| Issue |
A&A
Volume 573, January 2015
|
|
|---|---|---|
| Article Number | A100 | |
| Number of page(s) | 14 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/201423793 | |
| Published online | 06 January 2015 | |
The WFCAM multiwavelength Variable Star Catalog⋆
1 Departamento de Física Teórica e Experimental, Universidade Federal do Rio Grande do Norte, 59072-970 Natal, RN, Brazil
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Instituto de Astrofísica, Pontificia Universidad Católica de Chile, Av. Vicuña Mackenna 4860, 782-0436 Macul, Santiago, Chile
3 Millennium Institute of Astrophysics, Santiago, Chile
4 SUPA (Scottish Universities Physics Alliance) Wide-Field Astronomy Unit, Institute for Astronomy, School of Physics and Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
5 Gemini Observatory, Colina El Pino, Casilla 603, La Serena, Chile
Received: 11 March 2014
Accepted: 12 August 2014
Abstract
Context. Stellar variability in the near-infrared (NIR) remains largely unexplored. The exploitation of public science archives with data-mining methods offers a perspective for a time-domain exploration of the NIR sky.
Aims. We perform a comprehensive search for stellar variability using the optical-NIR multiband photometric data in the public Calibration Database of the WFCAM Science Archive (WSA), with the aim of contributing to the general census of variable stars and of extending the current scarce inventory of accurate NIR light curves for a number of variable star classes.
Methods. Standard data-mining methods were applied to extract and fine-tune time-series data from the WSA. We introduced new variability indices designed for multiband data with correlated sampling, and applied them for preselecting variable star candidates, i.e., light curves that are dominated by correlated variations, from noise-dominated ones. Preselection criteria were established by robust numerical tests for evaluating the response of variability indices to the colored noise characteristic of the data. We performed a period search using the string-length minimization method on an initial catalog of 6551 variable star candidates preselected by variability indices. Further frequency analysis was performed on positive candidates using three additional methods in combination, in order to cope with aliasing.
Results. We find 275 periodic variable stars and an additional 44 objects with suspected variability with uncertain periods or apparently aperiodic variation. Only 44 of these objects had been previously known, including 11 RR Lyrae stars on the outskirts of the globular cluster M 3 (NGC 5272). We provide a preliminary classification of the new variable stars that have well-measured light curves, but the variability types of a large number of objects remain ambiguous. We classify most of the new variables as contact binary stars, but we also find several pulsating stars, among which 34 are probably new field RR Lyrae, and 3 are likely Cepheids. We also identify 32 highly reddened variable objects close to previously known dark nebulae, suggesting that these are embedded young stellar objects. We publish our results and all light curve data as the WFCAM Variable Star Catalog.
Key words: stars: variables: general / infrared: stars / dust, extinction / stars: formation / techniques: photometric / methods: analytical
Tables 4–6 are only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/573/A100
© ESO, 2015
1. Introduction
Time-varying celestial phenomena in general represent one of the most substantial sources of astrophysical information, and their study has led to many fundamental discoveries in modern astronomy. Pulsating stars provide insight into to stellar interiors through asteroseismology (e.g., Handler 2012) and serve as standard candles (e.g., Walker 2012), eclipsing binaries allow us to determine the most accurate stellar masses and radii (e.g., Clausen et al. 2008), and supernovae provide important means for estimating cosmological distances and probing the large-scale structure of our Universe (e.g., Riess et al. 1998; Tonry et al. 2003) – just to mention some classical scopes among the countless aspects of time-domain astronomy.
The ever-growing interest in various astronomical time-series data, as well as the tremendous development in astronomical instrumentation and automation during the past two decades, have been giving rise to several time-domain surveys of increasing scale. Wide-field shallow optical imaging surveys using small, dedicated telescope systems have been scanning the sky since the early 2000s with aims ranging from comprehensive stellar variability searches to exoplanet hunting, such as the Northern Sky Variability Survey (NSVS, Hoffman et al. 2009), All Sky Automated Survey (ASAS, Pojmanski 2002), Wide Angle Search for Planets (WASP, Pollacco et al. 2006), and the Hungarian Automated Telescope Network (HATnet, Bakos et al. 2004). The interest in transient events like microlensing have led to deeper, higher-resolution photometric campaigns such as the Massive Astrophysical Compact Halo Objects Survey (MACHO, Alcock et al. 1993) and the Optical Gravitational Lensing Experiment (OGLE, Udalski 2003), and to some ultra-wide surveys such as the Palomar Transient Factory (PTF, Law et al. 2009) or the Catalina Real-time Transient Survey (Drake et al. 2009). The development of imaging technology is leading toward deep all-sky surveys with seeing-limited resolution, and Pan-STARRS (Kaiser et al. 2002), representing the first generation of such programs, is already operational. In the near future, even more ambitious programs, such as the Large Synoptic Survey Telescope (LSST, Krabbendam & Sweeney 2010) and Gaia (Perryman 2005), are planned to start monitoring the optical sky. These synoptic surveys are expected to be the new powerhouses of modern astronomy by providing a high data flow for a wide range of science applications, from the study of transients to understanding the dynamics of the Milky Way galaxy.
While optical synoptic surveys are getting wider and deeper, extending the systematic exploration of the variable sky toward other wavelengths, such as the infrared, is also indispensable, not only for a more complete understanding of the observed phenomena, but also for overcoming the problem of interstellar extinction. Infrared time-series photometry had long been constrained mostly to follow-up observations of known objects, but in recent years near-infrared (NIR) imagers have been converging to optical CCDs in terms of resolution and performance, hence wide-field surveys became feasible with some NIR instruments, such as the Wide-Field near-IR CAMera (WFCAM; Casali et al. 2007) on the 3.8 m United Kingdom Infrared Telescope (UKIRT), and the VISTA InfraRed CAMera (VIRCAM; Dalton et al. 2006) on the 4.1 m Visible and Infrared Survey Telescope for Astronomy (VISTA), both hosting a variety of deep Galactic and extragalactic surveys. Nevertheless there are only a handful of wide-field NIR time-domain surveys that have more than a handful of observational epochs, with only the VISTA Variables in the Vía Láctea survey (VVV; Minniti et al. 2010) being comparable to the optical ones in terms of both areal and time-domain coverage (e.g., Arnaboldi et al. 2007, 2012).
Besides the results from the large-scale surveys, valuable time-series data are also being generated by a variety of observational programs as sideproducts. Such data can well be quite heterogeneous and not always be complete completeness, since the original design of the data acquisition might have served various specific purposes. Nevertheless, multi-epoch data accumulated over a period of time from various observational programs using the same facility can hold vast unexploited information and represent a potential treasure trove for time-domain astronomy (see, e.g., the TAROT variable star catalog by Damerdji et al. 2007). An increasing number of observatories and projects realize the importance of standardizing their archives and incorporating them into the Virtual Observatory, allowing the community to exploit their data further once their proprietary periods have expired. There is already a wealth of fully public science-ready synoptic data from state-of-the-art instruments, which are accessible by standard data mining tools, waiting for analysis.
This paper is based on public time-domain data from the WFCAM Science Archive (WSA; Hambly et al. 2008). WFCAM was designed to be capable of carrying out ambitious large-scale survey programs such as the UKIRT Infrared Deep Sky Surveys (UKIDSS; Lawrence et al. 2007). The detector consists of four arrays of 2048 × 2048 pixels, arranged in a non-contiguous square pattern, providing a resolution of 0.4″ per pixel. A contiguous image with an areal coverage of 0.78 deg2 can be constructed by a mosaic of four consecutive offset pointings. Other properties of the instrument are discussed in full detail by Casali et al. (2007). The standard UKIRT photometric system consists of the MKO J, H, and K bands (see Simons & Tokunaga 2002; Tokunaga et al. 2002) complemented with the Z and Y filters. In addition, three narrow-band filters (H2, Brγ, and nbj) are also available (see Hewett et al. 2006 for further details).
