finally, in Sect. 6.5 we discuss what steps need to be taken in order to successfully apply our analysis method to a real sample of lenses.
6.1. The importance of the source position prior
As discussed above, assuming that the source position distribution is known is equivalent to knowing the strong lensing detection efficiency exactly. This is not a realistic assumption: the process of lens finding consists of several steps, typically including human visual inspection, which introduces selection effects that are difficult to model from first principles. In this section we investigate how critical this assumption is for the accuracy of the inference.
We fitted a modified version of the extended model to the data, in which we adopted an apparently uninformative prior on the source position: we set the model parameter βmax to infinity in Eq. (27). This is equivalent to assuming that the sources are drawn from a uniform distribution in the source plane, with no boundary. The inference on the hyper-parameters describing the average dark matter profile and the stellar population synthesis mismatch parameters are shown in Fig. 9 as blue contours, along with the inference obtained when the prior on the source position is known exactly. There is a −0.02 dex shift in the inference of log αsps, which is larger than the uncertainty on that hyper-parameter. The shift on the inference of the average dark matter slope is even bigger in relation to the corresponding uncertainty.
 |
Fig. 9. Posterior probability distribution of the hyper-parameters μh, 0, μγ, 0, and log αsps obtained under the assumption that source positions are drawn from a uniform distribution in the source plane with no boundary (blue contours) compared to the fiducial inference described in Sect. 5.1 (red contours). |
We therefore conclude that, at the precision level afforded by a sample of 1000 lenses, the choice of the source position prior does affect the inference. This is an example of how a seemingly minor detail, such as modifying the term ℬ in Eq. (23), can have a sizeable impact on the inference, because the posterior probability distribution depends on the product of a thousand such terms. This is an important issue that needs to be addressed when analysing a real sample of lenses, either by working with a sample for which the lens detection probability is well characterised or by developing a method that allows one to infer it directly from the data.
Alternatively, we can avoid modelling the source position distribution by compressing the image position information into a model-independent quantity, such as the Einstein radius. For example, the half-separation between the two images is a good proxy for the Einstein radius; it is exactly equal to the Einstein radius of a singular isothermal sphere lens:
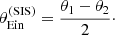 (36)
(36)
Assuming that 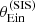 approximates the true Einstein radius of a lens well, we can use it as an observable constraint in place of
approximates the true Einstein radius of a lens well, we can use it as an observable constraint in place of 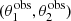 . By doing so, the source position no longer enters the problem explicitly: a derivation similar to that of Sect. 4.3 and Appendix A produces the following expression for the likelihood of observing the data relative to one lens,
. By doing so, the source position no longer enters the problem explicitly: a derivation similar to that of Sect. 4.3 and Appendix A produces the following expression for the likelihood of observing the data relative to one lens,
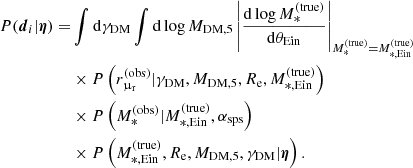 (37)
(37)
In the integral above,  is now the stellar mass needed to produce a total projected mass within the Einstein radius equal to
is now the stellar mass needed to produce a total projected mass within the Einstein radius equal to  , as a function of MDM, 5 and γDM.
, as a function of MDM, 5 and γDM.
By using 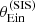 in place of
in place of 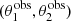 we are discarding part of the available information: we no longer fit the distribution in image configuration asymmetry ξasymm, which is sensitive to the density profile of the lenses. For this reason, we expect the resulting inference to be less precise. We performed such a fit to
we are discarding part of the available information: we no longer fit the distribution in image configuration asymmetry ξasymm, which is sensitive to the density profile of the lenses. For this reason, we expect the resulting inference to be less precise. We performed such a fit to 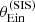 and rμr, the posterior probability distribution of which is shown in green in Fig. 9. As expected, the inference is less precise than that provided by the fiducial analysis. However, it is more accurate than the case in which an unbounded prior on the source position is assumed. Compressing the available information into model-independent observables is then a possible way of trading precision for accuracy in the case where it is not possible to obtain an accurate description of the source position distribution.
and rμr, the posterior probability distribution of which is shown in green in Fig. 9. As expected, the inference is less precise than that provided by the fiducial analysis. However, it is more accurate than the case in which an unbounded prior on the source position is assumed. Compressing the available information into model-independent observables is then a possible way of trading precision for accuracy in the case where it is not possible to obtain an accurate description of the source position distribution.
