| Issue |
A&A
Volume 596, December 2016
GREGOR first results
|
|
|---|---|---|
| Article Number | A4 | |
| Number of page(s) | 13 | |
| Section | The Sun | |
| DOI | https://doi.org/10.1051/0004-6361/201628407 | |
| Published online | 30 November 2016 | |
Magnetic fields of opposite polarity in sunspot penumbrae
1 Kiepenheuer Institut für Sonnenphysik, Schöneckstr. 6, 79104 Freiburg, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Instituto de Astrofísica de Canarias, c/Vía Láctea s/n, 38205 La Laguna, Spain
3 Departamento de Astrofísica, Universidad de La Laguna, 38205 La Laguna (Tenerife), Spain
4 Leibniz-Institut für Astrophysik Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
5 Max-Planck-Institut für Sonnensystemforschung, Justus von Liebig Weg 3, 37077 Göttingen, Germany
6 Institut für Astrophysik, Friedrich Hund Platz 1, 37077 Göttingen, Germany
7 Astronomical Institute, Academy of Sciences of the Czech Republic, Fričova 298, 25165 Ondřejov, Czech Republic
8 Kyung Hee University, Yongin, Gyeonggi-Do, 446 701 Republic of Korea
9 USRA Huntsville, 6767 Madison Pike # 450, Huntsville, AL 35806, USA
Received: 29 February 2016
Accepted: 1 August 2016
Abstract
Context. A significant part of the penumbral magnetic field returns below the surface in the very deep photosphere. For lines in the visible, a large portion of this return field can only be detected indirectly by studying its imprints on strongly asymmetric and three-lobed Stokes V profiles. Infrared lines probe a narrow layer in the very deep photosphere, providing the possibility of directly measuring the orientation of magnetic fields close to the solar surface.
Aims. We study the topology of the penumbral magnetic field in the lower photosphere, focusing on regions where it returns below the surface.
Methods. We analyzed 71 spectropolarimetric datasets from Hinode and from the GREGOR infrared spectrograph. We inferred the quality and polarimetric accuracy of the infrared data after applying several reduction steps. Techniques of spectral inversion and forward synthesis were used to test the detection algorithm. We compared the morphology and the fractional penumbral area covered by reversed-polarity and three-lobed Stokes V profiles for sunspots at disk center. We determined the amount of reversed-polarity and three-lobed Stokes V profiles in visible and infrared data of sunspots at various heliocentric angles. From the results, we computed center-to-limb variation curves, which were interpreted in the context of existing penumbral models.
Results. Observations in visible and near-infrared spectral lines yield a significant difference in the penumbral area covered by magnetic fields of opposite polarity. In the infrared, the number of reversed-polarity Stokes V profiles is smaller by a factor of two than in the visible. For three-lobed Stokes V profiles the numbers differ by up to an order of magnitude.
Key words: sunspots / Sun: infrared / Sun: photosphere / Sun: magnetic fields
© ESO, 2016
1. Introduction
Our knowledge of the way magnetic and velocity fields are configured in the penumbra has greatly improved during the past decade (see, e.g., Solanki 2003; Rempel & Schlichenmaier 2011; Borrero & Ichimoto 2011, for reviews).
One example of this improvement concerns the disappearance of the Evershed flow at the white-light boundary of the sunspots, which seemed to be at odds with the concept of mass conservation. A possible solution, that a significant part of the plasma flow continues into the sunspot canopy, was discarded by observations (Solanki et al. 1994). The contradiction was solved after spectropolarimetric observation of high quality became available, which allowed for the detection of strong downflow plumes in the outer parts of the penumbra and showed where the plasma of the Evershed flow returns into the Sun (Westendorp Plaza et al. 1997; del Toro Iniesta et al. 2001; Bellot Rubio et al. 2004; Franz & Schlichenmaier 2009).
Another example is the interplay of penumbral magnetic and velocity fields. As these are well aligned (Bellot Rubio et al. 2003), it seems likely that the magnetic field submerges together with the plasma in the outer penumbra. Naïvely, we would expect to find magnetic fields of opposite polarity together with penumbral downflows. As stated in Spruit & Scharmer (2006), however, even in high-resolution magnetograms by Langhans et al. (2005), only a small fraction of the penumbral downflows show an opposite-polarity signal.
This observational lack of opposite polarities may be explained by the magnetic field returning below the surface in the very deep photosphere (Westendorp Plaza et al. 2001; Ichimoto et al. 2007; Franz 2011). Since such a configuration creates asymmetric Stokes profiles (cf. Illing et al. 1975; Auer & Heasley 1978; Sanchez Almeida & Lites 1992), the opposite-polarity signal is obscured even for disk center observation. Therefore it is important to use data of high spatial and spectral resolution to accurately capture line asymmetries and study penumbral return fields at least indirectly.
Recently, asymmetric Stokes V profiles with three lobes have been investigated, as they are a proxy for magnetic fields of opposite polarity in the lower penumbral photosphere (Franz 2012; Rempel 2012; Ruiz Cobo & Asensio Ramos 2013; Scharmer et al. 2013; Franz & Schlichenmaier 2013). These studies showed that a large portion of the penumbral downflows are accompanied by a magnetic field of opposite polarity. Tiwari et al. (2013, 2015) analyzed of the magnetic field configuration in sunspot penumbrae based on Stokes inversions and took into account the point spread function (PSF) that affects the data.
Observation in the near-infrared part of the solar spectrum provides another possibility of studying magnetic fields close to the solar surface. The reason is that the continuum absorption coefficient is lowest in the infrared (IR; Unsöld & Baschek 2002), and spectral lines at this wavelength are sensitive to the deepest parts of the solar photosphere (Solanki et al. 1992; see also Penn 2014, for a recent review on IR solar physics). Yet another benefit is that some of the neutral iron lines around 1.5 μm have a high-excitation potential, causing them to be formed within a narrow photospheric layer. These lines are therefore less susceptible to gradients of the atmospheric parameters along the line of sight (LOS) and hence produce less asymmetric Stokes parameters (see Müller et al. 2002, for a comparison of the asymmetry of penumbral Stokes V profiles measured in the visible and the IR). These characteristics make spectropolarimetry in IR lines an ideal tool for directly probeing penumbral magnetic fields of opposite polarity.
A drawback of IR observations is a decrease in spatial resolution when compared to data available in the visible regime, which means that larger telescopes are required for compensation. The GREGOR Infrared Spectrograph (GRIS, Collados et al. 2012), which has been in operation since 2014, is able to provide spectropolarimetric IR data of unprecedented quality that are suited for our study. In this contribution, we use 71 datasets from the visible and IR parts of the solar spectrum to study magnetic fields of opposite polarity in different layers of the penumbral atmosphere.
2. Observations, data calibration and reduction
For this study, we combined Hinode-SP data from the visible and GRIS data from the IR part of the solar spectrum.
Data in the visible from Hinode-SP:
the spectropolarimeter (SP; Lites et al. 2001) of the solar optical telescope (Tsuneta et al. 2008) onboard the Hinode satellite measures the full Stokes vector of Fe I 630.15 nm (geff = 1.67) and Fe I 630.25 nm (geff = 2.5). The slit of the SP covers 164″ of the solar disk, while the scanning mechanism can displace the image by ± 239″ (Lites et al. 2013). Two-dimensional maps are obtained by scanning with the spectrograph slit across the target in steps of 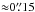 . Since the SP is designed to sample critically and since the pixel size along the slit corresponds to
. Since the SP is designed to sample critically and since the pixel size along the slit corresponds to 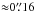 , the spatial resolution of the SP data is about
, the spatial resolution of the SP data is about 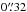 . The spectral sampling of the SP is 2.15 pm and the spectral PSF has a full width at half maximum (FWHM) of about 2.5 pm, and has been determined prior to launch using a tunable laser (Lites et al. 2013). For our study, we downloaded the raw data summarized in Table A.1 and reduced them, with the IDL routine sp_prep.pro provided by the Solar Soft package (Lites & Ichimoto 2013).
. The spectral sampling of the SP is 2.15 pm and the spectral PSF has a full width at half maximum (FWHM) of about 2.5 pm, and has been determined prior to launch using a tunable laser (Lites et al. 2013). For our study, we downloaded the raw data summarized in Table A.1 and reduced them, with the IDL routine sp_prep.pro provided by the Solar Soft package (Lites & Ichimoto 2013).
 |
Fig. 1 Panel a): an intensity image of NOAA 12049 recorded with GRIS close to disk center. White and gray contours outline the umbra and penumbra. Black contours encircle regions that are not taken into account in the calculation of an average QS profile. The white arrow points to the center of the solar disk. In panel b) we compare the average QS spectrum (black) with the FTS atlas (red). The regions shaded in gray are used in the analysis of the residual fringe pattern, see Sect. 3. Panel c): intensity variation in the continuum of the GRIS spectrum (black dots) and a polynomial fit (red) used for correction. |
Data in the near-infrared from GRIS:
with the integration of the scanning mechanism in April 2014, the IR spectropolarimeter of the new 1.5 m solar telescope GREGOR (von der Lühe et al. 2001; Schmidt et al. 2012; Denker et al. 2012) has become fully operational. Using the GREGOR Adaptive Optics System (GAOS, Berkefeldet al. 2012), we observed the disk passage of several active regions between April and July 2014 (see Table A.2 for a list of the sunspots observed in the IR). All datasets consist of raster scans with a length ranging from 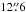 to
to 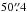 (i.e., 100 to 400 scan steps) and a width of
(i.e., 100 to 400 scan steps) and a width of 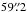 (i.e., 470 pixel along the slit). They cover a 4 nm wide spectral region around 1565 nm. Polarimetric calibration was performed using the GREGOR polarimetric calibration unit (Hofmann et al. 2012).
