| Issue |
A&A
Volume 611, March 2018
|
|
|---|---|---|
| Article Number | A83 | |
| Number of page(s) | 13 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201630281 | |
| Published online | 06 April 2018 | |
Super-sample covariance approximations and partial sky coverage
1
Département de Physique Théorique, Université de Genève,
24 quai Ernest Ansermet,
1211
Geneva,
Switzerland
e-mail: fabien.lacasa@unige.ch
2
Departamento de Física Matemática, Instituto de Física, Universidade de São Paulo,
CP 66318,
CEP
05314-970,
São Paulo-SP,
Brazil
Received:
18
December
2016
Accepted:
1
December
2017
Super-sample covariance (SSC) is the dominant source of statistical error on large scale structure (LSS) observables for both current and future galaxy surveys. In this work, we concentrate on the SSC of cluster counts, also known as sample variance, which is particularly useful for the self-calibration of the cluster observable-mass relation; our approach can similarly be applied to other observables, such as galaxy clustering and lensing shear. We first examined the accuracy of two analytical approximations proposed in the literature for the flat sky limit, finding that they are accurate at the 15% and 30–35% level, respectively, for covariances of counts in the same redshift bin. We then developed a harmonic expansion formalism that allows for the prediction of SSC in an arbitrary survey mask geometry, such as large sky areas of current and future surveys. We show analytically and numerically that this formalism recovers the full sky and flat sky limits present in the literature. We then present an efficient numerical implementation of the formalism, which allows fast and easy runs of covariance predictions when the survey mask is modified. We applied our method to a mask that is broadly similar to the Dark Energy Survey footprint, finding a non-negligible negative cross-z covariance, i.e. redshift bins are anti-correlated. We also examined the case of data removal from holes due to, for example bright stars, quality cuts, or systematic removals, and find that this does not have noticeable effects on the structure of the SSC matrix, only rescaling its amplitude by the effective survey area. These advances enable analytical covariances of LSS observables to be computed for current and future galaxy surveys, which cover large areas of the sky where the flat sky approximation fails.
Key words: large-scale structure of Universe / methods: analytical
© ESO 2018
1 Introduction
The large scale structure (LSS) of the Universe results from the growth of local density perturbations induced by gravitational collapse within an expanding background (e.g. Peebles 1980). The multi-point correlations and associated spectra that characterise this structure can be measured in real data and combined with theory predictions to constrain cosmological models, including gravity theories and relative amounts of dark matter and dark energy (Astier et al. 2006; Percival et al. 2010; Riess et al. 2009; Hildebrandt et al. 2017; Beutler et al. 2017; Hinton et al. 2017; DES Collaboration 2017). However, likelihood methods of parameter inference also require reliable estimates of the covariances associated with structure observables. Estimates of the covariances can be obtained from the actual data via methods such as jackknife and bootstrap, from simulations and Monte Carlo realisations, and from theoretical predictions that account for the known observational effects (Dodelson & Schneider 2013; Giannantonio et al. 2016; Crocce et al. 2016; O’Connell et al. 2016; Singh et al. 2017; Shirasaki et al. 2017; Blot et al. 2016; Escoffier et al. 2016; Pearson & Samushia 2016; Camacho et al. in prep.). In this work we focus on the latter approach.
Within the so-called halo model paradigm (Cooray & Sheth 2002), the LSS can be characterised by the statistical properties of the Universe building blocks, i.e. dark matter haloes. These haloes are characterised by their abundance, bias, and profiles, all of which can be studied from dark matter N-body simulations and also from high-quality data sets. As galaxy clusters develop within dark matter haloes, they trace the highest density peaks. Their number counts and covariances are very sensitive probes of structure growth and expansion of the Universe (Lima & Hu 2004, 2005, 2007; Schmidt et al. 2009; Aguena & Lima 2016). A number of past and current surveys have detected clusters in multiple wavelengths with hopes to use such detections for cosmological purposes (Miller et al. 2005; Koester et al. 2007; Soares-Santos et al. 2011; Dietrich et al. 2014; Rykoff et al. 2014, 2016; Bleem et al. 2015; Planck Collaboration XXVII 2016; Bayliss et al. 2016).
As we consider scales close to the survey maximum size, the number of modes available decreases significantly, which represents an intrinsic source of uncertainty for the inferred structure properties. The cosmic variance quantifies these uncertainties and may have contributions from scales much larger than the survey itself, in which case we refer to it as super-sample covariance (SSC), whose effects have been studied recently in multiple contexts (e.g. Takada & Hu 2013; Li et al. 2014a,b, 2016; Takahashi et al. 2014; Shirasaki et al. 2017; Hu et al. 2016). SSC has been shown to be particularly important for probe combinations as it couples observables together (Takada & Bridle 2007; Takada & Spergel 2014; Krause & Eifler 2017; Lacasa & Rosenfeld 2016). Within a local patch, large scale modes change the effective average density, which can differ significantly and unpredictably from the true background density, affecting the inferred correlations. In fact, SSC may be the dominant source of errors in Jackknife covariance estimations (Shirasaki et al. 2017).
Finally, the survey geometry or footprint and its selection function, which is characterised by, for example masks and depth maps, also affect the estimation of correlations and covariances (Takahashi et al. 2014). Not only the geometry and selection must be known to good precision, but their properties must be properly propagated into the measured and predicted correlations and covariances. Some predictions can only be directly made under certain approximations, for example for full sky calculations, while for the more realistic case of partial sky coverage, further complicating assumptionsneed to be made. As we attempt to extract maximum information from observations, we may end up with a complicated survey mask containing holes, for example owing to saturated pixels, asteroids, contamination from stars, or simply pixels that do not satisfy a depth criterion. All these effects must be accounted for in a proper cosmological analysis.
In this article, we study the effect of partial sky coverage and arbitrary masks in the estimation of the SSC of cluster counts. We propose a method to estimate this covariance efficiently for an arbitrary mask, and compare this approach to a number of approximated calculations in the literature. We show that our general calculation reduces to the approximated computations in the appropriate limits, but differs from such computations in general. Although beyond the scope of this work, we expect our theoretical estimation can be compared to other methods of estimating the covariance, which also attempt to account for the survey geometry and mask effects such as with simulations. One of the advantages of our method, however, is that it allows for the covariance to be computed as a function of cosmological and nuisance parameters at each step of a Monte Carlo Markov chain, allowing, for example for self-calibration of cluster observable-mass distribution in general cosmological analyses of cluster samples (Lima & Hu 2005). It is also unbiased, contrary to internal covariance estimators (Lacasa & Kunz 2017). Finally, it is numerically much cheaper than running thousands of N-body simulations, the latter needing to be much larger than the survey to capture super-survey modes efficiently.
This article is organised as follows. In Sect. 2.2, we introduce the cluster counts covariance and the formalism for an exact SSC computation, and we then consider the case of full sky and flat sky (small angles) limit, providing some comparisonsfor the covariance kernels between those cases. In Sect. 3 we consider the flat sky limit under various approximations that have been proposed in the literature for computing the SCC and compare the results to the exact computation. In Sect. 4, we propose a method to numerically compute SSC in the case of partial sky coverage with an arbitrary survey mask. In Sect. 5 we present our results, applying the method to the case of a geometry similar to that of the Dark Energy Survey (DES), discussing the mask effectsand recovering the flat sky limit. Finally, in Sect. 6 we present our conclusions and perspectives.
