| Issue |
A&A
Volume 689, September 2024
|
|
|---|---|---|
| Article Number | A87 | |
| Number of page(s) | 12 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202450002 | |
| Published online | 03 September 2024 | |
TDCOSMO
XV. Population analysis of lines of sight of 25 strong galaxy-galaxy lenses with extreme value statistics
1
Department of Physics and Astronomy, University of California, Davis, CA 95616, USA
2
Department of Physics and Astronomy, Stony Brook University, Stony Brook, NY 11794, USA
3
Department of Physics and Astronomy, University of California, Los Angeles, CA 90095, USA
Received:
15
March
2024
Accepted:
11
June
2024
Abstract
Context. Time-delay cosmography is a technique for measuring H0 with strong gravitational lensing. It requires a correction for line-of-sight perturbations, and thus it is necessary to build tools to assess populations of these lines of sight efficiently.
Aims. We demonstrate the techniques necessary to analyze line-of-sight effects at a population level, and investigate whether strong lenses fall in preferably overdense environments.
Methods. We analyzed a set of 25 galaxy-galaxy lens lines of sight in the Strong Lensing Legacy Survey sample using standard techniques, then performed a hierarchical analysis to constrain the population-level parameters. We introduce a new statistical model for these posteriors that may provide insight into the underlying physics of the system.
Reults. We find the median value of κext in the population model to be 0.033 ± 0.010. The median value of κext for the individual lens posteriors is 0.008 ± 0.015. Both approaches demostrate that our systems are drawn from an overdense sample. The different results from these two approaches show the importance of population models that do not multiply the effect of our priors.
Key words: methods: data analysis / methods: statistical / surveys / cosmological parameters / cosmology: observations
Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it. .
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Time-delay cosmography is a technique for inferring the value of the Hubble constant and other cosmological parameters based on multiply imaged time-variable sources. Its independence from standard early and late Universe probes make it an essential tool in resolving the ongoing tension between those techniques. Time-delay cosmography relies on four primary ingredients. The first is time delays, which are obtained by monitoring the system over many months or years. The second is a mass model based on high-quality imaging data. The third is stellar kinematics of the lensing galaxy, which is used to break the well-known mass sheet degeneracy. The fourth, and the subject of this paper, is the external convergence (denoted κext), which can be thought of as the cumulative effect of all additional perturbers along the line of sight.
As with many domains of astronomy and cosmology, time-delay cosmography is increasingly big data focused. The number of known time-delay lenses has increased dramatically with surveys such as the Dark Energy Survey (Dark Energy Survey Collaboration 2005, hereafter DES) and the Subaru Hyper-Suprime Cam Strategic Survey program (Aihara et al. 2017, hereafter HSC), and is expected to increase by orders of magnitude with the Vera Rubin Observatory Legacy Survey of Space and Time (Ivezić et al. 2019, hereafter LSST). Not only does this present unprecedented opportunities to do interesting astronomy, but it also introduces new and unique technical challenges. In particular, population modeling is an increasingly important tool for deriving constraints on interesting quantities by leveraging the statistical power of many systems. However utilizing this approach effectively is not possible without building high-quality tools that can ingest, process, and track the large amount of data required to perform the inference.
Each of the ingredients discussed above involves its own set of challenges. The κext measurement is different in that the challenge is largely a problem of data management. The relative density of a given field around some lens of interest is determined by comparing the field to a large number of fields randomly drawn from some large reference survey. The data for this procedure is readily available from the various survey teams. The challenge then is building tools that are capable of doing this comparison for dozens or even hundreds of lens fields at once, while being flexible enough to allow us to evolve our techniques forward without starting from scratch. However, if this challenge is solved, this analysis serves as an excellent testing ground for building systems that do astronomy at scale.
The long term goal of the cosmography community is to provide constraints on H0 with a precision comparable to that of more mature probes such as the distance ladder (e.g., Riess et al. 2022) or the cosmic microwave background (e.g., Aghanim et al. 2020). Being independent of these probes, cosmography is well positioned to provide an insight into the Hubble Tension (Di Valentino et al. 2021) once this higher level of precision is realized. The combined statistical power of the population of lenses that will become available in the next decade should be sufficient to provide such a constraint, but only if we have the analysis tools to match it. In this work, we analyze a population of 25 strong galaxy-galaxy lenses from the Strong Lensing Legacy Survey (SL2S) sample. We use the number counts techniques described in Wells et al. (2023) to estimate κext along the line of sight to each individual lens, and then use the hierarchical techniques discussed in Park et al. (2023) to infer population parameters. We introduce a new statistical model for the resultant distributions, which provides a potential insight into the primary source of signal in κext. This process additionally serves as a test of the ability of our techniques and software to work at scale.
In section 2, we present the essentials of time-delay cosmography and the techniques used to estimate κext along a given line of sight. In section 3, we discuss the challenges of operationalizing this analysis to run at scale, and the tools used in the analysis presented in this work. In section 4, we introduce the lens sample used in this work and discuss the choices made to estimate κext for the individual lines of sight. In section 5, we introduce a novel statistical model that provides insight into the source of signal in κext, while in section 6 we leverage these statistics to produce a population model of κext for our systems. Finally, in section 7 we present and discuss the results of our hierarchical analysis, and look forward to future work on this topic.
2. Time-delay cosmography and line-of-sight analysis
In this section, we present the essentials of time-delay cosmography and the associated line-of-sight analysis. For a more complete overview of time-delay cosmography and its current status, we refer the reader to Treu & Marshall (2016), Birrer et al. (2023), and references therein, while for a more complete discussion of the line-of-sight analysis we refer the reader to Wells et al. (2023) and Rusu et al. (2017).
