| Issue |
A&A
Volume 545, September 2012
|
|
|---|---|---|
| Article Number | A34 | |
| Number of page(s) | 11 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201118482 | |
| Published online | 03 September 2012 | |
Identification of galaxy clusters in cosmic microwave background maps using the Sunyaev-Zel’dovich effect
Divisão de Astrofísica, Instituto Nacional de Pesquisas Espaciais – INPE, São José dos Campos, SP, Brazil
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 18 November 2011
Accepted: 25 July 2012
Abstract
Context. The Planck satellite was launched in 2009 by the European Space Agency to study the properties of the cosmic microwave background (CMB). An expected result of the Planck data analysis is the distinction of the various contaminants of the CMB signal. Among these contaminants is the Sunyaev-Zel’dovich (SZ) effect, which is caused by the inverse Compton scattering of CMB photons by high energy electrons in the intracluster medium of galaxy clusters.
Aims. We modify a public version of the JADE (Joint Approximate Diagonalization of Eigenmatrices) algorithm, to deal with noisy data, and then use this algorithm as a tool to search for SZ clusters in two simulated datasets.
Methods. The first dataset is composed of simple “homemade” simulations and the second of full sky simulations of high angular resolution, available at the LAMBDA (Legacy Archive for Microwave Background Data Analysis) website. The process of component separation can be summarized in four main steps: (1) pre-processing based on wavelet analysis, which performs an initial cleaning (denoising) of data to minimize the noise level; (2) the separation of the components (emissions) by JADE; (3) the calibration of the recovered SZ map; and (4) the identification of the positions and intensities of the clusters using the SExtractor software.
Results. The results show that our JADE-based algorithm is effective in identifying the position and intensity of the SZ clusters, with the purities being higher then 90% for the extracted “catalogues”. This value changes slightly according to the characteristics of noise and the number of components included in the input maps.
Conclusions. The main highlight of our developed work is the effective recovery rate of SZ sources from noisy data, with no a priori assumptions. This powerful algorithm can be easily implemented and become an interesting complementary option to the “matched filter” algorithm (hereafter MF) widely used in SZ data analysis.
Key words: cosmic background radiation / surveys / galaxies: clusters: general / galaxies: clusters: intracluster medium
© ESO, 2012
1. Introduction
During the passage of the cosmic microwave background (CMB) radiation through clusters of galaxies, about 1% of the photons are Compton scattered by energetic electrons in the intracluster medium. This process causes a very distinctive signature in the CMB spectrum, that was first described by Zeldovich & Sunyaev (1969).
The Sunyaev Zel’dovich (SZ) effect is a secondary CMB anisotropy, meaning that it was produced after the decoupling era. Its angular size is of the order of arc minutes and an average intensity of a few hundred μK, which is difficult to separate from the primary CMB signal and therefore difficult to detect. However, some currently operating ground-based experiments, such as the South Pole Telescope (SPT) and the Atacama Cosmology Telescope (ACT), have sufficiently high sensitivities to measure the SZ effect with high signal-to-noise ratio data and enough angular resolution to obtain a very accurate SZ profile from the observed clusters (Sehgal et al. 2011).
Together with current optical and X-ray surveys, SZ measurements are expected to produce cluster images with the highest possible sensitivities across significant fractions of the sky (Carlstrom et al. 2011; Marriage et al. 2011; Planck Collaboration et al. 2011). The multiwavelength data will be used to shed light on the cluster physics, to improve our knowledge of scaling relations, and to produce catalogues to be used in cosmological studies. Measurements of the SZ effect offers a unique and powerful tool to test cosmological models and put strong constraints on the parameters describing the universe (e.g., Voit 2005; Allen et al. 2011). In addition to the SZ effect, the hot intracluster gas is also characterized by its strong bremsstrahlung emission in the X-ray band. Put together, both effects can be used to estimate the distance of clusters and the Hubble constant. In addition, the SZ effect can also be used to estimate the ΩB/ΩM ratio and the peculiar velocity of clusters. One can also use large SZ surveys to constrain the dark energy equation of state (see, e.g., Birkinshaw 1999; Carlstrom et al. 2000, 2002).
A full sky survey is being conducted by the Planck satellite, launched in 2009 and the first mission of the European Space Agency (ESA) dedicated to CMB studies. In January 2011, the Planck team released the first version of its full-sky SZ cluster catalogue (Planck Collaboration et al. 2011). These results are already being used to study the CMB contamination on angular scales smaller than a few arcminutes (ℓ ≳ 1000), where the SZ effect, together with radio and sub-mm point sources, dominate over the primary CMB contribution (e.g., Taburet et al. 2010).
A number of algorithms have been used to extract SZ signal from CMB maps, but most use a priori assumptions about the SZ signal contained in the input maps and identify the “unknown” clusters based upon spectral identification and information about shape, intensity, etc. (see, e.g., Mauskopf et al. 2003; Pierpaoli & Anthoine 2005; Bobin et al. 2008; Leach et al. 2008; Vanderlinde et al. 2010; Remazeilles et al. 2011).
The main purpose of this work is to present a method to identify SZ clusters in CMB maps, using a minimal set of a priori conditions. To do this, we developed a “blind search” method, based only on the spectral contributions of input signals, that has performed very well in simulated sky maps with include many of the public Planck satellite characteristics, such as the asymmetric sky coverage, detector noise level, frequency coverage, etc.
The outline of this paper is as follows: in Sect. 2, we briefly describe the SZ effect theory and the pressure profile described by Arnaud and collaborators. Section 3 contains the details of the two datasets used in this work, one composed of “homemade” simulations and another produced by Sehgal et al. (2010). The methodology used to identify SZ clusters is discussed in Sect. 3. Section 5 summarizes our results and our concluding remarks are presented in Sect. 6.
