| Issue |
A&A
Volume 616, August 2018
|
|
|---|---|---|
| Article Number | L16 | |
| Number of page(s) | 4 | |
| Section | Letters to the Editor | |
| DOI | https://doi.org/10.1051/0004-6361/201833800 | |
| Published online | 24 August 2018 | |
Letter to the Editor
Exploring galaxy evolution with generative models
1
Institute for Particle Physics and Astrophysics, Department of Physics, ETH Zurich, Wolfgang-Pauli-Strasse 27, 8093 Zürich, Switzerland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
, This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Systems Group, Department of Computer Science, ETH Zurich, Universitätstrasse 6, 8006 Zürich, Switzerland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
9
July
2018
Accepted:
6
August
2018
Abstract
Context. Generative models open up the possibility to interrogate scientific data in a more data-driven way.
Aims. We propose a method that uses generative models to explore hypotheses in astrophysics and other areas. We use a neural network to show how we can independently manipulate physical attributes by encoding objects in latent space.
Methods. By learning a latent space representation of the data, we can use this network to forward model and explore hypotheses in a data-driven way. We train a neural network to generate artificial data to test hypotheses for the underlying physical processes.
Results. We demonstrate this process using a well-studied process in astrophysics, the quenching of star formation in galaxies as they move from low-to high-density environments. This approach can help explore astrophysical and other phenomena in a way that is different from current methods based on simulations and observations.
Key words: methods: data analysis / methods: statistical / galaxies: evolution
© ESO 2018
1. Introduction
Many objects of interest in astrophysics appear effectively static as the relevant characteristic timescales are far beyond human lifetimes. For this reason, there are generally two approaches researchers take to understand the formation and evolution of objects such as galaxies and quasars: they either take observations and fit models to the data, or they propose some underlying physical model and implement it in a simulation. Observations are limited by the underlying processes we can infer from them, and simulations make assumptions for the processes modeled and are often computationally very expensive.
On the other hand, an emerging technique (Lample et al. 2017; Antipov et al. 2017; Mathieu et al. 2016; Bowman & Vilnis 2016; Kingma & Welling 2013; Rezende et al. 2014) has recently been developed by the machine-learning community that can perform tasks such as taking a photo of a human being as input, and manipulating a certain attribute (e.g. age) and generating a new photo of the same person (see Fig. 1). In this paper, we ask the following question: Can this method be used as a way to explore scientific hypotheses in a purely data-driven way? Can we achieve a similar physical understanding by using such a method?
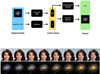 |
Fig. 1. Fader network architecture: Original galaxy images are input to an encoder E(x) which performs a mapping to a latent space of fixed dimension. The associated physical property is binarized into a label y. The parametres E(x) and y are input to a decoder D(E(x), y) which tries to reconstruct the original input image. The discriminator Dis(E(x)) tries to predict the label y from the latent code E(x). Below, we show two examples of changing a single attribute in latent space using a fader network: the aging of a human face learned from age labels (using a pretrained model; Lample et al. 2017), and the lowering of the sSFR of a galaxy using sSFR labels. |
What we propose here is that we can take the data and interrogate the network trained on the data to explore plausible hypotheses. We start with a neural network trained on a set of objects associated with a given measured physical property. Once trained, we can then use the network in two ways: we can encode a real object to a latent space, that is, obtain its representation in latent space by its latent space vector. We can also go the other way and construct a latent space vector and have the network decode the corresponding object into real space. This latent space contains a model of all the salient features of the objects the network is trained on, and so for the network to perform this transformation well, it needs to learn the most salient features of a group of objects. By changing the latent space vector entries, we can walk in latent space and so transform objects from one state to another (Fig. 1; Lample et al. 2017; Antipov et al. 2017; Mathieu et al. 2016; Bowman & Vilnis 2016; Kingma & Welling 2013; Rezende et al. 2014).
Using this structure, we can isolate the action of a parameter and observe its effect on the data by varying it independently of other properties. Suppose we start with a population of objects A which we suspect evolves into population B. Now we can ask two questions:
-
What are the changes that we observe when an object a ∈ A evolves into an object b ∈ B?