2.1. κext and its application to time-delay cosmography
Time-delay cosmography relies on the strong gravitational lensing of a time-variable source to place constraints on the distance scales of the combined observer-lens-source system and, ultimately, use these constraints to derive a constraint on H0. In a strongly lensed system in which multiple images are visible, the light from the various images will take different paths from the source to the observer. This difference will be directly visible when the luminosity of the source varies, as the brightness of the various images will change at different times. These techniques have been applied to strongly lensed quasars for a number of years (e.g., Kundic et al. 1997; Fassnacht et al. 2002; Vuissoz et al. 2008; Bonvin et al. 2016 More recently, time-delay techniques have been applied to the supernova Refsdal (Kelly et al. 2023), as well as cluster-scale lenses (Liu et al. 2023).
This time delay between two images at angular positions θA and θB of a source at (unobservable) angular position σ can be directly related to the gravitational potential of the lens by
![Mathematical equation: $$ \begin{aligned} \Delta t_{AB} = \frac{D_{\Delta T}}{c}[\tau (\theta _A, \sigma ) - \tau (\theta _B, \sigma )], \end{aligned} $$](/articles/aa/full_html/2024/09/aa50002-24/aa50002-24-eq1.gif) (1)
(1)
where τ is the Fermat potential of the lens given by
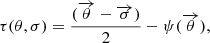 (2)
(2)
and 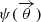 is the scaled lensing potential.
is the scaled lensing potential.
The cause of the time delay is the difference in the path length taken by the light of the various images plus the difference in the Shapiro delay. The quantity DΔt from Eq. 1 is known as the time-delay distance and is given by
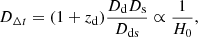 (3)
(3)
where Dd, Ds, and Dds are the angular diameter distances to the deflector, source, and from the deflector to the source, respectively. Given an accurate lens model and a measurement of a given time delay, it is therefore possible to measure H0.
However this analysis is complicated by the fact that lenses are embedded in the Universe, and therefore surrounded by mass structures that also have an impact on the lensing observables. This effect is paramaterized with the external convergence (κext). The result of these perturbations is difficult to pin down, both because the mass distribution along the line of sight cannot be directly observed, and because the effect is much less significant than the effect of the primary lens. However, correcting for the effect is essential in cosmography because it propagates directly to the inferred value of DΔt by
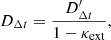 (4)
(4)
where 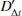 denotes the uncorrected value of the time-delay distance. The relationship to the inferred value of the Hubble constant is similarly straightforward:
denotes the uncorrected value of the time-delay distance. The relationship to the inferred value of the Hubble constant is similarly straightforward:
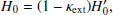 (5)
(5)
where 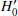 represents the uncorrected value. In general, κext is of order 10−2, and so failing to correct for this effect introduces bias of a few percent in the average case, up to around 10% in the most extreme cases. It is worth noting that the total convergence is the combination of κext and the convergence from the primary lens. In that sense, κext can be thought of as the residual convergence that would be present if the primary lens was removed.
represents the uncorrected value. In general, κext is of order 10−2, and so failing to correct for this effect introduces bias of a few percent in the average case, up to around 10% in the most extreme cases. It is worth noting that the total convergence is the combination of κext and the convergence from the primary lens. In that sense, κext can be thought of as the residual convergence that would be present if the primary lens was removed.
Because the underlying mass distribution in a given line of sight cannot be directly observed, we must infer it based on available data about the luminous matter in the field. The standard tools for doing this inference involve weighted number counts of galaxies within some distance of the lens. This technique has been used extensively by the TDCOSMO collaboration and its predecessors (see for example Fassnacht et al. 2010; Rusu et al. 2017; Wells et al. 2023) to provide an estimate of κext along a given line of sight. κext can be thought of as the density of mass sheet which, if placed coplanar to the lensing galaxy, would produce the same cumulative effect as all the perturbers along the line of sight. We note that this is distinct from the internal mass sheet transformation (see Chen et al. 2021; Gomer & Williams 2020). The combination of these two effects leads to the well-known mass sheet degeneracy, which is usually broken with measurements of stellar kinematics (Shajib et al. 2023; Schneider & Sluse 2013). Generically, κext results in the magnification or de-magnification of the images of the background source, but this effect is not directly measurable.
2.2. Essentials of the technique
In the context of lensing, κ is a dimensionless measurement of the underlying matter distribution in units of the lensing critical density, Σcr.
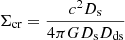 (6)
(6)
In strong lensing, κ > 1 and an appropriately-placed source will be lensed into multiple images and/or an Einstein ring. For lower mass concentrations (κ ≪ 1) lensing is instead evident by distortions in the shape of background sources, such as galaxies. Typical weak lensing techniques involve statistics based on distortions to the apparent shape of large numbers of galaxies. As a result, weak lensing analyses are typically done on much larger angular scales than is useful for the κext measurement. While weak lensing analyses of κext have been done (e.g., Tihhonova et al. 2018, 2020), these rely on high resolution imaging (typically space-based) of the field of interest. It is unrealistic to expect such imaging for the vast majority of lens fields in future surveys, and the techniques used to do this analysis must reflect this.
On larger scales, κ can be thought of a measurement of the relative density of a region of space as compared to the entire Universe. An “average” field will be assigned a value of κ near zero, while a slightly overdense field should receive a slightly positive value. For a given line of sight, we first make an empirical estimate of the density of the field. While we cannot directly observe the majority of the mass in a given field, we can use visible matter as a tracer of the underlying dark matter. In particular, a field with more galaxies is likely to have more dark matter than an identically shaped field with fewer galaxies. The relationship between luminous matter and dark matter is noisy, but we can readily estimate the amount of luminous matter in a given field with galaxy surveys. We measured the absolute density of a given field with summary statistics computed based on the galaxies in the region. Natural summary statistics include an inverse distance summary statistic, where galaxies closer to the center of the line of sight are weighted more heavily, or a weighting based on redshift, where sources are weighted more heavily where the lensing efficiency is higher. The value of the summary statistic for a given line of sight is just the sum of the weights of the individual galaxies:
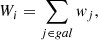 (7)
(7)
where wj denotes the weight for a single galaxy along the line of sight. In this context, the full posterior in κext can be written as
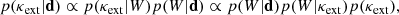 (8)
(8)
where the relationship between the second and third form follows from Bayes’ theorem. In general, we use constraints for several summary statistics when estimating κext. The likelihood p(W|κext) cannot be written down in closed form, and we must turn to Approximate Bayesian Computation to estimate it. We seek to compare our line of sight to similar lines of sight in a simulated dataset, where values of κext have already been calculated.
