| Issue |
A&A
Volume 535, November 2011
|
|
|---|---|---|
| Article Number | A36 | |
| Number of page(s) | 12 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201117529 | |
| Published online | 28 October 2011 | |
SDSS DR7 superclusters
Principal component analysis
1
Tartu Observatory, 61602 Tõravere, Estonia
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Institute of Physics, Tartu University, Tähe 4, 51010 Tartu, Estonia
3
Estonian Academy of Sciences, 10130 Tallinn, Estonia
4
ICRANet, Piazza della Repubblica 10, 65122 Pescara, Italy
5
Observatori Astronòmic, Universitat de València, Apartat de Correus 22085, 46071 València, Spain
Received: 20 June 2011
Accepted: 26 July 2011
Abstract
Context. The study of superclusters of galaxies helps us to understand the formation, evolution, and present-day properties of the large-scale structure of the Universe.
Aims. We use data about superclusters drawn from the SDSS DR7 to analyse possible selection effects in the supercluster catalogue, to study the physical and morphological properties of superclusters, to find their possible subsets, and to determine scaling relations for our superclusters.
Methods. We apply principal component analysis and Spearman’s correlation test to study the properties of superclusters.
Results. We have found that the parameters of superclusters do not correlate with their distance. The correlations between the physical and morphological properties of superclusters are strong. Superclusters can be divided into two populations according to their total luminosity: high-luminosity ones with Lg > 400 × 1010h-2L⊙ and low-luminosity systems. High-luminosity superclusters form two sets, which are more elongated systems with the shape parameter K1/K2 < 0.5 and less elongated ones with K1/K2 > 0.5. The first two principal components account for more than 90% of the variance in the supercluster parameters. We use principal component analysis to derive scaling relations for superclusters, in which we combine the physical and morphological parameters of superclusters.
Conclusions. The first two principal components define the fundamental plane, which characterises the physical and morphological properties of superclusters. Structure formation simulations for different cosmologies, and more data about the local and high redshift superclusters are needed to understand the evolution and the properties of superclusters better.
Key words: cosmology: observations / large-scale structure of the Universe / galaxies: clusters: general
© ESO, 2011
1. Introduction
The large-scale distribution of the dark and baryonic matter in the Universe can be described as the cosmic web – the network of galaxies, groups, and clusters of galaxies connected by filaments (Joeveer et al. 1978; Gregory & Thompson 1978; Zeldovich et al. 1982; de Lapparent et al. 1986). In this network superclusters are the largest density enhancements formed by the density perturbations on a scale of about 100 h-1Mpc (H0 = 100hkms-1Mpc-1). Numerical simulations show that high-density peaks in the density distribution (the seeds of supercluster cores) are seen already at very early stages of the formation and evolution of structure (Einasto 2010). These are the locations of the formation of the first objects in the Universe (e.g. Venemans et al. 2004; Mobasher et al. 2005; Ouchi et al. 2005; Hatch et al. 2011). Studying the properties of superclusters helps us to understand the formation, evolution, and properties of the large-scale structure of the Universe (Hoffman et al. 2007; Araya-Melo et al. 2009a; Bond et al. 2010, and references therein). Comparison of observed and simulated superclusters, especially extreme systems among them, is a test of cosmological models (Kolokotronis et al. 2002; Einasto et al. 2007a,e; Araya-Melo et al. 2009a; Einasto et al. 2011b; Sheth & Diaferio 2011).
The first step in supercluster studies is to compile supercluster catalogues, which serve as observational databases. Supercluster catalogues have been constructed using the friend-of-friend method or using a smoothed density field of galaxies. The first method has been applied to the data on rich (Abell) clusters of galaxies to obtain catalogues of superclusters of rich clusters, both from observations and simulations (Zucca et al. 1993; Einasto et al. 1994; Kalinkov & Kuneva 1995; Einasto et al. 1997, 2001; Wray et al. 2006). Density field superclusters have been determined using data of deep surveys of galaxies (Basilakos 2003; Einasto et al. 2003a; Erdoğdu et al. 2004; Einasto et al. 2006, 2007b; Liivamägi et al. 2010; Costa-Duarte et al. 2011; Luparello et al. 2011). The properties of superclusters have been studied, for example, by Jaaniste et al. (1998), Kolokotronis et al. (2002), Costa-Duarte et al. (2011), Luparello et al. (2011), Wray et al. (2006), and Einasto et al. (2001, 2007a,c,e, 2011a). These studies show that the properties of superclusters are correlated. More luminous superclusters are richer and larger, contain richer galaxy clusters, and have higher maximum densities of galaxies than less luminous systems. High-luminosity superclusters are more elongated and have more complicated inner structure than low-luminosity ones.
In the present paper we use the Spearman’s correlation test and the principal component analysis (PCA), an excellent tool for multivariate data analysis, to investigate how strong the correlations between the properties of superclusters are. Our goals are to analyse the presence of possible distance-dependent selection effects in the supercluster catalogue, to study the correlations between the physical and morphological properties of superclusters, to find the possible subsets and outliers of superclusters, and to determine the scaling relations for the superclusters.
Principal component analysis have been used in astronomy for a number of purposes: the study of the properties of stars (Tiit & Einasto 1964; Deeming 1964), spectral classification of galaxies (Sánchez Almeida et al. 2010, and references therein), morphological classification of galaxies (Coppa et al. 2010), studies of galaxies, galaxy groups, and dark matter haloes (Efstathiou & Fall 1984; Lanzoni et al. 2004; Ferreras et al. 2006; Woo et al. 2008; Chang et al. 2010; Ishida & de Souza 2011; Toribio et al. 2011; Skibba & Maccio’ 2011; Jeeson-Daniel et al. 2011, and references therein), for the Hubble parameter reconstruction (Ishida & de Souza 2011, and references therein), and for studies of star formation history in the universe using gamma ray bursts (Ishida et al. 2011). Our study is the first in which the PCA is applied to explore the properties of superclusters of galaxies.
In Sect. 2 we give data about superclusters. In Sect. 3 we describe the PCA and the Spearman’s correlation test, and apply them in Sect. 4 to study the physical and morphological properties of superclusters and to derive scaling relations for the superclusters. We discuss selection effects in Sect. 5 and give our conclusions in Sect. 6.
We assume the standard cosmological parameters: the Hubble parameter H0 = 100h km s-1 Mpc-1, the matter density Ωm = 0.27, and the dark energy density ΩΛ = 0.73.
2. Data
 |
Fig. 1 The distribution of superclusters in Cartesian coordinates, in units of h-1Mpc. The filled circles denote superclusters with the luminosity Lg > 400 × 1010h-2L⊙, empty circles denote less luminous superclusters. The numbers are ID’s of luminous supercluster from L10 (Table C.1). |
We selected the MAIN galaxy sample of the 7th data release of the Sloan Digital Sky Survey (Adelman-McCarthy et al. 2008; Abazajian et al. 2009) with the apparent r magnitudes 12.5 ≤ r ≤ 17.77, excluding duplicate entries. The sample is described in detail in Tago et al. (2010), hereafter T10. We corrected the redshifts of galaxies for the motion relative to the CMB and computed the co-moving distances (Martínez & Saar 2002) of galaxies.
We calculated the galaxy luminosity density field to reconstruct the underlying mass distribution. To determine superclusters (extended systems of galaxies) in the luminosity density field we created a set of density contours by choosing a density threshold and define connected volumes above a certain density threshold as superclusters. In order to choose proper density levels to determine individual superclusters, we analysed the density field superclusters at a series of density levels. As a result we used the density level D = 5.0 (in units of mean density; mean luminosity density of our sample is 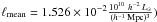 to determine individual superclusters. At this density level superclusters in the richest chains of superclusters in the volume under study still form separate systems; at lower density levels they join into huge percolating systems. At higher threshold density levels superclusters are smaller and their number decreases.
to determine individual superclusters. At this density level superclusters in the richest chains of superclusters in the volume under study still form separate systems; at lower density levels they join into huge percolating systems. At higher threshold density levels superclusters are smaller and their number decreases.
In our flux-limited catalogue the luminosity-dependent selection effects are the smallest at the distance interval 90 h-1Mpc ≤ D ≤ 320 h-1Mpc. For the present study we chose superclusters of galaxies in this distance interval. There are 125 superclusters in the sample. Even the poorest systems in our sample contain several groups of galaxies. These systems can be compared with the Local supercluster containing one cluster of galaxies with outgoing filaments. In the Appendix A we give the details of the calculations of galaxy luminosities and of the luminosity density field, as well as of the selection effects. The description of the supercluster catalogues is given in Liivamägi et al. (2010, hereafter L10)1.