2. The Sunyaev Zel’dovich effect
The SZ effect produces a small distortion in the CMB spectrum, with a temperature variation ΔTSZ given by 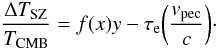 (1)The first term in Eq. (1) corresponds to the distortion caused by the thermal distribution of electrons located in the intracluster medium that scatter the CMB photons. The Comptonization parameter y is given by
(1)The first term in Eq. (1) corresponds to the distortion caused by the thermal distribution of electrons located in the intracluster medium that scatter the CMB photons. The Comptonization parameter y is given by 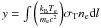 , where σT is the Thomson cross-section, ne the electron density, dl the line element along the line of sight, and f(x) the frequency dependence given by
, where σT is the Thomson cross-section, ne the electron density, dl the line element along the line of sight, and f(x) the frequency dependence given by 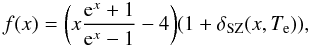 (2)where x = hν/kBTCMB and δSZ(x,Te) is the relativistic correction.
(2)where x = hν/kBTCMB and δSZ(x,Te) is the relativistic correction.
The second term in Eq. (1), the so-called kinetic SZ effect, refers to the spectral distortion caused by the movement of the cluster relative to the CMB radiation. It is caused by the cluster speed, which creates a Doppler distortion of the scattered photons, with τe being the optical depth, vpec the speed of the cluster towards the line of sight, and c the speed of light. This work considers both the thermal and kinetic contributions in the synthetic maps produced by Sehgal et al. (2010) and only the thermal contribution in our own simulations, since the thermal effect is usually at least one order of magnitude larger than the kinetic one.
Equation (1) can be rewritten to take into account the variation in the Comptonization parameter y as a function of the radial coordinate of the projected cluster, following the discussion in Komatsu et al. (2011)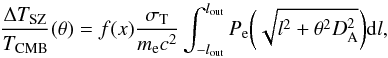 (3)where θ is the angular distance from the cluster centre, DA the angular diameter distance, l the radial coordinate from the centred of the cluster along the line of sight, σT the Thomson cross-section, me the electron mass, c the speed of light, and the electron pressure profile is given by Pe = nekBTe. For a given pressure profile Pe(r), the SZ temperature variation ΔTSZ can be written as
(3)where θ is the angular distance from the cluster centre, DA the angular diameter distance, l the radial coordinate from the centred of the cluster along the line of sight, σT the Thomson cross-section, me the electron mass, c the speed of light, and the electron pressure profile is given by Pe = nekBTe. For a given pressure profile Pe(r), the SZ temperature variation ΔTSZ can be written as 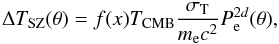 (4)where
(4)where 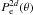 is the electron pressure profile projected in the sky given by
is the electron pressure profile projected in the sky given by 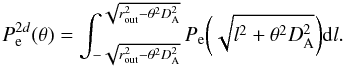 (5)Here, the pressure profile is truncated in rout. Arnaud et al. (2010) define an electron pressure profile Pe, based on the generalized Navarro-Frenk-White (NFW, Navarro et al. 1997) model described by Nagai et al. (2007). This profile closely describes the electron pressure profile obtained from X-ray data, and is given by
(5)Here, the pressure profile is truncated in rout. Arnaud et al. (2010) define an electron pressure profile Pe, based on the generalized Navarro-Frenk-White (NFW, Navarro et al. 1997) model described by Nagai et al. (2007). This profile closely describes the electron pressure profile obtained from X-ray data, and is given by ![Mathematical equation: \begin{eqnarray} P_{\rm e}(r)&=&1.65 \times 10^{-3} h(z)^{8/3} \left[\frac{M_{500}}{3 \times 10^{14}~h^{-1}_{70}~M_{\odot}}\right]^{2/3 + \alpha_p} \nonumber\\ & & \times ~ p(x) h^2_{70}~{\rm keV \, cm}^{-3}, \end{eqnarray}](/articles/aa/full_html/2012/09/aa18482-11/aa18482-11-eq31.png) (6)where h(z) is given by h(z) = [Ωm(1 + z)3 + ΩΛ] 1/2 and is the ratio of the Hubble constant at redshift z to its present value, H0. Moreover, αp = 0.12 and x = r/R500, where R500 is the radius within which the mean overdensity is 500 times the critical density of the universe at redshift z (ρc(z) = 2.775 × 1011E2(z)h2M⊙ Mpc), M500 is the mass within the radius R500, given by
(6)where h(z) is given by h(z) = [Ωm(1 + z)3 + ΩΛ] 1/2 and is the ratio of the Hubble constant at redshift z to its present value, H0. Moreover, αp = 0.12 and x = r/R500, where R500 is the radius within which the mean overdensity is 500 times the critical density of the universe at redshift z (ρc(z) = 2.775 × 1011E2(z)h2M⊙ Mpc), M500 is the mass within the radius R500, given by ![Mathematical equation: \begin{equation} M_{500} \equiv \frac{4 \pi}{3}[500 \rho_{\rm c}(z)]R_{500}^3, \end{equation}](/articles/aa/full_html/2012/09/aa18482-11/aa18482-11-eq41.png) (7)p(x) corresponds to the generalized NFW model
(7)p(x) corresponds to the generalized NFW model ![Mathematical equation: \begin{equation} p(x) = \frac{P_0}{(c_{500} x)^{\gamma}[1 + (c_{500} x)^{\alpha}]^{(\beta - \gamma)/\alpha}}, \end{equation}](/articles/aa/full_html/2012/09/aa18482-11/aa18482-11-eq43.png) (8)and the best-fit found by Arnaud et al. (2010) is given by
(8)and the best-fit found by Arnaud et al. (2010) is given by ![Mathematical equation: \begin{eqnarray} [P_0,c_{500},\gamma,\alpha,\beta] &=& [8.403 h^{-3/2}_{70},1.177,0.3081,\nonumber\\ & & 1.0510,5.4905]. \end{eqnarray}](/articles/aa/full_html/2012/09/aa18482-11/aa18482-11-eq44.png) (9)
(9)
3. Description of simulated data
To perform a thorough testing of our method, we used two different sets of simulations. The first group is a “homemade” dataset composed of five components (CMB, SZ effect, synchrotron, free-free, and dust emission) at the frequencies of 100, 143, 217, 353, and 545 GHz (five Planck/HFI frequencies). The second group is a more realistic set of sky maps, including, in addition to the aforementioned components, point sources. These simulated data were developed to test the data reduction pipeline for the Atacama Cosmology Telescope (ACT). These maps are available at the LAMBDA1 (Legacy Archive for Microwave Background Data Analysis) website. The details of our simulations are presented below, along with a summary of the second set of high-resolution sky simulations.