All WFCAM data produced by the UKIDSS surveys and other smaller campaigns and PI projects employing the instrument are processed by the VISTA Data Flow System (VDFS; Emerson et al. 2004). VDFS was designed to initially handle UKIDSS, and includes both pipeline processing at the Cambridge Astronomical Survey Unit (CASU1) and further pipeline processing of the CASU products and digital curation at the WSA. Data for standard photometric zero-point calibration of and color term determination for the WFCAM filters are taken regularly and are also fully processed and archived by the VDFS in the same way as the survey data. During the several years of operation of WFCAM, a large amount of fully processed, high-quality, multiband photometric data have been collected during the observations of calibration fields, which are publicly available at the WSA. Since the majority of these fields have been visited several times over many years, these data provide an excellent opportunity for studying variable stars in the NIR.
In this paper, we perform a comprehensive stellar variability analysis of the public WFCAM Calibration (WFCAMCAL) Database (release 08B) and present the photometric data and characteristics of the identified variable stars as the WFCAM Variable Star Catalog, version 1 (WVSC1). The paper is structured as follows. In Sect. 2, we present the database and its characteristics from a data miner’s point of view and describe the primary source selection procedure. In Sect. 3, we introduce and discuss a set of variability indices designed for synoptic data with correlated sampling, and we employ these indices as a first selection of candidate variable sources in the WFCAM data. We present a frequency analysis of the candidate variable sources in Sect. 4. In Sect. 5, we present the WVSC1 by describing its structure and discussing its variable star content. Finally, in Sect. 6, we draw our conclusions and discuss some future perspectives.
2. The WFCAMCAL database
WFCAM on-sky image data are pipeline-processed by the VDFS, which incorporates all data reduction steps from image processing to photometry. The various processing steps are described fully by Emerson et al. (2004), and accordingly we limit ourselves to discussing some key aspects. Individual exposures go through the standard preprocessing steps, such as flat fielding and dark subtraction. As is common practice in the NIR, science frames are composed of a set of dithered images, i.e. subsequent exposures taken in step patterns of several arcseconds, in order to allow for the removal of bad detector pixels and to image the structure of the atmospheric IR foreground for its subtraction before stacking the dither sequence. These so-called detector frame stacks are the final image products of calibration field observations, but we note that some WFCAM survey images are combined further to form contiguous mosaic images also known as tiles. Deep stack images are also produced, in order to push the limiting magnitudes and measure the fluxes of faint sources.
Further steps in the reduction include source extraction and aperture photometry using a set of small circular apertures with radii of 0.5, 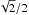 , 1,
, 1, 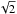 , and 2 arcsec, in order to maximize the signal-to-noise ratio and remedy systematics due to source crowding (Cross et al. 2009). Flux loss in the wings of the point spread functions (PSFs) is corrected for Irwin et al. (2004). Each identified source of the catalogs is classified based on the shape of its PSF, and various quality flags are also assigned. Astrometric calibration is performed using 2MASS (Skrutskie et al. 2006) stars as reference, and positions have a typical accuracy of 0.1″. Magnitudes are corrected for distortion effects and are zero-point-calibrated on a frame-by-frame basis using a many of secondary standard stars from the 2MASS catalog (Skrutskie et al. 2006). This involves color corrections from the 2MASS JHKs to WFCAM ZYJHK. The calibration process is described in detail in Hodgkin et al. (2009). Many calibration fields (which form the basis of this paper) are also observed repeatedly under photometric conditions, in order to provide standard star measurements for the calibrations of the Z, Y, and narrow-band magnitudes, as well as to provide data for the color-term determination for transforming 2MASS magnitudes into the WFCAM photometric system. The accuracy of the magnitude zero-points of these fields is a few percent. We note that all magnitude data in the WSA and in our study alike are on the WFCAM magnitude system.
, and 2 arcsec, in order to maximize the signal-to-noise ratio and remedy systematics due to source crowding (Cross et al. 2009). Flux loss in the wings of the point spread functions (PSFs) is corrected for Irwin et al. (2004). Each identified source of the catalogs is classified based on the shape of its PSF, and various quality flags are also assigned. Astrometric calibration is performed using 2MASS (Skrutskie et al. 2006) stars as reference, and positions have a typical accuracy of 0.1″. Magnitudes are corrected for distortion effects and are zero-point-calibrated on a frame-by-frame basis using a many of secondary standard stars from the 2MASS catalog (Skrutskie et al. 2006). This involves color corrections from the 2MASS JHKs to WFCAM ZYJHK. The calibration process is described in detail in Hodgkin et al. (2009). Many calibration fields (which form the basis of this paper) are also observed repeatedly under photometric conditions, in order to provide standard star measurements for the calibrations of the Z, Y, and narrow-band magnitudes, as well as to provide data for the color-term determination for transforming 2MASS magnitudes into the WFCAM photometric system. The accuracy of the magnitude zero-points of these fields is a few percent. We note that all magnitude data in the WSA and in our study alike are on the WFCAM magnitude system.
The calibrated source catalogs undergo further curation steps at the WSA, including quality control, source merging, and both internal and external cross-matching. Enhanced image products (e.g., deep stacks) are also created. Final science-ready data are ingested into a relational database, which offers various server-side data management tools. Data can be queried by using the Structured Query Language (SQL). The design of the WSA, the details of the data curation procedures and the layout of the database are described in great detail in Hambly et al. (2008) and Cross et al. (2009). In the following, we highlight some other properties of the data in the WFCAMCAL archive, with an emphasis on some important details for the time-series analysis.
2.1. Data characteristics
The WFCAMCAL archive’s data release 08B contains data from 52 individual pointings from both the northern and southern hemispheres, spread over nearly half of the sky. These calibration fields are located between declinations of 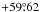 and
and 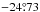 , distributed over the full range in right ascension in order to provide standard star data year-round. The positions of the pointings are shown Fig. 1. Each pointing consists of a non-contiguous area covered by the four WFCAM chips, covering ~0.05 square degrees each. The total area covered by all standard star fields is ~10.4 square degrees.
, distributed over the full range in right ascension in order to provide standard star data year-round. The positions of the pointings are shown Fig. 1. Each pointing consists of a non-contiguous area covered by the four WFCAM chips, covering ~0.05 square degrees each. The total area covered by all standard star fields is ~10.4 square degrees.
 |
Fig. 1 Celestial distribution of our initial database of stellar sources from the WFCAMCAL08B archive. |
The majority of the fields are observed repeatedly, with a rather irregular sampling. A field is usually visited at most a few times during a night, with the visits separated by up to a few hours. During each visit, the field is usually (but not necessarily) observed through the JHK or the ZYJHK filter set, and occasionally through the narrow-band filters as well, all within a few minutes. A certain field is usually observed again within a few days, although longer time gaps are common, and of course large seasonal gaps are also present in the data set. The total baseline of the time series is largely field-dependent and varies from a few months up to three years. The time sampling (cadence) in a single passband can be considered to be quasi-stochastic with rather irregular gaps, which is a favorable scenario for detecting periodic signals over a wide range of periods. Figure 2 shows the spectral window of a typical one among the well-sampled K-band light curves in the database, showing that only one-day and one-year aliases are significant. However, the sampling in different passbands is very strongly correlated.
