| Issue |
A&A
Volume 551, March 2013
|
|
|---|---|---|
| Article Number | A9 | |
| Number of page(s) | 7 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/201220430 | |
| Published online | 08 February 2013 | |
Maximum likelihood estimation of local stellar kinematics
Lund Observatory, Lund University, PO Box 43, 22100 Lund, Sweden
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
, This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 21 September 2012
Accepted: 28 November 2012
Abstract
Context. Kinematical data such as the mean velocities and velocity dispersions of stellar samples are useful tools to study galactic structure and evolution. However, observational data are often incomplete (e.g., lacking the radial component of the motion) and may have significant observational errors. For example, the majority of faint stars observed with Gaia will not have their radial velocities measured.
Aims. Our aim is to formulate and test a new maximum likelihood approach to estimating the kinematical parameters for a local stellar sample when only the transverse velocities are known (from parallaxes and proper motions).
Methods. Numerical simulations using synthetically generated data as well as real data (based on the Geneva-Copenhagen survey) are used to investigate the statistical properties (bias, precision) of the method, and to compare its performance with the much simpler “projection method” described by Dehnen & Binney (1998, MNRAS, 298, 387).
Results. The maximum likelihood method gives more correct estimates of the dispersion when observational errors are important, and guarantees a positive-definite dispersion matrix, which is not always obtained with the projection method. Possible extensions and improvements of the method are discussed.
Key words: methods: numerical / methods: analytical / astrometry
© ESO, 2013
1. Introduction
Statistical information about the motions of stars relative to the sun may contain important hints concerning the origin and history of the stars themselves (e.g., by identifying kinematic populations and streams) as well as of the physical properties of the Galaxy (through dynamical interpretation of the motions). Ideally this requires that all six components of phase space (positions and velocities) are known for all the stars in the investigated sample. This can in principle be achieved through a combination of astrometric data (providing positions and distances, from the parallaxes, and tangential velocities from the proper motions and parallaxes) and spectroscopic radial velocities. Very often, however, such complete data are not available for all the stars in a sample. For example, the Hipparcos Catalogue (ESA 1997) gives the required astrometric information for large samples of nearby stars, but not all of them have known radial velocities. Restricting the investigation to stars with measured radial velocities could introduce a serious selection bias (Binney et al. 1997). The Gaia mission (de Bruijne 2012) will not only provide vastly improved astrometric data for much larger stellar samples, but also radial-velocity measurements for stars brighter than ≃ 17 mag; for the fainter stars, however, the phase space data will still be incomplete. On the other hand, on-going spectroscopic surveys such as RAVE (Steinmetz et al. 2006) already provide radial velocities for large samples without the complementary astrometry. Thus we are often faced with the problem to estimate kinematical parameters (such as mean velocities and velocity dispersions) from incomplete phase space data, lacking either the radial or tangential velocity components, or the accurate distances needed to derive the tangential velocities from proper motions.
Dehnen & Binney (1998) derive a simple and elegant method to derive local stellar kinematics (mean velocity and velocity dispersion) for a group of stars, when the tangential velocities are known, but not the radial velocities. This method has become popular and can be considered a standard for this purpose. We will refer to it as the projection method (PM) throughout this paper. In addition to the original work by Dehnen & Binney (1998), the same method (or variants of it) has been used, e.g., by Mignard (2000), Brosche et al. (2001), van Leeuwen (2007), and Aumer & Binney (2009).
Despite its wide usage in the literature, the projection method is not founded on any particular estimation principle such as maximum likelihood (ML) or Bayesian estimation, but simply fit the projected first and second moments of the space velocities to the corresponding observed moments of the tangential velocities. This works well for large samples, provided that the observational uncertainties in the data are negligible compared to the uncertainties due to the sampling, but there is no guarantee that it is unbiased, or asymptotically efficient as expected for an ML estimate. On the contrary, by neglecting the observational errors the resulting velocity dispersions are probably overestimated. Moreover, for small samples the projection method may sometimes give unphysical results, in that the estimated dispersion tensor is not positive-definite – implying that the mean square velocity is negative in some directions. Since it is desirable that the kinematic parameters can be consistently and efficiently estimated also for small samples and in the presence of non-negligible observational uncertainties, we introduce here a new and more rigorous approach, based on the maximum likelihood method.
