| Issue |
A&A
Volume 597, January 2017
|
|
|---|---|---|
| Article Number | A125 | |
| Number of page(s) | 12 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201628716 | |
| Published online | 16 January 2017 | |
Spectral disentangling with Spectangular⋆
Leibniz-Institute for Astrophysics Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 14 April 2016
Accepted: 20 September 2016
Abstract
The paper introduces the software Spectangular for spectral disentangling via singular value decomposition with global optimisation of the orbital parameters of the stellar system or radial velocities of the individual observations. We will describe the procedure and the different options implemented in our program. Furthermore, we will demonstrate the performance and the applicability using tests on artificial data. Additionally, we use high-resolution spectra of Capella to demonstrate the performance of our code on real-world data. The novelty of this package is the implemented global optimisation algorithm and the graphical user interface (GUI) for ease of use. We have implemented the code to tackle SB1 and SB2 systems with the option of also dealing with telluric (static) lines.
Key words: methods: numerical / techniques: radial velocities / techniques: spectroscopic / binaries: spectroscopic
Based in part on data obtained with the STELLA robotic telescope in Tenerife, an AIP facility jointly operated by AIP and IAC.
© ESO, 2017
1. Introduction
Since stellar evolution depends on the mass of the object, measurement of radial velocities of binary stars is, besides the measurement of the inclination, an important step for stellar evolution studies. It has been shown, e.g. by Gallenne et al. (2016) and Holmgren (2004), that disentangling the spectra helps to improve determining the orbit of binaries. Furthermore, it allows detailed chemical analysis of the component spectra (Pavlovski & Hensberge 2005).
Firstly, we note that decomposition methods like direct and iterative subtraction (e.g., González & Levato 2006) are not understood as disentangling techniques. These subtraction methods rely on a fully analytical approach which is not fulfilled by real (noisy) measurements. Their procedure is to use as many spectra as there are components present in the stellar system, obtained at different phase positions. This yields an analytically determined system of equations as long as noise (and further errors, e.g., from wavelength calibration) are negligible. Solving this set of spectra results in decomposed spectra for each component. The result is commonly an average of solutions from several sets to reduce the noise of the decomposed spectra. Disentangling on the contrary, uses a larger set of observations that are spread over the whole orbit of the system, and identifies moving contributions of each component in the composite spectra. Its strength is derived from an overdetermined situation, which makes noise a less degrading factor. As long as all data are of equal quality, the result will have a significantly higher signal-to-noise ratio (S/N). Furthermore, disentangling does not assume information about the radial velocities since the result is coupled to an optimisation on the orbital elements.
Spectral disentangling can also be defined as template-independent separation of different contributions of sources to an observed composite spectrum. These contributions are mainly the components of multiple stellar systems. However, telluric lines and time-dependent line variability (e.g. Harmanec et al. 2004; Hadrava et al. 2009) can also be extracted from composite spectra. The first application of a decomposition procedure was published by Bagnuolo & Gies (1991), where they used a tomographic method to separate the spectra of the binary AO Cas. Simon & Sturm (1994) published the disentangling method based on singular value decomposition (SVD). They also implemented a global optimisation (Downhill-Simplex, Nelder & Mead 1965) method to find the best orbital fits to their observations. Independently, Hadrava (1995) developed his famous code based on a Fourier transform of the composed spectra. Further development resulted in KOREL (e.g., Hadrava 1997), FDBinary (and fd3, see Ilijic et al. 2004) and CRES (see Ilijic 2004). CRES uses SVD but it does not optimise the radial velocities of the observations.
A comparison between disentangling in Fourier and λ-space is given by Ilijic et al. (2002). The disentangling in the λ-space is more flexible in the sense that (1) each spectra can have its own sampling, (2) each data point can have its own weight, and (3) the output can be extended owing to the radial velocities (RVs) of the observations. In Fourier-disentangling all spectra need to have equal binning, weight and the output is a periodic function of the wavelength. Our code is written to elevate point (3). Hence, the solution will cover an extended wavelength range, defined by the radial velocities of the observations. Point (2) could in both Fourier and λ-space cases be achieved by rebinning all spectra to the same grid. However, it may be better to use different sampled data without resampling them to a common grid.
In Sect. 2 we collect all necessary basics of spectral disentangling in the λ-space and describe the procedure. We present tests of the code with artificial data in Sect. 3. An application to observations is presented in Sect. 4 and the conclusion follows in Sect. 5.
2. Method of disentangling in λ-space
2.1. Formulation of the problem
The time-series of spectra, spread over the orbital phase, needs to be carefully normalised. To account for the relative flux ratio of the components, additional data are required (e.g., from photometry). We also note, that disentangling is only applicable to well-detached systems. However, the components can have different spectral types.
At first, we assume that the flux is constant with phase, i.e., the spectra from a possible eclipse are not used. The spectra are furthermore corrected to the heliocentric system and rebinned to a logarithmic wavelength scale 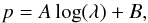 (1)where A and B are constant and p is the pixel number of the new scale. A given shift of the spectra by the Doppler effect yields a constant shift of p. If we assume that the resolution of the observations is sufficiently high (in a first approximation given by the rotational velocity of the components) we can apply a linear transformation between observations and individual spectra. The solution vector
(1)where A and B are constant and p is the pixel number of the new scale. A given shift of the spectra by the Doppler effect yields a constant shift of p. If we assume that the resolution of the observations is sufficiently high (in a first approximation given by the rotational velocity of the components) we can apply a linear transformation between observations and individual spectra. The solution vector 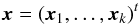 (2)is given by the individual spectra of the k components of the multiple system. If we collect all n observations in
(2)is given by the individual spectra of the k components of the multiple system. If we collect all n observations in 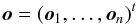 (3)the problem to be solved is given by
(3)the problem to be solved is given by 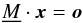 (4)where
(4)where 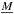 is the transformation matrix containing the radial velocity information of all spectra. This matrix can be further separated to
is the transformation matrix containing the radial velocity information of all spectra. This matrix can be further separated to 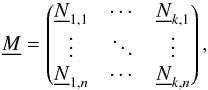 (5)where each of the sets
(5)where each of the sets  images the component spectra to one observation and contains the RV information
images the component spectra to one observation and contains the RV information 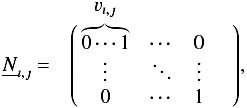 (6)where
(6)where 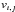 is the velocity in observation
is the velocity in observation 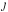 of component ı. As long as the SVD is applied to rank deficient and overdetermined systems, the solution behaves as a least square fit, i.e., it gives the solution of smallest residuum, which is
of component ı. As long as the SVD is applied to rank deficient and overdetermined systems, the solution behaves as a least square fit, i.e., it gives the solution of smallest residuum, which is 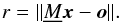 (7)This residuum can be used as the value to be minimised during the optimisation procedure. However, Simon & Sturm (1994) optimised on the orbit fit to the RVs from the optimisation algorithm. To fulfil the criterion of an overdetermined system we need at least one more observation since components, nmin = k + 1, are to be disentangled at different phases of the system.
