| Issue |
A&A
Volume 672, April 2023
|
|
|---|---|---|
| Article Number | A26 | |
| Number of page(s) | 23 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202244664 | |
| Published online | 28 March 2023 | |
Multiscale and multidirectional very long baseline interferometry imaging with CLEAN
Max-Planck-Institut für Radioastronomie,
Auf dem Hügel 69,
Bonn
53121,
Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
2
August
2022
Accepted:
27
January
2023
Abstract
Context. Very long baseline interferometry (VLBI) is a radio-astronomical technique whereby the correlated signal from various baselines is combined into an image of the highest possible angular resolution. Due to the sparsity of the measurements, this imaging procedure constitutes an ill-posed inverse problem. For decades, the CLEAN algorithm has been the standard choice in VLBI studies, despite it bringing on some serious disadvantages and pathologies that are brought on by the requirements of modern frontline VLBI applications.
Aims. We developed a novel multiscale CLEAN deconvolution method (DoB-CLEAN) based on continuous wavelet transforms that address several pathologies in CLEAN imaging. We benchmarked this novel algorithm against CLEAN reconstructions on synthetic data and reanalyzed BL Lac observations of RadioAstron with DoB-CLEAN.
Methods. The DoB-CLEAN method approaches the image via multiscalar and multidirectional wavelet dictionaries. Two different dictionaries were used: 1) a difference of elliptical spherical Bessel functions dictionary fitted to the uv-coverage of the observation that is used to sparsely represent the features in the dirty image; 2) a difference of elliptical Gaussian wavelet dictionary that is well suited to represent relevant image features cleanly. The deconvolution was performed by switching between the dictionaries.
Results. DoB-CLEAN achieves a super-resolution compared to CLEAN and remedies the spurious regularization properties of CLEAN. In contrast to CLEAN, the representation via basis functions has a physical meaning. Hence, the computed deconvolved image still fits the observed visibilities, in contrast to CLEAN.
Conclusions. State-of-the-art multiscalar imaging approaches seem to outperform single-scalar standard approaches in VLBI and are well suited to maximize the extraction of information in ongoing frontline VLBI applications.
Key words: techniques: interferometric / techniques: image processing / techniques: high angular resolution / methods: numerical / galaxies: nuclei / galaxies: jets
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open access funding provided by Max Planck Society.
1 Introduction
Very long baseline interferometry (VLBI) is a radio-interferometric technique that achieves an unmatched angular resolution. An array of single-dish antennas altogether form an instrument with angular resolution determined by the wavelength and longest separation between two antennas in the array (Thompson et al. 2017). The signal recorded at each antenna pair is correlated. The correlation product (visibility) is proportional to the Fourier-transform of the true sky-brightness distribution (van Cittert-Zernike theorem), where the spatial frequency is specified by the baseline separating the two antennas recording. In principle, the true image could be revealed from a complete sampling of the uυ-space by an inverse Fourier transform. However, since an interferometer is a sparse array of single antennas with a limited number of baselines, the coverage of Fourier coefficients (uυ-coverage) is often sparse and has significant gaps (Thompson et al. 2017). This makes imaging, namely, the procedure of creating an image from the correlated antenna outputs, an ill-posed inverse problem.
The imaging problem (inverse Fourier transform from sparsely sampled data) is often expressed equivalently as a deconvolution problem, namely, the dirty image (inverse Fourier transform of visibilities) is modeled as the convolution of the dirty beam (inverse Fourier transform of mask) and the true sky brightness distribution (Thompson et al. 2017).
CLEAN and its variants (Högbom 1974; Clark 1980; Schwab 1984) have been the standard in VLBI imaging for decades and are still widely used. CLEAN models the image iteratively as a set of point sources: CLEAN searches for the position of the maximum in the residual image, stores the intensity and the position in a list of delta-components, and updates the residual by subtracting the rescaled and shifted dirty beam from the residual image. Despite the general success of CLEAN in VLBI applications, a number of issues have arisen thus far: CLEAN is less precise than recently developed regularized maximum likelihood (RML) methods (Akiyama et al. 2017b,a; Chael et al. 2018; Event Horizon Telescope Collaboration 2019; Müller & Lobanov 2022) and Bayesian approaches (Arras et al. 2021), particularly when the true sky brightness distribution is uniform and extended, it offers a poorer resolution and relies on manual input from the astronomer performing the imaging to achieve a convergence to the true solution. Moreover, the sequential nature inherent to CLEAN makes CLEAN slow compared to modern optimization algorithms that were developed in an environment of parallel CPU computing facilities.
From a theoretical point of view, CLEAN is inadequate. An imaging procedure needs to satisfy two basic requirements. Firstly, the final image needs to fit the observed visibilities. Secondly, among all possible solutions that fit the data (i.e., among the kernel spanned by the convolution with the dirty beam), the imaging procedure should select the image that is most reasonable, namely, the one that interpolates the gaps in the uυ-coverage in the most reasonable way. CLEAN can only achieve one of these goals simultaneously. CLEAN separates between a model (the list of delta-components) that fits the observed data and the final image (the model convolved with a clean beam) that is thought to be a reasonable approximation to the true sky brightness distribution. However, strictly speaking, the final image that CLEAN produces in VLBI (and that is used in further studies) no longer provides a reasonable data fit.
In fact, the regularizing property of CLEAN is questionable as well. While CLEAN typically provides decent fits for the uυ-tracks that were observed, the (typically not plotted) fit in the gaps in the uυ-coverage is sometimes clearly unphysical, we will discuss this attribute in more detail in Sect. 4. A more thorough imaging approach is needed that takes the distribution of gaps in the uυ-coverage in account and provides more control over the non-measured Fourier coefficients.
Most of these issues are caused by CLEAN modeling of the image as a sequence of delta components which is inadequate to describe extended image features in real astronomical images. One possible solution is the use of multiscalar algorithms that model the image as a set of extended basis functions of different scales (Wakker & Schwarz 1988; Starck et al. 1994; Bhatnagar & Cornwell 2004; Cornwell 2008; Rau & Cornwell 2011; Müller & Lobanov 2022). While this is a great step forward in imaging, MS-CLEAN methods have not been widely adopted in frontline VLBI applications in the past. This is because the selection of suitable basis functions greatly affects the fitting procedure as various scales are sensitive to various parts of the uυ-coverage and do not necessarily solve the problem of missing regularization in CLEAN, namely, the unphysical fits in the gaps of the uυ-coverage. To also address this problem of missing regularization, we propose a more data-driven approach here: the basis functions are selected in a way that they fit to the uυ-coverage, namely, they define masks in the Fourier domain that are separate between visibilities covered by observations and visibilities that are not covered by observations (gaps in the uυ-coverage). The features from the latter should be suppressed during imaging, namely, the unphysical fit in the gaps occurring during CLEAN should be smoothed and regularized. As the uυ-coverage of an observation is typically not circularly symmetric, we propose (for the first time) not only a multiscalar, but also a multidirectional set of basis functions (i.e., dictionary).
In this way, our procedure allows for a more thorough separation between reliable image information, namely, image features introduced by regions in the Fourier domain that are covered by data and “nvisible distributions,”that is, image features that are most sensitive to regions of the uυ-coverage that are not covered by observations. This is certainly needed to match our second basic requirement for an imaging algorithm for frontline VLBI arrays; among all possible solutions, the one that is most physical (regularized) should be selected.
In this paper, we present an approach to constructing a suitable multiscalar and multidirectional dictionary for imaging and implementing this dictionary in a CLEAN-like algorithm called DoB-CLEAN (difference of elliptical Bessel functions CLEAN) that fits in the normal workflow that radio astronomers are used to.
2 Theory
2.1 Background
A radio interferometer observes a source with all antennas available in the array at the same time. The source typically appears point-like per antenna in the constructed array. The interferometric observation, however, reveals image features at a much greater resolution. We denote the (incoherent) sky-brightness distribution of the source by I (l, m). Here, l and m denote spatial on-sky coordinates. The recorded signals are correlated for each antenna pair at a fixed time. The antenna pair is specified by a corresponding separation vector (u, υ), namely, spatial frequencies in units of wavelengths, which is called baseline. While the Earth continues to rotate over the period of observations, the projected baselines vary as well, leading to the typical elliptical tracks in the uυ-coverage. Described by the van-Cittert-Zernike theorem (assuming the small-field approximation and a flat wavefront), the correlation product at a single baseline is the Fourier coefficient of the true sky brightness distribution at this baseline (Thompson et al. 2017):
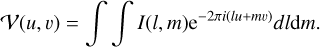 (1)
(1)
These Fourier coefficients are referred to as the “visibilities.”
Imaging is the problem of recovering the on-sky distribution, I, from the measured complex visibilities, 𝒱. From a full sample of the uυ-domain, this could be achieved by an (gridded) inverse Fourier transform. However, every antenna pair at a a particular instance in time gives rise to only one Fourier coefficient. Hence, the limited number of available antennas and the limited amount of observation time only allow for a very sparse coverage of the uυ-domain.
For imaging with CLEAN (Högbom 1974), Eq. (1) is equivalently reformulated as a deconvolution problem. The observed visibilities are gridded on a regular grid and possibly weighted – for instance, by baseline-dependent S/N and in the case of uniform weighting, by the number of data points per cell. The gridding cells corresponding to unmeasured Fourier coefficients are set to zero. The dirty image ID is now defined as the inverse Fourier transform of the gridded (and weighted) observed visibilities. Furthermore, the dirty beam BD is the response to a synthetic point-source, namely, the inverse Fourier transform of the gridding (and weighting) alone. It is:
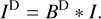 (2)
(2)
The imaging problem is now translated into a deconvolution problem. The dirty image and the dirty beam contain significant sidelobes that are caused by the gaps in the uυ-coverage, that is, the cells in the Fourier domain that are initialized with zero during gridding. These sidelobes are “cleaned,” that is, suppressed, by deconvolution. Hence, the deconvolution process can also be understood as an approach to interpolate the observed measured visibilities to the gaps.
Among the sparsity of the observed Fourier coefficients, the imaging procedure has to deal with further complications: scale-dependent thermal noise on different baselines and direction-independent calibration issues. The former complication is addressed by weighting the visibilities by their thermal noise level. The latter complication is factored in station-based multiplicative gains. In particular, the relative phase is often unknown in VLBI imaging. Station-based gains are corrected by gain-self-calibration loops alternating with deconvolution iterations. In principle, more complex calibration errors could also occur, which cannot be factored in station-based gains at all.
2.2 CLEAN
CLEAN directly solves the deconvolution in Eq. (2) by iteratively subtracting the dirty beam from the residual. Classical CLEAN (Högbom 1974) approaches the image as a sequence of point sources. Hence, once the position of a new component is found, the dirty beam is shifted to this position and rescaled to the intensity in the residual image at that location multiplied with some gain parameter. The residual image is updated by subtracting the shifted and rescaled dirty beam. The list of delta-components constitutes the model that CLEAN computes to fit the observed visibilities.
It is crucial for CLEAN to find a proper location of the next component. This is handled mostly manually by the astronomer by specifying search-windows for the next components. This procedure has proven successful, particularly in the presence of calibration errors. However, the iterative windowing, flagging, and self-calibration lacks reproducibility. Within the specified window, the location of the next component is found by the location of the peak in the current residual image. However, this is only approximately correct. If the assumption behind CLEAN, namely, that the true sky brightness distribution is modeled by a sum of point-sources, were true and we would ignore thermal noise for one moment, the current residual (ID) could be envisioned as the convolution of the dirty beam BD with the sum of point sources that are unmodeled by CLEAN until this step ({δl} with intensities al):
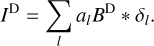 (3)
(3)
The most efficient selection criterion would be to find the largest of these unmodeled point sources, namely, the largest al. CLEAN takes the largest peak in the residual instead. This might not always be the optimal choice since overlapping sidelobes from different emission features can suppress real emission and can create a false source when the sidelobes are constructively added. In practice, this subtle difference however was not found to cause problems. However, we would like to note that the new multiscale CLEAN (DoB-CLEAN) algorithm that we propose in Sect. 3 is based on the same assumption (see Sect. 3.4).
