Fig. 3.
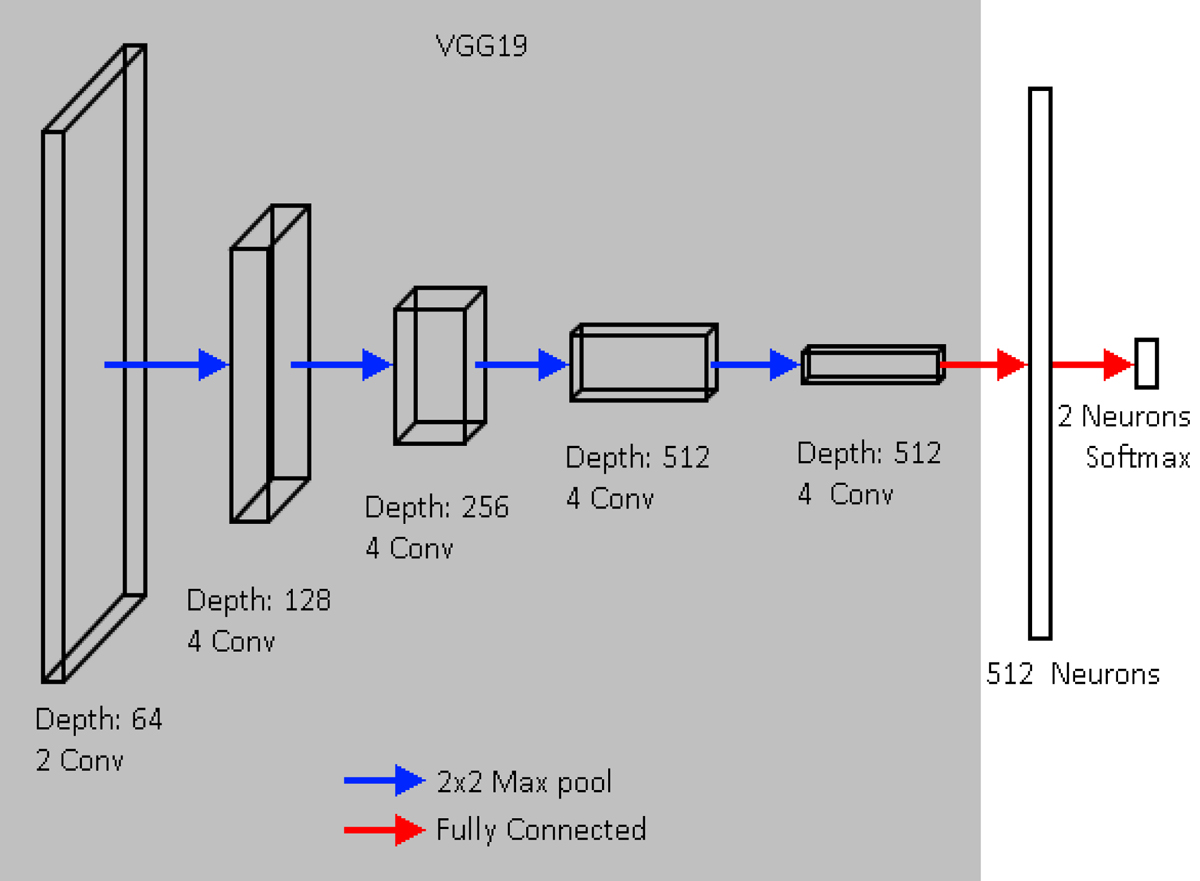
Architecture of the CNN used to identify major mergers and non-mergers. The pre-trained VGG network (shaded area) is used with the top three fully connected layers removed. There are five blocks containing 2, 4, 4, 4, and 4 convolutional layers with 64, 128, 256, 512, and 512 kernels respectively. All kernels are 3 × 3 pixels and each block is connected with a 2 × 2 pixel max pooling layer (blue arrows). We add a single fully connected layer with 512 neurons and a fully connected output layer with 2 neurons (unshaded area). The input to the network is a 88 × 88 pixel image with three identical channels.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.