| Issue |
A&A
Volume 620, December 2018
|
|
|---|---|---|
| Article Number | A168 | |
| Number of page(s) | 10 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/201833975 | |
| Published online | 12 December 2018 | |
Impact of measurement errors on the inferred stellar asteroseismic ages
Statistical models for intermediate age main sequence and red giant branch stars
1 INAF – Osservatorio Astronomico di Collurania, Via Maggini, 64100 Teramo, Italy
e-mail: valle@df.unipi.it
2 INFN, Sezione di Pisa, Largo Pontecorvo 3, 56127 Pisa, Italy
3 Dipartimento di Fisica “Enrico Fermi”, Università di Pisa, Largo Pontecorvo 3, 56127 Pisa, Italy
Received:
27
July
2018
Accepted:
5
October
2018
Aims. We aim to perform a theoretical investigation on the direct impact of measurement errors in the observational constraints on the recovered age for stars in main sequence (MS) and red giant branch (RGB) phases. We assumed that a mix of classical (effective temperature Teff and metallicity [Fe/H]) and asteroseismic (Δν and νmax) constraints were available for the objects.
Methods. Artificial stars were sampled from a reference isochrone and subjected to random Gaussian perturbation in their observational constraints to simulate observational errors. The ages of these synthetic objects were then recovered by means of a Monte Carlo Markov chains approach over a grid of pre-computed stellar models. To account for observational uncertainties the grid covers different values of initial helium abundance and mixing-length parameter, that act as nuisance parameters in the age estimation.
Results. The obtained differences between the recovered and true ages were modelled against the errors in the observables. This procedure was performed by means of linear models and projection pursuit regression models. The first class of statistical models provides an easily generalizable result, whose robustness is checked with the second method. From linear models we find that no age error source dominates in all the evolutionary phases. Assuming typical observational uncertainties, for MS the most important error source in the reconstructed age is the effective temperature of the star. An offset of 75 K accounts for an underestimation of the stellar age from 0.4 to 0.6 Gyr for initial and terminal MS. An error of 2.5% in νmax resulted the second most important source of uncertainty accounting for about −0.3 Gyr. The 0.1 dex error in [Fe/H] resulted particularly important only at the end of the MS, producing an age error of −0.4 Gyr. For the RGB phase the dominant source of uncertainty is νmax, causing an underestimation of about 0.6 Gyr; the offset in the effective temperature and Δν caused respectively an underestimation and overestimation of 0.3 Gyr. We find that the inference from the linear model is a good proxy for that from projection pursuit regression models. Therefore, inference from linear models can be safely used thanks to its broader generalizability. Finally, we explored the impact on age estimates of adding the luminosity to the previously discussed observational constraints. To this purpose, we assumed – for computational reasons – a 2.5% error in luminosity, much lower than the average error in the Gaia DR2 catalogue. However, even in this optimistic case, the addition of the luminosity does not increase precision of age estimates. Moreover, the luminosity resulted as a major contributor to the variability in the estimated ages, accounting for an error of about −0.3 Gyr in the explored evolutionary phases.
Key words: stars: fundamental parameters / methods: statistical / stars: evolution
© ESO 2018
1. Introduction
The problem of obtaining insight into the fundamental, but not directly observable, stellar parameters received growing attention in the last decade, owing to the improvement either in observational data availability and quality and to the development of fast and reliable inversion techniques. These methods adopt large sets of stellar models and estimate the best fundamental parameters by a maximum likelihood or Bayesian approach.
Despite of the popularity of these techniques, only few theoretical works have explored the basis of these approaches, focusing on the evaluation of the biases and random variability expected in the recovery procedure. As an example, Basu et al. (2010); Gai et al. (2011); Valle et al. (2014, 2015b) shed some light on the performances of inversion techniques based on local interpolation for single stars, while Valle et al. (2015a) report an analysis concerning binary systems. The theoretical bias in the recovered overshooting parameter is explored in Valle et al. (2015b, 2017). Recently Bellinger et al. (2016) has adopted a machine learning approach based on random forest to connect observable quantities of stars to other quantities inferred from models. Schneider et al. (2017) explores the influence on the maximum likelihood estimates of the correlation among the observables. They conclude that neglecting correlations causes a bias on the inferred stellar parameters and can alter their precision. Angelou et al. (2017) study the correlation among classical and asteroseismic observables in order to determine the capacity of each observable to probe structural components of stars and infer their evolutionary histories.
Ultimately, the theoretical understanding of several key points of these models is firmly established. However there are many questions that are still unexplored. A notable example is the quantification of how the errors in the observational constraints – either from random fluctuations or systematic offsets – impact on the reconstructed stellar age. Several studies mentioned above address some aspects related to this question, often providing a posterior age distribution obtained by propagating the assumed observational uncertainties through the fitting procedure. However, a comprehensive understanding of how much an error in an given observational quantity directly influences the reconstructed age, and how this is linked to the evolutionary stage of the star is still lacking. The question is indeed of non-negligible relevance, because this knowledge can help to focus the attention on the uncertainty source that most impacts the ages estimates. Refining the accuracy and precision of these error-influence observational constraints will be highly beneficial for age estimation.
This paper aims to partially fill this gap, quantifying the impact of observational errors on the estimated age for stars in the main sequence and in the red giant branch phase. We have focussed on the scenario in which classic and asteroseismic constraints are available. In detail, we adopted the effective temperature, the metallicity [Fe/H], the average large frequency spacing Δν and the frequency of maximum oscillation power νmax, which are measured from most of target stars. We also explored the case in which the stellar luminosity, provided by Gaia DR2 catalogue (Gaia Collaboration 2018), is available as supplementary constraint.