(7)This residuum can be used as the value to be minimised during the optimisation procedure. However, Simon & Sturm (1994) optimised on the orbit fit to the RVs from the optimisation algorithm. To fulfil the criterion of an overdetermined system we need at least one more observation since components, nmin = k + 1, are to be disentangled at different phases of the system.
If static lines, e.g., tellurics, are present, we add an additional column of matrices, 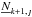 , without shifting the diagonal. Since telluric lines vary in strength from observation to observation, we need to take this into account. This can be done by using the relative line-depths as the elements for this matrix. Furthermore, heliocentric correction should not be applied since the static matrix does not account for shifts. In this case, the velocities are given by
, without shifting the diagonal. Since telluric lines vary in strength from observation to observation, we need to take this into account. This can be done by using the relative line-depths as the elements for this matrix. Furthermore, heliocentric correction should not be applied since the static matrix does not account for shifts. In this case, the velocities are given by 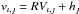 the sum of the radial velocities and the heliocentric correction. We note, that the minimum number of necessary observations nmin = k + 2 increases by one.
the sum of the radial velocities and the heliocentric correction. We note, that the minimum number of necessary observations nmin = k + 2 increases by one.
2.2. The procedure
We assume that the observations are carefully normalised and corrected for the heliocentric velocity, which should be applied by the spectroscopic data reduction. However, heliocentric correction is not necessary if the orbital motion is not of interest or if the velocities will be corrected afterwards. Moreover, in regions where telluric lines are present, no heliocentric correction should be applied. We have created an additional C++ GUI1 application (CroCo) for logarithmic rebinning and 2-dimensional cross-correlation, i.e., this tool is used to prepare the input data. The data are resampled to a new grid in the logarithmic scale. The step size I is set by the user in parts of the smallest δ = min(log (λℓ + 1)−log (λℓ)) difference between the sampling points on the logarithmic scale, such that the new sampling is δ′ = I·δ. This sampling is also applied to the templates and all data are cropped to an identical wavelength region for the cross-correlation. It is also possible to choose the spectral region of interest when it is not necessary to process the whole spectral range is not necessary. Linear interpolation is applied to find the values of the spectra on the new wavelength scale. Furthermore, the continuum value is subtracted since we perform the cross-correlation for zero-normalised spectra. The cross-correlation sum for these data is 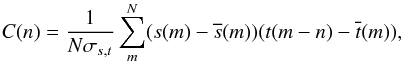 (8)where
(8)where 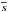 and
and 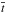 are the mean values and
are the mean values and 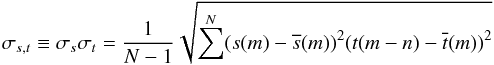 (9)the standard deviation product of the spectrum and template, respectively. Based on the new wavelength-sampling, CroCo performs the cross-correlation of all possible combinations of the templates in the specified velocity ranges with the observed spectrum. These ranges are defined by a value for maximum separation of the templates and maximum shift against the rest wavelength. In Fig. 1, we show an example of a cross-correlation for one spectrum (a) and the whole set (b) around the Li iλ6708 Å line of an artificial binary. All performed 2-dimensional cross-correlations are shown. The program picks out the one with the maximum value. In regions where no overlap between template and observation exists, we add 0 to the cross-correlation sum. Cross-correlation was performed using the templates from which the spectra themselves were constructed. More details on these data follow in Sect. 3.3.
(9)the standard deviation product of the spectrum and template, respectively. Based on the new wavelength-sampling, CroCo performs the cross-correlation of all possible combinations of the templates in the specified velocity ranges with the observed spectrum. These ranges are defined by a value for maximum separation of the templates and maximum shift against the rest wavelength. In Fig. 1, we show an example of a cross-correlation for one spectrum (a) and the whole set (b) around the Li iλ6708 Å line of an artificial binary. All performed 2-dimensional cross-correlations are shown. The program picks out the one with the maximum value. In regions where no overlap between template and observation exists, we add 0 to the cross-correlation sum. Cross-correlation was performed using the templates from which the spectra themselves were constructed. More details on these data follow in Sect. 3.3.
 |
Fig. 1 Example of the 2D cross-correlation as provided by CroCo. a) All cross-correlations (340) performed on one spectrum; b) the cross-correlations with maximum peak value for all (20) spectra equidistantly spread in phase of our artificial data. |
For this artificial binary, we applied an orbit comparable to Mizar (ζ UMa) with an eccentricity of e = 0.537, systemic velocity γ = −5.6 km s-1, and amplitudes of K1 = 68.6 km s-1 and K2 = 67.6 km s-1 for the primary and secondary, respectively. With the Binary Tool implemented in CroCo, two template-spectra can be combined to a composite spectra that covers the specified orbit. These data can be used to find systematic errors and to cross-check with the results of the observations. The orbit and the result from the cross-correlation are shown in Fig. 2. We note here, that we do not fit the correlation peak for a more precise determination because these values will be optimised during the disentangling procedure. However, the cross-correlation data are stored as ASCII files for further processing. The velocities from the cross-correlation can be used for the disentangling when a preliminary orbit is not known. As we describe below, optimisation can be performed directly on the RVs of each component and each observation or on the orbital parameters. Optimisation on the velocities can be advantageous in case of orbital distortions, e.g, a third component.
