| Issue |
A&A
Volume 611, March 2018
|
|
|---|---|---|
| Article Number | A86 | |
| Number of page(s) | 10 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/201731554 | |
| Published online | 04 April 2018 | |
Distribution of shape elongations of main belt asteroids derived from Pan-STARRS1 photometry
1
Institute of Astronomy, Faculty of Mathematics and Physics, Charles University,
V Holešovičkách 2,
180 00 Prague 8,
Czech Republic
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Department of Mathematics, Tampere University of Technology,
PO Box 553,
33101 Tampere, Finland
3
Harvard-Smithsonian Center for Astrophysics,
60 Garden St,
Cambridge,
MA 02138, USA
4
Institute for Astronomy University of Hawaii,
2680 Woodlawn Dr, Honolulu,
HI 96822, USA
5
Department of Physics and Astronomy,
PO Box 6010, Northern Arizona University,
Flagstaff,
AZ 86011, USA
Received:
12
July
2017
Accepted:
10
September
2017
Abstract
Context. A considerable amount of photometric data is produced by surveys such as Pan-STARRS, LONEOS, WISE, or Catalina. These data are a rich source of information about the physical properties of asteroids. There are several possible approaches for using these data. Light curve inversion is a typical method that works with individual asteroids. Our approach in focusing on large groups of asteroids, such as dynamical families and taxonomic classes, is statistical; the data are not sufficient for individual models.
Aim. Our aim is to study the distributions of shape elongation b∕a and the spin axis latitude β for various subpopulations of asteroids and to compare our results, based on Pan-STARRS1 survey, with statistics previously carried out using various photometric databases, such as Lowell and WISE.
Methods. We used the LEADER algorithm to compare the b∕a and β distributions for various subpopulations of asteroids. The algorithm creates a cumulative distributive function (CDF) of observed brightness variations, and computes the b∕a and β distributions with analytical basis functions that yield the observed CDF. A variant of LEADER is used to solve the joint distributions for synthetic populations to test the validity of the method.
Results. When comparing distributions of shape elongation for groups of asteroids with different diameters D, we found that there are no differences for D < 25 km. We also constructed distributions for asteroids with different rotation periods and revealed that the fastest rotators with P = 0 − 4 h are more spheroidal than the population with P = 4−8 h.
Key words: minor planets, asteroids: general / methods: statistical / techniques: photometric
© ESO 2018
1 Introduction
The spin states (rotational periods and directions of the spin axes) and shapes of individual asteroids can be determined from photometric data by light curve inversion (Kaasalainen & Lamberg 2006; Ďurech et al. 2015, and references therein). For these methods, mainly dense photometric data are used because they sample well the rotational period P. The preliminary estimate of P can substantially reduce the computational time required for the determination of unique sidereal rotational period. Up to now, almost a thousand models have been derived using this method and most of these are stored in Database of Asteroids Models from Inversion Techniques (DAMIT; Ďurech et al. 2010).
In Cibulková et al. (2016), we described a different approach that is suitable for photometric data that are sparse in time and produced by all-sky surveys and consist typically of a few measurements per night over ~10 yr. These data are not suitable for ordinary sparse light curve inversions (Ďurech et al. 2005, 2007). In Cibulková et al. (2016), we used the mean brightness and its dispersion in individual apparitions to derive the ecliptical longitude and latitude of the spin axis and the shape elongation of asteroids from photometric data stored in the Lowell Observatory database (Bowell et al. 2014). Even though the parameters could be determined for individual asteroids, the uncertainties are large and the results are only supposed to be used in a statistical sense. However, this model cannot be used for the photometric data from the Panoramic Survey Telescope & Rapid Response System (Pan-STARRS) because there are not enough measurements covering long enough time intervals.
Another statistical study was carried out by Nortunen et al. (2017) using data from the Wide-field Infrared Survey Explorer (WISE) database1. These data also could not be analyzed with the method from Cibulková et al. (2016), however, Nortunen et al. (2017) developed a new model and described physical parameters for subpopulations of asteroids using distribution functions. This method is not meant to invert the shape and spin characteristics of individual light curves; the inversion works only on a population scale, where we consider the shape and spin distributions of a large population. In Nortunen et al. (2017) as well as in this paper, we constructed cumulative distribution functions (CDFs) of the variation of brightness for selected groups of asteroids and studied the inverse problem. The parameters of the model are the shape elongation b∕a and the ecliptical latitude β of the spin axis. The advantage of this method is that it can be used even if only few points and one apparition are available for an asteroid. A similar approach was used by Szabó & Kiss (2008) and McNeill et al. (2016).
While in Nortunen et al. (2017) we mainly studied the validity and accuracy of the method and practical applicability on astronomical databases, in this work we applied the model on photometric data from Pan-STARRS1 and performed an analysis focusing on large subpopulations of asteroids using the Latitudes and Elongations of Asteroid Distributions Estimated Rapidly (LEADER) algorithm (Nortunen & Kaasalainen, 2017). The structure of this paper is as follows: in Sect. 2, we briefly describe the model; in Sect. 3, we describe the used data from Pan-STARRS1 sky survey; in Sect. 4, we test the accuracy of the determination of model parameters by simulations on synthetic data; in Sect. 5, we construct distributions of shape elongations b∕a and ecliptical latitudes β of the spin axis for some subpopulations of asteroids and analyze the results; and in Sect. 6, we summarize the main results.
2 Model
In our model, we approximate the shape of an asteroid with a simple, biaxial ellipsoid. We denote the semiaxes a ≥ b= c = 1, and we choose b∕a as the parameter that describes the shape elongation of an asteroid. We have 0 < b∕a ≤ 1, with a small b∕a presenting an elongated body and b∕a = 1 presenting a sphere. This shape approximation is very coarse, but with a high number of observations (∝ 103), it portrays statistical tendencies of a population accurately. For realistic shapes, the proportion of highly elongated values b∕a < 0.4 is negligible, and for most shapes, b∕a > 0.5. However, for completeness, we include all the values 0 < b∕a ≤ 1 in our grid; if the solved b∕a distribution contains an unusually high proportion of values below 0.4, it is usually an indicator of error in the solution, caused by noise and/or instabilities.