To this purpose one should carefully consider the several input entering in stellar model computations not constrained by the observations. These uncertainty sources can be roughly divided into two classes: single and multiple parameters. A notable example of the first class is the initial helium content; since helium lines are detectable in very hot stars, a direct measurement of the helium abundance is in most cases not achievable. Other examples in the first class stem from the lack of firm theoretical modelling of some precesses, such as the convective core overshooting and the superadiabatic convection. Both these processes are generally included in the stellar computations by free parameters, whose values should be calibrated. All the uncertainties on these parameters can be accounted for by adopting in the fit a grid of stellar models covering a wide range of the possible parameter values. The final age estimate is then marginalized over these nuisance parameters.
The second class poses a bigger problem and no sensible procedure can account for the uncertainty associated with them. Among multi-parameter uncertainty sources, the most important are probably the mean Rosseland opacities, the equation of state, the cross section of the nuclear reactions (for the physics of the models), and the adopted chemical mixture. These quantities are provided to the stellar evolutionary codes by means of pre-computed tables, typically without any associated uncertainty from the literature. A comparison of the tables computed by different authors can shed some light about the variability present in these values, but it also reveals a disparate range of differences for the various zones of the tables (Rose 2001; Badnell et al. 2005). Therefore a single parametric scaling – for example by increasing the values in a table by say 5% – could be helpful in providing a rough idea of the relevance of a parameter (see e.g. Valle et al. 2013). It is, however, of no real interest whenever one tries to obtain a reliable estimate of the error propagation on final fitted parameter. As a consequence, the uncertainty owing to these multi-parameter sources is usually neglected and the error propagation on the final estimate is usually provided by fixing the input physic. Given these difficulties, in this work we have adopted a pragmatic approach focusing only on the first class of uncertainty sources.
The study is organized in the following way. In Sect. 2 we describe the procedure adopted for the investigation, the grid of stellar models, and the approach to the age estimation through observations inversion. The statistical models to analyse the impact of the observational errors on the final age estimate are presented and discussed in Sect. 3. Results of adding the luminosity constraints provided by Gaia are discussed in Sect. 4. We give some concluding remarks in Sect. 5.
2. Methods
All the investigations were performed by assuming a reference scenario, with a fixed chemical composition and age. In the reference scenario we also fixed the efficiency of superadiabatic convection by adopting a value of the mixing-length parameter αml = 1.74, which corresponds to the solar calibrated value. The reference case chemical composition approximatively mimics the old cluster NGC6791 having a metallicity Z = 0.0267 and an initial helium value Y = 0.275, corresponding to a helium-to-metal enrichment ratio ΔY/ΔZ = 2.0. This choice implies [Fe/H] = 0.3, assuming the solar heavy-element mixture by Asplund et al. (2009). The reference age was chosen to be 7.5 Gyr.
A dense grid of stellar models was computed around the reference scenario. In fact, to obtain a sensible error estimate of the fitted age the stellar grid should span an appropriate range not only in mass (or age for isochrones) but also in other quantities that impact the stellar evolution, such as the initial chemical composition (Z and Y), and in parameters that affect the position of the red giant branch (RGB), such as the value of the mixing-length parameter αml. The grid of stellar models is presented in Sect. 2.1.
From the reference isochrone we sampled n = 20 stars from both the main sequence (MS) and the RGB stages. The stars were chosen by sampling uniformly in Δν the MS (Δν ∈ [1.75, 0.5] Δν⊙) and the RGB (Δν ∈ [0.08, 0.009] Δν⊙)). The choice implies a mass range [0.6, 1.1] M⊙ in MS and [1.15, 1.16] M⊙ in RGB. Figure 1 shows the reference isochrone with the positions of the synthetic stars considered in the analysis superimposed.
 |
Fig. 1. Left panel: main sequence of the reference isochrone at 7.5 Gyr (Z = 0.02674, Y = 0.2752, αml = 1.74) in the Teff – Δν plane. The circles mark the position of the synthetic stars adopted for the analysis. Right panel: as in left panel but for the RGB phase. |
The observables of each synthetic star were then subjected to a Gaussian perturbations, mimicking the observational errors. The assumed uncertainties are: 75 K in Teff, 0.1 dex in [Fe/H], 1% in Δν, and 2.5% in νmax. The errors in the asteroseismic quantities were chosen taking into account the values quoted in SAGA of 0.7% and 1.7% on Δν and νmax (Casagrande et al. 2014) and those in the APOKASC catalogue of 2.2% and 2.7% (Pinsonneault et al. 2014). However the exact value of the uncertainties is not of paramount importance, because the aim is not to obtain a posterior distribution for the reconstructed ages but to study the age dependence on the observables. Therefore it is only relevant that the errors cover a sensible range around the reference value.
Finally, ages for all the perturbed stars were recovered by means of pure geometrical isochrone fitting by Monte Carlo Markov chain (MCMC) simulations (Sect. 2.2). The median value of the recovered age was stored along with the perturbation of the four observables adopted in the fit. The whole procedure was repeated N = 200 times to assess the importance of the measurement errors. The adopted value of N was directly verified to be large enough to reduce the variability on the result to a negligible value. A final dataset of n × N = 4000 synthetic data was then subjected to statistical modelling by regressing the error in the fitted age against the errors in the observational variables. Statistical models were then adopted to evaluate the effects of the observational constraints on the recovered stellar ages.
2.1. Stellar model grid
The model grid was computed for masses in the range [0.4, 1.3] M⊙, with a step of 0.05 M⊙. The initial metallicity [Fe/H] was varied from 0.15 dex to 0.45 dex, with a step of 0.05 dex. The solar heavy-element mixture by Asplund et al. (2009) was adopted. Nine initial helium abundances were considered at fixed metallicity by adopting the commonly used linear relation 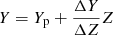 with the primordial abundance Yp = 0.2485 from WMAP (Peimbert et al. 2007a,b) and with a helium-to-metal enrichment ratio ΔY/ΔZ in the range [1, 3] with a grid step of 0.25 (Gennaro et al. 2010).
with the primordial abundance Yp = 0.2485 from WMAP (Peimbert et al. 2007a,b) and with a helium-to-metal enrichment ratio ΔY/ΔZ in the range [1, 3] with a grid step of 0.25 (Gennaro et al. 2010).
