| Issue |
A&A
Volume 635, March 2020
|
|
|---|---|---|
| Article Number | A124 | |
| Number of page(s) | 7 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201936883 | |
| Published online | 19 March 2020 | |
Machine-learning computation of distance modulus for local galaxies
1
Main Astronomical Observatory, National Academy of Sciences of Ukraine, 27 Akademika Zabolotnoho St., 04103 Kyiv, Ukraine
e-mail: andrii.elyiv@gmail.com
2
Bogolyubov Institute for Theoretical Physics of the NAS of Ukraine, 14-b Metrolohichna St., Kyiv 03143, Ukraine
Received:
10
October
2019
Accepted:
13
February
2020
Context. Quickly growing computing facilities and an increasing number of extragalactic observations encourage the application of data-driven approaches to uncover hidden relations from astronomical data. In this work we raise the problem of distance reconstruction for a large number of galaxies from available extensive observations.
Aims. We propose a new data-driven approach for computing distance moduli for local galaxies based on the machine-learning regression as an alternative to physically oriented methods. We use key observable parameters for a large number of galaxies as input explanatory variables for training: magnitudes in U, B, I, and K bands, corresponding colour indices, surface brightness, angular size, radial velocity, and coordinates.
Methods. We performed detailed tests of the five machine-learning regression techniques for inference of m−M: linear, polynomial, k-nearest neighbours, gradient boosting, and artificial neural network regression. As a test set we selected 91 760 galaxies at z < 0.2 from the NASA/IPAC extragalactic database with distance moduli measured by different independent redshift methods.
Results. We find that the most effective and precise is the neural network regression model with two hidden layers. The obtained root–mean–square error of 0.35 mag, which corresponds to a relative error of 16%, does not depend on the distance to galaxy and is comparable with methods based on the Tully–Fisher and Fundamental Plane relations. The proposed model shows a 0.44 mag (20%) error in the case of spectroscopic redshift absence and is complementary to existing photometric redshift methodologies. Our approach has great potential for obtaining distance moduli for around 250 000 galaxies at z < 0.2 for which the above-mentioned parameters are already observed.
Key words: galaxies: statistics / galaxies: distances and redshifts / galaxies: photometry / methods: data analysis
© ESO 2020
1. Introduction
Better-quality measurements of galaxy distances than those purely dependent on redshift are a fundamental goal in astronomy. Such measurements are important for establishing the extragalactic distance scale, estimating the Hubble constant and cosmological models (Zaninetti 2019; Hartnett 2006), and studying peculiar velocities of galaxies with respect to the Hubble flow (Karachentsev et al. 2015, 2006; Dupuy et al. 2019). Furthermore, reconstruction of the velocity field of galaxies is crucial for mapping the Universe, and will pave the way for exploration of the large-scale structure (LSS) elements such as galaxy groups (Melnyk et al. 2006; Makarov & Karachentsev 2011; Wang et al. 2012; Shen et al. 2016; Pulatova et al. 2015; Vavilova et al. 2005), clusters, filaments, and voids (Bertschinger et al. 1990; Erdoǧdu et al. 2006; Courtois et al. 2012; Elyiv et al. 2015; Tully et al. 2019), including the zone of avoidance of our galaxy (Sorce et al. 2017; Vavilova et al. 2018; Jones et al. 2019).
Traditionally, distances to galaxies have been measured using the distance modulus m−M which is the difference between absolute and apparent stellar magnitudes. Theoretical estimations of the absolute magnitude M of a whole galaxy or some objects inside it could be performed through primary and secondary indicators. Primary indicators are based on the standard candles, which are stars with known luminosity of which there are several types: Cepheids, RR Lyrae, Type Ia supernovae, and so on. These methods provide distances with errors ranging from 4% for the Local Group galaxies (Riess et al. 2012) to 10% for more distant galaxies. Secondary indicators, the Tully–Fisher (TF) and fundamental plane (FP) empirical relationships, provide distance errors of ∼20% and are usually applied for galaxies at z ∼ 0.1−0.2, where individual stars are not resolved.
Despite the machine learning technique being applied in astrophysics since the 1990s (Storrie-Lombardi et al. 1992), only in the last 10 years has computing power been sufficient to allow its widespread use (Bogdanos & Nesseris 2009; Nesseris & Shafieloo 2010; Nesseris & García-Bellido 2012; VanderPlas et al. 2012; Murrugarra-LLerena & Hirata 2017; Dobrycheva et al. 2017; Baron 2019). Such a trend is also seen in rapidly increasing observational data and the development of data-driven science, where mining of datasets uncovers new knowledge. Regression analysis occupies an important place among statistical techniques and is widely used for estimation of functional relationships between variables (Isobe et al. 1990) for spectroscopic (Bukvić et al. 2008) and photometric (Ascenso et al. 2012) data processing. A machine learning genetic algorithm was used to build model-independent reconstructions of the luminosity distance and Hubble parameter as a function of redshift using supernovae type Ia data by Arjona & Nesseris (2019), Bogdanos & Nesseris (2009). A detailed analysis and classification of contemporary published literature on machine learning in astronomy is presented by Fluke & Jacobs (2020).