After the final CLEAN-iteration, the list of delta components is typically convolved with a clean beam that represents the resolution limits of the instrument. Moreover, the last residual is added to the final image. This step is of direct meaning for the regularizing property of CLEAN: how does CLEAN fit the gaps in the uυ-coverage? Again we assume the model of point-sources from Eq. (3). Let us assume that CLEAN has computed a guess model: M = ∑l âlδl, where the weights, âl, should approximate the true weights, al, sufficiently well. Then, the final residual, R, reads:
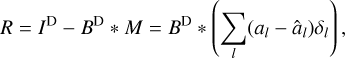 (4)
(4)
and the final model:
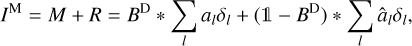 (5)
(5)
where 1 denotes the identity operator. The sum is decomposed in a part that corresponds to the measured Fourier coefficients – the first term, convolution with dirty beam sets the Fourier coefficients in the gaps exactly to zero) and a part that corresponds to the uncovered gaps in the uυ-coverage; and the second term, convolution with an “invisible” beam Id – B that is exactly zero for the measured Fourier coefficients and unequal to zero in the gaps. Hence, the model should always fit the data correctly (first term) in the unphysical, ideal situation of an infinite field of view and uniform weighted data without thermal noise and calibration errors. It becomes obvious that CLEAN (assuming that the âl values are good approximations to the true weights) interpolates the uncovered gaps in the uυ-coverage by assuming that the same pattern of delta components could be used to describe these signals once they were measured. This, however, is problematic primarily for two reasons: first, the uυ-coverage of a real VLBI array shows rich radial (e.g., a denser coverage on short baselines) and direction-dependent structural patterns (e.g., highly elliptical uυ-tracks for some antenna pairs that give rise to only a few directions in the uυ-domain). It is far from obvious that these different regions in the Fourier domain should encode the same feature. It is more likely that the small-scale structure hidden on short baselines and the large-scale structure on long baselines show less similarity. A more rigorous multiscalar (and multidirectional) approach is needed to separate these different structural features and to take the structural pattern of the uυ-coverage into account. Secondly, the convergence rates and fitting properties in the presence of thermal noise remain unclear (Schwarz 1978). In practice, the CLEAN model often results in severe overfitting when not stopped early enough. This problem is solved by convolving the final model by the clean beam, that is, the fits to the usual more-poorly-covered long baselines are generally suppressed. However, this only trades the problem of overfitting for a limited resolution that is challenged by modern state-of-the-art imaging algorithms and for an unphysical separation between the final image (that is used for further analysis, but does not fit the visibilities due to the convolution with the clean beam that causes disparity from the observed visibilities) and a model (that fits the visibilities, but is not useful for image analysis). Again a more rigorous multiscale approach that improves the separation between gaps and covered regions in the uυ-coverage (and suppresses the overfits in former one) is desired.
The regularization introduced by CLEAN can also be visualized in the image-domain instead of the Fourier domain: here, the extrapolation into gaps in the fit translates into suppressing sidelobes in the dirty image. Sidelobes are suppressed as the basis functions (delta-functions) are sidelobe-less and the dirty image and the dirty beam consist of the same sidelobe pattern. Hence, deconvolution suppresses sidelobes by subtracting the sidelobe pattern of the dirty beam from the residual. As we go on to discuss later in this paper, this stands be a major difference with regard to our new DoB-CLEAN algorithm.
2.3 Multiscale CLEAN and wavelets
Multiscale-CLEAN (MS-CLEAN) methods have been proposed in the past (Bhatnagar & Cornwell 2004; Cornwell 2008) to mitigate the problems detailed above. In a nutshell, the point-like basis functions from CLEAN are replaced by smooth, positive, extended basis functions that are suitable for representing the image structure. Bhatnagar & Cornwell (2004) used adaptive scale pixels (Asp) which could, in principle, compress any shape. Cornwell (2008) specified this and used tapered, truncated parabolas, namely, a function with a minor difference with regard to Gaussians (i.e., they have a finite support). In particular, Cornwell (2008) mentions that Gaussians would be possible as well, as long as a very high dynamic range is not desired or image-plane support constraints are required. Our new method is based on the spirit of MS-CLEAN developed in these works. However, we fit the image with a completely different wavelet-based dictionary resulting in a different imaging procedure. We explain how we theoretically compare our new algorithm with standard MS-CLEAN approaches in more detail in Sect. 4.2.
2.4 Alternative imaging approaches
CLEAN and its variants (Högbom 1974; Clark 1980; Schwab 1984; Bhatnagar & Cornwell 2004; Cornwell 2008; Rau & Cornwell 2011) have been the standard method in VLBI for the last decades. They remain in use due to their practical nature that allows the astronomer to interact with the imaging manually, to manipulate the data set and to self-calibrate the data set during imaging. We therefore aim to keep this workflow for our new proposed procedure. However, we like to mention the many modern methods developed for VLBI. This includes regularized maximum likelihood (RML) methods (e.g., Carrillo et al. 2012; Garsden et al. 2015; Akiyama et al. 2017b; Chael et al. 2018; Müller & Lobanov 2022) as well as Bayesian reconstructions (e.g., Junklewitz et al. 2016; Cai et al. 2018a,b; Arras et al. 2019, 2021; Broderick et al. 2020b,a). In comparison to CLEAN, the problem is solved by forward modeling instead of inverse modeling.
3 Algorithm
3.1 Overview
We demonstrated in Müller & Lobanov (2022) how a multiscale approach can improve imaging performance. Our algorithm was based on a wavelet-based sparsity promoting (compressed sensing) approach in the RML fashion. In this paper, we are interested in a more CLEAN-like algorithm as this working procedure is well established within the VLBI community. In particular, we are proposing a new version of MS-CLEAN (Cornwell 2008), but for the first time we are selecting the basis functions in a way that they fit to the uυ-coverage. This provides an optimal selection between observed image features and sidelobes induced by uυ-coverage defects.
We model the true image by a set of extended basis functions (a dictionary) Ψ = {Φ0, Φı,…} instead of delta functions, that is, I = Ψx with some coefficient array x. We try to recover the coefficient array x from the data and infer the recovered image from there by applying the dictionary on x once more, the recovered image will be I = Ψx (where x is the recovered array of coefficients). The basis functions, Φi, have some connection to the Fourier domain: convolving with Φi in the image domain is equivalent to multiplying with the Fourier transform, ℱΦi, in the Fourier domain. The basis functions of the dictionary therefore define filters in the Fourier domain which allow for information on the uυ-coverage to be injected during the imaging procedure, namely, every basis function, Φi, compresses features of a specific set of baselines.
Here, we consider which basis functions are most efficient in that regard. For the sake of optimally representing the image, we seek basis functions that are smooth, sidelobe-free, and positive (cf. the selection of basis functions in Cornwell 2008). An optimal fitting of the uυ-coverage calls for basis functions that provide steep radial masks in the Fourier domain and that are optimally orthogonal on each other are desired. These are demonstrably contradicting requirements. Typical orthogonal wavelet functions (e.g., Daubechies wavelets) already contain wide sidelobes (Starck et al. 2015). Therefore, we are dealing with two different dictionaries: with a dictionary of (radially) orthogonal wavelets, ΨDoB, referred to as the “difference of Bessel” (DoB) in the following, which enables the optimized handling of masks in the Fourier domain and with a dictionary of smooth and clean wavelets, ΨDoG, that can be used best to describe image features, referred to as “difference of Gaussian (DoG) in the following”. The two wavelet dictionaries are related to each other such that latter one (the image-driven dictionarym ΨDoG) contains only the central peak (without sidelobes) of the wavelets in the former one (the Fourier domain driven dictionary ΨDoB). This is a similar approximation to that of CLEAN and MS-CLEAN via the transition from the dirty beam to the clean beam, namely, by fitting a central Gaussian component to dirty beam pattern.
The CLEANing procedure is done with ΨDoB. We represent the dirty image by ID = BD * (ΨDoB x) and iteratively recover the coefficient array, x, by CLEAN loops, that is, we iteratively search for the maximum peak, store this in a list of multiscalar components and update the residual. The list of multiscalar components for the final image, however, is convolved with ΨDoG, instead of ΨDoB. In this sense, representing the model by shifted and rescaled DoB wavelets does not suppress sidelobes in the image (since the basis functions ΨDoB contain sidelobes on their own), but works as a feature-finder algorithm that decomposes the dirty image into a list of (extended) multiscalar basis functions. These are then replaced by more regular basis functions that compress the same image features (the same scales), but suppress the long elongating sidelobes. This is done in an alternating iterative procedure with iterative updates of the residual map: we represent the dirty image by the dictionary, ΨDoB, by CLEAN loops; we compute a guess solution by replacing the dictionary, ΨDoB, with the dictionary, ΨDoG; we update the residual image and repeat these steps until the residual image is noise-like. As opposed to CLEAN, the suppression of sidelobes is not done by finding the CLEAN components and subtracting the dirty beam from the image, but by replacing ΨDoB with ΨDoG.
In our previous paper Müller & Lobanov (2022), we presented a novel wavelet dictionary based on the DoG method, which proved flexible enough to compress information about the uυ-coverage of the observation. Thus, we reused this dictionary for the image domain, ΨDoG. It is the canonical extension to orthogonal wavelets to replace the Gaussians in the construction of the DoG wavelets by modified Bessel functions of the same width (i.e., the central peak of the Bessel functions has the same width as the Gaussians). The Fourier transform of modified Bessel functions is a uniform disk, hence, the Fourier transforms of difference of Bessel (DoB) wavelets are uniform rings. These have non-overlapping support in the Fourier domain, hence, they are orthogonal. We therefore construct the wavelets for fitting the uυ-coverage, ΨDoB, out of DoB wavelets. Moreover, we present ways to extend this concept also to direction-dependent wavelets. Some examples of our sequence of wavelets and their corresponding filter in Fourier domain are presented in Fig. 1. Moreover, we present the cross-section of two example wavelets in Figs. 2 and 3, demonstrating the correspondence between DoB wavelet scales and DoG wavelets. We present more details on this in the subsequent subsections.
 |
Fig. 1 Illustration of the used wavelet scales, ΦDoB, fitted to to a synthetic RadioAstron uυ-coverage in image and Fourier domain. Scales of various radial widths (scales 3, 4, scales 5–9, and scale 10) and four different elliptical directions are shown. The scales are fit to the uυ-coverage, as they are sensitive to gaps or covered coefficients, respectively. Upper panel: Fourier transform of the wavelet scales and the synthetic RadioAstron uυ-coverage (red points). Lower panels: respective wavelet basis function in image domain. |
 |
Fig. 2 Cross-section of the DoB and DoG wavelet scale 5 presented in Fig. 1. The DoB-wavelet fits the central peak, but suppresses the extended sidelobes. |
 |
Fig. 3 Cross-section of the DoB and DoG wavelet scale 7 presented in Fig. 1. The DoB wavelet fits the central peak, but suppresses the extended sidelobes. |
3.2 Wavelet-basis functions
We explain in this section the design of the wavelet functions used in this work. As discussed in Sect. 3.1, we aim to find a suitable dictionary, ΨDoG, that is flexible in its radial scales and smooth to compress image features best, and a dictionary, ΨDoB, that corresponds to the same radial (and angular) scales and provides an optimal analysis masks in the uυ-domain. Our wavelet dictionaries are based on the design of DoG wavelets that we successfully applied to VLBI imaging in Müller & Lobanov (2022). We first summarize the construction of the DoG wavelet dictionary from Müller & Lobanov (2022), then we discuss the straightforward extensions to difference of Bessel functions (DoB) and angular wavelet dictionaries. For more details we refer to Müller & Lobanov (2022).
One of the most frequently applied continuous wavelet functions is the “Mexican hat” wavelet (Murenzi 1989; Starck et al. 2015), which is known to offer image compressions for a wide range of model images. The Mexican hat wavelet is effectively a (rescaled) Laplacian of Gaussian (Gonzalez & Woods 2006). Hence, it is well approximated by the corresponding differential quotient for small variations (Assirati et al. 2014), which we call a DoG wavelet in the following:
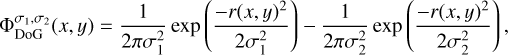 (6)
(6)
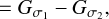 (7)
(7)
where, necessarily, σ1 ≤ σ2 and 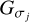 denotes a Gaussian with standard deviation σj.
denotes a Gaussian with standard deviation σj.
In the past, discrete à trous wavelet decompositions have been of special interest in radio astronomy (Starck & Murtagh 2006; Starck et al. 2015; Mohan & Rafferty 2015; Mertens & Lobanov 2015; Line et al. 2020). These wavelet decompositions (called starlets) were successfully applied to imaging and image segmentation. A starlet decomposition can be computed quickly by a hierarchical upstream filtering instead of repeated convolutions in high dimensions. The image is iteratively convolved with a small filter which has typically a small support of only a couple of coefficients. The filter is applied on the output of the preceding filtering operation, respectively. In this way, a sequence of smoothed images is computed, which we denote following our notation in Müller & Lobanov (2022) by cj, where j ∊ [0, 1, 2, …, J] labels the scale. Thus, the scales, cj, are smoothed copies of the original (full resolution) image smoothed by 2jρ pixels, where ρ is the limiting resolution of filter kernel in units of pixels. Wavelets are computed by the difference method:
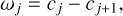 (8)
(8)
such that each wavelet scale, ωj, compresses the image information on spatial scales between 2jρ pixels and 2j+1ρ pixels. The sequence of discrete à trous wavelets is completed by the final smoothing scale cJ. The set [ω0, ω1, ω2, …, ωJ−1, cJ] is an over-complete representation of the original information, that is, no information is lost or suppressed during convolution. In particular, the image at limiting resolution, c0, is recovered by all scales by an easy superposition:
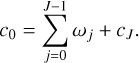 (9)
(9)
This property proved to be key to our application of wavelets in Müller & Lobanov (2022).