During the orbital motion, the wavelength window will vary according to the RV value. This leads to slight differences of the wavelength range that each individual observation covers. To prevent edge errors and to gather the maximum wavelength information, we construct the matrices in Eq. (6) such that they cover the maximum wavelength range. This in turn will enlarge the wavelength range of the solution vectors (Eq. (7)). As described in the introduction, this would not be possible using a procedure that is based on a Fourier-transform.
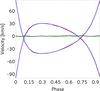 |
Fig. 2 Orbit of our test system. Red is calculated and blue is the result from the cross-correlation. Green and black show the differences between calculated and cross-correlation for both components. The velocity sampling was about 1.17 km s-1 and we have not fitted the CCF peak. |
The disentangling code Spectangular uses the Armadillo C++ linear algebra library (see Sanderson 2010) for efficient matrix and vector operations. It also provides three different algorithms for the SVD, the classical full SVD, an economical solution (ECON), and divide-and-conquer (DaC) method. For most data sizes, DaC is by far the fastest procedure and is implemented in the global optimisation algorithm. Nevertheless, for very small data sets, the classical SVD could be faster since it does not require any pre-calculations, e.g., DaC needs to separate the large transformation matrix into smaller ones and treats them separately. Disentangling without any optimisation can also be performed with all three methods. Furthermore, we use the OpenBLAS library, which provides parallel computing routines. This is especially advantageous for matrix operations, since it reduces the time for these calculations by approximately the reciprocal of the number of threads used.
The most time-consuming part of the optimisation algorithm is the initiation. In this first step, it creates the initial simplex which has (kn + 1) points, i.e., the SVD is performed (kn + 1)-times for the whole data set. This initial data is saved in case one wants to start the optimisation again. We note that the variation of the RV values to create this simplex is not random, i.e., for a given set of input RVs (or orbital parameters) the initial simplex will always be the same. This will be described in more detail in Sect. 2.3. After this initiation the algorithm performs as many iterations as specified by the user. Depending upon the data and initial values, the SVD is performed multiple times during one iteration. The most time-intensive transformation of the simplex is a total contraction, where kn points need to be re-calculated, i.e., it takes almost as long as the initiation itself. We have implemented direct optimisation on the radial velocities and on the orbital elements. When optimised on orbital elements, the initiation takes only eight (seven orbit elements) evaluations and, in general, this procedure leads to faster convergence. The value to be minimised in both cases is the residuum between result and observations given by Eq. (7). Additionally, it is also implemented to optimise on the peak-deviation, i.e., the maximum deviation of a single spectral bin to the disentangling result. This criterion, however, is not recommended since it is very sensitive to remaining cosmics, pixel errors, etc.
The resulting optimisation data are saved again to a local file and can be used if and when the optimisation needs to be continued. If the residuum r was reduced after a transformation, the result can be plotted in the main window of the program as a live view to control the procedure. After each evaluation of the SVD, the optimisation can be aborted in case that r is not minimsed any longer. Currently, the code is implemented for SB1 and SB2 data and the user can choose whether telluric (static) lines are present or not.
2.3. Details on downhill simplex implementation
For the downhill simplex method, it is common to use the standard deviation of all (kn + 1) function values (the residuum of the SVD in our case) of the simplex as the abort criterion for the optimisation. However, it is implemented to set the number of iterations of the downhill simplex algorithm (DSA). The arithmetic mean as well as the standard deviation of all residua of the simplex are calculated and written to the logfile after each iteration.
As already mentioned, the DSA performs transformations of the initial simplex. There is no general rule for constructing this initial simplex. In the case of optimisation on each RV, the initial simplex is constructed as 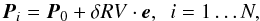 (10)where P0 is the point defined by the initial values, δRV is the change, e is the unit vector, i.e., only one of the values differs from point to point, and N = kn is the number of variables. The change in RV can be set by the user in fractions of the binning Bv of the spectra in velocity space, i.e., δRV = SBv, where S is the user-defined step size. In the case of optimisation on the orbital parameters, the step of each parameter is user-defined and N = 7 for the number of orbital parameters of an SB2 system and with the relation ω2 = ω1 + π for the longitude of periastron for the secondary.
(10)where P0 is the point defined by the initial values, δRV is the change, e is the unit vector, i.e., only one of the values differs from point to point, and N = kn is the number of variables. The change in RV can be set by the user in fractions of the binning Bv of the spectra in velocity space, i.e., δRV = SBv, where S is the user-defined step size. In the case of optimisation on the orbital parameters, the step of each parameter is user-defined and N = 7 for the number of orbital parameters of an SB2 system and with the relation ω2 = ω1 + π for the longitude of periastron for the secondary.
Furthermore, the coefficients for the transformations can also be changed. There are four transformations: (1) reflection 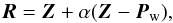 (11)of the worst point Pw (corresponds to highest r) over the centroid Z of the simplex, where α = 1 is the reflection coefficient; (2) expansion
(11)of the worst point Pw (corresponds to highest r) over the centroid Z of the simplex, where α = 1 is the reflection coefficient; (2) expansion 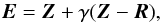 (12)over the reflected point, where γ = 2 is the expansion coefficient; (3) single contraction
(12)over the reflected point, where γ = 2 is the expansion coefficient; (3) single contraction 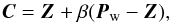 (13)of the worst point towards the centroid, where β = 0.5 is the contraction coefficient; (4) total contraction
(13)of the worst point towards the centroid, where β = 0.5 is the contraction coefficient; (4) total contraction 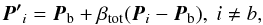 (14)towards the best point Pb, where βtot = 0.5 is the total contraction coefficient. All given values for the coefficients are defaults and used if user values are not defined.
(14)towards the best point Pb, where βtot = 0.5 is the total contraction coefficient. All given values for the coefficients are defaults and used if user values are not defined.
