| Issue |
A&A
Volume 532, August 2011
|
|
|---|---|---|
| Article Number | A116 | |
| Number of page(s) | 10 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/201117278 | |
| Published online | 03 August 2011 | |
Application of Bayesian model inadequacy criterion for multiple data sets to radial velocity models of exoplanet systems
1
University of Hertfordshire, Centre for Astrophysics Research, Science and Technology Research Institute, College Lane, AL10 9AB, Hatfield, UK
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
University of Turku, Tuorla Observatory, Department of Physics and Astronomy, Väisäläntie 20, 21500, Piikkiö, Finland
Received: 17 May 2011
Accepted: 27 June 2011
Abstract
We present a simple mathematical criterion for determining whether a given statistical model does not describe several independent sets of measurements, or data modes, adequately. We derive this criterion for two data sets and generalise it to several sets by using the Bayesian updating of the posterior probability density. To demonstrate the usage of the criterion, we apply it to observations of exoplanet host stars by re-analysing the radial velocities of HD 217107, Gliese 581, and υ Andromedae and show that the currently used models are not necessarily adequate in describing the properties of these measurements. We show that while the two data sets of Gliese 581 can be modelled reasonably well, the noise model of HD 217107 needs to be revised. We also reveal some biases in the radial velocities of υ Andromedae and report updated orbital parameters for the recently proposed 4-planet model. Because of the generality of our criterion, no assumptions are needed on the nature of the measurements, models, or model parameters. The method we propose can be applied to any astronomical problems, as well as outside the field of astronomy, because it is a simple consequence of the Bayes’ rule of conditional probabilities.
Key words: methods: statistical / techniques: radial velocities / stars: individual: GJ 581 / stars: individual: HD 217107 / stars: individual:υAndromedae
© ESO, 2011
1. Introduction
Since the discovery of the first clear-cut example of an extrasolar planet orbiting a normal star (Mayor & Queloz 1995), Doppler-spectroscopy, or radial velocity (RV), has been the most efficient method in detecting extrasolar planets orbiting nearby stars1.
Because the same nearby stars can be targets of several RV surveys, there is the possibility to combine the information of two or more RV data sets using the means of Bayesian inference (e.g. Gregory 2011; Tuomi 2011) and posterior updating. However, little is known about the possible biases individual data sets, or RV timeseries, may contain with respect to one another. Therefore, we use Bayesian tools in determining whether the common statistical models can be used to analyse RV timeseries without bias, and if not, how these models can be improved to receive trustworthy results. For these purposes we introduce a method for determining model inadequacy in describing multiple sets of measurements – the Bayesian model inadequacy criterion.
The Bayes’ rule leads naturally to the commonly used Bayesian model comparison methods (e.g. Jeffreys 1961). These methods can be used efficiently to compare the relative performance of different statistical models of some a priori selected model set. The Bayes’ rule can be used to calculate the relative posterior probabilities of the models in the set given some measurements that describe some aspect of the modelled system. However, because only the relative performances of the models can be compared, it cannot be said whether the model with the greatest posterior probability is adequately accurate in describing the measured quantities.
The Bayes’ factors (Kass & Raftery 1995; Chib & Jeliazkov 2001; Ford & Gregory 2007) and other related measures of model goodness, such as the various information criteria (e.g. Akaike 1973; Schwarz 1978; Spiegelhalter et al. 2002) derived using different approximations, can only be used to tell which one of the models in some model set describes the measurements the best – i.e. the relative “goodness” of the models can be determined reliably. However, they cannot be used to assess whether this best model is as accurate description as possible given the information in the measurements. Our method of determining model inadequacy in this sense can be used to assess whether the model set can be estimated to contain a sufficiently accurate model that can be used to describe the measurements reliably.
Whether a given statistical model can be used to describe several sets of data in an adequate manner or not, has not been studied very extensively in the statistics literature. In Kaasalainen (2011), the author presents a method for determining the optimal combination of two or more sources of data, or data modes. However, we are not aware of a single study discussing this problem in the Bayesian context, though Spiegelhalter et al. (2002) appear to discuss the “model adequacy” in their article introducing the deviance information criterion, but they use the term interchangeably with the term “fit”. Yet, determining whether a single model can describe two or more data sets without bias is of increasing importance in astronomy, particularly for indirect detections of the most interesting exoplanets whose signals lie close to the current limits of instrument sensitivity.
Since the RV variations of typical targets of Doppler-spectroscopy surveys are commonly modelled using a superposition of Keplerian signals, reference velocities, and possible linear trends, corrupted by some Gaussian noise, we use these models as a starting point of our analyses. However, we emphasise the fact that the RV variations caused by the stellar surface, usually referred to as the stellar jitter, are in general, despite some efforts in modelling their magnitude (Wright 2005), foreseen as arising from dark or bright spots primarily driven by stellar rotation ( Barnes et al. 2011; Boisse et al. 2011) and their effect on the RV’s is not understood very well at the moment. Therefore, we model the excess noise in the RV’s with care and show explicitly the statistical models we use in the analyses.
In Sect. 2 we describe what we mean by the model inadequacy in describing two or more independent measurements or sets of measurements and provide a simple way of determining it in practice. We describe the details of our model inadequacy criterion in the Appendix. Finally, in Sect. 3 we apply this criterion in practice by analysing astronomical RV exoplanet detections made using at least two different telescope-instrument combinations.
2. Bayesian analyses and model inadequacy
The Bayesian methods do not differentiate between determining the most probable parameter values or most probable models containing these parameters. They can all be arranged into a linear order, which yields information on the observed system if only the selected models describe the observed system realistically enough. It is possible to calculate the relative posterior probabilities of any number of models and determine their relative magnitudes in a similar way as it is possible to determine the posterior odds of having the measurements drawn from a probability density characterised by a certain parameter value of any one of the models. We do not describe the process of determining the posterior probability densities of the model parameters here, because several well-known posterior sampling methods exist and they have been well covered by the existing literature (e.g. Metropolis et al. 1953; Hastings 1970; Geman & Geman 1984; Haario et al. 2001). The performance of these methods has also been demonstrated by several re-analyses of existing RV data, revealing the existence of planets (e.g. Gregory 2005, 2007a,b; Tuomi & Kotiranta 2009) or disputing it (e.g. Tuomi 2011). In these works, the model probabilities have played an important role in assessing the number of planetary companions orbiting nearby stars.