The superclusters can be characterised by the following physical parameters: the total weighted luminosity of galaxies in a supercluster, Lg, the volume Volume, the diameter Diameter, and the number of galaxies in superclusters, Ngal. The supercluster volume is calculated from the density field as the number of connected grid cells multiplied by the cell volume: 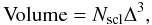 (1)where Δ is the grid cell length.
(1)where Δ is the grid cell length.
The total luminosity of the superclusters Lg is calculated as the sum of weighted galaxy luminosities: 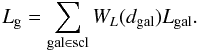 (2)Here the WL(dgal) is the distance-dependent weight of a galaxy (the ratio of the expected total luminosity to the luminosity within the visibility window). We describe the calculation of weights in Appendix A. The diameter of a supercluster is defined as the maximum distance between its galaxies. The distance of a supercluster is the distance to it’s density maximum. The peak density Dpeak is that of the highest density peak within the supercluster. Usually the highest values of densities coincide with the richest cluster of galaxies in a supercluster. For details we refer to L10.
(2)Here the WL(dgal) is the distance-dependent weight of a galaxy (the ratio of the expected total luminosity to the luminosity within the visibility window). We describe the calculation of weights in Appendix A. The diameter of a supercluster is defined as the maximum distance between its galaxies. The distance of a supercluster is the distance to it’s density maximum. The peak density Dpeak is that of the highest density peak within the supercluster. Usually the highest values of densities coincide with the richest cluster of galaxies in a supercluster. For details we refer to L10.
The overall morphology of a supercluster is described by the shapefinders K1 (planarity) and K2 (filamentarity), and their ratio, K1/K2 (the shape parameter). The shapefinders are calculated using the volume, area, and integrated mean curvature of a supercluster; they contain information both about the sizes of superclusters and about their outer shape. Systems with different shapes and similar sizes have different shape parameters (Einasto et al. 2008). For the first time the shapefinders were applied in the studies of galaxy systems by Basilakos et al. (2001) who analysed the shapes of the PSCz superclusters. We use the maximum value of the fourth Minkowski functional V3 (the clumpiness) to characterise the inner structure of the superclusters. The larger the value of V3, the more complicated the inner morphology of a supercluster is; superclusters may be clumpy, and they also may have holes or tunnels in them (Einasto et al. 2007e, 2011b).The formulae for the Minkowski functionals and shapefinders are given in Appendix B.
The large-scale distribution of superclusters is shown in Fig. 1 in Cartesian coordinates. These coordinates are defined as in Park et al. (2007) and in Liivamägi et al. (2010): 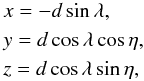 (3)\arraycolsep1.75ptwhere d is the comoving distance, and λ and η are the SDSS survey coordinates. Einasto et al. (2011a) gave detailed description of the large-scale distribution of rich superclusters.
(3)\arraycolsep1.75ptwhere d is the comoving distance, and λ and η are the SDSS survey coordinates. Einasto et al. (2011a) gave detailed description of the large-scale distribution of rich superclusters.
3. Principal component analysis
 |
Fig. 2 Distribution of the standardised physical parameters of superclusters. From left to right: the total weighted luminosity of galaxies Lg, the volume and the diameter of superclusters, the density of the highest density peak inside superclusters, Dpeak, and the number of galaxies in superclusters, Ngal. |
The idea of the principal component analysis is to find a small number of linear combinations of correlated parameters to describe most of the variation in the dataset with a small number of new uncorrelated parameters. The PCA transforms the data to a new coordinate system, where the greatest variance by any projection of the data lies along the first coordinate (the first principal component), the second greatest variance – along the second coordinate, and so on. There are as many principal components as there are parameters, but typically only the first few are needed to explain most of the total variation.
Principal components PCx (x ∈ N, x ≤ Ntot) are a linear combination of the original parameters: 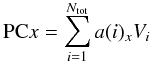 (4)where − 1 ≤ a(i)x ≤ 1 are the coefficients of the linear transformation, Vi are the original parameters and Ntot is the number of the original parameters.
(4)where − 1 ≤ a(i)x ≤ 1 are the coefficients of the linear transformation, Vi are the original parameters and Ntot is the number of the original parameters.
PCA is suitable tool to study simultaneously correlations between a large number of parameters, for finding subsets in data, and detecting outliers. Linear combinations of principal components can be used to reproduce parameters characterising objects in the dataset.
Principal components can be used to derive scaling relations. If data points lie along a plane, defined by the first two principal components, then the scaling relations along this plane are defined by the third principal component (Efstathiou & Fall 1984). For the analysis we use standardised parameters, centred on their means (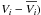 and normalised (divided by their standard deviations, σ(Vi)). Therefore we obtain for the scaling relations:
and normalised (divided by their standard deviations, σ(Vi)). Therefore we obtain for the scaling relations: 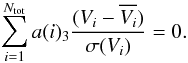 (5)For PCA, the parameters should be normally distributed. Therefore we use the logarithms of parameters in most cases; this makes the distributions more gaussian, and the range over which their values span are smaller, especially for luminosities and volumes. We do not use logarithms of morphological data, in order to not to exclude from the analysis those with negative values of shapefinders, which may occur in the case of compact superclusters with a complex overall morphology (Einasto et al. 2008, 2011b). Figures 2 and 3 show the distribution of the values of the standardised parameters. Deviations from the normal distribution are mostly caused by the most luminous (or by the poorest for the shape parameter) superclusters in our sample. In Table 1 we give the mean values and standard deviations of supercluster parameters. For poor superclusters of “spider” morphology the shape parameter is not always well defined (Einasto et al. 2011a). For five systems the value of the shape parameter |K1/K2| > 4; therefore we also calculated the mean value and standard deviation of the shape parameter without these systems (denoted as
(5)For PCA, the parameters should be normally distributed. Therefore we use the logarithms of parameters in most cases; this makes the distributions more gaussian, and the range over which their values span are smaller, especially for luminosities and volumes. We do not use logarithms of morphological data, in order to not to exclude from the analysis those with negative values of shapefinders, which may occur in the case of compact superclusters with a complex overall morphology (Einasto et al. 2008, 2011b). Figures 2 and 3 show the distribution of the values of the standardised parameters. Deviations from the normal distribution are mostly caused by the most luminous (or by the poorest for the shape parameter) superclusters in our sample. In Table 1 we give the mean values and standard deviations of supercluster parameters. For poor superclusters of “spider” morphology the shape parameter is not always well defined (Einasto et al. 2011a). For five systems the value of the shape parameter |K1/K2| > 4; therefore we also calculated the mean value and standard deviation of the shape parameter without these systems (denoted as 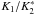 ). This effect does not affect the values of other parameters, thus we did not exclude these systems from our calculations.
). This effect does not affect the values of other parameters, thus we did not exclude these systems from our calculations.
We present in tables the values of principal components and the standard deviations, proportion of variance, and cumulative variance of principal components. The values of components show the importance of the original parameters in each PCx. We plot the principal planes for superclusters. For the calculations we used command prcomp from R, an open-source free statistical environment developed under the GNU GPL (Ihaka & Gentleman 1996, http://www.r-project.org).
To study correlations between properties of superclusters, we applied Spearman’s rank correlation test, in which the value of the correlation coefficient r shows the presence of correlation (r = 1 for perfect correlation), anticorrelation (r = −1 for perfect anticorrelation), or the absence of correlations when r ≈ 0.
Mean values and standard deviations of supercluster parameters.
 |
Fig. 3 Distribution of the standardised morphological parameters of superclusters. From left to right: the maximum value of the fourth Minkowski functional V3, the planarity K1, the filamentarity K2, and the shape parameter of superclusters, |
4. Results
4.1. PCA with physical parameters of superclusters
We start the calculations of principal components using physical characteristics of superclusters and their distances. Including the supercluster distances may show possible correlations between the other parameters of superclusters and their distance, which will indicate that the parameters of superclusters are affected by distance-dependent selection effects.
Results of the principal component analysis, with the distances of superclusters included.
Results of the Spearman’s rank correlation test.