3.1. “Homemade” simulations
Our goal was to generate simple synthetic maps to reproduce, in the simplest way for an outsider to the Planck Collaboration, the observations made by the Planck satellite.
All maps were simulated using the HEALPix (Hierarchical Equal Area iso-Latitude Pixelization) pixelization grid (Górski et al. 2005). The maps produced by Planck will have Nside = 2048, which means that each map will consist of Npix ≈ 5 × 107 pixels of size 1.7 arcmin.
However, as the angular resolutions of the Planck instruments for the simulated frequencies at which we simulated the maps are between 10′ and 4′, it was unnecessary to simulate these maps with pixels of 1.7′ in diameter, since this would be about of three times higher spatial resolution than Planck’s.
We therefore created maps with Nside = 1024 (Npix ≈ 1.2 × 107) and average angular diameters of 3.43′, which have lower resolutions than the quoted figures for the Planck frequencies. Higher resolutions would enhance the SZ features of the profiles, but since we search for previously unidentified clusters, instead of studying the characteristics of the cluster profile, this does not add significantly to the search process. Moreover, it increases the processing time by a factor of ~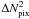 , with N being the number of pixels in the map. This set of maps were constructed at the frequencies of 100, 143, 217, 353, and 545 GHz. A description of the components used in the simulated maps are presented in the following subsections.
, with N being the number of pixels in the map. This set of maps were constructed at the frequencies of 100, 143, 217, 353, and 545 GHz. A description of the components used in the simulated maps are presented in the following subsections.
3.1.1. Cosmic microwave background anisotropies
We performed our simulations of the temperature fluctuations in the CMB based on the Cl coefficients created using the online interface of CMBFAST code (Seljak & Zaldarriaga 1996). We considered the ΛCDM standard model with ΩM ~ 0,27, ΩΛ ~ 0,73, Ωbh2 ~ 0,024, and h = 0,72. From this spectrum, the field of CMB primary anisotropies of the whole sky was generated using the SYNFAST routine of the HEALPix package. Figure 1 shows the synthetic CMB map, in thermodynamic temperature.
 |
Fig. 1 Cosmic microwave background anisotropy map in Mollweide projection, Galactic coordinates, and Kelvin temperatures. |
3.1.2. Galactic emission
The Galactic contribution to the synthetic maps was added using the WMAP 7-year (hereafter WMAP-7) “derived foreground products” maps (Jarosik et al. 2011; Gold et al. 2011) available at the LAMBDA website. However, the WMAP measurement frequencies are different from those used in this work and we had to scale the emission maps to the Planck frequencies, assuming that they follow a power law with indexes estimated by the WMAP team. The intensity Ie of each Galactic emission e, with spectral index βe, depends on the frequency ν according to (Bennett et al. 2003) 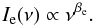 (10)Since Ie(ν1) and Ie(ν2) are the intensities of a given emission e at two different emission frequencies (ν1 and ν2), you can write the ratio of these intensities as
(10)Since Ie(ν1) and Ie(ν2) are the intensities of a given emission e at two different emission frequencies (ν1 and ν2), you can write the ratio of these intensities as 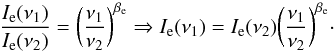 (11)Thus, we used a Iν2 map of a foreground component at a given frequency ν2 and the corresponding spectral index, to obtain a synthetically scaled map Iν1 of emission e.
(11)Thus, we used a Iν2 map of a foreground component at a given frequency ν2 and the corresponding spectral index, to obtain a synthetically scaled map Iν1 of emission e.
Equation (11) was applied, pixel-by-pixel, to maps of synchrotron, dust, and free-free emissions in W band (94 GHz). We did not scale the maps using a pixel-by-pixel fit but instead fixed spectral indices, where βs = −3,0, βd = 2,0, and βff = −2,16 (Gold et al. 2011) for the three types of emission, respectively. Both the maps of Galactic emission and the spectral index values used are part of the WMAP-7 products and results.
3.1.3. The SZ effect
The clusters were produced from the SZ temperature profiles corresponding to the generalized Navarro-Frenk-White model for the pressure profile of the intracluster gas, as described in Sect. 2, using the value rout = R500 for the integration. We simulated 1000 synthetic clusters positioned throughout the sky and outside the Galactic region, with random orientations and following a uniform distribution. The temperature profiles were constructed using an adaptation of the routine available at Eiichiro Komatsu’s website2, considering mass values 5 × 1013 M⊙ < M500 < 1 × 1015 M⊙ and a redshift interval 3 × 10-4 < z < 1.5. The resulting simulated maps, in the five selected frequencies, are shown in Fig. 2. A section around the north galactic pole was selected to provide a clearer view of the SZ signature at all of the five frequencies.
 |
Fig. 2 Gnomonic projection centered on the north Galactic pole and in Kelvin temperature, of SZ effect in 100, 143, 217, 353 and 545 GHz. |
3.1.4. Symmetric and asymmetric noise
The noise was simulated using the white noise sensitivities of each chosen Planck channel, which is given in thermodynamic CMB temperature units, estimated for the Planck mission (Table 1). The simulation was carried out to obtain a map of white Gaussian noise, by assuming both a roughly homogeneous coverage of the sky, and an asymmetric sky coverage mimicking a Planck observing scheme.