6.2. Model selection with posterior prediction
An apparent weakness in our approach is the decision process that led to the extension of the model of Sect. 5.1: we implemented the extended model after noticing that the base model was unable to recover the truth and stopped improving it once we realised that the new model afforded an accurate inference. This is something that can only be done if we already know the properties of the lens population in detail. Nevertheless, it is possible to gauge the degree of accuracy of a model by examining its goodness of fit.
When working with Bayesian hierarchical models, goodness of fit is determined with posterior predictive tests: mock observations are generated from the model and these are then compared to selected aspects of the observed data. In our case, the data consists of a distribution of image positions, image magnification ratios, stellar masses, and half-light radii. As an example, we show in this section a posterior predictive test that focuses on image positions.
We start by compressing the data into a handful of summary statistics, which we use as quantities to test our model against. We first reduce the image position distribution to a one-dimensional one by considering the half-separation between images defined in Eq. (36). We then consider the mean and standard deviation of the 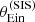 distribution,
distribution, 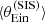 and
and 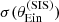 . The goal of our posterior predictive test is to determine how likely it is for our model to produce samples with values of these test quantities that are more extreme than the observed ones.
. The goal of our posterior predictive test is to determine how likely it is for our model to produce samples with values of these test quantities that are more extreme than the observed ones.
We obtained the posterior predicted test quantities as follows. We randomly drew 100 samples from the MCMC of the inference, we generated a sample of 1000 lenses for each draw, measured the value of 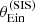 of each lens, and finally computed
of each lens, and finally computed 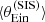 and
and 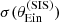 of the sample corresponding to each posterior draw. The resulting posterior predicted distribution of
of the sample corresponding to each posterior draw. The resulting posterior predicted distribution of 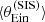 and
and 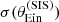 is shown in Fig. 10.
is shown in Fig. 10.
 |
Fig. 10. Posterior predicted distribution in the mean value of |
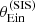
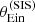
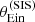
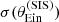
The posterior predicted average 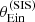 obtained from the base model (red histogram) tends to be smaller than the observed value, but realisations in which
obtained from the base model (red histogram) tends to be smaller than the observed value, but realisations in which 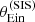 is larger are not uncommon. However, at the same time, all posterior predicted lens samples have a standard deviation in
is larger are not uncommon. However, at the same time, all posterior predicted lens samples have a standard deviation in 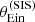 that is smaller than the observed one. This means that, if the base model is a faithful description of the truth, it will be extremely unlikely to find a sample of 1000 lenses with a value of
that is smaller than the observed one. This means that, if the base model is a faithful description of the truth, it will be extremely unlikely to find a sample of 1000 lenses with a value of 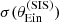 as large as the observed one. We therefore conclude from this test that the base model is unable to reproduce the observed distribution in Einstein radius of the lens sample in detail.
as large as the observed one. We therefore conclude from this test that the base model is unable to reproduce the observed distribution in Einstein radius of the lens sample in detail.
This test on its own tells us that the base model does not provide a good fit, but does not give explicit indications as to how to improve it. Additional posterior predictive tests can provide further insight: for example, the posterior predicted lens samples are also unable to match the observed correlations of 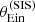 with
with  and Re, which suggests that correlations between the dark matter distribution and the structural parameters of the galaxy might be needed to provide a good description of the sample. The extended model introduced in Sect. 5.1 allows for such correlations and provides a much better match between its posterior predicted Einstein radius distribution and the observed one, as shown by the green histograms in Fig. 10.
and Re, which suggests that correlations between the dark matter distribution and the structural parameters of the galaxy might be needed to provide a good description of the sample. The extended model introduced in Sect. 5.1 allows for such correlations and provides a much better match between its posterior predicted Einstein radius distribution and the observed one, as shown by the green histograms in Fig. 10.
In general, the choice of the test quantity is arbitrary and must reflect the aspect of the model accuracy that the user wishes to assess, depending on their science goal. We are mostly interested in using our model to capture the average properties of the lens population; therefore, we focused on the mean and standard deviation of  , but in principle other choices are possible. For example, to check whether the model is able to reproduce the presence of outliers, one can use a high percentile of the
, but in principle other choices are possible. For example, to check whether the model is able to reproduce the presence of outliers, one can use a high percentile of the  distribution as a test quantity.
distribution as a test quantity.
