| Issue |
A&A
Volume 573, January 2015
|
|
|---|---|---|
| Article Number | A101 | |
| Number of page(s) | 6 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201424908 | |
| Published online | 06 January 2015 | |
BGLS: A Bayesian formalism for the generalised Lomb-Scargle periodogram⋆,⋆⋆
1 SUPA, School of Physics and Astronomy, University of St Andrews, St Andrews KY16 9SS, UK
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Centro de Astrofísica, Universidade do Porto, Rua das Estrelas, 4150-762 Porto, Portugal
3 Instituto de Astrofísica e Ciências do Espaço, Universidade do Porto, CAUP, Rua das Estrelas, 4150-762 Porto, Portugal
4 Departamento de Física e Astronomia, Faculdade de Ciências, Universidade do Porto, Portugal
Received: 3 September 2014
Accepted: 25 November 2014
Abstract
Context. Frequency analyses are very important in astronomy today, not least in the ever-growing field of exoplanets, where short-period signals in stellar radial velocity data are investigated. Periodograms are the main (and powerful) tools for this purpose. However, recovering the correct frequencies and assessing the probability of each frequency is not straightforward.
Aims. We provide a formalism that is easy to implement in a code, to describe a Bayesian periodogram that includes weights and a constant offset in the data. The relative probability between peaks can be easily calculated with this formalism. We discuss the differences and agreements between the various periodogram formalisms with simulated examples.
Methods. We used the Bayesian probability theory to describe the probability that a full sine function (including weights derived from the errors on the data values and a constant offset) with a specific frequency is present in the data.
Results. From the expression for our Baysian generalised Lomb-Scargle periodogram (BGLS), we can easily recover the expression for the non-Bayesian version. In the simulated examples we show that this new formalism recovers the underlying periods better than previous versions. A Python-based code is available for the community.
Key words: methods: data analysis / methods: statistical
A copy of the code is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/573/A101
© ESO, 2015
1. Introduction
Analysing unevenly sampled data in search for a periodic signal is very important in astronomy today. In the ever-growing search for exoplanets, for example, scientists search for periodicities in the radial velocity data of a star to detect a signal that can be attributed to an orbiting planet. When analysing the intensity of stellar activity, we also search for periodic signals, for example in the activity indicator 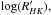 or in the photometric light curves (e.g. Dumusque et al. 2012; Bastien et al. 2014). In the field of asteroseismology, correctly finding periodic signals in the data is of great importance as well (e.g. Aerts et al. 2010).
or in the photometric light curves (e.g. Dumusque et al. 2012; Bastien et al. 2014). In the field of asteroseismology, correctly finding periodic signals in the data is of great importance as well (e.g. Aerts et al. 2010).
From a historical point of view, one of the main tools used in the frequency analysis of unevenly spaced time series is the Lomb-Scargle periodogram (LS – Lomb 1976; Scargle 1982). This LS periodogram, although useful, suffers from several drawbacks. First, it does not weigh the data points in any way. Secondly, it does not include a constant offset in the data. These two points, however, are very important when handling real observational data where some data points may be more precise than others due to observing conditions, for instance. The zeropoint of the data is typically not known exactly, either, which is very important in the case of irregularly sampled data. These problems were already accounted for by e.g. Ferraz-Mello (1981), Cumming et al. (1999), Zechmeister & Kürster (2009), resulting in a generalised LS periodogram (GLS) including weights and an offset.
The final drawback of the LS is also still present in the GLS. Both periodograms are expressed in an arbitrary power, which makes it difficult to compare one peak to another. To better assess the relative probability between two peaks, Bretthorst (2001) generalised the LS periodogram by using Bayesian probability theory. The resulting Bayesian LS periodogram (BLS) is in many ways similar to the regular LS periodogram, but the probability resulting from the BLS is much more informative than the arbitrary power in the LS.
In this work, we follow the formalisms of Bretthorst (2001) and Zechmeister & Kürster (2009) to extend the GLS one step further by using Bayesian probability theory. This results in a Bayesian generalised Lomb-Scargle periodogram (BGLS). In Sect. 2 we derive the equations needed for the BGLS, with a special case described in Sect. 3. Section 4 gives two examples based on simulated data to show the differences and agreements between the four discussed periodograms (LS, BLS, GLS, BGLS). We conclude in Sect. 5.