Our second parameter is the spin co-latitude β, which is defined as the ecliptic polar angle of the spin axis. The connection between β and the aspect angle of the pole is explained in Nortunen et al. (2017). In the ellipsoid model, the values of β are fixed in the interval [0, π∕2]. In other words, there is no way to distinguish whether the spin latitudes are above or below the ecliptic plane in our model. In our convention, β = 0 indicates that the spin direction is perpendicular to the ecliptic plane, while β = π∕2 means the spin is in the ecliptic plane; this was the convention in Nortunen et al. (2017), but it was the opposite in Cibulková et al. (2016). We assume that most orbits are in the ecliptic plane.
Assuming we have the brightness intensities, L, measured with the data given by an asteroid database, we use the brightness variation η as our observable,
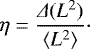 (1)
(1)
The squaredintensities L2 are used for the mean⟨L2⟩ and the variation 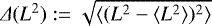 instead of the standard brightness L to obtain more simple, closed-form formula for η. From Nortunen et al. (2017), the amplitude A can be directly computed from η as follows:
instead of the standard brightness L to obtain more simple, closed-form formula for η. From Nortunen et al. (2017), the amplitude A can be directly computed from η as follows:
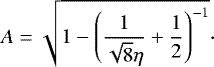 (2)
(2)
The amplitude A is based on intensity here, not on magnitudes. With the amplitudes known, we can create their CDF, C(A).
To solve the joint distribution for b∕a and β, we create a grid of bins ![Mathematical equation: $((b/a)_{i}, \beta_{j}) \in [0, 1] \, \times \, [0, \pi/2]$](/articles/aa/full_html/2018/03/aa31554-17/aa31554-17-eq4.png) , where i = 1, … , k and j = 1, … , l. Our goal is to determine the proportion of each bin. Now, the CDF can be written as a linear combination of other functions,
, where i = 1, … , k and j = 1, … , l. Our goal is to determine the proportion of each bin. Now, the CDF can be written as a linear combination of other functions,
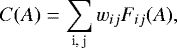 (3)
(3)
where Fij(A) are monotonously increasing basis functions derived by Nortunen et al. (2017), i.e.,
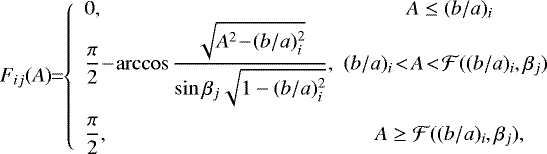 (4)
(4)
where 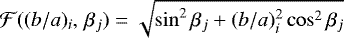 . Each basis function Fij (A) describes the contribution made by objects in a given bin
. Each basis function Fij (A) describes the contribution made by objects in a given bin 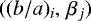 to the CDF C(A). The weights wij are the occupation numbers of each bin
to the CDF C(A). The weights wij are the occupation numbers of each bin 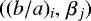 . We can write (3) in an equivalent form,
. We can write (3) in an equivalent form,
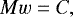 (5)
(5)
where each column of the matrix M contains a basis function Fij(A), the vector w contains the occupation numbers wij, and the vector C contains the CDF C(A). For solving (5), we use linear least squares methods in, for example, Matlab, along with regularization and a positivity constraint that wij ≥ 0. With the weights wij solved, we have the proportion of each bin 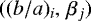 .
.
With the joint distribution for b∕a and β obtained, we compute the marginal DFs fb∕a and fβ for both parameters,
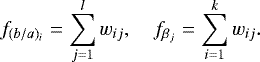 (6)
(6)
In addition,we compute the CDFs for the marginal DFs. Let us denote the CDFs as Fb∕a and Fβ . Now, we assume that we obtained these CDFs for two subpopulations, S1 and S2, where the CDFs are denoted as Fb∕a(S1), Fb∕a (S2), Fβ (S1), and Fβ (S2), and we want to measure statistical differences of the populations. Some of these measures were used in Nortunen et al. (2017) as follows:
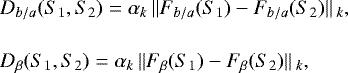 (7) (8)
(7) (8)
where k = 1;2;∞ and αk are norm-based scaling factors, α1 = 1∕4; α2 = 1 and α∞ = 2. Each norm provides a different kind of information about the statistical differences of the populations. The case k = ∞ corresponds with the Kolmogorov-Smirnov test (for details see Nortunen et al. 2017; or Nortunen & Kaasalainen 2017). As a general rule of thumb, two distributions are considered significantly different statistically if D ≳ 0.2. However, a visual inspection on the marginal DF and CDF plots is also recommended for obtaining a better understanding of the statistical differences. The detailed description of the LEADER software can be found in Nortunen & Kaasalainen (2017) and the software itself is available in DAMIT database2.
3 Data
The 1.8 m Pan-STARRS1 survey telescope (Hodapp et al. 2004; Tonry et al. 2012), build atop of Haleakala, Maui, started its three-year science mission in May 2010. Photometric data were obtained in six optical and near-infrared filters (g, r, i, z, y, and w). Because of the distinct survey goals and patterns, most of the asteroids were observed in a wideband w-filter (~400−700 nm). We used theunpublished high-precision calibrated chip-stage photometry (Schlafly et al. 2012) with photometric errors and selected detections of a good photometric quality. Only PSF-like and untrailed detections were considered. Our subset spanned from April 11, 2011 until May 19, 2012. In total, we had photometric data for 348 210 asteroids with about 20 measurements for an asteroid on average. The second highest number of measurements was in the i band, where we had data for 136 463 asteroids. Only the w-band data provided enough measurements for a reasonable application of our model. We briefly discuss the results from the i-filter and compare these with results from the w-filter in Sect. 5.7.