In the first case (of homogeneous white Gaussian noise, hereafter HWGN), we generated for each frequency, a Gaussian random distribution of zero mean and standard deviation given by the corresponding white noise sensitivity for 15 months of the mission.
In the second case, the Planck-like noise due to the asymmetric sky coverage (hereafter NASC) was estimated using the same white noise sensitivities and a scaled version of the observation number (Nobs) map of WMAP-7, which is also available at the LAMBDA website. Since the most frequently observed regions by both satellites are the ecliptic poles, we constructed a Nobs map that we considered an acceptable approximation for Planck coverage. The WMAP-7 Nobs map was adapted to match Planck values and the “ring” effect around the ecliptic poles, which is not present in the Planck Nobs maps, was smoothed out.
Using the above-mentioned Nobs map for 15 months and a Gaussian random distribution with zero mean and standard deviation given by the Planck white noise sensitivity (in μK s1/2), we created Planck-like noise maps (NASC) for each frequency.
Characteristics of the Planck satellite instruments (adapted from Planck Collaboration et al. 2011).
3.1.5. Construction of a simulated Planck sky
Using the components described above, we produced a “homemade” Planck sky. The maps were produced at 100, 143, 217, 353, and 545 GHz from a combination of maps of CMB, SZ effect, synchrotron, dust, and free-free emissions, together with noise, added with equal weights, as described in Eq. (12) 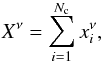 (12)where
(12)where 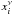 is the map of the component (emission) i at a given frequency ν and Xν is the resulting map of the linear combination of Nc components. Each frequency map was convolved with the corresponding beam, using the full width at half maximum (FWHM) values for the Planck channels (Table 1), then a realization of the noise was added to each map.
is the map of the component (emission) i at a given frequency ν and Xν is the resulting map of the linear combination of Nc components. Each frequency map was convolved with the corresponding beam, using the full width at half maximum (FWHM) values for the Planck channels (Table 1), then a realization of the noise was added to each map.
The SZ clusters were randomly placed all over the sky and we used the WMAP-7 KQ75 mask (also available at the LAMBDA website) to remove the Galactic plane neighbourhood, as usual in any CMB analysis. The resulting maps for the five Planck/HFI frequencies are shown in Fig. 3.
 |
Fig. 3 Linear combination of CMB, SZ effect, Galactic emission (synchrotron, dust, and free-free) and HWGN maps. The unit of the maps is K, in Galactic coordinates and Mollweide projection. |
3.2. High-resolution full-sky simulations
This second set of simulated maps was downloaded from the LAMBDA website. They have a Nside = 8192 pixelization, corresponding to a resolution of 0.4 arcmin in six different frequencies: 148, 219, and 277 GHz (the ACT observing frequencies) and the additional 30, 90, and 350 GHz, close to the Planck frequencies on the LFI and HFI. The maps are made of (1) the CMB affected by the lensing of an intervening structure between the last scattering surface and observers today; (2) the thermal and kinetic SZ effects, plus higher-order relativistic corrections, from galaxy clusters, groups, and the intergalactic medium; (3) a population of dusty star-forming galaxies that emit strongly at infrared (IR) wavelengths but still have significant microwave emission; (4) a population of galaxies, including active galactic nuclei, that emit strongly at radio wavelengths but still have significant microwave emission, and (5) the foreground emission of our own galaxy (dust, synchrotron, and free-free). A detailed explanation of these simulations can be found in Sehgal et al. (2010).
The catalogue of SZ halos and both IR and radio galaxies included in these simulations are also available at the LAMBDA website. The SZ catalogue contains 1 414 339 objects in the first octant, which are mirrored across the complete celestial sphere. The mass range is 2 × 1011 M⊙ < M500 < 1.5 × 1015 M⊙, with redshifts in the range 0 < z < 3.
The simulated sky maps available at LAMBDA (hereafter LAMBDA maps) have a very fine resolution, and to avoid a very large computation time in analysing them, we re-pixelized them from Nside = 8192 to Nside = 2048. We convolved the lower-resolution maps with Gaussian beams with a FWHM extrapolated from the Planck values (see Table 2), and then added noise. Following the same procedure used in our “homemade” simulations, two kinds of noise maps were used. One contained plain white Gaussian noise with a uniform coverage per pixel. The second considered an asymmetric sky coverage, which was identical to the one described in Sect. 3.1.4 (HWGN and NASC), but for which we used the white noise sensitivities given by the extrapolation of Planck values in Table 1. These values are shown in Table 2.
Sensitivities extrapolated from Planck frequencies.
 |
Fig. 4 Block diagram summarizing the SZ detection pipeline for simulated maps. |
4. Separation of components
A CMB data set contains a combination of signals from many sources. The most significant come from our galaxy, the CMB itself, the SZ effect, and radio/IR point sources. Electronic noise is also produced by the detector and associated electronics. This section describes the method used to distinguish between the signals from these various components.
Our method is based on a numerical algorithm called the Joint Approximate Diagonalization of Eigenmatrices (JADE) (Cardoso & Souloumiac 1993; Cardoso 1999) based on independent component analysis (ICA) (see, e.g., Hyvarinem & Oja 2000) and effective in extracting non-Gaussian components, as in the case of the SZ effect. We highlight its most interesting feature, that of not using any “prior” information about the input components. This feature sorts JADE from other methods used in the CMB/SZ analysis (Leach et al. 2008).
The original JADE code is inefficient in the presence of noise and we introduced a wavelet pre-cleaning method prior to feeding the data to JADE. After component separation, we used the SExtractor3 package (Bertin & Arnouts 1996) to detect and identify the positions and intensities of the clusters. We describe below the steps of our pipeline, from the initial data preparation to the elaboration of the final catalogue of cluster candidates.