-
What are the physical parameters that can explain these changes?
Using our proposed method we can address both questions in a data-driven way: we first train a network on populations A and B to visualize the differences between those two data distributions, that is, we can transform individual objects a ∈ A ⇒ T (a) ∈ B. Comparing a and T (a) we can use our domain knowledge and hypothesize possible physical parameters that can explain the changes that we see. With our set of possible parameters, x, y, z, we can train the network to perform transformations X, Y, Z based on these parameters. We then apply these transforms and compare X(A), Y(A), Z(A) to B and use some statistical measure to tell us how different they are from B. If, for example, transform X(A) is the closest to B it is most likely to be a good explanation for, though not a proof of, how A evolves into B. If none of the transforms are sufficient, for example, the distance between the data distributions is too large, then either all transforms are not a good explanation, or alternatively the training data or network structure was not sufficient to learn X, Y, Z well enough to test it, a possibility which affects all simulation-based hypotheses. The ability to generate and test hypotheses using this approach is limited by the available labels; a process could depend on parameters traced by multiple labels, or by parameters not captured by any of the available labels.
2. Method
We use the Fader network (Lample et al. 2017) architecture to demonstrate how we can use this approach to test hypotheses in real astrophysical settings. The Fader network (Fig. 1) is based on an encoder-decoder structure with a domain adversarial aspect that allows us to learn and manipulate images based on physical properties which have to be converted into binary labels. The key is that the Fader network is able to learn and visualise differences between two data distributions. Images x are input to a neural network called encoder E(x). The encoder E(x) performs a mapping from the space of images to a latent representation of fixed dimension. The decoder D(E(x), y), also a neural network, tries to reconstruct the image x given its latent representation E(x) and its label y (e.g. binary sSFR, dust). Thus the latent space is split into two parts. One part which should contain all the information on the labels and another part which should contain all the salient information needed to reconstruct the object. To perform this disentanglement, another neural network called discriminator Dis(E(x)) is trained to predict the label y from the latent code E(x). Given pairs of images and binary labels {x, y} the Fader network tries to minimise two objectives: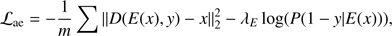 (1)
(1)
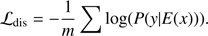 (2)
(2)
The first term in 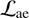 is the reconstruction loss and measures how well the auto-encoder can reconstruct the original input. The second term is the domain adversarial component and by minimising it should become impossible to predict the physical property/label y from the latent code E(x). At the same time the discriminator becomes better at predicting the physical property/label from the latent code E(x) by minimizing
is the reconstruction loss and measures how well the auto-encoder can reconstruct the original input. The second term is the domain adversarial component and by minimising it should become impossible to predict the physical property/label y from the latent code E(x). At the same time the discriminator becomes better at predicting the physical property/label from the latent code E(x) by minimizing 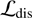 . This adversarial interplay between the two loss functions is what allows the fader network to disentangle salient and label information in the decoding process. During inference, the property/label information can be continuous and changing it will resemble what the original image would look like with the changed physical property/label.
. This adversarial interplay between the two loss functions is what allows the fader network to disentangle salient and label information in the decoding process. During inference, the property/label information can be continuous and changing it will resemble what the original image would look like with the changed physical property/label.
3. Specific scientific application
As a demonstration, we choose the question of satellite quenching in galaxy formation. This problem has several advantages: it is relatively well understood, it relies on changes in the imaging data and associated attributes, which are easy to visualize, and it has been probed both by observations and simulations in the astrophysics literature. When a galaxy enters a high-density environment such as a group or cluster, its specific star formation rate (sSFR) is likely to drop. This process is known as environment quenching and represents a subset of the overall quenching process in galaxies (Strateva et al. 2001; Bell et al. 2003; Faber et al. 2007; Martin et al. 2007; Schawinski et al. 2014). This quenching is associated with a number of structural changes: chiefly, the increasing prominence of a central bulge. These effects have been well studied in the observations (Gunn & Gott 1972; Oemler 1974; Davis & Geller 1976; Kauffmann et al. 2003; Bamford et al. 2009; Peng et al. 2010; Woo et al. 2013) and explored using numerical simulations (Moore et al. 1996, 1998; Tonnesen & Bryan 2009; De Lucia et al. 2012). We view the results from both observational studies and simulations as a baseline to test whether our data-driven approach can lead us to similar results. If yes, then our approach has comparable utility for exploring astrophysical phenomena.