We note, that the DSA could stagnate and minimisation of the residuum is not achieved even after many iterations. In this case the optimisation should be aborted. The current best values for the parameters should be used as the new start values to start a new optimisation. Hence, an automatic re-initiation option is implemented so that optimisation will be reinitiated after DSA has passed two iterations without a change in mean and STD values of the simplex points. Another complication can occur in computing the correct residuum between solution and observations at the edges of the spectra. The solution can lose its overdetermination, i.e., the solution is poorly defined at the edges. In this region the entries of the solution vector x(edge) (more precisely: the corresponding singular values) do only represent rounding errors. Computing the residuum against the whole spectra would yield wrong (higher) values of the residuum. Hence, there is the option to calculate the residuum in a (smaller) user-defined wavelength range.
2.4. Error estimation
The common way (e.g. Phillips & Eyring 1988; Nelder & Mead 1965) is to compute the curvature matrix 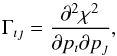 (15)where χ2 = ∑ wı(yı−fı)2. From this matrix one obtains the variance-covariance matrix according to
(15)where χ2 = ∑ wı(yı−fı)2. From this matrix one obtains the variance-covariance matrix according to 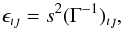 (16)where s2 = χ2/ (n−N). When the off-diagonal elements of
(16)where s2 = χ2/ (n−N). When the off-diagonal elements of 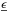 can be neglected, the standard deviation of parameter ı is given by
can be neglected, the standard deviation of parameter ı is given by 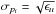 . To fit a quadratic function to the error surface additional points
. To fit a quadratic function to the error surface additional points 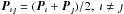 are required. This leads to an additional (N + 1)N/ 2 necessary SVDs, i.e., Eq. (4) needs to be solved 28× in case of an SB2 system to estimate the error. It becomes computationally expensive for large data sets and for optimisation on the individual RVs, e.g., 10 spectra of an SB2 system would require 210 SVDs of Eq. (4). However, it is an acceptable and necessary effort for the orbital parameters and the advantage is that no numerical increments for the derivatives need to be assumed (Eq. (15)).
are required. This leads to an additional (N + 1)N/ 2 necessary SVDs, i.e., Eq. (4) needs to be solved 28× in case of an SB2 system to estimate the error. It becomes computationally expensive for large data sets and for optimisation on the individual RVs, e.g., 10 spectra of an SB2 system would require 210 SVDs of Eq. (4). However, it is an acceptable and necessary effort for the orbital parameters and the advantage is that no numerical increments for the derivatives need to be assumed (Eq. (15)).
Nevertheless, there are two cases in which the quadratic fit is not applicable. Firstly, the final simplex could be too small, i.e., the error estimation is dominated by rounding errors. Secondly, the opposite case where the final simplex is too large for a quadratic fit. As pointed out by Phillips & Eyring (1988), the former case is the more important one. Indeed, if the optimisation is performed with already good parameters, it is possible that one of them is only changed by a small value or, even worse, not changed at all. This will make it impossible to compute the curvature matrix, since inversions are involved and they would be singular. In this case the critical parameter is varied in one vertex of the simplex and the residuum recalculated. However, this decision requires user-input and one should be aware that there is also the possibility of creating new optimisation data by using the best parameters and starting the optimisation again only for a few iterations.
Finally, based on experience, we note that a good alternative is to perform the optimisation on individual RVs and apply an orbit fit to the optimised RVs. This provides errors for the orbital parameters. Furthermore, errors introduced by a third component and uncertainties on the wavelength axis of the spectra (e.g., due to calibration errors) will have less of an effect on the resulting spectra.
3. Test with artificial data
3.1. Performance
We used artificial data with different sampling to test the computation time, depending on data size. In Fig. 3, we show a comparison between single core and eight logical cores. The spectra had a length of around 2000 points after rebinning to the logarithmic wavelength scale. Hence, the different data size comes from the number of used spectra. The time depends on both number of rows u and columns v of the u × v transformation matrix. For a rectangular matrix, v<u, it is sufficient to calculate only v singular values. The singular matrix is then a quadratic v × v matrix and only these column vectors need to be considered (this is one of three economical SVD methods – thin SVD).
 |
Fig. 3 CPU time vs. data size for the three SVD methods for computation on one and eight cores. SVD is the standard full SVD, ECON the economical SVD and DaC is for SVD with devide-and-conquer method. |
We note that our code development workstation had four physical cores and we enabled hyperthreading to split these into eight logical cores. Using eight threads, the computing time is reduced by a factor of eight.
The memory consumption can be estimated by the number of elements of the transformation matrix . Let lp be the number of spectral bins on the logarithmic scale. Neglecting the additional columns that are due to the velocity shift we get v = 2lp and u = nlp for the number of columns and rows, respectively. SVD decomposes into three matrices of dimensions v × v, u × v and u × u, respectively. We therefore get the following relation for memory usage: ![Mathematical equation: \hbox{$f(n)=l_{p}^{2}(n(n+2)+4)\times8\times 10^{-9} [GB]$}](/articles/aa/full_html/2017/01/aa28716-16/aa28716-16-eq80.png) . We show this dependency together with collected data for ECON and DaC in Fig. 4.
. We show this dependency together with collected data for ECON and DaC in Fig. 4.
 |
Fig. 4 Memory vs. data size for the economical (ECON) SVD, SVD with divide-and-conquer method (DaC) and the memory estimation f(n) (see text). |
3.2. SB1 and static lines
Here we demonstrate the disentangling of lines of SB1 systems that are blended, e.g., from telluric features. This is the case for the K i λ7699 Å line, e.g., in ϵ Aurigae (Strassmeier et al. 2014), which is hidden in the A-band of O2 around λ7600 Å. To demonstrate this, we created artificial data with an absorption at the K i line wavelength and applied the orbital parameters, as described in Sect. 2.2, and the time-series, as shown in Fig. 5. To get more realistic data, we added Gaussian noise resulting in an S/N of 100. Furthermore, we varied the line-strength of the telluric features and assume that the ratios are measured and known. Hence, the matrix is filled with these ratios. We alternately changed the line-strength from spectrum to spectrum by a factor of 0.5. Disentangling was performed with three iterations of the optimisation algorithm. The result of the disentangling is shown in Fig. 6. The top panel in Fig. 6a shows the disentangled SB1 line and the telluric lines. Figure 6b, at the bottom, shows the differences between the disentangled result and the composite spectra. These differences are computed with all composite spectra according to 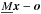 . We note, that the telluric features would also be successfully disentangled if the ratios are not given. In this case, the variation of line-strength would be present in the differences between observations and result. This is shown in the bottom panel of Fig. 6.