(i.e., 470 pixel along the slit). They cover a 4 nm wide spectral region around 1565 nm. Polarimetric calibration was performed using the GREGOR polarimetric calibration unit (Hofmann et al. 2012).
Dark subtraction, flat fielding, and polarimetric calibration were applied to the raw data using the GRIS data pipeline that was derived from the TIP instrument (see Collados 1999; Mártinez Pillet et al. 1999, for calibration steps included in the TIP pipeline). The raw images exhibit a fringe pattern that is most probably introduced by the pre-filter in front of the ferroelectric liquid crystals of the GRIS polarimeter or by the prisms that realign the beam to properly illuminate the IR camera (cf. Semel 2003, for a theoretical study on fringes in spectropolarimetric instruments). By subtracting a sinusoidal fit from the raw data, the fringes were significantly reduced a posteriori. Spikes in the spectrum were removed by applying a median filter to spectral regions where the intensity exceeded a certain threshold when compared to neighboring pixels.
Comparison to FTS atlas:
as part of the calibration process, we created masks that define the quiet Sun (QS), penumbra, and umbra of the respective sunspot. To this end, we used the original data without any smoothing and applied certain criteria such as intensity and total polarization to define the respective boundaries. If automatic detection failed, for instance, because of intensity variations during data acquisition, we manually selected the umbral and penumbral areas. Finally, we defined all regions that contain strong magnetic fields, for example pores or orphan penumbrae, or regions that have been marked because there was no spectral information. This is because some maps from early observations exhibit vignetting caused by an aperture within the beam path of GREGOR that was placed there to minimize scattered light. When the image shift due to the correction of the tip-tilt mirror was large, the beam was partially blocked and the spectrograph slit was not entirely illuminated (cf. lower right corner of Fig. 9 panel f). As an example we show the continuum intensity map of the following spot of active region NOAA 12 049 on May 3 in Fig. 1a.
An average QS profile was computed from all the spectra outside of the above mentioned contours. We then compared this average QS spectrum of GRIS to an FTS atlas by Livingston & Wallace (1991) to obtain a correction curve for the continuum intensity in the Stokes I profiles, see Fig. 1 panels b and c. To exclude the spectral lines, we selected all measurements from the average QS spectrum at a wavelength where the intensity of the FTS atlas is 0.99 <IFTS< 1.01 (black dots). We then fit a polynomial (red curve) to the data points following an optimization procedure. The order of the polynomial was allowed to vary between 1 and 30, and we chose the polynomial with the smallest difference between measurement and fit.
 |
Fig. 2 Top panel: merit function that was used to determine the best values, i.e. FWHM and constant offset of a Gauss function, to model the PSF of GRIS. Bottom panel: three spectral lines that are used in this study (black crosses) overplotted with the same lines from the FTS atlas (red) after they were convolved with the spectral PSF of GRIS. |
Spectral PSF:
following Allende Prieto et al. (2004) and Cabrera Solana et al. (2007), we approximated the spectral PSF of GRIS. To this end, we assumed that the PSF of the FTS is a delta function and degraded its spectrum until it overlapped with that of the average QS recorded by GRIS at disk center1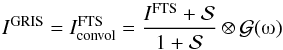 (1)with IGRIS and IFTS being the QS spectra from GRIS and FTS respectively.
(1)with IGRIS and IFTS being the QS spectra from GRIS and FTS respectively. 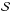 is the fraction of spectral scattered light and ⊗ represents a convolution. In first order, the spectral PSF is assumed to be a Gaussian
is the fraction of spectral scattered light and ⊗ represents a convolution. In first order, the spectral PSF is assumed to be a Gaussian 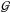 with FWHM of ω. In a next step, we altered and ω until the differences between IGRIS and
with FWHM of ω. In a next step, we altered and ω until the differences between IGRIS and 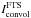 were minimal.
were minimal.
In the top panel of Fig. 2 we show the merit function for various and ω for a particular dataset of May 3. A minimal χ2, that is, the best agreement between GRIS measurement (black crosses) and convolved FTS spectrum (red line), is achieved for 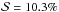 and ω = 17.8 pm. When we used these parameters for a Gauss function and convolved the FTS atlas with it, we obtaind the solid red line in the bottom panel of Fig. 2. Except for a small discrepancy in the line core of Fe I 1566.20 nm, the agreement between the degraded FTS atlas and GRIS measurements is good.
and ω = 17.8 pm. When we used these parameters for a Gauss function and convolved the FTS atlas with it, we obtaind the solid red line in the bottom panel of Fig. 2. Except for a small discrepancy in the line core of Fe I 1566.20 nm, the agreement between the degraded FTS atlas and GRIS measurements is good.
Image rotation:
GREGOR is a telescope with an altitude-azimuth mount (Volkmer et al. 2012), which causes the solar image to rotate on the detector plane. The rotation rate across the spectrograph slit is time dependent. Figure 3 shows a model of the rotation throughout the day for the first day of each month.
 |
Fig. 3 Rotation rate of the solar image in the focal plane of GREGOR. It shows the rotation rate on the first day of each month throughout 2014. |
From April to September and between 12 UT and 14 UT, the image rotated more than 1° per minute. No mechanical device was installed at GREGOR in 2014 to compensated for image rotation. This effect is visible in the image of panel a in Fig. 1 panel a, which was recorded at around 12 UT. The lock point of GAOS, which is kept at a fixed position, was on the light bridge, and the image rotates clockwise. Thus, toward the positive end of the slit, scanning and image rotation partly compensate for each other and the structures appear compressed perpendicular to the slit, see the elongated granules at (x,y) = (30,15). Toward the negative end of the slit, scanning and image rotation have the same direction and the structures appear stretched, see the granules at (x,y) = (−30,15). To avoid this distortion, we restricted our observations to times with an image rotation rate of less than 1° per minute. This value is acceptable because a typical observation takes less than 20 min.
One complication in the data evaluation process is due to the imperfect alignment of the optical and mechanical axes of the telescope. This causes the field of view to move along a complicated trajectory known as the beam wobble, when azimuth and elevation of the telescope are changed for the daily tracking of the Sun. During the observation this beam wobble is compensated for by GAOS, but it is very difficult to exactly translate the pointing coordinates of GREGOR into solar disk coordinates. To circumvent this problem we cross-correlated the scans with continuum images from the Helioseismic and Magnetic Imager (HMI, Schou et al. 2012) onboard the Solar Dynamics Observatory (SDO, Pesnell et al. 2012) to determine the heliocentric angle of the sunspots observed with GRIS.
3. Data description and analysis
In our investigation, we combined information from the two Hinode Fe I lines in the visible with three IR Fe I lines from the GRIS spectra. Table 1 summarizes the selected lines alongside relevant parameters such as the wavelength ˘ of the transition at ambient temperature and atmospheric pressure, atomic levels participating in the transition, excitation potential of the lower level Øe, and effective2 Landé g-factor geff. For a comparison of the sensitivity of the lines in Table 1 to various parameters such as temperature, velocity, and magnetic field at different atmospheric layers, we refer to Borrero et al. (2016).
Parameters of solar neutral iron lines.
Example of measured IR Stokes profiles:
for our analyses, we extracted a 12 nm and a 40 nm wide spectral window around the Hinode-SP and GRIS lines respectively. As an example, we show Stokes profiles for the IR lines from different solar regions such as QS, penumbra, and umbra in Fig. 4.
 |
Fig. 4 Stokes profiles of Fe 1564.85 nm (blue), Fe 1565.29 nm (green) and Fe 1566.20 nm (red) recorded with FTS and GRIS. Top row from left to right: Stokes I recorded with the FTS for the QS, a warm umbra and a medium warm umbra. Other rows from top to bottom: Stokes I normalized to the average QS, and Stokes Q, U and V in percent of the average continuum intensity. From left to right: Stokes vector from the QS, penumbra, umbra, and a region where the Stokes V profile shows three lobes. The Fe 1565.29 nm line is strongly blended by a hydroxyl radical line pair in the umbral example. The spectral regions used to estimate the noise in the polarimetric component are gray shaded in the lower left panel. The signal in the lower right panel is amplified by a factor of three and the spectral windows that are shifted across the spectrum to detect 3LPs are indicated in color. See main text for details. |
In the top row of Fig. 4 the intensity profiles from the FTS IR atlas are plotted (Wallace et al. 2001) for the photospheric QS (Livingston 1990), a so-called warm umbra with an estimated field strength of 2000 G (Giampapa 1983), and a so-called medium warm umbra with an estimated field strength of 2500 G (Giampapa 1982). In the following, we discuss the features seen in the GRIS spectra, which are plotted in the other rows.
