| Issue |
A&A
Volume 611, March 2018
|
|
|---|---|---|
| Article Number | A53 | |
| Number of page(s) | 26 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201731305 | |
| Published online | 29 March 2018 | |
Automated reliability assessment for spectroscopic redshift measurements★
1
Aix Marseille Univ. CNRS LAM, Laboratoire d’Astrophysique de Marseille,
13013 Marseille,
France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Université Lyon, Université Lyon 1, CNRS/IN2P3, Institut de Physique Nucléaire de Lyon, 69622 Villeurbanne cedex, France
3
INAF – Istituto di Astrofisica Spaziale e Fisica Cosmica Milano,
via Bassini 15,
20133 Milano,
Italy
4
Dipartimento di Fisica e Astronomia, Università di Bologna,
via Gobetti 93/2,
40129 Bologna,
Italy
5
INAF–Osservatorio Astronomico di Bologna,
via Gobetti 93/3,
40129 Bologna,
Italy
Received:
2
June
2017
Accepted:
9
September
2017
Abstract
Context. Future large-scale surveys, such as the ESA Euclid mission, will produce a large set of galaxy redshifts (≥106) that will require fully automated data-processing pipelines to analyze the data, extract crucial information and ensure that all requirements are met. A fundamental element in these pipelines is to associate to each galaxy redshift measurement a quality, or reliability, estimate.
Aim. In this work, we introduce a new approach to automate the spectroscopic redshift reliability assessment based on machine learning (ML) and characteristics of the redshift probability density function.
Methods. We propose to rephrase the spectroscopic redshift estimation into a Bayesian framework, in order to incorporate all sources of information and uncertainties related to the redshift estimation process and produce a redshift posterior probability density function (PDF). To automate the assessment of a reliability flag, we exploit key features in the redshift posterior PDF and machine learning algorithms.
Results. As a working example, public data from the VIMOS VLT Deep Survey is exploited to present and test this new methodology. We first tried to reproduce the existing reliability flags using supervised classification in order to describe different types of redshift PDFs, but due to the subjective definition of these flags (classification accuracy ~58%), we soon opted for a new homogeneous partitioning of the data into distinct clusters via unsupervised classification. After assessing the accuracy of the new clusters via resubstitution and test predictions (classification accuracy ~98%), we projected unlabeled data from preliminary mock simulations for the Euclid space mission into this mapping to predict their redshift reliability labels.
Conclusions. Through the development of a methodology in which a system can build its own experience to assess the quality of a parameter, we are able to set a preliminary basis of an automated reliability assessment for spectroscopic redshift measurements. This newly-defined method is very promising for next-generation large spectroscopic surveys from the ground and in space, such as Euclid and WFIRST.
Key words: methods: data analysis / methods: statistical / techniques: spectroscopic / galaxies: distances and redshifts / surveys
A table of the reclassified VVDS redshifts and reliability is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/611/A53
© ESO 2018
1 Introduction
Next-generation experiments in Cosmology face the formidable challenge of understanding dark matter (DM) and dark energy (DE), two major components seemingly dominating the Universe content and evolution.
To improve our understanding of the Universe evolution history, the investigation of the distribution of galaxies over large volumes of the Universe at different cosmic times now constitutes a key requirement for future observational programs such as Euclid (Laureijs et al. 2011), WFIRST (Green et al. 2012), and LSST (Ivezic et al. 2008) that will exploit cosmological probes such as Weak Lensing (WL) and Galaxy Clustering (GC: baryon acoustic oscillations – BAO, redshift space distortions – RSD) to define the role of the dark components (Albrecht et al. 2006).
In GC, the detection of the BAOs at the sound horizon scale (rs ≈ 105 h−1 Mpc) is used to investigate the role of DE in the evolution of the expansion through measurements of the Hubble parameter H(z) and the comoving angular distances DA(z) (Beutler et al. 2011), while the detection of the distorsions in the redshift space is used to probe the structures’ growth and DE models by measuring the parameter combination gθ = f(z)σ8(z), where f(z) and σ8 refer to the growth rate and the rms amplitude (in a sphere of radius 8 h−1 Mpc) of the density fluctuations (Beutler et al. 2012), respectively. The WL is used to map the matter distribution (dark + visible) in the Universe and constrain the expansion history through precise measurements of shapes and distances of lensed galaxies (Huterer 2002; Linder & Jenkins 2003).
In Cosmology, the redshift z is a fundamental quantity, which links distances and cosmic time through the use of a cosmological model. Accurate redshift measurements are at the core of all modern experiments aiming at precision cosmology for a better understanding of the Universe content, focused on the dominant DM and DE components, as the cosmological probes GC and WL that require precise redshift measurements to build robust statistical models to constrain the DE equation-of-state and investigate the content of the dark Universe (Abdalla et al. 2008; Wang et al. 2010). In particular, 3D galaxy distribution maps from GC measurements entail precise measurements of spectroscopic redshifts, while cosmic shear measurements in WL require, along with high-quality imaging and photometry, the selection of sources using redshift measurements for two reasons: First, the galaxies in front of the lens are not affected by the gravitational lensing but they dilute the signal of the galaxy source in the background, and second, the galaxies at the same redshift as the lens contribute to the intrinsic alignment that disrupts the WL measurements.
As part of the future large-scale experiments in Cosmology designed to address the DE and DM origin, the Euclid mission is a M-Class ESA mission from the ESA Cosmic Vision program that aims to probe the expansion and the LSS growth histories in the Universe. Through the combination of cosmological probes (BAO, RSD, WL, clusters of galaxies, supernovae – SNe), Euclid will achieve an unprecedented level of accuracy and control of systematic effects to derive precise measurements of the Hubble parameter H(z), the linear growth rate of structures γ, the DE equation-of-state parameters (ωp, ωa), the non-Gaussianity amplitude fNL and the rms fluctuation of the matter over-density σ8, among other cosmological parameters (Laureijs et al. 2011).
By covering a large fraction of the sky (Wide: ~15 000 deg2, Deep: a total of 40 deg2), the mission will perform a photometric survey in the visible and three near-infrared bands to measure the weak gravitational lensing by imaging approximately 1.5 billion galaxies with a photometric redshift accuracy of σz ∕(1 + z) ≤ 0.05, in addition to a spectroscopic slitless survey of approximately 25 million galaxies with a redshift accuracy of σz ∕(1 + z) ≤ 0.001 in order to derive precise measurements of the galaxy power spectrum (Laureijs et al. 2011). The wide-field Euclid survey will be particularly challenging because of the large-size sample of faint distant galaxies, for which the spectroscopic redshifts need to be automatically measured, and their corresponding reliability evaluated.
For large-scale surveys such as Euclid, the sheer amount of data requires the development of robust and fully automated data-processing pipelines to analyze the data, extract useful information (e.g., redshift) and ensure that all requirements are met.
Distinctapproaches to estimate redshifts have been used in a broad range of galaxy surveys. Photometric redshifts zphot are estimated using spectral energy distribution (SED) template fitting (e.g., Hyper-z Bolzonella et al. 2000; Le Phare Ilbert et al. 2006), classification with neural networks to produce a mapping between photometricobservables and reference data (e.g., ANNz, Collister & Lahav 2004), or Bayesian inference to compute a posterior zphot PDF with prior information from integrated flux in filters, colour or magnitude: BPZ (Benitez 1999), ZEBRA (Feldmann et al. 2006), EAZY (Brammer et al. 2008). On the other hand, spectroscopic redshifts zspec are estimated from the direct application of cross-correlation or chi-square-fitting methods between the observed data and a reference set of spectroscopic templates (Tonry & Davis 1979; Simkin 1974; Schuecker 1993; Machado et al. 2013), or using spectral feature detection (emission/absorption lines and continuum features including spectral discontinuities in the UV-visible domain such as the Lyman break or the Balmer and D4000A breaks) that can be very powerful (Schuecker 1993). Some codes (EZ, Garilli et al. 2010) combine spectral lines detection with cross-correlation or chi-square fitting to inject prior knowledge about more plausible redshift solutions.
Despite their overall performances in redshift estimation, most algorithms in use today still suffer from numerous modeling and computational deficiencies, as the major recurrent issues with the zspec estimation algorithms remain the strong correlation between reliable spectral feature detection and the quality of the observed spectrum, the difficulty to define a representative set of reference templates, and the use of a pre-generated redshift grid Θz that might be beneficial for rapid and parallel processing but could induce a “bias” regarding the redshift space to probe.
In galaxy surveys, a key issue often overlooked is the necessary evaluation of the quality of a redshift measurement because spectroscopic redshift measurement methods may be affected by a number of known or unknown observational biases that may produce some errors in the output redshift, ranging all the way to a catastrophic measurement far from the real galaxy redshift. Further, despite the general trend that consists in linking the reliability of a redshift measurement to the S/N of detected spectral features, the noise in the data usually presents a strongly non-linear dependency on the flux spectrum for various reasons (e.g., the wavelength-dependency of the background flux), which makes the definition of a precise redshift reliability criterion even more difficult.
A number of previous faint galaxy surveys have adopted redshift reliability assessments, either by using empirical thresholds applied to a single metric operator (Baldry et al. 2014; Cool et al. 2013), or by combining independent reliability assessments performed by more than two experienced astronomers in order to smooth-out the observer bias of each individual and produce a remarkably repetitive reliability assessment (Le Fèvre et al. 2013, 2015; Garilli et al. 2014; Guzzo et al. 2014). All methods imply subjective information, either by selecting “adequate” thresholds from a constructed sample or by involving a human operator within the (visual) verification process that becomes largely unfeasible for samples over 105 galaxies. For massive spectroscopic surveys such as Euclid or WFIRST, there is a critical need for a fully automated reliability flag definition that will adapt to the observed data and display a greater use of all available information.
In this paper, we propose to exploit a Bayesian framework for the spectroscopic redshift estimation to incorporate all sources of information and uncertainties of the estimation process (prior, data-model hypothesis), and produce a full zspec posterior PDF, that will be the starting point of our automated reliability flag definition.
To test the proposed methodology of assessing the redshift reliability, we use a new redshift estimation software called algorithms for massive automatic Z evaluation and determination (AMAZED) developed as part of the Processing function (PF-SPE) in charge of the 1D spectroscopic data-processing pipeline of the Euclid space mission.