 |
Fig. 2 Spectral window of a typical well-sampled K-band light curve from the WFCAMCAL database, showing two different frequency ranges. |
The VDFS performs an accurate and deep source extraction procedure on deep stack images, which, in the case of the WFCAMCAL database, is merged from the seven best-seeing frames to reduce any problems with blending (Cross et al. 2009). This curation step gives rise to database entities known as Sources. Positional cross-matches between these Sources and detections from different single detector frame stacks are then performed for each frame set (i.e., images with the same pointing). The prescriptions for this cross-matching procedure and its limitations are given by Hambly et al. (2008, see their Sect. 3.4.2). Each Source of the database contains only partial information from a set of source detections positionally matched with each other, but is related to a set of pointers that track all the attributes of the corresponding detections. We note that after cross-matching, the VDFS also recalibrates the individual epochs after comparison to the deep stack to improve the light curves. The resulting source-merged catalog is stored in WSA’s relational database, which in the case of WFCAMCAL data, follows a synoptic database model designed for observations with correlated sampling (Cross et al. 2009). Since the observations of the standard star fields through different filters are always taken within a time interval that is several orders of magnitude shorter than the interval between two successive observation batches (i.e., visits of the same field, see above), they can be considered to be virtually at the same epoch. Individual source detections in different filters for each epoch (i.e., filter sequence) are therefore merged and stored in a database entity called synoptic source, and these are linked to Sources (see above). Various metadata of the time series formed by the detections associated to each Source are also provided by WSA as the attributes of the variability table, providing the best aperture for a given source, together with basic statistics on the magnitude distribution, time sampling, etc. In passing we note that this table also provides a basic assessment on the probability that a source is variable in each band, based on the comparison of the rms scatter of the time series to its expected value from a simple noise model (see Cross et al. 2009). Although these pieces of information can provide useful guidance for the user, we opted not to use these attributes as criteria in our source selection, since our aim is to perform a more profound variability search in the data.
2.2. Initial source selection
Data were retrieved in a two-step procedure via WSA’s freeform SQL query facility2. We queried all Sources that were classified as a star or probable star based on the PSF statistics of the merged source, having at least ten unflagged epochs in either of the eight filter passbands.
Morphological classification of sources in the WFCAMCAL archive.
Number of sources, average total baseline (⟨ Ttot ⟩, in days), and average number of epochs ⟨ Nep ⟩ in each filter, in our initial database.
Our selection resulted in an initial database of 216 722 sources containing their identifiers and general attributes such as positions, basic flux, and sampling statistics. Figure 3 shows histograms of the queried light curves and the average total baseline length as a function of the number of epochs, while Tables 1 and 2 summarize some basic statistics of the queried data. The sampling of the time domain is rather heterogeneous, thus we must emphasize that the WFCAMCAL archive should not be considered as a synoptic survey database, for its completeness is highly varying from field to field; accordingly, care must be taken with any statistical interpretation based on these data. However, there are a large number of light curves with very good sampling that have ~100 data points in three to band broad-band filters, with a total baseline of up to 3 years. Since the number of data points in the narrow-band filters is generally very low, we do not use these measurements for the variability search, but they are provided (if available) for the detected variable sources in our catalog.
With the result of our first selection query at hand, we queried the complete light curves of each source by linking their entries in the Source table to the attributes of the Synoptic Source table. This procedure requires the generation of a temporary SQL table provided by the user containing the identifiers of the Sources from the first query. We note that some data, such as Julian Dates and zero-point errors, are stored in different database objects like the Multiframe table, which require the execution of further table joins. We selected magnitudes with sufficiently small error bits (<128), rejecting highly saturated measurements and data affected by various severe defects (e.g., bad pixels, poor flat-field region, detection close to frame boundary, etc.).
 |
Fig. 3 Number of sources (Ns) as a function of the number of epochs (Nep.) for the queried J- (left) and Z-band (right) light curves with a bin size of 10 days. The distribution corresponding to the other broad bands are very similar. The solid curves show the average total baseline length as a function of the number of epochs for the queried light curves in the same filters with a bin width of 2 days. |
3. Broad selection by variability indices
A key characteristic of the time-series data in the WFCAMCAL database is that, owing to the observation strategy, their sampling is strongly correlated in the different filters (see Sect. 2.1). The characteristic time lag between data points in different filters in an observing sequence (i.e., a standard visit of a calibration field) is not longer than a few minutes, which is orders of magnitude shorter than the typical time gap between such batches of data and also than the time scales of stellar variability at amplitudes that are typically recoverable by the present sampling and accuracy. This property of the data enables us to search for stellar variability through correlations between the temporal flux changes at different wavelengths.
In our approach to stellar variability searching, we make the following general assumptions: (i) intrinsic stellar variability is typically identifiable in a wavelength range that is wider than our broad-band filters (i.e., in more than one filter); (ii) it is sufficiently phase-locked at two close wavelengths, thus flux variations in neighboring wavebands will be correlated; and (iii) non-intrinsic variations will be typically stochastic. In point (iii) we also implicitly assume that wavelength-correlated systematics of instrumental and atmospheric origin, or due to possible data reduction anomalies, have amplitudes that are small to be enough comparable to those provided by stochastic variations. The most important deviation from this assumption for our data is due to the temporal saturation of bright objects, which can, however, be easily distinguished from stellar variability.
A commonly used approach to identifing stellar variability through correlations in flux changes is by the Welch-Stetson index (IWS; Welch & Stetson 1993; Stetson 1996). The idea behind this index is to separate stochastic variations from systematic trends by measuring the correlations in the deviations from the mean of data points that are located sufficiently close in time. It is defined as ![Mathematical equation: \begin{equation} I_{\rm WS} = \sqrt[]{\frac{1}{n(n - 1)}}\sum_{i=1}^{n}\left(\delta b_i \delta v_i \right), \label{eqstet} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq41.png) (1)
(1)
where 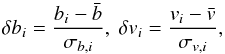 (2)
(2)
with bi, vi, and σb,i,σv,i denoting magnitudes and their errors (the latter computed following the prescriptions by Stetson 1981), respectively, taken on a time scale that is much shorter than that of the intrinsic stellar variations of interest. These magnitudes and errors can represent either successive monochromatic measurements or data points taken in two different filters. We also note that 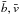 are weighted averages. Finally, n denotes the number of epochs, by which we also refer to the number of short time slots that contain subsequently taken measurements in the case of non-simultaneously observed data with strongly correlated sampling. The IWS index is found to be significantly more sensitive than the “traditional” χ2-test for single variance, which uses the magnitude-rms scatter distribution of the data as a predictor (see, e.g., Pojmanski 2002).
are weighted averages. Finally, n denotes the number of epochs, by which we also refer to the number of short time slots that contain subsequently taken measurements in the case of non-simultaneously observed data with strongly correlated sampling. The IWS index is found to be significantly more sensitive than the “traditional” χ2-test for single variance, which uses the magnitude-rms scatter distribution of the data as a predictor (see, e.g., Pojmanski 2002).
3.1. Extension of IWS to multiband data sets
According to the definition given in Eq. (1), IWS is limited to pairwise comparisons of fluxes. When it is applied its application to panchromatic data with measurements taken in several wavebands with correlated sampling, one would need to define some conversion of the pairwise indices into a single quantity. To accomplish this, we introduce the following modification to IWS, for quantifying panchromatic flux correlations (pfc): ![Mathematical equation: \begin{equation} I_{\rm pfc}^{(2)} = \sqrt{\frac{(n_{2}-2)!}{n_{2}!}}\sum_{i=1}^{n}\left\{ \sum_{j=1}^{m-1}\left[\sum_{k=j+1}^{m}\left( \delta u_{ij} \delta u_{ik} \right) \right] \right\}, \label{eq_pfc2} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq50.png) (3)
(3)
where n is the number of epochs, m is the number of wavebands, uij are the flux measurements, δuij is defined by Eq. (2) for each filter, and n2 = n·m ! / [2 ! (m − 2) !]. We note that, for m = 2, 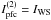 .
.
While Eq. (2) still measures variability through pairwise correlations of relative fluxes, we can generalize it for quasi-simultaneously measured batches of three data points (in case of m ≥ 3) by ![Mathematical equation: \begin{equation} I_{\rm pfc}^{(3)} = \sqrt{\frac{(n_{3}-3)!}{n_{3}!}}\sum_{i=1}^{n}\left\{ \sum_{j=1}^{m-2}\left[\sum_{k=j+1}^{m-1}\left( \sum_{l=k+1}^{m}\Lambda_{ijkl}^{(3)} \left| \delta u_{ij} \delta u_{ik} \delta u_{il} \right| \right) \right] \right\}, \label{eq_pfc3} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq58.png) (4)
(4)
where n3 = n·m ! / [3 ! (m − 3) !], and the Λ factor is defined as 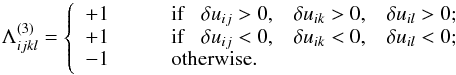 (5)
(5)
We note that we introduced Λ(3) to give the proper sign to the product in Eq. (4).