The typical time interval between two measurements in the w-band filter is ~17 min (see Fig. 1). However, not all the data were applicable to our model. Our conditions on the data were the following:
-
The time interval between measurements is greater than 0.01 day (~14 min). In the case of a shorter interval the rotational period would not be randomly sampled over one rotation of ~hours, and in the case of a longer minimum interval we would lose a significant amount of data, as we can see from Fig. 1.
-
Then, we limited the solar phase angle α to be ≤ 20°. In the model we assume this angle to be close to zero, however, in the data, there are not enough measurements with α ~ 0°, therefore, we have to choose some reasonable value (see also Fig. 2). As described in Nortunen et al. (2017; they used α ≤ 30°) the error caused by this condition is negligible.
-
Finally, we required at least five measurements satisfying previous conditions within three days to keep the geometry of observation sufficiently constant; this is the same condition as in Nortunen et al. (2017).
It is possible that for the same asteroid we had two (or even more) sets of measurements. In that case, each set was incorporated in the model.
 |
Fig. 1 Histogram of time intervals between measurements in the w-band filter from the Pan-STARRS1 survey. |
 |
Fig. 2 Histogram of the solar phase angle α for measurements in the w-filter. |
4 Synthetic simulations for accuracy estimation
Before we computed the solution of the inverse problem from Eq. (5) for any Pan-STARRS1 subpopulation, we performed a thorough analysis concerning whether the method is reliable and accurate with the given database. To do this, we used synthetic data created according to the procedure described in Nortunen & Kaasalainen (2017). We chose a peak of the (b∕a, β) distribution. For each asteroid in the considered population we chose a shape model from DAMIT, with |b∕aDAMIT − b∕awanted|≤ 0.075. The rotation period was chosen randomly between 3 and 12 h from a uniform distribution; we did not use rotation periods from DAMIT, as they could be biased. Next, we used the real Pan-STARRS1 geometries and times of observations and computed the synthetic brightness using a combination of Lommel-Seeliger and Lambert scattering laws. To simulate noise, we added a minor Gaussian perturbation 1− 2%. Our aim was to find how well the solution distribution computed from Eq. (5) coincides with the known, synthetic distribution. For simplicity, we were interested in reconstructing the highest peak of the joint (b∕a, β) distribution.The peak is defined as the bin with the highest occupation numbers. If there were any obvious systematic errors in the computed solution, we attempted to apply a posterior correction to the solution. Similar synthetic simulations were used by Nortunen et al. (2017) to estimate the accuracy of the method for the WISE database and to create a deconvolution filter to the contour image of the solution.
4.1 Number of bodies in a population
We created 50 synthetic populations, each containing N asteroids, and each population having a distinct, single peak chosen randomly. With each population, we plotted the actual (b∕a, β) peak versus the computed (b∕a, β) peak to see how well they coincide. We set the populations to have from 100 to 5000 asteroids. This was so that we could evaluate how the accuracy of our method increases with a growing number of asteroids. The results from these simulations were plotted in Fig. 3 for b∕a and Fig. 4 for β.
The b∕a plots in the left column of Fig. 3 show that the accuracy of the obtained b∕a distribution is improved substantially as the population size increases. There is always some overshoot and undershoot when b∕a ≲ 0.4, but this is a rare problem; with real data, we typically have b∕a ≳ 0.5, so the peak of the distribution is also expected to be above 0.5. With a population of less than 1000 asteroids, there is a slight overshoot when b∕a > 0.5; i.e., the solution suggests the shapes are slightly more spherical than they actually are. But as the population size exceeds 1000 asteroids, the computation of the b∕a peak is very accurate when b∕a > 0.5.
Unfortunately, much of the β information is lost in the inversion carried out for the Pan-STARRS1 database, as seen in Fig. 4. For a population of less than 500 asteroids, no actual information can be recovered. For 600–1000 bodies, there is a slight increase in accuracy, but overall, the solution is too noisy to provide accurate information on β. The improvement of the accuracy is noticeable for populations with 2000–5000 asteroids, and the method provides a rough estimate on the location of the peak; when the β peak is low (perpendicular to the ecliptic plane), the obtained solution also has a low β peak and vice versa. With the Pan-STARRS1 database, our assumption that the majority of the orbits is in the ecliptic plane may not hold well, which considerably reduces the accuracy of the beta distribution. Because of the low accuracy of the β solution, werecommend that caution is used when interpreting the computed β distribution. At best, our method can provide a coarse approximation regarding where the β peak is located.
In addition to determining the correct position of the peaks, we are interested in the overall shape of the joint distribution. It is a typical tendency that the computed distribution spreads too much, especially in β direction, and the distribution has a heavy tail toward the spin directions in the ecliptic plane. To correct this error, we applied a deconvolution filter to the computed distribution. In this post-solution correction, we introduced some dampening by reducing the occupation numbers of bins when moving further away from the highest peak, that is, the bin with the biggest occupation number. A similar method was used in Nortunen et al. (2017). An example of a typical solution and the effects of deconvolution is plotted in Fig. 5. In the simulation, we used a single, fixed (b∕a, β) peak for a population of 10 000 asteroids, with the geometries from Pan-STARRS1 database. We only reduced the spreading of the solved distribution in the post-solution correction; we did not shift the position of the (b∕a, β) peak.
We emphasize that the accuracy of the solution has a strong dependence on the asteroid database used. Our method should never be used as a black box for a database. Instead, whenever we begin to use a new database, we should always test the validity of our method with synthetic simulations. As the level and distribution of noise in the database is rarely known, synthetic simulations are typically the only way to estimate the error of our method. For comparison, we performed similar synthetic simulations for WISE database in Nortunen & Kaasalainen (2017), and the results obtained from WISE and Pan-STARRS1 databases are considerably different.
 |
Fig. 3 Synthetic simulations showing how the accuracy of our method improves for b∕a with a growing number of asteroids (from 100 to 5000). The plots have the real peak of the distribution plotted vs. the computed peak. The black dashed line of the form y = x depicts the ideal situation when the actual and computed peaks are the same. |
 |
Fig. 5 Synthetic simulations using a fixed (b∕a, β) peak for a population of 10 000 asteroids. The top left plot shows the actual (b∕a, β) distribution,the top right shows the computed (b∕a, β) distribution,and the bottom shows the top right solution with a deconvolution filter applied. |
4.2 Influence of the rotation period
Next, we studied how accurately we are able to reproduce the known (b∕a, β) distribution when we created synthetic data with different rotation periods P. We chose the following intervals of P: (i) 3−12 h; (ii) 12− 24 h; and (iii) 24− 96 h. The synthetic populations contained 2000 asteroids each. The results are plotted in Fig. 6. Considering the b∕a distribution, for P < 12 h our method provides reliable results. For P > 12 h the solution prefers values of b∕a ~ 1 (spheroidal bodies) and moreover, the solution becomes unstable for b∕a < 0.6. As to the β distribution, for 3 < P < 12 h we noticed a correlation between actual and computed β, but for P > 12 h, the β is too unstable to recover any accurate information about the distribution.