The implementation of our pipeline was done fully in IDL (Interactive Data Language) for a number of reasons. First, this environment is very popular in the astronomy community, second, it is one of the languages used by the HEALpix package and, third, it is the chosen language of the CMB community for image processing. We modified the JADE routine available at MRS4 (Multi-Resolution on the Sphere) package, including a pre-whitening, wavelet-based, and processing step described in the next section.
The processing time for the full cluster identification pipeline (pre-whitening+JADE+SExtractor) was ~18 min for the “homemade” simulations and ~1.2 h for the LAMBDA maps. Figure 4 summarizes the data flow in our pipeline.
4.1. Noise filtering
The presence of noise requires some sort of pre-processing to permit JADE to deal with the data. This pre-processing starts by wavelet-transforming each map. The transformation in wavelet space retains the information contained in the pixels while averaging the noise contribution and highlighting the data structures (Pires et al. 2006).
We used the Daubechies wavelet transform to remove the noise from the data. The reasons for choosing this wavelet family are comprehensively discussed in, e.g., Torrence & Compo (1998). After conducting several tests, varying the order and level of the wavelet transform applied to the data, and comparing the results obtained with JADE in each test, we conclude that the best choices for this dataset is an order N = 3 (db3) and a decomposition level n = 5. It is important to remember that the higher the level used in the transformation, the more noise-free the data.
However, our various runs show there is an optimal decomposition level, above which a kind of “saturation” occurs. When starting the denoising process, it is advisable to perform a few tests to verify the optimal level for a given dataset.
After the transformation of the data to the wavelet space, we filtered the maps with the HEALPix smoothing.f90 routine, using Gaussian beams with FWHM = 8′ for our “homemade” simulations and FWHM = 3′ for the LAMBDA set to minimize the noise level prior to the application of JADE.
It is important to stress, at this point, that no previous information about the input data is used. This means that the cluster shape, mass thresholds, or redshift information, for instance, are not taken into account. Our wavelet tests are based solely upon the spectral information contained in the data.
4.2. Sorting input signals: the JADE algorithm
Many methods developed for signal separation are based on ICA, and can be considered a class known as blind source separation (BSS) problems. A typical example of BSS is the processing of multidimensional data with no “a priori” information (Hyvarinen et al. 2001).
This problem consists primarily of retrieving a set of m statistically independent signals from m mixtures of these instantly observed signals (see, e.g., Cardoso & Souloumiac 1993; Cardoso 1994). In other words, the goal is to estimate the matrix of the sources (independent components), S, and the mixing matrix, A, from X, the matrix of linear combinations of individual sources. This mixture model is described by the equation 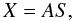 (13)where X is one m × T matrix, T the number of observed samples (each row is a mixture of m sources of a specific frequency), S is a m × T matrix (each row is the signal from a particular source), and A is a m × m invertible matrix, which specifies the original signal contributions of S to X.
(13)where X is one m × T matrix, T the number of observed samples (each row is a mixture of m sources of a specific frequency), S is a m × T matrix (each row is the signal from a particular source), and A is a m × m invertible matrix, which specifies the original signal contributions of S to X.
It is important to warn the user of some shortcomings and limitations of ICA (Hyvarinen et al. 2001). First, ICA assumes that the independent components are statistically independent. Second, at least one of the independent components must come from a non-Gaussian distribution, because Gaussian distributions have higher-order cumulants equal to zero, which mean that the ICA model cannot be applied. Finally, for the sake of simplicity, the model assumes that the mixed matrix is square, i.e., the number of independent components equals the number of observed mixtures. However, this is not a mandatory condition for using ICA; for details, we refer to Hyvarinen et al. (2001).
In addition to these limitations, the ICA method does not return the actual amplitudes of signals, since these are initially unknown. However, this is not a major problem, since the signal can be recalibrated after the separation of the components. This issue is discussed in Sect. 4.3. In addition, the method does not allow the user to determine the sequential ordering of the independent components in the S matrix rows, so the ordering can be freely changed.
Originally introduced by Cardoso & Souloumiac (1993), JADE is a statistical, ICA-based, technique that relies on high-order statistics. Its mixture model is given by Eq. (13) and assumes that the resulting sources in S are non-Gaussian random processes with a high signal-to-noise ratio. Since a real noise-free map does not exist, there is a need for data pre-processing before applying this method.
We now describe the data processing steps used by JADE to obtain the independent components (i.e. the sources) (Hyvarinen et al. 2001). The method starts by centralizing data, assuming that both the mixture variables and the independent components have zero means, and it then performs a whitening of the observed signals. For the model described by Eq. (13), the whitening of X is carried out by the whitening matrix V (the inverse of the square root of the covariance matrix of the data), generating the white vector Z = VX = VAS. We then compute a new orthogonal mixing matrix WT = VA and a new separation matrix W (Hyvarinen et al. 2001; Pires et al. 2006). The ICA Eq. (13) becomes Z = WTS, after the whitening of the data.
The cumulant tensor of the whitened matrix Z has a special structure, which can be seen from the eigenvalue decomposition, that accounts for the independent components. To achieve this, the whole matrix is assumed to have the form 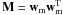 (para m = 1,..., n) which is an eigenmatrix of the cumulant tensor
(para m = 1,..., n) which is an eigenmatrix of the cumulant tensor 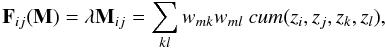 (14)where wm is a row of the W matrix and λ is the eigenvalue. Since the eigenvalues are distinct from each other, each eigenmatrix corresponds to an eigenvalue of the form
(14)where wm is a row of the W matrix and λ is the eigenvalue. Since the eigenvalues are distinct from each other, each eigenmatrix corresponds to an eigenvalue of the form 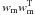 , giving one of the rows of W. Thus, with knowledge of the eigenmatrices of the cumulant tensor it is possible to obtain the independent components. JADE was designed to solve the case for indistinguishable eigenvalues.