The redshift could be approximately reconstructed from the photometric redshift calculation technique (Bolzonella et al. 2000). Supervised machine learning regression is commonly applied for this task (Salvato et al. 2019). Sets of galaxies with multi-band photometry and known spectroscopic redshifts are used in training regression models to map between high-dimensional photometric band space and redshifts. It is also possible to input new data into the trained model where spectroscopy is not available. The most popular computational tools for photometric redshift inferences are the Random Forests (Carliles et al. 2010, 2008; Carrasco Kind & Brunner 2013) and neural network regressions (Cavuoti et al. 2012; Bonnett 2015) including deep machine learning techniques (D’Isanto & Polsterer 2018).
Regression in a Bayesian framework was considered by Kügler & Gianniotis (2016) and was used to model the multimodal photometric redshifts. Zhou et al. (2019) published a catalogue of calibrated photometry of galaxies from the Extended Groth Strip field. These latter authors improved photometric redshift accuracy with an algorithm based on Random Forest regression.
The principle aim of our work is to exploit available observations for galaxy datasets at redshifts z < 0.2 in order to complement existing methods of distance measurement. For distance modulus m−M (angular size distance) reconstruction we used different observational characteristics such as photometry of galaxies, their surface brightness and angular sizes, radial velocity, colour indices as analogues of morphological types, and celestial coordinates.
The influence of some parameters is not direct but we took them into account because of their possible confounding effect on m−M. We also took into consideration the celestial coordinates of galaxies, which are distributed in a non-random manner in the Universe, forming a large-scale structure web, and so we assumed that direction in the sky is important. The probability density function (PDF) of distance to galaxy depends on the direction of observation because many galaxies are concentrated in clusters and filaments, whereas empty regions or cosmic voids occupy more than half of the volume of the Local Universe. Previously, the galaxy coordinates were taken into account for photometric redshift computations by maximizing the spatial cross-correlation signal between the unknown and the reference samples with redshifts (Newman 2008; Rahman et al. 2015). Aragon-Calvo et al. (2015) computed photometric redshifts from the product of PDFs obtained from the colours, the cosmic web, and the local density field.
The machine learning regression approach uses a data sample for which a target value, distance modulus in our case, has already been measured with some accuracy using another direct or indirect method. The model should be trained on a “training” sample to be able to make a regression on a new “test” sample that has never been input into the model. Award of training is getting minimal difference between predicted and real target value, which is an error of the model. Training of the model consists in a numerical minimisation of error by changing the model parameters. One important step is an error generalisation, where the model is evaluated on the test sample (Goodfellow et al. 2016).
We applied and compared the performances of five regression models: linear, polynomial, k-nearest-neighbour regression, gradient boosting, and artificial neural network (ANN). By comparing their respective benefits and disadvantages we evaluated the m−M error from the redshift-independent galaxy distance catalogue from the NASA/IPAC extragalactic database (Steer et al. 2017). We also considered a case where the radial velocity is not available, trying to recover m−M from the available observational data.
One advantage of our approach is that we do not cut the sample by luminosity or apparent magnitude and do not impose restrictions on galaxy distribution in space in order to avoid losing useful information. Also, we used easily observable basic parameters, which are known for a myriad of galaxies.
In Sect. 2 we describe the sample of local galaxies used in this work and training sample. In Sect. 3 we discuss the main principles of machine-learning regression on the basis of linear regression. Sections 4–7 represent the application of polynomial, k-nearest neighbour, gradient boosting, and neural network regressions, respectively. We present a discussion and our main conclusions in Sect. 8.
2. Local galaxy sample
We used the catalogue of redshift-independent distances from the NASA/IPAC extragalactic database (Steer et al. 2017). This is a compilation of distance measurements made using 75 different methods taken from more than 2000 refereed articles. The latest version 15.1.01 (December 2018) contains 66 388 distance measurements for 7156 galaxies. These are based on primary methods that use the standard candles such as Cepheids and Type Ia supernova, or standard rulers such as globular cluster radii and masers, among others. Also, the catalogue contains 204 038 distances for 141 249 galaxies based on secondary methods like TF, FP relations, and others. The following information is available for each galaxy: identity (ID), distance modulus in mag m−M, one-sigma statistical error of the distance modulus, distance indicator method, reference to a published article, reference to a published distance, and other parameters.
