| Issue |
A&A
Volume 497, Number 3, April III 2009
|
|
|---|---|---|
| Page(s) | 667 - 676 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/200809876 | |
| Published online | 09 February 2009 | |
Online Material
Appendix A: Full description of the extended halo removal
In this Appendix we give a detailed description of the whole procedure followed to remove the objects with extended halos.
This is the outline of the whole process, while the single steps are explained in some detail thereafter:
- 1.
- A background map is computed using the original images.
- 2.
- The extended objects (galaxies and stars) to be removed are selected interactively.
- 3.
- For each selected object, the following steps are performed:
- (a)
- The objects projected onto it are masked
![[*]](/icons/foot_motif.png) with an interactive procedure.
with an interactive procedure.
- (b)
- Its isophotes are fitted with the IRAF task ellipse.
- (c)
- The resulting elliptical isophotes are then used as the input of the task bmodel to construct a model of the extended object.
- (d)
- The model is subtracted from the original image.
- (e)
- In the case of galaxies, when the subtraction leaves residuals due to the structure of the galaxy, these are removed manually with imedit.
- 4.
- After removing all the selected objects from the initial image a new
background map is calculated.
- 5.
- A mask of the remaining objects is constructed with SExtractor. This
mask is then used in a second iteration to improve the
interactively-made masks (point (3a)) applied during the
isophote fitting procedure.
- 6.
- At this point, the procedure can be repeated from point (3) until the subtraction is satisfactory.
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{9876f16}
\end{figure}](/articles/aa/olm/2009/15/aa09876-08/img95.png) |
Figure A.1: Upper panel: fraction of galaxies that were modeled. Lower panel: total number of galaxies that were modeled. |
| Open with DEXTER | |
Now we explain in more detail all the steps of the procedure:
- First background computation:
- due to
the variations found from chip to chip and to avoid the influence of
the interchip regions (which SExtractor treats as if they were part of
the actual image) the images were split into their original chips.
After that, an initial background estimation was computed for each chip using SExtractor with BACK_SIZE=256 and BACK_FILTERSIZE=3 as input parameter values. To reduce the influence of bright pixels, those with intensities above an established threshold were replaced by the mode of the pixel intensity of the same chip, which can be considered as a first estimation of the background level. The threshold was set manually before starting the process seeking to not remove the bright part of the background.
Once the background was obtained for each chip, the single background images were mosaiced to construct a global background map. This background map was then subtracted from the original image.
- Selection of the objects to be removed:
- the selection
of the objects to be modeled and removed was done in a subjective
way but following several guidelines. First, the BCG was always
modeled. Elliptical galaxies highly blended and/or
surrounded by small objects were also modeled. The selection of the
stars to be modeled was more field-dependent. As the amount of work
needed increased substantially with the number of objects to be
modeled, in those fields with a high density of stars only the
brightest stars were modeled. Sometimes, a star was modeled to
avoid the contamination from a close bright galaxy.
Figure A.1 shows the distribution in V of the galaxies that have been processed in this way. Up to
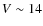 most of the
galaxies have been modeled.
most of the
galaxies have been modeled.
- Fitting and modeling:
- to reduce the computation
time, the process of isophote fitting, modeling and model
subtraction was done on small images of the selected objects
extracted from the background-subtracted global image.
The isophote fitting was done using the IRAF task ellipse. However, before that, all the projected objects and problematic regions (e.g. interchip regions) were masked. Due to the large number of objects that should be masked and taking advantage of the iterative process, this first step was enough to make a rough mask. Below we will show how the improvement is achieved.
A few differences were introduced when dealing with stars or galaxies. For stars the ellipticity was fixed to zero and the fitting did not reach the innermost region (usually saturated and, therefore, not suitable for fitting isophotes). Also, the center of the isophotes was not fixed because quite often the reflections of the stars were off-center with respect to the central regions. For galaxies no restrictions were imposed.
