Fig. 5.
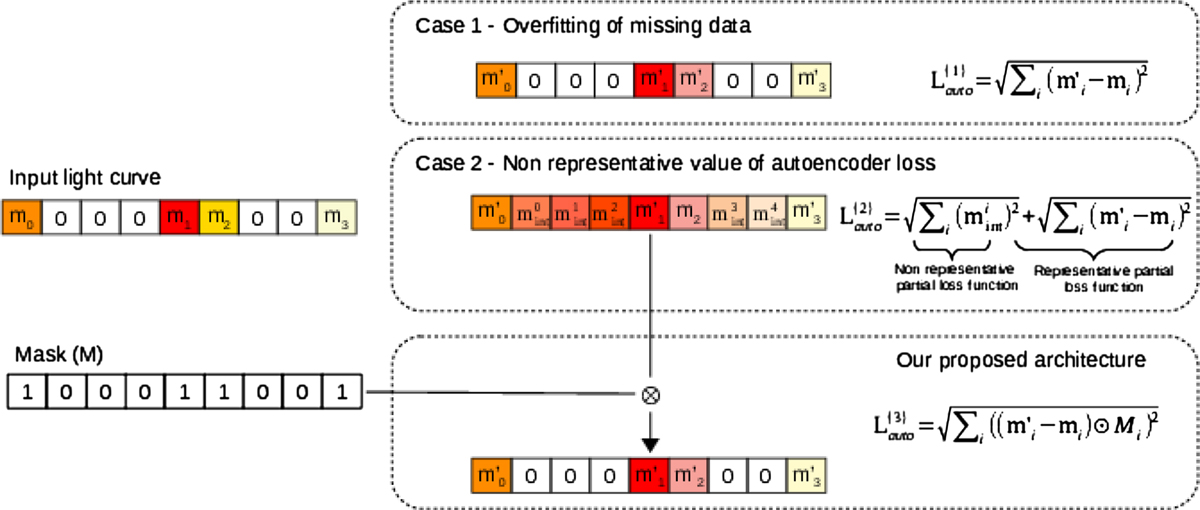
Illustration of the overfitting of the missing data that could appear in the autoencoder process and the solution proposed to overcome it. The input light curve is composed of different magnitudes (m0, m1, m2 m3) and missing values represented by zero values. In case 1, the algorithm has completely overfitted the missing data by replacing them at the same position on the light curve. So the loss function, ![]() , is ideally low. In case 2 the algorithm has completed the missing data by interpolating them. However, as the computation of the loss is made between the new values of magnitudes, (
, is ideally low. In case 2 the algorithm has completed the missing data by interpolating them. However, as the computation of the loss is made between the new values of magnitudes, (![]() ), compared to zero values, the value of the loss
), compared to zero values, the value of the loss ![]() is overestimated. The solution that we provided is to multiply the interpolated light curve by a mask M before the computation of the loss,
is overestimated. The solution that we provided is to multiply the interpolated light curve by a mask M before the computation of the loss, ![]() .
.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.