| Issue |
A&A
Volume 593, September 2016
|
|
|---|---|---|
| Article Number | A88 | |
| Number of page(s) | 14 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201628565 | |
| Published online | 28 September 2016 | |
A new model to predict weak-lensing peak counts
III. Filtering technique comparisons
1 Service d’Astrophysique, CEA Saclay, Orme des Merisiers, Bât 709, 91191 Gif-sur-Yvette, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Sorbonne Université, UPMC Univ. Paris 6 et CNRS, UMR 7095, Institut d’Astrophysique de Paris, 98bis bd Arago 75014 Paris, France
Received: 21 March 2016
Accepted: 8 June 2016
Abstract
Context. This is the third in a series of papers that develop a new and flexible model to predict weak-lensing (WL) peak counts, which have been shown to be a very valuable non-Gaussian probe of cosmology.
Aims. In this paper, we compare the cosmological information extracted from WL peak counts using different filtering techniques of the galaxy shear data, including linear filtering with a Gaussian and two compensated filters (the starlet wavelet and the aperture mass), and the nonlinear filtering method MRLens. We present improvements to our model that account for realistic survey conditions, which are masks, shear-to-convergence transformations, and non-constant noise.
Methods. We create simulated peak counts from our stochastic model, from which we obtain constraints on the matter density Ωm, the power spectrum normalisation σ8, and the dark-energy parameter w0de. We use two methods for parameter inference, a copula likelihood, and approximate Bayesian computation (ABC). We measure the contour width in the Ωm-σ8 degeneracy direction and the figure of merit to compare parameter constraints from different filtering techniques.
Results. We find that starlet filtering outperforms the Gaussian kernel, and that including peak counts from different smoothing scales helps to lift parameter degeneracies. Peak counts from different smoothing scales with a compensated filter show very little cross-correlation, and adding information from different scales can therefore strongly enhance the available information. Measuring peak counts separately from different scales yields tighter constraints than using a combined peak histogram from a single map that includes multiscale information.
Conclusions. Our results suggest that a compensated filter function with counts included separately from different smoothing scales yields the tightest constraints on cosmological parameters from WL peaks.
Key words: gravitational lensing: weak / large-scale structure of Universe / methods: statistical
© ESO, 2016
1. Introduction
Without the need to assume any relationship between baryons and dark matter, weak gravitational lensing (WL) is directly sensitive to the total matter distribution. WL probes massive structures in the Universe on large scales, providing information about the late-time evolution of the matter, which helps analyzing the equation of state of dark energy.
Recently, CFHTLenS (Heymans et al. 2012; Van Waerbeke et al. 2013; Kilbinger et al. 2013; Erben et al. 2013; Fu et al. 2014, etc.) has shown that the third generation lensing surveys provide interesting results on cosmological constraints. While other surveys such as KiDS (Kuijken et al. 2015), DES (The Dark Energy Survey Collaboration 2015), and the Subaru Hyper-Suprime Cam (HSC) survey are expected to deliver results in coming years, cosmologists also look forward to reaching higher precision with more ambitious projects like Euclid, LSST, and WFIRST.
Several methods to extract information from WL exist. Until now, a great focus has been put on two-point statistics, for example the matter power spectrum. This is motivated by the fact that the matter spectrum can be well modeled by theory on large scales. However, due to complex gravitational interactions, the matter distribution becomes nonlinear and non-Gaussian on small scales. In this case, not only the theoretical spectrum needs to be corrected (Makino et al. 1992; Bernardeau et al. 2002; Baumann et al. 2012; Carrasco et al. 2012), but also the rich non-Gaussian information is discarded. For these reasons, including non-Gaussian observables complementary to the power spectrum strongly enhances weak lensing studies.
A suitable candidate for extracting non-Gaussian information is WL peak counts. These local maxima of projected mass density trace massive regions in the Universe, and are thus a probe of the halo mass function. According to Liu et al. (2015a), it turns out that peak counts alone constrain cosmology better than the power spectrum, implying the importance of non-Gaussian observables. This strengthens the motivation for peak-count studies.
Previous analyses on peaks can be divided into two categories. The first category is concerned with cluster-oriented purposes. Motivated to search for galaxy clusters using WL, these studies (e.g. White et al. 2002; Hamana et al. 2004, 2012, 2015; Hennawi & Spergel 2005; Schirmer et al. 2007; Gavazzi & Soucail 2007; Abate et al. 2009) focus on very high peaks, in general with signal-to-noise ratio (S/N) larger than four, and study purity, completeness, positional offsets, the mass-concentration relation, etc. A cross-check with galaxy clusters is often done. On the other hand, the second category, which concerns cosmology-oriented purposes, focuses on peaks with a wider range of S/N (≳1). Peaks from this range can not necessarily be identified with massive clusters. They can also arise from large-scale structure projections, be spurious signals, or a mixture of all of these cases. Studies for this purpose model true and spurious peaks together and constrain cosmology. This second purpose is the focus of this paper.
For cosmology-oriented purposes, correctly predicting the total peak counts is essential. Until now, three methods have been proposed: analytical models (Maturi et al. 2010, 2011; Fan et al. 2010; Liu et al.2014b, 2015b), modeling using N-body simulations (Wang et al. 2009; Marian et al. 2009, 2010, 2011, 2012, 2013; Dietrich & Hartlap 2010; Kratochvil et al. 2010; Yang et al. 2011, 2013; Bard et al. 2013; Liu et al.2014a, 2015a; Martinet et al. 2015), and fast stochastic forward modeling (Lin & Kilbinger 2015a,b). While analytical models struggle when confronted by observational effects, N-body simulations are very costly for parameter constraints. Motivated by these drawbacks, Lin & Kilbinger (2015a, hereafter Paper I proposed a new model to predict WL peak counts, which is both fast and flexible. It has been shown that the new model agrees well with N-body simulations.
In WL, the convergence, which is interpreted as the projected mass, is not directly observable, while the (reduced) shear is. To reconstruct the mass, a common way is to invert the relation between convergence and shear (Kaiser & Squires 1993; Seitz & Schneider 1995). Then, to reduce the shape noise level, inverted maps are usually smoothed with a Gaussian kernel. However, inversion techniques create artefacts and modify the noise spectrum in realistic conditions. An alternative is to use the aperture mass (Kaiser et al. 1994), which applies a linear filter directly on the shear field. This is equivalent to filter the convergence with a compensated kernel.
Besides, there also exists various nonlinear reconstruction techniques. For example, Bartelmann et al. (1996) proposed to minimize the error on shear and magnification together. Other techniques are sparsity-based methods such as MRLens (Starck et al. 2006), FASTLens (Pires et al. 2009b), and Glimpse (Leonard et al. 2014). These approaches aim to map the projected mass through a minimization process.
Among these different filtering methods, some studies for optimal peak selection, such as Maturi et al. (2005) and Hennawi & Spergel (2005), have been made. These methods are optimal in different senses. On the one hand, Maturi et al. (2005) modeled large-scale structures as noise with respect to clusters. Following this reasoning, given a halo density profile on a given scale, they obtained the ideal shape for the smoothing kernel. On the other hand, Hennawi & Spergel (2005) constructed a tomographic matched filter algorithm. Given a kernel shape, this algorithm was able to determine the most probable position and redshift of presumed clusters. Actually, these two studies display two different strategies for dealing with multiple scales. The separated strategy (followed implicitly by Maturi et al. 2005, 2010; see also Liu et al.2015a) applies a series of filters at different scales. Cosmological constraints are then derived by combining the peak abundance information obtained in each filtered WL map. In the combined strategy (followed e.g. by Hennawi & Spergel 2005; Marian et al. 2012), sometimes called mass mapping, the significance from different scales are combined into a single filtered map from which we estimate peak abundance and derive constraints.
Up to now, the question of optimal filtering for cosmology-oriented purposes remains unsolved. For cluster-oriented purposes, the comparison is usually based on purity and completeness (Hennawi & Spergel 2005; Pires et al. 2012; Leonard et al. 2014). However, for cosmology-oriented purposes, since we are interested in constraining cosmological parameters, we should focus on indicators like the Fisher matrix, the figure of merit (FoM), etc. So far, no study has compared filtering techniques with regard to these indicators. This will be the approach that we adopt here for comparison.
In this paper, we address the following questions:
-
For a given kernel shape, with the separated strategy, what are thepreferable characteristic scales?
-
Which can extract more cosmological information, the compensated or non-compensated filters?
-
Which can extract more cosmological information, the separated or combined strategy?
-
How do nonlinear filters perform?
To obtain the constraints, we use two statistical techniques: the copula likelihood and approximate Bayesian computation (ABC). To perform the comparison, we use two indicators to measure the tightness of constraints. An example for this methodology has been shown by Lin & Kilbinger (2015b, hereafter Paper II, on the comparison between different definitions of data vector.