The FRANEC code (Degl’nnocenti et al. 2008; Tognelli et al. 2011) was used to compute the stellar models, in the same configuration as was adopted to compute the Pisa Stellar Evolution Data Base1 for low-mass stars (Dell’Omodarme et al. 2012). The models were computed for five different values of mixing-length parameter αml in the range [1.54, 1.94], with a step of 0.1, 1.74 being the solar-scaled value2. Microscopic diffusion is considered according to Thoul et al. (1994). Further details on the stellar models can be found in Valle et al. (2009, 2015a,b) and references therein. Isochrones, in the age range [5, 10] Gyr, with time steps of 100 Myr, were computed according to the procedure described in Dell’Omodarme et al. (2012); Dell’Omodarme & Valle (2013).
2.2. Fitting procedures
For age recovery the widely adopted pure geometrical isochrone fitting method was employed (see Valls-Gabaud 2014, and references therein), as described in Valle et al. (2018). For readers’ convenience we summarize here the method. Let θ = (αml, ΔY/ΔZ, Z, age) be the vector of parameters characterizing the isochrones and q ≡ {Teff, [Fe/H], Δν, νmax}i the vector of observed quantities for a star. Let σ be the vector of observational uncertainties. For each point j on a given isochrone we defined qj(θ) the vector of theoretical values. Finally we computed the geometrical distance dj(θ) between the observed star and the jth point on the isochrone, defined as
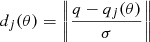
Then the statistic:
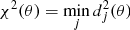
can be adopted to compute the probability P(θ) that the synthetic star comes from the given isochrone. In fact, assuming an independent Gaussian error model, we have
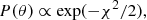
where we neglected the normalization constant. The method suffers for an intrinsic degeneracy – such as the age-metallicity degeneracy – and different sets of parameters can provide similar likelihood (see Valls-Gabaud 2014, and references therein). A possible proposed remedy is to factorize in the likelihood computation the evolutionary time step (see e.g. the discussion in Valls-Gabaud 2014; Valle et al. 2018), but direct verification for RGB phase showed that this alternative approach has its own difficulties because it can provide biased estimates (Valle et al. 2018).
The age estimation was performed adopting an MCMC process, using the likelihood in Eq. (3). The method has been widely adopted in the literature since the original formulation by Metropolis et al. (1953) and Hastings (1970). Briefly, one starts by establishing a good initial point in the θ space and by evaluating the scale over which the likelihood function varies. Such estimates were obtained by random sampling 2000 values in θ space spanned by the isochrone grid, and evaluating the relative likelihood. This step sets the initial value and the initial guess of the covariance matrix in the θ space for the jump function. Then a burning-in chain of 3000 points is generated in the following way. Let us call θk the value of the parameters after the step k and Σ the covariance matrix. A proposal point in the θ space is generated adopting a Gaussian jump function with mean θk and covariance Σ
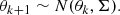
Let us call P(θ)k and P(θ)k + 1 the likelihood of the solutions θk and θk + 1. We define 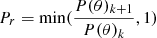 . Then the following chain rule applies:
. Then the following chain rule applies:
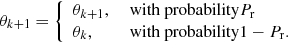
Due to the intrinsic degeneracy among the parameters θ the convergence speed of the chain is known to be sub-optimal (see Haario et al. 2001, and also Kirkby-Kent et al. 2016 for a specific discussion in a detached binary system fit). Therefore after the burn-in phase the covariance matrix of the last 50% of the proposed solutions is adopted to transform the θ variables to θ⊥ orthogonal ones. The step is performed by means of a principal component analysis (Feigelson & Babu 2012; Härdle & Simar 2012), a statistical technique that computes a set of independent and orthogonal linear combinations θ⊥ of the original θ variables. The chain is then built in the newly computed space, achieving a better convergence speed. Finally, the transformation is inverted and the results are remapped in the original θ space.
After the burning-in stage, the MCMC sampling consisted of eight chains of length 5000. The length of the chain is sufficient to achieve good convergence and mixing, according to the statistical tests of Gelman-Rubin and Geweke (Gelman & Rubin 1992; Geweke 1992).
3. Results
The two datasets (one for MS and one for RGB stars) resulting from the fit of the 4000 synthetic stars in both evolutionary stages were subjected to statistical modelling. The analysis was focussed on finding two multi-variate linear models with the age error (estimated minus true age) as dependent variable and the perturbations on the observables as predictors (perturbed values minus real ones). The models were then adopted to identify the contribution of the variation of each predictors to the recovered age. In this investigation we have to balance two opposite goals. First, we needed to identify a model that fits the data with some margin for improvements but adopting simple relations – such as only first degree predictors. Second, the inference from this model should be robust. While the latter aim come from obvious considerations, the former one was required because a model with only first-degree predictors and without interactions among them can be used for evaluating the impact of different observational errors σ1, by a simple scaling of the contributions with the ratio of σ1/σ. In particular, the analysis was focussed on searching for models with no interactions among predictors; this condition guarantees that the impact of each predictor can be evaluated independently from the values of the others.
In the following we adopt the error function ℰ(.) to indicate the difference between the true and perturbed value. Therefore ℰ(age) is the difference between the recovered and the true age, while ℰ(Teff) is the perturbation of the effective temperature. The errors in the asteroseismic quantities enter in the model as a percentage, as in the Monte Carlo simulations.
3.1. Linear models
In the search for the simplest models able to describe the data, the analyses for MS and RGB phases were begun by assessing the performance of linear models containing only the four predictors and no interactions of high power terms. However, the analysis of these models highlighted the presence of a trend in the model residuals versus the MS position and a butterfly-shaped behaviour. Figure 2 shows the MS model standardized residuals as a function of the Δν value. The line in the figure is a linear regression between these variables and evidences a significant trend. This trend, and the large inhomogeneity of the estimated residual variance (much larger at the Δν edges with respect to the centre) are characteristic signs of the presence of interactions among variables unaccounted by the model. As a result, the simple model is not equally effective for the whole MS phase, and a corrective term should be inserted.
