Fig. 2
Download original image
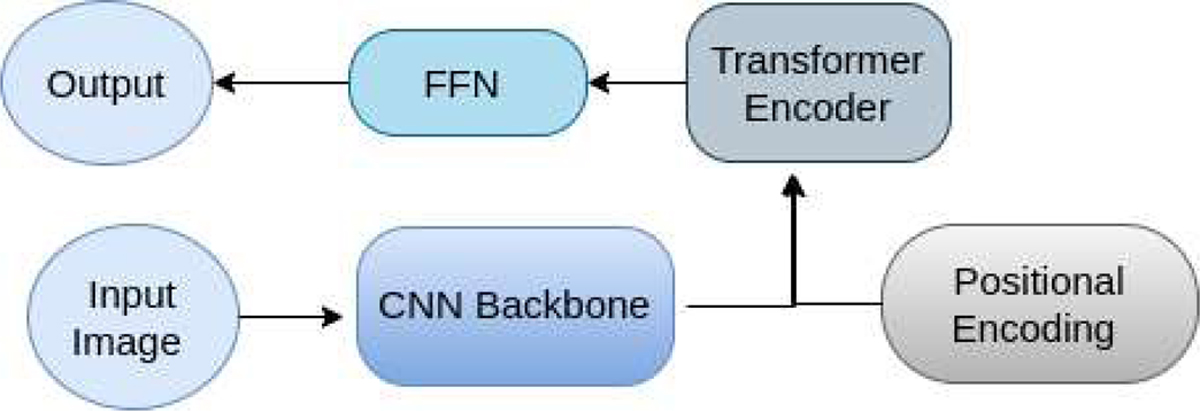
Scheme of the general architecture of the detection transformer (LSBG DETR) taken from Thuruthipilly et al. (2022b). The extracted features of the input image by the CNN backbone are combined with positional encoding and are passed on to the encoder layer to assign attention scores to each feature. The weighted features are then passed to the feed-forward neural network (FFN) to predict the probability.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.