For the QS, the continuum intensity of the GRIS Stokes I profile is slightly lower than that of the FTS atlas. The reason is that the former represents a pixel from an intergranular lane and is normalized to the intensity of the average QS, while the latter is an unresolved average QS profile by default because of the limited spatial resolution of the FTS. The resolving power of GRIS is high enough to identify weak lines such as the Fe I blend at 1564.74 nm or Cr I at 1566.34 nm, see red and blue profiles in the panels of Stokes I of Fig. 4.
For penumbral Stokes I profiles, the σ- and π-components of the line triplet of Fe I 1564.85 nm are visible as a result of the high g-factor. The profiles Fe I 1552.29 nm and Fe I 1566.20 nm are significantly broadened. The polarimetric components show no peculiarities.
In the umbra, the Fe I 1564.85 nm line shows widely split σ-components. The π-component is absent, since the magnetic field is oriented along the LOS for an umbra observed close to disk center. The Fe I 1565.29 nm line profile is very shallow and displays several blends. The shallow profile is due to the high-excitation potential (Fe I 1565.29 nm shows the highest excitation potential of all IR lines considered in this study), which causes the lower level of the transition to be weakly populated at umbral temperatures. Additionally, the low temperatures allow for the formation of magnetically sensitive hydroxyl radicals (see green line in the third column of Fig. 4). The − σ component is completely hidden by the blend of the hydroxy radical, while the + σ component remains visible at − 0.5 Å from the line core. The influence of the hydroxyl radicals is also apparent in Stokes V, where additional lobes appear in both wings of Fe I 1565.29 nm. Because of this, information from this line has to be taken with caution for spectra from the inner penumbra and umbra. The Fe I 1566.20 nm line profile is less split and significantly deeper than the other two lines. In the umbral spectra, there are CN and CO blends apparent around 1566.06 nm (red line in the third column of Fig. 4).
In the fourth column, we plot a profile from the penumbra where Stokes V shows three lobes (the signal is amplified by a factor of three). The shape is similar in all three lines, only the broadening is higher in Fe I 1564.85 nm that in the other lines.
Residual fringes:
one feature still visible in the intensity profile of the GRIS data are the wiggles in the continuum, which originate from the fringes attenuated during the reduction process. Modeling the fringes by a superposition of sine curves of various amplitudes and frequencies requires little computing time when compared to more involved approaches using wavelet analysis (Rojo & Harrington 2006) or 2D pattern recognition (Casini et al. 2012). Drawbacks are the danger of removing or modifying an actual signal, that is a spectral line. Therefore, the filter was applied in a conservative way, accepting residual fringes in the data.
To study the residual fringes in the spatial dimension, we subtracted the degraded FTS profile from each Stokes I profile (see Eq. (1)). Then we computed the RMS fluctuation in a region without lines. We chose λ = 1565.07 nm ± 0.08 nm as indicated by the dark gray region in Fig. 1 panel b. Figure 5 shows the spatial distribution of the fluctuation. The fluctuations were manually set to zero at the location of the sunspot. The columns at − 6″ and + 9″ are saturated because at this position along the slit a spike increases the RMS value significantly. The resulting pattern of the RMS values is stable for different scan positions, but varies along the slit with an amplitude of (3.5 ± 1.5) × 10-3 × Iqs.
 |
Fig. 5 Spatial distribution of residual fringes. The figure shows the RMS fluctuations around the continuum intensity at λ = 1565.07 nm ± 0.8 nm in GRIS data. Contours outline umbra, penumbra, and some nearby concentrations of magnetic field. The white arrow points to the center of the solar disk. The horizontal (dashed red) and vertical (dashed blue) lines mark regions where we investigated the residual fringes along the slit (Fig. 6) and for different slit positions (not shown). |
To visualize the spectral dependence of the fringes for all pixels along the slit, we removed the intensity variation that is due to granulation. This was done by subtracting the mean Stokes I value in the interval λ = 1562.76 nm ± 0.2 nm and λ = 1565.48 nm ± 0.2 nm, as indicated by the light gray regions in Fig. 1 panel b.
 |
Fig. 6 Spectral distribution of residual fringes. The figure shows the difference between GRIS Stokes I spectra and the degraded FTS profile (red line) along the slit. The GRIS Stokes I spectra have been corrected for granular intensity variation. |
The fringes have a peak-to-peak amplitude of approximately 1% and are highest at the lower and upper wavelength end of the spectrum. In addition to the vertical fringe pattern, a second and weaker diagonal fringe pattern is visible along the slit (see Fig. 6). The wavelength position of the fringes was stable during the scan, but the amplitude changed, possibly as a result of the varying seeing conditions.
Polarimetric accuracy:
to ensure that no residual fringes remain in the polarimetric parameters that might compromise our analysis, we estimated the noise in Stokes Q, U and V. To this end, we calculated maps of the maximum of the total polarization (Ptot) of the lines listed in Table 1, ![Mathematical equation: \begin{equation} {\rm{max}}~{P}_{\rm{tot}} = {\rm{max}} \left[\sqrt{ {Q(\lambda)}^{2}+ {U(\lambda)}^{2}+ {V(\lambda)}^{2}} \right]_{\lambda_{\rm{blue}}}^{\lambda_{\rm{red}}} \end{equation}](/articles/aa/full_html/2016/12/aa28407-16/aa28407-16-eq54.png) (2)in which Q, U, and V denote the polarimetric Stokes parameters normalized to the continuum intensity of the average QS, while λblue and λred represent the lower and upper limits of the spectral window under study. In a subsequent step, we extracted all Stokes V spectra that belong to the QS, that is, profiles for which max Ptot ≤ 5 × 10-3 × Ic. If the number of profiles in the resulting subset was not sufficient for averaging (we chose a minimum of 10 000 profiles), the threshold of max Ptot was increased to 7 × 10-3 × Ic or 1 × 10-2 × Ic, respectively. In a last step, we calculated the RMS fluctuation of the Stokes V spectra of the subset in the continuum regions. In Hinode-SP we defined the continuum as all the measurements that are at least ± 37 pm detuned from the line core. For the GRIS data we chose a minimal detuning of ±160 pm shown as gray shaded areas in the lower left panel of Fig. 4.
(2)in which Q, U, and V denote the polarimetric Stokes parameters normalized to the continuum intensity of the average QS, while λblue and λred represent the lower and upper limits of the spectral window under study. In a subsequent step, we extracted all Stokes V spectra that belong to the QS, that is, profiles for which max Ptot ≤ 5 × 10-3 × Ic. If the number of profiles in the resulting subset was not sufficient for averaging (we chose a minimum of 10 000 profiles), the threshold of max Ptot was increased to 7 × 10-3 × Ic or 1 × 10-2 × Ic, respectively. In a last step, we calculated the RMS fluctuation of the Stokes V spectra of the subset in the continuum regions. In Hinode-SP we defined the continuum as all the measurements that are at least ± 37 pm detuned from the line core. For the GRIS data we chose a minimal detuning of ±160 pm shown as gray shaded areas in the lower left panel of Fig. 4.
The average of the RMS fluctuation in the continuum region of all QS Stokes V spectra was then, in turn, interpreted as the 1σ noise level. It varies from 8.3 to 15.3 × 10-4 × Ic (see Table A.1) in the Hinode data and ranges3 from 6.8 to 11.2 × 10-4 × Ic (see Table A.2) in the GRIS data. Similar analyses were performed for Stokes Q and U. We did not find any indication of the fringe pattern in the polarimetric components above the 3σ noise level.
 |
Fig. 7 Distribution of three-lobed (red) and reversed-polarity (blue) Stokes V profiles in the penumbra. The left panel shows sunspot NOAA 10 933 recorded on January 5, 2007 with Hinode-SP at Θ ≈ 3°. The right panel shows NOAA 12 049 recorded on May 3, 2014 with GRIS at Θ ≈ 6° (right). The contours outline the penumbral boundaries and the black arrows point to the center of the solar disk. |
4. Results and discussion
We define a 3LP as a regular Stokes V profile with a third lobe on its red wing that is of the same polarity as the blue lobe of the regular Stokes V profile (cf. Borrero et al. 2005; Katsukawa & Jurčák 2010, for another type of three-lobed profile).
To detect such profiles, we applied the procedure described in Franz & Schlichenmaier (2013), which are summarized in the following. First, we corrected for the polarity of the sunspot in such a way that the blue lobe of the V profile was always positive. To analyze the Hinode-SP data, we extracted both Fe lines from the spectrum to be able to treat them separately. Then, we split the Stokes V profile into three spectral windows. The first two windows have a bandwidth of 20 pm, while the third is 45 pm wide. The position of these spectral windows may vary by 35 pm, but neither their width nor their order was allowed to change. This is indicated by the colored regions in the upper right panel of Fig. 1 in Franz & Schlichenmaier (2013). Because the IR lines are broader, we increased the width of the spectral windows, allowing us to employ the same algorithm as we used to work with GRIS data. The modified windows are indicated by the colored regions in the lower right panel of Fig. 4. They have a width of 60 pm (blue), 40 pm (yellow), and 80 pm (red). As before, their position may vary by ±60 pm (indicated by the black arrow), but neither their width nor their order was allowed to change.