In order to obtain galaxy coordinates and other available observational parameters we matched them by galaxy ID with the Lyon–Meudon Extragalactic Database2 (HyperLeda Makarov et al. 2014). We considered both the northern and southern sky, except for the low galactic latitudes |b| < 15° (Zone of Avoidance). Radial velocities of galaxies were limited to 1500 km s−1 < VLG < 60 000 km s−1. We did not use the nearby galaxies with VLG < 1500 km s−1 to avoid selection effects as the population of nearby galaxies mainly consists of dwarf galaxies (including dwarf galaxies of low surface brightness Tully et al. 2014; Makarov & Uklein 2012; Karachentseva & Vavilova 1994; Einasto 1991), which are not common among galaxy populations with VLG > 1500 km s−1. Also, the distribution of galaxies at small redshifts is very inhomogeneous due to the presence of the Virgo cluster and Tully void. This could create a bias for the model when the galaxy coordinates are used as input explanatory variables for regression. An upper limit at VLG = 60 000 km s−1 was chosen since the number of galaxies with known distances drops dramatically at this velocity; see Fig. 1.
 |
Fig. 1. Radial velocity distribution of galaxies that meet the criteria described in Sect. 2. The sample of galaxies is based on the catalogue of redshift-independent distances from the NASA/IPAC extragalactic database (Steer et al. 2017). |
We reduced all of the distance moduli to the common Hubble constant H0 = 70 km s−1 Mpc−1, since this is the default value used by the Supernova Cosmology Project and the Supernova Legacy Survey (Steer et al. 2017). Distance modulus error depends on the method used and varies in a wide range from 0.06 mag for Cepheids and RR Lyrae Stars to 0.42 mag for the FP and TF methods (Fig. 2). We used measurements made with primary3 and secondary4 methods with a mean error of less than 0.50 mag to train our models. However, all the individual measurements with error above 0.50 mag were removed from the sample. Some galaxies have several distance measurements taken by different authors using different methods. We aggregated such distances for each galaxy and calculated the weighted mean m−M with the weight inversely proportional to the square of the error.
 |
Fig. 2. Distribution of distance modulus errors for all galaxies from Steer et al. (2017) (black line). As an example, the distributions are shown for typical methods: Cepheids and RR Lyrae (red thin line), TF and FP relations methods (blue thick line). |
Finally, we obtained an initial sample of 91 760 galaxies, S0.50, with the following information: Supergalactic coordinates (SGB, SGL); radial velocity with respect to the Local Group, VLG; the decimal logarithm of the projected major axis length of the galaxy at the isophotal level of 25 mag arcsec−2 in the B-band log d25; mean surface brightness within 25 mag isophote in the B-band, bri25; the apparent total U, B, I, and K magnitudes; and U–I and B–K colours, which represent a morphological type of galaxy. We did not use other observational parameters like 21 cm line flux and velocity rotation since these are only available for <3% galaxies in our sample.
We created the second sample of galaxies limiting with m−M error of <0.25 mag and 1500 km s−1 < VLG < 30 000 km s−1. This sample contains 9360 galaxies with distances calculated mostly using accurate Cepheids and RR Lyrae methods. We refer to this sample as S0.25.
For the correct application of the machine-learning algorithms we reduced VLG to magnitude units using the following conversions.
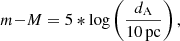
where angular size distance for the ΛCDM cosmological model:
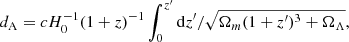
with parameters H0 = 70 km s−1 Mpc−1, Ωm = 0.3089, ΩΛ = 0.6911. Finally, the redshift could be expressed as a radial velocity VLG as:
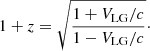
We do not consider the K-correction here because it is significantly smaller than a typical error of distance modulus at redshifts <0.2. We used a diameter of log d25 because it is already in logarithmic scale. Because supergalactic coordinates are periodic, as are any spherical coordinates, we converted them to 3D Cartesians with unit radial vector for all galaxies.
Here, we considered 12 attributes of galaxies, which are the input explanatory variables to predict our desired target: distance modulus m−M. We chose these variables because they are easily accessible for observation and are available for a large number of galaxies. In particular, galaxy coordinates provide information about the LSS, colour indices correlate with a morphological type, and photometric data and angular diameters correlate with distance modulus. Therefore, we used a compilation of different parameters, some of which, such as for example position in the sky, surface brightness, and colour indices, have never been used before for distance modulus estimation.
3. Linear regression
We explain the main principles of machine-learning regression on a linear model. This is a basic regression model that deals with linear combinations of input variables (also referred to as features or attributes). Multidimensional linear regression is a system that takes an n-size vector of input explanatory variables x ∈ Rn and predicts a scalar, so-called dependent variable, y ∈ R, with some approximation ŷ:
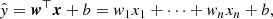
where the vector of model parameters is w ∈ Rn and b ∈ R is the intercept term (bias). Parameters w could be interpreted as the weights of the contribution of certain features to the composed output value ŷ. The larger the absolute weight of a feature, wi, the larger the impact of the ith feature on the prediction.
The mean squared error (MSE) of the predicted output values ŷ with respect to the real y,
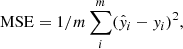
is widely used as an indicator of model performance; here m is the size of the sample. In other words, the model performance could be expressed as the Euclidean distance between predicted m-dimension vectors ŷ and y.
The main requirement of the machine learning regression is that the algorithm work well on new inputs that were not involved in the training stage. Therefore, we split our data into training and test samples. Typically, the test sample represents a randomly selected 20–35% subsample of the observations from the primary sample. It is important that the training and test samples be independent and have the same unbiased distributions.