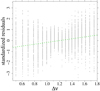 |
Fig. 2. Residual of the linear model in the MS as a function of Δν. The dashed line shows a linear regression of the standardized residuals versus Δν. |
Thus the MS model was adjusted by adding an explicit dependence on the Δν value, which decreases during the MS evolution, providing a proxy for the evolutionary stage. Moreover, the interactions among predictors and Δν were required. The final linear model for the MS phase is:
![$$ \begin{aligned} {\mathcal{E} }(\mathrm{age}) \, (\mathrm{\,Gyr}) = \Delta \nu * \left({\mathcal{E} }(T_{\rm eff}) + {\mathcal{E} }(\mathrm{[Fe/H]}) + {\mathcal{E} }(\Delta \nu ) + {\mathcal{E} }(\nu _{\rm max}) \right), \end{aligned} $$](/articles/aa/full_html/2018/12/aa33975-18/aa33975-18-eq8.gif)
where we adopt the operator “*” to mark the interaction between predictors: an interaction term A * B is interpreted as A + B + A × B. The explicit dependence on the fit coefficients was not expressed in the model to keep the notation compact and can be found in Appendix A.
The coefficients resulting from the least squares fit are reported in Table 1. Adopting these coefficients, it is possible to extract the quantity of direct interest in the present investigation, in other words, the impact on the estimated age of a 1σ offset in the predictors. We note that the models apply either to observational random errors and to systematic errors. This is particularly relevant since it is well known that there is an approximately 5% offset between the scaling relation masses and the true masses of giants (see e.g. Guggenberger et al. 2017; Themeßl et al. 2018) which reflects in incorrect ages. Moreover one of the predictors, namely the effective temperature, is subject to a non-negligible systematic uncertainty (see e.g. Ramírez & Meléndez 2005; Schmidt et al. 2016). By multiplying the coefficients of the fit by the synthetic observational error vector σ it is possible to evaluate the impact of 1σ observational error. Due to the dependence of the model on Δν, the computations were performed twice: first for a value Δν = 1.75 Δν⊙ (initial MS phase, see Fig. 1), and second for Δν = 0.50 Δν⊙ (end of MS phase). The impacts on the age (in Gyr) are reported in the first two rows of Table 3.
Fit of the least square MS model.
For the MS, the main contribution to the age error is the uncertainty on the effective temperature: an increase of Teff by 75 K offsets the age estimate by −0.42 Gyr in the initial part of the MS, and of −0.62 Gyr in its terminal part, that is, from about 6% to 8% of the nominal age of 7.5 Gyr. The second most important contributor is the error in νmax (2.5%), accounting for an offset from −0.24 Gyr to −0.33 Gyr. The 1σ error in the metallicity (0.1 dex) is particularly relevant at the MS end, when it accounts for −0.39 Gyr (about two thirds of the impact of the effective temperature error), while it is only −0.14 Gyr in the first part of the MS. Finally the effect on the age determination of the error in Δν gave the lowest impact, from −0.08 Gyr to +0.15 Gyr.
The assessment of the model validity, however, reveals some problems. The inspection of the residual plot versus the fitted values (left panel in Fig. 3) – a standard check for linear models – shows that some information is retained in the data. The trend is clearly seen in the solid line – a smoother of the data obtained by the LOESS (LOcal regrESSion) technique (Cleveland et al. 1988; Cleveland & Grosse 1991). The clear arc-shaped paths, with heavy variations at the wings present in both panels is a typical signature of interaction among predictors not accounted for in the model. Adding higher-order terms and interactions to improve the models did not cleanly solved the issue, while the complexity of the models increased very much. Moreover, the aim of the work is to develop models te be used to quantify the impact of different assumptions of the observational errors. In the lack of interactions and high-order terms, this can be simply obtained by scaling the values reported in Table 3 by the ratio of the new versus adopted σ values. On the contrary, in the presence of interactions, the impact of a parameter depends also on the values of the others, making the impact estimation a bit more complex.
 |
Fig. 3. Left panel: residuals of the linear model for the age of MS stars as a function of the predicted values. The solid line shows a smoother of the data obtained by the LOESS technique. Right panel: as in the left panel, but for RGB stars. |
Ultimately, we found that the exact form of interaction between the predictors is extremely cumbersome and required the adoption of a much more robust and versatile statistical technique to be accounted for. These models are discussed in Sect. 3.2, but happily the inference on the impact of the single error source, presented in this section, was found to be a very good proxy for that from the more complex models.
The analysis of the RGB phase was performed in a similar way. The adopted linear model was
![$$ \begin{aligned} {\mathcal{E} }(\mathrm{age}) \, (\mathrm{\,Gyr}) = {\mathcal{E} }(T_{\rm eff}) + {\mathcal{E} }(\mathrm{[Fe/H]}) + {\mathcal{E} }(\Delta \nu ) + {\mathcal{E} }(\nu _{\rm max}). \end{aligned} $$](/articles/aa/full_html/2018/12/aa33975-18/aa33975-18-eq9.gif)
The coefficients of the fit are reported in Table 2, while the impact of the 1σ errors are in the last row of Table 3. The most important uncertainty source in the recovered age is the error in νmax: an increase of νmax by 2.5% causes an age change of −0.58 Gyr (about 8% of the true age of 7.5 Gyr). An effective temperature increase of 75 K leads to an age offset of −0.27 Gyr, while an increase of 1% of Δν changes the age estimation by 0.31 Gyr. The contribution of the 0.1 dex metallicity error resulted negligible.
As for the MS model, the residuals plot for RGB stars (right panel in Fig. 3) also shows a clear path, suggesting that higher-order terms are required to properly account for the dependence of the age error on the predictors. Moreover, as for the MS phase, the adoption of high-order interaction terms does not pose a clear remedy to the problem but adding more complexity.