The output of ellipse was used as the input of the task bmodel which allows us to construct a two dimensional model of the object. This model was subtracted from the original image (i.e. before the first background subtraction).
This step was done for all selected objects.
- Second background estimation and object mask:
- the outcome of the
previous step was an image similar to the original one, in which
large objects have been removed. This allowed us to obtain an
improved background map, a better background subtracted image and a
better detection of the small objects. In fact, using SExtractor with
the background-subtracted images after removing the models, it
was possible to get a careful mask of all objects (except, of
course, from those that were removed from the image). This new
mask would serve to refine the previous (manually-done) one.
- Second fit and modeling:
- the fitting process done in
the first iteration was repeated using a refined mask for each
object. This helped to get a better fit and, as a result, a better
model.
The main difference with respect to the first iteration is that after the subtraction of the model from the galaxies, sometimes some residuals remained in the central regions. In such cases, these were manually edited using the IRAF task imedit. When editing the images only clearly spurious residuals were replaced by pixels simulating the background signal adding a Gaussian noise whose sigma was computed from surrounding regions. This has no effect on an object's photometry since the photometry of large galaxies is done with another image, avoiding the spurious detection of the residuals.
- Construction of the final images:
- in most fields, only
two iterations were enough to achieve a satisfactory result. After
modeling all the selected extended objects and subtracting them from
the initial image, the background was recomputed again and finally
subtracted from the model-subtracted image. The output of this
procedure was a background-subtracted image without the extended
modeled objects.
The final step was to produce the complementary image containing only the modeled galaxies. To be consistent in the photometry of the extended galaxies we do not use the models. We constructed a new image containing the original pixels (background subtracted) of the removed galaxies. However, to minimize the effect of the projected objects, the intensities of the pixels in which these fell were in fact replaced by the intensities of the models in the same pixels. In practice, this was done constructing a new mask of the objects contained in the background-subtracted image without large objects using SExtractor. Then, the final image was computed following these criteria for its pixels:
- If the pixel did not belong to an object (value in the mask
equal to zero) then the background-subtracted image value was
kept that corresponded to the original pixel of the galaxy.
- If the pixel indeed belonged to an object (value in the mask
greater than zero) then the value in the model was taken instead
of the value in the original image.
- If the pixel fell in an interchip region then the value from the model was used if available. In this way, we were able to improve the photometry of large galaxies with large regions lost in the interchip regions.
- If the pixel did not belong to an object (value in the mask
equal to zero) then the background-subtracted image value was
kept that corresponded to the original pixel of the galaxy.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{9876f17}
\end{figure}](/articles/aa/olm/2009/15/aa09876-08/img97.png) |
Figure A.2: Comparison of the real counts (continuous line) with that coming from the simulations. Long dashes line: input distribution of the simulated stars taken from Besançon models. Dotted line: simulated stars classified as stars. Long-short dashed line: simulated stars detected. |
| Open with DEXTER | |
Appendix B: Image simulations
One of the methods most commonly used to check the reliability of a procedure of star/galaxy classification is to test the procedure using images in which synthetic objects have been added. Of course, this method relies upon the idea that the artificial objects are similar enough (from the point of view of the classifying program) to the real objects so that one can extrapolate the results obtained from the simulations (from which the input and the output are known) to the real objects.
We followed this method using the tasks of the IRAF's package artdata. We made catalogs of galaxies and stars to build the artificial images that were added to the real images. In this way
we could test also the effects of the variations of the background and other real conditions that are difficult or impossible to simulate. The effects of crowding coming from adding more objects to real images were measured to produce less than 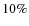 of the lost objects in the most crowded image. Then we proceeded with these images as with the real ones. The resulting parameters from SExtractor were compared between real and synthetic objects, showing that they were at first sight quite
similar, giving us confidence that the extrapolation from simulations to real objects could be done. However, the comparison of the final counts from the real and the simulated objects made us distrust the simulations, especially that of the faint stars. The reason for this conclusion is illustrated in Fig. A.2. This figure shows the star counts from the original catalogs of WINGS (continuous line) and from the simulations. For simulated stars three lines have been plotted. The long dashed one represents the input catalog and the numbers are taken from the models of the Galaxy from Besançon. The long-short dashed line represents the counts of detected simulated stars. Finally, the dotted line shows the counts of the simulated stars classified as stars, which should be the counts to be compared with the data from WINGS' stars catalog (continuous
line). From this figure it can be seen that, at the faintest magnitudes, it was easier for SExtractor to distinguish a real star than a simulated one, violating the initial premise that simulated objects are similar to real ones.