The model should optimise its parameters on a training sample with minimisation MSEtrain and evaluate the obtained (w, b) parameters on a test sample. The test error MSEtest should be minimised as well. This error with its variation reflects the expected level of error of y for the new inputs x. Such a procedure is called “generalisation” and differentiates the machine learning technique from a simple fitting. There are two main problems, which may appear during the training: underfitting, when the training error is too large, and overfitting, when the training error is small but the test error is still large (Goodfellow et al. 2016).
Linear regression is one of the simplest models, with a small capacity but a high parsimony and learning speed. For training of linear regression and all the models considered here, we used the free machine-learning library Scikit-learn5. To prevent very large parameters w, we applied the Ridge regularisation (Greiner 2004), where the loss function for minimisation is MSEtrain + ||w||2. We normalised all features before training by removing the mean and scaling to unit variance, which is a common requirement for many machine-learning estimators. To evaluate the accuracy of our predictive model with the new data, we used the k-folds cross-validation technique (Kohavi 1995): we randomly split our sample into five equally sized subsamples and trained the model five times, sequentially using one subsample as the test sample and the other four as the training samples, rotating the test subsample each time. This gave us five independent estimations of MSEtest from which we calculated the mean and its standard deviation.
For the larger S0.50 sample, a linear regression gives the test root–mean–square error RMSEtest = 0.376 ± 0.003 mag. Using Eq. (1) this error was converted to a linear relative distance error of 17.3% ± 0.2%. We obtained the following coefficients of linear regression w in decreasing order of absolute value: wVLG = 0.713, wK = 0.134, wlog d25 = −0.110, wbri25 = 0.103, wU = −8.92 × 10−2, wB − K = 6.75 × 10−2, wU − I = 6.37 × 10−2, wYSG = 3.08 × 10−2, wXSG = 1.25 × 10−3, wZSG = −7.45 × 10−5, wB = 0, wI = 0. The most important parameter here is the radial velocity VLG, and those with the least significance are the K magnitude, angular diameter, and surface brightness. The remaining parameters provide a smaller contribution to the distance estimation.
In cases where we do not have a redshift or VLG value, it is still possible to recover distance using other data with an accuracy of 0.52 mag or 24% of the angular size distance. The errors for different models considered in this paper can be found in Table 1. For the sample of nearby galaxies with more accurate measurements of distance modulus S0.25, we obtained RMSEtest = 0.288 ± 0.019 mag (13% ± 0.9%). In the case of radial velocity estimation, we obtained an error of 0.644 ± 0.029 mag (30% ± 1.3%).
Applied regression models with RMSEtest errors using all the attributes of galaxies and without the VLG value.
4. Polynomial regression
A polynomial regression is an extension of a linear regression, where a kth degree polynomial relation between the input explanatory variables x and the dependent variable y is used. We considered second- and third-order polynomial regressions.
For the second-order polynomial regression we obtained RMSEtest = 0.366 ± 0.003 mag (16.9% ± 0.1%) for S0.50 sample. For the third-order, 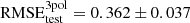 mag (16.7% ± 1.7%). As the third-order regression offers only a small improvement with respect to the second-order regression but with a greater uncertainty, we did not consider it. For the S0.25 sample we obtained an error of 0.276 ± 0.017 mag (13% ± 0.9%). When we eliminate the radial velocity, the test error is 0.607 ± 0.021 mag (28% ± 1%).
mag (16.7% ± 1.7%). As the third-order regression offers only a small improvement with respect to the second-order regression but with a greater uncertainty, we did not consider it. For the S0.25 sample we obtained an error of 0.276 ± 0.017 mag (13% ± 0.9%). When we eliminate the radial velocity, the test error is 0.607 ± 0.021 mag (28% ± 1%).
5. A k-nearest neighbours regression
The k-nearest neighbours (k-NN) regression uses the k closest training points around the test point in the feature nD space. The predicted variable ŷ in this case is the weighted average of the values y of the k nearest neighbours (Altman 1992). A k-NN algorithm computes distances or similarities between the new instance and the training instances to make a decision. Normally, it uses weighted averaging, where each neighbour among the closest k neighbours has a weight of 1/d, where d is the distance to the neighbour.
k-NN regression is a type of instance-based learning. Contrary to this approach, a linear regression and many other function-based approaches use explicit generalisation.
k-NN regression has one hyperparameter, k, which allows the number of near neighbours to be taken into account. We obtained our best results for the S0.50 sample for the case where distance weight to neighbour was inverse to the distance with Euclidean metric, with k = 56 near neighbours. We obtained an error of RMSEtest = 0.370 ± 0.003 mag (17.0% ± 0.1%) using radial velocity, angular diameters, and photometry in B and I bands. As can be seen from Fig. 3, the minimum error forms a plateau in the range 40 < k < 80. A combination of photometric data and angular diameter, simultaneously excluding radial velocity, provides an error of 0.50 (23%). The test errors of regression for the S0.25 sample are listed in Table 1.
 |
Fig. 3. Dependence of RMSEtest of k-NN regression on k number of neighbours for different sets of input features: I, B bands and angular diameter (red dots), radial velocity (black), I, B bands, angular diameter, and radial velocity (blue). |
6. Gradient-boosting regression
The gradient-boosting regression is a kind of ensemble algorithm, which is widely used in machine learning. The ensemble algorithm is a stack of simple prediction models, like decision tree, linear regression, and so on, joined together to make a final prediction. The theory behind this method is that many weak models predict a target variable with independent individual error. Superposition of these models could show better results than any single predictor alone.