Table 2 presents the results of this analysis. We show the values of only the first three principal components, enough for this test. The coefficients of the first principal component of the physical parameters are of almost equal value, while the coefficient corresponding to the distance is very small – the first principal component accounts for most of the variance of the physical parameters of superclusters. The second principal component accounts for most of the variance of the distances of superclusters. This shows that the physical parameters of superclusters are not correlated with distance. To ensure that this interpretation is correct we carried out the Spearman’s tests for correlations (Table 3). These tests showed a weak anticorrelation between the distance and the number of galaxies in superclusters, with a high statistical significance. This is not surprising since the catalogue of superclusters is based on the flux-limited sample in which the number of galaxies in superclusters depends on the distance. The sample of superclusters was chosen from a relatively narrow distance interval, so this dependence is weak. For other parameters of superclusters (luminosity, diameter, volume, and peak density), the tests showed a very weak correlation with distance (Spearman’s rank r ≈ 0.1 or less), but with no statistical significance, as the p-values show. Therefore we conclude that there are no correlations between the distances and physical parameters of superclusters, and the distance-dependent selection effects have been properly taken into account when generating the supercluster catalogue and calculating the physical properties of superclusters.
Results of the principal component analysis for the physical parameters.
We will proceed with the analysis of superclusters, taking only the physical parameters into account. Table 4, which presents the results of this analysis, demonstrates that the coefficients of the first principal component are almost equal for different parameters of superclusters. Therefore the parameters, which describe the full supercluster (the luminosity, richness, diameter, and volume), are almost equally important in determining the supercluster properties. The cumulative variance in Table 4 shows that the first two principal components account for more than 95% of the total variance in this supercluster sample. The first principal component accounts for most of the variance of the overall parameters of superclusters. The values of the second principal component show that the largest remaining variance in the sample comes from the peak density of superclusters. The values of the third principal component show that the coefficients corresponding to the luminosity, volume, and diameter have almost equal negative values, while the number of galaxies has large positive coefficients.
The PCA therefore suggests that the physical parameters of superclusters are strongly correlated. We checked for the presence of the correlations between the parameters with Spearman’s tests, which showed that the correlations between the parameters of superclusters are statistically of very high significance, both between the overall parameters of superclusters and between the overall parameters and the peak density inside the superclusters (Table 3). We only present the correlations between the luminosity and other parameters, to keep Table 3 short. The results of the tests of other correlations are similar. Especially tight are the correlations between the luminosities, the diameters, and the volumes of superclusters, as the correlation coefficients show in Table 3.
 |
Fig. 4 Principal planes for superclusters, PCA with physical parameters. Open circles: high-luminosity superclusters with luminosity Lg > 400 × 1010h-2L⊙, grey dots: superclusters of lower luminosity. |
Let us take a look at the locations of superclusters in the principal planes (Fig. 4). The upper lefthand panel shows the distribution of superclusters in the principal plane PC1-PC2. Most superclusters form here an elongated cloud with a very small scatter. These are low-luminosity superclusters with the luminosity Lg < 400 × 1010h-2L⊙. The scatter of positions of high-luminosity superclusters is larger. This suggests that we can divide superclusters into two populations according to their total luminosity. The transition between populations is smooth. We give the data about high-luminosity superclusters in Table C.1. The luminous superclusters with a high value of the peak density have higher negative values for the second PC, and the supercluster SCl 001 has the largest negative value of PC2. The superclusters with a lower value of the peak density have positive values of the second PC. The richest supercluster in the sample, SCl 061, is among them. This supercluster has the highest negative value of PC1. The lefthand panels of Fig. 4 show that the more luminous the supercluster, the higher is the negative value of it’s first principal component. The value of the peak density inside superclusters determines the location of superclusters along the axis of the second principal component. In PC1-PC3 plane (lower left panel of Fig. 4) superclusters also form an elongated cloud with larger scatter of high-luminosity superclusters. Upper right panel (PC3-PC2 plane) shows the third view of this cloud. Such an elongated, prolate shape is characteristic of the planar distribution on PC1-PC2 plane (Woo et al. 2008), which defines the fundamental plane for superclusters.
4.2. PCA for the morphological parameters of superclusters
Next, we use the PCA to study the morphological and physical properties of superclusters simultaneously. From the physical characteristics we only include the total luminosity, which is sufficient since the physical parameters of superclusters are strongly correlated. Table 3 shows that the mophological parameters of superclusters are not correlated with their distances. Table 5 shows the results of PCA for the luminosity and the morphological parameters. Here the absolute values of components for the luminosity, the clumpiness, and the shapefinders K1 and K2 are almost equal. Therefore the luminosity and these morphological parameters are equally important in shaping the properties of superclusters. The second principal component accounts for most of the variance of the shape parameter K1/K2. The higher the negative value of the PC1 for the supercluster, the more luminous the supercluster, has higher value planarities and filamentarities, and higher maximal value of the fourth Minkowski functional V3, hence a richer inner morphology.
Table 5 shows that the first two principal components account for about 93% of the total variance in the data.
The Spearman’s tests (Table 3) showed that the correlations between the supercluster luminosity and its morphological parameters are statistically highly significant. The correlation between the luminosity and the shape parameter of superclusters is weak.
Results of principal component analysis for the luminosity and morphological properties of superclusters.
 |
Fig. 5 Principal planes for superclusters. PCA with the morphological parameters. Open circles: high-luminosity superclusters with luminosity Lg > 400 × 1010h-2L⊙; grey dots: superclusters of lower luminosity. |
Figure 5 presents the locations of superclusters in the principal planes, defined by the luminosity and morphological parameters of superclusters. The upper lefthand panel shows the distribution of superclusters in the principal plane PC1-PC2. Here both high- and low-luminosity superclusters form an elongated cloud with very small scatter. The scatter of positions of the high-luminosity superclusters in PC1-PC3 plane is greater. Again, the more luminous the supercluster, the higher the negative value of its first principal component. High values of PC1 (and the highest values of PC3) correspond to luminous superclusters with high values of clumpiness V3 (Table 5). Large scatter along the second principal component PC2 in principal planes correspond to superclusters with high values of the shape parameter K1/K2. These are poor superclusters of “spider” morphology, for which the shape parameter is not well defined (Einasto et al. 2011a). We see that the luminosity and the morphological parameters of superclusters also define a fundamental plane for superclusters, where the physical and morphological properties are combined.
4.3. Scaling relations for superclusters and the fundamental plane
Results of principal component analysis for luminosity, diameters, and shapefinders.
The results of the PCA suggest that the first two principal components define the fundamental plane for superclusters. This motivates us to find the scaling relations between the supercluster parameters. The scaling relations have earlier been found between the properties of galaxies, of groups of galaxies and of dark matter haloes (Faber & Jackson 1976; Tully & Fisher 1977; Kormendy 1977; Efstathiou & Fall 1984; Djorgovski & Davis 1987; Dressler et al. 1987; Schaeffer et al. 1993; Adami et al. 1998; Lanzoni et al. 2004; D’Onofrio et al. 2008; Woo et al. 2008; Araya-Melo et al. 2009b, and references therein).
For scaling relations we use Eq. (5) and perform the PCA for the parameters log (Lg), (1 − K1)log (Diameter) and (1 − K2)log (Diameter). This set combines the easily detectable diameter of superclusters, and morphological parameters K1 and K2, which characterise the sizes and the shapes of superclusters, with the total luminosity of superclusters. For low values of shapefinders, (1 − K1) and (1 − K2) are less noisy than K1 and K2 (Einasto et al. 2011a).
 |
Fig. 6 Principal planes for superclusters. PCA for the luminosity, diameter, and shapefinders as described in the text. Open circles: high-luminosity superclusters with luminosity Lg > 400 × 1010h-2L⊙, grey dots: superclusters of lower luminosity. |
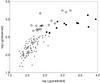 |
Fig. 7 Lg(observed) vs. Lg(predicted), in units of 1010h-2L⊙. Open circles denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 > 0.5 (less elongated superclusters), filled squares denote high-luminosity superclusters with the shape parameter K1/K2 < 0.5 (more elongated superclusters), grey dots denote superclusters of lower luminosity. |
Table 6 and Fig. 6 present the principal components and principal planes of superclusters. Table 6 shows that the first two principal components account for 99% of the total variance of the parameters. The highest positive values of PC3 in Fig. 6 come from high-luminosity, very elongated superclusters. The values of PC3 for superclusters SCl 061 and SCl 094 were much higher than for other superclusters, therefore we excluded them from the calculations as outliers. These are the richest, most luminous, and most elongated systems with the largest clumpiness in our sample (Table C.1 and Einasto et al. 2011a). The supercluster SCl 061 is the richest member of the Sloan Great Wall, an exceptional system in the nearby universe (Einasto et al. 2011b; Sheth & Diaferio 2011). The supercluster SCl 094 (the Corona Borealis supercluster) is the richest system in the dominant supercluster plane (Einasto et al. 2011a). This system has been studied by Small et al. (1998); look also at the references in Einasto et al. (2011a).