Commonly, the Bayesian tools are used to assess the probabilities of different statistical models given the measurements m that are being analysed using the models. These tools provide the relative probabilities of the selected models ℳi,i = 1,...,k in the a priori determined model set as 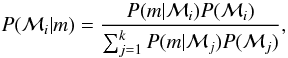 (1)where probabilities P(ℳi),i = 1,...,k are the prior probabilities of the different models and the marginal likelihoods P(m|ℳi) are defined as
(1)where probabilities P(ℳi),i = 1,...,k are the prior probabilities of the different models and the marginal likelihoods P(m|ℳi) are defined as 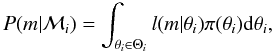 (2)where π(θi) is the prior probability density of the parameter or parameter vector θi of the model ℳi and l(m|θi) represents the likelihood function corresponding to the model.
(2)where π(θi) is the prior probability density of the parameter or parameter vector θi of the model ℳi and l(m|θi) represents the likelihood function corresponding to the model.
The interpretation of the posterior probabilities in Eq. (1) is a rather subjective matter because they are relative and it is only possible to assess how much confidence one has in one of the models compared to the rest of them. According to the views of Jeffreys (1961); Kass & Raftery (1995), a model would have to be at least 150 times more probable than the next best model to have strong evidence in favour of it. We adopt the same threshold because claiming that there are k + 1 planets orbiting a star instead of k needs to be on a solid ground with respect to the model probabilities. Especially, if the model with k + 1 planets was e.g. 50 times more probable than that with k planets, there would still be a roughly 2% possibility that the k planet model explains the data. Therefore, we choose a rather high threshold when interpreting the posterior probabilities of models with different numbers of Keplerian signals.
With the marginal likelihoods available according to Eq. (2), we define the model ℳ to be an inadequate description of independent measurements mi,i = 1,...,N, if it holds that for some small positive number r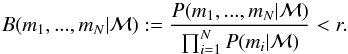 (3)This definition is based on the independence of the measurements and that they are being modelled with a single statistical model. It is a simple result of a relation of the marginal likelihoods of each of the measurement and the joint marginal likelihood of all of them shown in Eq. (A.8). We derive this criterion using the Bayes’ rule of conditional probabilities and the concept of independence, and also interpret the results in terms of information theory in the Appendix.
(3)This definition is based on the independence of the measurements and that they are being modelled with a single statistical model. It is a simple result of a relation of the marginal likelihoods of each of the measurement and the joint marginal likelihood of all of them shown in Eq. (A.8). We derive this criterion using the Bayes’ rule of conditional probabilities and the concept of independence, and also interpret the results in terms of information theory in the Appendix.
The number r has an interpretation as a threshold value. For instance, the model being inadequate with probabilities 90%, 95%, and 99% corresponds to threshold values of 0.111, 0.053, and 0.010, respectively (see Appendix). Therefore, if the best model according to Eq. (1) satisfies Eq. (3) for some reasonably small r, it can be concluded that the model does not describe the measurements without bias and the corresponding analysis results may be biased as well. In such a case, the model set has to be re-considered and expanded by adding better descriptions of the data to it. In practice, we use the 95% threshold value, but choosing its value is a subjective issue and only represents how confidently one wants to determine the model inadequacy.
We note that the model inadequacy can also be interpreted in terms of the measurements being inconsistent with one another with respect to the model used. This interpretation arises from the fact that the model may not take into account some features in one or more data sets that result from biases in the process of making the measurements or from some other unmodelled features in the data. We use the inadequacy of the model given the data sets and the inconsistency of the data sets with respect to this model interchangeably throughout this article.
We describe the parameter probability densities using three numbers. These numbers are the maximum a posteriori (MAP) estimate of the posterior density and the limits of the 99% Bayesian credibility set 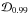 as defined in e.g. Tuomi & Kotiranta (2009). We calculate these estimates from the posterior densities of the model parameters received using the adaptive Metropolis posterior sampling algorithm (Haario et al. 2001), which is a modification of the famous Metropolis-Hastings (M-H) algorithm (Metropolis et al. 1953; Hastings 1970) that adapts the proposal density to the shape of the posterior density of the model parameters. Because of this property, it is not very sensitive to the choise of initial parameter vector nor proposal density – desired features that make the method significantly more robust than the common M-H algorithm by enabling a more rapid convergence to the posterior.
as defined in e.g. Tuomi & Kotiranta (2009). We calculate these estimates from the posterior densities of the model parameters received using the adaptive Metropolis posterior sampling algorithm (Haario et al. 2001), which is a modification of the famous Metropolis-Hastings (M-H) algorithm (Metropolis et al. 1953; Hastings 1970) that adapts the proposal density to the shape of the posterior density of the model parameters. Because of this property, it is not very sensitive to the choise of initial parameter vector nor proposal density – desired features that make the method significantly more robust than the common M-H algorithm by enabling a more rapid convergence to the posterior.
While the adaptive Metropolis algorithm assumes a Gaussian proposal density, it adapts to the posterior reasonably rapidly and a samples of roughly 106 are sufficient for the chain burn-in period in all the analyses, i.e. until the chain converges to the posterior. Because of the Gaussian posterior, the acceptance rate of the chain can sometimes decrease to as low values as 1% when the posterior density is highly nonlinear, as is comonly the case with RV data. However, in such cases, we simply increased the chain length by a factor of 10–20 and saved computer memory by only saving every 10th or 20th member of the chain to the output file. We verified that the chain had indeed converged by running up to five samplings with different initial values and required that they all produced marginal integrals that were equal up to the second digit. With a converged chain, we then calculated the marginal likelihoods using the method of Chib & Jeliazkov (2001).
For the sake of trustworthiness, throughout this article we also take into account the uncertainties in the stellar masses when calculating the semi-major axes and RV masses of the planets orbiting them. These uncertainties are taken into account by using a direct Monte Carlo simulation – i.e. by drawing random values from both the density of the model parameters and the estimated density of the stellar mass when calculating the densities of the semi-major axes and planetary RV masses. We assume that the estimated distribution of the stellar mass, usually reported using mean and stardard error, is independent of the densities of the orbital parameters from the posterior samplings.
3. Model inadequacy criterion and exoplanet detections
In principle, analysing RV data is reasonably simple because the planet induced stellar wobble can be modelled using the well-known Newtonian laws of motion – especially if the gravitational planet-planet interactions are not significant in the timescale of the observations and post-Newtonian effects are negligible. In practice, though, there are several aspects of the RV measurements that are not understood well enough to be able to consider that the models describe the measurements in an adequate manner. These aspects include e.g. disturbances caused by undetected planets or planets whose orbital periods cannot be constrained (e.g. Ford & Gregory 2007); noise caused by the inhomogeneities in the stellar surface, usually referred to as the stellar “jitter” (e.g. Wright 2005); and excess noise and possible biases that are particular to the various instruments and telescopes used to make the observations. All these aspects make the analyses of RV’s challenging and if not accounted for properly by the statistical models used, can lead to biased results and misleading interpretations.
In this section we re-analyse three RV data sets made using at least two telescope-instrument combinations. Assuming these sets are independent – which is a common assumption, though not explicitly stated most of the time when analysing several sets of measurements – we apply the model inadequacy criterion to find out if the common models should be modified and if the corresponding results are different from the ones found in the literature.