2. Kinematic parameters and the projection method
For a homogeneous population of stars the phase space density f(r,v,t) describes the density of stars as a function of position (r), velocity (v) and time t. By the local kinematics we mean the distribution function here (r = 0) and now (t = 0), that is f(v) ≡ f(0,v,0). It is usually assumed that f(v) is a smooth function, and the most common assumption is the Schwarzschild approximation, that f(v) is a three-dimensional Gaussian distribution (velocity ellipsoid), or a combination of a few Gaussian distributions. The velocity ellipsoid is completely described by the mean velocity v and the dispersion tensor D.
Throughout this paper we use heliocentric galactic coordinates (x,y,z) with + x pointing towards the Galactic Centre, + y in the direction of rotation at the Sun, and + z towards the north Galactic pole. The corresponding heliocentric velocity components are denoted (vx,vy,vz) or (u,v,w).
For a stellar population, the mean velocity and dispersion tensor are defined as ![Mathematical equation: \begin{eqnarray} \vec{\bar{v}}& =& \text{E}\left[ \vec{v} \right] , \label{eq:v} \\ {\bf D} &=& \text{E}\left[ (\vec{v}-\vec{\bar{v}}) (\vec{v}-\vec{\bar{v}})^\text{T} \right] , \label{eq:D} \end{eqnarray}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq16.png) where E is the expectation operator (population mean). Given the 3-dimensional velocities vi, i = 1, 2, ..., n for a sample of stars it is possible to estimate the population mean values by the sample mean values,
where E is the expectation operator (population mean). Given the 3-dimensional velocities vi, i = 1, 2, ..., n for a sample of stars it is possible to estimate the population mean values by the sample mean values, 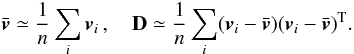 (3)Note that this estimate of D is always positive definite (except in trivial degenerate cases), but it requires 3-dimensional velocities and the dispersions are likely to be overestimated when the velocity components have significant observational errors.
(3)Note that this estimate of D is always positive definite (except in trivial degenerate cases), but it requires 3-dimensional velocities and the dispersions are likely to be overestimated when the velocity components have significant observational errors.
The tangential velocity of a star can be written 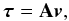 (4)where A is a projection matrix depending only on the position of the star. In the projection method the assumption that the positions (and hence the matrices A) are uncorrelated with the velocities is invoked to derive a relation between the mean of τ and the mean of A, allowing the latter to be solved. In a similar way, the elements of D are derived from the relation between the second moments of τ and v. For further details we refer to the paper by Dehnen & Binney (1998).
(4)where A is a projection matrix depending only on the position of the star. In the projection method the assumption that the positions (and hence the matrices A) are uncorrelated with the velocities is invoked to derive a relation between the mean of τ and the mean of A, allowing the latter to be solved. In a similar way, the elements of D are derived from the relation between the second moments of τ and v. For further details we refer to the paper by Dehnen & Binney (1998).
3. Maximum likelihood estimation of the kinematic parameters
3.1. Overview of the model
We assume a Gaussian distribution of the velocities in all directions. That is, the velocity of a star follows a 3-dimensional normal distribution, 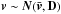 1. Given the position and true parallax p of the star we can calculate its true proper motion in longitude and latitude (μl,μb). Adding Gaussian observational errors to these we get the observed proper motions
1. Given the position and true parallax p of the star we can calculate its true proper motion in longitude and latitude (μl,μb). Adding Gaussian observational errors to these we get the observed proper motions 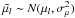 ,
, 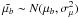 and the observed parallax
and the observed parallax 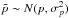 . The observational uncertainties σμ and σp are assumed to be known. The ML formulation requires that the probability density function of the observed data
. The observational uncertainties σμ and σp are assumed to be known. The ML formulation requires that the probability density function of the observed data 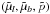 is written as a function of the model parameters.
is written as a function of the model parameters.
3.2. Exact expression for the likelihood
For a problem involving n stars, the parameters of the model are:
-
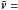 the mean velocity of the stellar population (a 3-vector, or 3 × 1 matrix);
the mean velocity of the stellar population (a 3-vector, or 3 × 1 matrix); -
D = the dispersion tensor of the stellar population (a symmetric 3 × 3 matrix; contains 6 non-redundant elements);
-
p = the true parallaxes of the stars (an n-vector, or n × 1 matrix).
It is necessary to introduce the true parallaxes pi as formal model parameters, although the strategy is that they will be eliminated on a star-by-star basis leaving us with a problem with only nine model parameters, namely the (non-redundant) components of 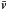 and D. We denote by the vector θ the complete set of model parameters (i.e., the unknowns to be estimated). For n stars the total number of model parameters is n + 9.
and D. We denote by the vector θ the complete set of model parameters (i.e., the unknowns to be estimated). For n stars the total number of model parameters is n + 9.