In all numerical computations, we take a cosmology for a flat Λ CDM Universe with parameter values h = 0.67, Ωb h2 = 0.022, Ωc h2 = 0.12, w = −1, nS = 0.96, σ8 = 0.83. Cluster counts are computed in two bins of redshift in the range z ∈ [0.4, 0.6] with Δz = 0.1, and four bins of mass in the range log[M∕(h−1M⊙)] ∈ [14, 16] with Δlog[M∕(h−1M⊙)] = 0.5. The halo mass function is from a fit to simulations from Tinker et al. (2008), the halo bias is from Tinker et al. (2010), and the linear matter power spectrum is from the transfer function by Eisenstein & Hu (1998). We set the following notational conventions: r(z) is the comoving distance, that is dr = c dz∕H(z) with H(z) the Hubble parameter, and dV = r2dr is the comoving volume element per steradian. We use short cuts such as d X12 = dX1 dX2 and Pm (k|z12) = Pm(k|z1, z2) = G(z1)G(z2)Pm(k) with G(z) the linear growth function. Often the limits of redshift or mass integrals are implicitly those of the redshift or mass bin considered.
2 Covariance of large scale structure observables and super-sample covariance
2.1 Covariance of large scale structure observables
LSS observables have a covariance that can be composed of many different terms (e.g. Lacasa & Rosenfeld 2016; Lacasa 2018). The particular case of interest to this article is that of cluster counts, which can be viewed as a halo 1-point correlation function summed over the survey area.
We address the covariance as given by a decomposition in two specific terms: 1-halo and 2-halo
 (1)
(1)
These termsare denoted respectively as shot-noise variance and sample (co)variance in the literature (e.g. Hu & Kravtsov 2003).
The 1-halo or shot-noise variance term is given by,
 (2)
(2)
where ΩS is the solid angle covered by the survey. In the following discussion, this term is accounted for when showing the total counts covariance. Its dependence on the survey footprint is a trivial scaling by ΩS 1 and does not require any particular formalism to be predicted for a survey with large and/or complicated coverage.
We refer to the 2-halo term as SSC, which is described in more detail in Sect. 2.2.
For observables other than cluster number counts (for instance the galaxy angular power spectrum; see e.g. Lacasa & Rosenfeld 2016; Lacasa 2018) the covariance may contain many more terms, whose dependence on the survey geometry may be far from trivial. In this article, we restrict ourselves to studying the geometry dependence of SSC, as needed for cluster number counts analyses.
2.2 Super-sample covariance
SSC is a source of uncertainties for LSS observables coming from modes of size larger than the survey. The effect of these large scale modes on structure comes from the fact that the effective or local matter density  averaged within the survey can be different from the true background density
averaged within the survey can be different from the true background density  averaged over the whole Universe or an ensemble of Universes written as
averaged over the whole Universe or an ensemble of Universes written as
![\begin{equation*} \widetilde{\rho}_m(z)=\bar{\rho}_m(z)[1+\delta_b(z)], \end{equation*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq5.png) (3)
(3)
where δb(z) is a background density perturbation induced by large scale modes. Equivalently, defining the density contrasts the ensemble average is ⟨δm(x)⟩ = 0 by definition, however the spatial average over the survey is  .
.
 (4)
(4)
We split the survey window function W(x) into its radial Wr(z) and angular  pieces, i.e.
pieces, i.e.  . The radial part simply specifies the redshift binning and we do not explicitly state this in our description below anymore because it is effectively included with implicit bounds on redshift integrals. On the other hand, the angular window
. The radial part simply specifies the redshift binning and we do not explicitly state this in our description below anymore because it is effectively included with implicit bounds on redshift integrals. On the other hand, the angular window  is the main object whose effect on the covariances we want to consider. In principle
is the main object whose effect on the covariances we want to consider. In principle  may depend on redshift as well. In fact, this is very often the case for surveys with significant depth variations across the sky. For simplicity, we keep the angular window only as a function of the angular vector, although the formalism can be easily generalised (see Appendix A).
may depend on redshift as well. In fact, this is very often the case for surveys with significant depth variations across the sky. For simplicity, we keep the angular window only as a function of the angular vector, although the formalism can be easily generalised (see Appendix A).
If the survey angular window  subtends a solid angle ΩS in the sky, and we denote the position vector
subtends a solid angle ΩS in the sky, and we denote the position vector  , the background perturbation δb is given by
, the background perturbation δb is given by
 (5)
(5)
As a result, all LSS observables respond to such change of background density, becoming correlated. Explicitly, the SSC term of the cross-covariance between twoobservables  and
and  is given by (e.g. Lacasa & Rosenfeld 2016)
is given by (e.g. Lacasa & Rosenfeld 2016)
 (6)
(6)
where 𝔬i is the density of observable  (per comoving volume dV), ∂𝔬i ∕∂δb is its reaction to the change in background δb, and σ2(z1, z2) is the covariance of δb, i.e.
(per comoving volume dV), ∂𝔬i ∕∂δb is its reaction to the change in background δb, and σ2(z1, z2) is the covariance of δb, i.e.
 (7)
(7)
where  is the Fourier transform of the survey window function.
is the Fourier transform of the survey window function.
In this article, we are mostly interested in the case of cluster number counts Ncl (iM, iz) per steradian within bins of mass iM and bins of redshift iz 2,
 (8)
(8)
where dnh∕dM is the halo mass function. The SSC of these counts is traditionally denoted simply as sample (co)variance in the cluster literature (Hu & Kravtsov 2003). It is important to notice though that super-horizon modes affect even full sky surveys and must always be accounted for. The SSC for clusters counts is given by (e.g. Lacasa & Rosenfeld 2016)
 (9)
(9)
where the response of the halo number density nh = dNcl∕dV to a change of background density is given by the number-weighted halo-bias averaged within the bin (e.g. Schmidt et al. 2013) as follows:
 (10)
(10)
where b(M, z) is the (first order) halo bias.
Most of the elements for the computation of the covariance pose no particular numerical problem. A notable exception is σ2 (z1, z2), as it depends on the survey geometry. Numerically tractable formulae are known only for a few cases with simple geometries. First, for the case of full sky, we have (Lacasa & Rosenfeld 2016)
 (11)
(11)
where ri = r(zi). Second, an expression for σ2(z1, z2) is also known in the flat sky limit (e.g. Hu & Kravtsov 2003; Lima & Hu 2007; Aguena & Lima 2016)
![\begin{align*}\sigma^2_{\mathrm{flatsky}}(z_1,z_2) =\,\, & \frac{1}{2\pi^2} \int k_{\perp} \, \mathrm{d} k_{\perp} \, 4 \frac{J_1(k_{\perp} \theta_S r_1)}{k_{\perp} \theta_S r_1} \frac{J_1(k_{\perp} \theta_S r_2)}{k_{\perp} \theta_S r_2} \nonumber \\ &\times \int \mathrm{d} k_{\parallel} \; \cos\left[k_{\parallel} (r_1-r_2)\right] \; P_m(k|z_{12}) , \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq25.png) (12)
(12)
for a cylindrical window function of radius θS delineating a survey solid angle  , and the wave-vector k = (k∥, k⊥) is split into its components parallel and perpendicular to the line of sight, where
, and the wave-vector k = (k∥, k⊥) is split into its components parallel and perpendicular to the line of sight, where  .
.
Figure 1 shows the comparison of σ2 resulting from the two expressions above for an angular window of radius θS = 5 deg. The full sky covariance was rescaled by a factor  , where fSKY = ΩS∕4π and
, where fSKY = ΩS∕4π and  for θS translated in radians.
for θS translated in radians.
We see that both covariances share the behaviour of peaking at z1 = z2 and decreasing to zero as |z1 − z2| increases3. Regarding the amplitudes, we see that rescaling the full sky covariance by the usual 1∕fSKY factor underpredicts the covariance by a factor ~ 3.4 in this case4. Even when rescaling the covariances to the same peak amplitude by hand, we find that their shapes are broadly similar but differ in details. The full sky covariance is more strongly peaked at the centre, then decreases and crosses zero, reaching a negative minima of height ~ 7% of its peak, beforeslowly asymptoting zero. By contrast, the flat sky covariance is a bit broader in its positive part, but its negative minimum is only ~ 0.8% of its peak, and it asymptotes faster to zero. This clearly indicates that SSC is non-trivially related to sky coverage, and a more general approach is required for its accurate computation.
3 Comparison of super-sample covariance approximations
The full Eq. (9) for SSC can be numerically expensive, as it requires a double redshift integral. Furthermore, for each pair of redshift, a double (k⊥, k∥) integral is required (e.g. in the flat sky case). To tame down this burden, several approximations have been devised in the literature. Below we consider two approximations in the flat sky regime.
First, in Eq. (9) we can assume that ∂nh∕∂δb varies slowly with redshift within the bins, such that it can be approximated by its bin-averaged value and taken out of the integral. In fact this may be a good approximation for sufficiently narrow bins. In this case, Eq. (9) takes the form (Hu & Kravtsov 2003)
 (13)
(13)