2. Formalism
A periodic signal in time series data can be described by a full sine function, including an offset and the errors on the observations. The model we used for the data is 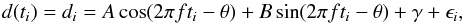 (1)where di is the data point taken at time ti, A and B are the cosine and sine amplitudes, f is the signal frequency, θ is an arbitrary phase offset that we defined below, γ is the data offset, and ϵi is the noise at time ti. This noise is per time ti Gaussian-distributed around 0 with a standard deviation of σi, which is the estimated uncertainty on the data at time ti(ϵi ~ N(0,σi)).
(1)where di is the data point taken at time ti, A and B are the cosine and sine amplitudes, f is the signal frequency, θ is an arbitrary phase offset that we defined below, γ is the data offset, and ϵi is the noise at time ti. This noise is per time ti Gaussian-distributed around 0 with a standard deviation of σi, which is the estimated uncertainty on the data at time ti(ϵi ~ N(0,σi)).
We are interested in the posterior probability of the frequency given the data D and our prior knowledge I, P(f | D,I). By marginalisation, we can write this (posterior) probability function as 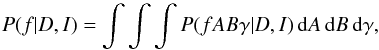 (2)where the frequency probability is calculated from the joint posterior probability of the three parameters A, B, and γ. By applying Bayes theorem (Bayes & Price 1763), we can write that
(2)where the frequency probability is calculated from the joint posterior probability of the three parameters A, B, and γ. By applying Bayes theorem (Bayes & Price 1763), we can write that 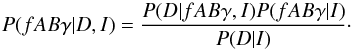 (3)The evidence, P(D | I), is a constant, and since we are only interested in the relative probability between frequencies, we can ignore this normalising factor. Furthermore, for the priors, P(fABγ | I), we assume that all the parameters f,A,B, and γ are independent, and we take the prior probability for each parameter as uniform. This assumption leads to an equal treatment of all possible signals in the data. With these assumptions, we can use the product rule for joint probabilities:
(3)The evidence, P(D | I), is a constant, and since we are only interested in the relative probability between frequencies, we can ignore this normalising factor. Furthermore, for the priors, P(fABγ | I), we assume that all the parameters f,A,B, and γ are independent, and we take the prior probability for each parameter as uniform. This assumption leads to an equal treatment of all possible signals in the data. With these assumptions, we can use the product rule for joint probabilities: 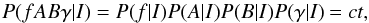 (4)with ct a constant that we can again ignore. This all leads to the fact that our posterior probability function is proportional to the integrated likelihood:
(4)with ct a constant that we can again ignore. This all leads to the fact that our posterior probability function is proportional to the integrated likelihood: 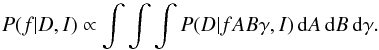 (5)To describe this likelihood analytically, we use the fact that the probability of the data is the same as the probability of the noise. This noise is normally distributed around 0, with the standard deviation σi for each time ti. We derive
(5)To describe this likelihood analytically, we use the fact that the probability of the data is the same as the probability of the noise. This noise is normally distributed around 0, with the standard deviation σi for each time ti. We derive ![Mathematical equation: \begin{eqnarray} P(D|fAB\gamma,I) & = & \prod_{i=1}^N \frac{1}{\sqrt{2\pi}\sigma_i} \exp\left(-\frac{\epsilon_i^2}{2\sigma_i^2} \right)\\ & = & \left( \prod_{i=1}^N \frac{1}{\sqrt{2\pi}\sigma_i} \right) \exp\left[-\frac{1}{2}\sum_{i=1}^N\left(\frac{\epsilon_i}{\sigma_i} \right)^2\right]. \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq25.png) The first factor in this expression can again be ignored and placed into the normalising factor. We use the standard deviations σi to assign the weights of the datapoints. The weight wi can be written as
The first factor in this expression can again be ignored and placed into the normalising factor. We use the standard deviations σi to assign the weights of the datapoints. The weight wi can be written as 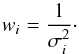 (8)The noise ϵi can be written in terms of the observables by using Eq. (1). To simplify the expressions, we introduce some definitions. We try to use the same expressions as in Zechmeister & Kürster (2009) so that it is easy to compare between the two formalisms.