While discrete à trous wavelets are very successful in the compression of image information, they are less flexible than a continuous wavelet transform due to the inherent upsampling by a factor of two. Hence, they lack the ability to fit sufficiently to the more complex uυ-coverage of real VLBI arrays. Therefore, we defined a flexible wavelet dictionary out of DoG wavelets in the same procedure as was done for the à trous wavelet: we defined an increasing set of widths [σ0, σ1, σ2, …, σJ] and computed the filtered scales of the original image by convolving with Gaussians, that is, 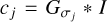 (where I denotes the original image). It is (compare Müller & Lobanov 2022):
(where I denotes the original image). It is (compare Müller & Lobanov 2022):
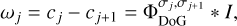 (10)
(10)
and the complete set of scale satisfies the completeness relation Eq. (9) again. If the original image, I, is noisy, the scales, ωj, will be noisy as well with a scale-specific noise-level. All in all, the DoG wavelet decomposition operation reads:
![Mathematical equation: ${{\rm{\Psi }}^{{\rm{DoG}}}}:I \mapsto \left[ {{\rm{\Phi }}_{{\rm{DoG}}}^{{\sigma _0},{\sigma _1}}*I,{\rm{\Phi }}_{{\rm{DoG}}}^{{\sigma _1},{\sigma _2}}*I, \ldots ,{G_{{\sigma _{\rm{J}}}}}*I} \right].$](/articles/aa/full_html/2023/04/aa44664-22/aa44664-22-eq13.png) (11)
(11)
Convolutions in the image domain translate to multiplicative masks in the Fourier domain. The Fourier transform of a DoG wavelet is a difference of non-normalized Gaussian functions:
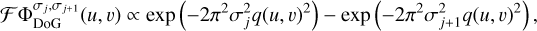 (12)
(12)
which defines ring-like masks in the uυ-domain, as described in Müller & Lobanov (2022). To have steep and orthogonal masks, however, we propose to replace Gaussians in the construction of wavelets by spherical Bessel functions. Hence:
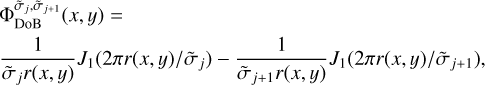 (13)
(13)
where J0 denotes the Bessel function of first order and 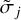 ·represents the widths of the Bessel functions. The widths for the DoB wavelets,
·represents the widths of the Bessel functions. The widths for the DoB wavelets, 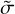 , are typically not the same as the widths that we use for the DoG-wavelets. In fact, we determine
, are typically not the same as the widths that we use for the DoG-wavelets. In fact, we determine 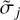 · first by fitting DoB wavelets to the uυ-coverage, as described in Sect. 3.3, then we select the widths for the DoG wavelets, σj·, such that the correlation between DoB wavelet and DoG wavelet is maximal (see our demonstration in Figs. 2 and 3).
· first by fitting DoB wavelets to the uυ-coverage, as described in Sect. 3.3, then we select the widths for the DoG wavelets, σj·, such that the correlation between DoB wavelet and DoG wavelet is maximal (see our demonstration in Figs. 2 and 3).
In 2D, it is:
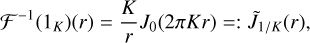 (14)
(14)
where 1K is a disc with a radius of K in the Fourier domain. Hence, the Fourier transform of the DoB wavelet is a ring-shaped mask with step-like cross-section:
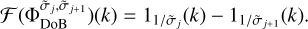 (15)
(15)
All DoB wavelets are therefore orthogonal to each other, as the Fourier transform is a unitary operation and the wavelets, 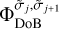 , have non-overlapping support in the Fourier domain.
, have non-overlapping support in the Fourier domain.
Up until now, we have only discussed the case of radially symmetric wavelets. To match the patterns in uυ-coverages of real VLBI arrays, a direction-dependent dictionary is desired as well. This extension is straightforward by replacing the radial symmetric Gaussian-Bessel functions via elliptical beams. We now demonstrate the construction of direction-dependent wavelet dictionary for the DoG wavelets. The construction for DoB wavelets is analogous.
We start with radial widths [σj·], and N angles 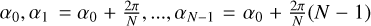 equidistantly distributed on a circle. We then calculate radial Gaussians
equidistantly distributed on a circle. We then calculate radial Gaussians 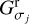 and elliptical Gaussians
and elliptical Gaussians 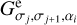 with major axis σj+1 and minor axis σj rotated by an angle αi. Hence, when decomposing an image I we compute filtered smoothed, radial bands
with major axis σj+1 and minor axis σj rotated by an angle αi. Hence, when decomposing an image I we compute filtered smoothed, radial bands 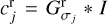 and elliptical bands
and elliptical bands 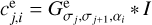 and compute the wavelets via:
and compute the wavelets via:
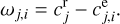 (16)
(16)
Due to the combination of radial wavelets and elliptic wavelets, ωji has a single directionality that is necessary to capture the direction dependence. Moreover, a construction in the spirit of Eq. (16) allows to complete the dictionary easily, that is, to satisfy a completeness property similar to Eq. (9). We completed the set of wavelets with the residual scales 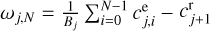 (where B is a normalization constant such that ‖ωj,N‖ = ‖ωj,N−1‖ for a response to a delta source). The final smoothing scale is
(where B is a normalization constant such that ‖ωj,N‖ = ‖ωj,N−1‖ for a response to a delta source). The final smoothing scale is 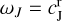 . We present the complete action of the dictionaries ΨDoG and ΨDoB in Appendix A. The complete set of wavelet scales {ωj,i, ωJ} satisfies a completeness property again:
. We present the complete action of the dictionaries ΨDoG and ΨDoB in Appendix A. The complete set of wavelet scales {ωj,i, ωJ} satisfies a completeness property again:
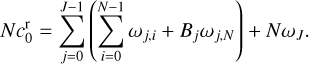 (17)
(17)
3.3 Radial widths
In this subsection, we explain which widths σ0 < σ1 < … < σJ were selected to get an optimal fit to the uυ-coverage. The selection of these basis functions has to be done prior to the imaging procedure. The basis functions are selected in a way that they allow for an optimal separation between covered Fourier coefficients and unsampled Fourier coefficients, such that some wavelet basis functions compress Fourier information that is covered by data and the remaining one compress scalar information that has not been observed (gaps). The only important criterion here is whether a scale is sampled or not. For the selection of scales we do not process the signal strength or phase observed in the visibilities. Hence, at this stage, only the uυ-coverage is processed. During the imaging a least-square fit to the visibilities at every scale will be done, with an effective suppression of the non-covered scales.
This selection is similar to the procedure that we already proposed in Müller & Lobanov (2022). We selected the radial widths only, while the angular elliptical beams are always constructed from the same array of angles equidistantly distributed on a circle at all radial scales, σj.
The angle offset, α0, was chosen to be the rotation of the major axis in the clean beam. For the selection of the radial scales, we extract the array of uυ-distances, sort this array in increasing order, and look for jumps in the sorted new array. If the increase from one component in the sorted array to the next one exceeds some (manually chosen) threshold, we store the radial baseline lengths, q(u, υ), for the two neighboring data points in a list of lengths in the Fourier domain. We translate these lengths in the Fourier domain into an increasing list of radial widths of spherical Bessel functions in the image plane [σi] by inverting. Finally, we complete this list: if there is an index, i, such that 2σi < σi+1, we add a scalar width σ = (σi+1 + σi·)/2 to avoid to large gaps between consecutive widths.
The resulting DoB wavelet dictionary fits the uυ-coverage well, as can be seen in the comparison of the Fourier filters presented in Fig. 1. As a next step, we have to find the radial widths for the DoG wavelets. We recall that the DoB wavelets were constructed with the à trous differential method. We constructed the DoG wavelets in the same way. Thus, we fit the Gaussians with varying radial widths to the central peaks of the spherical Bessel functions of widths [σi·]. We then constructed the DoG wavelets by the differential method from these Gaussians. The resulting DoG wavelets approximate the central peaks of the DoB-wavelets, but without the wide sidelobes of the DoB wavelets. This is demonstrated in Figs. 2 and 3. A sequence of examples of selected DoB scales and the respective Fourier transform masks is shown in Fig. 1.
The threshold parameter used in this procedure to identify the gaps in the uυ-coverage is a free parameter. If it is chosen too large, smaller gaps will be skipped. If it is chosen too small, the number of selected basis functions increases and samples the uυ-coverage more accurate than might be necessary. In this work, the threshold has always been chosen such that the most obvious radial gaps are kept and the number of basis functions does not exceed 50 to assure good numerical performance, but this may vary based on the array configuration.
3.4 Scale-selection criterion
We assume orthogonal wavelet functions, Φj, where j is the count of the scale.
We then assume the true image, I, is modeled via a sum of wavelets:
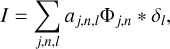 (18)
(18)
where j labels the (radial) scale in use, n labels the angle of the ellipse, and labels the pixels in the image (position of the wavelet). This assumption is well motivated by the great success that wavelet-based segmentation, image compression, and decomposition have in radio astronomy (Starck et al. 2015; Mertens & Lobanov 2015; Line et al. 2020); and, in particular, better motivated than the implicit pixel-based CLEAN assumption. We note that if we replace one scale, Φj, by two smaller scales, Φj1 and Φj2, satisfying Φj = 2Φj1 = 2Φj2, it would hold that aj = aj1 = aj2. Hence, the magnitude of aj,n,l does not depend on the relative size of the corresponding wavelet. Thus, in every CLEAN iteration, we would like to find the biggest aj,n,l still in the dirty image. However, some scales are not covered in the data. We therefore update our goal: we want to find the biggest aj,n,l still in the residual for which the corresponding wavelet basis function 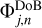 corresponds to sampled Fourier coefficients. How much a scale is covered in the data is measured by the dirty beam: if one scale is covered (i.e., the Fourier coefficients compressed by this scale are sampled), the product
corresponds to sampled Fourier coefficients. How much a scale is covered in the data is measured by the dirty beam: if one scale is covered (i.e., the Fourier coefficients compressed by this scale are sampled), the product 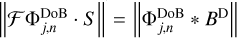 is large and vice versa (where S = ℱBD is a pixel-based mask in the Fourier domain). We therefore formulate our selection criterion as follows: we want to find the scale, j, angle, n, and position, l, such that:
is large and vice versa (where S = ℱBD is a pixel-based mask in the Fourier domain). We therefore formulate our selection criterion as follows: we want to find the scale, j, angle, n, and position, l, such that:
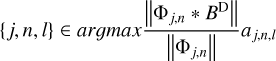 (19)
(19)
is maximal and whereby BD denotes the dirty beam. The question at hand is how we can fulfill this criterion in the selection of peaks. We note that the model parameters aj,n,l are not known to us. In fact, we want to determine them from the dirty image (in the following labeled as ID).
We demonstrate that we can fulfill our criterion if we convolve the dirty image with the beam:
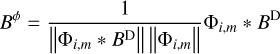 (20)
(20)
and search for the maximum over the scales, i, the angle, m, and the position of the peak, k, namely, {imax, mmax, kmax} ≈ {j, n, l}. In fact, when we search for the peak over all these scales, we solve the optimization problem:
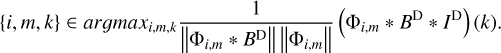 (21)
(21)
A detailed proof of this identification, namely, showing that we matched our selection criterion Eq. (20) with the optimization strategy Eq. (21), is presented in Appendix B.
3.5 Pseudocode and implementation
We summarize the parametersof DoB CLEAN in Algorithm 1. First, we computed the dirty image, ID, and the dirty beam, BD, as usual for CLEAN. We then fit the scale widths 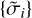 to the uυ-coverage as described in Sect. 3.3. Out of these scale-widths,
to the uυ-coverage as described in Sect. 3.3. Out of these scale-widths, 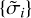 , we constructed the DoB wavelet dictionary,
, we constructed the DoB wavelet dictionary, 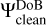 , via the difference method from modified Bessel functions. We find the widths of the corresponding DoG wavelet dictionary by fitting the central peak of the modified Bessel functions with Gaussian functions. We define the DoG wavelet dictionary,
, via the difference method from modified Bessel functions. We find the widths of the corresponding DoG wavelet dictionary by fitting the central peak of the modified Bessel functions with Gaussian functions. We define the DoG wavelet dictionary, 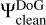 , via the difference method again from these Gaussians.
, via the difference method again from these Gaussians.
From Sect. 3.4, we recall that for the weights of the different scales and for the selection of the correct scales, the convolution of our wavelet functions with the dirty beam plays a vital role, as seen in Eq. (21). We therefore absorbed the dirty beams in the definition of the dictionaries to reduce computational cost, namely, we computed a “dirty” DoB wavelet dictionary: 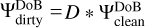 .
.
Now, before the cleaning process starts, we can precompute the data products required for the cleaning iterations later on. We decomposed the dirty image by 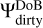 for the multiscalar search of the maximal peak in the residual during the minor loop. We have to use the “dirty” dictionary here according to our scale-selection criterion Eq. (21). Moreover, we have to decompose the dirty beam by our set of basis function that will represent the image in the first instance, that is, by
for the multiscalar search of the maximal peak in the residual during the minor loop. We have to use the “dirty” dictionary here according to our scale-selection criterion Eq. (21). Moreover, we have to decompose the dirty beam by our set of basis function that will represent the image in the first instance, that is, by 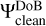 . These scales of the dirty beam
. These scales of the dirty beam 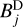 are then subtracted from the residual during the minor loop of the CLEAN iterations. It is further beneficial to compute the subtraction from the image-scales, Ii, scale-by-scale independently, instead of subtracting the complete beam
are then subtracted from the residual during the minor loop of the CLEAN iterations. It is further beneficial to compute the subtraction from the image-scales, Ii, scale-by-scale independently, instead of subtracting the complete beam 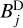 from the residual and recomputing the image-scale decomposition newly every iteration. Hence, we precomputed the scalar decomposition of the beam-scales,
from the residual and recomputing the image-scale decomposition newly every iteration. Hence, we precomputed the scalar decomposition of the beam-scales, 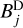 , by the “dirty” dictionary,
, by the “dirty” dictionary, 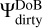 , as well. Moreover, we normalize these beams by their maximal peak. We note that these data products
, as well. Moreover, we normalize these beams by their maximal peak. We note that these data products 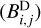 have to be computed only once before the CLEAN loops start until the dirty beam is changed (due to a new weighting scheme, flagging of data, and other operations). Later on, only convolutions of these wavelets with delta-components have to be computed. Hence, we can compute the subtractions of the multiscalar beams very efficiently by shifting and rescaling the precomputed beam scales Di,j·. Finally, we precomputed the multiscalar weights, wj·, explained in Sect. 3.4 – more specifically, the denominator in Eq. (21).
have to be computed only once before the CLEAN loops start until the dirty beam is changed (due to a new weighting scheme, flagging of data, and other operations). Later on, only convolutions of these wavelets with delta-components have to be computed. Hence, we can compute the subtractions of the multiscalar beams very efficiently by shifting and rescaling the precomputed beam scales Di,j·. Finally, we precomputed the multiscalar weights, wj·, explained in Sect. 3.4 – more specifically, the denominator in Eq. (21).