Finally, in the case of quasi-simultaneously measured batches of s data points (for m ≥ s), our variability index takes the following general form: ![Mathematical equation: \begin{equation} I_{\rm pfc}^{(s)} = \! \sqrt{\frac{(n_{s}-s)!}{n_{s}!}}\sum_{i=1}^{n}\left [\sum_{j_1=1}^{m-(s-1)}\!\!\!\cdots \left ( \sum_{j_s=j_{(s-1)}+1}^{m} \!\!\! \Lambda_{ij_1\cdots j_{s}}^{(s)} \left| \delta u_{ij_1} \cdots \delta u_{ij_s} \right| \right ) \right], \label{eq_pfcgen} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq65.png) (6)
(6)
where ns = n·m ! / [s ! (m − s) !], and the Λ(s) correction factor is 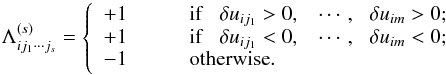 (7)
(7)
Clearly, these indices set increasingly strict constraints on the presence of variability with increasing order s.
3.2. An alternative variability index
While the 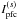 index is quite robust, in the sense that it is weighted with the individual errors, it can be insensitive to true variable stars for one or several substantially outlying data points when incorrect error estimates are present. Indeed, this index may even introduce false variability candidates if these outliers are correlated in two or more bands. Although such situations might seem rare, NIR data in particular can present us with these cases quite frequently, particularly in the case of bright stars. Since the sky foreground emitted by the atmosphere is highly variable in the NIR, it causes a highly time-varying saturation limit, which can affect large parts of otherwise highly accurate time-series data for bright stars with substantial outliers having very small formal error estimates. In case of correlated sampling, these outliers will probably be correlated between different filters, leading to a spurious impact upon the index.
index is quite robust, in the sense that it is weighted with the individual errors, it can be insensitive to true variable stars for one or several substantially outlying data points when incorrect error estimates are present. Indeed, this index may even introduce false variability candidates if these outliers are correlated in two or more bands. Although such situations might seem rare, NIR data in particular can present us with these cases quite frequently, particularly in the case of bright stars. Since the sky foreground emitted by the atmosphere is highly variable in the NIR, it causes a highly time-varying saturation limit, which can affect large parts of otherwise highly accurate time-series data for bright stars with substantial outliers having very small formal error estimates. In case of correlated sampling, these outliers will probably be correlated between different filters, leading to a spurious impact upon the index.
To alleviate the effect of such anomalous outliers, we introduce an alternative variability index that is similar to , but does not depend on the actual value of the flux deviations from the mean. This is simply obtained by keeping only the Λ function (Eq. (7)) in the sum that appears in Eq. (6). Thus, the flux-independent (fi) version of 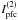 is defined as
is defined as ![Mathematical equation: \begin{equation} 2 \cdot I_{\rm fi}^{(2)} -1 = \frac{1}{n_{2}}\sum_{i=1}^{n}\left [\sum_{j=1}^{m-1}\left (\sum_{k=j+1}^m \Lambda_{ijk}^{(2)} \right ) \right], \label{eq_fi2} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq71.png) (8)
(8)
with 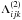 defined as
defined as 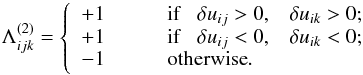 (9)
(9)
In this expression, the δu’s have the same meaning as before (e.g., Eq. (4)).
The righthand side of Eq. (8) thus gives the difference between the number of positive and negative terms in , so it can only take a number of discrete values (depending on the values of n and m). We note that, with the coefficients included on the lefthand side of Eq. (8), 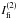 will always have absolute values between 0 and 1, analogously to a probability measure.
will always have absolute values between 0 and 1, analogously to a probability measure.
For higher orders s, 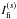 is defined similarly to Eq. (6):
is defined similarly to Eq. (6): ![Mathematical equation: \begin{equation} 2 \cdot I_{\rm fi}^{(s)} -1 = \frac{1}{n_{s}}\sum_{i=1}^{n}\left [\sum_{j_1=1}^{m-(s-1)}\cdots \left ( \sum_{j_s=j_{(s-1)+1}}^m \Lambda_{ij_1\cdots j_{s}}^{(s)} \right ) \right], \label{eq_figen} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq77.png) (10)
(10)
with  , and where
, and where 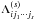 is defined as in Eq. (7).
is defined as in Eq. (7).
Thus, the index represents a problem of combining signals whose function 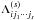 (Eq. (7)) assumes the values + 1 or − 1, depending on the sign of the correlation. The total number of possible combinations of signals in a set of s measurements, so that each group of signals is different from the other, is given by
(Eq. (7)) assumes the values + 1 or − 1, depending on the sign of the correlation. The total number of possible combinations of signals in a set of s measurements, so that each group of signals is different from the other, is given by 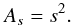 (11)
(11)
For the index , for instance, we have four possible configurations, namely (+ + , + − , − + , − −). According to elementary probability theory, in the case of statistically independent events, the probability that a given event will occur is obtained by dividing the number of events of the given type by the total number of possible events. For the index of any order, the desired events will be those in which all signals are either positive or negative, so that, irrespective of the value of s, the number of events desired always equals two, and the number of possible events is given by Eq. (11). In this way, the general expression that determines the probability value of a random event leading to a positive index is given by 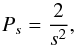 (12)
(12)
given that there are s2 events in total, but only two produce a positive value.
 |
Fig. 4 Number of combinations ns in the simulations described in the text. Since the |
3.3. Numerical tests
To establish robust criteria for selecting variable star candidates, we evaluated the responses of the and indices to statistical fluctuations. We generated a large number of test time-series sequences by shuffling the times (“bootstrapping”) of the WFCAMCAL data proper. By following this approach, we are able to keep part of the correlated nature of the noise intrinsic to the data, as opposed to numerical tests based on pure Gaussian noise. Figure 4 shows the histogram of the number of test time-series sequences as a function of the ns number of terms appearing in the variability indices (see Eqs. (6), (10)) for various s values. In total, 200 000 realizations were performed to our tests.
 |
Fig. 5 Variability indices versus the K-band magnitude, for the simulations (top two rows) and the actual data (bottom two rows), for three values of s, namely 2 (left), 3 (middle), and 4 (right). |
Figure 5 shows the distribution of the variability indices as a function of the average apparent brightness of the sources for both the bootstrapped and the corresponding original data. The excess of high values for bright sources, which is particularly evident for s = 2, is due to temporal saturation, which usually happens in more than one waveband at the same time. In this bright regime, as expected (Sect. 3.2), saturation affects the index much more frequently than it does . At the faint end, however, a number of effects can also be recognized. First, the quantized nature of the index (as opposed to the index; see Sect. 3) becomes pronounced in the distribution, owing to the higher relative frequency of sources with but a few epochs (typically ns ≲ 20) among the faint stars. (These are often not detected if the atmospheric foreground flux is too high.) Second, there is also an excess of sources with high index values at the faint end, which is due to the much lesser amount of data for these fainter sources, which makes the variability indices more sensitive to statistical fluctuations and systematics. The general trend in the distributions of the and are also rather different. Because it is sensitive only to the consistency in the direction of the flux changes, the is equally responsive to contaminating systematics of different amplitudes. This is reflected by both the slight increase in the main locus of the distribution of this index as a function of magnitude toward the bright end (see Fig. 5, lower panels) and the enhanced (false) response in the faint end, as discussed earlier. These are both caused by the increasing dominance of correlated noise over photon noise. We note that this is not shown by the bootstrapped data at the bright end, since the points of distinct pawprint batches were shuffled, and thus the correlations between them were mostly lost, while this is alleviated by the small number of points per light curve at the faint end.
