Fig. 2
Download original image
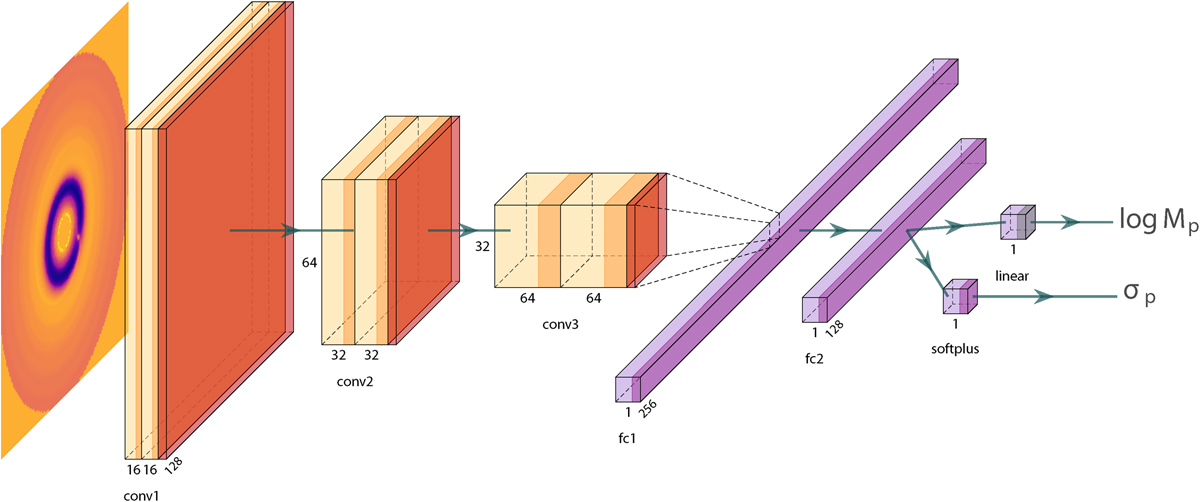
Architecture of the trained CNNs. The disc image is fed to the convolutional part of the neural network made of three blocks. Each of them consists of two convolutional layers with filter size 3 × 3 (light orange) followed by a max pooling layer with filter size 2 × 2 (dark orange). The second part of the CNN consists of two fully connected layers. We omit in this image the dropout and normalization layers.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.