As outlined previously, we carried out the CLEANing procedure by iterating between a CLEAN loop (with DoB wavelets as basis functions, i.e., the inner loop) and switching between dictionaries (from DoB dictionary to DoG dictionary, i.e., the outer loop). In the inner loop, we iteratively search for the largest peak among the image scales and we store the position, the scale, and intensity in a list of delta components. We then update the residual scale-by-scale by subtracting the recently found component. After a sufficient number of iterations, we compute a model M by summing our stored delta components, but applying the dictionary, 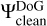 , instead of the dictionary,
, instead of the dictionary, 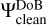 (outer loop). After this switch of dictionaries, we have to reinitialize the residual and the residual scales for the next DoB-CLEAN runs. At this step, further data manipulation steps, such as flagging, self-calibration, thresholding the image, or projecting to positive fluxes, could also be applied as required, depending on the data set under consideration. We also refer to Fig. 5, where we demonstrate the working procedure of DoB-CLEAN on one of the synthetic data sets that are used in Sect. 4. The dirty beam is successfully cleaned out of the image by the representation by DoB wavelets (small residual). However, the wavelets itself contain sidelobes and, hence, the DoB model has these sidelobes as well. By switching to DoG wavelets, we get a physical and smooth model that still fits the visibilities.
(outer loop). After this switch of dictionaries, we have to reinitialize the residual and the residual scales for the next DoB-CLEAN runs. At this step, further data manipulation steps, such as flagging, self-calibration, thresholding the image, or projecting to positive fluxes, could also be applied as required, depending on the data set under consideration. We also refer to Fig. 5, where we demonstrate the working procedure of DoB-CLEAN on one of the synthetic data sets that are used in Sect. 4. The dirty beam is successfully cleaned out of the image by the representation by DoB wavelets (small residual). However, the wavelets itself contain sidelobes and, hence, the DoB model has these sidelobes as well. By switching to DoG wavelets, we get a physical and smooth model that still fits the visibilities.
Wavelet CLEAN algorithm.
3.6 Comparison to CLEAN and MS-CLEAN
DoB-CLEAN succeeds over CLEAN by using a multi-resolution approach to imaging. This allows for a better separation between image features and sidelobes. Hence, DoB-CLEAN provides more reasonable regularization. Thus, we repeat the regularization analysis presented in Eqs. (4)–(5). We assume that the true model is expressed as:
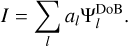 (22)
(22)
We note that although the wavelet functions 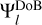 contain clearly unphysical sidelobe structures, this is not a stronger assumption than the point source assumption that we did for the analysis of CLEAN, namely, Eq. (2), due to the completeness of the wavelet dictionary, as in Eq. (9). The dirty image is then:
contain clearly unphysical sidelobe structures, this is not a stronger assumption than the point source assumption that we did for the analysis of CLEAN, namely, Eq. (2), due to the completeness of the wavelet dictionary, as in Eq. (9). The dirty image is then:
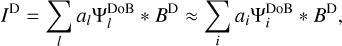 (23)
(23)
where the indices, i, are a typically sparse subset of the space of indices, l. This harvests one of the main advantages of DoB-CLEAN over CLEAN. While the sparsity assumption that is hard-coded in CLEAN is somewhat dubious, in particular if extended structures are studied, DoB-CLEAN tries to sparsely represent the dirty image with a dictionary especially designed for this purpose. The wavelet functions that correspond to scales in the Fourier domain that are not covered can be omitted in the sum above (the convolution with the dirty beam vanishes) and the sparsity assumption is really fulfilled. The dirty image is modeled by:
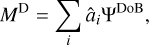 (24)
(24)
where âi denotes the estimated approximations to the true coefficients, ai, calculated by DoB-CLEAN. The cleaned image model reads:
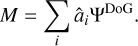 (25)
(25)
Hence, the residual is:
![Mathematical equation: $R = {I^{\rm{D}}} - {B^{\rm{D}}}*M \approx {B^{\rm{D}}}*\sum\limits_i {\left[ {{a_i}{\rm{\Psi }}_i^{{\rm{DoB}}} - {{\hat a}_i}{\rm{\Psi }}_i^{{\rm{DoB}}}} \right]} .$](/articles/aa/full_html/2023/04/aa44664-22/aa44664-22-eq72.png) (26)
(26)
Thus:
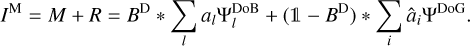 (27)
(27)
Again we recover the correct data fit for the covered scales. In the second term we process information from covered scales only (indices i). We therefore extrapolate the data fit to the gaps in the uυ-coverage by the same core-information as the signal from the covered scales (the DoG-wavelets fit the central peak of the DoB-wavelets), but we suppress the sidelobes. This can be translated to the Fourier domain in that we copy the same information that we recovered from covered scales in the uncovered scales as well, but the importance decreases with distance from the covered Fourier coefficients. We, therefore, in contrast to CLEAN, recover the final model from the measured visibility points only and suppress the information in the gaps to a level, such that the final recovered model appears smooth and free of sidelobes, but no image features are hidden in the gaps. This seems to be an optimal criterion for us given the sparsity of the measured visibilities. We will expand more on how CLEAN and DoB-CLEAN fit the gaps in the uv-coverage in Sect. 4.4.
The replacing of DoB wavelets by DoG wavelets is similar to a multiscalar variant of replacing the dirty beam by the clean beam as done for CLEAN. However, there are subtle differences. For DoB-CLEAN, the convolution is not done as a final step, but takes place within the minor loop, such that the new residuals are computed after convolution with ΨDoG. Moreover, in comparing with Algorithm 1, we replace, in the minor loop, the “dirty” scales, 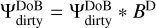 , with the “clean” scales,
, with the “clean” scales, 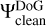 . Since the basis functions are already extended and fit to the uυ-coverage (i.e., the limiting resolution) a final additional convolution with a clean beam is not needed. This convolution is unphysical as it introduces a disparity between the model fitted to the visibilities and the final image. Our algorithm directly computes a clean (i.e., free of sidelobes) model that fits to the visibilities and that matches our perception of astronomical reality – in other words, it solves this disparity.
. Since the basis functions are already extended and fit to the uυ-coverage (i.e., the limiting resolution) a final additional convolution with a clean beam is not needed. This convolution is unphysical as it introduces a disparity between the model fitted to the visibilities and the final image. Our algorithm directly computes a clean (i.e., free of sidelobes) model that fits to the visibilities and that matches our perception of astronomical reality – in other words, it solves this disparity.
We go on to briefly discuss the convergence of DoB-CLEAN at this point. If the model is composed of extended DoG wavelet functions with widths equivalent to the limiting resolution, an additional convolution with the dirty beam to compute the residual could smear out the model image even more and cause divergence. This however is prevented by the scale selection criterion Eq. (21). Since we convolve the dirty image another time with the dirty beam to find the optimal scale, we select smaller scales (already respecting the fact that another convolution for the computation of the residual will smear out features).
DoB-CLEAN is based on the ideas pioneered in multiresolution CLEAN methods (Bhatnagar & Cornwell 2004; Cornwell 2008; Rau & Cornwell 2011). However, our new method has some significant differences. Most obviously, we use different dictionaries than in previous works. MS-CLEAN basis functions are selected on a best effort basis manually (Cornwell 2008). Asp-CLEAN (Bhatnagar & Cornwell 2004) is a variant of MS-CLEAN in which the proper scale widths of the basis functions (Asps) are selected by a fit to the data alternating with the minor loop iterations. Asp-CLEAN therefore shares some more philosophical similarities with DoB-CLEAN than standard MS-CLEAN. However, the basic outline remains the same: basis functions are selected based on the image domain to describe the perceived image structure best, thereby solving practical issues related to CLEAN in representing extended emission. Cornwell (2008) defined three requirements for such basis functions: each basis function should be astrophysically plausible, as well as radially symmetric, and the shape should allow support constraints (although the latter one can be weakened). In contrast, our dictionaries are designed on different requirements: we designed wavelet basis functions, ΨDoB, that fit to the uυ-coverage, namely, those that sparsely represent the dirty image. Hence, in contrast to MS-CLEAN and Asp-CLEAN, our selection of scales is purely driven by the instrument – with no perception of the image structure. This highlights a difference that is strictly specific to Asp-CLEAN: in Asp-CLEAN, the applied scales are meant to optimally fit the observed visibilities in every iteration and this selection strongly affects the minor loop iterations. In DoB-CLEAN, it is only the uυ-coverage, and not the visibilities, that is used to define scales and the selection of which scales fits the visibilities ideally is controlled by the minor loop. Moreover, we use, for the first time, a multidirectional dictionary. These requirements are not compatible. This has a couple of consequences that cause DoB-CLEAN to differ from MS-CLEAN algorithms. MS-CLEAN and Asp-CLEAN use the minor and major loops to suppress sidelobes (compare our discussion in Sect. 2.2) by a sparse representation of the true model. DoB-CLEAN uses the minor and major loop of CLEAN to find a sparse representation of the dirty image (not the true image). This makes the use of a second dictionary, ΨDoG, and a switch between both dictionaries needed. Sidelobes are suppressed by replacing the DoB wavelets (with large sidelobes) by the DoG wavelets (without sidelobes). Also, ΨDoB features some more advantages: it is orthogonal in radial dimension. Hence, in the DoB-CLEAN scalar features that, for example, only affect intermediate baselines, but not long or small baselines, can be expressed sparsely, while in MS-CLEAN and Asp-CLEAN, every basis function necessarily affects the shortest baselines. In particular, there is only one scale, cJ, that transports flux in the image (compare Eqs. (8) and (9)), all other scales have an integral of zero. The orthogonality offers the additional advantage that a solid scale-selection criterion could be derived (see Sect. 3.4), in contrast to Cornwell (2008), where the selection of the correct scale is done in an ad hoc manner by manually choosing a specific scale-bias. We, however, select for the first time the scale that provides the largest correlation to the dirty image. Moreover, the basis function dictionary is complete. Hence, opposite to Asp-CLEAN and MS-CLEAN, there is no doubling of information compressed at different scales.
All in all, compared to CLEAN and MS-CLEAN, DoB-CLEAN succeeds in two important aspects. First, the regularization property (i.e., how to fill the gaps in uυ-coverage) is more reasonable. Second, in CLEAN (Högbom 1974) and in MS-CLEAN (Cornwell 2008), the final model is blurred with the clean beam, which causes an unphysical separation between model and image as described in the introduction. In DoB-CLEAN however, the basis functions are already extended functions that represent the image features well and are used to fit to the visibilities. Thus, a final convolution with the clean beam is (theoretically) not needed in making the computed image the same as the computed model.
3.7 Software and pipeline
The method has been implemented in the new software package MrBeam, which makes explicit use of ehtim (Chael et al. 2018) and regpy (Regpy 2019). We designed the user interface to resemble standard VLBI software packages such as Difmap (Shepherd 1997). This has several practical benefits: it resembles a method of working that is common and familiar to scientists. Hence, MrBeam allows for the typical tools of interactive manipulation, visualization and inspection of data known from CLEAN softwares: interactive drawing of CLEAN windows (search masks for peaks in the residual), the option for various weighting schemes, taperings and flagging of data, a hybrid self-calibration routine, and so on. This proved practical in the past to address data corruption and calibration issues. However, the practical use of interactive tools remains restricted to small arrays in MrBeam as the multiscalar image decompositions have to be recomputed every time the weights or gains have been updated.
In principle, DoB-CLEAN needs two stopping rules to be specified. Firstly, we have to specify after how many iterations we want to stop the overall CLEANing procedure (stopping rule 1 in Algorithm 1). Secondly, we have to determine for how many iterations do we want to represent the image with DoB wavelets before we perform the change to the DoG wavelets (stopping rule 2 in Algorithm 1). The former stopping-rule is defined by the noise level of the observation and the current residual. We do not provide a quantitative stopping criterion here but stopped the iterations whenever the residual image looked Gaussian-like and the residuals were not reduced significantly with further iterations. For the latter stopping rule, changing the dictionaries every iteration proved to be the most practical solution, that is, we updated the model image every iteration.