Also noteworthy is that the simulated distributions that are shown in Fig. 5 are centered on the theoretically expected values (see Sect. 3), as given by Eq. (12), namely 0.5 in the case of s = 2, 0.25 in the case of s = 3, and 0.125 for s = 4. Moreover, the simulation results for the index show that the higher the order of the index, the lower the dispersion around 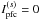 ; however, a pronounced level of scatter remains at both the bright and faint ends of the distribution. In addition, there is a symmetry between scatterings for the index and asymmetric scattering for
; however, a pronounced level of scatter remains at both the bright and faint ends of the distribution. In addition, there is a symmetry between scatterings for the index and asymmetric scattering for 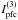 and
and 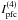 , both of which primarily scatter toward negative values, particularly at the bright end. This happens because the number of possible configurations of signs that lead to a Λ = + 1 (Eq. (7)) is always equal to two, whereas the number of possible configurations that lead to a Λ = −1 is instead given by s2 − 2. In this way, for s = 2, we have a symmetrical distribution of configurations of signs, whereas for s> 2 the asymmetry in relation to negative values grows as s2 − 2, as seen in the actual simulations.
, both of which primarily scatter toward negative values, particularly at the bright end. This happens because the number of possible configurations of signs that lead to a Λ = + 1 (Eq. (7)) is always equal to two, whereas the number of possible configurations that lead to a Λ = −1 is instead given by s2 − 2. In this way, for s = 2, we have a symmetrical distribution of configurations of signs, whereas for s> 2 the asymmetry in relation to negative values grows as s2 − 2, as seen in the actual simulations.
 |
Fig. 6 As in Fig. 5, but for the cutoff surfaces used to select our target list, and also adding ns as an independent variable. These surfaces set apart, at the 0.5% significance level, instances that are compatible with random noise (low values of the indices) from those that are compatible with coherent signal being present in the different passbands (high values of the indices). |
We estimated the significance levels of our variability indices based on their cumulative number density distributions obtained from our bootstrapped data set. In other words, we used our bootstrap simulations to set the signals apart that are compatible with pure random noise from the signals that indicate correlated variability in the different bandpasses. We expect these estimates to be highly dependent on the number of epochs n and the brightness (see above); accordingly, we obtained separate estimates for data within narrow ranges of n and K-band average magnitude, with values in between being obtained by interpolation. Figure 6 shows the result. In this figure, we show surfaces, in (index,ns,K) space that set random noise apart from correlated signals at the 0.5% significance level, according to our two variability indices, namely (top row) and (bottom row). As can be seen from Fig. 6, the corresponding cutoff values of the variability index show a relatively weak dependence on the magnitude and a strong dependence on ns, whereas the index depends strongly on both of these quantities. This is mainly attributed to the fact that the mean values of the formal errors (estimated from photon noise only), to which is very sensitive, increasingly underestimate the global scatter of the light curves toward lower magnitudes in this data set.
3.4. Initial selection of variable star candidates
We next computed the variability indices introduced in Sect. 3 for all sources in our initial database. As many as 99.3% of these sources had quasi-simultaneous observations in at least two filters, while 91.3% and 81.3% of them were observed in at least three and four filters, respectively. For each variability index, we selected all sources above its empirical, sampling, and magnitude-dependent 0.5% significance level described in Sect. 3.3. We considered a source as a candidate variable star if either value of its variability indices was significant. This procedure resulted in our initial catalog of 6651 candidate variable stars.
4. Frequency analysis
There are many methods available for computing periods in unevenly spaced time-series data, based mainly on Fourier analysis, information theory, and statistical techniques, among others (see, e.g., Templeton 2004, for a review). Some of these methods are based on the fact that the phase diagram of the light curve (also known as simply “phased light curve”) is smoothest when it is visualized using its real period. They transform the set of data by folding within the phase interval 0 ≤ ϕ(i) < 1, which is defined by the following expression: ![Mathematical equation: \begin{equation} \varphi(i) = \frac{t(i) - t_{0}}{P} - {\rm INT} \left[\frac{t(i) - t_{0}}{P} \right], \label{eqphi} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq109.png) (13)
(13)
where t is the time, t0 is the time origin, P is a test period, and INT denotes the integer function. Because of the presence of observational gaps, it often happens that computed phases can have the same numerical values for several different test periods. Many periods are spurious because they correspond to gaps that may be present in the data (e.g., daytime, seasons, etc.; Lafler & Kinman 1965). If P is the true period and Pgaps the period of gaps (Damerdji et al. 2007), spurious periods are given by 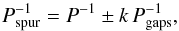 (14)
(14)
where k ∈N. In some cases, a spurious period could be ranked as the best period.
We searched for periodic variable stars in our initial catalog (see Sect. 3.4) by applying various frequency analysis methods in combination. To search for the best period (or, equivalently, frequency), many methods require that a search range (given by limiting frequencies f0 and fN at the low- and high-frequency ends, respectively) and resolution Δf be specified first. Since we are dealing with data sets with various different time spans, we adapted the f0 low-frequency limits to each light curve by f0 = 0.5 /Ttot, where Ttot is the total baseline of the observations, and we scaled the Δf frequency resolution bas Δf = 0.1 /Ttot. The method described by Eyer & Bartholdi (1999) was used to determine the high-frequency limit fN.
Initially, we applied the string-length minimization (SLM; Lafler & Kinman 1965; Stetson 1996) method on the light curves in our initial catalog of candidate variable stars. In this method, the period is found by minimizing the sum of the lengths of the segments joining adjacent points in the phase diagrams (called the “string lengths”) using a series of trial periods, i.e.: 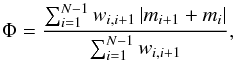 (15)
(15)
where 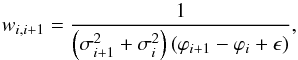 (16)
(16)
and ϕi, mi, and σi are phases, magnitudes, and corresponding magnitude uncertainties, respectively, sorted in order of increasing phase according to the trial period. The variable ϵ is a term that is added to reduce the weight of very closely spaced data in phase space, which otherwise could have a weight approaching infinity (Stetson 1996). In our work, we assumed ϵ = 1 /N, again following Stetson (1996).
To increase the probability that among the higher peaks of the periodogram derived on the basis of the SLM method the best period is included, we took the following additional steps:
-
the SLM periodogram was independently computed for each broadband filter (Y, Z, J, H, and K), based on which all periods that presented a power greater than the 3σ level every band were selected;
-
the SLM periodogram was also computed for the chromatic light curve, comprised of the sum of all broadband filters, and again all periods above the 3σ level were selected;
-
the results of the previous two steps were then combined, yielding the best periods (i.e., the ones with the highest amplitude peaks) from both types of analysis.
These steps are very important, because the same source can have photometry of high quality in some filters, but not others.
In the second step of the period search, we applied three additional frequency analysis methods, to select the ten best among the periods selected by the SLM method. For this step, we used the “classical” Lomb-Scargle (LS) periodogram (Lomb 1976; Scargle 1982), the generalized Lomb-Scargle (GLS) periodogram (Zechmeister & Külrster 2009), and the phase dispersion minimization (PDM; Stellingwerf 1978) methods. We included both LS and GLS because the latter gives unbiased estimates of the standard deviation of the measurements only when the photometric errors are good, easily leading to spurious results otherwise. The PDM method was included due to its high sensitivity to highly non-sinusoidal variations with alternating peaks, as in the case of the light curves of eclipsing binary systems.