In summary, posterior predictive tests provide a way of assessing the goodness of fit of a Bayesian hierarchical model and can be used to improve an existing model or discriminate between alternative ones. Nevertheless, we stress that these tests are by no means a way of building a model purely on the basis of the available data: physical insight should always be the guiding principle of any astrophysical model.
6.3. Possible sources of systematic errors
The method presented in this work produces an accurate inference of αsps and the dark matter distribution when our extended model is fitted to a population of lenses with the same properties as the mock that we generated for our experiment. However, there could be scenarios in which the same model returns a biased answer: any discrepancy between the model being fitted and the truth underlying the data is a potential source of bias. In our experiment we focused on what we consider to be the most important unknown in strong lens modelling: the dark matter density profile. Our mock lenses were generated with a non-trivial prescription for determining the dark matter distribution.
In principle, we could increase the complexity of the mock even further, for example by allowing for a bimodality in the dark matter content. Massive galaxies are known to have a bimodal distribution in their inner surface brightness profile (cored or cuspy; see e.g. Lauer et al. 2007) and in their velocity structure (the slow- and fast-rotator dichotomy: see Graham et al. 2018, and references therein), and the lensing and kinematics study of Oldham & Auger (2018) suggest the presence of a bimodal distribution in the inner slope of the dark matter halo.
Moreover, our mock was generated by assuming a single value for the stellar population synthesis mismatch parameter of the whole sample. In reality, there could be variations in the value of αsps among the population (Treu et al. 2010; Cappellari et al. 2012; Conroy & van Dokkum 2012; Sonnenfeld et al. 2015) and even spatial variations within individual objects (van Dokkum et al. 2017; Sonnenfeld et al. 2018b). Redshift evolution of either the dark matter distribution or αsps is also something that might occur in reality but is not considered in our mock.
Finally, the line-of-sight structure also contributes to the observed lensing signal. The lensing effect of the line-of-sight structure can be modelled –at the scale of a single lens– as a constant sheet of mass with surface mass density |κext|≲0.1 (see e.g. Millon et al. 2020). This external mass sheet is degenerate with the dark matter halo of the lens: for example, a positive value of κext can mimic the effect of increasing the dark matter mass enclosed within the Einstein radius and making the dark matter density profile shallower. However, if the line-of-sight structure correlates with the stellar distribution, neglecting it can potentially lead to biases on the inference of αsps as well.
In order to quantify the impact that these possible additional levels of complexity in the true mass structure of lens galaxies can have on the accuracy of the inference, it is necessary to test the method on dedicated simulations. However, this is beyond the goals of the present work.
6.4. Limitations of the lens modelling emulation
In order to reduce the computational burden of our investigation, we emulated the lens modelling step: we assumed that the information content of the strong lensing data of each lens can be summarised with two image positions and a radial magnification ratio. The rationale for the use of the radial magnification ratio is that this quantity is related directly to the radial density profile of the lens and can be measured once the width of the arc and the counter-image are obtained.
On the one hand, this is a conservative choice: in principle, the elongation and curvature of the arcs can also be used to constrain a lens model (although in practice part of this information is needed to determine the azimuthal structure of the lens: see Birrer 2021). On the other hand, when generating the mock we added an observational error of 0.05 to rμr. This value was estimated on the basis of the typical uncertainty on the radial density profile of a lens obtained by Shajib et al. (2021) when modelling high-resolution images of lenses, under the assumption that the constraining power comes primarily from the measurement of the radial magnification ratio (Shajib et al. 2021 also made this assumption in the interpretation of their measurements). However, a small uncertainty on the radial profile can also be the result of fitting a model that has an overly simple azimuthal structure: in such cases, the model is over-constrained and the uncertainty on the radial profile is underestimated (Kochanek 2021). Determining what model-independent quantities can be measured with different aspects of the data is an important problem, but is beyond the scope of this work. Nevertheless, there is the possibility that the true uncertainty on the radial magnification ratio that can be obtained in practice is higher than the value assumed in our experiment. In that case, our predicted uncertainty on the model hyper-parameters will be underestimated.
6.5. Application to real samples of lenses
The inference method presented in this work consists in fitting a model describing the population of lenses directly to the full ensemble of imaging data of a large sample of lenses with a Bayesian hierarchical approach. This method has never been applied to a real sample of lenses. In our experiment we simplified the problem by emulating the lens modelling step, compressing the strong lensing data of each lens down to three numbers. In reality, the data consist of images made of thousands of pixels. In order to fit these data, it is necessary to model the full surface brightness distribution of the lens and of the background source, and, because real lenses are not axisymmetric, to allow for additional degrees of freedom in the mass model related to the azimuthal structure.