, giving one of the rows of W. Thus, with knowledge of the eigenmatrices of the cumulant tensor it is possible to obtain the independent components. JADE was designed to solve the case for indistinguishable eigenvalues.
According to Hyvarinen et al. (2001), the eigenvalue decomposition can also be understood as a diagonalization process. Hence, the eigenvalue decomposition is also a diagonalization of the cumulant tensor F(M) that is performed by multiplying the matrix W for any M, as 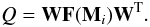 (15)Thus, Mi is chosen such that Q is as diagonal as possible.
(15)Thus, Mi is chosen such that Q is as diagonal as possible.
 |
Fig. 5 Our SZ-effect map recovered with JADE algorithm from the analysis of our “homemade” maps contaminated by HWGN. |
Since the W matrix is orthogonal, its multiplication by another matrix does not change the total sum of squares of the elements of this matrix, thus minimizing the sum of the squares of the off-diagonal elements is equivalent to maximizing the sum of the squares of the diagonal elements. Thus, this algorithm aims to maximize the equation 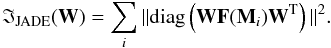 (16)The maximization of IJADE is a method of the joint approximate diagonalization of F(Mi). The Mi matrices are chosen from the eigenmatrices of the cumulant tensor, which provide all relevant information about the cumulants because they share the same space as the cumulant tensor.
(16)The maximization of IJADE is a method of the joint approximate diagonalization of F(Mi). The Mi matrices are chosen from the eigenmatrices of the cumulant tensor, which provide all relevant information about the cumulants because they share the same space as the cumulant tensor.
The A matrix is obtained by applying JADE to the data in wavelet space. Multiplying its inverse (A-1) by X, we obtain the S matrix of components. This result can be achieved because the application of wavelet transform does not affect the A matrix, but only increases the accuracy of the calculation. Since the A matrix was carefully calculated, it was applied to the input data to extract the SZ map.
Figure 5 shows an example of the extraction of an SZ map, obtained from the analysis of the “homemade” input maps with HWGN. It can be seen from these results that the temperature scale of the recovered SZ map does not match the scale of the simulated maps, since JADE loses the calibration information during data processing. The next section discusses the process of calibration recovery for each frequency.
4.3. Recovering calibration
The appropriate method for calibrating the recovered map is derived from an initial analysis comparing the output map to the input map to see how the fluxes of known clusters or other potential calibrators change in each map region. We found that the intensity of the recovered map by JADE differs from the input data by a nearly constant value across the whole map. Since we do not deal with real data, no known sources can be used to reconstruct the calibration, so we used our fake input clusters to accomplish this task. In a real map, however, prior knowledge of the fluxes of a few well-known sources allows the calibration for the full map to be made.
We took the clusters’ central values ΔTSZ in the input and output maps and calculated the ratio of both for each selected cluster. The average value of these ratios, at each of the frequencies, is the value by which the recovered map is multiplied to recover the calibration. In this work, we used 50 clusters randomly chosen to perform the procedure, since the larger the number of clusters used in the calibration, the more accurate the result.
A section of the map in Fig. 5 calibrated for each frequency is shown in Fig. 6, which can be inspected and visually compared to the same section of the simulated map (Fig. 2) to check for large differences in the temperature scales.
 |
Fig. 6 Gnomonic projection centred on the north Galactic pole, of the SZ map in Fig. 5 (“homemade” + HWGN result) when calibrated for each input frequency. |
We proceeded to compare the y values of the profile amplitude (the central value) calculated from both the simulated and calibrated ΔTSZ values of the clusters, shown in Fig. 7. In this graph, each point is equivalent to a single cluster and the diagonal lines represent the “equality line”. The closer the point to the diagonal, the closer the input (simulated) and output (recovered and calibrated) y values. Thus, the plot in Fig. 7 is a good indicator of accuracy of our calibration method for the JADE output maps. We also estimate the average dispersion D of the data 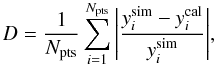 (17)obtaining 0.27.
(17)obtaining 0.27.
5. Cluster detection
After recovering the clusters from a “full sky with noise” using JADE, and recalibrating their fluxes, we used the SExtractor package (Bertin & Arnouts 1996; Holwerda 2005) to select the cluster candidates. The most important SExtractor parameters, and those that most strongly influence the results, are DETECT_THRESH (the detection threshold), DETECT_MINAREA (which sets the minimum number of pixels above the threshold triggering detection), and FILTER_NAME (which selects the file containing the filter definition).
SExtractor offers a number of filters to be used in this kind of analysis, that have various FWHM and sizes (both given in pixels). For our analysis, the filter that most closely recovered the input data was the Gaussian filter. For the “homemade” datasets, we used a FWHM of 4 pixels and a mask with 7 × 7 pixels. For the LAMBDA dataset, the values were, respectively, 2 and 5 × 5 pixels. In addition, we used threshold values of 2.5σ, 1.5σ, 2.0σ, and 2.0σ for the “homemade” datasets + HWGN, the “homemade” datasets + NASC, the LAMBDA datasets + HWGN, and the LAMBDA datasets + NASC, respectively. DETECT_MINAREA was set equal to 4 and 8 for the “homemade” and LAMBDA datasets.
 |
Fig. 7 Graph of simulated and calibrated y parameters, obtained analysing our “homemade” simulation with HWGN. The diagonal straight is the line of equality. |
Results for both datasets.
 |
Fig. 8 Relation between completeness and redshift intervals for recovered SZ catalogues. The graphics from top to down correspond to results of the analysis of “homemade” + HWGN, “homemade” + NASC, LAMBDA + HWGN and LAMBDA + NASC, respectively. |
 |
Fig. 9 Relation between the completeness and M500 intervals for the recovered SZ catalogues. The graphics from top to down correspond to the results of the analysis of “homemade” + HWGN, “homemade” + NASC, and LAMBDA + HWGN and LAMBDA + NASC datasets, respectively. |
We compare the positions of the calibrated clusters found by SExtractor with those included in the input sky maps, to account for false detections. The criterion used to make that determination was that for each position of cluster candidate indicated by SExtractor we checked for the existence of clusters in a circle, of radius equal to three pixels, around that position. If there was no cluster in the region, the candidate was considered a false detection. If there was more than one, the most massive cluster was assumed to be the detection, since it is more likely that one finds the most massive cluster. At this point, we did not consider the possibility of multiple detections.