Contribution to the age error (in Gyr) of a 1σ shift of the four predictors adopted in the linear models, in different evolutionary stages.
In summary, both MS and RGB linear models provide a very tight fit to the data. In fact the residual error from the MS model is σMS = 0.1 Gyr on a reference age of 7.5 Gyr, with a multiple correlation coefficient R 2 = 0.97, implying that 97% of the variability present in the data is correctly accounted by the model. For the RGB model, the residual variance is σMS = 0.08 Gyr and R 2 = 0.98. Thus, the models presented so far appear globally reliable. To explore the problem of the trends in the residuals (Fig. 3), more complex statistical models is adopted in the following section.
3.2. Projection pursuit regression models
The residual plots in Fig. 3 showed the presence of some interactions among the predictors, that cannot be neatly accounted for in the framework of linear models, even adopting higher order interactions. A much more versatile, although much more complex, statistical model is able to deal well with this problem. The inference from this method can be compared with that from linear models of the previous section to evaluate the improvement obtained with the more complex method.
To this aim, we adapted two projection pursuit regression (PPR) models to the data. The method is computationally intensive but allows us to deal – although not explicitly – with complex interactions among predictors. This statistical model is a generalization of the additive model and projects the data matrix of the predictors (i.e. the errors in the observable constraints) in the optimal direction before applying smoothing functions to these explanatory variables (see e.g. Friedman & Stuetzle 1981; Venables & Ripley 2002; Härdle & Simar 2012). The dimension M of the projection subspace is chosen by the modeller. In detail, let n be the sample size, X the matrix of the predictors (in our case, the offset in the observational constraints), and y the response variable (the age error). The PPR model is then
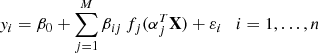
where the vectors αj are the projecting directions. The fj functions are empirically determined smooth functions, usually called ridge functions. βij are the coefficients to be estimated and εi the model residuals. The value of M is generally determined through cross-validation, adopting an iterative stepwise method that stops when the model fit no longer improves.
In summary, a PPR model is similar to an additive model but with the additional projection stage so that it fits the model α T X rather than the actual predictor X. The directions αj are chosen to optimize model fit and constrained to unit length. The ridge functions are estimated using some smoothing methods. The drawback of this flexibility and generality is that it is difficult to interpret the fitted model because each input variable enters into the model in a complex way. Thus the model is far more useful for prediction than for understanding the relations among data. Moreover, a PPR model – like many deep learning methods – suffers from a difficult that limit the adoption of a proposed model from different researchers (Ripley 1996; Venables & Ripley 2002; Härdle & Simar 2012). In fact, it depends on the empirically determined fj smoothing functions, which have no analytic expressions. Thus the use of the PPR model is limited by the need to know the fj functional forms exactly. The models were fitted adopting the ppr function in the MASS package of R 3.5.0 (R Core Team 2018; Venables & Ripley 2002).
The model for the MS phase adopts as predictor the offsets in the observational constraints and the Δν value, while the latter is not required in the RGB model. For the MS model a total of M = 3 functions were retained in the final model, while M = 2 was sufficient for the RGB phase. Interested reader can found the coefficients of the α vectors and the empirical smoothing functions in Appendix B.
The capability of the PPR model to account for the internal interactions is shown in the residual plots of Fig. 4. Both panels show that the models succeed in removing the trends resulting from the linear models for MS and RGB phase. The standard deviations of the residuals for the MS and RGB models are about 0.09 Gyr and 0.05 Gyr respectively, a remarkable precision being about 1% of the true age 7.5 Gyr.
Due to the correct modelling in the whole range of the fitted values, the inference from the PPR model is more robust than that from the linear model. To judge the relevance of this difference we evaluated the impact on the recovered age of the observable uncertainties from PPR models and compared them to those in Table 3. A non-negligible systematic difference would suggest that the inference from linear model is not adequate to describe the dependence of the age error on the observables offset. As a difference from the simple method of Sect. 3.1, the computation of the impact from PPR model is somewhat cumbersome. Due to the presence of hidden interactions, the impact of a predictor shift depends also on the values of the others so we need to evaluate the impact of a single predictor given different values of all the others. To this aim, we constructed a matrix of artificial predictors where the predictors Xj can take only two values: Xj = ±σj (σj is the observational uncertainty of the jth predictor). Then the predictions ŷ of the age shift were obtained from the computed PPR models in Eq. (8) adopting these artificial X predictors. Then, for the ith predictor, we computed the difference between the values of ŷ having equal predictor but i and the reference value for all unperturbed predictors. The sign of perturbations for a −σ offset was changed. Finally the range of these differences was computed providing the impact of the ith predictor on the age error.
The result of this computation is presented in Table 4 and in Fig. 5, which also reports the impact estimates for linear models. For a better evaluation of the relevance of the uncertainty, all the impacts in the figure are reported in absolute value. It appears that linear and PPR models estimates are well consistent, because the linear model estimated impact always lie within the range of PPR models, with the only exception of the νmax error in the RGB phase. Moreover, the impact ranges for PPR models are generally smaller than the effect on the age for the different predictors, allowing to firmly establish what are the major sources of uncertainty.
 |
Fig. 5. Impact on the estimated age (in Gyr) of the 1σ error in the predictors, classified according to the evolutionary stage (from low MS to RGB) and predictors (Teff, [Fe/H], Δν, and νmax). The segments identify the impact range estimated from PPR models, while the circles those from linear models (see text). |
In summary, it seems that the impact on the age error from linear models are a good proxy for the more precise results from PPR. This is a particularly pleasant finding; due to their simple nature, and to the possibility to directly generalize to different observational uncertainties, the results from the linear model can have a broader scope of applicability.
4. Effect of adding the luminosity to the observational constraints
The recent advent of the Gaia satellite (Prusti et al. 2016; Gaia Collaboration 2018) – whose main purpose is to determine accurate parallaxes and proper motions for over one billion stars – provided the astrophysical community with additional observational constraints to estimate the stellar age. The Gaia DR2 catalogue (Gaia Collaboration 2018) provides luminosities for about 100 millions stars. Thus it is worth exploring in some details if the adoption of this additional constraint, together with those adopted so far, can improve the precision of the estimated ages and how the error in luminosity propagates in the final estimates.