4. Experiment
Following the general outline proposed earlier, we take a population of 26 706 galaxies in the redshift range 0.02 < z < 0.05 with stellar masses log Mstellar > 10.0 from the Sloan Digital Sky Survey (York et al. 2000; Kauffmann et al. 2003; Brinchmann et al. 2004; Alam et al. 2015). We train the Fader network on the environment by using samples of galaxies in the field and satellites in groups and clusters (exact criteria Table 1; Yang et al. 2007). The underlying assumption is that field galaxies turn into satellite galaxies. We then take some field galaxies and use the trained network to show us what they would look like if they became satellites (Fig. 2).
 |
Fig. 2. Hypothesis of taking field galaxies and turning them into satellites. The Org column shows the original galaxy image, and the Rec column shows the best reconstruction of the original image. The remainder of each row shows the transformation from field galaxy to satellite as predicted by our environment Fader network. This figure represents our hypothesis-generation step as we see that when galaxies become satellites, they become redder, and their structure changes to become more centrally concentrated. |
Looking at Fig. 2, we note that as field galaxies become satellite galaxies, they become redder, and their bulges become more prominent. Using our domain knowledge, we can hypothesize two possible parameters which can explain the change in colour:
-
Shut down of SFR (quenching), or
-
increased amount of dust.
To test these hypotheses, we train the Fader network with sSFR measurements from Kauffmann et al. (2003) using a sample of 11 240 SDSS galaxies, and with dust measurements from Oh et al. (2011) using a sample of 1452 SDSS galaxies in the same redshift range (exact criteria Table 1).
That way we have learned two transforms, one which shuts down the SFR of a galaxy, and another one which increases the amount of dust. We verify that both sSFR and dust transform are learned correctly by training a ridge classifier to predict the sSFR and dust physical property. The ridge classifier is a standard and widely used linear classifier. We train it on labelled images so that it predicts the correct label given the image. We adjust the regularization strength to maximise the accuracy of the classifier. We see that both the sSFR and the dust distribution become shifted to the right, that is, lowered sSFR and increased dust.
We can now test these hypotheses by selecting a sample of 1476 blue field galaxies (u − r < 1.9) and 1476 red satellite galaxies (u − r > 2.6). We then train a ridge classifier to predict whether a galaxy is a blue field or a red satellite. We apply both transformations to a test set of 148 blue field galaxies, where we select the label parameter y ∈ [0, 1] such that the median of the transformed distribution lies closest to the median of the red satellite distribution. This results in 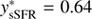 and
and 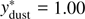 .
.
We find that the classifier has difficulty in differentiating between the artificially lowered sSFR sample and the set of red satellites. The dust transform on the other hand is clearly not able to explain the colour transformation (Fig. 3). This supports the hypothesis that it is a change in sSFR which changes the colours and morphologies of galaxies as they enter high-density environments, in concordance with what we know from both observations and simulations.
 |
Fig. 3. Top: the original blue field galaxy images (left), and the real red satellites (right). We use the two Fader networks to increase the dust (left centre) and lower the sSFR (right centre). The galaxies with lowered sSFRs are qualitatively closer to the real red satellites. Bottom: same information from the top panel shown quantitatively using a ridge classifier. We show the classifier prediction distributions of the real blue field and red satellite distributions (blue and red, respectively), and the results of the two Fader transforms of the real blue field galaxies. The increased dust population (yellow) is very different from the real red satellites, while the lowered sSFR Fader population (grey) is very close. This suggests that lowering the sSFR is a better explanation for the formation of red satellite galaxies. |
What we have shown is that an astrophysicist can address a complex problem such as galaxy quenching, and make rapid progress in testing hypotheses using our method. Not only is training a neural network much faster and computationally less expensive than running a hydrodynamical simulation, it also does not rely on strong assumptions about the underlying physics, or suffer from limitations arising from coarse resolution. Similarly, our approach takes much greater advantage of the data than conventional model fitting to observations. Nevertheless, we were able to reach similarly robust conclusions to the baseline observational and simulation-based studies of the subject.
