| Issue |
A&A
Volume 599, March 2017
|
|
|---|---|---|
| Article Number | A92 | |
| Number of page(s) | 9 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201629527 | |
| Published online | 06 March 2017 | |
Cosmic expansion history from SNe Ia data via information field theory: the charm code
1 University of Barcelona, Departament de Física Quàntica i Astrofísica, Martí i Franquès 1, 08028 Barcelona, Spain
e-mail: natalia_porqueres@hotmail.com
2 Max-Planck-Insitut für Astrophysik (MPA), Karl-Schwarzschild-Strasse 1, 85741 Garching, Germany
3 Institut de Ciències del Cosmos, Martí i Franquès 1, 08028 Barcelona, Spain
4 Instituto de Física Fundamental, CSIC, Serrano 121, 28006 Madrid, Spain
Received: 13 August 2016
Accepted: 3 December 2016
We present charm (cosmic history agnostic reconstruction method), a novel inference algorithm that reconstructs the cosmic expansion history as encoded in the Hubble parameter H(z) from SNe Ia data. The novelty of the approach lies in the usage of information field theory, a statistical field theory that is very well suited for the construction of optimal signal recovery algorithms. The charm algorithm infers non-parametrically s(a) = ln(ρ(a) /ρcrit0), the density evolution which determines H(z), without assuming an analytical form of ρ(a) but only its smoothness with the scale factor a = (1 + z)-1. The inference problem of recovering the signal s(a) from the data is formulated in a fully Bayesian way. In detail, we have rewritten the signal as the sum of a background cosmology and a perturbation. This allows us to determine the maximum a posteriory estimate of the signal by an iterative Wiener filter method. Applying charm to the Union2.1 supernova compilation, we have recovered a cosmic expansion history that is fully compatible with the standard ΛCDM cosmological expansion history with parameter values consistent with the results of the Planck mission.
Key words: methods: statistical / methods: data analysis / supernovae: general / distance scale
© ESO, 2017
1. Introduction
Combined observations of nearby and distant type Ia Supernovae (SNe Ia) have demonstrated that the expansion of the Universe is accelerating in the current epoch (Perlmutter et al. 1999; Riess et al. 1998). Such a Universe can be described by the cold dark matter (ΛCDM) model, in which the cosmic acceleration is determined by Einstein’s cosmological constant with a time-independent equation of state, ω ≡ p/ρ = −1. However, this is just one of the possible explanations of the expansion that is consistent with the SNe Ia measurements. Others include a new field component filling the Universe as a quintessence or modified gravity (Koyama 2016).
Constraining the cosmic expansion as a function of redshift is a task of major interest, since the evolution of the scale factor allows us to probe properties of the fundamental components of the Universe. This may lead to a better understanding of their nature as well possibly providing evidence for new fundamental physics.
Recent studies of the baryonic acoustic oscillations (BAO) have suggested different constraints on the density of dark energy at high redshifts (Delubac et al. 2015; Hee et al. 2016). Such a change in the evolution of the dark energy density in the early epoch could be determined from SNe Ia data at high redshifts (z > 1), which will be available shortly (Rubin et al. 2016). In addition, some years from now a sample of 105 SNe Ia is expected to be available from the LSST (LSST Science Collaboration et al. 2009). This upcoming data will open an entirely new chapter in the study of dark energy.
The aim of this work is to reconstruct the cosmic expansion history, encoded in the Hubble parameter H(z), from supernovae data in the framework of Information Field Theory (IFT; Enßlin et al. 2009). Conceptionally, IFT is a statistical field theory that permits the construction of optimal signal recovery algorithms. To this end, we developed the charm1 code, which is freely available2. We use the Union2.1 Supernova compilation, which is a database that contains 580 SNe Ia in the redshift range of 0.015 <z< 1.414.
Deriving the cosmic expansion history is a major goal of modern cosmology. To date, the low-redshift evolution of the Hubble parameter H(z) has been studied with different methods. Some recent studies present analysis of the cosmic expansion by χ2 minimization (Bernal et al. 2017; Melia & McClintock 2015) while others develop non-parametric methods to solve the inverse problem of reconstructing the Hubble parameter H(z) (Li et al. 2016; Montiel et al. 2014; Ishida & de Souza 2011; Shafieloo et al. 2006) or the equation of state of dark energy (España-Bonet & Ruiz-Lapuente 2005, 2008; Simon et al. 2005; Genovese et al. 2009). Common to all non-parametric reconstructions, the ones cited above and the one we develop here, is that a quantity to be reconstructed (Hubble parameter, cosmic density, equation of state, etc.) as well a regularization for the otherwise ill-posed inference problem must be chosen. The discussed methods differ in what regularization is chose.
Here, we develop a non-parametric reconstruction in natural coordinates for the reconstruction of the logarithm of the cosmic density s = ln(ϱ/ϱcrit0) as a function of the logarithm of the cosmic scale factor x = −lna and thereby the Hubble parameter H(z). The regularization arises from a Bayesian prior on potential solutions s(x). We construct this prior from the insight that constituents of the cosmic density are likely to scale with the inverse scale factor to some power typically (but not exclusively) between zero (cosmological constant) and four (radiation). Translated to the log-log coordinates we advocate this to be natural, this means that straight lines in s(x) are preferred over curved ones. We can also motivate the level of expected curvature: a transition from radiation to dark energy domination within a few e-folds of expansion has to be possible if our standard cosmological expansion history should be embraced by the prior.
An advantage of the adopted Bayesian methodology lies in the fact that it provides a flexible framework to question data: it can reconstruct the cosmic expansion history using different priors. For example, it can be asked how much the data requests a modification of a given cosmology or what the prefered expansion history is from a cosmological composition agnostic point of view. The main assumption is a smooth behavior of the logarithm of the density lnρ with the logarithmic scale factor, lna, whereas the strength of this assumption can also be varied.
