Fig. 1
Download original image
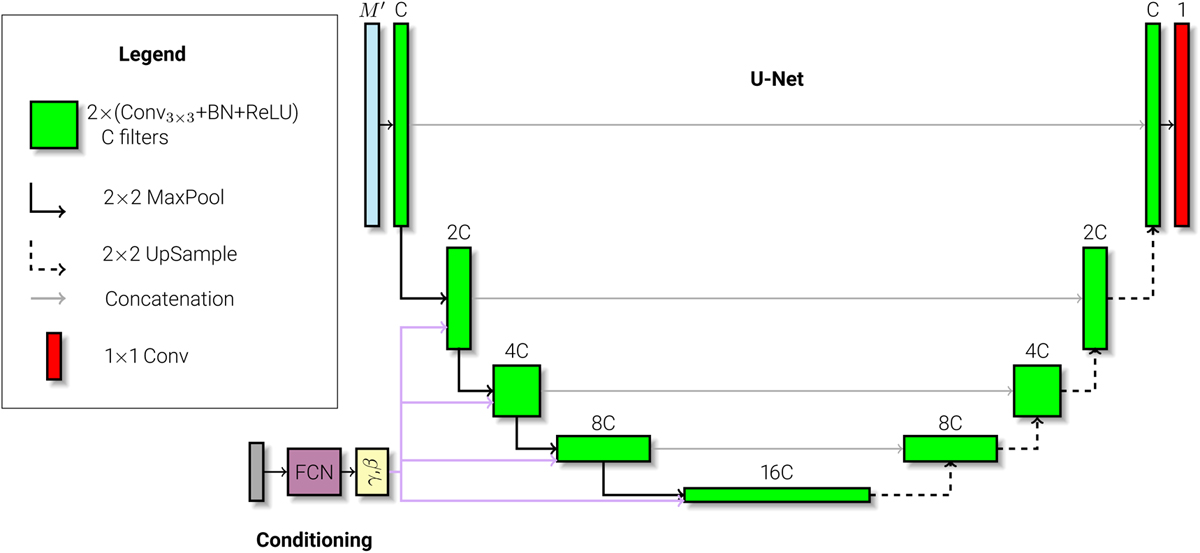
U-Net deep neural network used in the present work as an emulator for the spatially variant convolution. M′ = M + 1 is the number of channels of the input tensor, which is built by concatenating the image of interest and the spatially variant images of the M Karhunen-Loève. All green blocks of the encoder are conditioned to the specific instrumental configuration as described in Sect. 2.2.1 via the encoding fully connected network shown in the figure. The gray box refers to the one-hot encoding of the instrumental configuration.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.