Overview of the selection criteria used to learn the environment, sSFR, and dust transform.
5. Limitations and outlook
Our approach also has some limitations. First, we “solved” an already fairly well-understood problem. We chose this because if we had used it to approach an unsolved problem and claimed new physical insight, it might not have been clear that either our method or the insight offered was reliable. This does not mean that our approach is necessarily limited to such well-understood problems. Second, we stress that our approach can only help us test hypotheses, not prove them in a mathematical sense. Third, as with any scientific observations, there is scope for confusion between real physical effects and deficiencies and biases in the training data and the network architecture. Finally, we highlight that this approach is not fully automatic, and domain knowledge by the user is still required.
Nevertheless, we believe our approach of using generative models like the Fader network to forward model physical processes and test hypotheses in a data-driven way has significant potential in astrophysics and other fields. Its central advantage is its data-driven nature which makes no assumptions on the underlying physics. As we have shown, human insight is still required for high-level interpretation.
Acknowledgments
K.S. acknowledges support from Swiss National Science Foundation Grants PP00P2_138979 and PP00P2_166159 and the ETH Zurich Department of Physics. C.Z. and the DS3Lab gratefully acknowledge the support from the Swiss National Science Foundation NRP 75 407540_167266, IBM Zurich, Mercedes-Benz Research & Development North America, Oracle Labs, Swisscom, Zurich Insurance, Chinese Scholarship Council, the Department of Computer Science at ETH Zurich, and the cloud computation resources from Microsoft Azure for Research award program. The SDSS data used, the Jupyter notebooks with the Fader network implementation, and instructions for how to run them can be found at http://space.ml/proj/explore.
References
- Alam, S., Albareti, F. D., Allende Prieto, C., et al. 2015, ApJS, 219, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Antipov, G., Baccouche, M., & Dugelay, J. L. 2017, in ICIP 2017, IEEE International Conference on Image Processing, 17–20 September 2017, Beijing, China [Google Scholar]
- Bamford, S. P., Nichol, R. C., Baldry, I. K., et al. 2009, MNRAS, 393, 1324 [NASA ADS] [CrossRef] [Google Scholar]
- Bell, E. F., McIntosh, D. H., Katz, N., & Weinberg, M. D. 2003, ApJS, 149, 289 [NASA ADS] [CrossRef] [Google Scholar]
- Bowman, S. R., Vilnis, L., Vinyals, O., et al. 2016, in Proc. 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, August 11–12, 2016, 10 [Google Scholar]
- Brinchmann, J., Charlot, S., White, S. D. M., et al. 2004, MNRAS, 351, 1151 [NASA ADS] [CrossRef] [Google Scholar]
- Davis, M., & Geller, M. J. 1976, ApJ, 208, 13 [NASA ADS] [CrossRef] [Google Scholar]
- De Lucia, G., Weinmann, S., Poggianti, B. M., Aragón-Salamanca, A., & Zaritsky, D. 2012, MNRAS, 423, 1277 [NASA ADS] [CrossRef] [Google Scholar]
- Faber, S. M., Willmer, C. N. A., Wolf, C., et al. 2007, ApJ, 665, 265 [NASA ADS] [CrossRef] [Google Scholar]
- Gunn, J. E., & Gott, J. R., III 1972, ApJ, 176, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Kauffmann, G., Heckman, T. M., White, S. D. M., et al. 2003, MNRAS, 341, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Kingma, D. P., & Welling, M. 2013, ArXiv e-prints [arXiv:1312.6114] [Google Scholar]
- Lample, G., Zeghidour, N., & Usunier, N. 2017, ArXiv e-prints [arXiv:1706.00409] [Google Scholar]
- Martin, D. C., Wyder, T. K., Schiminovich, D., et al. 2007, ApJS, 173, 342 [NASA ADS] [CrossRef] [Google Scholar]