The fitting of the observed visibilities by extended, specially-designed basis functions proved to be helpful in introducing regularization. However, to account for every un-fitted source of flux in the final image, it could be beneficial to clean the already-cleaned residual with several Högbom CLEAN iterations on the complete field to improve the fit to observed visibilities. We provide such an option in the software package imagingbase underlying this work. However, this finalization step was not found to amend the final model on a level that is visible by eye.
Lastly, we would like to comment on the use of CLEAN windows. In standard Högbom CLEAN, windows are essential in the early iterations of the CLEANing and self-calibration to separate the essential true sky brightness distribution from sidelobes. After several iterations the residual is smaller, the sidelobes are suppressed and the underlying image structure becomes visible. The windows can be drawn larger. However, for DoB-CLEAN drawing sophisticated windows did not prove to be essential at all. The sidelobe structure of the beam is imprinted in the basis functions of the DoB wavelet dictionary and the role of the convolution with the dirty beam is in particular represented, for the first time, in our scale-selection criterion. The maximal correlation is achieved when the multiscalar component is centered in the sidelobe structure and components are not falsely set in the sidelobes, but rather where the true sky brightness distribution is located. Hence, for our tests on synthetic data in Sect. 4, we imaged with DoB-CLEAN on the complete field of view without setting any window.
3.8 Post-processing
The multiscalar and multidirectional decomposition offers rich possibilities for post-processing. The multiscale dictionary Ψ provides control over the fit of the model in the gaps within the uυ-coverage. This is a great advantage of DoB-CLEAN. In particular, we can identify the image features that are present in the observation and those that are not covered. The signal from the latter is suppressed. In this sense, we end up constructing a mostly sidelobe-free representation of the robustly-measured image information. However, we can use this information as well to reintroduce missing scales in the observation to the image. This step should be done with relative caution as we are adding extrapolated signals.
We implemented and tested the most natural approach to reintroduce missing information in the image, namely, by interpolating between neighboring scales. For that we first have to identify which scales are labeled as uncovered (i.e., which scales do we have to add to the image in post-processing). We can use the scale-selection criterion here again: we define a threshold t (usually we use t = 0.1), compute the initial dirty beam with uniform weighting, and label scales as missing if:
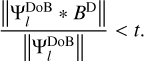 (28)
(28)
For each of these missing scales, we search for the next smaller scale in the same direction (for elliptical scales) and the next larger scale in the same direction and interpolate the coefficient array for the missing scale between these two. We evaluated the performance of post-processing by missing scales in Sect. 4.4. In a nutshell, adding missing (not measured) scales to the image proved useful to suppress artifacts that are introduced by gaps in the uυ-coverage. However, this option should be used only with relative caution as signal is predicted for Fourier coefficients that are not constrained by observations, that is, false image features could be added to the reconstruction when the adding of the missing scales is overdone. While it is a natural choice to interpolate the missing scale from adjacent scales, this does not always have to be the best option. This is in particular true when the structures at various scales have only a small correlation as common for example in VLBI studies of jets powered by an active galactic nuclei (AGN). The bright small-scale features (VLBI-core, innermost jet) and the large scale features (extended jet emission) can vary in morphology, localization and orientation (e.g., compare the multifrequency studies in Kim et al. 2020, with highly varying morphologies between scales). Recent progress in multifrequency observations, and the ongoing combination of short baseline and long baseline arrays (and, consequently, the desire to map galactic structures on a range of spatial scales) may further highlight the issue raised above.
3.9 Numerical challenges
In this subsection, we present some numerical issues and challenges for DoB-CLEAN and possible strategies to resolve them.
As the DoB wavelets are designed to define steep, orthogonal masks in the uυ-domain, we have to deal with the Gibbs-phenomenon at the edges of these masks. We found that the field of view should be large enough, such that roughly ten sidelobes of the spherical Bessel functions still fit in it to avoid numerical issues by the Gibbs phenomenon. Additionally, it proved beneficial to fight the rapid accumulation of numerical errors by reinitializing the decomposition of the dirty image from time to time.
Low-level negative fluxes are introduced into the images by the basis functions itself and have to be negated by neighboring scales (see the completeness relation Eq. (9)). However, this also reveals the great advantage of DoB-CLEAN over CLEAN. Due to the completeness relation Eq. (9) and the explicit allowance of negative wavelet coefficients, every structure in the current model could, in principle, be deleted again or completely altered and partly negated by other scales in later iterations. This is more difficult in CLEAN, where falsely set components (e.g., due to corrupted data, calibration issues, or falsely-identified windows) are typically removed from the model by flagging them manually. Hence, DoB-CLEAN interacts well with extended starting models similar to the working procedure standard in RML methods (iterative imaging with a new starting model and blurring). We therefore have a new RML-inspired ad hoc method to avoid negative fluxes in the final image: alternating with imaging we threshold (and blur) the image to the significant flux and reinitialize the residual and the DoB-CLEAN parameters with the thresholded model as a starting model.
After some iterations we project the recovered model to the significant fluxes – that is: we threshold the model by a small fraction, typically one percent of the peak flux, and, in particular, projecting all negative fluxes to zero; then we blur the image by the nominal resolution. We take this image as a proper starting model for the next imaging rounds. We recompute the residual and the corresponding decomposition and proceed with the CLEANing with the thresholded model as a starting model. This strategy is well motivated, every high dynamic range image structure that might be falsely deleted from the model, is reintroduced in the newly computed residual and will be reintroduced to the model in the subsequent CLEANing loops. In particular, a worse resolution after blurring will be corrected later by readding small-scale DoG wavelets that shift power from larger scales to smaller scales. As a weaker version of this strategy, we also can project only the negative fluxes to zero flux (i.e., use a zero-percentage threshold) and recompute the residuals that had proved to be sufficient in some cases. This blurring strategy is not a necessary requirement for DoB-CLEAN, but it does serve as an alternative way to guide the imaging, similar to how it is done with tapers in CLEAN; however, here, it is translated into the image domain due to the simple possibility to read any missing small-scale structure at a later point in the iterations.
4 Tests on synthetic data
4.1 Synthetic data
In the following, we explain how we checked our imaging algorithm on several test images. For these purpose, we chose a range of test images presenting various source structures and uυ-coverages: we study a synthetic image with a Gaussian core and faint ellipse observed with EVN coverage (Gaussian-evn), a double-sided core dominated synthetic source with a synthetic ring-like uυ-coverage (dumbbell-ring), and a synthetic observation of BL Lac with RadioAstron (bllac-space).
The Gaussian-evn model consists of a small Gaussian with width of 5 mas (0.5 Jy) and a (faint) elliptical blob with semi-axes of 50 mas and 20 mas directed to the south (0.5 Jy). The elliptical source is shifted by 100mas to the south. The Gaussian-evn model is chosen to artificially approximate typical core-jet structures. The model is plotted in the first panel of Fig. 4. We synthetically observe the model with a past EVN configuration from Lobanov et al. (2011) and observed the synthetic source by the software ehtim (Chael et al. 2018) with the observe_same option. The uυ-coverage of this observation is plotted in panel five of Fig. 4.
The dumbbell-ring model consists of an ellipse with 50 mas times 500 mas semi-axes (1 Jy) centered at the middle, a Gaussian with width 2 mas (0.3 Jy), and a second negative Gaussian with with 5 mas (−0.3 Jy). The Gaussians and ellipse were chosen in a way that no negative flux appears in the model. The source model is presented in panel 1 of row 2 of Fig. 4. We observed the source for testing purposes with a synthetic instrument with ring-like uυ-coverage; for this reason, we placed artificial antennas equally spaced from the south pole, observed the synthetic source, and flagged out all baselines that did not involve the central station. From this uniform uυ-distribution we then introduced two significant radial gaps by flagging. The corresponding uυ-coverage is presented in Fig. 4 (panel 5 of row 2).
Finally, we took RadioAstron observations of BL Lac as a more physical source model. We took the natural weighted image from Gómez et al. (2016) as the true source structure (see panel 1, row 3 in Fig. 4) and observed it, again with the observe_same option, with the array of that observation. The corresponding (time-averaged) uυ-coverage is plotted in Fig. 4 (panel 5 row 3). All the observations had thermal noise added, but without adding phase or amplitude calibration errors.
4.2 Qualitative comparison
Figure 4 presents the reconstructions of our three synthetic sources with DoB-CLEAN (second column) and with CLEAN (third column: final CLEAN image, fourth column: CLEAN model). For the bllac-space model, a set of rectangular windows that constrain the flux to the lower half of the image was used. For the Gaussian-evn and the dumbbell-ring reconstructions, no particular window was used. Figure 5 presents an outline for the imaging procedure done for the dumbbell-ring example. We remove the dirty beam successfully during the minor loop, but represent the image by a multiscalar set of DoB wavelets that contain sidelobes on its own. By replacing the DoB wavelets by DoG wavelets, we get a physically meaningful result, from which we recompute a significantly reduced residual.
We show additionally in Fig. 6, a comparison of the DoB-CLEAN reconstruction with MS-CLEAN reconstructions. For the MS-CLEAN reconstructions we used in all three examples a dictionary consisting of a delta component and Gaussians with one, two, and three times the width of the clean beam.
The DoB-CLEAN reconstructions were very successful overall. The core-jet-like structures were well represented, even if the array configuration was extremely sparse. The representation of the wider, extended emission, in particular in the Gaussian-evn example is excellent, opposed to CLEAN. As expected a similar effect is achieved by MS-CLEAN reconstructions opposed to Högbom CLEAN (compare the upper panels in Figs. 4 and 6. The reconstructions of the wide-field Gaussian-evn structure in Fig. 6 is of similar quality between DoB-CLEAN and MS-CLEAN. Moreover, the DoB-CLEAN reconstruction allows for the reconstruction of small scales simultaneously, as demonstrated with the two-component core in the bllac-space image (indicating a good use of space-baselines).
When comparing to CLEAN (third column), it becomes obvious that DoB-CLEAN achieves super-resolution. It reliably recovers structures smaller than the clean beam, particularly in the bllac-space example, even if these structures are faint compared to the central core region (fainter by a factor ≈ 100–1000 for bllac-space). This super-resolving feature, however, does not come at the price of reduced sensitivity to extended emission as discussed above. MS-CLEAN reconstructions are bound to the clean beam resolution as well, thus ending up outperformed by DoB-CLEAN in terms of resolution as well.
We present in the fourth column of Fig. 4 the single CLEAN model, that is, the composition of delta components. We recall that we identified the mismatch between the final image and the CLEAN model that fits the data as a main theoretical disadvantage of CLEAN. The same applies for MS-CLEAN. In fact, the model maps are no useful description of the source structure in either way. DoB-CLEAN directly computes a model with physical meaning. The reconstructions shown here match the model fitted to the visibilities. Hence, the cleaning with DoB-CLEAN leaves a similar final residual (dominated by thermal noise) as the standard Högbom CLEAN, but with a much more useful source model. In this sense, DoB-CLEAN produces more robust source structures.
While CLEAN and MS-CLEAN reconstructions are overall quite successful as well, we identify several qualitative metrics in which DoB-CLEAN clearly outperforms CLEAN and MS-CLEAN. All in all, we conclude from here that DoB-CLEAN seems to be an improvement over CLEAN in terms of resolution (achieving super-resolution), robustness (model matches to final image), and sensitivity to extended emission. The latter advantage becomes obvious, particularly for the Gaussian-evn data set in which the CLEAN beam is much smaller than the extended elliptical source structure, leading to a fractured reconstruction opposed to the smooth extended emission recovered by DoB-CLEAN.
 |
Fig. 4 Comparison of reconstructions on synthetic data. First row: Gaussian-evn; second row: dumbbell-ring; third row: bllac-space, with various algorithms. First column: true image, second column: DoB-CLEAN reconstruction. Third column: CLEAN image. Fourth column: CLEAN model. Fifth column: uv-coverage of the synthetic observations. Contour levels for the bllac-space example are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
4.3 Performance tests
We go on to use the Gaussian-evn example for a set of additional tests to study the features and performance of DoB-CLEAN further.
To discuss the advantage of super-resolution further, we redid the Gaussian-evn observation and reconstruction, but with a source structure scaled down by a factor of four in size to highlight the signal on longer baselines more. We present our reconstructions in Fig. 7. The extended, elliptical emission is still very well recovered by DoB-CLEAN. The small Gaussian core is overestimated in size due to the large beam size and a smaller central core component becomes visible as a signal from the long baselines. However, the CLEAN reconstruction again has bigger issues with the beam size and the (elliptical) beam shape. This example demonstrates the potential for super-resolving structures at the size of the clean beam with DoB-CLEAN.
With this excellent performance at hand for small source structures that require super-resolution, we advance on this statement by studying the Gaussian-evn source example with synthetic Radio Astron observations (as space-VLBI observations are typically designed to study sources at the highest resolution). VLBI observations with space antennas, however, pose a new range of challenges: the special uυ-coverage leading to highly elliptical beams, a bad signal-to-noise ratio on the long space baselines, and the complex calibration of the space baselines. In this study we ignored calibration issues, but we considered highly scale-dependent noise by mirroring a real observation (Gómez et al. 2016). We took the Gaussian-evn source, scaled it down in size from a field of view of 1′′ to a field of view of 16 mas (e.g., by a factor of ≈ 16) and synthetically observed it with Radio Astron. Our reconstructions are shown in Fig. 8. This test run again solidifies the problem that CLEAN reconstructions seem to have for highly elliptical beams. DoB-CLEAN works better in this regard, recovering a clearly visible core and a disconnected, approximately elliptical, extended emission pattern without many sidelobes. However, compared to the reconstructions that we presented in Fig. 7, the reconstruction is worse due to the sparsity at small scales (long baselines). The circular Gaussian core-component is represented by a dumb-bell structure instead, the elliptical faint emission is recovered by two connected Gaussian blobs. The dumb-bell structure is a consequence of relative sparsity at small scales as it represents the typical structure that a single scale out of the difference of elliptical beams dictionary features. Basically, only the scale oriented in the direction described by the longer-elongating space baselines is selected, all other scales at this radial width are suppressed. All in all, we can conclude that DoB-CLEAN is capable of reconstructing super-resolved images even with such challenging arrays such as Radio Astron, although a higher level of artifacts is visible at higher resolution.