. We note, that the telluric features would also be successfully disentangled if the ratios are not given. In this case, the variation of line-strength would be present in the differences between observations and result. This is shown in the bottom panel of Fig. 6.
 |
Fig. 5 Artificial time-series of our SB1 system with the stellar K iλ7699 Å line in the variable A band of O2. |
As described previously, the result vectors (2) cover a slightly larger wavelength range owing to the orbital motion. This can also be seen in Fig. 6a between the telluric and the stellar spectrum.
Additionally, we generated spectra with superimposed emission lines to simulate stars embedded in emission nebulae. We used emission line data from Osterbrock et al. (1992) of M42 and added Gaussian noise to our data. Again, we used the same orbit parameters as described in Sect. 2.2 to model an absorption that crosses a static emission. We show the time-series of these data in Fig. 7, where we created two sets of data. These sets differ in the width of the emission line compared to the width of the absorption line.
 |
Fig. 6 Result of the disentangling with optimisation of our SB1 system with the stellar K i λ7699 Å line in the variable A band of O2. a) Absorptions from the SB1 line and variable telluric lines; b) differences between all spectra and result; c) differences between all spectra and result without accounting for line-strength variation. |
 |
Fig. 7 Artificial time-series of our SB1 system with the superimposed broad a) and narrow b) emission. |
The disentangling results after three iterations of optimisation are shown in Fig. 8 for the broad emission and in Fig. 9 for the narrow emission line, respectively. The wavelength range of the result for the absorption spectra is, as expected, again slightly larger than that for the static lines. The residuum is of the order of 4.8 × 10-5 in both cases.
 |
Fig. 9 Disentangling result of the superimposed narrow emission line of the data shown on bottom in Fig. 7b. |
3.3. Artificial SB2 system
We use time-series of artificial spectra with different noise levels (S/N of 10, 20, 40, 60, 80 and 100) to demonstrate the optimisation and error estimation. One time-series with applied S/N of 100 is shown in Fig. 10. The vsin(i) for the sharp-lined and broad-lined component is 5 km s-1 and 20 km s-1, respectively. The corresponding results from disentangling with best parameters and the differences between these results and the artificial spectra are shown in Figs. 11a and b, respectively. As mentioned in Sect. 2.3, poor definition at the edges can influence the residuum. The plot of the differences in Fig. 11b shows this for the lower three spectra. Hence, the differences are not computed for the whole wavelength range at the red end.
 |
Fig. 10 All 20 spectra of our artificial binary around the Li i λ6708 Å line with S/N of 100. |
 |
Fig. 11 a) Disentangling result of our artifical binary with S/N of 100. b) Differences between result and all spectra. |
Table 1 summarises the data before and after optimisation. The first row lists the S/N values of the result for the sharp-lined component spectra measured in two wavelength regions. 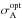 and
and 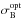 are the summed least squares between calculated RVs and the optimised values for the primary and secondary, respectively. We also list the summed least squares, σA and σB, between calculated RVs and those from the cross-correlation with CroCo. These values were used to start the optimisation. We performed 120 iterations of the optimisation on the RV values and fitted the orbit afterwards. The errors from the fit are also listed in Table 1.
are the summed least squares between calculated RVs and the optimised values for the primary and secondary, respectively. We also list the summed least squares, σA and σB, between calculated RVs and those from the cross-correlation with CroCo. These values were used to start the optimisation. We performed 120 iterations of the optimisation on the RV values and fitted the orbit afterwards. The errors from the fit are also listed in Table 1.
In all cases, the resulting spectra show a significantly higher S/N compared to the input data by at least a factor of two. Additionally, the resulting RVs from cross-correlation and from optimisation of disentangling improve with increasing S/N. From the errors for the masses of the components, which we are most likely interested in, we can see a significant reduction in the errors. These errors could be further reduced by continuing with the optimisation. We note that we used ideal input data, equally normalised, identical quality and equidistantly spread over the orbital phase. This itself yields good results for the cross-correlation method. However, disentangling further improved the results.
The way that unequal noise-levels in a time-series influence the result is shown in Fig. 12. We have replaced two spectra from the SN100 set by those from the SN10 set. The continuum is now less well determined and the noise in the resulting spectra is increased (compared to Fig. 11a). Only a few spectra with significant higher noise will make line-profile analysis difficult. Additionally, in Fig. 13 we show the result for unequal normalisation levels. Therefore, we have set the continuum of spectrum 2 to 0.98, spectrum 14 to 1.05 and spectrum 19 to 0.9. There is only a slight change in the continuum level in the results.
 |
Fig. 12 Result from disentangling of the SN100 set with two spectra replaced from the SN10 set. The continuum is less well determined and the noise in the result is increased. |
 |
Fig. 13 Result from the disentangling of SN100 set with three spectra on different continuum levels. Compared to the results in Fig. 11a, there is only a slight change in the continuum level of the results. |
 |
Fig. 14 Overplot of results for SN100 minimum case (three spectra) and all (20 spectra). a) for the narrow-lined component and b) for the broad-lined component. |
Furthermore, we show a comparison of the disentangling result between the minimum case, where we used three spectra, and the result from all 20 spectra in Fig. 14. We see that the contributions of the components are correctly separated. However, the noise level in the result is high and makes detailed line-profile analysis difficult.
Data for SB2 time-series for all 6 data sets.