There are two main approaches of forming the ensemble algorithm; “bagging”, where all simple models are independent and the final result is averaged over each model output. The second approach is referred to as boosting, where the predictors are lined up sequentially and each subsequent predictor learns from the errors of the previous one, reducing these errors. We applied gradient-boosting regression (Mason et al. 1999) using the open-source software library XGBoost6. This algorithm minimises the error function by iteratively choosing a function that points to the negative gradient direction in the space of model parameters.
To prevent overfitting we applied DART (Dropouts meet Multiple Additive Regression Trees) technique, which decreases the effect of overspecialisation when adding new trees. We found the optimal hyperparameters when using gradient-boosting regression and obtained a test error of RMSEtest = 0.355 ± 0.003 mag (16.3% ± 0.1%).
7. Neural-network regression
The Multilayer Perceptron is a type of feedforward ANN consisting of neurons grouped in parallel layers: an input layer, a hidden layer or layers, and an output layer. All the neurons of adjacent layers are connected. The main characteristic of an ANN is the ability to transmit a numerical signal from one artificial neuron to another in a “feedforward” direction from the input layer to the output layer. In a regression model, the output layer is a single neuron that computes the target value ŷ. The output of each neuron is transformed by some non-linear activation function of the sum of its inputs. The outputs of the neurons from one layer are the input for neurons of the next layer, and so on. The connection between neurons has a weight that adjusts as learning proceeds. This weight corresponds to the importance of a signal at its transmission.
The neural network is a very powerful tool for machine-learning regression since it can approximate the continuous function of many variables with any accuracy under certain conditions (Cybenko 1989). The ANN regression utilises a supervised learning technique called backpropagation of error (loss function) for its training. In this study, we used the mean squared error (Eq. (5)) as a loss function.
For our regression task we took all 12 input features mentioned in Sect. 2 as neurons of the input layer. The best model performance was reached by shallow ANN with two hidden layers with 24 and 228 neurons, respectively. As an activation function we used rectified linear unit function “relu”, f(x) = max(0, x). The Broyden–Fletcher–Goldfarb–Shanno algorithm is considered to be the most appropriate for our task; it is one of the quasi-Newton methods for solving ANN optimisation problems (Curtis & Que 2015). The regularisation term of L2 penalty was chosen as 0.0005 to avoid over-fitting. The learning rate was in mode “invscaling”.
Finally, we obtained a test error RMSEtest = 0.354 ± 0.003 mag (16.3% ± 0.1%), which is comparable to the gradient-boosting result. The plot of predicted versus true values is shown in Fig. 4.
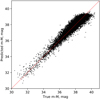 |
Fig. 4. Dependence of the predicted distance moduli versus the true distance moduli for an ANN regression model using all the attributes for the S0.5 sample. |
8. Discussion and conclusions
Table 1 presents root–mean–square test errors for the sample S0.5 (described in Sect. 2) after applying regression models for two sets of input attributes. The first set includes all attributes: photometric data, angular diameter, surface brightness, colour indices, radial velocity, and position of a galaxy in the sky (second column). The second set has the same attributes but without radial velocity (third column). The lowest errors are for the gradient-boosting and the neural network regressions. However, the ANN model has a smaller complexity than the gradient-boosting model and we chose ANN regression as the most appropriate model according to Occam’s razor principle, i.e. ANN regression has a good trade-off between simplicity and accuracy.
The last ten columns of Table 1 show the importance of each observable galaxy attribute. We quantified this importance as the increase in test error, as a percentage, due to leaving out a given attribute. The most important contribution comes from radial velocity, especially for linear, polynomial, and k-NN regressions (32–37%). At the same time, a radial velocity is less important for the gradient-boosting and ANN models (22–26%), as these approaches effectively also use information from other attributes. For ANN regression, the most important after VLG is Supergalactic coordinates of galaxy (1.09%), U − I colour (0.71%), I mag (0.47%), and angular diameter (0.33%). The rest of attributes individually have importance less than 0.22%.
Table 2 shows the mean errors of various methods for m−M computing applied to the S0.50 sample using all attributes. As can be seen, the ANN regression has an error of 0.35 mag, which lies between the values of the errors of the BCG7 and TF relation8 methods, and shows a better result than the FP relation (0.42 mag). Direct conversion of a radial velocity to m−M according to Eqs. (1)–(3) gives a mean error of 0.40 mag (Conv. VLG → m−M in Table 2). Therefore, usage of all available attributes improves the uncertainty from 0.40 to 0.35 mag.
Comparison of one-sigma statistical error of the distance modulus for different methods from the NASA/IPAC Extragalactic Database with three cases considered in our work: the ANN regression using all attributes and without radial velocity, and using direct conversation radial velocity to m−M according to Eqs. (1)–(3).