Currently available modelling codes are able to deal with these complexities (see e.g. Birrer & Amara 2018; Nightingale et al. 2019): the background source can be reconstructed with a pixellated model and the lens can be modelled as the sum of elliptical mass components. In practice, however, the lens modelling step needs to be automated, as the traditional approach requires a lot of human interaction, an approach that does not scale well to samples of thousands of lenses. Recently, there has been progress on this front: Nightingale et al. (2018) developed an automated lens-modelling algorithm and showed it to be accurate in a variety of cases. Machine learning can also be used to perform fast automated lens parameter inferences (see e.g. Hezaveh et al. 2017; Chianese et al. 2020; Schuldt et al. 2021; Park et al. 2021): in particular, Wagner-Carena et al. (2021) showed how it is possible to carry out hierarchical inferences on lens populations with Bayesian neural networks (Charnock et al. 2020). However, it is not clear whether or not these methods are able to sample the posterior probability distribution of the lens parameters in a way that is sufficiently accurate for our purposes: dedicated tests are needed.
On a related issue, our set of assumptions enabled us to greatly simplify an otherwise very computationally intensive step in our analysis: the marginalisation over the parameters describing individual lenses, Eq. (31). In principle, to compute the likelihood of each set of values of the hyper-parameters, one must average over all possible values taken by many individual lens parameters. In a sample of real lenses, these are at the very least the four parameters already employed in our model, plus additional ones describing the azimuthal structure of each lens and the surface brightness distribution of the source. Moreover, there is the added burden that the data vector is an image instead of a handful of numbers.
Clearly, it is necessary to find a way to approximate the computation of the integrals of the kind of Eq. (31) in practice. The method that we used, namely spline integration on a grid, does not scale well to a higher number of dimensions. One of the most commonly used approaches to compute fast integrals is Monte Carlo integration paired with importance sampling, but that method can lead to biases in cases in which the samples used for the integration do not cover the integrand function well over its entire support. We therefore leave this as a major open computational issue.
One could argue that the marginalisation over the individual lens parameters is not a necessary step in a Bayesian hierarchical analysis: the posterior probability distribution of the full ensemble of parameters, both those describing the population and the individual lens ones, can be explored with a Gibbs sampling approach. While that is true in principle, Gibbs sampling fails to converge in a regime where the individual object parameters are under-constrained by the data, which is the case when fitting complex mass models to strong lensing data, rendering such an approach impractical.
Finally, while all the lenses and sources in our mock are at the same redshift, this is not true in real samples of lenses. Varying the source redshift at fixed lens properties changes the Einstein radius. This means that having a distribution of source redshifts can allow us to probe the mass of the lens at different physical apertures. In principle, this information can be used to better constrain the lens structure: for example, measuring how the Einstein radius varies as a function of source redshift at fixed stellar mass, stellar density profile, and lens redshift can tell us about the dark matter halo density profile. However, in practice this signal is swamped by the scatter in the lens population, both intrinsic and observational (on 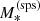 ). Therefore it is unclear whether working with a distribution of source redshifts can actually improve the inference.
). Therefore it is unclear whether working with a distribution of source redshifts can actually improve the inference.
7. Conclusions
We present a Bayesian hierarchical inference method for statistically combining strong lensing constraints from a large sample of lenses with the goal of measuring key aspects of the inner structure of lens galaxies: the stellar mass-to-light ratio, the dark matter mass, and the dark matter density profile. We tested the method on a simulated sample of 1000 lenses generated under the simplifying assumption that all lenses are axisymmetric and all lensed sources are point-like. We fitted two models to the mock observations, with increasing degrees of complexity. In both cases, the functional form of the fitted model was different from the properties of the simulation, both in terms of the density profile of individual lenses and in terms of the population distribution of the dark matter halo parameters. We found the following:
-
when image position and magnification information are used to constrain the model, a sample of 1000 lenses can constrain the stellar population synthesis mismatch parameter, the dark matter normalisation, and the inner slope with very high precision and accuracy compared to current observations. This means that it is possible to calibrate stellar mass measurements with high accuracy and obtain a firm detection of the effect of baryonic contraction on the dark matter halos, and therefore to settle the dark matter core versus cusp debate at the halo masses characteristic of galaxy-scale strong lenses.