The fact, that our computed distributions of b∕a for slow rotators (P > 12 h) peak at b∕a ~ 1 is probably due to the time distribution of Pan-STARRS1 measurements. For most asteroids, data were obtained during a single night, i.e., a few hours. If the real P is much longer, the data cover only a small fraction of the full light curve (showing the time evolution of brightness during the whole P). The changes of brightness are thus small and our model interprets these changes as belonging to a spheroidal asteroid. We constructed the distribution of P from the Asteroid Lightcurve Database3 (LCDB; Warner et al. 2009) for the asteroid included in Pan-STARRS1 database and we found that most of the asteroids have P ≲ 15 h. Nevertheless, the sample of objects in the LCDB database is biased and the number of slow rotators is underestimated since it is observationally difficult to determine long periods (Marciniak et al. 2015; Szabó et al. 2016).
 |
Fig. 6 Synthetic simulations showing the accuracy of our method for different values of rotation period P. The black dashed line denotes the ideal situation. |
4.3 Influence of the orbit inclination
Finally, we tested the influence of the orbit inclination sinI on our solution since in the model we assume sinI = 0. When creating the synthetic data, we used Pan-STARRS1 geometries of 2000 asteroids with sin I ≤ 0.2, i.e., the first population, and 2000 asteroids with sin I > 0.2, i.e., the second population. The resulting distributions of b∕a and β are not statistically different for populations with small and high inclinations of orbits. For b∕a, the computed peak corresponds with the actual peak, but for β, we find thatthe model shifts the peak to middle values, which is the same problem as in Fig. 4.
5 Distributions of the ratio of axes b/a
In this section, we first test how many asteroids have to be in a studied subpopulation to obtain reliable results because typically we compare subpopulations that contain different numbers of asteroids. Then we construct the distributions of shape elongation b∕a for various subpopulations of main-belt asteroids. Specifically, we tested asteroids with different diameters, different rotation periods, dynamical families, taxonomic classes, and subpopulations of asteroids located in various parts of the main belt (as in Cibulková et al. 2016). To compare the distributions, we calculated Db∕a and Dβ according to Eqs. (7) and (8). The bins in the distributions of b∕a and β were chosen randomly, hence, for each two subpopulations that were compared, we processed 10 runs and obtained 10 values of Db∕a and Dβ , from which we calculated the mean values. For the distribution of b∕a we chose 14 bins from 0 to 1, however, because the shape elongation b∕a < 0.25 is improbable, there was only one bin from 0 to 0.25, then one bin from 0.25 to 0.4 and 12 bins from 0.4 to 1. For the distribution of β we chose 20 bins from 0 to π∕2, specifically, 15 bins for β > 43.4° and then we always selected one bin in following intervals: 37.2°−43.4°, 31°− 37.2°, 24.7°−31°, 18.5°−24.7°, and 0°− 18.5° to consider that the distribution pole latitudes is uniform in sinβ.
5.1 Effect of the number of asteroids in a subpopulation
When comparing subpopulations with each other we have to take into account that they contain different numbers of asteroids. To find which population is large enough for stable results, we performed the following test. We used data for the Flora family and we randomly chose 100 of its members and ran our model 10 times. We obtained 10 distributions of b∕a and β from which we calculated one mean distribution of b∕a and one for β. We repeated this for a sample of 200 randomly chosen asteroids, then 300, 400, and so on, up to the sample of 2000 asteroids. All mean distributions of these subpopulations of Flora are shown in Figs. 7 and 8. For the distribution of b∕a we see that the results are stable from ~800 asteroids in the subpopulation. However, for β the results are much more unstable, the distributions are clearly different even in Fig. 8 that contains populations with 1100 to 2000 asteroids. With a growing number of bodies the peak of β distribution is higher and the number of asteroids with β ~ π∕2 decreases.
 |
Fig. 7 Distributions of b∕a and β for Flora family constructed for growing number of asteroids that were included (from 100 to 1000). |
5.2 Asteroids with different diameters
First, we focused on groups of asteroids with different diameters D. For asteroids that have D derived from the observationsof WISE satellite, we used that value and for other asteroids we used diameters from the AstOrb catalog. We divided asteroids into seven groups with D < 3 km, 3− 6 km, 6− 9 km, 9− 12 km, 12− 15 km, 15− 25 km, and D > 25 km, and compared these groups with each other. For D < 15 km, we have in all five groups more than 1200 asteroids, however, there are only 990 asteroids with 15 < D < 25 km and only 223 bodies in the last group (D > 25 km), which is not enough for a reliable result. The distributions for three groups with the largest D are shown in Fig. 9. Although, this is in agreement with the findings of Cibulková et al. (2016) that the asteroids larger than D > 25 km are more often spheroidal, in this case it might be just an effect of the low number of asteroids in the last subpopulation.
The mean values of Db∕a for distributions of b∕a for the three subpopulations with largest diameters are listed in Table 1. The distributions of b∕a for groups of asteroids with D < 15 km are not statistically different from the group of asteroids with 15 < D < 25 km and have a maximum for b∕a ~ 0.8. The average axial ratio b∕a from Pan-STARRS1 survey was also determined by McNeill et al. (2016). For asteroids with D < 8 km these authors found the average b∕a to be 0.85, which is a little more spheroidal than our result. For D < 25 km, Cibulková et al. (2016) found the maximum of distribution of b∕a for ~0.63, i.e., the asteroids are more elongated, nevertheless, the possibility is mentioned there that the results could be influenced by the underestimated data noise, which causes shape estimates to be more elongated.