3.1. HD 217107
The RV’s of HD 217107 are known to contain the signatures of two extrasolar planets (Fischer et al. 1999, 2001; Vogt et al. 2000; Naef et al. 2001; Vogt et al. 2005; Wittenmyer et al. 2007; Wright et al. 2009. The system consists of a massive short-period planet with an orbital period of roughly 7 days, and an outer long-period planet with an orbital period of 11 years. The RV’s of this target have been observed using 4 instruments mounted on 5 telescopes, namely, Euler (Naef et al. 2001), Harlam J. Smith (HJS) (Wittenmyer et al. 2007), Keck I (Wright et al. 2009), and Shane and Coude Auxiliary Telescope (CAT) at the Lick Observatory (Wright et al. 2009). Together, there are 293 RV measurements of this system.
The most up-to-date solution is that of Wright et al. (2009), where the combined Keck and Lick data with 207 measurements was analysed. However, the authors do not discuss the exact statistical model used in their analyses and therefore we feel that this combined data set should be re-analysed to see how the four data sets should be modelled to receive the most trustworthy results.
Following the common Bayesian approach (e.g. Gregory 2005, 2007a,b; Tuomi & Kotiranta 2009; Tuomi 2011), we choose our model set to consist of four models, namely, models ℳk,k = 0,...,3, where k denotes the number of planetary signals in the data. Therefore, there are 5k + 5 parameters in our models corresponding to 5 parameters for each planet – RV amplitude K, orbital eccentricity e, orbital period P, longitude of pericentre ω, and mean anomaly M0, i.e. the date of periastron passage as expressed in radians between 0 and 2π – four parameters decribing the reference velocities of each data set γl,l = 1,...,4, and the parameter describing the magnitude of stellar jitter σJ. Our set of statistical models describing the measurement mi,l made at time ti is 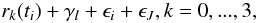 (4)where rk represents the k Keplerian signals and ϵi and ϵJ are Gaussian random variables with zero mean and known variance
(4)where rk represents the k Keplerian signals and ϵi and ϵJ are Gaussian random variables with zero mean and known variance 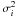 and an unknown variance
and an unknown variance 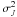 , respectively. The variance corresponds to the instrument uncertainty of each individual measurement, which is usually assumed known and is reported together with the data.
, respectively. The variance corresponds to the instrument uncertainty of each individual measurement, which is usually assumed known and is reported together with the data.
We analyse the combined data set using the models ℳk,k = 0,...,3 and receive the model probabilities in Table 1. These probabilities imply that there are two companions orbiting the star with high confidence. However, the Bayes factor determining the inadequacy of the best model in the model set has to be calculated to assess the reliability of this model. Denoting the four data sets as ml,l = 1,...,4, we receive B(m1,...,m4) = 0.05, which means that the model is an inadequate description of the data with a probability of 0.95. This implies, that the model set does not contain a sufficiently good model, i.e. the data sets are not consistent with one another given this model, and needs to be expanded.
The relative model probabilities of k planet models for the combined data set of HD 217107.
Because of the inadequacy of model ℳ2, we no longer assume that the instrument noise is known according to the variances but suspect that there could be unknown random variations or biases that differ between the data sets. Therefore, we expand our model set by models 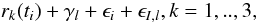 (5)where the Gaussian random variable ϵI,l is different for every data set and is assumed to consist of additional random variation caused by the instrument noise and stellar jitter. Therefore, in this model, the resulting values σI,l can only be interpreted as giving the upper limit for the stellar jitter. We denote these models as ℳI,k.
(5)where the Gaussian random variable ϵI,l is different for every data set and is assumed to consist of additional random variation caused by the instrument noise and stellar jitter. Therefore, in this model, the resulting values σI,l can only be interpreted as giving the upper limit for the stellar jitter. We denote these models as ℳI,k.
Using the expanded model set, we receive the model probabilities in Table 2. In this table, we show all the model probabilities on the same scale. These probabilities imply that there are indeed differences in the noise levels of the different data sets and that these differences have to be taken into account when assessing the orbital parameters of the planets. We calculate the model inadequacy Bayes factor B(m1,...,m4) for the best model ℳI,2. This time B(m1,...,m4) = 3.3 × 1012, which corresponds to an inadequacy probability of 3.0 × 10-13, a value that clearly states the best model cannot be considered inadequate.
The relative model probabilities of k planet models ℳk and ℳI,k for the combined data set of HD 217107.
We have listed the solution of the model with the greatest posterior probability, ℳI,2, in Table 3. While consistent with the results of Wright et al. (2009), our solution with the best model ℳI,2 has much more uncertain parameter values, especially for the period, RV mass, and RV amplitude of the outer companion, which is also found heavily correlated with the reference velocity parameters. We show the 99%, 95%, and 50% equiprobability contours of RV mass and period of the outer companion in Fig. 1 (the gap in the 50% contours arises from the numerical inaccuracy of the plot). This figure is similar to Fig. 8 in Wright et al. (2009), but they used the χ2 density for the plot instead of posterior density. Also, we note that the jitter of HD 217107 has a level of at most 6.0 m s-1 based on the noise in the Euler data, which turned out to contain the least noise out of the four data sets. It is also interesting to see that the Lick data had therefore at least 5 m s-1, but possibly even more than 10.0 m s-1, additional uncertainty that can only be caused by the telescopes and the instrument. Therefore, it cannot be said that the Lick instrument uncertainty is known according to the standard uncertainties of the data reduction pipeline, as reported when publishing Lick RV’s. This could in fact be one of the reasons the MAP parameter values in our solution (Table 3) appear to be more uncertain according to the sets than those reported by Wright et al. (2009), shown in the Table 3 for comparison, though they do not indicate the confidence-level of the reported uncertainties.
 |
Fig. 1 The equiprobability contours of the RV mass and orbital period of HD 217107 c containing 50%, 95%, and 99% of the probability density. |
The parameter MAP estimates and the limits of their sets for the two-planet solution of HD 217107 combined data set.
3.2. Gliese 581
The Gliese 581 planetary system has been claimed to be a host to as many as six relatively low-mass planets (Bonfils et al. 2005; Udry et al. 2007; Mayor et al. 2009; Vogt et al. 2010). Though the most likely number of planetary companions in the system is four (Tuomi 2011) or five (Gregory 2011), the RV’s of Gliese 581 provide a challenging analysis problem because the signals are only barely distinguishable from the relatively noisy measurements.
We start by analysing the combined data set of HARPS and HIRES RV measurements (see e.g. Vogt et al. 2010; Gregory 2011; Tuomi 2011) using the models ℳk and ℳI,k with k = 0,...,5. We choose this model set because we already suspect, based on the analysis of the RV’s of HD 217107, that this combined data set may have different noise levels corresponding to the different telescope-instrument combinations.