It is difficult to quantify the amount of super-resolution in general. Since the limiting resolution is not limited by a well-defined beam convolution, but, instead, due to the balancing between fitting the visibilities and a multiscale sparsity assumption. The achievable resolution depends both on the specifics of the instrument (i.e., uυ-coverage and scale-dependent noise-level) and the source structure itself. To get a rough impression of the resolution that is achievable with DoB-CLEAN we apply the following strategy: we observe the Gaussian-evn source model with Radio Astron coverage (see Fig. 9) and with EVN coverage (see Fig. 10). Iteratively, we minimize the source size (by keeping the same image array, but minimizing the pixel size, i.e., the field of view). Each time, we carried out a reconstruction with DoB-CLEAN and blur the (minimized) ground truth images on a predefined fine grid of circular Gaussian blurring kernels. We computed the correlation of the blurred synthetic ground truth images and the reconstructions in any case (left panels in Figs. 9 and 10). The correlation curves look reasonable with a clearly identifiable maximal peak. We show the blurring kernel size with the maximal correlation for the smallest source sizes in the right panels. If the source is that small that it becomes unresolved by DoB-CLEAN, the blurring kernel size needs to converge from below roughly towards the limiting resolution: indeed, the maximum correlation is roughly constant within the errorbars indicating an effective resolution for a Radio Astron configuration of ~20 µas (beam: ~290 × 31 µas) and an effective resolution for an EVN resolution of ~2 mas (beam: ~18 × 4 mas). Hence, a moderate super-resolution by a factor of 2–3 might be possible. However, while the representation of super-resolved features with wavelets is clearly more reasonable than a representation with delta components, we have to note that the reconstruction problem at a higher resolution is also more challenging and artifacts that are usually hidden under the convolution with the beam can be expected (and are visible, e.g., in Fig. 8).
Finally, we study the effect of thermal noise on the reconstruction. For this purpose we again observed the Gaussian-evn example, but this time, we added a constant thermal noise on all baselines at a level such that the final signal-to-noise ratio is approximately one. The reconstructions are presented in Fig. 11. Comparing the reconstruction shown in Fig. 4, the source structures recovered by DoB-CLEAN and CLEAN remain relatively unaffected. Faint, blobby background sidelobes as expected from Gaussian noise are introduced to the CLEAN image. In DoB-CLEAN, the effect is different: a coronal emission around the central component is introduced. This feature, however, is very weak and can only be seen at high dynamic range. This coronal feature has to be noted as an explicit image artifact that DoB-CLEAN introduces in the image when studying noisy images at high dynamic range.
 |
Fig. 5 Sketch of the imaging iterations for the dumbbell-ring example. Upper left: initial residual. Upper right: we remove the dirty beam by computing a multiscalar model composed of DoB wavelets. The panel presents the recovered model |
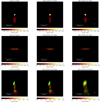 |
Fig. 6 Comparison of reconstructions on synthetic data. First row: Gaussian-evn; second row: dumbbell-ring; third row: bllac-space, with various algorithms. First column: true image; second column: DoB-CLEAN reconstruction; third column: MS-CLEAN image. Contour levels for the bllac-space example are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
4.4 Artifacts compared to CLEAN
We now compare DoB-CLEAN to CLEAN with the Gaussian-evn example with a reduced source size, as seen in Fig. 7, with special emphasis on the image artifacts introduced by these algorithms. We present the complete Fourier transform of the true image and the reconstructions (DoB-CLEAN, CLEAN model, and final CLEAN image) in Fig. 12. In the upper row, we show the amplitude of the Fourier transform of the true source model and the uυ-points over-plotted in red. In the lower panels, we show the fit between the measured and observed visibilities. Standard imaging software such as Difmap typically only show the latter ones indicating a successful fit of the observed visibilities for both CLEAN (i.e., the model) and DoB-CLEAN. However, the complete Fourier transform reveals that this might be inadequate. The CLEAN reconstruction shows a rich, periodic structure in the Fourier domain, in the gap between short and long baselines, but also at baselines longer than the observed ones. These structures in the gaps are not motivated by any measured visibility and, in particular, they are very slightly correlated with the signal measured at long baselines. This particular CLEAN problem is solved by convolving with the clean beam, but at the cost of a worsened fit of the final image to the observed visibilities (compare the bottom panel for the CLEAN image). The DoB-CLEAN reconstruction shows a much better fit to the Fourier coefficients. The signal in the large gap between short and long baselines is suppressed as well as the unphysical signal on Fourier coefficients longer than the longest baselines, but the fit to the observed baselines remains excellent.
Due to this suppression, minimal structural information is added in the gaps and only the robust, measured image information is processed. However, comparing to the true Fourier transform, this also gives rise to some possible problems in the imaging procedure: as the uυ-coverage is sparse and contains a prominent gap with unmeasured Fourier coefficients, there is image information in this gap that is not recovered in the final image with DoB-CLEAN. In particular, this gap introduces the spurious image structure visible in Fig. 7 in the core component. The core Gaussian is recovered by a small DoG component compressed by the longest baselines in the array and a wider Gaussian component compressed by the shorter baselines. The missing scale (i.e., a missing DoG-scale to satisfy completeness) is visible in the final image by the ring-like feature of weak flux sources around the inner component. While imaging only robust image features with a reduced sidelobe level would appear to be an optimal solution for imaging, these kinds of structures are a clear indicator of missing amplitudes on non-measured baselines. As explained in Sect. 3.8, DoB-CLEAN, as opposed to CLEAN, offers a unique way to identify these problems and to re-add these uncovered scales in the image. We demonstrate the usefulness of this approach in Fig. 13. With an increasing fraction of added missing scales, the interpolated flux in the gap becomes more prominent (upper panels). The artifact in the core component vanishes (bottom panels). When overdoing the interpolation however (i.e., adding too much information on small scales or long baselines), the elliptic extended emission gets erroneously estimated. Hence, when applied to observational data, this interpolation option should be used with relative caution as we are interpolating structural information in the image that is (in principle) unmeasured.
 |
Fig. 7 Reconstructions of the Gaussian-evn test case, but with smaller source size. The contour levels are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
 |
Fig. 8 Reconstructions of the Gaussian-evn test case with Radio Astron uυ-coverage. The contour levels are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
 |
Fig. 9 Illustration of the estimation procedure for the effective resolution of DoB-CLEAN. Left panel: correlation between DoB-CLEAN reconstructions for varying source sizes with Radio Astron synthetic observation of the Gaussian-evn ground truth image and the blurred ground truth images. Right panel: blurring at maximal correlation as a function of source size (field of view). |
 |
Fig. 10 Illustration of the estimation procedure for the effective resolution of DoB-CLEAN as in Fig. 9, but with EVN coverage. |
5 BL Lac
5.1 Data
We reanalyzed the public data set of BL Lac observations with RadioAstron (Gómez et al. 2016), as described in this section as an additional test with real observational data. In what follows, we summarize these observations and for more detailed information, we refer to Gómez et al. (2016). BL Lac was observed at 22 GHz on November 10 and 11, 2013. Due to some technical problems, BL Lac was only observed by 15 correlated antennas (instead of the 26 possible in the array). The data set was correlated at the DiFX correlator at the Max-Planck-Institut für Radioastronomie (MPIfR). Data reduction and calibration took place with AIPS and Difmap (Shepherd 1997). We used the self-calibrated data set of Gómez et al. (2016) as a starting point for reconstructions with DoB-CLEAN.
5.2 Reconstructions
We present our reconstruction results with DoB-CLEAN in Fig. 14. Moreover, we show our reconstructions blurred with the corresponding clean beam in Fig. 15.
Comparing our imaging results blurred with the clean beam (Fig. 15) to the reconstruction results with CLEAN (Fig. 16), we identify very similar structures, in particular, for natural weighting. We identify the central core with an elliptic shape and the two connected Gaussian blobs to the south. Some of the fine-structure in the CLEAN image is visible in the DoB-CLEAN image as well, such as the shape of the core or the orientation of the components in the jet. However, there are also some slight differences, such as the faint emission to the north-east that is not related to the jet. This emission could be an artifact of DoB-CLEAN reconstructions, as compared to the typical image artifacts that we discussed in Sect. 4.2, which are caused by the intrinsic sidelobes in the basis functions. In the middle panels, we show the reconstructions with uniform weighting, and in the right panels, a zoom-in on the central core region with uniform weighting. These reconstructions with their more highly resolved structures better highlight the core region. Overall, the similarity between the blurred DoB-CLEAN images (Fig. 15) and the CLEAN images (Fig. 16) is beneficial in uniform weighting, particularly in the zoom-in panels into the core. Interestingly, CLEAN finds stronger extended emission. Moreover, we find a possible edge-brightened structure in the reconstructions with DoB-CLEAN that is not apparent in the CLEAN images.
We demonstrated that DoB-CLEAN allows for superresolution and the actual model computed features a physical model, in contrast to CLEAN. We present in Fig. 14 the DoB-CLEAN reconstructions at full resolution. In fact, Fig. 14 shows more highly resolved structures of a narrow jet. We would like to mention some features that become visible in the full resolution DoB-CLEAN reconstructions, as opposed to the blurred reconstructions.
As visible in the natural-weighted image, we can identify three (instead of two) peaks in the jet emission and the central jet component is now resolved. Moreover, we observe a core structure of a very narrow central core component surrounded by a wider coronal emission. This structure cannot be seen with CLEAN or DoB-CLEAN at lower resolution as the feature is blurred out by the clean beam. We note that when comparing the reconstructions of the innermost core region, for instance, in the right panels in Figs. 16 and 15, also the CLEAN reconstructions show signs of a quasi-coronal emission around the core, namely, emission to the north-west and to the south-east of the central core component. However, in making a comparison to our discussions in Sect. 4, it is also possible that this feature is caused by missing scales in the reconstruction. A further analysis of this feature with alternative super-resolving algorithms, namely, RML algorithms (Chael et al. 2018; Müller & Lobanov 2022), is fully desired but we leave this aspect for subsequent works.
We observe a sign of possible edge-brightening in the jet base due to a second component towards the left. This was not observed with CLEAN reconstructions. This structural feature is also visible in the blurred DoB-CLEAN reconstructions, as shown in the middle panel of Fig. 15. Furthermore, the core structure in CLEAN and blurred DoB-CLEAN has a double-elliptic shape, as seen by comparing the right panels in Figs. 16 and 15. With the full-resolution DoB-CLEAN reconstructions, we see a more regular, circular reconstruction of the core, with a clearly visible jet basis in the innermost region.
While a concordance between all reconstructions is generally very high, the novel DoB-CLEAN reconstructions demonstrate some possible features that are different from CLEAN reconstructions, especially at the highest angular resolution. Some of them could be connected to imaging artifacts either by DoB-CLEAN or standard Högbom CLEAN. We discuss the robustness of these features in Appendix C in more detail. In a nutshell, both the possible edge-brightening and the coronal emission around the core could be associated with a common sidelobe pattern. The information regarding which emission is real and which emission is thought of to be caused by side-lobes is highly uncertain. This example once more highlights the need for more variety in the choice of reconstruction methods in VLBI. More work is required on the innermost jet in BL Lac with more modern methods based on Bayesian and RML approaches to establish a better concordance between various methods. This aspect will be the subject of subsequent works.
 |
Fig. 11 High dynamic range reconstructions of the Gaussian-evn test case, but higher thermal noise level. The contour levels are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
 |
Fig. 12 Comparison of the fits of the Gaussian-evn synthetic data reconstruction in the Fourier domain. Upper panels: complete Fourier transform of reconstructions (true, DoB-CLEAN, CLEAN image, and CLEAN model), with uυ-coverage over-plotted (red crosses). Lower panels: Radplot showing the fit of the recovered model to the observed visibilities. It is only for DoB-CLEAN that the fit is successful (lower panels) and the Fourier transform of the model is physically reasonable (upper panels). |
 |
Fig. 13 Fourier transform of recovered data with DoB-CLEAN (upper panels) and the recovered model (lower panels) in the Gaussian-evn test case. From left to right: missing (not measured) scales are interpolated from the covered scales with a higher fraction. The most right panels show the true image. The used contour-levels are [1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
 |
Fig. 14 BL Lac reconstructions with DoB-CLEAN at full resolution with natural weighting (left pane), uniform weighting (middle panel) and uniform weighting with smaller pixel size zoomed in the central core region (right panel). The contour levels are: [0.1,0.2,0.4,0.8,1.6,3.2,6.4, 12.8,25.6,51.2]% ([0.025, 0.05, 0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]%, [0.8,1.6,3.2,6.4,12.8,25.6,51.2]%) of the respective peak brightness. |
 |
Fig. 15 BL Lac reconstructions with DoB-CLEAN blurred with the clean beam with natural weighting (left panel), uniform weighting (middle panel) and uniform weighting with smaller pixel size zoomed in the central core region (right panel). The contour levels are: [0.1,0.2, 0.4,0.8, 1.6,3.2,6.4,12.8,25.6,51.2]% ([0.025, 0.05, 0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]%, [0.8,1.6,3.2,6.4,12.8,25.6,51.2]%) of the respective peak brightness. |
 |
Fig. 16 BL Lac reconstructions with DoB-CLEAN blurred with the clean beam with natural weighting (left panel), uniform weighting (middle panel) and uniform weighting with smaller pixel size zoomed in the central core region (right panel). The contour levels are: [0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]% ([0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]%, [0.8,1.6,3.2,6.4,12.8,25.6,51.2]%) of the respective peak brightness. |
6 Conclusion
In this work, we develop the novel multiscalar imaging algorithm DoB-CLEAN, which is based on the framework of CLEAN with the goal to still allow the straightforward manual manipulation and calibration of data that has proven successful in the VLBI community over recent decades. However, DoB-CLEAN addresses some pathologies of the CLEAN algorithm: CLEAN has spurious regularization properties, is inadequate to describe extended emission, and introduces a separation between the model fitted to the observed visibilites and the final astronomical image. These pathologies are mainly caused by CLEAN approaching the image as a set of delta functions. DoB-CLEAN basically replaces these CLEAN components by wavelets that compress radial and directional information in parallel. The wavelet dictionary is fitted to the uυ-coverage which provides a more data-driven approach to imaging. Sidelobes are suppressed by switching between a wavelet dictionary of steep, orthogonal masks in the Fourier domain and a sidelobe free representation in the image domain.