We probe that charm is sensitive to features in expansion history at any low-redshift, z< 1.5. In addition, the algorithm is easily extendible to include other datasets, such as BAO or Cepheids (Riess et al. 2016), which provide information of a transition epoch between deceleration and acceleration of the cosmic expansion (Moresco et al. 2016; Hee et al. 2016).
We develop and test charm, so that it is ready for application to the new catalog Union3 compilation, which is expected to provide information about the dark energy density at high-redshifts.
After this introduction, we establish our notation and present our assumptions and the inference problem in Sect. 2. In Sect. 3, the SN Ia catalog is described and we derive our reconstruction method in Sect. 4. In Sect. 5, we specify our prior knowledge and the cosmological expansion histories that we use to test charm. We present a comparison of charm with previous literature in Sect. 6. Finally, we present the results of the reconstruction in Sect. 7 and conclude in Sect. 8.
2. Inference approach
2.1. Basic notation
First of all, we needed to establish some notations and assumptions. We derived the algorithm of charm in the framework of IFT, following the notation of Enßlin et al. (2009). We have assumed that we are analyzing a discrete set of data d which may depend on a signal s, which contains the physical quantities of interest. In this case the signal is a field, s(x), chosen to be the logarithm of the cosmic density ρ(z) as a function of the logarithmic scale factor, x = −ln(a) = ln(1 + z), where z is the redshift.
This parametrization is natural, as it deals with dimensionless quantities, represents cosmic periods dominated by a constant equation of state ρ ∝ a1 + ω as straight lines s = s0 + (1 + ω)x, and converts relative variations of 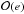 to additive variations of
to additive variations of 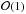 .
.
This coordinate system has the advantage that we can model the signal uncertainties by Gaussian fluctuations around a background cosmology, denoted as tbg(x): 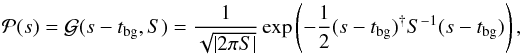 (1)where S is the prior covariance matrix S = ⟨ φφ† ⟩ (s | S) with φ = s−tbg. Scalar products of continuous quantities are defined as
(1)where S is the prior covariance matrix S = ⟨ φφ† ⟩ (s | S) with φ = s−tbg. Scalar products of continuous quantities are defined as 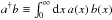 .
.
The diagonal of the prior covariance, 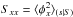 , encodes how much variation of the signal around the a priori background cosmology tbg is expected a priori at every location x. The off-diagonal terms of the covariance, Sxy = ⟨ φxφy ⟩ (s | S), specify how correlated such deviations form the background cosmology are expected to be between the points x and y. A larger correlation corresponds to smoother structures of the deviations. In Sect. 5, we will use simple and intuitive arguments about the expected roughness of s to specify S, as well as different choices of the background cosmology tbg. In particular, as no location of cosmic history is singled out a priori on a logarithmic scale, the prior covariance structure should be homogeneous, Sxy = Cs( | x−y |), with Cs(r) a correlation function that only depends on the distance r = | x−y |.
, encodes how much variation of the signal around the a priori background cosmology tbg is expected a priori at every location x. The off-diagonal terms of the covariance, Sxy = ⟨ φxφy ⟩ (s | S), specify how correlated such deviations form the background cosmology are expected to be between the points x and y. A larger correlation corresponds to smoother structures of the deviations. In Sect. 5, we will use simple and intuitive arguments about the expected roughness of s to specify S, as well as different choices of the background cosmology tbg. In particular, as no location of cosmic history is singled out a priori on a logarithmic scale, the prior covariance structure should be homogeneous, Sxy = Cs( | x−y |), with Cs(r) a correlation function that only depends on the distance r = | x−y |.
2.2. Signal inference
In the inference problem, we are interested in the probability of the signal given the data. This is described by the posterior P(s | d), given by Bayes’ Theorem, 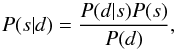 (2)which is the product of the likelihood P(d | s) and the signal prior P(s) normalized by the evidence P(d).
(2)which is the product of the likelihood P(d | s) and the signal prior P(s) normalized by the evidence P(d).
In the framework of IFT, inference problems are formulated in the language of statistical field theory. To that end we rewrite the posterior P(s | d) as 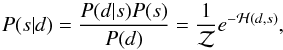 (3)where ℋ is called the information Hamiltonian and
(3)where ℋ is called the information Hamiltonian and 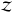 is the partition function. They are defined as
is the partition function. They are defined as 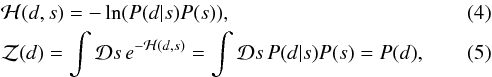 where
where  is a phase space integral.
is a phase space integral.
The information Hamiltonian comprises all available information and is for this reason the central mathematical object in our method development. Its minimum with respect to s for a given dataset d, for example, is the maximum of the posterior (MAP). Our algorithm calculates the MAP estimation (Lemm 1999) of the expansion history.
3. Database
SNe Ia have been found to be an excellent probe for studying the expansion history of the Universe. Observations of the nearby and distant SNe Ia led to the discovery of the accelerating expansion (Perlmutter et al. 1999; Riess et al. 1998). For this reason, we choose supernovae as our initial data set to develop an IFT based method for reconstructing the cosmic expansion history.
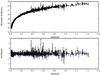 |
Fig. 1 Hubble diagram for the Union2.1 compilation (upper panel) and residuals of data respect to the Planck cosmology (bottom panel). |
Kowalski et al. (2008) described a method to analyze the SNe Ia data in a homogeneous manner and created a compilation, the Union SN Ia compilation, combining the world’s SN data sets. Both new data and literature SNe were fit using a spectral template for lightcurve fitting, also known as SALT (Guy et al. 2005).
Here, we use the Union2.1 compilation, which contains 580 SNe Ia: the 557 data from Union2 and 23 new measurements at redshift z> 1 (Suzuki et al. 2012). The data are distributed in a redshift range of 0.015 <z< 1.414 corresponding to an x-range of 0.014 <x< 0.881. Union2.1 provides the redshift, distance modulus and distance modulus error for each supernova, which are shown in Fig. 1. The catalog also includes uncertainty covariance matrix with systematics.