The posterior probabilities of the models in our model set are shown in Table 4. These probabilities, while having the greatest value for model ℳI,5, do not support the conclusion that there are five Keplerian signals in the data strongly enough because the probability of model ℳI,4 is highly significant. Therefore, we check the inadequacy of the latter model to see if our statistical model is good enough.
The Bayes factor in Eq. (3) has a value of 2.0 × 1010 for the four-planet model ℳI,4, which means that the probability of the HIRES and HARPS data sets being inadequately described by the model is 5.0 × 10-11, a value low enough to conclude that there is no need to revise the model. We note that this model, an order of magnitude more probable than the previously used model ℳ4 (Tuomi 2011), does not result in a revision of the orbital parameters according to the MAP estimates and the limits of the sets shown in Table 5. However, the noise parameters of the two data sets do differ from one another slightly. Denoting the HIRES data set with l = 1 and the HARPS data set with l = 2, the parameters σI,l,l = 1,2, have MAP estimates of 2.39 and 1.50 m s-1, respectively. The corresponding 99% credibility sets are [1.77, 3.09] and [1.00, 2.01] m s-1, respectively. Therefore, the noise in the HARPS measurements gives an upper limit for the jitter of Gliese 581 of 2.01 m s-1, whereas there is likely a small amount of additional instrument noise in the HIRES data.
The relative model probabilities of k planet models ℳk and ℳI,k for the combined data set of Gliese 581.
3.3. υ Andromedae
The RV’s of υ And have shown three strong Keplerian signals resulting from three massive planets orbiting the star (Butler et al. 1997, 1999; Fischer et al. 2003; Naef et al. 2004; Wittenmyer et al. 2007; Wright et al. 2009). The star has been a target of five RV surveys for several years, namely, Lick (Butler et al. 1999; Fischer et al. 2003; Wright et al. 2009), the Advanced Fiber-Optic Echelle spectrometer (AFOE) at the Whipple Observatory (Butler et al. 1999), HJS (Wittenmyer et al. 2007), ELODIE at the Haute-Provence Observatory (Naef et al. 2004), and the Hobby-Eberly Telescope (HET) (McArthur et al. 2010). Recently, the combined data of Lick (Fischer et al. 2003; Wright et al. 2009) and ELODIE (Naef et al. 2004) has been reported to contain a fourth planetary signal (Curiel et al. 2011).
We re-analyse the combined RV data of υ And by using the model inadequacy criterion. However, before we start, we check the consistency of the 248 Lick RV’s published in Fischer et al. (2003) and the 284 Lick RV’s published in Wright et al. (2009) (we denote these data sets as Lick1 and Lick2, respectively), because Curiel et al. (2011) used Lick2 data and the additional 30 RV points from Lick1 that were not included in Lick2. The fact that these 30 measurements were not included in Lick2 likely because of suspected biases or calibration errors suggests that there could be some biases within the combined Lick data analysed in Curiel et al. (2011) as well.
The Lick1 and Lick2 data sets appear to have one striking difference. While they both imply that there are indeed four Keplerian signals in the υ And RV’s, as concluded by Curiel et al. (2011), they do not agree on the orbital period of the proposed fourth signal. The probability of the three companion model is significantly lower than that of the four planet model – 10-4 and 10-24 times lower for Lick1 and Lick2, respectively. This implies that there is either a fourth Keplerian signal in the data or biases that mimic Keplerian periodicity. The MAP estimate and the corresponding set of the period of this fourth signal is 3120 [2560, 3940] days for Lick1 data and 3860 [3180, 5160] for Lick2 data. The latter of these estimates appears to be very close to the estimate of Curiel et al. (2011) of 3848.86 ± 0.74 days. However, because of the difference of more than 700 days between the MAP estimates of the periods from Lick1 and Lick2, we cannot conclude, based on the Lick data alone, that there are indeed four Keplerian signals in the data. This inconsistency is seen the most clearly when looking at the equiprobability contours of the parameter posterior densities given each data set. The contours containing 50%, 95%, and 99% of the density are shown in Fig. 2 for the period and amplitude parameters of υ And d (top) and the proposed υ And e (bottom). The Lick1 contours are shown in red and Lick2 contours in blue. As seen in this figure, the estimated period and amplitude of the υ And d differ also between the two Lick data sets.
The four-planet solution of GJ 581 combined HARPS and HIRES data.
 |
Fig. 2 The equiprobability contours of the period and amplitude parameters of υ And d (top) and υ And e (bottom) containing 50%, 95%, and 99% of the probability density. The red colour denotes the contours given the Lick1 data of Fischer et al. (2003) and blue is used to denote the contours given the Lick2 data of Wright et al. (2009). |
Because of the inconsistency of the Lick data sets published in Fischer et al. (2003) and Wright et al. (2009), we use the model inadequacy criterion to find out if either of these two data sets is also inconsistent with the combined ELODIE, AFOE, HET, and HJS data. We denote this combined data as m and use m1 and m2 to denote the Lick1 and Lick2 data, respectively, and calculate the Bayes factors B(m,m1) and B(m,m2) for the model ℳI,4. The logarithms of these factors are 4.01 and –10.20, respectively (Table 6). This implies that the Lick2 data set is inconsistent with the rest of the data and the 4-companion model is an inadequate description with a probability of more than 0.999, whereas the Lick1 data cannot be shown inconsistent with the rest of the data with a probability exceeding 5%. Therefore, it appears that Lick1 data (Fischer et al. 2003) is consistent with the other four data sets but the Lick2 data (Wright et al. 2009) is not.
We also investigated whether some of the ELODIE, AFOE, HET, HJS, and Lick data sets were inconsistent with the rest of the data by calculating the Bayes factors B(mi,m), where mi,i = 1,...,5, refers to each of these sets, respectively, and m contains all the data except the set mi. We performed these calculations using both Lick1 data and Lick2 data. The probabilities of the model ℳI,4 being inadequate in describing each of these sets with respect the the rest of the data are shown in Table 6. In this Table, we show the inadequacy probabilities for the Lick1 and Lick2 data sets separately.
The log-Bayes factors (log B) and probabilities (P) of model ℳI,4 being an inadequate description of each individual set of RV’s of υ And and the rest of the data.