Usage of simulations in this context may introduce bias into the inference based on the underlying cosmology of the simulation. To control this bias, we wish to estimate the relative density of a given line of sight compared to all lines of sight in the Universe, and then find lines of sight in the simulated dataset with the same relative density to estimate κext.
To estimate the relative density of a given line of sight, we compute the same set of summary statistics in a large number of randomly selected fields in an appropriately large sky survey. For each random field, we compute the ratio of the summary statistic in the field of interest to the summary statistic of the given random field. The resultant distribution of ratios gives an empirical estimate of the relative density of the field compared to the Universe as a whole, so long as the reference survey is large enough to avoid sampling bias. This caveat is increasingly less of a concern. Modern surveys such as HSC and DES have hundreds to thousands of square degrees of contiguous, high quality sky coverage. In the near future LSST will image nearly all of the southern sky with many thousands of strongly lensed objects expected to be discovered. Of these thousands of systems, several hundred are expected to be suitable for time-delay cosmography (Verma et al. 2019).
We then compute the same set of summary statistics in a simulated dataset with values of κext computed. We normalize the resultant distribution by its median. This allows us to more directly compare these lines of sight to lines of sight of interest. More concretely, if the median of a distribution for a summary statistic in the real data is 1.2, this implies that the value of the summary statistic for our line of sight is 20% higher than the median line of sight in our comparison survey. A line of sight from the simulated dataset with a normalized summary statistic of 1.2 is also 20% greater than the median value (for a further discussion of the summary statistics we use, and our techniques for matching to the simulated dataset, see Wells et al. 2023).
3. Line-of-sight analysis at scale
A crucial aspect of the work presented here is developing and validating the tools needed to perform line-of-sight studies at scale. In Wells et al. (2023), we presented heinlein, a data management tool for survey datasets, and lenskappa, which utilized the capabilities of heinlein to perform a line-of-sight analysis. lenskappa was quite limited in that it was only capable of performing a single lens analysis at a time, and had minimal flexibility to evolve our techniques forward. In particular, lenskappa required weighted number count analysis for each lens to be performed individually, even if all the analyses were using the same region of the sky for comparison. This problem was magnified when performing weighted number counts in the Millennium simulation, as many more samples are required to produce a reasonable posterior.
The core philosophy of the κext analysis is that simpler statistics can produce meaningful results when evaluated over very large datasets. In the context of this work, the correlation between the summary statistics and the quantity of interest (κext) is fairly weak. However, the advantage of these statistics is ease of computation. The true computational challenges of this style of analysis derive from the need to efficiently manage and query a large survey datasets. This challenge is not unique to our analysis, and building tools to efficiently solve it will be useful for a wide variety of analyses over the coming decade. We call this style of analysis “cosmological data sampling”, because it requires repeatedly drawing samples from a large survey dataset. We seek to build a tool that is capable of doing this style of analysis efficiently, and allows the user to iterate and build new analyses quickly.
To this end, we introduce cosmap1, a Python package for defining and running “cosmological data sampling” analyses like those discussed in this work. In practice, cosmap can be used to apply any computation across a large survey dataset quickly and reliably. cosmap is an evolution of the lenskappa package first presented in Wells et al. (2023), and has been written from the ground up to provide an easy-to-use tool for doing analysis with big data astronomy. cosmap makes use of pydantic2 for parameter validation and Dask3 to distribute work across available computing resources. Data management and result outputs can be handled by the library without user involvement, but a plugin architecture is included to modify default behavior if the user finds it insufficient for their analysis.
Crucially, all user-defined behavior in cosmap is written outside of the core library. Analyses are defined as a series of transformations on the data organized as a Directed Acyclic Graph (DAG), a structure in common use in pipeline orchestration and task scheduling. Analysis parameters must be declared, and their runtime values parsed by pydantic to ensure correctness. These decisions ensure that failures occur early in the runtime of the program, to avoid situations where processor (and astronomer) time is wasted.
While lenskappa was only capable of analyzing a single lens at a time, cosmap allows us to write an analysis that handles all the lenses in our sample in a single run. This saves a large amount of computation time over the previous model. The fundamentally modular nature of individual analysis definitions makes it simple to iterate on an existing analysis or define a new analysis entirely. We estimate cosmap saves over 95% of the computational time that would be required if this analysis was done with lenskappa.
4. Data and procedures for individual κ measurements
In this section, we discuss the dataset we use in this analysis and our procedures for performing κext measurements on our individual lens lines of sight. The basic procedure used to analyze the individual lenses is identical to the procedure discussed in section 2. One key difference is our ability to analyze many lenses at once, as we discussed in section 3. However, we note this is a computational optimization, and does not impact the results for individual lenses.
4.1. The CFHT Legacy Survey and the Strong Lensing Legacy Survey
The Canada-France-Hawaii Telescope Legacy survey (hereafter CFHTLS) is a 155 deg2 multiband imaging survey completed in 2012 (Gwyn 2012). After the completion of the survey, the data were re-processed with the goal of discovering strong lenses, resulting in the so-called Strong Lensing Legacy Survey (Cabanac et al. 2006, hereafter SL2S). CFHTLS has been used previously to to analyze other lens lines of sight (see, for example, Rusu et al. 2017). It is useful due to its depth (i ∼ 24.5) and relatively large size (at least historically) of its wide fields.