We implemented DoB-CLEAN and benchmarked its performance against CLEAN reconstructions on synthetic data. DoB-CLEAN succeeds over CLEAN in terms of resolution and accuracy. It removes the separation between model and image, that is, DoB-CLEAN fits a model to the uυ-coverage that, in fact, has a physical meaning. The biggest plausible advantage of DoB-CLEAN, however, is the control it offers over the fit in the gaps of the uυ-coverage offered by the multiscalar wavelet dictionary. First, this helps to prevent overfitting and fosters image robustness (i.e., only measured, robust image features are measured). Second, this offers rich opportunities for post-processing, that is, identifying missing scales and missing image features in the observation and imaging. These post-processing capabilities are also of general interest as they offer a way to identify an uncertainty estimate of cleaned features in VLBI observations.
Despite these great advantages, DoB-CLEAN does not solve any problem related to the sparsity of the uυ-coverage. The lack of certain scales in the observation can introduce artifacts in the DoB-CLEAN imaging results when completely suppressed. Moreover, the basis functions have negative flux; that is to say that on a low level, it is still present in the final images (i.e., the dynamic range remains limited).
Finally, we applied DoB-CLEAN to some existing and already calibrated data from Radio Astron observations of BL Lac. The reconstructions with DoB-CLEAN and with CLEAN share certan similarities when blurred to the same resolution, but there are also some visible differences that may alter the scientific interpretation, especially at the highest resolution. This, once more, elucidates the need for more variety in the imaging algorithms used in frontline VLBI observations to establish concordance between them and robustness of the scientific interpretation. We address this issue in subsequent works.
Appendix A Dictionaries
The dictionaries used in this paper are as follows::
![Mathematical equation: $\eqalign{ & \matrix{ {{\Psi ^{DoG}}:I \mapsto \left[ {G_{{\sigma _0}}^r * I - G_{{\sigma _0},{\sigma _1},{\alpha _0}}^e * I,} \right.G_{{\sigma _0}}^r * I - G_{{\sigma _0},{\sigma _1},{\alpha _1}}^e * I, \ldots ,G_{{\sigma _0}}^r * I - G_{{\sigma _0},{\sigma _1},{\alpha _{N - 1}}}^e * I,{1 \over {{B_0}}}\sum\limits_{i = 0}^{N - 1} {G_{{\sigma _0},{\sigma _1},{\alpha _i}}^e * I - G_{{\sigma _1}}^r * I,} } \cr {\matrix{ {G_{{\sigma _1}}^r * I - G_{{\sigma _1},{\sigma _2},{\alpha _0}}^e * I,} \hfill & \ldots \hfill & {,G_{{\sigma _1}}^r * I - G_{{\sigma _1},{\sigma _2},{\alpha _{N - 1}}}^e * I,{1 \over {{B_1}}}\sum\limits_{i = 0}^{N - 1} {G_{{\sigma _1},{\sigma _2},{\alpha _i}}^e * I - G_{{\sigma _2}}^r * I,} } \hfill \cr {G_{{\sigma _2}}^r * I - G_{{\sigma _2},{\sigma _3},{\alpha _0}}^e * I,} \hfill & \ldots \hfill & {,G_{{\sigma _2}}^r * I - G_{{\sigma _2},{\sigma _3},{\alpha _{N - 1}}}^e * I,{1 \over {{B_2}}}\sum\limits_{i = 0}^{N - 1} {G_{{\sigma _2},{\sigma _3},{\alpha _i}}^e * I - G_{{\sigma _3}}^r * I,} } \hfill \cr \vdots \hfill & {} \hfill & {} \hfill \cr {G_{{\sigma _{J - 1}}}^r * I - G_{{\sigma _{J - 1,}}{\sigma _J},{\alpha _0}}^e * I,} \hfill & \ldots \hfill & {,G_{{\sigma _{J - 1}}}^r * I - G_{{\sigma _{J - 1}},{\sigma _J},{\alpha _{N - 1}}}^e * I,{1 \over {{B_{J - 1}}}}\sum\limits_{i = 0}^{N - 1} {G_{{\sigma _{J - 1}},{\sigma _J},{\alpha _i}}^e * I - G_{{\sigma _{\rm{J}}}}^r * I,} } \hfill \cr {\left. {G_{{\sigma _{\rm{J}}}}^r * I} \right]} \hfill & {} \hfill & {} \hfill \cr } } \cr } \cr & \cr} $](/articles/aa/full_html/2023/04/aa44664-22/aa44664-22-eq79.png)
and:
![Mathematical equation: $\matrix{ {{\Psi ^{DoB}}:I \mapsto \left[ {\tilde J_{{{\tilde \sigma }_0}}^r * I - G_{{{\tilde \sigma }_0},{{\tilde \sigma }_1},{\alpha _0}}^e * I,\tilde J_{{{\tilde \sigma }_0}}^r * I - } \right.\tilde J_{{{\tilde \sigma }_0},{{\tilde \sigma }_1},{\alpha _1}}^e * I, \ldots ,\tilde J_{{{\tilde \sigma }_0}}^e * I - \tilde J_{{{\tilde \sigma }_0},{{\tilde \sigma }_1},{\alpha _{N - 1}}}^e * I,{1 \over {{B_0}}}\sum\limits_{i = 0}^{N - 1} {\tilde J_{{{\tilde \sigma }_0},{{\tilde \sigma }_1},{\alpha _i}}^e * I - \tilde J_{{{\tilde \sigma }_1}}^r * I,} } \cr {\matrix{ {\tilde J_{{{\tilde \sigma }_1}}^r * I - \tilde J_{{{\tilde \sigma }_1},{{\tilde \sigma }_2},{\alpha _0}}^e * I,} \hfill & \ldots \hfill & {,\tilde J_{{{\tilde \sigma }_1}}^r * I - \tilde J_{{{\tilde \sigma }_1},{{\tilde \sigma }_2},{\alpha _{N - 1}}}^e * I,{1 \over {{B_1}}}\sum\limits_{i = 0}^{N - 1} {\tilde J_{{{\tilde \sigma }_1},{{\tilde \sigma }_2},{\alpha _i}}^e * I - \tilde J_{{{\tilde \sigma }_2}}^r * I,} } \hfill \cr {\tilde J_{{{\tilde \sigma }_2}}^r * I - \tilde J_{{{\tilde \sigma }_2},{{\tilde \sigma }_2},{\alpha _0}}^e * I,} \hfill & \ldots \hfill & {,\tilde J_{{{\tilde \sigma }_2}}^r * I - \tilde J_{{{\tilde \sigma }_2},{{\tilde \sigma }_3},{\alpha _{N - 1}}}^e * I,{1 \over {{B_2}}}\sum\limits_{i = 0}^{N - 1} {\tilde J_{{{\tilde \sigma }_2},{{\tilde \sigma }_3},{\alpha _i}}^e * I - \tilde J_{{{\tilde \sigma }_3}}^r * I,} } \hfill \cr \vdots \hfill & {} \hfill & {} \hfill \cr {\tilde J_{{{\tilde \sigma }_{J - 1}}}^r * I - \tilde J_{{{\tilde \sigma }_{J - 1}},{{\tilde \sigma }_J},{\alpha _0}}^e * I,} \hfill & \ldots \hfill & {,\tilde J_{{{\tilde \sigma }_{J - 1}}}^r * I - \tilde J_{{{\tilde \sigma }_{J - 1}},{{\tilde \sigma }_J},{\alpha _{N - 1}}}^e * I,{1 \over {{B_{J - 1}}}}\sum\limits_{i = 0}^{N - 1} {\tilde J_{{{\tilde \sigma }_{J - 1}},{{\tilde \sigma }_J},{\alpha _i}}^e * I - \tilde J_{{{\tilde \sigma }_J}}^r * I,} } \hfill \cr {\left. {\tilde J_{{{\tilde \sigma }_J}}^r * I} \right]} \hfill & {} \hfill & {} \hfill \cr } } \cr } $](/articles/aa/full_html/2023/04/aa44664-22/aa44664-22-eq80.png)
where 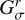 denotes a two-dimensional radially symmetric (normalized) Gaussian function with standard deviation σ and
denotes a two-dimensional radially symmetric (normalized) Gaussian function with standard deviation σ and 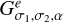 a 2D elliptical (and normalized) Gaussian function with minor axis, σ1, and major axis, σ2, that is rotated by an angle α.
a 2D elliptical (and normalized) Gaussian function with minor axis, σ1, and major axis, σ2, that is rotated by an angle α. 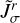 is a 2D radially symmetric modified Bessel function, namely,
is a 2D radially symmetric modified Bessel function, namely, 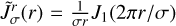 and
and 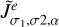 is the elliptical analog with a minor axis of σ1, major axis of σ2, and rotation angle α.
is the elliptical analog with a minor axis of σ1, major axis of σ2, and rotation angle α.
Appendix B Proof for the selection criterion
It is:
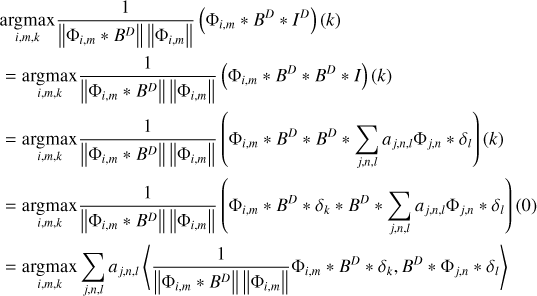 (B.1)
(B.1)
At this point we have to make an approximation. The maximum of the sum is approximately achieved at the maximal summand (this approximation also lies behind the minor loop of standard CLEAN, compare our discussion in Sect. 2.2). In other words, we solve:
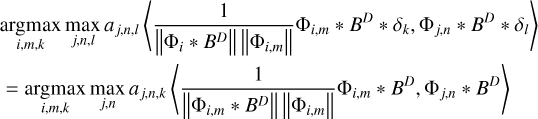 (B.2)
(B.2)
where equality holds since Φ * BD is centrally peaked. It is:
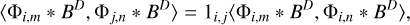 (B.3)
(B.3)
as the DoB wavelet functions of varying radial widths have distinct supports in the Fourier domain. Hence, we are left with the argmax-problem:
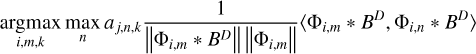 (B.4)
(B.4)
Then:
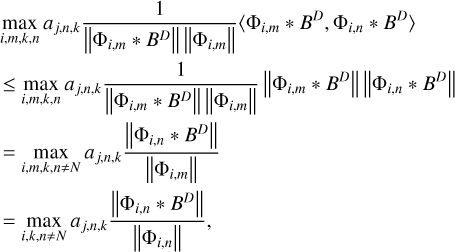 (B.5)
(B.5)
where the last equality holds since ||Φi,n1|| = ||Φi,n2|| for every n1, n2. This maximum gets reached exactly for m = n. Hence, our selection criterion Eq. 20 is met by this procedure.
Appendix C Reliability of features recovered with DoB-CLEAN
We now discuss the reliability of the new features recovered in the reanalysis of the BL Lac observations with DoB-CLEAN. Two features are in particular outstanding at highest resolution: the coronal emission around the core, and the possible sign of an edge-brightening. We have demonstrated in Sect. 4 that DoB-CLEAN addresses several pathologies of CLEAN, allows for moderate super-resolution and more accurate representation of extended emission. However, as was also demonstrated in Sect. 4, these advantages come to the cost of low-level imaging artifacts, in particular for the more challenging problem of recovering images with super-resolution (i.e., when not convolving with a beam). It is therefore unknown from a-priori how reliable the image features observed with DoB-CLEAN really are. Does DoB-CLEAN resolve some features that were not visible with CLEAN since DoB-CLEAN processes the uυ-coverage more seriously? Or does vice versa DoB-CLEAN pick up on some artifacts that were suppressed by CLEAN since the interactive data manipulation (self-calibration, tapering, CLEAN-windows, flagging,…) is more natural in CLEAN?