In this work, we attempt a tomographic inversion of the SN data into a cosmic expansion history, where the term tomographic means a reconstruction of a searched object properties distributed along a coordinate for which the allocation does not follow from observation, in this case a reconstruction along the line of sight. Tomography is very sensitive to systematic errors and therefore, we should use a non-diagonal noise covariance matrix N in our reconstruction in order to account for correlated systematic uncertainties. Some systematic errors are common in all the observations while other sources of systematic errors are controlled by the individual observers.
Kowalski et al. (2008), identified two categories of systematic errors: the ones that affect measurements independently for each SN Ia (e.g. due to observational method) and systematic errors that affect the measurements of SNe at similar redshifts (e.g. due to astrophysics). Since the different sources of systematic errors can be considered to be independent, the total error can be well approximated as a Gaussian error. In Appendix A we briefly discuss the sources of systematics.
4. Reconstruction
In order to reconstruct the cosmic expansion history, which is encoded in the Hubble parameter H(z), from supernovae data we write H in terms of the scale factor a = (1 + z)-1. Then we have 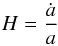 (6)and
(6)and 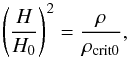 (7)where
(7)where 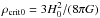 . The density ρ is usually assumed to be polynomial in a with three contributing terms:
. The density ρ is usually assumed to be polynomial in a with three contributing terms: 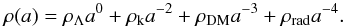 (8)However, as we aim for a non-parametric reconstruction, we do not assume this polynomial form but just that ρ is smooth with a-1 as well as that power-law like building blocks of ρ(a) are favored.
(8)However, as we aim for a non-parametric reconstruction, we do not assume this polynomial form but just that ρ is smooth with a-1 as well as that power-law like building blocks of ρ(a) are favored.
As data we use the distance moduli of SNe from Union2.1, assuming Gaussian noise. As our signal we define 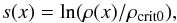 (9)with
(9)with 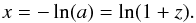 (10)The distance modulus is
(10)The distance modulus is ![\begin{equation} \mu(z)=5 \log_{10}\left[(1+z)d_H\int_0^z {\rm d}z' \frac{1}{E(z')}\right]-5, \label{mu} \end{equation}](/articles/aa/full_html/2017/03/aa29527-16/aa29527-16-eq64.png) (11)where dH is constant in a flat universe, dH = c/H0, and E = H/H0. In ΛCDM we have
(11)where dH is constant in a flat universe, dH = c/H0, and E = H/H0. In ΛCDM we have 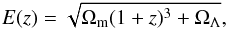 (12)while our generic parametrization we have
(12)while our generic parametrization we have 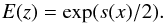 (13)
(13)
4.1. Response operator
Our cosmology signal s has been imprinted onto the data. The functional relationship between the noiseless data μ and the signal can be regarded as a non-linear response operator. To be precise, the response operator describes how the distance moduli at different redshifts of the SNe depend on the unknown cosmic expansion history encoded in our signal s.
Combining our parametrization (Eqs. (9)and (10)) with Eq. (11)yields the response as ![\begin{equation} R_j(s)=5 \log_{10}\Big[e^{x_j}d_H\int^{x_j}_0 {\rm d}x' e^{-\frac{1}{2}s(x')+x'}\Big]-5, \label{non-lin-response} \end{equation}](/articles/aa/full_html/2017/03/aa29527-16/aa29527-16-eq71.png) (14)with xj = ln(1 + zj).
(14)with xj = ln(1 + zj).
The response depends on an intergral over our signal s(x). The goal of our tomographic method is to invert this integration. Since the response is not a linear operation of the form R(s) = Rs + const. it cannot be algebraically inverted, which would allow us to minimize the information Hamiltonian directly.
4.2. Expansion of the information Hamiltonian
In order to build the information Hamiltonian ℋ(d,s) = −lnP(d | s)−lnP(s), we describe our a priori knowledge on s with a Gaussian 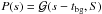 as described in Eq. (1). The background cosmology tbg and the signal covariance S are to be specified later. The noise is assumed to be Gaussian and independent of the signal, distributed as
as described in Eq. (1). The background cosmology tbg and the signal covariance S are to be specified later. The noise is assumed to be Gaussian and independent of the signal, distributed as 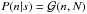 , since the sources of uncertainty which operate on the distance modulus μ can be approximately assumed to be independent from μ.
, since the sources of uncertainty which operate on the distance modulus μ can be approximately assumed to be independent from μ.
To perturbatively expand our problem, we can write the information Hamiltonian in terms of s = t + ϕ, where we call t the pivot field and ϕ its perturbation. By assuming a signal covariance S, the expanded Hamiltonian reads 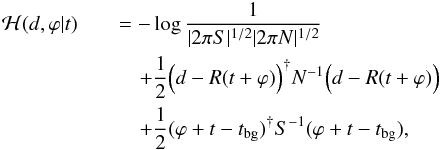 (15)where the prior background cosmology only affects the terms related to our prior. The amplitude of the perturbation is assumed to be |ϕ| < 1 and then we can expand the response operator since exp(t + ϕ) ≈ exp(t)(1 + ϕ).
(15)where the prior background cosmology only affects the terms related to our prior. The amplitude of the perturbation is assumed to be |ϕ| < 1 and then we can expand the response operator since exp(t + ϕ) ≈ exp(t)(1 + ϕ).
Our posterior is a non-Gaussian probability distribution function. In order to minimize the probability in an efficient and numerically robust way, we Gaussianize it by linearizing the response R(s) around the pivot field t, 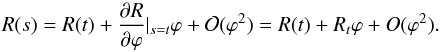 (16)The linearized response Rt is
(16)The linearized response Rt is 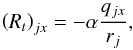 (17)with α = 5/(2ln10),
(17)with α = 5/(2ln10), 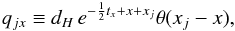 (18)and
(18)and 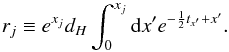 (19)The resulting approximated Hamiltonian,
(19)The resulting approximated Hamiltonian, 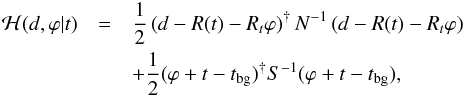 (20)is then minimized by m = Dj with
(20)is then minimized by m = Dj with 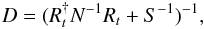 (21)the so-called information propagator operator and
(21)the so-called information propagator operator and 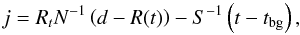 (22)the so-called information source field.
