Fig. 1.
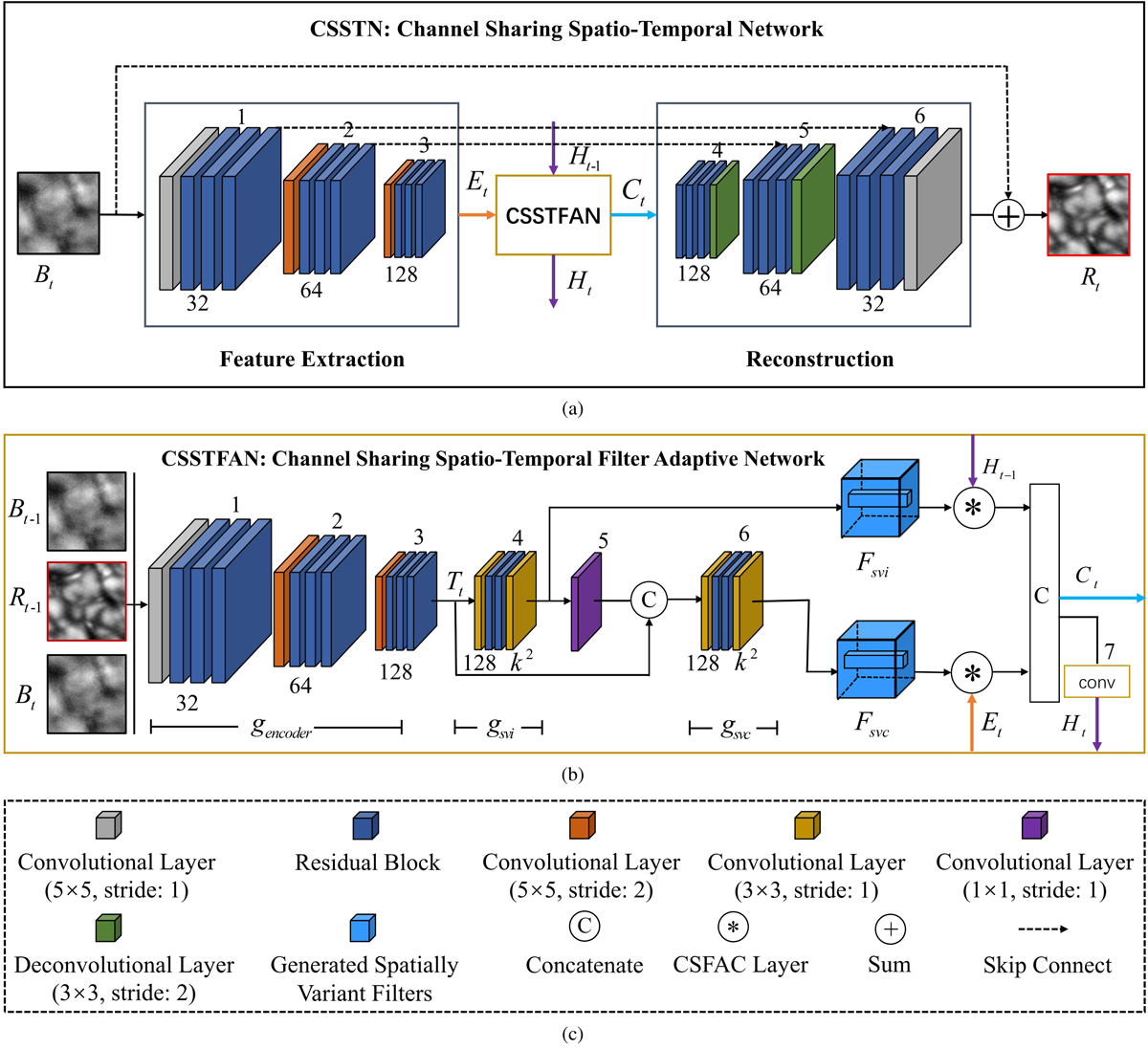
Proposed deep neural network architecture. Panel a: shows our proposed channel sharing spatio-temporal network (CSSTN). Panel b: is a channel sharing spatio-temporal filter adaptive network (CSSTFAN) sub-network. Panel c: is the meaning of different color blocks and symbols in the network. CSSTN consists of three sub-networks: a feature extraction network, a CSSTFAN, and a reconstruction network. Firstly the feature extraction network extracts features Et from the current blurry image Bt. Given the blurred image Bt − 1 and restored image Rt − 1 of the previous time step, and current input image Bt, the CSSTFAN generates the Fsvi and Fsvc in order. Using CSFAC layer ⊛, CSSTFAN convolves Fsvi with features Ht − 1 of the previous time step and convolves Fsvc with features Et. Finally, the reconstruction network restores the latent image from the fused features Ct. k denotes the filter size of CSFAC layer and it is 3 in our final network.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.