4. Application to Capella
This system is somehow unique owing to its very precisely determined masses (Weber & Strassmeier 2011) and evolutionary state (Torres et al. 2015). From our STELLA (see Weber et al. 2008) telescopes on Tenerife, a lot of spectroscopic data is available for Capella. We selected some for our disentangling study, which are listed in Table 2.
 |
Fig. 15 Radial velocities from Table 2 for the three special cases studied. The blue (red) curve show the primary’s (secondary’s) orbital motion (computed from orbital parameters from Torres et al. 2015), green (black) dots correspond to the primary (secondary) radial velocity of each spectrum. |
4.1. The ideal minimum case
To show the reliability of the code, we decided to use only a small data set. As described, as long as the SVD is applied to overdetermined and rank deficient systems it yields the solution of smallest residuum. The system of a binary without telluric lines has therefore two unknowns and, to fulfil the criterion of overdetermination, we need three independent spectra. The time-series of spectra is shown in Fig. 16 as well as the radial velocity curve with the measurements in Fig. 15a. We used different combinations of the spectra 2, 9, 16, 26, and 27 as listed in Table 2. The two additional spectra are used to show how they can help to reduce the noise in the result.
 |
Fig. 16 The five spectra from Capella around the Li i 6708 Å line used for our investigations for the minimum ideal case. Spectrum 1 at the bottom, 5 at the top. |
With these data, we study the minimum case for disentangling. The determined case where we used two spectra from following quadratures (spectra 9 and 26 in Table 2) is shown in Fig. 17a. Owing to the noise in the data it is not possible for the code to distinguish fully between the two components. Only strong lines in the secondary spectrum (blue) like the Li i itself and Ca i λ6718 Å are visible. The minimum case is shown in Fig. 17b, where we included an observation near conjunction (spectrum 16 in Table 2). These three spectra yield an overdetermined system and the solution is less affected by noise than is the case for the only determined system.
 |
Fig. 17 Results from disentangling around the Li i 6708 Å line of Capella from the observations indicated in Table 2. a) Result for the determined situation with one spectrum per two consecutive quadratures; b) as above but with an additional spectrum at conjunction, which is the minimal necessary set of required data; c) two spectra per two consecutive quadratures. This set yields only a determined system, which can distinguish better between noise and the signal of the components; d) all five spectra yield a minimum overdetermined system with good noise reduction. |
The next example (Fig. 17c) shows the result when all four spectra from the two consecutive quadratures are used (spectra 1, 2, 26 and 27 in Table 2). If we compare this result with the one above, we can see that the jitter of the solution as a result of noise in the measurements is reduced. However, since the binning of these spectra corresponds to a velocity of 1 km s-1, the two pixel resolution is around 2 km s-1. A glance on the RV values in Table 2 shows that the two observations for each pair differ by less than 2 km s-1. This will give the code a better estimate of the noise but not of the components, since we would need three independent conditions to get an overdetermined system. Figure 17d shows the result when we use all five spectra. Compared to the minimum case (Fig. 17b), the noise is greatly reduced.
4.2. Data at quadrature – a non-ideal case
Observations at maximum separation of the components lead to minimum blending of equal lines of both components and are, therefore, often used to study the properties of the individual components of spectroscopic binaries. The orbital distribution of the observations we chose for this test (indicated in the sixth column of Table 2) are shown in Fig. 15b. Spectrum 16 is near conjunction and all the others of the 25 spectra are at quadrature.
We studied six different cases: (1) the first one uses the spectra 1 to 15 from the first quadrature; (2) the second case is with spectra from both quadratures from 1 to 15, and 18 to 27; (3) the third case uses spectra from 1 to 16, i.e., all spectra from one quadrature, plus an additional spectrum near conjunction; (4) for the fourth case we used all 26 spectra; (5) for the fifth case, we use all spectra from the first quadrature and spectrum 22 from the following quadrature; (6) as per (5), but with spectrum 16 near conjunction. Since most of the spectra from the same quadrature differ little in their radial velocities, the overdetermination is weak for cases (1) and (2). As shown for the minimum ideal case, the spectrum near conjunction is advantageous to fulfil the criterion of an overdetermined system.
Spectrum 5 has the highest (lowest) RV for component A (B). The next spectra, which have an RV difference of at least ≈2 km s-1 are 9, 12, and 15, i.e., these 15 spectra lead to a weakly overdetermined system. Two spectra for the determined case, another two spectra for overdetermination, and the rest help to reduce the noise in the result (case 1). The number of independent spectra, NIS, for each case is listed in Table 3.
 |
Fig. 18 All the spectra from the non-ideal case at quadrature. The spectrum at the bottom is spectrum 16 near conjunction and all others are in the same order as in Table 2, from bottom to top. |
Data for the non-ideal case at quadrature.
The results shown in Fig. 19 show that data sets which prefer particular phase positions and suffer from many non-independent spectra, degrade the result. This can be especially seen from cases 2 (spectra from both quadratures) and 4 (all spectra). The other cases show a better separation of line-pairs that are close together. However, it is visible that the red wings of these lines show smearing towards the continuum. This comes from regions where line-blending is present and the SVD is unable to fully distinguish between the two components in these regions. This is even worse if data from both quadratures are used, since all the information about the line-profile in-between is missing. If precise measurements of line-profiles and equivalent widths are to be made on the resulting spectra, a good phase coverage is indispensable.
We define a quality factor which relates the number of independent spectra, NIS, to the total number of spectra used by their orbital coverage. Let 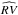 denote the peak-to-peak value of the radial velocity curve, SRV is the two pixel resolution in the velocity space, NS the number of all spectra, and NRS = NS−NIS is the number of reproductions. Thus we define
denote the peak-to-peak value of the radial velocity curve, SRV is the two pixel resolution in the velocity space, NS the number of all spectra, and NRS = NS−NIS is the number of reproductions. Thus we define 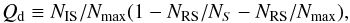 (17)where
(17)where 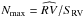 is the maximum number of independent spectra. This factor is at maximum unity as long as redundant measurements are not counted, NS ≤ Nmax. The bracket accounts for a statistical overweight of a specific phase position which leads to a negative Qd. Where independent spectra compensate reproductions, NRS = NIS, the factor is zero, i.e., the independent spectra compensate preferred phase positions. We list this factor for all six cases in the last column of Table 3 and note that for all cases Qd < 0 and case 6 indicates the best result. Moreover, we note that the quality factor is at 6% for the data set of only five spectra (NIS = 3) used in Sect. 4.1. Hence, this small data set is superior to the larger set that was used here. This can be seen from a comparison of line-separation, e.g., of the two Fe i lines blue from the strong Ca i λ6717.68 Å in the disentangled spectra of the primary (Figs. 19 and 17d, r = 0.83 × 10-4).