of the lost objects in the most crowded image. Then we proceeded with these images as with the real ones. The resulting parameters from SExtractor were compared between real and synthetic objects, showing that they were at first sight quite
similar, giving us confidence that the extrapolation from simulations to real objects could be done. However, the comparison of the final counts from the real and the simulated objects made us distrust the simulations, especially that of the faint stars. The reason for this conclusion is illustrated in Fig. A.2. This figure shows the star counts from the original catalogs of WINGS (continuous line) and from the simulations. For simulated stars three lines have been plotted. The long dashed one represents the input catalog and the numbers are taken from the models of the Galaxy from Besançon. The long-short dashed line represents the counts of detected simulated stars. Finally, the dotted line shows the counts of the simulated stars classified as stars, which should be the counts to be compared with the data from WINGS' stars catalog (continuous
line). From this figure it can be seen that, at the faintest magnitudes, it was easier for SExtractor to distinguish a real star than a simulated one, violating the initial premise that simulated objects are similar to real ones.
In the construction of the simulated stars we took bright but not saturated stars to have a well sampled point spread function (PSF) even at the wings. So, one expects simulated stars to be more concentrated than real ones and then easier to be classified as stars by SExtractor, which is the opposite of what was found. The doubts became greater when simulations were done using two different PSFs, one for bright stars computed from a bright start and another one for faint stars computed from a fainter star. In this case, the fraction of faint simulated stars identified as stars by SExtractor increased. Therefore, the simulations turn out to be too dependent on the input.
As this seemed to be a problem of the mkobjects task we tried with the addstars feature of the daophot package to create the synthetic stars. Since this is a package made to study stars we expected a better treatment of the simulations. However, the results were similar.
The origin of the difficulties is not clear. Probably, small variations of the local conditions where objects are added produce large effects in faint simulated objects.
All these results convinced us not to use the results of the simulations to measure the reliability of our star/galaxy classification at faint magnitudes. However, we did not find such problematic behavior at bright magnitudes. Figure A.2 shows that the problems of detection of simulated stars (before any classification as galaxy or star) start above 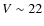 when the detection rate drops (see Fig. 5). For these reason we decided to still
rely on the simulations to estimate the photometric errors and the detection rates since, unfortunately, there is no better procedure to estimate such quantities.
when the detection rate drops (see Fig. 5). For these reason we decided to still
rely on the simulations to estimate the photometric errors and the detection rates since, unfortunately, there is no better procedure to estimate such quantities.
Appendix C: Comparison with WFPC2@HST image
To check the completeness estimations done with simulations we performed a comparison using data from the Hubble Space Telescope. We downloaded the images of the BCG of A1795 taken with the WFPC2 from the HST archive![]() . We chose the F555W filter which was the one that best matches the V band images that we used to construct our catalogs. From the mosaic of the WFPC2 we removed the PC chip in which the BCG was located since this produced problems for SExtractor and we were interested in knowing the completeness at faint magnitudes. After that, SExtractor was run on the image and the resulting catalog was matched and compared with the WINGS catalog. We performed the matching against the global WINGS catalogs, i.e. including stars, galaxies and objects of unknown classification. Figure C.1 (upper panel) shows the completeness computed for the A1795 field using the simulations (continuous line) and the completeness compared with the HST data. We also include the errors in the computation of these data since the area is quite small and therefore the number of detected objects (lower panel) is also quite low.