We also tried to reconstruct the cumulative distributions of absolute rate of change in magnitude from work McNeill et al. (2016), who constructed distributions for asteroids with 1 < D < 8 km dividing them into groups 1−2 km, 2− 3 km, and so on, to 7−8 km. They found that with decreasing diameter, the distributions show smaller change in magnitude. However, we could not find anydifferences between individual distributions (see Fig. 10 on the left). The possible explanation of this disagreement is that McNeill et al. (2016) used only measurements with magnitude uncertainty ≤0.02, however, weused all measurements; our only conditions were first, the solar phase angle α <10°, which is thesame condition as in McNeill et al. (2016), and, second, pairs of measurements separated by time interval 10 min < Δt < 20 min. We also constructed cumulative distributions of brightness variation η to see whether there would be any differences, but as shown in Fig. 10 on the right, the η distributions for groups of asteroids with different diameters are almost the same.
Then wefocused on the distributions of β. As we can see in Fig. 9 on the right, they look different from results of, for example, Cibulková et al. (2016) or Hanuš et al. (2011), where β is clustered around 0 due to the Yarkovsky-O’Keefe-Radzievskii-Paddack (YORP) effect, which shifts β near the pole of the ecliptic (e.g., Pravec & Harris 2000; Rubincam 2000). Nevertheless, as explained in Sects. 4 and 5.1, we found that the distribution of β is considerablyinfluenced by the number of asteroids in a given subpopulation and becomes flatter with decreasing number of asteroids. InFig. 4 we also see that the model tends to shift the peak to the middle values. The results on β are thus not reliable and in the following tests we only focus on the distributions of b∕a.
Because the number of asteroids with D > 25 km in data from Pan-STARRS1 is insignificant in comparison to the number of smaller asteroids (less than 1%), this dependence on diameter does not influence the results of the following tests.
 |
Fig. 9 DFs and CDFs of b∕a and β for asteroids with 12 < D < 15 km (red lines), 15 < D < 25 (blue lines) and D > 25 km (green lines). |
Parameter Db∕a for selected pairs of populations that were compared.
 |
Fig. 10 Left: cumulative distributions of absolute value of change in magnitude |Δmag | for groups of asteroids with different sizes. Right: cumulative distributions of η for groups of asteroids with different sizes. |
5.3 Different rotation periods
According to their rotation periods P provided bythe LCDB database, we divided asteroids into three groups. To ensure that all groups are populous enough for stable results we chose the following intervals: (i) P = 0−4 h (1081 bodies); (ii) 4− 8 h (1967 bodies); and (iii) 8−15 h (1071 bodies). We excluded asteroids with P > 15 h since our simulations with synthetic data showed the results are not reliable (see also Fig. 6).
We compare populations with each other and plot their distributions of b∕a in Fig. 11. We see that the fastest rotators (P = 0−4 h) are on average more spheroidal than the population with P = 4−8 h, but their b∕a distribution is not different from the third population with P = 8−15 h. The mean values of Db∕a are listed in Table 1.
The critical rotation rate is, for the same density, dependent on the elongation (Pravec & Harris 2000). The spheroidal bodies are thus able to rotate faster that the elongated bodies, which is in accordance with our results for the first two populations. However, we were not able to explain why the third population, with P = 8−15 h, should contain more spheroidal asteroids than the population with P = 4−8 h. Therefore, using the LCDB database we constructed distributions of light curve amplitudes for the three above-mentioned populations (see Fig. 12). Higher amplitudes correspond to larger elongations. The distributions of the first two groups are in accordance with the results from Pan-STARRS1 data, but for the third population (P = 8−15 h), we obtained similar distribution as for the population with P = 4−8 h.
To explain this discrepancy we performed another test with synthetic data. We used the same setup as in Sect. 4.2, where we studied the influence of the rotation period on the accuracy of the solution, but we chose populations with P = 4−8 h and P = 8−15 h. The resulting distributions of b∕a are shown in Fig. 12, on the right. The figure shows that our model is not able to correctly reproduce peak b∕a ≲ 0.6 for either population, nevertheless such elongation peak is uncommon; most of the asteroids have b∕a > 0.6. Considering 0.8 > b∕a > 0.6, for the population with P = 8−15 h, our model provides slightly more spheroidal objects (b∕a ~ b∕aactual + 0.1) and for the population with P = 4−8 h, it provides slightly more elongated objects (b∕a ~ b∕aactual − 0.05). We conclude that the difference between b∕a distributions for these two populations (shown in Fig. 11) is due to the method bias that shifts their b∕a values ~0.15 apart.
 |
Fig. 11 DFs and CDFs of b∕a for asteroid populations with different rotation periods. |
 |
Fig. 12 Left: distributions of light curve amplitudes from the LCDB database for different rotation periods P. Right: synthetic simulations showing the accuracy of our method for two different intervals of rotation period P. |
5.4 Period from estimated photometric slopes
From this analysis we learned that our distributions of b∕a for other asteroid populations can be strongly influenced by the appropriate period distributions. Unfortunately, our model does not provide the rotation period P and the LCDB database contains P for only ~ 14 000 asteroids. That sample, divided into individual populations, is not large enough for a statistical purpose. Nevertheless, if there are many measurements for an asteroid and if they are appropriately distributed in time P can be formally calculated directly from photometric data. More precisely, we need pairs of measurements close in time and also a sufficient number of such pairs.