is the maximum number of independent spectra. This factor is at maximum unity as long as redundant measurements are not counted, NS ≤ Nmax. The bracket accounts for a statistical overweight of a specific phase position which leads to a negative Qd. Where independent spectra compensate reproductions, NRS = NIS, the factor is zero, i.e., the independent spectra compensate preferred phase positions. We list this factor for all six cases in the last column of Table 3 and note that for all cases Qd < 0 and case 6 indicates the best result. Moreover, we note that the quality factor is at 6% for the data set of only five spectra (NIS = 3) used in Sect. 4.1. Hence, this small data set is superior to the larger set that was used here. This can be seen from a comparison of line-separation, e.g., of the two Fe i lines blue from the strong Ca i λ6717.68 Å in the disentangled spectra of the primary (Figs. 19 and 17d, r = 0.83 × 10-4).
4.3. The realistic ideal case
As shown in the previous two sections, data should be spread homogeneously over at least half the orbital period such that the SVD is able to identify the differential moving contributions. In this case we selected 18 spectra as indicated in Table 2 to get a realistic data set spread over one orbit. The radial velocities are shown in Fig. 15c. Unlike the data set at quadrature, these data do not show any strong preference in any particular orbit section. The quality factor Qd is approximately 20% and indicates much better coverage of the orbit information.
The result for this data is shown in Fig. 20, where better defined line-wings are visible when compared with the results from the previous section. The narrow lines are now much better separated.
5. Conclusion
Using artificial data, we have shown the applicability both of disentangling and of the presented code, in particular to a variety of spectroscopic data from SB1, as well as SB2 systems, including static lines. Additionally, the application to high-resolution data from Capella shows that, with well-sampled small data sets good results can be achieved. Owing to the broad lines and compared to the primary shallow secondary lines, Capella is a very challenging object.
We conclude that the ideal case for observations is given by a set of spectra spread over one period with a difference of two times the spectrum-sampling in radial velocities. This criterion is based on the Nyquist two-pixel-resolution. It requires only half the data since the criterion given by Simon & Sturm (1994), where they suggest one spectra per a single velocity bin. However, our tests with Capella have shown that these data are helpful to reducing noise, but they do not significantly contribute to determining the component spectra (increment of overdetermination). Furthermore, the data should not overweigh a specific phase position. The quality factor given by Eq. (10) should be used to plan observations, especially when the orbit is already known. We plot this relation in Fig. 21 for Nmax = 27 and for different NS in dependence of NIS. It is NS = Nmax for the purple curve and if all 27 spectra are independent, i.e., NIS = NS = Nmax it yields an Qd = 1. For the green curve it is NS = 20 <Nmax, i.e., Qd < 1 even if all observations are independent, NIS = NS = 20.
 |
Fig. 21 Example of the quality factor in dependence of NIS for Nmax = 27 for different NS as listed in the graph key. |
We also note that all the spectra within the data set need to be of equal quality with respect to S/N and normalisation. A good example is the time-series shown in Fig. 18 where all the spectra are nicely normalised and have identical S/N values.
When there is no initial information on the orbital parameters of a system, we recommended performing a cross-correlation first to get an estimate for the orbital parameters. The optimisation is then initiated with this orbit, which helps to avoid stagnation of the DSA since it should be already in the vicinity of the best fit. However, optimisation of individual RVs instead of orbital parameters, could be preferable in the case of the presence of a third component or systematics, e.g., in wavelength calibration. The orbital parameters and the corresponding errors are then found by fitting to the optimised RVs.
Furthermore, Spectangular is able to disentangle telluric lines that are variable in time if relative ratios of the line-depths are given. These ratios need to be measured for each of the spectra. As long as line-depths can be measured from unblended lines, it is also possible to account for line-depth variability of the component spectra itself. This will also make it possible to use spectra from an eclipse if a light curve of the system is available. This could help with getting better phase coverage. However, if the uncertainties in the flux ratios are high and the eclipse is short compared to the orbital period, they can be rejected.
However, despite parallel computing, SVD is a time-consuming procedure. This is underlined when optimisation needs to be performed. Also, the amount of necessary memory is high, since the number of elements to be stored grows quadratically with the spectrum size. Further applications related to time-dependent variability of line-shape rather than depth need to be investigated.
Finally, we note that we are working on the implementation of a third, non-static component. However, we will not couple this to an equation of orbital motion. Hence, the optimisation will be performed in the case of an SB3 system only on the individual RVs.
Code availability.
We will make the code available under the Apache 2.0 licence on github ASAP. This will include the disentangling program Spectangular as well as CroCo for data preparation. Furthermore, a support page on the internet and manuals for both programs will be made available2.
We use the Qt library for GUI programming: www.qt.io
Acknowledgments
We thank the referee for his constructive comments which helped to improve the content and the readability of this paper.