(22)the so-called information source field.
The terms information source j and information propagator D may require a brief explanation. In this linear response approximation the Hamiltonian is quadratic in s. This corresponds to a Gaussian joint probability of signal and data, implying a Gaussian posterior, 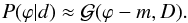 (23)In this approximation the information propagator is the a posterior uncertainty covariance D = ⟨ (ϕ−m) (ϕ−m)† ⟩ (s | d,S), very similar to the a priori covariance S = ⟨ (s−tbg) (s−tbg)† ⟩ (s | S). The covariance D is smaller than S, since the presence of the data has restricted the set of possible cosmologies. The information source j contains the data and has excited the increased knowledge on s. This approximative linear solution to the inference problem is known as Wiener filter solution and D is also called the Wiener variance.
(23)In this approximation the information propagator is the a posterior uncertainty covariance D = ⟨ (ϕ−m) (ϕ−m)† ⟩ (s | d,S), very similar to the a priori covariance S = ⟨ (s−tbg) (s−tbg)† ⟩ (s | S). The covariance D is smaller than S, since the presence of the data has restricted the set of possible cosmologies. The information source j contains the data and has excited the increased knowledge on s. This approximative linear solution to the inference problem is known as Wiener filter solution and D is also called the Wiener variance.
This Wiener filter solution is not at the minimum of the unapproximated Hamiltonian. To reach it we have to repeat the procedure after shifting the pivot cosmology to t ← t + ϕ until t no longer changes. We initialize the iteration by t = tbg and stop it when t becomes stationary. Our iterating Wiener filtering scheme can be regarded as a Newton method minimizing the full original Hamiltonian, regularized by expanding the response and not the Hamiltonian to ensure convergence of the Newton method, for which we had to simplify our propagator operator (Appendix B). Therefore, the correct MAP solution will be found at the end of the iterations.
5. Cosmology prior
In this section, we focus on the definition of the prior as a Gaussian process characterized by a power spectrum, which varies around a background cosmology (Lemm 1999; Enßlin et al. 2009).
First, we consider that the background expansion history tbg is that of the ΛCDM model, which is the currently accepted cosmology. To validate our reconstruction, we take two more expansion histories: (1) a CDM cosmology, without a dark energy, in order to check that charm is able to recover the cosmological constant even if the prior does not favor its presence. (2) An agnostic cosmology that has little knowledge of the equation of states of radiation, matter and dark energy for maximally model-independent cosmic history reconstruction.
5.1. Prior
As prior knowledge, we assume that the signal s(x) exhibits only limited curvature since all known contributions to s(x) like matter, radiation and dark energy contribute linear segments. We therefore punish curvature as measured by ∇2ϕ and write our negative log prior as 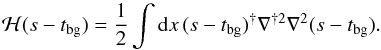 (24)This should control the degree of smoothness of ϱ(a) = ϱcrit0esx = lna in the following fashion. A one-sigma fluctuation in terms of this prior energy corresponds to a bending of the slope of s(x) by one per e-folding of cosmic expansion. Given that in the standard cosmological model from radiation domination until today the scale factor changed by eight e-foldings (four orders of magnitude) and the combined equation of state of mass in the Universe changed only by four (from radiation to dark energy) we see that that the standard cosmological expansion history is well contained within the one sigma contour of our prior. We can quantify the strength also with respect to data consistency: the variance of d2lnϱ(a)/(dlna)2 is punished with a strength, which requests that for this quantity being on a level of one it is required that the data is under stress by at least one sigma with the reconstructed expansion history.
(24)This should control the degree of smoothness of ϱ(a) = ϱcrit0esx = lna in the following fashion. A one-sigma fluctuation in terms of this prior energy corresponds to a bending of the slope of s(x) by one per e-folding of cosmic expansion. Given that in the standard cosmological model from radiation domination until today the scale factor changed by eight e-foldings (four orders of magnitude) and the combined equation of state of mass in the Universe changed only by four (from radiation to dark energy) we see that that the standard cosmological expansion history is well contained within the one sigma contour of our prior. We can quantify the strength also with respect to data consistency: the variance of d2lnϱ(a)/(dlna)2 is punished with a strength, which requests that for this quantity being on a level of one it is required that the data is under stress by at least one sigma with the reconstructed expansion history.
The signal prior covariance matrix S is then given by 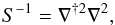 (25)which is a diagonal matrix in Fourier space3,
(25)which is a diagonal matrix in Fourier space3, 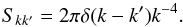 (26)
(26)
5.2. Planck cosmology
The ΛCDM model is based upon a spatially flat and expanding Universe, in which the dynamic of the cosmic expansion is dominated by the CDM and a cosmological constant (Λ) at late times.
According to the second Friedman equation, the expansion rate H(a) is given by 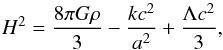 (27)where ρ is the energy density, k is the curvature and G is the gravitational constant.
(27)where ρ is the energy density, k is the curvature and G is the gravitational constant.
By defining the density parameters ΩX as the ratio between the density of X and the critical density, the second Friedman equation reads 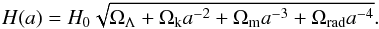 (28)In a flat universe, the curvature density parameter is null, ΩK = 0. Therefore, from the definition of our signal s(x) = ln(ρ(x) /ρcrit0), the background cosmology is given by
(28)In a flat universe, the curvature density parameter is null, ΩK = 0. Therefore, from the definition of our signal s(x) = ln(ρ(x) /ρcrit0), the background cosmology is given by  (29)as the Ωrad ≪ 1 in the late Universe.