Our results obtained from the analysis of both datasets and noise types are summarized in Table 3, which shows the number of cluster candidates indicated by SExtractor, the number of confirmed clusters, and finally both the purity and completeness of the recovered “catalogue”. Figures 8 and 9 present the completeness by redshift and mass interval for each dataset. The first one shows that the completeness does not change significantly with redshift, which highlights the redshift independence of the SZ effect, as expected. The second one shows the sensitivity of the SZ effect to the mass of the cluster, the completeness increasing with increasing mass. It can also be seen from these figures that the different noise models led to slightly different results, implying that one has to test the pipeline parameters to find the most appropriate filtering scheme (with respect t o instrumental properties such as beam size and expected noise level) for a given dataset.
There is a considerable difference between the two datasets used in this work, which allowed us to test and evaluate the pipeline under two very different conditions.
The total completeness obtained from the analysis of our simple “homemade” simulations provide a first indication of the efficiency of the method. However, it is insufficient, since it does not account for other contaminants of the SZ signal, such as the cross-terms of the thermal and kinetic SZ effects, radio sources, unresolved SZ clusters, and the SZ background. A more thorough testing was done by processing the LAMBDA maps through the pipeline. Despite the large differences between both datasets, we obtained a very similar result.
Another point worth mentioning is that, in this work, it makes no sense to discuss the total completeness of the resulting catalogue, since there is a very large number of clusters distributed over the full sky, most of them well below 5 × 1013 M⊙, and so unresolved via the SZ signal. Nevertheless, the results obtained using the LAMBDA maps presented a level of purity above 90%. The completeness of the mass and redshift intervals behave as expected, reaching a very low levels at lower masses and clearly increasing towards tens of percent for masses above 5 × 1014 M⊙.
6. Concluding remarks
We have presented our implementation of a method to identify galaxy clusters using the SZ effect in CMB observations. We have adapted JADE, a publicly available algorithm, to deal with noisy data by applying a pre-whitening, wavelet-based process and added a source detection package (SExtractor) at the end of our pipeline.
We have found the most attractive feature of this method is that it is based on a blind search algorithm, i.e., its application really does not require any a priori information about the targets. The essential contributions of this work were the following:
-
1)
The wavelet-based analysis tool has been adapted to performthe initial cleaning of the input data. Since JADE was designed toperform in the absence of noise, data preprocessing was essentialto ensure the efficient performance of our algorithm.
-
2)
A parameter set was determined for the full pipeline (wavelet tool, JADE, and SExtractor) that delivered catalogues from two simulated datasets with a level of purity (ratio of confirmed clusters to total detected clusters) above 90%.
Our method is a complementary approach to the MF algorithm currently used by the Planck, SPT and ACT collaborations (Planck Collaboration et al. 2011; Story et al. 2011; Hand et al. 2011), and can be used as a redundant tool in their data analysis pipeline. The results of using MF in CMB data analysis are widely described in the literature, hence we perform no further testing here. Our goal is to describe an alternative (and useful) technique to identify SZ clusters with no prior assumptions about the input data and under very different input conditions. We do not intend to perform a direct comparison between the two methods.
We have developed a full pipeline5, which is represented in the block diagram of Fig. 4 and can be summarized in four main steps: data preprocessing (de-noising) based on a wavelet tool, separation of components (emissions) by JADE, calibration of the recovered SZ map, and the identification of the positions and intensities of the clusters using the SExtractor package. Two simulated datasets were run through this pipeline: a “homemade” set and the more complete LAMBDA dataset, which were both described in Sects. 3.1 and 3.2.
The results presented in Table 3 of Sect. 5 indicate that our method performed very efficiently for both datasets. They vary slightly according to the characteristics of the data, especially in terms of the noise characteristics, and we caution that the whole pipeline may perform differently when applied to real data. Thus, the application of our method to real data may require some adjustment in the preprocessing phase to determine the optimal parameters for the denoising and target extraction, as discussed in Sects. 4.1 and 5.
The full package, with routines and instructions, will be available at http://www.das.inpe.br/~alex/SZ/SZHunter_pipeline.tar.gz after publication.
Acknowledgments
We are grateful to J. F. Cardoso for releasing the JADE code on web, to E. Komatsu for the routine adapted and used in the SZ effect profile simulations (available at http://gyudon.as.utexas.edu/~komatsu/CRL/index.html), and Moudden et al. for the MRS package. We thank the referee for the suggestions and, particularly, the insightful comments about our noise estimation. We also thank Rodrigo Leonardi for the discussions about the implementation of the pipeline and many interesting suggestions for testing it. We acknowledge the HEALPix collaboration for providing the pixelisation scheme used in this work and the LAMBDA website for storing and making available the WMAP data and the online version of CMBFAST. C.A. Wuensche acknowledges the CNPq grant 2010/300400-3.