The results in Table 6 show that while Lick2 data is inconsistent with the rest of the measurements with respect to the model ℳI,4, the AFOE data is also inconsistent with the rest of the measurements regardless of using the Lick1 or Lick2 data among the others in the analyses. We also note that the same inconsistency remains for the AFOE data when using the three-companion model ℳI,3 in the analyses. Therefore, as also noted by Curiel et al. (2011), we conclude that the AFOE data has additional biases and should not be used together with the rest of the data because the results would be prone to biases as well. To further demonstrate the inconsistency of the AFOE data and the other data sets, we show the RV residuals of the AFOE data when the three-companion model has been used to analyse the combined data of AFOE, Lick1, ELODIE, HET, and HJS (Fig. 3). These residuals appear to show a low-amplitude periodicity that roughly corresponds to the period of companion d, despite the fact that the signal of this companion (and those of b and c) has been subtracted.
 |
Fig. 3 The residuals of AFOE RV’s of the υ And with the planetary signals subtracted. |
We continue the analyses of υ And RV’s by neglecting the AFOE data and by using the older Lick1 data set (Fischer et al. 2003), because of the inconsistencies of the AFOE and Lick2 data with the rest of the data sets. The combined data set consists of Lick1, HET, ELODIE, and HJS data that contain 248, 79, 71, and 41 measurements, respectively. This combined data set with 439 measurements was analysed using two models, namely, ℳI,3 and ℳI,4, because there are clearly three strong Keplerian signals in the data as demonstrated already by Butler et al. (1999), and because the noise levels of the different data sets likely differ from one another based on the previous analyses.
Since we removed the AFOE data from the analyses, we need to assess whether the resulting restricted data set can be shown inadequate or not. For this purpose, we re-calculate the values in Table 6 for the restricted data sets and show them in Table 7. According to these results, none of the four data sets can be said to conflict with the others. Also, using the Bayesian model inadequacy for multiple data sets by calculating B(m1,...,m4), where mi,i = 1,...,4, correspond to Lick1, ELODIE, HJS, and HET data sets, respectively, we receive a value of 1.4 × 109, which means that these sets are inconsistent with a probability of less than 10-9 given the four-companion model. Therefore, these four sets can be combined reliably and we calculate our final solution of υ And RV’s using these four sets.
The log-Bayes factors (log B) and probabilities (P) of model ℳI,4 being an inadequate description of υ And RV’s.
The posterior probability of the model ℳI,3 is less than 10-8 of the probability of model ℳI,4. This implies that there are indeed four periodic signals in the combined data set. The revised orbital parameters with respect to the four-companions model are shown in Table 8. The RV variations corresponding to the longest periodicity in the data are shown in Fig. 4 together with the fitted Keplerian signal. The signals of the three inner companions have been subtracted from the residuals in Fig. 4.
The four-planet solution of υ Andromedae RV’s from Lick1, HET, ELODIE, and HJS.
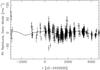 |
Fig. 4 The Lick1, ELODIE, HJS, and HET RV’s with the signals of the three inner companion removed. The solid curve represents the Keplerian corresponding to planet candidate υ And e. |
When comparing the orbital parameters of our solution in Table 8 with the solution of Curiel et al. (2011), it can be seen that the period of the υ And e is significantly lower in our solution. We received a MAP estimate for the orbital period of 2860 days (![Mathematical equation: \hbox{$\mathcal{D}_{0.99} = [2600, 3220]$}](/articles/aa/full_html/2011/08/aa17278-11/aa17278-11-eq116.png) ), whereas Curiel et al. (2011) reported a period of 3848.86 ± 0.74 days. This difference can arise from the fact that they used the more recent Lick2 data set of Wright et al. (2009), which is not consistent with the other RV’s according to our analyses. We also found another solution for the period of υ And e. This period is 5750 days (
), whereas Curiel et al. (2011) reported a period of 3848.86 ± 0.74 days. This difference can arise from the fact that they used the more recent Lick2 data set of Wright et al. (2009), which is not consistent with the other RV’s according to our analyses. We also found another solution for the period of υ And e. This period is 5750 days (![Mathematical equation: \hbox{$\mathcal{D}_{0.99} = [5220, 6610]$}](/articles/aa/full_html/2011/08/aa17278-11/aa17278-11-eq117.png) ), roughly twice the MAP periodicity, but its posterior probability is more than a thousand times lower than that of the solution in Table 8.
), roughly twice the MAP periodicity, but its posterior probability is more than a thousand times lower than that of the solution in Table 8.
We note that while Curiel et al. (2011) adopted a jitter of 10 m s-1 when analysing the RV’s of υ And, the estimate of Butler et al. (2006) is only 4.2 m s-1. Our results are consistent with the latter estimate because the upper limit of excess noise, including the stellar jitter, is 4.58 m s-1 based on the lowest noise level in the data sets of the HET data (Table 8). According to our results, the jitter has likely an even lower value of roughly 2.0 m s-1. This also implies that the Lick1, ELODIE, and HJS data contain an additional source of RV variations – likely the telescope-instrument combination used to measure these data.
4. Discussion
We have proposed a simple method for assessing whether a statistical model is an inadequate description of multiple independent data sets. This method is simply an application of the well known Bayesian model selection theory and the law of conditional probability but it also differs from the common model selection approach because it provides the means of determining whether a single model, i.e. the best model in the a priori selected model set, is not an adequate description of the data sets and needs to be improved.
Using this Bayesian model inadequacy criterion and common model comparisons, we re-analysed three combined RV data sets made using at least two telescope-instrument combinations. According to our results, the Gliese 581 RV’s observed using the HIRES and HARPS spectrographs can be described reliably using the model ℳI,4, where their uncertainties caused by stellar jitter and additional instrument uncertainty have been modelled to have different magnitudes – at least, the four-companion model cannot be shown to be an inadequate description of these two data sets. This suggests that the results in Tuomi (2011) are indeed reliable in this respect.
The RV’s of HD 207107 showed that there can be significant telescope-instrument – induced uncertainties in the data. Therefore, we were forced to describe these uncertainties with different parameters for each telescope-instrument – combination. According to our results, the telescope-instrument uncertainties can differ considerably between different data sets, which makes it more difficult to put reliable constraints to the stellar jitter. While the jitter of HD 217107 is not likely to exceed 6.0 m s-1 based on the noise in the Euler data, the Lick1 data turned out to have excess noise of 5–10 m s-1 with respect to this jitter estimate (Table 3). Therefore, we conclude that the instrument uncertainties cannot be assumed as known, and additional noise should always be assumed to exist in the data. When neglecting this additional uncertainty, the estimates of orbital parameters can be biased and their uncertainty estimates will certainly be unrealistically low with respect to the information in the measurements.
The RV’s of υ Andromedae proved a challenging analysis problem on their own. These data consisted of five independent RV data sets. According to our results, the Lick2 data of Wright et al. (2009) was not consistent with the other data sets with respect to our model inadequacy criterion but the earlier Lick1 data set of Fischer et al. (2003) should be used instead. Unfortunately, it is not possible to tell where this inadequacy arises from. Also, the AFOE data (Butler et al. 1999) turned out to contradict with the rest of the data, likely because of biases in the process of making the measurements, as also noted by Curiel et al. (2011). This leaved only four consistent data sets, Lick1 (Fischer et al. 2003), ELODIE (Naef et al. 2004), HET (McArthur et al. 2010), and HJS (Wittenmyer et al. 2007), to be used in the analyses. With differing noise levels for each of these sets, we calculated the revised orbital parameters for the υ And planetary system with four planetary companions (Table 8).