Compared to Paper I and Paper II, this study improves the model to account for more realistic observational features. We apply a redshift distribution for source galaxies, include masks, construct the convergence κ from the reduced shear instead of computing κ directly, test different filters, determine the noise level locally, and include the equation of state of dark energy for the constraints.
The paper is structured as follows. We begin with theoretical basics in Sect. 2. Then, we introduce the different filters used in this study in Sect. 3. In Sect. 4, we describe the methodology adopted in this study. In Sect. 5, we show our results both from the likelihood and ABC. And finally, a discussion is presented in Sect. 6.
2. Theoretical basics
2.1. Mass function
The halo mass function indicates the population of dark matter halos, depending on mass M and redshift z. This variation is usually characterized by the quantity f(σ) varying with regard to the density contrast dispersion of the matter field σ(z,M). Defining n(z,<M) as the halo number density at z with mass less than M, the function f is defined as 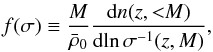 (1)where
(1)where 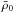 is the background matter density at the current time. The quantity σ(z,M) ≡ D(z)σ(M) can be furthermore defined as the product of the growth factor D(z) and σ(M), the dispersion of the smoothed matter field with a top-hat sphere of radius R such that
is the background matter density at the current time. The quantity σ(z,M) ≡ D(z)σ(M) can be furthermore defined as the product of the growth factor D(z) and σ(M), the dispersion of the smoothed matter field with a top-hat sphere of radius R such that 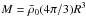 .
.
Several mass function models have been proposed (Press & Schechter 1974; Sheth & Tormen 1999, 2002; Jenkins et al. 2001; Warren et al. 2006; Tinker et al. 2008; Bhattacharya et al. 2011). Throughout this paper, we assume the universality of the mass function and adopt the model from Jenkins et al. (2001), which gives 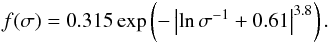 (2)
(2)
2.2. Halo density profiles
We assume in this work that halos follow Navarro-Frenk-White (NFW) density profiles (Navarro et al. 1996, 1997). The truncated version of these profiles is defined as 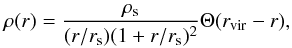 (3)where Θ is the Heaviside step function. The NFW profiles are parameterized by two numbers: the central mass density ρs and the scalar radius rs. Depending on the convention, these two quantities can have different definitions. A universal way to express them is as follows:
(3)where Θ is the Heaviside step function. The NFW profiles are parameterized by two numbers: the central mass density ρs and the scalar radius rs. Depending on the convention, these two quantities can have different definitions. A universal way to express them is as follows: 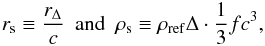 (4)where c is the concentration parameter and
(4)where c is the concentration parameter and 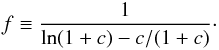 (5)Here, ρref is the reference density, which may be the current critical density ρcrit,0, the critical density at z: ρcrit(z), the current background density , or the background density at z:
(5)Here, ρref is the reference density, which may be the current critical density ρcrit,0, the critical density at z: ρcrit(z), the current background density , or the background density at z: 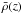 . The factor Δ is the virial threshold above which halos are considered bound, which means that
. The factor Δ is the virial threshold above which halos are considered bound, which means that 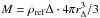 . This may be a redshift-dependent formula Δvir(z), or a constant such as 200 or 500. In this paper, we adopt the definitions below:
. This may be a redshift-dependent formula Δvir(z), or a constant such as 200 or 500. In this paper, we adopt the definitions below:  where rvir is the physical virial radius and Δvir(z) is a fitting function for a wCDM model, taken from Eqs. (16) and (17) from Weinberg & Kamionkowski (2003).
where rvir is the physical virial radius and Δvir(z) is a fitting function for a wCDM model, taken from Eqs. (16) and (17) from Weinberg & Kamionkowski (2003).
The concentration parameter c is redshift- and mass-dependent (Bullock et al. 2001; Bartelmann et al. 2002; Dolag et al. 2004). We use the expression proposed by Takada & Jain (2002), which leads to 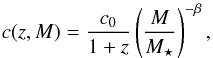 (8)where the pivot mass M⋆ satisfies the condition δc(z = 0) = σ(M⋆), where δc is the critical threshold for the spherical collapse model, given by Eq. (18) from Weinberg & Kamionkowski (2003).
(8)where the pivot mass M⋆ satisfies the condition δc(z = 0) = σ(M⋆), where δc is the critical threshold for the spherical collapse model, given by Eq. (18) from Weinberg & Kamionkowski (2003).
2.3. Weak gravitational lensing
Consider a source to which the comoving radial distance from the observer is w. From the Newtonian potential φ, one can derive the lensing potential ψ, following (see, e.g., Schneider et al. 1998) 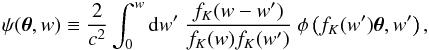 (9)where θ is the coordinates of the line of sight, fK the comoving transverse distance, and c light speed. At the linear order, the lensing distortion is characterized by two quantities, the convergence κ and the shear γ1 + iγ2, given by the second derivatives of ψ:
(9)where θ is the coordinates of the line of sight, fK the comoving transverse distance, and c light speed. At the linear order, the lensing distortion is characterized by two quantities, the convergence κ and the shear γ1 + iγ2, given by the second derivatives of ψ:  In other words, the linear distortion matrix
In other words, the linear distortion matrix 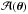 , defined as
, defined as 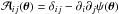 where δij is the Kronecker delta, can be parametrized as
where δij is the Kronecker delta, can be parametrized as 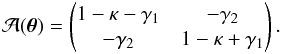 (13)Furthermore, the Newtonian potential is related to the matter density contrast δ via Poisson’s equation in comoving coordinates:
(13)Furthermore, the Newtonian potential is related to the matter density contrast δ via Poisson’s equation in comoving coordinates: 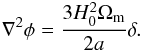 (14)This provides an explicit expression of κ as
(14)This provides an explicit expression of κ as 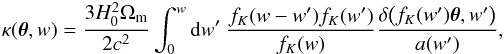 (15)where H0 is the Hubble parameter, Ωm the matter density, and a(w′) the scale factor at the epoch to which the comoving distance from now is w′.
(15)where H0 is the Hubble parameter, Ωm the matter density, and a(w′) the scale factor at the epoch to which the comoving distance from now is w′.
The lensing signal contribution from halos with truncated NFW profiles is known. Defining θs = rs/Dℓ as the ratio of the scalar radius to the angular diameter distance of the lens, if the density of the region not occupied by halos is assumed to be identical to the background, the convergence and the shear are given by computing the projected mass, which leads to 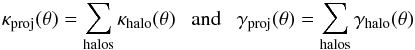 (16)with
(16)with 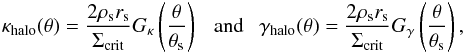 (17)where rs and ρs are respectively given by Eqs. (6)and (7), θ is the angular separation between the source and the center of the halo, and Σcrit ≡ (c2/ 4πG)(Ds/DℓDℓs) with G the gravitational constant, Ds the angular diameter distance of the source, and Dℓs the angular diameter distance between the lens and the source. The dimensionless functions Gκ and Gγ are provided by Takada & Jain (2003a,b). For computational reasons, it is useful to write
(17)where rs and ρs are respectively given by Eqs. (6)and (7), θ is the angular separation between the source and the center of the halo, and Σcrit ≡ (c2/ 4πG)(Ds/DℓDℓs) with G the gravitational constant, Ds the angular diameter distance of the source, and Dℓs the angular diameter distance between the lens and the source. The dimensionless functions Gκ and Gγ are provided by Takada & Jain (2003a,b). For computational reasons, it is useful to write 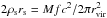 , which can be obtained from Eqs. (6)and (7).
, which can be obtained from Eqs. (6)and (7).
2.4. Local noise level
In principle, the intrinsic ellipticity of galaxies can not be measured directly. We assume that both components of the ellipticity ϵ = ϵ1 + iϵ2 follow the same Gaussian distribution, such that its norm precisely follows a Rayleigh distribution. Since the ellipticity is bound by ±1, both distributions are truncated. We note 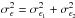 as the sum of the variances of both components. In this case, the noise for the smoothed convergence is also Gaussian, and its variance is given by (see e.g. Van Waerbeke 2000)
as the sum of the variances of both components. In this case, the noise for the smoothed convergence is also Gaussian, and its variance is given by (see e.g. Van Waerbeke 2000) 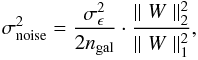 (18)where ngal is the galaxy number density and ∥ W ∥ p stands for the p-norm of W which is the smoothing kernel. The kernel does not need to be normalized because of the denominator in Eq. (18). For example, if W is Gaussian with width θker,
(18)where ngal is the galaxy number density and ∥ W ∥ p stands for the p-norm of W which is the smoothing kernel. The kernel does not need to be normalized because of the denominator in Eq. (18). For example, if W is Gaussian with width θker, 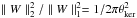 . For the starlet (see Sect. 3),
. For the starlet (see Sect. 3), 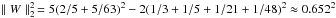 can be solved analytically.
can be solved analytically.