(8)The noise ϵi can be written in terms of the observables by using Eq. (1). To simplify the expressions, we introduce some definitions. We try to use the same expressions as in Zechmeister & Kürster (2009) so that it is easy to compare between the two formalisms. ![Mathematical equation: \begin{eqnarray} W & = & \sum_{i=1}^N w_i \\[2mm] Y & = & \sum_{i=1}^N w_i d_i\\[2mm] \widehat{YY} & = & \sum_{i=1}^N w_i d_i^2\\[2mm] \widehat{YC} & = & \sum_{i=1}^N w_i d_i \cos(2\pi ft_i - \theta) \\[2mm] \widehat{YS} & = & \sum_{i=1}^N w_i d_i \sin(2\pi ft_i - \theta) \\[2mm] C & = & \sum_{i=1}^N w_i \cos(2\pi ft_i - \theta) \\[2mm] S & = & \sum_{i=1}^N w_i \sin(2\pi ft_i - \theta) \\[2mm] \widehat{CC} & = & \sum_{i=1}^N w_i \cos^2(2\pi ft_i - \theta) \\[2mm] \widehat{SS} & = & \sum_{i=1}^N w_i \sin^2(2\pi ft_i - \theta) . \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq28.png) Furthermore, we define θ such that the cosine and sine functions are orthogonal (for the proof, see Appendix A):
Furthermore, we define θ such that the cosine and sine functions are orthogonal (for the proof, see Appendix A): ![Mathematical equation: \begin{equation} \label{EqTheta} \theta = \frac{1}{2}\tan^{-1}\left[\frac{\sum w_i\sin(4\pi f t_i)}{\sum w_i\cos(4\pi f t_i)} \right]\cdot \end{equation}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq29.png) (18)Using all these definitions, we find that
(18)Using all these definitions, we find that 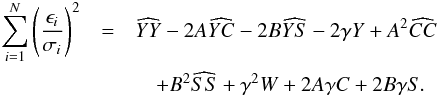 (19)Using this expression, we can now split the integrals from Eq. (5) into three separate integrals. First, we consider the integrals in A and B. These can be written as
(19)Using this expression, we can now split the integrals from Eq. (5) into three separate integrals. First, we consider the integrals in A and B. These can be written as ![Mathematical equation: \begin{eqnarray} \int_{-\infty}^{+\infty} \exp\left[- \frac{\widehat{CC}A^2-2\widehat{YC}A+2\gamma C A}{2} \right] {\rm d}A \\ \int_{-\infty}^{+\infty} \exp\left[- \frac{\widehat{SS}B^2-2\widehat{YS}B+2\gamma S B}{2} \right] {\rm d}B . \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq31.png) From now on, we assume that
From now on, we assume that 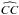 and
and 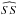 are strictly positive. Since cos2x ≥ 0 and sin2x ≥ 0, it follows that these expressions are positive. We explore the special cases where one of them is zero in Sect. 3. If they are strictly positive, we can easily solve the integrals in A and B using
are strictly positive. Since cos2x ≥ 0 and sin2x ≥ 0, it follows that these expressions are positive. We explore the special cases where one of them is zero in Sect. 3. If they are strictly positive, we can easily solve the integrals in A and B using 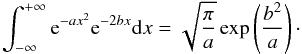 (22)Finally, only the integral in γ remains, and our posterior probability function is proportional to
(22)Finally, only the integral in γ remains, and our posterior probability function is proportional to 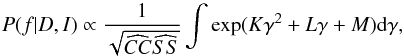 (23)where we have introduced the following functions of the frequency f:
(23)where we have introduced the following functions of the frequency f: ![Mathematical equation: \begin{eqnarray} K & = & \frac{C^2\widehat{SS} + S^2\widehat{CC} - W\widehat{CC}\widehat{SS}}{2\widehat{CC}\widehat{SS}} \\[2mm] L & = & \frac{Y\widehat{CC}\widehat{SS} - C\widehat{YC}\widehat{SS} - S\widehat{YS}\widehat{CC}}{\widehat{CC}\widehat{SS}} \\[2mm] M & = & \frac{\widehat{YC}^2\widehat{SS} + \widehat{YS}^2\widehat{CC}}{2\widehat{CC}\widehat{SS}} \cdot \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq38.png) To solve the integral in Eq. (23), we can again use Eq. (22) since K< 0. For data sets with N ≥ 3 (a frequency analysis is only useful for datasets with at least three datapoints) and unevenly spaced datapoints, this is always the case. We then finally obtain that
To solve the integral in Eq. (23), we can again use Eq. (22) since K< 0. For data sets with N ≥ 3 (a frequency analysis is only useful for datasets with at least three datapoints) and unevenly spaced datapoints, this is always the case. We then finally obtain that 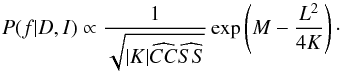 (27)As can be seen from Eq. (20) in Zechmeister & Kürster (2009), the power calculated in the GLS is proportional to M. The probability calculated by the BGLS is related to the GLS as it gives an exponential where part of the exponent is exactly the power from the GLS. The BGLS is thus very similar to the GLS, just as the BLS is similar to the LS (see discussion in Bretthorst 2001).