Because our four-planet solution of the RV’s of υ And differs significantly from the proposed solution of Curiel et al. (2011) with respect to the orbital period of the outer planet, numerical integrations of the orbits are needed to assess the stability of our solution. The lower estimate for the orbital period of υ And e does not support the conclusion that the d and e planets could be in a 3:1 mean motion resonance (MMR). However, our solution coincides roughly with a 2:1 MMR, which could enable the stability of the system over long time-scales. Investigating the stability of our solution is necessary to be able to determine whether it corresponds to a physically viable system and is not simply an artefact caused by noise, data sampling, and possible biases in the measurements.
For successful detections, it is crucial that the noise – i.e. all the other variations except the Keplerian signals – in the valuable measurements is modelled as realistically as possible and not simply minimised as is commonly the case when using simple χ2 minimisations and related methods. Our method can be used readily to detect whether the statistical model indeed describes the data adequately with respect to the selected noise model as well.
The application of our criterion to measurements of any complex systems is obvious. Systems whose behaviour, time-evolution, and dependence on different physical and other factors cannot be derived from fundamental physical principles, are difficult to model because the models are necessarily empirical descriptions, whose validity can only be assessed using measurements. In such systems, there can be numerous small-scale effects and/or biases, whose existence is not known and whose magnitude cannot be measured. These effects cannot therefore be taken into account in the model constructed to describe some desired features of the system. As briefly noted in Kaasalainen (2011), the ability to show that a model is an insufficient description of the measurements is therefore needed to be able to determine whether the model needs to be improved further to extract all the valuable information from the noisy data. According to the demonstrations in this article, our method can be said to satisfy these needs to significant extent. Also, as we did not make any assumptions regarding the exact nature of the model, the criterion can be applied to any problem for which it is possible to calculate the likelihoods of the measurements using the model.
Finally, we note that if the model has been constructed prior to the measurements, the model inadequacy means that the earlier data sets used to construct the model, i.e. to select the model formulae and calculate the posterior densities of the model parameters, conflict with the new ones with respect to the model. It could also be that the model is being developed using a single data set in hand. Then, despite being the best model in the sense of having the greatest posterior probability, the model could still be inadequate in describing some part of the data set with respect to another part (Kaasalainen 2011). Either way, the measurements cannot be described adequately using the selected model and we say that the model is inadequate. Our criterion can be used in these cases as well.
See The Extrasolar Planets Encyclopaedia for an up-to-date list of known planetary candidates: http://exoplanet.eu/
The reader should refer to any basic text on conditional probabilities and independence.
Acknowledgments
M. Tuomi is supported by RoPACS (Rocky Planets Around Cools Stars), a Marie Curie Initial Training Network funded by the European Commission’s Seventh Framework Programme.
References
- Akaike, H. 1973, in Second International Symposium on Information Theory, ed. B. N. Petrov, & F. Csaki (Akadémiai Kiadó), 267 [Google Scholar]
- Barnes, J. R., Jeffers, S. V., & Jones, H. R. A. 2011, MNRAS, 412, 1599 [NASA ADS] [CrossRef] [Google Scholar]
- Boisse, I., Bouchy, F., Hébrard, G., et al. 2011, A&A, 528, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bonfils, X., Forveille, T., Delfosse, X., et al. 2005, A&A, 443, L15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Butler, R. P., Marcy, G. W., Williams, E., et al. 1997, ApJ, 474, L115 [NASA ADS] [CrossRef] [Google Scholar]
- Butler, R. P., Marcy, G. W., Fischer, D. A., et al. 1999, ApJ, 526, 916 [NASA ADS] [CrossRef] [Google Scholar]
- Butler, R. P., Wright, J. T., Marcy, G. W., et al. 2006, ApJ, 646, 505 [NASA ADS] [CrossRef] [Google Scholar]
- Chib, S., & Jeliazkov, I. 2001, J. Am. Stat. Ass., 96, 270 [Google Scholar]
- Curiel, S., Cantó, J., Georgiev, L., et al. 2011, A&A, 525, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fischer, D. A., Marcy, G. W., Butler, R. P., et al. 1999, PASP, 111, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Fischer, D. A., Marcy, G. W., Butler, R. P., et al. 2001, ApJ, 551, 1107 [NASA ADS] [CrossRef] [Google Scholar]
- Fischer, D. A., Marcy, G. W., Butler, R. P., et al. 2003, ApJ, 586, 1394 [NASA ADS] [CrossRef] [Google Scholar]
- Ford, E. B., & Gregory, P. C. 2007, Statistical Challenges in Modern Astronomy IV, ed. G. J. Babu, & E. D. Feigelson, ASP Conf. Ser., 371, 189 [Google Scholar]
- Geman, S., & Geman, D. 1984, IEEE Trans. Patt. Anal. Mach. Int., 6, 721 [Google Scholar]
- Gregory, P. C. 2005, ApJ, 631, 1198 [NASA ADS] [CrossRef] [Google Scholar]
- Gregory, P. C. 2007a, MNRAS, 381, 1607 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Gregory P. C. 2007b, MNRAS, 374, 1321 [NASA ADS] [CrossRef] [Google Scholar]
- Gregory, P. C. 2011, MNRAS, in press [arXiv:1101.0800v1] [Google Scholar]
- Haario, H., Saksman, E., & Tamminen, J. 2001, Bernoulli, 7, 223 [CrossRef] [MathSciNet] [Google Scholar]
- Hastings, W. 1970, Biometrika 57, 97 [Google Scholar]
- Jeffreys, H. 1961, The Theory of Probability (The Oxford Univ. Press) [Google Scholar]
- Kaasalainen, M. 2011, Inverse Problems & Imaging, 5, 37 [Google Scholar]
- Kass, R. E., & Raftery, A. E. 1995, J. Am. Stat. Ass., 430, 773 [Google Scholar]
- Kullback, S., & Leibler, R. A. 1951, Ann. Math. Stat., 22, 76 [Google Scholar]
- Mayor, M., & Queloz, D. 1995, Nature, 378, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Mayor, M., Bonfils, X., Forveille, T., et al. 2009, A&A, 507, 487 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McArthur, B. E., Benedict, G. F., Barnes, R., et al. 2010, ApJ, 715, 1203 [NASA ADS] [CrossRef] [Google Scholar]
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., et al. 1953, J. Chem. Phys., 21, 1087 [NASA ADS] [CrossRef] [Google Scholar]
- Naef, D., Mayor, M., Pepe, F., et al. 2001, A&A, 375, 205 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Naef, D., Mayor, M., Beuzit, J. L., et al. 2004, A&A, 414, 351 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schwarz, G. E. 1978, Ann. Stat., 6, 461 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Spiegelhalter, D. J., Best, N. G., Carlin, B. P., & van der Linde, A. 2002, JRSS B, 64, 583 [Google Scholar]
- Tuomi, M. 2011, A&A, 528, L5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tuomi, M., & Kotiranta, S. 2009, A&A, 496, L13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Udry, S., Bonfils, X., Delfosse, X., et al. 2007, A&A, 469, L43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vogt, S. S., Marcy, G. W., Butler, R. P., & Apps, K. 2000. ApJ, 536, 902 [Google Scholar]
- Vogt, S. S., Butler, R. P., Marcy, G. W., et al. 2005, ApJ, 632, 638 [NASA ADS] [CrossRef] [Google Scholar]
- Vogt, S., Butler, P., Rivera, E., et al. 2010, ApJ, 723, 954 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wittenmyer, R. A., Endl, M., & Cochran, W. D. 2007, ApJ, 654, 524 [Google Scholar]
- Wright, J. T. 2005, PASP, 117, 657 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, J. T., Upadhyay, S., Marcy, G. W., et al. 2009. ApJ, 693, 1084 [Google Scholar]
Appendix A: Model inadequacy criterion
A.1. Two data sets
We start by defining what we mean by model inadequacy in describing two sets of data and derive its equations from the common Bayesian model comparison theory.