Several warnings were raised by the Gaia collaboration about the adoption of the luminosities provided by the catalogue. They are due to the neglect in their derivation of both the extinction and the error in effective temperature (Andrae et al. 2018). An optimistic estimate of the average error in the provided luminosities is about 15% (Andrae et al. 2018).
This quoted average error is much larger than those in the asteroseismic observables used in our analysis and cannot be adopted in our simulations. The computed grid of stellar models is not wide enough to explore the parameter space without suffering of severe edge effects. As a result, the estimates are severely shrunk and provide and unrealistic evaluation of the observational error impacts. Therefore we decided to drastically reduce the error in L – at a level of 2.5% – that maybe is not realistic and not achievable but for a very small minority of stars, but is comparable with the observational errors in asteroseismic constraints. We therefore repeated the sampling and estimation procedure described in Sects. 2 and 3 adding the luminosity to the observational constraints and linear models.
A first result is that the adoption of the luminosity to the observational constraints does not lead to higher precision on the age estimates. Even with an assumed error at 2.5% level, the standard deviation of the estimated ages in MS and RGB phases is not improved. Indeed the standard deviation of the estimated ages changes from 0.70 Gyr without L in the observation pool to 0.76 Gyr in MS and from 0.69 Gyr to 0.64 Gyr in RGB. This result is quite expected because the added constraint is strongly correlated with the asteroseismic ones, therefore providing no insight into a different evolutionary characteristic, and its error is comparable to the others.
However the impacts of 1σ error in each observable on the final error in the estimated age – provided in Table 5 – is quite different from the ones in Table 3. The main changes are about the relevance of the error in effective temperature in MS, which nearly vanishes when luminosity is added into the model. Moreover, the estimated impact of Δν and νmax in RGB vary significantly. The strong highlighted changes are not surprising because the luminosity is strongly correlated with Δν and νmax and depends on the effective temperature through the Stefan-Boltzmann relation 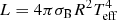 , where R is the stellar radius and σB is the Stefan-Boltzmann constant.
, where R is the stellar radius and σB is the Stefan-Boltzmann constant.
Overall, the impact of the error in L is very important in all the explored evolutionary phases being about −0.3 Gyr. Ultimately, the computations show how the insertion of an additional variable in the models can alter drastically the estimated impacts of all the others. This is clearly understandable for the quantities considered in this work, because either νmax and L have an explicit dependence on Teff. The simultaneous presence of these constraints causes the models to lower the direct dependence on the effective temperature in the age estimates.
In summary, it seems that in this case, the adoption of the luminosity from Gaia DR2 catalogue as a further constraint does not provide any improvement in the precision of the age estimates. This conclusion is strengthened by the much larger error in L expected for the vast majority of Gaia stars with respect to the one considered here.
5. Conclusions
Thanks to the availability of high-quality data and the development of sound statistical approaches the problem of inferring stellar ages has been widely addressed in the recent literature. While several works explored some aspects of the propagation of the observational uncertainties to the inferred ages and on the expected biases, the direct quantification of how measurement errors in single observational constraints propagate on the final estimate is still largely unexplored. The question has indeed a relevant importance for observational purposes because it would highlight the quantities for which a refinement in the measurement would be most beneficial.
We performed a theoretical investigation on the direct impact of observational errors on the recovered age for stars in MS and RGB phases. We assumed that a mix of classical (effective temperature and metallicity [Fe/H]) and asteroseismic (Δν and νmax) constraints were available for the objects.
We focussed on a reference isochrone at metallicity [Fe/H] = 0.3 and age 7.5 Gyr. Artificial stars were sampled from the reference isochrone and subjected to random Gaussian perturbation in their observational constraints. The age of these synthetic objects were then recovered by means of a Monte Carlo Markov chains approach.
The difference between the recovered and true ages were modelled against the offset in the observational values, either by means of linear models and by means of projection pursuit regression models. The first class of statistical models provides an easily interpretable and generalizable result, while the second one allows a check for the robustness of the inference. In fact, due to the complex way the offset in the observational quantities influence the recovered age, the hypotheses of linear model theory are not totally fulfilled. Luckily, we find that the inference from the linear model was a good proxy for that from projection pursuit regression models. Thus the inference on the impact of 1σ offset of the observational constraints obtained through them can be safely adopted for judging the criticality of an observational quantity.
For MS the effective temperature of the star is the most important source of variability. An offset of +75 K causes a change in the estimated age from −0.4 to −0.6 Gyr in the initial and terminal parts of the MS respectively. An observation error of +2.5% in νmax accounts for a change of about −0.3 Gyr. A 0.1 dex error in [Fe/H] results important only at the end of the MS, causing an age error of −0.4 Gyr. The contribution of Δν is negligible.
For the RGB phase the dominant source of uncertainty is νmax, whose variation causes an age underestimation of about 0.6 Gyr; the offset in the effective temperature and Δν account respectively for an underestimation and overestimation of 0.3 Gyr. The metallicity offset plays a minor role.
In the light of these results it is clear that no source of uncertainty is globally dominant in the whole stellar evolution to the purpose of age recovering. However, it seems that the effective temperature and the frequency of maximum oscillation power play an important role in both the explored phases. Unfortunately both these quantities are knowingly problematic either from the observational or from the theoretical point of view. In fact although it is not uncommon to find quoted errors in the effective temperature of the order of some tens of degrees, typically a comparison of results by different authors shows discrepancies even larger than 100 K (see e.g. Ramírez & Meléndez 2005; Masana et al. 2006; Casagrande et al. 2010; Schmidt et al. 2016). Regarding the maximum oscillation power, its theoretical understanding is far less certain than that of Δν, which is inversely proportional to the sound travel time through the star and directly to the square root of the stellar mean density (Ulrich 1986; Kjeldsen & Bedding 1995). Therefore the adoption of scaling relations to fit the data could be potentially problematic. Indeed, the validity of the scaling relation was questioned for both the adopted asteroseismic quantities in the late RGB stages (Epstein & Pinsonneault 2014; Gaulme et al. 2016; Viani et al. 2017).