-
In order to obtain an accurate inference, the model describing the population of lenses must allow for correlations between the parameters of the dark matter component and all dynamically relevant properties of the lens galaxies, such as the stellar mass and half-light radius.
-
When fitting image positions only, it is still possible to obtain an accurate inference, but by paying a large cost in terms of precision: even with 1000 lenses we cannot break the degeneracy between the dark matter profile and the stellar-mass-to-light ratio. Complementary information from another dynamical probe –such as weak lensing– is needed in that case.
-
A necessary condition for obtaining an accurate inference is being able to provide a faithful description of the source position probability distribution or, equivalently, to know the detection probability of a lens as a function of its image configuration. Alternatively, fitting the Einstein radius instead of the image positions provides a way of maintaining accuracy, but at the cost of precision.
-
Posterior predictive tests allow one to evaluate the goodness of fit of a Bayesian hierarchical inference and are therefore a useful tool for building accurate models.
The tests carried out in this paper provide a first forecast of the potential constraints that large samples of strong lenses can provide. In order to implement the method in practice, several challenges still need to be addressed. These include measuring the redshifts of large numbers of lenses and relative sources, making the individual lens modelling step as automated as possible, and ensuring that the likelihood evaluation and the marginalisation over the many parameters describing individual lenses, a requirement of our method, can be carried out in an accurate and computationally sustainable way.
This work was the first of a series. In a second paper we will quantify the constraining power of a combination of image position and time-delay information, and in a third paper we will use the number density of a complete sample of lenses as an additional constraint.
One could argue that an NFW profile could be used instead, as it naturally has two degrees of freedom, but varying the scale radius of an NFW profile has only a small effect on the density slope in the inner regions of a dark matter halo.
The magnification of the second image is not necessarily a monotonic function of β.
Acknowledgments
We thank Phil Marshall for useful discussions and suggestions. AS acknowledges funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement 792916 (Halos2020). MC acknowledges support by the EU Horizon 2020 research and innovation programme under a Marie Skłodowska-Curie grant agreement 794474 (DancingGalaxies).
References
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2010a, ApJ, 724, 511 [Google Scholar]
- Auger, M. W., Treu, T., Gavazzi, R., et al. 2010b, ApJ, 721, L163 [Google Scholar]
- Barnabè, M., Spiniello, C., Koopmans, L. V. E., et al. 2013, MNRAS, 436, 253 [NASA ADS] [CrossRef] [Google Scholar]
- Birrer, S. 2021, AAS J., submitted [arXiv:2104.09522] [Google Scholar]
- Birrer, S., & Amara, A. 2018, Phys. Dark Univ., 22, 189 [NASA ADS] [CrossRef] [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [CrossRef] [EDP Sciences] [Google Scholar]
- Blumenthal, G. R., Faber, S. M., Flores, R., & Primack, J. R. 1986, ApJ, 301, 27 [Google Scholar]
- Cappellari, M., McDermid, R. M., Alatalo, K., et al. 2012, Nature, 484, 485 [NASA ADS] [CrossRef] [Google Scholar]
- Cautun, M., Benítez-Llambay, A., Deason, A. J., et al. 2020, MNRAS, 494, 4291 [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Sonnenfeld, A., et al. 2020, A&A, 636, A87 [CrossRef] [EDP Sciences] [Google Scholar]