We assume that there are independent measurements, or series of measurements, mi:i = 1,...,N,N ≥ 2, that have been made to study the same system of interest. Because these measurements describe the same system, or at least contain information on the same aspects of the system of interest, they can be modelled with statistical models that have at least one parameter in common, namely, θ ∈ Θ. Throughout this article the parameter space Θ is a bounded subset of Rk. The parameter θ is used to quantify some features in the measurements mi,∀i. In addition, there are other parameters, namely ωi ∈ Θ:i = 1,...,N, that each quantify some additional features in the ith measurement.
The measurements can now be used to compare different statistical models using the Bayesian model selction theory. Let 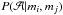 be the posterior probability of model
be the posterior probability of model 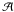 given the measurements mi and mj. The model can be any model for which a likelihood function exists. With this model, both measurements are modelled using the same parameter θ and different parameters ωi and ωj, respectively. Probability P(ℬ|mi,mj) is the corresponding probability when measurements mi and mj are modelled using the same model structure as model has, but this time with parameters φi and φj, where φk = (θk,ωk),k = i,j, respectively.
given the measurements mi and mj. The model can be any model for which a likelihood function exists. With this model, both measurements are modelled using the same parameter θ and different parameters ωi and ωj, respectively. Probability P(ℬ|mi,mj) is the corresponding probability when measurements mi and mj are modelled using the same model structure as model has, but this time with parameters φi and φj, where φk = (θk,ωk),k = i,j, respectively.
Therefore, because of the independence of the measurements and the independence of φi and φj, the marginal integral in Eq. (2) of the measurements with respect to the model ℬ can be written as2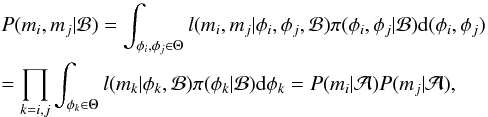 (A.1)where the model has been changed to , because given only one measurement, and ℬ are in fact the same model. In the above, we have used l and π to denote the likelihood function and the prior density, respectively.
(A.1)where the model has been changed to , because given only one measurement, and ℬ are in fact the same model. In the above, we have used l and π to denote the likelihood function and the prior density, respectively.
Now, let s ∈ [0,1] be a small threshold probability. We compare the probabilities of the models and ℬ given the measurements mi and mj. If 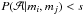 , we say, that the model is an inadequate description of the data with a probability of 1 − s and that the model cannot be used to model them both. In other words, the probability of model is so small, that the measurements should instead be modelled using different parameters θi and θj, i.e. using model ℬ. This condition is simply the common Bayesian model selection criterion (e.g. Jeffreys 1961). From this condition and Eq. (A.1), and when selecting the prior probabilities of the two models equal, the comparison of models and ℬ according to Eq. (1) leads to
, we say, that the model is an inadequate description of the data with a probability of 1 − s and that the model cannot be used to model them both. In other words, the probability of model is so small, that the measurements should instead be modelled using different parameters θi and θj, i.e. using model ℬ. This condition is simply the common Bayesian model selection criterion (e.g. Jeffreys 1961). From this condition and Eq. (A.1), and when selecting the prior probabilities of the two models equal, the comparison of models and ℬ according to Eq. (1) leads to 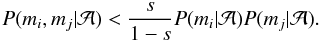 (A.2)We denote r = s(1 − s)-1 and leave the model out of the notation by denoting
(A.2)We denote r = s(1 − s)-1 and leave the model out of the notation by denoting 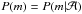 when it is clear which model has been used. Now, we define the model inadequacy as follows.
when it is clear which model has been used. Now, we define the model inadequacy as follows.
The model used to describe the measurements mi and mj is not adequate with level r if 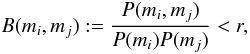 (A.3)where the factor B is actually the Bayes factor in favour of model and against model ℬ and r is some (small) positive number corresponding to the selected threshold probability s.
(A.3)where the factor B is actually the Bayes factor in favour of model and against model ℬ and r is some (small) positive number corresponding to the selected threshold probability s.
Because we have made no assumption on the exact nature of the measurements, the model, or the modelled system, the above condition applies to anything that can be measured and described with a statistical model. In fact, to be able to use Eq. (A.3), a sufficient condition is that the measurements mi and mj are modelled using statistical models that have at least one parameter, namely θ, in common. The model of the ith data set may have other parameters ωi and these have to be treated as free parameters as well, but they have no role in Eq. (A.3) because they are independent of the other data set.
Equation (A.3) in fact states that the measurements are not distributed according to the model used. However, the converse is not true. If the condition in Eq. (A.3) does not hold for some measurements mi and mj, it cannot be said that they are drawn from the same modelled density, even though it might be a reasonable assumption in practice.