Equation (6) and Fig. 7 show the resulting scaling relation. 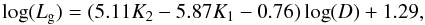 (6)where D denotes diameter. The standard deviation for the relation sd = 0.414. Most of the scatter comes from the parameters of luminous superclusters, for them sd = 0.507, for low-luminosity superclusters sd = 0.183.
(6)where D denotes diameter. The standard deviation for the relation sd = 0.414. Most of the scatter comes from the parameters of luminous superclusters, for them sd = 0.507, for low-luminosity superclusters sd = 0.183.
In Fig. 7 we denote the high-luminosity superclusters with different symbols, according to their shape parameter. Figure 7 shows that more elongated and less elongated high-luminosity superclusters populate the Lg(observed) − Lg(predicted) plane differently. This suggests that luminous superclusters can be divided into two populations according to their shapes. Our calculations show that there is no such difference for low-luminosity superclusters. The differences between the observed and predicted luminosity are the largest for five systems with the highest predicted luminosity in Fig. 7. These are very elongated luminous superclusters in the sample, systems of (multibranching) filament morphology, SCl 064, SCl 189, SCl 336, and SCl 474, and a multispider SCl 530 (for morphological classification of superclusters we refer to Einasto et al. 2011a).
Next we derived the scaling relations separately for more elongated and less elongated high-luminosity superclusters (correspondingly, Eq. (7) and Eq. (7)), and for all low-luminosity superclusters (Eq. (7)): 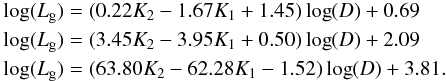 (7)Figure 8 demonstrates the observed vs. predicted luminosity of superclusters found with these relations. Now luminosities of high-luminosity superclusters are recovered well, with a very small scatter (sd = 0.16 and sd = 0.22 for more elongated and less elongated superclusters). Interestingly, this figure shows the absence of the correlation between the observed and predicted luminosity for low-luminosity superclusters. To understand this, we plot in Fig. 9 the shapefinders K1 − K2 plane for superclusters where the size of symbols is proportional to the diameters of superclusters. Here the values of shapefinders for high-luminosity superclusters are correlated, and these superclusters also have larger sizes. Most low-luminosity superclusters have very low, uncorrelated values of shapefinders (both K1 and K2 < 0.025). For the smallest systems they are even negative. An example of such a system is the Virgo supercluster (Einasto et al. 2007e). The results of the PCA show that, while pairwise correlations between the luminosity and other parameters in Table 3 are strong, the correlations between several parameters (diameters, shapefinders, and luminosities for most of low-luminosity superclusters) are almost absent, and so the scaling relation for them cannot be derived. Correlation between the observed and predicted luminosity for low-luminosity superclusters in Fig. 7 comes from the high-luminosity superclusters and from the low-luminosity superclusters with the shape parameters K1 and K2 > 0.025.
(7)Figure 8 demonstrates the observed vs. predicted luminosity of superclusters found with these relations. Now luminosities of high-luminosity superclusters are recovered well, with a very small scatter (sd = 0.16 and sd = 0.22 for more elongated and less elongated superclusters). Interestingly, this figure shows the absence of the correlation between the observed and predicted luminosity for low-luminosity superclusters. To understand this, we plot in Fig. 9 the shapefinders K1 − K2 plane for superclusters where the size of symbols is proportional to the diameters of superclusters. Here the values of shapefinders for high-luminosity superclusters are correlated, and these superclusters also have larger sizes. Most low-luminosity superclusters have very low, uncorrelated values of shapefinders (both K1 and K2 < 0.025). For the smallest systems they are even negative. An example of such a system is the Virgo supercluster (Einasto et al. 2007e). The results of the PCA show that, while pairwise correlations between the luminosity and other parameters in Table 3 are strong, the correlations between several parameters (diameters, shapefinders, and luminosities for most of low-luminosity superclusters) are almost absent, and so the scaling relation for them cannot be derived. Correlation between the observed and predicted luminosity for low-luminosity superclusters in Fig. 7 comes from the high-luminosity superclusters and from the low-luminosity superclusters with the shape parameters K1 and K2 > 0.025.
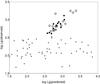 |
Fig. 8 Lg(observed) vs. Lg(predicted), in units of 1010h-2L⊙. Open circles denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 > 0.5 (less elongated superclusters), squares denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 < 0.5 (more elongated superclusters), and grey dots denote superclusters of lower luminosity. |
 |
Fig. 9 Shapefinders K1 − K2 plane for superclusters. The size of symbols is proportional to the diameters of superclusters. Open circles denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 > 0.5 (less elongated superclusters), squares denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 < 0.5 (more elongated superclusters), grey filled circles denote superclusters of lower luminosity. |
5. Selection effects
The main selection effect in our study comes from the use of a flux-limited sample of galaxies to determine the luminosity density field and superclusters. To have luminosity-dependent selection effects as small as possible, we used data about galaxies and galaxy systems from a distance interval 90–320 h-1Mpc, in which these effects are the least (we refer to T10 for details). We showed above that the parameters of superclusters (except the number of galaxies) do not correlate with distance, which shows that the distant-dependent selection effects are correctly taken into account when generating the supercluster catalogue.
If the number of cells used to define superclusters is too small then the supercluster catalogue may include objects that cannot be considered as real superclusters. Moreover, the detection of the shape parameter becomes unreliable. If the shape parameter is determined using the inertia tensor method then superclusters have to be defined using at least eight members (Kolokotronis et al. 2001). In our study we determine shapefinders with Minkowski functionals, and the minimum number of cells for defining superclusters is 64 (Appendix A). We analysed systems in a distance interval where the selection effects are small. Even the poorest systems contain at least 25 to 30 galaxies and several groups of galaxies. Therefore the detection of the shape parameter may only be affected weakly by the selection effects except for the poorest systems of “spider” morphology for which the shapefinders may be noisy. We note that Costa-Duarte et al. (2011) include systems with at least ten member galaxies in their supercluster catalogue to study of the shape parameter of superclusters.
Another selection effect comes from the choice of the threshold density to determine superclusters. At the density level used in the present paper (D = 5.0), rich superclusters do not percolate yet. If we use a lower threshold density, new galaxies are added to superclusters, and some superclusters may join to form huge systems. At a higher density level, galaxies in the outskirts of the superclusters no longer belong to superclusters, and superclusters become poorer and smaller.
Results of the principal component analysis for the threshold density level D = 5.5.
Results of the Spearman’s rank correlation test for the threshold density level D = 5.5.
To see the sensitivity of the PCA results to the small differences in the choice of the threshold density, we compared the results of the PCA for superclusters chosen at higher and lower threshold density levels. As an example we show in Table 7 the coefficients of the principal components for the superclusters chosen at the threshold density level D = 5.5. At this density level, Luparello et al. (2011) determined superclusters in the SDSS-DR7 for volume-limited samples of galaxies. We used flux-limited samples, thus the density levels cannot be compared directly, but we can still choose this level for the present test. Table 8 shows the results of the Spearman’s correlation test for this density level. The comparison with Tables 4 and 3 shows that the coefficients are almost the same. Therefore the results of the correlation test and the PCA are not very sensitive to the choise of the density level.
6. Discussion and conclusions
We studied the properties of superclusters drawn from the SDSS DR7 using the principal component analysis and Spearman’s correlation test. Several earlier studies have shown that the properties of superclusters are correlated (see the references in Sect. 1). However, it is surprising that the correlations between the various properties of superclusters are so tight. The first two principal components account for most of the variance in the data. Different physical parameters (the luminosity, volume, and diameter) and the morphological parameters (the clumpiness and the shape parameters) are almost equally important in shaping the properties of superclusters. This suggests that superclusters, as described by their overall physical and morphological properties and by their inner morphology and peak density, are objects that can be described with a few parameters. We derived the scaling relation for superclusters in which we combine their luminosities, diameters, and shapefinders.