When we exclude VLG from consideration, our method gives an error of 0.44 mag (20%), which is still acceptable for studying the LSS web and galaxy evolution. The case of using all the attributes but without radial velocity of galaxies is analogous to photometric redshift computation. The only difference is that the dependent variable is distance modulus instead of radial velocity. The relative RMSE test error of 20% will also apply to the redshift predictions. As can be seen from the second column of Table 2, the ANN regression (all attributes) could potentially be applied to 393 359 galaxies, which is the number of unique galaxies from the Lyon–Meudon Extragalactic Database for which all ten observational parameters needed for this model are available. The catalogue of distance modulus (Steer et al. 2017) contains 183 058 unique galaxies. Therefore, we expect to contribute an additional 210 301 distance moduli computed with an accuracy of 0.35 mag at z < 0.2. Furthermore, the Lyon–Meudon Extragalactic Database contains 436 140 galaxies with nine of the required observational parameters but with unknown radial velocity. We expect to compute m−M with an accuracy of 0.44 mag, and redshift with an accuracy of 20% for around 40 000 galaxies with unknown radial velocities.
We demonstrate how the ANN regression reconstructs m−M at different distances in Fig. 5. The black line represents one-sigma statistical error from the NASA/IPAC extragalactic database for galaxies from the S0.5 sample. The error increases from 0.2 to 0.4 at radial velocities below 10 000 km s−1. This can be explained by the decreased contribution of high-accuracy Cepheid and RR Lyrae measurements of m−M. The error reaches 0.46 mag for galaxies with VLG > 30 000 km s−1. The majority of the distance moduli for those galaxies were estimated using the FP method with an error of 0.46 mag.
 |
Fig. 5. Root-mean-square errors of m−M for various measurements of galaxies with different radial velocities. In order of line width increasing: distance modulus statistical errors from the NASA/IPAC extragalactic database used in our study (black line), after conversion VLG to m−M (red line), using the ANN regression without VLG (green line), using the ANN regression with all available attributes (blue line). |
Direct use of the radial velocity as an analogue of linear distance according to Eqs. (1)–(3) causes large errors of 0.5–0.6 mag for VLG < 7000 km s−1 due to the influence of collective motions caused by local galaxy clusters and voids. At larger distances, this kind of distance measurement provides almost constant error of around 0.40 mag.
Our ANN regression method, even without information about VLG, could improve the accuracy of distance measurements for nearby galaxies and provides RMSE 0.44 mag for all distances. Addition of the radial velocity to our ANN regression model decreases the error to 0.35 mag for all distances. The performance of our ANN model demonstrates the fact that the influence of velocity at small radial velocities should be decreased in favour of other parameters such as angular diameter, photometry, and so on. This is why for our model the influence of local clusters and voids is negligible and the distance modulus error is almost constant at 0.35 mag for all VLG (blue thick line Fig. 5).
Our approach is especially useful for measuring distances for galaxies with VLG > 10 000 km s−1, where primary methods are not working. Therefore, the regression model developed here is competitive against widely used secondary methods for m−M measurement such as the FP and TF relation.
We proposed the new data-driven approach for computing distance moduli to local galaxies based on ANN regression. In addition to traditionally used photometric data we also involved the surface brightness, angular size, radial velocity, and the position in the sky of galaxies to predict m−M. Applying our method to the test sample of randomly selected galaxies from the NASA/IPAC Extragalactic Database we obtained a root–mean–square error of 0.35 mag (16%), which does not depend on the distance to a galaxy and is comparable with the mean errors from the TF and FP methods. Our model provides an error of 0.44 mag (20%) in cases where radial velocity is not taken into consideration.
In the future we plan to make a more detailed comparison of our ANN regression approach with other physically based methods. Namely, we are going to build an analogue of the 2D redshift space correlation function with distance modulus instead of redshift. More accurate methods should reveal the smaller effects of distortion caused by both random peculiar velocities of galaxies and by the coherent motions of galaxies in the LSS. Also, we will apply our ANN model to measure m−M for galaxies with unknown distance moduli in the range of radial velocities 1500 < VLG < 60 000 km s−1 and release a corresponding catalogue. This catalogue will include distance moduli computed for around a quarter of a million galaxies with z < 0.2.
Maser, SNII optical, the old globular cluster luminosity function method (GCLF), planetary nebulae luminosity function (PNLF), surface brightness fluctuations (SBF) method, Miras, SNIa SDSS, TypeII Cepheids, SNIa, HII region diameter, Horizontal Branch, colour-magnitude diagram (CMD), Eclipsing Binary, tip of the red giant branch (TRGB), RR Lyrae, Cepheids, Red Clump.
A secondary distance indicator by the brightest galaxies in galaxy clusters as standard candles (Hoessel 1980).
Standard candles based on the absolute blue magnitudes of spiral galaxies (Tully & Fisher 1977).
Acknowledgments
We would like to thank very much referee for kind advices and useful remarks. This work was partially supported in frame of the budgetary program of the NAS of Ukraine “Support for the development of priority fields of scientific research” (CPCEL 6541230).