The paper is organized as follows. After introducing the subject, we present the data used in this study in Sect. 2, and in Sect. 3 we describe the Bayesian formalism of the spectroscopic redshift estimation. Section 4 is focused on the proposed automated reliability assessment method, where we first describe the principle, then present preliminary results of supervised and unsupervised classification techniques using the public database of the VIMOS VLT Deep Survey (VVDS, Le Fèvre et al. 2013). In Sect. 5, we present our results of redshift reliability predictions using preliminary simulations of Euclid spectra covering a wavelength range [1.25−1.85] μm, and we finally conclude in Sect. 6.
2 Reference data
To test the proposed method of assessing a redshift reliability, we use public data from the VIMOS VLT Deep Survey1 (VVDS) in this study. The large VIMOS VLT Deep Survey (Le Fèvre et al. 2013) is a combination of three i-band magnitude limited surveys: Wide (17.5 ≤ iAB ≤ 22.5; 8.6 deg2), Deep (17.5≤ iAB ≤ 24; 0.6 deg2) and Ultra-Deep (23 ≤ iAB ≤ 24.75; 512 arcmin2), that produced a total of 35 526 spectroscopic galaxy redshifts between 0 and 6.7 (22 434 in Wide, 12 051 in Deep and 1041 in UDeep) with a spectral resolution (R ≃ 230, dispersion 7.14A) approaching that of the upcoming Euclid mission (R ≥ 380 for a 0.5′′ object, dispersion 13.4A) as illustrated in Fig. 1.
The VIMOS Interactive Pipeline and Graphical Interface (VIPGI) data-processing software included background subtraction, decontamination, filtering and extraction of 1D spectra from 2D spectral images using sophisticated packages (Scodeggio et al. 2005). The VIMOS 1D spectroscopic data was processed using the EZ software (Garilli et al. 2010) to compute spectroscopic redshift measurements and reliability flags by combining reliability assessments (visual checks) of at least two experienced astronomers (Le Fèvre et al. 2013). The VVDS project provides a reference sample with a range of redshifts and reliability flags well-suited for testing our methods in a broad parameter space.
To evaluate our automated redshift reliability assessment method (Sect. 4), we use the VVDS data in two stages. First we exploit the existing redshift reliability flags of the VVDS data as a reference to assess the performances of supervised classification algorithms in predicting a similar redshift reliability label. Then, after partitioning the VVDS data into distinct clusters of redshift reliability flags using unsupervised classification, we compare these results with the original VVDS redshift flags to evaluate the performances of the proposed methodology and unveil possible discrepancies.
 |
Fig. 1 VVDS-Deep galaxy spectra with identifiable spectral features at known redshifts: emission/absorption line, D4000A break. |
3 Spectroscopic redshift estimation
3.1 Description
To derive a redshift, the widely used template-based algorithms rely on the hypothesis that “there exists a reference template spectrum that is a true (and sufficient) representation of the observed data”, implying that the observed spectrum can be described by at least one spectroscopic template of the reference library.
Using a set of rest-frame templates and a fixed grid of redshift candidates in Θz , for each pair (redshift z, template Mt) we compute the Least-Square metric:
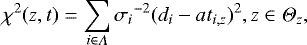 (1)
(1)
or the cross-correlation:
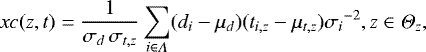 (2)
(2)
where di and σi refer respectively to the observed flux and noise spectra at pixel i, ti,z is the redshifted template interpolated at pixel i, and (μt,z; σt,z ) and (μd ; σd ) are the mean and standard-deviation of the redshifted template and the observed spectrum respectively. The wavelength range in use Λ contains n datapoints, Θz refers to the redshift space to probe, and a is a scale factor referring to the amplitude of the redshifted template that is usually computed at each trial from (weighted) least-square estimation.
The estimated zspec results from a joint-estimation of the pair (z, Mt) and is performed by optimizing a chosen metric: maximization of the cross-correlation function or minimization of the chi-square operator.
In general, the accuracy of the template-based methods is tied to the representativeness and wavelength coverage of the spectroscopic templates Mt in use.
3.2 Bayesian inference
Assuming a linear and Gaussian data model with i.i.d. (independent and identically distributed) residuals 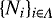 , the probability of observing the spectrum
, the probability of observing the spectrum 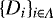 , at a redshift z given a template model Mt and any additional information I is described by the likelihood function
, at a redshift z given a template model Mt and any additional information I is described by the likelihood function 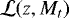 (cf. Appendix A):
(cf. Appendix A):
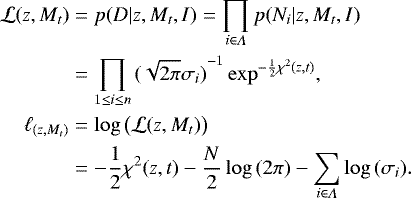 (3) (4)
(3) (4)
Via the Bayes rule, the joint posterior distribution is:
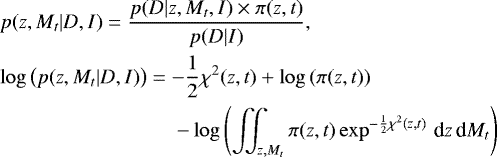 (5) (6)
(5) (6)
where π(z, t) is the joint-prior distribution of the pair (z, Mt).
The 1D posterior distribution is obtained by marginalizing over Mt :
 (7)
(7)
The “best” redshift 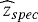 is the MAP (Maximum-A-Posteriori) estimate:
is the MAP (Maximum-A-Posteriori) estimate:
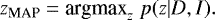 (8)
(8)
This Bayesian formalism was not clearly stated for the spectroscopic redshift estimation. As for now, a posterior zspec PDF can be computed and prior information, if available, can easily be integrated.
Furthermore if the hypothesis of the datamodel is readjusted, the equations can be rapidly and accurately revised in the likelihood expression (cf. Appendix A).
The template library used in this study includes a set of 9 continuum spectra of spiral, elliptical, starburst, and bulge galaxies, supplemented with 12 templates displaying different shapes and level for the continuum and the emission lines that were built by the VVDS team to take into account the diversity of galaxy spectra observed during the survey.
The spectroscopic templates that had only optical data were extended in the UV down to 912A by exploiting the closest templates with UV data, and below 912A by using nul flux spectra. In the infrared, a blackbody continuum was used to extrapolate the templates up to 20 000A.
This large wavelength coverage ensures that the intersection between the observed spectra and the templates is verified at each redshift trial.
3.3 Numerical computation
In the Bayesian inference, if our state of knowledge about a certain quantity θ is vague, a non-informative prior, such as the flat prior, is usually computed.
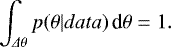 (9)
(9)
Using a flat prior for redshift estimation implies that all redshifts and all templates are viewed as equiprobable solutions. The estimation algorithm will explore the full template library and the entire redshift grid and compute a (marginalized) posterior redshift PDF as displayed in Fig. 2.
If extra information about the pair (z, Mt) is available, the joint prior will be more informative as it will display a refined structure in the (z, Mt) space. For example, to estimate photometric redshifts, integrated flux in filters, colour, or magnitude can be usedas priors to efficiently probe the redshift space. In Benitez (1999), the joint-prior p(z, T|m0) provides additional information about the most eligible spectral objects, T, with a magnitude, m0 , that could be observed at certain redshifts, z. However, for spectroscopic redshift estimation, there is no clear definition of a (data-independent) prior, a choice justified by the fact that spectroscopic data is more informative than photometry.
 |
Fig. 2 Posterior redshift PDF of two VVDS-Deep spectra. Top: a unimodal zPDF characterizes a very reliable
redshift measurement (a single peak at z=0.879). Bottom: a multimodal zPDF refers to multiple redshift solutions
(multiple peaks) possibly with similar probabilities associated to a diminished confidence level of the MAP estimate at
z = 1.159.
The quantity |
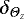
4 Reliability assessment
As the size of massive surveys in astronomy continues to expand, assessing redshifts’ reliability becomes increasingly challenging. The need for fully automated reliability assessment methods is now part of the requirements for future surveys, and is justified by the fact that automation provides predictable and consistent performances while the behavior of a human operator remains unpredictable and often inconsistent and therefore can require several independent observers to smooth out personal biases.
Moreover, the need for automation comes from the orders-of-magnitude increase in the total number of spectra that need to be processed. Visual examination of all spectra in a survey (2dF, DEEP2, VVDS, VIPERS, zCOSMOS, VUDS, PRIMUS, etc.) is extremely difficult for samples containing 105 objects or more, and will be completely impossible for next-generation spectroscopy surveys with more than 50 × 106 objects.
In general, existing approaches to automate the reliability assessment as well as the associated quality control in most engineering applications, such as the intrusion detection systems (IDS) that aim to evaluate the traffic quality by identifying any malicious activity or policy violation within a network, include:
-
1.
Anomaly detection systems (ADS), where a component is labeled as an outlier if it deviates from an expected behavior using a set of thresholds or reference data (Chandola et al. 2009; Patcha & Park 2007). The ADS usually proceed by monitoring the system activity and detecting any sort of violation based on specific criteria or invariable standards.
-
2.
Supervised classification that exploits prior knowledge of a referenced training set to predict a label (Shahid et al. 2014).
Both methods deliver great performances in general, but still have some limitations: irrelevant thresholds to new data for the ADS, and poor representativity of the training set in classification, and so on.
To automate the redshift reliability assessment, reproducing the ADS reasoning scheme by setting empirical thresholds might not be the best option when dealing with massive surveys. However, the use of machine learning (ML) techniques can still be a viable option but first requires the search for a valid model and a coherent set of entries.
In this work, the method to automate the redshift reliability flag definition stems from an attempt to address questions about the meaning of a “reliable” redshift:
-
1.
What guides an experienced astronomer to declare an estimated redshift as a plausible solution; apart from visual inspection of the data and its fitted template?
-
2.
Is there some disregarded information within the z-estimation process that we can further exploit?
-
3.
How cana system “perceive” the same information as a human does?
Spectroscopic redshift measurements are obtained from χ2 minimization or maximization of the posterior probability p(z|D, I) in Bayesian inference (cf. Sect. 3), and usually no further analysis of the computed functions is conducted afterwards. When computing the posterior redshift PDF, broadly two types of probability density function can be observed (cf. Fig. 2): a unimodal PDF versus a multimodal distribution. In both cases, a pipeline will provide a redshift estimation zMAP but the estimated redshifts from these two different types of PDFs definitely do not show the same level of reliability. In fact, the multimodal PDF refers to numerous redshift candidates possibly with similar probabilities, while a strong unimodal PDF with a prominent peak and low dispersion depicts a more “reliable” redshift estimation of the data.