(27)As can be seen from Eq. (20) in Zechmeister & Kürster (2009), the power calculated in the GLS is proportional to M. The probability calculated by the BGLS is related to the GLS as it gives an exponential where part of the exponent is exactly the power from the GLS. The BGLS is thus very similar to the GLS, just as the BLS is similar to the LS (see discussion in Bretthorst 2001).
3. Special case
In the previous section, we have assumed that and are strictly positive. Now, we consider the case when one of them is zero1. This can be the case if, for a specific frequency f, all datapoints ti can be expressed as 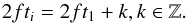 (28)Basically, this means that the data are equally spaced, while gaps without observations are allowed. From Eq. (18) we can then derive that
(28)Basically, this means that the data are equally spaced, while gaps without observations are allowed. From Eq. (18) we can then derive that 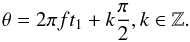 (29)By placing these two expressions together, we obtain that
(29)By placing these two expressions together, we obtain that 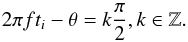 (30)Now, and will be zero if k is odd or even, respectively. If k is even, we see that
(30)Now, and will be zero if k is odd or even, respectively. If k is even, we see that 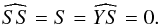 (31)With these simplified expressions, we find that the integral in B is proportional to a constant. The integral in A can still be solved, and we can follow the same reasoning as in the previous section. Accordingly, the BGLS can be expressed as
(31)With these simplified expressions, we find that the integral in B is proportional to a constant. The integral in A can still be solved, and we can follow the same reasoning as in the previous section. Accordingly, the BGLS can be expressed as 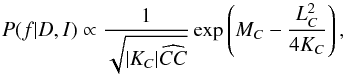 (32)where we have used the following definitions:
(32)where we have used the following definitions: ![Mathematical equation: \begin{eqnarray} K_C & = & \frac{C^2 - W\widehat{CC}}{2\widehat{CC}} \\[2mm] L_C & = & \frac{Y\widehat{CC} - C\widehat{YC}}{\widehat{CC}} \\[2mm] M_C & = & \frac{\widehat{YC}^2}{2\widehat{CC}} \cdot \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq49.png) For the case where k in Eq. (30) is odd, we can reason the same way, but now all the terms with cosines are zero and the terms with sines are left (introducing the three functions KS,LS, and MS).
For the case where k in Eq. (30) is odd, we can reason the same way, but now all the terms with cosines are zero and the terms with sines are left (introducing the three functions KS,LS, and MS).
These cases may occur for equally spaced data sets (even if they have gaps). With real ground-based observations, it is very unlikely that these cases would ever occur. However, this is more likely for space-based surveys, where the observations are made at fixed times following the spacecraft clock. Therefore the frequencies for which these special cases apply need to be checked always.
4. Simulated examples
In this section we provide two examples of simulated data sets that expose the differences between the LS, the GLS and their Bayesian versions.
The main difference between the non-Bayesian and the Bayesian periodograms lies in the peak comparison, as already mentioned in the introduction. Non-Bayesian periodograms use an arbitrary power, which makes it difficult to assess the importance of specific periods over other periods in the data. Bayesian periodograms, on the other hand, express the probability that a signal with a specific period is present in the data. The relative probability between two periods can then be easily assessed. In the examples below, we show that the Baysian periodograms typically have one very clear peak (probability-wise), in contrast to their non-Bayesian versions.