We present in Fig. C.1 the progress of the CLEANing procedure with DoB-CLEAN on the BL Lac data set. The residuals show a ring-like sidelobe structure that indicates the missing of certain scales in the not yet fully converged reconstructions. These scales will be added during later iterations as can be seen from the final reconstruction, namely, the vanishing residual, in the most-right panel. However, the progress of the DoB-CLEAN procedure highlights a specific requirement: since the image is composed by a sequence of wavelet sub-bands that each encode information on a specific spatial scale (i.e., the scale of the ring-like sidelobe pattern, the scale of the second ring-like sidelobe-pattern, …) a final and clean reconstruction result will be only achievable if the various scales enter the recovered image with the correct weighting relative to each other. If one scale is over-weighted by the reconstruction procedure, the recovered image will contain sidelobes at this spatial scale as well. The correct relative weighting of scales is taken into account by our scale-selection criterion that was proven to be optimal in the absence of calibration issues. However, this fosters an important essential in the application to real, observational data: the self-calibration procedure needs to produce well estimates to the true gains such that no scale will be preferred or suppressed as a consequence of gain variations. Vice versa, the absence of sidelobe emission in the final reconstruction, see the most-right panel in Fig. C.1, indicates that the calibration and imaging procedure is consistent and was successful.
We note that the coronal emission around the central core component appears at the size of the first sidelobe scale, while the second edge-brightened blob left to the main jet-feature corresponds well to the second sidelobe scale (see Fig. C.1). This questions the robustness of the presence (DoB-CLEAN) or absence (CLEAN) of these image features. According to our reasoning above, we admit that DoB-CLEAN might be more prone than CLEAN to capture on sidelobe artifacts. However, the overall success of the reconstruction points towards a robust recovery. Moreover, also the CLEAN reconstructions seem to indicate emission to the north-west and south-east of the central core component, comparable to the coronal emission found with DoB-CLEAN (e.g., compare the most right panels in Fig. 16 and 14, working towards consistency). Typically, in CLEAN-like algorithms (such as CLEAN and DoB-CLEAN), the decision which emission is true and which emission is thought to be caused by a sidelobe is answered manually by setting proper CLEAN windows and by self calibration. A final answer regarding which reconstruction is more correct cannot be answered here. We recommend the use of a RML based method that fit the closure quantities instead of the visibilities (e.g., Chael et al. 2018; Müller & Lobanov 2022) for consecutive works to build concordance between various reconstructions.
 |
Fig. C.1 Progress of the cleaning with DoB-CLEAN. Shown is the sum of the recovered image and the residual after 4000 iterations (left panel), 5000 iterations and phase self-calibration (middle panel) and the final ground-only image (right panel). The contour levels are [0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]% of the peak brightness. |
References
- Akiyama, K., Ikeda, S., Pleau, M., et al. 2017a, AJ, 153, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Akiyama, K., Kuramochi, K., Ikeda, S., et al. 2017b, ApJ, 838, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Arras, P., Frank, P., Leike, R., Westermann, R., & Enßlin, T.A. 2019, A&A, 627, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arras, P., Bester, H.L., Perley, R.A., et al. 2021, A&A, 646, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Assirati, L., Silva, N.R., Berton, L., Lopes, A.A., & Bruno, O.M. 2014, J. Phys.: Conf. Ser., 490, 012020 [NASA ADS] [CrossRef] [Google Scholar]
- Bhatnagar, S., & Cornwell, T.J. 2004, A&A, 426, 747 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Broderick, A.E., Gold, R., Karami, M., et al. 2020a, ApJ, 897, 139 [NASA ADS] [CrossRef] [Google Scholar]
- Broderick, A.E., Pesce, D.W., Tiede, P., Pu, H.-Y., & Gold, R. 2020b, ApJ, 898, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Cai, X., Pereyra, M., & McEwen, J.D. 2018a, MNRAS, 480, 4154 [NASA ADS] [CrossRef] [Google Scholar]
- Cai, X., Pereyra, M., & McEwen, J.D. 2018b, MNRAS, 480, 4170 [NASA ADS] [CrossRef] [Google Scholar]
- Carrillo, R.E., McEwen, J.D., & Wiaux, Y. 2012, MNRAS, 426, 1223 [NASA ADS] [CrossRef] [Google Scholar]
- Chael, A.A., Johnson, M.D., Bouman, K.L., et al. 2018, ApJ, 857, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Clark, B.G. 1980, A&A, 89, 377 [NASA ADS] [Google Scholar]
- Cornwell, T.J. 2008, IEEE J. Sel. Top. Signal Process., 2, 793 [NASA ADS] [CrossRef] [Google Scholar]
- Event Horizon Telescope Collaboration (Akiyama, K., et al.) 2019, ApJ, 875, L4 [Google Scholar]
- Garsden, H., Girard, J.N., Starck, J.L., et al. 2015, A&A, 575, A90 [CrossRef] [EDP Sciences] [Google Scholar]
- Gómez, J.L., Lobanov, A.P., Bruni, G., et al. 2016, ApJ, 817, 96 [CrossRef] [Google Scholar]
- Gonzalez, R., & Woods, R. 2006, Digital Image Processing, 3rd edn. [Google Scholar]
- Högbom, J.A. 1974, A&AS, 15, 417 [Google Scholar]
- Junklewitz, H., Bell, M.R., Selig, M., & Enßlin, T.A. 2016, A&A, 586, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kim, J.-Y., Krichbaum, T.P., Broderick, A.E., et al. 2020, A&A, 640, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Line, J.L.B., Mitchell, D.A., Pindor, B., et al. 2020, PASA, 37, e027 [NASA ADS] [CrossRef] [Google Scholar]
- Lobanov, A.P., Horns, D., & Muxlow, T.W.B. 2011, A&A, 533, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mertens, F., & Lobanov, A. 2015, A&A, 574, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mohan, N., & Rafferty, D. 2015, Astrophysics Source Code Library [record ascl:1502.007] [Google Scholar]
- Müller, H., & Lobanov, A.P. 2022, A&A, 666, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Murenzi, R. 1989, in Wavelets. Time-Frequency Methods and Phase Space, eds. J.-M. Combes, A. Grossmann, & P. Tchamitchian, 239 [CrossRef] [Google Scholar]
- Rau, U., & Cornwell, T.J. 2011, A&A, 532, A71 [CrossRef] [EDP Sciences] [Google Scholar]
- Regpy. 2019, “Regpy: Python tools for regularization methods”, https://github.com/regpy/regpy [Google Scholar]
- Schwab, F.R. 1984, AJ, 89, 1076 [NASA ADS] [CrossRef] [Google Scholar]
- Schwarz, U.J. 1978, A&A, 65, 345 [NASA ADS] [Google Scholar]
- Shepherd, M.C. 1997, ASP Conf. Ser., 125, 77 [NASA ADS] [Google Scholar]
- Starck, J.L., & Murtagh, F. 2006, Astronomical Image and Data Analysis (Springer) [CrossRef] [Google Scholar]
- Starck, J.-L., Bijaoui, A., Lopez, B., & Perrier, C. 1994, A&A, 283, 349 [NASA ADS] [Google Scholar]
- Starck, J.-L., Murtagh, F., & Fadili, J. 2015, Sparse Image and Signal Processing: Wavelets and Related Geometric Multiscale Analysis, 2nd edn., 1 [Google Scholar]
- Thompson, A.R., Moran, J.M., & Swenson, George W., 2017, Interferometry and Synthesis in Radio Astronomy, 3rd edition [CrossRef] [Google Scholar]
- Wakker, B.P., & Schwarz, U.J. 1988, A&A, 200, 312 [Google Scholar]
All Tables
All Figures
|
Fig. 1 Illustration of the used wavelet scales, ΦDoB, fitted to to a synthetic RadioAstron uυ-coverage in image and Fourier domain. Scales of various radial widths (scales 3, 4, scales 5–9, and scale 10) and four different elliptical directions are shown. The scales are fit to the uυ-coverage, as they are sensitive to gaps or covered coefficients, respectively. Upper panel: Fourier transform of the wavelet scales and the synthetic RadioAstron uυ-coverage (red points). Lower panels: respective wavelet basis function in image domain. |
| In the text | |
|
Fig. 2 Cross-section of the DoB and DoG wavelet scale 5 presented in Fig. 1. The DoB-wavelet fits the central peak, but suppresses the extended sidelobes. |
| In the text | |
|
Fig. 3 Cross-section of the DoB and DoG wavelet scale 7 presented in Fig. 1. The DoB wavelet fits the central peak, but suppresses the extended sidelobes. |
| In the text | |
|
Fig. 4 Comparison of reconstructions on synthetic data. First row: Gaussian-evn; second row: dumbbell-ring; third row: bllac-space, with various algorithms. First column: true image, second column: DoB-CLEAN reconstruction. Third column: CLEAN image. Fourth column: CLEAN model. Fifth column: uv-coverage of the synthetic observations. Contour levels for the bllac-space example are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
| In the text | |
|
Fig. 5 Sketch of the imaging iterations for the dumbbell-ring example. Upper left: initial residual. Upper right: we remove the dirty beam by computing a multiscalar model composed of DoB wavelets. The panel presents the recovered model |
| In the text | |
|
Fig. 6 Comparison of reconstructions on synthetic data. First row: Gaussian-evn; second row: dumbbell-ring; third row: bllac-space, with various algorithms. First column: true image; second column: DoB-CLEAN reconstruction; third column: MS-CLEAN image. Contour levels for the bllac-space example are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
| In the text | |
|
Fig. 7 Reconstructions of the Gaussian-evn test case, but with smaller source size. The contour levels are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
| In the text | |
|
Fig. 8 Reconstructions of the Gaussian-evn test case with Radio Astron uυ-coverage. The contour levels are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
| In the text | |
|
Fig. 9 Illustration of the estimation procedure for the effective resolution of DoB-CLEAN. Left panel: correlation between DoB-CLEAN reconstructions for varying source sizes with Radio Astron synthetic observation of the Gaussian-evn ground truth image and the blurred ground truth images. Right panel: blurring at maximal correlation as a function of source size (field of view). |
| In the text | |
|
Fig. 10 Illustration of the estimation procedure for the effective resolution of DoB-CLEAN as in Fig. 9, but with EVN coverage. |
| In the text | |
|
Fig. 11 High dynamic range reconstructions of the Gaussian-evn test case, but higher thermal noise level. The contour levels are [0.5%, 1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
| In the text | |
|
Fig. 12 Comparison of the fits of the Gaussian-evn synthetic data reconstruction in the Fourier domain. Upper panels: complete Fourier transform of reconstructions (true, DoB-CLEAN, CLEAN image, and CLEAN model), with uυ-coverage over-plotted (red crosses). Lower panels: Radplot showing the fit of the recovered model to the observed visibilities. It is only for DoB-CLEAN that the fit is successful (lower panels) and the Fourier transform of the model is physically reasonable (upper panels). |
| In the text | |
|
Fig. 13 Fourier transform of recovered data with DoB-CLEAN (upper panels) and the recovered model (lower panels) in the Gaussian-evn test case. From left to right: missing (not measured) scales are interpolated from the covered scales with a higher fraction. The most right panels show the true image. The used contour-levels are [1%, 2%, 4%, 8%, 16%, 32%, 64%] of the peak flux. |
| In the text | |
|
Fig. 14 BL Lac reconstructions with DoB-CLEAN at full resolution with natural weighting (left pane), uniform weighting (middle panel) and uniform weighting with smaller pixel size zoomed in the central core region (right panel). The contour levels are: [0.1,0.2,0.4,0.8,1.6,3.2,6.4, 12.8,25.6,51.2]% ([0.025, 0.05, 0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]%, [0.8,1.6,3.2,6.4,12.8,25.6,51.2]%) of the respective peak brightness. |
| In the text | |
|
Fig. 15 BL Lac reconstructions with DoB-CLEAN blurred with the clean beam with natural weighting (left panel), uniform weighting (middle panel) and uniform weighting with smaller pixel size zoomed in the central core region (right panel). The contour levels are: [0.1,0.2, 0.4,0.8, 1.6,3.2,6.4,12.8,25.6,51.2]% ([0.025, 0.05, 0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]%, [0.8,1.6,3.2,6.4,12.8,25.6,51.2]%) of the respective peak brightness. |
| In the text | |
|
Fig. 16 BL Lac reconstructions with DoB-CLEAN blurred with the clean beam with natural weighting (left panel), uniform weighting (middle panel) and uniform weighting with smaller pixel size zoomed in the central core region (right panel). The contour levels are: [0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]% ([0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]%, [0.8,1.6,3.2,6.4,12.8,25.6,51.2]%) of the respective peak brightness. |
| In the text | |
|
Fig. C.1 Progress of the cleaning with DoB-CLEAN. Shown is the sum of the recovered image and the residual after 4000 iterations (left panel), 5000 iterations and phase self-calibration (middle panel) and the final ground-only image (right panel). The contour levels are [0.1,0.2,0.4,0.8,1.6,3.2,6.4,12.8,25.6,51.2]% of the peak brightness. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.