. We chose the F555W filter which was the one that best matches the V band images that we used to construct our catalogs. From the mosaic of the WFPC2 we removed the PC chip in which the BCG was located since this produced problems for SExtractor and we were interested in knowing the completeness at faint magnitudes. After that, SExtractor was run on the image and the resulting catalog was matched and compared with the WINGS catalog. We performed the matching against the global WINGS catalogs, i.e. including stars, galaxies and objects of unknown classification. Figure C.1 (upper panel) shows the completeness computed for the A1795 field using the simulations (continuous line) and the completeness compared with the HST data. We also include the errors in the computation of these data since the area is quite small and therefore the number of detected objects (lower panel) is also quite low.
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{9876f18}
\end{figure}](/articles/aa/olm/2009/15/aa09876-08/img98.png) |
Figure C.1:
Comparison of the completeness of the WINGS catalog of the field of A1795. Upper panel: the continuous line shows the completeness computed from simulations while the dots with the error bars show the completeness when comparing from HST data. The error bars are constructing using |
| Open with DEXTER | |
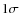 Poisson errors. Lower panel: number of objects detected in the HST image. Since the area is quite small the total numbers are also small producing the large uncertainties in the computation of the completeness.
Poisson errors. Lower panel: number of objects detected in the HST image. Since the area is quite small the total numbers are also small producing the large uncertainties in the computation of the completeness.Although the HST image is much sharper than our ground-based image, it is not much deeper and it also shows problems of completeness in the range of comparison (lower panel of Fig. C.1). This and other issues in the matching procedure (such as pairs of objects that are not resolved in the WINGS image) introduce uncertainties in the comparison so this should be considered as a complementary check to the completeness computed using the simulations.
Appendix D: Additional information
In addition to the data of the single objects found in each field we include several tables containing information about observational features and peculiarities of either the single clusters or the fields on which they are projected.
Position, redshift, Abell richness, Bautz-Morgan type, X-ray luminosity and galactic extinction of the whole WINGS sample can be found in Table 5 of Paper I.
In Table D.1 we summarize the conversion factors used for this work from CCD related units (pixels) to angular unit (arcsecs) and from these to linear units (kpc) at the redshift of the target cluster using a cosmological model with parameters H0=75 km s-1 Mpc-1,
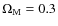 and
and
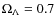 .
We have also included the effective total area of each image which is the real area used to make the catalogs which is slightly smaller than the total field of view (for WFC@INT images, the effective area is
.
We have also included the effective total area of each image which is the real area used to make the catalogs which is slightly smaller than the total field of view (for WFC@INT images, the effective area is 
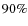 of the total field of view while for WFI@ESO this value is
of the total field of view while for WFI@ESO this value is 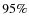 ). We report the angular sizes of the apertures of R=2 kpc, 5 kpc and 10 kpc used to construct our catalogs.
). We report the angular sizes of the apertures of R=2 kpc, 5 kpc and 10 kpc used to construct our catalogs.
In Table D.2 we list the detection limits in surface brightness, or surface brightness thresholds, (
 )
as well as the V band magnitude at which the detection rate goes down to ,
)
as well as the V band magnitude at which the detection rate goes down to ,
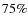 and
and 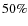 .
These last values are average values
obtained from the simulations.
.
These last values are average values
obtained from the simulations.
Table D.3 reports the positions of the brightest cluster galaxies. In most cases we preferred the coordinates of the peak of the emission instead of the coordinates of the barycenter because the latter are more affected by irregularities in the outer isophotes.
Finally, Table D.4 lists comments or issues about the clusters and the fields which we find interesting or useful when working with our catalogs.
Table D.1: Useful parameters of the WINGS' clusters sample.
Table D.2: Completeness limits and surface brightness detection limits.
Table D.3: Coordinates of the emission peak of the brightest cluster galaxies.
Table D.4: Remarks about the individual fields.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.