First we derived a general result for the time series of any signal I that is of pure sinusoidal form of nth order only, augmented by the mean term I0 (0th order),
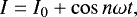 (9)
(9)
where ω is the rotation frequency; we chose this form since the starting point is irrelevant. If the estimates of the time derivative d I∕dt are available (i.e., measurements of I within a short time interval as with Pan-STARRS1), we can use these to estimate ω and hence the period P = 2π∕ω in a simple manner. Using the variation (standard deviation) Δ as defined with Eq. (1), with I = L2, and computing the mean ⟨|dI∕dt|⟩ from Eq. (9) by integrating dI∕dt over the interval [0, π∕2], we directly obtain
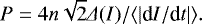 (10)
(10)
Since I = L2 for an ellipsoid is of the pure n = 2 double-sinusoidal form (Nortunen et al. 2017), we used Pan-STARRS1 slope estimates |d L2∕dt| and their mean ⟨|dL2∕dt|⟩ to obtain the period with the aid of Eq. (10). However, for each asteroid this requires a number of slope estimates. The derivation dL2∕dt can be approximately calculated from pairs of measurements that are close in time, but there is a lower limit due to the accuracy of data. We chose dt > 10 min to distinguish the change of brightness from data noise.
To verify if this relation can be used in practice, we performed the following test on synthetic data. We used the DAMIT models and the Hapke scattering model (Hapke 1981, 1993) with randomly chosen parameters and randomly chosen rotational period P (uniformly distributed from 2 to 50 h). Next, we calculated synthetic brightness,which we assigned to ~1000 asteroids observed with Pan-STARRS1 (leaving the geometry of observations unchanged), for which we had the largest number of measurements. From these new synthetic brightnesses we calculated the period P according to Eq. (10) that should approximate the synthetic P.
The derivative ⟨|dL2∕dt|⟩ was computed from pairs of measurements separated by time interval 10 < Δt < 20 min and we required at least 12 pairs (to calculate the mean value) within five days. The variation ΔL2 was also computed within five days. We tested synthetic data without any noise and also data with Gaussian noise of 2%. We compared the calculated P with the synthetic P by computing the correlation coefficient; data with noise show no correlation (the coefficient is 0.19) and Fig. 13 (blue points) shows there is a strong preference for low values of P. Interestingly enough, the bias is systematic and amounts to an underestimation factor of about 0.5 for the point fan. Apparently noise systematically increases the slope average from the pairwise slope estimates. The situation for data without noise is slightly better (coefficient 0.30) and if we consider only periods from interval 2 to 30 h, the correlation coefficient is 0.65 (see also Fig. 13). For periods under 10 h, the points are even more tightly clustered near the x = y correlation line.
The possible reason for this bad correlation could be the insufficient number of measurements from which the mean values are calculated. Therefore, to each measurement we added two others, one 0.01 d (14.4 min) earlier and the second 0.01 d later. In total, we had three times more measurements for each asteroid. However, the resulting P were not significantly different from the previous test; in the interval of P from 2 to 30 h, the correlation coefficient is 0.60.
We also tested the relation (10) on real data from Pan-STARRS1 survey, however, there were only few asteroids for which we had the required number of measurements (as described above) and at the same time also the information about the real rotational period from the LCDB database. For these bodies we did not obtain a good agreement between the estimated and real periods. Apparently the use of the period estimate Eq. (10) requires a large number of well-distributed slope pairs over a rotation cycle. Also, a low number of pairs exacerbates the effects of noise and deviations from the pure double-sinusoidal form. Estimates based on the derivative of a function are usually considerably more unstable than those based on the function itself. This approach is thus not applicable in practice and we are not able to correct b∕a distributions of other asteroid populations to have the same P distributions.
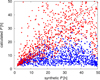 |
Fig. 13 Comparison of calculated and synthetic rotational period P. The red points denote synthetic data without noise, the blue points synthetic data with noise 0.02. |
5.5 Dynamical families
Next, we compared distributions of dynamical families with their background. The family membership of asteroids was taken from Nesvorný et al. (2015). The background for a family is formed by asteroids from the same part of the main belt as the family (inner, middle, pristine, and outer), which do not belong to any other family. We focused on 13 of the most populous families: Vesta, Massalia, Flora, Nysa Polana, and Phocaea in the inner belt; Eunomia, Gefion, and Maria in the middle belt; Koronis in the pristine belt; and Themis, Eos, Hygiea and Alauda in the outer belt (see also Fig. 14). The typical number of asteroids (for which we have enough data) in a family is few thousand, for Vesta, Flora and Nysa Polana it is slightly more than ten thousand and for Phocaea and Alauda it is less than 1000 (the exact numbers are in Table 2). Unlike Cibulková et al. (2016), who did not reveal any differences among families, we found that Massalia has a significantly different distribution of b∕a from its background, containing more elongated asteroids. Distributions are shown in the left panel of Fig. 15. Also the cumulative distributions of brightness variation η of Massalia and its background are significantly different; these are shown in the left panel of Fig. 16. Unfortunately, we cannot compare our distribution of b∕a for Massalia with the distribution from Nortunen et al. (2017) based on WISE data because their sample contained an insufficient number of bodies. The mean values of Db∕a for all families are listed in Table 1. The second largest difference between distribution of b∕a is for the Phocaea family and its background (see Fig. 15 on the right), nevertheless the value Db∕a(L1) = 0.175 is not high enough for a definite answer. For Phocaea we only have data for 812 asteroids, however, the small number of asteroids cause the population to be more spheroidal and, as we can see in Fig. 15 on the right, Phocaea, in comparison to its background, contains more elongated objects.
The difference between Massalia family and its background could be due to the different period distributions. To test this possibility we used the LCDB database and constructed distributions of P for Massalia and its background. We found that Massalia really contains fewer objects with P = 0−4 h and more with P = 4−8 h than its background, which is in accordance with the family members being more elongated (compare with Fig. 11). However, we have to emphasize that the distribution of P for Massalia contains only 100 bodies and its background is represented by 420 bodies, which is not enough for a solid conclusion. For the Phocaea family, we do not have enough determined periods to perform such test as for Massalia.
