Fig. 2
Download original image
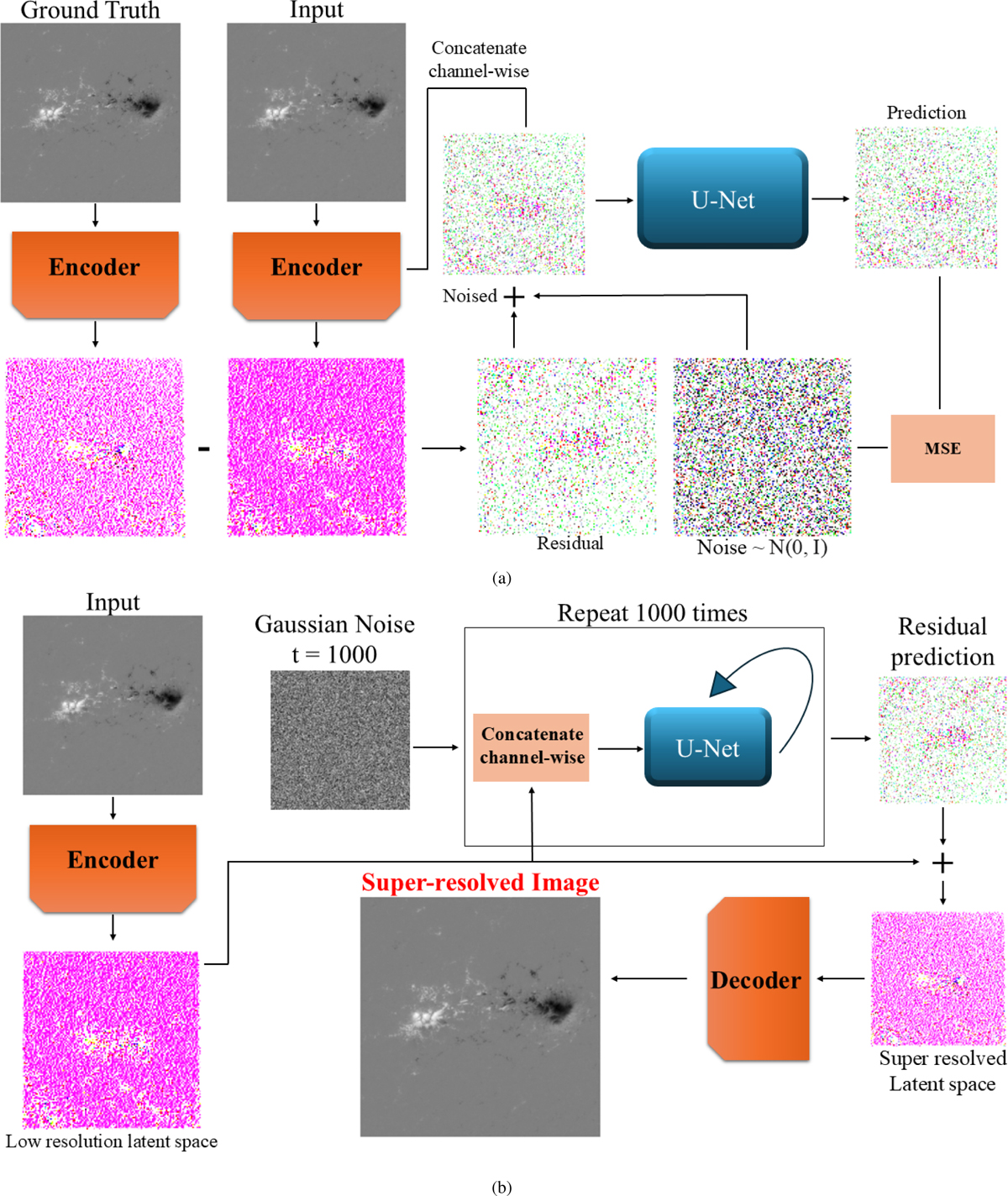
(a) The top image demonstrates the training process of the Latent diffusion residual model (LDM) for image super-resolution. In this process, both the Input and Ground Truth images are passed through an Encoder; subsequently, the residual (difference) between them is calculated and injected with noise with a random magnitude determined by the timestep parameter t. This noisy latent representation is then processed by the LDM, which predicts the injected noise. Finally, Mean Squared Error (MSE) loss is computed between the predicted noise and the original injected noise. (b) The bottom image illustrates the inference algorithm of the LDM for super-resolution. Here, the Input is encoded and concatenated channel-wise with Gaussian noise which corresponds at t=1000. The prediction process iterates 1000 times, refining the residual prediction, which is ultimately added back to the encoded input image. The result is then decoded to produce the super-resolved image.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.