Our sample includes 28 lenses from this survey. The sample was selected to be analogues of the kinds of systems analyzed by TDCOSMO, with the original goal of obtaining population-level constraints on the mass distribution of the lensing galaxies in the sample. The choice of lenses is discussed in more detail in TDCOSMO Collaboration (in prep). The lensing galaxies have redshifts between 0.238 and 0.884, while the source galaxies have redshifts between 1.19 and 3.39. Because our analysis relies on a high-quality galaxy catalog of the line of sight, we remove three lenses where a nearby bright star has corrupted the resultant catalog such that more than half of the field is missing galaxy photometry. Table A.1 summarizes the essential information about each lens system included in this work, while Figure 1 illustrates the typical quality of imaging data used to derive catalog products. However, we do not re-derive any catalog products, instead using the fiducial measurements performed by the survey team.
 |
Fig. 1. Image showing the field around SL2SJ1405+5243. The inner and outer red circles mark the inner and outer cutoff radius we use when computing weighted number counts. |
4.2. Individual κext measurements
We used the techniques discussed in Section 2 and in Wells et al. (2023) to infer the posterior on κext for each individual line of sight. At this stage, there is no information about the population-level statistics. Each line of sight is analyzed on its own, with a prior set by the Millennium simulation.
4.2.1. Comparison field and cuts
To compute weighted number counts for the individual lenses, we used 50 deg2 from the CFHTLS W1 field, bound by 31° < RA < 38.5° and −11° < Dec < 4° as a control field. We computed weighted number counts in a 120″ aperture, and limited our counts to objects brighter than 24th magnitude in i-band. These choices were consistent with choices made in previous work (see for example Wells et al. 2023; Rusu et al. 2017). In particular, the magnitude limit is sufficiently bright as to be meaningfully above the survey’s detection limit, while being sufficiently faint to catch all structures that are likely to contribute meaningfully to κext (Collett et al. 2013). For each lens, we also ignored objects beyond the redshift of the source quasar, and performed the same cut when comparing to the reference survey. Additionally, we removed all objects from the underlying catalog within 5″ of the center of the field. For time-delay lenses, objects near the center of the field are typically included in the mass model explicitly, and removed during the κext measurement accordingly.
4.2.2. Selecting Summary Statistics
Selecting appropriate summary statistics is an important step in the analysis described here. This has been explored extensively in previous TDCOSMO and H0licow papers (e.g., Rusu et al. 2017; Wells et al. 2023). We based our result in this work on the following summary statistics:
-
Pure number counts (wj = 1).
-
Inverse Distance Weighting (wj = 1/rj).
-
Redshift-Distance Combination (
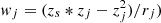 ).
).
A primary challenge of this techniques is the fairly limited data that are available on individual objects in wide-field galaxy surveys. These summary statistics provide information on how much mass is clustered near the center of the line of sight, and how much mass is clustered where the lensing efficiency is high. Importantly, these summary statistics depend on quantities which are reasonably robust in modern galaxy surveys. However in general these summary statistics are poor tracers of the underlying mass distribution, as evidenced by the width of the posteriors on indiviual lines of sight. This challenge is one of the primary motivations behind combining information behind many systems into a population-level inference. More sophisticated and/or higher order summary statistics (such as two-point galaxy clustering) may provide additional useful information but are left for a future analysis.
4.2.3. Uncertainty and comparison to the Millennium simulation
After computing these weighted number counts, we treated the median value of the distribution as the estimate of the overdensity or underdensity. To estimate an uncertainty in this quantity, we utilized the photometric redshift uncertainties present in the underlying catalogs. We produced 1000 copies of the original line-of-sight catalog, with redshifts for each object randomly sampled from that object’s photo-z PDF. We computed weighted number counts for each of the resultant catalog and treated the fractional width of the resultant distribution as the fractional uncertainty in our measurement of the median.
When computing weighted number counts in the Millennium simulation, we used the same limits described above. We used the semi-analytic galaxy catalogs of De Lucia & Blaizot (2007), which were shown in Rusu et al. (2017) to provide the best results for this analysis.
To match summary statistics, we selected lines of sight from the Millennium simulation that were similar in density to the lens lines of sight based on the value of the summary statistics. The values of κext for each line of sight were drawn from the maps produced in Hilbert et al. (2009), which cover the simulation in a grid with spacing between points ≈3.5″. The contribution from a given line of sight was weighted by a multidimensional Gaussian centered on the distribution medians with widths set by the uncertainties discussed above. We took into account correlations between the weights when constructing this Gaussian. This is, in essence, an Approximate Bayesian Computation computation, with one key limitation. We were limited by the lines of sight available to us in the Millennium simulation, and by the computational time required to search for lines of sight matching a given lens. For the majority of lenses this is not an issue, as there were more than enough similar lines of sight in the simulation to produce posteriors that are well fit by a smooth Generalized Extreme Value (GEV) distribution. For very overdense lenses where the posterior is noisy due to a small number of matching sightlines, we widened the search Gaussian. The majority of lenses in our sample do not require this intervention, or require only a modest widening to achieve acceptable results. We note that this procedure may bias more extreme lenses towards more moderate values of κext, as widening the search region will naturally include more lines of sight from the central peak of the distribution.
For each lens posterior, we determinde a best-fit Generalized Extreme Value distribution with a least-squares optimizer. Using these distributions allowed us to quickly and easily draw from our priors and posteriors when sampling the population posterior. We discuss the GEV distrubtion and its interpretations in the following section.
5. Extreme-value statistics and applications in astronomy
Extreme-value statistics describe the expected distribution of extreme values (maxima or minima) of samples drawn from a single underlying distribution. Despite relatively minimal use in astronomy, they have numerous applications in many applied disciplines. For example, extreme value statistics can be used to model the maximum daily rainfall expected over some number of consecutive days at some location. This model is crucial for engineers working to design flood-resistant infrastructure (e.g., Papalexiou & Koutsoyiannis 2013).