Our distributions of b∕a look different from the results of Szabó & Kiss (2008), who determined distributions for eight families using data from the Sloan Digital Sky Survey (SDSS); however these authors assumed a fixed value of spin axis latitude for all asteroids, which probably influenced the results. We also did not find any dependence of the distribution of b∕a on the age of family that they suggested.
 |
Fig. 14 Four parts of the main asteroid belt defined according to the proper semimajor axis a; we used proper values of a and I from Asteroids Dynamic Site (Knežević & Milani 2003). |
Number of asteroids in individual families and corresponding backgrounds for which we have data from Pan-STARRS1 survey in filters w and i.
 |
Fig. 15 Left: DFs and CDFs of b∕a for Massaliafamily (blue lines) and its background (red lines). Right: the same for Phocaea family is shown. |
 |
Fig. 16 Left: cumulative distributions of brightness variation η for Massalia family and its background. Right: the same for Vesta family in filter w and filter i is shown. |
5.6 Taxonomic classes and different parts of the main belt
We also compared the distributions of b∕a of the two most populated taxonomic classes: S that dominates in the inner mail belt, and C that dominates in the middle and outer belt. We assigned a taxonomic class to asteroids according to the SDSS-based Asteroid Taxonomy (Hasselmann et al. 2010, data are available on Planetary Data System4 ). For both classes we had data for ~10 000 asteroids. We did not find these two groups to have different distributions of the shape elongation b∕a.
Finally, we compared groups of asteroids with different semimajor axes (inner, middle, pristine, outer) and with different inclinations of orbit. None of the subpopulations is significantly different from others.
5.7 Comparison of results from filters w and i
We also analyzed Pan-STARRS1 data in the i-filter (~700−800 nm, Tonry et al. 2012) and compared the results with the w-filter. We had data for 136 463 asteroids and on average, there were ~10 measurements for one asteroid. We focused only on taxonomic classes and dynamical families. There were not enough asteroids to study the dependence of the elongation of asteroids on the diameter; only a few asteroids were in the two subpopulations with the largest D.
The number of asteroids in subpopulations containing the taxonomic class S was 6349 and for the taxonomic class C 5813. As in the w-filter, the difference between these two groups is insignificant. Then we focused on dynamical families. As in the w-filter, we found that Massalia family has a significantly different distribution of b∕a from its background. Moreover, the result for Phocaea (Db∕a(L1) = 0.212) also suggests that this family could have a different distribution of b∕a from its background. However, Fig. 17 does not show a significant difference.
To compare results from the filters w and i directly, we constructed distributions of b∕a for some families in both filters and calculated Db∕a. We did not find any significant differences between filters. As an example, distributions of Nysa Polana are shown in Fig. 18. We also constructed cumulative distributions of the brightness variation η for some families in both filters to check that there are no differences between filters before the inversion (see Fig. 16 on the right).
 |
Fig. 18 DFs (left) and CDFs (right) of b∕a for Nysa Polana family in filter i (blue lines) and filter w (red lines). |
6 Conclusions
In this work, we analyzed photometric data from the Pan-STARRS1 survey via a statistical approach based on cumulative distribution functions. We applied the model and software package LEADER from Nortunen et al. (2017) and Nortunen & Kaasalainen (2017), which allows us to construct distribution functions of the shape elongation b∕a and the ecliptical latitude β of the spin axis for some subpopulations of asteroids and compare these functions with each other. Limitations of this model are that it does not provide the pole longitude and it provides only the combined distribution of the β of both ecliptic hemispheres. Moreover, by testing on synthetic data we found that our model shifts the peak of the β distribution to the middle values and is strongly influenced by the number of objects in studied subpopulations. Distribution of β also appears to be highly sensitive to the used database. For the distribution of b∕a we found that the model provides stable results for numbers of objects higher than ~800. The test with synthetic data also revealed that our model provides reliable results only for asteroids with rotation periods P ≲ 12 h. This is due to the time distribution of measurements of the Pan-STARRS1 survey and thus it is not a limitation of the method in general.
We mainly analyzed data in the wide w-band filter. The most populous subpopulations were studied also in the i-filter. The main results of this paper are the following. Groups of asteroids with diameter D < 25 km do not have significantly different distributions of b∕a; the maximum of these distributions is for b∕a ≃ 0.8. The distribution for asteroids larger than 25 km suggests that these objects are more spheroidal in comparison with the smaller objects, nevertheless, the number of objects in this subpopulation is insufficient for a strong result. By comparing distributions of b∕a for different intervals of rotation period P we found that the fastest rotators with P = 0−4 h are more spheroidal (the maximum is for b∕a ~ 0.75) than the population with P = 4−8 h (the maximum is for b∕a ~ 0.6). We also constructed distributions of b∕a for 13 most populous dynamical families and we revealed two families in the inner belt, Massalia and Phocaea, to be significantly different from their background. Both families have members that are more elongated than corresponding backgrounds. One possible explanation is that such a result is due to the dependence of shape elongation on the
rotationperiod. Finally, by analyzing data in the i-filter, we confirmed previous results and we did not find any significant differences between subpopulations studied in the w-filter in comparison with the i-filter.
Acknowledgements
H. Cibulková and J. Ďurech were supported by the grant 15-04816S of the Czech Science Foundation. The research by H. Nortunen and M. Kaasalainen was supported by the Academy of Finland (Centre of Excellence in Inverse Problems), and H.N. was additionally supported by the grant of Jenny and Antti Wihuri Foundation. We would like to thank Matti Viikinkoski for valuable comments and feedback, and assistance with the software.