(29)as the Ωrad ≪ 1 in the late Universe.
In terms of the coordinate x = −ln(a) of our signal-space, the former equation is written as 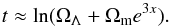 (30)The values we adopt for the density parameters at present time are the ones found by the Planck mission from the cosmic microwave background (CMB) data, Ωm = 0.314 and ΩΛ = 0.686 (Planck Collaboration XVI 2014).
(30)The values we adopt for the density parameters at present time are the ones found by the Planck mission from the cosmic microwave background (CMB) data, Ωm = 0.314 and ΩΛ = 0.686 (Planck Collaboration XVI 2014).
The same values of the Ωm and H0 are used for the CDM model. We use this unrealistic CDM scenario to test how much our reconstruction depends on the assumed background cosmology. Since in this case Ω < 1, we allow for a curvature term Ωk = 1−Ωm, which evolve with a-2.
5.3. Agnostic cosmology
In order to reconstruct the cosmic expansion history in a way that is agnostic about the assumed constituents of the Universe, like matter, radiation and dark energy, we assume another background cosmology, which we called agnostic cosmology.
As the ΛCDM model has contributions to the density evolution of terms proportional to a-4 and a0, the agnostic background cosmology is taken as being proportional to a-2, which is the geometric mean between these extremes. The exponent 2 of this background slope is then on log-log scale 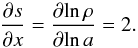 (31)Thus, the agnostic background expansion history is given by tbg = 2x.
(31)Thus, the agnostic background expansion history is given by tbg = 2x.
The prior for the variation around this background expansion is assumed to be the same prior as before, since we do not expect the signal to have any strong curvature. In fact, the agnostic cosmology is the ideal background expansion history for this non-parametric reconstruction, as log-log density expansion s(x) is not curved and therefore any bending of s and ϕ are exactly equivalent.
6. Comparison with other methods
In order to emphasize the advantages of our approach, we compare charm to previous literature. Ishida & de Souza (2011) develop a non-parametric method for the reconstruction of the H(z) based on the principal component analysis (PCA) of the Fisher matrix F = DTΛD. This Fisher matrix corresponds in our notation to the term R†N-1R in our propagator operator. While Ishida & de Souza (2011) regularize their solution by cutting off higher order PCA components, we can preserve all modes of the expansion, just weight their contribution to the solution according to their bending on log-log scale. Furthermore, our method enforces the positivity of the density ρ = ρcrit0es.
Shafieloo et al. (2006) reconstructs the expansion history with a non-parametric method that also enforces smoothness of the solution. However, in their work the data is smoothed directly to suppress noise (while a background expansion history is temporarily subtracted), while we just encourage smoothness via a prior without modifying the data. In the end, also our approach averages nearby data to suppress noise, but it does this in an adaptive way, having a shorter effective smoothing length in regions of dense data, whereas Shafieloo et al. (2006) employ a constant smoothing kernel in redshift space and have to experiment with the kernel size.
To summarize, our approach requires less tuning of regularization parameters compared to previous approaches, as our prior assumption on the problem solution, that power law equation of states within a certain range are more natural, already fully specifies the necessary regularization.
7. Results
We investigate in this section how far the assumption of a prior cosmology affects the reconstruction.
First of all, in Sect. 7.1, we show that the iterative Wiener filter is able to successfully reconstruct a perturbation of the ΛCDM model. For this purpose, a mock data catalog is simulated from a randomly perturbed cosmology.
Once we have convinced ourselves that our algorithm reconstructs the cosmology from data accurately, we apply it to real data. Now the impact of a prior background cosmology needs to be investigated. For this reason, we start with different expansion histories: the ΛCDM model, for which we expect that the reconstructed corrections are nearly a constant around zero. Then, we assume the CDM model as our initial guess, for which we expect that the cosmological constant is recovered. Finally we test the agnostic cosmology, in order to see if the iterative Wiener filter is able to reconstruct the standard ΛCDM cosmology from a non-informative prior.
7.1. Mock data
Before applying charm to the real data, we validate it with a simulated database. These data were generated from a perturbed Planck cosmology, where the perturbation was a random field.
The aim of generating mock data is to show that our mechanism for the reconstruction of the cosmology is able to find a perturbation of the ΛCDM model if it is present in the data, even in case the perturbation amplitude is much smaller than the Planck cosmology amplitude.
The perturbation is introduced as an additive term to the ΛCDM model, s = tΛCDM + ϕ. It is generated from Gaussian probability density, ![\begin{equation} P(\varphi)\propto \exp\!\Bigg\{\frac{1}{\sigma_A}\int \Bigg[\frac{1}{2\sigma_c^2} \Bigg(\frac{\partial^2 \varphi}{\partial x^2}\Bigg)^2+\frac{1}{2\sigma_\alpha^2} \Bigg(\frac{\partial \varphi}{\partial x}\Bigg)^2\Bigg] {\rm d}x \Bigg\}, \end{equation}](/articles/aa/full_html/2017/03/aa29527-16/aa29527-16-eq137.png) (32)that ensures the smoothness of the perturbed field. Here, σα can be considered as a parameter to control the slope of the perturbation, which we assume to be σα = 2 since this should naturally permit slopes of ρ ∝ a-4 to ρ ∝ a0 bracketing our agnostic background cosmology ρ ∝ a-2 in case of σA = 1. The parameter σc controls the curvature of the perturbation, which is assume to be 0.5, since we do not expect much curvature, while σA is a normalization constant to control the amplitude of the perturbation. As we focus on small perturbations, which are the realistic ones, this parameter is fixed to 10-1. We note that the perturbation is generated from a different probability distribution than the prior used in our inference. This is on purpose to test the robustness of charm.