However, Eq. (18) is the global noise level, which implies that sources are distributed regularly. In realistic conditions, random fluctuations, mask effects, and clustering of source galaxies can all lead to irregular distributions, which results in a non-constant noise level. To properly take this into account, we define the variance of the local noise as 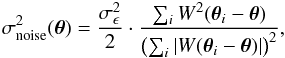 (19)where θi is the position of the ith galaxy, and i runs over all (non-masked) galaxies under the kernel W. Equation (19)is also valid for the aperture mass (see next section), by replacing W with Q (Schneider 1996).
(19)where θi is the position of the ith galaxy, and i runs over all (non-masked) galaxies under the kernel W. Equation (19)is also valid for the aperture mass (see next section), by replacing W with Q (Schneider 1996).
3. Filtering
3.1. Linear filters
In this work, we vary the filtering technique and study its impact on peak counts. Here, we present the linear filters W used in this study. The description of the nonlinear technique can be found in Sect. 3.2.3. Let θker the size of the kernel and x = θ/θker. Then, the Gaussian smoothing kernel can be simply written as 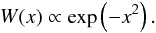 (20)The second kernel that we study is the 2D starlet function (Starck et al. 2002). It is defined as
(20)The second kernel that we study is the 2D starlet function (Starck et al. 2002). It is defined as 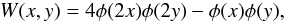 (21)where φ is the B-spline of order 3, given by
(21)where φ is the B-spline of order 3, given by 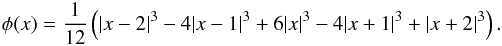 (22)Because of the property the B-spline, the starlet is a compensated function with compact support in [− 2,2] × [ − 2,2]. It does not conserve circular symmetry, but its isolines tend to be round. Since the starlet is compensated, it is similar to the U function of the aperture mass, which is the last linear case that we consider.
(22)Because of the property the B-spline, the starlet is a compensated function with compact support in [− 2,2] × [ − 2,2]. It does not conserve circular symmetry, but its isolines tend to be round. Since the starlet is compensated, it is similar to the U function of the aperture mass, which is the last linear case that we consider.
The aperture mass Map can be obtained from all pairs of filters (U,Q) such that (1) U is circularly symmetric; (2) U is a compensated function; and (3) filtering the convergence field with U is equivalent to applying Q to the tangential shear γt(θ = θeiϕ) ≡ − γ1cos(2ϕ) − γ2sin(2ϕ), where ϕ is the complex angle of the source position with regard to the kernel center. With these conditions, convolving γt with Q results in a filtered convergence map that is not affected by the mass-sheet degeneracy and the inversion problem.
To satisfy the third condition, Q has to be related to U by 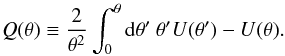 (23)In this case, Map is given by
(23)In this case, Map is given by 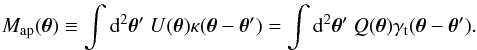 (24)Here, we are particularly interested in the Q function proposed by Schirmer et al. (2004) and Hetterscheidt et al. (2005), given by
(24)Here, we are particularly interested in the Q function proposed by Schirmer et al. (2004) and Hetterscheidt et al. (2005), given by 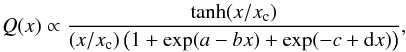 (25)with a = 6, b = 150, c = 47, d = 50 to have a cutoff around x = 1. This filter shape has been motivated by the tangential shear pattern generated by NFW halo profiles. Also, we set xc = 0.1 as suggested by Hetterscheidt et al. (2005). Note that x = θ/θker is the distance to the center of the filter normalized by the kernel’s size.
(25)with a = 6, b = 150, c = 47, d = 50 to have a cutoff around x = 1. This filter shape has been motivated by the tangential shear pattern generated by NFW halo profiles. Also, we set xc = 0.1 as suggested by Hetterscheidt et al. (2005). Note that x = θ/θker is the distance to the center of the filter normalized by the kernel’s size.
3.2. A sparsity-based nonlinear filter
In this section, we introduce a nonlinear filtering technique using the sparsity of signals.
3.2.1. Sparse representation
In signal processing, a signal is sparse in a specific representation if most of the information is contained in only a few coefficients. This means that either only a finite number of coefficients is non zero, or the coefficients decrease fast when rank-ordered.
A straightforward example is the family of sine functions. In the real space, sine functions are not sparse. However, they are sparse in the Fourier space since they become the Dirac delta functions. More generally, periodic signals are sparse in the Fourier space.
Why is this interesting? Because white noise is not sparse in any representation. Therefore, if the information of the signal can be compressed into a few strong coefficients, it can easily be separated from the noise. This concept of sparsity has been widely used in the signal processing domain for applications such as denoising, inpainting, deconvolution, inverse problem, or other optimization problems (Daubechies et al. 2004; Candes & Tao 2006; Elad & Aharon 2006; Candès et al. 2008; Fadili et al. 2009). Examples can also be found for studying astophysical signals (Lambert et al. 2006; Pires et al. 2009b; Bourguignon et al. 2011; Carrillo et al. 2012; Bobin et al. 2014; Ngolè Mboula et al. 2015; Lanusse et al. 2016).
3.2.2. Wavelet transform
From the previous section, one can see that the sparsity of a signal depends on its representation basis. In which basis is the weak lensing signal sparse? A promising candidate is the wavelet transform which decomposes the signal into a family of scaled and translated functions. Wavelet functions are all functions ψ which satisfy the admissibility condition: 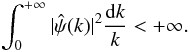 (26)One of the properties implied by this condition is ∫ψ(x)dx = 0, which restricts ψ to a compensated function. In other words, one can consider wavelet functions as highly localized functions with a zero mean. Such a function ψ is called the mother wavelet, which can generate a family of daughter wavelets such as
(26)One of the properties implied by this condition is ∫ψ(x)dx = 0, which restricts ψ to a compensated function. In other words, one can consider wavelet functions as highly localized functions with a zero mean. Such a function ψ is called the mother wavelet, which can generate a family of daughter wavelets such as 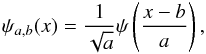 (27)which are scaled and translated versions of the mother ψ.
(27)which are scaled and translated versions of the mother ψ.
 |
Fig. 1 Left panel: profile of the 2D starlet. It has a finite support [–2, 2]. Right panel: bird-eye view of the 2D starlet. |
The wavelet transform (see e.g. Chaps. 2 and 3 of Starck et al. 2002) refers to the decomposition of an input image into several ones of the same size each associated to a specific scale. Due to the property of wavelet functions, each resulting image gives the details of the original one at different scales. If we stack all the images, we recover the original signal.
In the peak-count scenario, peaks which are generated by massive clusters are considered as signals. Like clusters, these signals are local point-like features, and therefore have a sparse representation in the wavelet domain. As described in Sect. 3.2.1, white noise is not sparse. So one simple way to reduce the noise is to transform the input image into the wavelet domain, set a relatively high threshold λ, cut out weak coefficients smaller than λ, and reconstruct the clean image by stacking the thresholded images. In this paper, we use the 2D starlet function as the mother wavelet, given by Eq. (21), which satisfies the admissibility condition. As shown by Fig. 1, it highlights round features as we assume for dark matter halos.
3.2.3. The MRLens filter
In this study, we apply the nonlinear filtering technique MultiResolution tools for gravitational Lensing (MRLens, Starck et al. 2006) to lensing maps. MRLens is an iterative filtering based on Bayesian framework that uses a multiscale entropy prior and the false discovery rate (FDR, Benjamini & Hochberg 1995) which allows to derive robust detection levels in wavelet space.
More precisely, MRLens first applies a wavelet transform to a noisy map. Then, in the wavelet domain, it determines the threshold by FDR. The denoising problem is regularized using a multiscale entropy prior only on the non-significant wavelet coefficients. Readers are welcome to read Starck et al. (2006) for a detailed description of the method.
Note that, whereas Pires et al. (2009a) selected peaks from different scales separately before final reconstruction, in this paper, we count peaks on the final reconstructed map. In fact, the methodology of Pires et al. (2009a) is close to filtering with a lower cutoff in the histogram defined by FDR, thus similar to starlet filtering. With the vocabulary defined in Sect. 1, Pires et al. (2009a) followed the separated strategy and here we attempt the combined strategy. This choice provides a comparison between cosmological information extracted with two strategies, by comparing starlet filtering to the MRLens case.
4. Methodology
In this section, we review our peak count model, and detail the improvements Papers I and II that we introduce here.
4.1. General concept of our model
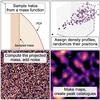 |
Fig. 2 Illustration of our model in four panels. |
In Paper I and II, we proposed a fast stochastic model for predicting weak lensing peak counts. The general concept is to bypass the complex and time-consuming N-body process. Our model generates “fast simulations” based on halo sampling, and counts peaks from lensing maps obtained from these simulation boxes, as illustrated in Fig. 2.