We exploit such characteristics of the posterior PDF to build a discretized descriptor space that will be the entry point for ML techniques to predict a reliability label. Our approach aims to build the “experience” of an automated system in order to assess the quality of a redshift measurement from the zPDF.
4.1 Description
In machine learning, the typical entries of the model are a response vector Y and a feature matrix X:
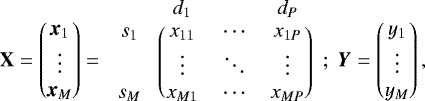 (10)
(10)
where xj = (xj,1…xj,P) is the P-dimensional feature vector of the jth observational data 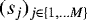 , and yj is its response variable. If the response vector Y of the model is unknown, the prediction of a label yj using only the distribution of X in the feature space refers to clustering (unsupervised classification). Otherwise, we talk about supervised classification whose goal is to define a mapping between the observable entries X and their associated response variables Y through a dual training/test scheme.
, and yj is its response variable. If the response vector Y of the model is unknown, the prediction of a label yj using only the distribution of X in the feature space refers to clustering (unsupervised classification). Otherwise, we talk about supervised classification whose goal is to define a mapping between the observable entries X and their associated response variables Y through a dual training/test scheme.
In ML, the design of the entry model is decisive. What could be the optimal selection of informative and independent features to accurately describe the zPDF? Can a single operator, such as the integral under the redshift solution zMAP or the difference in probability between the first two peaks (modes), be a unique and sufficient descriptor? No definite answers can be given, since this approach of “quantifying the spectroscopic redshift reliability” from the zPDF is new. Each set of selected features will define a different descriptor space that a classifier could separate differently.
In this study, our selected ML entries are redshift reliability flags (Y) and descriptors of the zPDFs (X), where the feature vector xj associated to the observation sj = {D} consists of alist of eight tailored descriptors of the zPDF:
-
The quantity
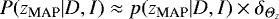 ,
where
,
where 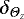 is the fixed step of the redshift grid.
is the fixed step of the redshift grid. -
The number of significant modes in the PDF. The “significance” of a mode is determined by partitioning the set of detected peaks of the PDF into two categories (strong/weak) based on their prominence and height in order to avoid including the extremely-low density peaks (10−100 usually) that result from the conversion of logPDFs into a linear scale.
-
The difference in probability of the first two best redshift solutions (zMAP, z2): P(zMAP|D, I) − P(z2|D, I).
-
The dispersion
![Mathematical equation: $\sigma=[{\int (z-\bar{z})^2 p(z)\textrm{d}z}]^{1/2}$](/articles/aa/full_html/2018/03/aa31305-17/aa31305-17-eq16.png) ,
with
,
with 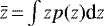 .
. -
The cumulative probability in the region
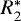 :
: ![Mathematical equation: $\big[z_{\textrm{MAP}} \pm \delta \big]$](/articles/aa/full_html/2018/03/aa31305-17/aa31305-17-eq19.png) where the parameter δ
is chosen equal to 0.001.
where the parameter δ
is chosen equal to 0.001. -
The characteristics of the CR*(restricted version of the credibility region with 95% in probability): number of z candidates, width Δz, cumulative probability. In Bayesian Inference, the CR is analogous to the frequentist CI (confidence interval). For a 100(1 − α)% level of credibility, the CR is defined as: ∫ CRp(z|D, I)dz = 1 − α. The restricted CR* used sets (optional) maximal bounds to the search region around zMAP to accelerate the operation.
Displays of distinct zPDFs are presented in Figs. 3–6, where the descriptors listed above highlight interesting features of the zPDFs. For example, it is possible to obtain a similar dispersion for two zPDFs but a different number of significant redshift modes (Fig. 3), or the other way around: multimodal zPDFs with a comparable number of redshift modes with different amplitudes, and a different dispersion (cf. Fig. 4) or difference in probability between the first two best redshift solutions (cf. Fig. 5). Also, unimodal zPDFs can vary as they can display wider or narrower restricted CR (cf. Fig. 6) or different values of the dispersion σ.
Using the eight listed key descriptors, we estimate that the main features of the zPDF can be inferred. This design is not immutable. Supplementing the feature matrix with additional information about the observed spectra, s, or designing a different feature selection can also be explored.
 |
Fig. 3 Display of two zPDFs with multiples modes and a similar dispersion. |
 |
Fig. 4 Display of two zPDFs with multiples modes and a different dispersion. |
 |
Fig. 5 Display of two zPDFs with multiples modes and different characteristics of the two best z solutions. |
 |
Fig. 6 Display of two zPDFs with a single mode and a different width of CR * . |
4.2 Classification
4.2.1 Model
The ML entries in this study are obtained from a collection of zPDFs computed from M spectra of the VVDS to which a reliability label 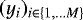 is known to belong to one of the flags (Le Fèvre et al. 2005, 2013):
is known to belong to one of the flags (Le Fèvre et al. 2005, 2013):
-
Flag 1, “Unreliable redshift”.
-
Flag 2, “Reliable redshift”.
-
Flag 9, “Reliable redshift, detection of a single emission line”.
-
Flag 3, “Very reliable redshift with strong spectral features”.
-
Flag 4, “Very reliable redshift with obvious spectral features”.
The redshift reliability flags in the VVDS are determined by confronting independent redshift measurements performed by several observers onthe same spectra.
By comparing the redshift measurements with internal duplicated observations or with published redshifts from different surveys, the VVDS spectroscopic redshift flags have been empirically paired with a probability for “a redshift to be correct”: the VVDS redshift reliability flags {1, 2, 9, 3, 4} are associated with probabilities of [50–75]%, [75–85]%, ~80%, [95–100]%, and 100% , respectively, that the measured redshifts are correct.
Using supervised classification, the objective is to predict similar redshift reliability flags for new unlabeled data. However, since the reproducibility of the VVDS redshift reliability flags is difficult because of their subjective definition and the confusion between “quality of a redshift” and “specific information about the data”, we first decided to regroup the VVDS flags, as following:
-
“Class 0”, consisting of the “VVDS flags 1” to depict the uncertain redshifts.
-
“Class +1”, consisting of the “VVDS flags 2–9” to depict the reliable redshifts.
-
“Class +2”, consisting of the “VVDS flags 3–4” to depict the very reliable redshifts.
A three-class classification problem is then set. For multi-class problems, the error-correcting-output-codes (ECOC), as introduced in Dietterich & Bakiri (1995), are adapted for several learners, such as support vector machines (SVM), Tree templates, and Ensemble classifiers. A description of the ECOC is provided in Appendix B.
4.2.2 Preliminary tests
Classification tests are conducted using a VVDS subset of 24519 spectra with a constraint on the redshift accuracy |zMAP − zref|∕(1 + zref) ≤ 10−3 for the VVDS flags {2, 9, 3, 4}. Our main objective is to build a descriptor space from a diverse set of zPDFs and evaluate the ability of the system to predict a redshift reliability label.
The dataset is decomposed into a “Training set” and a “Test set” (cf. Tables 1–3).
Different classifiers are tested in this study to carry out a careful analysis and avoid blindly trusting the results in cases of overfitting. We assess that different techniques should provide a different but not very disparate level of performance. Three classifiers are selected: the SVMs with linear and Gaussian kernels, an ensemble of bagging trees (referred to simply as TreeBagger) and a GentleBoost ensemble of decision trees. A general description of the classifiers and the multi-class measures is provided in Appendices C and D.
To evaluate the performance of a classifier, two tests are conducted:
-
Test 1: resubstitution.
-
Test 2: test prediction.
In the resubstitution, the “Training set” is reused as the “Test set” during the prediction phase. Extremely low prediction errors are expected ( ≲1% classification error rate): if a bijective relation exists between the observables Xtrain and the response vector Ytrain, the generated mapping from the training phase is supposedly accurate. The predicted labels Ypred in resubstitution tests are therefore expected to resemble the true labels Ytrain with high accuracy, otherwise a clear mismatch between the features matrix X and the response vector Y of the ML model is reported. In such a case, the predictions of the second test (“Test prediction”) would be baseless, since the mapping produced from the training phase is truly unusable. The overall performances reportedin Tables F.9 and F.10 in addition to the confusion matrices (cf. Tables F.1 to F.8) representing the fraction of the predicted labels versus the true classes in Ytest, support thisconclusion. Most classifiers seem unable to predict the true labels in resubstitution: non-zero off-diagonal elements in the matricesand a high error-rate, implying that a correct mapping between the feature matrix and the existing VVDS redshift reliability flags cannot be produced.
We would like to point out the singular case of the TreeBagger that seems to generate a good mapping in resubstitution (error rate 0.08% on average) in comparison with the SVMs that are commonly-known as robust classifiers (error rate >10% in average). It seems reasonable to consider that the observed dissimilarity between the different classifiers in resubstitution is due to the sensitivity of the bagging trees to several parameters as the number of learners or the trees depth that can coerce the training into focusing on irregular patterns and establish an erroneous mapping). As anticipated from the resubstitution results (high error rate), we also find that the test predictions present a significant error rate ( ~ 40% on average).To summarize, these first results of supervised classification show that trying to match the subjective VVDS flags with descriptors of the zPDF gives poor results.
The entries and hypotheses for ML have to be reexamined.
Description of the VVDS dataset used in this study.
Training set (total of 16346 VVDS spectra).
Test set (total of 8173 VVDS spectra).
4.3 Clustering and fuzzy classification
From the previous results, doubts can be raised regarding the engineered zPDF feature space derived from a collection of 24519 VVDS spectra. However the selected set of descriptors seems to be a viable description that portrays an existing but hidden structure of the feature space.
Clustering, known as unsupervised classification, is used in this Section to unveil the intricate structure and bring into light some properties of the data in the descriptor space.
4.3.1 Partitioning the descriptor space
In unsupervised classification, prior knowledge about class membership is unavailable. Partitioning the descriptor space into K manifolds is realized by applying separation rules only to the feature matrix X .
By representing the zPDFs feature matrix X in 3D (cf. Fig. 7), a simple bi-partitioning is introduced:
-
Group 1: high dispersion and low P(zMAP|D, I) referring to multimodal PDFs or platykurtic unimodal PDFs.
-
Group 2: medium dispersion and high P(zMAP|D, I) depicting strongly peaked unimodal PDFs.