Differences between the non-generalised and the generalised periodograms always have to do with the fact that the (B)GLS includes weights and a possible offset in the data. Below, we give an example of the effect of each of these additions using simulated data2. For every example we provide the LS and GLS expressed in the arbitrary power and the BLS and BGLS expressed in a normalised probability (so that the highest peak represents 100% probability). We show the Bayesian periodograms on a linear scale and on a logscale, where it is clearer that they are indeed linked to their non-Bayesian versions. Note that the plots on logscale show a horizontal offset between the BLS and BGLS. This is due to the normalisation of the highest peak to 100%.
 |
Fig. 1 Simulated data (black points) to show the effect of weighting the datapoints using the errorbars. The real underlying signal with a period of 105 days and a semi-amplitude of 1 is represented by the black curve. |
 |
Fig. 2 Periodograms of the simulated data from Fig. 1. The top panel shows the non-Bayesian versions, the middle and bottom panels show the Bayesian versions on a linear and logscale. |
To consider the weighting of the data points, we simulated 100 unevenly spaced data points over a range of 180 days. The real underlying signal in these data has a period of 105 days and a semi-amplitude of 1. Half of the points have a mean error bar of 0.4, the other half have a mean error bar of 1.1. Furthermore, by this addition of random white noise, the less precise points also deviate more from the underlying periodic signal. In real observations, this can easily occur because the precision of measurements strongly depends on the observing conditions (e.g. seeing, exposure time, instrument setup), and periodic signals hidden in the data often have semi-amplitudes of the order of the error bars.
The simulated data and the real underlying signal are shown in Fig. 1. The resulting periodograms are shown in Fig. 2. While the 105-day period signal is clearly detected by the (B)GLS, the (B)LS does not single out that period as the most significant. Instead, it settles on a period of around 50 days. In both the non-Bayesian and Bayesian periodograms, this is clear. Furthermore, the second peak in the (B)LS lies not exactly at 105 days either, but more towards a slightly shorter period.
 |
Fig. 3 Simulated data (black points) to show the effect of including an offset in the analysis. The real underlying signal with a period of 50 days and a semi-amplitude of 1 is represented by the black curve. |
Including a constant offset in the data analysis allows for the mean of the data to be different from the mean of the fitted sine function. These two means can be very different depending on the sampling of the data. For real observations, especially if they are ground-based, the sampling is constrained by the observation opportunities (night versus day, weather conditions, seasonal visibility, etc.). To illustrate the effect of this periodic sampling and thus the inclusion of an offset, we simulated 100 unevenly spaced data points over a range of 170 days. The real underlying signal in these data has a period of 50 days, a semi-amplitude of 1, and a mean of zero. The data were chosen so that most points lie above −0.3 thus creating large gaps in the data of almost no observations.
The simulated data are shown in Fig. 3 together with the underlying sine function. The data have a mean of 0.5484, substantially different from the mean of the underlying sine function, which is zero. The resulting periodograms are shown in Fig. 4. It is immediately clear that only the GLS and BGLS are able to correctly identify the true period. It is also interesting to note that the GLS shows two peaks of about the same height at 50 and 25 days. By using the GLS alone, it would not be possible to know unambiguously which period is the real one in the data. In the BGLS, on the other hand, it is very clear that the longer period (which is the true one) is about 1010 times more probable than the other period.
 |
Fig. 4 Periodograms of the simulated data from Fig. 3. The top panel shows the non-Bayesian versions, the middle and bottom panels show the Bayesian versions on a linear and logscale. |
If the data are randomly sampled and include an offset, the mean of the data will be close enough to the value of this offset so that it can easily be subtracted. In this case, all four periodograms we discussed will identify the correct period. More details can be found in Appendix B.
5. Conclusion
We formulated an expression for calculating the Bayesian generalised Lomb-Scargle periodogram (given in Eq. (27)). Part of the exponent in that expression is the power for the GLS as given by Zechmeister & Kürster (2009), clearly linking the two expressions. A Python-based code is available for the community at https://www.astro.up.pt/exoearths/tools.html.
This expression is valid for all unevenly sampled datasets for which Eq. (30) does not hold for all even or all odd values of k. If these equations would hold anyway, we provided the corresponding (simplified) expressions in Sect. 3.