(32)that ensures the smoothness of the perturbed field. Here, σα can be considered as a parameter to control the slope of the perturbation, which we assume to be σα = 2 since this should naturally permit slopes of ρ ∝ a-4 to ρ ∝ a0 bracketing our agnostic background cosmology ρ ∝ a-2 in case of σA = 1. The parameter σc controls the curvature of the perturbation, which is assume to be 0.5, since we do not expect much curvature, while σA is a normalization constant to control the amplitude of the perturbation. As we focus on small perturbations, which are the realistic ones, this parameter is fixed to 10-1. We note that the perturbation is generated from a different probability distribution than the prior used in our inference. This is on purpose to test the robustness of charm.
Once the perturbed Planck cosmology and mock data are generated, we can apply charm. The number of simulated SNe Ia is 580 spread in a redshift range of 0.015 <z< 1.414, as in the real database. The amplitude of the noise, σn, is set to the amplitude of the perturbation, σA. In the results shown in Fig. 2, the initial background cosmology is assumed to be the Planck model. It is seen that the perturbation is small, since the perturbated cosmology, used to generate the data, is similar to the Planck cosmology. The prior used for the reconstruction is the one from Eq. (25) and the result follows the perturbed expansion history. In order to see that the perturbation can be recovered, we plot its reconstruction in the bottom panel of Fig. 2.
 |
Fig. 2 Reconstruction using mock data generated with a perturbed Planck cosmology with σA = 0.1 (upper panel). The blue and yellow regions correspond to the prior and posterior 1σ uncertainty limits respectively, which are obtained from the diagonal of the prior and the diagonal of the propagator operator via |
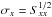
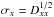
7.2. Reconstructed cosmology
Now, we can apply charm to real data from Union2.1 compilation under the various prior background cosmologies as described before.
 |
Fig. 3 Upper panel: reconstruction assuming Planck cosmology as background cosmology. The blue and yellow regions correspond to the prior and posterior 1σ uncertainty limits respectively. Middle panel: residuals of the reconstruction; bottom panel: deviation of the reconstruction from Planck cosmology. |
Figure 3 displays the results assuming the ΛCDM model as the cosmology background. The reconstruction is compatible with Planck ΛCDM cosmology. The displayed uncertainty limits of the reconstruction are provided by the diagonal of the Hessian, considering all the terms in the inverse propagator D-1 plus the term from Eq. (B.1) that was was omitted during the numerical minimization of the Hamiltonian for stability reasons. From this, we can conclude that the data agree with the ΛCDM model, as expected.
In order to study the agreement of the data with the Planck cosmology, we calculate the signal response, Rs, for our reconstruction. The residuals of the real data with respect to this are shown in the bottom panel of Fig. 1 and they can be compared to the residuals of the Planck cosmology in the middle panel of Fig. 3, calculated by applying the response operator to the Planck cosmology and substracting the real data. We can see that the residuals are almost the same for the Planck cosmology and for our reconstruction.
 |
Fig. 4 Reconstruction assuming CDM model as background cosmology (upper panel) and deviation of the reconstruction from Planck cosmology (bottom panel). |
Figure 4 shows the reconstruction for the CDM model as prior background cosmology. Although this model differs significantly from the Planck cosmology, our reconstruction is compatible with the ΛCDM model. This shows that the data strongly favors a cosmological expansion history dominated by CDM and a cosmological constant. In the following subsection, we recover the density of the cosmological constant ΩΛ by fitting this reconstruction. The residuals in this case are equivalent to the ones in the middle panel of Fig. 3.
 |
Fig. 5 Reconstruction assuming agnostic cosmology as background cosmology (upper panel) and deviation of the reconstruction from Planck cosmology (bottom panel). |
Finally, we adopt the agnostic cosmology as our prior background dcosmology. The result is shown in Fig. 5 and demonstrates that the Planck cosmology is recovered even in case charm is not informed about the specific equations of state of matter, radiation and dark energy.
From the results in this section, we can conclude that the assumed prior background cosmology does not strongly affect our results. The ΛCDM is better recovered if it is assumed in the prior, but also a CDM or the agnostic cosmology prior yield a reconstruction close to the Planck ΛCDM model. Furthermore, we verified by not here displayed experiments that the initial pivot cosmology has no impact on the finally reconstructed cosmology.
7.3. Fitting ΩΛ from the reconstruction
We have seen in Fig. 4 that the reconstruction from CDM model recovered the cosmological constant. We can take advantage of this to validate charm by comparing the density of the cosmological constant that we obtained with the values in the literature.
In order to obtain the value of ΩΛ from our reconstruction, we transform our reconstruction in such a way that we can fit a linear regression model. From the definition of the signal as s = lnE2(x), this transformation reads as 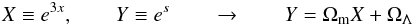 (33)and thus, the slope of the linear regression corresponds to the mass density and the independent term is identified as the density of dark energy.
(33)and thus, the slope of the linear regression corresponds to the mass density and the independent term is identified as the density of dark energy.
The result of the fitting is ΩΛ = 0.670, which is compatible with the value obtained by Planck mission, ΩΛ = 0.686 ± 0.020 (Planck mission, 2014). This parametric fit to our non-parametric reconstruction should just illustrate the consistency of our reconstruction with other measurements. For a proper uncertainty quantification the parametric model should be fit to the data directly, which was already done by many other works.
7.4. Constraints and Union3
Rubin et al. (2016) announced recently that a new update of the Union catalog is in preparation, called Union3 Supernova compilation. This new compilation will include high-redshift (z> 1) supernovae observed with the Hubble Space Telescope.
 |
Fig. 6 Reconstruction of a perturbation of the Planck expansion history at high-redshifts. |
The study of the BAO provides constraints to the evolution of dark energy density. Recently, BAO measurements have suggested a change in the density parameter of the dark energy at large redshifts z > 1 (Delubac et al. 2015; Aubourg et al. 2015). This early evolution of dark energy could be determined more precisely when data of SNe Ia at high-redshift are available.
In order to prepare our reconstruction algorithm for future work, we check that it is able to reconstruct a perturbation that exists only for large redshifts (z > 1). We generate a perturbation at z > 2 by adding a parabola to the Planck cosmology as a test. As in Sect. 7.1, the number of simulated SNe Ia is 580 but now spread in a redshift range of 0.015 <z < 3.0, that is an anticipation of the future improved datasets. We can see in Fig. 6 that this perturbation can be recovered by charm. This reconstruction assumed a Planck model as initial background cosmology and the prior from Eq. (25).