Finally, a Stokes V profile is counted as a 3LP when the following conditions apply to the extrema of the positive and negative lobes and to their adjacent spectral measurements:
-
a)
They are positive in the blue and red windows, but negative in theyellow window.
-
b)
They are above the 3σ noise level in all windows.
As an example of our results, Fig. 7 compares a Hinode-SP dataset (Fe I 630.25 nm) to a dataset recorded with GRIS (Fe I 1566.2 nm). Even though the data were not recorded simultaneously, a line-up like this is justified because the data are very similar in terms of sunspot size (1900 arcsec2 vs. 1450 arcsec2), heliocentric angle (Θ ≈ 3° vs. Θ ≈ 6°), spatial resolution (0.̋32 vs. ≈0.̋4), spectral sampling (2.15 pm vs. 4.0 pm), and polarimetric accuracy (9.8 × 10-4 in both cases). The main differences are the observatory itself (space-borne vs. ground-based) and spectroscopic line (visible vs. IR). The latter implies a different sampling of the solar atmosphere. The Hinode-SP lines in the visible are sensitive to a broad atmospheric layer reaching up to the mid-photosphere.The formation of the IR lines of GRIS, on the other hand, occurs in a narrow, very deep layer of the photosphere, see Fig. 9 in Borrero et al. (2016). However, this is a simplification since the two lines have different temperatures and different Zeeman sensitivities.
We indicate the regions with 3LPs in red and regions with reversed-polarity Stokes V profiles (RPPs) in blue. In both datasets, 3LPs appear predominantly in the outer penumbra, with some patches also present in the middle penumbra. For Fe I 630.25 nm, however, they are more frequent and larger than for Fe I 1566.2 nm. The largest patch in the left panel of Fig. 7 at (x,y) = (−2, −22) has a diameter of 5′′, while it is only 2′′ for the largest patch in the right panel at (x,y) = (3, −25). An excess of 3LPs is visible on the limb-side penumbra of both datasets. Several narrow and elongated regions of 3LPs with a width of about 0.̋5, for instance, at (x,y) = (18, 12), are visible throughout the penumbra in the Fe I 630.25 nm data. Structures like this are very rare in Fe I 1566.2 nm and completely absent from the center-side penumbra. Regions of RPPs are only located in the outer penumbra and are similar in terms of morphology and abundance for both spectral lines. The majority appears close to regions of 3LPs, some of them are even entirely encircled by them, for instance, (x,y) = (12, −19) in the left panel and (x,y) = (3, 19) in the right panel, while others are completely independent of 3LPs, for example, (x,y) = (−8, −25) in the left panel and (x,y) = (18, −9) in the right panel.
Comparison of penumbral area showing RPPs and 3LPs together with the amount of total area showing opposite polarity as measured in visible and IR lines.
For the other lines under study, we find similar results, which we summarize in Table 2. In the visible, a few percent of the penumbral area are covered by RPPs, while 3LPs occupy an additional 12% to 15%, which means that up to 17% of the penumbral area is covered by magnetic fields of opposite polarity. In the IR the numbers for the RPPs are about a factor of two smaller, while the amount of 3LPs is less than a few percent and thus up to an order of magnitude smaller than in the visible.
The lack of penumbral 3LPs in the IR is expected from models explaining such profiles as due to a magnetic field of reversed polarity in the lower part of a two-layer atmosphere (see Fig. 9 panel a and Fig. 7 in Franz & Schlichenmaier 2013). Within such a scenario, the visible line would be sensitive to both atmospheric layers, but the IR line only to the lower one. As a result, IR data should show fewer 3LPs, but since the total amount of magnetic fields of reversed polarity should stay constant, we would expect an increase in RPPs. However, as illustrated by the blue area in Fig. 7 and summarized by the numbers in Table 2, we did not find such an increase in any line of the IR data. As a consequence, the amount of penumbral area covered by magnetic fields of opposite polarity in Fe I 1566.2 nm appears up to one order of magnitude lower than Fe I 630.25 nm. The disagreement of the numbers summarized in Table 2 might be due to several reasons. We mention spatial stray light, problems with the detection algorithm, and selection bias or poor statistics. Spatial stray light, resulting from a combination of atmospheric seeing and instrumental effects, smears out signals over a certain region. This dilutes the signature of a localized 3LP (cf., e.g., Lagg et al. 2016), making a detection more difficult. An analysis of the influence of spatial stray light is quite involved, especially if the time-dependent PSF is unknown, and will therefore be treated in a separate publication. In addition the higher Zeeman sensitivity in the infrared, which requires larger velocity gradients to produce asymmetric Stokes V profiles at 1.5 μm than in the visible (Grossmann-Doerth et al. 1989), might influence on the amount of detected 3LPs. In the following, we investigate the influence of the some of the above-mentioned phenomena on the detection of 3LPs.
Comparison of 3LPs in visible and IR lines:
first, we address the question whether the strategy we adopted to detect 3LPs in visible data is applicable to IR data. We argue that 3LPs in the visible and in the IR look very similar and thereby justify the modifications to the algorithm described above. Since there are no simultaneous observations of Hinode and GREGOR for a sunspot at disk center, we chose a theoretical approach of inversion and subsequent forward modeling. We revisited the downflow case described in Franz & Schlichenmaier (2013), where we inverted a 3LP of the Fe I 630.25 nm line with SIR (Ruiz Cobo & del Toro Iniesta 1992). Then we used the resulting atmosphere to synthesize a 3LP as would be observed by GRIS for Fe I 1566.2 nm.
 |
Fig. 8 Shape of 3LP in visible and IR lines. A profile measured by Hinode-SP (black crosses) is drawn alongside the results of a SIR inversion (solid black). The corresponding model atmosphere is used to synthesize a profile in the IR at 1566.2 nm (solid red), which is shown together with the subsequently degraded profile as would be measured by GRIS (red triangles). For comparison, we show a 3LP from a GRIS observation (blue diamonds). |
A summary of our results is shown in Fig. 8, where we plot a 3LP from Hinode-SP measurements of Fe I 630.25 nm (black crosses) alongside the output profile from a SIR inversion (solid black) of that line. The inversion reproduces all the features of the observed profile, although the amplitude of the negative lobe is smaller in the inversion than in the measurements. A large number of nodes might lead to better agreement, but our aim was to reproduce all features with the fewest number of free parameters.
In a next step, the model atmosphere that corresponds to this output profile was used to synthesize the Stokes V profile of the Fe I 1566.20 nm IR line (solid red). Both Stokes V profiles exhibit three lobes and, at least for this example, this demonstrates that an atmosphere that causes a 3LP for Fe I 630.25 nm yields a 3LP in Fe I 1566.20 nm. In the following, we discuss the details of these 3LPs.
When compared to the Stokes V profile in the visible, the resulting IR profile is significantly broader. This is mainly caused by the Zeeman effect, which has a quadratic wavelength dependence, and the Doppler broadening, which depends linearly on wavelength. For Fe I 630.25 nm, the profile shows a positive and a negative lobe with similar amplitudes located symmetrically around the zero crossing wavelength λ0. A third lobe with positive polarity but smaller amplitude is located 0.3 Å on the red side of λ0. For the synthetic Fe I 1566.2 nm, there are a positive and a negative lobe with the same amplitudes located around λ0. The negative lobe, however, is slightly wider than the positive lobe. The third lobe is located at + 0.75Å on the red side of λ0 and shows a larger amplitude than the other two lobes.
The difference between the inverted and the synthesized 3LPs may be explained by the configuration of the model atmosphere, that is, by an increase of inclination and strength of the magnetic field with optical depth. The two lobes around λ0 are more sensitive to the higher atmospheric layers, while the third lobe on the red side of the profile receives more contribution from the lower atmospheric layers. Since the Fe I 1566.2 nm is more sensitive to these lower layers, a larger amplitude for the third lobe in Fe I 630.25 nm can be expected. This can can only be considered an estimate because a model atmosphere resulting from the inversion of one line always falls short of representing the other, for instance, because they do not sample exactly the same range of heights and have different sensitivities to temperature, magnetic field, etc.