References
- Altman, N. 1992, Am. Stat., 46, 175 [Google Scholar]
- Aragon-Calvo, M. A., van de Weygaert, R., Jones, B. J. T., & Mobasher, B. 2015, MNRAS, 454, 463 [NASA ADS] [CrossRef] [Google Scholar]
- Arjona, R., & Nesseris, S. 2019, ArXiv e-prints [arXiv:1910.01529] [Google Scholar]
- Ascenso, J., Lombardi, M., Lada, C. J., & Alves, J. 2012, A&A, 540, A139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baron, D. 2019, ArXiv e-prints [arXiv:1904.07248] [Google Scholar]
- Bertschinger, E., Dekel, A., Faber, S. M., Dressler, A., & Burstein, D. 1990, ApJ, 364, 370 [NASA ADS] [CrossRef] [Google Scholar]
- Bogdanos, C., & Nesseris, S. 2009, JCAP, 0905, 006 [NASA ADS] [CrossRef] [Google Scholar]
- Bolzonella, M., Miralles, J. M., & Pelló, R. 2000, A&A, 363, 476 [NASA ADS] [Google Scholar]
- Bonnett, C. 2015, MNRAS, 449, 1043 [NASA ADS] [CrossRef] [Google Scholar]
- Bukvić, S., Spasojević, D., & Žigman, V. 2008, A&A, 477, 967 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carliles, S., Budavári, T., Heinis, S., Priebe, C., & Szalay, A. 2008, ASP Conf. Ser., 521, 394 [Google Scholar]
- Carliles, S., Budavári, T., Heinis, S., Priebe, C., & Szalay, A. S. 2010, ApJ, 712, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Carrasco Kind, M., & Brunner, R. J. 2013, MNRAS, 432, 1483 [NASA ADS] [CrossRef] [Google Scholar]
- Cavuoti, S., Brescia, M., Longo, G., & Mercurio, A. 2012, A&A, 546, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Courtois, H. M., Hoffman, Y., Tully, R. B., & Gottlöber, S. 2012, ApJ, 744, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Curtis, F., & Que, X. 2015, Math. Prog. Comp., 7, 399 [CrossRef] [Google Scholar]
- Cybenko, G. 1989, Math. Control Signals Syst., 2, 303 [Google Scholar]
- D’Isanto, A., & Polsterer, K. L. 2018, A&A, 609, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dobrycheva, D. V., Vavilova, I. B., Melnyk, O. V., & Elyiv, A. A. 2017, ArXiv e-prints [arXiv:1712.08955] [Google Scholar]
- Dupuy, A., Courtois, H. M., & Kubik, B. 2019, MNRAS, 486, 440 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, M. 1991, MNRAS, 250, 802 [NASA ADS] [CrossRef] [Google Scholar]
- Elyiv, A., Marulli, F., Pollina, G., et al. 2015, MNRAS, 448, 642 [NASA ADS] [CrossRef] [Google Scholar]
- Erdoǧdu, P., Lahav, O., Huchra, J. P., et al. 2006, MNRAS, 373, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Fluke, C. J., & Jacobs, C. 2020, WIREs Data Mining and Knowledge Discovery, in press [arXiv:1912.02934] [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (MIT Press), 781 [Google Scholar]
- Greiner, R. 2004, in Feature Selection, L1 vs. L2 Regularization, and Rotational Invariance, Proceedings of the Twenty-first International Conference on Machine Learning, 78 [Google Scholar]
- Hartnett, J. G. 2006, Found. Phys., 36, 839 [NASA ADS] [CrossRef] [Google Scholar]
- Hoessel, J. G. 1980, ApJ, 241, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Isobe, T., Feigelson, E. D., Akritas, M. G., & Babu, G. J. 1990, ApJ, 364, 104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, D., Schroeder, A., & Nitschke, G. 2019, ArXiv e-prints [arXiv:1903.07461] [Google Scholar]
- Karachentseva, V. E., & Vavilova, I. B. 1994, Bull. Spec. Astrophys. Obs., 37, 98 [NASA ADS] [Google Scholar]
- Karachentsev, I. D., Kudrya, Y. N., Karachentseva, V. E., & Mitronova, S. N. 2006, Astrophysics, 49, 450 [NASA ADS] [CrossRef] [Google Scholar]
- Karachentsev, I. D., Tully, R. B., Makarova, L. N., Makarov, D. I., & Rizzi, L. 2015, ApJ, 805, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Kohavi, R. 1995, Morgan Kaufmann, 1, 1137 [Google Scholar]
- Kügler, S. D., & Gianniotis, N. 2016, ArXiv e-prints [arXiv:1607.06059] [Google Scholar]
- Makarov, D., & Karachentsev, I. 2011, MNRAS, 412, 2498 [NASA ADS] [CrossRef] [Google Scholar]
- Makarov, D. I., & Uklein, R. I. 2012, Astrophys. Bull., 67, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Makarov, D., Prugniel, P., Terehova, N., Courtois, H., & Vauglin, I. 2014, A&A, 570, A13 [CrossRef] [EDP Sciences] [Google Scholar]
- Mason, L., Baxter, J., Bartlett, P. L., & Frean, M. 1999, Advances in Neural Information Processing Systems (MIT Press), 512 [Google Scholar]
- Melnyk, O. V., Elyiv, A. A., & Vavilova, I. B. 2006, Kinematika i Fizika Nebesnykh Tel, 22, 283 [NASA ADS] [Google Scholar]