8. Conclusions
In this work we have developed charm, a Bayesian inference method to reconstruct non-parametrically the cosmic expansion history from SNe Ia data and applied it to the Union2.1 dataset. As shown in Sect. 7, the choice of the background prior cosmological expansion history does not significantly affect the final result of the reconstruction.
We found that the Planck cosmology is reconstructed independently of a prior assumed background cosmological expansion history. We have also recovered the density parameter ΩΛ in Sect. 7.3 and found a value of 0.670 which is compatible with the one from Planck Collaboration XVI (2014).
Although no evidence for a deviation from the standard cosmological expansion history has been found, we have tested our method whether it is able to reconstruct a perturbation if it existed. Our method was able to reconstruct a relative perturbation to ΛCDM even with an amplitude as low as 10-1.
Since recent analysis of BAO showed new constraints on the evolution of dark energy density at early epochs (Delubac et al. 2015), the study of SNe Ia at high-redshift will be crucial in the future for constraining any time variation in dark energy. In order to have charm prepared for the release of the database with supernovae at high-redshift, we have checked that the reconstruction method could find a perturbation that existed only at high-redshifts. Thus, charm will be a useful tool to study dark energy in a more model-independent way when the new SNe Ia datasets become available.
Acknowledgments
Part of this work was supported by Deutscher Akademischer Austauschdienst (DAAD). The computations were done using the NIFTy4 package for numerical information field theory (Selig et al. 2013).
References
- Amanullah, R., Lidman, C., Rubin, D., et al. 2010, ApJ, 716, 712 [NASA ADS] [CrossRef] [Google Scholar]
- Aubourg, É., Bailey, S., Bautista, J. E., et al. 2015, Phys. Rev. D, 92, 123516 [NASA ADS] [CrossRef] [Google Scholar]
- Bernal, C., Cardenas, V. H., & Motta, V. 2017, Phys. Lett. B, 765, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Delubac, T., Bautista, J. E., Busca, N. G., et al. 2015, A&A, 574, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Enßlin, T. A., Frommert, M., & Kitaura, F. S. 2009, Phys. Rev. D, 80, 105005 [NASA ADS] [CrossRef] [Google Scholar]
- España-Bonet, C., & Ruiz-Lapuente, P. 2005, Astrophysics, High Energy Physics – Phenomenology [arXiv:hep-ph/0503210] [Google Scholar]
- España-Bonet, C., & Ruiz-Lapuente, P. 2008, J. Cosmol. Astropart. Phys., 2, 018 [NASA ADS] [CrossRef] [Google Scholar]
- Genovese, C., Freeman, P., Wasserman, L., Nichol, R., & Miller, C. 2009, Ann. Appl. Statist., 3, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Guy, J., Astier, P., Nobili, S., Regnault, N., & Pain, R. 2005, A&A, 443, 781 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hee, S., Handley, W. J., Hobson, M. P., & Lasenby, A. N. 2016, MNRAS, 455, 2461 [NASA ADS] [CrossRef] [Google Scholar]
- Ishida, E. E. O., & de Souza, R. S. 2011, A&A, 527, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kowalski, M., Rubin, D., Aldering, G., et al. 2008, ApJ, 686, 749 [NASA ADS] [CrossRef] [Google Scholar]
- Koyama, K. 2016, Rep. Prog. Phys., 79, 046902 [NASA ADS] [CrossRef] [Google Scholar]
- Lemm, J. C. 1999, Physics [arXiv:physics/9912005] [Google Scholar]
- Li, Z., Gonzalez, J. E., Yu, H., Zhu, Z.-H., & Alcaniz, J. S. 2016, Phys. Rev. D, 93, 043014 [NASA ADS] [CrossRef] [Google Scholar]
- LSST Science Collaboration 2009, ArXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Mannucci, F., Della Valle, M., & Panagia, N. 2006, MNRAS, 370, 773 [NASA ADS] [CrossRef] [Google Scholar]
- Melia, F., & McClintock, T. M. 2015, AJ, 150, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Montiel, A., Lazkoz, R., Sendra, I., Escamilla-Rivera, C., & Salzano, V. 2014, Phys. Rev. D, 89, 043007 [NASA ADS] [CrossRef] [Google Scholar]
- Moresco, M., Pozzetti, L., Cimatti, A., et al. 2016, J. Cosmol. Astropart. Phys., 5, 014 [Google Scholar]
- Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XVI. 2014, A&A, 571, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Macri, L. M., Hoffmann, S. L., et al. 2016, ApJ, 826, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Rubin, D., Aldering, G. S., Amanullah, R., et al. 2016, in AAS Meeting Abstracts, 227, 139.18 [Google Scholar]
- Selig, M., Bell, M. R., Junklewitz, H., et al. 2013, A&A, 554, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shafieloo, A., Alam, U., Sahni, V., & Starobinsky, A. A. 2006, MNRAS, 366, 1081 [NASA ADS] [CrossRef] [Google Scholar]
- Simon, J., Verde, L., & Jimenez, R. 2005, Phys. Rev. D, 71, 123001 [Google Scholar]
- Suzuki, N., Rubin, D., Lidman, C., et al. 2012, ApJ, 746, 85 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Systematic errors
Appendix A.1: Color corrections
The empirical color corrections account for dust and intrinsic color–magnitude relation. The validity of the color correction, which is an empirical relation, relies on the assumption that nearby and distant SNe Ia have the same color–magnitude relation. This correction could become a source of systematic error if different corrections were required for different SN populations or if the distance to the SN affected this magnitude–color relation.
The second case seems to be unlikely since the color correction relation at high and low redshift agree. Although this agreement could arise from a different proportion of reddening and intrinsic color at different redshift, it supports the empirical relation for color correction (Kowalski et al. 2008).