5.1. The generalized extreme-value distribution and subtypes
The generalized extreme value distribution is a continuous, unimodal distribution with location parameter μ, scale parameter σ, and shape parameter ξ Its probability distribution is given by
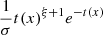 (9)
(9)
where
![Mathematical equation: $$ \begin{aligned} t(x) = \left\{ \begin{array}{lr} \big [1+\xi \big (\frac{x-\mu }{\sigma })]^{\frac{1}{\xi }},&\xi \ne 0\\ \exp (-\frac{x-\mu }{\sigma }),&\xi = 0 \end{array} \right\} \end{aligned} $$](/articles/aa/full_html/2024/09/aa50002-24/aa50002-24-eq14.gif) (10)
(10)
This generalized distribution is broken down into three subtypes based on the value of ξ. Type I (or “Gumbel”) when ξ = 0, type II (or “Fréchet”) when ξ > 0, and type III (or “Weibull”) when ξ < 04.
The Gumbel distribution typically arises when the underlying sample is normally or exponentially distributed. However for cases where the underlying distribution is bounded, the Fréchet and Weibull distributions are more appropriate. For an example of this distribution and an application to our work, see Figure 2. We do not restrict our GEV fits to any of these sub-distributions at any point within this work. The corresponds to allowing the shape parameter to take on both positive and negative values, or zero as dictated by the data.
 |
Fig. 2. Comparison of best-fit GEV distribution (left) and best-fit log-normal distribution(right) to the κext distribution of lines of sight in the Millennium simulation at redshift z = 2.34 from Hilbert et al. (2009). The best-fit GEV parameters are ξ = 0.145, μ = −0.0235, and log(σ) = − 3.46, while the best-fit log-normal parameters are μ = −0.098 and log(σ) = − 0.78. |
5.2. Extreme-value statistics in astronomy
While extreme-value statistics have found limited use in astronomy, previous work has been done showing applications in cosmic structure problems. Davis et al. (2011) showed analytically that the most massive halo in a given region of the Universe should follow Gumbel statistics (that is, the resultant distribution should be a GEV distribution with ξ = 0). Antal et al. (2009) demonstrated that the number of galaxies within some physical distance of a given location on the sky also followed Gumbel statistics at a wide range of scales. This second result is of particular interest, because it is nearly identical to some of the techniques discussed in section 2 of this work. The Gumbel distribution has additionally found use in areas such as modeling the weak lensing (Capranico et al. 2013) and modeling anomalies in the Cosmic Microwave Background (Mikelsons et al. 2009). Crucially, all these analyses have implications about cosmic structure which would have a direct impact on the measured mass density in a given region of space.
5.3. Application to Millennium simulation and individual lens lines of sight
The values of κ measured in the Millennium simulation by Hilbert et al. (2009) clearly follow extreme value statistics, as can be seen in Figure 2. Our posteriors on individual lenses are effectively this distribution convolved with the gaussian we use to select matching lines of sight (see Section 4.2), so it is sensible they too would follow these statistics. We emphasize this choice is empirical, but the excellent fit does suggest interesting interpretations.
The distribution of κ in the Millennium simulation and in our posteriors suggests that its value along a given line of sight may be dominated by contribution from a small number of mass structures which themselves follows extreme value statistics. The result presented in Davis et al. (2011) is of particular interest, because it demonstrates that the largest halo measured in a given region of the Universe should also follow extreme value statistics. This relationship suggests several interpretations that may be worth investigating in the future.
5.3.1. κext may be dominated by a single mass structure
The appearance of extreme-value statistics in our model suggests κ may be dominated by a single massive structure along the line of sight. This structure is not necessarily the most massive halo in the field, but may be a more moderately sized halo situated near the center of the field. In this context, the posterior on κext could be interpreted as the range of mass structures (or more accurately their relative density) that are possible given some set of observables (i.e. luminous galaxies). Placing better constraints on this particular mass structure may allow us to improve the precision of the κext measurement.
5.3.2. Number counts may be able to distinguish between different halo mass models
The appearance of extreme-value statistics both in galaxy number counts and the underlying halo mass function suggests an interesting relationship. Number count statistics are nothing new in cosmology. Many analyses have used cluster number counts within surveys to place constraints on cosmological parameters (e.g., Costanzi et al. 2021). A primary limiting factor of these techniques is the measurement of the cluster masses themselves. The power of the number counts techniques is its ease of applicability. Given some set of statistics, we can use cosmap to evaluate its behavior over a large region of the sky quickly and reliably. Given a set of dark matter models which make quantitatively different statements about “clustering” on small angular scales, it may be possible to quickly assess which of these models is consistent with the data available in some large galaxy survey. In this case, the constraining power of a well-measured mass structure is traded for the constraining power that derives from the scale of the dataset.
5.4. Comparison to log-normal distribution
A general rule of thumb in statistics is to use models with the fewest number of parameters that fit the data well. As the GEV distribution is a three parameter distribution, it is reasonable to question whether it is necessary in this context when two parameter distributions with similar shape exist. In particular, log-normal distributions have found frequent use in cosmic structure problems (e.g., Coles & Jones 1991; Xavier et al. 2016) and generally provide good fits to large scale convergence and shear data (e.g., Taruya et al. 2002; Clerkin et al. 2016).
Our work here differs in several key ways. In particular, we are working on very small angular scales (2′) and only measuring out to z ≈ 2. Nonlinear structure becomes a significant concern in this regime and it is reasonable to suggest that this may introduce complications to the standard log-normal picture.
The best-fit log-normal distribution is included in figure 2 in addition to the GEV fit. The log-normal fit meaningfully underestimates the peak, overestimates the decay, and slightly underestimates the tail of the emperical distribution. Both best-fit models were determined using the stats.fit function of scipy on unbinned values of κ. The best-fit log-normal distribution results in a Bayesian Information Criteria (BIC) of 219.5, while the GEV best-fit distribution yields a BIC of 174.8.
6. Population-level environment studies in time-delay cosmography
Astronomy is increasingly a big data field, and time-delay cosmography is no exception. The LSST is expected to uncover many thousands of lenses in its full footprint, with many hundreds of time-delay lenses that will be suitable for cosmographic analysis (Verma et al. 2019). Time-delay Cosmography is still in a regime where its errors are dominated by the random variance that is to be expected from a small sample of systems. Increasingly, the community is turning to population analyses to estimate cosmological parameters as well as to more informed priors on other ingredients of the analysis such as lensing galaxy mass profiles (see for example Birrer et al. 2020).