and the normalised number-weighted halo bias within the bin is
 (15)
(15)
This approximation implicitly assumes that b(M, z) varies slowlywith redshift within the bin iz, compared toσ2(z1, z2). For a cylindrical window function of height δr in the flat sky case, the sample variance matrix  takes the form (Hu & Kravtsov 2003; Lima & Hu 2007; Aguena & Lima 2016)
takes the form (Hu & Kravtsov 2003; Lima & Hu 2007; Aguena & Lima 2016)
![\begin{align*} S_{i_z,j_z} & = \frac{1}{2\pi^2} \int k_{\perp} \, \mathrm{d} k_{\perp} \; 4 \; \frac{J_1(k_{\perp} \theta_S r_1)}{k_{\perp} \theta_S r_1} \; \frac{J_1(k_{\perp} \theta_S r_2)}{k_{\perp} \theta_S r_2}\nonumber \\ & \ \ \ \times \int \mathrm{d} k_{\parallel} \; j_0\left(\frac{k_{\parallel} \delta r_1}{2}\right) j_0\left(\frac{k_{\parallel} \delta r_2}{2}\right) \cos\left[k_{\parallel} (r_1-r_2)\right] P_m(k|z_{12}), \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq34.png) (16)
(16)
where the power spectrum Pm(k|z12) is evaluated at the centre of the respective redshift bins. A nice feature of this approximation is that it removes the need to compute a double redshift integral. Furthermore the double integral over (k⊥, k∥) only needs to be computed  times (where nz is the number of redshift bins), instead of all redshift pairs (z1, z2) needed to compute the redshift integral otherwise. This speeds up considerably the computation of SSC. We call this approximation the Sij method.
times (where nz is the number of redshift bins), instead of all redshift pairs (z1, z2) needed to compute the redshift integral otherwise. This speeds up considerably the computation of SSC. We call this approximation the Sij method.
Second, another approximation used (e.g. Krause & Eifler 2017) is that σ2 (z1, z2) is a Dirac delta function at z1 = z2, so that the double redshift integral collapses into a single integral
 (17)
(17)
where, following notation from Krause & Eifler (2017), we have
![\begin{equation*} \sigma_b(\mathrm\Omega_S,z) = \int \frac{k_{\perp} \, \mathrm{d} k_{\perp}}{2\pi} \ P_m(k_{\perp},z) \ \left[\frac{2 J_1(k_{\perp} r(z) \theta_S)}{k_{\perp} r(z) \theta_S}\right]^2 , \end{equation*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq37.png) (18)
(18)
where Pm(k⊥, z) = Pm(k = k⊥, z), and we note that the k∥ integral has disappeared and that σb has units of Mpc/h.
The assumption behind this approximation is that the 3D window function W(x) is much wider in the radial direction than in the transverse direction. Thus super-survey modes have k∥ ≪ k⊥, and Pm (k) can be taken as approximately constant within the k∥ integral of Eq. (12). We thus expect the approximation to fare better for wide redshift bins and small angles. By limiting the computation to equal redshift bins iz = jz, and reducing the multiple integrals to a single redshift and a single wave-vector k⊥ integral, the approximation speeds up the SSC computation considerably. Hereafter, we call this approximation the KE method.
We implemented all three SSC methods numerically: (1) full computation from Eqs. (9) and (12), (2) Sij approximation, and (3) KE approximation. Figure 2 shows the ratio of the auto-z covariances to the full computation, plotted as a function of  ; i.e. the first four points show the covariance ratio for iM = iz = 0 (14 < logM < 14.5 and 0.4 < z < 0.5) and varying jM, the next four points are for iM = 1, iz = 0, etc. This order is simply convenient to plotting this multi-variable function. As visible in Fig. 2 both the Sij and KE approximations underpredict the amplitude of the covariance by 30–35% and by ~15%, respectively. The fact that the Sij approximation underpredicts the covariance conforms to our intuition; indeed, by taking values at the centre of the redshift bins, the approximation neglects the fact that the mass function and matter power spectrum both grow with time, which makes their integral larger5. We checked that the Sij method and full computation are in much better agreement for smaller redshift bins, and indeed it can be seen analytically that they reduce to each other in the limit Δ z → 0.
; i.e. the first four points show the covariance ratio for iM = iz = 0 (14 < logM < 14.5 and 0.4 < z < 0.5) and varying jM, the next four points are for iM = 1, iz = 0, etc. This order is simply convenient to plotting this multi-variable function. As visible in Fig. 2 both the Sij and KE approximations underpredict the amplitude of the covariance by 30–35% and by ~15%, respectively. The fact that the Sij approximation underpredicts the covariance conforms to our intuition; indeed, by taking values at the centre of the redshift bins, the approximation neglects the fact that the mass function and matter power spectrum both grow with time, which makes their integral larger5. We checked that the Sij method and full computation are in much better agreement for smaller redshift bins, and indeed it can be seen analytically that they reduce to each other in the limit Δ z → 0.
In Fig. 3, we show the correlation matrices for cluster counts obtained from each of the three SSC computations. The data points are ordered with increasing mass then increasing redshift, i.e. the number count index is iM + nM iz6.
As visible in Fig. 3, for cross-redshift covariances the full computation gives a positive correlation between our two redshift bins, reaching ~ 13% at maximum for Δz = 0.1. On the other hand, the Sij approximation predicts anti-correlation between the bins, reaching at maximum − 16%, while the KE approximation by construction predicts zero correlation. We checked that the Sij method performs better as the redshift bin width decreases. For instanceat Δz = 0.01, the agreement with the full computation is very good.
As a conclusion of this section, we see that the full computation is necessary to faithfully predict the SSC covariance matrix in the case Δz = 0.1. In fact, thisis a representative binning for current photometric galaxy surveys whose present photo-z errors are ofthis order (e.g. Sánchez et al. 2014).
 |
Fig. 1 Comparison of σ2(z1, z2) for z1 = 0.5 in different cases. In blue the flat sky formula Eq. (12) for a survey angular radius θS = 5 deg. In green the full sky formula Eq. (11) rescaled by a factor 1∕fSKY. |
 |
Fig. 2 Ratio of the SSC covariances from the Sij approximation and KE approximation to the full computation. Auto-z covariances are ordered as a function of |