The observables are, for each star i = 1...n, the observed components of proper motion, 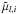 and
and 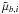 , and the observed parallax
, and the observed parallax 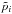 . The total number of observables is 3n. These have observational uncertainties that are given by the 3 × 3 covariance matrix Ci. Sometimes it is useful to denote by the vector x the complete set of observables (or data).
. The total number of observables is 3n. These have observational uncertainties that are given by the 3 × 3 covariance matrix Ci. Sometimes it is useful to denote by the vector x the complete set of observables (or data).
Given the observations, the likelihood function 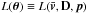 numerically equals the probability density function (pdf) fx(x | θ) of the observables x, given the model parameters θ. The objective is to find the ML estimate of θ, denoted
numerically equals the probability density function (pdf) fx(x | θ) of the observables x, given the model parameters θ. The objective is to find the ML estimate of θ, denoted 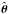 , i.e., the (hopefully unique) set of parameter values that maximizes L(θ) or, equivalently, the log-likelihood ℓ(θ) = lnL(θ). The total log-likelihood function is given by
, i.e., the (hopefully unique) set of parameter values that maximizes L(θ) or, equivalently, the log-likelihood ℓ(θ) = lnL(θ). The total log-likelihood function is given by ![Mathematical equation: \begin{equation} \label{e01} \ell(\bar{\vec{v}},{\bf D},\vec{p}) = \sum_i \left[ \ln f_{\tilde{\vec{\mu}},i}(\tilde{\vec{\mu}}_i|p_i) + \ln g_i(\tilde{p}_i-p_i) \right] \, , \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq55.png) (5)where gi is the centered normal pdf with standard deviation
(5)where gi is the centered normal pdf with standard deviation ![Mathematical equation: \hbox{$\sigma_{p,i}=[{\bf C}_i]_{33}^{1/2}$}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq57.png) , i.e., the uncertainty of the parallax pi. It is clear that the parameter pi only affects the ith term in the sum above. Therefore, when maximizing with respect to pi we only need to consider that one term. For simplicity we drop, for the moment, the subscript i so that the term to consider (for one star) can be written:
, i.e., the uncertainty of the parallax pi. It is clear that the parameter pi only affects the ith term in the sum above. Therefore, when maximizing with respect to pi we only need to consider that one term. For simplicity we drop, for the moment, the subscript i so that the term to consider (for one star) can be written: 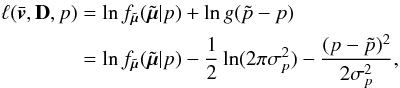 (6)where we have used
(6)where we have used 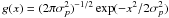 for the normal pdf with standard deviation σp. Note that
for the normal pdf with standard deviation σp. Note that 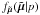 of course depends on and D as well, although we focus on the dependence on p here. We now need an explicit expression for the pdf of the observed proper motion
of course depends on and D as well, although we focus on the dependence on p here. We now need an explicit expression for the pdf of the observed proper motion 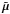 when the true parallax p is known. This is clearly a two-dimensional Gaussian (since both the velocities and the observational errors are Gaussian), with expected value
when the true parallax p is known. This is clearly a two-dimensional Gaussian (since both the velocities and the observational errors are Gaussian), with expected value ![Mathematical equation: \begin{equation} \label{e101} \text{E}\left[ \tilde{\vec{\mu}} \right] = {\bf M}\bar{\vec{v}} . \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq63.png) (7)Here, M is the 2 × 3 matrix
(7)Here, M is the 2 × 3 matrix 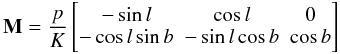 (8)projecting any vector (in this case ) to its components in the directions of increasing galactic coordinates l and b. The factor p/K converts the velocity to proper motion (numerically, K = 4.7405 if the units used are km s-1, mas, and mas yr-1). Assuming that the observational errors are not correlated with the velocities, the covariance of is the sum of the covariance due to the velocity dispersion and the covariance due to the observational errors, i.e.:
(8)projecting any vector (in this case ) to its components in the directions of increasing galactic coordinates l and b. The factor p/K converts the velocity to proper motion (numerically, K = 4.7405 if the units used are km s-1, mas, and mas yr-1). Assuming that the observational errors are not correlated with the velocities, the covariance of is the sum of the covariance due to the velocity dispersion and the covariance due to the observational errors, i.e.: ![Mathematical equation: \begin{equation} \label{e103} \text{Cov}\left[ \tilde{\vec{\mu}} \right] \equiv {\bf C}_{\tilde{\vec{\mu}}} = {\bf M}{\bf D}{\bf M}^{\rm T} + \begin{bmatrix} \sigma_{\mu l}^2 & \rho\sigma_{\mu l}\sigma_{\mu b} \\ \rho\sigma_{\mu l}\sigma_{\mu b} & \sigma_{\mu b}^2 \end{bmatrix}, \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq72.png) (9)where σμl and σμb are the observational uncertainties in μl and μb, and ρ their correlation coefficient. The pdf is then
(9)where σμl and σμb are the observational uncertainties in μl and μb, and ρ their correlation coefficient. The pdf is then ![Mathematical equation: \begin{equation} \label{e104} f_{\tilde{\vec{\mu}}}(\tilde{\vec{\mu}}|p) = (2\pi)^{-1} \left| {\bf C}_{\tilde{\vec{\mu}}} \right|^{-1/2} \exp\left[ -\frac{1}{2}\left(\tilde{\vec{\mu}}-{\bf M}\bar{\vec{v}}\right)' {\bf C}_{\tilde{\vec{\mu}}}^{-1}\left(\tilde{\vec{\mu}}-{\bf M}\bar{\vec{v}}\right) \right] \, . \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq78.png) (10)
(10)
3.3. Eliminating the parallaxes
The large number of parameters in the likelihood function in Eq. (5) makes it difficult to maximize. We approach this problem by finding the maximum of Eq. (6) with respect to p for each star and thus eliminating p. Since the expression for is quite complicated, it is not likely that this can be done exactly, by analytical means, but we can find an approximate solution valid in the limit of small relative parallax error, σp/p ≪ 1.
To eliminate p we take the partial derivative of Eq. (6) with respect to p and set it equal to 0. The result is 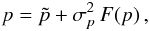 (11)where we introduced for brevity
(11)where we introduced for brevity 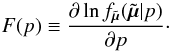 (12)So far no approximation has been made. However, in Eq. (11) the function F is to be evaluated for the value of p which we are seeking, so we have not really solved the problem. But if σp ≪ p we can evaluate F(p) at
(12)So far no approximation has been made. However, in Eq. (11) the function F is to be evaluated for the value of p which we are seeking, so we have not really solved the problem. But if σp ≪ p we can evaluate F(p) at 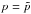 to obtain the explicit formula
to obtain the explicit formula 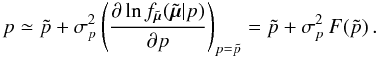 (13)This approximation is safe to do under the assumption of small relative parallax error, since Eq. (13) is obviously correct to first order in
(13)This approximation is safe to do under the assumption of small relative parallax error, since Eq. (13) is obviously correct to first order in 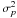 . Inserting the first-order Taylor expansion
. Inserting the first-order Taylor expansion 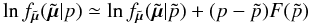 (14)in Eq. (6) and using
(14)in Eq. (6) and using 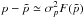 from Eq. (13), the log-likelihood maximized with respect to p becomes:
from Eq. (13), the log-likelihood maximized with respect to p becomes: 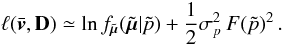 (15)Here we have neglected the additive constant
(15)Here we have neglected the additive constant  , which does not depend on the model parameters and therefore is irrelevant for the ML problem.
, which does not depend on the model parameters and therefore is irrelevant for the ML problem.
Recalling that this is just the log-likelihood term for one star, the total log-likelihood function, after maximization with respect to p, is therefore: ![Mathematical equation: \begin{equation} \label{e12} \ell(\bar{\vec{v}},{\bf D}) \simeq \sum_i \left[ \ln f_{\tilde{\vec{\mu}},i}(\tilde{\vec{\mu}}_i|\vec{\bar{v}},{\bf D},\tilde{p}_i) + \frac{1}{2}\sigma_{p,i}^2\,F_i(\tilde{p}_i)^2 \right]. \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq93.png) (16)
(16)
3.4. Numerical solution method
We make use of a numerical method for maximizing the likelihood function, rather than an analytical one, as the derivatives of Eq. (16) become very complicated. We have used the Nelder-Mead simplex method (Lagarias et al. 1998), implemented in MATLAB as the function fminsearch, to minimize the negative of the log-likelihood. The simplex method is useful as it does not require us to know the derivatives.
As soon as there are enough stars in the sample the minimization works fine but we have found two situations in which the algorithm diverges. The first happens when some stars in the sample have very small parallaxes or very large tangential velocities. The second situation may occur when the sample is very small. What happens in both cases is that the estimated dispersion tends towards zero in some direction, apparently because the measurement errors are enough to explain the observed dispersion, resulting in a singular dispersion matrix.