We saw in Fig. 7 that more elongated and less elongated high-luminosity superclusters populate the Lg(observed) − Lg(predicted) plane differently. This suggests that luminous superclusters can be divided into two populations according to their shapes – more elongated systems with the shape parameter K1/K2 < 0.5 and less elongated ones with K1/K2 > 0.5. Einasto et al. (2011a) got a similar result using multidimensional normal mixture modelling. It is remarkable that two different multivariate methods reveal information about the data in such good agreement. However, there are few high-luminosity superclusters in our sample. There are 14 systems with the shape parameter K1/K2 < 0.5 among them, and 17 systems with K1/K2 > 0.5. A larger sample of superclusters has to be analysed to confirm this result.
Parameters used to characterise superclusters in the present study do not reflect all the properties of superclusters. For example, rich superclusters contain high-density cores that may contain merging X-ray clusters and may be collapsing (Small et al. 1998; Bardelli et al. 2000; Einasto et al. 2001; Rose et al. 2002; Einasto et al. 2007c, 2008). A supercluster environment with a wide range of densities affects the properties of galaxies, groups, and clusters located there (Einasto et al. 2003b, 2007d, 2011b; Plionis 2004; Wolf et al. 2005; Haines et al. 2006; Porter et al. 2008; Tempel et al. 2009, 2011; Fleenor & Johnston-Hollitt 2010). Einasto et al. (2011b) showed that the dynamical evolution of one of the richest superclusters in the Sloan Great Wall (SCL 111, SCl 024 in L10 catalogue) is almost finished, while the richest member of the Wall, SCl 126 (SCl 061) is still dynamically active. Therefore our results reflect only certain aspects of the properties of superclusters.
Systems of galaxies determined in the SDSS have been studied by a number of authors (Pandey & Bharadwaj 2005; Gott et al. 2005; Park et al. 2005; Pandey & Bharadwaj 2006; Gott et al. 2008; Pandey & Bharadwaj 2008; Kitaura et al. 2009; Choi et al. 2010; Sousbie et al. 2011; Einasto et al. 2011b,a; Sheth & Diaferio 2011; Pimbblet et al. 2011; Platen et al. 2011). The overall shapes of superclusters have been described by the shape parameters or approximated by triaxial ellipses (Jaaniste et al. 1998; Basilakos et al. 2001; Kolokotronis et al. 2002; Basilakos 2003; Einasto et al. 2007a, 2011b,a; Costa-Duarte et al. 2011; Luparello et al. 2011). These studies showed that elongated, prolate structures dominate among superclusters. The results obtained using the moments of inertia tensor (Basilakos et al. 2001; Basilakos 2003) or the Minkowski functionals are in a good agreement (see also Einasto et al. 2007e, 2011a). In addition, Basilakos et al. (2006) analysed correlations between supercluster properties from simulations and find that the amplitude of the supercluster – cluster alignment increases (weakly) with superclusters filamentarity.
The properties of superclusters are determined by their formation and evolution. Kolokotronis et al. (2002) show that the shapes of superclusters agree better with a ΛCDM model than with a τCDM model. Also Luparello et al. (2011) found that the shapes of observed superclusters agree with those in the ΛCDM model. In the ΛCDM concordance cosmological model, the matter density Ωm dominated in the early universe and the structures formed by hierarhical clustering driven by gravity. As the universe expands, the average matter density decreases. At a certain epoch, the dark energy density ΩΛ became higher than the matter density, and the universe started to expand acceleratingly. Simulations of the evolution and the future of the structure in an accelerating universe show the freezing of the web – the large-scale evolution of structures slows down (Loeb 2002; Nagamine & Loeb 2003; Dünner et al. 2006; Hoffman et al. 2007; Krauss & Scherrer 2007, and references therein). Araya-Melo et al. (2009a) show that this affects the sizes, the shapes, and the inner structure of superclusters, and they become rounder, smaller, and their multiplicity decreases. According to our present results, this suggests that in the future superclusters become less elongated and the scatter in the scaling relation of superclusters may decrease.
Summarising, our study showed that:
-
1)
The PCA and Spearman’s correlation test showed the absenceof correlations between the physical properties of superclustersand their distance, therefore the distance-dependent selectioneffects were taken into account properly when generatingsupercluster catalogue.
-
2)
The correlations between the properties of superclusters are tight. Different physical parameters (the luminosity, the volume, and the diameter) and the morphological parameters (the clumpiness and the shapefinders) of superclusters are equally important in shaping the properties of superclusters.
-
3)
The first two principal components account for more than 90% of the variance of the supercluster properties and define the fundamental plane of superclusters. This suggests that superclusters can be described with a few physical and morphological parameters. We derived the scaling relation for superclusters using data about their luminosities, diameters, and shapefinders.
-
4)
Superclusters can be divided into two populations according to their luminosity, using the luminosity limit Lg = 400 × 1010h-2L⊙. In agreement with Einasto et al. (2011a), we find that high-luminosity superclusters can be divided into two sets: more elongated systems with the shape parameter K1/K2 < 0.5 and less elongated ones with K1/K2 > 0.5.
For our study we chose a small sample of superclusters least affected by selection effects. To understand the properties of superclusters better the next step is to study a large sample of superclusters and high-redshift superclusters. A few superclusters at very high redshifts have already been discovered (Nakata et al. 2005; Swinbank et al. 2007; Gal et al. 2008; Tanaka et al. 2009; Planck Collaboration et al. 2011; Schirmer et al. 2011). Deep surveys like the ALHAMBRA project (Moles et al. 2008) will provide us with data about (possible) very distant superclusters. We also need more simulations with various cosmologies to understand the evolution and the properties of superclusters in detail.
The supercluster catalogues can be downloaded from: http://atmos.physic.ut.ee/~juhan/super/
Acknowledgments
We thank the referee, Dr. S. Basilakos, for the comments and suggestions that helped to improve the paper. Funding for the Sloan Digital Sky Survey (SDSS) and SDSS-II has been the National Science Foundation, the U.S. Department of Energy, the National Aeronautics and Space Administration, the Japanese Monbukagakusho, and the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web site is http://www.sdss.org/. The SDSS is managed by the Astrophysical Research Consortium (ARC) for the Participating Institutions. The Participating Institutions are the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, University of Cambridge, Case Western Reserve University, The University of Chicago, Drexel University, Fermilab, the Institute for Advanced Study, the Japan Participation Group, The Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Chinese Academy of Sciences (LAMOST), Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, Ohio State University, University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory, and the University of Washington. We acknowledge the Estonian Science Foundation for support under grants No. 8005 and 7146, 7765, and the Estonian Ministry for Education and Science support by grant SF0060067s08. This work has also been supported by ICRAnet through a professorship for Jaan Einasto, by the University of Valencia through a visiting professorship for Enn Saar and by the Spanish MEC project AYA2006-14056, “PAU” (CSD2007-00060), including FEDER contributions, and the Generalitat Valenciana project of excellence PROMETEO/2009/064. The density maps and the supercluster catalogues were calculated at the High Performance Computing Centre, University of Tartu. In this paper we use R, an open-source free statistical environment developed under the GNU GPL (Ihaka & Gentleman 1996, http://www.r-project.org).