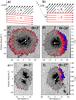 |
Fig. 9 Top: sketch of a simple atmospheric model capable of producing 3LPs in penumbrae at disk center (panel a)) and larger heliocentric angles (panel b)). B1, B2, v1 and v2 represent magnetic field strength and velocity in the lower and upper atmospheric layer. The LOS is parallel to the local vertical z at disk center and seen under the projection of Θ for increasing heliocentric angles. Middle: Hinode-SP intensity image of a sunspot at disk center (panel c)) and off center (panel d)). Regions with 3LPs are indicated in red, and regions with RPPs are shown in blue. Bottom: same as above, but for GRIS observations. The black and white contours indicate the penumbral boundaries, and the white arrow points to the center of the solar disk. |
In a final step, we degraded the synthetic IR profile with the spectral PSF calculated in Sect. 2, thereby simulating a profile as would be recorded by GRIS (red triangles). Except that the amplitude of the peaks is slightly diminished, there is no significant change. When we plot the simulated IR profile alongside a profile as observed by GRIS (blue diamonds), we find that the third lobe is largely overestimated by the synthetic profile, but the width and wavelength position of the individual lobes are reproduced correctly. We performed this test with Fe I 1564.8 nm and Fe I 1565.2 nm and obtained similar results. This comparison has to be taken with caution as the simulated and observed GRIS profiles represent the atmospheric conditions in different spots observed at different times. Nevertheless, it shows that the IR lines do indeed exhibit 3LPs and that the modification of the spectral windows in our detection algorithm is reasonable and does not cause of the lack of 3LPs in the IR.
Geometrical considerations:
Franz & Schlichenmaier (2013), used the synthesis module of SIR to study the effect of atmospheric parameters on the shape of Stokes V profiles. Our goal was to create a simple model that yields 3LPs with a non-vanishing area asymmetry. For all the realizations where we succeeded, the overall configuration of the model was the following:
-
1)
An atmosphere consisting of two layers.
-
2)
Magnetic fields in both layers, but of opposite polarity.
-
3)
Plasma moving away from the observer in one layer.
Our observations show that Stokes V profiles with three lobes are accompanied by asymmetric Stokes I profiles in which the line wing is redshifted, while the line core appears unshifted. Owing to the temperature stratification of the solar photosphere, information about the lower atmospheric region is encoded in the wings of the spectral lines, while the core of the line is in turn more sensitive to higher atmospheric regions (Mihalas 1978; del Toro Iniesta 2003). Furthermore, plasma motions occur predominantly in the same direction as the magnetic field (Bellot Rubio et al. 2003). Thus, it is reasonable to assume that both the plasma flow and the magnetic field of opposite polarity are present in the lower atmospheric layer.
Figure 9 shows an atmospheric configuration similar to that of Solanki & Montavon (1993), which was modified in such a way that it yields 3LPs in penumbrae at disk center, panel a, and at larger heliocentric angles, panel b. We drew the magnetic field and the velocity of the plasma in the lower atmospheric layer, moving away from the observer, in red.
At disk center, the combination of penumbral downflows and magnetic fields of opposite polarity causes 3LPs in the outer penumbra (see panels c and e of Fig. 9). At larger heliocentric angles, projection effects have to be considered. For sunspots away from disk center, the horizontal Evershed outflow, which is present in the lower layers (Maltby 1964) of the penumbral intraspines (Lites et al. 1993; Ichimoto et al. 2007), causes a red-shift of the spectral line in the limb-side penumbra. While the more vertical magnetic field in the penumbral spines (Lites et al. 1993) still shows the same polarity as the umbra, the horizontal fields of the intraspines (Bellot Rubio et al. 2004) show reversed polarity at and beyond the magnetic neutral line. The combination of these two effects yields 3LPs and explains why they appear predominantly in the dark filaments of the limb-side penumbra (see Fig. 9 panels d and f and cf. also Sanchez Almeida & Lites 1992; Sánchez Almeida & Ichimoto 2009).
Center-to-limb variation of 3LPs:
so far, we have described only two different sunspots at disk center that were recorded individually by Hinode-SP and GRIS. To rule out that the resulting discrepancy of 3LPs in the visible and in the IR is due to selection bias, we performed a statistical analysis. We included 71 sunspot maps from the Hinode-SP and GRIS data archives, which were recorded at various heliocentric angles. From these data we computed the center-to-limb variation (CLV) of the penumbral area covered by 3LPs and RPPs. This allowed us to extrapolate the amount of 3LPs and RPPs to Θ = 0°, where the opposite polarity signal is exclusively due to the penumbral magnetic field returning into the Sun. The drawback of this procedure is that away from disk center, 3LPs and RPPs may be caused by projection effects and are not necessarily proxies of opposite polarities anymore. This has to be kept in mind when studying the CLV of the area coverage of penumbral 3LPs.
 |
Fig. 10 Center-to-limb variation of the amount of penumbral 3LPs (left) and RPPs (right). Results for Fe I 630.25 nm and Fe I 1566.2 nm are depicted in the top and bottom panels respectively. Each symbol represents a particular sunspot, followed during its disk passage. To extrapolate the values to disk center, we fit a third-order polynomial to the data points of 3LPs (solid black) and a straight line to the RPPs (dashed black). |
The top left panel of Fig. 10 shows the results for the Fe I 630.25 nm line observed by Hinode-SP. Each symbol represents the area coverage of 3LPs normalized to the area of the penumbra for one sunspot at various heliocentric positions. Different symbols represent the disk passage of different sunspots. For example, for AR 10923 (red crosses) we found 21% 3LPs at Θ = 9°, reaching a maximum of approximately 25% at Θ ≈ 20° before their amount gradually decreases to 1% at Θ = 75°. For all the spots in our survey, we found a similar behavior: from disk center to Θ ≈ 25°, we measured an increase of the amount of penumbral 3LPs before numbers decrease and vanish around Θ = 75°. To illustrate this relationship, we fit a third-order polynomial (solid black line in the top left panel of Fig. 10) to the measurements. The scatter of the individual values is fairly large, for instance, ± 5% at Θ ≈ 30°, which hampers correctly deduceing the dependence of the amount of 3LPs on Θ.
In the top right panel of Fig. 10 we plot the fractional area coverage of RPPs normalized to the penumbral area. For AR 10923 (red crosses), we found that the amount of RPPs depends almost linearly on the heliocentric angle. For Θ = 9° we found 6%, which gradually increases to 40% at Θ = 75°. The other sunspots showed a similar trend, which we visualized assuming a linear behavior (dashed black line in the top left panel of Fig. 10). Again, the individual scatter is significant, for instance, ± 10% for AR 10930 at Θ ≈ 40°. This explains why the small numbers of RPPs for Θ < 5° are not correctly modeled by the fit.
In the bottom left panel of Fig. 10, we plot the results of the Fe I 1566.2 nm line observed by GRIS. Again, each symbol represents the amount of penumbral 3LPs during its disk passage, while different symbols represent the different sunspots. The GRIS dataset covers fewer sunspots than the Hinode dataset, but contains more observations at disk center. We distinguish between a leading (AR 12049 l) and a following (AR 12049 f) spot. For the leading spot (orange squares), we found 3% 3LPs at Θ = 5°, a maximum of 15% at Θ ≈ 40°, and 2% at Θ = 75°. As before, we fit a third-order polynomial (solid black) to the dataset to visualize the trend in the IR data. This curve looks significantly different from the Fe I 630.25 nm data. It increases gradually, peaks at Θ = 45° before it drops more rapidly, vanishing at Θ = 75°. The maximum of the penumbral area occupied by 3LPs is 12% instead of 20% as measured in the Fe I 630.25 nm line at Θ ≈ 20°. The scatter here, i.e. ± 3% at Θ ≈ 20°, is slightly smaller than in the Hinode data.
In the bottom right panel of Fig. 10 we plot the penumbral area covered by RPPs in the GRIS data. For AR 12049 l (red crosses) we found 2% at Θ = 6° which increases to 50% at Θ = 75°. The other spots show a similar trend, which we visualized using a linear fit (dashed black line). Again, the small numbers of RPPs at disk center are not modeled correctly for Θ < 5°. The slope of the linear fit is slightly steeper than for the Hinode data, but it is important to note that there is no qualitative difference between the CLV curves of the amount of RPPs in Fe I 630.25 nm and Fe I 1566.2 nm.
The reasons for the variance of the data points in Fig. 10 are manifold. If the penumbra is asymmetric or only part of the spot was scanned (see Figs. B.1 and B.2), one side may appear larger than the other. This means that the fractional area covered by 3LPs is higher or lower, depending on whether the limb- or the center-side penumbra appears larger in the dataset. Furthermore, the Wilson depression results in a foreshortening of the center-side penumbra, causing a systematic increase in the amount of 3LPs and RPP. Sometimes the algorithm does not detect the boundaries of the penumbra accurately (see Fig. B.1), which diminishes the correct value of 3LPs. Finally there are magneto-optical effects, which manifest themselves as two additional lobes of opposite polarity around the zero crossing position of Stokes V profiles in Fe I 630.25 nm (see Fig. B.2). This leads to an incorrect detection of 3LPs in the inner penumbra of large sunspots with a strong magnetic field. A manual correction of these effects is not necessary because they do not change the overall picture and would be subjective.