In each category, we choose to reapply a bi-partitioning to decompose the data into a dichotomized pattern (cf. Fig. 8). This partitioning strategy, applied to the entire descriptor components and not only to the two descriptor components as in the displays, alongside with the number of clusters, the feature selection and the ML algorithms tested in this work as a novelty to automate the redshift reliability, are not immutable and can be readjusted according to the data in hand. Further evaluations will be conducted on these aspects of ML to develop a robust and precise automated assessment of redshift reliability.
Using the classic clustering algorithm FCM (Fuzzy C-Means) to minimize the intraclass variance (cf. Appendix E), the final groups identify distinct partitions in the feature space (cf. Figs. 9 to 11). In this study, the selection of the number of clusters is an empirical process based on the analysis of the intermediate partitions and testing different configurations. We assess that the final architecture is a viable solution amongst others.
-
“Cluster C1”: highly dispersed PDFs with multiple equiprobable modes, P(zMAP) ~ 0.028 ± 0.023.
-
“Cluster C2”: less dispersed PDFs, with few modes and low probabilities P(zMAP) ~ 0.087 ± 0.033.
-
“Cluster C3”: low σ, intermediate probabilities P(zMAP) ~ 0.166 ± 0.035.
-
“Cluster C4”: unimodal PDFs with low dispersion, higher probabilities P(zMAP) ~ 0.290 ± 0.059.
-
“Cluster C5”: strong unimodal PDFs with extremely low dispersion, better probabilities P(zMAP) ~ 0.618 ± 0.204.
The coordinates of the clusters’ centroids in the descriptor space are reported in Table 4.
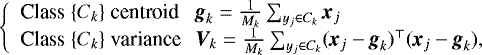 (11)
(11)
where Mk is the number of elements in cluster Ck.
Tables 5 and 6 report the intraclass dispersion 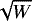 and the interclass dispersion
and the interclass dispersion 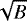 that characterize the newly defined clusters:
that characterize the newly defined clusters:
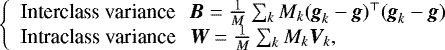 (12)
(12)
with the total variance:
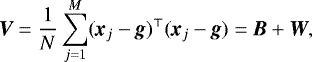 (13)
(13)
where g is the global centroid and M is the full number of elements in the descriptor space.
The variance tables show that the intraclass variance, W, is generally small in comparison to the interclass variance, B, except for two descriptors (the dispersion and the number of modes). This results from the fact that the cluster C1 allows wider variations for these two components. Since the class C1 refers by definition to multimodal zPDFs associated to very unreliable redshift measurement, the results remain coherent.
Given the possibility that the clustering results might be unreliable due to inherent computational limitations or an incorrect modeling of the descriptor space, the full content of each partition 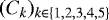 is investigated. We find that, overall, the zPDFs within each class, Ck , verify the properties listed above. The newly defined partitions genuinely describe a homogeneous representation of the data in the feature space.
is investigated. We find that, overall, the zPDFs within each class, Ck , verify the properties listed above. The newly defined partitions genuinely describe a homogeneous representation of the data in the feature space.
 |
Fig. 7 3D representation of the feature matrix X. Broadly, two categories are noticeable. The first group refers to the zPDFs with high dispersion, large zMAP peak and low probability P(zMAP|D, I) that can be assimilated to multimodal PDFs or platykurtic unimodal PDFs. The second group characterizes the zPDFs with medium-to-low dispersion, narrow zMAP peak and high P(zMAP|D, I) that depict strongly peaked unimodal PDFs. |
 |
Fig. 8 Clustering the zPDFs features X
in a dichotomized pattern. The clustering strategy exploits the classic FCM algorithm at each step to
decompose the input data into two sub-classes using the entire set of descriptors. The final categories
|
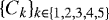
 |
Fig. 9 Representative zPDFs for each clusters. Display of representative zPDFs in
each cluster obtained from clustering. The shift in the confidence level in the
|
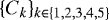
 |
Fig. 10 Clusters repartition in a selected 3D space. The five zReliability clusters described in Sect. 4.3.1 are associated to different types of redshift PDFs, where the two extreme categories C1 and C5 , respectively,describe highly dispersed multimodal zPDFs and peaked unimodal zPDFs. |
 |
Fig. 11 Distribution of the probability value P(zMAP|D, I) within the five partitions. The distribution of the probability values (component of the descriptor space) P(zMAP|D, I) show distinct properties of the clusters. The five zReliability clusters (cf. Sect. 4.3.1) are associated with different categories of redshift PDFs. |
Coordinates of the clusters’ centroids in the descriptor space.
Intraclass dispersion in the descriptor space.
Class dispersions in the descriptor space.
4.3.2 Cluster analysis
In this section, we compare the initial VVDS redshift reliability flags and the new clusters in order to point out peculiar cases of misclassifications: unexplained discrepancies between the manually attributed flags in the VVDS database and those resulting from the unsupervised classification (cf. Sect. 4.3.1).
Two examples of misclassification are reported in Figs. 12 and 13:
-
1.
A misclassification of a “VVDS Flag 1: unreliable redshift estimation” as C5 (unimodal zPDF and very reliable
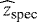 )
is presented in Fig. 12. The misclassification is due to the mismatch between the flux
spectrum and its noise component, where the latter seems very inadequate when considering the good quality
of the data. A problem regarding the generation of the 1D data (flux & noise components) from the
2D → 1D
extraction can be noted.
)
is presented in Fig. 12. The misclassification is due to the mismatch between the flux
spectrum and its noise component, where the latter seems very inadequate when considering the good quality
of the data. A problem regarding the generation of the 1D data (flux & noise components) from the
2D → 1D
extraction can be noted. -
2.
A different type of misclassification illustrated in Fig. 13, where a “VVDS flag 9: secure redshift estimation with an identifiable strong EL” is identified as C1 (for very multimodal zPDFs and extremely unreliable
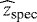 ).
This discrepancy between the VVDS flag and the new label from clustering could be ascribed to an imprecise
computation of the zPDF due to a lack of representative templates at the given redshift, or a biased evaluation of a
human operator.
).
This discrepancy between the VVDS flag and the new label from clustering could be ascribed to an imprecise
computation of the zPDF due to a lack of representative templates at the given redshift, or a biased evaluation of a
human operator.
To evaluate the misclassification rate for the entire VVDS dataset used in this study, Tables 7 and 8 summarize the repartition of the initial VVDS flags {1; 2;9;3;4} within the predicted reliability clusters.
We find that:
-
The green cells represent the “expected” behavior: the cluster C1 is mainlycomposed of the unreliable redshift “VVDS flags 1” ( ~86%), while themajority of the “VVDS flags 4” are in C4/C5 ( ~81%) and the “VVDS flags 3” are in C3/C4 ( ~68%).
-
The graycells represent a “gray area”: the clustering provides homogeneous partitioning in comparison with the VVDS flags, as it properly incorporates the full information from the input data (cf. observed flux and its associated noise component).
We find that the “VVDS flags 2−9” in C4/C5 ( ~20% each) are associated with extremely bright objects with easily identifiable spectral features that make the estimated redshifts very secure.
On the other hand, the “VVDS flags 4” predicted in C3 ( ~15%) are associated to noisier spectra with scarce spectral features in comparison with the “VVDS flags 4” in C5. The redshift reliability level for these spectra is thereby diminished.
Similarly, the prediction of “VVDS flag 2” in C2 ( ~43%) is due to the degradation of data quality in comparison with the “VVDS flags 2” located in C3.
The main reason behind these discrepancies lies in having different observers conducting the redshift-quality checks, as each person has their own understanding of a “redshift reliability” depending on their experience and knowledge of objectively assessing whether a redshift is deemed a secure estimation or not.
-
The red cells are associated with peculiar cases of “abnormal” zPDFs resulting from incorrect noise spectra and/or human misclassification. In particular, the 71 cases listed of “VVDS flag 1” in C5 result from a mismatch between the flux and noise components; the noise component seems extremely low considering the reduced data quality. Having very low noise components contributes to reinforce that the flux information depicts a real observation even when it is not the case. We obtain, finally, extremely peaked zPDFs that are predicted as C5.
For the 23 spectra of “VVDS flag 4” in C1, 13 cases are related to highly dispersed multimodal zPDFs where a confusion between the oxygen emission line [OII]3726A and Ly α is reported: both emission lines are strong candidates which gives at least two significant modes detected in the zPDF. Also, the fact that the associated peaks are very distant in the redshift space results in a high dispersion value, σ, of the zPDF. The prediction in C1 is highly driven by these characteristics. We also report four cases within these 23 spectra that are associated to low S/N spectra: an important noise component annihilates the confidence in the flux vector and therefore produces highly multimodal zPDFs predicted in C1. For the remaining six cases of “VVDS flag 4” in C1, they result from an excessively-high noise component that produces very degenerate zPDFs, also predicted in C1.
The main result from the cluster analysis is that existing redshift reliability flags cannot be reproduced with a 100% accuracy due to their subjective definition, however a general trend can be retrieved as the majority of the VVDS initial redshift flags can be described by one or two of the redshift reliability clusters 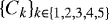 .
.
 |
Fig. 12 Misclassification – case 1. A “VVDS flag 1: very unreliable redshift” is predicted by the classifier in the new category “C5” for very reliable redshifts. The spectrum displays very low noise components that reinforce the confidence in the measured flux pixels. However the extracted 1D spectrum appears distorted considering the initial 2D spectrum. The extraction 2D → 1D induced a bias in the estimation of the (falsely unimodal) zPDF. |
 |
Fig. 13 Misclassification – case 2. A “VVDS flag 9: reliable redshift, detection of a single emission line” is predicted by the classifier in the new category “C1” for very unreliable redshifts. The spectrum displays a strong noise component that annihilates the confidence in the measured flux pixels (especially the spectral emission line [OII] 3726 at 7365A). Several redshift solutions are declared as plausible solutions (a multimodal zPDF). |
Repartition of the initial VVDS redshift reliability flags within the predicted labels (in absolute values).
Repartition of the initial VVDS redshift reliability flags within the predicted labels (in percent).
4.3.3 Re-using the clusters for redshift reliability label predictions
– Classification tests
The clustering results showed a great coherency between the automated definition of redshift reliability labels using the zPDF’s features matrix and our understanding of “a redshift reliability”.