We proceeded with our analysis as follows:
 |
Fig. 7 Phase-folded light curves of selected objects from our catalog of periodic variables (C1), showing data in all five broadband filters of WFCAM. ID’s, types, and periods for each object are shown in the headers. The object WVSC-208 was only detected in the Z and Y bands. |
-
for all light curves that were preselected by the SLM method, weindependently computed the periodogram using each of thesemethods and for each filter separately;
-
after inverting the spectra from the PDM and SLM methods, the periodograms for each filter were then normalized by the maximum power;
-
a single, normalized power spectrum was then obtained for each method by averaging over all filters the results obtained in the previous step for each filter independently;
-
finally, we obtained a ranked list of the best periods for each method.
The best periods should in principle be those that ranked highest in all four methods. However, not all methods rank periods in the same way. Therefore, to choose of periods in a more objective fashion, we computed a “super rank” index as the sum of the ranks provided by each of these five methods. We then selected the ten best periods as those ten most highly ranked, according to this new index.
Finally, in order to select the very best period, we use the χ2 test, in which Fourier coefficients (a0,ai,bi) are derived that fit the data according to the following expression: ![Mathematical equation: \begin{equation} f(i) = a_{0} + \sum_{i = 1}^{n}\left\{ a_{i}\sin\left[2 k \pi \varphi(i) \right] + b_{i}\cos\left[2 k \pi \varphi(i) \right] \right\}, \label{eq_best_harm} \end{equation}](/articles/aa/full_html/2015/01/aa23793-14/aa23793-14-eq135.png) (17)
(17)
where k = 1 /P. We used the Levenberg-Marquardt (Levenberg 1944; Marquardt 1963) method to find the solutions and employed the statistical F-test to evaluate the results. We limited the amplitude of the fit to the observed magnitude range (mmax − mmin) and kept the number of harmonics to n ≤ 20. The period that produced the lowest reduced χ2 value was selected as the true main period. Finally, we visually inspected the phase diagrams, which narrowed down our selection to our final catalog containing 275 periodic variable stars, as described in more detail in the next section.
5. Results and discussions
5.1. Catalog of periodic variable stars (C1)
Proceeding as described in the previous section, we have thus obtained our final sample of 275 clearly periodic variable stars (C1). Their coordinates, periods, mean magnitudes, and the number of epochs in each filter are listed in Table 4. We also provide preliminary classifications for most of the newly discovered variables. The variability types of these sources were assigned by visual inspection of their phase diagrams, and are also listed in Table 4, using the nomenclature of the General Catalog of Variable Stars3 (GCVS, Samus 1977). Phase-folded light curves for some of these objects are shown in Fig. 7.
 |
Fig. 8 Distribution of Ifi versus Ipfc variability indices, for orders 2 (left) and 3 (right). The C1 and C2 sources are indicated by red and green circles, respectively. |
Number of variable star candidates selected by the different variability indices at different significance levels before and after (in parentheses) visual inspection.
5.2. Catalog of aperiodic variable stars (C2)
We also searched for those stars that, in spite of showing reasonably coherent light curves, do not show a clear main periodicity in the WFCAMCAL data, either because their variations are intrinsically aperiodic or because they have such long periods that these data were insufficient for deriving them. To identify such sources, we relied only on the variability indices, requiring that these have highly significant values, indicating the presence of correlated variations in the different WFCAM bandpasses. First, we selected sources by using a strong cutoff at the sampling- and magnitude-dependent 0.1% significance level, equivalently to the procedure described in Sect. 3.4. Table 3 shows the number of selected sources based on each of the cutoff surfaces shown in Fig. 5, before and after visual inspection. The number of sources selected by the index is less than a third of the sources selected using the index, and at the same time, it includes 80% of all sources in C1 (Sect. 5.1). This high efficiency at a relatively low false alarm rate favored the application of the index alone for selecting aperiodic variable candidates, which was followed by a visual inspection in order to reject likely false candidates.
Our procedure has led to an additional 44 sources, comprising our catalog of semi-regular or aperiodic variable stars and stars with uncertain periods (C2), shown in Table 5. The selected variable star candidates, including both periodic (C1) and non-periodic (C2) sources, are shown in the [, ] plane (for s = 2 and 3) in Fig. 8. This figure clearly shows that the index is significantly more powerful, as far as distinguishing the variability in the WFCAM data is concerned, compared with the index, since there is much less overlap between variable and non-variable sources in the former than the latter. As a word of caution, we note that the C2 catalog could still contain spurious sources, mainly due to sources that show correlated seasonal variations and/or correlated noise variations. Follow-up studies of these sources is thus strongly recommended, before conclusively establishing their variability status.
 |
Fig. 9 Color-color (left panel) and color–magnitude (right panel) diagrams of the analyzed sample. New objects in C1 (in blue) and C2 (in red) and previously known objects (in green) are shown with colored points. Red arrows indicate the reddening vectors. |
5.3. Cross-identifications
As the final step in our analysis, we performed a systematic cross-check of the sample of 319 sources in C1 and C2 catalogs to identify previously known sources and complement our catalog with data already in the literature. Among the cross-checked catalogs, one finds the SIMBAD database, the latest version of the General Catalog of Variable Stars (Samus et al. 2012), the AAVSO International Variable Star Index (VSX v1.1, now including 284 893 variable stars; Watson et al. 2014), the New Catalog of Suspected Variable Stars (Kazarovets et al. 1998), and the Northern Sky Variability Survey (NSVS; Hoffman et al. 2009) catalog, among many other databases incorporated in the International Virtual Observatory Alliance (IVOA), using the Astrogrid facility4.
A delicate issue that we face when performing these extensive cross-checks between surveys with such diverse technical properties is their different astrometric accuracy. In this sense, we assumed a positional accuracy of 2″ in the sky coordinates for WFCAM, and then used optimized search radii according to the specific nature of each cross-matched database.
Taking the distribution of our sources across the sky into account, along with the specific nature of the observations that comprise the WFCAMCAL catalog, which were aimed at observing standard star fields and hence tended to avoid very crowded regions, it did not come as a surprise that the cross-checking with variability surveys of the southern sky and Galactic central regions, such as OGLE, MACHO, and ASAS, did not result in any positive match. We extended the search further to other astronomical catalogs of non stellar and/or extragalactic objects (e.g., planetary nebulae, quasars, optical counterparts of GRBs, just to mention a few) and in different spectral bands (from radio to X-rays), but again finding no superpositions with our WFCAM sources.
At the end of this search, we found a total of 44 stars that were already known from previous studies. Among them, 37 sources are included in the VSX catalog, three of which are also GCVS objects (i.e., AM Tau, EH Lyn, UV Vir, which are an Algol-type eclipsing binary, a contact binary, and an ab-type RR Lyrae, respectively). The GCVS also lists five other eclipsing binaries and another RRab Lyrae (HM Vir).
The outer part of the globular cluster M 3 (NGC 5272) is also partly covered by the WFCAMCAL pointings. Indeed, among our preselected variable candidates, we were able to recover 11 stars that had already been identified as RR Lyrae stars by Cacciari et al. (2005), Jurcsik et al. (2012), and Watson et al. (2014). Cross-identifications and literature variability types of the previously known sources are given for C1 and C2 in Tables 4 and 5, respectively.
5.4. Detection efficiency
To estimate the variable star detection efficiency of our method, we determined whether any variable stars in the WFCAM calibration fields that are known from other catalogs were not detected by us. Similar to the procedure described in Sect. 5.3, we performed positional cross-matches of our initial database of 216 722 light curves with all existing survey catalogs of variable stars incorporated in the IVOA. We found a total of 15 known variables (all of them periodic) that were missed by our search. Thirteen of them were excluded in the first broad selection phase (see Sect. 3) owing to the low values of their variability indices. The properties of these stars are listed in Table 6, and their WFCAM photometry is added to our catalog of periodic variable stars (C1), including a flag that refers to their non-detection as variables by our analysis.
Figure 10 shows four typical examples among the non-detected variables. The non-detection of these sources is either due to the insufficient phase coverage of their magnitude variations by WFCAM data (primarily in the cases of long-periodic eclipsing binaries with very low fractional transit lengths, see Fig. 10, upper panels) or due to saturation (Fig. 10, lower left panel) or to a very low signal-to-noise ratio.