The measurement of κext for a single lens is very much prior dominated. While easy to compute, the summary statistics we use are fairly weak tracers of the underlying matter distribution. This results in wide posteriors that often deviate only modestly from the prior except in particularly extreme cases. By combining statistical information from many lines of sight at the likelihood level, deviations of the population from the prior become more apparent.
There is a general expectation from previous studies that lenses lie in preferably overdense lines of sight (e.g., Wong et al. 2018; Fassnacht et al. 2010). This is consistent with well-known work from Dressler (1980) which showed that massive elliptical galaxies are more likely to be found in overdense regions. This suggests that the primary contributor to κext in many lines of sight may be this group or cluster, as is suggested in Fassnacht et al. (2010). As will be demonstrated shortly, the analysis presented here confirms this previous work while allowing us to quantify this overdensity in a way that can be directly useful in time-delay cosmography.
6.1. Procedures for population analysis
To estimate the population-level parameters of the lines of sight in our sample, we used the framework developed in Wagner-Carena et al. (2021) and applied in Park et al. (2023) to mock lines of sight. We used results from individual lines of sight to fit a distribution for the entire population. For a given value of location parameter μ, scale parameter σ, and shape parameter ξ the posterior takes the form:
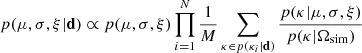 (11)
(11)
where p(μ, σ, ξ) is our hyperprior on the population-level parameters, and p(κ|Ωsim) is the probability of a given value of kappa in the prior imposed by the simulation. The sum was done over 20 000 samples taken from the individual posteriors for each line of sight. We use σ as the scale parameter in the equation above to emphasize that our target distribution is not necessarily Gaussian. We discuss our choice of target distribution in the following section.
Each value of the product term can be thought of as a likelihood for a given lens. By dividing out the prior, we avoid multiplying its effects across the population. As a result, it is reasonable to expect the population constraints to favor a more significant overdensity than a naive average of the individual posteriors. This is a statistical effect. Bayes theorem is designed as a tool for updating posteriors as new information comes in. In our case the “new information” in our analysis is that our lines of sight, looked at as a population, show significant signs of being biased when compared to the population of all lines of sight in the Universe.
6.2. Hierarchical analysis with SL2S lenses
Once we have posteriors for each line of sight, we move on to a hierarchical analysis of the population. We use the emcee Python package (Foreman-Mackey et al. 2013) to sample from the posterior given in section 6.1.
We emphasize that the value of the prior in the Millennium simulation is not unique to a particular value of the hyperparameters, as it also depends on the redshift of the lens. It is reasonable to suggest that the redshift of sources in our sample should be included as a population parameter, but given the tight constraints on individual redshifts our sample is too small to determine this distribution. When drawing from individual posteriors, we use the best-fit GEV distribution as provided by scipy.
We use a flat hyperprior with −0.5 < ξ < 0.5, −0.1 < μ < 0.3 and −5.0 < log(σ) < − 2.0. These ranges include the values of the best-fit parameters for the full population of lines of sight in the Millennium simulation.
6.3. Interpretation of population posteriors
When interpreting our results, it is crucial to appreciate the difference between the posterior on κext produced for a single lens and the posterior on the population parameters. For a single lens, the value of κext is (presumably) nearly constant across the lens system. The posterior therefore is largely a statement about our uncertainty based on the incomplete information that goes into our analysis. With better information or a more sophisticated model, it may in principle be possible to shrink the width of the posterior. However this is a posterior on only a single parameter: κext
However when doing a population analyses, the location, width, and shape of the population distribution are themselves parameters with associated uncertainties. These parameters are making a statement about the distribution of lines of sight in which we find strong lenses, while the issue of “incomplete information” appears in the uncertainty on the individual parameters. For the sake of intuition, it is helpful to compare the distribution produced by the parameter point estimates to the prior from the simulated dataset. However unlike the distribution for individual lines of sight, the width of this distribution has an astrophysical interpretation and may be fundamental to the population. Additionally, individual lens posteriors are prior dominated, as the data available is a fairly weak tracer of the underlying mass distribution in the field. By combining the constraining power of many lenses, it may be possible to constrain this population better than we could constrain any single lens system.
7. Results
Our results show clearly that the lines of sight in our sample are drawn from a population that is more dense than the population of all lines of sight in the Universe.
7.1. Individual lines of sight
A summary of the best-fit parameters for individual lines of sight can be found in table A.1, and a plot of our measured value of κext with respect to redshift in Figure 3. From the individual results, it is reasonable to suggest that our lines of sight are drawn from a population that is more dense on average than the population of all lines of sight in the Universe. Our results also demonstrate a modest trend towards greater density for longer lines of sight, but this is inconclusive.
 |
Fig. 3. Measured median values of κext for the lenses in our sample as a function of deflector and source redshift, respectively. Error bars denote the 68% confidence interval. The red dotted line represents the trend of the median value of κext. |
Figure 3 also demonstrates the necessity of population studies. The posteriors on individual lines of sight are quite wide, and most lines of sight individually are consistent with κext = 0. This is a result of the fact that the summary statistics we use are fairly weak tracers of the underlying mass distribution. This amount of scatter for individual κext is consistent with previous analyses on other systems.