The presence of two SN populations is supported by two types of SN-progenitors timescales argued by Mannucci et al. (2006). If this two populations are present, they might evolve in a different way with redshift. If the full sample is divided into equal subsamples by splitting by color, the color correction is significantly different for the two subsamples (Amanullah et al. 2010). This suggests that the color–magnitude relation could be more complex than a linear relation.
Appendix A.2: Sample contamination
In order to avoid the contamination of the data by non-type Ia SNe, which are not standard candles, an analysis technique was developed by Kowalski et al. (2008). This method, which is based on χ2 minimization, rejects the outliers from the sample. However, the systematic uncertainties are cast into an uncertainty of the absolute magnitude ΔM. In order to consider the sample contamination, an uncertainty ΔM = 0.015 was added to the covariant matrix due to contamination.
Appendix A.3: Lightcurve model
The lightcurve model is a fit with two parameters and it becomes a limit in capturing the diversity of SNe Ia. A problem arises when different techniques are used to observe nearby and distant supernovae, which implies that the parameters are obtained by fitting a different part of the curve in high-redshift SNe.
A Monte-Carlo simulation was performed by Kowalski et al. (2008) in order to quantify this systematic error, obtaining that the difference of nearby and distant SNe is ΔM = 0.02 mag.
Appendix A.4: Photometric peak magnitude
The uncertainty of the peak magnitude is due to the color correction. In order to measure the color, the flux is measured in at least two bands. Since the spectra of the SNe at different redshifts are obtained from different bands, their color is determined from different spectral regions. Then, the uncertainty in the different regions of the reference Vega spectrum limits the accuracy of SNe color measurement.
The Union compilation assumes an uncertainty in the absolute magnitude of ΔM = 0.03 for the photometric peak magnitude. Later, in the Union2 compilation, the numerical effect of each passband on the distance modulus was computed. This was a more efficient way to include this systematic error than including a constant magnitude covariance for all SNe (Amanullah et al. 2010).
Appendix A.5: Malmiquist bias
Malmiquist bias arises in flux limited surveys. The Union compilation attributes a systematic uncertainty of ΔM = 0.02 in absolute magnitude due to this bias.
Appendix A.6: Gravitational lensing
Gravitational lensing causes dispersion in the Hubble diagram at high redshift (Kowalski et al. 2008). This effect is treated statistically in the Union compilation. The uncertainty due to gravitational lensing is larger than the intrinsic dispersion only for high-redshift SNe but it causes a bias of magnitudes. This bias is not present if fluxes are used instead of magnitudes.
Appendix A.7: Galactic extinction
The photometry is corrected for galactic extinction using an extinction law that assumes RV = 3.1, together with dust maps (Amanullah et al. 2010). The galactic extinction is more important in nearby SNe, since the distant ones are measured in redder bands and then, its RR is approximately the color correction, without an important effect of the galactic extinction.
Appendix A.8: Host-mass correction coefficient
The SNe Ia luminosity is related to the mass of the host galaxy, even after color corrections (Suzuki et al. 2012). The host galaxies for low-redshift SNe Ia are more massive on average than the host galaxies for high-redshift SNe Ia. This can bias cosmological results and it can be corrected by fitting a step in the mass of the host-galaxy at mthreshold = 1010M⊙. The problem is that for the Union2.1 compilation the individual host galaxy masses are not known. To overcome this problem, a probabilistic method was defined to determine the host mass correction. This procedure could carry systematic errors, that are taken into account in the covariance matrix as ΔM = 0.02.
Appendix B: Simplification of the propagator operator
The propagator operator D measures the convex part of curvature of the information Hamiltonian, since it is the Hamiltonian second derivative except for terms due to higher order non-linearities in the response. This D operator is mostly used to guide our gradient descent via the regularized Newton method. Since the Newton method is not suited for negative curvatures, the term 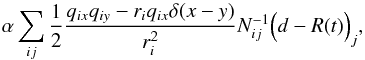 (B.1)which would be part of the Hessian of the full Hamiltonian is dropped by our response linearisation in order to avoid numerical problems caused by negative Eigenvalues of D. This is justified, as D only guides the numerical scheme, while the unmodified j determines where the scheme finally converges to.
(B.1)which would be part of the Hessian of the full Hamiltonian is dropped by our response linearisation in order to avoid numerical problems caused by negative Eigenvalues of D. This is justified, as D only guides the numerical scheme, while the unmodified j determines where the scheme finally converges to.
This simplification is allowed because we are iterating the Wiener filter to find the global minimum of the information Hamiltonian, and for this, it is not necessary to perform an optimal step in each iteration just that all steps go in the right direction. Inhibiting negative Eigenvalues of our simplified Hamiltonian ensures that the resulting Newton method always descends toward the global minimum of the Hamiltonian.
All Figures
|
Fig. 1 Hubble diagram for the Union2.1 compilation (upper panel) and residuals of data respect to the Planck cosmology (bottom panel). |
| In the text | |
|
Fig. 2 Reconstruction using mock data generated with a perturbed Planck cosmology with σA = 0.1 (upper panel). The blue and yellow regions correspond to the prior and posterior 1σ uncertainty limits respectively, which are obtained from the diagonal of the prior and the diagonal of the propagator operator via |
| In the text | |
|
Fig. 3 Upper panel: reconstruction assuming Planck cosmology as background cosmology. The blue and yellow regions correspond to the prior and posterior 1σ uncertainty limits respectively. Middle panel: residuals of the reconstruction; bottom panel: deviation of the reconstruction from Planck cosmology. |
| In the text | |
|
Fig. 4 Reconstruction assuming CDM model as background cosmology (upper panel) and deviation of the reconstruction from Planck cosmology (bottom panel). |
| In the text | |
|
Fig. 5 Reconstruction assuming agnostic cosmology as background cosmology (upper panel) and deviation of the reconstruction from Planck cosmology (bottom panel). |
| In the text | |
|
Fig. 6 Reconstruction of a perturbation of the Planck expansion history at high-redshifts. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.