- Mathieu, M. F., Zhao, J. J., & Zhao, J. et al. 2016, in Advances in Neural Information Processing Systems, eds. D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, & R. Garnett (Curran Associates, Inc.), 29, 5040 [Google Scholar]
- Moore, B., Katz, N., Lake, G., Dressler, A., & Oemler, A. 1996, Nature, 379, 613 [NASA ADS] [CrossRef] [Google Scholar]
- Moore, B., Lake, G., & Katz, N. 1998, ApJ, 495, 139 [NASA ADS] [CrossRef] [Google Scholar]
- Oemler, A., Jr. 1974, ApJ, 194, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Oh, K., Sarzi, M., Schawinski, K., & Yi, S. K. 2011, ApJS, 195, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Peng, Y.-J., Lilly, S. J., Kovač, K., et al. 2010, ApJ, 721, 193 [NASA ADS] [CrossRef] [Google Scholar]
- Rezende, D. J., Mohamed, S., & Wierstra, D. 2014, ArXiv e-prints [arXiv:1401.4082] [Google Scholar]
- Schawinski, K., Urry, C. M., Simmons, B. D., et al. 2014, MNRAS, 440, 889 [NASA ADS] [CrossRef] [Google Scholar]
- Strateva, I., Ivezić, Ž., Knapp, G. R., et al. 2001, AJ, 122, 1861 [Google Scholar]
- Tonnesen, S., & Bryan, G. L. 2009, ApJ, 694, 789 [NASA ADS] [CrossRef] [Google Scholar]
- Woo, J., Dekel, A., Faber, S. M., et al. 2013, MNRAS, 428, 3306 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Mo, H. J., van den Bosch, F. C., et al. 2007, ApJ, 671, 153 [NASA ADS] [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E., Jr., et al. 2000, AJ, 120, 1579 [CrossRef] [Google Scholar]
All Tables
Overview of the selection criteria used to learn the environment, sSFR, and dust transform.
All Figures
|
Fig. 1. Fader network architecture: Original galaxy images are input to an encoder E(x) which performs a mapping to a latent space of fixed dimension. The associated physical property is binarized into a label y. The parametres E(x) and y are input to a decoder D(E(x), y) which tries to reconstruct the original input image. The discriminator Dis(E(x)) tries to predict the label y from the latent code E(x). Below, we show two examples of changing a single attribute in latent space using a fader network: the aging of a human face learned from age labels (using a pretrained model; Lample et al. 2017), and the lowering of the sSFR of a galaxy using sSFR labels. |
| In the text | |
|
Fig. 2. Hypothesis of taking field galaxies and turning them into satellites. The Org column shows the original galaxy image, and the Rec column shows the best reconstruction of the original image. The remainder of each row shows the transformation from field galaxy to satellite as predicted by our environment Fader network. This figure represents our hypothesis-generation step as we see that when galaxies become satellites, they become redder, and their structure changes to become more centrally concentrated. |
| In the text | |
|
Fig. 3. Top: the original blue field galaxy images (left), and the real red satellites (right). We use the two Fader networks to increase the dust (left centre) and lower the sSFR (right centre). The galaxies with lowered sSFRs are qualitatively closer to the real red satellites. Bottom: same information from the top panel shown quantitatively using a ridge classifier. We show the classifier prediction distributions of the real blue field and red satellite distributions (blue and red, respectively), and the results of the two Fader transforms of the real blue field galaxies. The increased dust population (yellow) is very different from the real red satellites, while the lowered sSFR Fader population (grey) is very close. This suggests that lowering the sSFR is a better explanation for the formation of red satellite galaxies. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.