To achieve this, we made two major assumptions. First, diffuse matter was considered to contribute little to peak counts. Second, we supposed that halo correlation had a minor impact. In Paper I, we found that neither of them can be neglected alone. However, combining these two assumptions yielded a good approximation for the peak count prediction.
The advantages provided by our model can be characterized by three properties: they are fast, flexible, and they provide the full PDF information. First, sampling from the mass function is very efficient. It requires about ten seconds for creating a 36-deg2 field on a single-CPU computer. Second, our model is flexible because survey-related properties, such as masking and realistic photo-z errors, can be included in a straightforward way thanks to its forward nature. Third, because of the stochasticity, the PDF of the observables is available. As we showed in Paper II, this PDF information allows us not only to estimate the covariance matrix, but also to use other more sophisticated inference methods, such as approximate Bayesian computation.
Our model has been implemented in the language C as the software Camelus, which is available on GitHub1.
4.2. Settings for the pipeline: from the mass function to peak catalogs
In this section, we explain in detail how peak counts are generated from an initial cosmological model. We first sampled halos from Eq. (2). The sampling range was set to M = [5 × 1012, 1017] M⊙/h. This was done for 30 equal redshift bins from 0 to 3, on a field adequately larger than 36 deg2 so that border effects were properly eliminated. For each bin, we estimated the volume of the slice, the mass contained in the volume and in the sampling range, such that the total mass of the samples corresponded to this value. Then, these halos were placed randomly and associated with truncated NFW profiles using Eq. (3), where the mass-concentration relation was given by Eq. (8). We note that studying the impact of the mass function modeling or profile modeling with our model is possible. Nevertheless, this is not the aim of this paper.
We extended our model from Papers I and II to include realistic observing properties as follows. First, we considered a realistic redshift distribution of sources for the analysis. We assumed a gamma distribution following Efstathiou et al. (1991)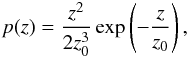 (28)where z0 = 0.5 is the pivot redshift value. The positions of sources were random. We set the source number density to ngal = 12 ′-2, which corresponded to a CFHTLenS-like survey (Heymans et al. 2012). The intrinsic ellipticity dispersion was σϵ = 0.4, which is also close to the CFHTLenS survey (Kilbinger et al. 2013).
(28)where z0 = 0.5 is the pivot redshift value. The positions of sources were random. We set the source number density to ngal = 12 ′-2, which corresponded to a CFHTLenS-like survey (Heymans et al. 2012). The intrinsic ellipticity dispersion was σϵ = 0.4, which is also close to the CFHTLenS survey (Kilbinger et al. 2013).
Second, we considered masks in our model. We applied the same characteristic mask to each of the realizations of our model. This mask was taken from the W1 field of CFHTLenS.
For each galaxy, we computed κproj and γproj using Eqs. (16)and (17). However, as we already evoked in Paper I, κproj can not be considered as the true convergence since it is always positive. In fact, Eq. (16) can be derived from Eq. (15) by replacing the density contrast δ with 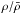 , thus it becomes positive. To handle this difference, we subtracted the mean of the field
, thus it becomes positive. To handle this difference, we subtracted the mean of the field 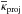 from κproj. This subtraction is supported by N-body simulations. For example, for simulations used in Paper I, we found
from κproj. This subtraction is supported by N-body simulations. For example, for simulations used in Paper I, we found 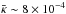 , that implied that the mean almost vanished. Finally, we computed the observed ellipticity as ϵ(o) = gproj + ϵ(s), where
, that implied that the mean almost vanished. Finally, we computed the observed ellipticity as ϵ(o) = gproj + ϵ(s), where 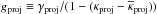 is the reduced shear and ϵ(s) is the intrinsic ellipticity.
is the reduced shear and ϵ(s) is the intrinsic ellipticity.
Comparing different mass mapping techniques is the subject of this study. We tested the Gaussian kernel, the starlet function, the aperture mass with the hyperbolic tangent function, and the nonlinear filtering technique MRLens in our model. Except for the aperture mass, we first binned galaxies into map pixels and took the mean of ϵ(o) as the pixel’s value for the reason of efficiency. The pixel size was 0.8 arcmin. This resulted in regularly spaced data so that the algorithm can be accelerated. Then, the Kaiser-Squires inversion (KS inversion, Kaiser & Squires 1993) was used before filtering. We did not correct for the reduced shear, for example by iteratively using the KS inversion, since the linear inversion conserves the original noise spectrum and produces less artefacts. By applying exactly the same processing to both observation and model prediction, we expect the systematics related to inversion (e.g., boundary effects, missing data, and negative mass density) to be similar so that the comparison is unbiased. For the aperture mass, the pixel’s value was evaluated by convolving directly the lensing catalog with the Q filter (Eq. (24)), successively placed at the center of each pixel (see also Marian et al. 2012; Martinet et al. 2015). The choice of filter sizes is detailed in Sect. 4.3.
Because of the presence of masks, we selected peaks based on the concept of the filling factor f(θ) (Van Waerbeke et al. 2013; Liu et al.2015b). A local maximum was selected as a peak only if 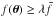 , where
, where 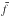 is the mean of f over the map. We set λ = 0.5. For analyses using binning, the filling factor was simply defined as the number of galaxies N(θ) inside the pixel at θ. For the aperture mass, it was the Q-weighted sum of the number counts. In other words,
is the mean of f over the map. We set λ = 0.5. For analyses using binning, the filling factor was simply defined as the number of galaxies N(θ) inside the pixel at θ. For the aperture mass, it was the Q-weighted sum of the number counts. In other words, 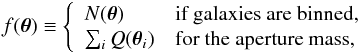 (29)where θi is the position of the ith galaxy.
(29)where θi is the position of the ith galaxy.
Furthermore, peaks were selected based on their local noise level. For linear filters (the Gaussian, the starlet, the aperture mass), the local noise level was determined by Eq. (19). The height of peaks ν was then defined as the S/N by 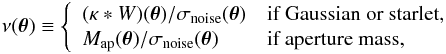 (30)where ∗ is the convolution operator. However, for the nonlinear technique, the noise after filtering is not Gaussian anymore. The so-called noise level cannot be properly defined. In this case, we simply selected peaks on κ.
(30)where ∗ is the convolution operator. However, for the nonlinear technique, the noise after filtering is not Gaussian anymore. The so-called noise level cannot be properly defined. In this case, we simply selected peaks on κ.
Kernel sizes θker.
4.3. Settings for filters and data vectors
The aim of this paper is to compare the performance of linear and nonlinear filters for peak counts. The linear filters were parametrized with a single parameter, which is the size of the kernel θker. We proposed two possible solutions for comparing between kernels of different shape. The first was to choose θker such that the 2-norms have the same value if kernels are normalized (by their respective 1-norms). The reason for this is that if the ratio of the 2-norm to the 1-norm is identical, then the comparison is based on the same global noise level (Eq. (18)). Table 1 shows various values of θker that we used in this studies and the corresponding σnoise for different linear filters. The second way was to calculate peak-count histograms, and set θker such that peak abundance was similar. Figure 3 shows an example for the Gaussian and starlet kernels with θker taken from Table 1. We observe that, for Gaussian filtering with θker = 1.2, 2.4, and 4.8 arcmin, the correspondence for starlet filtering based on peak abundance is θker = 4, 8, and 16 arcmin if we focus on peaks with 2.5 ≤ ν ≤ 4.5, while the correspondence based on the noise level is θker = 2, 4, and 8 arcmin. In Sect. 5.1, we will examine both comparison methods.
The data vector x, for linear filters, was defined as the concatenation of several S/N histograms. In Paper II, we have found that the number counts from histograms are the most appropriate form to derive cosmological information from peak counts. After testing several values of νmin, we only kept peaks above νmin = 1 for each kernel size. This choice maximized the figure of merit of parameter constraints. Thus, we reconfirm that ignoring peaks with ν ≤ 3 corresponds to a loss of cosmological information (Yang et al. 2013). Peaks were then binned with width of Δν = 0.5 up to ν = 5, and the last bin was [5, + ∞ [ for each scale. For each x, the effective field size from which peaks were selected was 6 × 6 deg2. Border effects were mitigated by taking adequately larger fields for halos and galaxies. The pixel size was 0.8 arcmin, so a map contained 450 × 450 pixels.
For the nonlinear filter, the notion of noise level does not easily apply. In fact, to determine the significance of a rare event from any distribution, instead of using the emperical standard deviation, it is more rigourous to obtain first the p-value and find how much σ this value is associated with if the distribution was Gaussian. However, even if we compute the standard deviation instead, this process is still too expensive computationally for our purpose. Therefore, we bin peaks directly by their κ values into [0.02, 0.03, 0.04, 0.06, 0.10, 0.16, + ∞[. This configuration was chosen such that the average count per bin is large enough to assume a Gaussian fluctuation.
 |
Fig. 3 Peak function for different kernel sizes for an input cosmology |
4.4. Sampling in the parameter space
In this paper, we considered a three-dimensional parameter space, constructed with 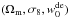 , where
, where 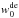 is the constant term of the equation of state of the dark energy. The values of other cosmological parameters were h = 0.78, Ωb = 0.047, and ns = 0.95. We assumed a flat Universe. The mock observation was generated by a realization of our model, using a particular set
is the constant term of the equation of state of the dark energy. The values of other cosmological parameters were h = 0.78, Ωb = 0.047, and ns = 0.95. We assumed a flat Universe. The mock observation was generated by a realization of our model, using a particular set 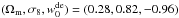 as input parameters. In this way, we only focus on the precision of our model.
as input parameters. In this way, we only focus on the precision of our model.