The Bayes factor in Eq. (A.3) has an interesting property when interpreted in terms of the information gain defined using the Kullback-Leibler (K-L) divergence (Kullback & Leibler 1951) between prior and the posterior. The K-L divergence is defined for two continuous random variables with probability densities u(x) and v(x) as 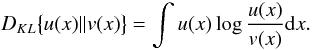 (A.4)With this notation, we can write the K-L divergence of moving from the prior to the posterior (given both data sets). Hence, it follows that
(A.4)With this notation, we can write the K-L divergence of moving from the prior to the posterior (given both data sets). Hence, it follows that 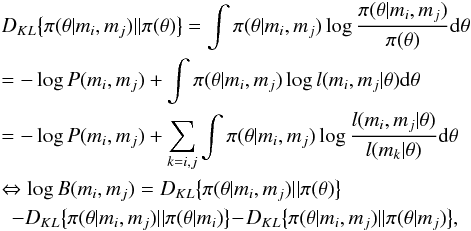 (A.5)where we have used the Bayes rule and the facts that integral over a probability density equals unity and mi and mj are independent.
(A.5)where we have used the Bayes rule and the facts that integral over a probability density equals unity and mi and mj are independent.
This means that the logarithm of the Bayes factor used to determine the model inadequacy in describing measurements mi and mj can in fact be interpreted as the total information gain of the two measurements minus the information gains of moving from the posterior with respect to each measurement alone to the full posterior.
Alternatively, the Bayes factor can be written using the information losses, or K-L divergences, of moving from the posteriors back to the prior (as opposed to the information gain of moving from prior to the posterior). With this terminology, and using a similar derivation as for the information gain in Eq. (A.5), the expression in Eq. (A.5) can be replaced by 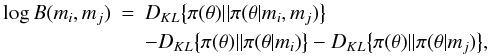 (A.6)which means that the logarithm of the Bayes factor can be interpreted as the total information loss of the two measurements minus the information losses of the two measurements separately.
(A.6)which means that the logarithm of the Bayes factor can be interpreted as the total information loss of the two measurements minus the information losses of the two measurements separately.
A.2. Multiple data sets
When there are more than two data sets available, the model inadequacy criterion can be derived easily following the considerations in the previous subsection. For measurements mi,i = 1,...,N, it can be seen that 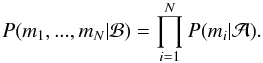 (A.7)It then follows that the model inadequacy criterion corresponding to that in Eq. (A.2) can be written as
(A.7)It then follows that the model inadequacy criterion corresponding to that in Eq. (A.2) can be written as 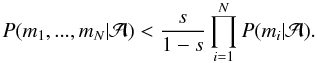 (A.8)We again use B to denote the Bayes factor and write this criterion in the following way.
(A.8)We again use B to denote the Bayes factor and write this criterion in the following way.
The model used to describe measurements mi,...,mN does not describe the measurements adequately accurately with level r if 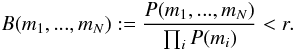 (A.9)From Eq. (A.9), it can be seen that for N data sets, the marginal integral needs to be determined N + 1 times to receive the Bayes factor that is used to assess the model inadequacy. This requirement cannot be considered very limiting, because in practice, the data sets are commonly analysed separately anyway.
(A.9)From Eq. (A.9), it can be seen that for N data sets, the marginal integral needs to be determined N + 1 times to receive the Bayes factor that is used to assess the model inadequacy. This requirement cannot be considered very limiting, because in practice, the data sets are commonly analysed separately anyway.
In terms of K-L information loss of moving from the posterior to the prior, the Bayes factor B can again be interpreted in a simple manner using similar derivation as in Eq. (A.5). As a consequence, it follows that 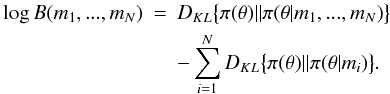 (A.10)However, the information gains cannot be used in a similar manner as in Eq. (A.5). Instead, using the information gain of the measurements the generalisation of Eq. (A.5) to several measurements is
(A.10)However, the information gains cannot be used in a similar manner as in Eq. (A.5). Instead, using the information gain of the measurements the generalisation of Eq. (A.5) to several measurements is 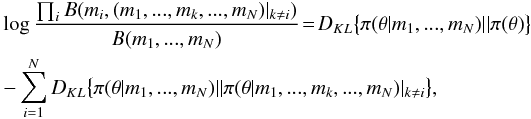 (A.11)where B(mi,(m1,...,mk,...,mN)|k ≠ i) is the Bayes factor describing the model inadequacy with respect to two data sets, namely, mi and the combined data set (m1,...,mk,...,mN)|k ≠ i, which denotes all the data except the measurement mi.
(A.11)where B(mi,(m1,...,mk,...,mN)|k ≠ i) is the Bayes factor describing the model inadequacy with respect to two data sets, namely, mi and the combined data set (m1,...,mk,...,mN)|k ≠ i, which denotes all the data except the measurement mi.
Therefore, the Bayes factor determining the model inadequacy in Eq. (A.9) can be interpreted as a measure of information loss that results from disregarding the measurements to gain information on the posterior minus the corresponding information losses of disregarding each measurement one at the time. Naturally, the gain and loss Eqs. (A.11) and (A.10) are equivalent if N = 2, as was seen in the previous subsection.
Assuming that B(m1,...,mN) ≥ 1, which means that model has a greater probability than ℬ, has an interesting consequence. From this assumption, it follows that 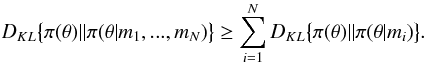 (A.12)When again interpreted in terms of information loss, this means that given a model that cannot be shown inadequate with r = 1,
(A.12)When again interpreted in terms of information loss, this means that given a model that cannot be shown inadequate with r = 1,
the amount of information in the combined data set is greater than the information in the individual data sets.
All Tables
The relative model probabilities of k planet models for the combined data set of HD 217107.
The relative model probabilities of k planet models ℳk and ℳI,k for the combined data set of HD 217107.
The parameter MAP estimates and the limits of their sets for the two-planet solution of HD 217107 combined data set.
The relative model probabilities of k planet models ℳk and ℳI,k for the combined data set of Gliese 581.
The log-Bayes factors (log B) and probabilities (P) of model ℳI,4 being an inadequate description of each individual set of RV’s of υ And and the rest of the data.
The log-Bayes factors (log B) and probabilities (P) of model ℳI,4 being an inadequate description of υ And RV’s.
All Figures
|
Fig. 1 The equiprobability contours of the RV mass and orbital period of HD 217107 c containing 50%, 95%, and 99% of the probability density. |
| In the text | |
|
Fig. 2 The equiprobability contours of the period and amplitude parameters of υ And d (top) and υ And e (bottom) containing 50%, 95%, and 99% of the probability density. The red colour denotes the contours given the Lick1 data of Fischer et al. (2003) and blue is used to denote the contours given the Lick2 data of Wright et al. (2009). |
| In the text | |
|
Fig. 3 The residuals of AFOE RV’s of the υ And with the planetary signals subtracted. |
| In the text | |
|
Fig. 4 The Lick1, ELODIE, HJS, and HET RV’s with the signals of the three inner companion removed. The solid curve represents the Keplerian corresponding to planet candidate υ And e. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.