5. Summary, conclusion, and outlook
We used observations of the infrared spectropolarimeter of GREGOR and of the spectropolarimeter onboard Hinode to investigate penumbral magnetic fields of opposite polarity at different atmospheric heights. For the infrared data, we determined the spectral PSF and estimated the influence of image rotation on the data quality. Additionally, we studied the spatial and spectral distribution of residual artifacts, that is, spectral fringes, which are not completely removed during the calibration process. We found that they have a peak-to-peak amplitude of approximately 1% in Stokes I but well below 10-3 in the polarimetric components. We concluded that these residual artifacts do not influence our results.
We compared in detail the morphology and fractional area covered by reversed-polarity Stokes V profiles (RPPs) and three-lobed Stokes V profiles (3LPs) in visible and IR spectral lines for sunspots close to disk center. The patches of RPPs have a roundish shape and are located in the outer penumbra. In the observation of visible spectral lines, they are about twice as frequent as in the IR observation. Regions with 3LPs appear roundish and are located in the middle and outer penumbra. In Fe I 630.25 nm, however, their size and frequency is up to one order of magnitude larger than in Fe I 1566.2 nm. In the data of the visible spectral lines, some patches appear elongated and are located in the center-side penumbra. This cannot be caused by projection effects and indicates true penumbral return flux. Such elongated features are absent from the IR data. From our observation, we found that magnetic fields of opposite polarity cover a significantly smaller fraction of the penumbra when observed in IR instead of visible lines.
We performed spectral inversion and forward synthesis on a typical 3LP in Fe I 630.25 nm and Fe I 1566.2 nm to verify that our algorithm is able to detect 3LPs in the Hinode-SP and GRIS data. We studied the center-to-limb variation of penumbral 3LPs and used a polynomial fit to extrapolate our results to Θ = 0°. We found that at disk center, 13.5% of the penumbra is covered with 3LPs for Fe I 630.25 nm, but only 1.5% for Fe I 1566.2 nm. For a given heliocentric angle, the morphology of the patches of penumbral 3LPs is similar in all of the spectral lines. For increasing Θ, their position shifts toward the limb-side penumbra, where they appear predominantly along the magnetic neutral line and follow the filamentary structure of dark penumbral filaments. These results demonstrate that the different findings in visible and IR data are not due to selection bias, but a systematic effect.
An explanation of the different numbers of RPP patches in the Hinode-SP and GRIS data seems possible within the framework of the following scenario: the downflows in the outer penumbra are typically associated with magnetic fields that are stronger than the penumbral background field (Tiwari et al. 2013; Franz & Schlichenmaier 2013). Such a flux concentration or flux tube causes evacuation, and spectral lines are formed deeper within that tube than outside of it. As a result of pressure balance and the stratification with height of the photosphere, the flux tube narrows with depth. The area showing RPPs is therefor expected to be smaller for lines which form deeper, that is, for the IR lines.
Asymmetric Stokes V profiles are commonly explained using a multilayer atmosphere with a strong gradient or discontinuity of the atmospheric parameters, especially the velocity, along the LOS (Auer & Heasley 1978; Landi Degl’Innocenti 1983). Such a configuration cannot only reproduce the observed net circular polarization, but also causes 3LPs if unequal plasma flows and magnetic fields of opposite polarity are present within the atmosphere (Borrero et al. 2004; Franz & Schlichenmaier 2013). A scenario with strong plasma flows and magnetic fields of opposite polarity in the lower atmospheric layer would also explain the asymmetric Stokes I profiles with the strongly shifted line wing. If the lines observed by Hinode form in a similar atmospheric region as the IR lines of GRIS, then we should measure a similar amount of penumbral 3LPs. This is not the case. If the Hinode lines form in such a way that they sense the gradient of the atmospheric parameters, while the GRIS lines, which form in a deeper and narrower layer, are not sensitive to the gradient, then we should expect more RPPs in the near-infrared lines. We found that this is not the case. To reproduce our findings, an atmosphere with opposite-polarity fields and downflows only in the higher layer would be required, at least in the context of the simple model discussed above. Such an atmospheric configuration seems unphysical and cannot explain the strong line shift in the wing of Stokes I profiles.
It should be noted that the low formation height of IR lines does not necessarily mean that they are equally well-suited for studying the atmospheric conditions of all physical parameters in the deep photosphere. Using an analytical model for the shape of spectral lines, Cabrera Solana et al. (2005) showed that the response of Fe I 1564.85 nm to velocity perturbation is weaker than of Fe I 630.25 nm. The occurrence of a 3LP requires plasma velocities in the deep line-formation layers. If Fe I 1564.85 nm is less sensitive to velocities, then the uncertainty in the determination of the third lobe in the Stokes V profile would increase and the number of detected 3LPs would decrease.
Unfortunately, it is not straightforward to apply these results to our investigation. The study of Cabrera Solana et al. (2005) investigated one atmospheric parameter at a time, while a 3LP requires combined plasma velocities and magnetic fields with various inclinations in different layers of the line-forming region of the atmosphere. Furthermore, the approximation of a spectral line with a Gaussian function encounters difficulties for asymmetric Stokes I profiles with strongly shifted line wings. Finally, the sensitivities of Fe I 1565.29 nm and Fe I 1566.20 nm to velocity perturbations were not studied by these authors. Especially the Fe I 1566.20 nm line, which has a higher line-depth to line-width shape ratio, should be more sensitive to velocities.
To improve the observational data base, we plan to perform coordinated observations of sunspots with Hinode, the GREGOR infrared spectrograph, and the GREGOR Fabry Perot Interferometer (GFPI, Puschmann et al. 2012, 2013). From such strictly simultaneous observations, information about the strength and inclination of the magnetic field at various atmospheric heights could be obtained. This would enable us to calculate numbers for the penumbral return flux throughout the atmosphere.
The amount of spatial stray light is another difference between the Hinode measurements and any ground-based observation. In the seeing-free environment of space, the spatial stray light is only influenced by the telescope and the instrument itself. Even then, a number of instruments display significant amounts of stray light going beyond the theoretical PSF, as deduced from a transit of Mercury for the Hinode Broadband Filter Imager (Wedemeyer-Böhm & Rouppe van der Voort 2009; Mathew et al. 2009), from limb profiles for the Michelson Doppler Imager (Mathew et al. 2007), or from a Venus transit for the Helioseismic and Magnetic Imager (Yeo et al. 2014). Danilovic et al. (2008) degraded magneto-hydrodynamic simulations with a theoretical PSF and found excellent agreement to observation of the spectropolarimeter onboard Hinode in terms of the root-mean-square contrast of the continuum intensity and its probability-density function (see Riethmüller et al. 2014, for an application of this strategy to Sunrise data). Lagg et al. (2016) used this method approximate the power outside the core of the PSF and to estimate the amount of spatial stray light in GRIS data. However, this technique does not allow determining the exact shape of the PSF, which is required for a deconvolution of the GRIS data prior to the analysis.
Borrero et al. (2016) approximated the PSF with two Gaussians. To obtain the required parameters, they used pinhole measurements and an average umbral Stokes I profile, where the magnetic field is oriented along the LOS. An umbral Fe I 1564.85 nm Stokes I profile should show only the σ-components of the transition, while any indication of π-component is ascribed to the influence of stray light. The drawback of this method is that the observations allow for a large number of parameters and do not yield a unique solution for the PSF.
In the future, we plan to synthesize the visible Hinode lines at 630.2 nm and the infrared lines of GREGOR around 1.55 μm from a magnetohydrodynamic sunspot simulation (see Rempel 2012; Borrero et al. 2014). Degrading these synthetic data spatially and spectrally with a number of theoretical PSFs provides another possibility of studying the influence of stray light on the detectable amount of RPPs and 3LPs in the penumbra. The PSF that yields the best match between degraded synthetic data and GRIS observation could be used to compensate for the influence of stray light.
Since the FTS atlas was recorded at the center of the solar disk, this process only works well for disk center maps. With increasing heliocentric angle, this procedure becomes less applicable.
The g-factor of only one level of the IR lines is known from laboratory measurements. The other is calculated assuming LS coupling.
This is due to various combinations of exposure time (30 ms to 100 ms) and number of accumulations (3 to 10).
Acknowledgments
We wish to thank J. C. del Toro Iniesta for valuable comments on the manuscript. The 1.5-m GREGOR solar telescope was built by a German consortium under the leadership of the Kiepenheuer Institut für Sonnenphysik in Freiburg with the Leibniz Institut für Astrophysik Potsdam, the Institut für Astrophysik Göttingen, and the Max-Planck Institut für Sonnensystemforschung in Göttingen as partners, and with contributions by the Instituto de Astrofśica de Canarias and the Astronomical Institute of the Academy of Sciences of the Czech Republic. The GRIS instrument was developed thanks to the support by the Spanish Ministry of Economy and Competitiveness through the project AYA2010-18029 (Solar Magnetism and Astrophysical Spectropolarimetry). Hinode is a Japanese mission developed and launched by ISAS/JAXA, with NAOJ as domestic partner and NASA and STFC (UK) as international partners. It is operated by these agencies in cooperation with ESA and NSC (Norway). NSO/Kitt Peak FTS data used here were produced by NSF/NOAO. This research has made use of NASA’s Astrophysics Data System.