We processed simulation runs in two different ways. The first one consists of interpolating the likelihood, from which we draw credible regions from Bayesian inference, and the second is approximate Bayesian computation. Both approaches are explained in the following sections.
4.4.1. Copula likelihood
The copula likelihood comes from the copula transform which is a series of 1D transformations, which turn the marginals of a multivariate distribution into the desired target functions. In other words, it corresponds to applying successive changes of variables to a multivariate distribution. According to Sklar’s theorem (Sklar 1959), these transformations always exist. One may be interested in specific transformations such that in the new space, all marginals of the studied distribution are Gaussian. Then, the joint distribution in the new variables is closer to Gaussian in most cases. By combining the transformations mentioned above with the Gaussian likelihood, one obtains the copula likelihood.
We use the copula likelihood with covariances varying with cosmology. Let d be the dimension of the data vector. Given a parameter set π, for all i = 1,...,d, we note 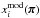 as the ith component of the model prediction,
as the ith component of the model prediction, 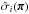 as the corresponding dispersion, and
as the corresponding dispersion, and 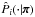 the ith initial marginal. We also note xobs,
the ith initial marginal. We also note xobs, 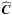 and
and 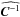 as the observed data vector, the estimated covariance, and its inverse, respectively. The copula log-likelihood is
as the observed data vector, the estimated covariance, and its inverse, respectively. The copula log-likelihood is ![Mathematical equation: \begin{eqnarray} L &\equiv& \ln\left[\det \widehat{\bC}(\bpi)\right] \notag\\[3mm] &&\quad+ \sum_{i=1}^d \sum_{j=1}^d \left(q_i^\obs(\bpi) - x^\model_i(\bpi)\right) \widehat{C\inv_{ij}}(\bpi) \left(q_j^\obs(\bpi) - x^\model_j(\bpi)\right) \notag\\[3mm] &&\quad- 2 \sum_{i=1}^d \ln\hat{\sigma}_i(\bpi) - \sum_{i=1}^d \left(\frac{q_i^\obs(\bpi) - x^\model_i(\bpi)}{\hat{\sigma}_i(\bpi)}\right)^2 \notag\\[3mm] &&\quad- 2 \sum_{i=1}^d \ln\hat{P}_i(x^\obs_i|\bpi),\label{for:likelihood} \end{eqnarray}](/articles/aa/full_html/2016/09/aa28565-16/aa28565-16-eq165.png) (31)where
(31)where 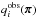 is such that
is such that 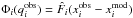 , knowing that
, knowing that 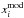 is the model prediction,
is the model prediction, 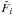 is the cumulative distribution of
is the cumulative distribution of 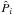 , and Φi is the cumulative of the normal distribution with the same mean and variance as . A more detailed description and the derivation of the copula can be found in Sect. 4 of Paper II.
, and Φi is the cumulative of the normal distribution with the same mean and variance as . A more detailed description and the derivation of the copula can be found in Sect. 4 of Paper II.
All the quantities required by the copula likelihood are provided by our model. Consider a set of N model realizations. Denoting 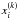 as the ith component of the kth realization, we use
as the ith component of the kth realization, we use 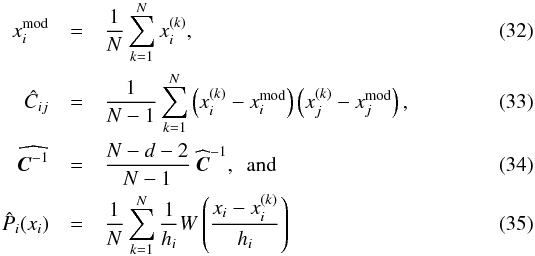 for the estimations, where d is the dimension of x, W is the Gaussian kernel, and
for the estimations, where d is the dimension of x, W is the Gaussian kernel, and 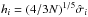 . Note that the model prediction xmod is nothing but the average over the realization set; the inverse covariance matrix is unbiased (Hartlap et al. 2007) to good accuracy (see also Sellentin & Heavens 2016); and Eq. (35) is a kernel density estimation (KDE).
. Note that the model prediction xmod is nothing but the average over the realization set; the inverse covariance matrix is unbiased (Hartlap et al. 2007) to good accuracy (see also Sellentin & Heavens 2016); and Eq. (35) is a kernel density estimation (KDE).
We evaluated the copula likelihoods, given by Eq. (31), on a grid. The range of is [–1.8, 0], with 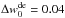 . Concerning Ωm and σ8, only some particular values were chosen for evaluation in order to reduce the computing cost. This resulted in 816 points in the Ωm-σ8 plane, as displayed in Fig. 4, and the total number of parameter sets was 37536. For each parameter set, we carried out N = 400 realizations of our model, to estimate L using Eqs. (31)–(35). Each realization produced data vectors for three cases: (1) the Gaussian kernel; (2) the starlet kernel; (3) MRLens, so that the comparisons between cases are based on the same stochasticity. The aperture mass was not included here because of the time consuming convolution of the unbinned shear catalog with the filter Q. The FDR α of MRLens was set to 0.05. A map example is displayed in Fig. 5 for the three cases and the input simulated κ field.
. Concerning Ωm and σ8, only some particular values were chosen for evaluation in order to reduce the computing cost. This resulted in 816 points in the Ωm-σ8 plane, as displayed in Fig. 4, and the total number of parameter sets was 37536. For each parameter set, we carried out N = 400 realizations of our model, to estimate L using Eqs. (31)–(35). Each realization produced data vectors for three cases: (1) the Gaussian kernel; (2) the starlet kernel; (3) MRLens, so that the comparisons between cases are based on the same stochasticity. The aperture mass was not included here because of the time consuming convolution of the unbinned shear catalog with the filter Q. The FDR α of MRLens was set to 0.05. A map example is displayed in Fig. 5 for the three cases and the input simulated κ field.
 |
Fig. 4 Distribution of evaluated parameter points on the Ωm-σ8 plane. This figure can be considered as a slice of points with the same |
 |
Fig. 5 Maps taken from one of the simulations. The true map is made by calculating κproj without noise. The panels of the rest are different filtering techniques applied on the map obtained from a KS inversion after calculating ϵ(o) = gproj + ϵ(s). The black areas are masks. The unit of kernel sizes is arcmin. |
Definition of the data vector x for PMC ABC runs.
4.4.2. Population Monte Carlo approximate Bayesian computation
The second analysis adopts the approximate Bayesian computation (ABC) technique. ABC bypasses the likelihood evaluation to estimate directly the posterior by accept-reject sampling. It is fast and robust, and has already had several applications in astrophysics (Cameron & Pettitt 2012; Weyant et al. 2013; Robin et al. 2014; Paper II; Killedar et al. 2016). Here, we use the Population Monte Carlo ABC (PMC ABC) algorithm to constrain parameters. This algorithm adjusts the tolerance level iteratively, such that ABC posterior converges. A detailed description of the PMC ABC algorithm can be found in Sect. 6 of Paper II.
We ran PMC ABC for four cases: the Gaussian kernel, the starlet kernel, the aperture mass with the hyperbolic tangent function, and MRLens with α = 0.05. For the three first linear cases, the data vector x was composed of three scales. The S/N bins of each scale were [1, 1.5, 2, ..., 4, 4.5, 5, + ∞[, which result in 27 bins in total (Table 2). For MRLens, x was a 6-bin κ histogram, which is the same as for the analysis using the likelihood.
Concerning the ABC parameters, we used 1500 particles in the PMC process. The iteration stoped when the success ratio of accept-reject processes fell below 1%. Finally, we tested two distances. Between the sampled data vector x and the observed one, xobs, we considered a simplified distance D1 and a fully correlated one D2, which are respectively defined as 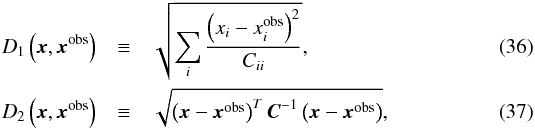 where Cii and C-1 are now independent from cosmology, estimated using Eqs. (33) and (34)under . Note that D1 has been shown in Paper II to be able to produce constraints which agree well with the likelihood. However, with multiscale data, bins could be highly correlated, and therefore we also ran ABC with D2 in this paper.
where Cii and C-1 are now independent from cosmology, estimated using Eqs. (33) and (34)under . Note that D1 has been shown in Paper II to be able to produce constraints which agree well with the likelihood. However, with multiscale data, bins could be highly correlated, and therefore we also ran ABC with D2 in this paper.