 |
Fig. 3 Comparison of the cluster counts correlation matrix for different SSC computations, for a survey with angular radius θS = 5 deg. The SSC matrix is shown in 2 blocks for the redshift bins, and each block has 4 entries for the logarithmic mass bins. From left to right: full numerical computation from Eq. (9), Sij approximation, and KE approximation. |
4 Super sample covariance for partial sky coverage
In this section, we assume for simplicity that the survey mask is independent of redshift, as we in fact already did implicitly in Eq. (5). It is however straightforward to generalise the formalism to a redshift-dependent mask (see Appendix A).
4.1 Formal derivation
We want to compute the covariance of the background mode
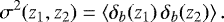 (19)
(19)
Given that the mask has zero value outside the survey, and given the normalisation of spherical harmonics such that  , the background mode of the survey is related to the monopole of the masked matter density as
, the background mode of the survey is related to the monopole of the masked matter density as
 (20)
(20)

where  is the angular power spectrum at ℓ = 0 of the masked matter density field. From Cℓ pseudo-spectrum methods (e.g. Hivon et al. 2002), we know that the masked power spectrum is related to the true spectrum via the so-called coupling matrix, such that
is the angular power spectrum at ℓ = 0 of the masked matter density field. From Cℓ pseudo-spectrum methods (e.g. Hivon et al. 2002), we know that the masked power spectrum is related to the true spectrum via the so-called coupling matrix, such that
 (22)
(22)
where  (hereafter simply
(hereafter simply  ) is the angular spectrum of matter density in an infinitesimal redshift shell. The coupling matrix is given by
) is the angular spectrum of matter density in an infinitesimal redshift shell. The coupling matrix is given by
 (23)
(23)
where Cℓ(W) is the angular power spectrum of the angular window  . In our case, given the properties of Wigner symbols, this simplifies to
. In our case, given the properties of Wigner symbols, this simplifies to
 (24)
(24)
Furthermore we have  and thus
and thus
 (25)
(25)
where ΩS = 4π fSKY and the matter angular power spectrum  is given by (e.g. Campagne et al. 2017)
is given by (e.g. Campagne et al. 2017)
 (26)
(26)
The combined Eqs. (25) and (26) represent the main analytical result of this article.
4.2 Limiting cases and remarks
It is interesting to examine a few limiting cases of Eqs. (25) and (26). In the full sky case, we have Cℓ (W) = 4π δ0,ℓ and fSKY = 1, and therefore thus we have
 (27)
(27)
recovering indeed Eq. (11).
In partial sky,  , such that
, such that
 (28)
(28)
i.e. the full sky covariance term is the first in the sum contributing to the partial-sky covariance.
If  is scale independent, i.e.
is scale independent, i.e.  independently of ℓ (e.g. for Pm(k|z12) = const., see Sect. 5.2), we have
independently of ℓ (e.g. for Pm(k|z12) = const., see Sect. 5.2), we have
 (29)
(29)
and therefore  , i.e. we obtain the usual fSKY approximation to partial sky covariance. Conversely the reverse is also true: if the fSKY approximation holds for any mask, then
, i.e. we obtain the usual fSKY approximation to partial sky covariance. Conversely the reverse is also true: if the fSKY approximation holds for any mask, then  is constant. Given that for viable cosmological models
is constant. Given that for viable cosmological models  is not constant, this shows that SSC is a non-trivial source of covariance that cannot be treated by classical approximations.
is not constant, this shows that SSC is a non-trivial source of covariance that cannot be treated by classical approximations.
Now we notice that Eq. (25) can be rewritten as
 (30)
(30)

such that in full sky  . Applying this to the SSC covariance of two observables, for example number counts, we have
. Applying this to the SSC covariance of two observables, for example number counts, we have
 (32)
(32)

Therefore the combined Eqs. (30)–(33), along with the window spectrum Cℓ (W), allow for the computation of the SSC in partial sky for a general window and binning choice.
Numerically, we can pre-compute and tabulate  , and then just change Cℓ(W) as the mask varies. This enables easier studies of the mask effect such as optimisations of survey strategy (Takahashi et al. 2014), forecasts for improvements as a survey area grows, and comparisons between different surveys. Conversely, for a fixed survey with a well-defined mask, we can pre-compute Cℓ (W) for the specific survey mask, and change
, and then just change Cℓ(W) as the mask varies. This enables easier studies of the mask effect such as optimisations of survey strategy (Takahashi et al. 2014), forecasts for improvements as a survey area grows, and comparisons between different surveys. Conversely, for a fixed survey with a well-defined mask, we can pre-compute Cℓ (W) for the specific survey mask, and change  as a function of cosmology within likelihood cosmological analyses, taking full account of geometry, mask, selection, and cosmological dependencies in the covariances, and therefore deriving reliable parameter uncertainties.
as a function of cosmology within likelihood cosmological analyses, taking full account of geometry, mask, selection, and cosmological dependencies in the covariances, and therefore deriving reliable parameter uncertainties.
4.3 Implementation
When estimating the SSC from Eq. (32), one numerical difficulty is the evaluation of the integral in Eq. (31), given that the Bessel functions highly oscillate with slow damping as kri →∞.
For the first multipoles, we may express the Bessel functions in terms of sine and cosine. Through trigonometrical identities, the integralswith products of Bessel function can thus be expressed as a sum of Fourier transforms. Derivations and expressions for the first three multipoles are given in Appendix C. For illustrative purposes we give below the expression for ℓ = 0
 (34)
(34)

is a continuous cosine transform that can be efficiently approximated numerically with a discrete fast Fourier transform (FFT). However, as argued in Appendix C, this method becomes too cumbersome at high ℓ and may also become numerically unstable. We could carry it out only for ℓ = 0, 1, 2.
As an alternative, we decided not to evaluate σ2(z1, z2), but instead to switch the order of the integrals over k and z, to compute the covariance directly as
 (36)
(36)
where the kernel  is given by
is given by
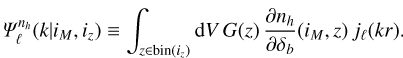 (37)
(37)
As can be seen in Fig. 4, this redshift integral effectively damps out the Bessel oscillations on scales k > kpeak + 2π∕Δr(iz), where Δ r(iz) = r(zmax) − r(zmin) is the width of the redshift bin in terms of comoving distance. This damping makes the k integral Eq. (36) much easier to deal with numerically compared to Eq. (26), since the integrand support is now more compact. So numerically we could just compute the later integrals by brute force, and this is the method we use for all numerical results shown hereafter in this article. We note that this method does not compute σ2 (z1, z2) as an intermediary product, and thus prevents from comparison of this quantity in partial sky with its alter ego in the full sky or flat sky limits, as in Fig. 1.
We remark that alternatively, Eq. (37) can be expressed as a Hankel transform
 (38)
(38)
via the inversion of the r(z) relation and defining a radial bin ir from iz. Equation (38) can be efficiently evaluated using Fourier transform methods such as FFTLog (e.g. Hamilton 2000; Camachoet al. in prep.). Although this is not the numerical method we used in this article, we note it can be a useful approach for future high-precision applications.
The results presented in this article consider the case of cluster counts, and the equations can be straightforwardly generalised to other probes of the LSS; see Appendix B.
 |
Fig. 4
|

5 Results
First, as a consistency test, we checked  against the full sky covariance matrix computed via
against the full sky covariance matrix computed via  given in Eq. (11) (e.g. Lacasa & Rosenfeld 2016). We find good agreement, to 0.8% precision on the auto-redshift covariance, and 7% precision on the cross-redshift covariance.
given in Eq. (11) (e.g. Lacasa & Rosenfeld 2016). We find good agreement, to 0.8% precision on the auto-redshift covariance, and 7% precision on the cross-redshift covariance.
Second, we show in Fig. 5 the general results for  in two representative cases: auto-covariance of the same redshift bin and cross-correlation (i.e. cross-covariance normalised by the corresponding auto-covariances) between two redshift bins. Both plots are for the lowest mass bin (iM = jM = 0, corresponding to logM = 14–14.5), although the shape of the curves does not change significantly when taking other mass bins (even with iM ≠ jM), only their amplitude changes.
in two representative cases: auto-covariance of the same redshift bin and cross-correlation (i.e. cross-covariance normalised by the corresponding auto-covariances) between two redshift bins. Both plots are for the lowest mass bin (iM = jM = 0, corresponding to logM = 14–14.5), although the shape of the curves does not change significantly when taking other mass bins (even with iM ≠ jM), only their amplitude changes.
For theauto-covariance (left plot), we see that it first rises with ℓ, to a maximum corresponding to the angular scale of the matter-radiation equality (i.e. the peak of Pm (k)) at that redshift, and then decreases monotonically. This behaviour conforms to our expectations, since the scale dependence is that of a projection of the 3D power spectrum Pm(k). This means that  is not constantwith ℓ, and thus, as already discussed in Sect. 4, it means that the fSKY approximation does not hold for SSC.
is not constantwith ℓ, and thus, as already discussed in Sect. 4, it means that the fSKY approximation does not hold for SSC.
For the cross-covariance (right plot), the situation is interesting as we see that the covariance is first negative, increases, crosses zero, and reaches a maximum towards ℓ = 25, and then decreases asymptotically to zero. This means that small surveys have a robustly negligible covariance between redshift bins (at least for this bin width Δz = 0.1), and can thus use block-diagonal covariance matrices to speed up their likelihoods estimations. However for surveys with a large sky coverage, the cross-covariance is non-negligible and depends on the survey area and shape, becoming either positive or negative depending on the mask. In those cases, careful estimation of the SSC is thus critical.
 |
Fig. 5
|