Since the heterogeneity and small number of objects known from other variable star catalogs overlap with the WFCAMCAL fields make them insufficient for a quantitative assessment of our detection efficiency, we performed further tests using synthetic data. To do this we first built a database of noise-free LCs as being harmonic fits (see Eq. (17)) of actual C1 data, in each filter. Next, we generated 105 synthetic light curves, following the distributions of periods, amplitudes, and sampling of the final C1 catalog. Then, these synthetic light curves were added to segments of the real light curves of non-variable stars from the WFCAMCAL database. Finally, we applied the same procedures of variability search and period analysis that we discussed in Sects. 3 and 4 on the simulated data.
The result of our test is summarized by Fig. 11, which shows the detection efficiency Edet. = Ndet./Nall as a function of K magnitude using bins of 0.25 mag, where Ndet. is the number of detected variables, and Nall is the number of all variables, respectively. Based on this test, we estimate an average detection efficiency of 93% over the complete magnitude range of the WFCAM database. Detection rates lower than 90% are only present in the two extremes of the magnitude range, dominated by saturation in the bright end and low signal-to-noise ratio in the faint end. We note that the lower overall detection efficiency suggested by the catalog cross-matches is due to the biased magnitude distribution of the cross-matched sources toward the bright end of the WFCAM magnitude range.
 |
Fig. 10 Example light curves of 4 previously known variable stars that were not detected in our analysis. ID’s, variability types, and periods for each star are shown in the headers. |
 |
Fig. 11 Detection efficiency Edet. vs. K mean magnitude for 105 synthetic variables. |
5.5. Photometric properties of the variables
Figure 9 shows the variable and non-variable sources on the (H − K) − (J − H) color−color and the K − (J − K) color−magnitude planes. The variable sources cover the entire range of stellar parameter space in these planes. It is also clear from this figure that the area covered by the WFCAM Calibration fields have significant differential reddening, and a great fraction of the variables are reddened sources. This, together with the large aperture of the UKIRT telescope, explains the relatively low number of cross-identifications with previously known objects (Sect. 5.3): the WFCAMCAL database covers a range of faint NIR magnitudes where most of the optical variability surveys cannot penetrate, while most of the known variables in those catalogs are too bright for WFCAM.
We found 32 highly reddened (Z − K> 3) variable sources, 17 of which are periodic. We found that the positions of these red sources are strongly clustered around the positions α = 18h29.5m,δ = +1°36′ (25 sources), and α = 7h0m,δ = −4°51′ (8 sources). They are surrounded by a number of dark nebulae previously cataloged by Dobashi (2011) and Dutra & Bica (2002), respectively, suggesting that these sources might be embedded young stellar objects (see Tables 4, 5).
6. Conclusions
In this paper, we have established the WFCAM Variable Star Catalog, based on a detailed analysis of the WFCAMCAL NIR database. Our catalog contains 319 variable point sources, among which are 275 that are clearly periodic, and it includes 44 previously known objects. All catalog entries including multiband light curve data are available online via the WFCAM Science Archive (WSA)5. Our approach to variability analysis included introducing a new, flux-independent variability index that is highly insensitive to the presence of outliers in the time-series data. A cross-matching procedure with previous variable star catalogs was also carried out, and the few sources with previous identification in the literature are noted. These catalogs represent one of the first such resource in the NIR, and thus an important first step toward the interpretation of future, more extensive NIR variability data sets, such as will be provided by the Vista Variables in the Vía Láctea (VVV) Survey in particular (Catelan et al. 2013). A more detailed analysis of the different classes of variable stars detected in our catalog will be presented in a forthcoming paper.
A full description of the nomenclature can be found at http://www.sai.msu.su/gcvs/gcvs/iii/vartype.txt
Acknowledgments
Research activities of the Observational Astronomy Stellar Board of the Universidade Federal do Rio Grande do Norte are supported by continuous grants from the CNPq and FAPERN Brazilian agencies. We also acknowledge financial support from INCT INEspaco/CNPq/MCT. CEFL acknowledges a CAPES graduate fellowship and a CNPq/INEspaço postoctoral fellowship. Support for C.E.F.L., M.C., and I.D. is provided by the Chilean Ministry for the Economy, Development, and Tourism’s Programa Inicativa Científica Milenio through grant IC 12009, awarded to The Millennium Institute of Astrophysics (MAS); by Proyectos FONDECYT Regulares #1110326 and 1141141; by Proyecto Basal PFB-06/2007; and by Proyecto Anillo de Investigación en Ciencia y Tecnología PIA CONICYT-ACT 86. RA is supported by the Gemini Observatory, which is operated by the Association of Universities for Research in Astronomy, Inc., on behalf of the international Gemini partnership of Argentina, Australia, Brazil, Canada, Chile, and the United States of America. Additional support by project VRI-PUC 25/2011 is also gratefully acknowledged. ICL acknowledges a CNPq/PNPD postdoctral fellowship.
References
- Alcock, C., Allsman, R. A., Axelrod, T. S., et al. 1993, Sky Surveys. Protostars to Protogalaxies, 43, 291 [Google Scholar]
- Arnaboldi, M., Neeser, M. J., Parker, L. C., et al. 2007, The Messenger, 127, 28 [NASA ADS] [Google Scholar]
- Arnaboldi, M., Rejkuba, M., Retzlaff, J., et al. 2012, The Messenger, 149, 7 [NASA ADS] [Google Scholar]
- Bakos, G., Noyes, R. W., Kovács, G., et al. 2004, PASP, 116, 266 [NASA ADS] [CrossRef] [Google Scholar]
- Blažko, S. 1907, Astron. Nachr., 175, 325 [NASA ADS] [CrossRef] [Google Scholar]
- Blomme, J., Sarro, L. M., O’Donovan, F. T., et al. 2011, MNRAS, 418, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Cacciari, C., Corwin, T. M., & Carney, B. W. 2005, AJ, 129, 267 [NASA ADS] [CrossRef] [Google Scholar]
- Casali, M., Adamson, A., Alves de Oliveira, C., et al. 2007, A&A, 467, 777 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Catelan, M., Minniti, D., Lucas, P. W., et al. 2013, in 40 Years of Variable Stars: A Celebration of Contributions by Horace A. Smith, 139 [arXiv:1310.1996] [Google Scholar]
- Cincotta, P. M., Mendez, M., & Nunez, J. A. 1995, ApJ, 449, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Clausen, J. V., Torres, G., Bruntt, H., et al. 2008, A&A, 487, 1095 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cross, N. J. G., Collins, R. S., Hambly, N. C., et al. 2009, MNRAS, 399, 1730 [NASA ADS] [CrossRef] [Google Scholar]
- Dalton, G. B., Caldwell, M., Ward, A. K., et al. 2006, Proc. SPIE, 6269, 62690X-1 [CrossRef] [Google Scholar]
- Damerdji, Y., Klotz, A., & Boër, M. 2007, AJ, 133, 1470 [NASA ADS] [CrossRef] [Google Scholar]
- Deeming, T. J. 1975, Ap&SS, 36, 137 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Distefano, E., Lanzafame, A. C., Lanza, A. F., et al. 2012, MNRAS, 421, 2774 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Dobashi, K. 2011, PASJ, 63, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Drake, A. J., Djorgovski, S. G., Mahabal, A., et al. 2009, ApJ, 696, 870 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Dutra, C. M., & Bica, E. 2002, A&A, 383, 631 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dworetsky, M. M. 1983, MNRAS, 203, 917 [NASA ADS] [Google Scholar]