The idea presented in this Section consists in re-using the new labels of the 24519 VVDS spectra as the response vector Y train in supervised classification, to train a classifier to predict redshift reliability labels for new unlabeled data. For this purpose, classification tests are performed using the Training and Test sets in Tables 9 and 10. The resubstitution and test predictions are also used to verify once again the accuracy of the partitioning and objectively assess whether the FCM dichotomized strategy produced “random results” or a “a true description of the zPDFs” in the descriptor space.
Similar performances are observed for several classifiers in resubstitution, with extremely low off-diagonal elements in the confusion matrices and an average per-class error rate ≲ 1% (cf. Tables F.11 to F.14, and Table F.19) for all four classifiers, which is a clear contrast with the results in Sect. 4.2. By having low resubstitution errors, the mapping is deemed a reliable reproduction of the input data, and the prediction of Xtest can be examined. We find in test predictions that the confusion matrices for several classifiers offer a good predictive power (average per-class error rate < 2%), with the Linear SVM scoring slightly lower results (cf. Tables F.15 to F.18, and Table F.20).
– Fuzzy approach In ML, two main approaches exist: “hard” partitioning where an object is said to belong to a unique class (binary membership), and “soft/fuzzy” partitioning where the membership of an object to a class is expressed in terms of a probability between 0 and 1 (Wahba 1998, 2002).
In the classification tests, “soft” partitioning is used to compute the posterior class prediction probability in order to evaluate the classifier predictive power. The class posterior probabilities  are obtained by minimizing the Kullback-Leibler divergence (Hastie & Tibshirani 1998).
are obtained by minimizing the Kullback-Leibler divergence (Hastie & Tibshirani 1998).
In the test predictions on the evaluated VVDS dataset, we find that most class prediction probabilities fall between 0.7 and 1.0 (bright colors in Fig. 14). However, we estimate that it could be possible for new data to be assigned to a redshift reliability label with a lower probability, meaning that the classifier cannot project with certainty the unlabeled zPDF into the descriptor space as a result of an incorrect PDF (numerical limitations, degraded input spectra, etc.), or if it is located close to the margins of two or more clusters. For such cases, a new class of “Unidentified” objects has to be set apart from the labeled clusters 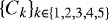 . This particular point on the class prediction using soft partitioning is addressed further in the following section.
. This particular point on the class prediction using soft partitioning is addressed further in the following section.
Training set (total of 16347 VVDS spectra).
Test set (total of 8172 VVDS spectra).
 |
Fig. 14 Class posterior probabilities. The predictive power of several classifiers is displayed for each true class in Y test . Most prediction probabilities fall between ~[70–100]% (bright colors). For example: the Linear SVM correctly predicts ~92% (2060 elements) of the subset of “true C2” (around 2240 elements) in Y test (cf. Table F.17) with class prediction probabilities between 0.7 and 1 (bright colors). |
5 Tests on mock simulations for the Euclid space mission
An end-to-end simulation pipeline is currently under development for Euclid using catalogs of realistic input sources with spectro-photometric information and an instrumental model for the spectrophotometer NISP designed to perform slitless spectroscopy and imaging photometry in the near-infrared (NIR) wavelength domain. For Euclid, observationsof the same field will be obtained from the combination of three or more different roll angles (referring to different orientations of the grisms) in order to alleviate the superposition of overlapping spectra due to the slitless mode.
Using the pixel simulator software TIPS (Zoubian et al. 2014), 1D spectra are obtained from 2D dispersed images after subtracting the sky background from the raw data and combining co-added image stamps of different roll angles. In these preliminary simulations for Euclid, a contamination model (zodiacal light, adjacent sources, etc.) is not included.
Table 11 reports the main characteristics of the simulated data of H α EL galaxies at redshifts in the range 0.95 ≤ z ≤ 1.40.
The Euclid simulations are not associated with a redshift reliability flag, and thereby are qualified as “unlabeled data” in this work. To test the performance of the redshift reliability assessment method, two sets of unlabeled spectra are used (S1, S2), with a total of 3169 spectra per set.
By varying the source size and the sky background level, the difference in data quality between the two datasets is noticeable: Fig. 15 displays sample spectra for each dataset.
Parameters of preliminary mock simulations for Euclid.
 |
Fig. 15 Simulated Euclid spectra. Left: simulated galaxy spectrum (id: 53678850) in the dataset S1 with an identifiable H α line at 12803A. Right: simulated galaxy spectrum (id: 56932048) in the dataset S2 with a H α emission line at 12908A. |
5.1 Reliability class predictions
The redshift PDFs of the Euclid simulated datasets are computed using a constant prior in Θz (cf. Figs. 16 and 17), and projected into the mapping (cf. Sect. 4.3) using soft partitioning to predict redshift reliability labels. Class prediction results are reported in Tables 12 and 13.
The system computes predominantly multimodal zPDFs with high dispersion when the useful information cannot be retrieved from the data because of low S/N: the estimated redshifts are deemed unreliable, which explains the high percentage of S2 spectra in the clusters C1∕C2 ( ~52.3%). In contrast, for high S/N data, the system identifies the majority of redshifts as very reliable: high percentage of S1 spectra in the clusters C4∕C5 ( ~88.1%).
Moreover, the highlighted cells (in magenta) within the result tables indicate two particular cases we anticipated to be null fractions when considering the data quality: We denote on one hand few spectra in the dataset S1 (high S/N) that are associated with unreliable redshift measurements ( ~ 2% predicted in C1∕C2), and on the other hand a small fraction of spectra in S2 (low S/N) that is linked to very reliable redshifts ( ~ 9% predicted in C5). Such results can easily be understood by looking at the distribution in [ log (f H α ), JAB] of the input spectra (cf. Fig. 18). We find that:
-
Bright objects are mainly located in C5, while themajority of faint objects are predicted as C1/C2, in particular when the flux spectrum is embedded in a strong noise (S2). This distribution can be assimilated to a shift C1 → C5 according to the intrinsic properties of the observed object.
-
The difference in absolute values (cf. Table 12) between the results in S1 and S2 is due to the increased noise level from the sky background that injects a higher uncertainty in the observed flux spectrum. The redshift reliability is decreased in S2 in comparison with less noisy data (S1). The repartition in absolute values seems to describe a shift C5 → C1 according to observational constraints (S/N).
 |
Fig. 16 Computed zPDF for a galaxy spectrum in the dataset S1. The redshift probability density function is computed using a constant prior over Θz. |
 |
Fig. 17 Computed zPDF for a galaxy spectrum in the dataset S2. The redshift probability density function is computed using a constant prior over Θz. |
zReliability predictions (in percent) of preliminary mock simulations for Euclid.
 |
Fig. 18 log(f H α ), JAB distribution of the reliability class predictions for unlabeled simulated galaxy spectra for Euclid. The number of faint objects predicted in C1/C2 increases when the noise component in the data is important (S1 → S2). The increased sky background injects a strong noise component of the spectra that annihilates the confidence in a measured redshift, resulting in multimodal zPDFs with high dispersion (C1/C2). In contrast, extremely bright objects with an identifiable Hα line are located in C4∕C5, because the redshift estimation is deemed very reliable when distinct spectral features are found. |
zReliability predictions (in absolute values) of preliminary mock simulations for Euclid.
5.2 Redshift error distribution
We further investigate the distribution of the redshift error εz = |zMAP − zref|∕(1 + zref) within the predicted clusters (cf. Table 14).
We find that the majority of incorrect redshift estimations (εz > 10−3) are located in the clusters C1/C2 for “unreliable redshifts” since low S/N data are more likely to be associated with inaccurate redshift measurements.
For the two datasets, the fraction of spectra associated with low redshift error (εz ≤ 10−3) is ~100%, ~99%, ~95%, and <70% in C5/C4, C3, C2, and C1, respectively.
From this particular result, one approach would be to identify a possible correlation between the redshift reliability clusters and a specific range of redshift errors in order to define a probability for “a redshift to be correct” within the {Ck } clusters, in a similar way to that used for VVDS.
In this direction, the next step will be to conduct similar tests on a wide basis of Euclid simulated datasets (with a contamination model) to statistically constrain the correlation between redshift errors and the redshift reliability clusters.
Redshift error distribution within the predicted redshift reliability classes for preliminary mock simulations for Euclid.
5.3 Fuzzy approach for label prediction
As previously stated in Sect. 4.3.3, soft partitioning in ML provides extra information about the classifier predictive power that can be affected by several factors as possible outliers in the training set or numerical limitations associated to the zPDF computation.
In this study, we find that the majority of S1 and S2 spectra are associated with class probability predictions higher than 99%, as in the example of Table 15. However, peculiar cases, related to class predictions falling within the margins of two or more reliability clusters are detected, as in the example reported in Table 16 where the class posterior probabilities of the cluster C4 are quite close to the predicted class C3.
In this study, the predictions associated to lower-class probabilities are extremely few, with a confusion clearly stated between adjacent clusters (C1 with C2 or C4 with C5 for example).
A confusion entailing predicting a label C4/C5 as C1 (and vice-versa) could have been more problematic and can result from an erroneous computation of the zPDF or an incorrect spectroscopic data (flux and noise components). We estimate that soft partitioning can be used to unveil such peculiar cases and improve the clustering by identifying possible outliers in the descriptor space that can be assigned to the “Unidentified” class independently from the 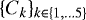 clusters.
clusters.
Class posterior probabilities of two simulated Euclid spectra.
Class posterior probabilities for a simulated spectrum in S2.
| true | ||||
|---|---|---|---|---|
| pos | neg | Total | ||
| predicted | pos | TP | FP | TP+FP |
| neg | FN | TN | FN+TN | |
| Total | TP+FN | TN+FP | TP+FP+TN+FN | |
| true | |||||
|---|---|---|---|---|---|
| “0” | “+1” | “+2” | Total | ||
| predicted | “0” | 4503 | 2 | 1 | 4506 |
| “+1” | 9 | 3581 | 203 | 3793 | |
| “+2” | 0 | 0 | 8047 | 8047 | |
| Total | 4512 | 3583 | 8251 | 16346 | |
| Measures per class | |||
|---|---|---|---|
| “0” | “+1” | “+2” | |
| TP | 4503 | 3581 | 8047 |
| FP | 3 | 212 | 0 |
| FN | 9 | 2 | 204 |
| TN | 11831 | 12551 | 8095 |
multi-class classification 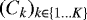 |
||
|---|---|---|
| measures per-class | accuracy(Ck) | 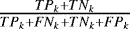 |
| precision(Ck) | 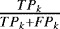 |
|
| sensitivity(Ck) | 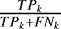 |
|
| f-score(Ck) | 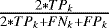 |
|
| specificity(Ck) | 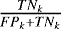 |
|
| average per-class | accuracy | 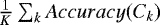 |
| error rate | 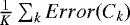 |
|
| precision | 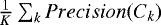 |
|
| sensitivity | 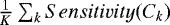 |
|
| f-score | 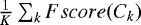 |
|
5.4 Discussion
The results obtained using preliminary mock simulations for Euclid show that the new automated reliability redshift definition can be used to quantify the reliability level of spectroscopic redshift measurements. This method could be useful for cosmological studies that require accurate redshift measurements. By using 1D spectra of newly released Euclid simulations, upcoming studies will focus on the correlation between the distribution of redshift errors and the redshift reliability clusters to define the probability for “a redshift to be correct” in the 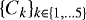 clusters in asimilar approach as in VVDS.
clusters in asimilar approach as in VVDS.