References
- Bagnuolo, Jr., W. G., & Gies, D. R. 1991, ApJ, 376, 266 [NASA ADS] [CrossRef] [Google Scholar]
- Gallenne, A., Pietrzyński, G., Graczyk, D., et al. 2016, A&A, 586, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- González, J. F., & Levato, H. 2006, A&A, 448, 283 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hadrava, P. 1995, A&AS, 114, 393 [NASA ADS] [Google Scholar]
- Hadrava, P. 1997, A&AS, 122 [Google Scholar]
- Hadrava, P., Šlechta, M., & Škoda, P. 2009, A&A, 507, 397 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harmanec, P., Uytterhoeven, K., & Aerts, C. 2004, A&A, 422, 1013 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Holmgren, D. E. 2004, in Spectroscopically and Spatially Resolving the Components of the Close Binary Stars, eds. R. W. Hilditch, H. Hensberge, & K. Pavlovski, ASP Conf. Ser., 318, 95 [Google Scholar]
- Ilijic, S. 2004, in Spectroscopically and Spatially Resolving the Components of the Close Binary Stars, eds. R. W. Hilditch, H. Hensberge, & K. Pavlovski, ASP Conf. Ser., 318, 107 [Google Scholar]
- Ilijic, S., Hensberge, H., & Pavlovski, K. 2002, Fizika B, 10, 357 [Google Scholar]
- Ilijic, S., Hensberge, H., Pavlovski, K., & Freyhammer, L. M. 2004, in Spectroscopically and Spatially Resolving the Components of the Close Binary Stars, eds. R. W. Hilditch, H. Hensberge, & K. Pavlovski, ASP Conf. Ser., 318, 111 [Google Scholar]
- Nelder, J. A., & Mead, R. 1965, Comput. J., 7, 308 [CrossRef] [Google Scholar]
- Osterbrock, D. E., Tran, H. D., & Veilleux, S. 1992, ApJ, 389, 305 [NASA ADS] [CrossRef] [Google Scholar]
- Pavlovski, K., & Hensberge, H. 2005, A&A, 439, 309 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Phillips, G. R., & Eyring, E. M. 1988, Analytical Chemistry, 60, 738 [CrossRef] [Google Scholar]
- Sanderson, C. 2010, Tech. Rep. NICTA, Australia [Google Scholar]
- Simon, K. P., & Sturm, E. 1994, A&A, 281, 286 [NASA ADS] [Google Scholar]
- Strassmeier, K. G., Weber, M., Granzer, T., et al. 2014, Astron. Nachr., 335, 904 [NASA ADS] [CrossRef] [Google Scholar]
- Torres, G., Claret, A., Pavlovski, K., & Dotter, A. 2015, ApJ, 807, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Weber, M., & Strassmeier, K. G. 2011, A&A, 531, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Weber, M., Granzer, T., Strassmeier, K. G., & Woche, M. 2008, in The STELLA robotic observatory: first two years of high-resolution spectroscopy, eds. A. Bridger, & N. M. Radziwill, Proc. SPIE, 7019, 12 [Google Scholar]
All Tables
All Figures
|
Fig. 1 Example of the 2D cross-correlation as provided by CroCo. a) All cross-correlations (340) performed on one spectrum; b) the cross-correlations with maximum peak value for all (20) spectra equidistantly spread in phase of our artificial data. |
| In the text | |
|
Fig. 2 Orbit of our test system. Red is calculated and blue is the result from the cross-correlation. Green and black show the differences between calculated and cross-correlation for both components. The velocity sampling was about 1.17 km s-1 and we have not fitted the CCF peak. |
| In the text | |
|
Fig. 3 CPU time vs. data size for the three SVD methods for computation on one and eight cores. SVD is the standard full SVD, ECON the economical SVD and DaC is for SVD with devide-and-conquer method. |
| In the text | |
|
Fig. 4 Memory vs. data size for the economical (ECON) SVD, SVD with divide-and-conquer method (DaC) and the memory estimation f(n) (see text). |
| In the text | |
|
Fig. 5 Artificial time-series of our SB1 system with the stellar K iλ7699 Å line in the variable A band of O2. |
| In the text | |
|
Fig. 6 Result of the disentangling with optimisation of our SB1 system with the stellar K i λ7699 Å line in the variable A band of O2. a) Absorptions from the SB1 line and variable telluric lines; b) differences between all spectra and result; c) differences between all spectra and result without accounting for line-strength variation. |
| In the text | |
|
Fig. 7 Artificial time-series of our SB1 system with the superimposed broad a) and narrow b) emission. |
| In the text | |
 |
Fig. 8 Disentangling result of the superimposed broad emission line of the data shown in Fig. 7a. |
| In the text | |
|
Fig. 9 Disentangling result of the superimposed narrow emission line of the data shown on bottom in Fig. 7b. |
| In the text | |
|
Fig. 10 All 20 spectra of our artificial binary around the Li i λ6708 Å line with S/N of 100. |
| In the text | |
|
Fig. 11 a) Disentangling result of our artifical binary with S/N of 100. b) Differences between result and all spectra. |
| In the text | |
|
Fig. 12 Result from disentangling of the SN100 set with two spectra replaced from the SN10 set. The continuum is less well determined and the noise in the result is increased. |
| In the text | |
|
Fig. 13 Result from the disentangling of SN100 set with three spectra on different continuum levels. Compared to the results in Fig. 11a, there is only a slight change in the continuum level of the results. |
| In the text | |
|
Fig. 14 Overplot of results for SN100 minimum case (three spectra) and all (20 spectra). a) for the narrow-lined component and b) for the broad-lined component. |
| In the text | |
|
Fig. 15 Radial velocities from Table 2 for the three special cases studied. The blue (red) curve show the primary’s (secondary’s) orbital motion (computed from orbital parameters from Torres et al. 2015), green (black) dots correspond to the primary (secondary) radial velocity of each spectrum. |
| In the text | |
|
Fig. 16 The five spectra from Capella around the Li i 6708 Å line used for our investigations for the minimum ideal case. Spectrum 1 at the bottom, 5 at the top. |
| In the text | |
|
Fig. 17 Results from disentangling around the Li i 6708 Å line of Capella from the observations indicated in Table 2. a) Result for the determined situation with one spectrum per two consecutive quadratures; b) as above but with an additional spectrum at conjunction, which is the minimal necessary set of required data; c) two spectra per two consecutive quadratures. This set yields only a determined system, which can distinguish better between noise and the signal of the components; d) all five spectra yield a minimum overdetermined system with good noise reduction. |
| In the text | |
|
Fig. 18 All the spectra from the non-ideal case at quadrature. The spectrum at the bottom is spectrum 16 near conjunction and all others are in the same order as in Table 2, from bottom to top. |
| In the text | |
 |
Fig. 19 Results for all six cases of the data from quadrature. See text and Table 3 for details. |
| In the text | |
 |
Fig. 20 Result of the disentangling of the data indicated in the last column of Table 2. |
| In the text | |
|
Fig. 21 Example of the quality factor in dependence of NIS for Nmax = 27 for different NS as listed in the graph key. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.