5.1 Application to a realistic survey mask
In order to illustrate the SSC method in a realistic case, we used two Healpix (Górski et al. 2005) masks visible in Fig. 6. The first mask is binary and is broadly similar to the footprint of DES7,8, although wewarn that it does not in any way represent the actual DES survey area, and we do not attempt to draw any particular conclusion for that survey. The second mask represents a more pessimistic case, where we considered that 15% of the survey area had to be discarded due to bright stars, satellite trails, or other systematics. In order to simulate this effect, we simply upgraded the mask to high resolution (nside = 4096), poked random holes in it, then degraded the mask back to the original resolution (nside = 1024).
The angular power spectra Cℓ(W) for these two masks can be seen on Fig. 7.
At low multipoles, the two spectra differ by a constant multiplicative factor 0.852, which is simply the ratio of the respective sky coverages. A second component in the spectrum of the second mask appears on smaller scales, which is a constant shot noise due to the random holes. However we see that this component is very subdominant, hence we can already expect that the only difference between the covariance of the two masks is due to the different sky coverage.
When implementing the sum over multipoles of Eq. (32), we find that we reached 1% convergence already at ℓmax = 50. This means that  need only be computed on a small number of multipoles for current and future surveys with large sky coverage, rendering the partial sky formalism developed here even more computationally efficient. Comparing the SSC covariances of the two masks, we find that they indeed only differ due to the different sky fraction, but when renormalised by fSKY they are identicalto numerical precision (0.01% in our case). The total correlation matrix (including shot-noise) for the first mask is shown in Fig. 8.
need only be computed on a small number of multipoles for current and future surveys with large sky coverage, rendering the partial sky formalism developed here even more computationally efficient. Comparing the SSC covariances of the two masks, we find that they indeed only differ due to the different sky fraction, but when renormalised by fSKY they are identicalto numerical precision (0.01% in our case). The total correlation matrix (including shot-noise) for the first mask is shown in Fig. 8.
We see that the SSC is an important contribution to the covariance matrix, dominating the error bars at log M ≤ 14.5. Concerning cross-redshifts, the SSC yields an anti-correlation between the adjacent bins reaching up to −10%. The cross-covariance is thus far from negligible for such a large survey.
The formalism presented in Sect. 4 is thus perfectly adapted to the numerical prediction of SSC, even in the case of a complex survey geometry. In fact we see that such computation is indeed necessary to reproduce the non-trivial behaviour of SSC, yielding, for example non-negligible anti-correlation of redshift bins, in the case presented above.
 |
Fig. 6 Masks used in the analysis. Top: simple footprint, assumed observed uniformly. Bottom: same but with simulated 15% rejection of observations due to systematics (see text for details). |
 |
Fig. 8 Total correlation matrix (SSC + shot-noise) of cluster counts for the first mask. The matrix is organised, as in Fig. 3, in two redshift blocks of increasing mass. |
5.2 Flat sky limit
One remaining question is that of the link between the partial sky approach developed in Sect. 4 and the flat sky approximation used previously in the literature and shown in Eq. (12). The two approaches cannot be compared or related at the level of the formalism because the (k⊥, k∥) splitting does not apply for sufficiently large angles. However, we can compare what covariance the two formalisms predict in some limits.
First, we can compare the equations analytically in the case of a constant spectrum Pm (k|z12) = cst ≡ 1. In the partial sky formalism we have
 (39)
(39)

is independent of ℓ. Thus the SSC is given by
 (41)
(41)
where we made the counts Ncl implicit for the sake of clarity.
Now in the flat sky formalism we have
![\begin{align*} \nonumber \sigma^2(z_1,z_2) &= \frac{1}{2\pi^2} \int_0^{\infty} k_{\perp} \, \mathrm{d} k_{\perp} \, 4 \frac{J_1(k_{\perp} \theta_S r_1)}{k_{\perp} \theta_S r_1} \frac{J_1(k_{\perp} \theta_S r_2)}{k_{\perp} \theta_S r_2} \nonumber \\ &\quad \times \underbrace{\int_0^{\infty} \mathrm{d} k_{\parallel} \; \cos\left[k_{\parallel} (r_1-r_2)\right] \times 1}_{=(2\pi) \,\delta(r_1-r_2)/2} \nonumber \\ &=\frac{2}{\pi} \ \delta(r_1-r_2) \ \frac{1}{(\theta r_1)^2} \ \underbrace{\int x \, \mathrm{d} x \ \left(J_1(x)/x\right)^2}_{=1/2} \nonumber \\ &= \frac{\delta(r_1 - r_2)}{r_1^2} \times \frac{1}{\mathrm\Omega_S}, \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq84.png) (42)
(42)
where we changed variables x = k⊥θSr1 and recall  . Inserting this into Eq. (9), we again obtain Eq. (41). Therefore the two approaches indeed agree in the flat sky limit for a constant spectrum.
. Inserting this into Eq. (9), we again obtain Eq. (41). Therefore the two approaches indeed agree in the flat sky limit for a constant spectrum.
Second, we can compare the results numerically for a mask with small enough sky coverage. To do so, we created a polar cap mask of radius 5 deg9. The power spectrum of this mask is shown in Fig. 9.
Compared to Fig. 7, we see that power extends to smaller angular scales or higher multipoles. In this case, we found that we had to extend the sum in Eq. (32) to higher multipoles, ℓmax = 250 to reach 1% level convergence of the covariance prediction. This stays however numerically tractable, through the observation that the ℓ dependence of  is very smooth, especially after ℓpeak = 25. Thus we can sample this dependence only for a small number of logarithmically spaced multipoles and interpolate when computing the sum in Eq. (32).
is very smooth, especially after ℓpeak = 25. Thus we can sample this dependence only for a small number of logarithmically spaced multipoles and interpolate when computing the sum in Eq. (32).
We found good agreement between the covariance derived from the partial sky formalism and that derived from the flat sky limit Eq. (12). This is visible, for example in Fig. 10 showing both auto-z covariances as a function of  , i.e. the same ordering as in Fig. 2.
, i.e. the same ordering as in Fig. 2.
The partial sky formalism thus successfully recovers the flat sky approximation in the flat sky limit. Numerically, we even found the partial sky formalism to be faster than the full computation of Eq. (12), and only three times slower than the Sij approximation Eq. (13).
 |
Fig. 9 Angular power spectrum of the 5 deg polar cap mask. |
 |
Fig. 10 Comparison of the SSC covariances derived from the partial sky formalism and the flat sky formula for a 5 deg circular sky patch. Auto-z covariances are shown as a function of |