5. Results
5.1. Comparing filtering techniques using the likelihood
We propose two methods to measure the quality of constraints. The first indicator is the uncertainty on the derived parameter Σ8. Here, we define Σ8 differently from the literature: 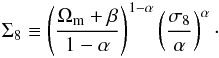 (38)The motivation for this definition is to measure the contour width independently from α. With the common definition Σ8 ≡ σ8(Ωm/ pivot)α, the variation on Σ8 under different α does not correspond to the same width on the Ωm-σ8 plane. The 1σ error bar on Σ8, ΔΣ8, is obtained using the same method as in Paper II. The second indicator is the FoM defined as the inverse of the 2σ contour area for Ωm and σ8.
(38)The motivation for this definition is to measure the contour width independently from α. With the common definition Σ8 ≡ σ8(Ωm/ pivot)α, the variation on Σ8 under different α does not correspond to the same width on the Ωm-σ8 plane. The 1σ error bar on Σ8, ΔΣ8, is obtained using the same method as in Paper II. The second indicator is the FoM defined as the inverse of the 2σ contour area for Ωm and σ8.
First, we test the maximum information that Gaussian kernels can extract. Table 3 shows the FoM from the marginalized likelihood. We can see that adding θker = 2.4 and 4.8 arcmin to the filter with 1.2 arcmin has no siginificant effect on constraints. The constraints from the smallest filter are the most dominant ones among all.
 |
Fig. 6 Ωm-σ8 constraints from four different cases. Left panel: Gaussian case (colored regions) and the starlet case with three corresponding scales based on the noise level (solid and dashed contours, θker = 2, 4, and 8 arcmin). Right panel: starlet case with three corresponding scales based on number counts (colored regions, θker = 4, 8, and 16 arcmin) and the MRLens case (solid and dashed contours). The Gaussian and count-based starlet cases yield almost identical constraints. Between four cases, the best result is given by the noise-based starlet case. Black stars represent the input cosmology. Gray zones are excluded in this analysis. |
Next, we use all three Gaussian scales as the reference for the comparisons with the starlet function. As mentioned in Sect. 4.3, for the Gaussian filter scales of 1.2, 2.4, and 4.8 arcmin, we chose scales for the starlet based on two criteria: for an equal noise level, these are 2, 4, and 8 arcmin, and for equal number counts the corresponding scales are 4, 8, and 16 arcmin. The results are shown in Fig. 6. For the equal-number-count criterion, we see that if each scale gives approximately the same number of peaks, the Ωm-σ8 constraints obtained from the Gaussian and the starlet are similar (colored regions in the left and right panels). However, the starlet kernel leads to tighter constraints than the Gaussian when we match the same noise levels (lines and colored regions in the left panel). This results suggests that compensated kernels could be more powerful to extract cosmological information than non-compensated filters.
We also draw constraints from individual scales of the starlet filter in (Fig. 7). It shows a very different behavior and seems to suggest that different scales could be sensitive to different cosmologies. However, this is actually a stochastic effect. We verify this statement by redoing the constraints with other observation vectors. It turns out that the scale-dependent tendency disappears. Nevertheless, when different cosmologies are prefered by different scales, the effect is less pronounced for the Gaussian filter. This is likely to be due to the fact that the starlet is a compensated filter, which is a band-pass function in the Fourier space. Since different filtering scales could be sensitive to different mass ranges of the mass function, band-pass filters could have a greater potential to separate better the multiscale information. The stochasticity of the observation vector suggests that the simulated field of view is rather small. While this should not affect the filter comparison nor contour sizes, actual cosmological constraints seem to require substantially larger data sets.
 |
Fig. 7 Ωm-σ8 1σ region from individual scales of the starlet kernel. The plotted scales are 2 (blue), 4 (red), and 8 arcmin (green). The fact that different regions are preferred by different scales is more likely to be due to stochasticity. Gray zones are excluded in this analysis. |
The right panel of Fig. 6 shows the constraints from nonlinear filtering using MRLens (solid and dashed lines). We observe that MRLens conserves a strong degeneracy between Ωm and σ8. The reasons for this result are various. First, large and small scales tend to sensitive to different halo masses which could help break the degeneracy. Using the combined strategy loses this advantage. Second, we have chosen a strict FDR. This rules out most of the spurious peaks, but also a lot of the signal. Third, as mentioned before, it is inappropriate to define S/N when the filter is not linear. As a consequence, it is hardly possible to find bins for κ peaks which are equivalent to ν bins in linear filtering. This is supported by Fig. 5, where we observe less peaks in the MRLens map than in the other maps. Last, because of a low number of peaks, the binwidths need to be enlarged to contain larger number counts and to get closer to a Gaussian distribution, and large binwidths also weaken the signal.
A possible solution for exploring the MRLens technique is to enhance the FDR and to redesign the binning. By increasing the number of peaks, thinner bins would be allowed. Another solution to better account for rare events in the current configuration is to use the Poisson likelihood. Finally, one could adopt the separated strategy, that is turning back to the methodology used by Pires et al. (2009a) that consists in estimating the peak abundance in the different scales before final reconstruction. Our comparison between linear and nonlinear techniques is basically the one between the separated and combined strategies.
Table 3 measures numerical qualities for constraints with different filtering techniques. It indicates that the width of contours does not vary significantly. The tightest constraint that we obtain is derived from a compensated filter.
Regarding results for , we show a representative case of starlet with θker = 2, 4, and 8 arcmin. Figure 8 presents the marginalized constraints of each doublet of parameters that we study. Those containing are noisy because of the usage of the copula likelihood. We see that the current configuration of our model does not allow to impose constraints on . To measure this parameter, it could be useful to perform a tomography analysis to separate information of different stages of the late-time Universe. Nevertheless, our results successfully highlight the degeneracies of with two other parameters. We fit the posterior density with:  We obtain for the slopes a1 = 0.108 and a2 = 0.128 for Fig. 8. The results for the other filter functions are similar.
We obtain for the slopes a1 = 0.108 and a2 = 0.128 for Fig. 8. The results for the other filter functions are similar.
5.2. Results from PMC ABC
 |
Fig. 8 Ωm-σ8- |
 |
Fig. 9 ABC constraints on Ωm, σ8, and |
We perform parameter constraints using the PMC ABC algorithm for our four cases. In Fig. 9, we show the results derived from the starlet case using the fully correlated distance D2. The contours are marginalized posteriors for all three pairs of parameters. They show the same degeneracy as we have found in Sect. 5.1. We measure a1 and a2 from the ABC posteriors and obtain a1 = 0.083 and a2 = 0.084.
Quality indicators for Ωm-σ8 constraints with likelihood.
Quality indicators for Ωm-σ8 constraints with PMC ABC.
 |
Fig. 10 Correlation coefficient matrices under the input cosmology. Left panel: Gaussian case with θker = 1.2, 2.4, and 4.8 arcmin. Right panel: starlet case with θker = 2, 4, and 8 arcmin. Each of the 3 × 3 blocks corresponds to the correlations between two filter scales. With each block, the S/N bins are [1, 1.5, 2, ..., 5, +∞[. The data vector by starlet is less correlated. |
Using the same starlet filters, we compare two distances used for PMC ABC runs. When D1 is used with the starlet, which means that data are treated as if uncorrelated, we find that the contour sizes do not change (see Table 4) compared to D2. For the Gaussian case, however, constraints from D1 are tighter than those from D2. This phenomenon is due to the off-diagonal elements of the covariance matrix. For non-compensated filters, the cross-correlations between bins are much stronger, as shown by Fig. 10. If these cross-correlations are ignored, the repeated peak counts in different bins are not properly accounted for. This overestimates the additional sensitivity to massive structures, and therefore produces overly tight constraints. As shown in Fig. 10, in the Gaussian case, adjacent filter scales show a 20–30% correlation. The blurring of the off-diagonal stripes indicate a leakage to neighboring S/N bins due to noise, and the fact that clusters produce WL peaks with different S/N for different scales. On the contrary, in the case of the starlet, except for the highest S/N bin there are negligible correlations between different scales.
Table 4 shows the ABC constraints from both the aperture mass and the starlet. We find that the FoM are close. However, in Fig. 11, we see that the contours from the aperture mass is shifted toward high-Ωm regions. The explanation for this shift is once again the stochasticity. We simulated another observation data vector for Map, and the maximum-likelihood point for different methods do not coincide.
From Table 4, one can see that the difference between MRLens and linear filters using ABC is similar to using the likelihood. This suggests once again that the combined strategy leads to less tighter constraints than the separated strategy. Note that we also try to adjust α and run PMC ABC. However, without modifying the κ bin choice, the resulting constraints do not differ substantially from α = 0.05.