- Emerson, J. P., Irwin, M. J., Lewis, J., et al. 2004, Proc. SPIE, 5493, 401 [NASA ADS] [CrossRef] [Google Scholar]
- Eyer, L. 2006, Astrophysics of Variable Stars, ASP Conf. Ser., 349, 15 [NASA ADS] [Google Scholar]
- Eyer, L., & Bartholdi, P. 1999, A&AS, 135, 1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fruth, T., Kabath, P., Cabrera, J., et al. 2012, AJ, 143, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Hambly, N. C., Collins, R. S., Cross, N. J. G., et al. 2008, MNRAS, 384, 637 [NASA ADS] [CrossRef] [Google Scholar]
- Handler, G. 2012, in Planets, Stars and Stellar Systems eds. T. D. Oswalt, & M. A. Barstow (Dordrecht: Springer Science+Business Media), Vol. 4 [Google Scholar]
- Hewett, P. C., Warren, S. J., Leggett, S. K., & Hodgkin, S. T. 2006, MNRAS, 367, 454 [NASA ADS] [CrossRef] [Google Scholar]
- Hoffman, D. I., Harrison, T. E., & McNamara, B. J. 2009, AJ, 138, 466 [NASA ADS] [CrossRef] [Google Scholar]
- Hodgkin, S. T., Irwin, M. J., & Hewett, P. C. 2009, MNRAS, 394, 675 [NASA ADS] [CrossRef] [Google Scholar]
- Irwin, M. J., Lewis, J., Hodgkin, S., et al. 2004, Proc. SPIE, 5493, 411 [NASA ADS] [CrossRef] [Google Scholar]
- Jurcsik, J., Hajdu, G., Szeidl, B., et al. 2012, MNRAS, 419, 2173 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N., Aussel, H., Burke, B. E., et al. 2002, Proc. SPIE, 4836, 154 [NASA ADS] [CrossRef] [Google Scholar]
- Kazarovets, E. V., Samus, N. N., & Durlevich, O. V. 1998, IBVS, 4655, 1 [NASA ADS] [Google Scholar]
- Krabbendam, V. L., & Sweeney, D. 2010, Proc. SPIE, 7733 [Google Scholar]
- Lafler, J., & Kinman, T. D. 1965, ApJS, 11, 216 [NASA ADS] [CrossRef] [Google Scholar]
- Law, N. M., Kulkarni, S., Ofek, E., et al. 2009, BAAS, 41, 418 [NASA ADS] [Google Scholar]
- Lawrence, A., Warren, S. J., Almaini, O., et al. 2007, MNRAS, 379, 1599 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Levenberg, K. 1944, Quart. Appl. Math., 2, 164 [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [NASA ADS] [CrossRef] [Google Scholar]
- Marquardt, D. W. 1963, SIAM J. Appl. Math., 11, 431 [Google Scholar]
- McCommas, L. P., Yoachim, P., Williams, B. F., et al. 2009, AJ, 137, 4707 [NASA ADS] [CrossRef] [Google Scholar]
- Minniti, D., Lucas, P. W., Emerson, J. P., et al. 2010, New A, 15, 433 [NASA ADS] [CrossRef] [Google Scholar]
- Perryman, M. A. C. 2005, Astrometry in the Age of the Next Generation of Large Telescopes, 338, 3 [NASA ADS] [Google Scholar]
- Pojmanski, G. 2002, Acta Astron., 52, 397 [NASA ADS] [Google Scholar]
- Pollacco, D. L., Skillen, I., Collier Cameron, A., et al. 2006, PASP, 118, 1407 [NASA ADS] [CrossRef] [Google Scholar]
- Riello, M., & Irwin, M. 2008, 2007 ESO Instrument Calibration Workshop, 581 [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Samus, N. N., Durlevich, O. V., & Kazarovets, R. V. 1997, Balt. Astron., 6, 296 [NASA ADS] [Google Scholar]
- Samus N. N., Durlevich O. V., Kazarovets, E. V., et al. 2012, General Catalog of Variable Stars, VizieR On-line Data Catalog: B/gcvs [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [NASA ADS] [CrossRef] [Google Scholar]
- Shin, M.-S., Yi, H., Kim, D.-W., Chang, S.-W., & Byun, Y.-I. 2012, AJ, 143, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Siegel, M. H., & Majewski, S. R. 2000, AJ, 120, 284 [NASA ADS] [CrossRef] [Google Scholar]
- Simons, D. A., & Tokunaga, A. 2002, PASP, 114, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Stellingwerf, R. F. 1978, ApJ, 224, 953 [NASA ADS] [CrossRef] [Google Scholar]
- Stetson, P. B. 1981, AJ, 86, 1500 [NASA ADS] [CrossRef] [Google Scholar]
- Stetson, P. B. 1996, PASP, 108, 851 [NASA ADS] [CrossRef] [Google Scholar]
- Templeton, M. 2004, JAAVSO, 32, 41 [NASA ADS] [Google Scholar]
- Tokunaga, A. T., Simons, D. A., & Vacca, W. D. 2002, PASP, 114, 180 [NASA ADS] [CrossRef] [Google Scholar]
- Tonry, J. L., Schmidt, B. P., Barris, B., et al. 2003, ApJ, 594, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Udalski, A. 2003, AcA, 53, 291 [Google Scholar]
- Walker, A. R. 2012, Ap&SS, 341, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Watson, C., Henden, A. A., & Price, A. 2014, VizieR Online Data Catalog, 1, 2027 [Google Scholar]
- Welch, D. L., & Stetson, P. B. 1993, AJ, 105, 1813 [NASA ADS] [CrossRef] [Google Scholar]
- Zechmeister, M., & Külrster, M. 2009, A&A, 496, 577 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Tables
Number of sources, average total baseline (⟨ Ttot ⟩, in days), and average number of epochs ⟨ Nep ⟩ in each filter, in our initial database.
Number of variable star candidates selected by the different variability indices at different significance levels before and after (in parentheses) visual inspection.
All Figures
|
Fig. 1 Celestial distribution of our initial database of stellar sources from the WFCAMCAL08B archive. |
| In the text | |
|
Fig. 2 Spectral window of a typical well-sampled K-band light curve from the WFCAMCAL database, showing two different frequency ranges. |
| In the text | |
|
Fig. 3 Number of sources (Ns) as a function of the number of epochs (Nep.) for the queried J- (left) and Z-band (right) light curves with a bin size of 10 days. The distribution corresponding to the other broad bands are very similar. The solid curves show the average total baseline length as a function of the number of epochs for the queried light curves in the same filters with a bin width of 2 days. |
| In the text | |
|
Fig. 4 Number of combinations ns in the simulations described in the text. Since the |
| In the text | |
|
Fig. 5 Variability indices versus the K-band magnitude, for the simulations (top two rows) and the actual data (bottom two rows), for three values of s, namely 2 (left), 3 (middle), and 4 (right). |
| In the text | |
|
Fig. 6 As in Fig. 5, but for the cutoff surfaces used to select our target list, and also adding ns as an independent variable. These surfaces set apart, at the 0.5% significance level, instances that are compatible with random noise (low values of the indices) from those that are compatible with coherent signal being present in the different passbands (high values of the indices). |
| In the text | |
|
Fig. 7 Phase-folded light curves of selected objects from our catalog of periodic variables (C1), showing data in all five broadband filters of WFCAM. ID’s, types, and periods for each object are shown in the headers. The object WVSC-208 was only detected in the Z and Y bands. |
| In the text | |
|
Fig. 8 Distribution of Ifi versus Ipfc variability indices, for orders 2 (left) and 3 (right). The C1 and C2 sources are indicated by red and green circles, respectively. |
| In the text | |
|
Fig. 9 Color-color (left panel) and color–magnitude (right panel) diagrams of the analyzed sample. New objects in C1 (in blue) and C2 (in red) and previously known objects (in green) are shown with colored points. Red arrows indicate the reddening vectors. |
| In the text | |
|
Fig. 10 Example light curves of 4 previously known variable stars that were not detected in our analysis. ID’s, variability types, and periods for each star are shown in the headers. |
| In the text | |
|
Fig. 11 Detection efficiency Edet. vs. K mean magnitude for 105 synthetic variables. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.