References
- Allende Prieto, C., Asplund, M., & Fabiani Bendicho, P. 2004, A&A, 423, 1109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Auer, L. H., & Heasley, J. N. 1978, A&A, 64, 67 [NASA ADS] [Google Scholar]
- Bellot Rubio, L. R., Balthasar, H., Collados, M., & Schlichenmaier, R. 2003, A&A, 403, L47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bellot Rubio, L. R., Balthasar, H., & Collados, M. 2004, A&A, 427, 319 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Berkefeld, T., Schmidt, D., Soltau, D., von der Lühe, O., & Heidecke, F. 2012, Astron. Nachr., 333, 863 [NASA ADS] [CrossRef] [Google Scholar]
- Borrero, J. M., & Ichimoto, K. 2011, Liv. Rev. Sol. Phys., 8, 4 [Google Scholar]
- Borrero, J. M., Solanki, S. K., Bellot Rubio, L. R., Lagg, A., & Mathew, S. K. 2004, A&A, 422, 1093 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borrero, J. M., Lagg, A., Solanki, S. K., & Collados, M. 2005, A&A, 436, 333 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borrero, J. M., Lites, B. W., Lagg, A., Rezaei, R., & Rempel, M. 2014, A&A, 572, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borrero, J., Asensio Ramos, A., Collados, M., et al. 2016, A&A, 596, A2 (GREGOR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cabrera Solana, D., Bellot Rubio, L. R., & del Toro Iniesta, J. C. 2005, A&A, 439, 687 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cabrera Solana, D., Bellot Rubio, L. R., Beck, C., & Del Toro Iniesta, J. C. 2007, A&A, 475, 1067 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casini, R., de Wijn, A. G., & Judge, P. G. 2012, ApJ, 757, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Collados, M. 1999, in Third Advances in Solar Physics Euroconference: Magnetic Fields and Oscillations, eds. B. Schmieder, A. Hofmann, & J. Staude, ASP Conf. Ser., 184, 3 [Google Scholar]
- Collados, M., López, R., Páez, E., et al. 2012, Astron. Nachr., 333, 872 [NASA ADS] [CrossRef] [Google Scholar]
- Danilovic, S., Gandorfer, A., Lagg, A., et al. 2008, A&A, 484, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- del Toro Iniesta, J. C. 2003, Introduction to Spectropolarimetry (Cambridge, UK: Cambridge University Press), 244 [Google Scholar]
- del Toro Iniesta, J. C., Bellot Rubio, L. R., & Collados, M. 2001, ApJ, 549, L139 [NASA ADS] [CrossRef] [Google Scholar]
- Denker, C., von der Lühe, O., Feller, A., et al. 2012, Astron. Nachr., 333, 810 [NASA ADS] [CrossRef] [Google Scholar]
- Franz, M. 2011, Ph.D. Thesis, University of Freiburg, 176 [Google Scholar]
- Franz, M. 2012, Astron. Nachr., 333, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Franz, M., & Schlichenmaier, R. 2009, A&A, 508, 1453 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Franz, M., & Schlichenmaier, R. 2013, A&A, 550, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Giampapa, M. 1982, Spectrum in the NSO-FTS archive (N.S.O. Tech. Report 1982/05/16#05) [Google Scholar]
- Giampapa, M. 1983, Spectrum in the NSO-FTS archive (N.S.O. Tech. Report 1983/06/16#01) [Google Scholar]
- Grossmann-Doerth, U., Schuessler, M., & Solanki, S. K. 1989, A&A, 221, 338 [NASA ADS] [Google Scholar]
- Hofmann, A., Arlt, K., Balthasar, H., et al. 2012, Astron. Nachr., 333, 854 [NASA ADS] [CrossRef] [Google Scholar]
- Ichimoto, K., Shine, R. A., Lites, B., et al. 2007, PASJ, 59, S593 [NASA ADS] [Google Scholar]
- Illing, R. M. E., Landman, D. A., & Mickey, D. L. 1975, A&A, 41, 183 [NASA ADS] [Google Scholar]
- Katsukawa, Y., & Jurčák, J. 2010, A&A, 524, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lagg, A., Sami, K., Solanki, S. K., Doerr, H. P., et al. 2016, A&A, 596, A6 (GREGOR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Landi Degl’Innocenti, E., & Landolfi, M. 1983, Sol. Phys., 87, 221 [NASA ADS] [Google Scholar]
- Langhans, K., Scharmer, G. B., Kiselman, D., Löfdahl, M. G., & Berger, T. E. 2005, A&A, 436, 1087 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lites, B. W., & Ichimoto, K. 2013, Sol. Phys., 283, 601 [NASA ADS] [CrossRef] [Google Scholar]
- Lites, B. W., Elmore, D. F., Seagraves, P., & Skumanich, A. P. 1993, ApJ, 418, 928 [NASA ADS] [CrossRef] [Google Scholar]
- Lites, B. W., Elmore, D. F., & Streander, K. V. 2001, in Advanced Solar Polarimetry – Theory, Observation, and Instrumentation, ed. M. Sigwarth, ASP Conf. Ser., 236, 33 [Google Scholar]
- Lites, B. W., Akin, D. L., Card, G., et al. 2013, Sol. Phys., 283, 579 [NASA ADS] [CrossRef] [Google Scholar]
- Livingston, W. 1990, Spectrum in the NSO-FTS archive. (N.S.O. Tech. Report 1990/12/18#06) [Google Scholar]
- Livingston, W., & Wallace, L. 1991, An atlas of the solar spectrum in the infrared from 1850 to 9000 cm-1 (1.1 to 5.4 micrometer) (N.S.O. Tech. Report #91-001) [Google Scholar]
- Maltby, P. 1964, Astrophysica Norvegica, 8, 205 [NASA ADS] [Google Scholar]
- Mártinez Pillet, V., Collados, M., Sánchez Almeida, J., et al. 1999, in High Resolution Solar Physics: Theory, Observations, and Techniques, eds. T. R. Rimmele, K. S. Balasubramaniam, & R. R. Radick, ASP Conf. Ser., 183, 264 [Google Scholar]
- Mathew, S. K., Martínez Pillet, V., Solanki, S. K., & Krivova, N. A. 2007, A&A, 465, 291 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mathew, S. K., Zakharov, V., & Solanki, S. K. 2009, A&A, 501, L19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mihalas, D. 1978, Stellar atmospheres 2nd ed. (San Francisco: W. H. Freeman and Co), 650 [Google Scholar]
- Müller, D. A. N., Schlichenmaier, R., Steiner, O., & Stix, M. 2002, A&A, 393, 305 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nave, G., Johansson, S., Learner, R. C. M., Thorne, A. P., & Brault, J. W. 1994, ApJS, 94, 221 [NASA ADS] [CrossRef] [Google Scholar]
- Penn, M. J. 2014, Liv. Rev. Sol. Phys., 11, 2 [Google Scholar]
- Pesnell, W. D., Thompson, B. J., & Chamberlin, P. C. 2012, Sol. Phys., 275, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Puschmann, K. G., Denker, C., Kneer, F., et al. 2012, Astron. Nachr., 333, 880 [NASA ADS] [Google Scholar]
- Puschmann, K. G., Denker, C., Balthasar, H., et al. 2013, Opt. Eng., 52, 081606 [NASA ADS] [CrossRef] [Google Scholar]
- Ramsauer, J., Solanki, S. K., & Biemont, E. 1995, A&AS, 113, 71 [NASA ADS] [Google Scholar]
- Rempel, M. 2012, ApJ, 750, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Rempel, M., & Schlichenmaier, R. 2011, Liv. Rev. Sol. Phys., 8, 3 [Google Scholar]
- Riethmüller, T. L., Solanki, S. K., Berdyugina, S. V., et al. 2014, A&A, 568, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rojo, P. M., & Harrington, J. 2006, ApJ, 649, 553 [NASA ADS] [CrossRef] [Google Scholar]
- Ruiz Cobo, B., & Asensio Ramos, A. 2013, A&A, 549, L4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ruiz Cobo, B., & del Toro Iniesta, J. C. 1992, ApJ, 398, 375 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez Almeida, J., & Ichimoto, K. 2009, A&A, 508, 963 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanchez Almeida, J., & Lites, B. W. 1992, ApJ, 398, 359 [NASA ADS] [CrossRef] [Google Scholar]
- Scharmer, G. B., de la Cruz Rodriguez, J., Sütterlin, P., & Henriques, V. M. J. 2013, A&A, 553, A63 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schmidt, W., von der Lühe, O., Volkmer, R., et al. 2012, Astron. Nachr., 333, 796 [NASA ADS] [CrossRef] [Google Scholar]
- Schou, J., Scherrer, P. H., Bush, R. I., et al. 2012, Sol. Phys., 275, 229 [Google Scholar]
- Semel, M. 2003, A&A, 401, 1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Solanki, S. K. 2003, A&ARv, 11, 153 [Google Scholar]
- Solanki, S. K., & Montavon, C. A. P. 1993, A&A, 275, 283 [NASA ADS] [Google Scholar]
- Solanki, S. K., Pantellini, F. G. E., & Stenflo, J. O. 1987, Sol. Phys., 107, 57 [Google Scholar]
- Solanki, S. K., Rueedi, I. K., & Livingston, W. 1992, A&A, 263, 312 [NASA ADS] [Google Scholar]
- Solanki, S. K., Montavon, C. A. P., & Livingston, W. 1994, A&A, 283, 221 [NASA ADS] [Google Scholar]
- Spruit, H. C., & Scharmer, G. B. 2006, A&A, 447, 343 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tiwari, S. K., van Noort, M., Lagg, A., & Solanki, S. K. 2013, A&A, 557, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tiwari, S. K., van Noort, M., Solanki, S. K., & Lagg, A. 2015, A&A, 583, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tsuneta, S., Ichimoto, K., Katsukawa, Y., et al. 2008, Sol. Phys., 249, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Unsöld, A., & Baschek, B. 2002, Der neue Kosmos. Einführung in die Astronomie und Astrophysik (Berlin, Germany: Springer), 575 [Google Scholar]
- Volkmer, R., Eisenträger, P., Emde, P., et al. 2012, Astron. Nachr., 333, 816 [NASA ADS] [CrossRef] [Google Scholar]
- von der Lühe, O., Schmidt, W., Soltau, D., et al. 2001, Astron. Nachr., 322, 353 [NASA ADS] [CrossRef] [Google Scholar]
- Wallace, L., Hinkle, K., & Livingston, W. 2001, Sunspot umbral spectra in the region 4000 to 8640 cm(−1) (1.16 to 2.50 [microns]) (N.S.O. Tech. Report #01-001) [Google Scholar]
- Wedemeyer-Böhm, S., & Rouppe van der Voort, L. 2009, A&A, 503, 225 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Westendorp Plaza, C., del Toro Iniesta, J. C., Ruiz Cobo, B., et al. 1997, Nature, 389, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Westendorp Plaza, C., del Toro Iniesta, J. C., Ruiz Cobo, B., et al. 2001, ApJ, 547, 1130 [NASA ADS] [CrossRef] [Google Scholar]
- Yeo, K. L., Feller, A., Solanki, S. K., et al. 2014, A&A, 561, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: List of sunspots
Details of Hinode data.