References
- Abazajian, K. N., Adelman-McCarthy, J. K., Agüeros, M. A., et al. 2009, ApJS, 182, 543 [NASA ADS] [CrossRef] [Google Scholar]
- Adami, C., Mazure, A., Biviano, A., Katgert, P., & Rhee, G. 1998, A&A, 331, 493 [NASA ADS] [Google Scholar]
- Adelman-McCarthy, J. K., Agüeros, M. A., Allam, S. S., et al. 2008, ApJS, 175, 297 [NASA ADS] [CrossRef] [Google Scholar]
- Araya-Melo, P. A., Reisenegger, A., Meza, A., et al. 2009a, MNRAS, 399, 97 [Google Scholar]
- Araya-Melo, P. A., van de Weygaert, R., & Jones, B. J. T. 2009b, MNRAS, 400, 1317 [NASA ADS] [CrossRef] [Google Scholar]
- Bardelli, S., Zucca, E., Zamorani, G., Moscardini, L., & Scaramella, R. 2000, MNRAS, 312, 540 [NASA ADS] [CrossRef] [Google Scholar]
- Basilakos, S. 2003, MNRAS, 344, 602 [NASA ADS] [CrossRef] [Google Scholar]
- Basilakos, S., Plionis, M., & Rowan-Robinson, M. 2001, MNRAS, 323, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Basilakos, S., Plionis, M., Yepes, G., Gottlöber, S., & Turchaninov, V. 2006, MNRAS, 365, 539 [NASA ADS] [CrossRef] [Google Scholar]
- Blanton, M. R., & Roweis, S. 2007, AJ, 133, 734 [NASA ADS] [CrossRef] [Google Scholar]
- Bond, N. A., Strauss, M. A., & Cen, R. 2010, MNRAS, 409, 156 [NASA ADS] [CrossRef] [Google Scholar]
- Chang, Y.-Y., Chao, R., Wang, W.-H., & Chen, P. 2010 [arXiv:1009.0030] [Google Scholar]
- Choi, Y.-Y., Park, C., Kim, J., et al. 2010, ApJS, 190, 181 [NASA ADS] [CrossRef] [Google Scholar]
- Coppa, G., Mignoli, M., Zamorani, G., et al. 2011, A&A, 535, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Costa-Duarte, M. V., Sodré, Jr., L., & Durret, F. 2011, MNRAS, 411, 1716 [NASA ADS] [CrossRef] [Google Scholar]
- de Lapparent, V., Geller, M. J., & Huchra, J. P. 1986, ApJ, 302, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Deeming, T. J. 1964, MNRAS, 127, 493 [NASA ADS] [Google Scholar]
- Djorgovski, S., & Davis, M. 1987, ApJ, 313, 59 [NASA ADS] [CrossRef] [Google Scholar]
- D’Onofrio, M., Fasano, G., Varela, J., et al. 2008, ApJ, 685, 875 [NASA ADS] [CrossRef] [Google Scholar]
- Dressler, A., Lynden-Bell, D., Burstein, D., et al. 1987, ApJ, 313, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Dünner, R., Araya, P. A., Meza, A., & Reisenegger, A. 2006, MNRAS, 366, 803 [NASA ADS] [CrossRef] [Google Scholar]
- Efstathiou, G., & Fall, S. M. 1984, MNRAS, 206, 453 [NASA ADS] [Google Scholar]
- Einasto, J. 2010, in AIP Conf. Ser. 1205, ed. R. Ruffini, & G. Vereshchagin, 72 [Google Scholar]
- Einasto, J., Hütsi, G., Einasto, M., et al. 2003a, A&A, 405, 425 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Einasto, M., Saar, E., et al. 2006, A&A, 459, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Einasto, M., Saar, E., et al. 2007a, A&A, 462, 397 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Einasto, M., Tago, E., et al. 2007b, A&A, 462, 811 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Dalton, G. B., & Andernach, H. 1994, MNRAS, 269, 301 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, M., Tago, E., Jaaniste, J., Einasto, J., & Andernach, H. 1997, A&AS, 123, 119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Müller, V., & Andernach, H. 2001, AJ, 122, 2222 [CrossRef] [Google Scholar]
- Einasto, M., Jaaniste, J., Einasto, J., et al. 2003b, A&A, 405, 821 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., et al. 2007c, A&A, 464, 815 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., et al. 2007d, A&A, 464, 815 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Saar, E., Liivamägi, L. J., et al. 2007e, A&A, 476, 697 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Saar, E., Martínez, V. J., et al. 2008, ApJ, 685, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, M., Liivamägi, L. J., Tago, E., et al. 2011a, A&A, 532, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Liivamägi, L. J., Tempel, E., et al. 2011b, ApJ, 736, 51 [NASA ADS] [CrossRef] [Google Scholar]
- Erdoğdu, P., Lahav, O., Zaroubi, S., et al. 2004, MNRAS, 352, 939 [NASA ADS] [CrossRef] [Google Scholar]
- Faber, S. M., & Jackson, R. E. 1976, ApJ, 204, 668 [NASA ADS] [CrossRef] [Google Scholar]
- Ferreras, I., Pasquali, A., de Carvalho, R. R., de la Rosa, I. G., & Lahav, O. 2006, MNRAS, 370, 828 [NASA ADS] [CrossRef] [Google Scholar]
- Fleenor, M. C., & Johnston-Hollitt, M. 2010, in ASP Conf. Ser. 423, ed. B. Smith, J. Higdon, S. Higdon, & N. Bastian, 81 [Google Scholar]
- Gal, R. R., Lemaux, B. C., Lubin, L. M., Kocevski, D., & Squires, G. K. 2008, ApJ, 684, 933 [NASA ADS] [CrossRef] [Google Scholar]
- Gott, J. R. I., Jurić, M., Schlegel, D., et al. 2005, ApJ, 624, 463 [Google Scholar]
- Gott, J. R. I., Hambrick, D. C., Vogeley, M. S., et al. 2008, ApJ, 675, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Gregory, S. A., & Thompson, L. A. 1978, ApJ, 222, 784 [NASA ADS] [CrossRef] [Google Scholar]
- Haines, C. P., Merluzzi, P., Mercurio, A., et al. 2006, MNRAS, 371, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Hatch, N. A., De Breuck, C., Galametz, A., et al. 2011, MNRAS, 410, 1537 [NASA ADS] [Google Scholar]
- Hoffman, Y., Lahav, O., Yepes, G., & Dover, Y. 2007, J. Cosmol. Astropart. Phys., 10, 16 [Google Scholar]
- Ihaka, R., & Gentleman, R. 1996, J. Comp. Graph. Stat., 5, 299 [CrossRef] [Google Scholar]
- Ishida, E. E. O., & de Souza, R. S. 2011, A&A, 527, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ishida, E. E. O., de Souza, R. S., & Ferrara, A. 2011, MNRAS, in press [arXiv:1106.1745] [Google Scholar]
- Jaaniste, J., Tago, E., Einasto, M., et al. 1998, A&A, 336, 35 [NASA ADS] [Google Scholar]
- Jeeson-Daniel, A., Dalla Vecchia, C., Haas, M. R., & Schaye, J. 2011, MNRAS, 415, L69 [NASA ADS] [Google Scholar]
- Joeveer, M., Einasto, J., & Tago, E. 1978, MNRAS, 185, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Kalinkov, M., & Kuneva, I. 1995, A&AS, 113, 451 [NASA ADS] [Google Scholar]
- Kitaura, F. S., Jasche, J., Li, C., et al. 2009, MNRAS, 400, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Kolokotronis, V., Basilakos, S., & Plionis, M. 2002, MNRAS, 331, 1020 [NASA ADS] [CrossRef] [Google Scholar]
- Kolokotronis, V., Basilakos, S., Plionis, M., & Georgantopoulos, I. 2001, MNRAS, 320, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Kormendy, J. 1977, ApJ, 218, 333 [NASA ADS] [CrossRef] [Google Scholar]
- Krauss, L. M., & Scherrer, R. J. 2007, Gen. Relat. Gravit., 39, 1545 [NASA ADS] [CrossRef] [Google Scholar]
- Lanzoni, B., Ciotti, L., Cappi, A., Tormen, G., & Zamorani, G. 2004, ApJ, 600, 640 [NASA ADS] [CrossRef] [Google Scholar]
- Liivamägi, L. J., Tempel, E., & Saar, E. 2010, A&A, submitted [arXiv:1012.1989] [Google Scholar]
- Loeb, A. 2002, Phys. Rev. D, 65, 047301 [NASA ADS] [CrossRef] [Google Scholar]
- Luparello, H., Lares, M., Lambas, D. G., & Padilla, N. 2011, MNRAS, 415, 964 [NASA ADS] [CrossRef] [Google Scholar]
- Martínez, V. J., Arnalte-Mur, P., Saar, E., et al. 2009, ApJ, 696, L93 [NASA ADS] [CrossRef] [Google Scholar]
- Martínez, V. J., & Saar, E. 2002, Statistics of the Galaxy Distribution (Chapman & Hall/CRC, Boca Raton) [Google Scholar]
- Mobasher, B., Dickinson, M., Ferguson, H. C., et al. 2005, ApJ, 635, 832 [NASA ADS] [CrossRef] [Google Scholar]
- Moles, M., Benítez, N., Aguerri, J. A. L., et al. 2008, AJ, 136, 1325 [Google Scholar]
- Nagamine, K., & Loeb, A. 2003, New A, 8, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Nakata, F., Kodama, T., Shimasaku, K., et al. 2005, MNRAS, 357, 1357 [NASA ADS] [CrossRef] [Google Scholar]
- Ouchi, M., Shimasaku, K., Akiyama, M., et al. 2005, ApJ, 620, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Pandey, B., & Bharadwaj, S. 2005, MNRAS, 357, 1068 [NASA ADS] [CrossRef] [Google Scholar]
- Pandey, B., & Bharadwaj, S. 2006, MNRAS, 372, 827 [NASA ADS] [CrossRef] [Google Scholar]
- Pandey, B., & Bharadwaj, S. 2008, MNRAS, 387, 767 [NASA ADS] [CrossRef] [Google Scholar]
- Park, C., Choi, Y., Vogeley, M. S., Gott, III, J. R., & Blanton, M. R. 2007, ApJ, 658, 898 [NASA ADS] [CrossRef] [Google Scholar]
