Fig. D.1.
Download original image
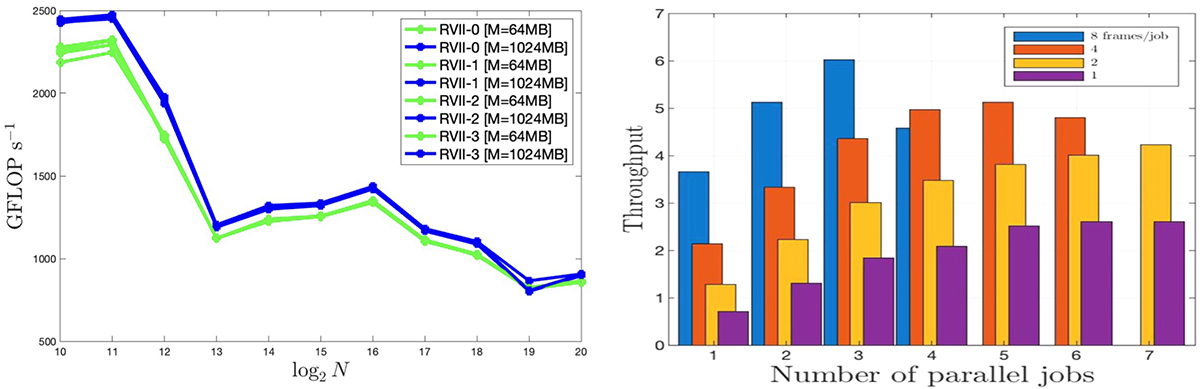
Performance overview of GPU-accelerated butterfly matched filtering on a quad-GPU node. Performance of clFFT in CSP/Out-of-Place as a function of array size N for two batch sizes measured by allocation M in global memory (left panel). Array sizes exceeding 212 cause a drop in performance as matrix transpose exceeds 32 kB of local memory, limited now by 1TB/s bandwidth to Global Memory in HBM2. We note that clButterfly uses a default size N = 217 (32 s of data at 4096Hz sampling rate) with batch size over n = 128 per frame of 4096 s. A quad-GPU node hereby features a maximum of about 5 teraFLOPs, circumventing limitations of PCIe bandwidth optimized by pre- and post-callback functions (van Putten 2017). The throughput of this quad-GPU node is shown up to six times real-time over a template bank normalized to size 220 (right panel). GPU-CPU communication passes through a post-callback function, limiting data-transfer to tails exceeding a threshold κ = 2 in normalized butterfly matched filtering output, effectively 0.1% of all matched filtering results. Throughput peaks in multi-frame analysis at a cross-correlation rate of about 200kHz.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.