Finally, we show the likelihood and ABC constraint contours for the Gaussian and starlet cases in Fig. 12. It turns out that ABC contours are systematically larger in the high-Ωm, low-σ8 region. This phenomenon was not observed in Paper II where a similar comparison was made. We speculate that by including a third parameter the contour becomes less precise, and ABC might be more sensitive to this effect. Note also that KDE is a biased estimator of posteriors (Paper II). It smoothes the posterior and makes contours broader. Nevertheless, the ABC and likelihood constraints agree with each other. To be free from the bias, a possible alternative is to map the samples to a Gaussian distribution via some nonlinear mapping techniques (Schuhmann et al. 2016).
 |
Fig. 11 ABC Ωm-σ8 constraints from the starlet and the aperture mass. The distance D2 is used in both cases. The black star is the input cosmology. The difference between two cases is that another observation data vector is created for the aperture mass and the direct comparison is not valid anymore. |
6. Summary and discussion
In this work, we studied WL peak counts for cosmology-oriented purposes. This means that we do not compare WL peaks with clusters of galaxies or study cluster properties, but use directly the peak abundance to constrain cosmological parameters.
We tested different filtering techniques by using our stochastic model for WL peak counts. The goal is not to find out the optimal filter, but to provide a standard procedure for comparison and to establish a roadmap for future studies. We claim that, rather than other indicators such as completeness and purity, it is more fair to study directly the tightness of constraint contours in order to maximize cosmological information extraction. In this work, we applied this principle with both the likelihood and ABC.
We compared Gaussian smoothing to starlet filtering, which is a comparison between compensated and non-compensated filters. Our results suggest that compensated filters are more suitable to capture cosmological information than the non-compensated ones. This comes from the fact that band-pass functions better separate multiscale information.
To handle multiscale data, we explored two strategies: the combined strategy creates a single mass map and the associated peak-count histogram; the separated strategy chooses some characteristic scales, produces one histogram per scale, and concatenates them into one data vector. We compared starlet filtering using the separated strategy with a nonlinear filter MRLens, for which data were arranged using the combined strategy. The combined strategy, which mixes information of all scales yielded more elongated contours.
 |
Fig. 12 Comparison of Ωm-σ8- |
Concerning nonlinear methods, we would like to highlight that the linear-nonlinear comparison often contains a part of the separated-combined comparison. Although we did not carry out separate comparisons with regard to these two concepts in this work, some evidences still suggest that the separated-combined duality could be more influential than the linear-nonlinear issue. A possible design for the separated-combined comparison is the comparison between the matched filter of Hennawi & Spergel (2005) and the multiscale aperture mass, or between MRLens used as Pires et al. (2009a) with our MRLens case. Also, the comparison between MRLens used as Pires et al. (2009a) and linear starlet filtering can properly test the impact of nonlinear filters on constraints. However, this difference could be minor.
In this work, we found tighter constraints from the likelihood than from ABC. Since we had found in Paper II that the copula likelihood closely approximates the true one, the constraints from ABC probably overestimate the true parameter errors. Using ABC, we performed parameter constraints for the aperture mass. This yielded a very similar FoM compared to the starlet, both compensated filters.
Concering the equation of state of dark energy, our results could not constrain in general since is degenerated with Ωm and σ8. We fit these degeneracies with linear relations 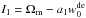 and
and 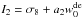 and found a1 = 0.108 and a2 = 0.128.
and found a1 = 0.108 and a2 = 0.128.
Our model for weak-lensing peak counts has been improved to be adapted to more realistic observational conditions. We have shown that our model is very general, and can be applied to weak-lensing data that is processed with conceptually different filtering approaches.
Acknowledgments
This work is supported by Région d’Île-de-France with the DIM-ACAV thesis fellowship. We acknowledge the anonymous referee for reporting questions and comments. We also acknowledge support from the French national program for cosmology and galaxies (PNCG). The computing support from the in2p3 Computing Centre is thanked gratefully. Chieh-An Lin would like to thank Sarah Antier, Cécile Chenot, Samuel Farrens, Marie Gay, Zoltán Haiman, Olivier Iffrig, Ming Jiang, François Lanusse, Yueh-Ning Lee, Sophia Lianou, Jia Liu, Fred Ngolè, Austin Peel, Jean-Luc Starck, and Jose Manuel Zorrilla Matilla for useful discussions, suggestions on diverse subjects, and technical support.
References
- Abate, A., Wittman, D., Margoniner, V. E., et al. 2009, ApJ, 702, 603 [NASA ADS] [CrossRef] [Google Scholar]
- Bard, D., Kratochvil, J. M., Chang, C., et al. 2013, ApJ, 774, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Bartelmann, M., Narayan, R., Seitz, S., & Schneider, P. 1996, ApJ, 464, L115 [NASA ADS] [CrossRef] [Google Scholar]
- Bartelmann, M., Perrotta, F., & Baccigalupi, C. 2002, A&A, 396, 21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baumann, D., Nicolis, A., Senatore, L., & Zaldarriaga, M. 2012, J. Cosmol. Astropart. Phys., 7, 051 [Google Scholar]
- Benjamini, Y., & Hochberg, Y. 1995, J. Roy. Stat. Soc., Ser. B, 57, 289 [Google Scholar]
- Bernardeau, F., Colombi, S., Gaztañaga, E., & Scoccimarro, R. 2002, Phys. Rep., 367, 1 [NASA ADS] [CrossRef] [EDP Sciences] [MathSciNet] [Google Scholar]
- Bhattacharya, S., Heitmann, K., White, M., et al. 2011, ApJ, 732, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Bobin, J., Sureau, F., Starck, J.-L., Rassat, A., & Paykari, P. 2014, A&A, 563, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bourguignon, S., Mary, D., & Slezak, E. 2011, IEEE J. Selected Topics in Signal Processing, 5, 1002 [NASA ADS] [CrossRef] [Google Scholar]
- Bullock, J. S., Kolatt, T. S., Sigad, Y., et al. 2001, MNRAS, 321, 559 [Google Scholar]
- Cameron, E., & Pettitt, A. N. 2012, MNRAS, 425, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Candes, E., & Tao, T. 2006, Information Theory, IEEE Transactions, 52, 5406 [Google Scholar]
- Candès, E. J., Wakin, M. B., & Boyd, S. P. 2008, J. Fourier Anal. Appl., 14, 877 [Google Scholar]
- Carrasco, J. J. M., Hertzberg, M. P., & Senatore, L. 2012, J. High Energy Phys., 9, 82 [Google Scholar]
- Carrillo, R. E., McEwen, J. D., & Wiaux, Y. 2012, MNRAS, 426, 1223 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Daubechies, I., Defrise, M., & De Mol, C. 2004, Communications Pure and Applied Mathematics, 57, 1413 [Google Scholar]
- Dietrich, J. P., & Hartlap, J. 2010, MNRAS, 402, 1049 [NASA ADS] [CrossRef] [Google Scholar]
- Dolag, K., Bartelmann, M., Perrotta, F., et al. 2004, A&A, 416, 853 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Efstathiou, G., Bernstein, G., Tyson, J. A., Katz, N., & Guhathakurta, P. 1991, ApJ, 380, L47 [NASA ADS] [CrossRef] [Google Scholar]
- Elad, M., & Aharon, M. 2006, Image Processing, IEEE Transactions, 15, 3736 [Google Scholar]
- Erben, T., Hildebrandt, H., Miller, L., et al. 2013, MNRAS, 433, 2545 [NASA ADS] [CrossRef] [Google Scholar]
- Fadili, M., Starck, J.-L., & Murtagh, F. 2009, Comp. J., 52, 64 [CrossRef] [Google Scholar]
- Fan, Z., Shan, H., & Liu, J. 2010, ApJ, 719, 1408 [NASA ADS] [CrossRef] [Google Scholar]
- Fu, L., Kilbinger, M., Erben, T., et al. 2014, MNRAS, 441, 2725 [NASA ADS] [CrossRef] [Google Scholar]
- Gavazzi, R., & Soucail, G. 2007, A&A, 462, 459 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamana, T., Takada, M., & Yoshida, N. 2004, MNRAS, 350, 893 [NASA ADS] [CrossRef] [Google Scholar]
- Hamana, T., Oguri, M., Shirasaki, M., & Sato, M. 2012, MNRAS, 425, 2287 [NASA ADS] [CrossRef] [Google Scholar]
- Hamana, T., Sakurai, J., Koike, M., & Miller, L. 2015, PASJ, 67, 34 [NASA ADS] [Google Scholar]
- Hartlap, J., Simon, P., & Schneider, P. 2007, A&A, 464, 399 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hennawi, J. F., & Spergel, D. N. 2005, ApJ, 624, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Hetterscheidt, M., Erben, T., Schneider, P., et al. 2005, A&A, 442, 43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Miller, L., et al. 2012, MNRAS, 427, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Jenkins, A., Frenk, C. S., White, S. D. M., et al. 2001, MNRAS, 321, 372 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Kaiser, N., & Squires, G. 1993, ApJ, 404, 441 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N., Squires, G., Fahlman, G., & Woods, D. 1994, in Clusters of Galaxies, Atlantica Séguier Frontières, 1, 269 [Google Scholar]