- Park, C., Choi, Y., Vogeley, M. S., et al. 2005, ApJ, 633, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Pimbblet, K. A., Andernach, H., Fishlock, C. K., Roseboom, I. G., & Owers, M. S. 2011, MNRAS, 410, 1837 [NASA ADS] [Google Scholar]
- Planck Collaboration 2011, A&A, 536, A8 DOI: 10.1051/0004-6361/201116474 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Platen, E., van de Weygaert, R., Jones, B. J. T., Vegter, G., & Aragón-Calvo, M. A. 2011, MNRAS, 1062 [Google Scholar]
- Plionis, M. 2004, in Outskirts of Galaxy Clusters: Intense Life in the Suburbs, ed. A. Diaferio, IAU Coll., 195, 19 [Google Scholar]
- Porter, S. C., Raychaudhury, S., Pimbblet, K. A., & Drinkwater, M. J. 2008, MNRAS, 388, 1152 [NASA ADS] [Google Scholar]
- Rose, J. A., Gaba, A. E., Christiansen, W. A., et al. 2002, AJ, 123, 1216 [NASA ADS] [CrossRef] [Google Scholar]
- Saar, E. 2009, in Data Analysis in Cosmology, ed. V. J. Martínez, E. Saar, E. Martínez-Gonzalez, & M.-J. Pons-Bordería (Berlin: Springer-Verlag), 523 [Google Scholar]
- Saar, E., Martínez, V. J., Starck, J., & Donoho, D. L. 2007, MNRAS, 374, 1030 [NASA ADS] [CrossRef] [Google Scholar]
- Sahni, V., Sathyaprakash, B. S., & Shandarin, S. F. 1998, ApJ, 495, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez Almeida, J., Aguerri, J. A. L., Muñoz-Tuñón, C., & de Vicente, A. 2010, ApJ, 714, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Schaeffer, R., Maurogordato, S., Cappi, A., & Bernardeau, F. 1993, MNRAS, 263, L21 [NASA ADS] [CrossRef] [Google Scholar]
- Schirmer, M., Hildebrandt, H., Kuijken, K., & Erben, T. 2011, A&A, 532, A57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shandarin, S. F., Sheth, J. V., & Sahni, V. 2004, MNRAS, 353, 162 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., & Diaferio, A. 2011 [arXiv:1105.3378] [Google Scholar]
- Silverman, B. W. 1986, Density Estimation for Statistics and Data Analysis (Chapman & Hall, CRC Press, Boca Raton) [Google Scholar]
- Skibba, R. A., & Maccio’, A. V. 2011, MNRAS, 416, 2388 [NASA ADS] [CrossRef] [Google Scholar]
- Small, T. A., Ma, C., Sargent, W. L. W., & Hamilton, D. 1998, ApJ, 492, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Sousbie, T., Pichon, C., & Kawahara, H. 2011, MNRAS, 414, 384 [NASA ADS] [CrossRef] [Google Scholar]
- Swinbank, A. M., Edge, A. C., Smail, I., et al. 2007, MNRAS, 379, 1343 [NASA ADS] [CrossRef] [Google Scholar]
- Tago, E., Saar, E., Tempel, E., et al. 2010, A&A, 514, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tanaka, M., Finoguenov, A., Kodama, T., et al. 2009, A&A, 505, L9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tempel, E., Einasto, J., Einasto, M., Saar, E., & Tago, E. 2009, A&A, 495, 37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tempel, E., Saar, E., Liivamägi, L. J., et al. 2011, A&A, 529, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tiit, E., & Einasto, J. 1964, Publ. Tartu Astrofiz. Obs., 34, 156 [NASA ADS] [Google Scholar]
- Toribio, M. C., Solanes, J. M., Giovanelli, R., Haynes, M. P., & Martin, A. M. 2011, ApJ, 732, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Tully, R. B., & Fisher, J. R. 1977, A&A, 54, 661 [NASA ADS] [Google Scholar]
- Venemans, B. P., Röttgering, H. J. A., Overzier, R. A., et al. 2004, A&A, 424, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wolf, C., Gray, M. E., & Meisenheimer, K. 2005, A&A, 443, 435 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Woo, J., Courteau, S., & Dekel, A. 2008, MNRAS, 390, 1453 [NASA ADS] [Google Scholar]
- Wray, J. J., Bahcall, N. A., Bode, P., Boettiger, C., & Hopkins, P. F. 2006, ApJ, 652, 907 [NASA ADS] [CrossRef] [Google Scholar]
- Zeldovich, I. B., Einasto, J., & Shandarin, S. F. 1982, Nature, 300, 407 [NASA ADS] [CrossRef] [Google Scholar]
- Zucca, E., Zamorani, G., Scaramella, R., & Vettolani, G. 1993, ApJ, 407, 470 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Luminosity density field and superclusters
To calculate the luminosity density field, we calculate the luminosities of groups first. In flux-limited samples, galaxies outside the observational window remain unobserved. To take into account the luminosities of the galaxies that lie outside the sample limits also we multiply the observed galaxy luminosities by the weight Wd. The distance-dependent weight factor Wd was calculated as 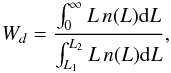 (A.1)where L1,2 = L⊙100.4(M⊙ − M1,2) are the luminosity limits of the observational window at a distance d, corresponding to the absolute magnitude limits of the window M1 and M2; we took M⊙ = 4.64 mag in the r-band (Blanton & Roweis 2007). Due to their peculiar velocities, the distances of galaxies are somewhat uncertain; if the galaxy belongs to a group, we use the group distance to determine the weight factor.
(A.1)where L1,2 = L⊙100.4(M⊙ − M1,2) are the luminosity limits of the observational window at a distance d, corresponding to the absolute magnitude limits of the window M1 and M2; we took M⊙ = 4.64 mag in the r-band (Blanton & Roweis 2007). Due to their peculiar velocities, the distances of galaxies are somewhat uncertain; if the galaxy belongs to a group, we use the group distance to determine the weight factor.
The luminosity weights for the groups of the SDSS DR7 in the distance interval 90 h-1Mpc ≥ D ≤ 320 h-1Mpc are plotted as a function of the distance from the observer in Fig. A.1. The mean weight is slightly higher than unity (about 1.4) within the sample limits. When the distance is greater, the weights increase owing to the absence of faint galaxies. Details of the calculations of weights are given also in Tempel et al. (2011). In the final flux-limited group catalogue, the richness of groups decreases rapidly at distances D > 320 h-1Mpc due to selection effects (Tago et al. 2010; Einasto et al. 2011a). This is another reason to choose for our study superclusters from the distance interval 90 h-1Mpc ≤ D ≤ 320 h-1Mpc where the selection effects are weak. Even the poorest systems in our sample contain several groups of galaxies being real galaxy systems comparable to the Local supercluster.
To calculate a luminosity density field, we convert the spatial positions of galaxies ri and their luminosities Li into spatial (luminosity) densities using kernel densities (Silverman 1986): 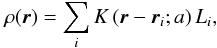 (A.2)where the sum is over all galaxies, and K(r;a) is a kernel function of a width a. Good kernels for calculating densities on a spatial grid are generated by box splines BJ. Box splines are local and they are interpolating on a grid:
(A.2)where the sum is over all galaxies, and K(r;a) is a kernel function of a width a. Good kernels for calculating densities on a spatial grid are generated by box splines BJ. Box splines are local and they are interpolating on a grid: 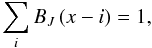 (A.3)for any x and a small number of indices that give non-zero values for BJ(x). We use the popular B3 spline function:
(A.3)for any x and a small number of indices that give non-zero values for BJ(x). We use the popular B3 spline function: 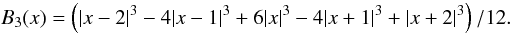 (A.4)The (one-dimensional) B3 box spline kernel
(A.4)The (one-dimensional) B3 box spline kernel 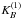 of the width a is defined as
of the width a is defined as 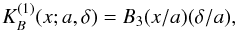 (A.5)where δ is the grid step. This kernel differs from zero only in the interval x ∈ [−2a,2a] . It is close to a Gaussian with σ = 0.6 in the region x ∈ [−a,a] , so its effective width is 2a (see, e.g., Saar 2009). The kernel preserves the interpolation property exactly for all values of a and δ, where the ratio a/δ is an integer. (This kernel can be used also if this ratio is not an integer, and a ≫ δ; the kernel sums to 1 in this case, too, with a very small error.) This means that if we apply this kernel to N points on a one-dimensional grid, the sum of the densities over the grid is exactly N.