6 Conclusion
SSC, also often called sample variance, is the dominant error for cluster counts at low cluster masses. For instance, Hu & Cohn (2006) have shown that even for a survey radius θ = 2.4 deg, the sample covariance is of the same order of magnitude as shot noise for cluster counts above log M = 14.2, although shot noise dominates for a threshold logM = 14.4. As shot-noise decreases faster with survey area than SSC, careful predictions of SSC become crucial for current and future surveys covering ever larger sky areas. It becomes even more crucial as these surveys are able to probe lower cluster masses through a higher density of galaxy detections. SSC is also crucial to the analysis of galaxy clustering and lensing shear, where it dominates statistical errors on small scales, and for probe combinations as it has been shown to couple probes (Takada & Bridle 2007; Takada & Spergel 2014; Lacasa & Rosenfeld 2016).
In the case of cluster counts covariance, we examined theoretical SSC computation methods in the flat sky limit, comparing two analytical approximations proposed in the literature to a full computation. We found that both approximations underpredict the auto-z covariance by 15% to 30–35%.
We then presented a harmonic expansion method for efficiently and accurately computing SSC for an arbitrary survey window function. We developed the method in the case of cluster counts, but it can be straightforwardly generalised to other probes such as galaxy clustering or lensing shear. Our derived expressions generalise previous full sky and flat sky equations found in the literature, properly reducing to these equations in the corresponding limits. We have cast the final covariance expression from the partial sky formalism in a way that allows easy modification of the survey mask. This is particularly suitable for comparison of surveys, design of survey strategy, and tests of data cuts due to quality selection criteria or systematics.
When applying our partial sky formalism to a mask broadly similar to the DES footprint with fSKY ~ 10%, we found a ~−15% cross-z covariance, meaning that the observables in the two redshift bins considered are anti-correlated. Hence the covariance matrix cannot be taken as block diagonal, as is the case for the approximation by Krause & Eifler (2017), which is however restricted to the flat sky limit. We also examined the possibility that the survey area is further reduced by pixel removal due to bright stars or systematics, for example. We found that this does not have important effects on the structure of the SSC matrix, only rescaling its amplitude by the effective survey area.
The results presented in this article thus render possible the theoretical computation of LSS covariances that account for selection and mask effect and also vary as a function of model parameters, as is the case in CMB analyses, for example. The latter parameter dependence is important in the case of likelihood analysis of cluster constraints, as it allows for self-calibration of the cluster observable-mass relation (Lima & Hu 2005; Hu & Cohn 2006; Baxter et al. 2016). For general probes, it can also improve cosmological parameter constraints from likelihood inference analyses compared to methods that either neglect these effects or fix the covariance from data or simulations, thereby avoiding the risk of fixing the covariance at a potentially incorrect cosmology.
Acknowledgements
We thank Flavia Sobreira for providing us with a mask of a DES-like survey footprint. We acknowledge the use of the Healpix package by Górski et al. (2005). F. L. acknowledges support by the Swiss National Science Foundation. M. L. is partially supported by FAPESP and CNPq. M. A. is supported by FAPESP.
Appendix A: Redshift-dependent mask
In the case where the survey angular mask W depends on redshift (e.g. when there are significant depth variations in the sky), the definition of the background mode Eq. (5) is simply changed to
 (A.1)
(A.1)
where now the survey solid angle ΩS depends on redshift.
Then Eq. (25) for σ2(z1, z2) is changed to
![\begin{align*}\sigma^2(z_1,z_2) & = \frac{1}{\mathrm\Omega_S(z_1) \, \mathrm\Omega_S(z_2)} \sum_{\ell} \left\{ \right.(2\ell+1) \ C_{\ell}[W(z_1),W(z_2)] \nonumber \\ & \ \ \ \times C_{\ell}^m(z_1,z_2) \left.\right\}, \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq89.png) (A.2)
(A.2)
where Cℓ[W(z1), W(z2)] is the angular cross-spectrum between the two masks at the two redshifts. This equation can then be integrated over (z1, z2) through Eq. (6) to yield the SSC covariance.
We note that in this redshift-dependent case, we can no longer permute the k and z integrals as was done in Sect. 4.3, which yielded a numerically efficient method. Recent advances by Campagne et al. (2017) may however render Eq. (A.2) numerically computable through the AngPow software.
Appendix B: Super-sample covariance for other probes
The main results of this article were derived for the covariance of cluster number counts. However, it is straightforward to generalise the equations to other LSS probes, such as galaxy clustering and lensing shear. In those cases, the covariance equations are simpler for the angular power spectrum Cℓ than for the angular correlation function. For instance, using Limber’s approximation, Lacasa & Rosenfeld (2016) have shown that the SSC of the galaxy angular power spectrum is given by
 (B.1)
(B.1)
where  .
.
For lensing shear, we would get a similar equation, replacing the galaxy number density by the lensing selection function and the 3D galaxy power spectrum by the matter power spectrum. The equation can thus be generalised to
 (B.2)
(B.2)
where the α index refers to either lensing or galaxy, and Wα is the corresponding selection function. In that case, it is straightforward to generalise Eq. (36), even including the possibility of the cross-covariance between galaxy and shear,
 (B.3)
(B.3)

and the cross-covariance between cluster counts and either galaxy or shear,
 (B.5)
(B.5)
which gives us all the equations needed to compute the auto and cross-covariances of cluster counts, galaxy angular power spectrum, and lensing shear power spectrum, i.e. the three main cosmological probes of current and future photometric galaxy surveys.
Appendix C: First multipoles
The spherical Bessel functions jn(x) obey the recurrence relation
 (C.1)
(C.1)
such that they can be written analytically in terms of sines, cosines and polynomials, given the initial conditions

The first few spherical Bessel functions are given by

We are trying to compute the following integrals:
 (C.7)
(C.7)
For jℓ(x) of the form Aℓ(x)sin(x)∕x − Bℓ(x)cos(x)∕x, this yields
![\begin{align*}\nonumber C_{\ell}^{\mathrm{m}}(z_{12}) &= \frac{2}{\pi} \int k^2 \mathrm{d} k \ \frac{P_m(k|z_{12})}{k^2 r_1 r_2}\\ \nonumber &\ \ \ \times \frac{1}{2}\ \Big[\big(A_{\ell}(kr_1)A_{\ell}(kr_2)+B_{\ell}(kr_1)B_{\ell}(kr_2)\big)\\ \nonumber & \qquad \qquad \times \cos\big(k(r_1-r_2)\big)\\ \nonumber &\ \ \ +\big(-A_{\ell}(kr_1)A_{\ell}(kr_2)+B_{\ell}(kr_1)B_{\ell}(kr_2)\big) \\ \nonumber & \qquad \qquad \times \cos\big(k(r_1+r_2)\big)\\ \nonumber &\ \ \ -\big(A_{\ell}(kr_1)B_{\ell}(kr_2)-B_{\ell}(kr_1)A_{\ell}(kr_2)\big) \\ \nonumber & \qquad \qquad \times \sin\big(k(r_1-r_2)\big)\\ \nonumber &\ \ \ -\big(A_{\ell}(kr_1)B_{\ell}(kr_2)+B_{\ell}(kr_1)A_{\ell}(kr_2)\big) \\ & \qquad \qquad \times \sin\big(k(r_1+r_2)\big)\Big] , \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq100.png) (C.8)
(C.8)
where the four integrals are Fourier (sine or cosine) transforms and can be computed numerically with FFTs. Let us note