References
- Bowell, E., Oszkiewicz, D. A., Wasserman, L. H., et al. 2014, Meteorit. Planet. Sci., 49, 95 [Google Scholar]
- Carvano, J. M., Hasselmann, P. H., Lazzaro, D., & Mothé-Diniz, T. 2010, A&A, 510, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cibulková, H., Durech, J., Vokrouhlický, D., Kaasalainen, M., & Oszkiewicz, D. A. 2016, A&A, 596, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Durech, J., Grav, T., Jedicke, R., Denneau, L., & Kaasalainen, M. 2005, Earth Moon and Planets, 97, 179 [NASA ADS] [CrossRef] [Google Scholar]
- Durech, J., Scheirich, P., Kaasalainen, M., et al. 2007, in IAU Symp. 236, eds. G. B. Valsecchi, D. Vokrouhlický, & A. Milani, 191 [Google Scholar]
- Durech, J., Sidorin, V., & Kaasalainen, M. 2010, A&A, 513, A46 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Durech, J. Carry, B., Delbo, M., Kaasalainen, M., & Viikinkoski, M. 2015, in Asteroid Models from Multiple Data Sources, eds. P. Michel, F. E. DeMeo, & W. F. Bottke, 183 [Google Scholar]
- Hanus, J., Ďurech, J., Brož, M., et al. 2011, A&A, 530, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hapke, B. 1981, J. Geophys. Res., 86, 4571 [NASA ADS] [Google Scholar]
- Hapke, B. 1993, Theory of reflectance and emittance spectroscopy (UK: Cambridge University Press) [CrossRef] [Google Scholar]
- Hodapp, K. W., Kaiser, N., Aussel, H., et al. 2004, Astron. Nachr., 325, 636 [Google Scholar]
- Kaasalainen, M., & Lamberg, L. 2006, Inverse Problems, 22, 749 [Google Scholar]
- Knezević, Z., & Milani, A. 2003, A&A, 403, 1165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marciniak, A., Pilcher, F., Oszkiewicz, D., et al. 2015, Planet. Space Sci., 118, 256 [NASA ADS] [CrossRef] [Google Scholar]
- McNeill, A., Fitzsimmons, A., Jedicke, R., et al. 2016, MNRAS, 459, 2964 [NASA ADS] [CrossRef] [Google Scholar]
- Nesvorný, D., Broz M., & Carruba, V. 2015, in Identification and Dynamical Properties of Asteroid Families, eds. P. Michel, F. E. DeMeo, & W. F. Bottke, 297 [Google Scholar]
- Nortunen, H., & Kaasalainen, M. 2017, A&A, 608, A91 [CrossRef] [EDP Sciences] [Google Scholar]
- Nortunen, H., Kaasalainen, M., Durech, J., et al. 2017, A&A, 601, A139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pravec, P., & Harris, A. W. 2000, Icarus, 148, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Rubincam, D. P. 2000, Icarus, 148, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Schlafly, E. F., Finkbeiner, D. P., Jurić, M., et al. 2012, ApJ, 756, 158 [NASA ADS] [CrossRef] [Google Scholar]
- Szabó, G. M., & Kiss, L. L. 2008, Icarus, 196, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Szabó, R., Pál, A., Sárneczky, K., et al. 2016, A&A, 596, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tonry, J. L., Stubbs, C. W., Lykke, K. R., et al. 2012, ApJ, 750, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Warner, B. D., Harris, A. W., & Pravec, P. 2009, Icarus, 202, 134 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Number of asteroids in individual families and corresponding backgrounds for which we have data from Pan-STARRS1 survey in filters w and i.
All Figures
|
Fig. 1 Histogram of time intervals between measurements in the w-band filter from the Pan-STARRS1 survey. |
| In the text | |
|
Fig. 2 Histogram of the solar phase angle α for measurements in the w-filter. |
| In the text | |
|
Fig. 3 Synthetic simulations showing how the accuracy of our method improves for b∕a with a growing number of asteroids (from 100 to 5000). The plots have the real peak of the distribution plotted vs. the computed peak. The black dashed line of the form y = x depicts the ideal situation when the actual and computed peaks are the same. |
| In the text | |
 |
Fig. 4 Synthetic simulations similar to Fig. 3, but for β. |
| In the text | |
|
Fig. 5 Synthetic simulations using a fixed (b∕a, β) peak for a population of 10 000 asteroids. The top left plot shows the actual (b∕a, β) distribution,the top right shows the computed (b∕a, β) distribution,and the bottom shows the top right solution with a deconvolution filter applied. |
| In the text | |
|
Fig. 6 Synthetic simulations showing the accuracy of our method for different values of rotation period P. The black dashed line denotes the ideal situation. |
| In the text | |
|
Fig. 7 Distributions of b∕a and β for Flora family constructed for growing number of asteroids that were included (from 100 to 1000). |
| In the text | |
 |
Fig. 8 Same as Fig. 7, but for greater number of asteroids (from 1100 to 2000). |
| In the text | |
|
Fig. 9 DFs and CDFs of b∕a and β for asteroids with 12 < D < 15 km (red lines), 15 < D < 25 (blue lines) and D > 25 km (green lines). |
| In the text | |
|
Fig. 10 Left: cumulative distributions of absolute value of change in magnitude |Δmag | for groups of asteroids with different sizes. Right: cumulative distributions of η for groups of asteroids with different sizes. |
| In the text | |
|
Fig. 11 DFs and CDFs of b∕a for asteroid populations with different rotation periods. |
| In the text | |
|
Fig. 12 Left: distributions of light curve amplitudes from the LCDB database for different rotation periods P. Right: synthetic simulations showing the accuracy of our method for two different intervals of rotation period P. |
| In the text | |
|
Fig. 13 Comparison of calculated and synthetic rotational period P. The red points denote synthetic data without noise, the blue points synthetic data with noise 0.02. |
| In the text | |
|
Fig. 14 Four parts of the main asteroid belt defined according to the proper semimajor axis a; we used proper values of a and I from Asteroids Dynamic Site (Knežević & Milani 2003). |
| In the text | |
|
Fig. 15 Left: DFs and CDFs of b∕a for Massaliafamily (blue lines) and its background (red lines). Right: the same for Phocaea family is shown. |
| In the text | |
|
Fig. 16 Left: cumulative distributions of brightness variation η for Massalia family and its background. Right: the same for Vesta family in filter w and filter i is shown. |
| In the text | |
 |
Fig. 17 Same as in Fig. 15, but in filter i. |
| In the text | |
|
Fig. 18 DFs (left) and CDFs (right) of b∕a for Nysa Polana family in filter i (blue lines) and filter w (red lines). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.