Fig. 7.
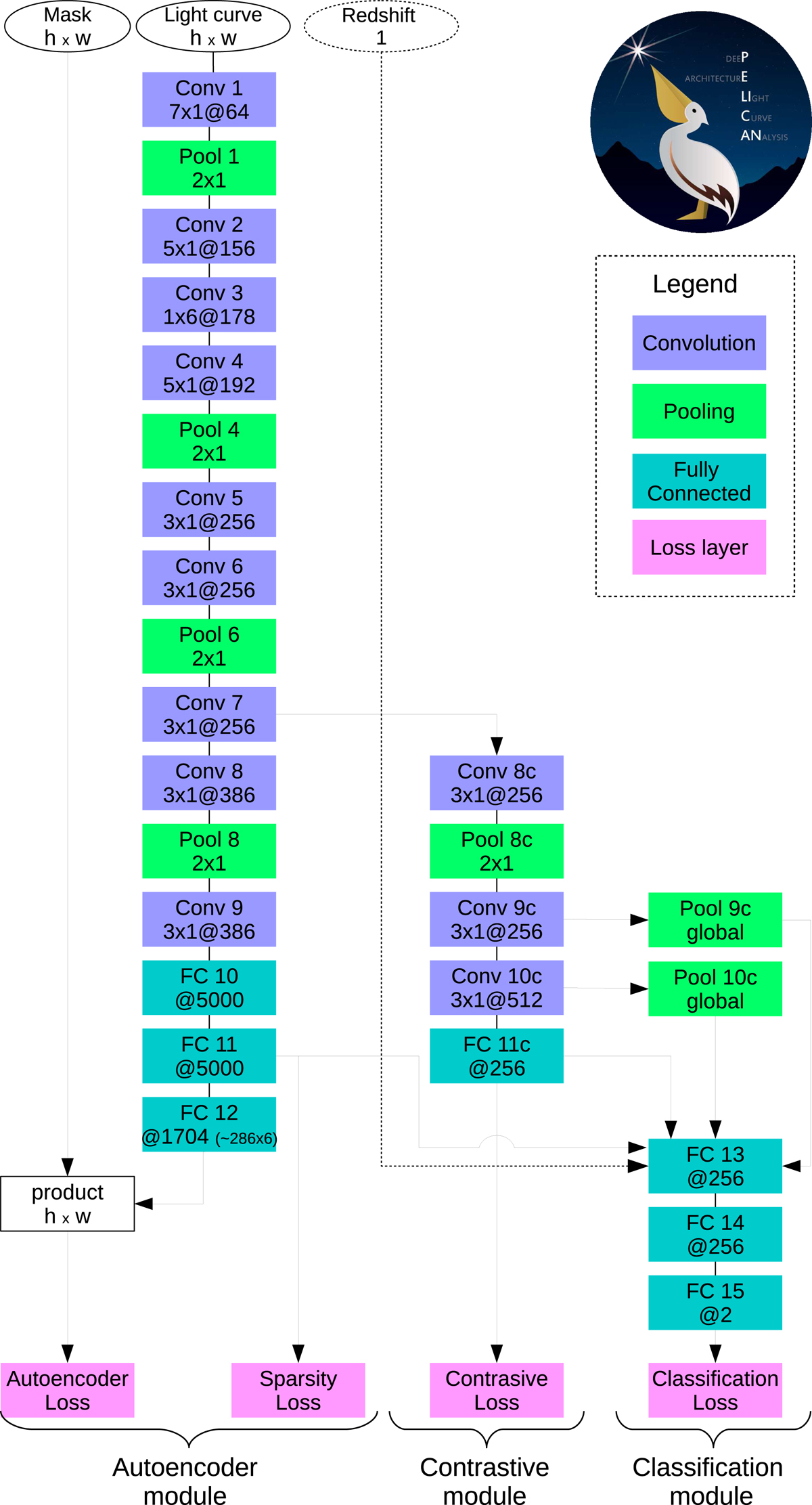
Representation of PELICAN architecture, which is composed of three modules: the autoencoder, the contrastive, and the classification modules. The first module optimizes the autoencoder loss containing a sparsity parameter (see Eq. (10)). In the second module, the contrastive loss (see Eq. (11)) is optimized to bring the features with the same label together. Finally the third module performs the classification step optimizing a standard classification loss.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.