Then Eq. (C.8) can be rewritten as
![\begin{align*} \nonumber C_{\ell}^{\mathrm{m}}(z_{12}) &= \frac{1}{2}\Big[ I_c^-\big(A_{\ell,1}A_{\ell,2}+B_{\ell,1}B_{\ell,2}\big)\\ \nonumber & \quad +I_c^+\big(-A_{\ell,1}A_{\ell,2}+B_{\ell,1}B_{\ell,2}\big)\\ \nonumber & \quad -I_s^-\big(A_{\ell,1}B_{\ell,2}-B_{\ell,1}A_{\ell,2}\big)\\ & \quad -I_s^+\big(A_{\ell,1}B_{\ell,2}+B_{\ell,1}A_{\ell,2}\big) \Big], \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq102.png) (C.13)
(C.13)
with Aℓ,i = Aℓ(kri). For ℓ = 0 we have A0 = 1 and B0 = 0, thus
![\begin{equation*} C_0^{\mathrm{m}}(z_{12}) = \frac{1}{2}\ \Big[ I_c^-\big(1\big)-I_c^+\big(1\big)\Big]. \end{equation*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq103.png) (C.14)
(C.14)
For ℓ = 1 we have A1 = 1∕x and B1 = 1. Therefore
![\begin{align*} \nonumber C_1^{\mathrm{m}}(z_{12})& = \frac{1}{2} \Bigg[ I_c^-\left(\frac{1}{k^2 r_1 r_2}+1\right) +I_c^+\left(-\frac{1}{k^2 r_1 r_2}+1\right) \nonumber \\ &\ \ \ -I_s^-\left(\frac{1}{k r_1}-\frac{1}{k r_2}\right) -I_s^+\left(\frac{1}{k r_1}+\frac{1}{k r_2}\right) \Bigg]. \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq104.png) (C.15)
(C.15)
If we define  , the above equations yield
, the above equations yield
![\begin{align}C_0^{\mathrm{m}}(z_{12})&=\frac{1}{2}\ \Big[I_{c,0}^- - I_{c,0}^+\Big],\\ \nonumber C_1^{\mathrm{m}}(z_{12})&=\frac{1}{2}\ \Bigg[I_{c,0}^- + I_{c,0}^+ -I_{s,1}^-\left(\frac{1}{r_1}-\frac{1}{r_2}\right) \\ & \quad -I_{s,1}^+\left(\frac{1}{r_1}+\frac{1}{r_2}\right) + \frac{I_{c,2}^- - I_{c,2}^+}{r_1r_2} \Bigg]. \end{align}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq106.png)
For ℓ = 2 we have A2 = 3∕x2 − 1 and B2 = 3∕x, thus
![\begin{align}\nonumber C_2^{\mathrm{m}}(z_{12}) &= \frac{1}{2}\ \Bigg[ I_c^-\left(\frac{9}{k^4 r_1^2 r_2^2}+\frac{3}{k^2}\left(\frac{3}{r_1 r_2}-\frac{1}{r_1^2}-\frac{1}{r_2^2}\right)+1 \right)\\ \nonumber & \ \ \ +I_c^+\left(-\frac{9}{k^4 r_1^2 r_2^2}+\frac{3}{k^2}\left(\frac{3}{r_1 r_2}+\frac{1}{r_1^2}+\frac{1}{r_2^2}\right)-1\right)\\ \nonumber &\ \ \ -I_s^-\left(\frac{9}{k^3 r_1 r_2}+\frac{3}{k}\right)\times\left(\frac{1}{r_1}-\frac{1}{r_2}\right)\\ &\ \ \ -I_s^+\left(\frac{9}{k^3 r_1 r_2}-\frac{3}{k}\right)\times\left(\frac{1}{r_1}+\frac{1}{r_2}\right) \Bigg]\\ \nonumber &=\frac{1}{2}\ \Bigg[I_{c,0}^- - I_{c,0}^+ - 3 \, I_{s,1}^-\left(\frac{1}{r_1}-\frac{1}{r_2}\right)\\ \nonumber &\ \ \ +3 \, I_{s,1}^+\left(\frac{1}{r_1}+\frac{1}{r_2}\right) +3\,I_{c,2}^-\left(\frac{3}{r_1 r_2}-\frac{1}{r_1^2}-\frac{1}{r_2^2}\right)\\ \nonumber &\ \ \ +3\,I_{c,2}^+\left(\frac{3}{r_1 r_2}+\frac{1}{r_1^2}+\frac{1}{r_2^2}\right) -\frac{9 \, I_{s,3}^-}{r_1 r_2}\left(\frac{1}{r_1}-\frac{1}{r_2}\right)\\ &\ \ \ -\frac{9 \, I_{s,3}^+}{r_1 r_2}\left(\frac{1}{r_1}+\frac{1}{r_2}\right) +\frac{9\left(I_{c,4}^- - I_{c,4}^+\right)}{r_1^2 r_2^2}\Bigg].\end{align}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq107.png)
We note that Aℓ and Bℓ follow the same recurrence relation Eq. (C.1) as the spherical Bessel functions jn. As such we can look at whether there is a recurrence relation that would allow us to get the analytical formula for a general  . Our efforts in this direction have shown only partially fruitful and are described below. We have
. Our efforts in this direction have shown only partially fruitful and are described below. We have
![\begin{align*} \nonumber C_{\ell+1}^{\mathrm{m}}(z_{12}) &= \frac{1}{2}\Big[ I_c^-\big(A_{{\ell+1},1}A_{{\ell+1},2}+B_{{\ell+1},1}B_{{\ell+1},2}\big) \nonumber \\ &\quad +I_c^+\big(-A_{{\ell+1},1}A_{{\ell+1},2}+B_{{\ell+1},1}B_{{\ell+1},2}\big)\nonumber \\ &\quad -I_s^-\big(A_{{\ell+1},1}B_{{\ell+1},2}-B_{{\ell+1},1}A_{{\ell+1},2}\big) \nonumber \\ &\quad -I_s^+\big(A_{{\ell+1},1}B_{{\ell+1},2} +B_{{\ell+1},1}A_{{\ell+1},2}\big) \Big] \nonumber \\ &\equiv \frac{1}{2} \left(C_{\ell+1}^{c,-}+C_{\ell+1}^{c,+}-C_{\ell+1}^{s,-}-C_{\ell+1}^{s,+}\right), \end{align*}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq109.png) (C.20)
(C.20)
![\begin{align}\nonumber C_{\ell+1}^{c,-} =& I_c^-\bigg[ \left(\frac{2\ell+1}{k r_1}A_{\ell,1}-A_{\ell-1,1}\right)\left(\frac{2\ell+1}{k r_2}A_{\ell,2}-A_{\ell-1,2}\right)\\* &+ \left(\frac{2\ell+1}{k r_1}B_{\ell,1}-B_{\ell-1,1}\right)\left(\frac{2\ell+1}{k r_2}B_{\ell,2}-B_{\ell-1,2}\right) \bigg]\\* \nonumber=& \ C_{\ell-1}^{c,-}+\frac{(2\ell+1)^2}{r_1 r_2} I_c^-\big[\left(A_{{\ell},1}A_{{\ell},2}+B_{{\ell},1}B_{{\ell},2}\right)/k^2\big]\\* \nonumber &-(2\ell+1) \ I_c^-\big[(A_{{\ell-1},1}A_{{\ell},2}+B_{{\ell-1},1}B_{{\ell},2})/kr_1\\* & +(1\leftrightarrow2)\big] \label{Eq:C_{l+1}^{c,-}}. \end{align}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq110.png)
Now we define the following quantities
![\begin{align}D_{\ell}^{c,-} &\equiv I_c^-\big[(A_{{\ell-1},1}A_{{\ell},2}+B_{{\ell-1},1}B_{{\ell},2})/kr_1+(1\leftrightarrow2)\big] ,\\ E_{\ell}^{c,-} &\equiv I_c^-\big[(A_{{\ell-1},1}A_{{\ell},2}+B_{{\ell-1},1}B_{{\ell},2})/kr_2+(1\leftrightarrow2)\big] , \end{align}](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq111.png)
and decompose  ,
,  and
and  onto the basis
onto the basis 

Then Eq. (C.22) gives a first recurrence relation
 (C.28)
(C.28)
By computing  and
and  , we can see that we have the two other recurrence relations
, we can see that we have the two other recurrence relations

The system is closed through the initial conditions

The following properties can easily be shown by recurrence:

With a bit more work, we can in principle solve for  and
and  ; since
; since  ,
,

This can be put in the form
 (C.40)
(C.40)

