| Issue |
A&A
Volume 562, February 2014
|
|
|---|---|---|
| Article Number | A109 | |
| Number of page(s) | 19 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/201322001 | |
| Published online | 13 February 2014 | |
Online material
Appendix A: Genetic algorithm
A correct sampling for a model depending on a large number of free parameters would yield a huge (unmanageable) grid of models. For instance, in a case where observations could be modelled with six parameters, by sampling each parameter with 15 values, which would generate 615 different sets of parameters. Depending on the time employed by a computer to calculate each model, the amount of time could last for weeks for a good sampling. Instead, a clever way to select the particular set of parameters to be tested can save us a lot of time. This is actually the main goal of the so-called genetic algorithms (GA).
We have written a genetic algorithm (IDL-based) to explore the whole parameter space without the need of creating a model grid. Basically, a range (minimum and maximum) for each parameter must be supplied, and optionally a prior (initial guessed) value for each parameter. The program performs the following steps:
-
1.
If provided, it uses the prior values as parents for the zero-agegeneration of individuals (i.e. sets of parameters).
-
2.
It generates a random population of N individuals within the range limits set by the user and based on the parents in step 1, modifying their values from −20% to 20% of the total range, with a given probability (also provided by the user but typically 10−30%). This allows some of the parameters to change while other maintain the same values.
-
3.
It generates the N models with the corresponding parameters. To get these models, the user has to provide the function to this end. For instance, in the case of transit fitting, one should provide a function that calculates the Mandel & Agol (2002) model for a given set of parameters or individuals.
-
4.
It obtains the χ2 value for each individual by comparing the models calculated in (3) to the provided datapoints.
-
5.
It selects the best 10% individuals and used them as parents for the new generation to be created in step (1).
The process is reiteratively repeated until a stable point is reached. This occurs when, after a specified number of generations, the best χ2 does not change more than 1% with respect to the best value of the previous generation. At this point, a random population of 10 × N new individuals is added to destabilize the minimum achieved to avoid local minima. If the stable point remains, we start again steps (1)−(5) until we reach again a stable point. The process is then repeated ten times. The final value has thus remained stable during more than 100 generations, with ten inclusions of 10 × N random points in the whole parameter space.
Once the final value has been obtained, we proceed to obtain the errors. We use generated χ2 maps for each pair of parameters centred on the best-fit parameters obtained by the GA. We slightly modify the GA values of each pair while keeping the others with the best-fit values. Then we measure the goodness of the fit (χ2). Finally, we compute χ2 contours for each pair for values 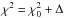 , where Δ is a tabulated value depending on the number of free parameters and the confidence limits to be achieved. We use 99% confident limits to ensure a good determination of the uncertainties in our parameters. Finally, if no correlation between parameters is found (the so-called banana-shaped contours), we select the upper and lower errors for each parameter as the largest ones obtained for all pairs.
, where Δ is a tabulated value depending on the number of free parameters and the confidence limits to be achieved. We use 99% confident limits to ensure a good determination of the uncertainties in our parameters. Finally, if no correlation between parameters is found (the so-called banana-shaped contours), we select the upper and lower errors for each parameter as the largest ones obtained for all pairs.
© ESO, 2014
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.