Details of GRIS data.
Appendix B: Outliers in CLV curves
 |
Fig. B.1 NOAA AR 10923 on November 13, 2007 with 3LPs (red) and RPPs (blue). The penumbra is asymmetric with a larger limb-ward side. It also includes regions where a more detailed inspection shows that the algorithm incorrectly identified granular regions (black and white arrows) as part of the penumbra. The white arrow points toward the center of the solar disk. |
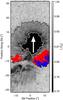 |
Fig. B.2 Leading spot of NOAA AR 12049 on April 30, 2014 was not scanned completely. The penumbra is asymmetric with a limb-ward part being detached from the sunspot. 3LPs and RPPs are indicated in red and blue. The white arrow points toward the center of the solar disk. |
 |
Fig. B.3 NOAA AR 10923 on November 14, 2007 with 3LPs (red) and RPPs (blue). Regular Stokes V profiles with a strong magneto-optical effect (inlay) that are incorrectly interpreted as 3LPs (yellow). The white arrow points toward the center of the solar disk. |
All Tables
Comparison of penumbral area showing RPPs and 3LPs together with the amount of total area showing opposite polarity as measured in visible and IR lines.
All Figures
|
Fig. 1 Panel a): an intensity image of NOAA 12049 recorded with GRIS close to disk center. White and gray contours outline the umbra and penumbra. Black contours encircle regions that are not taken into account in the calculation of an average QS profile. The white arrow points to the center of the solar disk. In panel b) we compare the average QS spectrum (black) with the FTS atlas (red). The regions shaded in gray are used in the analysis of the residual fringe pattern, see Sect. 3. Panel c): intensity variation in the continuum of the GRIS spectrum (black dots) and a polynomial fit (red) used for correction. |
| In the text | |
|
Fig. 2 Top panel: merit function that was used to determine the best values, i.e. FWHM and constant offset of a Gauss function, to model the PSF of GRIS. Bottom panel: three spectral lines that are used in this study (black crosses) overplotted with the same lines from the FTS atlas (red) after they were convolved with the spectral PSF of GRIS. |
| In the text | |
|
Fig. 3 Rotation rate of the solar image in the focal plane of GREGOR. It shows the rotation rate on the first day of each month throughout 2014. |
| In the text | |
|
Fig. 4 Stokes profiles of Fe 1564.85 nm (blue), Fe 1565.29 nm (green) and Fe 1566.20 nm (red) recorded with FTS and GRIS. Top row from left to right: Stokes I recorded with the FTS for the QS, a warm umbra and a medium warm umbra. Other rows from top to bottom: Stokes I normalized to the average QS, and Stokes Q, U and V in percent of the average continuum intensity. From left to right: Stokes vector from the QS, penumbra, umbra, and a region where the Stokes V profile shows three lobes. The Fe 1565.29 nm line is strongly blended by a hydroxyl radical line pair in the umbral example. The spectral regions used to estimate the noise in the polarimetric component are gray shaded in the lower left panel. The signal in the lower right panel is amplified by a factor of three and the spectral windows that are shifted across the spectrum to detect 3LPs are indicated in color. See main text for details. |
| In the text | |
|
Fig. 5 Spatial distribution of residual fringes. The figure shows the RMS fluctuations around the continuum intensity at λ = 1565.07 nm ± 0.8 nm in GRIS data. Contours outline umbra, penumbra, and some nearby concentrations of magnetic field. The white arrow points to the center of the solar disk. The horizontal (dashed red) and vertical (dashed blue) lines mark regions where we investigated the residual fringes along the slit (Fig. 6) and for different slit positions (not shown). |
| In the text | |
|
Fig. 6 Spectral distribution of residual fringes. The figure shows the difference between GRIS Stokes I spectra and the degraded FTS profile (red line) along the slit. The GRIS Stokes I spectra have been corrected for granular intensity variation. |
| In the text | |
|
Fig. 7 Distribution of three-lobed (red) and reversed-polarity (blue) Stokes V profiles in the penumbra. The left panel shows sunspot NOAA 10 933 recorded on January 5, 2007 with Hinode-SP at Θ ≈ 3°. The right panel shows NOAA 12 049 recorded on May 3, 2014 with GRIS at Θ ≈ 6° (right). The contours outline the penumbral boundaries and the black arrows point to the center of the solar disk. |
| In the text | |
|
Fig. 8 Shape of 3LP in visible and IR lines. A profile measured by Hinode-SP (black crosses) is drawn alongside the results of a SIR inversion (solid black). The corresponding model atmosphere is used to synthesize a profile in the IR at 1566.2 nm (solid red), which is shown together with the subsequently degraded profile as would be measured by GRIS (red triangles). For comparison, we show a 3LP from a GRIS observation (blue diamonds). |
| In the text | |
|
Fig. 9 Top: sketch of a simple atmospheric model capable of producing 3LPs in penumbrae at disk center (panel a)) and larger heliocentric angles (panel b)). B1, B2, v1 and v2 represent magnetic field strength and velocity in the lower and upper atmospheric layer. The LOS is parallel to the local vertical z at disk center and seen under the projection of Θ for increasing heliocentric angles. Middle: Hinode-SP intensity image of a sunspot at disk center (panel c)) and off center (panel d)). Regions with 3LPs are indicated in red, and regions with RPPs are shown in blue. Bottom: same as above, but for GRIS observations. The black and white contours indicate the penumbral boundaries, and the white arrow points to the center of the solar disk. |
| In the text | |
|
Fig. 10 Center-to-limb variation of the amount of penumbral 3LPs (left) and RPPs (right). Results for Fe I 630.25 nm and Fe I 1566.2 nm are depicted in the top and bottom panels respectively. Each symbol represents a particular sunspot, followed during its disk passage. To extrapolate the values to disk center, we fit a third-order polynomial to the data points of 3LPs (solid black) and a straight line to the RPPs (dashed black). |
| In the text | |
|
Fig. B.1 NOAA AR 10923 on November 13, 2007 with 3LPs (red) and RPPs (blue). The penumbra is asymmetric with a larger limb-ward side. It also includes regions where a more detailed inspection shows that the algorithm incorrectly identified granular regions (black and white arrows) as part of the penumbra. The white arrow points toward the center of the solar disk. |
| In the text | |
|
Fig. B.2 Leading spot of NOAA AR 12049 on April 30, 2014 was not scanned completely. The penumbra is asymmetric with a limb-ward part being detached from the sunspot. 3LPs and RPPs are indicated in red and blue. The white arrow points toward the center of the solar disk. |
| In the text | |
|
Fig. B.3 NOAA AR 10923 on November 14, 2007 with 3LPs (red) and RPPs (blue). Regular Stokes V profiles with a strong magneto-optical effect (inlay) that are incorrectly interpreted as 3LPs (yellow). The white arrow points toward the center of the solar disk. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.