Fig. 2.
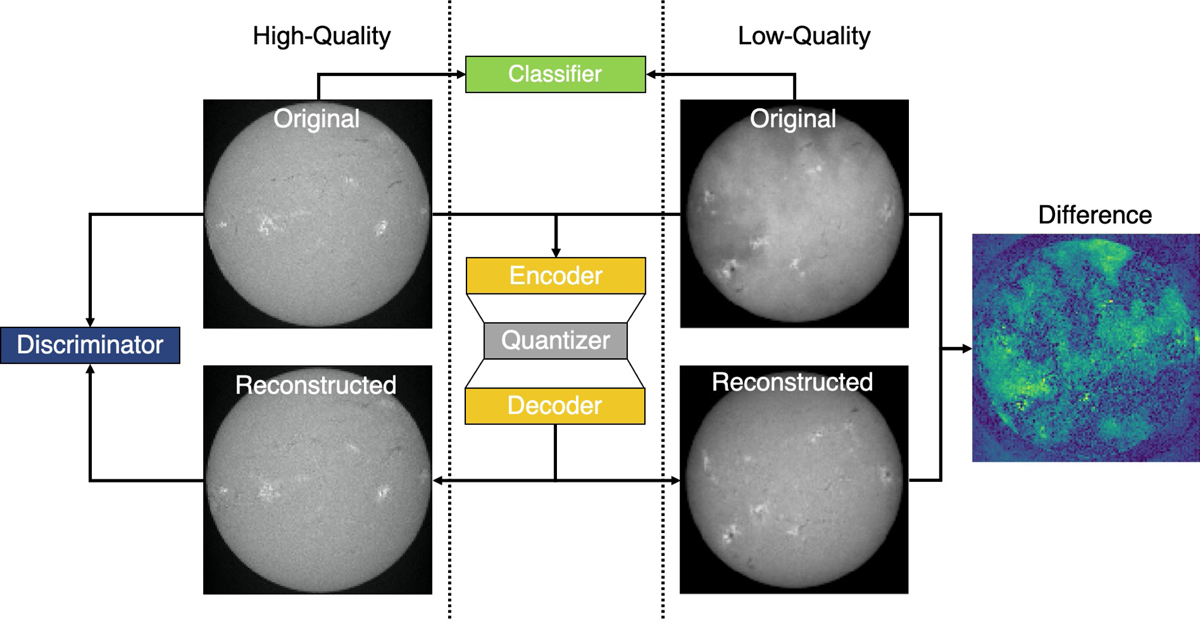
Overview of the proposed method. The generator consists of an encoder, quantizer, and decoder. The generator is trained with high-quality images (left), where the encoder transforms the original image to a compressed representation and further information is truncated by the quantizer. The decoder uses this representation to reconstruct the original image. The discriminator optimizes the perceptual quality of the reconstruction and provides the content loss for the quality metric, which encourages the generator to model the high-quality domain. In addition, an optional classifier can be used which is trained to distinguish between the two image-quality classes. When low-quality images (right) are transformed by the pre-trained generator, the reconstruction shows deviations from the original, which allows us to identify the affected regions and to estimate the image quality.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.