- Charnock, T., Perreault-Levasseur, L., & Lanusse, F. 2020, ArXiv e-prints [arXiv:2006.01490] [Google Scholar]
- Chianese, M., Coogan, A., Hofma, P., Otten, S., & Weniger, C. 2020, MNRAS, 496, 381 [Google Scholar]
- Ciotti, L., & Bertin, G. 1999, A&A, 352, 447 [NASA ADS] [Google Scholar]
- Collett, T. E. 2015, ApJ, 811, 20 [Google Scholar]
- Conroy, C., & van Dokkum, P. G. 2012, ApJ, 760, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Dark Energy Survey Collaboration (Abbott, T., et al.) 2016, MNRAS, 460, 1270 [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Boxhoorn, D. R., et al. 2015, A&A, 582, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Falco, E. E., Gorenstein, M. V., & Shapiro, I. I. 1985, ApJ, 289, L1 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Gnedin, O. Y., Kravtsov, A. V., Klypin, A. A., & Nagai, D. 2004, ApJ, 616, 16 [Google Scholar]
- Goodman, J., & Weare, J. 2010, Commun. Appl. Math. Comput. Sci., 5, 65 [Google Scholar]
- Graham, M. T., Cappellari, M., Li, H., et al. 2018, MNRAS, 477, 4711 [Google Scholar]
- Grillo, C. 2012, ApJ, 747, L15 [Google Scholar]
- Hezaveh, Y. D., Perreault Levasseur, L., & Marshall, P. J. 2017, Nature, 548, 555 [NASA ADS] [CrossRef] [Google Scholar]
- Jacobs, C., Collett, T., Glazebrook, K., et al. 2019, ApJS, 243, 17 [Google Scholar]
- Kochanek, C. S. 2021, MNRAS, 501, 5021 [Google Scholar]
- Koopmans, L. V. E., Treu, T., Bolton, A. S., Burles, S., & Moustakas, L. A. 2006, ApJ, 649, 599 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [Google Scholar]
- Lauer, T. R., Gebhardt, K., Faber, S. M., et al. 2007, ApJ, 664, 226 [Google Scholar]
- Li, R., Napolitano, N. R., Tortora, C., et al. 2020, ApJ, 899, 30 [Google Scholar]
- Millon, M., Galan, A., Courbin, F., et al. 2020, A&A, 639, A101 [CrossRef] [EDP Sciences] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Nightingale, J. W., Dye, S., & Massey, R. J. 2018, MNRAS, 478, 4738 [NASA ADS] [CrossRef] [Google Scholar]
- Nightingale, J. W., Massey, R. J., Harvey, D. R., et al. 2019, MNRAS, 489, 2049 [NASA ADS] [Google Scholar]
- Oguri, M., Rusu, C. E., & Falco, E. E. 2014, MNRAS, 439, 2494 [NASA ADS] [CrossRef] [Google Scholar]
- Oldham, L. J., & Auger, M. W. 2018, MNRAS, 476, 133 [Google Scholar]
- Park, J. W., Wagner-Carena, S., Birrer, S., et al. 2021, ApJ, 910, 39 [Google Scholar]
- Petrillo, C. E., Tortora, C., Vernardos, G., et al. 2019, MNRAS, 484, 3879 [Google Scholar]
- Posacki, S., Cappellari, M., Treu, T., Pellegrini, S., & Ciotti, L. 2015, MNRAS, 446, 493 [Google Scholar]
- Rusin, D., & Kochanek, C. S. 2005, ApJ, 623, 666 [Google Scholar]
- Schaller, M., Frenk, C. S., Bower, R. G., et al. 2015, MNRAS, 451, 1247 [Google Scholar]
- Schaye, J., Crain, R. A., Bower, R. G., et al. 2015, MNRAS, 446, 521 [Google Scholar]
- Schechter, P. L., Pooley, D., Blackburne, J. A., & Wambsganss, J. 2014, ApJ, 793, 96 [Google Scholar]
- Schneider, P., Ehlers, J., & Falco, E. E. 1992, Gravitational Lenses (Berlin, Heidelberg: Springer-Verlag) [Google Scholar]
- Schuldt, S., Chirivì, G., Suyu, S. H., et al. 2019, A&A, 631, A40 [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Meinhardt, T., et al. 2021, A&A, 646, A126 [EDP Sciences] [Google Scholar]
- Shajib, A. J., Treu, T., & Agnello, A. 2018, MNRAS, 473, 210 [NASA ADS] [CrossRef] [Google Scholar]
- Shajib, A. J., Treu, T., Birrer, S., & Sonnenfeld, A. 2021, MNRAS, 503, 2380 [Google Scholar]
- Smith, R. J., Lucey, J. R., & Conroy, C. 2015, MNRAS, 449, 3441 [Google Scholar]
- Sonnenfeld, A. 2018, MNRAS, 474, 4648 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2012, ApJ, 752, 163 [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2013a, ApJ, 777, 98 [Google Scholar]