6 Summary and conclusions
By mapping the posterior PDF p(z|D, I) into a discretized feature space and exploiting ML algorithms, we are able to design a new automated method that correlates relevant characteristics of the posterior zPDF, such as the dispersion of the probability distribution and the number of significant modes, with a reliability assessment of the estimated redshift.
The proposed methodology consists of three steps:
-
1.
Using a set of representative spectra, compute the redshift posterior PDFs p(z|D, I) and extract a set of features to build the descriptor matrix X.
-
2.
Generate a reliable partitioning Y of the feature space using clustering techniques and prior knowledge, if available.
-
3.
Use the partitioning to train a classifier that will predict a quality label for new unlabeled observations.
Using the zPDFs descriptors, we first tried to bypass the first two steps by exploiting existing reliability flags to train a classifier (supervised classification), but the results obtained (Sect. 4.2) justify the need for new homogeneous partitions [steps 1 and 2] of the feature space because the reproducibility of the existing quality flags cannot be achieved due to their subjective definition: the combination of several visual checks performed by different observers cannot derive homogeneous and objective criteria of redshift reliability for an automated system to learn from.
The results of unsupervised classification in Sect. 4.3 displayed great coherency in describing distinct categories of zPDFs: the multimodal zPDFs with equiprobable redshift solutions and high dispersion, versus the unimodal zPDFs with a narrower peak around the zMAP solution, each depicting a different level of reliability for the measured redshift.
To predict a redshift reliability flag for unlabeled data (Sect. 5), our methodology consists in projecting the unlabeled zPDF [step 3] into the mapping generated from known zPDF descriptors X and their associated z reliability labels Y to predict the class membership.
A fuzzy approach can also be used to predict the class prediction probability and provide relevant information about the classifier performance and possible discrepancies in the input data.
To conclude, the proposed method to automate the redshift reliability assessment is simple and flexible; the only requirement being robust redshift estimation algorithms with representative templates and a good computational efficiency to produce accurate redshift PDFs. For the spectroscopic redshift estimation, the use of the Bayesian framework allows to incorporate multiple sources of information as a prior and any readjustment of the data/model hypotheses into the estimation process and produce a posterior zPDF.
In this work, we have demonstrated that by using a simple entry model and a few ML-algorithms that exploit descriptors of the redshift PDF, it is possible to capture an accurate description of the spectroscopic redshift reliability. This approach paves the way for fully automated processing pipelines of large spectroscopic samples as for next-generation large-scale galaxy surveys. We expect to further develop and test our method for the needs of the Euclid space mission when large simulations of realistic spectra become available. Advanced techniques in ML, such as neural networks and deep learning, will be explored to build a complex learning scheme.
Acknowledgements
We thank the referee for helpful comments and multiple suggestions that significantly improved this paper. This work is part of a thesis co-funded by the University Aix-Marseille and the Centre National d’Études Spatiales (CNES) in the context of the upcoming Euclid mission of the European Space Agency, as developed by the Euclid Consortium. The authorswould like to thank the members of the AMAZED team who provided helpful feedback and insightful discussions on this topic. This work benefitted from access to databases managed by the CESAM (Astrophysical Data Center of Marseille) in LAM (Laboratoire d’Astrophysique de Marseille). We would also like to express our thanks to all the contributors whose fruitful comments and revision of this manuscript helped us expand our understanding and improve the paper.
Appendix A Assigning probabilities
In the data, if the noise is assumed Gaussian, additive, and i.i.d., the data model for a single observation Dk is:
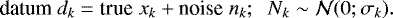 (A.1)
(A.1)
The variables dk, nk , and xk are realizations of the random variables (r.v.) Dk, Nk and Xk .
By marginalizing over the r.v. Xk and Nk:
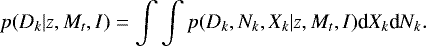 (A.2)
(A.2)
Assuming Xk ⊧Nk:
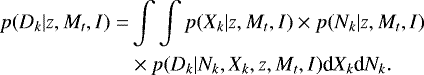 (A.3)
(A.3)
From Eq. (A.1), the likelihood function is:
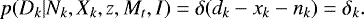 (A.4)
(A.4)
The Kronecker function δk implies nk = dk − xk and allows to rewrite p(Dk|z, Mt, I) as:
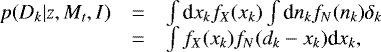 (A.5)
(A.5)
where fX(xk) and fN (nk) are the probability density functions of the random variables Xk and Nk.
If the true value Xk is considered as a deterministic variable:
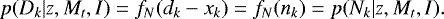 (A.6)
(A.6)
Otherwise, the probabilistic model of xk has to be integrated into the full expression of p(Dk|z, Mt, I).
The likelihood 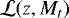 describes the probability of observing the full set of independent observations
describes the probability of observing the full set of independent observations 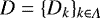 given a redshift z and a template model Mt and any additional information I.
given a redshift z and a template model Mt and any additional information I.
Considering the aforementioned hypotheses on the data model, the likelihood is defined as following:
![Mathematical equation: $ \begin{array}{lll} \mathcal{L}(z,M_t ) &=& p( D | z , M_t ,I ) = p(D_1, \dots D_n | z, M_t ,I ) \\ &=& p(N_1,\dots N_n | z,M_t ,I ) = \prod_{k\in\Lambda} p(N_k | z, M_t ,I ) \\ &=& \prod_{1\leq i\leq n}{{(\sqrt{2\pi}\sigma_i)}^{-1}} \exp \Big({- \frac{1}{2} \chi^2{(z, t)} } \Big) \\ &&\vspace{-.5cm}\\ \chi^2{(z, t)} &=& \sum_{i=1}^{n} \sigma_i^{-2} [d_i - a_{\textrm{opt}}\hspace{0.05cm}t_{i,z}]^2, \\ \end{array}$](/articles/aa/full_html/2018/03/aa31305-17/aa31305-17-eq42.png) (A.7)
(A.7)
where Λ is the wavelength range in use (with n datapoints), di and σi are the observed flux and noise spectra at pixel i, respectively, ti,z is the redshifted template interpolated at pixel i, and aopt is the optimal amplitude obtained from (weighted) Least-Square (LS) estimation.
We would like to point out that the estimation is in reality obtained from marginalizing over nuisance parameters θ, such as the amplitude A (r.v.) in the chi-square expression:
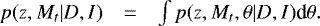 (A.8)
(A.8)
The joint-posterior PDF can be rewritten as:
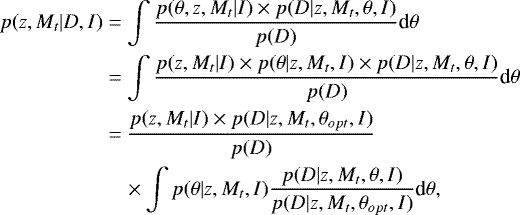 (A.9)
(A.9)
where the highlighted integral in blue is usually approximated by a constant, and the computed likelihood in redshift estimation englobes the optimal estimation aopt of the amplitude parameter in Eq. (A.7).
The amplitude aopt is estimated at each trial (z, t):
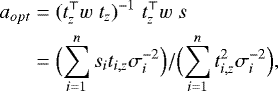 (A.10)
(A.10)
where 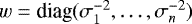 is the weight matrix.
is the weight matrix.
Appendix B ECOC for multi-class problems
The principle of ECOC (Error-Correcting-Output-Codes) is based on the binary reduction of the multi-class problem using a coding matrix 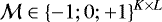 to design a codeword.
to design a codeword.
 (B.1)
(B.1)
where:
-
L: number of learners;
-
K: number of distinct classes.
The codewords mk = (mk,1, …, mk,L) translate the membership information for each class ck given a binary scheme:
-
mkj = −1: ck is the negative class for learner lj,
-
mkj = 0: All observations associated with ck are ignored by the learner lj,
-
mkj = +1: ck is the positive class for learner lj.
Codewords are generated using existing coding strategies such as OVA (one-versus-all), OVO (one-versus-one) and dense random. Coding matrices for a example of a four-class problem are shown in Fig. B.1.
 |
Fig. B.1 [Examples of ECOC coding design] . The black, white, and gray boxes refer respectively to mk,j = +1, –1 or 0. |
Each learner lj is associated with two superclasses,  referring to the positive and the negative classes, respectively, that are used to encode the response vector Y train into a binary vector
referring to the positive and the negative classes, respectively, that are used to encode the response vector Y train into a binary vector ![Mathematical equation: $[\bf Y_{\textrm{train}}]_{\textrm{j}}$](/articles/aa/full_html/2018/03/aa31305-17/aa31305-17-eq50.png) .
.
Trainingthe learner lj with ![Mathematical equation: $\left\{\bf X_{\textrm{train}}; [\bf Y_{\textrm{train}}]_{\textrm{j}}\right\}$](/articles/aa/full_html/2018/03/aa31305-17/aa31305-17-eq51.png) is performed with the usual classifiers such as SVM, MLP, and so on.
is performed with the usual classifiers such as SVM, MLP, and so on.
A class prediction for an unlabeled spectra x0 in Xest is achieved in two steps:
-
Step 1: each trained learner lj provides a binary prediction:
 .
. -
Step 2: the bit vector y0 for all learners is decoded into the initial K-class by minimizing a distance metric Δ as the Euclidean distance
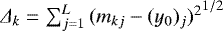 or a binary loss function
or a binary loss function 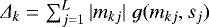 ,
where g
is a binary loss function and sj
the scorefor learner j.
,
where g
is a binary loss function and sj
the scorefor learner j.