We repeat that this formalism was reached by making some assumptions. First, we assumed that the parameters f, A, B, and γ are independent. Second, we assumed uniform priors for these parameters. The same assumptions were made in Bretthorst (2001). If different assumptions were used, the formalisms in either works are no longer valid.
We simulated two datasets to show the differences between the LS, BLS, GLS, and BGLS. We showed that the generalised periodograms work best for recovering the correct frequencies. Furthermore, we showed that for two peaks with similar heights in the GLS, the BGLS can clarify which peak is the more probable and by how much. We therefore conclude that the BGLS is the most powerful way to explore periodicities in unevenly spaced datasets.
As a final note, we caution that the four periodograms we described and used all assume a single-frequency signal in the data. If multiple frequencies are present in the data (with similar or different amplitudes), all of these formalisms can fail in detecting the correct frequencies. There are some codes in the literature to make multi-frequency periodograms (e.g. Baluev 2013). However, these also rely on single-frequency periodograms for an initial assessment of the possible frequencies since correctly calculating a multi-frequency periodogram needs too much computing time (Baluev 2013). Furthermore, we note that a periodogram gives no information about the physical nature of the signal it detects, and one should always be careful with using the periodogram output.
They cannot be zero at the same time.
We chose to label the ordinates as RV and they are expressed in arbitrary units.
Acknowledgments
The research leading to these results received funding from the European Union Seventh Framework Programme (FP7/2007-2013) under grant agreement number 313014 (ETAEARTH). We also acknowledge the support from Fundação para a Ciência e a Tecnologia (FCT, Portugal) through FEDER funds in program COMPETE, as well as through national funds, in the form of grants reference RECI/FIS-AST/0176/2012 (FCOMP-01-0124-FEDER-027493) and RECI/FIS-AST/0163/2012 (FCOMP-01-0124-FEDER-027492). We also acknowledge the support from the European Research Council/European Community under the FP7 through Starting Grant agreement number 239953 and the Marie Curie Intra-European Fellowship with reference FP7-PEOPLE-2011-IEF, number 300162 (for CC). N.C.S. was supported by FCT through the Investigador FCT contract reference IF/00169/2012 and POPH/FSE (EC) by FEDER funding through the program Programa Operacional de Factores de Competitividade - COMPETE. A.S. is supported by the European Union under a Marie Curie Intra-European Fellowship for Career Development with reference FP7-PEOPLE-2013-IEF, number 627202.
References
- Aerts, C., Christensen-Dalsgaard, J., & Kurtz, D. W. 2010, Asteroseismology, Astron. Astrophys. Lib. (Springer Science) [Google Scholar]
- Baluev, R. V. 2013, MNRAS, 436, 807 [NASA ADS] [CrossRef] [Google Scholar]
- Bastien, F. A., Stassun, K. G., Pepper, J., et al. 2014, AJ, 147, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Bayes, M., & Price, M. 1763, Philosophical Transactions, 53, 370 [Google Scholar]
- Bretthorst, G. L. 2001, in Bayesian Inference and Maximum Entropy Methods in Science and Engineering, ed. A. Mohammad-Djafari, AIP Conf. Ser., 568, 241 [Google Scholar]
- Cumming, A., Marcy, G. W., & Butler, R. P. 1999, ApJ, 526, 890 [NASA ADS] [CrossRef] [Google Scholar]
- Dumusque, X., Pepe, F., Lovis, C., et al. 2012, Nature, 491, 207 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Ferraz-Mello, S. 1981, AJ, 86, 619 [NASA ADS] [CrossRef] [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [NASA ADS] [CrossRef] [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [NASA ADS] [CrossRef] [Google Scholar]
- Zechmeister, M., & Kürster, M. 2009, A&A, 496, 577 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Proof for Eq. (18)
If the cosine and sine functions are orthogonal, it holds that 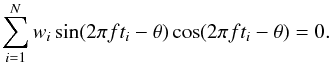 (A.1)We can evaluate the sine and the cosine by using the trigonometric addition formulae:
(A.1)We can evaluate the sine and the cosine by using the trigonometric addition formulae: ![Mathematical equation: \appendix \setcounter{section}{1} \begin{eqnarray} \sin(2\pi ft_i - \theta) &=& \sin(2\pi ft_i)\cos\theta - \cos(2\pi ft_i)\sin\theta \\[3mm] \cos(2\pi ft_i - \theta) &=& \cos(2\pi ft_i)\cos\theta + \sin(2\pi ft_i)\sin\theta . \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq67.png) The product of the sine and cosine then becomes
The product of the sine and cosine then becomes ![Mathematical equation: \appendix \setcounter{section}{1} \begin{eqnarray} &&\hspace*{-3mm}\sin(2\pi ft_i)\cos(2\pi ft_i)\cos^2\theta + \sin^2(2\pi ft_i)\sin\theta\cos\theta\nonumber \\[3mm] &&\hspace*{-3mm}- \sin(2\pi ft_i)\cos(2\pi ft_i)\sin^2\theta - \cos^2(2\pi ft_i)\sin\theta\cos\theta . \end{eqnarray}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq68.png) (A.4)Now we can use the double-angle formulae to derive that Eq. (A.1) can be written as
(A.4)Now we can use the double-angle formulae to derive that Eq. (A.1) can be written as 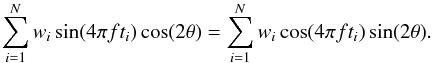 (A.5)From here it easily follows that
(A.5)From here it easily follows that 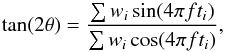 (A.6)and thus that Eq. (18) holds,
(A.6)and thus that Eq. (18) holds, ![Mathematical equation: \appendix \setcounter{section}{1} \begin{equation} \theta = \frac{1}{2}\tan^{-1}\left[\frac{\sum w_i\sin(4\pi f t_i)}{\sum w_i\cos(4\pi f t_i)} \right]\cdot \end{equation}](/articles/aa/full_html/2015/01/aa24908-14/aa24908-14-eq71.png) (A.7)
(A.7)
Appendix B: Example with offset on randomly sampled data
To illustrate the effect of an offset if the data are randomly sampled, we include here an additional example. We simulated 100 nevenly spaced, but randomly sampled data points over a range of 180 days. The real underlying signal in these data has a period of 50 days, a semi-amplitude of 1, and an offset of 2.5. To calculate the LS and the BLS, the mean of the data is subtracted first. In this case, the mean is 2.42, thus very close to the offset value.
The simulated data, including the offset, is shown in Fig. (B.1) together with the underlying sine function, which includes no offset. The resulting periodograms are shown in Fig. (B.2). As expected, the four periodograms all identify the same (and correct) period. From the Bayesian periodograms, it is clear that the identified period is more probable using the BGLS than it is using the BLS (though both are highly significant). This is because the mean of the data is very close to the offset value, but not exactly the offset value.
 |
Fig. B.1 Simulated data (black points) to show the effect of an offset (of 2.5) on randomly sampled data. The underlying signal with a period of 50 days and a semi-amplitude of 1 is represented without the offset (black curve). |
 |
Fig. B.2 Periodograms of the simulated data from Fig. B.1. The top panel shows the non-Bayesian versions, the middle and bottom panel show the Bayesian versions on a linear and logscale. |
All Figures
|
Fig. 1 Simulated data (black points) to show the effect of weighting the datapoints using the errorbars. The real underlying signal with a period of 105 days and a semi-amplitude of 1 is represented by the black curve. |
| In the text | |
|
Fig. 2 Periodograms of the simulated data from Fig. 1. The top panel shows the non-Bayesian versions, the middle and bottom panels show the Bayesian versions on a linear and logscale. |
| In the text | |
|
Fig. 3 Simulated data (black points) to show the effect of including an offset in the analysis. The real underlying signal with a period of 50 days and a semi-amplitude of 1 is represented by the black curve. |
| In the text | |
|
Fig. 4 Periodograms of the simulated data from Fig. 3. The top panel shows the non-Bayesian versions, the middle and bottom panels show the Bayesian versions on a linear and logscale. |
| In the text | |
|
Fig. B.1 Simulated data (black points) to show the effect of an offset (of 2.5) on randomly sampled data. The underlying signal with a period of 50 days and a semi-amplitude of 1 is represented without the offset (black curve). |
| In the text | |
|
Fig. B.2 Periodograms of the simulated data from Fig. B.1. The top panel shows the non-Bayesian versions, the middle and bottom panel show the Bayesian versions on a linear and logscale. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.