- Murrugarra-LLerena, J. H., & Hirata, N. S. T. 2017, in Galaxy Image Classification, eds. R. P. Torchelsen, E. R. D. Nascimento, D. Panozzo, et al., Conference on Graphics, Patterns and Images (SIBGRAPI), 30 [Google Scholar]
- Nesseris, S., & García-Bellido, J. 2012, JCAP, 1211, 033 [NASA ADS] [CrossRef] [Google Scholar]
- Nesseris, S., & Shafieloo, A. 2010, MNRAS, 408, 1879 [NASA ADS] [CrossRef] [Google Scholar]
- Newman, J. A. 2008, ApJ, 684, 88 [NASA ADS] [CrossRef] [Google Scholar]
- Pulatova, N. G., Vavilova, I. B., Sawangwit, U., Babyk, I., & Klimanov, S. 2015, MNRAS, 447, 2209 [NASA ADS] [CrossRef] [Google Scholar]
- Rahman, M., Ménard, B., Scranton, R., Schmidt, S. J., & Morrison, C. B. 2015, MNRAS, 447, 350 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Fliri, J., & Valls-Gabaud, D. 2012, ApJ, 745, 156 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Ilbert, O., & Hoyle, B. 2019, Nat. Astron., 3, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Shen, S.-Y., Argudo-Fernández, M., Chen, L., et al. 2016, Res. Astron. Astrophys., 16, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Sorce, J. G., Colless, M., Kraan-Korteweg, R. C., & Gottlöber, S. 2017, MNRAS, 471, 3087 [NASA ADS] [CrossRef] [Google Scholar]
- Steer, I., Madore, B. F., & Mazzarella, J. M. 2017, AJ, 153, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Storrie-Lombardi, M. C., Lahav, O., Sodre, Jr., L., & Storrie-Lombardi, L. J. 1992, MNRAS, 259, 8P [NASA ADS] [CrossRef] [Google Scholar]
- Tully, R. B., & Fisher, J. R. 1977, A&A, 54, 661 [NASA ADS] [Google Scholar]
- Tully, R. B., Courtois, H., Hoffman, Y., & Pomarède, D. 2014, Nature, 513, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Tully, R. B., Pomarède, D., Graziani, R., et al. 2019, ApJ, 880, 24 [NASA ADS] [CrossRef] [Google Scholar]
- VanderPlas, J., Connolly, A. J., Ivezic, Z., & Gray, A. 2012, Proceedings of Conference on Intelligent Data Understanding (CIDU), 47 [Google Scholar]
- Vavilova, I. B., Karachentseva, V. E., Makarov, D. I., & Melnyk, O. V. 2005, Kinematika i Fizika Nebesnykh Tel, 21, 3 [Google Scholar]
- Vavilova, I. B., Elyiv, A. A., & Vasylenko, M. Y. 2018, Russ. Radio Phys. Radio Astron., 23, 244 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, H., Mo, H. J., Yang, X., & van den Bosch, F. C. 2012, MNRAS, 420, 1809 [NASA ADS] [CrossRef] [Google Scholar]
- Zaninetti, L. 2019, Int. J. Astron. Astrophys., 9, 51 [CrossRef] [Google Scholar]
- Zhou, R., Cooper, M. C., Newman, J. A., et al. 2019, MNRAS, 488, 4565 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Applied regression models with RMSEtest errors using all the attributes of galaxies and without the VLG value.
Comparison of one-sigma statistical error of the distance modulus for different methods from the NASA/IPAC Extragalactic Database with three cases considered in our work: the ANN regression using all attributes and without radial velocity, and using direct conversation radial velocity to m−M according to Eqs. (1)–(3).
All Figures
|
Fig. 1. Radial velocity distribution of galaxies that meet the criteria described in Sect. 2. The sample of galaxies is based on the catalogue of redshift-independent distances from the NASA/IPAC extragalactic database (Steer et al. 2017). |
| In the text | |
|
Fig. 2. Distribution of distance modulus errors for all galaxies from Steer et al. (2017) (black line). As an example, the distributions are shown for typical methods: Cepheids and RR Lyrae (red thin line), TF and FP relations methods (blue thick line). |
| In the text | |
|
Fig. 3. Dependence of RMSEtest of k-NN regression on k number of neighbours for different sets of input features: I, B bands and angular diameter (red dots), radial velocity (black), I, B bands, angular diameter, and radial velocity (blue). |
| In the text | |
|
Fig. 4. Dependence of the predicted distance moduli versus the true distance moduli for an ANN regression model using all the attributes for the S0.5 sample. |
| In the text | |
|
Fig. 5. Root-mean-square errors of m−M for various measurements of galaxies with different radial velocities. In order of line width increasing: distance modulus statistical errors from the NASA/IPAC extragalactic database used in our study (black line), after conversion VLG to m−M (red line), using the ANN regression without VLG (green line), using the ANN regression with all available attributes (blue line). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.