7.2. Population constraints
Although individual sightlines provide limited information, our population model demonstrates clearly that our lines of sight are drawn from a biased sample. A corner plot of our MCMC samples and a comparison of best-fit distributions can be found in Figure B.1. The median value of the population distribution on κext inferred by our model κmed = 0.033 ± 0.010. This result demonstrates that our lines of sight are drawn from a sample that is more dense than the general population at this redshift under the assumption the Millennium simulation provides a reasonable prior for the distribution of κ on small scales in the Universe. However for the purposes of time-delay cosmography, the important factor is whether the median value of κext is above or below zero. If our population median was exactly zero, we would anticipate that no real population-level correction from κext would be necessary. Our model does not show this conclusively, but does provide evidence for this conclusion at ≈3σ confidence. Our sample size is not large enough to provide strong constrxaints on the shape and scale parameters of the distribution, but this may change in the future with larger samples. In our tests, our posterior on log(σ) remains nearly constant in the range −8 < log(σ) < − 5, indicating the inability of our data to cleanly. Such a narrow posterior would indicate an extremely specific selection function, in clear contention with our knowledge of these systems. We therefore choose to cut off our hyperprior at log(σ) = − 5.
It is interesting to compare the population median to the median of the individual results (the “median of medians”). Simply averaging the individual lens posteriors results in a “population” median of 0.008 ± 0.015. We emphasize that this approach implicitly includes the effect of the prior once for each lens posterior, whereas the population model divides out this prior before averaging. The overdensity from our population model is not excessive, but is more significant than would be expected by a naive averaging of the results for the individual sightlines. This demonstrates that correcting for line of sight effects on a population level is necessary when performing time-delay cosmography on large samples of lenses. We remind the reader that κext measures the residual overdensity that remains after removing the lens and any immediate neighbors from the line of sight. The actual value of the total convergence κ at the location of the lens itself will be quite different.
8. Conclusions and future work
In this paper, we have demonstrated a technique for estimating κext along strong lens lines of sight at a population level and applied it to a sample of 25 lenses in the Strong Lensing Legacy Survey. This work has been built on previous work that allows us to perform κext inferences on individual lenses much faster than was previously possible. We have demonstrated the infrastructure and statistical frameworks necessary to apply this technique at massive scale and provide constraints on populations of lines of sight. We have shown that the populations of lines of sight that are used in this analysis are likely drawn from a biased sample that is overdense when compared to the population of a lines of sight in the Universe, with median κext = 0.033 ± 0.010
8.1. Future improvements to κext measurement
The primary goal of this work is to develop and demonstrate the tools and frameworks necessary to provide constraints on large populations of lens lines of sight. While we have made much progress in this direction, there are still a number of improvements that should be made:
8.1.1. Upgrade our simulation
While of significant historical significance, the Millennium simulation has been surpassed in recent years by larger and more sophisticated simulations, which take the last two decades of improved understanding into account. We continue to use Millennium because of the high-resolution weak lensing maps that are available. However the MillenniumTNG team has produced high-resolution weak lensing maps that include the effects of baryons (Ferlito et al. 2023) which would be suitable for our analysis once the data products are released publicly. In particular MillenniumTNG has a mass resolution around one order of magnitude better than the original Millennium simulation, which may allow us to more cleanly map small-scale real-Universe sightlines onto equivalent simulated sightlines.
8.1.2. More efficient summary statistic mapping with machine learning
Additionally, finding matching lines of sight in the simulated dataset is quite slow, as we must iterate through the entire dataset. Training a neural network to reproduce the relationship between summary statistics and κext at a single redshift should be straightforward. However expanding this to encompass the entire volume of the dataset would be a much more significant challenge. Taking on this challenge may be unavoidable given the number of lenses that will discovered in LSST.
8.1.3. Summary statistics that better target the primary mass structure
Our work here has suggested that the primary contribution to κext may be a single mass structure. Placing further constraints on this mass structure may be a way to improve the precision of the measurement. As always, a primary challenge is finding techniques that can easily be applied to a large number of systems.
8.2. Further work on population modeling
This work has demonstrated the techniques necessary for placing constraints on the distribution of κext populations of strong lens lines of sight. While our work demonstrates with a high degree of confidence that this population of lenses fall in overdense environments, we cannot place clear constraints on the width or scale of that distribution. Additionally, we cannot say with confidence that the result derived from the SL2S sample is applicable to strong gravitational lenses as a whole. A much larger set of lenses (on the order of a few hundred) is needed to better constrain this population and boost confidence that our conclusions can be generalized. The strong lenses expected to be discovered in LSST will be an ideal sample for this type of work, and we look forward to working with these data when they become available.
Availabile from pip or https://github.com/PatrickRWells/cosmap
Throughout this work, we report values with the standard sign convention used here. The scipy implementation of the GEV distribution which we use for our computational work uses the opposite convention.
Acknowledgments
P.R.W and C.D.F acknowledge support for this work from the National Science Foundation under Grant No. AST-1907396. This work is partially based on observations with the NASA/ESA Hubble Space Telescope obtained at the Space Telescope Science Institute, which is operated by the Association of Universities for Research in Astronomy, Incorporated, under NASA contract NAS5-26555. Support for Program number HST-GO-17130 was provided through a grant from the STScI under NASA contract NAS5-26555. P.W. thanks Kenneth Wong for reviewing this work prior to submission. P.W. thanks the TDCOSMO environment working group for useful discussion throughout the preparation of this work.