To compute a solution even in these cases, we introduce a regularization parameter α > 0. The regularized log-likelihood is: ![Mathematical equation: \begin{equation} \label{e13} \ell(\bar{\vec{v}},{\bf D}) \simeq \sum_i \left[ \ln f_{\tilde{\vec{\mu}},i}(\tilde{\vec{\mu}}_i|\vec{\bar{v}},{\bf D},\tilde{p}_i) + \frac{1}{2}\sigma_{p,i}^2\,F_i(\tilde{p}_i)^2 \right]- \alpha \ln \frac{S_{\rm max}}{S_{\rm min}}, \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq95.png) (17)where Smax and Smin are the extreme singular values of the singular value decomposition of D. Smax/Smin is the square of the ratio of the longest and shortest axes of the velocity ellipsoid. If α is large the algorithm will tend to favour a small axis ratio, resulting in an isotropic velocity dispersion in the limit of large α. In order to use as little regularization as necessary we try Eq. (17) with α = 0 and, if diverging, increase α by steps of 0.5 until a converged estimate is obtained. The result is a dispersion matrix that is always positive-definite, but when α > 0 it may be more isotropic than it should be (Table 1).
(17)where Smax and Smin are the extreme singular values of the singular value decomposition of D. Smax/Smin is the square of the ratio of the longest and shortest axes of the velocity ellipsoid. If α is large the algorithm will tend to favour a small axis ratio, resulting in an isotropic velocity dispersion in the limit of large α. In order to use as little regularization as necessary we try Eq. (17) with α = 0 and, if diverging, increase α by steps of 0.5 until a converged estimate is obtained. The result is a dispersion matrix that is always positive-definite, but when α > 0 it may be more isotropic than it should be (Table 1).
An example with 100 stars illustrating how the estimated velocity dispersion depends on the value of α.
The derivative in Eq. (12) is calculated numerically, using the approximation 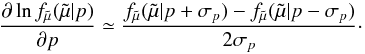 (18)Using a step size of ± σp is logical as we are looking for solutions typically within one standard deviation of the observed value.
(18)Using a step size of ± σp is logical as we are looking for solutions typically within one standard deviation of the observed value.
4. Testing on synthetic and real samples
We test our method (ML) together with the projection method (PM) as described by Dehnen & Binney (1998) on two types of samples. The first type is a synthetic sample, where nearby “stars” with known mean velocity and velocity dispersion have been generated. This sample allows us to investigate the bias of the two methods. The second type is a sample of real stars taken from the Geneva–Copenhagen survey of nearby F and G dwarfs (Nordström et al. 2004). These stars have measured radial velocities which allow us to estimate their mean velocity and velocity dispersion directly from Eq. (3). We use the resulting estimates as the “true” values when comparing the methods.
4.1. Synthetic samples
4.1.1. Generating the data
The generation of synthetic stars strictly follows the probabilistic model outlined in Sect. 3.1. Observational uncertainties were set to σμ = 1, 3, 10 and 30 mas yr-1 for the components of the proper motions, and to σp = 1 mas for the parallaxes. The stars have randomly generated positions (x,y,z) (in pc) within a radius of 100 pc from the sun. Each star is also given a randomized velocity using a normal distribution with the mean parameter 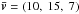 km s-1 and dispersion matrix D = diag(222, 142, 102) km2 s-2. From the rectangular coordinates the galactic longitude l and galactic latitude b are obtained with
km s-1 and dispersion matrix D = diag(222, 142, 102) km2 s-2. From the rectangular coordinates the galactic longitude l and galactic latitude b are obtained with 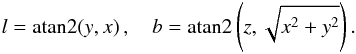 (19)Then for any position in sky (l,b) we define three orthogonal unit vectors
(19)Then for any position in sky (l,b) we define three orthogonal unit vectors ![Mathematical equation: \begin{equation} \vec{u} = \left[ \begin{array}{c} \vspace{2pt} \cos b \cos l \\ \vspace{2pt} \cos b \sin l\\ \sin b \end{array} \right] \quad \vec{l} = \left[ \begin{array}{c} \vspace{2pt} -\sin l \\ \vspace{2pt} \cos l\\ 0 \end{array} \right] \quad \vec{b} = \left[ \begin{array}{c} \vspace{2pt} -\sin b \cos l \\ \vspace{2pt} -\sin b \sin l\\ \cos b \end{array} \right], \end{equation}](/articles/aa/full_html/2013/03/aa20430-12/aa20430-12-eq141.png) (20)where u is the direction towards the star, and l and b are unit vectors in the tangential plane in the sky: + l in the direction of increasing longitude, and + b in the direction of increasing latitude. [u,l,b] is called the normal galactic triad at the point (l,b).