- Sonnenfeld, A., Gavazzi, R., Suyu, S. H., Treu, T., & Marshall, P. J. 2013b, ApJ, 777, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018a, PASJ, 70, S29 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Leauthaud, A., Auger, M. W., et al. 2018b, MNRAS, 481, 164 [Google Scholar]
- Sonnenfeld, A., Jaelani, A. T., Chan, J., et al. 2019a, A&A, 630, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Wang, W., & Bahcall, N. 2019b, A&A, 622, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Verma, A., More, A., et al. 2020, A&A, 642, A148 [CrossRef] [EDP Sciences] [Google Scholar]
- Spiniello, C., Koopmans, L. V. E., Trager, S. C., et al. 2015, MNRAS, 452, 2434 [Google Scholar]
- Suyu, S. H., Marshall, P. J., Hobson, M. P., & Blandford, R. D. 2006, MNRAS, 371, 983 [NASA ADS] [CrossRef] [Google Scholar]
- Suyu, S. H., Bonvin, V., Courbin, F., et al. 2017, MNRAS, 468, 2590 [Google Scholar]
- Treu, T., Auger, M. W., Koopmans, L. V. E., et al. 2010, ApJ, 709, 1195 [Google Scholar]
- van Dokkum, P., Conroy, C., Villaume, A., Brodie, J., & Romanowsky, A. J. 2017, ApJ, 841, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Vegetti, S., & Koopmans, L. V. E. 2009, MNRAS, 392, 945 [NASA ADS] [CrossRef] [Google Scholar]
- Vogelsberger, M., Genel, S., Springel, V., et al. 2014, MNRAS, 444, 1518 [NASA ADS] [CrossRef] [Google Scholar]
- Wagner-Carena, S., Park, J. W., Birrer, S., et al. 2021, ApJ, 909, 187 [Google Scholar]
- Warren, S. J., & Dye, S. 2003, ApJ, 590, 673 [NASA ADS] [CrossRef] [Google Scholar]
- Wong, K. C., Sonnenfeld, A., Chan, J. H. H., et al. 2018, ApJ, 867, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Yıldırım, A., Suyu, S. H., & Halkola, A. 2020, MNRAS, 493, 4783 [CrossRef] [Google Scholar]
Appendix A: Marginalisation over the stellar mass and source position
In order to evaluate the posterior probability distribution of the model hyper-parameters given the data, we need to compute integrals of the kind of that in Eq. (31). Let us consider the first term of the integrand function. This is the product of four terms, one for each observable:
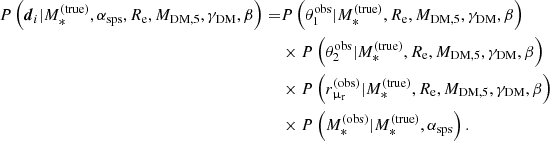 (A.1)
(A.1)
Because the two image positions are measured exactly, each of the first two terms is a Dirac delta function,
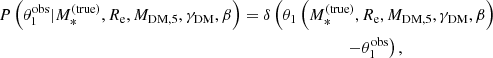 (A.2)
(A.2)
and a similar expression holds for the term relative to image 2. Here θ1 indicates the position of image 1 as predicted by the model parameters and is a function of the latter. In order to integrate out these Dirac delta functions, we first apply the following variable change:
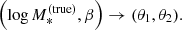 (A.3)
(A.3)
If detJ is the Jacobian determinant of this variable change, Eq. (31) then becomes
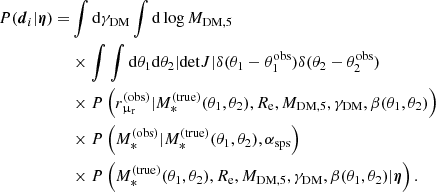 (A.4)
(A.4)
We can now integrate over θ1 and θ2 to obtain
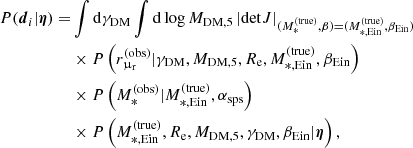 (A.5)
(A.5)
where we define 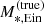 and βEin as the values of the true stellar mass and source position needed to produce images at
and βEin as the values of the true stellar mass and source position needed to produce images at 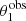 and
and  . We point out that, for certain combinations of values of the lens model parameters, the source is not strongly lensed, and therefore θ2 is not defined. In those regions of the parameter space, the likelihood is simply zero.
. We point out that, for certain combinations of values of the lens model parameters, the source is not strongly lensed, and therefore θ2 is not defined. In those regions of the parameter space, the likelihood is simply zero.
All Tables
Inference on the hyper-parameters of the base model given mock data from a sample of 1000 strong lenses.
Inference on the hyper-parameters of the extended model given mock data from a sample of 1000 strong lenses.