Finally, Eq. (C.40) has the following solution:
 (C.44)
(C.44)
which in principle gives the solution for  and
and  . We can insert this into Eq. (C.28) for i = 2 to get a closed recurrence relation for
. We can insert this into Eq. (C.28) for i = 2 to get a closed recurrence relation for  and solve for it. In turn, this can be inserted into Eqs. (C.29) and (C.30) for i = 4 to get a closed recurrence relation for
and solve for it. In turn, this can be inserted into Eqs. (C.29) and (C.30) for i = 4 to get a closed recurrence relation for  , and so on. So this represents a procedure for solving this set of equations and get analytical expressions for
, and so on. So this represents a procedure for solving this set of equations and get analytical expressions for  . Similarly, we could derive recurrence relations for
. Similarly, we could derive recurrence relations for  ,
,  , and
, and  . In practice this represents a daunting task, as even the formula for ℓ = 2 (Eq. (C.19)) is already cumbersome.
. In practice this represents a daunting task, as even the formula for ℓ = 2 (Eq. (C.19)) is already cumbersome.
Moreover, we may expect that these analytical formulae are doomed to present numerical instability at high ℓ. Indeed, the expansion of the spherical Bessel functions in terms of powers of 1∕x as in Eqs. (C.4)–(C.6) is ill-advised at high ℓ, as it leads to delicate cancellations of the numerous terms, in particular for x ≤ ℓ. We thus expect that our analytical formulae for Cℓ also leads to delicate cancellations that may be numerically unstable. Another way of seeing this is to notice that, at high ℓ, we have from Limber’s approximation that ![$C_{\ell}\propto P_m\left[k=(\ell+1/2)/r(z)\right]$](/articles/aa/full_html/2018/03/aa30281-16/aa30281-16-eq138.png) , and is thus a decreasing function of ℓ. However we saw that
, and is thus a decreasing function of ℓ. However we saw that  and thus Cℓ always contains a term
and thus Cℓ always contains a term  . This term hence needs to be (at least partially) cancelled by higher order terms, and this cancellation needs to be increasingly precise at high ℓ, since Pm (k) is a steep decreasing function of k.
. This term hence needs to be (at least partially) cancelled by higher order terms, and this cancellation needs to be increasingly precise at high ℓ, since Pm (k) is a steep decreasing function of k.
Given these issues, in practice, we implemented this low multipole method only for ℓ = 0, 1, 2, and used these to check our results obtained from the numerical method described in Sect. 4.3.
References
- Aguena, M., & Lima, M. 2016, Phys. Rev. D, submitted [arXiv:1611.05468] [Google Scholar]
- Astier, P., Guy, J., Regnault, N., et al. 2006, A&A, 447, 31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baxter, E. J., Rozo, E., Jain, B., Rykoff, E., & Wechsler, R. H. 2016, MNRAS, 463, 205 [NASA ADS] [CrossRef] [Google Scholar]
- Bayliss, M. B., Ruel, J., Stubbs, C. W., et al. 2016, ApJS, 227, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Beutler, F., Seo, H.-J., Ross, A. J., et al. 2017, MNRAS, 464, 3409 [NASA ADS] [CrossRef] [Google Scholar]
- Bleem, L. E., Stalder, B., de Haan, T., et al. 2015, ApJS, 216, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Blot, L., Corasaniti, P. S., Amendola, L., & Kitching, T. D. 2016, MNRAS, 458, 4462 [NASA ADS] [CrossRef] [Google Scholar]
- Campagne, J.-E., Neveu, J., & Plaszczynski, S. 2017, A&A, 602, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cooray, A., & Sheth, R. 2002, Phys. Rep., 372, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Crocce, M., Carretero, J., Bauer, A. H., et al. 2016, MNRAS, 455, 4301 [NASA ADS] [CrossRef] [Google Scholar]
- DES Collaboration. 2017, ArXiv e-prints [arXiv:1708.01530] [Google Scholar]
- Dietrich, J. P., Zhang, Y., Song, J., et al. 2014, MNRAS, 443, 1713 [NASA ADS] [CrossRef] [Google Scholar]
- Dodelson, S., & Schneider, M. D. 2013, Phys. Rev. D, 88, 063537 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [NASA ADS] [CrossRef] [Google Scholar]
- Escoffier, S., Cousinou, M.-C., Tilquin, A., et al. 2016, ArXiv e-prints [arXiv:1606.00233] [Google Scholar]
- Giannantonio, T., Fosalba, P., Cawthon, R., et al. 2016, MNRAS, 456, 3213 [NASA ADS] [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Hamilton, A. J. S. 2000, MNRAS, 312, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Viola, M., Heymans, C., et al. 2017, MNRAS, 465, 1454 [Google Scholar]
- Hinton, S. R., Kazin, E., Davis, T. M., et al. 2017, MNRAS, 464, 4807 [NASA ADS] [CrossRef] [Google Scholar]
- Hivon, E., Górski, K. M., Netterfield, C. B., et al. 2002, ApJ, 567, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, W., & Cohn, J. D. 2006, Phys. Rev. D, 73, 067301 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, W., & Kravtsov, A. V. 2003, ApJ, 584, 702 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, W., Chiang, C.-T., Li, Y., & LoVerde, M. 2016, Phys. Rev. D, 94, 023002 [NASA ADS] [CrossRef] [Google Scholar]
- Koester, B. P., McKay, T. A., Annis, J., et al. 2007, ApJ, 660, 221 [NASA ADS] [CrossRef] [Google Scholar]
- Krause, E., & Eifler, T. 2017, MNRAS, 470, 2100 [Google Scholar]
- Lacasa, F. 2018, A&A, in press, DOI:10.1051/0004-6361/201732343 [Google Scholar]
- Lacasa, F., & Kunz, M. 2017, A&A, 604, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lacasa, F., & Rosenfeld, R. 2016, JCAP, 8, 005 [Google Scholar]
- Li, Y., Hu, W., & Takada, M. 2014a, Phys. Rev. D, 89, 083519 [NASA ADS] [CrossRef] [Google Scholar]
- Li, Y., Hu, W., & Takada, M. 2014b, Phys. Rev. D, 90, 103530 [NASA ADS] [CrossRef] [Google Scholar]
- Li, Y., Hu, W., & Takada, M. 2016, Phys. Rev. D, 93, 063507 [NASA ADS] [CrossRef] [Google Scholar]
- Lima, M., & Hu, W. 2004, Phys. Rev. D, 70, 043504 [NASA ADS] [CrossRef] [Google Scholar]
- Lima, M., & Hu, W. 2005, Phys. Rev. D, 72, 043006 [NASA ADS] [CrossRef] [Google Scholar]
- Lima, M., & Hu, W. 2007, Phys. Rev. D, 76, 123013 [NASA ADS] [CrossRef] [Google Scholar]
- Miller, C. J., Nichol, R. C., Reichart, D., et al. 2005, AJ, 130, 968 [Google Scholar]
- O’Connell, R., Eisenstein, D., Vargas, M., Ho, S., & Padmanabhan, N. 2016, MNRAS, 462, 2681 [NASA ADS] [CrossRef] [Google Scholar]
- Pearson, D. W., & Samushia, L. 2016, MNRAS, 457, 993 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E. 1980, The Large-Scale Structure of the Universe (Princeton: Princeton University Press) [Google Scholar]
- Percival, W. J., Reid, B. A., Eisenstein, D. J., et al. 2010, MNRAS, 401, 2148 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XXVII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Riess, A. G., Macri, L., Casertano, S., et al. 2009, ApJ, 699, 539 [NASA ADS] [CrossRef] [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Rykoff, E. S., Rozo, E., Hollowood, D., et al. 2016, ApJS, 224, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez, C., Carrasco Kind, M., Lin, H., et al. 2014, MNRAS, 445, 1482 [NASA ADS] [CrossRef] [Google Scholar]
- Schmidt, F., Lima, M., Oyaizu, H., & Hu, W. 2009, Phys. Rev. D, 79, 083518 [NASA ADS] [CrossRef] [Google Scholar]
- Schmidt, F., Jeong, D., & Desjacques, V. 2013, Phys. Rev. D, 88, 023515 [NASA ADS] [CrossRef] [Google Scholar]
- Shirasaki, M., Takada, M., Miyatake, H., et al. 2017, MNRAS, 470, 3476 [NASA ADS] [CrossRef] [Google Scholar]
- Singh, S., Mandelbaum, R., Seljak, U., Slosar, A., & Vazquez Gonzalez, J. 2017, MNRAS, 471, 3827 [NASA ADS] [CrossRef] [Google Scholar]
- Soares-Santos, M., de Carvalho, R. R., Annis, J., et al. 2011, ApJ, 727, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Bridle, S. 2007, New J. Phys., 9, 446 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Hu, W. 2013, Phys. Rev. D, 87, 123504 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Spergel, D. N. 2014, MNRAS, 441, 2456 [NASA ADS] [CrossRef] [Google Scholar]
- Takahashi, R., Soma, S., Takada, M., & Kayo, I. 2014, MNRAS, 444, 3473 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J. L., Robertson, B. E., Kravtsov, A. V., et al. 2010, ApJ, 724, 878 [NASA ADS] [CrossRef] [Google Scholar]


All Figures
|
Fig. 1 Comparison of σ2(z1, z2) for z1 = 0.5 in different cases. In blue the flat sky formula Eq. (12) for a survey angular radius θS = 5 deg. In green the full sky formula Eq. (11) rescaled by a factor 1∕fSKY. |
| In the text | |
|
Fig. 2 Ratio of the SSC covariances from the Sij approximation and KE approximation to the full computation. Auto-z covariances are ordered as a function of |
| In the text | |
|
Fig. 3 Comparison of the cluster counts correlation matrix for different SSC computations, for a survey with angular radius θS = 5 deg. The SSC matrix is shown in 2 blocks for the redshift bins, and each block has 4 entries for the logarithmic mass bins. From left to right: full numerical computation from Eq. (9), Sij approximation, and KE approximation. |
| In the text | |
|
Fig. 4
|
| In the text | |
|
Fig. 5
|
| In the text | |
|
Fig. 6 Masks used in the analysis. Top: simple footprint, assumed observed uniformly. Bottom: same but with simulated 15% rejection of observations due to systematics (see text for details). |
| In the text | |
 |
Fig. 7 Angular power spectra of the two masks used in the analysis and shown in Fig. 6. |
| In the text | |
|
Fig. 8 Total correlation matrix (SSC + shot-noise) of cluster counts for the first mask. The matrix is organised, as in Fig. 3, in two redshift blocks of increasing mass. |
| In the text | |
|
Fig. 9 Angular power spectrum of the 5 deg polar cap mask. |
| In the text | |
|
Fig. 10 Comparison of the SSC covariances derived from the partial sky formalism and the flat sky formula for a 5 deg circular sky patch. Auto-z covariances are shown as a function of |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.