(20)where u is the direction towards the star, and l and b are unit vectors in the tangential plane in the sky: + l in the direction of increasing longitude, and + b in the direction of increasing latitude. [u,l,b] is called the normal galactic triad at the point (l,b).
The true parallax is given by 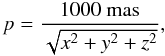 (21)whereupon the true proper motion in longitude and latitude is calculated as
(21)whereupon the true proper motion in longitude and latitude is calculated as 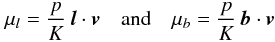 (22)respectively. Here, K = 4.7405 km s-1 kpc-1 (mas yr-1)-1 is the numerical constant relating mas yr-1 to km s-1 kpc-1.
(22)respectively. Here, K = 4.7405 km s-1 kpc-1 (mas yr-1)-1 is the numerical constant relating mas yr-1 to km s-1 kpc-1.
To get the observed proper motions and parallax, the errors in proper motion and parallax are added to the true values. Errors were drawn from the normal distribution with zero mean value and standard deviation equal to the observational uncertainties σμ and σp.
As the simulated data set depends on many different parameters it is not possible to investigate the methods for all possible combination of the parameters. We restrict ourselves to keep most of the parameters fixed (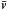 , D, R and σp), and only study how the methods perform as a function of n, the number of stars in the sample, and σμ, the uncertainty in proper motion. We use n = 30, 100, 300, 1000 and σμ = 1, 3, 10, 30 mas yr-1, which gives 16 different combinations. For each combination 100 samples are generated with different seeds for the random generator. The 100 samples are thus different in the generated true positions and velocities, as well as in the observational errors. The PM and ML methods were applied to all 1600 samples and the mean values and RMS variations of the estimated parameters calculated.
, D, R and σp), and only study how the methods perform as a function of n, the number of stars in the sample, and σμ, the uncertainty in proper motion. We use n = 30, 100, 300, 1000 and σμ = 1, 3, 10, 30 mas yr-1, which gives 16 different combinations. For each combination 100 samples are generated with different seeds for the random generator. The 100 samples are thus different in the generated true positions and velocities, as well as in the observational errors. The PM and ML methods were applied to all 1600 samples and the mean values and RMS variations of the estimated parameters calculated.
4.1.2. Results
With the synthetic sample we can see a difference in how the uncertainty in proper motion affects the values of the calculated velocities and velocity dispersions for the two methods.
In the left column of Fig. 1, results from the PM are shown. As expected, the dispersions are increasingly biased towards higher values when the uncertainty in proper motion increases. The effect is negligible when σμ = 1 or 3 mas yr-1, but for σμ = 10 or 30 mas yr-1 the increase in the dispersions is quite significant. This is reasonable since an error of 30 mas yr-1, at the median distance of the sample (80 pc), corresponds to a linear velocity error of about 11 km s-1, which is comparable to the true velocity dispersion. As can be seen in the bottom left panel of Fig. 1, the dispersion component in w is most severely overestimated ( ≃ 15 km s-1 versus the true value 10 km s-1), while the v and u components are somewhat less affected (18 versus 14 km s-1 and 25 versus 22 km s-1, respectively). Indeed, in all the cases the estimated dispersion (for n ≥ 100) is roughly equal to the sum in quadrature of the true dispersion and the linear velocity error corresponding to the proper motion uncertainty. This is a useful rule-of-thumb to estimate the expected bias of the PM under more general conditions. A more unexpected result is that, for the smallest samples (n = 30), the resulting dispersion matrix is unphysical (not positive definite) in about 1% of the cases. However, this does not happen with the larger samples.
 |
Fig. 1 Plots illustrating velocity dispersion versus the number of stars, for different values of σμ, as calculated for the synthetic samples described in Sect. 4.1. Diagrams in the left column are for the projection method (PM), the right column is for the maximum likelihood method (ML). The symbols represent the different galactic components of the dispersion: σu (•), σv (▾), σw (▴). The true values are indicated by the horizontal lines. |
The column to the right in Fig. 1 show the results of the ML method. We note that:
-
1.
Unlike the PM, the ML method is able to give unbiaseddispersions even for very large σμ, at least if the sample is not too small (n ≥ 100).