The predicted class
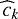 for x0 is associated with the index k for which the vector Δ is minimal.
for x0 is associated with the index k for which the vector Δ is minimal.
Appendix C Description of classification algorithms: SVM – Ensemble methods
Support-machine vectors
The SVM method classifies the data by finding the best hyperplane separating the datapoints of one class from those of another category.
Given a training set of M datapoints 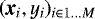 , where xi refers to the P-dimensional feature vector and yi the associated label that indicates whether the datapoint belongs to the positive class (yi = +1) or the negative class (yi = −1), the objective of SVM is to separate the data into distinct classes using a separating rule in form of a parametrized function f(x ).
, where xi refers to the P-dimensional feature vector and yi the associated label that indicates whether the datapoint belongs to the positive class (yi = +1) or the negative class (yi = −1), the objective of SVM is to separate the data into distinct classes using a separating rule in form of a parametrized function f(x ).
For linearly separable data, the equation of the hyperplane is:
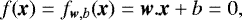 (C.1)
(C.1)
where the scalar product w.x is equivalentto w⊤x.
An infinity of hyperplanes verify Eq. (C.1), but only one hyperplane maximizing the margins between the observationsand the hyperplane exists. This optimal hyperplane verify:
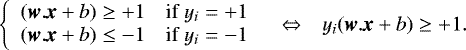 (C.2)
(C.2)
To find the“best” linear hyperplane minimizing the margins  , the SVM algorithm consists in solving a quadratic problem:
, the SVM algorithm consists in solving a quadratic problem:
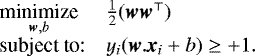 (C.3)
(C.3)
For non-linearly separable data, the use of a kernel φ trick enables to map the distribution of the datapoints x into a projected space where φ(x) can be linearly separable, and defines, in the same approach as in Eq. (C.2), a quadratic problem:
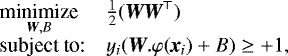 (C.4)
(C.4)
where f(x) = fW,B(x) = W.φ(x) + B = 0.
The selection of an adequate kernel K is determined by a list of criteria. By definition, a kernel must be symmetric, definite positive, square integrable and satisfy:
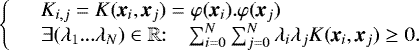 (C.5)
(C.5)
Among commonly used kernels:
-
Linear: K(xi, xj) = xi.xj
-
Power:
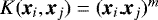
-
Gaussian (rbf):
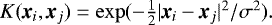
Further details about the SVMs are available in Vapnik (2000) and Cristianini & Shawe-Taylor (2000).
C.2:
Ensemble classifiers
The principle of ensemble methodology is to combine a set of predictions from different learners in order to improve the accuracy of a single learner.
Among the ensemble methods, two distinct approaches are identified:
-
1.
Averaging methods: Bagging/ Random forests...
-
2.
Boosting methods: AdaBoost/GentleBoost/RSBoost/...
– AdaBoost
AdaBoost, known also as “Adaptive Boosting” refers to a specific algorithm of boosted classifier defined as the sum of individual predictions from T weak learners. The algorithm aims to minimize the (weighted) classification error at each iteration:
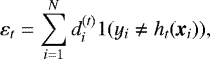 (C.6)
(C.6)
where:
-
xi is the feature vector of the ith observation.
-
yi is the true label of the ith observation.
-
ht is the prediction of learner t.
-
1 is the indicator function.
-
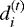 is the weight of the ith
observation at step t.
is the weight of the ith
observation at step t. -
t the iteration step from 1 to T.
At the first iteration, the weights 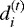 are initialized (e.g.,
are initialized (e.g., 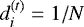 ) and the weak learner ht is obtained by minimizing the error εt . For the next iteration, the weights of the learner (t + 1) are adjusted according to the performance of the previous one (t): whether increase
) and the weak learner ht is obtained by minimizing the error εt . For the next iteration, the weights of the learner (t + 1) are adjusted according to the performance of the previous one (t): whether increase 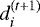 for misclassified observationsby learner t, or reduce the weights otherwise. The learner ht+1 is trained using the updated weights
for misclassified observationsby learner t, or reduce the weights otherwise. The learner ht+1 is trained using the updated weights 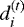 in the error εt+1.
in the error εt+1.
After training, the prediction for a new data point, x, is obtained by combining the individual predictions of all weak learners:
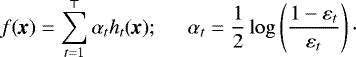 (C.7)
(C.7)
The AdaBoost algorithm can also be viewed as a minimization of an exponential loss function:
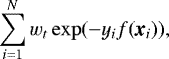 (C.8)
(C.8)
where wt are normalized observational weights.
– LogitBoost
Following a similar approach to AdaBoost, the LogitBoost consists in training learners sequentially by minimizing an error function εt ; the only difference being the minimization of the error function with respect to a fitted regression model  instead of y:
instead of y:
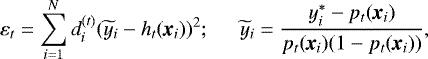 (C.9)
(C.9)
where:
-
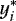 are modified labels:
are modified labels: 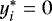 if yi = −1;
and
if yi = −1;
and 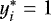 otherwise.
otherwise. -
pt(xi) is the predicted class probability for the ith observation to be in the positive class “+1” given by the learner t.
– GentleBoost
Also called Gentle AdaBoost, this algorithm combines the methodology of AdaBoost and LogitBoost. An exponential loss function is minimized with a different optimization strategy to AdaBoost. Further, similarly to LogiBoost, weak learners fit a regression model  to the response variables y.
to the response variables y.
– Bagging
Bagging, referring to “bootstrap aggregation”, consists in generating m new training sets Pj , each of size N′ , by uniformly sampling with replacement from the initial training set 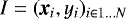 .
.
The m models are trained separately and the class prediction of an unlabeled data x is obtained by combining the individual predictions of the m models: “averaging” if regression, or “voting” if classification.
Further details on the ensemble algorithms can be found in Dietterich (2000).
Appendix D Measures for multi-class classification
For a binary classification, the confusion matrix represents the fraction of predicted labels versus the true classes. Four quantities are directly measured:
-
TP: True Positives.
-
TN: True Negatives.
-
FP: False Positives.
-
FN: False Negatives.
For multi-class classification, the approach consists in estimating these measures for each class. For example:
From the confusion matrix, the overall performances of the classification are quantified with the following measures:
Further details are provided in Fawcett (2006).
Appendix E Description of the FCM clustering algorithm
Similar to the k-means algorithm that aims to minimize the intraclass variance, the FCM (Fuzzy C-Means) algorithm exploits additional information about membership of the data to multiple clusters.
To partition a dataset 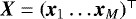 of P-dimensional vectors into K clusters, thealgorithm aims to solve a quadratic problem in order to determine the optimal solution (U, G), where G = (g1…gM) refers to the centroids of the final K clusters and
of P-dimensional vectors into K clusters, thealgorithm aims to solve a quadratic problem in order to determine the optimal solution (U, G), where G = (g1…gM) refers to the centroids of the final K clusters and 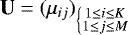 is a coefficient matrix of class memberships for each element.
is a coefficient matrix of class memberships for each element.
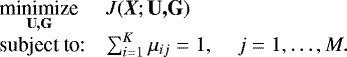 (E.1)
(E.1)
The algorithm proceeds iteratively and converges when the estimated coefficient matrix at the iteration t is not very different from its previous estimation:
(E.2)
Further, the elements 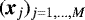 are said to belong to the class
are said to belong to the class  for which the final coefficient μij is maximal.
for which the final coefficient μij is maximal.
The matrix U can be further exploited to assess the membership level of the element x j to its predicted class.
The cost function to minimize is:
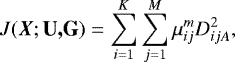 (E.3)
(E.3)
where the distance DijA, the coefficient μij and the centroid gi are defined as following:
 (E.4) (E.5) (E.6)
(E.4) (E.5) (E.6)
In the FCM,the fuzzifier parameter m ≥ 1 is used to determine the level of fuzziness: if m = 1, the coefficient matrix is binary, which is equivalent to a hard partitioning. Usually, in the absence of prior information about the datamodel, the value m = 2 is used.
For the norm  in Eq. (E.4 ), a common choice for the matrix A is the identity matrix, but it can be designed to incorporate individual variances of the data as
in Eq. (E.4 ), a common choice for the matrix A is the identity matrix, but it can be designed to incorporate individual variances of the data as  or the inverse of the covariance matrix.
or the inverse of the covariance matrix.
Appendix F Additional tables
[Resubstitution prediction] – Bagging Trees.
[Resubstitution prediction] – Gentle Boost.
[Resubstitution prediction] – SVM (Linear kernel).
[Resubstitution prediction] – SVM (Gaussian kernel).
[Test prediction] – Bagging Trees.
[Test prediction] – Gentle Boost.
[Test prediction] – SVM (Linear kernel).
[Test prediction] – SVM (Gaussian kernel).
[Resubstitution prediction] – Measures from confusion matrices
[Test prediction] – Measures from confusion matrices.
[Resubstitution prediction] – Bagging Trees.
[Resubstitution prediction] – Gentle Boost.
[Resubstitution prediction] – SVM (Linear kernel).
[Resubstitution prediction] – SVM (Gaussian kernel).
[Test prediction] – Bagging Trees.
[Test prediction] – Gentle Boost.
[Test prediction] – SVM (Linear kernel).
[Test prediction] – SVM (Gaussian kernel).
[Resubstitution prediction] – Measures from confusion matrices.
