Fig. 2
Download original image
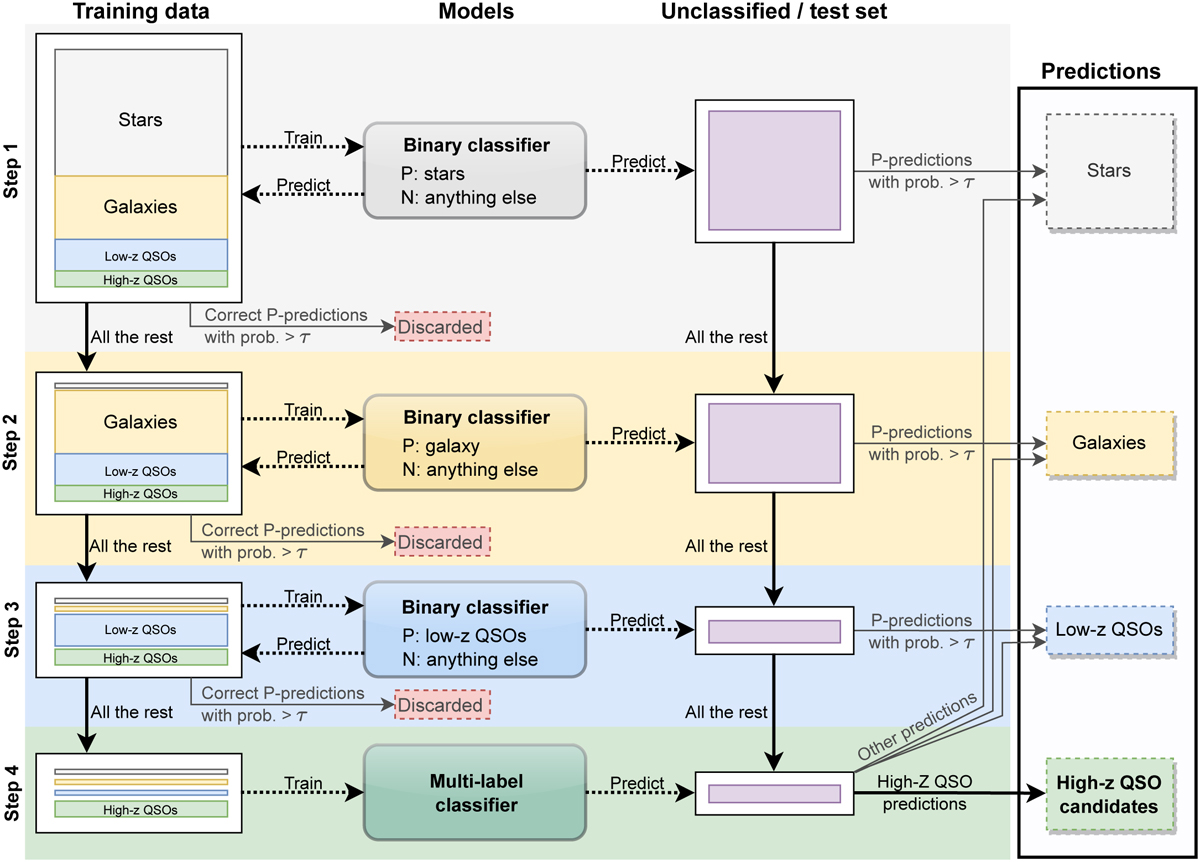
Schema of the reverse selection method. In the first three steps a binary classifier is used to predict classification on all datasets, including the training one. If the probability of belonging to the noninteresting P-class is greater than a threshold τ the source is discarded before proceeding to the next step. By doing so all datasets decrease in size and, most importantly, they are rebalanced toward the interesting sources, namely the high-z QSOs. The last step is a simple multi-label classification, just like the direct selection method.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.