References
- Aghanim, N., Akrami, Y., Ashdown, M., et al. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2017, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Antal, T., Labini, F. S., Vasilyev, N. L., & Baryshev, Y. V. 2009, EPL (Europhys. Lett.), 88, 59001 [NASA ADS] [CrossRef] [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Birrer, S., Millon, M., Sluse, D., et al. 2023, Space Sci. Rev., 30 [Google Scholar]
- Bonvin, V., Courbin, F., Suyu, S. H., et al. 2016, MNRAS, 465, 4914 [Google Scholar]
- Cabanac, R. A., Alard, C., Dantel-Fort, M., et al. 2006, A&A, 461, 813 [Google Scholar]
- Capranico, F., Kalovidouris, A. F., & Schaefer, B. M. 2013, ArXiv e-prints [arXiv:1305.1485] [Google Scholar]
- Chen, G. C.-F., Fassnacht, C. D., Suyu, S. H., et al. 2021, A&A, 652, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clerkin, L., Kirk, D., Manera, M., et al. 2016, MNRAS, 466, 1444 [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Collett, T. E., Marshall, P. J., Auger, M. W., et al. 2013, MNRAS, 432, 679 [NASA ADS] [CrossRef] [Google Scholar]
- Costanzi, M., Saro, A., Bocquet, S., et al. 2021, Phys. Rev. D, 103, 043522 [Google Scholar]
- Dark Energy Survey Collaboration 2005, ArXiv e-prints [arXiv:astro-ph/0510346] [Google Scholar]
- Davis, O., Devriendt, J., Colombi, S., Silk, J., & Pichon, C. 2011, MNRAS, 413, 2087 [NASA ADS] [CrossRef] [Google Scholar]
- De Lucia, G., & Blaizot, J. 2007, MNRAS, 375, 2 [Google Scholar]
- Di Valentino, E., Mena, O., Pan, S., et al. 2021, CQG, 38, 153001 [NASA ADS] [CrossRef] [Google Scholar]
- Dressler, A. 1980, ApJ, 236, 351 [Google Scholar]
- Fassnacht, C. D., Xanthopoulos, E., Koopmans, L. V. E., & Rusin, D. 2002, ApJ, 581, 823 [NASA ADS] [CrossRef] [Google Scholar]
- Fassnacht, C. D., Koopmans, L. V. E., & Wong, K. C. 2010, MNRAS, 410, 2167 [Google Scholar]
- Ferlito, F., Springel, V., Davies, C. T., et al. 2023, MNRAS, 524, 5591 [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Gomer, M., & Williams, L. 2020, JCAP, 2020, 045 [CrossRef] [Google Scholar]
- Gwyn, S. D. J. 2012, AJ, 143, 38 [Google Scholar]
- Hilbert, S., Hartlap, J., White, S. D. M., & Schneider, P. 2009, A&A, 499, 31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, V., Kahn, S. M., Anthony Tyson, J., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Kelly, P. L., Rodney, S., Treu, T., et al. 2023, Science, 380, abh1322 [NASA ADS] [CrossRef] [Google Scholar]
- Kundic, T., Turner, E. L., Colley, W. N., et al. 1997, ApJ, 482, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, Y., Oguri, M., & Cao, S. 2023, Phys. Rev. D, 108, 083532 [Google Scholar]
- Mikelsons, G., Silk, J., & Zuntz, J. 2009, MNRAS, 400, 898 [NASA ADS] [CrossRef] [Google Scholar]
- Papalexiou, S. M., & Koutsoyiannis, D. 2013, Water Resour. Res., 49, 187 [CrossRef] [Google Scholar]
- Park, J. W., Birrer, S., Ueland, M., et al. 2023, ApJ, 953, 178 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Yuan, W., Macri, L. M., et al. 2022, ApJ, 934, L7 [NASA ADS] [CrossRef] [Google Scholar]
- Rusu, C. E., Fassnacht, C. D., Sluse, D., et al. 2017, MNRAS, 467, 4220 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., & Sluse, D. 2013, A&A, 559, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shajib, A. J., Mozumdar, P., Chen, G. C.-F., et al. 2023, A&A, 673, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Taruya, A., Takada, M., Hamana, T., Kayo, I., & Futamase, T. 2002, ApJ, 571, 638 [NASA ADS] [CrossRef] [Google Scholar]
- Tihhonova, O., Courbin, F., Harvey, D., et al. 2018, MNRAS, 477, 5657 [NASA ADS] [CrossRef] [Google Scholar]
- Tihhonova, O., Courbin, F., Harvey, D., et al. 2020, MNRAS, 498, 1406 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., & Marshall, P. J. 2016, A&A Rev., 24, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Verma, A., Collett, T., Smith, G. P., Strong Lensing Science Collaboration& the DESC Strong Lensing Science Working Group 2019, arXiv e-prints [arXiv:1902.05141] [Google Scholar]
- Vuissoz, C., Courbin, F., Sluse, D., et al. 2008, A&A, 488, 481 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wagner-Carena, S., Park, J. W., Birrer, S., et al. 2021, ApJ, 909, 187 [Google Scholar]
- Wells, P., Fassnacht, C. D., & Rusu, C. E. 2023, A&A, 676, A95 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wong, K. C., Sonnenfeld, A., Chan, J. H. H., et al. 2018, ApJ, 867, 107 [Google Scholar]
- Xavier, H. S., Abdalla, F. B., & Joachimi, B. 2016, MNRAS, 459, 3693 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Results for individual lenses in the SL2S sample
Results for individual lenses with best fit generalized extreme-value parameters and 1σ confidence for κext posterior.
Appendix B: Results of population analysis
 |
Fig. B.1. Corner plot showing results of our MCMC, with the median value of each sample distribution included as a derived parameter. The red mark indicates the best-fit values for the entire population of lines of sight in the Millennium simulation. |
All Tables
Results for individual lenses with best fit generalized extreme-value parameters and 1σ confidence for κext posterior.
All Figures
|
Fig. 1. Image showing the field around SL2SJ1405+5243. The inner and outer red circles mark the inner and outer cutoff radius we use when computing weighted number counts. |
| In the text | |
|
Fig. 2. Comparison of best-fit GEV distribution (left) and best-fit log-normal distribution(right) to the κext distribution of lines of sight in the Millennium simulation at redshift z = 2.34 from Hilbert et al. (2009). The best-fit GEV parameters are ξ = 0.145, μ = −0.0235, and log(σ) = − 3.46, while the best-fit log-normal parameters are μ = −0.098 and log(σ) = − 0.78. |
| In the text | |
|
Fig. 3. Measured median values of κext for the lenses in our sample as a function of deflector and source redshift, respectively. Error bars denote the 68% confidence interval. The red dotted line represents the trend of the median value of κext. |
| In the text | |
|
Fig. B.1. Corner plot showing results of our MCMC, with the median value of each sample distribution included as a derived parameter. The red mark indicates the best-fit values for the entire population of lines of sight in the Millennium simulation. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.