- Kilbinger, M., Fu, L., Heymans, C., et al. 2013, MNRAS, 430, 2200 [NASA ADS] [CrossRef] [Google Scholar]
- Killedar, M., Borgani, S., Fabjan, D., et al. 2016, MNRAS, submitted [arXiv:1507.05617] [Google Scholar]
- Kratochvil, J. M., Haiman, Z., & May, M. 2010, Phys. Rev. D, 81, 043519 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [NASA ADS] [CrossRef] [Google Scholar]
- Lambert, P., Pires, S., Ballot, J., et al. 2006, A&A, 454, 1021 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lanusse, F., Starck, J.-L., Leonard, A., & Pires, S. 2016, A&A, 591, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Leonard, A., Lanusse, F., & Starck, J.-L. 2014, MNRAS, 440, 1281 [NASA ADS] [CrossRef] [Google Scholar]
- Lin, C.-A., & Kilbinger, M. 2015a, A&A, 576, A24 (Paper I) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lin, C.-A., & Kilbinger, M. 2015b, A&A, 583, A70 (Paper II) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, J., Haiman, Z., Hui, L., Kratochvil, J. M., & May, M. 2014a, Phys. Rev. D, 89, 023515 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, X., Wang, Q., Pan, C., & Fan, Z. 2014b, ApJ, 784, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, J., Petri, A., Haiman, Z., et al. 2015a, Phys. Rev. D, 91, 063507 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, X., Pan, C., Li, R., et al. 2015b, MNRAS, 450, 2888 [NASA ADS] [CrossRef] [Google Scholar]
- Makino, N., Sasaki, M., & Suto, Y. 1992, Phys. Rev. D, 46, 585 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Smith, R. E., & Bernstein, G. M. 2009, ApJ, 698, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Smith, R. E., & Bernstein, G. M. 2010, ApJ, 709, 286 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Hilbert, S., Smith, R. E., Schneider, P., & Desjacques, V. 2011, ApJ, 728, L13 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Smith, R. E., Hilbert, S., & Schneider, P. 2012, MNRAS, 423, 1711 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Smith, R. E., Hilbert, S., & Schneider, P. 2013, MNRAS, 432, 1338 [NASA ADS] [CrossRef] [Google Scholar]
- Martinet, N., Bartlett, J. G., Kiessling, A., & Sartoris, B. 2015, A&A, 581, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maturi, M., Meneghetti, M., Bartelmann, M., Dolag, K., & Moscardini, L. 2005, A&A, 442, 851 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maturi, M., Angrick, C., Pace, F., & Bartelmann, M. 2010, A&A, 519, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maturi, M., Fedeli, C., & Moscardini, L. 2011, MNRAS, 416, 2527 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Ngolè Mboula, F. M., Starck, J.-L., Ronayette, S., Okumura, K., & Amiaux, J. 2015, A&A, 575, A86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pires, S., Starck, J.-L., Amara, A., Réfrégier, A., & Teyssier, R. 2009a, A&A, 505, 969 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pires, S., Starck, J.-L., Amara, A., et al. 2009b, MNRAS, 395, 1265 [NASA ADS] [CrossRef] [Google Scholar]
- Pires, S., Leonard, A., & Starck, J.-L. 2012, MNRAS, 423, 983 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [NASA ADS] [CrossRef] [Google Scholar]
- Robin, A. C., Reylé, C., Fliri, J., et al. 2014, A&A, 569, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, P. 1996, MNRAS, 283, 837 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., Van Waerbeke, L., Jain, B., & Kruse, G. 1998, MNRAS, 296, 873 [NASA ADS] [CrossRef] [Google Scholar]
- Schirmer, M., Erben, T., Schneider, P., Wolf, C., & Meisenheimer, K. 2004, A&A, 420, 75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schirmer, M., Erben, T., Hetterscheidt, M., & Schneider, P. 2007, A&A, 462, 875 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuhmann, R. L., Joachimi, B., & Peiris, H. V. 2016, MNRAS, 459, 1916 [NASA ADS] [CrossRef] [Google Scholar]
- Seitz, C., & Schneider, P. 1995, A&A, 297, 287 [NASA ADS] [Google Scholar]
- Sellentin, E., & Heavens, A. F. 2016, MNRAS, 456, L132 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., & Tormen, G. 1999, MNRAS, 308, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., & Tormen, G. 2002, MNRAS, 329, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Sklar, A. 1959, Publ. Inst. Statist. Univ. Paris, 8, 229 [Google Scholar]
- Starck, J.-L., Murtagh, F., & Fadili, J. M. 2002, Sparse Image and Signal Processing (Cambridge University Press) [Google Scholar]
- Starck, J.-L., Pires, S., & Réfrégier, A. 2006, A&A, 451, 1139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Takada, M., & Jain, B. 2002, MNRAS, 337, 875 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Jain, B. 2003a, MNRAS, 340, 580 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Jain, B. 2003b, MNRAS, 344, 857 [NASA ADS] [CrossRef] [Google Scholar]
- The Dark Energy Survey Collaboration 2015, ArXiv e-prints [arXiv:1507.05552] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Van Waerbeke, L. 2000, MNRAS, 313, 524 [NASA ADS] [CrossRef] [Google Scholar]
- Van Waerbeke, L., Benjamin, J., Erben, T., et al. 2013, MNRAS, 433, 3373 [Google Scholar]
- Wang, S., Haiman, Z., & May, M. 2009, ApJ, 691, 547 [NASA ADS] [CrossRef] [Google Scholar]
- Warren, M. S., Abazajian, K., Holz, D. E., & Teodoro, L. 2006, ApJ, 646, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, N. N., & Kamionkowski, M. 2003, MNRAS, 341, 251 [NASA ADS] [CrossRef] [Google Scholar]
- Weyant, A., Schafer, C., & Wood-Vasey, W. M. 2013, ApJ, 764, 116 [NASA ADS] [CrossRef] [Google Scholar]
- White, M., van Waerbeke, L., & Mackey, J. 2002, ApJ, 575, 640 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Kratochvil, J. M., Wang, S., et al. 2011, Phys. Rev. D, 84, 043529 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Kratochvil, J. M., Huffenberger, K., Haiman, Z., & May, M. 2013, Phys. Rev. D, 87, 023511 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1 Left panel: profile of the 2D starlet. It has a finite support [–2, 2]. Right panel: bird-eye view of the 2D starlet. |
| In the text | |
|
Fig. 2 Illustration of our model in four panels. |
| In the text | |
|
Fig. 3 Peak function for different kernel sizes for an input cosmology |
| In the text | |
|
Fig. 4 Distribution of evaluated parameter points on the Ωm-σ8 plane. This figure can be considered as a slice of points with the same |
| In the text | |
|
Fig. 5 Maps taken from one of the simulations. The true map is made by calculating κproj without noise. The panels of the rest are different filtering techniques applied on the map obtained from a KS inversion after calculating ϵ(o) = gproj + ϵ(s). The black areas are masks. The unit of kernel sizes is arcmin. |
| In the text | |
|
Fig. 6 Ωm-σ8 constraints from four different cases. Left panel: Gaussian case (colored regions) and the starlet case with three corresponding scales based on the noise level (solid and dashed contours, θker = 2, 4, and 8 arcmin). Right panel: starlet case with three corresponding scales based on number counts (colored regions, θker = 4, 8, and 16 arcmin) and the MRLens case (solid and dashed contours). The Gaussian and count-based starlet cases yield almost identical constraints. Between four cases, the best result is given by the noise-based starlet case. Black stars represent the input cosmology. Gray zones are excluded in this analysis. |
| In the text | |
|
Fig. 7 Ωm-σ8 1σ region from individual scales of the starlet kernel. The plotted scales are 2 (blue), 4 (red), and 8 arcmin (green). The fact that different regions are preferred by different scales is more likely to be due to stochasticity. Gray zones are excluded in this analysis. |
| In the text | |
|
Fig. 8 Ωm-σ8- |
| In the text | |
|
Fig. 9 ABC constraints on Ωm, σ8, and |
| In the text | |
|
Fig. 10 Correlation coefficient matrices under the input cosmology. Left panel: Gaussian case with θker = 1.2, 2.4, and 4.8 arcmin. Right panel: starlet case with θker = 2, 4, and 8 arcmin. Each of the 3 × 3 blocks corresponds to the correlations between two filter scales. With each block, the S/N bins are [1, 1.5, 2, ..., 5, +∞[. The data vector by starlet is less correlated. |
| In the text | |
|
Fig. 11 ABC Ωm-σ8 constraints from the starlet and the aperture mass. The distance D2 is used in both cases. The black star is the input cosmology. The difference between two cases is that another observation data vector is created for the aperture mass and the direct comparison is not valid anymore. |
| In the text | |
|
Fig. 12 Comparison of Ωm-σ8- |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.