-
2.
For the smallest samples (n = 30) it is often necessary to use regularization. In most of these cases it is sufficient to use α = 0.5, which does not change the axis ratio much. Only in very few cases was α > 3 needed, which gives a nearly isotropic dispersion.
For the smallest sample size both PM and ML tend to underestimate the dispersion, especially along the major axis (u component) of the velocity ellipsoid.
4.2. Application to the Geneva-Copenhagen survey
The Geneva-Copenhagen survey (Nordström et al. 2004) is the largest and most complete study of a magnitude-limited, kinematically unbiased sample of F and G stars in the solar neighbourhood. It contains space velocities, Strömgren photometry, metallicities, rotation velocities and ages for more than 16 000 stars. The catalogue gives complete (u,v,w) space velocities based on Hipparcos data and radial velocities, from which the “true” vales of the mean velocity and velocity dispersion can be computed using Eq. (3).
4.2.1. Data used
Not all stars in the Geneva–Copenhagen survey could be used in this study. Stars with large relative parallax errors (p/σp < 10), large peculiar tangential velocities (|Δτ | > 200 km s-1), or missing some of the necessary data were eliminated. The remaining 7796 stars were divided into 10 bins of approximately equal size, sorted by their Strömgren color index b − y.
4.2.2. Results
Table 2 and Fig. 2 give results of both estimation methods (PM and ML) using tangential velocities only, as well as from the full space velocities (GC). No error bars are given here as the computation of the formal errors has not been implemented (cf. Sect. 5). It is seen that PM and ML give very similar results for all the samples and for all nine kinematic parameters, and they both agree well with the “true” values (GC). In the light of the experiments with the synthetic samples this is not surprising since the observational errors in this case are generally small (few mas), resulting in almost negligible tangential velocity errors. However, it is gratifying to note that the ML performs at least as well as the PM in this case.
Results of both the projection method (PM) and our maximum likelihood method (ML) applied to samples from the Geneva-Copenhagen survey (Nordström et al. 2004).
 |
Fig. 2 Left: mean velocities |
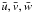
5. Conclusions
Galactic astrophysics is entering a new era in which large-scale astrometric, photometric and spectroscopic surveys provide vast quantities of data that need to be interpreted in terms of different structural, kinematic and evolutionary models. In this context it is essential to have at our disposal estimation techniques that can deal with incomplete data (e.g., missing radial velocities) and that are statistically efficient and reasonably unbiassed. It is also important to take the observational uncertainties into account, for although some of the surveys are much more precise than earlier ones (e.g., Gaia versus Hipparcos), they are also applied to much more distant stars, making the observational errors no less important.
For many stars brighter than 17th magnitude Gaia will provide the complete space velocity vector through a combination of its astrometric and spectroscopic measurements. However, the vast majority of stars observed by Gaia are fainter than 17th magnitude and will have no radial velocities. This is also the magnitude range where the astrometric errors in parallax and proper motion start to become problematic for studies of the galactic kinematics beyond the solar neighbourhood. For example, solar-type stars at 5 kpc distance will be observed at apparent magnitude 18 to 20, depending on the extinction, resulting in relative parallax errors of at least 50% and transverse velocity errors of several km s-1. The very large number of such stars will permit a detailed mapping of their distribution functions provided that the statistical biases can be mastered.
In this paper we have considered a seemingly very simple problem, namely to estimate the nine parameters describing the velocity distribution of stars under the Schwarzschild approximation, based exclusively on astrometric data and taking into account the observational uncertainities in the parallaxes and proper motions. The rigorous application of the maximum likelihood method to this problem turns out to be surprisingly complex, and we have devised an approximate numerical method to solve it. We have tested the method on both synthetic and real samples of stellar data, and found that it performs slightly better than the simple projection method (Dehnen & Binney 1998), especially when the observational errors are important and for small samples. For very small samples (less than about 30 stars) the projection method sometimes gives unphysical results. This is avoided with our method, which however may require regularization for such small samples, leading to a more isotropic dispersion tensor.
Several authors have applied maximum likelihood or Bayesian methods to estimate stellar kinematics using formulations that differ in various aspects from our approach. For example, Dehnen (1998) describes how general three-dimensional velocity distributions can be derived from tangential velocities, using the so-called maximum penalized likelihood estimate, i.e., a maximum-likelihood estimate constrained to give a smooth velocity distribution. While this method is very general, it does not take into account the observational uncertainties. Hogg et al. (2005) and Bovy et al. (2009) derive the parameters for a mixture of Gaussian distributions from tangential velocity data. While they do include the observational uncertainties through a linear propagation to the tangential velocities, their formalism is quite different from ours in the treatment of the parallax errors. It could be interesting to compare the two methods as they both depend on (different) approximations for small relative parallax errors.