We also investigate the relevance of adopting as additional observational constraint the stellar luminosity, since this quantity is provided by the Gaia DR2 catalogue. To this purpose – giving computational limitations – we strongly reduced the suggested average error in the luminosity in the Gaia DR2 catalogue from 15% to 2.5%. Even in this very favourable configuration the adoption of the luminosity constraint does not allow better precision on the estimated ages, while changing the individual contribution of the single error sources. Overall, the impact of the adopted 1σ luminosity error on the age estimates is about −0.3 Gyr for all the explored evolutionary phases. A much larger error is expected when adopting the typical precision provided by the Gaia DR2 catalogue.
While the present work sheds some light on the complex way in which individual observational uncertainties affects the stellar age estimation, it only scrapes the surface of this problem. Without direct verification it is not clear if the results of the present investigation can be generalized to other mass ranges and metallicities. While the latter hypothesis is quite probable, the former is much more questionable due to the different morphology of evolutionary tracks for heavier stellar objects, which occurs after the development of a convective core. Moreover, other evolutionary phases, such as the central helium burning stage, should be explored in similar way. Additional theoretical work is still needed before grasping a sound comprehension of the relevance of a single predictor in the estimation of stellar ages.
Acknowledgments
We thanks our anonymous referee for the stimulating suggestions and useful comments. This work has been supported by PRA Università di Pisa 2018–2019 (Le stelle come laboratori cosmici di Fisica fondamentale, PI S. Degl’Innocenti) and by INFN (Iniziativa specifica TAsP).
References
- Andrae, R., Fouesneau, M., Creevey, O., et al. 2018, A&A, 616, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Angelou, G. C., Bellinger, E. P., Hekker, S., & Basu, S. 2017, ApJ, 839, 116 [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Badnell, N. R., Bautista, M. A., Butler, K., et al. 2005, MNRAS, 360, 458 [NASA ADS] [CrossRef] [Google Scholar]
- Basu, S., Chaplin, W. J., & Elsworth, Y. 2010, ApJ, 710, 1596 [NASA ADS] [CrossRef] [Google Scholar]
- Bellinger, E. P., Angelou, G. C., Hekker, S., et al. 2016, ApJ, 830, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Casagrande, L., Ramírez, I., Meléndez, J., Bessell, M., & Asplund, M. 2010, A&A, 512, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casagrande, L., Silva Aguirre, V., Stello, D., et al. 2014, ApJ, 787, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Cleveland, W. S., Devlin, S. J., & Grosse, E. 1988, J. Econometrics, 37, 87 [CrossRef] [Google Scholar]
- Cleveland, W. S., & Grosse, E. 1991, Stat. Comput., 1, 47 [CrossRef] [Google Scholar]
- Degl’nnocenti, S., Prada Moroni, P. G., Marconi, M., & Ruoppo, A. 2008, Ap&SS, 316, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Dell’Omodarme, M., & Valle, G. 2013, The R Journal, 5, 108 [Google Scholar]
- Dell’Omodarme, M., Valle, G., Degl’nnocenti, S., & Prada Moroni, P. G. 2012, A&A, 540, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Epstein, C. R., & Pinsonneault, M. H. 2014, ApJ, 780, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Feigelson, E. D., & Babu, G. J. 2012, Modern Statistical Methods for Astronomy with R applications (Cambridge: Cambridge University Press) [CrossRef] [Google Scholar]
- Friedman, J. H., & Stuetzle, W. 1981, J. Am. Stat. Assoc., 76, 817 [CrossRef] [MathSciNet] [Google Scholar]
- Gai, N., Basu, S., Chaplin, W. J., & Elsworth, Y. 2011, ApJ, 730, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaulme, P., McKeever, J., Jackiewicz, J., et al. 2016, ApJ, 832, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Gelman, A., & Rubin, D. B. 1992, Stat. Sci., 7, 457 [Google Scholar]
- Gennaro, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2010, A&A, 518, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Geweke, J. 1992, Bayesian Statistics (University Press), 169 [Google Scholar]
- Guggenberger, E., Hekker, S., Angelou, G. C., Basu, S., & Bellinger, E. P. 2017, MNRAS, 470, 2069 [NASA ADS] [CrossRef] [Google Scholar]
- Haario, H., Saksman, E., & Tamminen, J. 2001, Bernoulli, 7, 223 [CrossRef] [MathSciNet] [Google Scholar]
- Härdle, W. K., & Simar, L. 2012, Applied Multivariate Statistical Analysis (Berlin: Springer) [CrossRef] [Google Scholar]
- Hastings, W. K. 1970, Biometrika, 57, 97 [Google Scholar]
- Kirkby-Kent, J. A., Maxted, P. F. L., Serenelli, A. M., et al. 2016, A&A, 591, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kjeldsen, H., & Bedding, T. R. 1995, A&A, 293, 87 [NASA ADS] [Google Scholar]
- Masana, E., Jordi, C., & Ribas, I. 2006, A&A, 450, 735 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. 1953, J. Chem. Phys., 21, 1087 [NASA ADS] [CrossRef] [Google Scholar]
- Peimbert, M., Luridiana, V., & Peimbert, A. 2007a, ApJ, 666, 636 [NASA ADS] [CrossRef] [Google Scholar]
- Peimbert, M., Luridiana, V., Peimbert, A., & Carigi, L. 2007b, ASP Conf. Ser., 374, 81 [NASA ADS] [Google Scholar]
- Pinsonneault, M. H., Elsworth, Y., Epstein, C., et al. 2014, ApJS, 215, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Prusti, T., de Bruijne, J. H. J., Brown, A. G. A., et al. 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- R Core Team 2018, R: A Language and Environment for Statistical Computing (Vienna, Austria: R Foundation for Statistical Computing) [Google Scholar]
