Fig. 3
Download original image
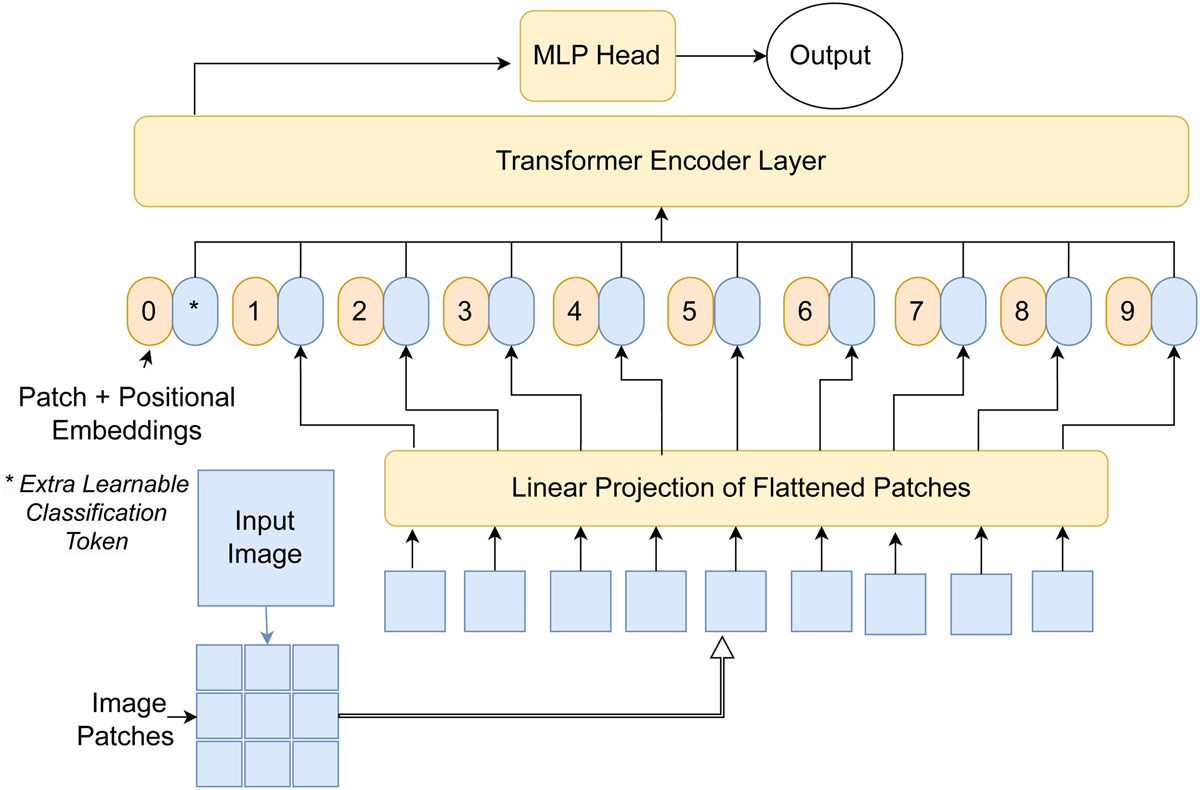
Scheme of the general architecture of the LSBG ViT. The input image is split into small patches and flattened into a sequence of 1D vectors and combined with positional encoding. The numbered circular patches represent the position encoding, and the counterpart represents the flattened 1D sequence of the image patches. The combined 1D sequence is passed to the transformer layers. The extra learnable class embedding encodes the class of the input image after being updated by self-attention and passes it on to an MLP head to predict the output.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.