The present method could be extended and generalized in various ways. One obvious extension is to allow that some stars have a measured radial velocity instead of, or in addition to the astrometric data. Another is to consider a more complex velocity distribution, e.g., a superposition of several Gaussian components. It is also desirable to apply a more efficient numerical solution technique than the downhill simplex method which was chosen for the present experiments for its ease of implementation. Alternative methods such as a quasi-Newton with finite differences (Press et al. 2007) would almost certainly be much more efficient. We note that the computing time scales linearly with the number of stars (for a fixed number of kinematical parameters), which makes it feasible to apply the ML method also to much larger samples than in our experiments. Finally, the formal errors (or more generally confidence regions) of the estimated quantities need to be computed, which could be done with moderate effort by mapping the log-likelihood function around its maximum.
This notation x ~ N(m,V) means that the random variable x follows the multi-dimensional normal distribution with mean value m and covariance matrix V. Similarly for a one-dimensional normal variable x ~ N(m,s2), m is the mean value and s2 the variance.
Acknowledgments
We wish to thank the anonymous referee for several useful suggestions which helped to improve the manuscript.
References
- Aumer, M., & Binney, J. J. 2009, MNRAS, 397, 1286 [NASA ADS] [CrossRef] [Google Scholar]
- Binney, J. J., Dehnen, W., Houk, N., Murray, C. A., & Penston, M. J. 1997, in Hipparcos – Venice ’97, eds. R. M. Bonnet, E. Høg, P. L. Bernacca, L. Emiliani, A. Blaauw, C. Turon, J. Kovalevsky, L. Lindegren, H. Hassan, M. Bouffard, B. Strim, D. Heger, M. A. C. Perryman, & L. Woltjer, ESA Spec. Publ., 402, 473 [Google Scholar]
- Bovy, J., Hogg, D. W., & Roweis, S. T. 2009, ApJ, 700, 1794 [NASA ADS] [CrossRef] [Google Scholar]
- Brosche, P., Schwan, H., & Schwarz, O. 2001, Astron. Nachr., 322, 15 [Google Scholar]
- de Bruijne, J. H. J. 2012, Ap&SS, 341, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Dehnen, W. 1998, AJ, 115, 2384 [NASA ADS] [CrossRef] [Google Scholar]
- Dehnen, W., & Binney, J. J. 1998, MNRAS, 298, 387 [NASA ADS] [CrossRef] [Google Scholar]
- ESA. 1997, The Hipparcos and Tycho Catalogues, ESA SP-1200 [Google Scholar]
- Hogg, D. W., Blanton, M. R., Roweis, S. T., & Johnston, K. V. 2005, ApJ, 629, 268 [NASA ADS] [CrossRef] [Google Scholar]
- Lagarias, J. C., Reeds, J. A., Wright, M. H., & Wright, P. E. 1998, SIAM J. Optimizat., 9, 112 [Google Scholar]
- Mignard, F. 2000, A&A, 354, 522 [NASA ADS] [Google Scholar]
- Nordström, B., Mayor, M., Andersen, J., et al. 2004, A&A, 418, 989 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Press, W., Teukolsky, S., Vetterling, W., & Flannery, B. 2007, Numerical Recipes: The Art of Scientific Computing, 3rd edn. (Cambridge University Press) [Google Scholar]
- Steinmetz, M., Zwitter, T., Siebert, A., et al. 2006, AJ, 132, 1645 [NASA ADS] [CrossRef] [Google Scholar]
- van Leeuwen, F. 2007, A&A, 474, 653 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Tables
An example with 100 stars illustrating how the estimated velocity dispersion depends on the value of α.
Results of both the projection method (PM) and our maximum likelihood method (ML) applied to samples from the Geneva-Copenhagen survey (Nordström et al. 2004).
All Figures
|
Fig. 1 Plots illustrating velocity dispersion versus the number of stars, for different values of σμ, as calculated for the synthetic samples described in Sect. 4.1. Diagrams in the left column are for the projection method (PM), the right column is for the maximum likelihood method (ML). The symbols represent the different galactic components of the dispersion: σu (•), σv (▾), σw (▴). The true values are indicated by the horizontal lines. |
| In the text | |
|
Fig. 2 Left: mean velocities |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.