- Ramírez, I., & Meléndez, J. 2005, ApJ, 626, 465 [NASA ADS] [CrossRef] [Google Scholar]
- Ripley, B. D. 1996, Pattern Recognition and Neural Networks (Cambridge: Cambridge University Press) [CrossRef] [Google Scholar]
- Rose, S. J. 2001, J. Quant. Spectr. Rad. Transf., 71, 635 [NASA ADS] [CrossRef] [Google Scholar]
- Schmidt, S. J., Wagoner, E. L., Johnson, J. A., et al. 2016, MNRAS, 460, 2611 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, F. R. N., Castro, N., Fossati, L., Langer, N., & de Koter, A. 2017, A&A, 598, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Themeßl, N., Hekker, S., Southworth, J., et al. 2018, MNRAS, 478, 4669 [NASA ADS] [CrossRef] [Google Scholar]
- Thoul, A. A., Bahcall, J. N., & Loeb, A. 1994, ApJ, 421, 828 [NASA ADS] [CrossRef] [Google Scholar]
- Tognelli, E., Prada Moroni, P. G., & Degl’nnocenti, S. 2011, A&A, 533, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ulrich, R. K. 1986, ApJ, 306, L37 [NASA ADS] [CrossRef] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2013, A&A, 549, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2014, A&A, 561, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2015a, A&A, 579, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2015b, A&A, 575, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2015b, A&A, 587, A16 [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’nnocenti, S. 2017, A&A, 600, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Tognelli, E., & Prada Moroni, P. G. 2018, A&A, 619, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Marconi, M., Degl’Innocenti, S., & Prada Moroni, P. G. 2009, A&A, 507, 1541 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valls-Gabaud, D. 2014, EAS Pub. Ser., 65, 225 [Google Scholar]
- Venables, W., & Ripley, B. 2002, Modern applied statistics with S, Statistics and computing (Berlin: Springer) [Google Scholar]
- Viani, L. S., Basu, S., Chaplin, W. J., Davies, G. R., & Elsworth, Y. 2017, ApJ, 843, 11 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Full form of the linear models
The full form of linear model, with explicit coefficient dependence, for the MS phase is
![$$ \begin{aligned} {\mathcal{E} }(\mathrm{age}) \, (\mathrm{Gyr})&= \beta _0 + \beta _1 \Delta \nu * [\beta _2 {\mathcal{E} }(T_{\rm eff}) + \beta _3 {\mathcal{E} }(\mathrm{[Fe/H]}) + \nonumber \\&+ \beta _4 {\mathcal{E} }(\Delta \nu ) + \beta _5 {\mathcal{E} }(\nu _{\rm max}) ]. \end{aligned} $$](/articles/aa/full_html/2018/12/aa33975-18/aa33975-18-eq12.gif)
The β coefficients are listed, in order, in the first column of Table 1. So β0 corresponds to the Intercept term, β1 to the Δν term and so on.
For the RGB phase, the full model is
![$$ \begin{aligned} {\mathcal{E} }(\mathrm{age}) \, (\mathrm{Gyr})&= \beta _0 + \beta _1 {\mathcal{E} }(T_{\rm eff}) + \beta _2 {\mathcal{E} }(\mathrm{[Fe/H]}) + \nonumber \\&+ \beta _3 {\mathcal{E} }(\Delta \nu ) + \beta _4 {\mathcal{E} }(\nu _{\rm max}). \end{aligned} $$](/articles/aa/full_html/2018/12/aa33975-18/aa33975-18-eq13.gif)
The coefficients are listed in Table 2.
Appendix B: PPR detailed results
The coefficients of the α vectors in Eq. (8) are provided in Tables B.1 and B.2, while the empirical smoothing function are shown in Fig. B.1.
Components of α vectors for the PPR model of the MS phase, for the M = 3 fitted terms.
Components of α vectors for the PPR model of the RGB phase, for the M = 2 fitted terms.
 |
Fig. B.1. Top row: three identified ridge functions for PPR models specified in Eq. (8) for the MS phase. The β coefficients from the fit are also shown. Bottom row: same as in the top row but for the two ridge function in the RGB phase. |
All Tables
Contribution to the age error (in Gyr) of a 1σ shift of the four predictors adopted in the linear models, in different evolutionary stages.
Components of α vectors for the PPR model of the MS phase, for the M = 3 fitted terms.
Components of α vectors for the PPR model of the RGB phase, for the M = 2 fitted terms.
All Figures
|
Fig. 1. Left panel: main sequence of the reference isochrone at 7.5 Gyr (Z = 0.02674, Y = 0.2752, αml = 1.74) in the Teff – Δν plane. The circles mark the position of the synthetic stars adopted for the analysis. Right panel: as in left panel but for the RGB phase. |
| In the text | |
|
Fig. 2. Residual of the linear model in the MS as a function of Δν. The dashed line shows a linear regression of the standardized residuals versus Δν. |
| In the text | |
|
Fig. 3. Left panel: residuals of the linear model for the age of MS stars as a function of the predicted values. The solid line shows a smoother of the data obtained by the LOESS technique. Right panel: as in the left panel, but for RGB stars. |
| In the text | |
 |
Fig. 4. As in Fig. 3, but for the PPR models. |
| In the text | |
|
Fig. 5. Impact on the estimated age (in Gyr) of the 1σ error in the predictors, classified according to the evolutionary stage (from low MS to RGB) and predictors (Teff, [Fe/H], Δν, and νmax). The segments identify the impact range estimated from PPR models, while the circles those from linear models (see text). |
| In the text | |
|
Fig. B.1. Top row: three identified ridge functions for PPR models specified in Eq. (8) for the MS phase. The β coefficients from the fit are also shown. Bottom row: same as in the top row but for the two ridge function in the RGB phase. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.