References
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [NASA ADS] [CrossRef] [Google Scholar]
- Arnaud, M., Pratt, G. W., Piffaretti, R., et al. 2010, A&A, 517, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bennett, C. L., Hill, R. S., Hinshaw, G., et al. 2003, ApJS, 148, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Birkinshaw, M. 1999, Phys. Rep., 310, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Bobin, J., Moudden, Y., Starck, J.-L., Fadili, J., & Aghanim, N. 2008, Statistical Methodology, 5, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Cardoso, J. F. 1994, In Proc. EUSIPCO, 776 [Google Scholar]
- Cardoso, J. F. 1999, Neural Computation, 11, 157 [CrossRef] [PubMed] [Google Scholar]
- Cardoso, J. F., & Souloumiac, A. 1993, IEE Prec., 140, 362 [CrossRef] [Google Scholar]
- Carlstrom, J. E., Ade, P. A. R., Aird, K. A., et al. 2011, PASP, 123, 568 [NASA ADS] [CrossRef] [Google Scholar]
- Carlstrom, J. E., Joy, M. K., Grego, L., et al. 2000, Phys. Scr. T, 85, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Carlstrom, J. E., Holder, G. P., & Reese, E. D. 2002, ARA&A, 40, 643 [NASA ADS] [CrossRef] [Google Scholar]
- Gold, B., Odegard, N., Weiland, J. L., et al. 2011, ApJS, 192, 15 [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Hand, N., Appel, J. W., Battaglia, N., et al. 2011, ApJ, 736, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Holwerda, B. W. 2005, [arXiv:astro-ph/0512139] [Google Scholar]
- Hyvarinem, A., & Oja, E. 2000, Neural Networks, 13, 411 [Google Scholar]
- Hyvarinen, A., Karhunen, J., & Oja, E. 2001, Independent Component Analysis (New York: John Wiley & Sons) [Google Scholar]
- Jarosik, N., Bennett, C. L., Dunkley, J., et al. 2011, ApJS, 192, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Komatsu, E., Smith, K. M., Dunkley, J., et al. 2011, ApJS, 192, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Leach, S. M., Cardoso, J.-F., Baccigalupi, C., et al. 2008, A&A, 491, 597 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marriage, T. A., Acquaviva, V., Ade, P. A. R., et al. 2011, ApJ, 737, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Mauskopf, P. D., Ade, P. A. R., Balbi, A., et al. 2003, New A Rev., 47, 733 [NASA ADS] [CrossRef] [Google Scholar]
- Nagai, D., Kravtsov, A. V., & Vikhlinin, A. 2007, ApJ, 668, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Pierpaoli, E., & Anthoine, S. 2005, Adv. Space Res., 36, 757 [NASA ADS] [CrossRef] [Google Scholar]
- Pires, S., Juin, J. B., Yvon, D., et al. 2006, A&A, 455, 741 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration 2011, A&A, 536, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Remazeilles, M., Delabrouille, J., & Cardoso, J.-F. 2011, MNRAS, 410, 2481 [NASA ADS] [CrossRef] [Google Scholar]
- Sehgal, N., Bode, P., Das, S., et al. 2010, ApJ, 709, 920 [NASA ADS] [CrossRef] [Google Scholar]
- Sehgal, N., Trac, H., Acquaviva, V., et al. 2011, ApJ, 732, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Seljak, U., & Zaldarriaga, M. 1996, ApJ, 469, 437 [NASA ADS] [CrossRef] [Google Scholar]
- Story, K., Aird, K. A., Andersson, K., et al. 2011, ApJ, 735, L36 [NASA ADS] [CrossRef] [Google Scholar]
- Taburet, N., Douspis, M., & Aghanim, N. 2010, MNRAS, 404, 1197 [NASA ADS] [Google Scholar]
- Torrence, C., & Compo, G. P. 1998, Bull. Amer. Meteor. Soc., 79, 61 [CrossRef] [Google Scholar]
- Vanderlinde, K., Crawford, T. M., de Haan, T., et al. 2010, ApJ, 722, 1180 [NASA ADS] [CrossRef] [Google Scholar]
- Voit, G. M. 2005, Rev. Mod. Phys., 77, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Zeldovich, Y. B., & Sunyaev, R. A. 1969, Ap&SS, 4, 301 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Characteristics of the Planck satellite instruments (adapted from Planck Collaboration et al. 2011).
All Figures
|
Fig. 1 Cosmic microwave background anisotropy map in Mollweide projection, Galactic coordinates, and Kelvin temperatures. |
| In the text | |
|
Fig. 2 Gnomonic projection centered on the north Galactic pole and in Kelvin temperature, of SZ effect in 100, 143, 217, 353 and 545 GHz. |
| In the text | |
|
Fig. 3 Linear combination of CMB, SZ effect, Galactic emission (synchrotron, dust, and free-free) and HWGN maps. The unit of the maps is K, in Galactic coordinates and Mollweide projection. |
| In the text | |
|
Fig. 4 Block diagram summarizing the SZ detection pipeline for simulated maps. |
| In the text | |
|
Fig. 5 Our SZ-effect map recovered with JADE algorithm from the analysis of our “homemade” maps contaminated by HWGN. |
| In the text | |
|
Fig. 6 Gnomonic projection centred on the north Galactic pole, of the SZ map in Fig. 5 (“homemade” + HWGN result) when calibrated for each input frequency. |
| In the text | |
|
Fig. 7 Graph of simulated and calibrated y parameters, obtained analysing our “homemade” simulation with HWGN. The diagonal straight is the line of equality. |
| In the text | |
|
Fig. 8 Relation between completeness and redshift intervals for recovered SZ catalogues. The graphics from top to down correspond to results of the analysis of “homemade” + HWGN, “homemade” + NASC, LAMBDA + HWGN and LAMBDA + NASC, respectively. |
| In the text | |
|
Fig. 9 Relation between the completeness and M500 intervals for the recovered SZ catalogues. The graphics from top to down correspond to the results of the analysis of “homemade” + HWGN, “homemade” + NASC, and LAMBDA + HWGN and LAMBDA + NASC datasets, respectively. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.