(A.5)where δ is the grid step. This kernel differs from zero only in the interval x ∈ [−2a,2a] . It is close to a Gaussian with σ = 0.6 in the region x ∈ [−a,a] , so its effective width is 2a (see, e.g., Saar 2009). The kernel preserves the interpolation property exactly for all values of a and δ, where the ratio a/δ is an integer. (This kernel can be used also if this ratio is not an integer, and a ≫ δ; the kernel sums to 1 in this case, too, with a very small error.) This means that if we apply this kernel to N points on a one-dimensional grid, the sum of the densities over the grid is exactly N.
The three-dimensional kernel 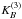 is given by the direct product of three one-dimensional kernels:
is given by the direct product of three one-dimensional kernels: 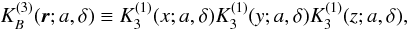 (A.6)where r ≡ { x,y,z } . Although this is a direct product, it is isotropic to a good degree (Saar 2009).
(A.6)where r ≡ { x,y,z } . Although this is a direct product, it is isotropic to a good degree (Saar 2009).
In Einasto et al. (2007e) we compared the Epanechnikov, the Gaussian, and B3 box spline kernels for calculating the density field. The Epanechnikov and the B3 kernels are both compact, while the Gaussian kernel is infinite and has to be cut off at a fixed radius, which introduces an extra parameter. We also found that both the Epanechnikov and the B3 kernels describe the overall shape of superclusters well, while the B3 box spline kernel resolves the inner structure of superclusters better. This is why we used this kernel in the present study.
 |
Fig. A.1 Weights used to correct for probable group members outside the observational luminosity window. |
The densities were calculated on a Cartesian grid based on the SDSS η, λ coordinate system, as it allowed the most efficient fit of the galaxy sample cone into a brick. Using the rms velocity σv, translated into distance, and the rms projected radius σr from the group catalogue (T10), we suppress the cluster finger redshift distortions. We divide the radial distances between the group galaxies and the group centre by the ratio of the rms sizes of the group finger: 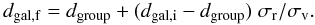 (A.7)This removes the smudging effect the fingers have on the density field.
(A.7)This removes the smudging effect the fingers have on the density field.
The grid coordinates are calculated according to Eq. (3). We used an 1 h-1Mpc step grid and chose the kernel width a = 8 h-1Mpc. This kernel differs from zero within the radius 16 h-1Mpc, but significantly so only inside the 8 h-1Mpc radius. As a lower limit for the volume of superclusters we used the value (a/2) h-1Mpc3 (64 grid cells). In this way we exclude small spurious density field objects which include almost no galaxies. Liivamägi et al. (2010) tested the method generating the superclusters from the Millenium simulations. This comparison showed that supercluster algorithms work well, and, in addition, the selection effects have been properly taken into account when generating a supercluster catalogue from flux-limited sample of galaxies.
Before extracting superclusters we apply the DR7 mask constructed by Arnalte-Mur (Martínez et al. 2009; Liivamägi et al. 2010) to the density field and convert densities into units of mean density. The mean density is defined as the average over all pixel values inside the mask. The mask is designed to follow the edges of the survey and the galaxy distribution inside the mask is assumed to be homogeneous.
Appendix B: Minkowski functionals and shapefinders
The supercluster morphology is fully characterised by the four Minkowski functionals V0–V3. For a given surface the four Minkowski functionals (from the first to the fourth) are proportional to the enclosed volume V, the area of the surface S, the integrated mean curvature C, and the integrated Gaussian curvature χ (Sahni et al. 1998; Martínez & Saar 2002; Shandarin et al. 2004; Saar et al. 2007; Saar 2009).
With the first three Minkowski functionals, we calculate the dimensionless shapefinders K1 (planarity) and K2 (filamentarity) (Sahni et al. 1998; Shandarin et al. 2004). See also Basilakos et al. (2001), in this study the shapefinders were determined with the moments of inertia method. First we calculate the shapefinders H1 − H3 with a combination of Minkowski functionals: H1 = 3V/S (thickness), H2 = S/C (width), and H3 = C/4π (length). Then we use the shapefinders H1 − H3 to calculate two dimensionless shapefinders K1 (planarity) and K2 (filamentarity): K1 = (H2 − H1)/(H2 + H1) and K2 = (H3 − H2)/(H3 + H2). We characterise the overall shape of superclusters using planarity K1 and filamentarity K2, and their ratio, K1/K2 (the shape parameter).
The fourth Minkowski functional V3, describes the topology of the surface and gives the number of isolated clumps, the number of void bubbles, and the number of tunnels (voids open from both sides) in the region (see, e.g. Saar et al. 2007). Morphologically the superclusters with low values of the fourth Minkowski functional V3 can be described as simple spiders or simple filaments. High values of the fourth Minkowski functional V3 suggest a complicated (clumpy) morphology of a supercluster, described as multispiders or multibranching filaments (Einasto et al. 2007e, 2011a).
Appendix C: Data on luminous (Lg > 400 × 1010 h-2 L⊙) superclusters
Data on luminous (Lg > 400 × 1010h-2L⊙) superclusters.
All Tables
Results of the principal component analysis, with the distances of superclusters included.
Results of principal component analysis for the luminosity and morphological properties of superclusters.
Results of principal component analysis for luminosity, diameters, and shapefinders.
Results of the principal component analysis for the threshold density level D = 5.5.
Results of the Spearman’s rank correlation test for the threshold density level D = 5.5.
All Figures
|
Fig. 1 The distribution of superclusters in Cartesian coordinates, in units of h-1Mpc. The filled circles denote superclusters with the luminosity Lg > 400 × 1010h-2L⊙, empty circles denote less luminous superclusters. The numbers are ID’s of luminous supercluster from L10 (Table C.1). |
| In the text | |
|
Fig. 2 Distribution of the standardised physical parameters of superclusters. From left to right: the total weighted luminosity of galaxies Lg, the volume and the diameter of superclusters, the density of the highest density peak inside superclusters, Dpeak, and the number of galaxies in superclusters, Ngal. |
| In the text | |
|
Fig. 3 Distribution of the standardised morphological parameters of superclusters. From left to right: the maximum value of the fourth Minkowski functional V3, the planarity K1, the filamentarity K2, and the shape parameter of superclusters, |
| In the text | |
|
Fig. 4 Principal planes for superclusters, PCA with physical parameters. Open circles: high-luminosity superclusters with luminosity Lg > 400 × 1010h-2L⊙, grey dots: superclusters of lower luminosity. |
| In the text | |
|
Fig. 5 Principal planes for superclusters. PCA with the morphological parameters. Open circles: high-luminosity superclusters with luminosity Lg > 400 × 1010h-2L⊙; grey dots: superclusters of lower luminosity. |
| In the text | |
|
Fig. 6 Principal planes for superclusters. PCA for the luminosity, diameter, and shapefinders as described in the text. Open circles: high-luminosity superclusters with luminosity Lg > 400 × 1010h-2L⊙, grey dots: superclusters of lower luminosity. |
| In the text | |
|
Fig. 7 Lg(observed) vs. Lg(predicted), in units of 1010h-2L⊙. Open circles denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 > 0.5 (less elongated superclusters), filled squares denote high-luminosity superclusters with the shape parameter K1/K2 < 0.5 (more elongated superclusters), grey dots denote superclusters of lower luminosity. |
| In the text | |
|
Fig. 8 Lg(observed) vs. Lg(predicted), in units of 1010h-2L⊙. Open circles denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 > 0.5 (less elongated superclusters), squares denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 < 0.5 (more elongated superclusters), and grey dots denote superclusters of lower luminosity. |
| In the text | |
|
Fig. 9 Shapefinders K1 − K2 plane for superclusters. The size of symbols is proportional to the diameters of superclusters. Open circles denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 > 0.5 (less elongated superclusters), squares denote high-luminosity superclusters with the luminosity Lg > 400 × 1010h-2L⊙ and the shape parameter K1/K2 < 0.5 (more elongated superclusters), grey filled circles denote superclusters of lower luminosity. |
| In the text | |
|
Fig. A.1 Weights used to correct for probable group members outside the observational luminosity window. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.