All Figures
|
Fig. 1. Solutions of the lens equation for axisymmetric power-law lens models. The coloured solid curves show θ − α(θ) as a function of θ for two lenses with the same Einstein radius and different values of the density slope parameter γ. The horizontal dashed line marks the position β of a background source. Its images form at solutions of the lens equation, β = θ − α(θ), indicated by the vertical dotted lines with the colour of the corresponding lens model. For the lens with density profile shallower than isothermal, γ < 2, three images form, while the γ > 2 lens produces only two images. The slope of the θ − α(θ) curve is the inverse of the radial magnification. Stationary points, only visible in the γ < 2 case, correspond to the radial critical curve. |
| In the text | |
|
Fig. 2. Radial magnification ratio between image 1 and 2 for a lens with a power-law density profile, as a function of the power-law index γ. Curves obtained for image configurations with different values of the asymmetry parameter ξasymm defined in Eq. (10) are shown. The vertical shaded region indicates the typical uncertainty on the power-law slope, Δγ = 0.05, obtained by modelling high-resolution images of strongly lensed extended sources (Shajib et al. 2021). The horizontal shaded region is the uncertainty on rμr corresponding to an error on the power-law slope of Δγ = 0.05 in the case of an image asymmetry ξasymm = 0.4. |
| In the text | |
|
Fig. 3. Projected surface mass density of a dark matter halo with mass log M200 = 13, contracted following the procedure described in Sect. 3.2 (magenta line). Cyan line: original, pre-contraction dark matter halo described by an NFW profile. Blue dotted line: gNFW profile fitted to the contracted dark matter halo. Black line: stellar component of the lens, consisting of a de Vaucouleurs profile with total mass log M* = 11.5 and half-light radius Re = 7 kpc. The values of the halo mass, stellar mass, and half-light radius are close to the median of the distribution of the simulated lens sample. |
| In the text | |
|
Fig. 4. Distribution of the Einstein radii of a sample of 1000 lenses, simulated following the procedure described in Sect. 3. |
| In the text | |
|
Fig. 5. Left panel: inner density slope of the dark matter halo of the simulated lenses, γDM, obtained by fitting a gNFW density profile to the projected surface mass density of a lens, as a function of the logarithm of the ratio between the stellar and dark matter halo mass. Middle panel: γDM as a function of the logarithm of the ratio between the stellar half-mass radius and the average half-mass radius of galaxies with the same stellar mass. The latter is given by Eq. (15). Right panel: γDM as a function of the gNFW concentration parameter, defined as the ratio between the virial radius and the scale radius obtained from the gNFW profile fit. The vertical dashed line marks the value of c200 adopted for the NFW profile describing the initial (pre-contraction) density profile of the dark matter halo. |
| In the text | |
|
Fig. 6. Distribution in the image configuration asymmetry parameter ξasymm, defined in Eq. (10), of 1000 lenses simulated following the procedure described in Sect. 3. |
| In the text | |
|
Fig. 7. Posterior probability distribution of the hyper-parameters of the model described in Sect. 4, dubbed the ‘base model’, given the mock data of a sample of 1000 lenses generated with the procedure described in Sect. 3. Red lines show the fit to the whole dataset (image positions and radial magnification ratios). Filled contours show the fit to image position only. Contour levels correspond to 68% and 95% enclosed probability regions. Dashed lines indicate the true values of the hyper-parameters, which are defined by fitting each model directly to the distribution of log M200, γDM, and log αsps of the mock sample. |
| In the text | |
|
Fig. 8. Posterior probability distribution of the hyper-parameters of the extended model introduced in Sect. 5.1 given the mock data of a sample of 1000 lenses. Red lines show the fit to the whole dataset (image positions and radial magnification ratios). Filled contours show the fit to image position only. Contour levels correspond to 68% and 95% enclosed probability regions. Dashed lines indicate the true values of the hyper-parameters, which are defined by fitting the each model directly to the distribution of log M200, γDM, and log αsps of the mock sample. |
| In the text | |
|
Fig. 9. Posterior probability distribution of the hyper-parameters μh, 0, μγ, 0, and log αsps obtained under the assumption that source positions are drawn from a uniform distribution in the source plane with no boundary (blue contours) compared to the fiducial inference described in Sect. 5.1 (red contours). |
| In the text | |
|
Fig. 10. Posterior predicted distribution in the mean value of |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.