[Test prediction] – Measures from confusion matrices.
| Average per-class | ||
|---|---|---|
| tree bagger | Accuracy | 99.48% |
| Error rate | 0.52% | |
| Precision | 98.85% | |
| Sensitivity | 98.68% | |
| F-score | 98.76% | |
| gentle boost | Accuracy | 98.17% |
| Error rate | 1.83% | |
| Precision | 95.81% | |
| Sensitivity | 95.76% | |
| F-score | 95.79% | |
| svm (linear) | Accuracy | 98.05% |
| Error rate | 1.95% | |
| Precision | 95.64% | |
| Sensitivity | 95.96% | |
| F-score | 95.80% | |
| svm (rbf) | Accuracy | 99.44% |
| Error rate | 0.56% | |
| Precision | 98.69% | |
| Sensitivity | 98.70% | |
| F-score | 98.69% | |
References
- Abdalla, F. B., Amara, A., Capak, P., et al. 2008, MNRAS, 387, 969 [NASA ADS] [CrossRef] [Google Scholar]
- Albrecht, A., Bernstein, G., Cahn, R., et al. 2006, ArXiv e-prints [arxiv:astro-ph/0609591] [Google Scholar]
- Baldry, I. K., Alpaslan, M., Bauer, A. E., et al. 2014, MNRAS, 441, 2440 [NASA ADS] [CrossRef] [Google Scholar]
- Benitez, N. 1999, in ASP Conf. Ser., 536, 571 [Google Scholar]
- Beutler, F., Blake, C., Colless, M., et al. 2011, MNRAS, 416, 3017 [NASA ADS] [CrossRef] [Google Scholar]
- Beutler, F., Blake, C., Colless, M., et al. 2012, MNRAS, 423, 3430 [NASA ADS] [CrossRef] [Google Scholar]
- Bolzonella, M., Miralles, J.-M., & Pelló, R. 2000, A&A, 363, 476 [NASA ADS] [Google Scholar]
- Brammer, G. B., van Dokkum, P. G., & Coppi, P. 2008, ApJS, 686, 1503 [NASA ADS] [CrossRef] [Google Scholar]
- Chandola, V., Banerjee, A., & Kumar, V. 2009, ACM Comput. Surv., 41, 15 [CrossRef] [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Cool, R. J., Moustakas, J., Blanton, M. R., et al. 2013, ApJ, 767, 118 [NASA ADS] [CrossRef] [Google Scholar]
- Cristianini, N., & Shawe-Taylor, J. 2000, An Introduction to Support Vector Machines: and Other Kernel-based Learning Methods (Cambridge University Press) [Google Scholar]
- Dietterich, T. G. 2000, in Multiple Classifier Systems (Springer), 1 [Google Scholar]
- Dietterich, T. G., & Bakiri, G. 1995, J. Artificial Intelligence Res., 2, 263 [Google Scholar]
- Fawcett, T. 2006, Pattern Recognition Lett., 27, 861 [NASA ADS] [CrossRef] [Google Scholar]
- Feldmann, R., Carollo, C. M., Porciani, C., et al. 2006, MNRAS, 372, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Garilli, B., Fumana, M., Franzetti, P., et al. 2010, PASP, 122, 827 [NASA ADS] [CrossRef] [Google Scholar]
- Garilli, B., Guzzo, L., Scodeggio, M., et al. 2014, A&A, 562, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Green, J., Schechter, P., Baltay, C., et al. 2012, ArXiv e-prints [arxiv:1208.4012] [Google Scholar]
- Guzzo, L., Scodeggio, M., Garilli, B., et al. 2014, A&A 566, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hastie, T., & Tibshirani, R. 1998, Annals Stat., 26, 451 [CrossRef] [Google Scholar]
- Huterer, D. 2002, Phys. Rev. D, 65, 3001 [NASA ADS] [CrossRef] [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezic, Z., Tyson, J. A., Abel, B., et al. 2008, ArXiv e-prints [arxiv:0805.2366] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arxiv:1110.3193] [Google Scholar]
- Le Fèvre, O., Vettolani, G., Garilli, B., et al. 2005, A&A, 439, 845 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Le Fèvre, O., Cassata, P., Cucciati, O., et al. 2013, A&A, 559, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Le Fèvre, O., Tasca, L., Cassata, P., et al. 2015, A&A, 576, A79 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Linder, E. V., & Jenkins, A. 2003, MNRAS, 346, 573 [NASA ADS] [CrossRef] [Google Scholar]
- Machado, D. P., Leonard, A., Starck, J.-L., Abdalla, F. B., & Jouvel, S. 2013, A&A, 560, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Patcha, A., & Park, J.-M. 2007, Computer Networks, 51, 3448 [NASA ADS] [CrossRef] [Google Scholar]
- Schuecker, P. 1993, ApJS, 84, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Scodeggio, M., Franzetti, P., Garilli, B., et al. 2005, PASP, 117, 1284 [NASA ADS] [CrossRef] [Google Scholar]
- Shahid, M., Rossholm, A., Lovstrom, B., & Zepernick, H.-J. 2014, EURASIP J. Image Video Processing, 2014, 40 [CrossRef] [Google Scholar]
- Simkin, S. M. 1974, A&A, 31, 129 [NASA ADS] [Google Scholar]
- Tonry, J., & Davis, M. 1979, ApJ, 84, 1511 [Google Scholar]
- Vapnik, V. N. 2000, The Nature of Statistical Learning Theory (Springer) [Google Scholar]
- Wahba, G. 1998, Support Vector Machines, Reproducing Kernel Hilbert Spaces and the Randomized GACV(MIT Press) [Google Scholar]
- Wahba, G. 2002, PNAS, 99, 16524 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, Y., Percival, W., Cimatti, A., et al. 2010, MNRAS, 409, 737 [NASA ADS] [CrossRef] [Google Scholar]
- Zoubian, J., Kümmel, M., Kermiche, S., et al. 2014, in ASP Conf. Ser., 485, 509 [Google Scholar]
All Tables
Repartition of the initial VVDS redshift reliability flags within the predicted labels (in absolute values).
Repartition of the initial VVDS redshift reliability flags within the predicted labels (in percent).
zReliability predictions (in percent) of preliminary mock simulations for Euclid.
zReliability predictions (in absolute values) of preliminary mock simulations for Euclid.
Redshift error distribution within the predicted redshift reliability classes for preliminary mock simulations for Euclid.
All Figures
|
Fig. 1 VVDS-Deep galaxy spectra with identifiable spectral features at known redshifts: emission/absorption line, D4000A break. |
| In the text | |
|
Fig. 2 Posterior redshift PDF of two VVDS-Deep spectra. Top: a unimodal zPDF characterizes a very reliable
redshift measurement (a single peak at z=0.879). Bottom: a multimodal zPDF refers to multiple redshift solutions
(multiple peaks) possibly with similar probabilities associated to a diminished confidence level of the MAP estimate at
z = 1.159.
The quantity |
| In the text | |
|
Fig. 3 Display of two zPDFs with multiples modes and a similar dispersion. |
| In the text | |
|
Fig. 4 Display of two zPDFs with multiples modes and a different dispersion. |
| In the text | |
|
Fig. 5 Display of two zPDFs with multiples modes and different characteristics of the two best z solutions. |
| In the text | |
|
Fig. 6 Display of two zPDFs with a single mode and a different width of CR * . |
| In the text | |
|
Fig. 7 3D representation of the feature matrix X. Broadly, two categories are noticeable. The first group refers to the zPDFs with high dispersion, large zMAP peak and low probability P(zMAP|D, I) that can be assimilated to multimodal PDFs or platykurtic unimodal PDFs. The second group characterizes the zPDFs with medium-to-low dispersion, narrow zMAP peak and high P(zMAP|D, I) that depict strongly peaked unimodal PDFs. |
| In the text | |
|
Fig. 8 Clustering the zPDFs features X
in a dichotomized pattern. The clustering strategy exploits the classic FCM algorithm at each step to
decompose the input data into two sub-classes using the entire set of descriptors. The final categories
|
| In the text | |
|
Fig. 9 Representative zPDFs for each clusters. Display of representative zPDFs in
each cluster obtained from clustering. The shift in the confidence level in the
|
| In the text | |
|
Fig. 10 Clusters repartition in a selected 3D space. The five zReliability clusters described in Sect. 4.3.1 are associated to different types of redshift PDFs, where the two extreme categories C1 and C5 , respectively,describe highly dispersed multimodal zPDFs and peaked unimodal zPDFs. |
| In the text | |
|
Fig. 11 Distribution of the probability value P(zMAP|D, I) within the five partitions. The distribution of the probability values (component of the descriptor space) P(zMAP|D, I) show distinct properties of the clusters. The five zReliability clusters (cf. Sect. 4.3.1) are associated with different categories of redshift PDFs. |
| In the text | |
|
Fig. 12 Misclassification – case 1. A “VVDS flag 1: very unreliable redshift” is predicted by the classifier in the new category “C5” for very reliable redshifts. The spectrum displays very low noise components that reinforce the confidence in the measured flux pixels. However the extracted 1D spectrum appears distorted considering the initial 2D spectrum. The extraction 2D → 1D induced a bias in the estimation of the (falsely unimodal) zPDF. |
| In the text | |
|
Fig. 13 Misclassification – case 2. A “VVDS flag 9: reliable redshift, detection of a single emission line” is predicted by the classifier in the new category “C1” for very unreliable redshifts. The spectrum displays a strong noise component that annihilates the confidence in the measured flux pixels (especially the spectral emission line [OII] 3726 at 7365A). Several redshift solutions are declared as plausible solutions (a multimodal zPDF). |
| In the text | |
|
Fig. 14 Class posterior probabilities. The predictive power of several classifiers is displayed for each true class in Y test . Most prediction probabilities fall between ~[70–100]% (bright colors). For example: the Linear SVM correctly predicts ~92% (2060 elements) of the subset of “true C2” (around 2240 elements) in Y test (cf. Table F.17) with class prediction probabilities between 0.7 and 1 (bright colors). |
| In the text | |
|
Fig. 15 Simulated Euclid spectra. Left: simulated galaxy spectrum (id: 53678850) in the dataset S1 with an identifiable H α line at 12803A. Right: simulated galaxy spectrum (id: 56932048) in the dataset S2 with a H α emission line at 12908A. |
| In the text | |
|
Fig. 16 Computed zPDF for a galaxy spectrum in the dataset S1. The redshift probability density function is computed using a constant prior over Θz. |
| In the text | |
|
Fig. 17 Computed zPDF for a galaxy spectrum in the dataset S2. The redshift probability density function is computed using a constant prior over Θz. |
| In the text | |
|
Fig. 18 log(f H α ), JAB distribution of the reliability class predictions for unlabeled simulated galaxy spectra for Euclid. The number of faint objects predicted in C1/C2 increases when the noise component in the data is important (S1 → S2). The increased sky background injects a strong noise component of the spectra that annihilates the confidence in a measured redshift, resulting in multimodal zPDFs with high dispersion (C1/C2). In contrast, extremely bright objects with an identifiable Hα line are located in C4∕C5, because the redshift estimation is deemed very reliable when distinct spectral features are found. |
| In the text | |
|
Fig. B.1 [Examples of ECOC coding design] . The black, white, and gray boxes refer respectively to mk,j = +1, –1 or 0. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.